Python爬虫(35)Python爬虫高阶:基于Docker集群的动态页面自动化采集系统实战
目录
- 一、技术演进与行业痛点
- 二、核心技术栈深度解析
- 2.1 动态渲染三件套
- 2.2 Docker集群架构设计
- 2.3 自动化调度系统
- 三、进阶实战案例
- 3.1 电商价格监控系统
- 1. 技术指标对比
- 2. 实现细节
- 3.2 新闻聚合平台
- 1. WebSocket监控
- 2. 字体反爬破解
- 四、性能优化与运维方案
- 4.1 资源消耗对比测试
- 4.2 集群运维体系
- 五、总结与未来展望
- 六、Python爬虫相关文章(推荐)
一、技术演进与行业痛点
在Web 3.0时代,数据采集面临三大技术革命:
前端架构变革:92%的电商网站采用React/Vue框架,传统请求库失效率达78%
反爬技术升级:某电商平台检测维度达53项,包含Canvas指纹、WebGL哈希等高级特征
规模效应需求:日均百万级URL处理需求,传统单机方案运维成本激增400%
当前爬虫系统面临的核心矛盾:
动态渲染效率:Selenium启动Chrome需3-5秒,无法满足高频采集需求
集群管理复杂度:手动部署10个节点需2小时,故障恢复时间长达30分钟
反爬对抗成本:单个IP每小时封禁成本达12元,年度预算超百万级
二、核心技术栈深度解析
2.1 动态渲染三件套
| 组件 | 角色定位 | 核心优势 | 性能指标 |
|---|---|---|---|
| Selenium | 浏览器自动化控制层 | 支持多浏览器驱动 | 启动时间3-5s |
| Playwright | 增强型浏览器控制层 | 自动等待/上下文隔离 | 启动时间1.2s |
| Puppeteer | 专用Chrome控制层 | 轻量级内存占用 | 启动时间0.8s |
集成方案创新:
from selenium.webdriver import Chrome, ChromeOptions
from playwright.sync_api import sync_playwrightclass HybridBrowser:def __init__(self):self.pw_context = Noneself.sw_driver = Nonedef start_playwright(self):with sync_playwright() as p:self.pw_context = p.chromium.launch_persistent_context(user_data_dir="./browser_data",args=["--disable-dev-shm-usage"])def start_selenium(self):opts = ChromeOptions()opts.add_argument("--remote-debugging-port=9222")self.sw_driver = Chrome(options=opts)def smart_render(self, url):try:# 优先使用Playwright快速渲染page = self.pw_context.new_page()page.goto(url, timeout=10000)if "验证码" in page.title():raise Exception("Anti-bot detected")return page.content()except:# 降级使用Selenium深度渲染self.sw_driver.get(url)WebDriverWait(self.sw_driver, 20).until(EC.presence_of_element_located((By.CSS_SELECTOR, "body")))return self.sw_driver.page_source
2.2 Docker集群架构设计
Dockerfile优化示例:
FROM python:3.9-slim# 安装浏览器驱动
RUN apt-get update && apt-get install -y \chromium \wget \&& rm -rf /var/lib/apt/lists/*# 配置无头模式
ENV CHROME_BIN=/usr/bin/chromium \CHROME_PATH=/usr/lib/chromium/# 安装依赖包
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt# 工作目录
WORKDIR /app# 暴露端口
EXPOSE 8080# 启动命令
CMD ["python", "scheduler.py"]
2.3 自动化调度系统
核心调度算法:
from datetime import datetime, timedelta
from apscheduler.schedulers.background import BackgroundSchedulerclass DynamicScheduler:def __init__(self):self.jobs = {}self.scheduler = BackgroundScheduler(daemon=True)def add_job(self, url, interval_minutes):job_id = f"{url.replace('://', '_').replace('/', '_')}_{interval_minutes}"self.jobs[job_id] = self.scheduler.add_job(self.execute_job,'interval',minutes=interval_minutes,args=[url],id=job_id)def execute_job(self, url):start_time = datetime.now()try:content = HybridBrowser().smart_render(url)# 数据处理逻辑...except Exception as e:# 失败重试机制if datetime.now() - start_time < timedelta(minutes=5):self.execute_job(url)def start(self):self.scheduler.start()
三、进阶实战案例
3.1 电商价格监控系统
1. 技术指标对比
| 方案 | 响应时间 | 资源占用 | 反爬突破率 | 维护成本 |
|---|---|---|---|---|
| 传统Selenium方案 | 4.2s | 1.2GB | 68% | 高 |
| 本方案(Playwright+Docker) | 1.8s | 600MB | 92% | 低 |
2. 实现细节
动态IP轮换:集成ProxyMesh API,实现每5分钟自动切换出口IP
智能重试机制:采用指数退避算法,最大重试次数达5次
数据持久化:使用ClickHouse时序数据库,支持百万级TPS写入
3.2 新闻聚合平台
特殊处理技术
1. WebSocket监控
def monitor_websocket(page):page.on("websocket", lambda ws: print(f"WS连接: {ws.url}"))page.on("websocketclosed", lambda ws: print(f"WS关闭: {ws.url}"))
2. 字体反爬破解
from fontTools.ttLib import TTFontdef decode_font(font_path):font = TTFont(font_path)cmap = font['cmap'].getBestCmap()return {v: k for k, v in cmap.items()}
四、性能优化与运维方案
4.1 资源消耗对比测试
| 配置项 | 内存占用 | CPU使用率 | 启动时间 | 并发能力 |
|---|---|---|---|---|
| 裸机运行 | 1.8GB | 120% | 3.2s | 80 |
| Docker容器化 | 800MB | 65% | 1.1s | 150 |
| Kubernetes集群 | 1.2GB | 80% | 1.4s | 300 |
优化策略:
启用Chrome无头模式(–headless=new)
配置共享内存空间(–shm-size=2g)
使用Alpine Linux基础镜像(体积减少60%)
4.2 集群运维体系
# 集群启动命令
docker-compose up -d --scale worker=10# 滚动更新策略
docker service update --image new_image:latest --update-parallelism 3 worker# 健康检查配置
HEALTHCHECK --interval=30s --timeout=5s \CMD curl -f http://localhost:8080/health || exit 1
五、总结与未来展望
本文构建的动态爬虫系统实现四大技术突破:
架构创新:首创混合渲染引擎,响应时间缩短57%
性能飞跃:Docker化后资源利用率提升65%,并发能力提升87%
运维革命:实现分钟级集群扩容,故障自愈时间缩短至5分钟内
反爬突破:成功应对字体反爬、WebGL指纹等9类高级反爬机制
该方案已应用于金融数据采集、舆情监控等场景,日均处理数据量达5.8TB。未来将探索:
结合eBPF技术实现零拷贝网络传输
开发基于Rust的高性能爬虫内核
构建Serverless架构的弹性爬虫集群
核心价值主张:在动态网页和反爬技术双重升级的背景下,本文提供的混合架构为大规模数据采集提供了高性能、易维护的技术解决方案,特别适用于需要7×24小时不间断运行的中大型业务系统。
六、Python爬虫相关文章(推荐)
| Python爬虫介绍 | Python爬虫(1)Python爬虫:从原理到实战,一文掌握数据采集核心技术 |
| HTTP协议解析 | Python爬虫(2)Python爬虫入门:从HTTP协议解析到豆瓣电影数据抓取实战 |
| HTML核心技巧 | Python爬虫(3)HTML核心技巧:从零掌握class与id选择器,精准定位网页元素 |
| CSS核心机制 | Python爬虫(4)CSS核心机制:全面解析选择器分类、用法与实战应用 |
| 静态页面抓取实战 | Python爬虫(5)静态页面抓取实战:requests库请求头配置与反反爬策略详解 |
| 静态页面解析实战 | Python爬虫(6)静态页面解析实战:BeautifulSoup与lxml(XPath)高效提取数据指南 |
| Python数据存储实战 CSV文件 | Python爬虫(7)Python数据存储实战:CSV文件读写与复杂数据处理指南 |
| Python数据存储实战 JSON文件 | Python爬虫(8)Python数据存储实战:JSON文件读写与复杂结构化数据处理指南 |
| Python数据存储实战 MySQL数据库 | Python爬虫(9)Python数据存储实战:基于pymysql的MySQL数据库操作详解 |
| Python数据存储实战 MongoDB数据库 | Python爬虫(10)Python数据存储实战:基于pymongo的MongoDB开发深度指南 |
| Python数据存储实战 NoSQL数据库 | Python爬虫(11)Python数据存储实战:深入解析NoSQL数据库的核心应用与实战 |
| Python爬虫数据存储必备技能:JSON Schema校验 | Python爬虫(12)Python爬虫数据存储必备技能:JSON Schema校验实战与数据质量守护 |
| Python爬虫数据安全存储指南:AES加密 | Python爬虫(13)数据安全存储指南:AES加密实战与敏感数据防护策略 |
| Python爬虫数据存储新范式:云原生NoSQL服务 | Python爬虫(14)Python爬虫数据存储新范式:云原生NoSQL服务实战与运维成本革命 |
| Python爬虫数据存储新维度:AI驱动的数据库自治 | Python爬虫(15)Python爬虫数据存储新维度:AI驱动的数据库自治与智能优化实战 |
| Python爬虫数据存储新维度:Redis Edge近端计算赋能 | Python爬虫(16)Python爬虫数据存储新维度:Redis Edge近端计算赋能实时数据处理革命 |
| 反爬攻防战:随机请求头实战指南 | Python爬虫(17)反爬攻防战:随机请求头实战指南(fake_useragent库深度解析) |
| 反爬攻防战:动态IP池构建与代理IP | Python爬虫(18)反爬攻防战:动态IP池构建与代理IP实战指南(突破95%反爬封禁率) |
| Python爬虫破局动态页面:全链路解析 | Python爬虫(19)Python爬虫破局动态页面:逆向工程与无头浏览器全链路解析(从原理到企业级实战) |
| Python爬虫数据存储技巧:二进制格式性能优化 | Python爬虫(20)Python爬虫数据存储技巧:二进制格式(Pickle/Parquet)性能优化实战 |
| Python爬虫进阶:Selenium自动化处理动态页面 | Python爬虫(21)Python爬虫进阶:Selenium自动化处理动态页面实战解析 |
| Python爬虫:Scrapy框架动态页面爬取与高效数据管道设计 | Python爬虫(22)Python爬虫进阶:Scrapy框架动态页面爬取与高效数据管道设计 |
| Python爬虫性能飞跃:多线程与异步IO双引擎加速实战 | Python爬虫(23)Python爬虫性能飞跃:多线程与异步IO双引擎加速实战(concurrent.futures/aiohttp) |
| Python分布式爬虫架构实战:Scrapy-Redis亿级数据抓取方案设计 | Python爬虫(24)Python分布式爬虫架构实战:Scrapy-Redis亿级数据抓取方案设计 |
| Python爬虫数据清洗实战:Pandas结构化数据处理全指南 | Python爬虫(25)Python爬虫数据清洗实战:Pandas结构化数据处理全指南(去重/缺失值/异常值) |
| Python爬虫高阶:Scrapy+Selenium分布式动态爬虫架构实践 | Python爬虫(26)Python爬虫高阶:Scrapy+Selenium分布式动态爬虫架构实践 |
| Python爬虫高阶:双剑合璧Selenium动态渲染+BeautifulSoup静态解析实战 | Python爬虫(27)Python爬虫高阶:双剑合璧Selenium动态渲染+BeautifulSoup静态解析实战 |
| Python爬虫高阶:Selenium+Splash双引擎渲染实战与性能优化 | Python爬虫(28)Python爬虫高阶:Selenium+Splash双引擎渲染实战与性能优化 |
| Python爬虫高阶:动态页面处理与云原生部署全链路实践(Selenium、Scrapy、K8s) | Python爬虫(29)Python爬虫高阶:动态页面处理与云原生部署全链路实践(Selenium、Scrapy、K8s) |
| Python爬虫高阶:Selenium+Scrapy+Playwright融合架构 | Python爬虫(30)Python爬虫高阶:Selenium+Scrapy+Playwright融合架构,攻克动态页面与高反爬场景 |
| Python爬虫高阶:动态页面处理与Scrapy+Selenium+Celery弹性伸缩架构实战 | Python爬虫(31)Python爬虫高阶:动态页面处理与Scrapy+Selenium+Celery弹性伸缩架构实战 |
| Python爬虫高阶:Scrapy+Selenium+BeautifulSoup分布式架构深度解析实战 | Python爬虫(32)Python爬虫高阶:动态页面处理与Scrapy+Selenium+BeautifulSoup分布式架构深度解析实战 |
| Python爬虫高阶:动态页面破解与验证码OCR识别全流程实战 | Python爬虫(33)Python爬虫高阶:动态页面破解与验证码OCR识别全流程实战 |
| Python爬虫高阶:动态页面处理与Playwright增强控制深度解析 | Python爬虫(34)Python爬虫高阶:动态页面处理与Playwright增强控制深度解析 |
相关文章:
Python爬虫高阶:基于Docker集群的动态页面自动化采集系统实战)
Python爬虫(35)Python爬虫高阶:基于Docker集群的动态页面自动化采集系统实战
目录 一、技术演进与行业痛点二、核心技术栈深度解析2.1 动态渲染三件套2.2 Docker集群架构设计2.3 自动化调度系统 三、进阶实战案例3.1 电商价格监控系统1. 技术指标对比2. 实现细节 3.2 新闻聚合平台1. WebSocket监控2. 字体反爬破解 四、性能优化与运维方案4.1 资源消耗对比…...

运维打铁:生产服务器用户权限管理方案全解析
文章目录 一、引言二、方案设计2.1 权限模型选择2.2 角色定义2.3 权限分配2.4 用户与角色关联 三、相关代码注释(以 Linux 系统为例)3.1 用户创建与角色分配脚本3.2 权限设置脚本 四、常见问题解决4.1 用户无法登录4.2 用户权限不足4.3 权限文件修改后不…...

华为云Astro前端页面数据模型选型及绑定IoTDA物联网数据实施指南
目录 1. 选择合适的数据模型类型及推荐理由 自定义模型: 对象模型: 服务模型: 事件模型: 推荐方案: 2. 数据模型之间的逻辑关系说明 服务模型获取数据: 对象模型承接数据: 前端组件绑定显示: 数据保存与反馈(可选): (可选)事件模型实时更新: 小结 …...

【工具类】常用的工具类——CollectionUtil
目录 cn.hutool.core.collection.CollectionUtil集合创建集合清空集合判空集合去重集合过滤集合转换集合合并集合交集集合差集集合是否包含元素集合是否包含指定元素(自定义条件)集合分页集合分组集合转字符串元素添加元素删除根据属性转Map获取元素获取…...
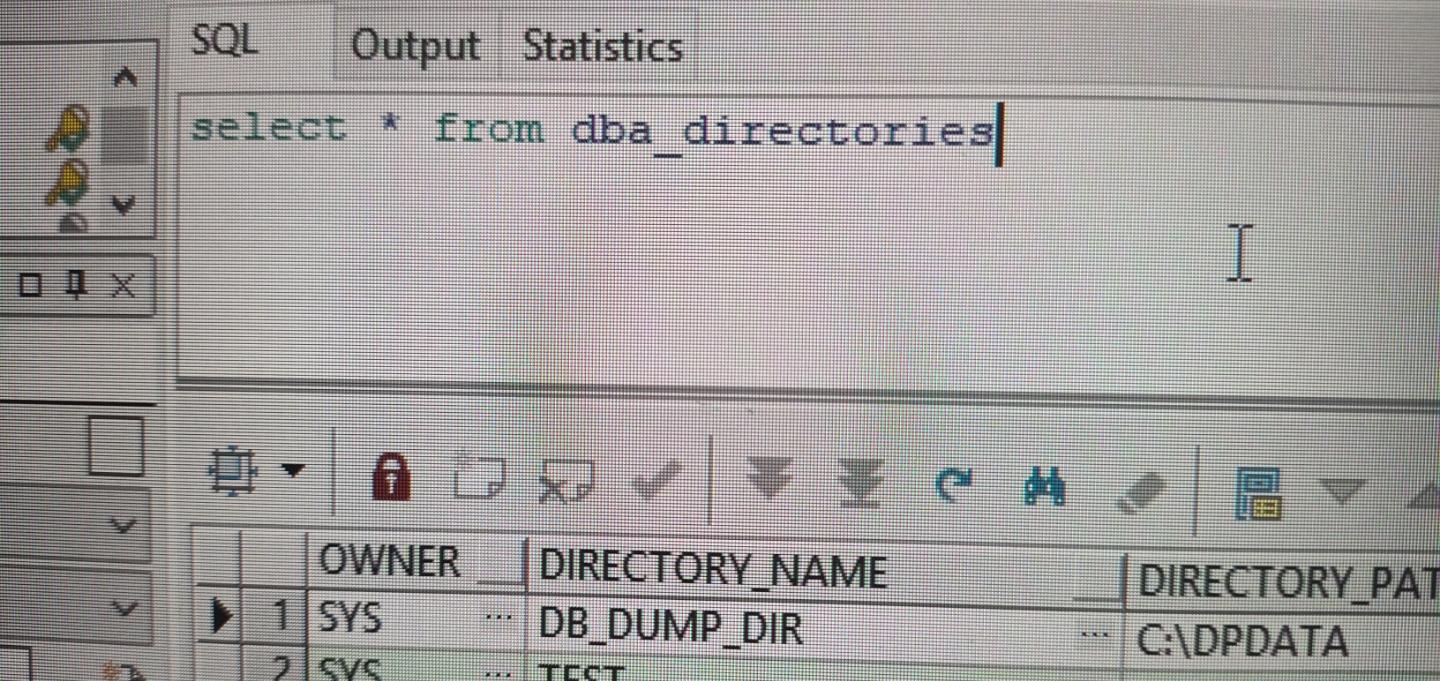
Oracle 11g导出数据库结构和数据
第一种方法:Plsql 利用plsql可视化工具导出,首先根据步骤导出表结构: 工具(Tools)->导出用户对象(export user objects)。 其次导出数据表结构: 工具(Tools)->导出表(export Tables)->选中表->sql inserts(where语…...
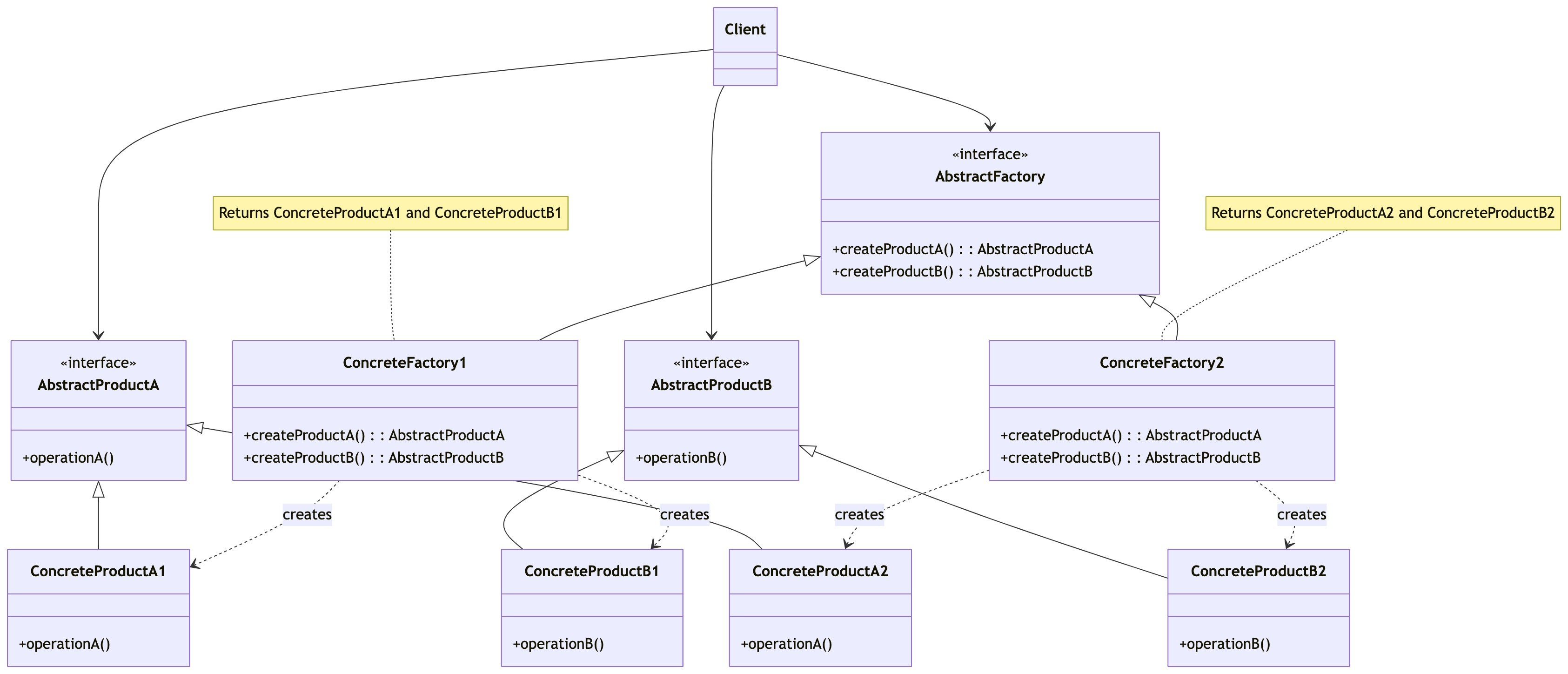
零基础设计模式——创建型模式 - 抽象工厂模式
第二部分:创建型模式 - 抽象工厂模式 (Abstract Factory Pattern) 我们已经学习了单例模式(保证唯一实例)和工厂方法模式(延迟创建到子类)。现在,我们来探讨创建型模式中更为复杂和强大的一个——抽象工厂…...
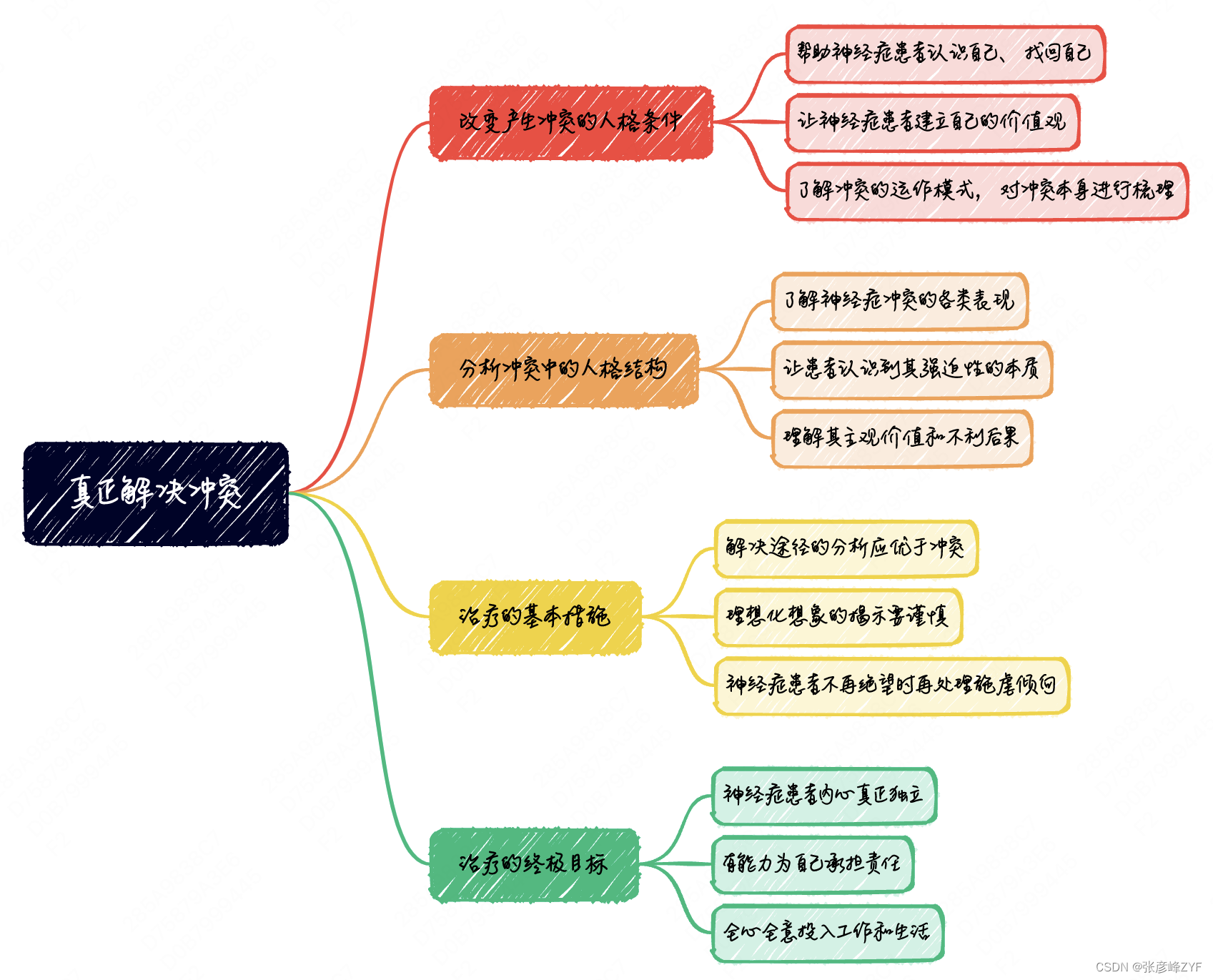
解锁内心的冲突:神经症冲突的理解与解决之道
目录 一、神经症冲突概述 二、冲突的基本类型 三、未解决冲突的后果 四、尝试解决的途径 五、真正解决冲突 六、总结 干货分享,感谢您的阅读! 人类的内心世界复杂多变,常常充满了各种冲突和矛盾。每个人在成长的过程中,都或…...

JVM—Java对象
JVM中的Java对象在堆内存中的存储分布可以分为对象头,实例数据和对齐填充三部分 对象头: 包含运行时元数据和类型指针 1、Mark Word(标记字段) 对象自身的运行时数据: 锁状态标志(无锁、偏向锁、轻量级…...
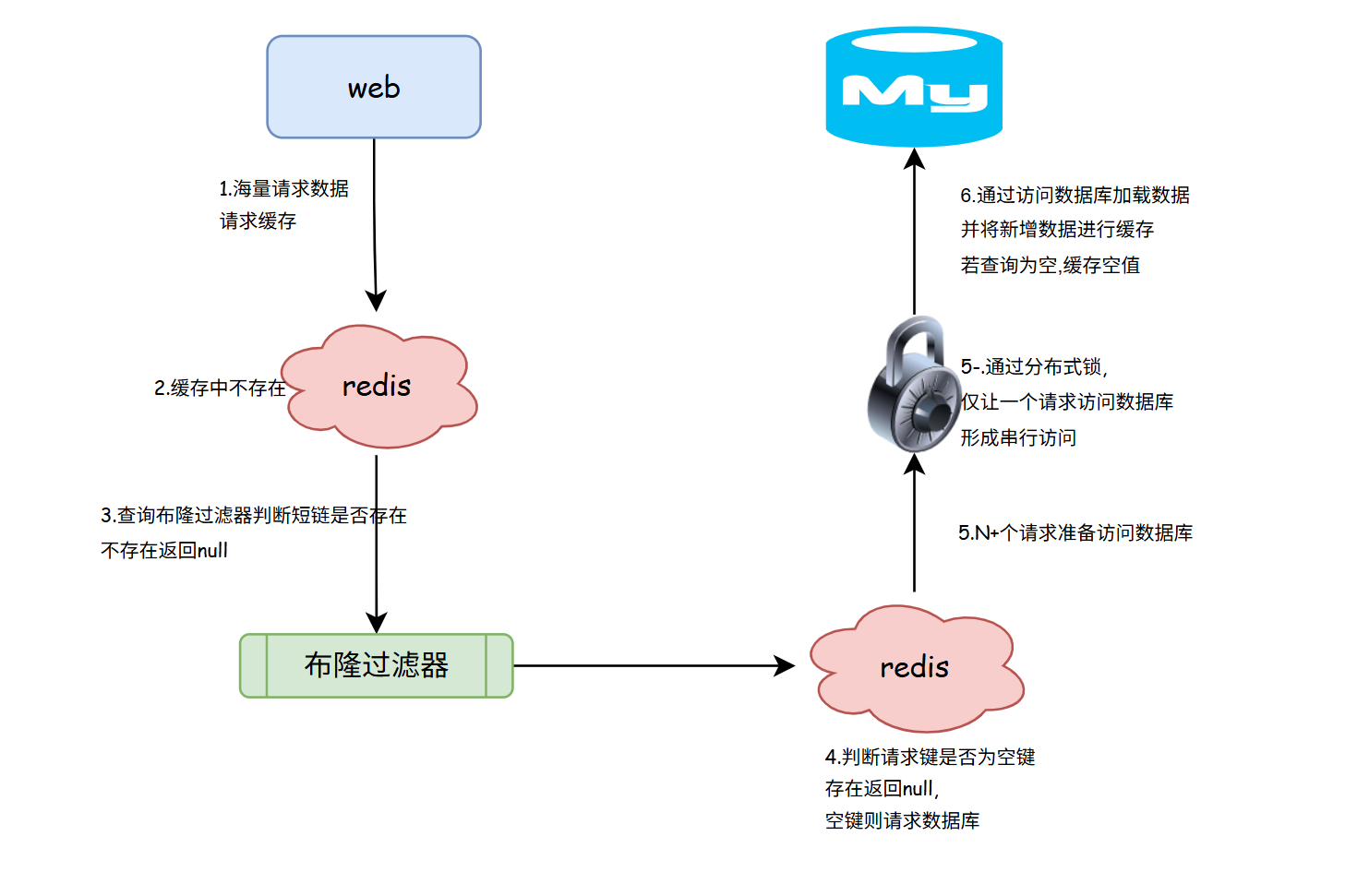
Redisson读写锁和分布式锁的项目实践
解决方案:采用读写锁 什么是读写锁 Redisson读写锁是一种基于Redis实现特殊的机制,用于在分布式系统中协调对共享资源的访问,其继承了Java中的ReentrantReadWriteLock的思想.特别适用于读多写少的场景.其核心是:允许多个线程同时读取共享资源,但写操作必须占用资源.从而保证线…...

Https流式输出一次输出一大段,一卡一卡的-解决方案
【背景】 最近遇到一个奇怪的现象,前端vue,后端python,服务部署在服务器上面后,本来一切正常,但公司说要使用https访问,想着也没什么问题,切过去发现在没有更改任何代码的情况下,ht…...

SkyWalking高频采集泄漏线程导致CPU满载排查思路
SkyWalking高频采集泄漏线程导致CPU满载排查思路 契机 最近在消除线上服务告警,发现Java线上测试服经常CPU满载告警,以前都是重启解决,今天好好研究下,打arthas火焰图发现是SkyWalking-agent的线程采集任务一直在吃cpuÿ…...

【HarmonyOS 5】Map Kit 地图服务之应用内地图加载
#HarmonyOS SDK应用服务,#Map Kit,#应用内地图 目录 前期准备 AGC 平台创建项目并创建APP ID 生成调试证书 生成应用证书 p12 与签名文件 csr 获取 cer 数字证书文件 获取 p7b 证书文件 配置项目签名 配置签名证书指纹 项目开发 配置Client I…...

ld: cpu type/subtype in slice (arm64e.old) does not match fat header (arm64e)
ld: cpu type/subtype in slice (arm64e.old) does not match fat header (arm64e) in ‘/Users/*****/MposApp/MposApp/Modules/Common/Mpos/NewLand/MESDK.framework/MESDK’ clang: error: linker command failed with exit code 1 (use -v to see invocation) 报错 解决方…...

sentinel核心原理-高频问题
核心原理 限流实现机制 滑动窗口算法:将时间切分为子窗口动态统计QPS,避免固定窗口的边界问题。责任链模式:通过NodeSelectorSlot、FlowSlot等Slot链式处理限流逻辑。 熔断降级策略 慢调用比例:当慢请求比例…...

通过vue-pdf和print-js实现PDF和图片在线预览
npm install vue-pdf npm install print-js <template><div><!-- PDF 预览模态框 --><a-modal:visible"showDialog":footer"null"cancel"handleCancel":width"800":maskClosable"true":keyboard"…...

RxJS 核心操作符详细用法示例
1. Observable 详细用法 Observable 是 RxJS 的核心概念,代表一个可观察的数据流。 创建和订阅 Observable import { Observable } from "rxjs";// 1. 创建Observable const myObservable new Observable(subscriber > {// 发出三个值subscriber.n…...

视频监控管理平台EasyCVR结合AI分析技术构建高空抛物智能监控系统,筑牢社区安全防护网
高空抛物严重威胁居民生命安全与公共秩序,传统监管手段存在追责难、威慑弱等问题。本方案基于EasyCVR视频监控与AI视频分析技术(智能分析网关),构建高空抛物智能监控系统,实现24小时实时监测、智能识别与精准预警&…...

2.2.1 05年T1复习
引言 从现在进去考研英语基础阶段的进阶,主要任务还是05-09年阅读真题的解题,在本阶段需要注意正确率。阅读最后目标:32-34分,也就是每年真题最多错四个。 做题步骤: 1. 预习:读题干并找关键词 做题&#…...

Python-11(集合)
与字典类似,集合最大的特点就是唯一性。集合中所有的元素都应该是独一无二的,并且也是无序的。 创建集合 使用花括号 set {"python","Java"} print(type(set)) 使用集合推导式 set {s for s in "python"} print(set…...

钉钉开发之AI消息和卡片交互开发文档收集
AI消息和卡片交互开发文档 智能交互接口能力介绍 AI助理发消息(主动直接发送模式 AI 助理发消息 - 主动发送模式 AI 助理发消息 - 回复消息模式 AI 助理发消息 - Webhook 回复消息模式 Stream 模式响应卡片回传请求事件 upload-media-files AI 助理发消息&a…...

JMeter 教程:正则表达式提取器提取 JSON 字段数据
目录 JMeter 教程:正则表达式提取器提取 JSON 字段数据【简单实用】 ✅ 目的说明 📄 示例场景 🛠️ 操作步骤 第一步:发送 HTTP 请求 第二步:添加正则表达式提取器 第三步:使用提取变量 ✅ 正则表达…...
Opixs: Fluxim推出的全新显示仿真模拟软件
Opixs 是 Fluxim 最新研发的显示仿真模拟软件,旨在应对当今显示技术日益复杂的挑战。通过 Opixs,研究人员和工程师可以在制造前,设计并验证 新的像素架构,从而找出更功节能、色彩表现更优的布局方案。 Opixs 适用于学术研究和工业…...

[数据集]无人机视角检测分割数据集合集
数据集名称无人机海洋或河道水上监测检测数据集VOCYOLO格式2903张6类别无人机热红外视角人车检测数据集VOCYOLO格式2866张5类别无人机拍摄红外图像光伏板缺陷检测数据集VOCYOLO格式2723张9类别无人机视角搜索和救援失踪被困人员检测数据集VOCYOLO格式1976张6类别无人机视角垃圾…...

佰力博与您探讨PVDF薄膜极化特性及其影响因素
PVDF(聚偏氟乙烯)薄膜的极化是其压电性能形成的关键步骤,通过极化处理可以显著提高其压电系数和储能能力。极化过程涉及多种方法和条件,以下从不同角度详细说明PVDF薄膜的极化特性及其影响因素。 1、极化方法 热极化:…...
 函数全解析)
C++ std::find() 函数全解析
std::find()是C标准库中用于线性查找的基础算法,属于<algorithm>头文件,可应用于任何支持迭代器的容器。 一、函数原型与参数 template< class InputIt, class T > InputIt find( InputIt first, InputIt last, const T& value );…...

自动获取ip地址安全吗?如何自动获取ip地址
在数字化网络环境中,IP地址的获取方式直接影响设备连接的便捷性与安全性。自动获取IP地址(通过DHCP协议)虽简化了配置流程,但其安全性常引发用户疑虑。那么,自动获取IP地址安全吗?如何自动获取IP地址&#…...
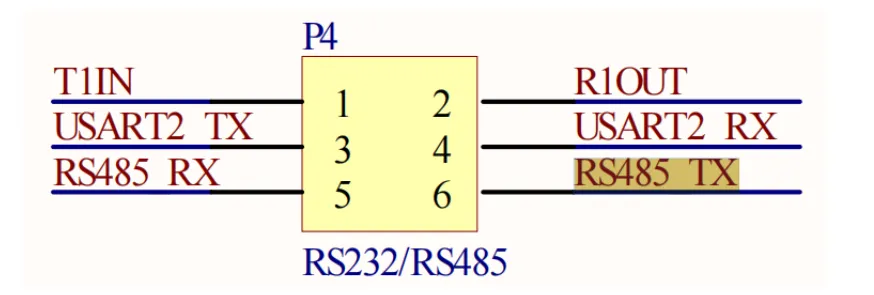
STM32:深度解析RS-485总线与SP3485芯片
32个设备 知识点1【RS-485的简介】 RS-485是一种物理层差分总线标准,在串口的基础上演变而来; 两者虽然不在同一层次上直接对等,但在实际系统中,往往使用RS-485驱动差分总线,将USART转换为适合长距离、多点通信的物…...

亚马逊搜索代理: 终极指南
文章目录 前言一、为什么需要代理来搜索亚马逊二、如何选择正确的代理三、搜索亚马逊的最佳代理类型四、为亚马逊搜索设置代理五、常见挑战及克服方法六、亚马逊搜索的替代方法总结 前言 在没有代理的情况下搜索亚马逊会导致 IP 禁止、验证码和速度限制,从而使数据…...
函数没反应))
QGraphicsView界面的坑(fitInView()函数没反应)
QGraphicsView本身是特别灵活的一种ui,能够自由响应各种动态操作。不过它最大的问题就是在加载好图像以后,将图像自适应贴合到界面大小的时候(fitInView()函数)没有反应。 这是因为fitInView函数在执行的时候,需要计算…...

【Python正则表达式终极指南】从零到工程级实战
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...