【Python 基础与实战】从基础语法到项目应用的全流程解析
(1)列表和元组的区别是什么?如何从列表创建元组?如何从元组创建列表?
列表和元组的区别:
- 可变性:列表是可变的,即可以对列表进行元素的增、删、改操作。例如,可以使用
append()方法添加元素,remove()方法删除元素,通过索引修改元素值。而元组是不可变的,一旦创建,其元素内容和数量都不能改变,尝试修改元组元素会引发错误。- 语法表示:列表使用方括号
[]来表示,如my_list = [1, 2, 3];元组使用圆括号()来表示,如my_tuple = (1, 2, 3),不过在创建只包含一个元素的元组时,需要在元素后面加逗号,如single_tuple = (1,),否则(1)会被视为整数1。- 应用场景:由于列表的可变性,常用于需要频繁修改数据的场景,如动态存储用户输入的数据。元组的不可变性使其更适合存储一些固定不变的数据,比如坐标值、函数的多个返回值等,同时元组还可作为字典的键,因为字典键要求是不可变类型。
- 性能:在创建相同内容的数据时,元组的创建时间和占用内存空间通常比列表小。因为列表除了存储元素外,还需额外存储长度、闲置位置等信息。
从列表创建元组 可以使用内置函数
tuple(),将列表作为参数传入,即可将列表转换为元组。从元组创建列表 使用内置函数
list(),把元组作为参数传入,就能将元组转换为列表。
(2)下面代码的错误是什么?
t=(1,2.3)
t.append(4)
t.remove(0)
t[0]=1
元组是不可变的,不能进行添加、删除操作。
(3)下面的代码正确吗?
t1 = (1,2,3,7,9,0,5)
t2 = (1,2,5)
t1 = t2
正确,t2赋值给t1。
(4)给出下面代码的输出?
t1=(1,2,3,7,9,0,5)
t2=(1,3,22,7,9,0,5)
print(t1 == t2)
print(t1 != t2)
print(t1 > t2)
print(t1 < t2)
False
True
False
True
(5)列表、集合或元组能有不同类型的元素吗?
列表和元组可以有不同类型的元素
集合里面的元素必须是可哈希的(即不可变类型)
(6)下面哪个集合是被正确创建的?
s ={1,3,4}
s ={{1,2},{4,5}}
s ={[1,2],[4,5]}
s ={(1,2),(4,5)}
1 4集合是被正确创建的
(7)给出下面代码的输出。
students ={"peter","john"}
print(students)
students.add("john")
print(students)
students.add("peterson")
print(students)
students.remove("peter")
print(students)
{‘peter’, ‘john’}
{‘peter’, ‘john’}
{‘peter’, ‘john’, ‘peterson’}
{‘john’, ‘peterson’}
(8)给出下面代码的输出。
student1 ={"peter","john","tim"}
student2 ={"peter","johnson","tim"}
print(student1.issuperset({"john"}))
print(studentl.issubset(student2))
print({1,2,3} > {1,2,4})
print({1,2,3} < {1,2,4})
print({1,2} < {1,2,4})
print({1,2} <= {1,2,4})
True
False
False
False
True
True
(9)给出下面代码的输出。
s1={1,4,5,6}
s2={1,3,6,7}
print(s1.union(s2))
print(s1 | s2)
print(s1.intersection(s2))
print(s1 & s2)
print(s1.difference(s2))
print(s1 - s2)
print(s1.symmetric_difference(s2))
print(s1 ^ s2)
{1, 3, 4, 5, 6, 7}
{1, 3, 4, 5, 6, 7}
{1, 6}
{1, 6}
{4, 5}
{4, 5}
{3, 4, 5, 7}
{3, 4, 5, 7}
(10)给出下面代码的输出。
set1 = {1,2,3}
set2 = {3,4,5}
set3 = set1 | set2
print(set1,set2,set3)
set3 = set1 - set2
print(set1,set2,set3)
set3=set1 & set2
print(set1,set2,set3)
set3=set1 ^ set2
print(set1,set2,set3)
{1, 2, 3} {3, 4, 5} {1, 2, 3, 4, 5}
{1, 2, 3} {3, 4, 5} {1, 2}
{1, 2, 3} {3, 4, 5} {3}
{1, 2, 3} {3, 4, 5} {1, 2, 4, 5}
(11)下面哪个字典是被正确创建的?
d={1:[1,2],3:[3,4]}
d={[1,2]:1,[3,4]:3}
d={(1,2):1,(3,4):3}
d={1:"john", 3:"peter"}
d={"john":1,"peter":3}
1 3 4 5被正确创建
(12)假设一个名为 students 的字典是 {“john”:3,“peter”:2}。下面的语句实现什么功能?
(a) print(len(students))
(b) print(students.keys())
(c) print(students.values())
(d) print(students.items())
(a) 打印字典student的长度:2
(b)打印字典的键:dict_keys([‘john’, ‘peter’])
©打印字典的值:dict_values([3, 2])
(d)打印字典的键值对:dict_items([(‘john’, 3), (‘peter’, 2)])
(13)给出下面代码的输出。
def main():d = {"red":4,"blue":1,"green":14,"yellow":2}print(d["red"])print(list(d.keys()))print(list(d.values))print("blue" in d)print("purple" in d)d["blue"] += 10print(d["blue"])main() #Call the main function
4
[‘red’, ‘blue’, ‘green’, ‘yellow’]
[4, 1, 14, 2]
True
False
11
(14)给出下面代码的输出。
def main():d = {}d["susan"]= 50d["jim"]= 45d["joan"]= 54d["susan"]= 51d["john"]= 53print(len(d))
main() #Call the main function
4
二、编程题
(15)学生成绩统计
学校记录了学生们多门课程的成绩,每门课程成绩以字典形式存储,学生姓名作为键,成绩作为值。现在需要统计每个学生的平均成绩,并找出平均成绩最高的学生。
# 每门课学生的成绩
course_scores = [{'Alice': 85, 'Bob': 90, 'Charlie': 78},{'Alice': 92, 'Bob': 88, 'Charlie': 85},{'Alice': 79, 'Bob': 94, 'Charlie': 82}
]
# 每门课学生的成绩
course_scores = [{'Alice': 85, 'Bob': 90, 'Charlie': 78},{'Alice': 92, 'Bob': 88, 'Charlie': 85},{'Alice': 79, 'Bob': 94, 'Charlie': 82}
]dic_course_scores = {}
#遍历列表 即获取每一组字典
for i in range(len(course_scores)):#遍历字典 取每一组键值for key, values in course_scores[i].items():# 判断当前学生是否在新字典中,如果不存在则记录if key not in dic_course_scores:dic_course_scores[key] = values#存在 求新的平均值else:dic_course_scores[key] = (dic_course_scores[key] + values) / (i + 1)
#找出平均成绩最高的学生姓名
max_key = max(dic_course_scores, key = dic_course_scores.get)print(f"每个学生的平均成绩为{dic_course_scores}")
print(f"平均成绩最高的学生是:{max_key}")
(16)商品库存管理
一家商店有多个商品的库存信息,以字典形式存储,键为商品名称,值为库存数量。每天会有新的进货和销售记录,需要更新库存信息。如果库存数量变为负数,则输出警告信息。
# 初始货物量
inventory = {'苹果': 100, '香蕉': 80, '橙子': 120}
# 进货/销售记录
transactions = [{'苹果': -20, '香蕉': 30},{'橙子': -50, '苹果': 10}
]
# 初始货物量
inventory = {'苹果': 100, '香蕉': 80, '橙子': 120}
# 进货/销售记录
transactions = [{'苹果': -220, '香蕉': 30},{'橙子': -50, '苹果': 10, '西瓜': 50}
]for goods in transactions:# 遍历交易中的商品和数量for fruits, num in goods.items():if fruits not in inventory:inventory[fruits] = 0# 更新inventory[fruits] += numfor fruit in inventory:# 检查库存if inventory[fruit] < 0:print(f"{fruit}库存不够,请及时补充!!!")
print(inventory)
(17)社交网络好友关系【录制讲解】
视频链接::https://meeting.tencent.com/crm/KDLyo5PXf2
在一个社交网络中,用户之间的好友关系用字典表示,键为用户名称,值为该用户的好友集合。现在需要找出哪些用户是所有用户的共同好友。
# 好友关系表
friendships = {'Alice': {'Bob', 'Charlie', 'David'},'Bob': {'Alice', 'Charlie'},'Charlie': {'Alice', 'Bob', 'David'},'David': {'Alice', 'Charlie'}
}
# 好友关系表
friendships = {'Alice': {'Bob', 'Charlie', 'David'},'Bob': {'Alice', 'Charlie'},'Charlie': {'Alice', 'Bob', 'David'},'David': {'Alice', 'Charlie'}
}
for user in friendships.keys():friendships[user].add(user)common_friends = set(friendships[list(friendships.keys())[0]])
for friends in friendships.values():common_friends = common_friends & set(friends)
print(common_friends)
(18)在线游戏玩家组队匹配
在线游戏中有多个玩家,每个玩家有不同的游戏角色和技能等级,用字典表示,键为玩家名,值为角色和技能等级的字典。现在要根据玩家的角色和技能等级进行组队匹配,使每个队伍的综合实力尽量均衡。
# 玩家数据
players = {'Player1': {'Warrior': 80, 'Mage': 20},'Player2': {'Warrior': 30, 'Mage': 70},'Player3': {'Warrior': 60, 'Mage': 40},'Player4': {'Warrior': 40, 'Mage': 60}
}
# 玩家信息字典,键为玩家名,值为角色和对应技能等级的字典
game_players = {'Player1': {'Warrior': 80, 'Mage': 20},'Player2': {'Warrior': 30, 'Mage': 70},'Player3': {'Warrior': 60, 'Mage': 40},'Player4': {'Warrior': 40, 'Mage': 60}
}# 用于存储每个玩家综合实力的字典
player_power_dict = {}
# 计算每个玩家的综合实力,即各角色技能等级之和
for gamer, skills in game_players.items():total_power = sum(skills.values())player_power_dict[gamer] = total_power# 分别提取玩家名列表和对应的综合实力值列表
player_names = list(player_power_dict.keys())
player_powers = list(player_power_dict.values())# 使用冒泡排序对玩家按综合实力从高到低排序
n = len(player_powers)
for i in range(n - 1):for j in range(0, n - i - 1):if player_powers[j] < player_powers[j + 1]:player_powers[j], player_powers[j + 1] = player_powers[j + 1], player_powers[j]player_names[j], player_names[j + 1] = player_names[j + 1], player_names[j]# 初始化左右指针,用于组队
left_index = 0
right_index = len(player_names) - 1
# 进行组队匹配,输出组队结果
while left_index < right_index:print({player_names[left_index]}, {player_names[right_index]})left_index += 1right_index -= 1
(19)餐厅菜品搭配分析
餐厅有多个菜品分类,每个分类有不同的菜品,用字典表示,键为分类名,值为菜品集合。现在要找出所有可能的菜品搭配,每个搭配包含主菜、配菜和饮品。
# 菜品分类信息
menu_categories = {'主菜': {'牛排', '披萨', '寿司'},'配菜': {'薯条', '沙拉', '烤蔬菜'},'饮品': {'可乐', '咖啡', '果汁'}
}
menu_categories = {'主菜': {'牛排', '披萨', '寿司'},'配菜': {'薯条', '沙拉', '烤蔬菜'},'饮品': {'可乐', '咖啡', '果汁'}
}for zhucai in menu_categories['主菜']:for peicai in menu_categories['配菜']:for drink in menu_categories['饮品']:print(f"主菜:{zhucai}, 配菜:{peicai}, 饮品:{drink}")
(20)科研项目人员分配优化【录制讲解】
视频链接: https://meeting.tencent.com/crm/NbVzmYpJ5a
有多个科研项目,每个项目需要不同技能的人员,用字典表示,键为项目名,值为所需技能集合。同时有多个研究人员,每个人员具备的技能也用集合表示。现在要为每个项目分配合适的人员,使每个项目尽量满足所需技能。
# 项目及技能需求
projects = {'ProjectA': {'Python', '数据分析', '机器学习'},'ProjectB': {'Java', '数据库管理', '算法设计'},'ProjectC': {'C++', '图像处理', '计算机视觉'}
}
# 人员及具备技能
researchers = {'Researcher1': {'Python', '数据分析'},'Researcher2': {'Java', '数据库管理'},'Researcher3': {'C++', '图像处理'},'Researcher4': {'机器学习', '算法设计', '计算机视觉'}
}
# 项目及技能需求
projects = {'ProjectA': {'Python', '数据分析', '机器学习'},'ProjectB': {'Java', '数据库管理', '算法设计'},'ProjectC': {'C++', '图像处理', '计算机视觉'}
}
# 人员及具备技能
researchers = {'Researcher1': {'Python', '数据分析'},'Researcher2': {'Java', '数据库管理'},'Researcher3': {'C++', '图像处理'},'Researcher4': {'机器学习', '算法设计', '计算机视觉'}
}
dic = {}
for key_pro, values_pro in projects.items():for key_res, values_res in researchers.items():if values_pro & values_res:if key_pro not in dic:dic[key_pro] = []dic[key_pro].append(key_res)
print(dic)
相关文章:

【Python 基础与实战】从基础语法到项目应用的全流程解析
(1)列表和元组的区别是什么?如何从列表创建元组?如何从元组创建列表? 列表和元组的区别: 可变性:列表是可变的,即可以对列表进行元素的增、删、改操作。例如,可以使用append()方法添加元素,r…...
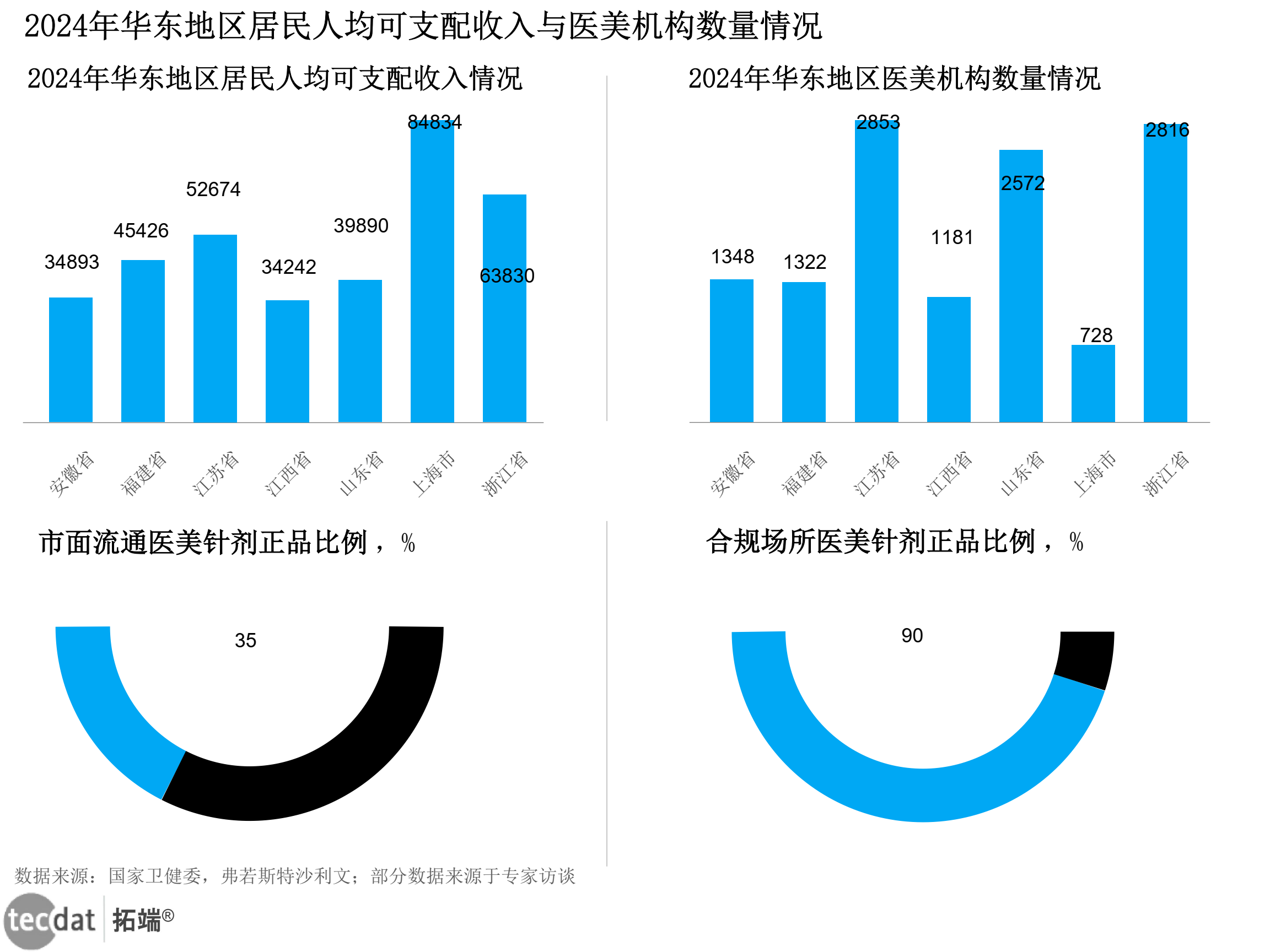
2025年医美行业报告60+份汇总解读 | 附 PDF 下载
原文链接:https://tecdat.cn/?p42122 医美行业在消费升级与技术迭代的双重驱动下,已从边缘市场逐步走向主流。数据显示,2024 年中国医美市场规模突破 3000 亿元,年复合增长率达 15%,但行业仍面临正品率不足、区域发展…...

API自动化与持续集成核心实战知识点!
想象一下,你开发的API像一辆跑车,性能强劲,但你如何确保它每次启动都完美无缺?或者你的代码像一道复杂的菜肴,如何保证每次更新都不破坏原有味道?答案就是API自动化测试与持续集成!SuperTest让你…...
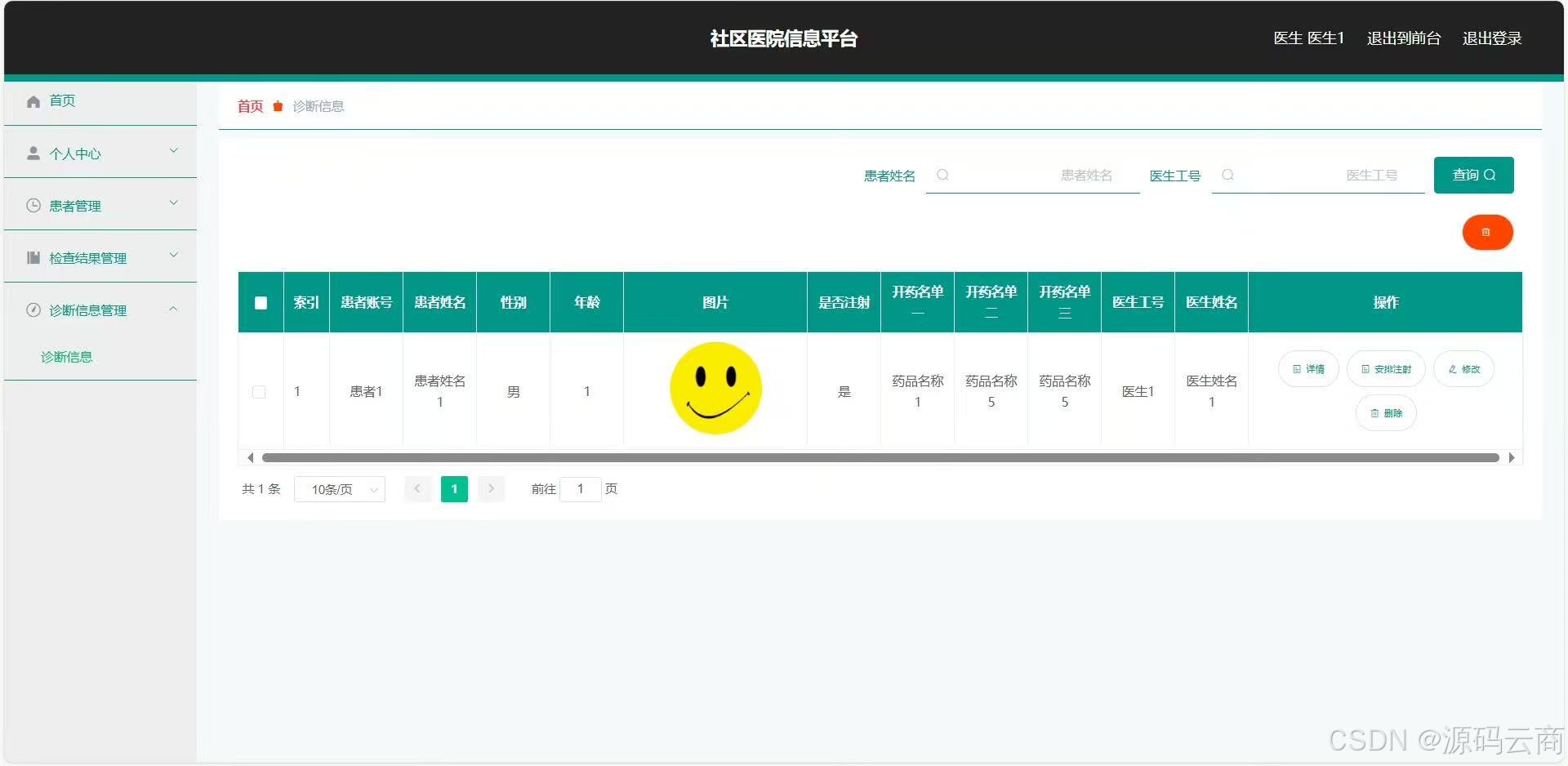
基于SpringBoot+Vue的社区医院信息平台设计与实现
项目背景与概述 随着医疗健康信息化的发展,社区医院的管理逐渐由传统的手工模式转向信息化管理。为了提高医院的管理效率、减少人工操作、提升服务质量,开发一个高效且实用的社区医院信息平台显得尤为重要。本系统基于Spring Boot框架与MySQL数据库设计…...
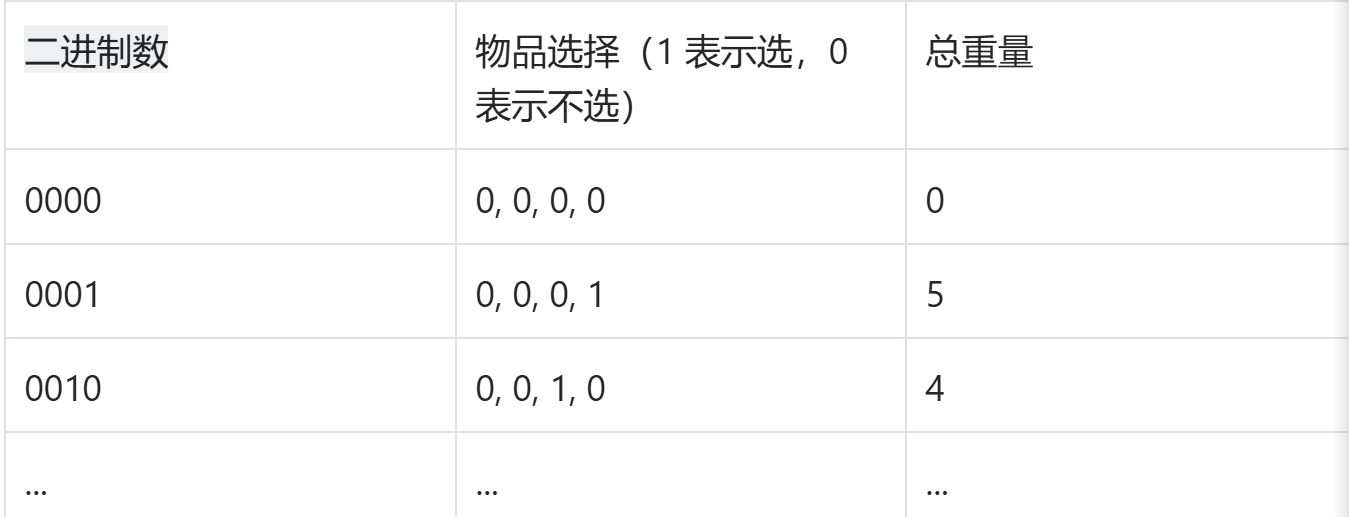
C++ 中的暴力破解算法
一、暴力破解算法原理 暴力破解算法,顾名思义,就是通过穷举所有可能的解,逐一验证,直到找到满足条件的解。它不依赖复杂的逻辑推导或数学优化,而是依靠计算机强大的计算能力,将所有可能的情况都尝试一遍…...

前端[插件化]设计思想_Vue、React、Webpack、Vite、Element Plus、Ant Design
前端插件化设计思想旨在提升应用的可扩展性、可维护性和模块化程度。这种思想不仅体现在框架(如 Vue、React)中,也广泛应用于构建工具(如 Webpack、Vite)以及 UI 库(如 Element Plus、Ant Design࿰…...

率先实现混合搜索:使用 Elasticsearch 和 Semantic Kernel
作者:来自 Elastic Enrico Zimuel 及 Florian Bernd 混合搜索功能现在已在 .NET Elasticsearch Semantic Kernel 连接器中提供。阅读这篇博客文章了解如何开始使用。 Elasticsearch 已原生集成业内领先的生成式 AI 工具和服务提供商。欢迎观看我们的网络研讨会&…...
:js语法、css语法)
uni-app(4):js语法、css语法
1 js语法 uni-app的js API由标准ECMAScript的js API 和 uni 扩展 API 这两部分组成。标准ECMAScript的js仅是最基础的js。浏览器基于它扩展了window、document、navigator等对象。小程序也基于标准js扩展了各种wx.xx、my.xx、swan.xx的API。node也扩展了fs等模块。uni-app基于E…...

基于SpringBoot的网上租赁系统设计与实现
项目简介 本项目是基于 Spring Boot Vue 技术栈开发的 网上租赁系统。该系统通过前后端分离的架构,提供用户和管理员两种角色的操作权限,方便用户进行商品租赁、订单管理、信息查询等操作,同时也为管理员提供了商品管理、用户管理、订单管理…...

kafka吞吐量提升总结
前言 原本自以为阅读了很久kafka的源码,对于kafka的了解已经深入到一定程度了,后面在某大厂的面试中,面试官询问我,如果需要提升kafka的性能,应该怎么做,我发现我能答上来的点非常的少,也暴露了…...

AI浪潮下,第五消费时代的商业进化密码
解锁 AI 与第五消费时代 在时代的长河中,消费浪潮的更迭深刻地影响着商业的格局。当下,我们正处于第五消费时代,这个时代有着鲜明的特征,如老龄化、单身化趋势日益显著,社会逐渐步入低欲望、个性化与共享化并行的阶段 。随着人工智能技术的飞速发展,它在商业领域的渗透也…...

Vue组件开发深度指南:构建可复用与可维护的UI
Vue组件开发深度指南:构建可复用与可维护的UI 在现代前端开发中,组件化是构建复杂用户界面的核心思想。Vue.js 以其简洁、高效的组件系统,成为了众多开发者的首选框架之一。理解并熟练运用Vue组件开发,能够显著提升开发效率、代码…...

青少年编程与数学 02-019 Rust 编程基础 20课题、面向对象
青少年编程与数学 02-019 Rust 编程基础 20课题、面向对象 一、面向对象的编程特性(一)封装(Encapsulation)(二)多态(Polymorphism)(三)继承(Inhe…...
Jouier 普及组十连测 R4
反思 本次比赛到时没有什么细节错误,不过代码思路不好所以分数也不是很高。 T1 代码思路 看题意,发现数据范围不大,直接动用码力暴力即可。 代码 #include<bits/stdc.h> using namespace std;vector<vector<int> > a(110…...
bi平台是什么意思?bi平台具体有什么作用?
目录 一、BI平台是什么意思 1. 具体内涵 2. 主要构成 二、BI 平台具体有什么作用 1. 提供全面的数据洞察 2. 支持快速决策 3. 优化业务流程 4. 提升企业协作 三、BI 平台的应用场景 1. 金融行业 2. 零售行业 3. 制造行业 4. 医疗行业 总结 “每天在海量数据中反复…...
】)
【机械视觉】Halcon—【二、Halcon算子全面介绍(超详细版)】
介绍 Halcon 的算子(operators)按照功能被系统性地划分为多个类别,官方文档中目前(Halcon 22.11 版本)共有 19 个主分类,每个主分类下还有若干子分类。 本人在此对这19个分类的常用核心算子进行了一系列的…...
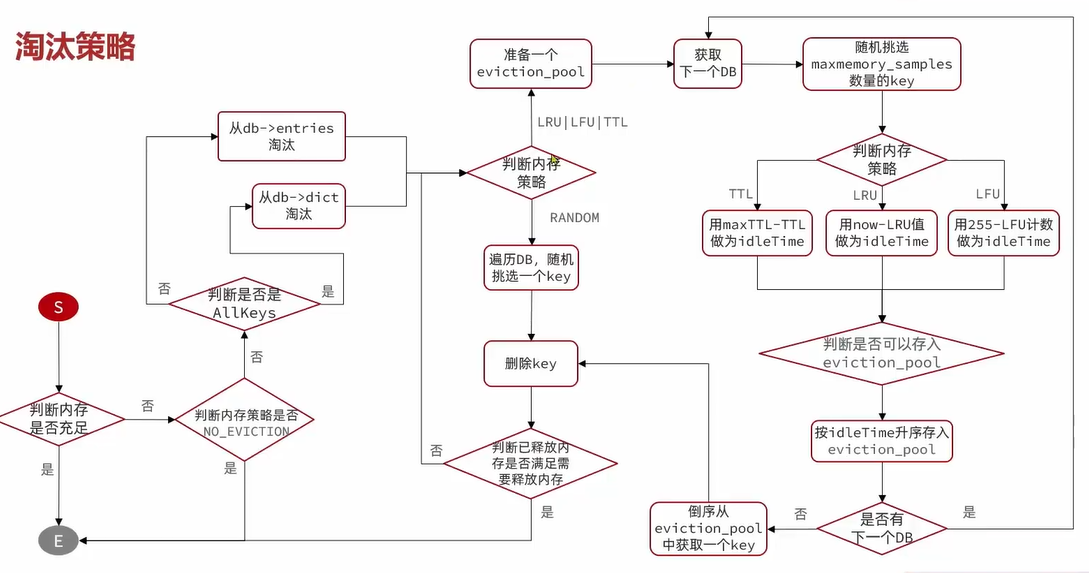
Redis从入门到实战 - 原理篇
一、数据结构 1. 动态字符串SDS 我们都知道Redis中保存的key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。 不过Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题: 获取字符串长…...

26考研|高等代数:线性变换
前言 线性变换这一章节是考频较高的一部分,此部分涉及考点较多,涉及的考题也较多,学习线性变换时,应该注意搭建线性变换与矩阵之间的联系,掌握如何利用矩阵表示一个线性变换结构,同时介绍了最简单的线性变…...
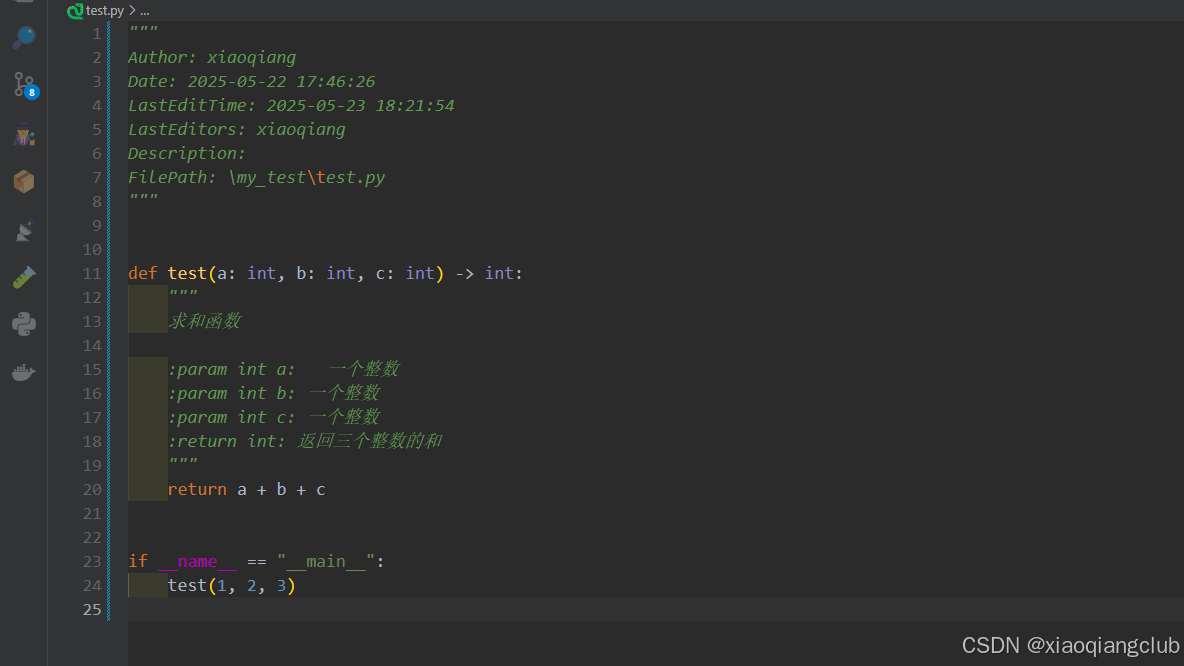
VSCode如何像Pycharm一样“““回车快速生成函数注释文档?如何设置文档的样式?autoDocstring如何设置自定义模板?
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 让VSCode拥有PyCharm级注释生成能力 📒🚀 实现方案🛠️ 备用方案📒 自定义注释文档格式样式 📒🔄 切换主流注释风格✨ 深度自定义模板🛠️ 类型提示与注释联动优化⚓️ 相关链接 ⚓️📖 介绍 📖 用PyCharm写P…...
——再谈操作系统)
Linux(5)——再谈操作系统
当我们打开电脑或手机,看到熟悉的桌面界面或 App 图标时,是否想过这些功能背后是谁在“指挥”?答案就是:操作系统(Operating System, 简称 OS)。今天,我们来初步认识一下这个掌管我们设备的“幕…...

TCP实现双向通信练习题
1. 客户端代码:Client.java package com.xie.javase.net3;import java.io.*; import java.net.InetAddress; import java.net.Socket;/*** TCP客户端:向服务端发送图片,并接收服务端响应*/ public class Client {public static void main(St…...
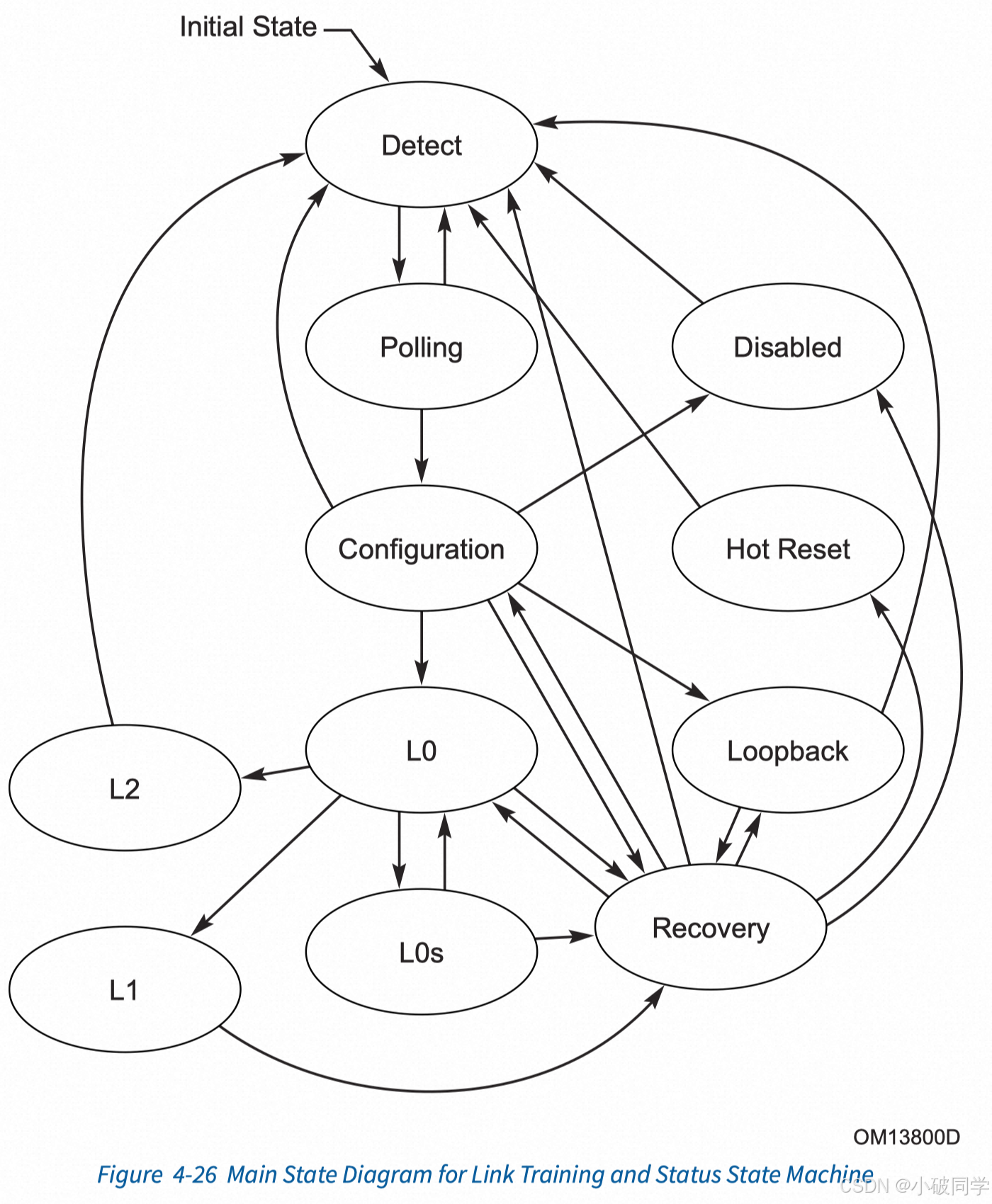
PCIe学习笔记(3)链路初始化和训练
PCIe学习系列往期文章 PCIe学习笔记(1)Hot-Plug机制 PCIe学习笔记(2)错误处理和AER/DPC功能 文章目录 链路训练概述Bit LockSymbol Lock (Gen1/2)Block Alignment (Gen3)Lane Polarity InversionLane ReversalLane-to-Lane De-ske…...
Python爬虫高阶:基于Docker集群的动态页面自动化采集系统实战)
Python爬虫(35)Python爬虫高阶:基于Docker集群的动态页面自动化采集系统实战
目录 一、技术演进与行业痛点二、核心技术栈深度解析2.1 动态渲染三件套2.2 Docker集群架构设计2.3 自动化调度系统 三、进阶实战案例3.1 电商价格监控系统1. 技术指标对比2. 实现细节 3.2 新闻聚合平台1. WebSocket监控2. 字体反爬破解 四、性能优化与运维方案4.1 资源消耗对比…...

运维打铁:生产服务器用户权限管理方案全解析
文章目录 一、引言二、方案设计2.1 权限模型选择2.2 角色定义2.3 权限分配2.4 用户与角色关联 三、相关代码注释(以 Linux 系统为例)3.1 用户创建与角色分配脚本3.2 权限设置脚本 四、常见问题解决4.1 用户无法登录4.2 用户权限不足4.3 权限文件修改后不…...

华为云Astro前端页面数据模型选型及绑定IoTDA物联网数据实施指南
目录 1. 选择合适的数据模型类型及推荐理由 自定义模型: 对象模型: 服务模型: 事件模型: 推荐方案: 2. 数据模型之间的逻辑关系说明 服务模型获取数据: 对象模型承接数据: 前端组件绑定显示: 数据保存与反馈(可选): (可选)事件模型实时更新: 小结 …...

【工具类】常用的工具类——CollectionUtil
目录 cn.hutool.core.collection.CollectionUtil集合创建集合清空集合判空集合去重集合过滤集合转换集合合并集合交集集合差集集合是否包含元素集合是否包含指定元素(自定义条件)集合分页集合分组集合转字符串元素添加元素删除根据属性转Map获取元素获取…...
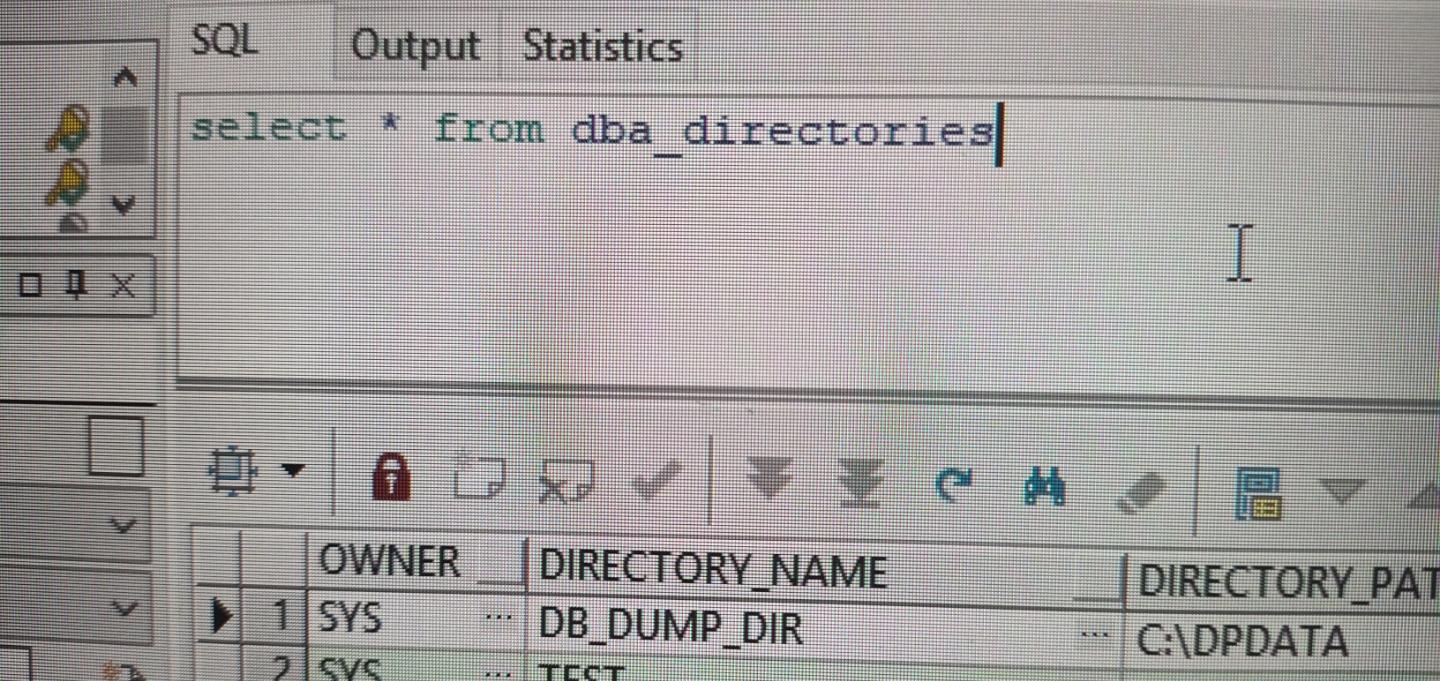
Oracle 11g导出数据库结构和数据
第一种方法:Plsql 利用plsql可视化工具导出,首先根据步骤导出表结构: 工具(Tools)->导出用户对象(export user objects)。 其次导出数据表结构: 工具(Tools)->导出表(export Tables)->选中表->sql inserts(where语…...
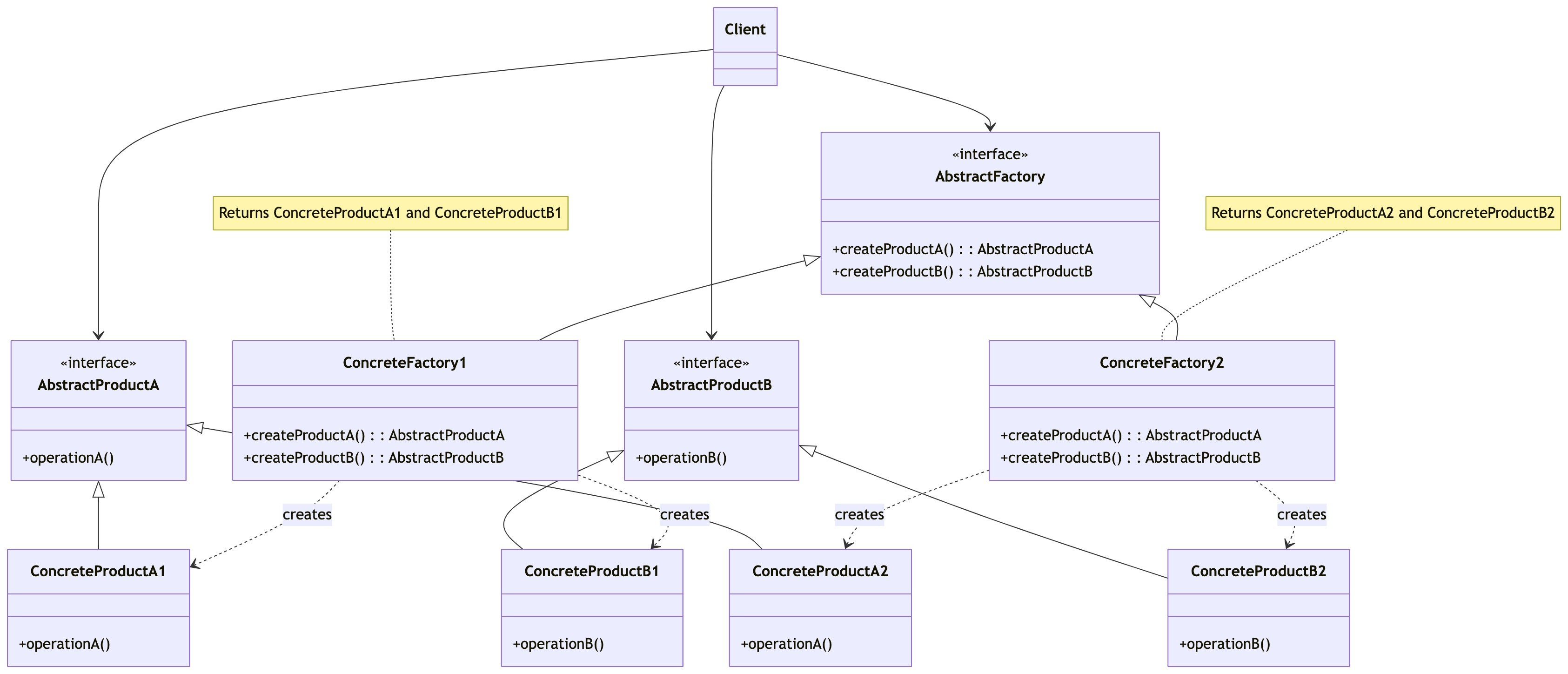
零基础设计模式——创建型模式 - 抽象工厂模式
第二部分:创建型模式 - 抽象工厂模式 (Abstract Factory Pattern) 我们已经学习了单例模式(保证唯一实例)和工厂方法模式(延迟创建到子类)。现在,我们来探讨创建型模式中更为复杂和强大的一个——抽象工厂…...
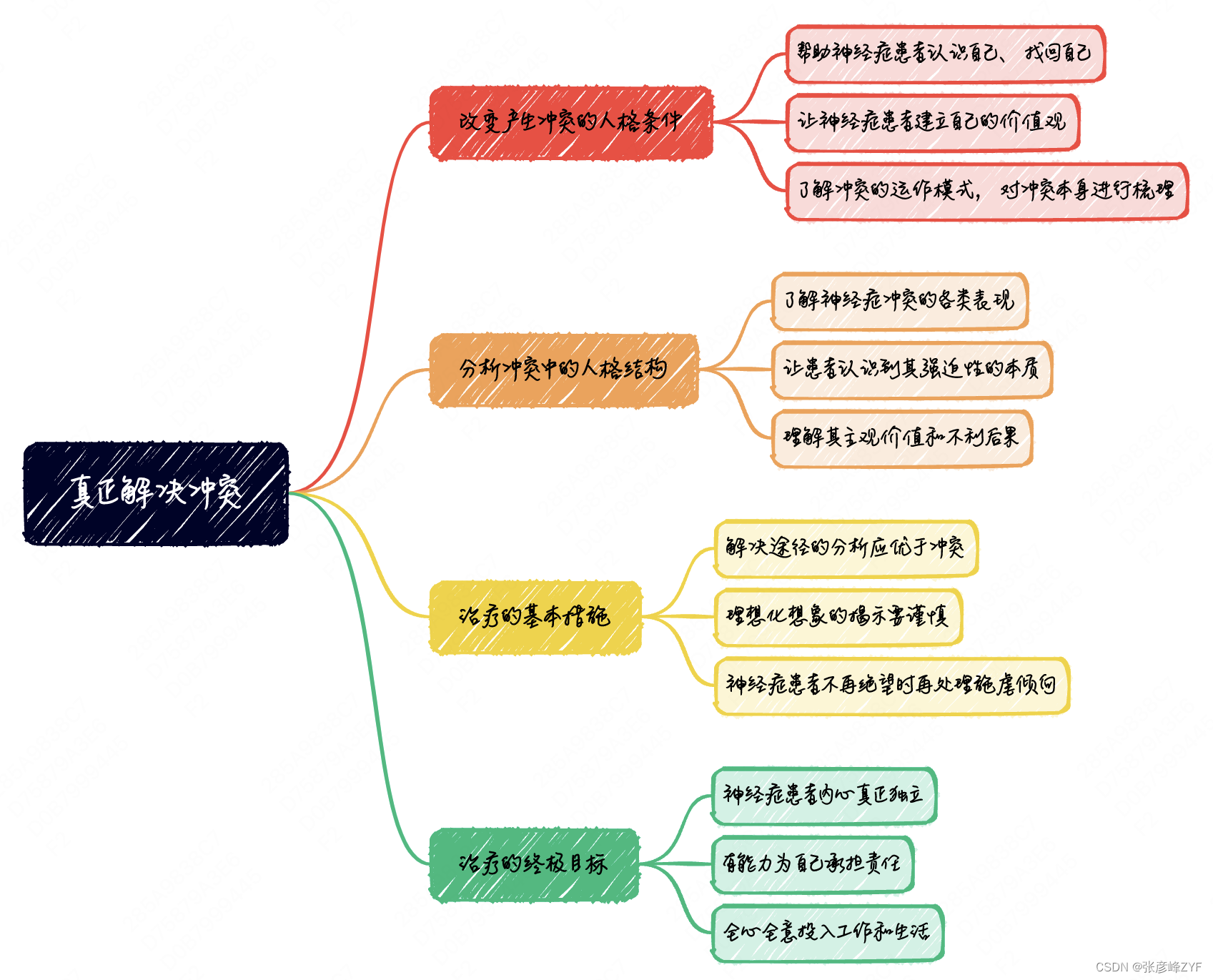
解锁内心的冲突:神经症冲突的理解与解决之道
目录 一、神经症冲突概述 二、冲突的基本类型 三、未解决冲突的后果 四、尝试解决的途径 五、真正解决冲突 六、总结 干货分享,感谢您的阅读! 人类的内心世界复杂多变,常常充满了各种冲突和矛盾。每个人在成长的过程中,都或…...

JVM—Java对象
JVM中的Java对象在堆内存中的存储分布可以分为对象头,实例数据和对齐填充三部分 对象头: 包含运行时元数据和类型指针 1、Mark Word(标记字段) 对象自身的运行时数据: 锁状态标志(无锁、偏向锁、轻量级…...