MySQL——基本查询内置函数
目录
CRUD
Create
Retrieve
where
order by
limit
Update
Delete
去重操作
聚合函数
聚合统计
内置函数
日期函数
字符函数
数学函数
其它函数
实战OJ
批量插入数据
找出所有员工当前薪水salary情况
查找最晚入职员工的所有信息
查找入职员工时间升序排名的情况下的倒数第三的员工所有信息
查找薪水记录超过15条的员工号emp_no
获取所有部门当前manager的当前薪水情况
从titles表获取按照title进行分组
查找重复的电子邮箱
大的国家
第N高的薪水
查找字符串中逗号出现的次数
CRUD
表的增查改删:C(Create),R(Retrieve),U(Update),D(Delete)
Create
创建表

创建完表后插入数据,有两种方式:指定插入和全列插入

除了单行数据插入,mysql也支持多行数据插入
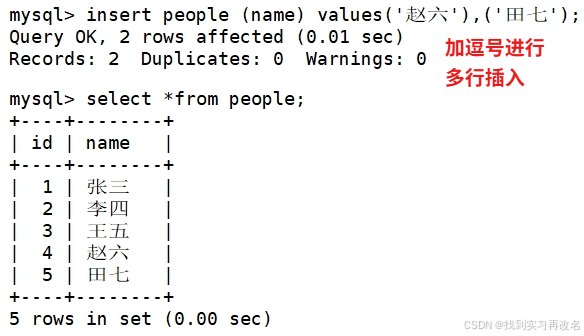
当插入数据在表中出现时,mysql会拦截你不让你插入;但是你想把原先存在的数据进行替换,有以下两种操作:
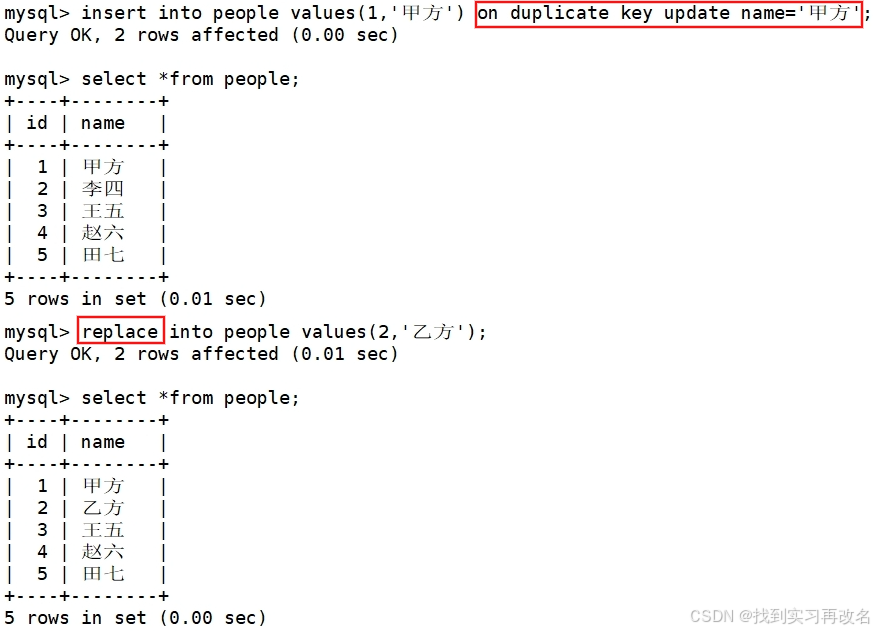
Retrieve
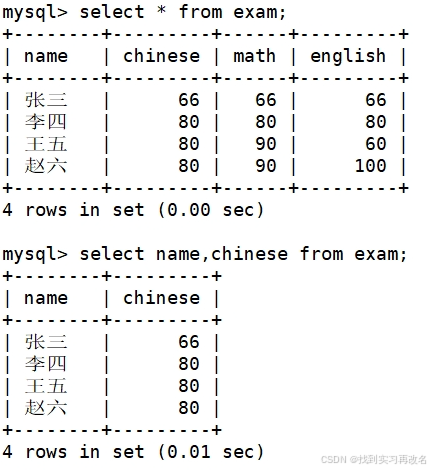
对数据作查询;查询数据之前先有表,表中还有有数据

查询语句select 对表中插入数据进行查看:有全列查询与指定查询
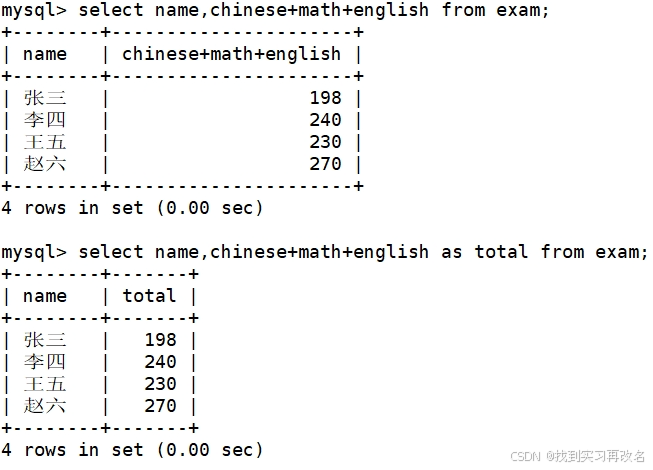
还能使用表达式统计它们的分数总和
如果分数出现重复,也可以使用 select 进行去重(这里 unique key 就不会出现数据)

where
select 搭配 where 进行使用时,where 后面接的是判断语句,与 if 用法是一样的,但在 mysql 中运算符的表示上就有区别
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为FALSE(0) |
英语小于70的同学及英语成绩

数学成绩在 [80, 90] 分的同学及其数学成绩:共有两种方法:比较法 和 between
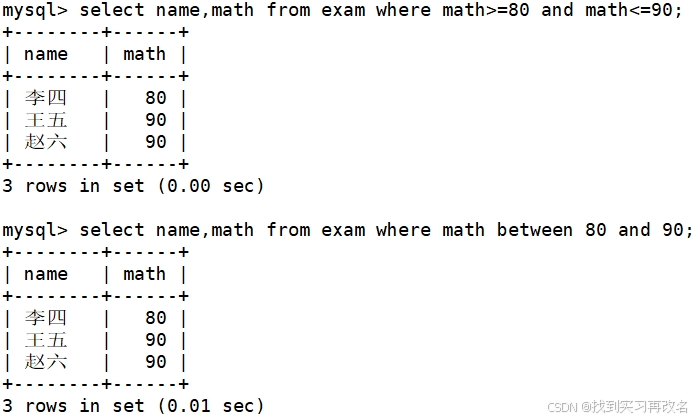
英语成绩是 60 或者 80 或者 100 分的同学及英语成绩,两种方法:比较法 和 in

找姓找同学和找赵某同学,使用%匹配多个字符,使用_匹配单个字符

总分在 200 分以下的同学:此时查询时如果是把总分的结果起别名,再把别名进行where 比较,会出现报错:因为 select 语句是从where开始执行,此时起别名操作还没生效!

语文成绩超过 80 分并且不姓孙的同学

找张某同学,或者要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80 的同学

order by
升序搭配 asc ;降序搭配 desc
全部学生的数学成绩按照升序排列,order by 不加desc 时默认排的是升序,但不推荐省略排升序
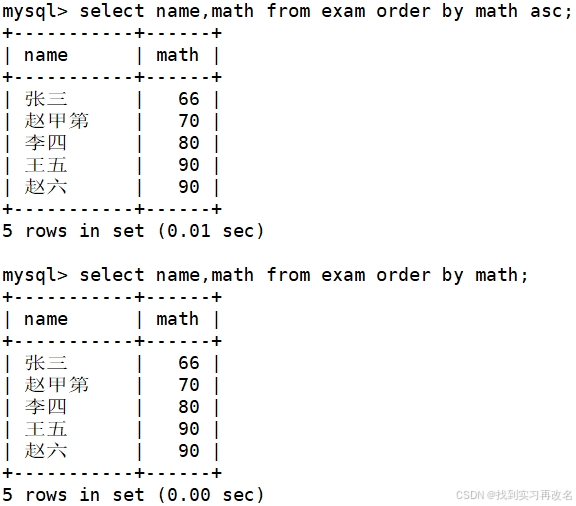
而NULL进行排序时,结果都比任何一个数要小
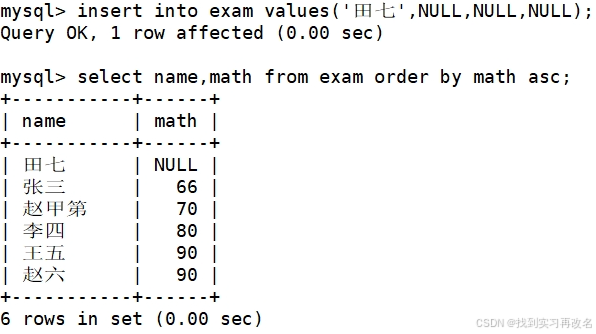
将同学各门成绩,依次按:数学降序,英语升序,语文升序的方式显示,多种情况排序是排序顺序按照书写顺序

查询同学及总分,由高到低

在 where中不能使用别名操作,这里怎么可以使用别名来进行排序? 因为进行排序时数据一定要准备好的,也就说前面的语句先执行(要有合适的数据再排序,而where不需要)
查询姓李的同学或者姓赵的同学数学成绩,结果按数学成绩由高到低显示

limit
查询表中数据时,不推荐直接使用 * 查询全部数据:数据有千万条,* 查询会一直刷屏查找不完,所以推荐查找时加上 limit 按找目标行下标查询想要的数据量(mysql也是从下标0开始)
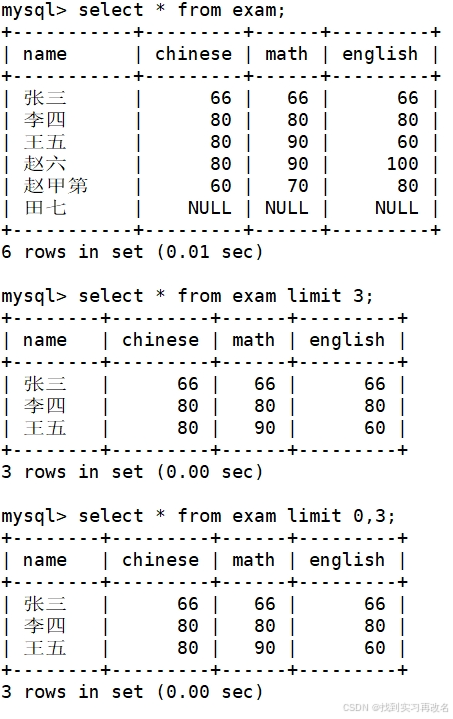
也可以使用 offset 的方式设置下标
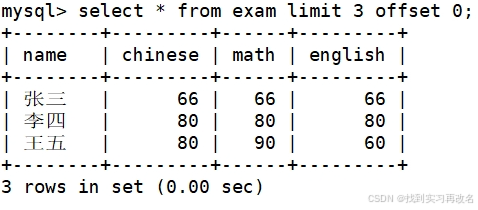
在平常看电子书的分页功能就是设置了指定的offset 下标实现分页功能

用 limit 时也可以使用别名的方式进行"显示"数据:先要展示数据,数据是不是要先准备好!

Update
对查询结果进行更新
将张三的数学成绩变更为 80 分
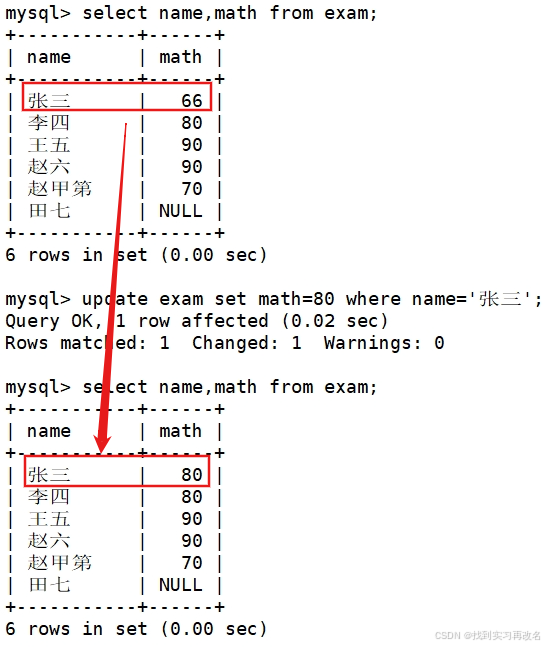
将田七的数学成绩变更为 60 分,语文成绩变更为 80 分
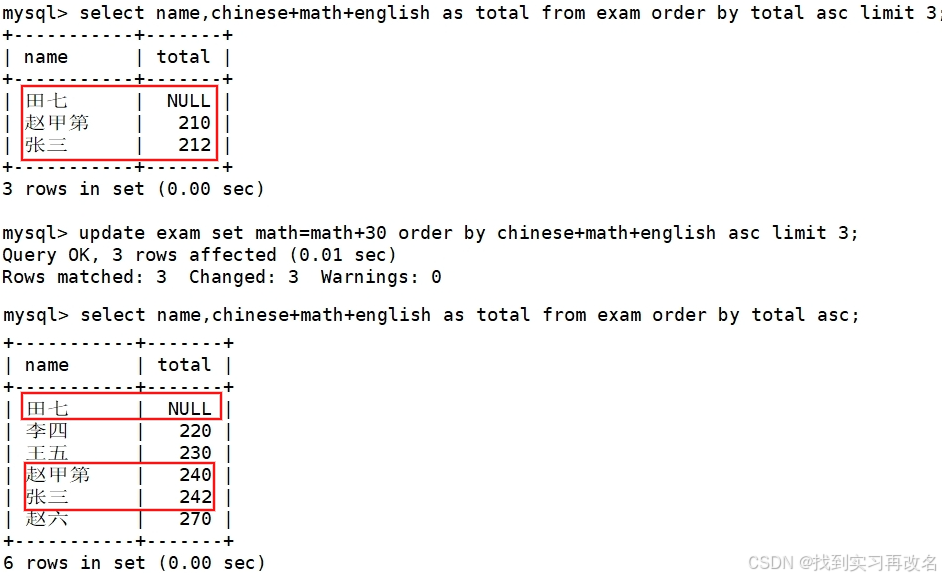
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分(mysql 不支持+=操作)
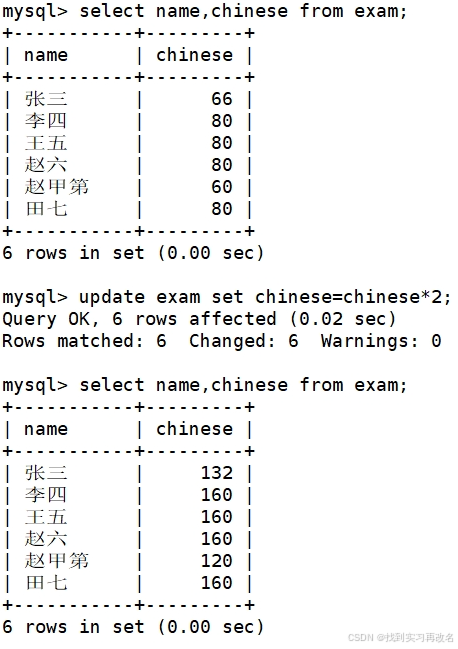
将所有同学的语文成绩更新为原来的 2 倍(在平时使用时慎用该操作)
Delete
只对表中的数据进行删除,不会把表也给删除掉
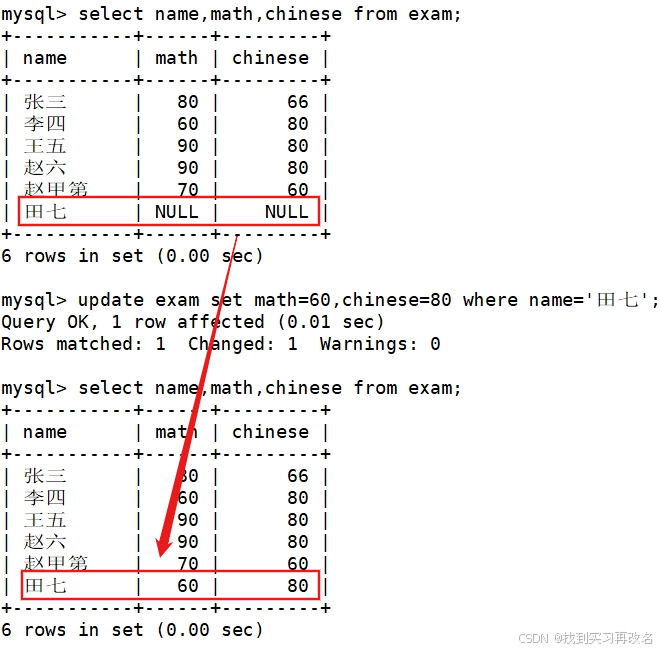
删除田七同学的考试成绩

删除整张表数据(注意:删除整表操作要慎用!)准备测试表,插入数据后进行测试
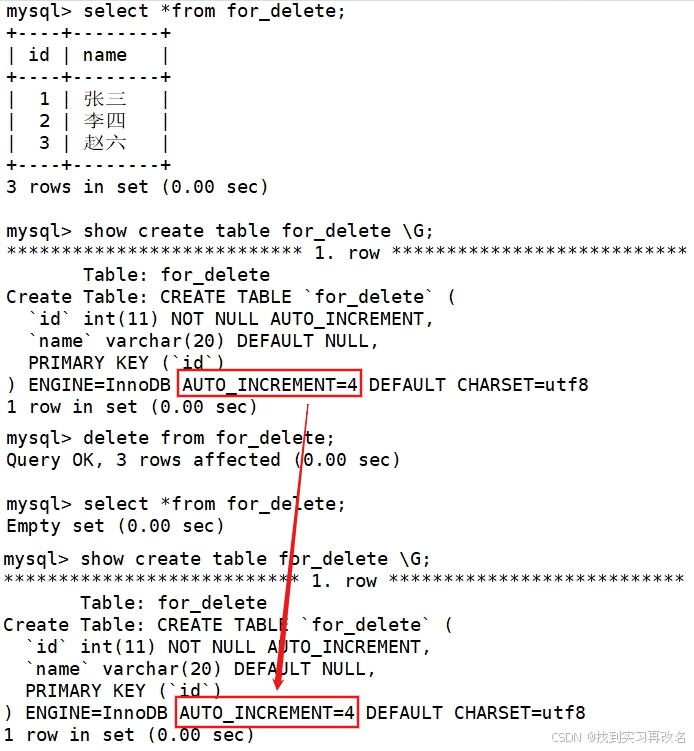
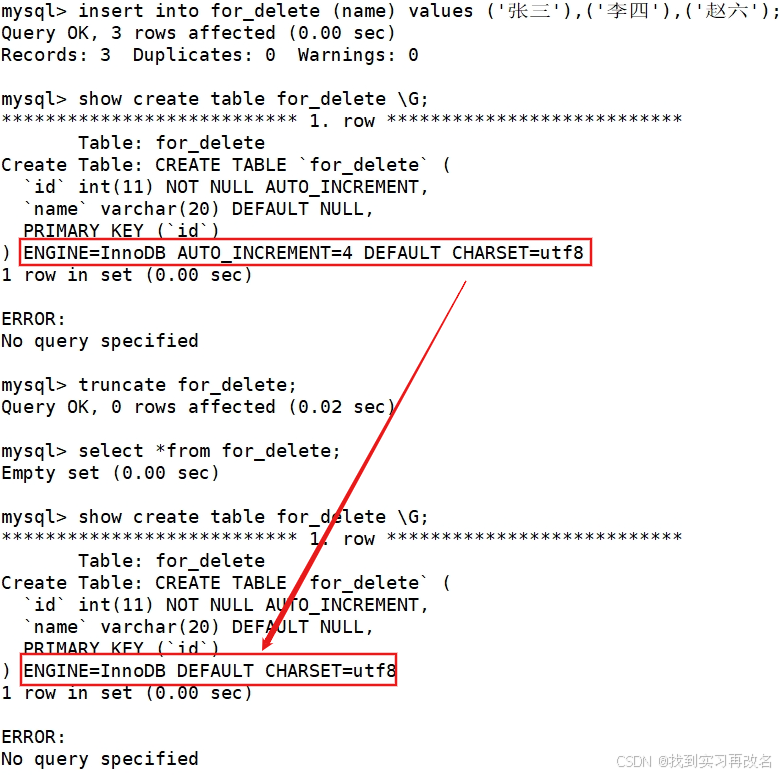
删除后,表中id的auto_increment没变,下次插入的数据开始为4;但如果想让下次开始为1的话,我们还有另一种方式:使用截断表:truncate 删除数据的同时改变表的auto_increment
| delete | truncate |
|---|---|
| 部分数据删除或者全部数据删除 | 只能全部数据删除 |
| 对数据操作,进行保留 | 不对数据操作,不经过事务无法进行回滚 |
| 不能重置 auto_increment | 重置 auto_increment |
去重操作
准备工作:先准备两张一样表
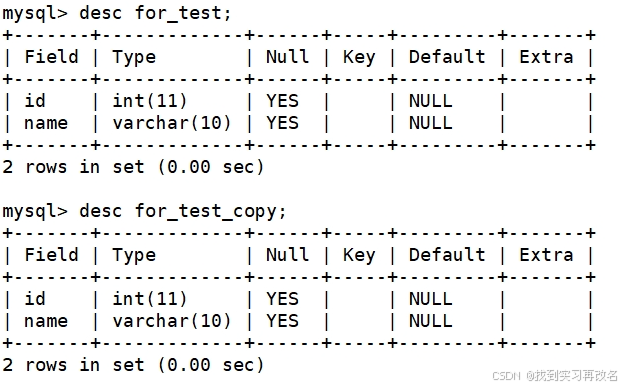
for_test 表中有重复数据;将它进行去重后的结果保留在 for_test_copy 表中
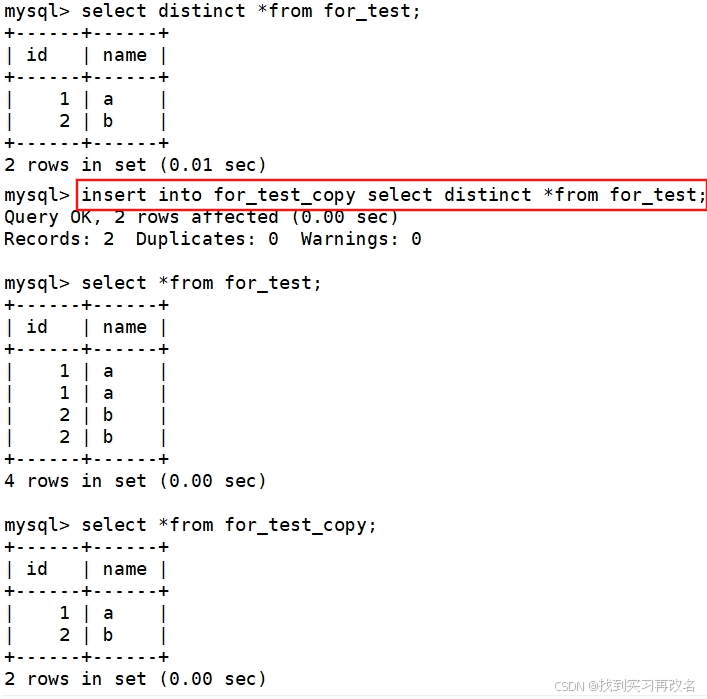
通过重命名表,实现表的原子操作
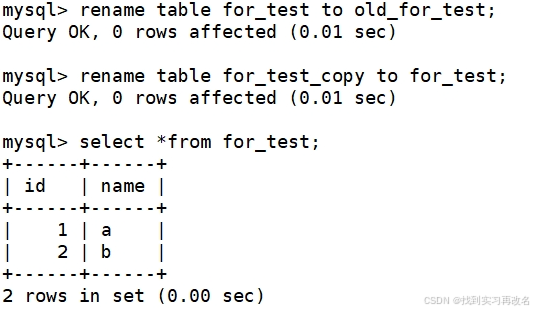
为什么最后是通过 rename 的方式进行的?
建表操作对应到Linux上就是在特定的目录下新建文件,进行 rename 操作其实是对文件进行重命名 mv 操作;当上传很大的数据文件到指定的目录上时,我们一般不直接进行这个操作,而是将数据文件统一上传到临时目录中,当数据文件统一上传完成后再对数据进行 mv 移动到特定的目录下使用:这个过程其实就是原子操作:只有成功与失败两种结果,保证安全性与可靠性;进行 rename 方式也类似:等一切数据就绪了,然后统一放入,更新,生效
聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义,可以是任何数字 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义,可以是任何数字 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义,可以是任何数字 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义,可以是任何数字 |
统计班级共有多少同学参加了考试
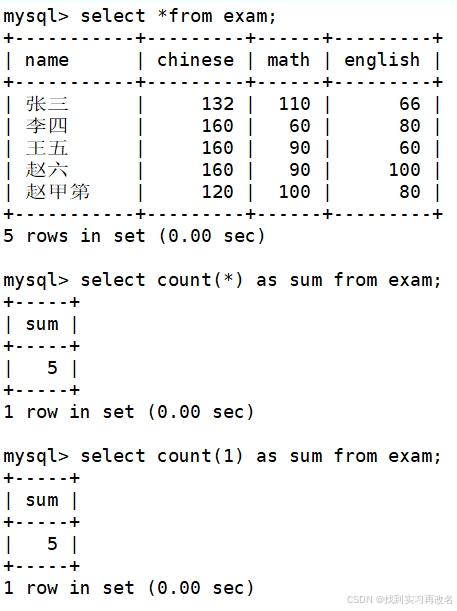
统计本次考试的英语成绩分数个数(去掉重复分数)
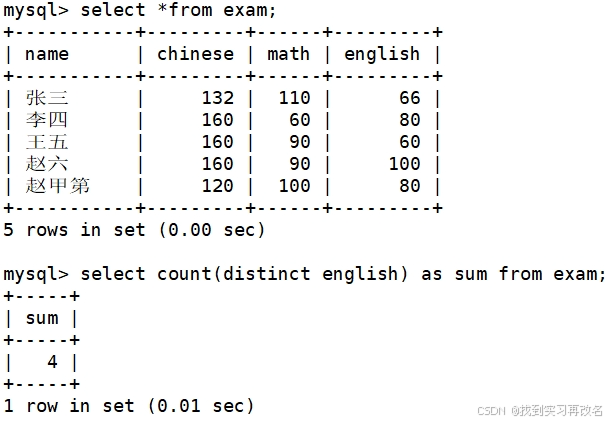
统计数学成绩总分并找出超过80分的人数
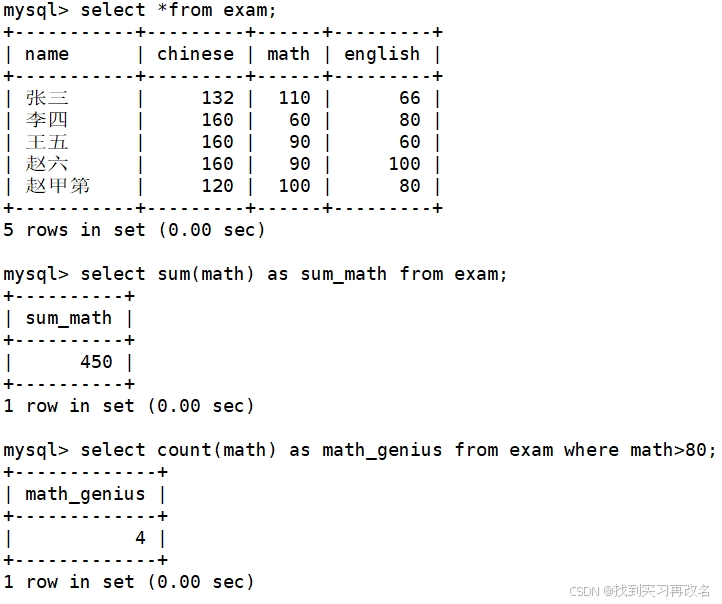
统计平均总分
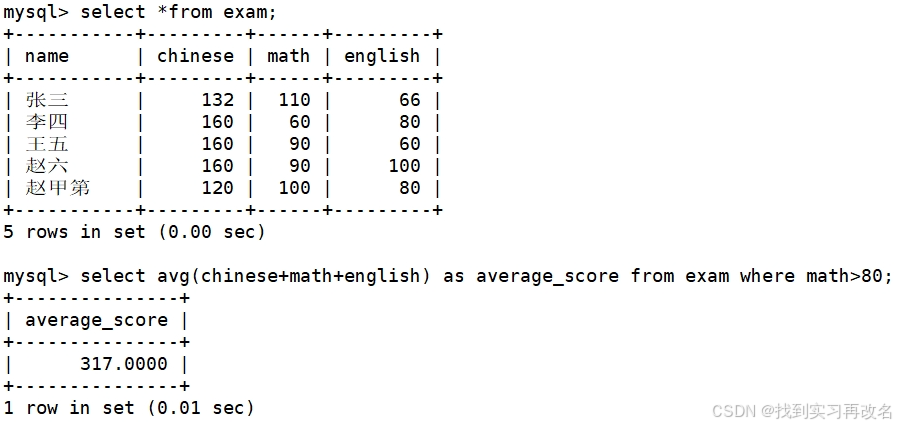
返回 > 70 分以上的数学最低分
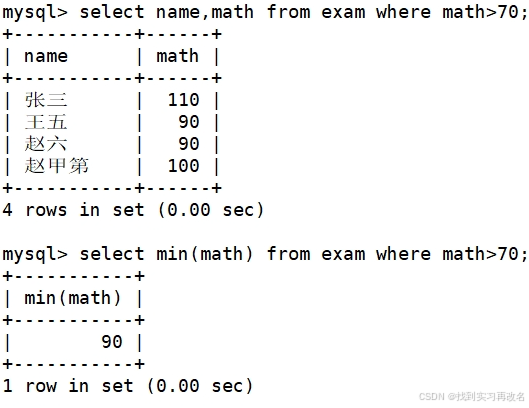
聚合统计
在select中使用 group by子句可以对指定列进行分组,实现聚合统计
准备工作:创建雇员信息表(来自oracle 9i的经典测试表)(往后有很多使用场景要用到它)
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;USE `scott`;DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
员工的部门表和薪资等级表
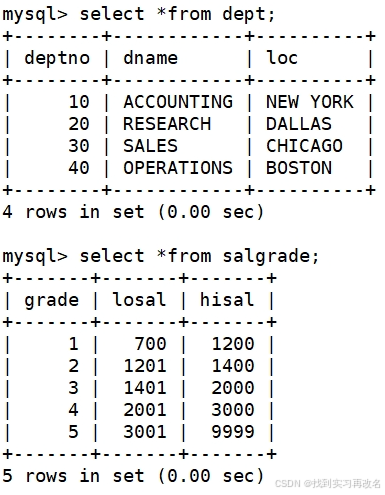
还有员工表
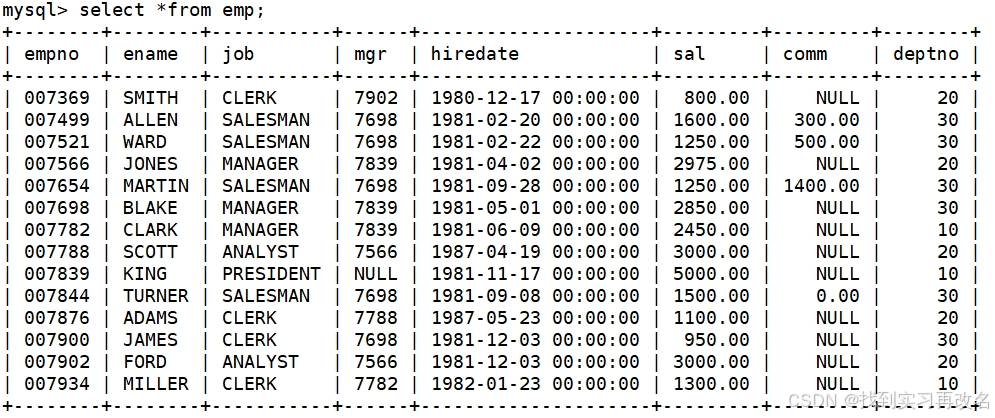
显示每个部门的平均工资和最高工资
group by 指定列名:实际分组,是按不同的列名的行数据进行分组,组内的指定列名一定相同,从而进行聚合统计,聚合压缩
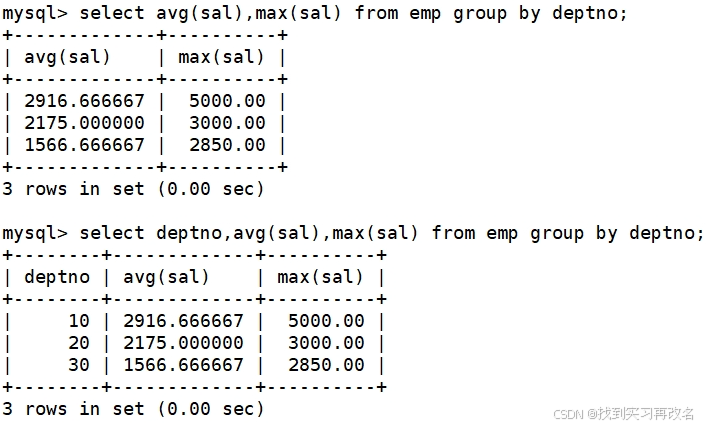
每个部门的每种岗位的平均工资和最低工资:先分为每个部门,再从每个部门中分成每种岗位后进行聚合统计
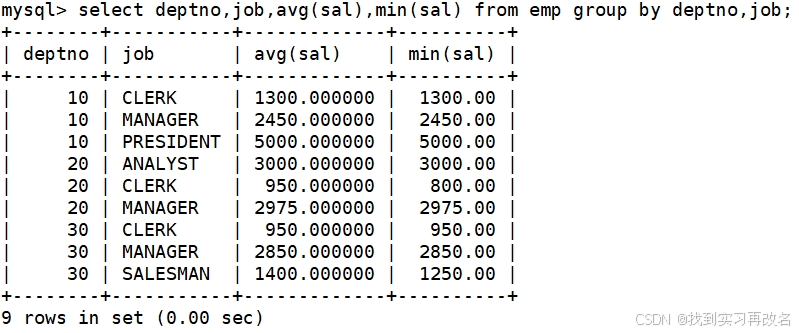
平均工资低于2000的部门和它的平均工资:先要聚合统计出各个部门的平均工资,再进行判断那个部门的工资低于2000,这里难道要使用where 语句? 使用where 语句会报错,要使用 having 语句,对聚合统计的数据进行条件筛选,一般与 group by 搭配使用
这里可能会有疑惑:where 和 having 都是进行条件筛选,区别在哪呢?
先来解决:除了SMITE的工资外,平均工资低于2000的部门和它的平均工资
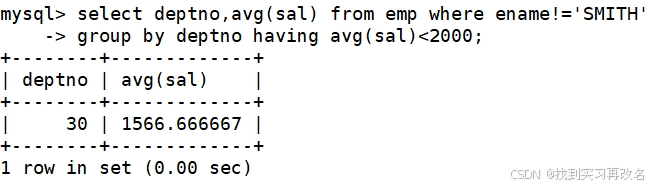
上面语句执行的顺序是:先提取表数据 from emp,再对表数据进行判断 where 判断,接着对‘结果’进行分组 group by,再进行聚合统计 avg(sal),最后对聚合统计后的‘结果’进行条件筛选平均工资低于2000的部门 avg(sal);所以:where 是对具体的列进行判断,而having 是对聚合后的结果进行判断,两者在条件筛选的阶段是不同的
对‘结果’的理解:不要单纯地认为,保存在数据库中的表才是表,中间筛选出来的各种结果数据在我看来都是(逻辑)表,因为在mysql中一切皆表:只要掌握了单表的CRUD,未来所有的场景我们都能够应对解决!
内置函数
日期函数
| 函数名称 | 描述 |
|---|---|
| current_date() | 当前日期 |
| current_time() | 当前时间 |
| current_timestamp() | 当前时间戳 |
| date(datetime) | 返回datetime的日期部分 |
| date_add(date , interval d_value_type) | 添加date的时间,单位可以是year,day,minute,second |
| date_sub(date,interval d_value_type) | 将去date的时间,单位可以是year,day,minute,second |
| datediff(date1 , date2) | 两个日期的时间差,单位是天 |
| now() | 当前的时间 |
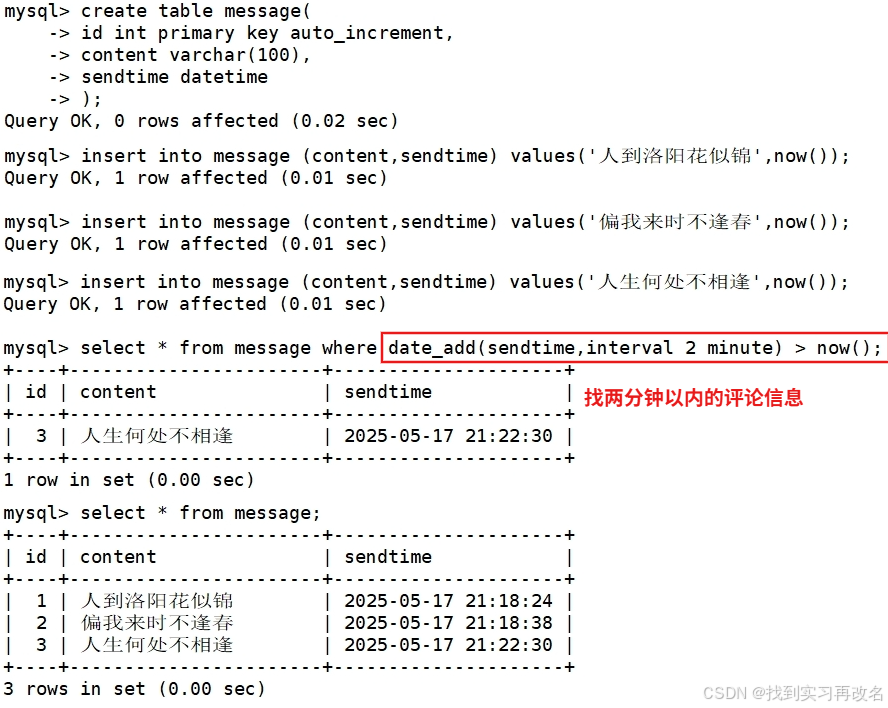
创建一个留言表并插入评论
字符函数
| charset(str) | 返回字符串字符集 |
| concat(string , ...) | 连接字符串 |
| instr(string1, string2) | 返回string2在string1出现的位置,没有返回0 |
| ucase(string) | string转大写 |
| lcase(string) | string转小写 |
| left(string , length) | 从string左边起取length个长度 |
| length(string) | 返回string的长度 |
| replace(str , string1 , string2) | 在str中的string1用string2替换 |
| substring(str , postion , length) | 从position位置开始取length个字符 |
| ltrim(string) | 去除左边所有空格 |
| trim(string) | 去除中间所有空格 |
| rtrim(string) | 去除右边所有空格 |
获取emp表的ename列的字符集

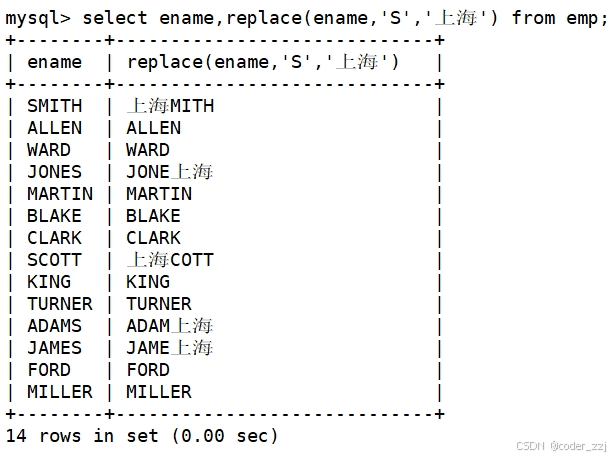
将emp表中所有名字中有S的替换成'上海'
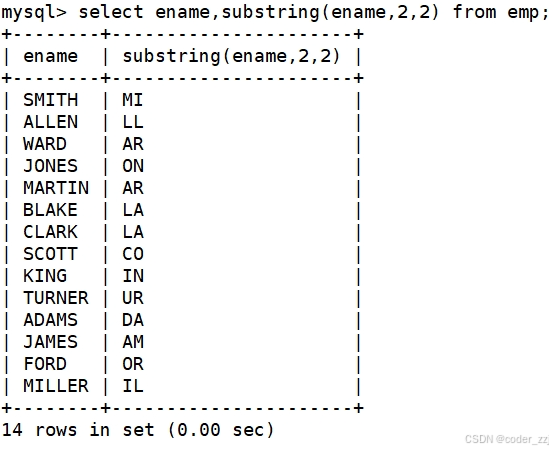
截取emp表中ename字段的第二个到第三个字符
以首字母小写的方式显示所有员工的姓名(三个函数联合使用)
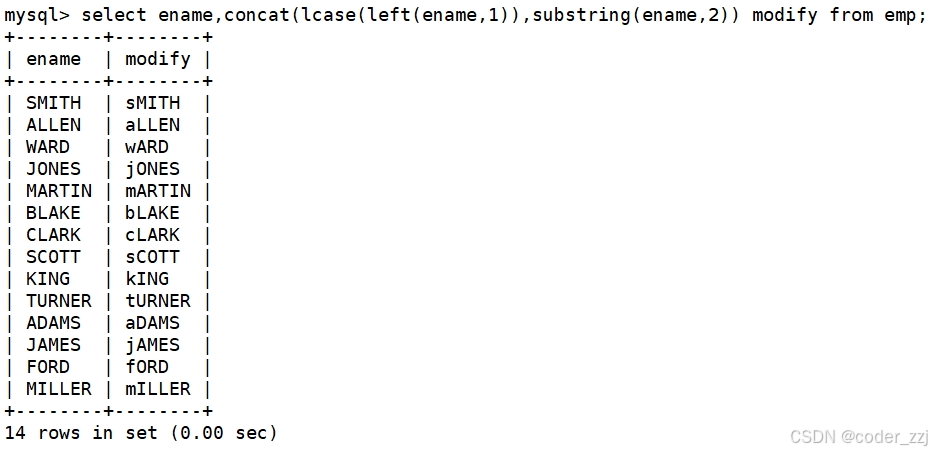
学生表中的信息的显示格式:“姓名:XXX 语文:XXX分,数学:XXX分,英语:XXX分”
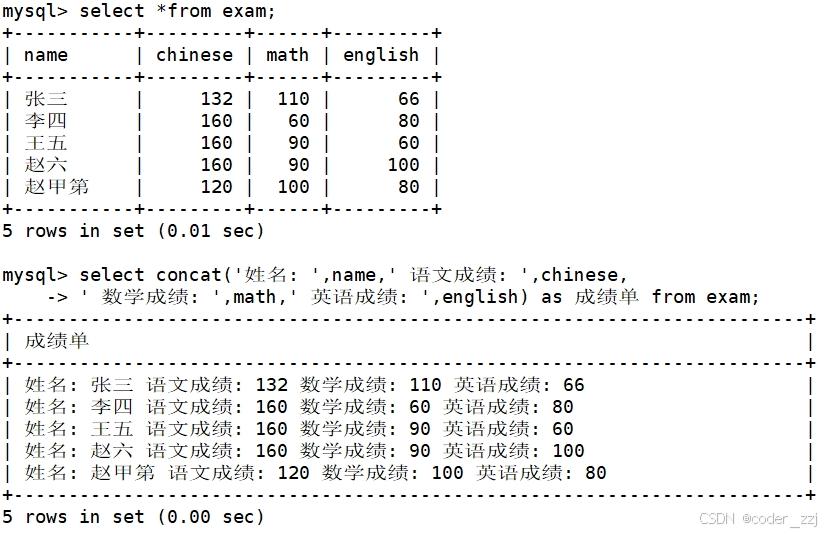
求学生表中学生姓名占用的字节数

length返回大小以字节为单位。如果是多字节字符则计算多个字节数;如果是单字节字符则算作一个字节。比如:字母,数字算作一个字节,中文表示多个字节数(与字符集编码相关)
数学函数
| abs(n) | n的绝对值 |
| bin(n) | n转成二进制 |
| hex(n) | n转成十六进制 |
| conv(n , from , to) | n是什么进制要转成什么进制 |
| ceiling(n) | n向上取整 |
| floor(n) | n向下取整 |
| format(n , cnt) | n格式化时保留cnt位小数 |
| rand() | 生成随机浮点数,范围【0.0 , 1.0】 |
| mod(n,m) | 返回n % m |
其它函数
| user() | 查询当前用户 |
| database() | 查询当前正在使用的数据库 |
| md5(str) | 对字符串str进行md5摘要,生成32位字符串 |
| password(str) | 对用户的密码str进行加密 |
| ifnull(val1 , val2) | 对val1作判断:不为空返回val1,为空返回val2(C语言的三目操作符) |
实战OJ
批量插入数据
insert into actor values (1,'PENELOPE','GUINESS','2006-02-15 12:34:33');
insert into actor values (2,'NICK','WAHLBERG','2006-02-15 12:34:33');找出所有员工当前薪水salary情况
select distinct salary from salaries order by salary desc;查找最晚入职员工的所有信息
select *from employees order by hire_date desc limit 1;查找入职员工时间升序排名的情况下的倒数第三的员工所有信息
可能有多个相同入职日期在倒数第三,所以要先分组后再排序
select *from employees
where hire_date= (select hire_date from employees group by hire_date order by hire_date desc limit 2,1);查找薪水记录超过15条的员工号emp_no
select emp_no,count(emp_no) as t from salaries group by emp_no having t >15;获取所有部门当前manager的当前薪水情况
两张表的emp_no相同才能找到经理对应的薪水
//方法1
select d.dept_no,d.emp_no,s.salary
from dept_manager as d,salaries as s
where d.emp_no = s.emp_no
and d.to_date = '9999-01-01'
and s.to_date = '9999-01-01'
order by d.dept_no;//方法2
select d.dept_no,d.emp_no,s.salary
from dept_manager as d inner join salaries as s on d.emp_no = s.emp_no
and d.to_date = '9999-01-01'
and s.to_date='9999-01-01'
order by d.dept_no;从titles表获取按照title进行分组
通过 emp_no 去重的个数来统计title个数:不同的emp_no下不同组的人(标题)的个数
select title,count(distinct emp_no) as t from titles group by title having t>=2;查找重复的电子邮箱
select email as Email from Person group by email having count(email) > 1;大的国家
select name,population,area from World where area >=3000000 or population >=25000000;第N高的薪水
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare M int;set M = N-1;RETURN (select distinct salary from Employee order by salary desc limit M,1);
END查找字符串中逗号出现的次数
select id,length(string)-length(replace(string,',','')) as cnt from strings;SQL查询中各个关键字的执行先后顺序:
from > on> join > where > group by > with > having > select > distinct > order by > limit
以上便是全部内容,有问题欢迎在评论区指正,感谢观看!
相关文章:
MySQL——基本查询内置函数
目录 CRUD Create Retrieve where order by limit Update Delete 去重操作 聚合函数 聚合统计 内置函数 日期函数 字符函数 数学函数 其它函数 实战OJ 批量插入数据 找出所有员工当前薪水salary情况 查找最晚入职员工的所有信息 查找入职员工时间升序排…...
Day34打卡 @浙大疏锦行
知识点回归: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前向传播时可以直接写作self.fc1(x) 作业 计算资…...
Docker安装Jitsi Meet指南-使用内网IP访问)
【Jitsi Meet】(腾讯会议的平替)Docker安装Jitsi Meet指南-使用内网IP访问
Docker安装Jitsi Meet指南-使用内网IP访问 下载官方代码配置环境变量复制示例环境文件并修改配置:编辑 .env 文件: 修改 docker-compose.yml 文件生成自签名证书启动服务最终验证 腾讯会议的平替。我们是每天开早晚会的,都是使用腾讯会议。腾…...

AdGuard解锁高级版(Nightly)_v4.10.36 安卓去除手机APP广告
AdGuard解锁高级版(Nightly)_v4.10.36 安卓去除手机APP广告 AdGuard Nightly是AdGuard团队为及时更新软件而推出的最新测试版本,适合追求最新功能和愿意尝试新版本的用户。但使用时需注意其潜在的不稳定性和风险。…...
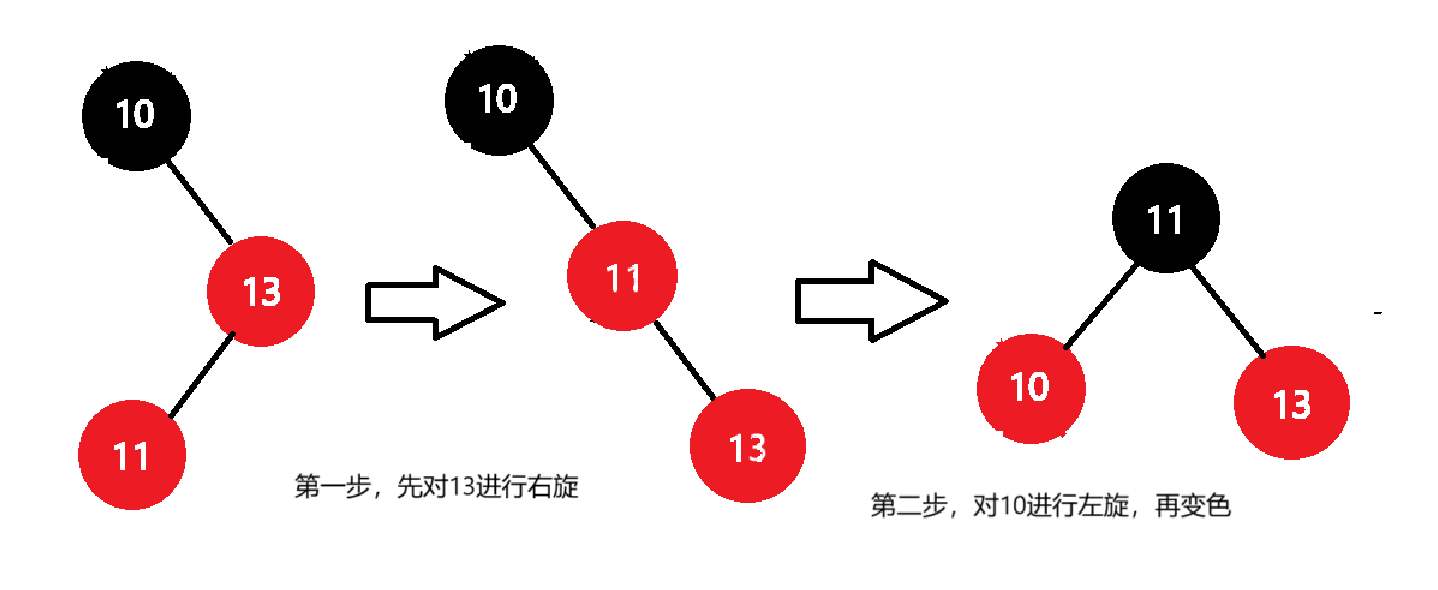
C++修炼:红黑树的模拟实现
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C修炼之路》 欢迎点赞,关注&am…...
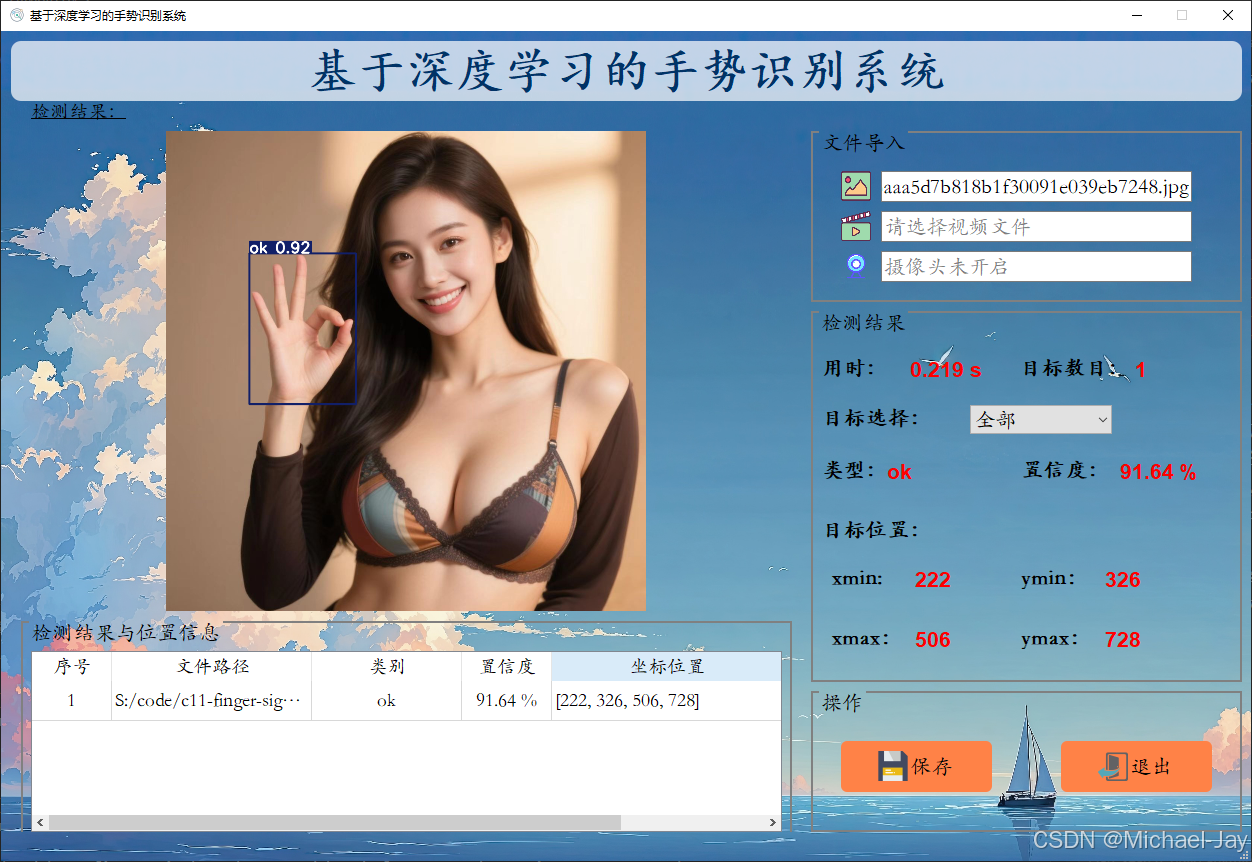
基于Python+YOLO模型的手势识别系统
本项目是一个基于Python、YOLO模型、PyQt5的实时手势识别系统,通过摄像头或导入图片、视频,能够实时识别并分类不同的手势动作。系统采用训练好的深度学习模型进行手势检测和识别,可应用于人机交互、智能控制等多种场景。 1、系统主要功能包…...
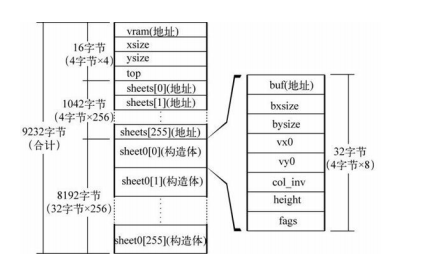
自制操作系统day10叠加处理
day10叠加处理 叠加处理(harib07b) 现在是鼠标的叠加处理,以后还有窗口的叠加处理 涉及图层 最上面小图层是鼠标指针,最下面的一张图层用来存放桌面壁纸。移动图层的方法实现鼠标指针的移动以及窗口的移动。 struct SHEET { u…...

docker初学
加载镜像:docker load -i ubuntu.tar 导出镜像:docker save -o ubuntu1.tar ubuntu 运行: docker run -it --name mu ubuntu /bin/bash ocker run -dit --name mmus docker.1ms.run/library/ubuntu /bin/bash 进入容器:docke…...

## Docker 中 Elasticsearch 启动失败:日志文件权限问题排查与解决
好的,这是一份关于你遇到的 Docker Elasticsearch 启动报错问题的笔记,包含问题描述、我的分析判断以及最终的解决方案,适合用于整理成文章。 Docker 中 Elasticsearch 启动失败:日志文件权限问题排查与解决 在使用 Docker部署 E…...
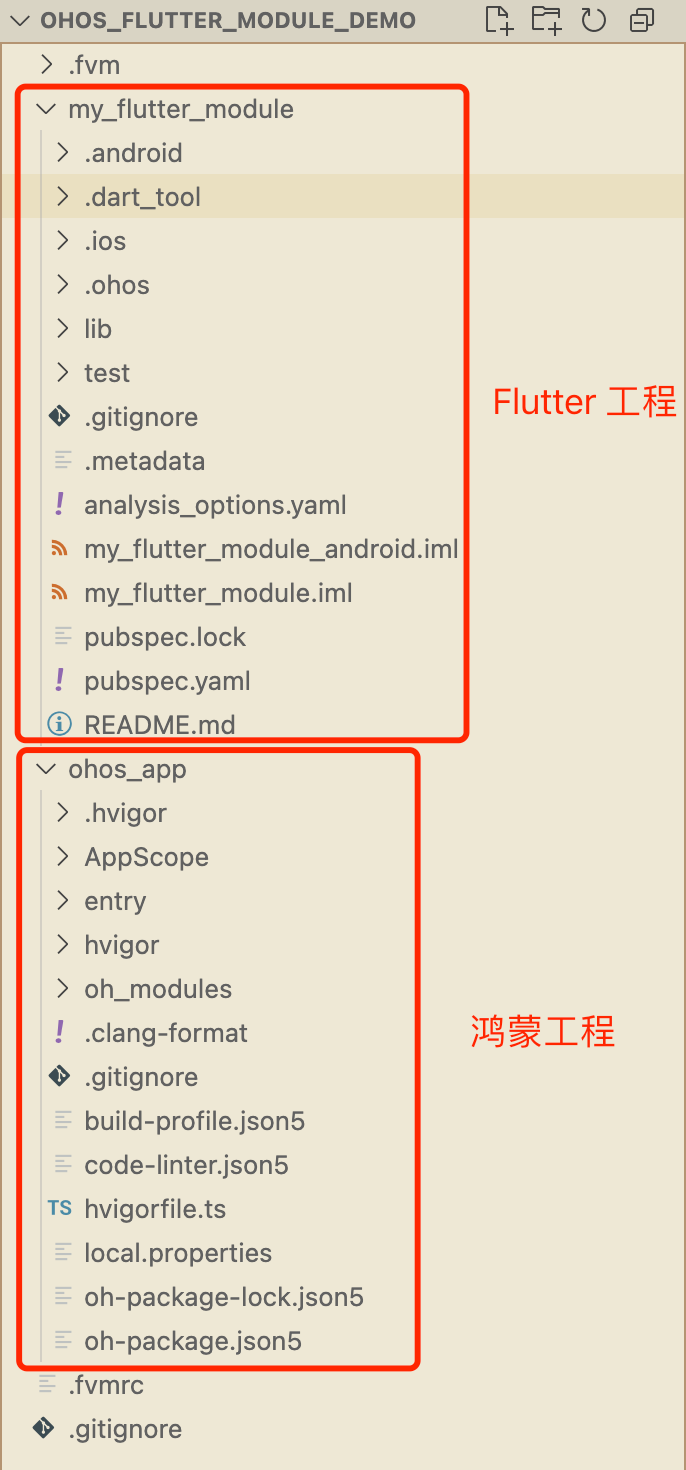
鸿蒙Flutter实战:23-混合开发详解-3-源码模式引入
引言 在前面的文章混合开发详解-2-Har包模式引入中,我们介绍了如何将 Flutter 模块打包成 Har 包,并引入到原生鸿蒙工程中。本文中,我们将介绍如何通过源码依赖的方式,将 Flutter 模块引入到原生鸿蒙工程中。 创建工作 创建一个…...
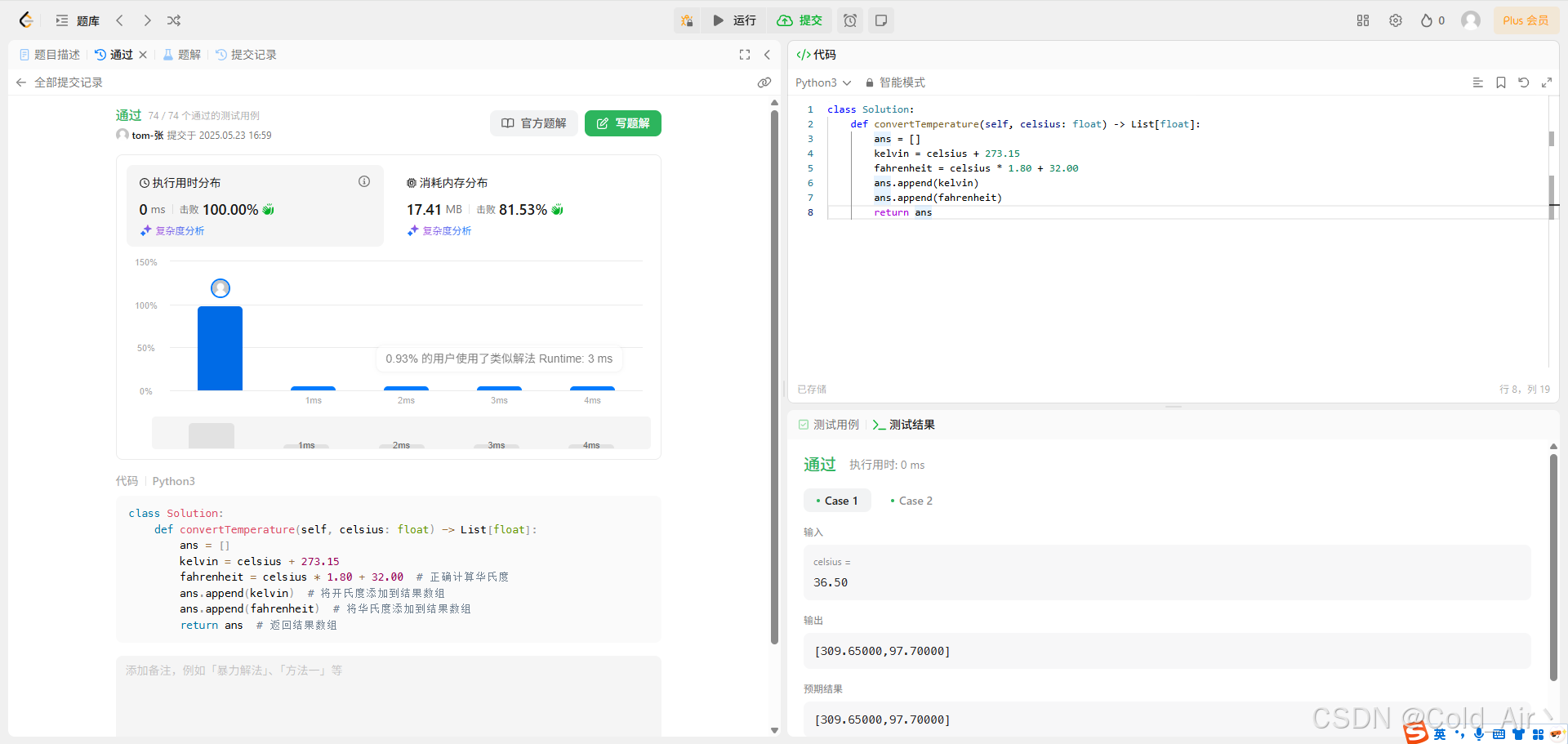
leetcode:2469. 温度转换(python3解法,数学相关算法题)
难度:简单 给你一个四舍五入到两位小数的非负浮点数 celsius 来表示温度,以 摄氏度(Celsius)为单位。 你需要将摄氏度转换为 开氏度(Kelvin)和 华氏度(Fahrenheit),并以数…...
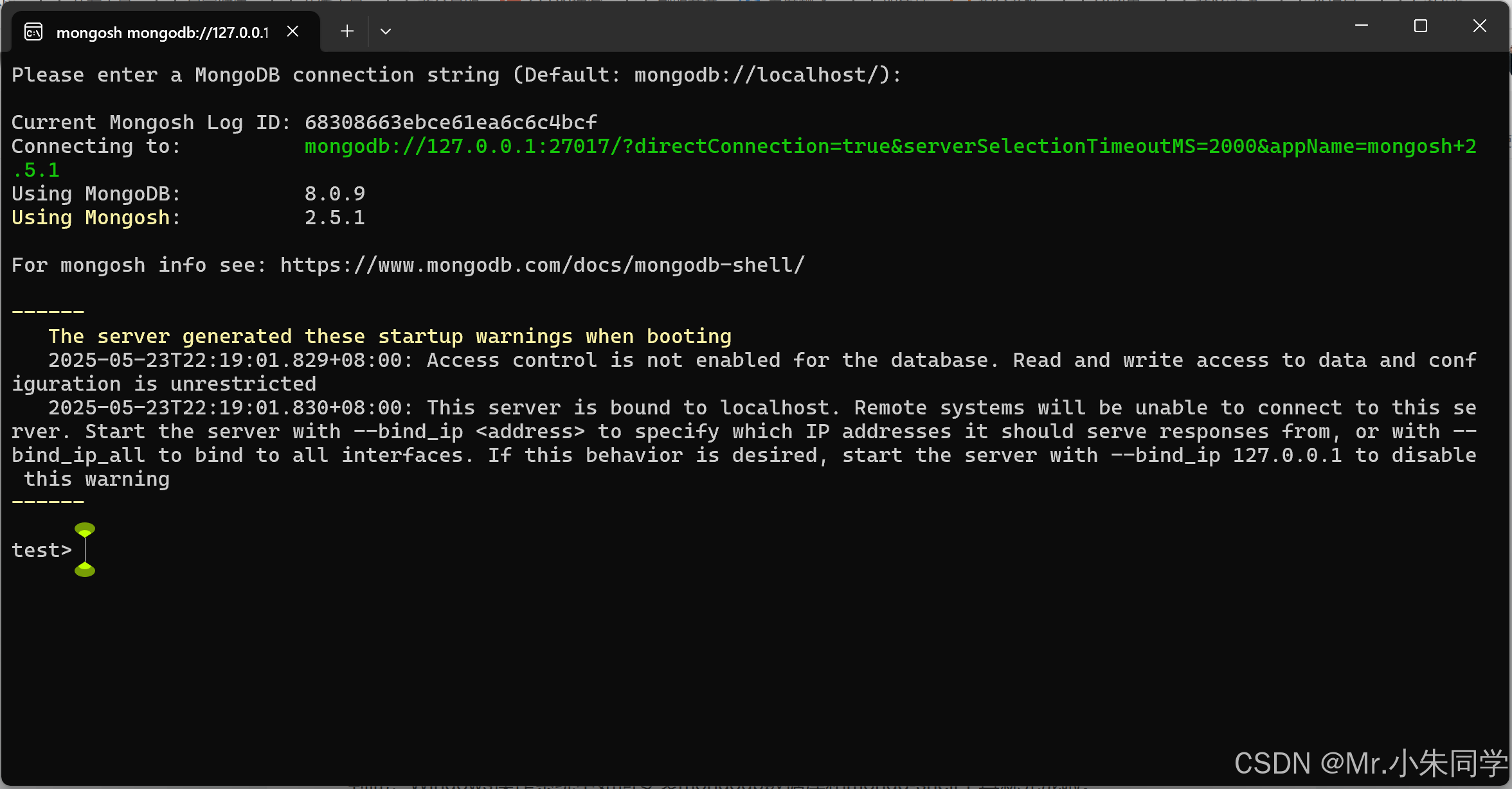
【软件安装】Windows操作系统中安装mongodb数据库和mongo-shell工具
这篇文章,主要介绍Windows操作系统中如何安装mongodb数据库和mongo-shell工具。 目录 一、安装mongodb数据库 1.1、下载mongodb安装包 1.2、添加配置文件 1.3、编写启动脚本(可选) 1.4、启动服务 二、安装mongo-shell工具 2.1、下载mo…...

跨域问题及其CORS解决方案:gin框架中配置跨域
一、同源策略 浏览器的同源策略(Same-Origin Policy)要求:只有协议、域名和端口都相同的请求才被视为同源,才允许正常访问。 两个URL在以下三个方面完全相同时称为"同源": 协议相同(如都是http或…...

记共享元素动画导致的内存泄露
最近在给项目的预览图片页增加共享元素动画的时候,发现了LeakCanary一直报内存泄露。 LeakCanary日志信息 ┬─── │ GC Root: Thread object │ ├─ java.lang.Thread instance │ Leaking: NO (the main thread always runs) │ Thread name: main │ …...
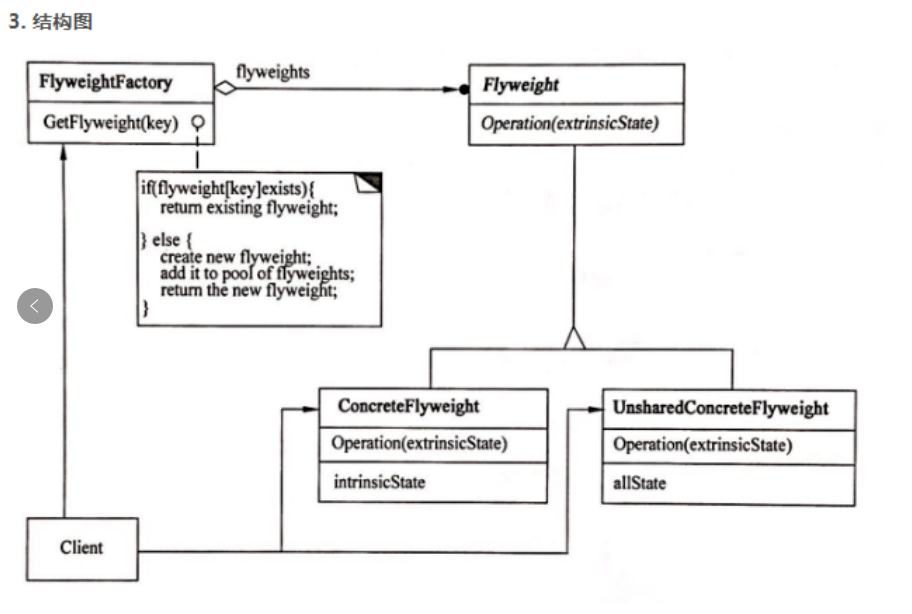
Flyweight(享元)设计模式 软考 享元 和 代理属于结构型设计模式
1.目的:运用共享技术有效地支持大量细粒度的对象 Flyweight(享元)设计模式 是一种结构型设计模式,它的核心目的是通过共享对象来减少内存消耗,特别是在需要大量相似对象的场景中。Flyweight 模式通过将对象的共享细节与…...

Win/Linux安装flash attention2
1.Win 安装Flash_attn (1)第一步:下载flash_attn-xxx.whl 文件 在 1)地址1:HuggingFace 官网 Flash-attn页面 2)地址2:Github 地址 下载对应cuda、torch、python版本的whl文件; …...

【原创】ubuntu22.04下载编译AOSP 15
安装依赖的库,顺便把vim 也安装一下 sudo apt-get install vim sudo apt-get install git gnupg flex bison build-essential zip curl zlib1g-dev libc6-dev-i386 x11proto-core-dev libx11-dev lib32z1-dev libgl1-mesa-dev libxml2-utils xsltproc unzip font…...
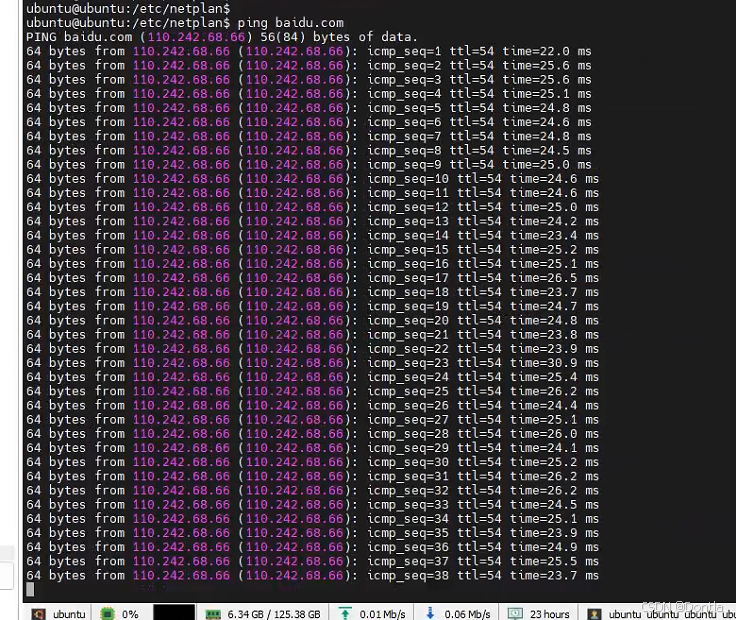
服务器网络配置 netplan一个网口配置两个ip(双ip、辅助ip、别名IP别名)
文章目录 问答 问 # This is the network config written by subiquity network:ethernets:enp125s0f0:dhcp4: noaddresses: [192.168.90.180/24]gateway4: 192.168.90.1nameservers:addresses:- 172.0.0.207- 172.0.0.208enp125s0f1:dhcp4: trueenp125s0f2:dhcp4: trueenp125…...
响应面法(Response Surface Methodology ,RSM)
响应面法是一种结合统计学和数学建模的实验优化技术,通过有限的实验数据,建立输入变量与输出响应之间的数学模型,找到最优操作条件。 1.RSM定义 RSM通过设计实验、拟合数学模型(如多项式方程)和分析响应曲面ÿ…...

针对面试-java集合篇
1.什么是数组 数组(Array)是一种用连续的内存空间存储相同数据类型数据的线性数据结构。 2.数组下标为什么从0开始 寻址公式是:baseAddressi*dataTyeSize,计算下标的内存地址效率较高 3.查找的时间复杂度 随机(通过下标)查询的时间复杂度是O(1) 查找元素(未知…...

Spring Boot 拦截器:解锁5大实用场景
一、Spring Boot中拦截器是什么 在Spring Boot中,拦截器(Interceptor)是一种基于AOP(面向切面编程)思想的组件,用于在请求处理前后插入自定义逻辑,实现权限校验、日志记录、性能监控等非业务功能…...

展锐 Android 15 锁定某个App版本的实现
Android 15 系统锁定Antutu版本的实现方法 在Android系统开发中,有时需要锁定特定应用的版本以确保系统稳定性或测试一致性。本文将介绍如何通过修改Android源码来锁定Antutu跑分软件的版本。 修改概述 这次修改主要涉及以下几个方面: 禁用产品复制文件的检查添加指定版本…...
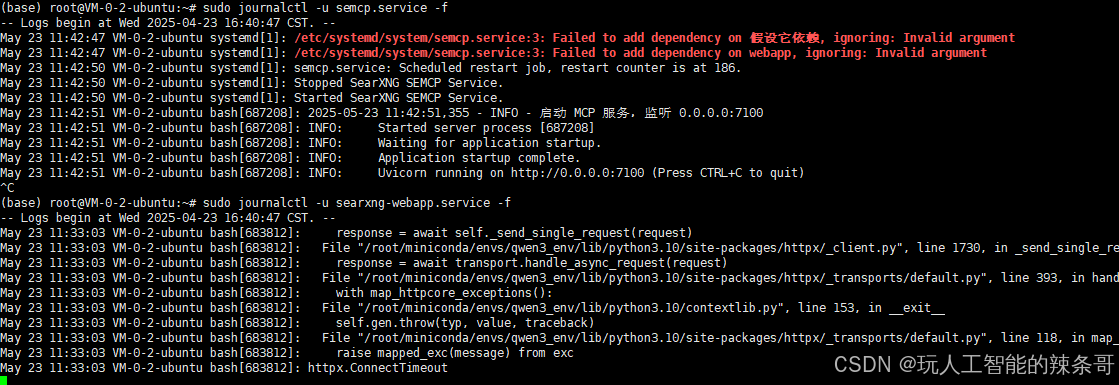
有两个Python脚本都在虚拟环境下运行,怎么打包成一个系统服务,按照顺序启动?
环境: SEMCP searx.webapp python 问题描述: 有两个python脚本都在虚拟环境下运行,怎么打包成一个系统服务,按照顺序启动? 解决方案: 将这两个 Python 脚本打包成有启动顺序的系统服务,最…...

【Linux cmd】查找进程信息
1、包含 "Test" 关键字的进程 ps -ef | grep Test 显示系统中所有进程的详细信息,包括用户 ID(UID)、进程 ID(PID)、父进程 ID(PPID)、启动时间(STIME)、终端…...
)
与网格共舞 - 服务网格的运维与问题排查 (Istio 实例)
与网格共舞 - 服务网格的运维与问题排查 (Istio 实例) 在领略了服务网格(以 Istio 为例)在流量管理、可观测性和安全方面提供的强大能力后,我们自然会思考:如何将这个“神器”请进我们的生产环境,并让它稳定、可靠地运行?这需要我们关注运维层面的实践。 部署与升级:网…...
Python 脚本执行命令的深度探索:方法、示例与最佳实践
在现代软件开发过程中,Python 脚本常常需要与其他工具和命令进行交互,以实现自动化任务、跨工具数据处理等功能。Python 提供了多种方式来执行外部命令,并获取其输出,重定向到文件,而不是直接在终端中显示。这种能力使…...
PotPlayer 4K 本地万能影音播放器
今日分享一款来自吾爱论坛大佬分享的啥都能播的的本地播放器,不管是不管是普通视频、4K超清、蓝光3D,还是冷门格式,它基本都能搞定。而且运行流畅不卡顿,电脑配置低也能靠硬件加速,让你根本停不下来。 自带解码器&…...
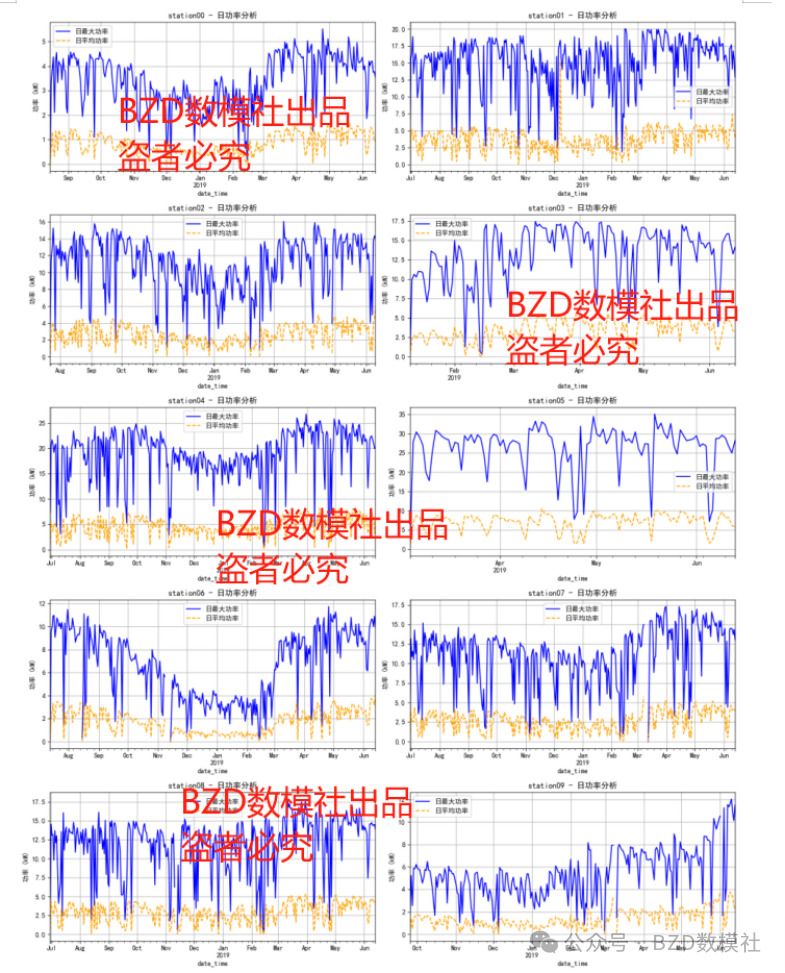
2025年电工杯A题第一版本Q1-Q4详细思路求解+代码运行
A题 光伏电站发电功率日前预测问题 问题背景 光伏发电是通过半导体材料的光电效应,将太阳能直接转化为电能的技术。光伏电站是由众多光伏发电单元组成的规模化发电设施。 光伏电站的发电功率主要由光伏板表面接收到的太阳辐射总量决定,不同季节太阳光…...
基于阿里云DashScope API构建智能对话指南
背景 公司想对接AI智能体,用于客服系统,经过调研和实施,觉得DashScope 符合需求。 阿里云推出的DashScope灵积模型服务为开发者提供了便捷高效的大模型接入方案。本文将详细介绍如何基于DashScope API构建一个功能完善的智能对话系统&#x…...

HOW - 基于组件库组件改造成自定义组件基本规范
文章目录 Select 选择器改造1. 明确组件目标2. 定义组件 API3. 合理使用默认值4. 支持类型安全的 options 传递5. 支持 ForwardRef(可选)6. 封装样式(可选)7. 使用示例 ...props 位置推荐顺序:最后原因:简要…...