大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战
大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战
系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu
文章目录
- 大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战
- 摘要
- 引言
- 一、轻量化技术路径对比
- 1. 参数剪枝:移除冗余连接
- 2. 知识蒸馏:教师-学生模型迁移
- 3. 量化压缩:精度与性能的平衡
- 4. 结构优化:轻量级架构设计
- 二、框架与硬件协同优化
- 1. PyTorch vs TensorFlow Lite部署对比
- 2. 边缘端部署实战:Android端LLaMA-2推理
- 三、典型场景落地挑战
- 1. 车载系统:实时性要求与安全冗余
- 2. IoT设备:功耗与算力双重约束
- 四、未来展望
- 结论
摘要
随着大模型技术从实验室走向产业落地,模型轻量化成为破解推理成本高、部署门槛高、边缘端适配难等问题的关键。本文系统梳理了从LLaMA到MobileBERT等主流模型的轻量化技术路径,涵盖参数剪枝、知识蒸馏、量化压缩、结构优化四大方向,结合Meta、谷歌、华为等企业的开源实践,深入分析不同方法在精度损失、推理速度、硬件兼容性等维度的权衡策略。通过对比PyTorch与TensorFlow Lite框架下的部署流程,结合移动端、IoT设备、车载系统等典型场景的实战案例,为开发者提供可复用的轻量化方案与性能调优指南。

引言
自2020年GPT-3问世以来,大模型参数规模呈现指数级增长:从GPT-3的1750亿参数到GPT-4的1.8万亿参数,再到谷歌PaLM-2的5400亿参数,模型规模与性能提升的边际效应逐渐显现。然而,高昂的推理成本与硬件依赖性成为商业化落地的瓶颈:
- 成本压力:GPT-4单次推理成本约$0.02,日均调用量超1亿次时年成本达7.3亿美元;
- 硬件门槛:运行LLaMA-70B需至少8块A100 GPU,功耗超过3kW;
- 边缘限制:移动端芯片算力仅约10 TOPS,无法直接部署千亿参数模型。
在此背景下,模型轻量化技术成为学术界与工业界的研究热点:
- 参数剪枝:通过移除冗余神经元降低模型复杂度;
- 知识蒸馏:用小模型拟合大模型输出分布;
- 量化压缩:将FP32精度降至INT8甚至INT4;
- 结构优化:设计轻量级网络架构(如MobileBERT)。
本文将从技术原理、工具链、实战案例三个层面,系统解析大模型轻量化的核心方法与落地挑战。
一、轻量化技术路径对比
1. 参数剪枝:移除冗余连接
技术原理:
通过评估神经元重要性(如基于梯度、权重绝对值或激活值),移除对输出贡献最小的连接。典型方法包括:
- 非结构化剪枝:随机删除权重(如Han等人的Deep Compression);
- 结构化剪枝:按通道/层删除(如L1范数剪枝)。
实战案例:LLaMA-2剪枝
使用Hugging Face的optimum工具包对LLaMA-2-7B进行结构化剪枝:
from optimum.intel import INTFasterTransformerConfig, INTFasterTransformerForCausalLM
from transformers import AutoTokenizer, AutoModelForCausalLM# 加载模型
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")# 配置剪枝参数(保留50%权重)
config = INTFasterTransformerConfig.from_pretrained("meta-llama/Llama-2-7b-hf",sparsity=0.5, # 剪枝比例sparsity_type="block" # 结构化剪枝
)# 执行剪枝并导出模型
model = INTFasterTransformerForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf",config=config
)
model.save_pretrained("./llama2-7b-pruned")
效果评估:
- 模型参数减少至3.5B,推理速度提升2.3倍;
- 精度损失:在MMLU基准上从67.2%降至64.8%。
2. 知识蒸馏:教师-学生模型迁移
技术原理:
通过最小化学生模型与教师模型输出分布的KL散度,将大模型的知识迁移到小模型。典型框架包括:
- Hinton蒸馏:直接匹配教师与学生模型的logits;
- TinyBERT:分层蒸馏(嵌入层、注意力层、隐藏层)。
实战案例:BERT→MobileBERT蒸馏
使用谷歌开源的TinyBERT工具链:
# 安装依赖
pip install transformers==4.35.0 torch==2.1.0# 下载预训练模型
wget https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-12_H-768_A-12.zip
unzip uncased_L-12_H-768_A-12.zip -d bert_base# 执行蒸馏(学生模型为4层MobileBERT)
python distill.py \--teacher_model bert_base \--student_config configs/mobilebert_config.json \--output_dir ./mobilebert_distilled \--num_train_epochs 3 \--per_device_train_batch_size 128
效果评估:
- 学生模型参数从110M降至25M,GLUE基准平均分从82.1降至80.5;
- 推理延迟从120ms降至35ms(在骁龙888上)。
3. 量化压缩:精度与性能的平衡
技术原理:
将模型权重从FP32转换为低精度(如INT8、INT4),通过量化感知训练(QAT)减少精度损失。主流工具链包括:
- TensorFlow Lite:支持动态范围量化与全整数量化;
- PyTorch Quantization:提供Eager Mode与FX Graph Mode量化。
实战案例:LLaMA-2-7B量化
使用PyTorch的FX Graph Mode量化:
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer# 加载模型
model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")# 配置量化
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
model_prepared = torch.quantization.prepare(model, inplace=False)# 执行校准(使用100条样本)
def calibrate(model, dataloader):model.eval()with torch.no_grad():for inputs, _ in dataloader:model(**inputs)# 转换量化模型
model_quantized = torch.quantization.convert(model_prepared, inplace=False)
model_quantized.save_pretrained("./llama2-7b-quantized")
效果评估:
- INT8量化后模型体积从14GB降至3.5GB;
- 推理速度提升1.8倍,但MMLU精度下降1.2%。
4. 结构优化:轻量级架构设计
技术原理:
通过设计更高效的神经网络结构减少计算量,典型方法包括:
- MobileBERT:采用瓶颈层(Bottleneck)与注意力共享;
- ALBERT:参数共享与嵌入矩阵分解;
- TinyLLaMA:动态通道剪枝与注意力头合并。
实战案例:MobileBERT架构解析
MobileBERT的核心优化:
效果评估:
- 模型参数仅25M,但GLUE基准分达80.5;
- 推理能耗比BERT降低78%。
二、框架与硬件协同优化
1. PyTorch vs TensorFlow Lite部署对比
| 特性 | PyTorch Mobile | TensorFlow Lite |
|---|---|---|
| 量化支持 | FX Graph Mode QAT | 动态范围/全整数量化 |
| 硬件加速 | OpenCL/Metal/Vulkan | NNAPI/Hexagon/CoreML |
| 模型转换 | TorchScript | TFLite Converter |
| 典型延迟(骁龙888) | LLaMA-2-7B 1.2s | LLaMA-2-7B 0.8s |
2. 边缘端部署实战:Android端LLaMA-2推理
// 使用TensorFlow Lite加载量化模型
try (Interpreter tflite = new Interpreter(loadModelFile(context))) {// 预处理输入float[][] input = preprocess(text);// 执行推理float[][] output = new float[1][1024];tflite.run(input, output);// 后处理结果String response = postprocess(output);
}private MappedByteBuffer loadModelFile(Context context) throws IOException {AssetFileDescriptor fileDescriptor = context.getAssets().openFd("llama2-7b-quantized.tflite");FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());FileChannel fileChannel = inputStream.getChannel();long startOffset = fileDescriptor.getStartOffset();long declaredLength = fileDescriptor.getDeclaredLength();return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}
性能优化技巧:
- 使用
Delegate接口调用NNAPI硬件加速; - 启用
NUM_THREADS参数调节线程数; - 对输入数据进行FP16量化以减少内存带宽占用。
三、典型场景落地挑战
1. 车载系统:实时性要求与安全冗余
- 挑战:自动驾驶场景要求推理延迟<50ms,但轻量化模型可能牺牲长尾场景覆盖;
- 解决方案:华为MDC平台采用“轻量化模型+安全兜底策略”,在ADS 3.0中部署双模型架构(主模型处理常规场景,备用模型应对极端情况)。
2. IoT设备:功耗与算力双重约束
- 挑战:ESP32芯片仅4MB RAM,无法直接运行BERT类模型;
- 解决方案:采用知识蒸馏+量化压缩,将模型压缩至1.2MB,结合二进制神经网络(BNN)技术实现实时语音识别。
四、未来展望
- 混合精度量化:INT4/INT8混合精度将精度损失控制在0.5%以内;
- 动态模型架构:根据硬件条件动态调整模型层数(如华为的“弹性神经网络”);
- 跨平台统一标准:ONNX Runtime 3.0将支持多框架量化模型互操作。
结论
大模型轻量化是技术演进的必然趋势,但需在精度、速度、成本间寻找平衡点。从LLaMA到MobileBERT的实践表明:
- 参数剪枝适合快速降本,但可能破坏模型结构;
- 知识蒸馏能保留更多知识,但依赖高质量教师模型;
- 量化压缩实现硬件友好,但需处理精度损失;
- 结构优化提供长期竞争力,但开发门槛较高。
随着NPU硬件加速普及与量化算法创新,2025年或迎来千亿参数模型在边缘端的常态化部署,推动AI技术从云端走向万物智能。
相关文章:
大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战
大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战摘要引言一、轻量化技术…...

从逻辑视角学习信息论:概念框架与实践指南
文章目录 一、信息论的逻辑基础与哲学内涵1.1 信息的逻辑本质:区分与差异1.2 逆范围原理与信息内容 二、信息论与逻辑学的概念交汇2.1 熵作为逻辑不确定性的度量2.2 互信息与逻辑依赖2.3 信道容量的逻辑极限 三、信息论的核心原理与逻辑基础3.1 最大熵原理的逻辑正当…...

springboot配置mysql druid连接池,以及连接池参数解释
文章目录 前置配置方式参数解释 前置 springboot 项目javamysqldruid 连接池 配置方式 在 springboot 的 application.yml 中配置基本方式 # Druid 配置(Spring Boot YAML 格式) spring:datasource:url: jdbc:mysql://localhost:3306/testdb?useSSL…...

Spring Boot集成Resilience4j实现微服务容错机制
在Spring Boot中集成Resilience4j实现微服务容错 引言 在微服务架构中,服务之间的调用不可避免,但由于网络延迟、服务不可用等问题,调用失败的情况时有发生。为了提高系统的稳定性和可用性,我们需要引入容错机制。Resilience4j是…...
 本地hadoop虚拟机系统设置)
(一) 本地hadoop虚拟机系统设置
1.配置固定IP地址(每一台都配置) 开启node1,修改主机名为node1,并修改固定IP为:192.168.88.131 # 修改主机名 hostnamectl set-hostname node1# 修改IP vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR"…...

TDengine 运维—容量规划
概述 若计划使用 TDengine 搭建一个时序数据平台,须提前对计算资源、存储资源和网络资源进行详细规划,以确保满足业务场景的需求。通常 TDengine 会运行多个进程,包括 taosd、taosadapter、taoskeeper、taos-explorer 和 taosx。 在这些进程…...

【MySQL成神之路】MySQL索引相关介绍
1 相关理论介绍 一、索引基础概念 二、索引类型 1. 按数据结构分类 2. 按功能分类 三、索引数据结构原理 B树索引特点: 哈希索引特点: 四、索引使用原则 1. 创建索引原则 2. 避免索引失效情况 五、索引优化策略 六、索引维护与管理 七、特殊…...

PPP 拨号失败:ATD*99***1# ... failed
从日志来看,主要有两类问题: 一、led_indicator_stop 报 invalid p_handle E (5750) led_indicator: …/led_indicator.c:461 (led_indicator_stop):invalid p_handle原因分析 led_indicator_stop() 的参数 p_handle (即之前 led_indicator…...

PostgreSQL跨数据库表字段值复制实战经验分
场景需求 在实际工作中,我们经常需要将一个PostgreSQL数据库中的表字段值复制到另一个数据库中。最近我在处理两个ERP系统数据库(A库和B库)之间的数据同步时,就遇到了这样的需求:需要将B库中sale_order表的合同信息&a…...
【计网】五六章习题测试
目录 1. (单选题, 3 分)某个网络所分配到的地址块为172.16.0.0/29,能接收目的地址为172.16.0.7的IP分组的最大主机数是( )。 2. (单选题, 3 分)若将某个“/19”的CIDR地址块划分为7个子块,则可能的最小子块中的可分配IP地址数量…...
汇川EasyPLC MODBUS-RTU通信配置和编程实现
累积流量计算(MODBUS RTU通信数据处理)数据处理相关内容。 累积流量计算(MODBUS RTU通信数据处理)_流量积算仪modbus rtu通讯-CSDN博客文章浏览阅读219次。1、常用通信数据处理MODBUS通信系列之数据处理_modbus模拟的数据变化后会在原来的基础上累加是为什么-CSDN博客MODBUS通…...

从 CANopen到 PROFINET:网关助力物流中心实现复杂的自动化升级
使用 CANopen PLC 扩展改造物流中心的传送带 倍讯科技profinet转CANopen网关BX-601-EIP将新的 PROFINET PLC 系统与旧的基于 CANopen 的传送带连接起来,简化了物流中心的自动化升级。 新建还是升级?这些问题通常出现在复杂的内部物流设施中,…...
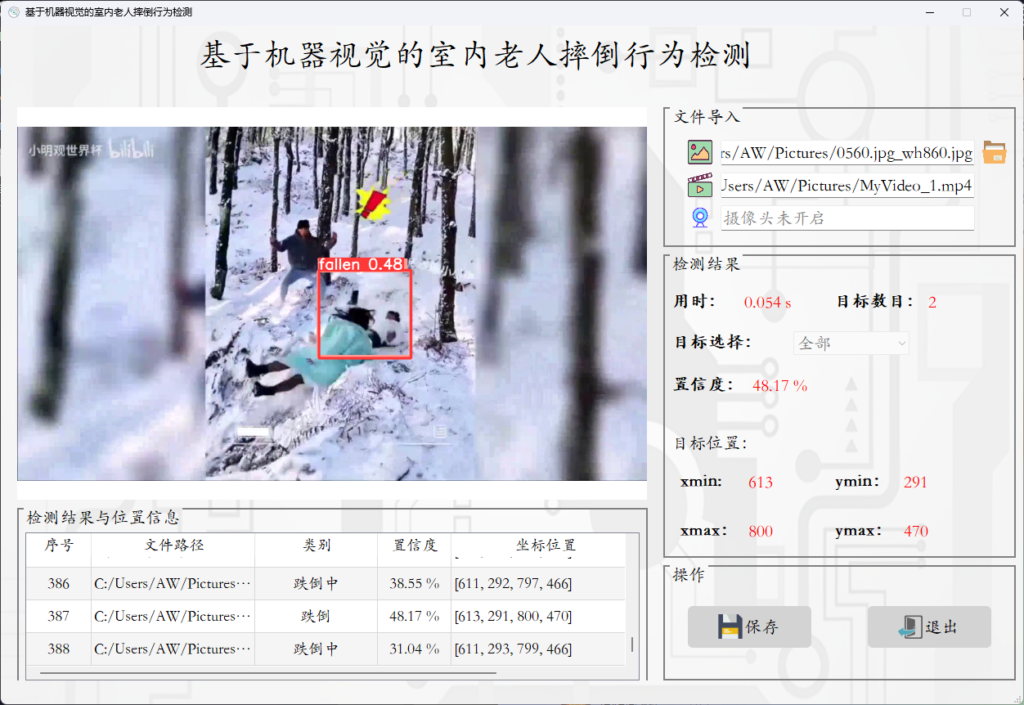
基于Yolov8+PyQT的老人摔倒识别系统源码
概述 基于Yolov8PyQT的老人摔倒识别系统,该系统通过深度学习算法实时检测人体姿态,精准识别站立、摔倒中等3种状态,为家庭或养老机构提供及时预警功能。 主要内容 完整可运行代码 项目采用Yolov8目标检测框架结合PyQT5开发…...
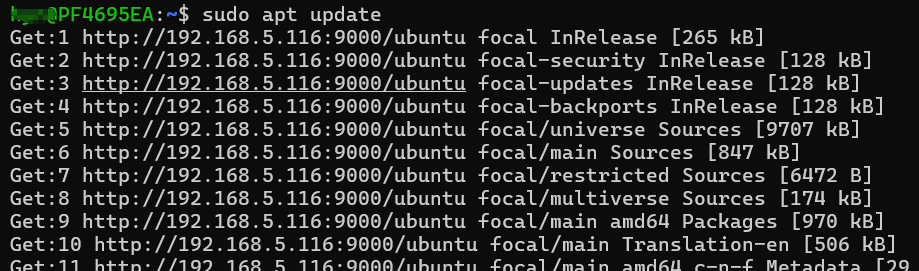
wsl2 不能联网
wsl2 安装后用 wifi 共享是能联网,问题出在公司网络限制 wsl2 IP 访问网络,但是主机可以上网。 解决办法,在主机用 nginx 设置代理,可能需要开端口权限 server {listen 9000;server_name localhost;location /ubuntu/ {#…...

双击重复请求的方法
1、限制点击次数 2、vue中 可以自定义一个属性指令 preventReClick.js中定义: import Vue from vue Vue.directive(preventReClick, {inserted: (el, binding) > {el.addEventListener(click, () > {if (!el.disabled) {el.disabled truesetTimeout(() >…...
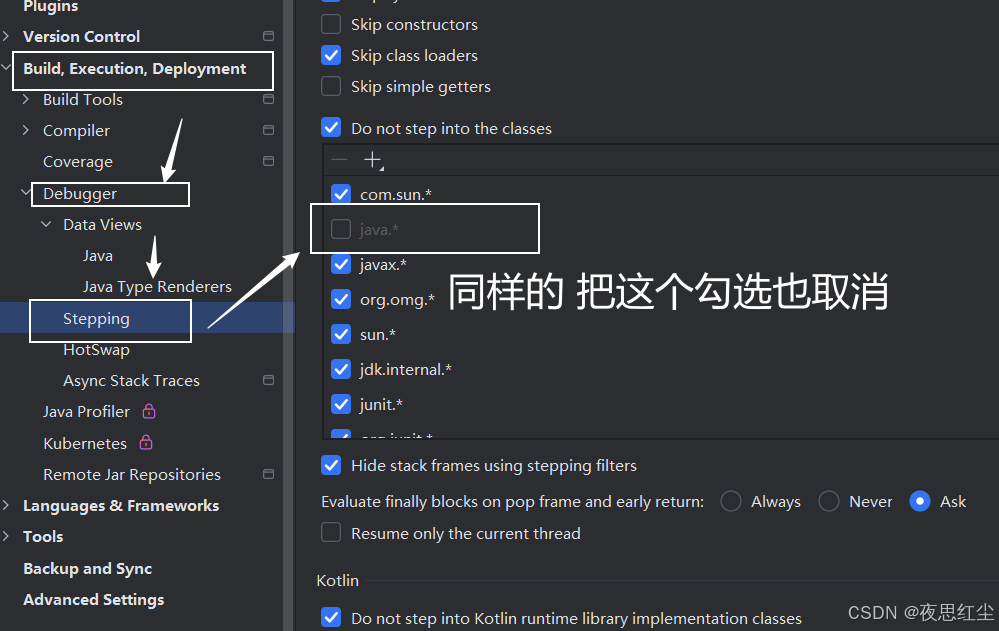
Java[IDEA]里的debug
目录 前言 Debug 使用Debug 总结 前言 这里我说一下就是 java IDEA 工具里的debug工具 里的一个小问题 就是 当我们使用debug去查看内部文档 查看不到 是为什么 Debug 所谓 debug 工具 他就是用来调试程序的 当我们写代码 报错 出错时 我们就可以使用这个工具 因此这个工具…...

一条SQL语句的旅程:解析、优化与执行全过程研究
1、引言 在现代信息系统中,数据库是核心组件之一。SQL(结构化查询语言)作为与数据库交互的主要方式,其执行效率直接影响到整个系统的性能表现。虽然开发者常常只需编写一行简单的 SQL,但数据库内部却经历了一个复杂而精密的过程来完成这条 SQL 的处理。 本文将以一个完整…...

动态规划经典三题_完全平方数
279. 完全平方数 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而…...
)
LVGL(lv_textarea文本框控件)
文章目录 一、lv_textarea 是什么?二、基本用法1. 创建 lv_textarea 对象2. 设置提示文字(占位符)3. 设置最大长度4. 设置密码模式(显示为\*号)5. 获取和设置内容6. 配合虚拟键盘使用(常用于触摸屏…...

蓝桥杯国14 互质
问题描述 请计算在 [1,2023的2023次幂] 范围内有多少个整数与 2023 互质。由于结果可能很大,你只需要输出对 1097 取模之后的结果。 答案提交 这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个…...

DAO模式
1. 持久化 简单来说,就是把代码的处理结果转换成需要的格式进行储存。 2. JDBC的封装 3. DAO模式 4. Properties类与Properties配置文件 添加 读取 5. 使用实体类传递数据 6. 总结 附录: BaseDao指南 BaseDao指南-CSDN博客...
ECharts图表工厂,完整代码+思路逻辑
Echart工厂支持柱状图(bar)折线图(line)散点图(scatter)饼图(pie)雷达图(radar)极坐标柱状图(polarBar)和极坐标折线图(po…...

Logback 在 Spring Boot 中的详细配置
1. Logback 配置文件 Spring Boot 默认会加载 classpath 下的 logback-spring.xml(推荐)或 logback.xml 作为 Logback 的配置文件。 推荐使用 logback-spring.xml,因为 Spring Boot 提供了扩展支持(例如基于 Profile 的配置&am…...

写起来比较复杂的深搜题目
年轻的拉尔夫开玩笑地从一个小镇上偷走了一辆车,但他没想到的是那辆车属于警察局,并且车上装有用于发射车子移动路线的装置。 那个装置太旧了,以至于只能发射关于那辆车的移动路线的方向信息。 编写程序,通过使用一张小镇的地图…...

MySQL强化关键_016_存储引擎
目 录 一、概述 二、MySQL 支持的存储引擎 三、指定存储引擎 四、修改存储引擎 五、常用存储引擎及适用场景 一、概述 MySQL 存储引擎决定了数据在磁盘上的存储方式和访问方式;不同的存储引擎实现了不同的存储和检索算法;MySQL 常见的存储引擎&…...

CSS:margin的塌陷与合并问题
文章目录 一、margin塌陷问题二、margin合并问题 一、margin塌陷问题 二、margin合并问题...

防护等级IPxx含义 -雨天充电需要防护盖吗
指标快要到期,新买的电车,第一次碰到雨天充电的问题,有点担心漏电。然后电商平台上一查,果然有卖防护罩的,但是真的需要吗? 下面从充电口防护等级,国标要求、注意事项等几个方面分析。 一、防护…...

【设计模式】责任链+模板+工程模式使用模板
前言 方便写出优雅,解耦,高内聚,高复用的代码。 Demo // 1. 定义验证器接口(责任链模式) public interface Validator {Validator setNext(Validator next);boolean validate(Data data); }// 2. 创建抽象验证器&am…...
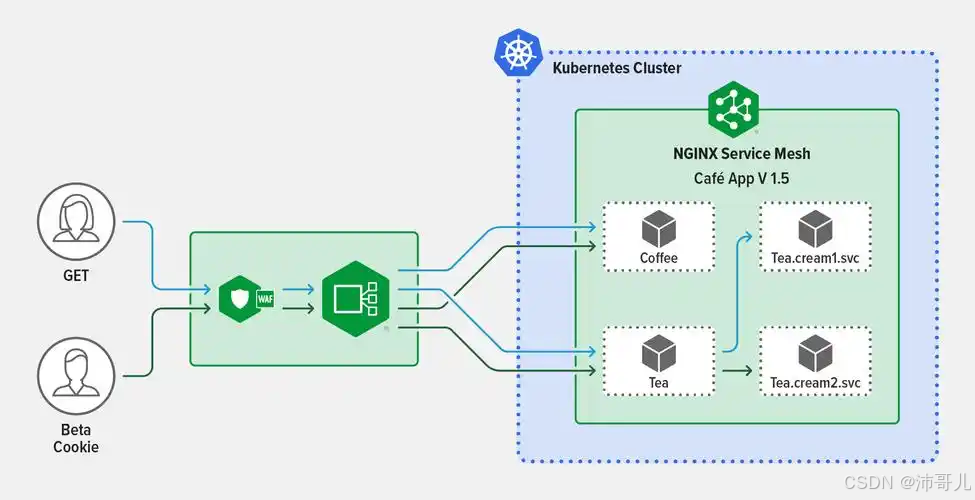
探索服务网格(Service Mesh):云原生时代的网络新范式
文章目录 一、引言二、什么是服务网格基本定义形象比喻 三、服务网格解决了哪些问题微服务通信复杂性可观察性安全性 四、常见的服务网格实现IstioLinkerdConsul Connect 五、服务网格的应用场景大型微服务架构混合云环境 六、服务网格的未来发展与其他技术的融合标准化和行业规…...
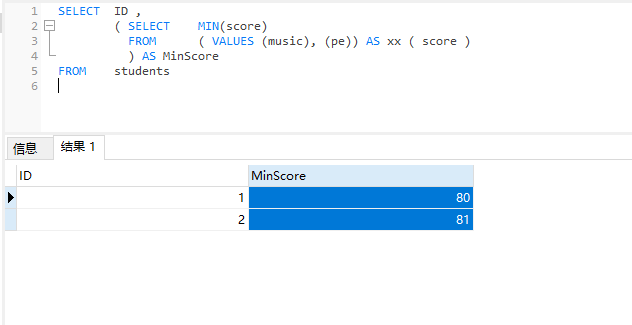
SQL SERVER中实现类似LEAST函数的功能,返回多列数据中的最小值
使用 LEAST()函数可以简洁地在一行SQL语句中找出多个值中的最小值,但在SQLServer数据库中,没有内置的LEAST函数。 我们可以使用values子句创建临时的数据集的办法,返回多列数据中的最小值。 创建表 CREATE TABLE stu…...