redis 进行缓存实战-18
使用 Redis 进行缓存
Redis 通常被认为只是一个数据存储,但它的速度和内存中特性使其成为缓存的绝佳选择。缓存是一种技术,通过将经常访问的数据存储在快速的临时存储位置来提高应用程序性能。通过使用 Redis 作为缓存,您可以显著减少主数据库的负载并缩短用户的响应时间。本课将探讨如何有效地使用 Redis 进行缓存,涵盖关键概念、策略和最佳实践。
了解缓存概念
缓存是软件开发中的一种基本优化技术。它涉及将数据副本存储在缓存中,缓存是一个高速数据存储层,以便将来可以更快地处理对该数据的请求。发出请求时,首先检查缓存。如果在缓存中找到数据(“缓存命中”),则直接从缓存中提供数据。如果未找到数据(“缓存未命中”),则会从原始数据源(例如数据库)中检索数据,将其存储在缓存中,然后提供给用户。
缓存的好处
- 改进的性能: 缓存通过从更快的存储层提供数据来减少延迟并缩短响应时间。
- 减少数据库负载: 通过从缓存中提供经常访问的数据,您可以减少主数据库的负载,使其能够处理更复杂的查询和作。
- 提高可扩展性: 缓存通过减少后端系统的负载,使您的应用程序能够处理更多的并发用户和请求。
- 节省成本: 通过减少数据库负载和提高资源利用率,缓存可以节省基础设施和运营费用方面的成本。
缓存策略
Redis 可以使用多种缓存策略,每种策略都有自己的优点和缺点:
- Cache-Aside (延迟加载): 应用程序首先检查缓存中的数据。如果找到数据,则直接返回数据。如果没有,应用程序将从数据库中检索数据,将其存储在缓存中,然后返回它。此策略易于实施,并确保缓存仅包含已请求的数据。
- 直写: 应用程序同时将数据写入缓存和数据库。这可确保缓存始终是最新的,但会增加写入延迟。
- 回写 (Write-Behind): 应用程序将数据写入缓存,缓存将数据异步写入数据库。此策略提供最低的写入延迟,但如果缓存在将数据写入数据库之前失败,则可能导致数据丢失。
- 通读: 应用程序与缓存交互,而缓存又与数据库交互。请求数据时,缓存会检查它是否包含数据。否则,它将从数据库中检索数据,将其存储在缓存中,然后将其返回给应用程序。
对于大多数使用案例,Cache-Aside 策略是 Redis 最实用且最常用的策略,因为它简单高效。
使用 Redis 作为缓存
Redis 非常适合缓存,因为它的速度、内存数据存储和对各种数据结构的支持。以下是将 Redis 用作缓存的方法:
设置和检索数据
您可以使用 SET 和 GET 命令在 Redis 中存储和检索数据。例如:
SET user:123 '{"id": 123, "name": "John Doe", "email": "john.doe@example.com"}'
GET user:123
在此示例中,我们将一个 JSON 字符串存储在 Redis 中,该字符串表示用户对象,其键为 user:123。使用 GET user:123 检索数据时,Redis 返回 JSON 字符串。
设置过期时间 (TTL)
为防止缓存无限增长,您可以使用 EXPIRE 命令或带有 SET 命令的 EX 选项为缓存数据设置过期时间(TTL - 生存时间):
SET user:123 '{"id": 123, "name": "John Doe", "email": "john.doe@example.com"}' EX 3600 # Expires in 3600 seconds (1 hour)
EXPIRE user:123 3600 # Expires in 3600 seconds (1 hour)
TTL user:123 # Check the remaining time to live
这可确保在指定时间段后自动删除缓存的数据,从而防止提供过时的数据。
数据序列化
缓存复杂数据结构时,您需要在将数据存储在 Redis 中之前对其进行序列化,并在检索数据后对其进行反序列化。常见的序列化格式包括 JSON 和 Protocol Buffers。
以下是在 Python 中使用 JSON 的示例:
import redis
import json# Connect to Redis
redis_client = redis.Redis(host='localhost', port=6379, db=0)# Data to cache
user_data = {"id": 123, "name": "John Doe", "email": "john.doe@example.com"}# Serialize the data to JSON
user_data_json = json.dumps(user_data)# Store the JSON string in Redis with an expiration time
redis_client.set('user:123', user_data_json, ex=3600)# Retrieve the data from Redis
cached_user_data_json = redis_client.get('user:123')# Deserialize the JSON string back to a Python dictionary
if cached_user_data_json:cached_user_data = json.loads(cached_user_data_json)print(cached_user_data)
else:print("Data not found in cache")
缓存失效策略
缓存失效是在基础数据更改时删除或更新缓存数据的过程。缓存失效有几种策略:
- 基于 TTL 的失效: 在指定的 TTL 之后,数据会自动从缓存中删除。这是最简单的策略,但如果基础数据在 TTL 过期之前发生更改,则可能会导致数据过时。
- 基于事件的失效: 当发生特定事件(例如数据库更新)时,缓存将失效。此策略可确保缓存始终是最新的,但它需要与数据源进行更复杂的集成。
- 手动失效: 缓存由管理员或应用程序代码手动失效。此策略对缓存失效提供了最大的控制,但它需要仔细监控和管理。
示例:缓存数据库查询
假设您有一个从数据库中检索用户数据的函数:
import redis
import json
import time# Assume this function fetches data from a database
def get_user_from_db(user_id):# Simulate a database query with a delaytime.sleep(1)user_data = {"id": user_id, "name": f"User {user_id}", "email": f"user{user_id}@example.com"}return user_datadef get_user(user_id, redis_client):"""Retrieves user data from cache if available, otherwise fetches from the database,caches it, and returns it."""cache_key = f'user:{user_id}'cached_user_data = redis_client.get(cache_key)if cached_user_data:# Cache hitprint(f"Cache hit for user {user_id}")user_data = json.loads(cached_user_data)else:# Cache missprint(f"Cache miss for user {user_id}. Fetching from DB.")user_data = get_user_from_db(user_id)user_data_json = json.dumps(user_data)redis_client.set(cache_key, user_data_json, ex=3600) # Cache for 1 hourreturn user_data# Example usage
redis_client = redis.Redis(host='localhost', port=6379, db=0)user1 = get_user(123, redis_client)
print(user1)user1_cached = get_user(123, redis_client) #This time it will be a cache hit
print(user1_cached)user2 = get_user(456, redis_client)
print(user2)
在此示例中,get_user 函数首先检查用户数据在 Redis 缓存中是否可用。如果是,则从缓存中检索数据并返回数据。否则,将从数据库中检索数据,将其存储在缓存中,过期时间为 1 小时,然后返回。
高级缓存技术
缓存防盗
当大量请求同时命中缓存,并且缓存已过期或为空时,就会发生缓存加速。这可能会使数据库过载,因为所有请求都尝试同时检索数据。
要防止缓存踩踏,可以使用以下技术:
- Probabilistic Early Expiration(概率提前到期): 您可以向过期时间添加一个小的随机延迟,而不是为所有缓存条目设置固定的过期时间。这有助于分配数据库上的负载。
- 锁定: 当发生缓存未命中时,您可以获取一个锁,以防止其他请求同时尝试从数据库中检索数据。只有第一个请求会检索数据,将其存储在缓存中,然后释放锁。
- 后台刷新: 您可以在缓存过期之前在后台刷新缓存。这可确保缓存始终是最新的,并降低缓存被踩踏的可能性。
使用 Redis 数据结构进行缓存
Redis 提供了各种可用于缓存不同类型数据的数据结构:
- Strings: 用于缓存简单的键值对,例如用户 ID 和名称。
- Hashes: 用于缓存具有多个字段的对象,例如用户配置文件。
- Lists: 用于缓存有序数据,例如最近的活动源。
- Sets: 用于缓存唯一数据,例如用户角色。
- Sorted Sets: 用于缓存排名数据,例如排行榜。
选择正确的数据结构可以提高缓存的效率和性能。
示例:缓存博客文章列表
假设您要缓存最近的博客文章列表。您可以使用 Redis 列表来存储帖子 ID,然后在需要时从数据库中检索完整的帖子数据。
import redis
import json# Connect to Redis
redis_client = redis.Redis(host='localhost', port=6379, db=0)# Assume this function fetches blog posts from a database
def get_blog_posts_from_db():# Simulate a database queryblog_posts = [{"id": 1, "title": "Redis Caching", "content": "..."},{"id": 2, "title": "NoSQL Databases", "content": "..."},{"id": 3, "title": "Python Programming", "content": "..."}]return blog_postsdef get_recent_blog_posts(redis_client, limit=10):"""Retrieves recent blog posts from cache if available, otherwise fetches from the database,caches it, and returns it."""cache_key = 'recent_blog_posts'cached_post_ids = redis_client.lrange(cache_key, 0, limit - 1)if cached_post_ids:# Cache hitprint("Cache hit for recent blog posts")post_ids = [int(post_id) for post_id in cached_post_ids]# In a real application, you would fetch the full post data from the database# based on these IDs. Here, we just return the IDs.return post_idselse:# Cache missprint("Cache miss for recent blog posts. Fetching from DB.")blog_posts = get_blog_posts_from_db()post_ids = [post['id'] for post in blog_posts]# Store the post IDs in Redisfor post_id in reversed(post_ids): # Add in reverse order to maintain orderredis_client.lpush(cache_key, post_id)redis_client.expire(cache_key, 3600) # Cache for 1 hourreturn post_ids[:limit]# Example usage
recent_posts = get_recent_blog_posts(redis_client)
print(recent_posts)recent_posts_cached = get_recent_blog_posts(redis_client) #This time it will be a cache hit
print(recent_posts_cached)
实践练习
- 实施 Cache-Aside 策略: 创建一个使用 Redis 缓存 API 调用结果的函数。该函数应首先检查数据在缓存中是否可用。如果是,则返回缓存的数据。如果没有,请进行 API 调用,将结果存储在缓存中并指定过期时间,然后返回结果。
- 实施缓存失效: 修改前面的函数,以便在底层数据更改时使缓存失效。您可以通过更新数据库中的值或调用其他 API 终端节点来模拟数据更改。
- 使用 Redis 哈希来缓存对象: 创建一个使用 Redis 哈希缓存用户配置文件的函数。该函数应将每个用户配置文件存储为单独的哈希值,其中包含 name、email 和其他相关信息的字段。
- 实施缓存踩踏防护: 修改 API 缓存功能,以防止使用概率提前过期或锁定的缓存踩踏。
相关文章:

redis 进行缓存实战-18
使用 Redis 进行缓存 Redis 通常被认为只是一个数据存储,但它的速度和内存中特性使其成为缓存的绝佳选择。缓存是一种技术,通过将经常访问的数据存储在快速的临时存储位置来提高应用程序性能。通过使用 Redis 作为缓存,您可以显著减少主数据…...

JFace中MVC的表的单元格编辑功能的实现
一、实现流程 在JFace中实现MVC模式的表格编辑功能通常需要以下步骤: 1、启用编辑模式: 调用TableVierer对象的setCellModifier()方法,设置一个ICellModifier对象,以便在表格中启用编辑模式。实现ICellModifier接口的canModify(…...

在 Excel xll 自动注册操作 中使用东方仙盟软件2————仙盟创梦IDE
// 获取当前工作表名称string sheetName (string)XlCall.Excel(XlCall.xlfGetDocument, 7);// 构造动态名称(例如:Sheet1!MyNamedCell)string fullName $"{sheetName}!MyNamedCell";// 获取引用并设置值var namedRange (ExcelRe…...

canal实现mysql数据同步
目录 1、canal下载 2、mysql同步用户创建和授权 3、canal admin安装和启动 4、canal server安装和启动 5、java 端集成监听canal 同步的mysql数据 6、java tcp同步只是其中一种方式,还可以通过kafka、rabbitmq等方式进行数据同步 1、canal下载 canal实现mysq…...

解决 MySQL 表结构修改中锁定异常的全链路实战指南:从表结构设计到版本调优
引言 在 MySQL 中执行ALTER TABLE修改表结构(如新增字段、调整字段类型)时,锁定异常是最常见的阻碍。无论是 5.7 的 “锁等待超时”、8.0 的 “MDL 锁阻塞”,还是高并发下的 “长事务死锁”,本质都是表结构修改需要获…...
)
动态规划应用场景 + 代表题目清单(模板加上套路加上题单)
1. 序列型DP(Sequence DP) ✅ 应用场景 单个或多个序列(数组/字符串),求最优子结构。 常见问题:最长递增子序列、最长公共子序列、回文子序列。 🧠 套路总结 单序列:dp[i] max(…...
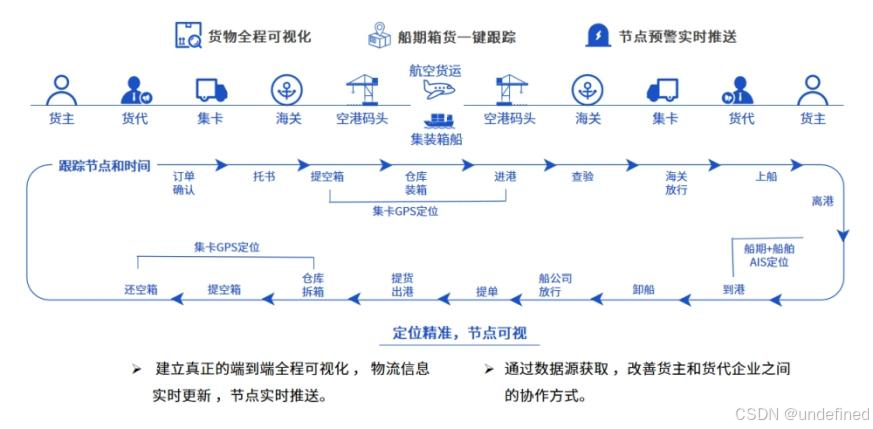
易境通专线散拼系统:全方位支持多种专线物流业务!
在全球化电商快速发展的今天,跨境电商物流已成为电商运营中极为重要的环节。为了确保物流效率、降低运输成本,越来越多的电商卖家选择专线物流服务。专线物流作为五大主要跨境电商物流模式之一,通过固定的运输路线和流程,极大提高…...

nvm版本管理下pnpm 安装失败问题解决
检查当前使用的 Node.js 是否由 nvm 管理 nvm current 应显示类似 18.16.0 这样的版本号,而不是 system。如果是 system,说明你正在使用系统中其他位置的 Node.js 而不是 nvm 管理的版本。 切换回 nvm 管理的版本 nvm use 18.16.0清除 npm 缓存和全局安装…...

C++高频面试考点 -- 智能指针
C高频面试考点 – 智能指针 C11中引入智能指针的概念,方便堆内存管理。这是因为使用普通指针,容易造成堆内存泄漏,二次释放,程序发生异常时内存泄漏等问题。 智能指针在C11版本之后提供,包含在头文件<memory>中…...
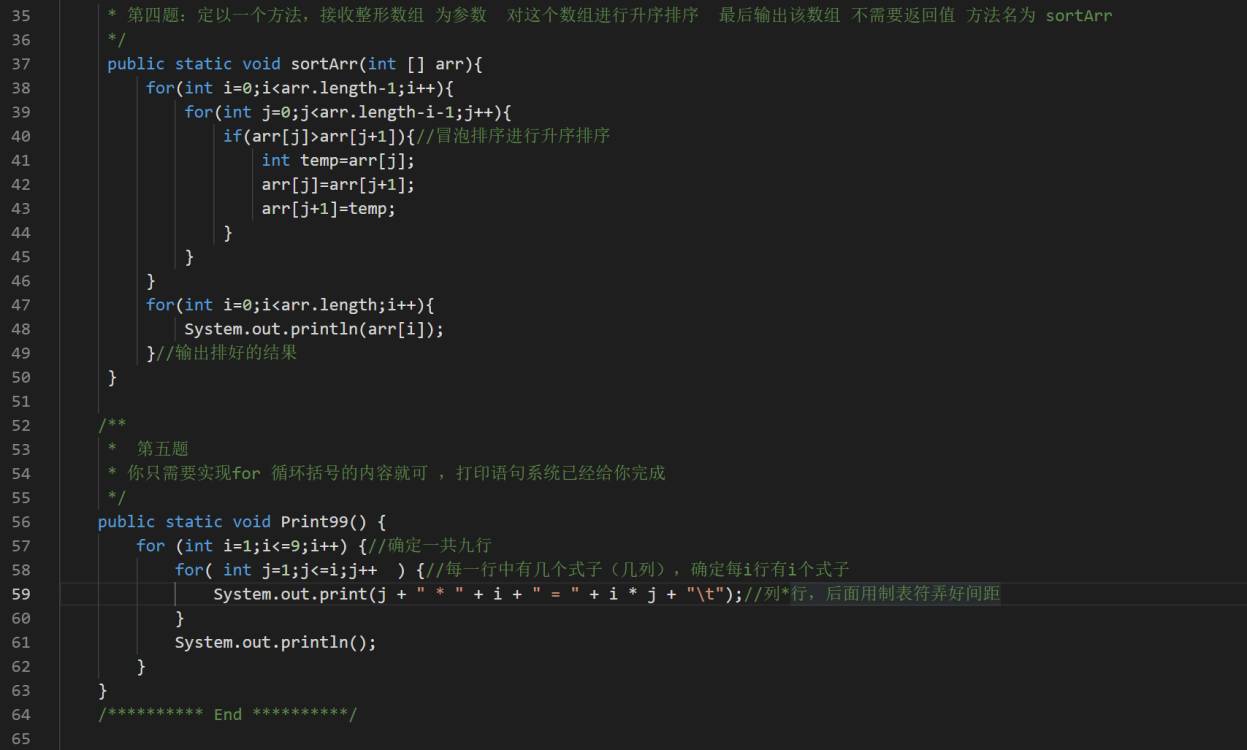
06 如何定义方法,掌握有参无参,有无返回值,调用数组作为参数的方法,方法的重载
1.调用方法 2.掌握有参函数 3.调用数组作为参数 一个例题:数组参数,返回值 方法的重载 两个例题:冒泡排序和九九乘法表的格式学习...
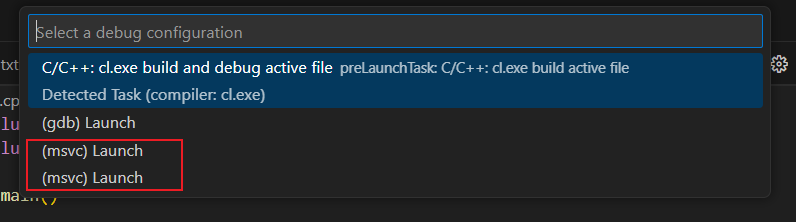
使用vscode MSVC CMake进行C++开发和Debug
使用vscode MSVC CMake进行C开发和Debug 前言软件安装安装插件构建debuug方案一debug方案二其他 前言 一般情况下我都是使用visual studio来进行c开发的,但是由于python用的是vscode,所以二者如果统一的话能稍微提高一点效率。 软件安装 需要安装的软…...

C# AutoMapper对象映射详解
引言 在现代软件开发中,特别是采用分层架构的应用程序,我们经常需要在不同的对象类型之间进行转换。例如,从数据库实体(Entity)转换为数据传输对象(DTO),或者从视图模型(…...
)
Keil5 MDK LPC1768 RT-Thread KSZ8041NL uIP1.3.1实现UDP网络通讯(服务端接收并发数据)
作为服务端,嵌入式软件实现流程: [上位机A/B/C/...] ↓ UDP [uIP 协议栈接收] ↓ [udp_appcall()] |-> 复制数据 |-> 保存源IP/端口 |-> 推送到接收队列 …...

提升开发运维效率:原力棱镜游戏公司的 Amazon Q Developer CLI 实践
引言 在当今快速发展的云计算环境中,游戏开发者面临着新的挑战和机遇。为了提升开发效率,需要更智能的工具来辅助工作流程。Amazon Q Developer CLI 作为亚马逊云科技推出的生成式 AI 助手,为开发者提供了一种新的方式来与云服务交互。 Ama…...
)
20250523-BUG-E1696:无法打开元数据文件“platform.winmd(已解决)
BUG:E1696:无法打开元数据文件“platform.winmd(已解决) 最近在用VisualStudio2022打开一个VisualStudio2017的C老项目后报了这个错,几经周折终于解决了,以下是我用的解决方法: 将Debug从Win32改…...

职业规划:动态迭代的系统化路径
1. 底层逻辑:构建职业规划的3大支柱 1.1 价值观锚定 1.1.1 生涯幻游法 通过想象理想生活的场景,包括工作环境、时间分配、人际关系、经济状态等,明确自己内心真正渴望的生活和工作状态,为职业规划提供方向指引。 1.1.2 价值观筛选 使用「价值观筛选卡」从30个常见职业价值…...

redisson-spring-boot-starter 版本选择
以下是更详细的 Spring Boot 与 redisson-spring-boot-starter 版本对应关系,按照 Spring Boot 主版本和子版本细分: 1. Spring Boot 3.x 系列 3.2.x 推荐 Redisson 版本:3.23.1(最新稳定版,兼容 Redis 7.x…...

Docker run -v 的 rw 和 ro 模式_docker ro
一、前言 在使用 Docker 启动容器时,通常需要将宿主机的文件或目录挂载到容器中,以便于管理配置、持久化数据和调试日志。本篇博客将重点介绍 -v/--volume 参数的使用方式、挂载权限(rw 与 ro)的区别,以及如何通过 do…...
)
CentOS相关操作hub(更新中)
CentOS介绍: CentOS(Community Enterprise Operating System)是基于 Red Hat Enterprise Linux(RHEL)源代码编译的开源企业级操作系统,提供与 RHEL 二进制兼容的功能 完全兼容 RHEL,可直接使用…...
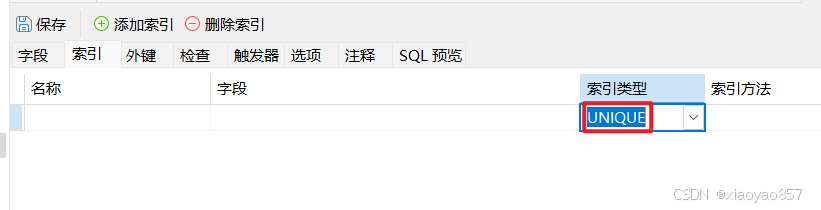
@Column 注解属性详解
提示:文章旨在说明 Column 注解属性如何在日常开发中使用,数据库类型为 MySql,其他类型数据库可能存在偏差,需要注意。 文章目录 一、name 方法二、unique 方法三、nullable 方法四、insertable 方法五、updatable 方法六、column…...
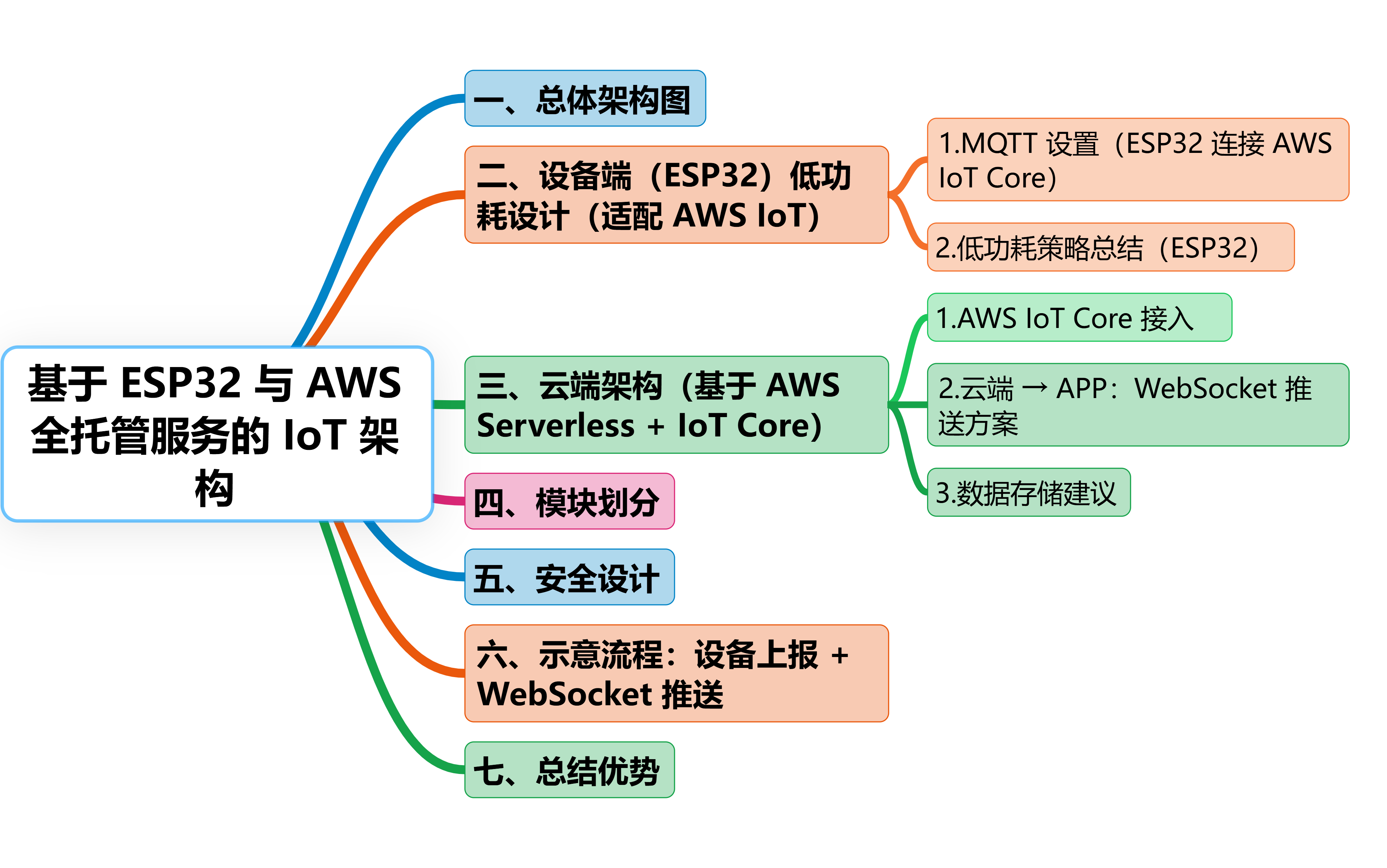
基于 ESP32 与 AWS 全托管服务的 IoT 架构:MQTT + WebSocket 实现设备-云-APP 高效互联
目录 一、总体架构图 二、设备端(ESP32)低功耗设计(适配 AWS IoT) 1.MQTT 设置(ESP32 连接 AWS IoT Core) 2.低功耗策略总结(ESP32) 三、云端架构(基于 AWS Serverless + IoT Core) 1.AWS IoT Core 接入 2.云端 → APP:WebSocket 推送方案 流程: 3.数据存…...
unity在urp管线中插入事件
由于在urp下,打包后传统的相机事件有些无法正确执行,这时候我们需要在urp管线中的特定时机进行处理一些事件,需要创建继承ScriptableRenderPass和ScriptableRendererFeature的脚本,示例如下: PluginEventPass…...

前后端的双精度浮点数精度不一致问题解决方案,自定义Spring的消息转换器处理JSON转换
在 Java 中,Long 是一个 64 位的长整型,通常用于表示很大的整数。在后端,Long 类型的数据没有问题,因为 Java 本身使用的是 64 位的整数,可以表示的范围非常大。 但是,在前端 JavaScript 中,Lo…...
docker安装es连接kibana并安装分词器
使用Docker部署Elasticsearch、Kibana并安装分词器有以下主要优点: 1. 快速部署与一致性 一键式部署:通过Docker Compose可以快速搭建完整的ELK栈环境 环境一致性:确保开发、测试和生产环境完全一致,避免"在我机器上能运行…...

线性回归中涉及的数学基础
线性回归中涉及的数学基础 本文详细地说明了线性回归中涉及到的主要的数学基础。 如果数学基础很扎实可以直接空降博文: 线性回归(一)-CSDN博客 一、概率、似然与概率密度函数 1. 概率(Probability) 定义:概率是描述…...
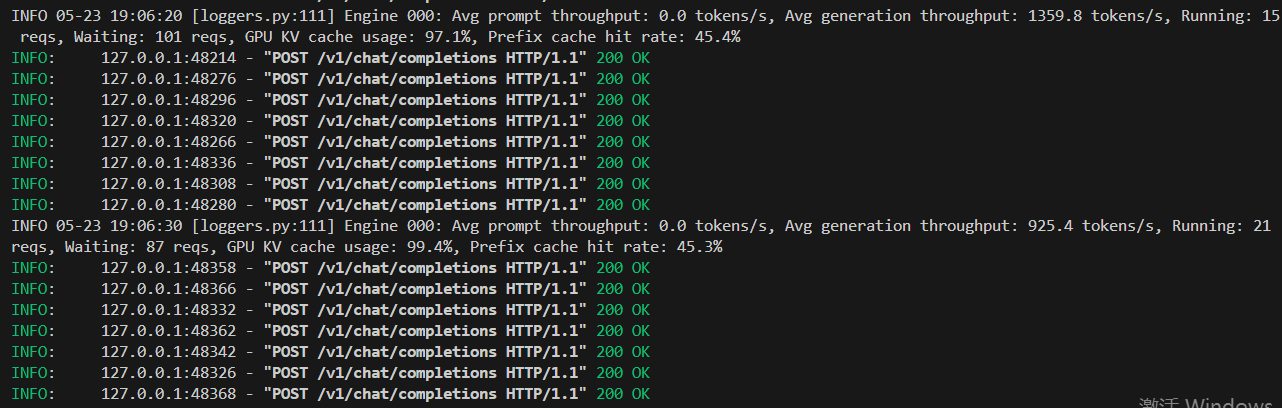
如何计算VLLM本地部署Qwen3-4B的GPU最小配置应该是多少?多人并发访问本地大模型的GPU配置应该怎么分配?
本文一定要阅读我上篇文章!!! 超详细VLLM框架部署qwen3-4B加混合推理探索!!!-CSDN博客 本文是基于上篇文章遗留下的问题进行说明的。 一、本文解决的问题 问题1:我明明只部署了qwen3-4B的模型…...

PostgreSQL日常维护
目录 一:基本使用 1.登录数据库 2.数据库操作 2.1列出库 2.2创建库 2.3删除库 2.4切换库 2.5查看库大小 3.数据表操作 3.1 列出表 3.2创建表 3.3复制表 3.4删除表 4.模式操作命令 4.1创建模式 4.2默认模式 4.3删除模式 4.4查看所有模式 4.5 在指定…...
Attu下载 Mac版与Win版
通过Git地址下载 Mac 版选择对于的架构进行安装 其中遇到了安装不成功,文件损坏等问题 一般是两种情况导致 1.安装版本不对 2.系统权限限制 https://www.cnblogs.com/similar/p/11280162.html打开terminal执行以下命令 sudo spctl --master-disable安装包Git下载地…...
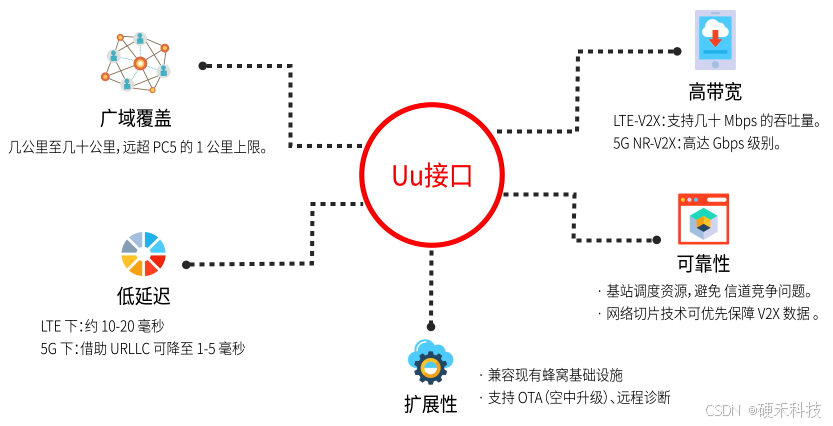
V2X协议|如何做到“车联万物”?【无线通信小百科】
1、什么是V2X V2X(Vehicle-to-Everything)即“车联万物”,是一项使车辆能够与周围环境实现实时通信的前沿技术。它允许车辆与其他交通参与者和基础设施进行信息交互。通过V2X,车辆不仅具备“远程感知”能力,还能在更大…...

【zookeeper】--部署3.6.3
文章目录 下载解压创建data和logs配置文件1)创建目录并且编辑 zoo.cfg2)接下来将 node01 的 ZooKeeper 所有文件拷贝至 node02 和 node03。推荐从 node02 和 node03 拷贝4)最后 vim /etc/profile 配置环境变量,环境搭建结束。配完环境变量后 source /etc…...