MYSQL优化(1)
MYSQL调优强调的是如何提高MYSQL的整体性能,是一套整体方案。根据木桶原理,MYSQL的最终性能取决于系统中性能表现最差的组件。可以这样理解,即使MYSL拥有充足的内存资源,CPU资源,如果外存IO性能低下,那么系统的总体性能取决于当前最慢的硬盘IO速度,而不是当前最优越的CPU或者内存资源。
1.影响数据库系统系统性能的组件
典型的影响数据库系统的组件包括:CPU,内存,硬盘,IO,网络环境,SQL语句与索引,表结构设计,锁竞争,连接等。
(1)内存
内存IO的速度要比硬盘IO读写快很多,为了提升数据库系统IO整体性能,通常需要将常用的核心数据读入内存。然而与硬盘相比,内存的储存空间小的可怜,内存存储空间的不足通常会成为制约数据库系统整体性能提升的罪魁祸首。内存国小,将导致缓存过小,可能导致缓存失效,此时CPU将频繁地执行与应用需求无关的页面置换算法。
(2)硬盘IO
内存仅仅是数据的暂存的地方,最终需要保存到硬盘。然而与内存相比,硬盘IO读写的速度比内存IO慢很多,MYSQL服务运行期间,抵消的硬盘IO会拖累整个数据库系统。
(3)连接
MYSQL客户机与服务器的连接需要经过网络握手,身份验证,权限验证的环节,占用了一定的网络资源,如果有较多的低效连接,不仅影响用户体验,也消耗额外的服务器资源。
(4)网络环境
对网络数据进行读写的情况与硬盘IO类似。由于网络环境的不确定性,尤其是对互联网或者局域网的数据读写,网络的速度可能比本地硬盘IO更慢,因此,如果不加特殊处理,也极可能成为系统瓶颈。
(5)CPU
多个运算性能要求较高的应用如果同时,长时间,不间断地占用CPU资源,那么对CPU的争夺将导致性能问题,如科学计算,空间数据处理等应用。
(6)表结构设计
数据库的操作最终转化成数据库各种数据文件,索引文件的操作,不良表结构导致某条SQL语句长时间占用某个数据文件,索引文件,导致锁竞争。
(7)锁竞争
对于并发性能要求较高的数据库而言,如果存在激烈的锁竞争,对数据库的性能将是致命的打击。锁竞争将会明显增加线程上下文切换的开销,而且,这些开销都是与应用需求无关的系统开销,拜占用的CPU资源,内存资源和连接资源了
2.参数信息和状态信息
(1)show status
显示当前MYSQL服务器连接的会话状态变量信息。
(2)show variables
查看系统变量
3.缓存机制
数据访问速度的最大性能瓶颈一般来自于硬盘IO,数据库服务器的缓存占用的是数据库服务器的内存空间,提供缓存的目的是为了让硬盘IO的速度适应CPU的处理速度。很多数据库管理系统引入缓存机制减少硬盘IO次数以及寻道时间,提供IO整体性能,加快数据的访问性能。
4.缓存的分类
MYSQL缓存可以分为按照读写功能分为Cache缓存和Buffer缓存,还可以按照缓存的生存周期长短,分为全局缓存,会话缓存,临时缓存。二进制日志开启期间,存在二进制日志缓存等
5.超时
使用MYSQL可能会出现各种超时异常,典型有连接超时,锁等待超时等,使用MYSQL命令show variables like '%timeout%'可以查看各种类型的超时时间。
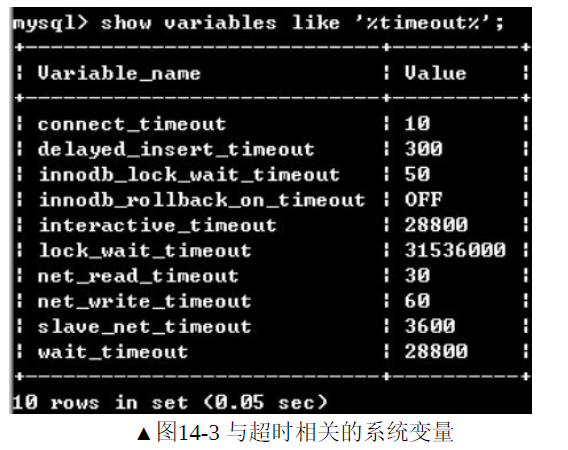
(1)connect_timeout连接超时
设置连接超时的时间,单位为秒,默认值是10秒。当网络出现故障,可以有效防止反复“握手”
(2)wait_timeout
默认值28800秒,即使网络没有问题,也不允许非交互式MYSQL客户机一直占用连接。对于保持睡眠状态超过了wait_timeout的非交互式客户机,服务器会主动断开连接
(3)interactive_timeout
默认值28800秒,即使网络没有问题,也不允许交互式MYSQL客户机一直占用连接。对于保持睡眠状态超过了wait_timeout的交互式客户机,服务器会主动断开
注意:终端运行mysql出现mysql>就是交互式连接,而mysql -e 'select 1’这样的直接返回结果的方式就是非交互式连接。
(4)net_write_timeout
默认值60秒。即使连接没有处于睡眠状态,如果MYSQL服务器产生一个大的结果集,此后MYSQL客户机将耗费大量时间接受该结果集。如果MYSQL客户机耗费的时间大于net_write_timeout的值,MYSQL主动断开连接,避免连接的浪费。
(5)net_read_timeout
默认值为30秒。即使连接没有处于睡眠状态,如果MYSQL客户机读取了一个“大的数据源,此后MYSQL客户机将耗费大量时间读取该数据源。如果MYSQL客户机耗费的时间大于net_read_timeout的值,MYSQL主动断开连接,避免连接的浪费。
(6)innodb_lock_wait_timeout
默认值50秒,设置行级锁锁等待的时间阈值,当锁等待时间超过阈值后,会导致行级锁锁等待的SQL语句回滚。如果希望整个事务回滚,启动MYSQL服务时,开启innodb_rollback_on_timeout参数。
(7)innodb_rollback_on_timeout
默认值为OFF,如果事务因为行级锁锁等待超时,会回滚上一条语句执行的操作。如果设置为ON,则回滚整个事务的操作。
(8)lock_wait_timeout
指定元数据锁的超时时间,取值范围是1-31536000(一年),默认值31536000。
(9)slave_net_timeout
MYSQL从服务器从主服务器读取二进制日志失败后,从服务器会等待slave_net_timeout设置的描述后,重连主服务器并获取数据。默认值3600秒,建议设置为30秒,可以减少网络问题导致的主从数据同步延迟。
(10)delayed_insert_timeout
MYISAM表的延迟插入
6.MYSQL连接的优化
1.连接参数
(1)如果遇到“MYSQL:ERROR 1040:Too many connections”的错误提示,一种原因是访问量确实很高;另一种原因是配置文件中max_connections值太小。使用show variables like ‘%connect%’;
查看当前连接信息
(2)max_connections:设置当前MYSQL服务实例能够通过是接受的最大并发连接数。
(3)max_user_connections:设置指定的MYSQL账号能同时连接到MYSQL服务器的最大并发连接数
(4)max_connect_errors:某台主机连接MYSQL服务器失败次数过多,超过max_connect_errors值后,MYSQL服务器会直接拒绝该主机的所有连接。
(5)init_connect:每次客户机连接mysql服务器时,mysql会先执行init_connect参数指定的一个或者多个sql语句;如果init_connect设定的语句存在错误,连接将会出现错误。需要注意的时:super权限的账户连接服务器时,init_connect不会执行。
2.连接状态
show status like '%connections%;'可以查看连接的状态信息。
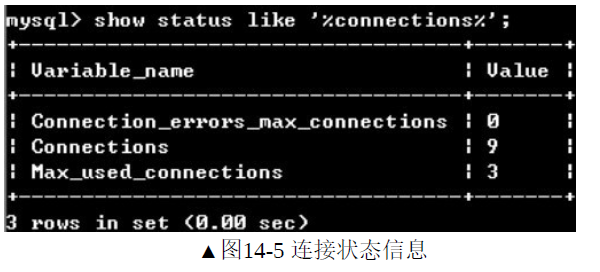
(1)connections
MYSQL服务器从启动到现在尝试连接的请求数
(2)Max_used_connections
表示MYSQL服务器从启动到现在,同一时刻并行连接数的最大值。如果max_used_connections跟max_connections相同,则说明max_connections设置过低或者超过服务器负载上限了。
(3)Connection_errors_max_connections
由于MYSQL服务器已经达到max_connections的上限,连接被拒绝的次数。如果Connection_errors_max_connections的次数较多,则说明max_connections设置过低或者超过服务器负载上限了。
3.连接线程的参数
(1)thread_cache_size
设置连接线程池线程的数目
(2)thread_concurency
主要针对solaris操作系统。thread_concurrency应设为CPU核数的2倍
(3)thread_handling:
值为no-threads时,表示MYSQL服务器在任意时刻最多提供一个连接线程,一般用于实验性质。
值为one-thread-per-connection时,表示为每个连接创建一个线程来处理这个连接的所有请求,直到连接断开,线程才会结束,这是thread_handling的默认方式。
(4)thread_stack
每个连接线程都有自身的标识信息,如线程ID,线程运行时上下文基本信息等。通过thread_stack参数可以设置为每一个连接线程分配多大的内存,以便保存每个连接线程信息。默认情况下为了每个连接线程分配192KB的内存堆栈空间。
4.连接线程状态
(1)Theads_cached
当前连接池的线程数
(2)Threads_connected
当前连接数
(3)Threads_created
连接线程创建数,该值越小越好,较高的值意味着需要增加thread_cache_size的参数值
(4)Threads_running
不在睡眠状态的连接线程数量
5.连接请求堆栈
当MYSQL在很短的时间内接收到非常多的连接请求时,MYSQL会将“疲于应付”的连接请求保存在堆栈中,以便MYSQL将来“慢慢处理”。back_log参数值设置了堆栈的容量,设定了侦听的队列大小,默认值50.
6.连接异常
Aborted_clients:MYSQL客户机被异常关闭的次数,例如MYSQL语句太长或者select语句结果太大,超过了max_allowed_packet参数值,都会导致异常中断
Aborted_connects:试图连接到MYSQL服务器而失败的连接次数
7.其他
Slow_launch_threads:记录了创建时间超过slow_launch_time秒的线程数。
Connection_errors_accept:调用accept()函数监听端口期间,发生连接错误的次数
Connection_errors_internal:由于服务器内部错误导致连接失败的次数
Connection_errors_peer_address:查找MYSQL客户机IP地址发生错误的数量
Connection_errors_select:调用select()或者pool()函数监听端口发生错误的数量
Connection_errors_tcpwrap:被libwrap库拒绝的连接数
7.缓存的优化
1.查询缓存
查询缓存不仅将查询语句结构缓存起来,还将查询结果缓存起来。当基表数据与查询缓存数据不一致时,MYSQL会自动使查询缓存失效,也就是说查询缓存最忌讳表的数据更新。在查询操作频繁的环境中,查询缓存可以显著地提高查询性能,而当表的数据频繁变化时,使用查询缓存会带来额外的系统开销,反而得不偿失。
(1)开启查询缓存
需要设置3个参数
have_query_cache:标识是否支持查询缓存
query_cache_type:0(OFF)标识查询缓存是关闭的,1(on)表示查询总是先到查询缓存中查找的,2(DEMOND)表示不使用查询缓存,除非在select语句中包含sql_cache选项。
query_cache_size:开启上述两项参数设置后,可以使用该参数设置查询缓存的内存大小,如果值为零,表示没有开启查询缓存。查询缓存所占用的内存不能太小,也不能太大,需要根据查询缓存的命中率进行适当调整
(2)query_cache_limit
某条select语句的结果集的大小超过了query_cache_limit参数值,这个结果集将不会被添加到查询缓存,例如某个select语句的查询结果集是一个大型报表时。
(3)query_cache_min_res_unit
查询缓存以块为单位的申请内存空间,query_cache_min_res_unit设置了分配查询缓存时块的大小。如果query_cache_min_res_unit设置得过小,结果集的大小大于query_cache_min_res_unit时,当一块缓存不够时,再分配一块,如此反复。如果再一次查询中进行多次内存的分配,此时内存分配操作过于频繁,系统性能也随之下降。如果query_cache_min_res_unit设置的过大,可能导致缓存中的碎片数量过多。
(4)query_cache_wlock_invalidate
该参数用于设置行级排他锁与查询缓存之间的关系,默认值0(false),表示施加行级排他锁的同时,该表的所有查询缓存依然有效。如果设置为1(true),表示施加行级排他锁的同时,该表的所有查询缓存将失效。
(5)查询缓存的命中率
使用如下命令将查询缓存所占用的内存大小设置为98M。
set global query_cache_size=102760448;
使用MYSQL命令"show status like ‘Qcache%’;",可以获取当前MYSQL服务实例查询缓存的状态信息,从而可以计算出当前查询缓存的命中率,继而确定query_cache_size的设置是否合理。
Qcache_free_memory:表示当前MYSQL服务器的查询缓存区还有多少可用内存
Qcache_lowmem_prunes:表示因为查询缓存已满溢出,删除的查询结果的个数。如果该值较大,表示经常出现查询缓存不够的情况,此时需要增加查询缓存。
Qcache_hits:表示使用查询缓存的次数,该值会依次递增。如果Qcache_hits的值较大,则表明查询缓存使用非常频繁,此时需要增加查询缓存。如果Qcache_hits较小,则表明很少用刀查询缓存,反而影响效率。
Qcache_total_blocks:表示查询缓存的总快数
Qcache_free_blocks:表示查询缓存中处于空闲状态的内存块数。如果值较大,则表明缓存中碎片较多,查询结果集较小,此时可以减小query_cache_min_res_unit的设置。使用MYSQL命令“flush query cache”会对缓存中的若干碎片进行整理
Qcache_inserts:表示查询缓存中此前总共缓存过多少条select语句的结果集
Qcache_not_cached:表示没有进入过查询缓存select语句的个数
Qcache_querirs_in_cache:表示查询缓存中缓存着多少条select语句的结果集。
Com_select:执行select语句的个数
命中率=Qcache_hits/(Qcache_hits+Com_select)
2.结果集缓存
客户机的结果信息,服务器会进行缓存,结果集缓存的初始大小为net_buffer_length参数值定义的值。此后会根据实际运行中的结果集自动扩充,但是不会超过max_allowed_packet
3.排序缓存
排序缓存分为普通排序缓存,MYISAM排序缓存以及INNODB排序缓存。使用“show variables like ‘%sort%’;”可以查看排序缓存从参数设置
(1)普通排序缓存
普通排序缓存是会话缓存,运行的select语句设计排序操作,mysql查询优化器将选择相应的排序算法,排序后进行缓存。该缓存大小由sort_buffer_size参数定义,默认值256KB。
max_length_for_sort_data:对每一列进行排序操作时,如果该列的值长度较长,通过增加max_length_for_sort_data参数值可以提升MYSQL性能。
max_sort_length:排序或者分组时,只使用该列的前max_sort_length个字节进行排序。
排序操作完成后,MYSQL会记录排序的状态信息,使用MYSQL命令“show status like ‘%sort%’;”可以查看这些状态信息。
(2)MYISAM排序缓存
有时由于MYISAM表的索引以及损坏,许哟啊使用repair table命令重建MYISAM表的索引;有时需要使用alter table或者create index语句创建MYISAM表索引;有时需要使用load data infile命令加载批量数据。这些操作都会导致索引重建,为了加快重建索引的效率,MYISAM提供了排序缓存用于实现索引的排序工作,以便排序工作尽量在内存中完成。MYISAM排序缓存的大小由myisam_sort_buffer_size参数定义。重建索引后,MYISAM排序缓存立即释放。
重建MYISAM索引时,如果MYISAM排序缓存不够用,此时需要在外存临时文件中完成索引字段的排序工作,外存临时文件的大小由myisam_max_sort_file_size参数定义,索引重建后,临时文件立即删除。
(3)innodb排序缓存
innodb在内存提供了三个innodb排序缓存用于实现索引的排序工作,每个排序缓存大小由innodb_sort_buffer_size参数定义,创建索引后,innodb排序缓存立即释放。
4.join连接缓存
由join_buffer_size定义了连接缓存的大小(默认值256KB)。可以用于提升join操作多个表连接时的性能。
5.表缓存cache与表结构定义缓存cache
这两种缓存是全局缓存,可提升访问表的速度
通过show open tables命令可以查看当前缓存中缓存了哪些表
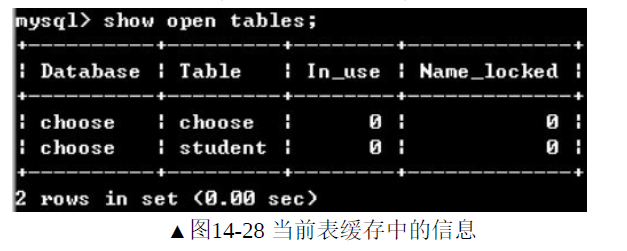
In_use:当前有多少线程正在使用该表
Name_locked:当前该表是否被锁定,值为0表示没有锁定,值为1表示被锁定。被锁定通常发生在删除表或者重命名表的过程中。
6.表扫描缓存buffer
7.MYISAM索引缓存buffer
通过缓存MYI索引文件的内容,可以加快读索引的速度以及写索引的速度
通过show status like ‘Key%’;可以查看当前MYSQL服务实例索引读和索引写的状态值。
8.日志缓存
(1)二进制日志缓存
更新操作产生的二进制日志不会立即写入硬盘,而是首先写入二进制日志缓存中,更新操作提交后,才将缓存中的二进制日志信息写入硬盘。
命令"show variables like ‘%binlog%cache%;’“可以查看二进制日志缓存的配置信息。
(2)innodb重做日志缓存
commit之前,会将产生的重做日志写入innodb重做日志缓存,然后由innodb择机采用轮询策略,将缓存中的重做日志写入ib_logfile0和ib_logfile1重做日志文件中。使用命令”show variables like ‘innodb_log_buffer_size’;“ 可以查看innodb重做日志缓存的大小。
9.预读机制
通过分析数据请求的特点,自动判断出客户在请求当前数据库之后可能会继续请求的数据块。MYSQL就会一次性地将当前请求的数据块以及未来可能请求的下一个数据块一次性全部读出,以便减少硬盘IO次数,提升IO整体性能。
相关文章:
MYSQL优化(1)
MYSQL调优强调的是如何提高MYSQL的整体性能,是一套整体方案。根据木桶原理,MYSQL的最终性能取决于系统中性能表现最差的组件。可以这样理解,即使MYSL拥有充足的内存资源,CPU资源,如果外存IO性能低下,那么系…...

C++可变参数宏定义语法笔记
1. 基础语法 定义格式: #define MACRO_NAME(fixed_args, ...) macro_body#define LOG(fmt, ...) printf(fmt, __VA_ARGS__) LOG("Value: %d, Name: %s", 42, "Alice"); // 展开为 printf("Value: %d, Name: %s", 42, "Alice&q…...
基于BERT预训练模型(bert_base_chinese)训练中文文本分类任务(AI老师协助编程)
新建项目 创建一个新的虚拟环境 创建新的虚拟环境(大多数时候都需要指定python的版本号才能顺利创建): conda create -n bert_classification python3.9激活虚拟环境: conda activate myenvPS:虚拟环境可以避免权限问题,并隔离…...

Windows逆向工程提升之IMAGE_EXPORT_DIRECTORY
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 什么是 IMAGE_EXPORT_DIRECTORY? PE 文件与 Export Table 的关系 PE 文件的整体视角 Export Table 在 PE 中的定位 IMAGE_EXPORT_DIRECTORY 结构 数据结构定义 字段详解…...

python与flask框架
一、理论 Flask是一个轻量级的web框架,灵活易用。提供构建web应用所需的核心工具。 Flask依赖python的两个库 Werkzeug:flask的底层库,提供了WSGI接口、HTTP请求和响应处理、路由等核心功能。 Jinja2:模板引擎࿰…...

【普及+/提高】洛谷P2613 【模板】有理数取余——快读+快速幂
题目来源 P2613 【模板】有理数取余 - 洛谷 题目描述 给出一个有理数 cba,求 cmod19260817 的值。 这个值被定义为 bx≡a(mod19260817) 的解。 输入格式 一共两行。 第一行,一个整数 a。 第二行,一个整数 b。 输出格式 一个整数&a…...
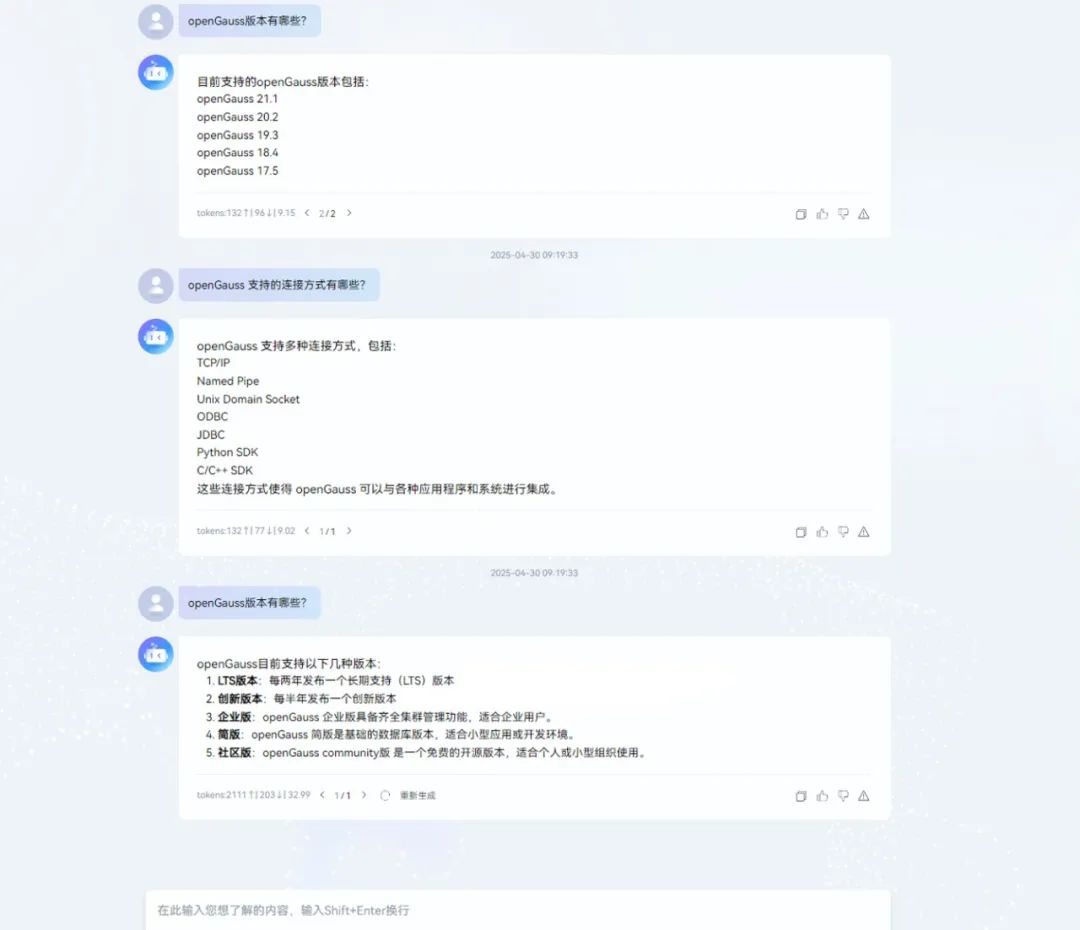
从数据到智能:openGauss+openEuler Intelligence的RAG架构实战
随着人工智能和大规模语言模型技术的崛起,传统的搜索引擎由于其只能提供简单的关键字匹配结果,已经越来越无法满足用户对于复杂、多样化和上下文相关的知识检索需求。与此相对,RAG(Retrieval-Augmented Generation)技术…...

【Linux】初见,基础指令
前言 本文将讲解Linux中最基础的东西-----指令,带大家了解一下Linux中有哪些基础指令,分别有什么作用。 本文中的指令和选项并不全,只介绍较为常用的 pwd指令 语法:pwd 功能:显示当前所在位置(路径…...

什么是实时流数据?核心概念与应用场景解析
在当今数字经济时代,实时流数据正成为企业核心竞争力。金融机构需要实时风控系统在欺诈交易发生的瞬间进行拦截;电商平台需要根据用户实时行为提供个性化推荐;工业物联网需要监控设备状态预防故障。这些场景都要求系统能够“即时感知、即时分…...

工业RTOS生态重构:从PLC到“端 - 边 - 云”协同调度
一、引言 在当今数字化浪潮席卷全球的背景下,工业领域正经历着深刻变革。工业自动化作为制造业发展的基石,其技术架构的演进直接关系到生产效率、产品质量以及企业的市场竞争力。传统的PLC(可编程逻辑控制器)架构虽然在工业控制领…...
----动态规划·状态机模型)
数据结构与算法学习笔记(Acwing 提高课)----动态规划·状态机模型
数据结构与算法学习笔记----动态规划状态机模型 author: 明月清了个风 first publish time: 2025.5.20 ps⭐️背包终于结束了,状态机模型题目不多。状态机其实是一种另类的状态表示方法,将某一个点扩展为一个状态进行保存并在多个状态之间转移…...

基于开源链动2+1模式AI智能名片S2B2C商城小程序的社群构建与新型消费迎合策略研究
摘要:随着个性化与小众化消费的崛起,消费者消费心理和模式发生巨大变化,社群构建对商家迎合新型消费特点、融入市场经济发展至关重要。开源链动21模式AI智能名片S2B2C商城小程序的出现,为社群构建提供了创新工具。本文探讨该小程序…...
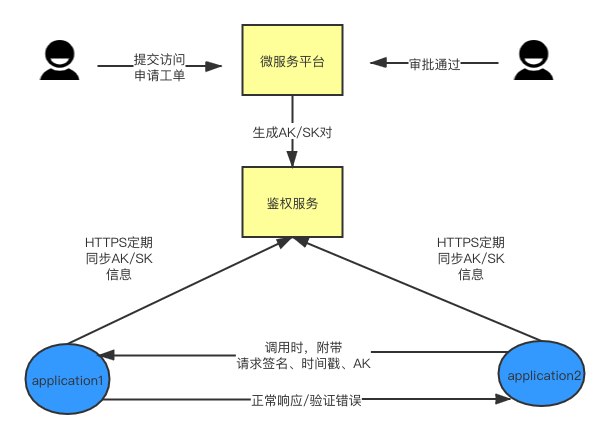
高性能RPC框架--Dubbo(五)
Filter: filter过滤器动态拦截请求(request)或响应(response)以转换或使用请求或响应中包含的信息。同时对于filter过滤器不仅适合消费端而且还适合服务提供端。我们可以自定义在什么情况下去使用filter过滤器 Activa…...
)
计算机视觉与深度学习 | PSO-MVMD粒子群算法优化多元变分模态分解(Matlab完整代码和数据)
以下是一个基于PSO优化多元变分模态分解(MVMD)的Matlab示例代码框架,包含模拟数据生成和分解结果可视化。用户可根据实际需求调整参数。 %% 主程序:PSO优化MVMD参数 clc; clear; close all;% 生成模拟多变量信号 fs = 1000; % 采样频率 t = 0:1/fs:...

搭建自己的语音对话系统:开源 S2S 流水线深度解析与实战
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...

feign调用指定服务ip端口
1 背景 在springcloud开发时候,同时修改了feign接口和调用方的代码,希望直接在某个环境调用修改的代码,而线上的服务又不希望被下线因为需要继续为其他访问页面的用户提供功能后端服务,有时候甚者包含你正在修改的功能。 2 修改…...
【深尚想!爱普特APT32F1023H8S6单片机重构智能电机控制新标杆】
在智能家电与健康器械市场爆发的今天,核心驱动技术正成为产品突围的关键。传统电机控制方案面临集成度低、开发周期长、性能瓶颈三大痛点,而爱普特电子带来的APT32F1023H8S6单片机无感三合一方案,正在掀起一场智能电机控制的技术革命。 爆款基…...

vue2 中的过滤器以及vue3中的替换方案
在 Vue 2 中,过滤器(filters) 是一种非常实用的语法糖,用于在模板中对数据进行格式化输出处理。我们来深入理解过滤器的原理、使用方式、最佳实践以及其局限性。 vue2 🧠 本质是什么? Vue 2 的过滤器是一…...
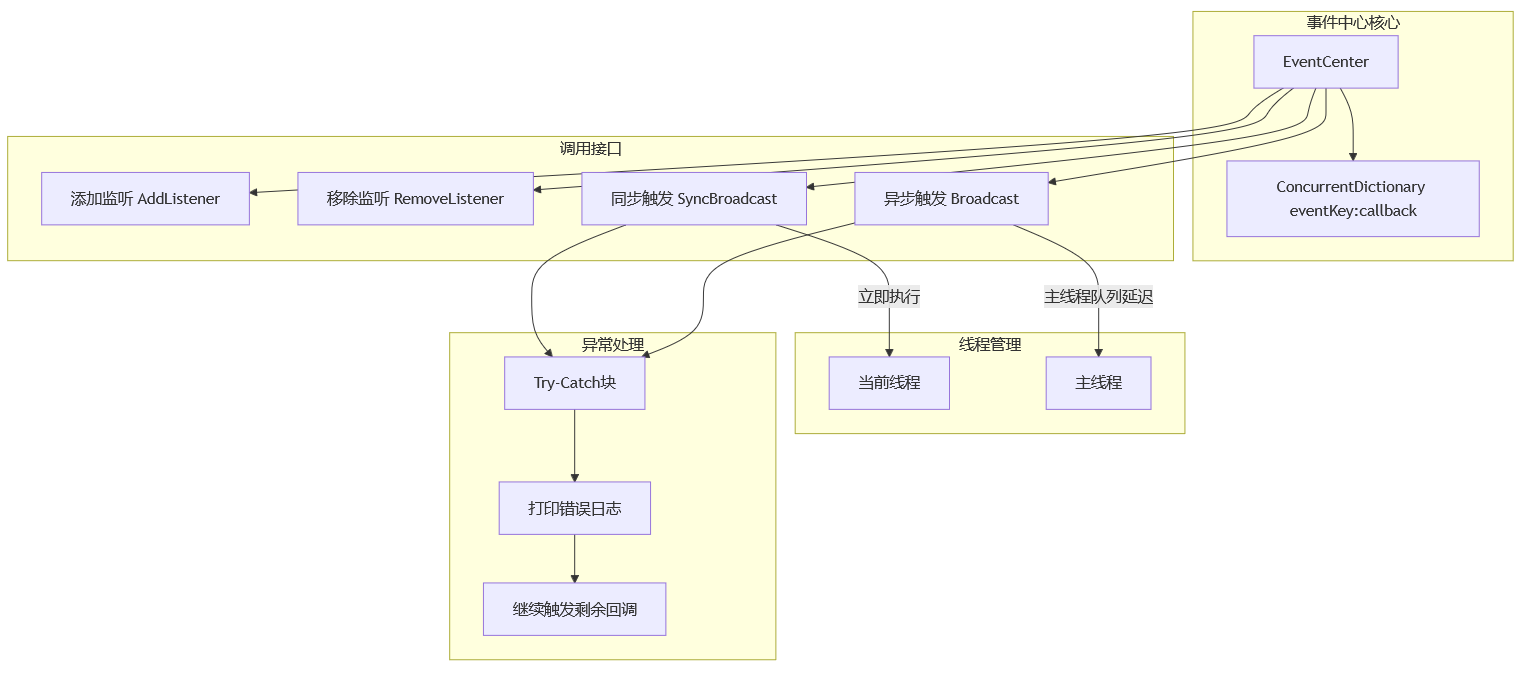
Unity EventCenter 消息中心的设计与实现
在开发过程中,想要传递信号和数据,就得在不同模块之间实现通信。直接通过单例调用虽然简单,但会导致代码高度耦合,难以维护。消息中心提供了一种松耦合的通信方式:发布者不需要知道谁接收事件,接收者不需要…...

瑞萨单片机笔记
1.CS for CC map文件中显示变量地址 Link Option->List->Output Symbol information 2.FDL库函数 pfdl_status_t R_FDL_Write(pfdl_u16 index, __near pfdl_u08* buffer, pfdl_u16 bytecount) pfdl_status_t R_FDL_Read(pfdl_u16 index, __near pfdl_u08* buffer, pfdl_…...
 】)
300. 最长递增子序列【 力扣(LeetCode) 】
文章目录 零、原题链接一、题目描述二、测试用例三、解题思路3.1 动态规划3.2 贪心 二分 四、参考代码4.1 动态规划4.2 贪心 二分 零、原题链接 300. 最长递增子序列 一、题目描述 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组…...

MySQL远程连接10060错误:防火墙端口设置指南
问题描述: 如果你通过本机服务器远程连接MySQL,出现10060错误,那可能是你的防火墙的问题 解决: 第一步:查看防火墙规则 通过以下命令查询,看ports是否开放了3306端口,目前只开放了22端口 f…...
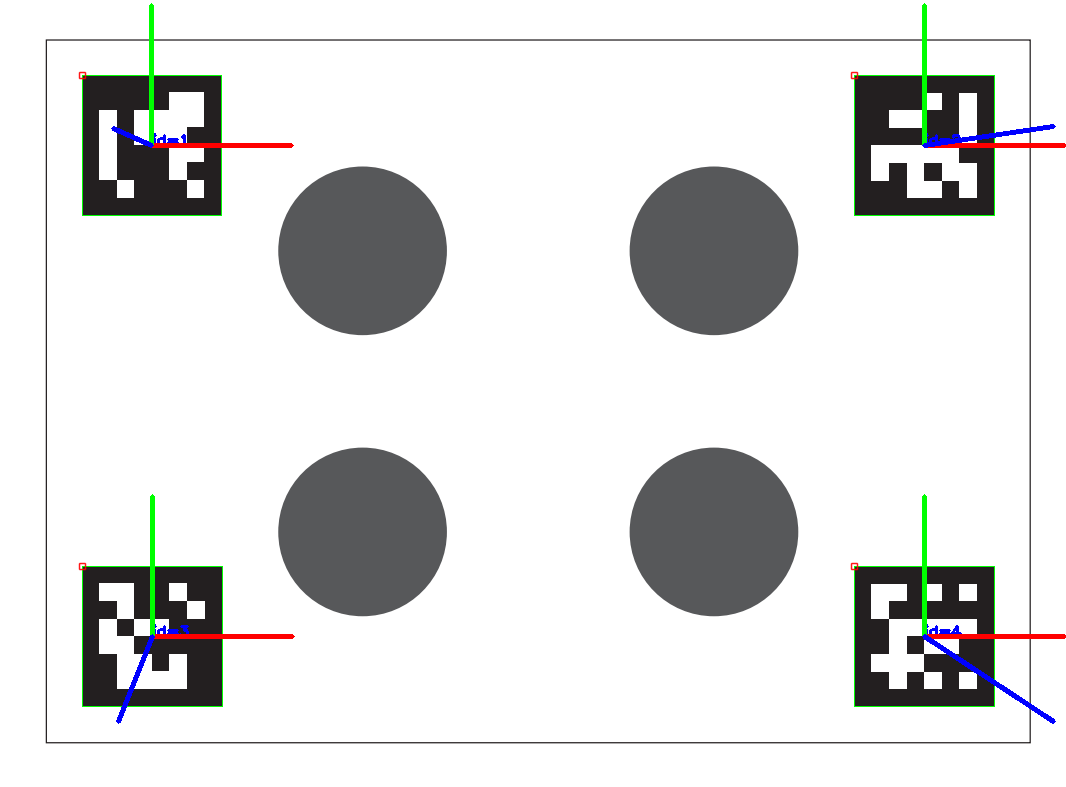
使用 OpenCV 实现 ArUco 码识别与坐标轴绘制
🎯 使用 OpenCV 实现 ArUco 码识别与坐标轴绘制(含Python源码) Aruco 是一种广泛用于机器人、增强现实(AR)和相机标定的方形标记系统。本文将带你一步一步使用 Python OpenCV 实现图像中多个 ArUco 码的检测与坐标轴…...

2024CCPC辽宁省赛 个人补题 ABCEGJL
Dashboard - 2024 CCPC Liaoning Provincial Contest - Codeforces 过题难度 B A J C L E G 铜奖 4 953 银奖 6 991 金奖 8 1664 B: 模拟题 // Code Start Here string s;cin >> s;reverse(all(s));cout << s << endl;A:很…...

#6 百日计划第六天 java全栈学习
今天学的啥 上午 算法byd图论 图遍历dfs bfs 没学懂呵呵 找到两个良心up 图码 labuladong 看算法还好 尚硅谷讲的太浅了 那你问我 下午呢 下午 java 看了会廖雪峰的教程 回顾基础 小林coding Java基础八股文 还有集合的八股文 有的不是很懂 今天把Java基础算是完…...

AOP的代理模式
AOP的代理模式 1. AOP的实现方式 Spring AOP 主要通过两种动态代理技术实现: JDK动态代理:基于接口的代理,要求目标类必须实现至少一个接口。通过反射机制在运行时生成代理类(实现目标接口),并重写接口…...

解决leetcode第3548题.等和矩阵分割II
3548.等和矩阵分割II 难度:困难 问题描述: 给你一个由正整数组成的mxn矩阵grid。你的任务是判断是否可以通过一条水平或一条垂直分割线将矩阵分割成两部分,使得: 分割后形成的每个部分都是非空的。 两个部分中所有元素的和相…...

深入解析自然语言处理中的语言转换方法
在数字化浪潮席卷全球的今天,自然语言处理(Natural Language Processing,NLP)作为人工智能领域的核心技术之一,正深刻地改变着我们与机器交互的方式。其中,语言转换方法更是 NLP 的关键组成部分,…...

redis 进行缓存实战-18
使用 Redis 进行缓存 Redis 通常被认为只是一个数据存储,但它的速度和内存中特性使其成为缓存的绝佳选择。缓存是一种技术,通过将经常访问的数据存储在快速的临时存储位置来提高应用程序性能。通过使用 Redis 作为缓存,您可以显著减少主数据…...

JFace中MVC的表的单元格编辑功能的实现
一、实现流程 在JFace中实现MVC模式的表格编辑功能通常需要以下步骤: 1、启用编辑模式: 调用TableVierer对象的setCellModifier()方法,设置一个ICellModifier对象,以便在表格中启用编辑模式。实现ICellModifier接口的canModify(…...