yolov11使用记录(训练自己的数据集)
官方:Ultralytics YOLO11 -Ultralytics YOLO 文档
1、安装 Anaconda
Anaconda安装与使用_anaconda安装好了怎么用python-CSDN博客
2、 创建虚拟环境
安装好 Anaconda 后,打开 Anaconda 控制台
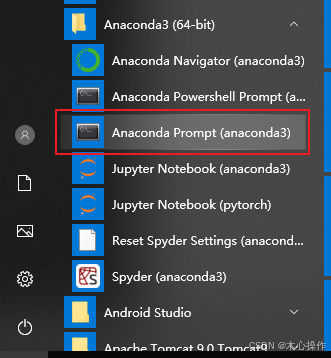
创建环境
conda create -n yolov11 python=3.10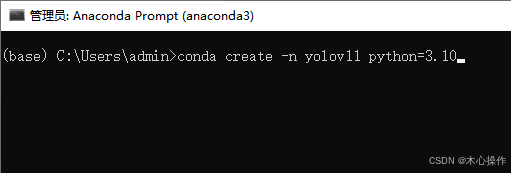
创建完后,进入环境
conda activate yolov11 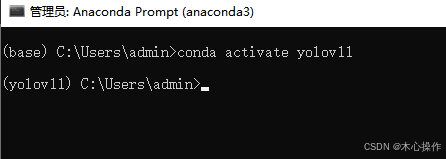
安装依赖
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118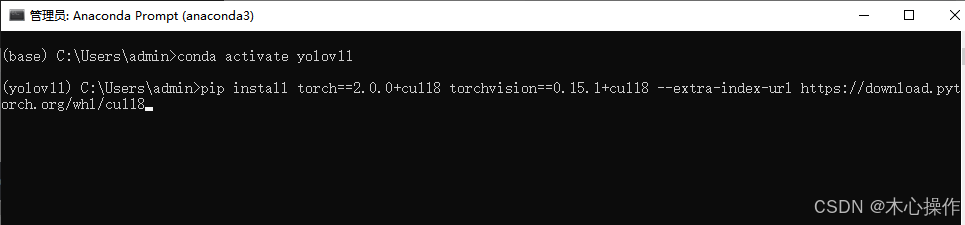
安装 ultralytics 库
pip install ultralytics安装低版本 numpy
pip install numpy==1.26.43、下载 YOLOv11 源码
GitHub - ultralytics/ultralytics at v8.3.143
下载后解压,用 PyCharm 打开源码,选择前面创建的环境
下载 YOLO11 模型,放到项目根目录
在项目根目录创建一个 test.py 文件;cat.png 是一张猫咪图片(可以在百度随便搜一张)下载后放到一起
from ultralytics import YOLO# 加载预训练的 YOLOv11n 模型
model = YOLO('yolo11n.pt')
source = 'cat.png'results = model.predict(source)for i, r in enumerate(results):r.show()
运行 test.py
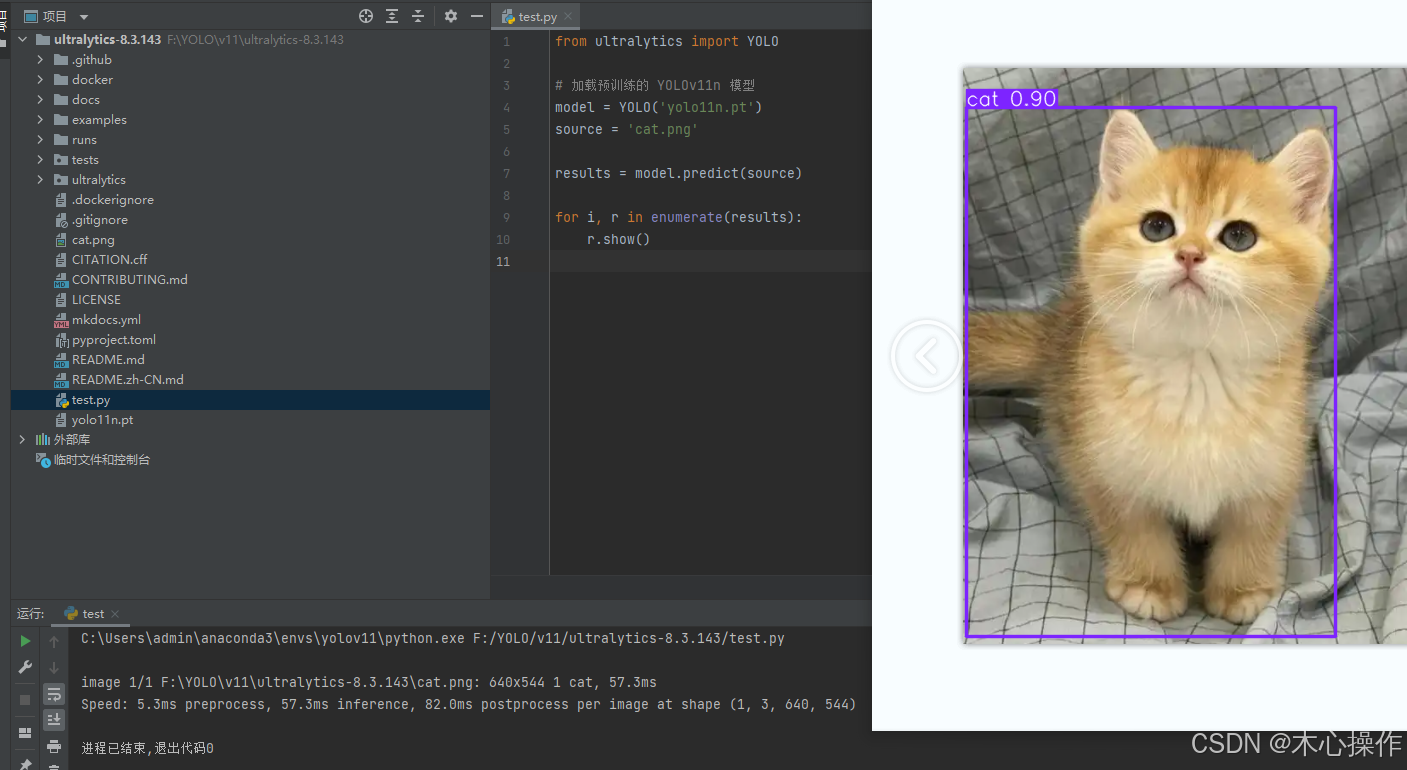
运行成功,代表环境也没问题
3.1、运行遇到问题
如运行中遇到问题,可参考此博主的文章走一遍:
目标检测:YOLOv11(Ultralytics)环境配置,适合0基础纯小白,超详细-CSDN博客
4、训练自己的模型
4.1、安装 labelimg 工具
新建一个虚拟环境,命名 labelimg,python版本3.8
conda create -n labelimg python=3.8 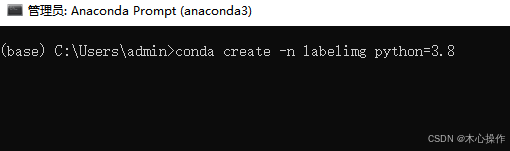
进入环境
conda activate labelimg 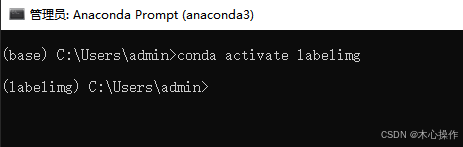
安装 labelimg 包
pip install labelimg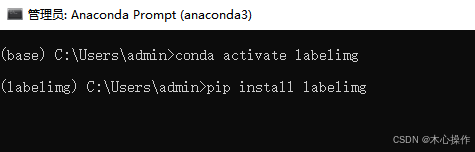
安装好后启动 labelimg
labelimg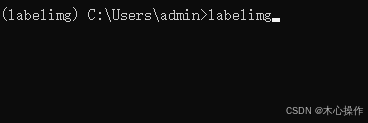
启动后会弹出一个窗口
4.2、准备数据
在根目录创建一个 data 文件夹,里面分别创建 images、labels
在 images 里面放入要训练的图片
4.3、标注数据
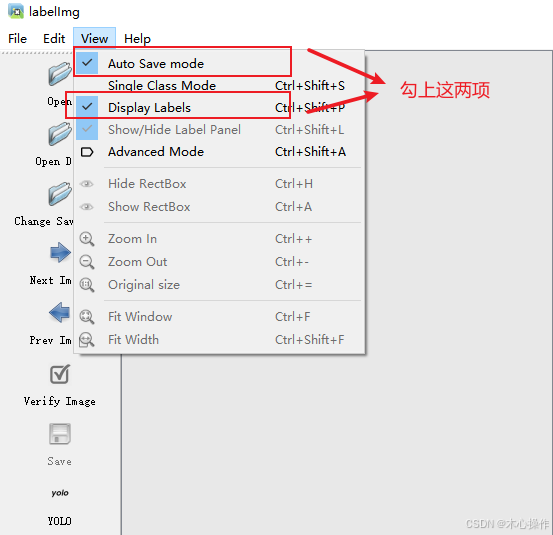
设置 labelimg
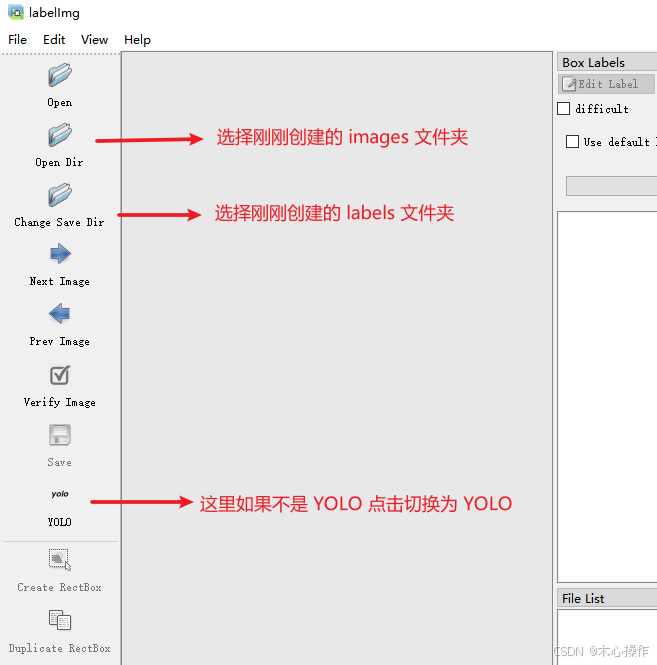
常用快捷键
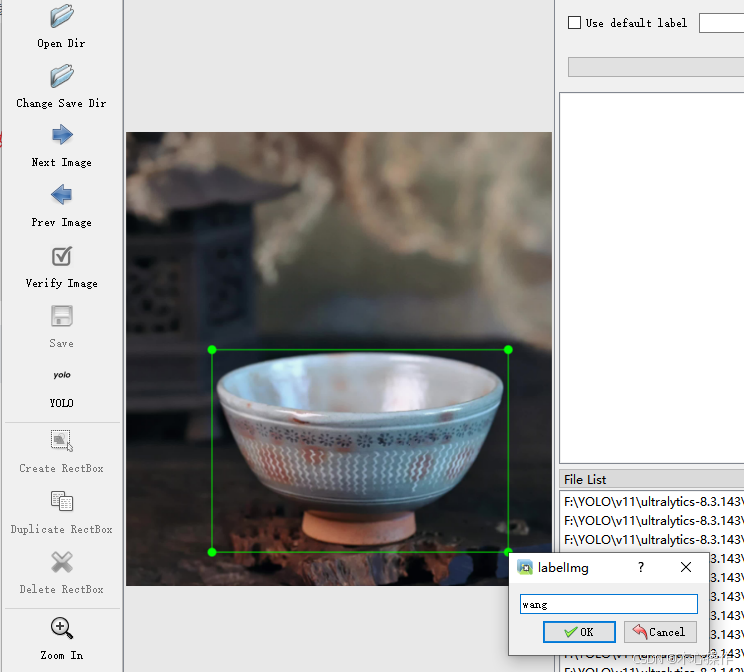
W:调出标注十字架A:切换到上一张图片D:切换到下一张图片Delete :删除标注框按 W 键开始标注,标注后输入分类名称(输入一次后,后面可以直接选择对应分类即可),按 ok 保存后,按 D 键切换下一张需要标注的图片
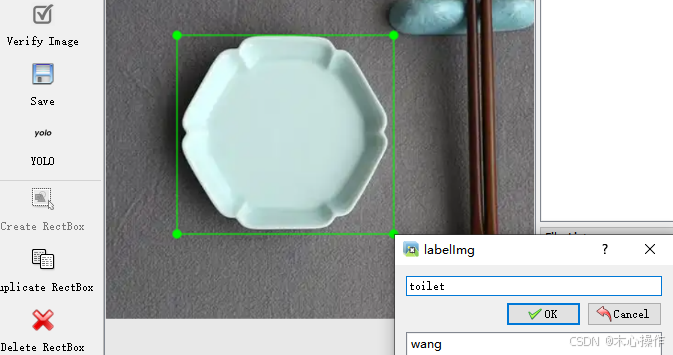
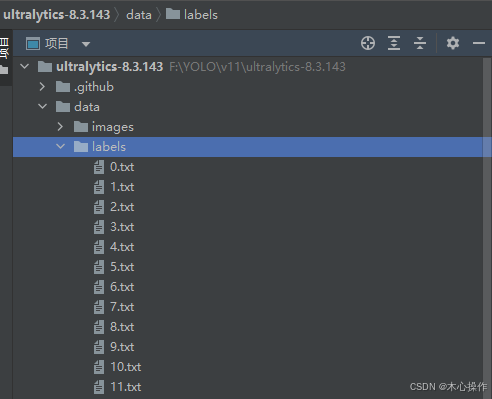
全部标注后,在 labels 文件夹里面可以查看已标注的数据,名称与图片是对应的
4.4、划分数据集
创建一个 data_split.py
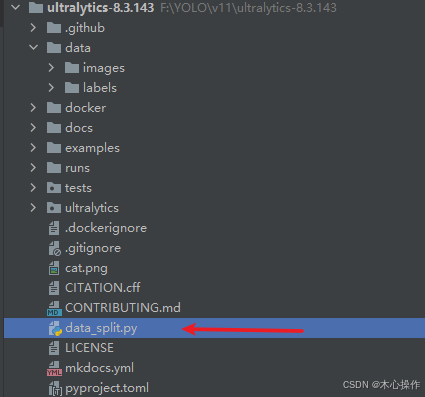
data_split.py 代码
import os
import random
import shutildef split_dataset(input_image_folder, input_label_folder, output_folder, test_ratio=0.2):# 创建训练集和验证集文件夹train_images_folder = os.path.join(output_folder, 'train', 'images')train_labels_folder = os.path.join(output_folder, 'train', 'labels')val_images_folder = os.path.join(output_folder, 'val', 'images')val_labels_folder = os.path.join(output_folder, 'val', 'labels')os.makedirs(train_images_folder, exist_ok=True)os.makedirs(train_labels_folder, exist_ok=True)os.makedirs(val_images_folder, exist_ok=True)os.makedirs(val_labels_folder, exist_ok=True)# 获取所有图像文件列表images = [f for f in os.listdir(input_image_folder) if f.endswith('.jpg') or f.endswith('.png')]# 随机打乱图像文件列表random.shuffle(images)# 计算验证集的数量val_size = int(len(images) * test_ratio)# 划分验证集和训练集val_images = images[:val_size]train_images = images[val_size:]# 复制验证集图像和标签for image in val_images:label = os.path.splitext(image)[0] + '.txt'if os.path.exists(os.path.join(input_label_folder, label)):shutil.copy(os.path.join(input_image_folder, image), os.path.join(val_images_folder, image))shutil.copy(os.path.join(input_label_folder, label), os.path.join(val_labels_folder, label))else:print(f"Warning: Label file {label} not found for image {image}")# 复制训练集图像和标签for image in train_images:label = os.path.splitext(image)[0] + '.txt'if os.path.exists(os.path.join(input_label_folder, label)):shutil.copy(os.path.join(input_image_folder, image), os.path.join(train_images_folder, image))shutil.copy(os.path.join(input_label_folder, label), os.path.join(train_labels_folder, label))else:print(f"Warning: Label file {label} not found for image {image}")input_image_folder = 'data/images' # 图片路径
input_label_folder = 'data/labels' # 标签路径
output_folder = 'datasets' # 输出目录
split_dataset(input_image_folder, input_label_folder, output_folder, test_ratio=0.2)
运行 data_split.py 会生成一个 datasets 目录,里面存放着划分后的数据集
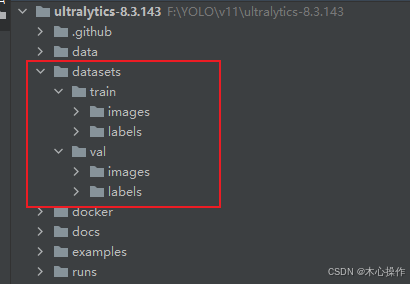
4.5、训练准备
创建一个 data.yaml 文件
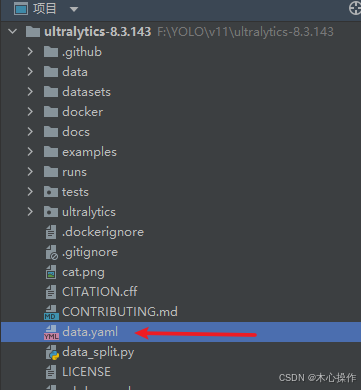
data.yaml 内容
train:前面数据划分里面 train 下面的 images 目录
val:前面数据划分里面 val 下面的 images 目录
nc:所有分类数量
names:所有分类名称
train: F:/YOLO/v11/ultralytics-8.3.143/datasets/train/images # train images (relative to 'path') 128 images
val: F:/YOLO/v11/ultralytics-8.3.143/datasets/val/images # val images (relative to 'path') 128 imagesnc: 2# Classes
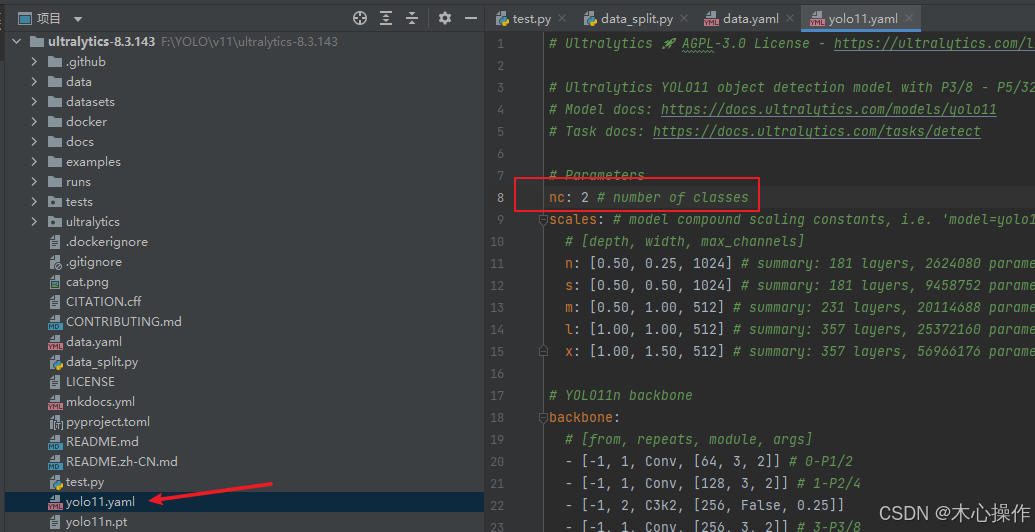
names: [ 'wang', 'toilet' ]找到源码里面的 yolo11.yaml 复制一份到根目录
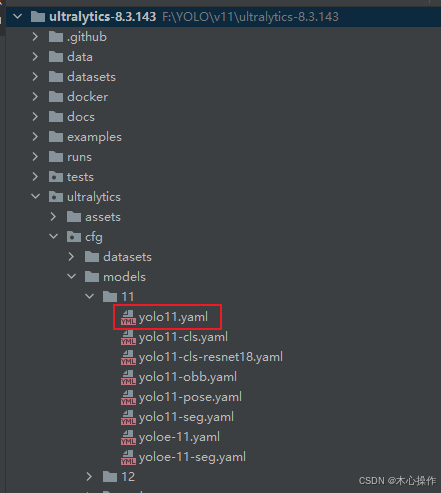
修改 yolo11.yaml 里面的 nc 数量与前面的分类数量一致
4.6、开始训练
创建一个 train.py
train.py 代码
from ultralytics import YOLOif __name__ == '__main__':# 初始训练model = YOLO("yolo11.yaml").load("yolo11n.pt") # 加载预训练模型,如果本地没有会自动下载results = model.train(data="data.yaml", # 数据集配置文件的路径(例如 coco8.yaml)。该文件包含数据集特定的参数,包括训练和验证数据的路径、类名和类数。optimizer='auto', # 训练使用优化器,可选 auto,SGD,Adam,AdamW 等epochs=200, # 总训练周期数。每个周期代表对整个数据集的一次完整遍历。调整此值会影响训练时长和模型性能。imgsz=640, # 训练目标图像大小。所有图像在输入模型之前都会被调整为这个尺寸。影响模型精度和计算复杂度。device=0, # 指定训练的计算设备:单个 GPU(device=0)、多个 GPU(device=0,1)、CPU(device=cpu),或 Apple Silicon 的 MPS(device=mps)。batch=4, # 批量大小,即单次输入多少图片训练,有三种模式:设置为整数(例如 batch=16),自动模式为60% GPU内存利用率(batch=-1),或指定利用率的自动模式(batch=0.70)。workers=8, # 数据加载的工作线程数(每个 RANK 如果是多 GPU 训练)。影响数据预处理和输入模型的速度,尤其在多 GPU 设置中非常有用。patience=100 # 在验证指标无改进的情况下等待的周期数,超过该周期后提前停止训练。帮助防止过拟合,当性能停滞时停止训练。)
运行 train.py 开始训练
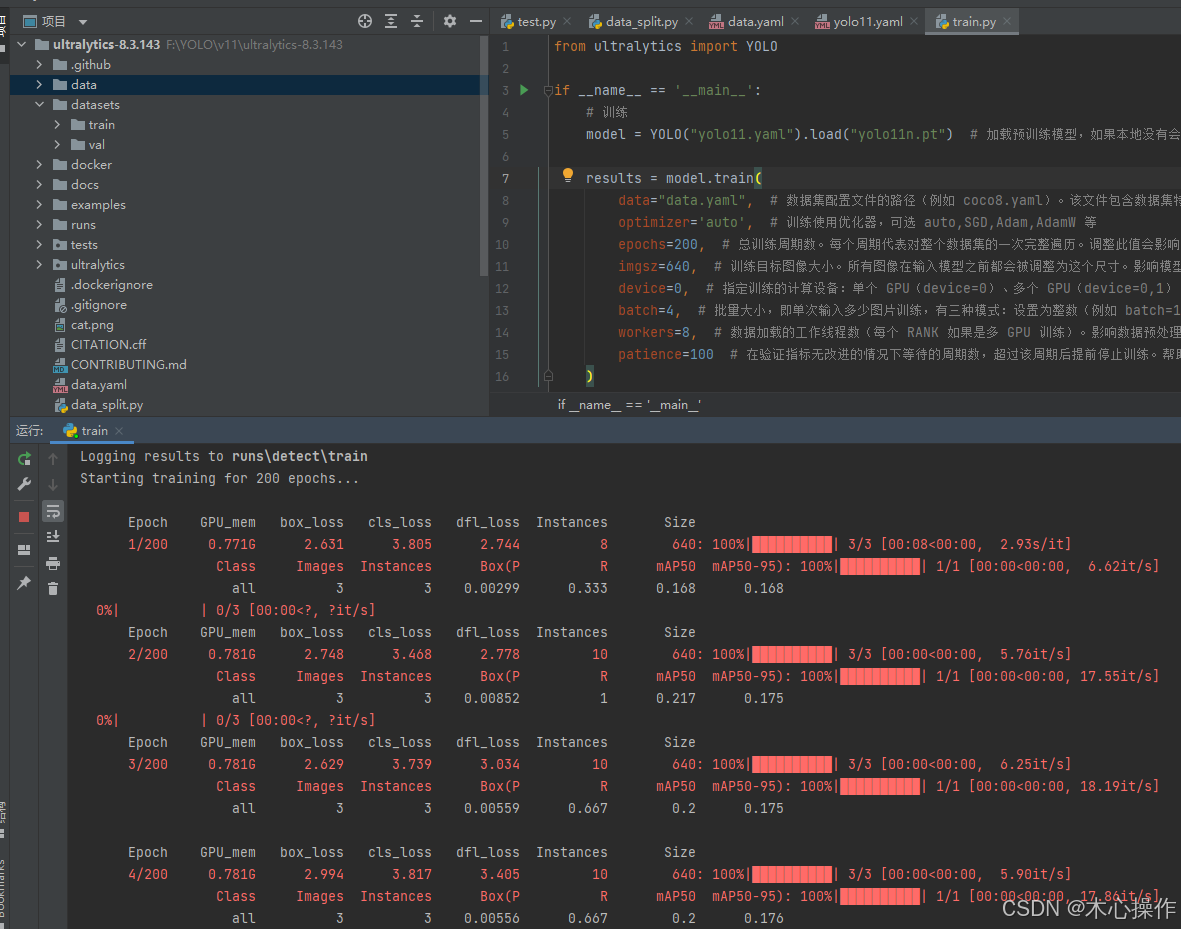
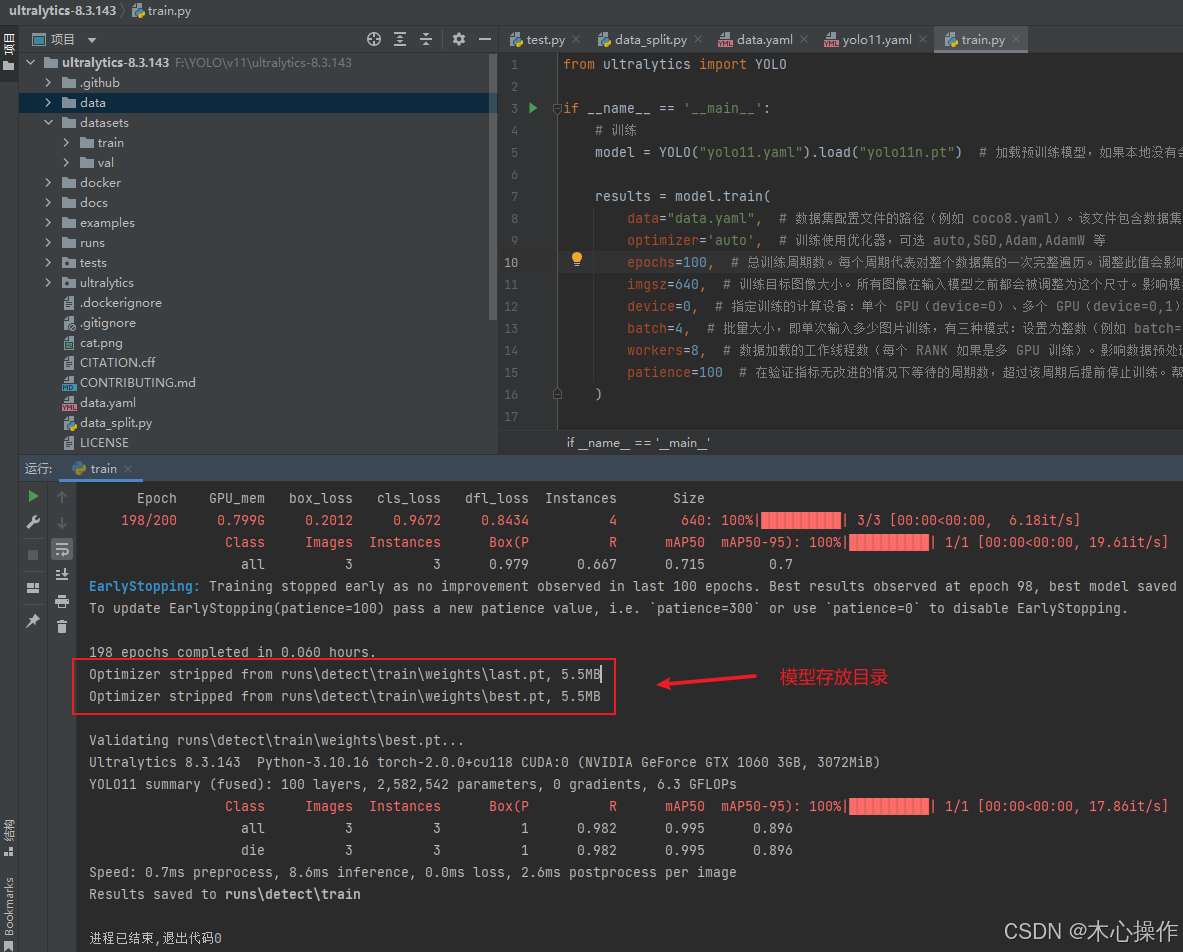
训练完后,可以看到模型所在目录
4.7、使用模型
创建一个 predict.py
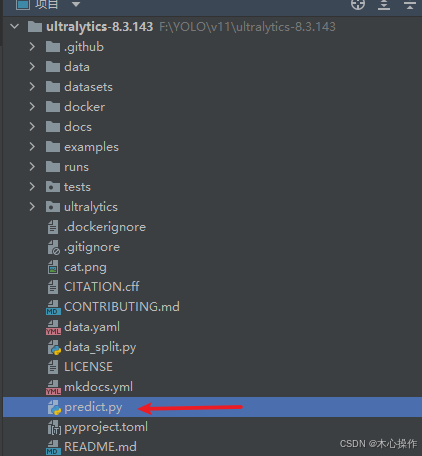
predict.py 代码
from ultralytics import YOLO# 加载前面训练的模型
model = YOLO('runs/detect/train/weights/best.pt')img_list = ['data/images/1.png']for img in img_list:# 运行推理,并附加参数 save:是否保存文件model.predict(img, save=True, conf=0.5, )
运行 predict.py 开始评估
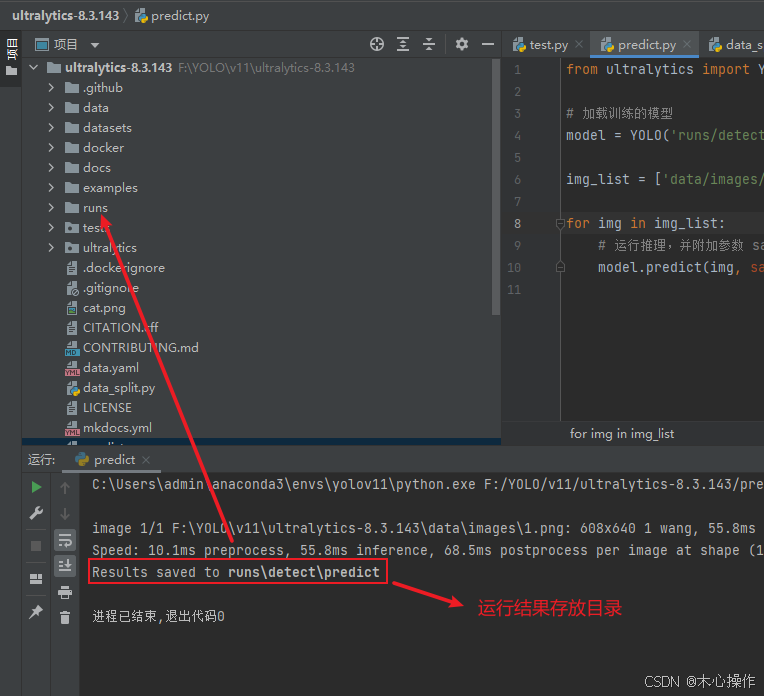
可以进入目录查看结果
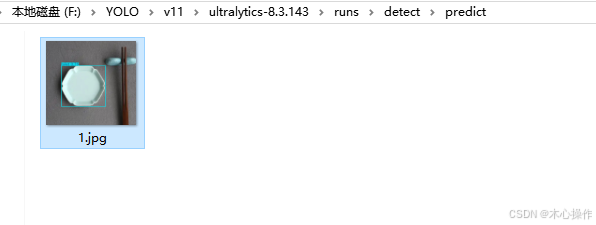
参考
yolov8训练自己的数据集(简单最快上手版)-CSDN博客
超详细目标检测:YOLOv11(ultralytics)训练自己的数据集,新手小白也能学会训练模型,手把手教学一看就会-CSDN博客
YOLOv11来了,使用YOLOv11训练自己的数据集和推理(附YOLOv11网络结构图)-CSDN博客
5、训练分割模型
5.1、安装 labelme 工具
pip install labelme
启动 labelme 工具
labelme
如启动中遇到报错,可问 AI 或参考:
lableme 标图 训练 labelme标注技巧_clghxq的技术博客_51CTO博客
5.2、准备数据
在根目录创建一个 data-seg 文件夹,里面分别创建 images、json、labels
在 images 里面放入要训练的图片
5.3、标注数据
设置 labelme
输出路径选择前面创建的 json 文件夹
打开目录选择前面创建的 images 文件夹,打开目录后再选一下前面的 输出路径
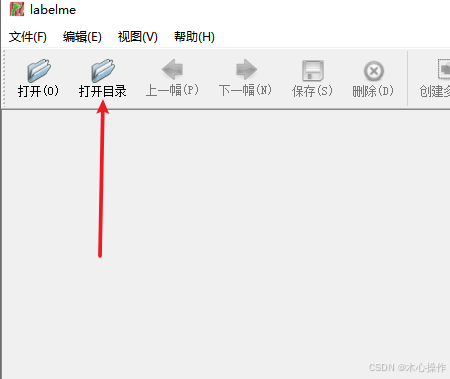
选择创建多边形,开始标注
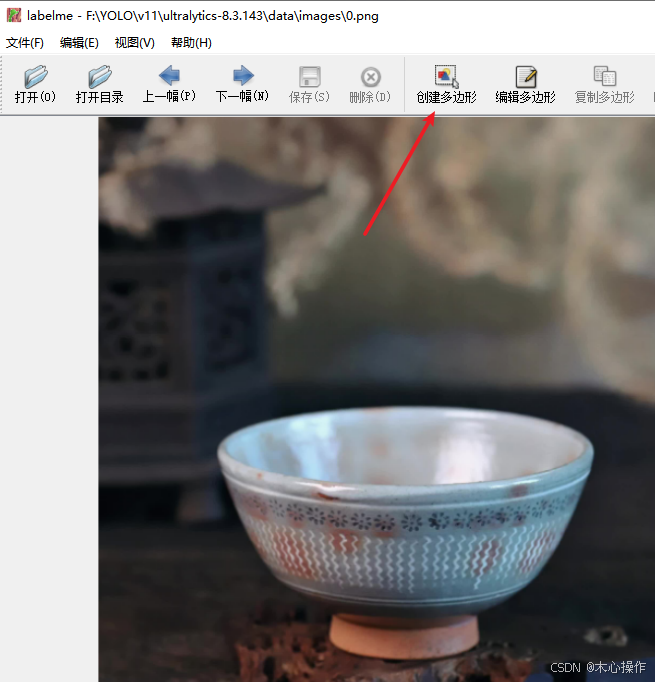
标注完后(首尾相连),点击上面的菜单【下一幅】
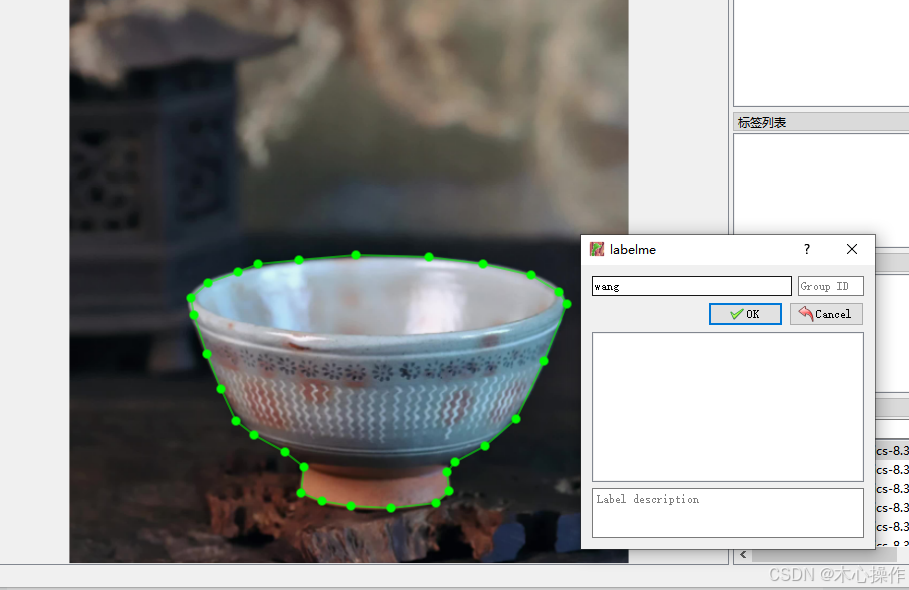
全部标注完后,在 json 目录查看
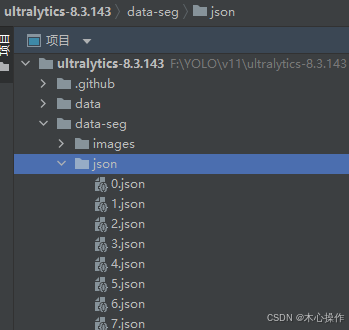
5.4、数据转换
创建一个 label_format-seg.py;
也可以使用【4.4】步骤的代码,修改目录即可;此处为防止搞混,单独创建
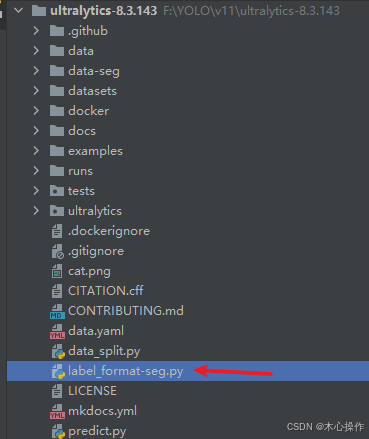
label_format-seg.py 代码
import json
import oslabel_to_class_id = {"wang": 0, # 从0开始"toilet": 1,# 其他类别...
}def convert_labelme_json_to_yolo(json_file, output_dir):try:with open(json_file, 'r') as f:labelme_data = json.load(f)img_width = labelme_data["imageWidth"]img_height = labelme_data["imageHeight"]file_name = os.path.splitext(os.path.basename(json_file))[0]txt_path = os.path.join(output_dir, f"{file_name}.txt")with open(txt_path, 'w') as txt_file:for shape in labelme_data['shapes']:label = shape['label']points = shape['points']if not points:continueclass_id = label_to_class_id.get(label)if class_id is None:print(f"Warning: 跳过未定义标签 '{label}'")continue# 检查多边形是否闭合if points[0] != points[-1]:points.append(points[0])normalized = [(x / img_width, y / img_height) for x, y in points]line = f"{class_id} " + " ".join(f"{x:.6f} {y:.6f}" for x, y in normalized)txt_file.write(line + "\n")except Exception as e:print(f"处理文件 {json_file} 时出错: {str(e)}")if __name__ == "__main__":json_dir = "data-seg/json" # labelme标注存放的目录output_dir = "data-seg/labels" # 输出目录if not os.path.exists(output_dir):os.makedirs(output_dir)for json_file in os.listdir(json_dir):if json_file.endswith(".json"):json_path = os.path.join(json_dir, json_file)convert_labelme_json_to_yolo(json_path, output_dir)
运行 label_format-seg.py
5.5、划分数据集
创建一个 data_split-seg.py
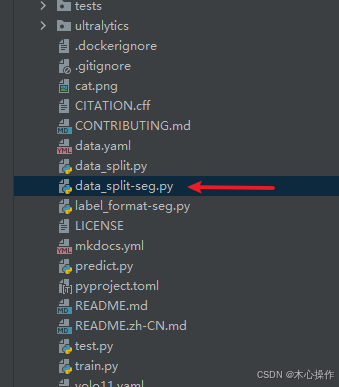
data_split-seg.py 代码
import os
import random
import shutildef split_dataset(input_image_folder, input_label_folder, output_folder, test_ratio=0.2):# 创建训练集和验证集文件夹train_images_folder = os.path.join(output_folder, 'train', 'images')train_labels_folder = os.path.join(output_folder, 'train', 'labels')val_images_folder = os.path.join(output_folder, 'val', 'images')val_labels_folder = os.path.join(output_folder, 'val', 'labels')os.makedirs(train_images_folder, exist_ok=True)os.makedirs(train_labels_folder, exist_ok=True)os.makedirs(val_images_folder, exist_ok=True)os.makedirs(val_labels_folder, exist_ok=True)# 获取所有图像文件列表images = [f for f in os.listdir(input_image_folder) if f.endswith('.jpg') or f.endswith('.png')]# 随机打乱图像文件列表random.shuffle(images)# 计算验证集的数量val_size = int(len(images) * test_ratio)# 划分验证集和训练集val_images = images[:val_size]train_images = images[val_size:]# 复制验证集图像和标签for image in val_images:label = os.path.splitext(image)[0] + '.txt'if os.path.exists(os.path.join(input_label_folder, label)):shutil.copy(os.path.join(input_image_folder, image), os.path.join(val_images_folder, image))shutil.copy(os.path.join(input_label_folder, label), os.path.join(val_labels_folder, label))else:print(f"Warning: Label file {label} not found for image {image}")# 复制训练集图像和标签for image in train_images:label = os.path.splitext(image)[0] + '.txt'if os.path.exists(os.path.join(input_label_folder, label)):shutil.copy(os.path.join(input_image_folder, image), os.path.join(train_images_folder, image))shutil.copy(os.path.join(input_label_folder, label), os.path.join(train_labels_folder, label))else:print(f"Warning: Label file {label} not found for image {image}")input_image_folder = 'data-seg/images' # 图片路径
input_label_folder = 'data-seg/labels' # 标签路径
output_folder = 'datasets-seg' # 输出目录
split_dataset(input_image_folder, input_label_folder, output_folder, test_ratio=0.2)
运行 data_split-seg.py
5.6、训练准备
创建一个 data-seg.yaml 文件,与【4.5】一样步骤
train: F:/YOLO/v11/ultralytics-8.3.143/datasets-seg/train/images # train images (relative to 'path') 128 images
val: F:/YOLO/v11/ultralytics-8.3.143/datasets-seg/val/images # val images (relative to 'path') 128 imagesnc: 2# Classes
names: [ 'wang', 'toilet' ]找到源码里面的 yolo11-seg.yaml 复制一份到根目录
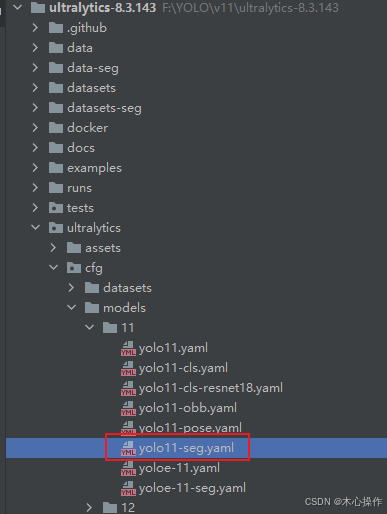
修改 yolo11-seg.yaml 里面的 nc 数量与分类数量一致
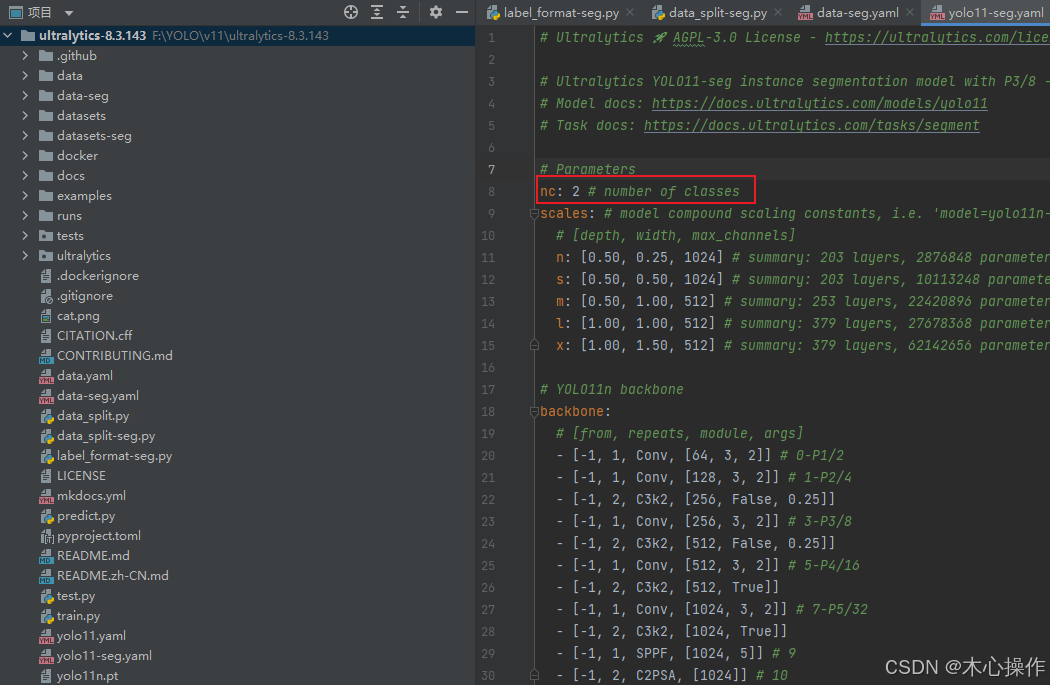
5.7、开始训练
下载 YOLO11n-seg 放到根目录
这个下载地址是 github (偶尔需要代理才能访问)
创建一个 train-seg.py
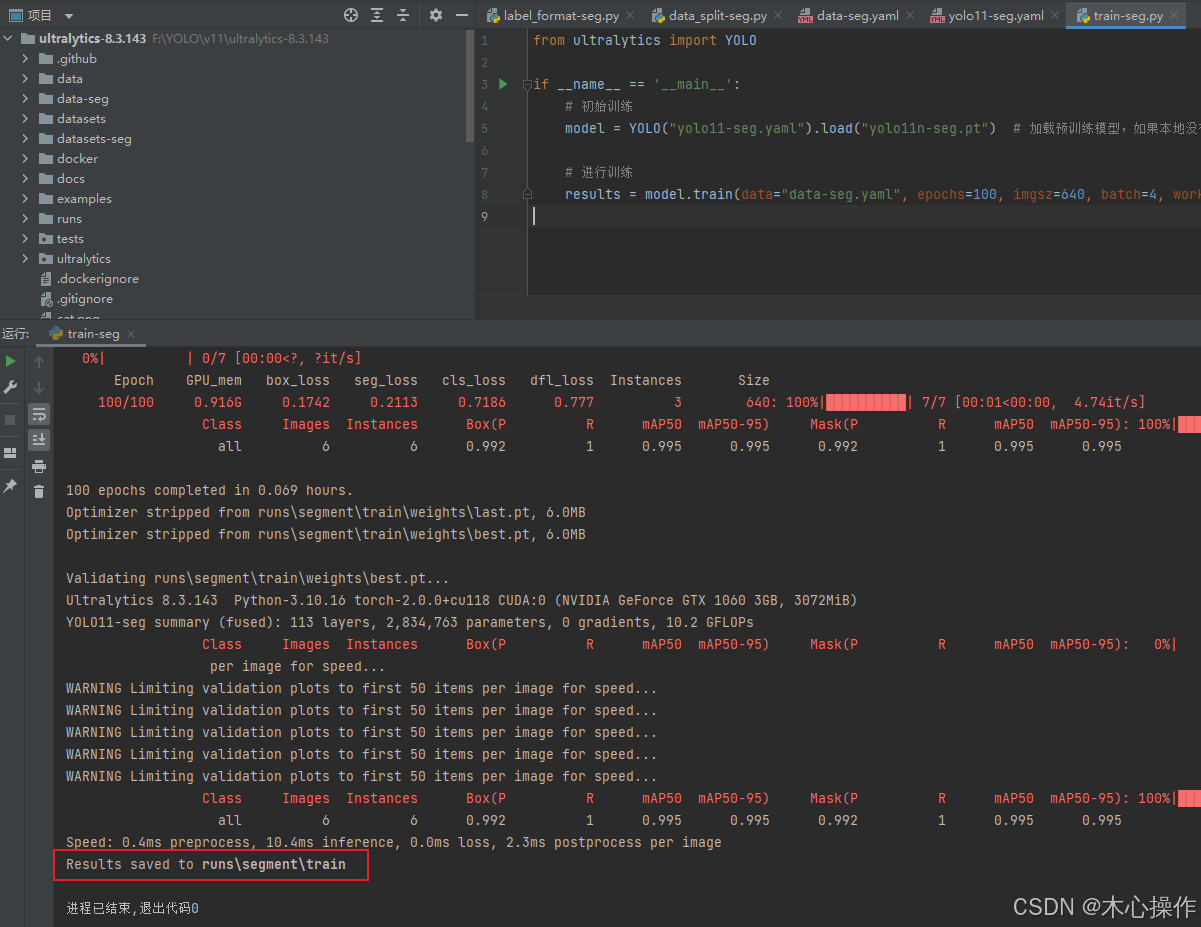
from ultralytics import YOLOif __name__ == '__main__':# 初始训练model = YOLO("yolo11-seg.yaml").load("yolo11n-seg.pt") # 加载预训练模型,如果本地没有会自动下载# 进行训练results = model.train(data="data-seg.yaml", epochs=100, imgsz=640, batch=4, workers=8)
训练完成后模型所在位置
5.8、使用模型
创建 predict-seg.py
from ultralytics import YOLO# 加载训练的模型
model = YOLO('runs/segment/train/weights/best.pt')img_list = ['data/images/1.png']for img in img_list:# 运行推理,并附加参数 save:是否保存文件 retina_masks:返回高分辨率分割掩码model.predict(img, save=True, conf=0.5, retina_masks=True)
评估运行结果

predict-seg-info.py 获取识别信息方法
from ultralytics import YOLO
import numpy as np
import cv2# 加载训练的模型
model = YOLO('runs/segment/train/weights/best.pt')results = model.predict(source="data/images/1.png", retina_masks=True)for result in results:if not hasattr(result, 'masks') or result.masks is None:continueimg = result.orig_img.copy()orig_h, orig_w = result.orig_shapeprint(f'宽:{orig_w},高:{orig_h}')masks = result.masksboxes = result.boxesfor index, (mask, box) in enumerate(zip(masks, boxes)):# 获取检测框坐标x1, y1, x2, y2 = map(int, box.xyxy[0].cpu().numpy())print(f"目标 {index + 1} 边框坐标: ({x1}, {y1}) ({x2}, {y2})")width = x2 - x1height = y2 - y1# 计算实例中心点center_x = int((x1 + x2) / 2)center_y = int((y1 + y2) / 2)# 绘制边界框和中心点cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)cv2.circle(img, (center_x, center_y), 5, (0, 0, 255), -1)# 显示宽高和中心点信息info_text = f"W:{width:.1f} H:{height:.1f} Center:({center_x},{center_y})"cv2.putText(img, info_text, (int(x1), int(y1) - 10),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)# 绘制中心点到边界框的线cv2.line(img, (x1 + 5, center_y), (center_x - 10, center_y), (255, 0, 0), 2)cv2.line(img, (x2 - 5, center_y), (center_x + 10, center_y), (255, 0, 0), 2)# 绘制掩膜轮廓mask_xy = mask.xy[0]print(f"目标 {index + 1} 轮廓点数: {len(mask_xy)}") # 每个目标的轮廓点数量print(f'目标 {index + 1} 轮廓面积:', cv2.contourArea(mask_xy)) # 计算轮廓面积contours = [np.array(mask_xy, dtype=np.int32)] # 转换为int32类型img = cv2.drawContours(img, contours, -1, (0, 255, 0), 2) # 绘制轮廓# 绘制掩膜区域mask_data = mask.data.cpu().numpy()mask_data = (mask_data > 0.5).astype(np.uint8)mask_resized = cv2.resize(mask_data[0], (orig_w, orig_h), interpolation=cv2.INTER_NEAREST) # 调整掩膜尺寸new_img = img.copy()y_coords, x_coords = np.where(mask_resized == 1)print(f'掩膜点数:', len(y_coords))for x, y in zip(x_coords, y_coords):cv2.circle(new_img, (x, y), 1, (255, 0, 0), -1)alpha = 0.6cv2.addWeighted(img, alpha, new_img, 1 - alpha, 0, img)cv2.imshow('result', img)cv2.waitKey(0)cv2.destroyAllWindows()
训练参数
配置 -Ultralytics YOLO 文档
预测参数
配置 -Ultralytics YOLO 文档
labelme使用参考
labelme使用-CSDN博客
相关文章:
yolov11使用记录(训练自己的数据集)
官方:Ultralytics YOLO11 -Ultralytics YOLO 文档 1、安装 Anaconda Anaconda安装与使用_anaconda安装好了怎么用python-CSDN博客 2、 创建虚拟环境 安装好 Anaconda 后,打开 Anaconda 控制台 创建环境 conda create -n yolov11 python3.10 创建完后&…...

历史数据分析——宁波港
个股走势 公司简介: 货物吞吐量和集装箱吞吐量持续保持全球港口前列。 经营分析: 码头开发经营、管理;港口货物的装卸、堆存、仓储、包装、灌装;集装箱拆拼箱、清洗、修理、制造、租赁;在港区内从事货物驳运,国际货运代理;铁路货物运输代理,铁路工程承建,铁路设备…...

知识宇宙:技术文档该如何写?
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、技术文档的价值与挑战1. 为什么技术文档如此重要2. 技术文档面临的挑战 二、撰…...

DeepSeek 赋能数字农业:从智慧种植到产业升级的全链条革新
目录 一、数字农业的现状与挑战二、DeepSeek 技术解析2.1 DeepSeek 的技术原理与优势2.2 DeepSeek 在人工智能领域的地位与影响力 三、DeepSeek 在数字农业中的应用场景3.1 精准种植决策3.2 病虫害监测与防治3.3 智能灌溉与施肥管理3.4 农产品质量追溯与品牌建设 四、DeepSeek …...
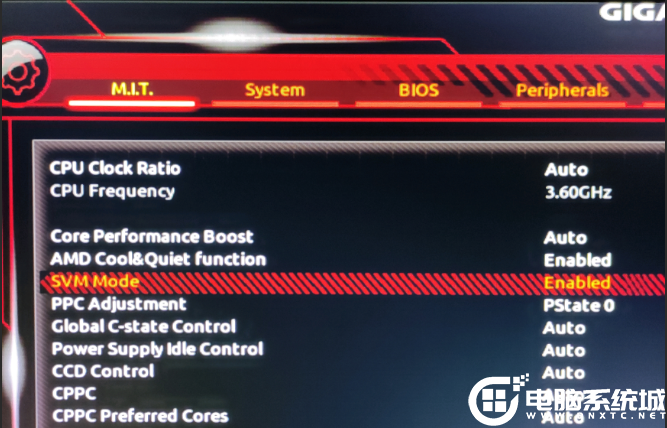
技嘉主板怎么开启vt虚拟化功能_技嘉主板开启vt虚拟化教程(附intel和amd开启方法)
最近使用技嘉主板的小伙伴们问我,技嘉主板怎么开启vt虚拟。大多数可以在Bios中开启vt虚拟化技术,当CPU支持VT-x虚拟化技术,有些电脑会自动开启VT-x虚拟化技术功能。而大部分的电脑则需要在Bios Setup界面中,手动进行设置ÿ…...

Java 并发编程高级技巧:CyclicBarrier、CountDownLatch 和 Semaphore 的高级应用
Java 并发编程高级技巧:CyclicBarrier、CountDownLatch 和 Semaphore 的高级应用 一、引言 在 Java 并发编程中,CyclicBarrier、CountDownLatch 和 Semaphore 是三个常用且强大的并发工具类。它们在多线程场景下能够帮助我们实现复杂的线程协调与资源控…...
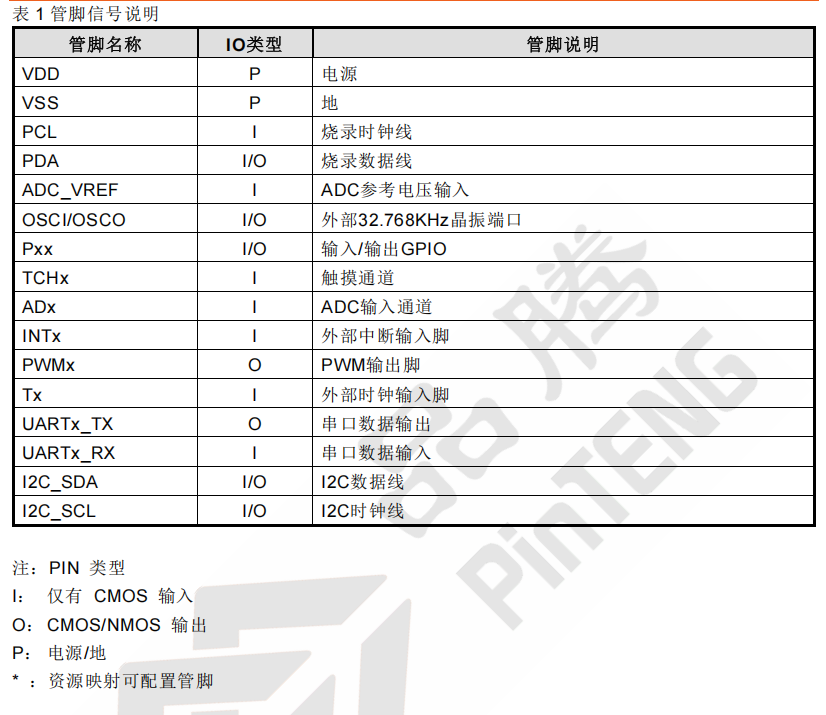
PT5F2307触摸A/D型8-Bit MCU
1. 产品概述 ● PT5F2307是一款51内核的触控A/D型8位MCU,内置16K*8bit FLASH、内部256*8bit SRAM、外部512*8bit SRAM、触控检测、12位高精度ADC、RTC、PWM等功能,抗干扰能力强,适用于滑条遥控器、智能门锁、消费类电子产品等电子应用领域。 …...

矩阵方程$Ax=b$的初步理解.
对于矩阵方程 A x b A\textbf{\textit{x}}\textbf{\textit{b}} Axb,可能就是一学而过,也可能也就会做做题,但是从如何直观地理解它呢? 这个等式可以用多种理解方式,这里就从向量变换角度浅谈一下。其中的 A A A是矩阵&#…...
线性代数中的向量与矩阵:AI大模型的数学基石
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

[特殊字符] 使用增量同步+MQ机制将用户数据同步到Elasticsearch
在开发用户搜索功能时,我们通常会将用户信息存储到 Elasticsearch(简称 ES) 中,以提高搜索效率。本篇文章将详细介绍我们是如何实现 MySQL 到 Elasticsearch 的增量同步,以及如何通过 MQ 消息队列实现用户信息实时更新…...

LeetCode 2942.查找包含给定字符的单词:使用库函数完成
【LetMeFly】2942.查找包含给定字符的单词:使用库函数完成 力扣题目链接:https://leetcode.cn/problems/find-words-containing-character/ 给你一个下标从 0 开始的字符串数组 words 和一个字符 x 。 请你返回一个 下标数组 ,表示下标在数…...

【mediasoup】MS_DEBUG_DEV 等日志形式转PLOG输出
输出有问题 MS_DEBUG_DEV("[pacer_updated pacing_kbps:%" PRIu32 ",padding_budget_kbps:%" PRIu32 "]",pacing_bitrate_kbps_,/*cc给出的目标码率 * 系数*/padding_rate_bps / 1000 /*设置值*/);...

打卡第27天:函数的定义与参数
知识点回顾: 1.函数的定义 2.变量作用域:局部变量和全局变量 3.函数的参数类型:位置参数、默认参数、不定参数 4.传递参数的手段:关键词参数 5.传递参数的顺序:同时出现三种参数类型时 作业: 题目1&a…...
python训练营day34
知识点回归: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前向传播时可以直接写作self.fc1(x) 作业 复习今…...

人工智能在医疗影像诊断上的最新成果:更精准地识别疾病
摘要:本论文深入探讨人工智能在医疗影像诊断领域的最新突破,聚焦于其在精准识别疾病方面的显著成果。通过分析深度学习、多模态影像融合、三维重建与可视化以及智能辅助诊断系统等关键技术的应用,阐述人工智能如何提高医疗影像诊断的准确性和…...

塔能节能平板灯:点亮苏州某零售工厂节能之路
在苏州某零售工厂的运营成本中,照明能耗占据着一定比例。为降低成本、提升能源利用效率,该工厂与塔能科技携手,引入塔能节能平板灯,开启了精准节能之旅,并取得了令人瞩目的成效。 一、工厂照明能耗困境 苏州该零售工厂…...

3DMAX插件UV工具UV Tools命令参数详解
常规: 打开UV工具设置对话框。 右键点击: 隐藏/显示主界面。 添加 为选定对象添加展开修改器。 将从下拉菜单中选择映射通道。 Ctrl+点击: 克隆任何当前的修饰符。 右键点击: 找到第一个未展开的修改器。 地图频道 设置展开映射通道。 Ctrl+Click:添加选定的映射通道的展开…...
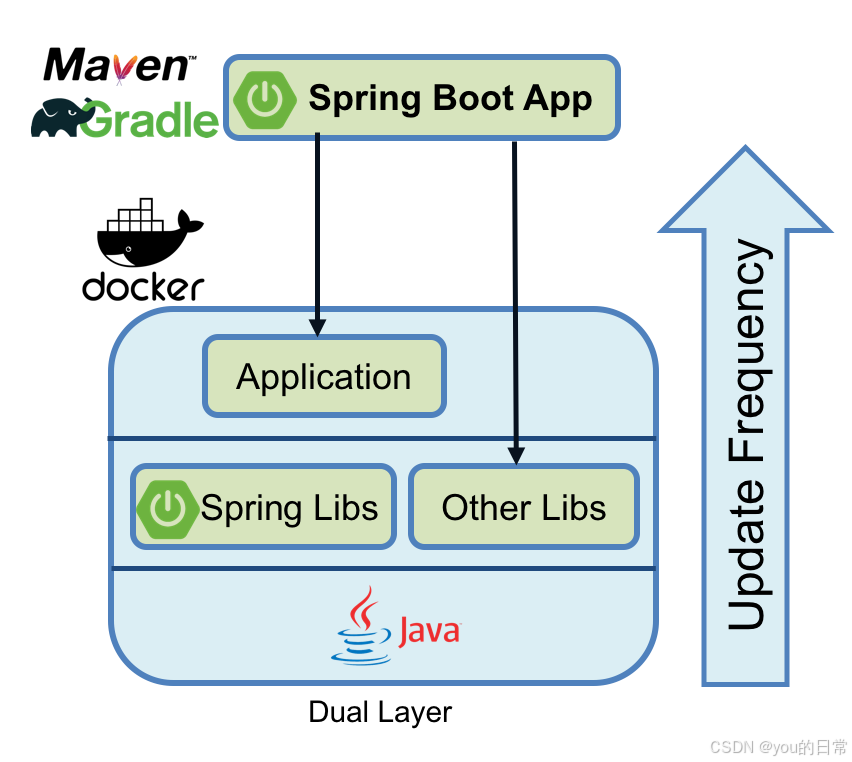
Docker 与微服务架构:从单体应用到容器化微服务的迁移实践
随着软件系统规模和复杂性的日益增长,传统的单体应用(Monolithic Application)在开发效率、部署灵活性和可伸缩性方面逐渐暴露出局限性。微服务架构(Microservice Architecture)作为一种将大型应用拆分为一系列小型、独立、松耦合服务的模式,正成为现代企业构建弹性、敏捷…...

《岁月深处的童真》
在那片广袤而质朴的黄土地上,时光仿佛放慢了脚步,悠悠地流淌着。画面的中央,是一个扎着双髻的小女孩,她静静地伫立着,宛如一朵绽放在岁月缝隙中的小花。 小女孩身着一件略显陈旧的中式上衣,布料的纹理间似乎…...
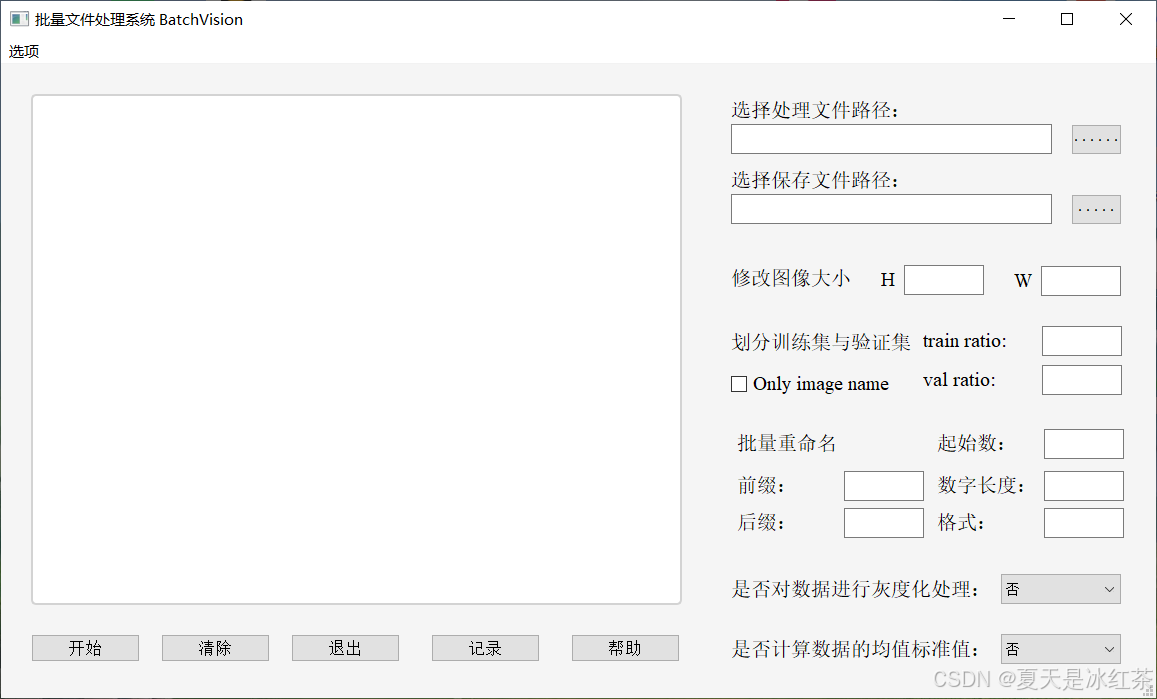
文件夹图像批处理教程
前言 因为经常对图像要做数据清洗,又很费时间去重新写一个,我一直在想能不能写一个通用的脚本或者制作一个可视化的界面对文件夹图像做批量的修改图像大小、重命名、划分数据训练和验证集等等。这里我先介绍一下我因为写过的一些脚本,然后我…...
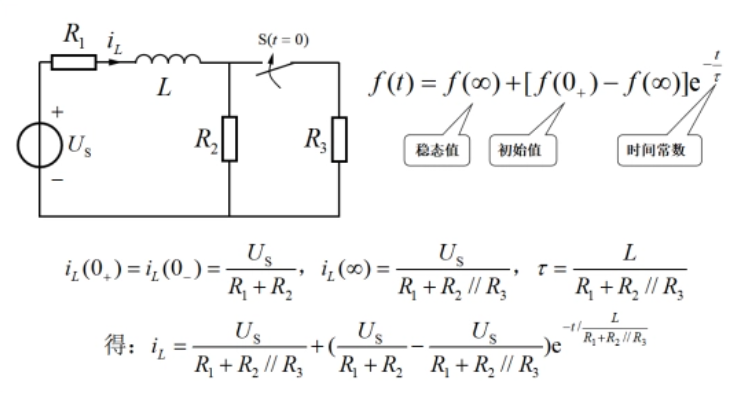
RL电路的响应
学完RC电路的响应,又过了一段时间了,想必很多人都忘了RC电路响应的一些内容。我们这次学习RL电路的响应,以此同时,其实也是带大家一起回忆一些之前所学的RC电路的响应的一些知识点。所以,这次的学习,其实也…...
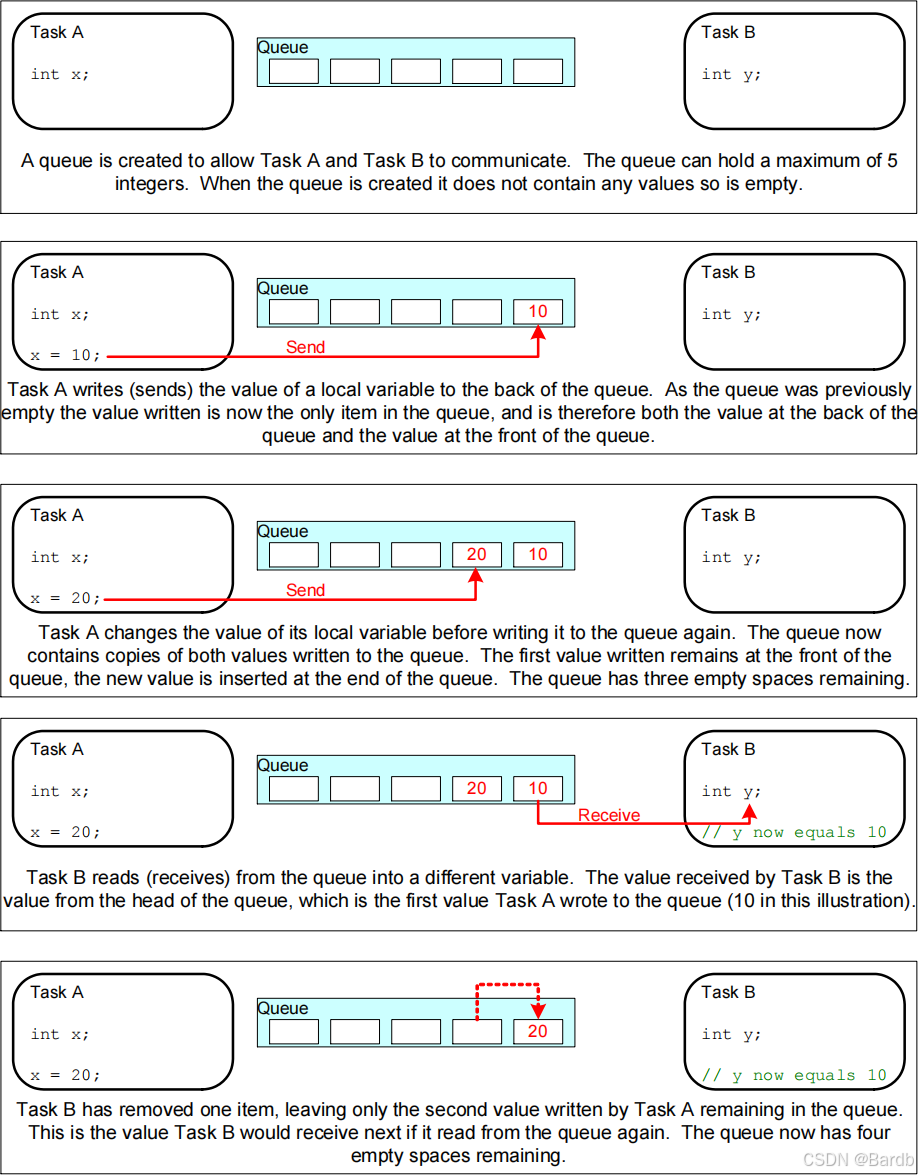
30-消息队列
一、消息队列概述 队列又称消息队列,是一种常用于任务间通信的数据结构,队列可以在任务与任务间、 中断和任务间传递信息,实现了任务接收来自其他任务或中断的不固定长度的消息,任务能够从队列里面读取消息,当队列中的…...

跨域解决方案之JSONP
目录 一、JSONP 核心原理 二、JSONP 实现步骤 (一)客户端代码 (二)服务器端代码(ASP.NET实现) 1. ASP.NET Web Forms 实现 2. ASP.NET Core 实现 三、JSONP 优缺点 (一)优点 …...

【AI测试革命】第七期:AI性能测试的深度实践——从智能建模到自动化调优的全链路升级
在微服务架构与高并发场景普及的当下,性能测试作为保障系统稳定性和用户体验的核心环节,正面临负载模型构建复杂、脚本维护成本高、瓶颈定位效率低等挑战。Copilot凭借代码生成、数据分析和智能决策能力,为性能测试全流程注入新动能ÿ…...
Thinkphp6使用token+Validate验证防止表单重复提交
htm页面加 <input type"hidden" name"__token__" value"{:token()}" /> Validate 官方文档 ThinkPHP官方手册...

AppAgentx 开源AI手机操控使用分享
项目地址: https://appagentx.github.io/?utm_sourceai-bot.cn GitHub仓库: https://github.com/Westlake-AGI-Lab/AppAgentX/tree/main arXiv技术论文:https://arxiv.org/pdf/2503.02268 AppAgentx是什么: AppAgentX 是西湖大学推出的一种自我进化式 GUI 代理框架。它通过…...
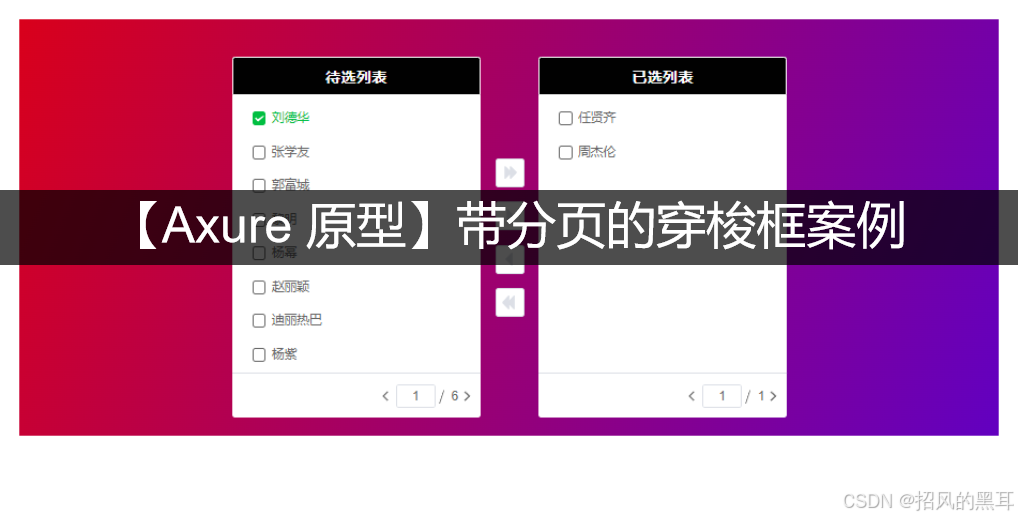
Axure设计之带分页的穿梭框原型
穿梭框(Transfer)是一种常见且实用的交互组件,广泛应用于需要批量选择或分配数据的场景。 一、应用场景 其典型应用场景包括: 权限管理系统:批量分配用户角色或系统权限数据筛选工具:在大数据集中选择特…...

嵌入式硬件篇---陀螺仪|PID
文章目录 前言1. 硬件准备主控芯片陀螺仪模块电机驱动电源其他2. 硬件连接3. 软件实现步骤(1) MPU6050初始化与数据读取(2) 姿态解算(互补滤波或DMP)(3) PID控制器设计(4) 麦克纳姆轮协同控制4. 主程序逻辑5. 关键优化与调试技巧(1) 传感器校准(2) PID参数整定先调P再调D最后…...
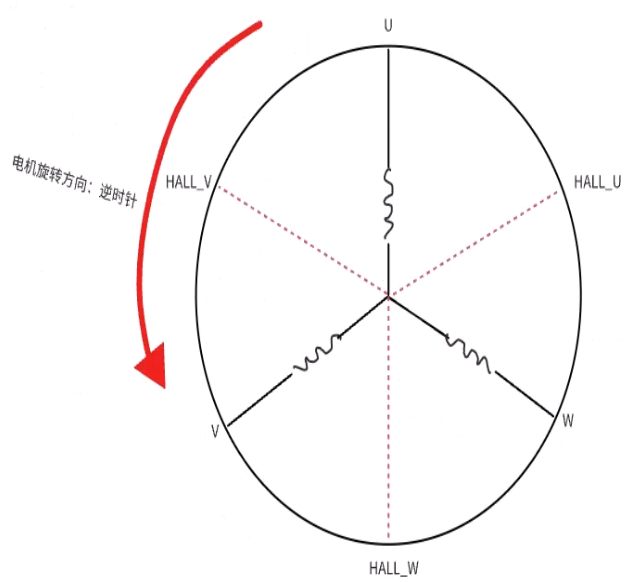
电机控制储备知识学习(五) 三项直流无刷电机(BLDC)学习(四)
目录 电机控制储备知识学习(五)一、三项直流无刷电机(BLDC)学习(四)1)软件方法控制电机转速2)PWM概念和PWM的产生3)转子位置检测和霍尔传感器的工作原理分析4)霍尔传感器安装角度和电…...

Java—— 网络爬虫
案例要求 https://hanyu.baidu.com/shici/detail?pid0b2f26d4c0ddb3ee693fdb1137ee1b0d&fromkg0 http://www.haoming8.cn/baobao/10881.html http://www.haoming8.cn/baobao/7641.html上面三个网址分别表示百家姓,男生名字,女生名字,如…...