Python之两个爬虫案例实战(澎湃新闻+网易每日简报):附源码+解释
目录
一、案例一:澎湃新闻时政爬取
(1)数据采集网站
(2)数据介绍
(3)数据采集方法
(4)数据采集过程
二、案例二:网易每日新闻简报爬取
(1)数据采集网站
(2)数据介绍
(3)数据采集方法
(4)数据采集过程
(5)完整代码与爬取结果
一、案例一:澎湃新闻时政爬取
(1)数据采集网站
1. 网站名称:澎湃新闻网
2. 网站链接:时事_澎湃新闻-The Paper
(2)数据介绍
本次采集的数据为澎湃新闻网时事频道的新闻标题及发布时间。新闻标题反映了社会热点、政策动态、民生实事等各方面内容,是公众了解国家大事、社会变迁的重要信息来源;发布时间则体现了新闻的时效性,有助于分析不同时段的热点话题分布情况以及信息传播的速度与规律。通过对这些数据的整理与分析,可为后续的大数据分析、新闻热点预测、舆情监测等研究提供丰富且实用的素材。
(3)数据采集方法
本次数据采集基于 Python 语言,借助 webdriver_manager 创建 Chrome 浏览器实例,运用 selenium 库模拟网页滚动行为,突破动态网页加载限制,成功获取完整数据,并将其保存于本地文本文件中。随后,利用 BeautifulSoup 解析 HTML 结构,结合 re 正则表达式精准定位目标数据,匹配 class 为 small_cardcontent__BTALp 的 div 标签,进而提取每个新闻卡片下的 h2 标题数据和 span 日期数据,实现对澎湃新闻时政新闻关键信息的高效抓取。
(4)数据采集过程
步骤一:导入time,re,bs4,selenium,webdriver_manager库,其中,time 库用于设置滚动等待时间,re 库负责正则表达式匹配,bs4 库中的 BeautifulSoup 用于解析 HTML 文本,而 selenium 及其相关模块配合 webdriver_manager 则是实现网页动态加载的关键工具。
import timeimport refrom bs4 import BeautifulSoupfrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.chrome.service import Servicefrom webdriver_manager.chrome import ChromeDriverManager步骤二:使用 webdriver 创建 Chrome 浏览器实例,访问澎湃新闻网时事频道。通过模拟滚动到底部操作,持续加载更多内容,直至无法继续加载为止。获取完整 HTML 结构并保存至 “澎湃新闻时政.txt” 文件中,确保采集到的数据完整且可后续处理;
# 启动浏览器
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://www.thepaper.cn/channel_25950")
# 模拟滚动到底部以加载更多内容
last_height = driver.execute_script("return document.body.scrollHeight")
while True:# 滚动到底部driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")# 等待页面加载新内容time.sleep(2) # 可以根据实际情况调整时间# 获取新的页面高度new_height = driver.execute_script("return document.body.scrollHeight")# 如果页面高度没有变化,说明已经到底部了if new_height == last_height:breaklast_height = new_height# 获取完整的HTML
html = driver.page_source# 保存完整的HTML到文件
with open("澎湃新闻时政.txt", "w", encoding="utf-8") as f:f.write(html)# 关闭浏览器
driver.quit(
print("已保存至澎湃新闻时政.txt")
步骤三:定义 extract_news 函数,利用 BeautifulSoup 解析 HTML 文本,构建正则匹配式精准定位 class 为 small_cardcontent__BTALp 的 div 标签。通过遍历每个新闻卡片,提取 h2 标签内的标题文本以及符合特定时间格式的 span 标签内容,将提取到的标题和时间信息存储为字典格式并返回结果列表。最终将提取的新闻数据逐条写入 “澎湃新闻时政爬取.txt” 文件中;
def extract_news(html_content):soup = BeautifulSoup(html_content, 'html.parser')results = []# 遍历每个新闻卡片for card in soup.find_all('div', class_=re.compile(r'small_cardcontent__\w+')):# 提取标题h2_tag = card.find('h2')title = h2_tag.get_text(strip=True) if h2_tag else "无标题"# 提取时间:定位到包含时间信息的 span 标签time_span = None# 遍历卡片内的所有 p 标签,寻找符合结构的 spanfor p_tag in card.find_all('p'):spans = p_tag.find_all('span')# 若 p 标签下有至少两个 span,且第二个 span 包含时间特征if len(spans) >= 2:candidate = spans[1].get_text(strip=True)# 检查是否符合时间格式(相对时间或日期)if re.match(r'(\d+[天小时分钟前]+)|(\d{4}-\d{2}-\d{2})|(\d{1,2}月\d{1,2}日)', candidate):time_span = candidatebreak # 找到后立即退出循环time = time_span if time_span else "时间未找到"results.append({"标题": title, "时间": time})return resultsnews_list = extract_news(html_content)
for i, news in enumerate(news_list):with open("澎湃新闻时政爬取.txt", "a", encoding="utf-8") as f:f.write(f"第{i+1}条时政\n")f.write(f"标题:{news['标题']}\n时间:{news['时间']}\n\n")# print(f"标题:{news['标题']}\n时间:{news['时间']}\n---")
(5)完整代码与爬取结果
1. 完整代码
# 时政
import time
import re
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager# 基础URL用于拼接完整链接
BASE_URL = "https://www.thepaper.cn"
# 请求头设置(防止反爬)
HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}# ----------------------
# 核心修改部分
# ----------------------def get_secondary_content(url):"""获取二级页面正文内容"""try:response = requests.get(url, headers=HEADERS, timeout=10)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')# 提取目标div中的p标签内容content_div = soup.find('div', class_='index_cententWrap__Jv8jK')if not content_div:return "内容未找到"# 提取所有p标签文本并拼接paragraphs = [p.get_text(strip=True) for p in content_div.find_all('p') if p.get_text(strip=True)]return '\n'.join(paragraphs)except Exception as e:print(f"获取二级页面失败: {url},错误: {str(e)}")return "内容获取失败"def extract_news(html_content):"""提取新闻数据(新增链接提取)"""soup = BeautifulSoup(html_content, 'html.parser')results = []for card in soup.find_all('div', class_=re.compile(r'small_cardcontent__\w+')):# 提取标题h2_tag = card.find('h2')title = h2_tag.get_text(strip=True) if h2_tag else "无标题"# 提取链接a_tag = card.find('a', href=True)relative_link = a_tag['href'] if a_tag else Nonefull_link = f"{BASE_URL}{relative_link}" if relative_link else None# 提取时间time_span = Nonefor p_tag in card.find_all('p'):spans = p_tag.find_all('span')if len(spans) >= 2 and re.match(r'(\d+[天小时分钟前]+)', spans[1].get_text(strip=True)):time_span = spans[1].get_text(strip=True)breakresults.append({"标题": title,"时间": time_span if time_span else "时间未找到","链接": full_link})return results# ----------------------
# 主流程修改
# ----------------------
if __name__ == "__main__":# 初始化浏览器driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))driver.get("https://www.thepaper.cn/channel_25950")# 滚动加载逻辑(保持不变)last_height = driver.execute_script("return document.body.scrollHeight")while True:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")time.sleep(2)new_height = driver.execute_script("return document.body.scrollHeight")if new_height == last_height:breaklast_height = new_height# 获取页面源码html = driver.page_sourcedriver.quit()# 提取新闻列表news_list = extract_news(html)# 清空旧文件open("时政.txt", "w", encoding="utf-8").close()# 遍历处理每个新闻for idx, news in enumerate(news_list):# 获取二级页面内容content = get_secondary_content(news["链接"]) if news["链接"] else "链接无效"# 写入文件with open("时政.txt", "a", encoding="utf-8") as f:f.write(f"标题:{news['标题']}\n")f.write(f"内容:{content}\n\n")print(f"已处理第{idx+1}/{len(news_list)}条: {news['标题'][:20]}...")print("所有内容已保存至 时政.txt")2. 爬取结果

二、案例二:网易每日新闻简报爬取
(1)数据采集网站
1. 网站名称:网易
2. 网站链接: 每天一分钟知晓天下事
(2)数据介绍
本次采集的数据为网易 “每天一分钟知晓天下事” 栏目下的新闻简报。数据内容涵盖了从 [起始日期] 至 [结束日期] 期间的每日热点新闻,每条新闻简报包含日期信息以及当日 15 条左右的新闻条目。日期格式统一为 “YYYY 年 MM 月 DD 日 星期 X (农历 XX)”,新闻条目以序号编号,内容简洁明了,涵盖了社会、经济、文化、科技等多个领域的重要资讯。数据以文本(txt)形式存储,结构清晰,每条新闻独占一行,便于后续的数据分析、处理与展示。
(3)数据采集方法
本次数据采集基于 Python 语言,利用 requests 库获取网页的 response,当状态码为 200 时,表示网页获取成功。此时,可拿到网页的 html 结构。由于本次采集的数据涉及网页结构中 URL 的嵌套,因此采用 re 正则匹配库匹配所需的字符串(URL),通过循环的方式请求 URL,再根据请求的网页结构继续使用正则匹配的方式获取需要的文本信息。
(4)数据采集过程
步骤一:导入requests,re,bs4,tqdm库,分别为发送网络请求、进行正则表达式匹配、网页解析和显示进度条;
import requests
import re
from tqdm import tqdm
from bs4 import BeautifulSoup
步骤二:设定目标网页 URL,配置请求头以模拟浏览器请求,监听状态码判断请求是否成功。若成功,通过 response.text 获取网页的字符串信息,并将其保存至本地文件 “网易.txt” 以便后续分析和处理;
url = 'https://www.163.com/dy/media/T1603594732083.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3','Referer': 'https://www.163.com/'
}response = requests.get(url, headers=headers)
response.encoding = 'utf-8'if response.status_code == 200:page_text = response.textprint(page_text)with open("网易.txt", "w", encoding="utf-8") as f:f.write(page_text)
else:
print("Request failed with status code:", response.status_code)
步骤三:依据 response.text 的返回结果,运用正则表达式匹配,定位 h4 标签下的 a 标签的 href 属性,从而获取二级网页的 URL 字符串。通过打印输出,可得知匹配到的链接数量;
# 匹配里面的子链接-正则匹配式
pattern = r'<h4[^>]*>[\s\S]*?<a\s[^>]*?href="([^"]*)"'
result = re.findall(pattern, page_text, re.IGNORECASE)print(f"总共有{len(result)}个链接") # 107个
步骤四:依次遍历二级网页 URL,采用与步骤二相同的请求方式获取页面内容。利用 BeautifulSoup 定位目标容器,结合正则表达式匹配,分别提取新闻的日期和新闻条目。将提取到的信息按指定格式追加写入至 “网易每日新闻简报.txt” 文件中,同时通过 tqdm 显示进度条;
for index, url in tqdm(enumerate(result[0: 35])):response = requests.get(url, headers=headers)response.encoding = 'utf-8'page_text = Noneif response.status_code == 200:page_text = response.text# print(page_text)else:print("Request failed with status code:", response.status_code)soup = BeautifulSoup(page_text, 'html.parser')# 定位到目标容器post_body = soup.find('div', class_='post_body')# 获取第二个<p>标签(索引1)target_p = post_body.find_all('p')[1]# 提取所有文本行(自动处理<br>换行)text_lines = [line.strip() for line in target_p.stripped_strings]# 使用正则匹配日期(兼容不同分隔符)date_pattern = re.compile(r'(\d{4}年\d{1,2}月\d{1,2}日.*?(?:星期[一二三四五六日]).*?(?:农历.*?))(?:$|\s)')date_match = next((line for line in text_lines if date_pattern.match(line)), None)# 提取新闻条目(兼容全角数字/罗马数字)news_pattern = re.compile(r'^(\d+|[\u2160-\u217F])+[\.。]\s*(.*)')news_items = [news_pattern.match(line).group(2) for line in text_lines if news_pattern.match(line)]with open("网易每日新闻简报.txt", "a", encoding="utf-8") as f:f.write(f"日期:{date_match}\n")f.write(f"新闻条目:\n")for i, item in enumerate(news_items, 1):f.write(f"{i}. {item}\n")print(f"第{index}条链接的新闻简报提取完成!")
(5)完整代码与爬取结果
1. 完整代码
# 每天一分钟,知晓天下事-新闻简报
import requests
import re
from tqdm import tqdm
from bs4 import BeautifulSoupurl = 'https://www.163.com/dy/media/T1603594732083.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3','Referer': 'https://www.163.com/'
}response = requests.get(url, headers=headers)
response.encoding = 'utf-8'if response.status_code == 200:page_text = response.textprint(page_text)with open("网易.txt", "w", encoding="utf-8") as f:f.write(page_text)
else:print("Request failed with status code:", response.status_code)# 匹配里面的子链接-正则匹配式
pattern = r'<h4[^>]*>[\s\S]*?<a\s[^>]*?href="([^"]*)"'
result = re.findall(pattern, page_text, re.IGNORECASE)print(f"总共有{len(result)}个链接") # 107个# 通过循环的方式继续向链接发起请求信息
# 为了避免一次性发起过多的请求,下面只请求前35条链接
for index, url in tqdm(enumerate(result[0: 35])):response = requests.get(url, headers=headers)response.encoding = 'utf-8'page_text = Noneif response.status_code == 200:page_text = response.text# print(page_text)else:print("Request failed with status code:", response.status_code)soup = BeautifulSoup(page_text, 'html.parser')# 定位到目标容器post_body = soup.find('div', class_='post_body')# 获取第二个<p>标签(索引1)target_p = post_body.find_all('p')[1]# 提取所有文本行(自动处理<br>换行)text_lines = [line.strip() for line in target_p.stripped_strings]# 使用正则匹配日期(兼容不同分隔符)date_pattern = re.compile(r'(\d{4}年\d{1,2}月\d{1,2}日.*?(?:星期[一二三四五六日]).*?(?:农历.*?))(?:$|\s)')date_match = next((line for line in text_lines if date_pattern.match(line)), None)# 提取新闻条目(兼容全角数字/罗马数字)news_pattern = re.compile(r'^(\d+|[\u2160-\u217F])+[\.。]\s*(.*)')news_items = [news_pattern.match(line).group(2) for line in text_lines if news_pattern.match(line)]with open("网易每日新闻简报.txt", "a", encoding="utf-8") as f:f.write(f"日期:{date_match}\n")f.write(f"新闻条目:\n")for i, item in enumerate(news_items, 1):f.write(f"{i}. {item}\n")print(f"第{index}条链接的新闻简报提取完成!")2. 爬取结果

相关文章:
Python之两个爬虫案例实战(澎湃新闻+网易每日简报):附源码+解释
目录 一、案例一:澎湃新闻时政爬取 (1)数据采集网站 (2)数据介绍 (3)数据采集方法 (4)数据采集过程 二、案例二:网易每日新闻简报爬取 (1&#x…...

HarmonyOS NEXT~鸿蒙系统与mPaaS三方框架集成指南
HarmonyOS NEXT~鸿蒙系统与mPaaS三方框架集成指南 1. 概述 1.1 鸿蒙系统简介 鸿蒙系统(HarmonyOS)是华为开发的分布式操作系统,具备以下核心特性: 分布式架构:支持跨设备无缝协同微内核设计:提高安全性和性能一次开…...

系统安全及应用学习笔记
系统安全及应用学习笔记 一、账号安全控制 (一)账户管理策略 冗余账户处理 非登录账户:Linux 系统中默认存在如 bin、daemon 等非登录账户,其登录 Shell 应为 /sbin/nologin,需定期检查确保未被篡改。冗余账户清理&…...

STC89C52RC/LE52RC
STC89C52RC 芯片手册原理图扩展版原理图 功能示例LED灯LED灯的常亮效果LED灯的闪烁LED灯的跑马灯效果:从左到右,从右到左 数码管静态数码管数码管计数App.cApp.hCom.cCom.hDir.cDir.hInt.cInt.hMid.cMid.h 模板mian.cApp.cApp.hCom.cCom.hDir.cDir.hInt.…...
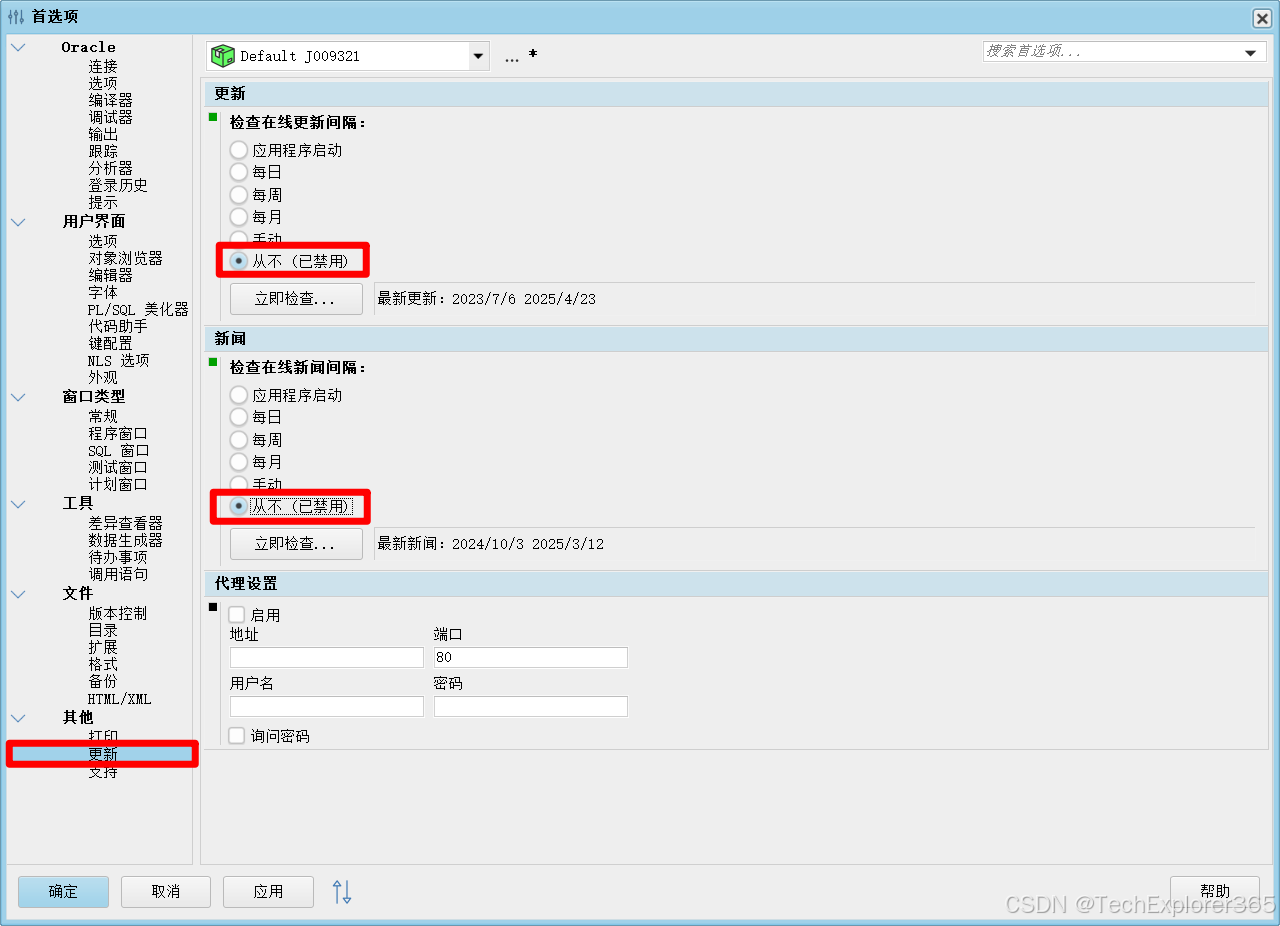
✨ PLSQL卡顿优化
✨ PLSQL卡顿优化 1.📂 打开首选项2.🔧 Oracle连接配置3.⛔ 关闭更新和新闻 1.📂 打开首选项 2.🔧 Oracle连接配置 3.⛔ 关闭更新和新闻...

yum命令常用选项
刷新仓库列表 sudo yum repolist清理 Yum 缓存并生成新的缓存 sudo yum clean all sudo yum makecache验证 EPEL 源是否已正确启用 sudo yum repolist enabled安装软件包 sudo yum install <package-name> -y更新软件包 sudo yum update -y仅更新指定的软件包。 su…...
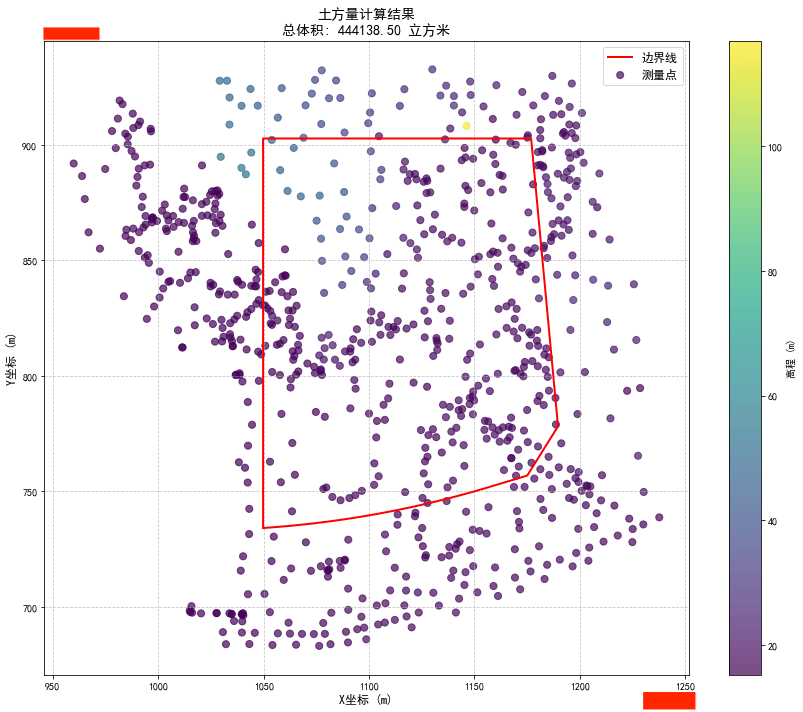
python+vlisp实现对多段线范围内土方体积的计算
#在工程中,经常用到计算土方回填、土方开挖的体积。就是在一个范围内,计算土被挖走,或者填多少,这个需要测量挖填前后这个范围内的高程点。为此,我开发一个app,可以直接在autocad上提取高程点,然…...

鸿蒙Flutter实战:25-混合开发详解-5-跳转Flutter页面
概述 在上一章中,我们介绍了如何初始化 Flutter 引擎,本文重点介绍如何添加并跳转至 Flutter 页面。 跳转原理 跳转原理如下: 本质上是从一个原生页面A 跳转至另一个原生页面 B,不过区别在于,页面 B是一个页面容器…...
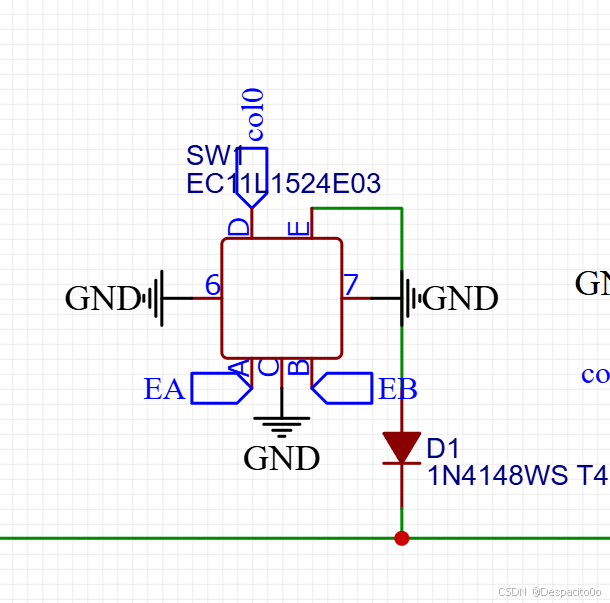
APM32小系统键盘PCB原理图设计详解
APM32小系统键盘PCB原理图设计详解 一、APM32小系统简介 APM32微控制器是国内半导体厂商推出的一款高性能ARM Cortex-M3内核微控制器,与STM32高度兼容,非常适合DIY爱好者用于自制键盘、开发板等电子项目。本文将详细讲解如何基于APM32 CBT6芯片设计一款…...

【C/C++】多线程开发:wait、sleep、yield全解析
文章目录 多线程开发:wait、sleep、yield全解析1 What简要介绍详细介绍wait() — 条件等待(用于线程同步)sleep() — 睡觉,定时挂起yield() — 自愿让出 CPU 2 区别以及建议区别应用场景建议 3 三者协作使用示例 多线程开发&#…...

uint8_t是什么数据类型?
一、引言 在C语言编程中,整数类型是最基本的数据类型之一。然而,你是否真正了解这些看似简单的数据类型?本文将深入探索C语言中的整数类型,在编程中更加得心应手。 二、C语言整数类型的基础 2.1 标准整数类型 C语言提供了多种…...

SystemUtils:你的Java系统“探照灯“——让环境探测不再盲人摸象
各位Java系统侦探们好!今天要介绍的是Apache Commons Lang3中的SystemUtils工具类。这个工具就像编程界的"雷达系统",能帮你一键获取所有系统关键信息,再也不用满世界找System.getProperty()了! 一、为什么需要SystemU…...
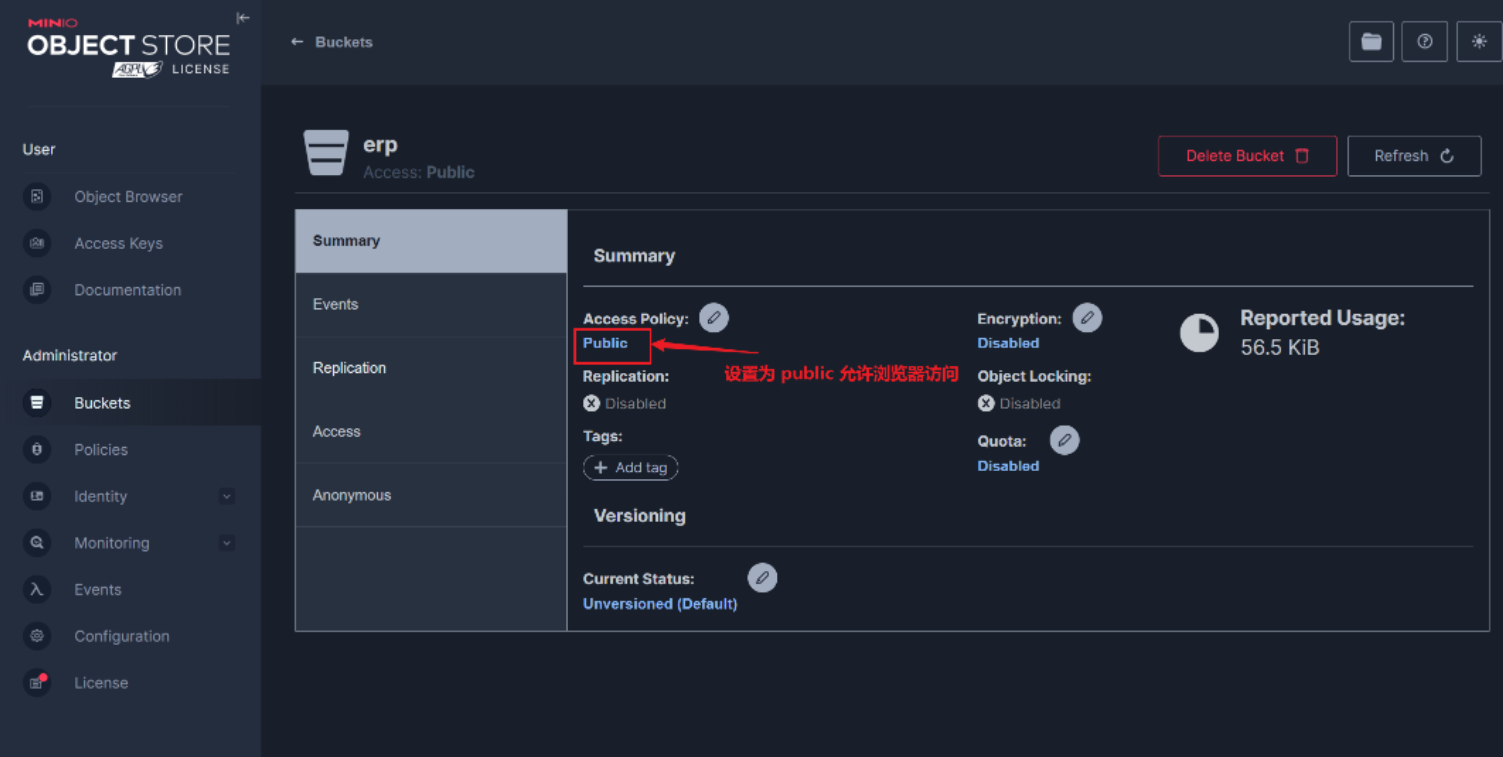
对象存储(Minio)使用
目录 1.安装 MinIO(Windows) 2.启动minio服务: 3.界面访问 4.进入界面 5.前后端代码配置 1)minio前端配置 2)minio后端配置 1.安装 MinIO(Windows) 官方下载地址:[Download High-Perform…...

yolov11使用记录(训练自己的数据集)
官方:Ultralytics YOLO11 -Ultralytics YOLO 文档 1、安装 Anaconda Anaconda安装与使用_anaconda安装好了怎么用python-CSDN博客 2、 创建虚拟环境 安装好 Anaconda 后,打开 Anaconda 控制台 创建环境 conda create -n yolov11 python3.10 创建完后&…...

历史数据分析——宁波港
个股走势 公司简介: 货物吞吐量和集装箱吞吐量持续保持全球港口前列。 经营分析: 码头开发经营、管理;港口货物的装卸、堆存、仓储、包装、灌装;集装箱拆拼箱、清洗、修理、制造、租赁;在港区内从事货物驳运,国际货运代理;铁路货物运输代理,铁路工程承建,铁路设备…...

知识宇宙:技术文档该如何写?
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、技术文档的价值与挑战1. 为什么技术文档如此重要2. 技术文档面临的挑战 二、撰…...

DeepSeek 赋能数字农业:从智慧种植到产业升级的全链条革新
目录 一、数字农业的现状与挑战二、DeepSeek 技术解析2.1 DeepSeek 的技术原理与优势2.2 DeepSeek 在人工智能领域的地位与影响力 三、DeepSeek 在数字农业中的应用场景3.1 精准种植决策3.2 病虫害监测与防治3.3 智能灌溉与施肥管理3.4 农产品质量追溯与品牌建设 四、DeepSeek …...
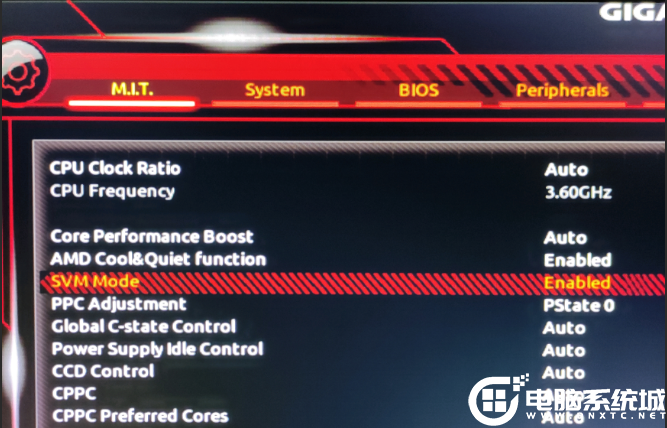
技嘉主板怎么开启vt虚拟化功能_技嘉主板开启vt虚拟化教程(附intel和amd开启方法)
最近使用技嘉主板的小伙伴们问我,技嘉主板怎么开启vt虚拟。大多数可以在Bios中开启vt虚拟化技术,当CPU支持VT-x虚拟化技术,有些电脑会自动开启VT-x虚拟化技术功能。而大部分的电脑则需要在Bios Setup界面中,手动进行设置ÿ…...

Java 并发编程高级技巧:CyclicBarrier、CountDownLatch 和 Semaphore 的高级应用
Java 并发编程高级技巧:CyclicBarrier、CountDownLatch 和 Semaphore 的高级应用 一、引言 在 Java 并发编程中,CyclicBarrier、CountDownLatch 和 Semaphore 是三个常用且强大的并发工具类。它们在多线程场景下能够帮助我们实现复杂的线程协调与资源控…...
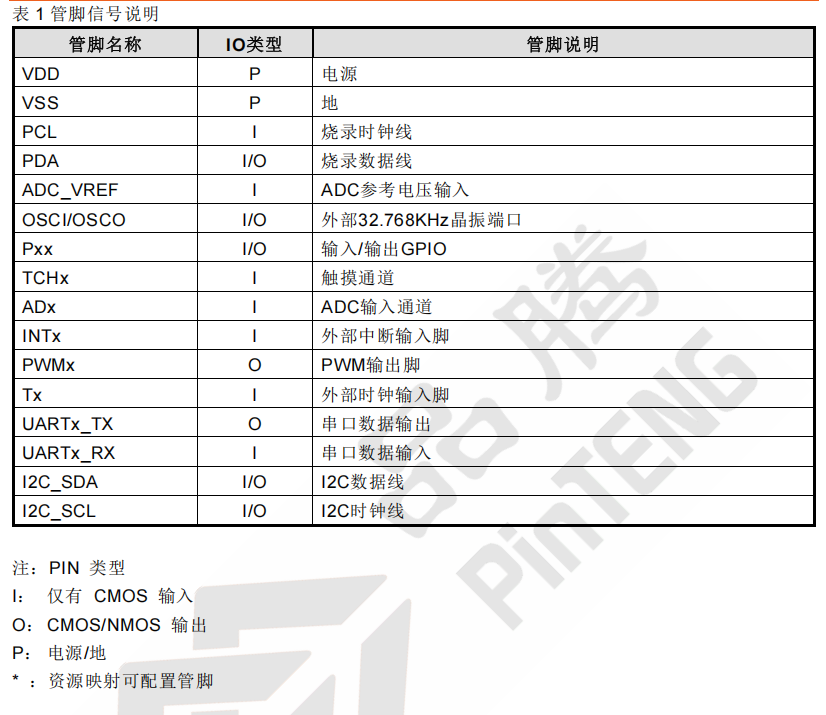
PT5F2307触摸A/D型8-Bit MCU
1. 产品概述 ● PT5F2307是一款51内核的触控A/D型8位MCU,内置16K*8bit FLASH、内部256*8bit SRAM、外部512*8bit SRAM、触控检测、12位高精度ADC、RTC、PWM等功能,抗干扰能力强,适用于滑条遥控器、智能门锁、消费类电子产品等电子应用领域。 …...

矩阵方程$Ax=b$的初步理解.
对于矩阵方程 A x b A\textbf{\textit{x}}\textbf{\textit{b}} Axb,可能就是一学而过,也可能也就会做做题,但是从如何直观地理解它呢? 这个等式可以用多种理解方式,这里就从向量变换角度浅谈一下。其中的 A A A是矩阵&#…...
线性代数中的向量与矩阵:AI大模型的数学基石
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

[特殊字符] 使用增量同步+MQ机制将用户数据同步到Elasticsearch
在开发用户搜索功能时,我们通常会将用户信息存储到 Elasticsearch(简称 ES) 中,以提高搜索效率。本篇文章将详细介绍我们是如何实现 MySQL 到 Elasticsearch 的增量同步,以及如何通过 MQ 消息队列实现用户信息实时更新…...

LeetCode 2942.查找包含给定字符的单词:使用库函数完成
【LetMeFly】2942.查找包含给定字符的单词:使用库函数完成 力扣题目链接:https://leetcode.cn/problems/find-words-containing-character/ 给你一个下标从 0 开始的字符串数组 words 和一个字符 x 。 请你返回一个 下标数组 ,表示下标在数…...

【mediasoup】MS_DEBUG_DEV 等日志形式转PLOG输出
输出有问题 MS_DEBUG_DEV("[pacer_updated pacing_kbps:%" PRIu32 ",padding_budget_kbps:%" PRIu32 "]",pacing_bitrate_kbps_,/*cc给出的目标码率 * 系数*/padding_rate_bps / 1000 /*设置值*/);...

打卡第27天:函数的定义与参数
知识点回顾: 1.函数的定义 2.变量作用域:局部变量和全局变量 3.函数的参数类型:位置参数、默认参数、不定参数 4.传递参数的手段:关键词参数 5.传递参数的顺序:同时出现三种参数类型时 作业: 题目1&a…...
python训练营day34
知识点回归: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前向传播时可以直接写作self.fc1(x) 作业 复习今…...

人工智能在医疗影像诊断上的最新成果:更精准地识别疾病
摘要:本论文深入探讨人工智能在医疗影像诊断领域的最新突破,聚焦于其在精准识别疾病方面的显著成果。通过分析深度学习、多模态影像融合、三维重建与可视化以及智能辅助诊断系统等关键技术的应用,阐述人工智能如何提高医疗影像诊断的准确性和…...

塔能节能平板灯:点亮苏州某零售工厂节能之路
在苏州某零售工厂的运营成本中,照明能耗占据着一定比例。为降低成本、提升能源利用效率,该工厂与塔能科技携手,引入塔能节能平板灯,开启了精准节能之旅,并取得了令人瞩目的成效。 一、工厂照明能耗困境 苏州该零售工厂…...

3DMAX插件UV工具UV Tools命令参数详解
常规: 打开UV工具设置对话框。 右键点击: 隐藏/显示主界面。 添加 为选定对象添加展开修改器。 将从下拉菜单中选择映射通道。 Ctrl+点击: 克隆任何当前的修饰符。 右键点击: 找到第一个未展开的修改器。 地图频道 设置展开映射通道。 Ctrl+Click:添加选定的映射通道的展开…...