如何设计Agent的记忆系统
最近看了一张画Agent记忆分类的图
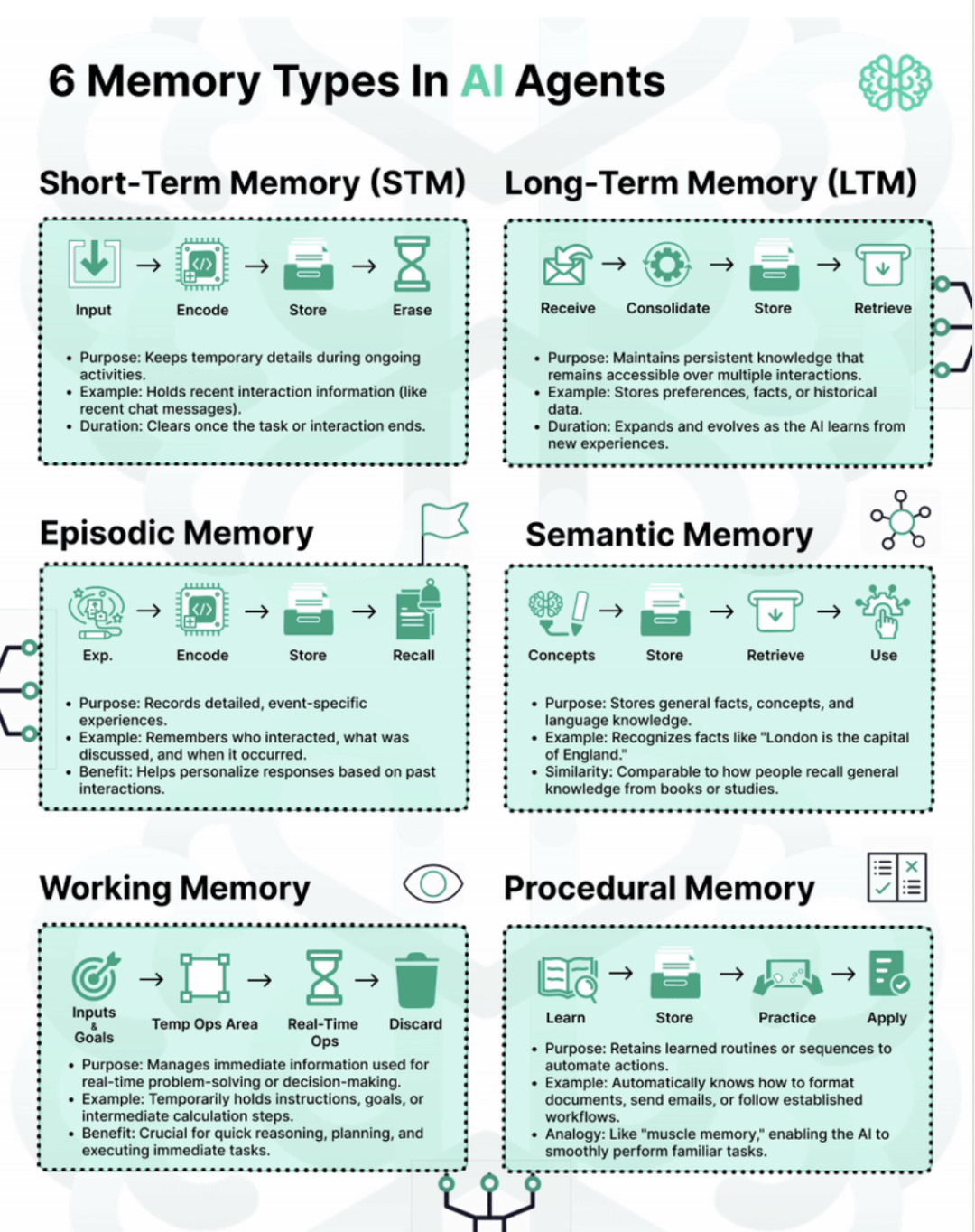
我觉得分类分的还可以,但是太浅了,于是就着它的逻辑,仔细得写了一下在不同的记忆层,该如何设计和选型
先从流程,作用,实力和持续时间的这4个维度来解释一下这几种记忆:
1. 短期记忆(Short-Term Memory, STM)
流程:Input(输入)→ Encode(编码)→ Store(存储)→ Erase(清除)
作用:在进行活动时保持临时细节,类似于我们在对话中临时记住的信息。
示例:保存最近的交互信息,比如刚刚发送的聊天内容。
持续时间:任务或对话结束后即被清除,不会保留。
2. 长期记忆(Long-Term Memory, LTM)
流程:Receive(接收)→ Consolidate(整合)→ Store(存储)→ Retrieve(提取)
作用:维持持久的知识,跨多次交互都能访问这些知识。
示例:保存偏好设置、事实知识、历史数据等。
持续时间:会随着AI不断学习新信息而增加和演变。
3. 情节记忆(Episodic Memory)
流程:Experience(体验)→ Encode(编码)→ Store(存储)→ Recall(回忆)
作用:记录详细的、事件性的经历。
示例:记住是和谁互动(这个不见的“who”代表的是user,也可能是agent)、讨论了什么、何时发生等。
好处:有助于AI根据过往经历,个性化地回应当前请求。
4. 语义记忆(Semantic Memory)
流程:Concepts(概念)→ Store(存储)→ Retrieve(提取)→ Use(使用)
作用:保存事实、概念、语言等一般知识,防止常识性幻觉
示例:知道“伦敦是英国的首都”这种事实。
特性:类似于人类从书本或知识学习中获得并提取的常识。
5. 工作记忆(Working Memory)
流程:Inputs & Goals(输入和目标)→ Temp Ops Area(暂存操作区)→ Real-Time Ops(实时操作)→ Discard(丢弃)
作用:处理即时信息,便于现场决策和解决问题。
示例:临时保存指令、目标或计算步骤。
好处:对即时推理、计划和执行任务至关重要。
6. 程序性记忆(Procedural Memory)
流程:Learn(学习)→ Store(存储)→ Practice(练习)→ Apply(应用)
作用:保留已学会的操作和流程,可自动化执行。
示例:自动知道如何格式化文档、发邮件或跟随既有流程。
类比:“肌肉记忆”,让AI能流畅地完成熟悉的任务。
以上六种记忆类型,分别服务于AI在不同场景下的存储、处理和应用:从即时、临时的信息处理,到持久、自动化的技能与知识运用。
但是这个概念要是落到纸面上其实还有很多工作要做吧,最起码得知道用啥存储组件吧,或者数据格式推荐?
那我们继续。
下面我根据上面这个图,整一个面向LLM Agent的存储设计建议,目的是能说明 6 类记忆各自应选用的存储类型、数据格式、关键组件及设计要点。
线说思路核心:
1) 根据记忆的寿命(瞬时 , 短期 , 长期)、读写频率、访问延迟需求选介质;
2) 根据查询方式(键值检索 , 语义相似度 , 结构化查询 , 顺序重放)选数据库模型;
3) 最好能用统一的记忆编排层抽象读写接口,屏蔽底层异构存储差异。
我就不按上面的顺序来写了啊,咱们就从短长开始设计,这样看着逻辑性强一点。
1. 短期记忆 (Short-Term Memory, STM)
• 典型访问特征:生命周期 = 一次对话/任务,毫秒级读写,键值直取,不需要持久化。
• 推荐组件的话呢?
首选:进程内缓存(Python Dict、Go map)或轻量化 KV 内存数据库(Redis、Dragonfly)。
高并发多实例可用 Redis Cluster + TTL 到期删除。
• 数据模型/格式
结构简单:
{conversation_id: [{role, content, ts}]}或者直接token 缓存。
若需少量向量召回,可把 embedding 作为 field 存 Hash/JSON 里,或附带到本地 Faiss index(RAM),有钱Faiss可以上GPU,但是其实也没太大必要。
• 设计要点
TTL 必须 小于 上下文窗口时间,其实这个挺好理解,如果你TTL设置得太长,超过了当前任务/对话上下文窗口,那么旧的短期记忆有可能被下一轮新的对话或任务意外挂载和复用,导致“前一个用户/任务”的内容泄露进来(典型的“越权存取”风险)
关闭持久化 (AOF/RDB) 以获得极低延迟;
同步删除:对话结束立即 DEL / EXPIRE 0。
2. 工作记忆 (Working Memory)
• 定义:Agent 正在推理时的scratchpad。持续几秒~几分钟,需要频繁更新、顺序遍历。
• 推荐组件
直接放在 LLM 的 Prompt 构造器里(临时 Python 对象 / JS 对象);
如需多人协作或 DAG 工作流,可用内存流数据库(Materialize、RisingWave)或流框架(Kafka + ksqlDB)暂存。
• 数据模型
JSON/Dict:
{"goal": "...", "current_step": 3, "intermediate_results": [...]} • 设计要点
可随时丢弃原则;
若任务超长,用 Write-Ahead Log 落盘到本地 SSD 防节点故障。
这俩没啥特别可解释的
3. 情节记忆 (Episodic Memory)
• 定义:带时间戳的交互事件流,需要按语义+时间检索。
• 推荐组件(Hybrid Store)
1-事件日志:Append-only 列式或时序库 Apache Iceberg / Parquet on S3、ClickHouse、TimescaleDB,这东西太多了,要我就clickhouse了,因为简单,但是特别要注意时间上下文的,可能还得去找专门的TSDB来搞
2-语义索引:向量数据库 Milvus / Weaviate / pgvector / Pinecone。
• 数据模型
基表的设计example:event_id, agent_id, user_id, timestamp, text, meta(json)
向量表:event_id, embedding VECTOR(768看你处理的数据业务形态,768就是个建议值) + HNSW/IVF 索引
• 设计要点
双写:事件落盘时同步写入向量库;
支持 “who/when/what” 过滤(涉及时间,事件和角色) + 近似向量检索;
定期离线合并老分区、分层存储 (hot ↔ cold)。
4. 语义记忆 (Semantic Memory)
• 定义:事实、概念、知识图谱,强调结构化关系和可推理。
• 推荐组件
知识图谱:RDF 三元组库 (Blazegraph, Virtuoso) 或图数据库 (Neo4j, TigerGraph);
补充全文/向量:Elasticsearch + KNN(有没有估计能差点意思)、或者同上向量库。
• 数据模型
三元组:(entity, relation, entity)
为每个实体存 description, embedding,支持 embedding 相似度 + Cypher(图)/SPARQL(EDF) 查询,当然也可以加上BM25座个hyberid,最后再rerank。
• 设计要点
明确本体 / schema;
版本化知识 (snapshot + diff) 以便回溯;
支持批量导入(主要是产业和公司内部文档这些玩意,对,还有wiki)。
5. 长期记忆 (Long-Term Memory, LTM)
• 定义:用户偏好、持久配置、历次学习成果的总汇,需要可扩展、持久、多模式查询。
• 推荐组件(分层架构)
结构化偏好:PostgreSQL / MySQL
大文件/文档:对象存储 (S3类的)
语义检索:统一指向上面的向量库(可与情节/语义共用集群省点钱)。
• 数据模型
偏好表:user_id, key, value(jsonb), updated_at
文档索引:doc_id, s3_uri, summary, embedding
• 设计要点
多租户隔离、如果有强烈的compliance需求,那上面GDPR 啥的也可以在这个基础上建设,总而言之就是不能混用了;
写放大:批量 consolidate 后写,减少频繁小更新;
定期迁移冷数据到低成本存储 ,比如类Glacier的纯冷层,但是我其实还时更推荐放在温层里面进行存储,虽然长期记忆不见的总能用到,但是一旦用到,折腾Glacier还是挺麻烦的,另外一个必须做的工作就是,长期记忆的定期summary,短期记忆可以周期性的汇总形成长期记忆,长期记忆也可以定期汇总形成超长期记忆,来避免context和storage的双重上限压力。
6. 程序性记忆 (Procedural Memory)
• 定义:可复用的技能 / 工作流 / 宏;更新频次低、读频次高,需要版本控制和安全审计。
• 推荐组件
Git 仓库 (GitLab / GitHub Enterprise或者任何企业里面用的仓库,愿意用啥都行) + CI;
若技能用 DSL/JSON 表示,可再加文档数据库 (MongoDB) 缓存可解析的 AST;
运行时加载:在容器或函数服务等serverless服务中按需调用。
• 数据模型
代码 / YAML / BPMN 文件;
元数据表:skill_id, name, version, checksum, entry_point, permissions.
• 设计要点
版本标签+语义化发布 (SemVer);
审批/回滚链路;
延迟加载 + 本地 LRU 缓存,保证首调用体验。
跨层 Memory Orchestrator 设计要点
1) 统一 API:store(memory_type, data, **meta)、retrieve(memory_type, query)
2) 读写策略:
• 写入时自动路由到对应存储;
• 读取时支持级联:先 STM 到LTM 到 语义 / 图谱。
3) 安全合规:数据分级、加密 at-rest + in-transit,PII 脱敏。
4) 指标观测:每层暴露 QPS、延迟、命中率,Prometheus + Grafana。
5) 弹性伸缩:冷热分层、Auto-Scaling、备份与灾难恢复策略。
如果按着我以上的设计来经营你的Agent记忆系统,那肯定既能保证超低延迟的对话体验,又能让 Agent 正确的调用长短期记忆的知识,演化技能,而且复杂度相当高,为了做AI自动化,手动创建了极其精密和复杂的存储系统,就又可以借机会招人了,创造了就业机会

相关文章:
如何设计Agent的记忆系统
最近看了一张画Agent记忆分类的图 我觉得分类分的还可以,但是太浅了,于是就着它的逻辑,仔细得写了一下在不同的记忆层,该如何设计和选型 先从流程,作用,实力和持续时间的这4个维度来解释一下这几种记忆&am…...
毕业论文格式(Word)
目录 Word目录怎么自动生成?快速生成试试这3个方法! - 知乎https://zhuanlan.zhihu.com/p/692056836目录生成需要先设置标题样式,这个不仅是目录生成需要,和后续的图表也有关系。 最好不要自己创建新的样式,而是在现有…...

学习STC51单片机14(芯片为STC89C52RC)
接下来我们进入学会了HC—SR04 还有舵机那么现在我们将他们融合在一起,用超声波来引导舵机的转动 我们这个最后的成果是做一个智能垃圾桶 成品是这样的,是不是可有意思了 成品视频 现在我们将舵机的代码和超声波测距模块的代码整合到一起,实…...
基于CodeBuddy实现本地网速的实时浏览小工具
本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 前言 在数字化浪潮席卷全球的今天,网络已成为人们生活和工作中不可或缺的基础设施。无论是在线办公、学习、娱乐,还是进行大数据传输和云计算&…...
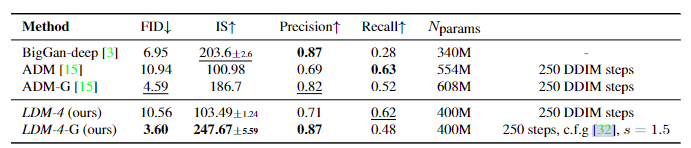
stable diffusion论文解读
High-Resolution Image Synthesis with Latent Diffusion Models 论文背景 LDM是Stable Diffusion模型的奠基性论文 于2022年6月在CVPR上发表 传统生成模型具有局限性: 扩散模型(DM)通过逐步去噪生成图像,质量优于GAN&#x…...

计算机网络(3)——传输层
1.概述 1.1 传输层的服务和协议 (1)传输层为允许在不同主机(Host)上的进程提供了一种逻辑通信机制 (2)端系统(如手机、电脑)运行传输层协议 发送方:将来自应用层的消息进行封装并向下提交给 网络层接收方:将接收到的Segment进行组装并向上提交给应用层 …...

LangChain构建RAG的对话应用
目录 Langchain是什么? LangSmith是什么? 编辑 使用Python构建并使用AI大模型 数据解析器 提示模版 部署 记忆功能 Chat History -- 记忆 代码执行流程: 流式输出 构建向量数据库和检索器 检索器 代码执行流程 LLM使用检索器…...
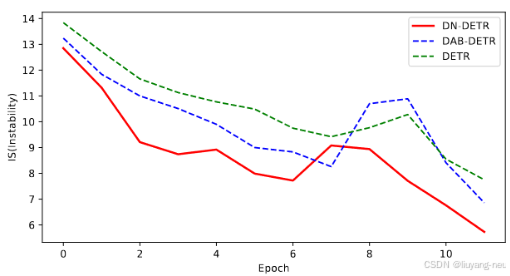
目标检测DN-DETR(2022)详细解读
文章目录 gt labels 和gt boxes加噪query的构造attention maskIS(InStability)指标 在DAB-Detr的基础上,进一步分析了Detr收敛速度慢的原因:二分图匹配的不稳定性(也就是说它的目标在频繁地切换,特别是在训…...
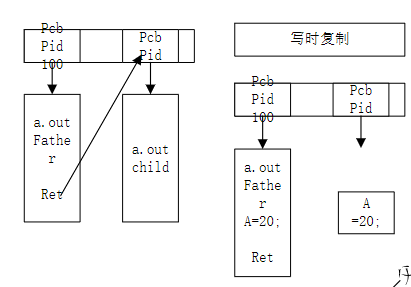
嵌入式培训之系统编程(四)进程
一、进程的基本概念 (一)定义 进程是一个程序执行的过程(也可以说是正在运行的程序),会去分配内存资 源,cpu的调度,它是并发的 (二)PCB块 1、PCB是一个结构体&#x…...
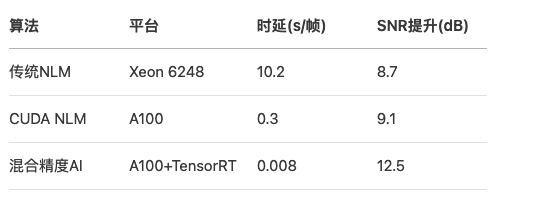
天文数据处理:基于CUDA的射电望远镜图像实时去噪算法(开源FAST望远镜数据处理代码解析)
一、射电天文数据处理的挑战与CUDA加速的必要性 作为全球最大的单口径射电望远镜,中国天眼(FAST)每秒产生38GB原始观测数据,经预处理后生成数千万张图像。这些数据中蕴含的脉冲星、中性氢等天体信号常被高斯白噪声、射频干扰&…...
VS编码访问Mysql数据库
安装 MySQL Connector/C 的开发包 libmysqlcppconn-dev是 MySQL Connector/C 的开发包,它的主要用途是让 C 开发者能够方便地在应用程序中与 MySQL 数据库进行交互。它提供了以下功能: 数据库连接:通过标准的 C 接口连接到 MySQL 数据库。S…...
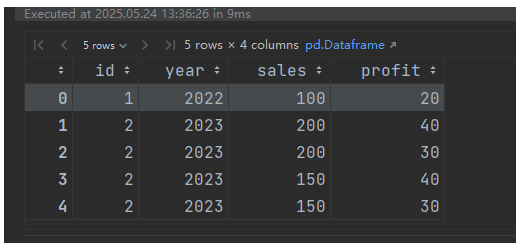
一周学会Pandas2 Python数据处理与分析-Pandas2数据合并与对比-pd.merge():数据库风格合并
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili pd.merge():数据库风格合并 **核心功能**:基于列值(类似 SQL JOIN)合…...

leetcode 862. 和至少为 K 的最短子数组
这段代码使用了前缀和单调队列的组合策略来高效解决"和至少为K的最短子数组"问题。我将从问题定义、核心思路到代码实现逐步拆解: 问题定义 给定数组 nums 和整数 k,找到和 ≥k 的最短非空子数组,返回其长度。 示例:n…...

CodeBuddy 实现图片转素描手绘工具
本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 前言 最近在社交媒体上,各种素描风格的图片火得一塌糊涂,身边不少朋友都在分享自己的 “素描照”,看着那些黑白线条勾勒出的独特韵味&a…...

3.8.2 利用RDD计算总分与平均分
在本次实战中,我们利用Spark的RDD完成了成绩文件的总分与平均分计算任务。首先,准备了包含学生成绩的文件并上传至HDFS。接着,通过交互式方式逐步实现了成绩的读取、解析、总分计算与平均分计算,并最终输出结果。此外,…...

29-FreeRTOS事件标志组
一、概述 事件是一种实现任务间通信的机制,主要用于实现多任务间的同步,但事件通信只能是事件类型的通信,无数据传输。与信号量不同的是,它可以实现一对多,多对多的同步。 即一个任务可以等待多个事件的发生࿱…...
)
天地图实景三维数据分享(江苏)
1、天地图介绍 “天地图”(MAPWORLD)是国家地理信息公共服务平台 ,2011年正式上线 ,是自然资源部门向社会提供各类在线地理信息公共服务、推动地理信息数据开放共享的政府网站 ;是中国区域内基础地理信息数据资源最全…...

Jenkins的Pipline中有哪些区块,以及其它知识点整理
目录 ■模板 ■Jenkins的Pipline中有哪些区块 1. pipeline(顶层区块) 2. agent(执行节点) 3. stages(阶段集合) 4. stage(单个阶段) 5. steps(具体步骤࿰…...
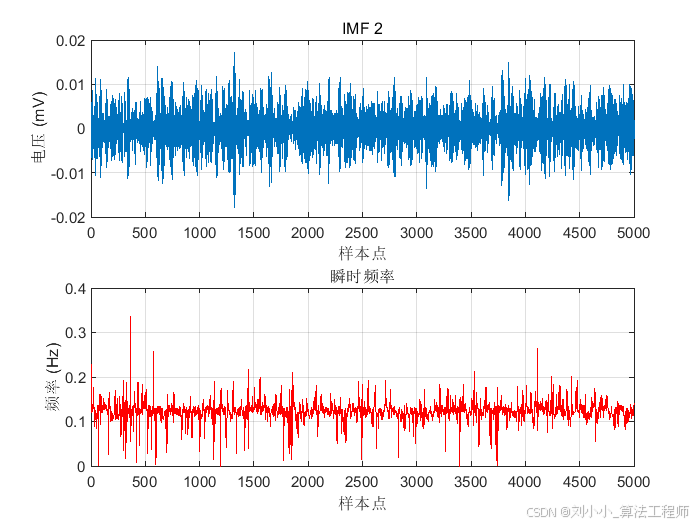
「EMD/EEMD/VMD 信号分解方法 ——ECG信号处理-第十四课」2025年5月23日
一、引言 上一节,我们介绍了希尔伯特黄变换(HHT)及其经验模态分解(EMD)的相关内容,这一节,我们继续拓展EMD分解技术,补充介绍集合经验模态分解(Ensemble Empirical Mode …...
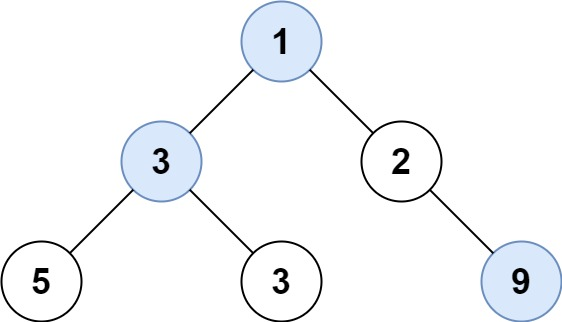
二叉树层序遍历6
INT_MIN的用法: INT_MIN是C/C 中的一个宏常量 ,在 <limits.h> (C 中也可使用 <climits> )头文件中定义,代表 int 类型能表示的最小整数值 。其用法主要体现在以下方面: 1.初始化变量 …...

【论文精读】2023 AAAI--FastRealVSR现实世界视频超分辨率(RealWorld VSR)
文章目录 一、摘要二、Method2.1 现象(问题)--对应文中隐状态的分析(Analysis of Hidden State)2.2 怎么解决 --对应文中Framework2.2.1 整体流程:2.2.2 HSA模块怎么工作?2.2.2.1 隐藏状态池2.2.2.2 选择性…...
IPython 常用魔法命令
文章目录 IPython 魔法命令(Magic Commands)一、系统与文件操作1. %ls2. %cd和%pwd3. %%writefile4. %run 二、性能分析与计时1. %timeit2. %prun3. %%timeit 三、代码处理与交互1. %load2. %edit3. %store 四、调试与诊断2. …...

数据同步自动化——如何用Python打造高效工具?
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...

开源与闭源之争:AI时代的创新博弈与未来抉择
在人工智能技术狂飙突进的今天,开源与闭源之争已不再局限于技术圈的讨论,而是演变为一场关乎技术伦理、商业格局乃至人类文明走向的深度博弈。当Meta的Llama 3开源模型下载量突破百万,当OpenAI的GPT-5继续加固技术壁垒,这场没有硝…...

flutter dart class语法说明、示例
🔹 Dart 中的 class 基本语法 class ClassName {// 属性(字段)数据类型 属性名;// 构造函数ClassName(this.属性名);// 方法返回类型 方法名() {// 方法体} }✅ 示例:创建一个简单的 Person 类 class Person {// 属性String name;…...
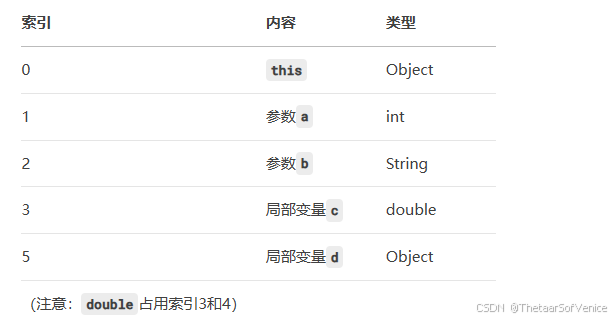
Java虚拟机 - 程序计数器和虚拟机栈
运行时数据结构 Java运行时数据区程序计数器为什么需要程序计数器执行流程虚拟机栈虚拟机栈作用虚拟机栈核心结构运行机制 Java运行时数据区 首先介绍Java运行时数据之前,我们要了解,对于计算机来说,内存是非常重要的资源,因为内…...
)
SpringMVC04所有注解按照使用位置划分| 按照使用层级划分(业务层、视图层、控制层)
目录 一、所有注解按照使用位置划分(类、方法、参数) 1. 类级别注解 2. 方法级别注解 3. 参数级别注解 4. 字段/返回值注解 二、按照使用层级划分(业务层、视图层、控制层) 1、控制层(Controller Layer&#x…...

新能源汽车产业链图谱分析
1. 产业定义 新能源汽车是指采用非常规的车用燃料作为动力来源,综合车辆的动力控制和驱动方面的先进技术,形成的具有新技术、新结构、技术原理先进的汽车。 新能源车包括四大类型:混合动力电动汽车(HEV)、纯电动汽车…...
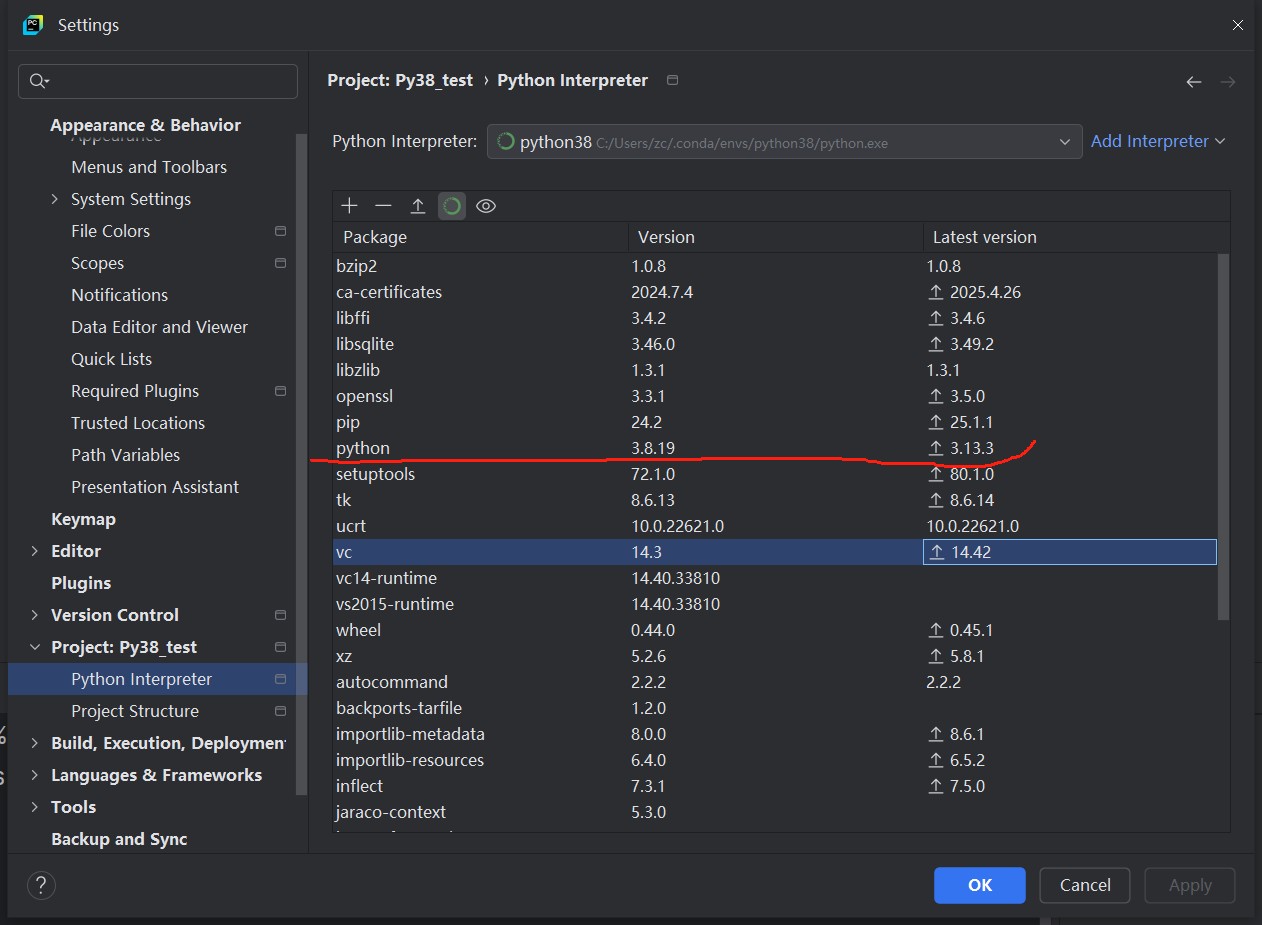
如何在PyCharm2025中设置conda的多个Python版本
前言 体验的最新版本的PyCharm(Community)2025.1.1,发现和以前的版本有所不同。特别是使用Anaconda中的多个版本的Python的时候。 关于基于Anaconda中多个Python版本的使用,以及对应的Pycharm(2023版)的使用,可以参考…...
算法详解:图解+代码+经典例题)
005 深度优先搜索(DFS)算法详解:图解+代码+经典例题
📌 什么是深度优先搜索? 深度优先搜索(Depth-First Search,DFS)是算法竞赛和面试中最高频的暴力搜索算法之一。其核心思想是“一条路走到黑”,从起点出发,优先探索最深的节点,直到无…...