【算法】力扣体系分类
第一章 算法基础题型
1.1 排序算法题
1.1.1 冒泡排序相关题
冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
常见题型
- 数组排序:给定一个无序数组,使用冒泡排序将其按升序或降序排列。例如,对于数组
[5, 3, 8, 4, 2],经过冒泡排序后变为[2, 3, 4, 5, 8]。 - 排序过程模拟:要求写出冒泡排序每一轮的具体交换过程,帮助理解算法的执行步骤。
示例代码(Python)
def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n - i - 1):if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]return arrarr = [5, 3, 8, 4, 2]
print(bubble_sort(arr)) # 输出: [2, 3, 4, 5, 8]
1.1.2 选择排序相关题
选择排序是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到全部待排序的数据元素排完。
常见题型
- 数组排序:和冒泡排序类似,给定无序数组,用选择排序进行排序。
- 优化选择排序:在基本选择排序的基础上,考虑如何减少比较次数或交换次数。
示例代码(Python)
def selection_sort(arr):n = len(arr)for i in range(n):min_idx = ifor j in range(i + 1, n):if arr[j] < arr[min_idx]:min_idx = jarr[i], arr[min_idx] = arr[min_idx], arr[i]return arrarr = [5, 3, 8, 4, 2]
print(selection_sort(arr)) # 输出: [2, 3, 4, 5, 8]
1.1.3 插入排序相关题
插入排序是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
常见题型
- 数组排序:对给定数组使用插入排序进行排序。
- 部分有序数组排序:如果数组已经部分有序,插入排序的效率会更高,可针对这种情况出题。
示例代码(Python)
def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i - 1while j >= 0 and key < arr[j]:arr[j + 1] = arr[j]j -= 1arr[j + 1] = keyreturn arrarr = [5, 3, 8, 4, 2]
print(insertion_sort(arr)) # 输出: [2, 3, 4, 5, 8]
1.1.4 快速排序相关题
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
常见题型
- 数组排序:用快速排序对数组进行排序。
- 快速排序的优化:如随机选择基准元素,避免最坏情况的发生。
示例代码(Python)
def quick_sort(arr):if len(arr) <= 1:return arrelse:pivot = arr[0]left = [x for x in arr[1:] if x <= pivot]right = [x for x in arr[1:] if x > pivot]return quick_sort(left) + [pivot] + quick_sort(right)arr = [5, 3, 8, 4, 2]
print(quick_sort(arr)) # 输出: [2, 3, 4, 5, 8]
1.1.5 归并排序相关题
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
常见题型
- 数组排序:使用归并排序对数组进行排序。
- 链表排序:归并排序也适用于链表,可出相关题目。
示例代码(Python)
def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):result = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])j += 1result.extend(left[i:])result.extend(right[j:])return resultarr = [5, 3, 8, 4, 2]
print(merge_sort(arr)) # 输出: [2, 3, 4, 5, 8]
1.1.6 堆排序相关题
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
常见题型
- 数组排序:使用堆排序对数组进行排序。
- 堆的构建和调整:考察对堆的基本操作,如构建最大堆或最小堆。
示例代码(Python)
def heapify(arr, n, i):largest = il = 2 * i + 1r = 2 * i + 2if l < n and arr[i] < arr[l]:largest = lif r < n and arr[largest] < arr[r]:largest = rif largest != i:arr[i], arr[largest] = arr[largest], arr[i]heapify(arr, n, largest)def heap_sort(arr):n = len(arr)for i in range(n // 2 - 1, -1, -1):heapify(arr, n, i)for i in range(n - 1, 0, -1):arr[i], arr[0] = arr[0], arr[i]heapify(arr, i, 0)return arrarr = [5, 3, 8, 4, 2]
print(heap_sort(arr)) # 输出: [2, 3, 4, 5, 8]
1.2 搜索算法题
1.2.1 线性搜索相关题
线性搜索是一种在数组中查找特定元素的简单方法。它从数组的第一个元素开始,逐个检查每个元素,直到找到目标元素或遍历完整个数组。
常见题型
- 查找元素位置:给定一个数组和一个目标值,找出目标值在数组中的位置。
- 判断元素是否存在:判断数组中是否存在某个元素。
示例代码(Python)
def linear_search(arr, target):for i in range(len(arr)):if arr[i] == target:return ireturn -1arr = [5, 3, 8, 4, 2]
target = 8
print(linear_search(arr, target)) # 输出: 2
1.2.2 二分搜索相关题
二分搜索是一种在有序数组中查找特定元素的高效算法。它每次将搜索范围缩小一半,直到找到目标元素或确定目标元素不存在。
常见题型
- 查找元素位置:在有序数组中查找目标元素的位置。
- 查找第一个或最后一个出现的位置:对于有重复元素的有序数组,查找目标元素第一次或最后一次出现的位置。
示例代码(Python)
def binary_search(arr, target):left, right = 0, len(arr) - 1while left <= right:mid = (left + right) // 2if arr[mid] == target:return midelif arr[mid] < target:left = mid + 1else:right = mid - 1return -1arr = [2, 3, 4, 5, 8]
target = 5
print(binary_search(arr, target)) # 输出: 3
1.2.3 广度优先搜索(BFS)相关题
广度优先搜索是一种用于遍历或搜索树或图的算法。它从根节点开始,逐层地访问节点,直到找到目标节点或遍历完整个图。
常见题型
- 最短路径问题:在图中找到从起点到终点的最短路径。
- 层序遍历:对树进行层序遍历。
示例代码(Python,图的 BFS)
from collections import dequegraph = {'A': ['B', 'C'],'B': ['A', 'D', 'E'],'C': ['A', 'F'],'D': ['B'],'E': ['B', 'F'],'F': ['C', 'E']
}def bfs(graph, start):visited = set()queue = deque([start])visited.add(start)while queue:vertex = queue.popleft()print(vertex, end=" ")for neighbor in graph[vertex]:if neighbor not in visited:queue.append(neighbor)visited.add(neighbor)bfs(graph, 'A') # 输出: A B C D E F
1.2.4 深度优先搜索(DFS)相关题
深度优先搜索是一种用于遍历或搜索树或图的算法。它沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。
常见题型
- 路径查找:在图中找到从起点到终点的一条路径。
- 连通分量:找出图中的所有连通分量。
示例代码(Python,图的 DFS)
graph = {'A': ['B', 'C'],'B': ['A', 'D', 'E'],'C': ['A', 'F'],'D': ['B'],'E': ['B', 'F'],'F': ['C', 'E']
}def dfs(graph, start, visited=None):if visited is None:visited = set()if start not in visited:print(start, end=" ")visited.add(start)for neighbor in graph[start]:dfs(graph, neighbor, visited)dfs(graph, 'A') # 输出: A B D E F C
1.3 哈希表相关题
1.3.1 哈希表基础应用
哈希表是根据键(Key)而直接访问在内存存储位置的数据结构。它通过哈希函数将键映射到存储桶中,从而实现快速的插入、查找和删除操作。
常见题型
- 统计元素频率:给定一个数组,统计每个元素出现的次数。
- 查找重复元素:找出数组中重复出现的元素。
示例代码(Python)
arr = [1, 2, 3, 2, 4, 3, 5]
frequency = {}
for num in arr:if num in frequency:frequency[num] += 1else:frequency[num] = 1
print(frequency) # 输出: {1: 1, 2: 2, 3: 2, 4: 1, 5: 1}
1.3.2 哈希表解决重复元素问题
哈希表可以高效地解决重复元素问题,因为它可以快速判断一个元素是否已经存在。
常见题型
- 去重:去除数组中的重复元素。
- 判断数组是否有重复元素:判断数组中是否存在重复的元素。
示例代码(Python)
arr = [1, 2, 3, 2, 4, 3, 5]
unique_arr = []
seen = set()
for num in arr:if num not in seen:unique_arr.append(num)seen.add(num)
print(unique_arr) # 输出: [1, 2, 3, 4, 5]
1.3.3 哈希表与其他数据结构结合
哈希表可以与其他数据结构(如链表、栈、队列等)结合使用,以解决更复杂的问题。
常见题型
- LRU 缓存:实现一个最近最少使用(LRU)缓存,使用哈希表和双向链表。
- 分组问题:根据元素的某个属性将元素分组。
1.4 双指针相关题
1.4.1 对撞指针相关题
对撞指针是指在数组或链表中,使用两个指针分别从两端向中间移动,直到两个指针相遇。
常见题型
- 两数之和:在有序数组中找到两个数,使得它们的和等于目标值。
- 反转数组:使用对撞指针反转数组。
示例代码(Python,两数之和)
arr = [2, 3, 4, 5, 8]
target = 7
left, right = 0, len(arr) - 1
while left < right:current_sum = arr[left] + arr[right]if current_sum == target:print(left, right) # 输出: 0 3breakelif current_sum < target:left += 1else:right -= 1
1.4.2 快慢指针相关题
快慢指针是指在数组或链表中,使用两个指针,一个指针移动速度快,一个指针移动速度慢。
常见题型
- 链表中环的检测:判断链表中是否存在环。
- 寻找链表的中间节点:使用快慢指针找到链表的中间节点。
示例代码(Python,链表中环的检测)
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = next# 创建一个有环的链表
head = ListNode(1)
node2 = ListNode(2)
node3 = ListNode(3)
node4 = ListNode(4)
head.next = node2
node2.next = node3
node3.next = node4
node4.next = node2 # 形成环slow = fast = head
while fast and fast.next:slow = slow.nextfast = fast.next.nextif slow == fast:print("链表中存在环")break
1.4.3 滑动窗口相关题
滑动窗口是一种常用的算法技巧,用于解决数组或字符串中的子数组或子串问题。
常见题型
- 最大子数组和:找到数组中连续子数组的最大和。
- 无重复字符的最长子串:找到字符串中无重复字符的最长子串。
示例代码(Python,最大子数组和)
arr = [-2, 1, -3, 4, -1, 2, 1, -5, 4]
max_sum = float('-inf')
current_sum = 0
for num in arr:current_sum = max(num, current_sum + num)max_sum = max(max_sum, current_sum)
print(max_sum) # 输出: 6
第二章 数据结构题型
2.1 数组与字符串题
2.1.1 数组基础操作题
数组是一种基本的数据结构,它由相同类型的元素组成,并且这些元素在内存中是连续存储的。数组的基础操作题主要涉及以下几个方面:
1. 数组的创建与初始化
- 静态初始化:在创建数组时直接指定元素的值。例如在 Java 中:
int[] arr = {1, 2, 3, 4, 5};
- 动态初始化:先指定数组的长度,然后再为元素赋值。例如在 Python 中:
arr = [0] * 5 # 创建一个长度为 5 的数组,初始值都为 0
2. 元素的访问与修改
- 访问元素:通过数组的索引来访问元素,索引从 0 开始。例如在 C++ 中:
#include <iostream>
int main() {int arr[5] = {1, 2, 3, 4, 5};std::cout << arr[2] << std::endl; // 输出第 3 个元素,结果为 3return 0;
}
- 修改元素:同样通过索引来修改数组中的元素。例如在 JavaScript 中:
let arr = [1, 2, 3, 4, 5];
arr[2] = 10; // 将第 3 个元素修改为 10
console.log(arr);
3. 数组的遍历
- for 循环遍历:这是最常见的遍历方式。例如在 Java 中:
int[] arr = {1, 2, 3, 4, 5};
for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");
}
- 增强 for 循环遍历:在 Java 中可以使用增强 for 循环更简洁地遍历数组。
int[] arr = {1, 2, 3, 4, 5};
for (int num : arr) {System.out.print(num + " ");
}
2.1.2 二维数组相关题
二维数组可以看作是数组的数组,它在处理矩阵、表格等数据时非常有用。二维数组相关题主要有以下几种:
1. 二维数组的创建与初始化
- 静态初始化:在 Java 中可以这样创建二维数组:
int[][] arr = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};
- 动态初始化:先指定二维数组的行数和列数,然后再为元素赋值。例如在 Python 中:
rows = 3
cols = 3
arr = [[0 for _ in range(cols)] for _ in range(rows)]
2. 二维数组的访问与修改
- 访问二维数组的元素需要使用两个索引,第一个索引表示行,第二个索引表示列。例如在 C++ 中:
#include <iostream>
int main() {int arr[3][3] = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};std::cout << arr[1][2] << std::endl; // 输出第 2 行第 3 列的元素,结果为 6return 0;
}
- 修改元素的方式与访问类似,通过两个索引来定位元素并修改。例如在 JavaScript 中:
let arr = [[1, 2, 3], [4, 5, 6], [7, 8, 9]];
arr[1][2] = 10; // 将第 2 行第 3 列的元素修改为 10
console.log(arr);
3. 二维数组的遍历
- 嵌套 for 循环遍历:这是最常用的遍历二维数组的方式。例如在 Java 中:
int[][] arr = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};
for (int i = 0; i < arr.length; i++) {for (int j = 0; j < arr[i].length; j++) {System.out.print(arr[i][j] + " ");}System.out.println();
}
2.1.3 字符串匹配题
字符串匹配题主要是在一个主字符串中查找一个子字符串是否存在,以及它的位置。常见的算法有以下几种:
1. 暴力匹配算法
- 暴力匹配算法的基本思想是从主字符串的第一个字符开始,依次与子字符串的字符进行比较,如果匹配失败则主字符串的指针向后移动一位,重新开始比较。例如在 Python 中实现:
def brute_force_search(text, pattern):n = len(text)m = len(pattern)for i in range(n - m + 1):j = 0while j < m:if text[i + j] != pattern[j]:breakj += 1if j == m:return ireturn -1text = "abcabcabd"
pattern = "abcabd"
result = brute_force_search(text, pattern)
print(result)
2. KMP 算法
- KMP 算法(Knuth-Morris-Pratt 算法)是一种高效的字符串匹配算法,它通过预处理子字符串,利用已经匹配的部分信息,避免了不必要的回溯。KMP 算法的时间复杂度为 O ( n + m ) O(n + m) O(n+m),其中 n n n 是主字符串的长度, m m m 是子字符串的长度。
2.1.4 字符串编码与解码题
字符串编码与解码题主要涉及将字符串按照一定的规则进行编码,以及将编码后的字符串解码还原成原始字符串。常见的编码方式有以下几种:
1. 简单的替换编码
- 例如将字符串中的每个字符替换为它的 ASCII 码加 1 的字符。在 Python 中实现如下:
def encode_string(s):encoded = ""for char in s:encoded += chr(ord(char) + 1)return encodeddef decode_string(s):decoded = ""for char in s:decoded += chr(ord(char) - 1)return decodeds = "abc"
encoded = encode_string(s)
decoded = decode_string(encoded)
print(encoded)
print(decoded)
2. Base64 编码与解码
- Base64 是一种常用的编码方式,它将二进制数据转换为可打印的 ASCII 字符。在 Python 中可以使用
base64模块进行编码和解码:
import base64s = "abc"
encoded = base64.b64encode(s.encode())
decoded = base64.b64decode(encoded).decode()
print(encoded)
print(decoded)
2.2 链表题
2.2.1 单链表操作题
单链表是一种常见的数据结构,它由一个个节点组成,每个节点包含一个数据域和一个指向下一个节点的指针。单链表的操作题主要有以下几种:
1. 单链表的创建
- 可以通过逐个创建节点并连接它们来创建单链表。例如在 Python 中:
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = next# 创建一个单链表 1 -> 2 -> 3
head = ListNode(1)
head.next = ListNode(2)
head.next.next = ListNode(3)
2. 单链表的插入操作
- 在单链表的头部插入节点:
def insert_at_head(head, val):new_node = ListNode(val)new_node.next = headreturn new_node
- 在单链表的尾部插入节点:
def insert_at_tail(head, val):new_node = ListNode(val)if not head:return new_nodecurrent = headwhile current.next:current = current.nextcurrent.next = new_nodereturn head
3. 单链表的删除操作
- 删除单链表的头部节点:
def delete_at_head(head):if not head:return Nonereturn head.next
- 删除单链表中值为指定值的节点:
def delete_node(head, val):dummy = ListNode(0)dummy.next = headcurrent = dummywhile current.next:if current.next.val == val:current.next = current.next.nextelse:current = current.nextreturn dummy.next
2.2.2 双链表操作题
双链表与单链表类似,但每个节点除了指向下一个节点的指针外,还包含一个指向前一个节点的指针。双链表的操作题主要有以下几种:
1. 双链表的创建
- 双链表的节点类可以定义如下:
class DoublyListNode:def __init__(self, val=0, prev=None, next=None):self.val = valself.prev = prevself.next = next# 创建一个双链表 1 <-> 2 <-> 3
head = DoublyListNode(1)
node2 = DoublyListNode(2)
node3 = DoublyListNode(3)head.next = node2
node2.prev = head
node2.next = node3
node3.prev = node2
2. 双链表的插入操作
- 在双链表的头部插入节点:
def insert_at_head(head, val):new_node = DoublyListNode(val)if not head:return new_nodenew_node.next = headhead.prev = new_nodereturn new_node
- 在双链表的尾部插入节点:
def insert_at_tail(head, val):new_node = DoublyListNode(val)if not head:return new_nodecurrent = headwhile current.next:current = current.nextcurrent.next = new_nodenew_node.prev = currentreturn head
3. 双链表的删除操作
- 删除双链表的头部节点:
def delete_at_head(head):if not head:return Noneif head.next:head.next.prev = Nonereturn head.next
- 删除双链表中值为指定值的节点:
def delete_node(head, val):current = headwhile current:if current.val == val:if current.prev:current.prev.next = current.nextif current.next:current.next.prev = current.previf current == head:head = current.nextbreakcurrent = current.nextreturn head
2.2.3 环形链表相关题
环形链表是指链表的尾节点指向链表中的某个节点,形成一个环。环形链表相关题主要有以下几种:
1. 判断链表是否为环形链表
- 可以使用快慢指针的方法来判断链表是否为环形链表。快指针每次移动两步,慢指针每次移动一步,如果快指针追上了慢指针,则说明链表是环形链表。例如在 Python 中实现:
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextdef has_cycle(head):slow = headfast = headwhile fast and fast.next:slow = slow.nextfast = fast.next.nextif slow == fast:return Truereturn False
2. 找到环形链表的入口节点
- 同样可以使用快慢指针的方法,当快慢指针相遇后,将其中一个指针重新指向链表的头节点,然后两个指针都以每次一步的速度移动,它们再次相遇的节点就是环形链表的入口节点。例如在 Python 中实现:
def detect_cycle(head):slow = headfast = headhas_cycle = Falsewhile fast and fast.next:slow = slow.nextfast = fast.next.nextif slow == fast:has_cycle = Truebreakif not has_cycle:return Noneslow = headwhile slow != fast:slow = slow.nextfast = fast.nextreturn slow
2.2.4 链表排序与合并题
1. 链表排序
- 可以使用归并排序的方法对链表进行排序。归并排序的时间复杂度为 O ( n l o g n ) O(n log n) O(nlogn)。例如在 Python 中实现:
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextdef merge_sort(head):if not head or not head.next:return head# 找到链表的中间节点slow = headfast = head.nextwhile fast and fast.next:slow = slow.nextfast = fast.next.nextmid = slow.nextslow.next = None# 递归地对左右两部分进行排序left = merge_sort(head)right = merge_sort(mid)# 合并两个有序链表return merge(left, right)def merge(left, right):dummy = ListNode(0)current = dummywhile left and right:if left.val < right.val:current.next = leftleft = left.nextelse:current.next = rightright = right.nextcurrent = current.nextif left:current.next = leftif right:current.next = rightreturn dummy.next
2. 链表合并
- 合并两个有序链表是一个常见的问题。可以使用递归或迭代的方法来实现。例如在 Python 中使用迭代的方法实现:
def merge_two_lists(l1, l2):dummy = ListNode(0)current = dummywhile l1 and l2:if l1.val < l2.val:current.next = l1l1 = l1.nextelse:current.next = l2l2 = l2.nextcurrent = current.nextif l1:current.next = l1if l2:current.next = l2return dummy.next
2.3 栈与队列题
2.3.1 栈的基本应用题
栈是一种后进先出(LIFO)的数据结构,它的基本操作有入栈(push)和出栈(pop)。栈的基本应用题主要有以下几种:
1. 括号匹配问题
- 可以使用栈来解决括号匹配问题。遍历字符串,遇到左括号时将其入栈,遇到右括号时从栈中弹出一个左括号进行匹配。例如在 Python 中实现:
def is_valid(s):stack = []mapping = {")": "(", "]": "[", "}": "{"}for char in s:if char in mapping:top_element = stack.pop() if stack else '#'if mapping[char] != top_element:return Falseelse:stack.append(char)return not stack
2. 后缀表达式求值
- 后缀表达式(逆波兰表达式)是一种将运算符放在操作数后面的表达式。可以使用栈来计算后缀表达式的值。例如在 Python 中实现:
def eval_rpn(tokens):stack = []for token in tokens:if token in ['+', '-', '*', '/']:right_operand = stack.pop()left_operand = stack.pop()if token == '+':result = left_operand + right_operandelif token == '-':result = left_operand - right_operandelif token == '*':result = left_operand * right_operandelse:result = int(left_operand / right_operand)stack.append(result)else:stack.append(int(token))return stack.pop()
2.3.2 队列的基本应用题
队列是一种先进先出(FIFO)的数据结构,它的基本操作有入队(enqueue)和出队(dequeue)。队列的基本应用题主要有以下几种:
1. 广度优先搜索(BFS)
- 广度优先搜索是一种用于遍历或搜索树或图的算法,它使用队列来实现。例如在 Python 中实现图的广度优先搜索:
from collections import dequedef bfs(graph, start):visited = set()queue = deque([start])visited.add(start)while queue:vertex = queue.popleft()print(vertex, end=" ")for neighbor in graph[vertex]:
# 第三章 动态规划题型动态规划(Dynamic Programming,简称 DP)是一种通过把原问题分解为相对简单的子问题,并保存子问题的解来避免重复计算,从而解决复杂问题的方法。下面我们来详细介绍不同类型的动态规划题型。## 3.1 基础动态规划题### 3.1.1 斐波那契数列相关题斐波那契数列是一个经典的数列,其定义为:$F(0) = 0$,$F(1) = 1$,$F(n) = F(n - 1) + F(n - 2)$($n \geq 2$)。也就是说,从第三项开始,每一项都等于前两项之和。数列形式为:$0, 1, 1, 2, 3, 5, 8, 13, 21, 34, \cdots$**问题描述**:通常会要求计算斐波那契数列的第 $n$ 项的值。**解题思路**:
- **递归方法**:根据斐波那契数列的定义,直接使用递归函数来计算。但这种方法会有大量的重复计算,时间复杂度为 $O(2^n)$,效率较低。示例代码(Python)如下:
```python
def fibonacci_recursive(n):if n == 0:return 0elif n == 1:return 1else:return fibonacci_recursive(n - 1) + fibonacci_recursive(n - 2)
- 动态规划方法:使用一个数组来保存中间结果,避免重复计算,时间复杂度为 O ( n ) O(n) O(n)。示例代码(Python)如下:
def fibonacci_dp(n):if n == 0:return 0elif n == 1:return 1dp = [0] * (n + 1)dp[0] = 0dp[1] = 1for i in range(2, n + 1):dp[i] = dp[i - 1] + dp[i - 2]return dp[n]
3.1.2 爬楼梯问题
问题描述:假设你正在爬楼梯,需要 n n n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
解题思路:
- 设 d p [ i ] dp[i] dp[i] 表示爬到第 i i i 阶楼梯的方法数。
- 对于第 i i i 阶楼梯,你可以从第 i − 1 i - 1 i−1 阶爬 1 个台阶到达,也可以从第 i − 2 i - 2 i−2 阶爬 2 个台阶到达。所以状态转移方程为 d p [ i ] = d p [ i − 1 ] + d p [ i − 2 ] dp[i] = dp[i - 1] + dp[i - 2] dp[i]=dp[i−1]+dp[i−2]。
- 边界条件: d p [ 1 ] = 1 dp[1] = 1 dp[1]=1(只有一种方法,爬 1 个台阶), d p [ 2 ] = 2 dp[2] = 2 dp[2]=2(可以一次爬 2 个台阶,也可以分两次每次爬 1 个台阶)。
示例代码(Python)如下:
def climb_stairs(n):if n == 1:return 1elif n == 2:return 2dp = [0] * (n + 1)dp[1] = 1dp[2] = 2for i in range(3, n + 1):dp[i] = dp[i - 1] + dp[i - 2]return dp[n]
3.1.3 背包问题(0 - 1 背包、完全背包)
0 - 1 背包问题
问题描述:有 n n n 个物品和一个容量为 W W W 的背包,每个物品有自己的重量 w i w_i wi 和价值 v i v_i vi。对于每个物品,你只能选择放入背包或者不放入(即 0 - 1 选择),问如何选择物品,使得背包中物品的总价值最大。
解题思路:
- 设 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示前 i i i 个物品放入容量为 j j j 的背包中所能获得的最大价值。
- 状态转移方程:
- 当 j < w i j < w_i j<wi 时(当前背包容量不足以放入第 i i i 个物品), d p [ i ] [ j ] = d p [ i − 1 ] [ j ] dp[i][j] = dp[i - 1][j] dp[i][j]=dp[i−1][j]。
- 当 j ≥ w i j \geq w_i j≥wi 时(可以选择放入或不放入第 i i i 个物品), d p [ i ] [ j ] = max ( d p [ i − 1 ] [ j ] , d p [ i − 1 ] [ j − w i ] + v i ) dp[i][j] = \max(dp[i - 1][j], dp[i - 1][j - w_i] + v_i) dp[i][j]=max(dp[i−1][j],dp[i−1][j−wi]+vi)。
示例代码(Python)如下:
def knapsack_01(weights, values, capacity):n = len(weights)dp = [[0] * (capacity + 1) for _ in range(n + 1)]for i in range(1, n + 1):for j in range(1, capacity + 1):if j < weights[i - 1]:dp[i][j] = dp[i - 1][j]else:dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weights[i - 1]] + values[i - 1])return dp[n][capacity]
完全背包问题
问题描述:与 0 - 1 背包问题类似,不同之处在于每个物品可以选择无限次放入背包。
解题思路:
- 设 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示前 i i i 个物品放入容量为 j j j 的背包中所能获得的最大价值。
- 状态转移方程:
- 当 j < w i j < w_i j<wi 时, d p [ i ] [ j ] = d p [ i − 1 ] [ j ] dp[i][j] = dp[i - 1][j] dp[i][j]=dp[i−1][j]。
- 当 j ≥ w i j \geq w_i j≥wi 时, d p [ i ] [ j ] = max ( d p [ i − 1 ] [ j ] , d p [ i ] [ j − w i ] + v i ) dp[i][j] = \max(dp[i - 1][j], dp[i][j - w_i] + v_i) dp[i][j]=max(dp[i−1][j],dp[i][j−wi]+vi)。
示例代码(Python)如下:
def knapsack_complete(weights, values, capacity):n = len(weights)dp = [[0] * (capacity + 1) for _ in range(n + 1)]for i in range(1, n + 1):for j in range(1, capacity + 1):if j < weights[i - 1]:dp[i][j] = dp[i - 1][j]else:dp[i][j] = max(dp[i - 1][j], dp[i][j - weights[i - 1]] + values[i - 1])return dp[n][capacity]
3.2 状态压缩动态规划题
3.2.1 棋盘问题
问题描述:在一个 m × n m \times n m×n 的棋盘上,每个格子有一个非负整数的权值。从棋盘的左上角 ( 0 , 0 ) (0, 0) (0,0) 出发,每次只能向下或向右移动一步,到达棋盘的右下角 ( m − 1 , n − 1 ) (m - 1, n - 1) (m−1,n−1)。问路径上经过的格子的权值之和的最小值是多少。
解题思路:
- 设 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示到达第 i i i 行第 j j j 列格子的最小权值和。
- 状态转移方程:
- 当 i = 0 i = 0 i=0 且 j = 0 j = 0 j=0 时, d p [ 0 ] [ 0 ] = g r i d [ 0 ] [ 0 ] dp[0][0] = grid[0][0] dp[0][0]=grid[0][0]。
- 当 i = 0 i = 0 i=0 时, d p [ 0 ] [ j ] = d p [ 0 ] [ j − 1 ] + g r i d [ 0 ] [ j ] dp[0][j] = dp[0][j - 1] + grid[0][j] dp[0][j]=dp[0][j−1]+grid[0][j]。
- 当 j = 0 j = 0 j=0 时, d p [ i ] [ 0 ] = d p [ i − 1 ] [ 0 ] + g r i d [ i ] [ 0 ] dp[i][0] = dp[i - 1][0] + grid[i][0] dp[i][0]=dp[i−1][0]+grid[i][0]。
- 当 i > 0 i > 0 i>0 且 j > 0 j > 0 j>0 时, d p [ i ] [ j ] = min ( d p [ i − 1 ] [ j ] , d p [ i ] [ j − 1 ] ) + g r i d [ i ] [ j ] dp[i][j] = \min(dp[i - 1][j], dp[i][j - 1]) + grid[i][j] dp[i][j]=min(dp[i−1][j],dp[i][j−1])+grid[i][j]。
可以使用状态压缩的方法,将二维数组 d p dp dp 压缩为一维数组,因为在计算 d p [ i ] [ j ] dp[i][j] dp[i][j] 时,只需要用到 d p [ i − 1 ] [ j ] dp[i - 1][j] dp[i−1][j] 和 d p [ i ] [ j − 1 ] dp[i][j - 1] dp[i][j−1] 的值。
示例代码(Python)如下:
def min_path_sum(grid):m = len(grid)n = len(grid[0])dp = [0] * ndp[0] = grid[0][0]for j in range(1, n):dp[j] = dp[j - 1] + grid[0][j]for i in range(1, m):dp[0] += grid[i][0]for j in range(1, n):dp[j] = min(dp[j], dp[j - 1]) + grid[i][j]return dp[n - 1]
3.2.2 子集问题
问题描述:给定一个整数数组 n u m s nums nums,问是否存在一个子集,使得子集中元素的和等于给定的目标值 t a r g e t target target。
解题思路:
- 设 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示前 i i i 个元素中是否存在一个子集,其和等于 j j j。
- 状态转移方程:
- 当 j = 0 j = 0 j=0 时, d p [ i ] [ 0 ] = T r u e dp[i][0] = True dp[i][0]=True(空子集的和为 0)。
- 当 i = 0 i = 0 i=0 且 j > 0 j > 0 j>0 时, d p [ 0 ] [ j ] = F a l s e dp[0][j] = False dp[0][j]=False。
- 当 j < n u m s [ i − 1 ] j < nums[i - 1] j<nums[i−1] 时, d p [ i ] [ j ] = d p [ i − 1 ] [ j ] dp[i][j] = dp[i - 1][j] dp[i][j]=dp[i−1][j]。
- 当 j ≥ n u m s [ i − 1 ] j \geq nums[i - 1] j≥nums[i−1] 时, d p [ i ] [ j ] = d p [ i − 1 ] [ j ] or d p [ i − 1 ] [ j − n u m s [ i − 1 ] ] dp[i][j] = dp[i - 1][j] \text{ or } dp[i - 1][j - nums[i - 1]] dp[i][j]=dp[i−1][j] or dp[i−1][j−nums[i−1]]。
同样可以使用状态压缩的方法,将二维数组 d p dp dp 压缩为一维数组。
示例代码(Python)如下:
def subset_sum(nums, target):n = len(nums)dp = [False] * (target + 1)dp[0] = Truefor num in nums:for j in range(target, num - 1, -1):dp[j] = dp[j] or dp[j - num]return dp[target]
3.3 区间动态规划题
3.3.1 最长回文子串问题
问题描述:给定一个字符串 s s s,找出 s s s 中最长的回文子串。
解题思路:
- 设 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示字符串 s s s 中从第 i i i 个字符到第 j j j 个字符的子串是否为回文串。
- 状态转移方程:
- 当 i = j i = j i=j 时, d p [ i ] [ j ] = T r u e dp[i][j] = True dp[i][j]=True(单个字符是回文串)。
- 当 j − i = 1 j - i = 1 j−i=1 时, d p [ i ] [ j ] = ( s [ i ] = = s [ j ] ) dp[i][j] = (s[i] == s[j]) dp[i][j]=(s[i]==s[j])(两个字符是否相等)。
- 当 j − i > 1 j - i > 1 j−i>1 时, d p [ i ] [ j ] = ( s [ i ] = = s [ j ] ) and d p [ i + 1 ] [ j − 1 ] dp[i][j] = (s[i] == s[j]) \text{ and } dp[i + 1][j - 1] dp[i][j]=(s[i]==s[j]) and dp[i+1][j−1]。
在遍历过程中,记录最长回文子串的长度和起始位置。
示例代码(Python)如下:
def longest_palindrome(s):n = len(s)if n < 2:return sdp = [[False] * n for _ in range(n)]start = 0max_len = 1for j in range(n):for i in range(j + 1):if j - i < 2:dp[i][j] = (s[i] == s[j])else:dp[i][j] = (s[i] == s[j]) and dp[i + 1][j - 1]if dp[i][j] and j - i + 1 > max_len:max_len = j - i + 1start = ireturn s[start:start + max_len]
3.3.2 矩阵链乘法问题
问题描述:给定 n n n 个矩阵 A 1 , A 2 , ⋯ , A n A_1, A_2, \cdots, A_n A1,A2,⋯,An,其中 A i A_i Ai 的维度为 p i − 1 × p i p_{i - 1} \times p_i pi−1×pi。问如何给矩阵链加上括号,使得矩阵乘法的总标量乘法次数最少。
解题思路:
- 设 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示矩阵链 A i A i + 1 ⋯ A j A_i A_{i + 1} \cdots A_j AiAi+1⋯Aj 的最少标量乘法次数。
- 状态转移方程:
- 当 i = j i = j i=j 时, d p [ i ] [ j ] = 0 dp[i][j] = 0 dp[i][j]=0(单个矩阵不需要乘法)。
- 当 i < j i < j i<j 时, d p [ i ] [ j ] = min i ≤ k < j { d p [ i ] [ k ] + d p [ k + 1 ] [ j ] + p i − 1 p k p j } dp[i][j] = \min_{i \leq k < j} \{dp[i][k] + dp[k + 1][j] + p_{i - 1} p_k p_j\} dp[i][j]=mini≤k<j{dp[i][k]+dp[k+1][j]+pi−1pkpj}。
示例代码(Python)如下:
def matrix_chain_order(p):n = len(p) - 1dp = [[0] * n for _ in range(n)]for l in range(2, n + 1):for i in range(n - l + 1):j = i + l - 1dp[i][j] = float('inf')for k in range(i, j):q = dp[i][k] + dp[k + 1][j] + p[i] * p[k + 1] * p[j + 1]if q < dp[i][j]:dp[i][j] = qreturn dp[0][n - 1]
3.4 树形动态规划题
3.4.1 树的最大独立集问题
问题描述:给定一棵无向树,求树的最大独立集的大小。独立集是指图中一组两两不相邻的顶点。
解题思路:
- 对于树中的每个节点 u u u,设 d p [ u ] [ 0 ] dp[u][0] dp[u][0] 表示不选择节点 u u u 时以 u u u 为根的子树的最大独立集大小, d p [ u ] [ 1 ] dp[u][1] dp[u][1] 表示选择节点 u u u 时以 u u u 为根的子树的最大独立集大小。
- 状态转移方程:
- d p [ u ] [ 0 ] = ∑ v ∈ children ( u ) max ( d p [ v ] [ 0 ] , d p [ v ] [ 1 ] ) dp[u][0] = \sum_{v \in \text{children}(u)} \max(dp[v][0], dp[v][1]) dp[u][0]=∑v∈children(u)max(dp[v][0],dp[v][1])(不选择节点 u u u,则其子节点可以选择或不选择)。
- d p [ u ] [ 1 ] = 1 + ∑ v ∈ children ( u ) d p [ v ] [ 0 ] dp[u][1] = 1 + \sum_{v \in \text{children}(u)} dp[v][0] dp[u][1]=1+∑v∈children(u)dp[v][0](选择节点 u u u,则其子节点都不能选择)。
最终答案为 max ( d p [ r o o t ] [ 0 ] , d p [ r o o t ] [ 1 ] ) \max(dp[root][0], dp[root][1]) max(dp[root][0],dp[root][1])。
3.4.2 树的最小顶点覆盖问题
问题描述:给定一棵无向树,求树的最小顶点覆盖的大小。顶点覆盖是指图中的一个顶点子集,使得图中的每条边至少有一个端点在该子集中。
解题思路:
- 对于树中的每个节点 u u u,设 d p [ u ] [ 0 ] dp[u][0] dp[u][0] 表示不选择节点 u u u 时以 u u u 为根的子树的最小顶点覆盖大小, d p [ u ] [ 1 ] dp[u][1] dp[u][1] 表示选择节点 u u u 时以 u u u 为根的子树的最小顶点覆盖大小。
- 状态转移方程:
- d p [ u ] [ 0 ] = ∑ v ∈ children ( u ) d p [ v ] [ 1 ] dp[u][0] = \sum_{v \in \text{children}(u)} dp[v][1] dp[u][0]=∑v∈children(u)dp[v][1](不选择节点 u u u,则其子节点都必须选择)。
- d p [ u ] [ 1 ] = 1 + ∑ v ∈ children ( u ) min ( d p [ v ] [ 0 ] , d p [ v ] [ 1 ] ) dp[u][1] = 1 + \sum_{v \in \text{children}(u)} \min(dp[v][0], dp[v][1]) dp[u][1]=1+∑v∈children(u)min(dp[v][0],dp[v][1])(选择节点 u u u,则其子节点可以选择或不选择)。
最终答案为 min ( d p [ r o o t ] [ 0 ] , d p [ r o o t ] [ 1 ] ) \min(dp[root][0], dp[root][1]) min(dp[root][0],dp[root][1])。
🎉 通过对以上不同类型动态规划题型的学习,相信你对动态规划有了更深入的理解和掌握。加油,继续挑战更多的算法问题吧!
第四章 数学与位运算题型
4.1 数学基础题
4.1.1 质数相关题
1. 质数的定义
质数又称素数,是指在大于 1 的自然数中,除了 1 和它本身以外不再有其他因数的自然数。例如,2、3、5、7、11 等都是质数,而 4 不是质数,因为 4 除了 1 和 4 之外,还有因数 2。😃
2. 判断一个数是否为质数
- 方法:可以从 2 开始,到该数的平方根为止,检查是否存在能整除该数的数。如果存在,则该数不是质数;否则,该数是质数。
- 示例代码(Python):
import mathdef is_prime(n):if n < 2:return Falsefor i in range(2, int(math.sqrt(n)) + 1):if n % i == 0:return Falsereturn Trueprint(is_prime(7)) # 输出: True
print(is_prime(4)) # 输出: False
3. 常见的质数相关题目类型
- 找出一定范围内的所有质数:可以使用埃拉托斯特尼筛法(Sieve of Eratosthenes),该算法的时间复杂度为 O ( n l o g l o g n ) O(n log log n) O(nloglogn)。
- 质数分解:将一个合数分解成若干个质数的乘积。
4.1.2 最大公约数与最小公倍数题
1. 最大公约数(GCD)
- 定义:指两个或多个整数共有约数中最大的一个。例如,12 和 18 的最大公约数是 6,因为 12 的约数有 1、2、3、4、6、12,18 的约数有 1、2、3、6、9、18,它们共有的约数中最大的是 6。😎
- 计算方法:可以使用欧几里得算法(辗转相除法),其原理是: g c d ( a , b ) = g c d ( b , a gcd(a, b) = gcd(b, a % b) gcd(a,b)=gcd(b,a,其中 a > b a > b a>b。
- 示例代码(Python):
def gcd(a, b):while b:a, b = b, a % breturn aprint(gcd(12, 18)) # 输出: 6
2. 最小公倍数(LCM)
- 定义:指两个或多个整数公有的倍数中最小的一个。例如,12 和 18 的最小公倍数是 36,因为 12 的倍数有 12、24、36、48 等,18 的倍数有 18、36、54 等,它们公有的倍数中最小的是 36。🤓
- 计算方法:可以利用公式 l c m ( a , b ) = a ∗ b g c d ( a , b ) lcm(a, b) = \frac{a * b}{gcd(a, b)} lcm(a,b)=gcd(a,b)a∗b。
- 示例代码(Python):
def lcm(a, b):return a * b // gcd(a, b)print(lcm(12, 18)) # 输出: 36
3. 常见的最大公约数与最小公倍数题目类型
- 求解多个数的最大公约数和最小公倍数:可以先求出两个数的最大公约数和最小公倍数,再依次与其他数进行计算。
- 利用最大公约数和最小公倍数解决实际问题,如安排周期性事件等。
4.1.3 排列组合问题
1. 排列
- 定义:从 n n n 个不同元素中取出 m m m( m ≤ n m \leq n m≤n)个元素,按照一定的顺序排成一列,叫做从 n n n 个不同元素中取出 m m m 个元素的一个排列。排列数记为 A n m A_{n}^m Anm,计算公式为 A n m = n ! ( n − m ) ! A_{n}^m = \frac{n!}{(n - m)!} Anm=(n−m)!n!。例如,从 3 个不同元素中取出 2 个元素的排列数为 A 3 2 = 3 ! ( 3 − 2 ) ! = 3 × 2 = 6 A_{3}^2 = \frac{3!}{(3 - 2)!} = 3 \times 2 = 6 A32=(3−2)!3!=3×2=6。🎉
- 示例代码(Python):
import mathdef permutation(n, m):return math.factorial(n) // math.factorial(n - m)print(permutation(3, 2)) # 输出: 6
2. 组合
- 定义:从 n n n 个不同元素中取出 m m m( m ≤ n m \leq n m≤n)个元素组成一组,不考虑元素的顺序,叫做从 n n n 个不同元素中取出 m m m 个元素的一个组合。组合数记为 C n m C_{n}^m Cnm,计算公式为 C n m = n ! m ! ( n − m ) ! C_{n}^m = \frac{n!}{m!(n - m)!} Cnm=m!(n−m)!n!。例如,从 3 个不同元素中取出 2 个元素的组合数为 C 3 2 = 3 ! 2 ! ( 3 − 2 ) ! = 3 C_{3}^2 = \frac{3!}{2!(3 - 2)!} = 3 C32=2!(3−2)!3!=3。😜
- 示例代码(Python):
import mathdef combination(n, m):return math.factorial(n) // (math.factorial(m) * math.factorial(n - m))print(combination(3, 2)) # 输出: 3
3. 常见的排列组合题目类型
- 计算排列组合的具体数值:根据题目给定的 n n n 和 m m m,使用上述公式进行计算。
- 解决实际问题中的排列组合情况,如计算抽奖的中奖概率、安排座位的方案数等。
4.2 位运算题
4.2.1 位运算基础应用
1. 常见的位运算符
- 按位与(&):对应位都为 1 时结果为 1,否则为 0。例如, 5 & 3 = 1 5 \& 3 = 1 5&3=1,因为 5 5 5 的二进制表示为 101 101 101, 3 3 3 的二进制表示为 011 011 011,按位与后得到 001 001 001,即十进制的 1。😏
- 按位或(|):对应位只要有一个为 1 结果就为 1,只有都为 0 时结果才为 0。例如, 5 ∣ 3 = 7 5 | 3 = 7 5∣3=7,二进制计算为 101 ∣ 011 = 111 101 | 011 = 111 101∣011=111,即十进制的 7。
- 按位异或(^):对应位不同时结果为 1,相同时结果为 0。例如, 5 3 = 6 5 ^ 3 = 6 53=6,二进制计算为 101 0 11 = 110 101 ^ 011 = 110 101011=110,即十进制的 6。
- 按位取反(~):将每一位取反,0 变为 1,1 变为 0。例如,~5 在 8 位二进制中表示为 11111010 11111010 11111010,在有符号整数中表示为 -6。
- 左移(<<):将二进制数向左移动指定的位数,右边补 0。例如, 5 < < 2 = 20 5 << 2 = 20 5<<2=20,因为 5 5 5 的二进制是 101 101 101,左移 2 位后变为 10100 10100 10100,即十进制的 20。
- 右移(>>):将二进制数向右移动指定的位数,左边补符号位(正数补 0,负数补 1)。例如, 5 > > 1 = 2 5 >> 1 = 2 5>>1=2,二进制计算为 101 > > 1 = 10 101 >> 1 = 10 101>>1=10,即十进制的 2。
2. 位运算的基础应用场景
- 判断奇偶性:一个数的二进制表示中,最后一位为 0 则为偶数,为 1 则为奇数。可以使用 n & 1 n \& 1 n&1 来判断,结果为 0 是偶数,结果为 1 是奇数。
- 交换两个数的值:可以使用异或运算实现,代码如下:
a = 5
b = 3
a = a ^ b
b = a ^ b
a = a ^ b
print(a, b) # 输出: 3 5
4.2.2 位运算解决奇偶性问题
1. 判断单个数字的奇偶性
- 方法:使用按位与运算符
&,将数字与 1 进行按位与运算。如果结果为 0,则该数字为偶数;如果结果为 1,则该数字为奇数。 - 示例代码(Python):
def is_even(n):return (n & 1) == 0print(is_even(4)) # 输出: True
print(is_even(5)) # 输出: False
2. 处理数组中数字的奇偶性问题
- 问题描述:给定一个数组,将数组中的奇数和偶数分开,使得奇数在前,偶数在后。
- 解决方法:可以使用双指针法,一个指针从左向右移动,一个指针从右向左移动,当左指针指向偶数且右指针指向奇数时,交换两个元素的位置。
- 示例代码(Python):
def separate_odd_even(arr):left, right = 0, len(arr) - 1while left < right:while left < right and arr[left] % 2 == 1:left += 1while left < right and arr[right] % 2 == 0:right -= 1if left < right:arr[left], arr[right] = arr[right], arr[left]return arrarr = [1, 2, 3, 4, 5, 6]
print(separate_odd_even(arr)) # 输出: [1, 5, 3, 4, 2, 6]
4.2.3 位运算实现加法、减法等操作
1. 位运算实现加法
- 原理:使用异或运算
^实现不进位加法,使用按位与运算&和左移运算<<计算进位,然后将不进位加法的结果和进位相加,直到没有进位为止。 - 示例代码(Python):
def add(a, b):while b:carry = (a & b) << 1a = a ^ bb = carryreturn aprint(add(5, 3)) # 输出: 8
2. 位运算实现减法
- 原理:减法可以转化为加法,即 a − b = a + ( − b ) a - b = a + (-b) a−b=a+(−b),而负数在计算机中以补码形式表示,补码的计算方法是原码取反加 1。
- 示例代码(Python):
def subtract(a, b):# 求 -b 的补码b = add(~b, 1)return add(a, b)print(subtract(5, 3)) # 输出: 2
🎯 总结:数学与位运算在算法和编程中有着广泛的应用,掌握这些基础知识可以帮助我们更好地解决各种问题。通过不断练习相关的题目,可以提高我们的编程能力和思维能力。💪
第五章 贪心算法题型
贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法。接下来我们看看贪心算法的具体题型。
5.1 基础贪心算法题
5.1.1 活动选择问题
1. 问题描述
假设有一个礼堂,有多个活动想要使用这个礼堂,每个活动都有开始时间和结束时间。我们的目标是在这个礼堂安排尽可能多的活动,使得这些活动的时间不会相互冲突。
例如,有以下活动:
| 活动编号 | 开始时间 | 结束时间 |
|---|---|---|
| 1 | 1 | 4 |
| 2 | 3 | 5 |
| 3 | 0 | 6 |
| 4 | 5 | 7 |
| 5 | 3 | 9 |
我们需要找出一种安排方式,让礼堂能举办最多的活动。
2. 贪心策略
我们采用按照活动结束时间进行排序的贪心策略。优先选择结束时间早的活动,这样可以为后续活动留出更多的时间。
3. 解题步骤
- 首先,将所有活动按照结束时间从小到大进行排序。
- 然后,选择第一个结束的活动,因为它结束得最早,能为后续活动提供更多的时间窗口。
- 接着,依次遍历剩下的活动,只要活动的开始时间不早于上一个已选择活动的结束时间,就选择该活动。
对于上面的例子,排序后为:
| 活动编号 | 开始时间 | 结束时间 |
|---|---|---|
| 1 | 1 | 4 |
| 2 | 3 | 5 |
| 4 | 5 | 7 |
| 3 | 0 | 6 |
| 5 | 3 | 9 |
首先选择活动 1,其结束时间是 4。然后看活动 2,开始时间 3 早于 4,不选;活动 4,开始时间 5 晚于 4,选择;活动 3,开始时间 0 早于 5,不选;活动 5,开始时间 3 早于 5,不选。所以最终选择的活动是 1 和 4。🎉
5.1.2 找零问题
1. 问题描述
在日常生活中,我们去商店买东西,付款后商家需要找零。例如,我们买了价值 37 元的商品,给了商家 100 元,商家需要找给我们 63 元。现在的问题是,如何用最少数量的纸币和硬币来完成找零。
假设我们有以下几种面额的货币:100 元、50 元、20 元、10 元、5 元、1 元。
2. 贪心策略
每次都选择面额最大的货币,直到找零金额为 0。
3. 解题步骤
- 对于找零金额 63 元,首先看最大面额 100 元,63 小于 100,不选。
- 接着看 50 元,63 大于 50,选择 1 张 50 元,此时还需找零 63 - 50 = 13 元。
- 再看 20 元,13 小于 20,不选。
- 看 10 元,13 大于 10,选择 1 张 10 元,此时还需找零 13 - 10 = 3 元。
- 看 5 元,3 小于 5,不选。
- 看 1 元,3 大于 1,选择 3 张 1 元,此时找零金额为 0。
所以最终找零方案是 1 张 50 元、1 张 10 元、3 张 1 元。👏
5.2 区间贪心算法题
5.2.1 区间覆盖问题
1. 问题描述
给定一个大区间和若干个小区间,每个小区间都有自己的起始和结束位置。我们的目标是用最少的小区间完全覆盖大区间。
例如,大区间是 [1, 10],有以下小区间:
| 小区间编号 | 起始位置 | 结束位置 |
|---|---|---|
| 1 | 1 | 3 |
| 2 | 2 | 5 |
| 3 | 4 | 7 |
| 4 | 6 | 9 |
| 5 | 8 | 10 |
2. 贪心策略
首先,将所有小区间按照起始位置从小到大排序。然后,在每一步中,选择所有起始位置能衔接上当前已覆盖区间末尾的小区间中,结束位置最远的那个小区间。
3. 解题步骤
- 初始时,已覆盖区间为空,当前需要覆盖的起始位置是大区间的起始位置 1。
- 按照起始位置排序后,首先看小区间 1,它的起始位置是 1,能覆盖起始位置,且结束位置是 3,选择它。此时已覆盖区间是 [1, 3]。
- 接着,在剩下的小区间中,起始位置能衔接上 3 的有小区间 2 和 3,小区间 2 结束位置是 5,小区间 3 结束位置是 7,选择小区间 3。此时已覆盖区间是 [1, 7]。
- 然后,起始位置能衔接上 7 的有小区间 4,选择它。此时已覆盖区间是 [1, 9]。
- 最后,起始位置能衔接上 9 的有小区间 5,选择它。此时已覆盖区间是 [1, 10],刚好覆盖大区间。
所以最少需要 4 个小区间(1、3、4、5)来覆盖大区间。👍
5.2.2 区间合并问题
1. 问题描述
给定一组区间,每个区间由起始位置和结束位置表示。我们的任务是将所有重叠的区间合并成一个大区间,最终得到一组不重叠的区间。
例如,给定以下区间:
| 区间编号 | 起始位置 | 结束位置 |
|---|---|---|
| 1 | 1 | 3 |
| 2 | 2 | 6 |
| 3 | 8 | 10 |
| 4 | 15 | 18 |
2. 贪心策略
先将所有区间按照起始位置从小到大进行排序。然后,依次遍历这些区间,对于相邻的区间,如果它们有重叠部分,就将它们合并成一个更大的区间。
3. 解题步骤
- 首先对区间进行排序,排序后顺序不变。
- 从第一个区间 [1, 3] 开始,看第二个区间 [2, 6],它们有重叠部分(2 - 3 之间),将它们合并成 [1, 6]。
- 接着看第三个区间 [8, 10],它与 [1, 6] 没有重叠,保留。
- 再看第四个区间 [15, 18],它与 [8, 10] 没有重叠,保留。
所以最终合并后的区间是 [1, 6]、[8, 10]、[15, 18]。😎
第六章 设计题
6.1 数据结构设计题
6.1.1 设计栈、队列
1. 栈的设计
定义与特点
栈是一种遵循后进先出(LIFO - Last In First Out)原则的数据结构,就像一摞盘子,最后放上去的盘子总是最先被拿走😉。
设计思路
- 数据存储:可以使用数组来实现栈,数组的一端作为栈顶。
- 操作方法:
push(element):将元素压入栈顶。pop():移除并返回栈顶元素。peek():返回栈顶元素,但不移除。isEmpty():判断栈是否为空。size():返回栈中元素的数量。
代码示例(Python)
class Stack:def __init__(self):self.items = []def push(self, element):self.items.append(element)def pop(self):if not self.isEmpty():return self.items.pop()return Nonedef peek(self):if not self.isEmpty():return self.items[-1]return Nonedef isEmpty(self):return len(self.items) == 0def size(self):return len(self.items)2. 队列的设计
定义与特点
队列是一种遵循先进先出(FIFO - First In First Out)原则的数据结构,就像排队买票,先到的人先买到票🎫。
设计思路
- 数据存储:同样可以使用数组来实现队列,数组的一端作为队头,另一端作为队尾。
- 操作方法:
enqueue(element):将元素添加到队尾。dequeue():移除并返回队头元素。peek():返回队头元素,但不移除。isEmpty():判断队列是否为空。size():返回队列中元素的数量。
代码示例(Python)
class Queue:def __init__(self):self.items = []def enqueue(self, element):self.items.append(element)def dequeue(self):if not self.isEmpty():return self.items.pop(0)return Nonedef peek(self):if not self.isEmpty():return self.items[0]return Nonedef isEmpty(self):return len(self.items) == 0def size(self):return len(self.items)6.1.2 设计哈希表
定义与特点
哈希表(Hash Table)是一种根据键(Key)直接访问内存存储位置的数据结构,它通过哈希函数将键映射到存储桶(Bucket)中,以实现快速的查找、插入和删除操作🔍。
设计思路
- 哈希函数:将键转换为存储桶的索引。一个好的哈希函数应该尽量减少冲突(不同的键映射到相同的索引)。
- 冲突处理:当发生冲突时,有多种处理方法,如链地址法(每个存储桶是一个链表)和开放寻址法(如线性探测、二次探测等)。
- 操作方法:
put(key, value):将键值对插入哈希表。get(key):根据键获取对应的值。remove(key):根据键移除对应的键值对。
代码示例(Python,使用链地址法处理冲突)
class HashTable:def __init__(self, size):self.size = sizeself.table = [[] for _ in range(size)]def _hash(self, key):return hash(key) % self.sizedef put(self, key, value):index = self._hash(key)for pair in self.table[index]:if pair[0] == key:pair[1] = valuereturnself.table[index].append([key, value])def get(self, key):index = self._hash(key)for pair in self.table[index]:if pair[0] == key:return pair[1]return Nonedef remove(self, key):index = self._hash(key)for i, pair in enumerate(self.table[index]):if pair[0] == key:del self.table[index][i]return6.1.3 设计 LRU 缓存
定义与特点
LRU(Least Recently Used)缓存是一种缓存淘汰策略,当缓存满时,会优先淘汰最近最少使用的数据。它结合了哈希表和双向链表,以实现快速的查找和插入操作,同时能够维护数据的访问顺序🧐。
设计思路
- 哈希表:用于快速查找数据,键为缓存的键,值为双向链表中的节点。
- 双向链表:用于维护数据的访问顺序,链表头部表示最近使用的数据,链表尾部表示最近最少使用的数据。
- 操作方法:
get(key):根据键获取对应的值,并将该数据移到链表头部。put(key, value):插入或更新键值对,如果缓存已满,淘汰链表尾部的数据。
代码示例(Python)
class DLinkedNode:def __init__(self, key=0, value=0):self.key = keyself.value = valueself.prev = Noneself.next = Noneclass LRUCache:def __init__(self, capacity):self.capacity = capacityself.cache = {}self.size = 0self.head = DLinkedNode()self.tail = DLinkedNode()self.head.next = self.tailself.tail.prev = self.headdef _add_to_head(self, node):node.prev = self.headnode.next = self.head.nextself.head.next.prev = nodeself.head.next = nodedef _remove_node(self, node):node.prev.next = node.nextnode.next.prev = node.prevdef _move_to_head(self, node):self._remove_node(node)self._add_to_head(node)def _remove_tail(self):node = self.tail.prevself._remove_node(node)return nodedef get(self, key):if key not in self.cache:return -1node = self.cache[key]self._move_to_head(node)return node.valuedef put(self, key, value):if key in self.cache:node = self.cache[key]node.value = valueself._move_to_head(node)else:node = DLinkedNode(key, value)self.cache[key] = nodeself._add_to_head(node)self.size += 1if self.size > self.capacity:removed = self._remove_tail()self.cache.pop(removed.key)self.size -= 16.2 系统设计题
6.2.1 设计短网址系统
需求分析
短网址系统的主要功能是将长网址转换为短网址,方便用户分享和传播。用户输入长网址,系统生成对应的短网址,当用户访问短网址时,系统将其重定向到原始的长网址。
设计思路
- 数据库设计:使用数据库(如 MySQL)存储长网址和短网址的映射关系,表结构可以包含
id、long_url、short_url等字段。 - 短网址生成算法:可以使用哈希算法(如 MD5、SHA - 1)将长网址转换为固定长度的哈希值,然后截取部分哈希值作为短网址的一部分,也可以使用自增 ID 转换为 62 进制字符串的方法生成短网址。
- 服务端架构:采用分层架构,包括 Web 层、业务逻辑层和数据访问层,使用 HTTP 协议处理用户请求。
- 缓存设计:使用缓存(如 Redis)来提高短网址查询的性能,减少数据库的访问压力。
工作流程
- 用户提交长网址。
- 系统检查缓存中是否存在该长网址的映射,如果存在,直接返回短网址;否则,查询数据库。
- 如果数据库中也不存在该长网址的映射,生成短网址,将长 - 短网址映射关系存入数据库和缓存。
- 用户访问短网址,系统先从缓存中查找对应的长网址,如果未找到,再查询数据库。
- 将用户重定向到原始的长网址。
6.2.2 设计分布式缓存系统
需求分析
分布式缓存系统用于在分布式环境中缓存数据,以提高系统的性能和响应速度。多个应用服务器可以共享缓存数据,减少对后端数据源(如数据库)的访问压力。
设计思路
- 缓存节点:使用多个缓存节点组成分布式缓存集群,每个节点负责存储部分缓存数据。
- 数据分片:将缓存数据按照一定的规则(如哈希算法)分片存储到不同的缓存节点上,以实现数据的均匀分布。
- 一致性哈希:使用一致性哈希算法来解决节点增减时的数据迁移问题,减少数据的重新分布。
- 缓存更新策略:可以采用主动更新(当数据发生变化时,主动更新缓存)或被动更新(当缓存过期时,重新从数据源获取数据)的策略。
- 缓存淘汰策略:当缓存空间不足时,采用 LRU、LFU(Least Frequently Used)等淘汰策略来淘汰部分缓存数据。
工作流程
- 应用服务器向分布式缓存系统发送缓存请求。
- 缓存系统根据请求的键计算哈希值,确定该键对应的缓存节点。
- 如果该节点存在缓存数据,直接返回给应用服务器;否则,从后端数据源获取数据,并将数据存入缓存节点。
- 当后端数据源的数据发生变化时,根据更新策略更新缓存数据。
通过以上设计,可以构建一个高效、可靠的分布式缓存系统,为分布式应用提供强大的缓存支持👍。
相关文章:

【算法】力扣体系分类
第一章 算法基础题型 1.1 排序算法题 1.1.1 冒泡排序相关题 冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,…...

sql:如何查询一个数据表字段:Scrp 数据不为空?
在SQL中,要查询一个数据表中的字段 Scrp 不为空的记录,可以使用 IS NOT NULL 条件。以下是一个基本的SQL查询示例: SELECT * FROM your_table_name WHERE Scrp IS NOT NULL;在这个查询中,your_table_name 应该替换为你的实际数据…...

深入浅出人工智能:机器学习、深度学习、强化学习原理详解与对比!
各位朋友,大家好!今天咱们聊聊人工智能领域里最火的“三剑客”:机器学习 (Machine Learning)、深度学习 (Deep Learning) 和 强化学习 (Reinforcement Learning)。 听起来是不是有点高大上? 别怕,我保证把它们讲得明明…...
)
索引下探(Index Condition Pushdown,简称ICP)
索引下探(Index Condition Pushdown,简称ICP)是一种数据库查询优化技术,常见于MySQL等关系型数据库中。 1. 核心概念 作用:将原本在服务器层执行的WHERE条件判断尽可能下推到存储引擎层执行。减少回表查询次数支持部…...
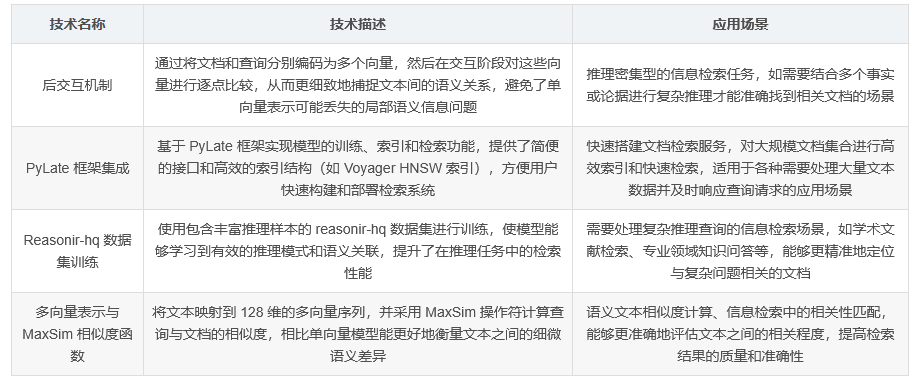
基于 ColBERT 框架的后交互 (late interaction) 模型速递:Reason-ModernColBERT
一、Reason-ModernColBERT 模型概述 Reason-ModernColBERT 是一种基于 ColBERT 框架的后交互 (late interaction) 模型,专为信息检索任务中的推理密集型场景设计。该模型在 reasonir-hq 数据集上进行训练,于 BRIGHT 基准测试中取得了极具竞争力的性能表…...
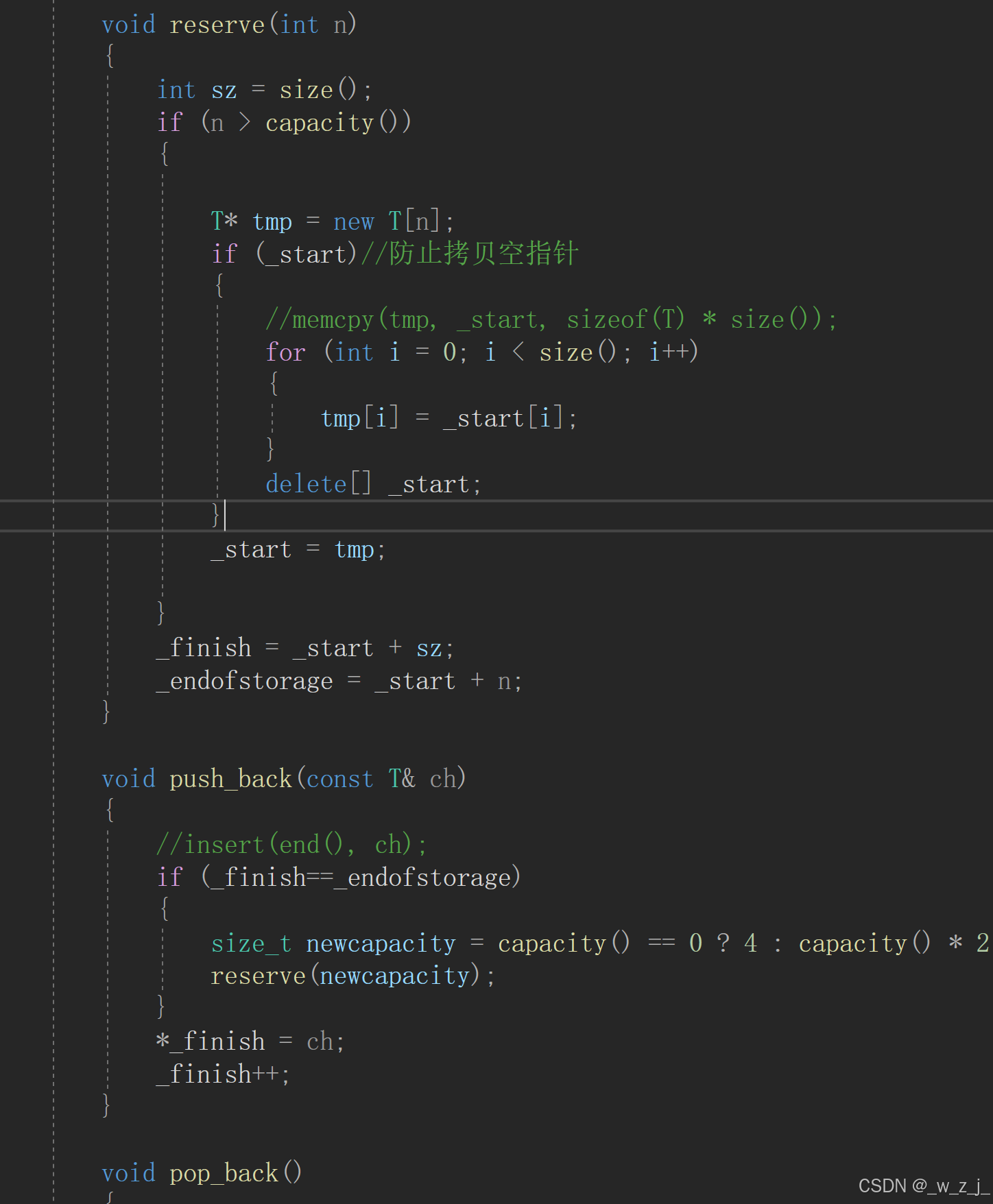
vector中reserve导致的析构函数问题
接上一节vector实现,解决杨辉三角问题时,我在最后调试的时候,发现return vv时,调用析构函数,到第四步时才析构含有14641的vector。我设置了一个全局变量i来记录。 初始为35: 当为39时,也就是第…...
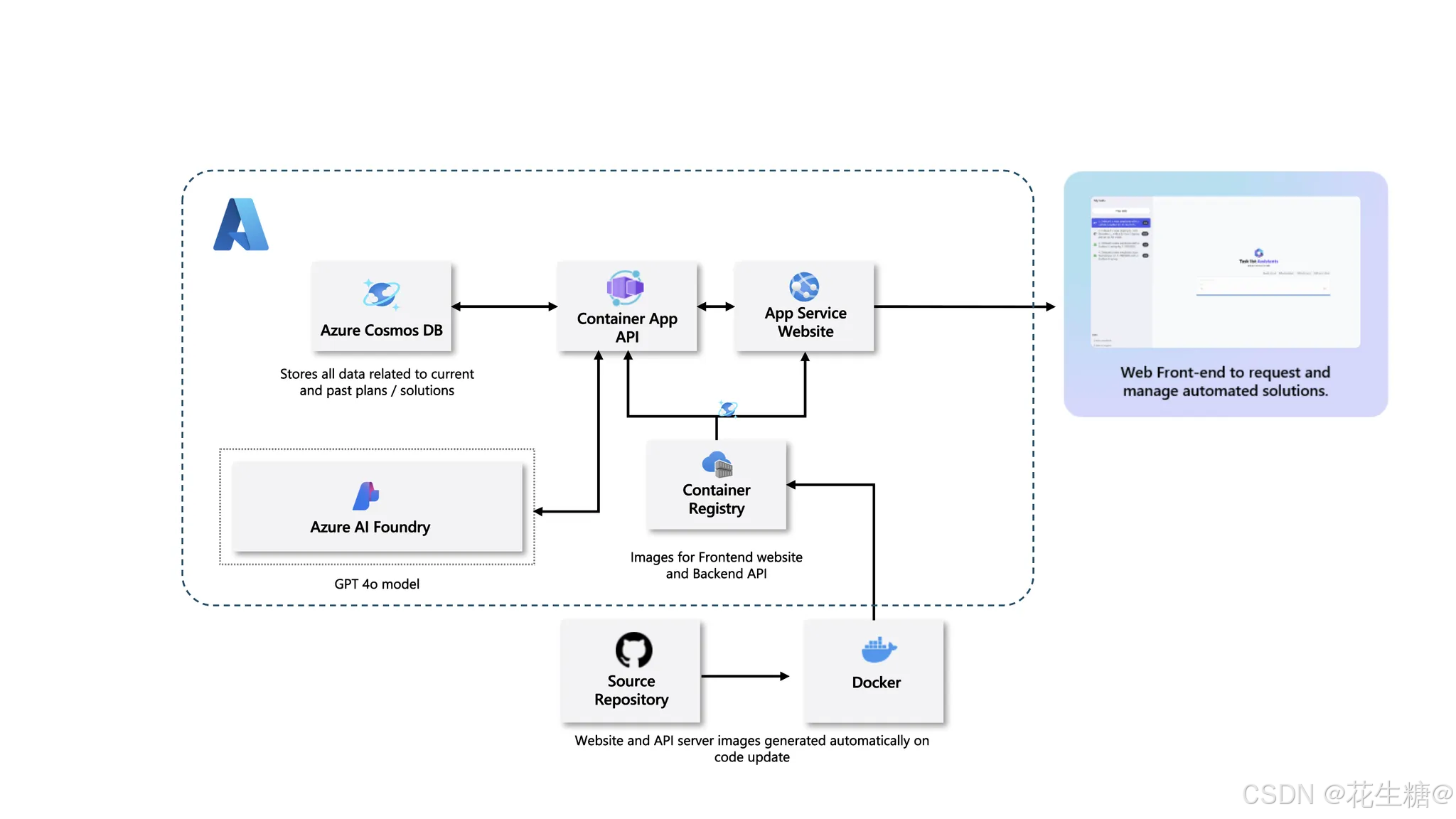
微软开源多智能体自定义自动化工作流系统:构建企业级AI驱动的智能引擎
微软近期推出了一款开源解决方案加速器——Multi-Agent Custom Automation Engine Solution Accelerator,这是一个基于AI多智能体协作的自动化工作流系统。该系统通过指挥多个智能体(Agent)协同完成复杂任务,显著提升企业在数据处理、业务流程管理等场景中的效率与准确性。…...

关于vector、queue、list哪边是front、哪边是back,增加、删除元素操作
容器的 front、back 及操作方向 1.1vector(动态数组) 结构:连续内存块,支持快速随机访问。 操作方向: front:第一个元素(索引 0)。 back:最后一个元素(索引…...

KubeVela入门到精通-K8S多集群交付
目录 1、介绍 2、部署 3、部署UI界面 4、御载 5、Velaux概念 6、OAM应用模型介绍 7、应用部署计划 8、系统架构 9、基础环境配置 9.1 创建项目 9.2 创建集群 9.3 创建交付目标 9.4 创建环境 9.5、创建服务测试 9.6、服务操作 10、插件、项目、权限管理 10.1 插…...

RocketMq的消息类型及代码案例
RocketMQ 提供了多种消息类型,以满足不同业务场景对 顺序性、事务性、时效性 的要求。其核心设计思想是通过解耦 “消息传递模式” 与 “业务逻辑”,实现高性能、高可靠的分布式通信。 一、主要类型包括 普通消息(基础类型)顺序…...

Eigen 直线拟合/曲线拟合/圆拟合/椭圆拟合
一、直线拟合 使用Eigen库进行直线拟合是数据分析和科学计算中的常见任务,主要通过最小二乘法实现。以下是关键实现方法和示例: 核心原理最小二乘法通过最小化点到直线距离的平方和来求解最优直线参数间接平差法是最小二乘法的具体实现形式,适用于直线拟合场景通过构建误差…...

安卓无障碍脚本开发全教程
文章目录 第一部分:无障碍服务基础1.1 无障碍服务概述核心功能: 1.2 基本原理与架构1.3 开发环境配置所需工具:关键依赖: 第二部分:创建基础无障碍服务2.1 服务声明配置2.2 服务配置文件关键属性说明: 2.3 …...

svn迁移到git保留记录和Python字符串格式化 f-string的进化历程
svn迁移到git保留记录 and Python字符串格式化(二): f-string的进化历程 在将项目从SVN迁移到Git时,保留完整的版本历史记录非常重要。下面是详细的步骤和工具,可以帮助你完成这一过程: 安装Git和SVN工具 首先&#…...
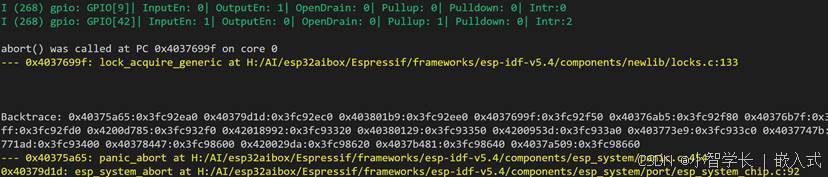
SOC-ESP32S3部分:10-GPIO中断按键中断实现
飞书文档https://x509p6c8to.feishu.cn/wiki/W4Wlw45P2izk5PkfXEaceMAunKg 学习了GPIO输入和输出功能后,参考示例工程,我们再来看看GPIO中断,IO中断的配置分为三步 配置中断触发类型安装中断服务注册中断回调函数 ESP32-S3的所有通用GPIO…...

【神经网络与深度学习】扩散模型之原理解释
引言: 在人工智能的生成领域,扩散模型(Diffusion Model)是一项极具突破性的技术。它不仅能够生成高质量的图像,还可以应用于音频、3D建模等领域。扩散模型的核心思想来源于物理扩散现象,其工作方式类似于从…...
跳跃与重复问题的解析:成因、机制及解决方案)
语音合成之十六 语音合成(TTS)跳跃与重复问题的解析:成因、机制及解决方案
语音合成(TTS)跳跃与重复问题的解析:成因、机制及解决方案 引言TTS中跳跃与重复问题的根本原因注意力机制的失效文本到语音的对齐挑战自回归(AR)TTS模型的固有挑战时长建模的重要性输入数据特征的影响 构建鲁棒性&…...

战略-2.1 -战略分析(PEST/五力模型/成功关键因素)
战略分析路径,先宏观(PEST)、再产业(产品生命周期、五力模型、成功关键因素)、再竞争对手分析、最后企业内部分析。 本文介绍:PEST、产品生命周期、五力模型、成功关键因素、产业内的战略群组 一、宏观环境…...
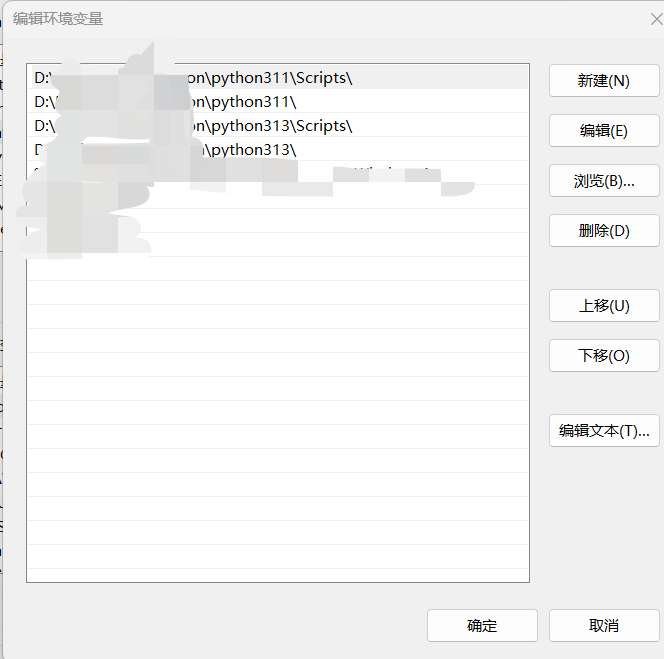
python第三方库安装错位
问题所在 今天在安装我的django库时,我的库安装到了python3.13版本。我本意是想安装到python3.11版本的。我的pycharm右下角也设置了python3.11 但是太可恶了,我在pycharm的项目终端执行安装命令的时候还是给我安装到了python3.13的位置。 解决方法 我…...
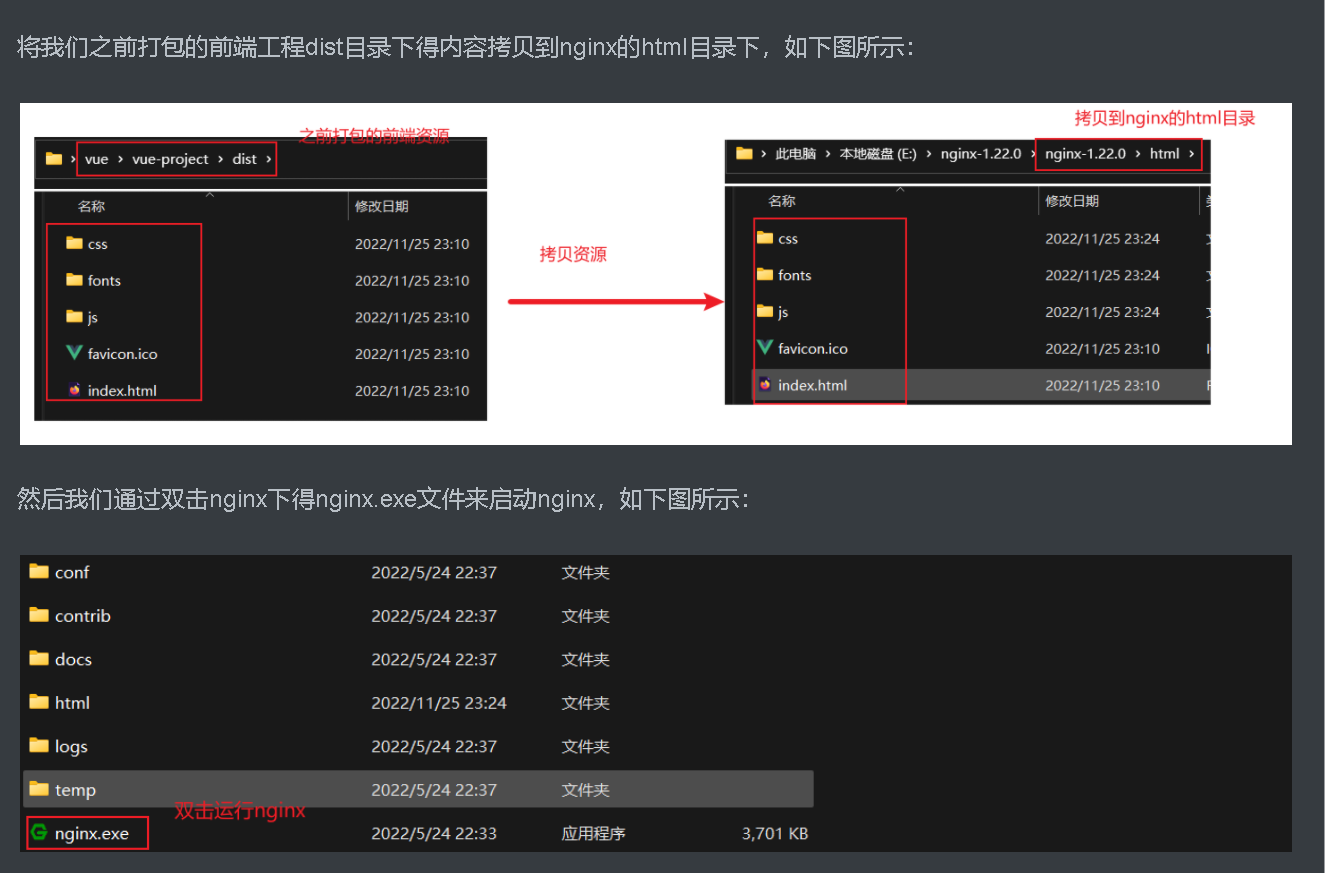
如何把vue项目部署在nginx上
1:在vscode中把vue项目打包会出现dist文件夹 按照图示内容即可把vue项目部署在nginx上...

Vue3集成Element Plus完整指南:从安装到主题定制下-实现后台管理系统框架搭建
本文将详细介绍如何使用 Vue 3 构建一个综合管理系统,包括路由配置、页面布局以及常用组件集成。 一、路由配置 首先,我们来看系统的路由配置,这是整个应用的基础架构: import {createRouter, createWebHistory} from vue-rout…...
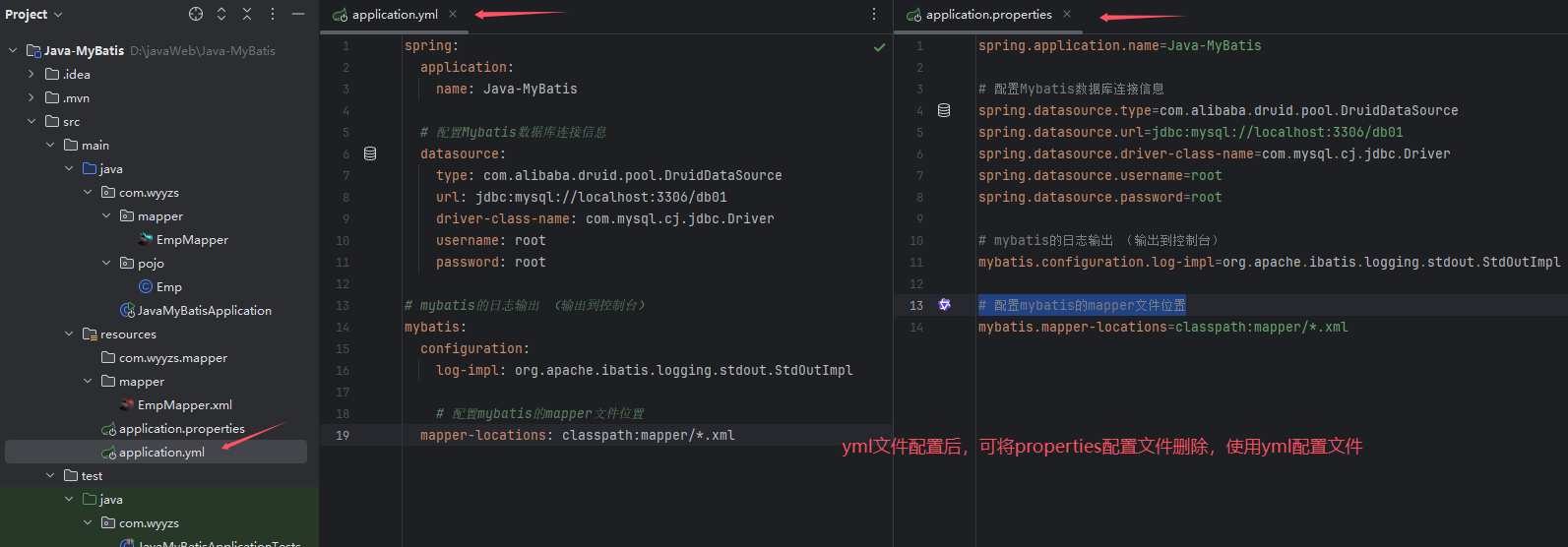
SpringBoot项目配置文件、yml配置文件
一. 配置文件格式 1. SpringBoot项目提供了多种属性配置方式(properties、yaml、yml)。 二. yml配置文件 1. 格式: (1) 数值前边必须有空格,作为分隔符。 (2) 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能使用空…...

Linux性能监控:工具与最佳实践
引言 在Linux系统管理中,性能监控是确保系统健康运行的关键环节。无论是排查系统瓶颈、优化资源分配,还是预防潜在问题,有效的监控工具和技术都能为管理员提供宝贵的数据支持。本文将介绍Linux性能监控的核心工具、方法论和最佳实践。 一、…...
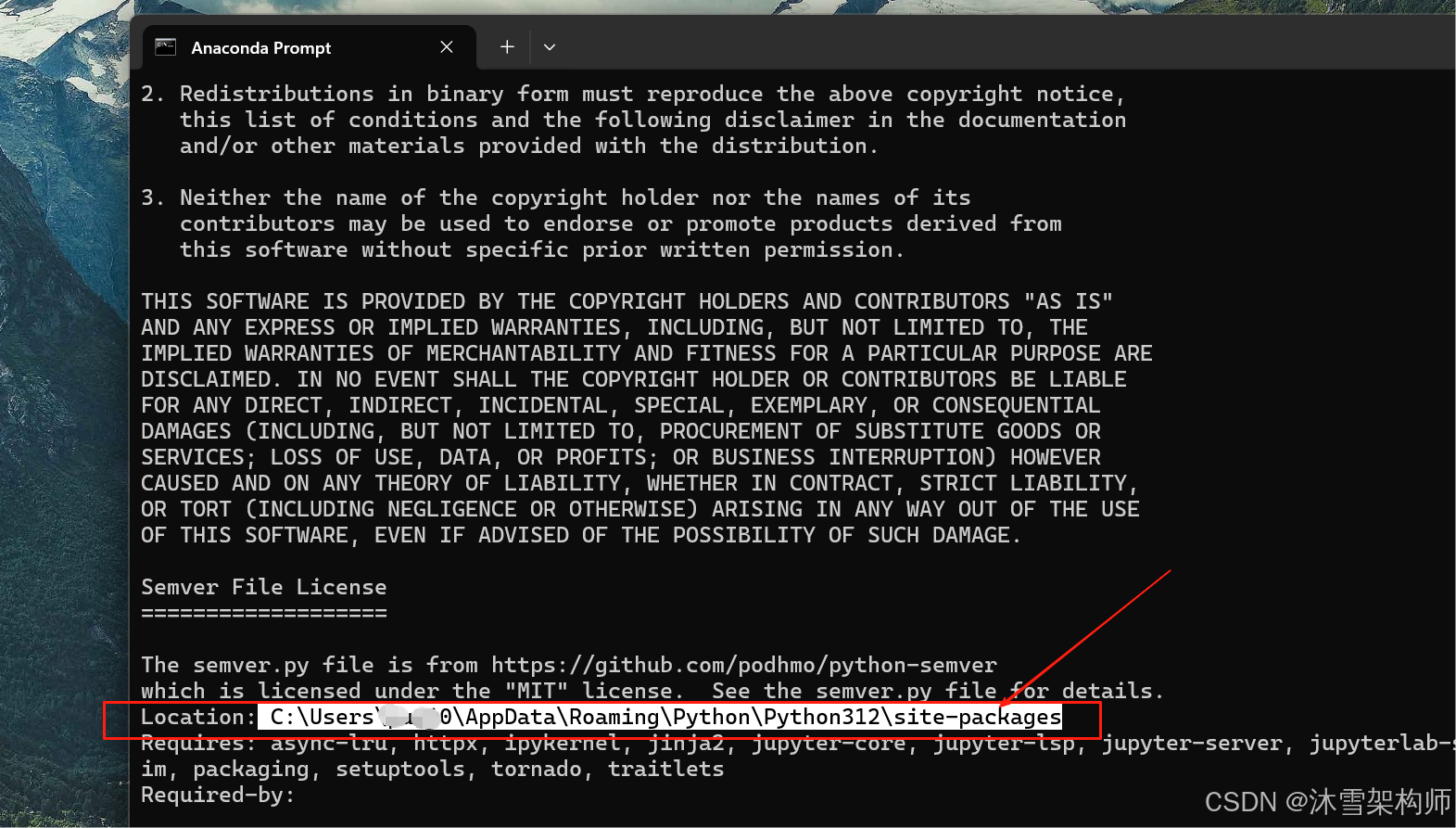
windows11 安装 jupyter lab
1、安装python环境 略 2、安装jupyterlab pip install jupyterlab 3、将jupyterlab的目录配置到path pip show jupyterlab 看到location的值,那么 jupyterlab就安装在与之同级的Scripts下,将Scripts目录设置在Path即可。...

【算法】:动态规划--背包问题
背包问题 引言 什么是背包问题? 背包问题就是一个有限的背包,给出一定的物品,如何合理的装入物品使得背包中的物品的价值最大? 01背包 01背包,顾名思义就是每一种给定的物品要么选择,要么不选ÿ…...
Nginx核心功能
目录 前言一. 正向代理1.配置正向代理(1)添加正向代理(2)验证正向代理 二. 反向代理1.配置nginx七层代理(1)环境安装(2)配置nginx七层代理转发(3)测试 2. 配置…...

AG-UI:重构AI代理与前端交互的下一代协议标准
目录 技术演进背景与核心价值协议架构与技术原理深度解析核心功能与标准化事件体系典型应用场景与实战案例开发者生态与集成指南行业影响与未来展望1. 技术演进背景与核心价值 1.1 AI交互的三大痛点 当前AI应用生态面临三大核心挑战: 交互碎片化:LangGraph、CrewAI等框架各…...
upload-labs通关笔记-第15关 文件上传之图片马getimagesize绕过
系列目录 upload-labs通关笔记-第1关 文件上传之前端绕过(3种渗透方法) upload-labs通关笔记-第2关 文件上传之MIME绕过-CSDN博客 upload-labs通关笔记-第3关 文件上传之黑名单绕过-CSDN博客 upload-labs通关笔记-第4关 文件上传之.htacess绕过-CSDN…...

FFmpeg中使用Android Content协议打开文件设备
引言 随着Android 10引入的Scoped Storage(分区存储)机制,传统的文件访问方式发生了重大变化。FFmpeg作为强大的多媒体处理工具,也在不断适应Android平台的演进。本文将介绍如何在FFmpeg 7.0版本中使用Android content协议直接访…...

SQL语句的执行流程
文章目录 一、执行流程二、建立连接三、预处理器四、解析器4.1 词法分析4.2 语法分析4.3 语义分析 五、优化器六、执行器七、返回结果 一、执行流程 阶段主要功能关键组件1. 建立连接身份验证、权限检查连接器2. 预处理器缓存检查、SQL预处理查询缓存3. 解析器词法分析、语法分…...

Spring 框架的JDBC 模板技术
一、JDBC 模板技术概述 1、什么模板技术? Spring 框架中提供了很多持久层的模板类来简化编程,使用模板类编写程序会变的简单。 2、template 模板 都是 Spring 框架来提供XxxTemplate,比如Spring框架提供了 JDBC 模板。 JdbcTemplate 类&…...