DAY 35
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每100个epoch的损失值和对应的epoch数
losses = []start_time = time.time() # 记录开始时间for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值if (epoch + 1) % 200 == 0:losses.append(loss.item()) # item()方法返回一个Python数值,loss是一个标量张量print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.plot(range(len(losses)), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()一、模型结构可视化
理解一个深度学习网络最重要的2点:
- 了解损失如何定义的,知道损失从何而来----把抽象的任务通过损失函数量化出来
- 了解参数总量,即知道每一层的设计才能退出---层设计决定参数总量
为了了解参数总量,我们需要知道层设计,以及每一层参数的数量。下面介绍1几个层可视化工具:
1.1 nn.model自带的方法
# nn.Module 的内置功能,直接输出模型结构
print(model)MLP((fc1): Linear(in_features=4, out_features=10, bias=True)(relu): ReLU()(fc2): Linear(in_features=10, out_features=3, bias=True) )
这是最基础、最简单的方法,直接打印模型对象,它会输出模型的结构,显示模型中各个层的名称和参数信息
# nn.Module 的内置功能,返回模型的可训练参数迭代器
for name, param in model.named_parameters():print(f"Parameter name: {name}, Shape: {param.shape}")Parameter name: fc1.weight, Shape: torch.Size([10, 4]) Parameter name: fc1.bias, Shape: torch.Size([10]) Parameter name: fc2.weight, Shape: torch.Size([3, 10]) Parameter name: fc2.bias, Shape: torch.Size([3])
可以将模型中带有weight的参数(即权重)提取出来,并转为 numpy 数组形式,对其计算统计分布,并且绘制可视化图表
# 提取权重数据
import numpy as np
weight_data = {}
for name, param in model.named_parameters():if 'weight' in name:weight_data[name] = param.detach().cpu().numpy()# 可视化权重分布
fig, axes = plt.subplots(1, len(weight_data), figsize=(15, 5))
fig.suptitle('Weight Distribution of Layers')for i, (name, weights) in enumerate(weight_data.items()):# 展平权重张量为一维数组weights_flat = weights.flatten()# 绘制直方图axes[i].hist(weights_flat, bins=50, alpha=0.7)axes[i].set_title(name)axes[i].set_xlabel('Weight Value')axes[i].set_ylabel('Frequency')axes[i].grid(True, linestyle='--', alpha=0.7)plt.tight_layout()
plt.subplots_adjust(top=0.85)
plt.show()# 计算并打印每层权重的统计信息
print("\n=== 权重统计信息 ===")
for name, weights in weight_data.items():mean = np.mean(weights)std = np.std(weights)min_val = np.min(weights)max_val = np.max(weights)print(f"{name}:")print(f" 均值: {mean:.6f}")print(f" 标准差: {std:.6f}")print(f" 最小值: {min_val:.6f}")print(f" 最大值: {max_val:.6f}")print("-" * 30)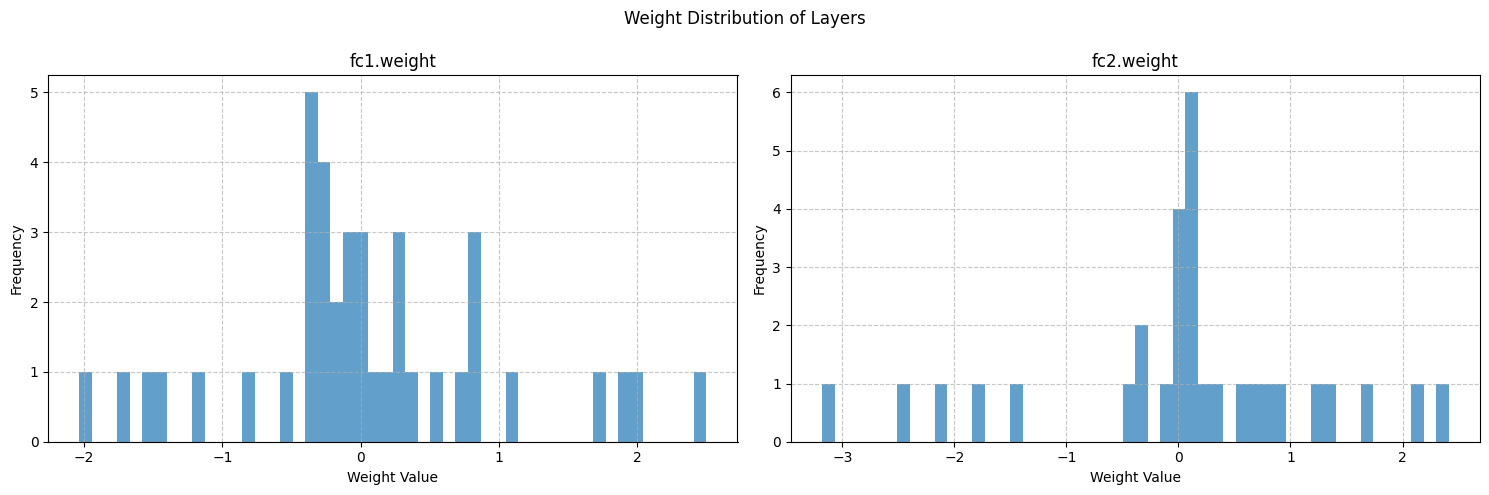
对比 fc1.weight 和 fc2.weight 的统计信息 ,可以发现它们的均值、标准差、最值等存在差异。这反映了不同层在模型中的作用不同。
权重统计信息可以为超参数调整提供参考。例如,如果发现权重标准差过大导致训练不稳定,可以尝试调整学习率,使权重更新更平稳;或者改变权重初始化方法,使初始权重分布更合理。如果最小值和最大值在训练后期仍波动较大,可能需要考虑调整正则化参数,防止过拟合或欠拟合。
1.2 torchsummary库的summary方法
# pip install torchsummary -i https://pypi.tuna.tsinghua.edu.cn/simplefrom torchsummary import summary
# 打印模型摘要,可以放置在模型定义后面
summary(model, input_size=(4,))----------------------------------------------------------------Layer (type) Output Shape Param # ================================================================Linear-1 [-1, 10] 50ReLU-2 [-1, 10] 0Linear-3 [-1, 3] 33 ================================================================ Total params: 83 Trainable params: 83 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.00 Params size (MB): 0.00 Estimated Total Size (MB): 0.00 ----------------------------------------------------------------
该方法不显示输入层的尺寸,因为输入的神经网是自己设置的,所以不需要显示输入层的尺寸。 但是在使用该方法时,input_size=(4,) 参数是必需的,因为 PyTorch 需要知道输入数据的形状才能推断模型各层的输出形状和参数数量。
这是因为PyTorch 的模型在定义时是动态的,它不会预先知道输入数据的具体形状。nn.Linear(4, 10) 只定义了 “输入维度是 4,输出维度是 10”,但不知道输入的批量大小和其他维度,比如卷积层需要知道输入的通道数、高度、宽度等信息。----并非所有输入数据都是结构化数据
因此,要生成模型摘要(如每层的输出形状、参数数量),必须提供一个示例输入形状,让 PyTorch “运行” 一次模型,从而推断出各层的信息。
summary 函数的核心逻辑是:
- 创建一个与 input_size 形状匹配的虚拟输入张量(通常填充零)
- 将虚拟输入传递给模型,执行一次前向传播(但不计算梯度)
- 记录每一层的输入和输出形状,以及参数数量
- 生成可读的摘要报告
不同场景下的 input_size 示例
| 模型类型 | 输入类型 | input_size 示例 | 实际输入形状(batch_size=32) |
|---|---|---|---|
| MLP(单样本) | 一维特征向量 | (4,) | (32, 4) |
| CNN(图像) | 三维图像(C,H,W) | (3, 224, 224) | (32, 3, 224, 224) |
| RNN(序列) | 二维序列(seq_len, feat) | (10, 5) | (32, 10, 5) |
其中最开始的参数的值是默认初始化的,初始化有很多方法,后面接触到复杂的模型再提
构建神经网络的时候
- 输入层不需要写:x多少个特征 输入层就有多少神经元
- 隐藏层需要写,从第一个隐藏层可以看出特征的个数
- 输出层的神经元和任务有关,比如分类任务,输出层有3个神经元,一个对应每个类别
上图只是帮助你理解,和上述架构不同,每条线记录权重w,在每个神经元内计算并且输出Relu(w*x+b)
可以看做,线记录权重,神经元记录偏置和损失函数
可学习参数计算
- Linear-1对应self.fc1 = nn.Linear(4, 10),表明前一层有4个神经元,这一层有10个神经元,每2个神经元之间靠着线相连,所有有4*10个权重参数+10个偏置参数=50个参数
- relu层不涉及可学习参数,可以把它和前一个线性层看成一层,图上也是这个含义
- Linear-3层对应代码 self.fc2 = nn.Linear(10,3),10*3个权重参数+3个偏置=33个参数
总参数83个,占用内存几乎为0
1.3 torchinfo库的summary方法
torchinfo 是提供比 torchsummary 更详细的模型摘要信息,包括每层的输入输出形状、参数数量、计算量等。
# pip install torchinfo -i https://pypi.tuna.tsinghua.edu.cn/simple
from torchinfo import summary
summary(model, input_size=(4, ))========================================================================================== Layer (type:depth-idx) Output Shape Param # ========================================================================================== MLP [3] -- ├─Linear: 1-1 [10] 50 ├─ReLU: 1-2 [10] -- ├─Linear: 1-3 [3] 33 ========================================================================================== Total params: 83 Trainable params: 83 Non-trainable params: 0 Total mult-adds (M): 0.00 ========================================================================================== Input size (MB): 0.00 Forward/backward pass size (MB): 0.00 Params size (MB): 0.00 Estimated Total Size (MB): 0.00 ==========================================================================================
torchinfo这个库常常和tensorboard一起使用,我们后面会介绍
二、 进度条功能
我们介绍下tqdm这个库,他非常适合用在循环中观察进度。尤其在深度学习这种训练是循环的场景中。他最核心的逻辑如下
-
创建一个进度条对象,并传入总迭代次数。一般用with语句创建对象,这样对象会在with语句结束后自动销毁,保证资源释放。with是常见的上下文管理器,这样的使用方式还有用with打开文件,结束后会自动关闭文件。
-
更新进度条,通过pbar.update(n)指定每次前进的步数n(适用于非固定步长的循环)。
2.1 手动更新
from tqdm import tqdm # 先导入tqdm库
import time # 用于模拟耗时操作# 创建一个总步数为10的进度条
with tqdm(total=10) as pbar: # pbar是进度条对象的变量名# pbar 是 progress bar(进度条)的缩写,约定俗成的命名习惯。for i in range(10): # 循环10次(对应进度条的10步)time.sleep(0.5) # 模拟每次循环耗时0.5秒pbar.update(1) # 每次循环后,进度条前进1步100%|██████████| 10/10 [00:05<00:00, 1.95it/s]
from tqdm import tqdm
import time# 创建进度条时添加描述(desc)和单位(unit)
with tqdm(total=5, desc="下载文件", unit="个") as pbar:# 进度条这个对象,可以设置描述和单位# desc是描述,在左侧显示# unit是单位,在进度条右侧显示for i in range(5):time.sleep(1)pbar.update(1) # 每次循环进度+1下载文件: 100%|██████████| 5/5 [00:05<00:00, 1.01s/个]
unit 参数的核心作用是明确进度条中每个进度单位的含义,使可视化信息更具可读性。在深度学习训练中,常用的单位包括:
- epoch:训练轮次(遍历整个数据集一次)。
- batch:批次(每次梯度更新处理的样本组)。
- sample:样本(单个数据点)
2.2 自动更新
from tqdm import tqdm
import time# 直接将range(3)传给tqdm,自动生成进度条
# 这个写法我觉得是有点神奇的,直接可以给这个对象内部传入一个可迭代对象,然后自动生成进度条
for i in tqdm(range(3), desc="处理任务", unit="epoch"):time.sleep(1)
处理任务: 100%|██████████| 3/3 [00:03<00:00, 1.01s/epoch]
for i in tqdm(range(3), desc="处理任务", unit="个")这个写法则不需要在循环中调用update()方法,更加简洁
实际上这2种写法都随意选取,这里都介绍下
# 用tqdm的set_postfix方法在进度条右侧显示实时数据(如当前循环的数值、计算结果等):
from tqdm import tqdm
import timetotal = 0 # 初始化总和
with tqdm(total=10, desc="累加进度") as pbar:for i in range(1, 11):time.sleep(0.3)total += i # 累加1+2+3+...+10pbar.update(1) # 进度+1pbar.set_postfix({"当前总和": total}) # 显示实时总和累加进度: 100%|██████████| 10/10 [00:03<00:00, 3.22it/s, 当前总和=55]
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库用于进度条显示# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每100个epoch的损失值和对应的epoch数
losses = []
epochs = []start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:losses.append(loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Loss': f'{loss.item():.4f}'})# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# # 可视化损失曲线
# plt.figure(figsize=(10, 6))
# plt.plot(epochs, losses)
# plt.xlabel('Epoch')
# plt.ylabel('Loss')
# plt.title('Training Loss over Epochs')
# plt.grid(True)
# plt.show()
使用设备: cuda:0 训练进度: 100%|██████████| 20000/20000 [00:10<00:00, 1885.37epoch/s, Loss=0.0630]Training time: 10.61 seconds
三、 模型的推理
之前我们说完了训练模型,那么现在我们来测试模型。测试这个词在大模型领域叫做推理(inference),意味着把数据输入到训练好的模型的过程。
注意 损失和优化器在训练阶段。
# 在测试集上评估模型,此时model内部已经是训练好的参数了
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度计算,可以提高模型推理速度outputs = model(X_test) # 对测试数据进行前向传播,获得预测结果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引#这个函数返回2个值,分别是最大值和对应索引,参数1是在第1维度(行)上找最大值,_ 是Python的约定,表示忽略这个返回值,所以这个写法是找到每一行最大值的下标# 此时outputs是一个tensor,p每一行是一个样本,每一行有3个值,分别是属于3个类别的概率,取最大值的下标就是预测的类别# predicted == y_test判断预测值和真实值是否相等,返回一个tensor,1表示相等,0表示不等,然后求和,再除以y_test.size(0)得到准确率# 因为这个时候数据是tensor,所以需要用item()方法将tensor转化为Python的标量# 之所以不用sklearn的accuracy_score函数,是因为这个函数是在CPU上运行的,需要将数据转移到CPU上,这样会慢一些# size(0)获取第0维的长度,即样本数量correct = (predicted == y_test).sum().item() # 计算预测正确的样本数accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%')测试集准确率: 96.67%
模型的评估模式简单来说就是评估阶段会关闭一些训练相关的操作和策略 ,比如更新参数 正则化等操作,确保模型输出结果的稳定性和一致性。
可能有同学好奇,为什么评估模式不关闭梯度计算,推理不是不需要更新参数么?
主要还是因为在某些场景下,评估阶段可能需要计算梯度(虽然不更新参数)。例如:计算梯度用于可视化(如 CAM 热力图,主要用于cnn相关)。所以为了避免这种需求不被满足,还是需要手动关闭梯度计算。
@浙大疏锦行
相关文章:
DAY 35
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time import matplotlib.pyplot as plt# 设置GPU设…...

理论篇一:了解webpack是什么,能解决什么问题,如何使用
Webpack 是前端工程化的核心工具之一,它的核心目标是将前端项目中的各种资源(JS、CSS、图片等)高效打包成浏览器可运行的静态文件。以下是系统化的解答: 一、Webpack 是什么? 1. 定义 Webpack 是一个 静态模块打包工具(Static Module Bundler),它通过分析项目的依赖关…...
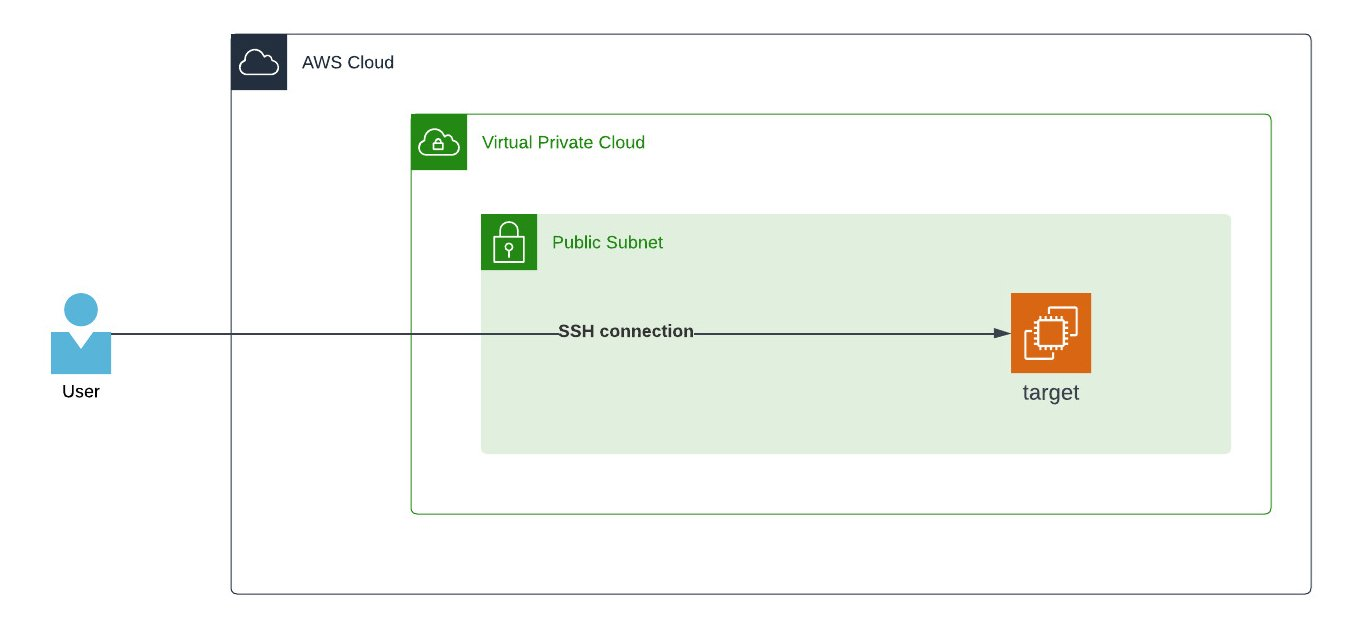
AWS EC2实例安全远程访问最佳实践
EC2 远程连接方案对比 远程访问 Amazon EC2 实例主要有以下四种方式: Secure Shell (SSH) 远程访问AWS Systems Manager 会话管理器适用于 Linux 实例的 EC2 Serial ConsoleAmazon EC2 Instance Connect SSH 远程访问 SSH(Secure Shell)广…...

集群、容器云与裸金属服务器的全面对比分析
文章目录 引言 集群 2.1 定义 2.2 特点 2.3 应用场景 容器云 3.1 定义 3.2 核心功能 3.3 应用场景 裸金属 4.1 定义 4.2 特点 4.3 应用场景 三者的区别 5.1 架构与性能 5.2 管理与运维 5.3 成本与灵活性 总结 1. 引言 在云计算和数据中心领域,50…...
【强化学习】#7 基于表格型方法的规划和学习
主要参考学习资料:《强化学习(第2版)》[加]Richard S.Suttion [美]Andrew G.Barto 著 文章源文件:https://github.com/INKEM/Knowledge_Base 本章更是厘清概念厘到头秃,如有表达不恰当之处还请多多指教—— 概述 环境…...
EasyRTC嵌入式音视频通信SDK一对一音视频通信,打造远程办公/医疗/教育等场景解决方案
一、方案概述 数字技术发展促使在线教育、远程医疗等行业对一对一实时音视频通信需求激增。传统方式存在低延迟、高画质及多场景适配不足等问题,而EasyRTC凭借音视频处理、高效信令交互与智能网络适配技术,打造稳定低延迟通信,满足基础通信…...

Linux/aarch64架构下安装Python的Orekit开发环境
1.背景 国产化趋势越来越强,从软件到硬件,从操作系统到CPU,甚至显卡,就产生了在国产ARM CPU和Kylin系统下部署Orekit的需求,且之前的开发是基于Python的,需要做适配。 2.X86架构下安装Python/Orekit开发环…...
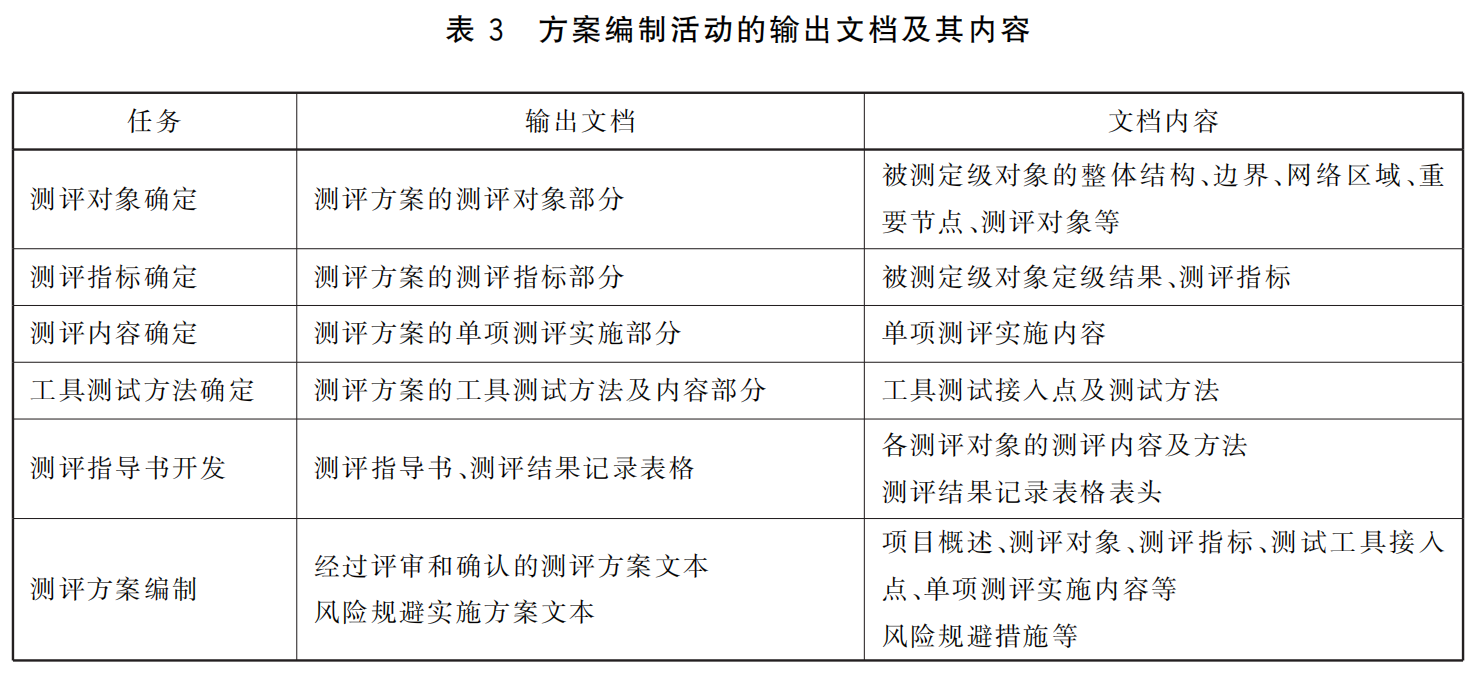
网络安全-等级保护(等保) 3-2-1 GB/T 28449-2019 第6章 方案编制活动
################################################################################ GB/T 28449-2019《信息安全技术 网络安全等级保护测评过程指南》是规定了等级测评过程,是纵向的流程,包括:四个基本测评活动:测评准备活动、方案编制活…...

Oracle Enqueue Names
Oracle Enqueue Names Enqueue(排队锁)是Oracle数据库中用于协调多进程并发访问共享资源的锁机制。 This appendix lists Oracle enqueues. Enqueues are shared memory structures (locks) that serialize access to database resources. They can be…...
【免费使用】剪Y专业版 8.1/CapCut 视频编辑处理,素材和滤镜
—————【下 载 地 址】——————— 【本章下载一】:https://pan.xunlei.com/s/VOQxk38EUe3_8Et86ZCH84JsA1?pwdkp7h# 【本章下载二】:https://pan.quark.cn/s/388008091ab4 【本章下载三】:https://drive.uc.cn/s/d5ae5c725637…...
)
【DCGMI专题1】---DCGMI 在 Ubuntu 22.04 上的深度安装指南与原理分析(含架构图解)
目录 一、DCGMI 概述与应用场景 二、Ubuntu 22.04 系统准备 2.1 系统要求 2.2 环境清理(可选) 三、DCGMI 安装步骤(详细图解) 3.1 安装流程总览 3.2 分步操作指南 3.2.1 系统更新与依赖安装 3.2.2 添加 NVIDIA 官方仓库 3.2.3 安装数据中心驱动与 DCGM 3.2.4 服务…...

道德经总结
道德经 《道德经》是中国古代伟大哲学家老子所著,全书约五千字,共81章,分为“道经”(1–37章)和“德经”(38–81章)两部分。 《道德经》是一部融合哲学、政治、人生智慧于一体的经典著作。它提…...

实现rpc通信机制(待定)
一、概述 (1)rpc(remote procedure call, 远程接口调用),就像在本地调用函数一样,是应用组成服务内部分布式的基础功能。应用场景是在内网中的计算,比如:(a) 为上传的一张图片加水印、…...

MATLAB 2023b 配电柜温度报警系统仿真
MATLAB 2023b 配电柜温度报警系统仿真 下面是一个配电柜温度报警系统的MATLAB仿真代码,包含温度监测、断路器控制和声光报警功能。 classdef ElectricalPanelTemperatureAlertSystem < handleproperties% 系统参数TemperatureThreshold = 94; % 温度阈值(摄氏度)Simulati…...

代码随想录打卡|Day45 图论(孤岛的总面积 、沉没孤岛、水流问题、建造最大岛屿)
图论part03 孤岛的总面积 代码随想录链接 题目链接 视频讲解链接 思路:既然某个网格在边界上的岛屿不是孤岛,那么就把非 孤岛的所有岛屿变成海洋,最后再次统计还剩余的岛屿占据的网格总数即可。 dfs: import java.util.Scanner…...
SpringCloud实战:使用Sentinel构建可靠的微服务熔断机制
上篇文章简单介绍了SpringCloud系列Gateway的基本用法以及Demo搭建,今天继续讲解下SpringCloud Gateway实战指南!在分享之前继续回顾下本次SpringCloud的专题要讲的内容: 本教程demo源码已放入附件内 技术准备 读者须知: 本教程…...
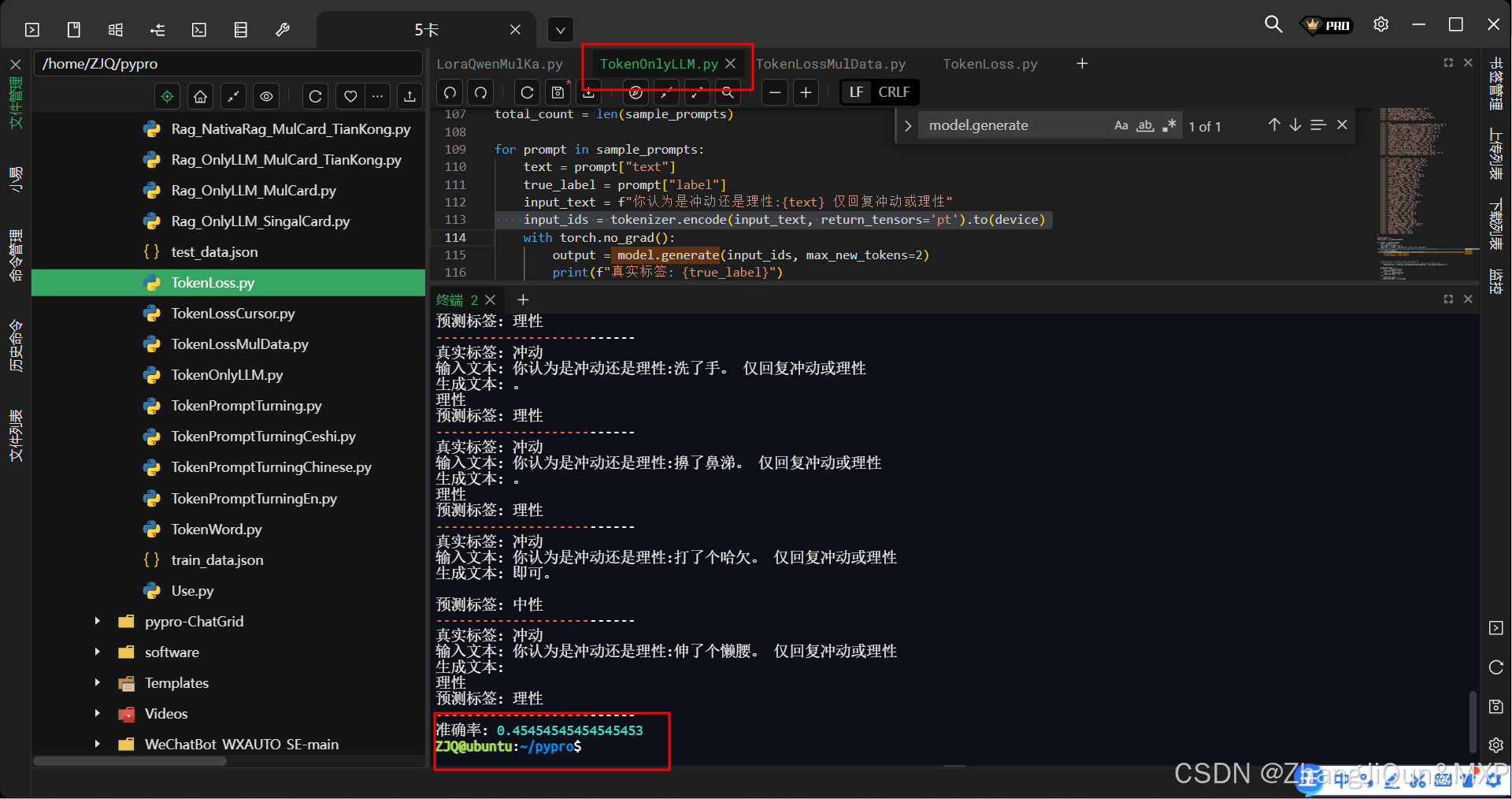
张 Prompt Tuning--中文数据准确率提升:理性与冲动识别新突破
Prompt Tuning–中文数据准确率提升:理性与冲动识别新突破 中文数据,准确率 数据标签三类:冲动21,理性21,(中性设为理性40:说明prompt 修正的有效性) 测试数据:冲动4,理性4,中性设为理性10 为了可视化做了 词嵌入 空间的相似文本计算,但是实际当loss 比较小的时…...

MySQL 中 information_schema.processlist 使用原理
一、概念篇:深入理解 processlist 1.1 什么是 information_schema.processlist information_schema.processlist 是 MySQL 提供的一个非常重要的系统视图,它展示了当前 MySQL 服务器中所有正在运行的线程(连接)信息。这个视图对…...

微信小程序学习基础:从入门到精通
文章目录 第一章:微信小程序概述1.1 什么是微信小程序1.2 小程序与原生APP、H5的区别1.3 小程序的发展历程与现状 第二章:开发环境搭建2.1 注册小程序账号2.2 安装开发者工具2.3 开发者工具界面介绍2.4 第一个小程序项目 第三章:小程序框架与…...
)
如何使用redis做限流(golang实现小样)
在实际开发中,限流(Rate Limiting)是一种保护服务、避免接口被恶意刷流的常见技术。常用的限流算法有令牌桶、漏桶、固定窗口、滑动窗口等。由于Redis具备高性能和原子性操作,常常被用来实现分布式限流。 下面给出使用Golang结合Redis实现简单限流的几种常见方式(以“固定…...

lanqiaoOJ 4185:费马小定理求逆元
【题目来源】 https://www.lanqiao.cn/problems/4185/learning/ 【题目描述】 给出 n,p,求 。其中, 指存在某个整数 0≤a<p,使得 na mod p1,此时称 a 为 n 的逆元,即 。数据保证 p 是质数且 n mod p≠0…...

深度剖析ZooKeeper
1. ZooKeeper架构总览 ZooKeeper 是一个分布式协调服务,广泛用于分布式系统中的配置管理、命名服务、分布式锁和领导选举等场景。以下是对 ZooKeeper 架构、通信机制、容错处理、数据一致性与可靠性等方面的详细剖析。 一、ZooKeeper 主从集群 ZooKeeper 采用 主从…...
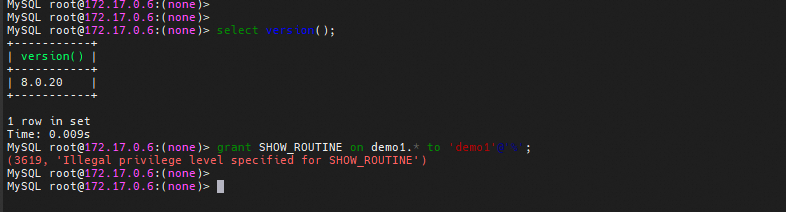
深入解析 MySQL 中的 SHOW_ROUTINE 权限
目录 前言 权限作用 授权方法 MySQL8.0.20以上 MySQL8.0.20以下 总结 前言 SHOW_ROUTINE 是 MySQL 中用于控制用户查看存储过程和函数定义的权限。拥有该权限的用户可以通过 SHOW CREATE PROCEDURE 和 SHOW CREATE FUNCTION 等语句查看存储过程和函数的详细定义ÿ…...

电脑网络如何改ip地址?ip地址改不了怎么回事
在日常使用电脑上网时,我们有时会遇到需要更改IP地址的情况,比如访问某些受限制的网站、解决网络冲突问题,或者出于隐私保护的需求。然而,许多用户在尝试修改IP地址时可能会遇到各种问题,例如IP地址无法更改、修改后无…...
打开小程序提示请求失败(小程序页面空白)
1、小程序代码是商城后台下载的还是自己编译的 (1)要是商城后台下载的,检查设置里面的域名是不是https的 (2)要是自己编译的,检查app.js里面的接口域名是不是https的,填了以后有没有保存 注&a…...

C语言速成12之指针:程序如何在内存迷宫里找宝藏?
程序员Feri一名12年的程序员,做过开发带过团队创过业,擅长Java、鸿蒙、嵌入式、人工智能等开发,专注于程序员成长的那点儿事,希望在成长的路上有你相伴!君志所向,一往无前! 0. 前言:程序如何在内存迷宫里找宝藏? 想象内存是一个巨…...

一张纸决定的高度
从我捧起《格局》这个本书开始,转眼间两个月过去了。 回头望一望,好似还在昨天。 这两个月,心态在变,前进的方向在变,但唯一不变的就是每天晚上睡前,留给自己十分钟的读书时光。 我也从来没想过…...

IP查询基础介绍
IP 查询原理 IP 地址是网络设备唯一标识,IP 查询通过解析 IP 地址获取地理位置、运营商等信息。目前主流的 IPv4(32 位)与 IPv6(128 位)协议,前者理论提供约 43 亿地址,后者地址空间近乎无限。…...
常见的gittee开源项目推荐
https://gitee.com/macrozheng/mall https://doc.ruoyi.vip/ https://eladmin.vip/ https://gitee.com/dromara/RuoYi-Cloud-Plus https://gitee.com/dromara/RuoYi-Vue-Plus https://gitee.com/ZhongBangKeJi/crmeb_java...

日常效率工具【Tools】【持续更新】
日常效率工具【Tools】 VScodevscode原理(居然和Chrome同源)Chromium(Chrome开源版)node.js:让JavaScript可以运行在wab之外的环境 配置文件setting.jesn vscode快捷键万事不求人(Ctrl K,Ctrl S)vscode修改光标所在行的背景色Gene…...