深度剖析ZooKeeper
1. ZooKeeper架构总览
ZooKeeper 是一个分布式协调服务,广泛用于分布式系统中的配置管理、命名服务、分布式锁和领导选举等场景。以下是对 ZooKeeper 架构、通信机制、容错处理、数据一致性与可靠性等方面的详细剖析。
一、ZooKeeper 主从集群
ZooKeeper 采用 主从架构(Leader-Follower),通过 ZAB 协议(ZooKeeper Atomic Broadcast) 实现数据一致性。主要角色如下:
| 角色 | 描述 |
|---|---|
| Leader | 负责事务请求的处理和集群数据的一致性维护(事务写操作) |
| Follower | 接受客户端请求(读为主),参与投票,转发写请求给 Leader |
| Observer | 只参与读取和转发,不参与投票(提高读扩展性) |
| Client | ZooKeeper 的使用者,连接到任意一个 Server 进行读写操作 |
二、集群内部通信机制
ZooKeeper 使用 TCP 进行集群间通信,关键通信通道包括:
1. Leader 选举通信
-
通过 Fast Leader Election(快速选举算法)
-
所有节点在启动时进行投票,目标是选出一个具有最大 ZXID(事务ID)的节点为 Leader
-
采用 majority 投票机制(过半) 来保证选举成功
2. 数据同步通信
-
写请求(事务):Follower → Leader → Follower
-
Follower 将写请求转发给 Leader
-
Leader 提议(Proposal),广播给 Followers
-
超过半数 Follower 发送 ACK,Leader 才 Commit
-
Leader 广播 Commit 指令,所有节点应用事务(数据最终一致)
-
-
读请求:默认从本地节点直接返回(可能是旧数据)
-
可使用
sync()保证强一致读取,强制与 Leader 同步
-
三、ZAB 协议:核心一致性算法
ZAB(ZooKeeper Atomic Broadcast)是 ZooKeeper 的核心协议,类似于 Raft/Paxos,专为:
-
崩溃恢复
-
高吞吐事务广播
-
顺序一致性
ZAB 工作流程
1. 广播阶段(消息广播)
-
所有写请求必须由 Leader 提议(Proposal)
-
使用事务日志(事务ID 为 ZXID)
-
写入 WAL(预写日志) → 发送 Proposal → Follower ACK → Leader Commit → 全部同步
2. 崩溃恢复阶段
-
Leader 崩溃后重新选举
-
新 Leader 同步所有 Follower 的日志,选择拥有最大 ZXID 的日志进行恢复
-
多数节点同步成功后进入广播阶段
四、数据一致性保证
ZooKeeper 提供 顺序一致性模型(Sequential Consistency):
| 特性 | 说明 |
|---|---|
| 顺序一致性 | 所有客户端看到的更新顺序一致 |
| 原子性 | 请求要么成功,要么失败,不存在部分完成 |
| 单一系统镜像 | 所有节点表现一致 |
| 会话保证 | 客户端对某一节点的操作具有顺序性 |
| 可靠性 | 一旦数据写入成功,不会丢失 |
ZooKeeper 不是强一致系统,但通过事务日志(WAL)+ ZAB 实现了最终一致性,对于客户端使用是顺序一致的。
五、容错与故障处理机制
1. 节点故障
-
Follower 故障:不会影响服务,只要多数节点存在即可
-
Leader 故障:触发重新选举,客户端连接自动迁移到其他节点
2. 脑裂防护
-
所有写操作必须获得过半节点 ACK,防止部分节点更新数据造成不一致(如3节点集群至少2个同意)
3. 客户端重连
-
ZooKeeper 提供 session 重连机制
-
临时节点与 Watch 会话相关,一旦会话失效即删除
六、数据可靠性保障机制
1. 事务日志 + 快照
-
所有写操作先写入磁盘事务日志(
log文件) -
定期保存快照(
snapshot),用于恢复和启动
2. 磁盘刷写机制
-
默认配置下使用
fsync确保日志落盘,防止系统崩溃导致数据丢失
3. 写入机制
-
写入成功只有在Leader 收到大多数 Follower 的 ACK后才确认
-
防止单点写入造成脏数据
七、部署建议与集群规模
| 集群节点数 | 最小推荐为奇数 |
|---|---|
| 推荐 3、5、7 个节点 | 保证过半多数投票机制可用 |
| Observer 节点 | 可扩展读能力,不影响写一致性 |
2. ZooKeeper在Hadoop中的应用
结合 Hadoop 的使用场景深入分析 ZooKeeper 的应用和作用,可以从以下几个方面切入:组件依赖、协调作用、故障应对、集群一致性维护,以及实战部署建议等。下面逐一详解。
一、ZooKeeper 在 Hadoop 生态中的应用场景
在 Hadoop 生态中,ZooKeeper 扮演“分布式协调器”的角色,提供高可用性控制、状态协调和元数据一致性保障。其关键应用包括:
1. HDFS 高可用(HA)中的 NameNode 选主
-
ZooKeeper 用于协调 Active-Standby NameNode 的状态切换
-
ZKFailoverController (ZKFC)组件与 ZooKeeper 通信,实现自动主备切换 -
原理:
-
NameNode 启动后注册临时节点(ephemeral znodes)到 ZooKeeper
-
只有一个节点能成功注册(获得锁)成为 Active
-
一旦 Active 宕机,znode 自动删除,Standby 重新竞选
-
2. YARN ResourceManager HA
-
与 HDFS 类似,YARN 的 ResourceManager 高可用也依赖 ZooKeeper 来协调 Active/Standby
-
客户端从 ZooKeeper 获取当前 Active RM 地址进行资源请求
3. HBase Master 和 RegionServer 协调
-
HBase 完全依赖 ZooKeeper 来实现Master 主备选举、RegionServer 注册/心跳管理、Region 元数据存储
-
RegionServer 会在 ZooKeeper 上注册自己的状态,并维持心跳
-
一旦宕机,ZooKeeper 自动删除 znode,Master 感知并触发 region 重分配
4. Hive/Impala/Presto 元数据锁与 HA
-
Hive Server2 可通过 ZooKeeper 实现服务发现与负载均衡
-
Impala 使用 ZooKeeper 来协调 catalog 服务主备状态
二、ZooKeeper 协调 Hadoop 的原理机制
1. 分布式锁机制
-
Hadoop 使用 ZooKeeper 的 ephemeral nodes + sequential nodes 来实现公平锁(如主备 NameNode)
-
谁先成功创建顺序节点,谁获得锁;失败者 watch 上一个节点变化
2. 状态监听机制
-
Watcher 机制用于监控 znode 状态变化,Hadoop 的 ZKFC/RegionServer 都依赖这点来感知系统状态变化
3. 心跳保活机制
-
使用 ephemeral 节点反映各组件存活状态,一旦宕机,节点消失,Master 能立即感知
三、故障处理流程示例:HDFS HA 切换过程
场景:Active NameNode 宕机
处理流程:
-
ZooKeeper 会删除该 NameNode 的 ephemeral znode
-
其他 Standby NameNode 通过 ZKFC 监听该 znode 的删除事件
-
发起选举,尝试创建新的 ephemeral znode
-
先创建成功的 Standby 升级为 Active,开始对外提供服务
-
新 Active 节点接管 editlog 并恢复 Namespace 元数据
优势:
-
自动感知故障、快速切换
-
数据不依赖 ZooKeeper,只协调状态和锁
四、数据一致性与 ZooKeeper 的保障角色
HDFS 与 ZK 的配合重点在“元状态一致性”
-
元数据一致性:Active NameNode 的切换需严格串行,避免“脑裂”
-
ZooKeeper 确保 NameNode 选主是“单点可见”的,通过事务型 znode(例如
/hdfs-ha/namespace/ActiveBreadCrumb)实现
HBase 的强一致保障
-
HBase 在写入时将 Region 信息注册至 ZooKeeper
-
所有读写都依赖这个元数据,避免客户端误访问错误 Region
五、ZooKeeper 与 Hadoop 协同部署建议
| 配置项 | 建议 |
|---|---|
| ZooKeeper 节点数量 | 推荐奇数(3、5),确保多数机制 |
| 部署独立于 Hadoop | 避免 ZooKeeper 与 NameNode、RM 等同部署,隔离故障域 |
| 数据目录存储 | 使用 SSD,本地磁盘,启用 fsync 保证 WAL 写入可靠 |
| 使用 Observer 节点 | 对于大规模读取(如 HBase),可扩展 ZooKeeper 集群读吞吐 |
| Watcher 控制 | 避免过多 Watch(HBase 支持 Watch batch),否则 ZooKeeper 压力大 |
| 会话超时调优 | HBase 推荐 30~90 秒,YARN 与 HDFS 可适当缩短,提升故障感知速度 |
六、典型问题与优化建议
| 问题场景 | 分析 | 优化建议 |
|---|---|---|
| Leader 崩溃后切换慢 | ZKFC 监听响应时间过长 | 调整 zk.session.timeout、ZKFC 配置 |
| ZooKeeper 节点负载高 | Watch 数量多、读写大 | 增加 Observer 节点,限制监听粒度 |
| 脑裂问题 | NameNode 多实例均认为自己是 Active | 加强 zk ACL 管理,配置 fencing 脚本 |
| ZooKeeper WAL 损坏 | 节点宕机或磁盘掉电 | 启用 forceSync=yes,定期快照备份 |
七、总结
| 维度 | 作用 |
|---|---|
| 可用性保障 | HDFS/YARN HA 通过 ZooKeeper 自动主备切换 |
| 状态协调 | HBase 使用 ZooKeeper 管理 RegionServer 和 Region 元数据 |
| 故障检测 | ZooKeeper 的 ephemeral node 和 Watch 实现自动感知机制 |
| 一致性保障 | ZAB 协议确保元状态更新在多节点间的一致广播 |
| 集群弹性 | Observer 模式支持横向读扩展;Leader 只负责写一致性 |
3. ZooKeeper 故障演练手册(针对 Hadoop/HBase 高可用架构)
针对 ZooKeeper 在 Hadoop(HDFS/YARN)与 HBase 高可用架构中的故障演练手册,涵盖常见故障类型、预期表现、演练方法、验证指标、恢复步骤和演练目标,适合于生产环境灰度测试或灾备演练。
一、基础环境前提
-
ZooKeeper 集群:3 或 5 节点部署(如 zk1, zk2, zk3)
-
HDFS 启用 HA(nn1, nn2 + zkfc)
-
YARN 启用 HA(rm1, rm2)
-
HBase 启用 HA(master1, master2 + 多个 RegionServer)
-
所有系统均正确配置 ZooKeeper
二、演练目标
-
验证 ZooKeeper 单节点/多节点故障时系统的可用性表现
-
验证 HDFS、YARN、HBase 的自动 failover 能力与数据一致性保障
-
检查报警触发、系统自恢复能力、手动干预流程有效性
-
提升运维人员处理 ZooKeeper 故障的能力
三、演练项列表
| 编号 | 故障类型 | 影响模块 | 预期表现 |
|---|---|---|---|
| F1 | 单个 ZooKeeper 节点宕机 | 所有 | 集群正常,功能不受影响 |
| F2 | 超过半数 ZooKeeper 节点宕机 | 所有 | ZK 失效,HDFS/HBase 选主失败 |
| F3 | NameNode Active 宕机 | HDFS | Standby 自动切换为 Active |
| F4 | ZooKeeper 日志写满 | HBase | RegionServer 心跳失效,异常下线 |
| F5 | ZooKeeper 网络延迟或抖动 | HDFS/HBase | 选主超时,短暂不可用 |
| F6 | RegionServer zk 会话过期 | HBase | Region 自动重分配,数据不中断 |
四、详细演练操作与恢复
F1. ZooKeeper 单节点宕机(zk1)
操作步骤:
ssh zk1
systemctl stop zookeeper
预期表现:
-
ZooKeeper 仍能选主
-
HDFS、YARN、HBase 正常运行
-
zkServer.sh status显示 zk2 为 leader,zk3 为 follower
验证点:
-
ZooKeeper
mntr端口输出正常 -
HDFS
hdfs haadmin -getServiceState输出正确 -
HBase Master UI/日志无选主异常
恢复步骤:
systemctl start zookeeper
F2. ZooKeeper 超半数节点宕机(zk1 + zk2)
操作步骤:
ssh zk1 && systemctl stop zookeeper
ssh zk2 && systemctl stop zookeeper
预期表现:
-
ZooKeeper 无法选主,HDFS ZKFC 无法执行自动 failover
-
HBase RegionServer 报 SessionTimeout
-
HDFS 客户端重试失败,写入卡顿或报错
验证点:
-
ZooKeeper
ruok无响应 -
HDFS zkfc 日志:
ConnectionLossException -
HBase Master 日志:
SessionExpiredException
恢复步骤:
systemctl start zookeeper (zk1/zk2)
等待 ZooKeeper quorum 恢复,验证系统恢复自动化状态
F3. NameNode Active 宕机
操作步骤:
ssh nn1
kill -9 `jps | grep NameNode | awk '{print $1}'`
预期表现:
-
ZKFC 触发自动切换,Standby 成为 Active
-
HDFS 客户端正常写入/读取
验证点:
hdfs haadmin -getServiceState nn1
# 输出:unknown 或无响应hdfs haadmin -getServiceState nn2
# 输出:active
恢复步骤:
start-dfs.sh
F4. ZooKeeper 日志爆满模拟(zk1)
操作步骤:
# 禁用快照清理
echo "autopurge.purgeInterval=0" >> zoo.cfg# 写入大量 znodes(可用 zkCli.sh 创建临时节点批量)
for i in {1..10000}; do create /test$i data$i; done
预期表现:
-
ZooKeeper 写失败或性能急剧下降
-
HBase RegionServer zk 会话丢失,出现 down 现象
验证点:
-
查看 zk 日志:
WARN fsync-ing the write ahead log -
RegionServer 日志:
SessionTimeoutException
恢复步骤:
# 清理 zk 日志文件
rm -rf /data/zookeeper/version-2/log.*# 启用自动清理
autopurge.purgeInterval=1
systemctl restart zookeeper
F5. ZooKeeper 网络抖动
操作步骤:
在 zk1 上模拟网络延迟:
tc qdisc add dev eth0 root netem delay 200ms loss 20%
预期表现:
-
部分 znode 请求超时
-
ZKFC 或 RegionServer 可能发生异常切换或短暂连接中断
验证点:
-
zkfc 日志有连接断开重连记录
-
ZooKeeper metrics 显示 client连接数波动
恢复:
tc qdisc del dev eth0 root netem
F6. 模拟 HBase RegionServer zk 会话过期
操作步骤:
-
在 RegionServer 上挂起进程(模拟无响应)
kill -STOP `jps | grep HRegionServer | awk '{print $1}'`
预期表现:
-
zk 会话断开,znode 被删除
-
HMaster 检测 RegionServer 失联,自动重分配 Region
恢复步骤:
kill -CONT <pid>
五、补充建议
| 方面 | 建议 |
|---|---|
| 告警系统 | 整合 ZK 连接数、延迟、会话异常到 Prometheus + Alertmanager |
| 演练频率 | 每季度进行一次 HA 故障模拟 |
| 自动化 | 使用 Ansible/ChaosBlade 自动化注入故障和恢复 |
| 日志收集 | 所有组件 zk 相关日志单独汇总便于排查 |
4. 故障演练脚本合集
以下是 ZooKeeper + Hadoop/HBase 高可用集群下的故障演练脚本合集,涵盖 bash 脚本 和 Ansible Playbook 两种方式,支持自动注入故障与恢复操作,便于定期进行演练或集成至 CI/CD 流程。
一、Bash 脚本合集(适合手动测试或定时调度)
1. 模拟 ZooKeeper 单节点宕机
#!/bin/bash
ZK_NODE=$1ssh $ZK_NODE "sudo systemctl stop zookeeper"
echo ">> ZooKeeper on $ZK_NODE stopped."
2. 模拟 ZooKeeper 多节点(过半)宕机
#!/bin/bash
ZK_NODES=("zk1" "zk2")for node in "${ZK_NODES[@]}"; dossh $node "sudo systemctl stop zookeeper"echo ">> ZooKeeper on $node stopped."
done
3. 模拟 HDFS Active NameNode 宕机
#!/bin/bash
NN_ACTIVE_HOST="nn1"ssh $NN_ACTIVE_HOST "kill -9 \$(jps | grep NameNode | awk '{print \$1}')"
echo ">> NameNode on $NN_ACTIVE_HOST killed."
4. 模拟 RegionServer 会话过期
#!/bin/bash
RS_HOST=$1
ssh $RS_HOST "kill -STOP \$(jps | grep HRegionServer | awk '{print \$1}')"
echo ">> RegionServer on $RS_HOST frozen (STOP)."
恢复:
ssh $RS_HOST "kill -CONT \$(jps | grep HRegionServer | awk '{print \$1}')"
5. 模拟 ZooKeeper 网络抖动
#!/bin/bash
ZK_NODE=$1
DELAY=300ms
LOSS=20%ssh $ZK_NODE "sudo tc qdisc add dev eth0 root netem delay $DELAY loss $LOSS"
echo ">> Network delay/loss injected on $ZK_NODE"
恢复:
ssh $ZK_NODE "sudo tc qdisc del dev eth0 root netem"
二、Ansible 演练剧本合集(适合批量、自动化)
1. 目录结构
zk-fault-injection/
├── inventory
├── playbooks/
│ ├── zk_stop.yml
│ ├── zk_network_delay.yml
│ ├── nn_kill.yml
│ ├── rs_suspend.yml
2. inventory 示例
[zookeeper]
zk1 ansible_host=192.168.1.10
zk2 ansible_host=192.168.1.11
zk3 ansible_host=192.168.1.12[namenodes]
nn1 ansible_host=192.168.1.20[hbase_rs]
rs1 ansible_host=192.168.1.30
3. zk_stop.yml
- name: Stop ZooKeeper nodeshosts: zookeeperbecome: truetasks:- name: Stop ZooKeeper servicesystemd:name: zookeeperstate: stopped
4. nn_kill.yml
- name: Kill Active NameNodehosts: namenodestasks:- name: Kill NameNode processshell: "kill -9 $(jps | grep NameNode | awk '{print $1}')"
5. zk_network_delay.yml
- name: Inject network delayhosts: zookeeperbecome: truetasks:- name: Add network delayshell: "tc qdisc add dev eth0 root netem delay 300ms loss 20%"
恢复:
- name: Remove network delayhosts: zookeeperbecome: truetasks:- name: Clear netemshell: "tc qdisc del dev eth0 root netem"
6. rs_suspend.yml
- name: Suspend RegionServer processhosts: hbase_rstasks:- name: STOP RegionServershell: "kill -STOP $(jps | grep HRegionServer | awk '{print $1}')"- name: Wait 30spause:seconds: 30- name: RESUME RegionServershell: "kill -CONT $(jps | grep HRegionServer | awk '{print $1}')"
三、扩展建议
| 场景 | 建议 |
|---|---|
| 大规模多集群 | 使用标签化 inventory 支持多集群参数管理 |
| 灰度环境定时演练 | 将脚本接入 Jenkins、Airflow 或 Kube-native Job |
| 监控联动 | 自动触发 Prometheus 告警/Slack 报警联动 |
| 日志追踪 | 配合 ELK 统一采集 zkfc、HMaster、RS 的故障日志 |
5. ZooKeeper 在 Kafka中的应用
ZooKeeper 是 Kafka 早期架构中的核心协调组件,主要负责 Kafka 中控制器(Controller)的选举、分区 Leader 的元数据维护等。下面我们将系统剖析 Kafka 与 ZooKeeper 的协调机制,并详细说明主节点(Controller)挂掉后 Kafka 如何选举新的 Leader。
一、Kafka 与 ZooKeeper 的协调机制(核心职责)
Kafka 依赖 ZooKeeper 进行以下几方面协调:
| 功能 | 说明 |
|---|---|
| Controller 选举 | Kafka 启动时,第一个抢占 /controller ZNode 的 Broker 成为 Controller。 |
| Topic 元数据存储 | topic 配置、副本关系、分区状态等写入 ZooKeeper |
| 分区 Leader 分配 | Controller 将每个 partition 的 leader 副本记录到 /brokers/topics/<topic>/partitions/<n>/state |
| Broker 状态监控 | 每个 Kafka Broker 向 ZooKeeper 注册临时节点 /brokers/ids/<brokerId>,宕机会自动删除 |
| ISR 列表维护 | Kafka Controller 根据 ZooKeeper 记录的 ISR 列表决定 leader 切换策略 |
二、Kafka Controller 是什么?
Kafka 集群中会从所有 Broker 中选出一个 Controller,它负责:
-
监控所有 Broker 和 Topic 元数据变化
-
为所有 Partition 分配 Leader、副本、ISR
-
在 Broker 宕机或恢复时,重新分配 Leader
-
管理分区迁移(rebalance)
Controller 仅有一个,通过 ZooKeeper 中的 /controller 节点实现锁机制,其他 Broker 会监听该节点变化。
三、主节点(Controller)挂掉后的选举流程详解
1. 故障检测
-
Kafka 的所有 Broker 都在监听 ZooKeeper 的
/controller节点 -
当前 Controller Broker 挂掉后,其 ZooKeeper 会话失效,临时节点
/controller被自动删除
2. Controller 选举触发
-
所有其他 Broker 接收到
/controller节点被删除的 Watcher 事件后,开始竞争 Controller -
Kafka 使用“先到先得”的方式尝试创建
/controller节点:zkClient.createEphemeral("/controller", brokerId) -
创建成功者即成为新的 Controller
3. 新 Controller 执行恢复任务
新 Controller 会立即进行以下动作:
| 操作 | 说明 |
|---|---|
| 重建集群元数据缓存 | 读取 ZooKeeper 上所有 Topic、Partition、Broker、ISR 信息 |
| 重新选举 Partition Leader | 遍历所有 partition,如果当前 leader 已失效,则从 ISR 中选出新的 leader |
| 更新 ZooKeeper state 节点 | 写入新的 /brokers/topics/.../state,客户端即可读取新 leader 信息 |
4. Leader 更新通知给各 Broker
-
Kafka 使用 Controller-to-Broker channel(RPC),通知各个 Broker 相关分区的 leader 有更新
-
每个 Broker 本地更新自己的分区 leader 表(PartitionStateInfo)
四、举例说明
假设有如下 Kafka 架构:
-
ZooKeeper 集群:zk1, zk2, zk3
-
Kafka Broker:broker-101, broker-102, broker-103
-
Partition:
topic-A有 3 个分区,副本因子为 3
初始状态:
-
Controller 为 broker-101
-
topic-A partition-0 的 leader 是 broker-101
broker-101 突然宕机:
-
/controller节点在 ZooKeeper 中消失(zk 会话失效) -
broker-102 和 broker-103 同时监听到事件
-
broker-102 抢占成功
/controller,成为新 Controller -
broker-102 查询 ZooKeeper ISR 列表,发现 broker-103 仍在 ISR 中
-
将 partition-0 的 leader 变更为 broker-103,并写入 ZooKeeper
-
通知所有相关 Broker 更新本地 leader 缓存
五、可靠性保证机制
| 机制 | 说明 |
|---|---|
| ZooKeeper 强一致性 | 所有 Leader 元数据写入 ZK,确保故障恢复时状态不丢失 |
| ISR 保证数据同步副本安全性 | 只从 ISR(In-Sync Replica)中选 Leader,避免数据丢失 |
| Watcher + 临时节点机制 | Broker 宕机会自动触发 Leader 恢复流程 |
| Kafka Controller 高可用 | 所有 Broker 都能竞争成为 Controller,保障不中断 |
六、Kafka 2.8+ 后的变化(基于 KRaft 模式)
在 Kafka 2.8+ 中,引入了KRaft 模式(Kafka Raft Metadata Mode),完全去除了 ZooKeeper,改为使用自建的 Raft 协议进行 Controller 集群选举和元数据同步:
-
Controller 成为一个 Raft Leader
-
所有元数据写入专用 topic(__cluster_metadata)
-
彻底摆脱 ZooKeeper,简化运维
相关文章:

深度剖析ZooKeeper
1. ZooKeeper架构总览 ZooKeeper 是一个分布式协调服务,广泛用于分布式系统中的配置管理、命名服务、分布式锁和领导选举等场景。以下是对 ZooKeeper 架构、通信机制、容错处理、数据一致性与可靠性等方面的详细剖析。 一、ZooKeeper 主从集群 ZooKeeper 采用 主从…...
深入解析 MySQL 中的 SHOW_ROUTINE 权限
目录 前言 权限作用 授权方法 MySQL8.0.20以上 MySQL8.0.20以下 总结 前言 SHOW_ROUTINE 是 MySQL 中用于控制用户查看存储过程和函数定义的权限。拥有该权限的用户可以通过 SHOW CREATE PROCEDURE 和 SHOW CREATE FUNCTION 等语句查看存储过程和函数的详细定义ÿ…...

电脑网络如何改ip地址?ip地址改不了怎么回事
在日常使用电脑上网时,我们有时会遇到需要更改IP地址的情况,比如访问某些受限制的网站、解决网络冲突问题,或者出于隐私保护的需求。然而,许多用户在尝试修改IP地址时可能会遇到各种问题,例如IP地址无法更改、修改后无…...
打开小程序提示请求失败(小程序页面空白)
1、小程序代码是商城后台下载的还是自己编译的 (1)要是商城后台下载的,检查设置里面的域名是不是https的 (2)要是自己编译的,检查app.js里面的接口域名是不是https的,填了以后有没有保存 注&a…...

C语言速成12之指针:程序如何在内存迷宫里找宝藏?
程序员Feri一名12年的程序员,做过开发带过团队创过业,擅长Java、鸿蒙、嵌入式、人工智能等开发,专注于程序员成长的那点儿事,希望在成长的路上有你相伴!君志所向,一往无前! 0. 前言:程序如何在内存迷宫里找宝藏? 想象内存是一个巨…...

一张纸决定的高度
从我捧起《格局》这个本书开始,转眼间两个月过去了。 回头望一望,好似还在昨天。 这两个月,心态在变,前进的方向在变,但唯一不变的就是每天晚上睡前,留给自己十分钟的读书时光。 我也从来没想过…...

IP查询基础介绍
IP 查询原理 IP 地址是网络设备唯一标识,IP 查询通过解析 IP 地址获取地理位置、运营商等信息。目前主流的 IPv4(32 位)与 IPv6(128 位)协议,前者理论提供约 43 亿地址,后者地址空间近乎无限。…...
常见的gittee开源项目推荐
https://gitee.com/macrozheng/mall https://doc.ruoyi.vip/ https://eladmin.vip/ https://gitee.com/dromara/RuoYi-Cloud-Plus https://gitee.com/dromara/RuoYi-Vue-Plus https://gitee.com/ZhongBangKeJi/crmeb_java...

日常效率工具【Tools】【持续更新】
日常效率工具【Tools】 VScodevscode原理(居然和Chrome同源)Chromium(Chrome开源版)node.js:让JavaScript可以运行在wab之外的环境 配置文件setting.jesn vscode快捷键万事不求人(Ctrl K,Ctrl S)vscode修改光标所在行的背景色Gene…...

PyTorch中TensorBoardX模块与torch.utils.tensorboard模块的对比分析
文章目录 说明1. 模块起源与开发背景2. 功能特性对比3. 安装与依赖关系4. 性能与使用体验5. 迁移与兼容性策略6. 最佳实践与建议7. 未来展望8. 结论实际相关信息推荐资源 说明 TensorBoard:独立工具,只需安装tensorboard。TensorFlow:非必需…...
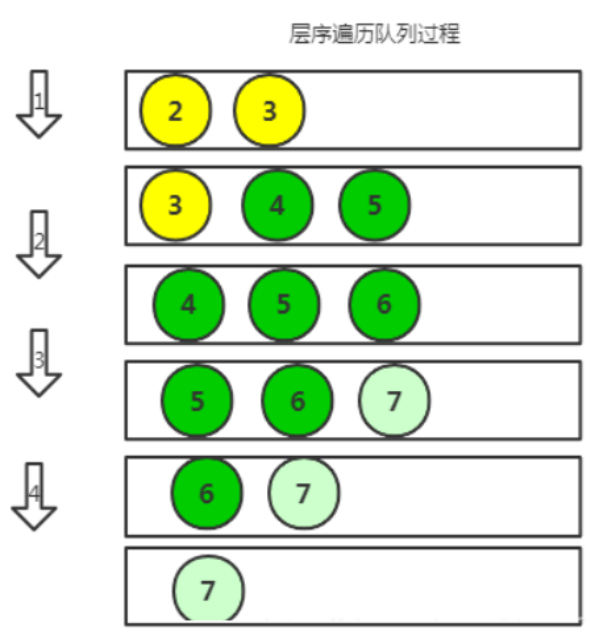
数据结构与算法——链式二叉树
链式二叉树 遍历方式与其规则代码的实现递归的复习前,中,后序遍历的实现二叉树结点个数二叉树叶子结点个数二叉树第k层结点个数二叉树的深度/高度二叉树查找值为x的结点二叉树销毁层序遍历 遍历方式与其规则 前序遍历:访问根结点的操作发⽣在…...
Android12 launcher3修改App图标白边问题
Android12 launcher3修改App图标白边问题 1.前言: 今天在Android12 Rom定制客制化系统应用时发现改变系统App图标的形状会出现一个问题,那就是图标被缩小了,没有显示完整,有一个白边,这在普通的App开发很少遇到&…...
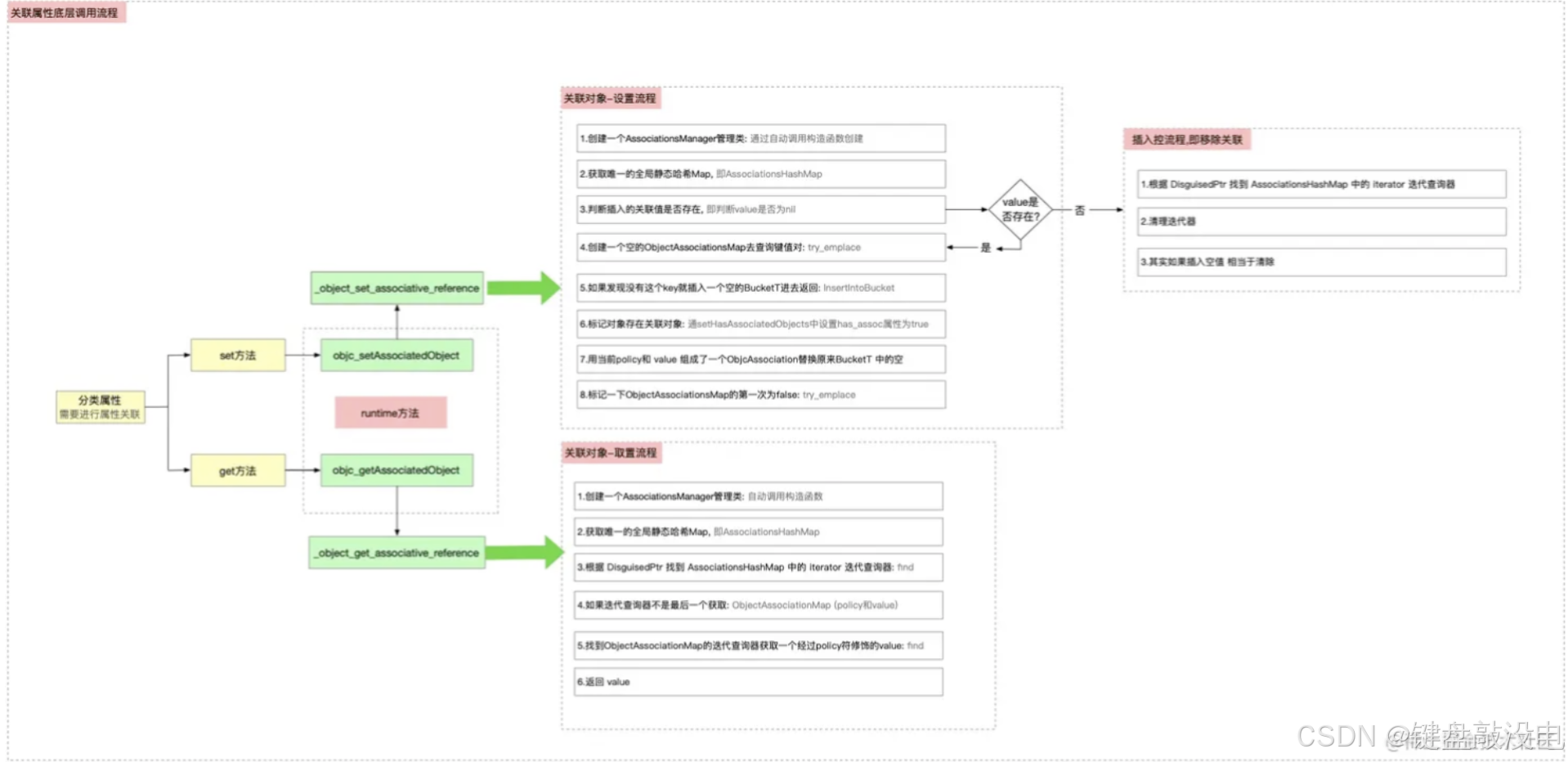
【iOS】分类、扩展、关联对象
分类、扩展、关联对象 前言分类扩展扩展和分类的区别关联对象key的几种用法流程 总结 前言 最近的学习中笔者发现自己对于分类、扩展相关知识并不是很熟悉,刚好看源码类的加载过程中发现有类扩展与关联对象详解。本篇我们来探索一下这部分相关知识,首先…...

内蒙古工程系列建设工程技术人才评审条件
关于印发《内蒙古自治区工程系列建设工程专业技术人才职称评审条件》的通知 内蒙古工程系列建设工程技术人才评审条件适用范围 内蒙古工程系列建设工程技术人才评审条件之技术员评审要求 内蒙古工程系列建设工程技术人才评审条件之助理工程师评审要求 内蒙古工程系列建设工程技…...
)
Elasticsearch超详细安装部署教程(Windows Linux双系统)
文章目录 一、前言二、Windows系统安装部署2.1 环境准备2.2 Elasticsearch安装2.3 安装为Windows服务2.4 Head插件安装2.5 Kibana集成(可选) 三、Linux系统安装部署3.1 环境准备3.2 Elasticsearch安装3.3 系统优化3.4 启动服务3.5 安全配置(可…...

第十六章:数据治理之数据架构:数据模型和数据流转关系
本章我们说一下数据架构,说到数据架构,就很自然的想到企业架构、业务架构、软件架构,因为个人并没有对这些内容进行深入了解,所以这里不做比对是否有相似或者共通的地方,仅仅来说一下我理解的数据架构。 1、什么是架构…...
目标检测DINO-DETR(2023)详细解读
文章目录 对比去噪训练混合查询选择look forward twice 论文全称为:DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection 提出了三个新的方法: 首先,为了改进一对一的匹配效果,提出了一种对比去噪训练方法…...

基于 STM32 的蔬菜智能育苗系统硬件与软件设计
一、系统总体架构 蔬菜智能育苗系统通过单片机实时采集温湿度、光照等环境数据,根据预设阈值自动控制灌溉、补光、通风等设备,实现育苗环境的智能化管理。系统主要包括以下部分: 主控芯片:STM32F103C8T6(32 位 ARM Cortex-M3 单片机,性价比高,适合嵌入式控制)传感器模…...

实现一个带有授权码和使用时间限制的Spring Boot项目
生成和验证授权码记录授权时间和过期时间实现授权逻辑 以下是具体的实现方法: 1. 生成和验证授权码 可以使用加密技术生成和验证授权码。授权码中可以包含有效期等信息,并使用密钥进行签名。 示例代码: java复制代码 import javax.crypt…...

SGlang 推理模型优化(PD架构分离)
一、技术背景 随着大型语言模型(LLM)广泛应用于搜索、内容生成、AI助手等领域,对模型推理服务的并发能力、响应延迟和资源利用效率提出了前所未有的高要求。与模型训练相比,推理是一个持续进行、资源消耗巨大的任务,尤…...

TuyaOpen横空出世!涂鸦智能如何用开源框架重构AIoT开发范式?
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引子:AIoT开发的“不可能三角”被打破 当AI与物理世界深度融合的浪潮席卷全球,开发者们却始终面临一个“不可能三角”——开发…...
Vue语法【2】
1.插值表达式: 语法规则: {{Vue实例中data的变量名}}使用场景: 插值表达式一般使用在文本内容中,如果是元素的属性内容中则无法使用; 案例: <!DOCTYPE html> <html lang"en"> &l…...

2.2.1 05年T2
引言 本文将从一预习、二自习、三学习、四复习等四个阶段来分析2005年考研英语阅读第二篇文章。为了便于后续阅读,我将第四部分复习放在了首位。 四、复习 方法:错误思路分析总结考点文章梳理 4.1 错题分析 题目:26(细节题&…...
)
每日c/c++题 备战蓝桥杯(修理牛棚 Barn Repair)
修理牛棚 Barn Repair 题解 问题背景与挑战 在一个暴风雨交加的夜晚,Farmer John 的牛棚遭受了严重的破坏。屋顶被掀飞,大门也不翼而飞。幸运的是,许多牛正在度假,牛棚并未住满。然而,为了保护那些还在牛棚里的牛&am…...

6个月Python学习计划 Day 3
🎯 今日目标 掌握 while 和 for 循环的使用方式理解 range() 的工作机制实践:打印 1~100、累加、九九乘法表等常见程序逻辑 🧠 学习内容详解 while 循环 i 1 while i < 5:print(f"第 {i} 次循环")i 1📌 特点&…...

Linux虚拟文件系统(2)
2.3 目录项-dentry 目录项,即 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。和上一章中超级块和索引节点不同,目录项并不是实际存在于磁盘上的,…...
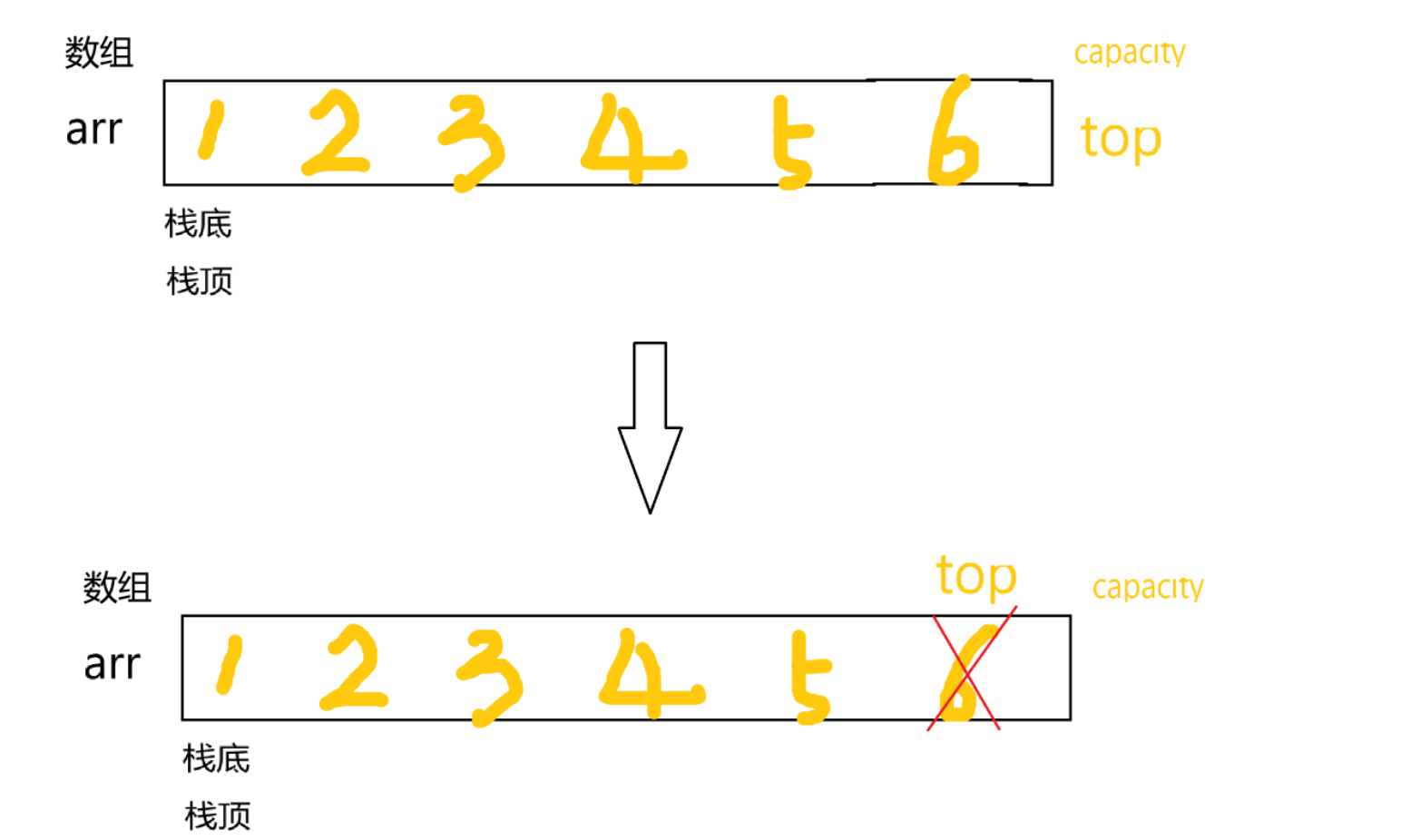
【数据结构】栈和队列(上)
目录 一、栈(先进后出、后进先出的线性表) 1、栈的概念及结构 2、栈的底层结构分析 二、代码实现 1、定义一个栈 2、栈的初始化 3、入栈 3、增容 4、出栈 5、取栈顶 6、销毁栈 一、栈(先进后出、后进先出的线性表) 1、…...

科技赋能·长效治理|无忧树建筑修缮渗漏水长效治理交流会圆满举行!
聚焦行业痛点,共话长效未来!5月16日,由无忧树主办的主题为“科技赋能长效治理”的建筑修缮渗漏水长效治理技术交流会在上海圆满举行。来自全国的建筑企业代表、专家学者、技术精英齐聚一堂,共探渗漏治理前沿技术,见证科…...
【闲聊篇】java好丰富!
1、在学习mybatis-plus的文档时,发现引入了solon依赖,才发现这是一个对标spring生态的框架,有意思! 还有若依框架,真的好丰富~~~~~~~ 2、今天面试官问我,他说很少遇到用redission做延迟队列的。后面我就反…...

STL中list的模拟
这里写目录标题 list 的节点 —— ListNodelist 的 “导览员” —— ListIteratorlist 的核心 —— list 类构造函数迭代器相关操作容量相关操作 结尾 在 C 的 STL(标准模板库)中,list 是一个十分重要的容器,它就像一个灵活的弹簧…...