SGlang 推理模型优化(PD架构分离)
一、技术背景
随着大型语言模型(LLM)广泛应用于搜索、内容生成、AI助手等领域,对模型推理服务的并发能力、响应延迟和资源利用效率提出了前所未有的高要求。与模型训练相比,推理是一个持续进行、资源消耗巨大的任务,尤其在实际业务中,推理服务需要同时支持大量用户请求,保证实时性和稳定性。
在传统架构中,LLM 的输入处理(Prefill)和输出生成(Decode)阶段往往混合部署在同一批 GPU 上。这种“统一架构”虽然实现简单,但很快暴露出严重的性能瓶颈和资源调度困境:Prefill 阶段计算密集、耗时长,容易阻塞 Decode 阶段对低延迟的需求,导致整体吞吐和响应速度下降;而 Decode 阶段则受制于 KV Cache 带宽和访问延迟,难以并发扩展
二、PD 分离介绍讨论
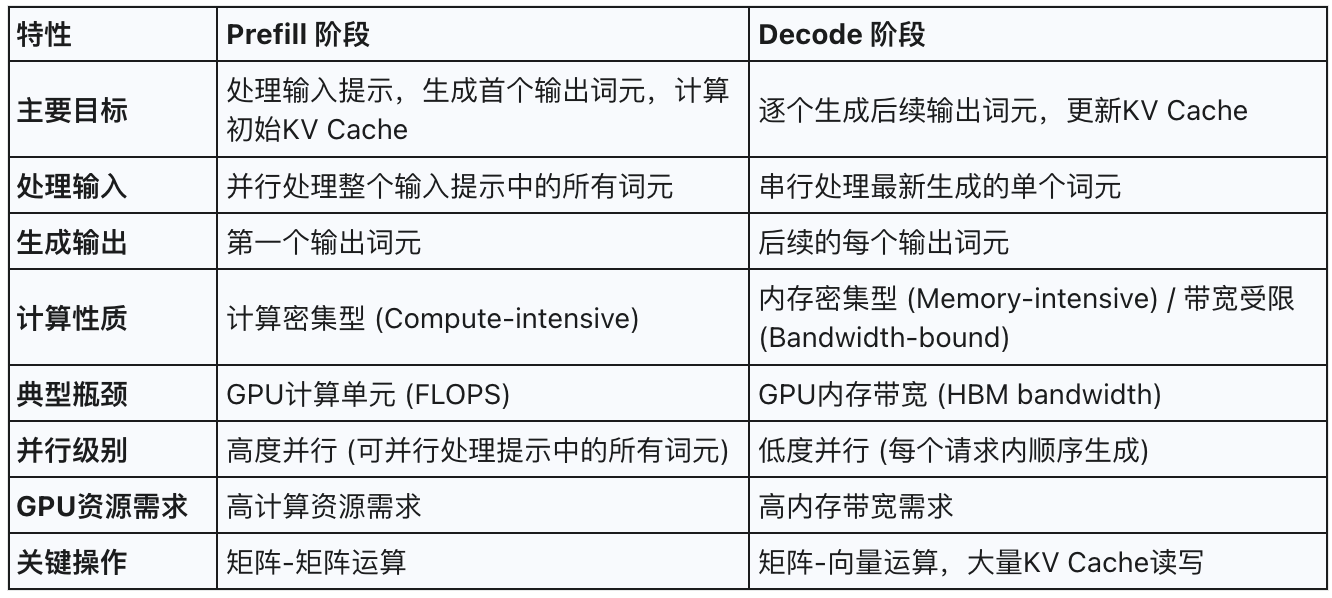
2.1 Prefill阶段:特征与计算需求
Prefill阶段负责并行处理输入提示中的所有词元,生成第一个输出词元,并计算初始的键值缓存 (Key-Value Cache, KV Cache) 。其主要特征是计算密集型 (computationally intensive),通常受限于计算资源 (compute-bound),尤其是在处理较长提示时。在此阶段,模型对输入序列中的每个词元进行并行计算,通常涉及大规模的矩阵-矩阵运算,能够充分利用GPU的并行计算能力,甚至使其达到饱和状态。
2.3 Decode阶段:特征与计算需求
Decode阶段以自回归的方式逐个生成后续的输出词元。在Decode的每一步中,模型仅处理最新生成的那个词元,并结合先前存储在KV Cache中的上下文信息来预测下一个词元。与Prefill阶段不同,Decode阶段每个词元的计算量相对较小,但其主要瓶颈在于内存带宽 (memory-bandwidth-bound) 。这是因为每个解码步骤都需要频繁访问和读取不断增长的KV Cache,涉及的操作主要是矩阵-向量运算。尽管只处理一个新词元,但其对模型权重和KV Cache的I/O需求与Prefill阶段相似。Decode阶段可以看作是“逐字逐句地续写回应”的过程
2.4. KV Cache 机制
KV Cache 是 LLM 高效推理的核心技术。它将每个词元在 Transformer 计算中生成的 Key 和 Value 向量缓存到 GPU 显存,避免重复计算,大幅提升生成效率。
-
Prefill 阶段:为所有输入词元批量生成 KV Cache,计算密集型、强并行。
-
Decode 阶段:每生成一个新词元,都会增量更新 KV Cache,并频繁读取全部缓存内容,这使得 Decode 主要受内存带宽限制。
KV Cache 的容量会随着输入和生成序列的长度线性增长,是 GPU 显存消耗的主要来源。自回归生成的顺序性决定了 Decode 难以高并发,访问 KV Cache 的效率成为系统瓶颈。高效的 KV Cache 管理和分阶段调优是优化大模型推理的关键。
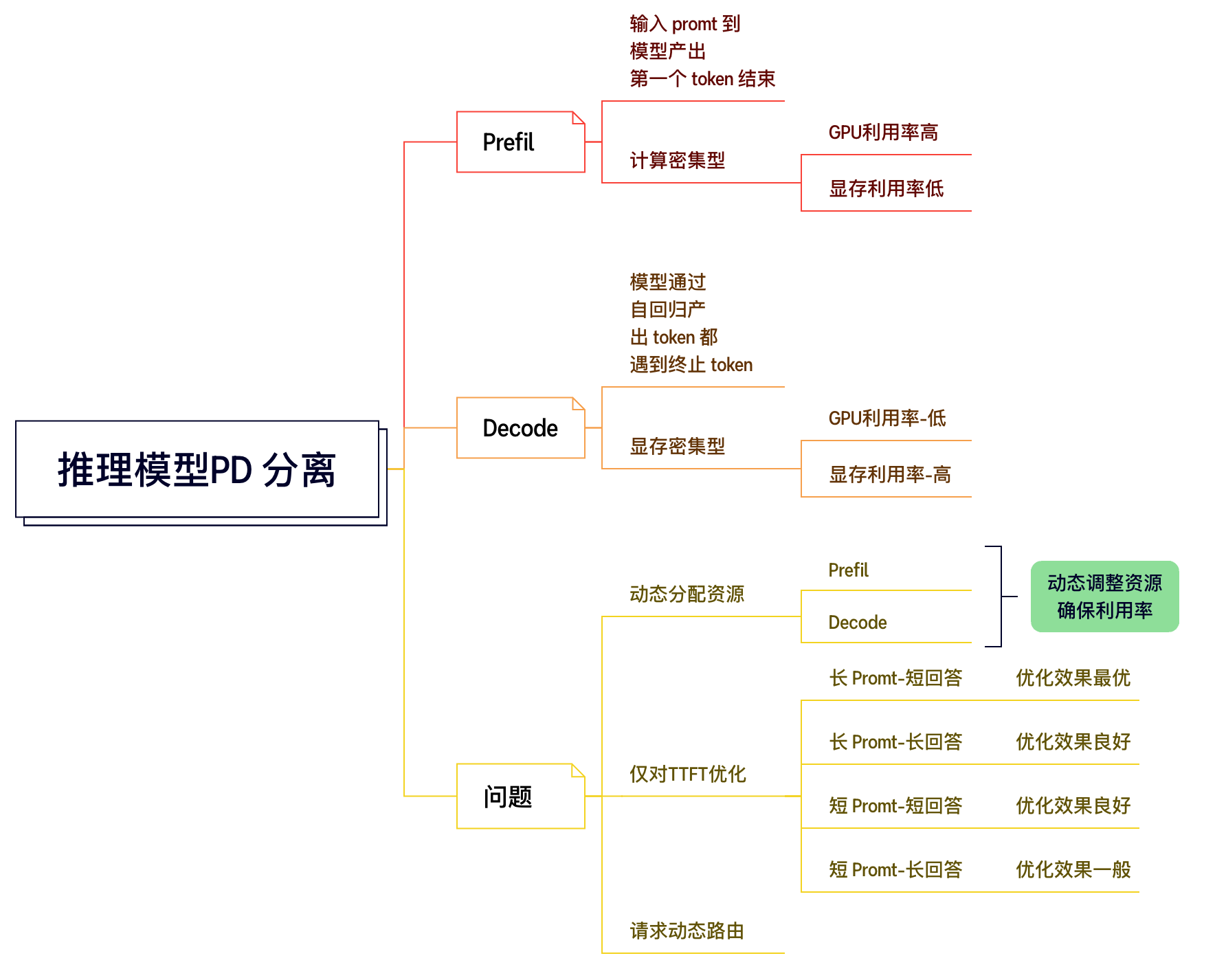
2.4 统一架构的局限性(PD Fusion)
实现相对简单,无需复杂的跨节点通信,Prefill (计算密集) 和 Decode (内存密集) 两个阶段的资源需求和计算特性差异大,在同一组GPU上运行时容易相互干扰,导致GPU资源利用率不均衡。例如,Prefill 可能会抢占 Decode 的计算资源,导致 Decode 延迟增加;或者为了 Decode 的低延迟,Prefill 的批处理大小受限。
2.5 PD 分离式系统 (PD Disaggregation)
优点:
-
消除干扰: Prefill 和 Decode 在独立的硬件资源池中运行,避免了相互的性能干扰。
-
资源优化: 可以为 Prefill 阶段配置计算密集型硬件,为 Decode 阶段配置内存密集型硬件,从而更有效地利用资源。
-
独立扩展: 可以根据 Prefill 和 Decode 各自的负载情况独立扩展资源。
-
提升吞吐量和效率: 通过上述优化,通常能实现更高的系统总吞吐量。
缺点:
-
KV Cache 传输: 在 Prefill 阶段计算完成的 KV Cache 需要传输到 Decode 节点,这个过程会引入额外的延迟和网络开销,是 PD 分离架构需要重点优化的环节。
-
调度复杂性: 需要一个全局调度器来协调 Prefill 和 Decode 任务的分发和管理。
三、kv 缓存分析
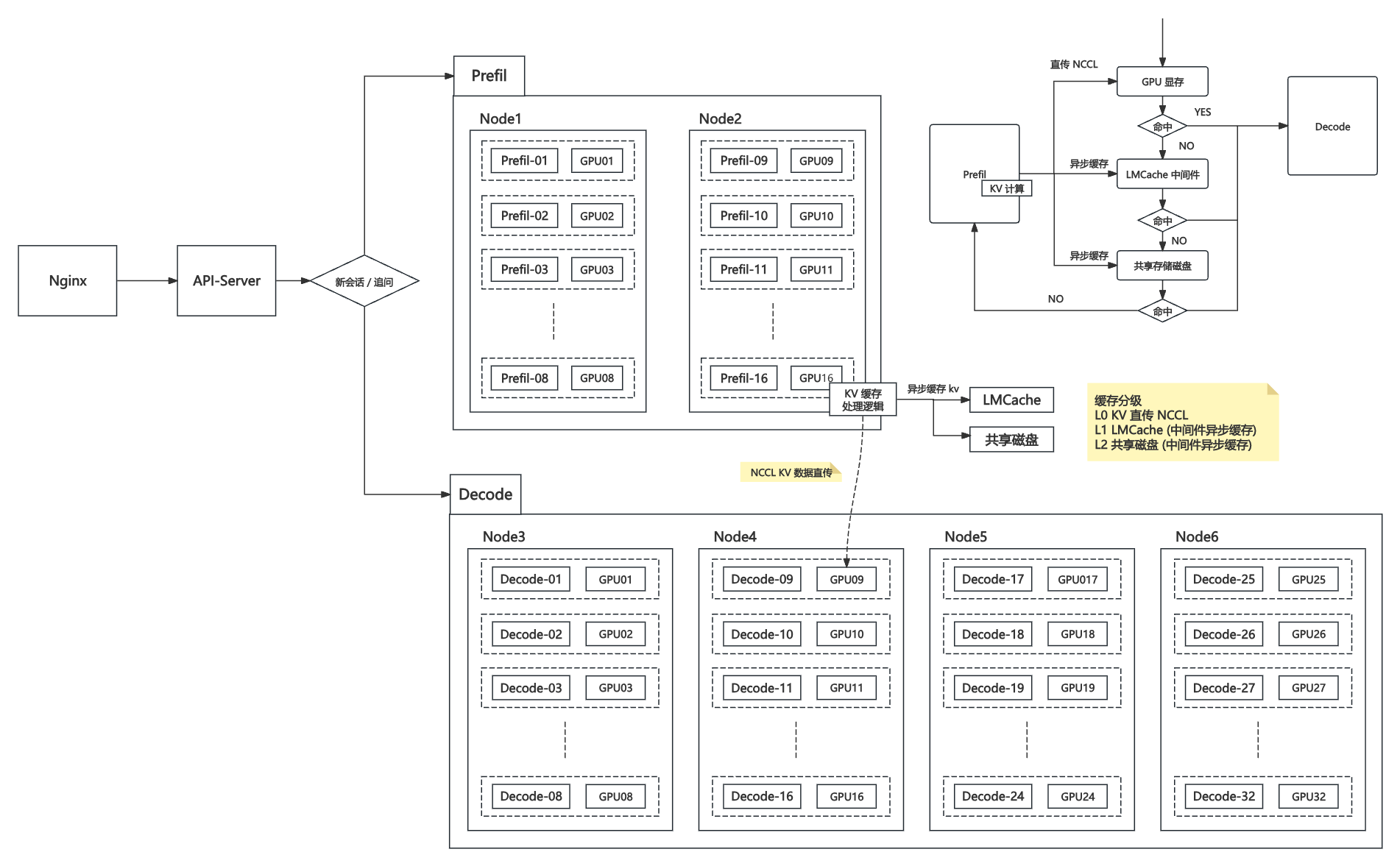
3.1 直传 KV 缓存
通过高速互联(如 NVIDIA NCCL、NVLink、Infiniband 等)在多 GPU 之间直接传递 KV 缓存,无需落盘或经过主机内存。
-
优点:延迟极低、带宽极高,非常适合同机或高速互联环境下多 GPU 间的数据交互。
-
典型场景:Prefill 生成 KV 后,直接推送到 Decode GPU,适合高性能集群内部。
3.2 LMCache
利用独立的 KV 缓存服务(如 LMCache),在集群节点间通过高性能网络或主机内存中转和管理 KV 数据。
-
优点:跨主机节点灵活,缓存可设定有效期,支持异步读写,适合中大型分布式环境。
-
典型场景:Prefill 结果写入 LMCache,Decode 阶段可在任意节点拉取所需 KV 缓存,实现解耦与弹性扩缩容。
3.3 共享缓存磁盘
将 KV 缓存写入分布式文件系统或本地共享存储(如 NFS、Ceph、HDFS),供多节点共享访问。
-
优点:实现跨节点持久化、可恢复,可用于极大规模或需要历史缓存复用的场景。
-
缺点:读写延迟和带宽通常劣于显存直传和内存缓存,仅适合低频访问或大规模冷数据。
-
典型场景:大规模集群、节点动态加入/重启恢复等需持久化的情况。
3.4 多级缓存
多级缓存是为最大化缓存命中率、降低延迟、平衡成本和容量而设计的一套分层缓存体系,广泛应用于高性能分布式大模型推理服务中。其核心思想是:优先在最快速的存储介质中查找和存取 KV 数据,逐层回退至更慢但容量更大的存储层。
四、SGlang PD 分离实战
4.1 基础环境准备
1) GPU 服务器
这里直接选择单卡双卡/H800配置测试
2) NCCL 通信网卡
# 查看可用于nccl通信的网卡 在SGlang地方需要指定网卡
ibdev2netdev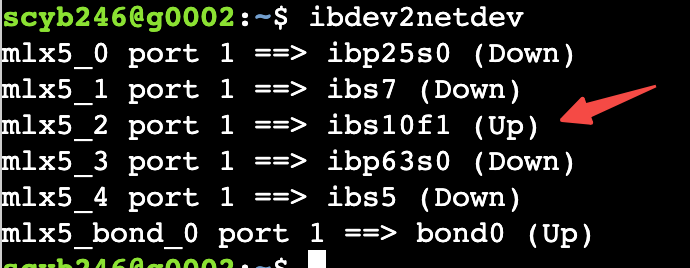
3) 推理模型环境
这里为了测试方便我直接采用sglang[all]全部下载。如果有需要可以按需下载各个组件
pip install sglang[all]
pip install mooncake-transfer-engine4) 基础模型准备
4.2 推理模型部署
1) prefil 服务启动
CUDA_VISIBLE_DEVICES=0 python -m sglang.launch_server \--model-path /data/public/model/qwen2.5/qwen2.5-7b-instruct \--port 7000 \--host 0.0.0.0 \--tensor-parallel-size 1 \--disaggregation-mode prefill \--disaggregation-bootstrap-port 8998 \--disaggregation-transfer-backend mooncake \--disaggregation-ib-device mlx5_2 \--max-total-tokens 4096 \--dtype float16 \--trust-remote-code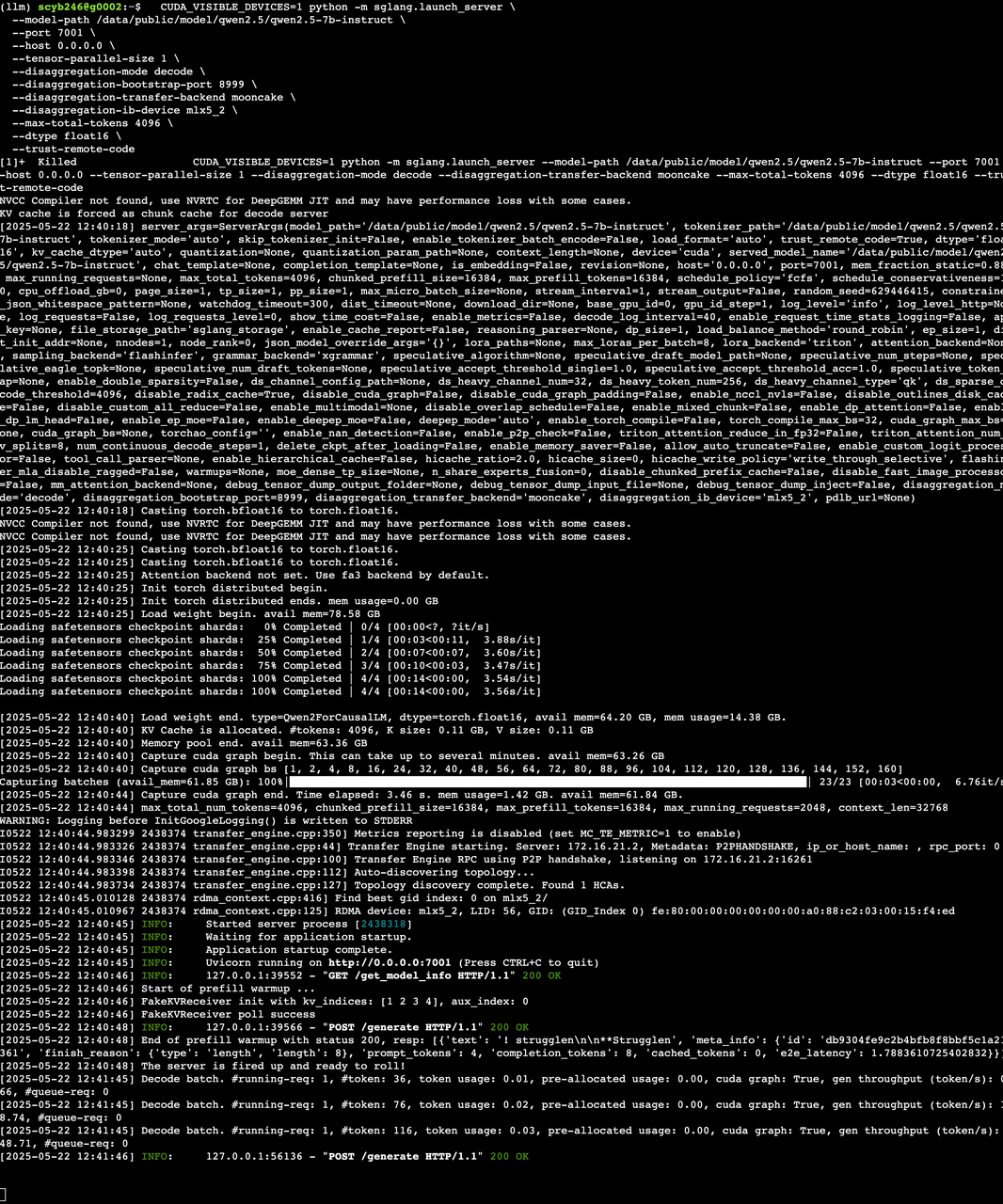
2) decode 服务启动
CUDA_VISIBLE_DEVICES=1 python -m sglang.launch_server \--model-path /data/public/model/qwen2.5/qwen2.5-7b-instruct \--port 7001 \--host 0.0.0.0 \--tensor-parallel-size 1 \--disaggregation-mode decode \--disaggregation-bootstrap-port 8999 \--disaggregation-transfer-backend mooncake \--disaggregation-ib-device mlx5_2 \--max-total-tokens 4096 \--dtype float16 \--trust-remote-code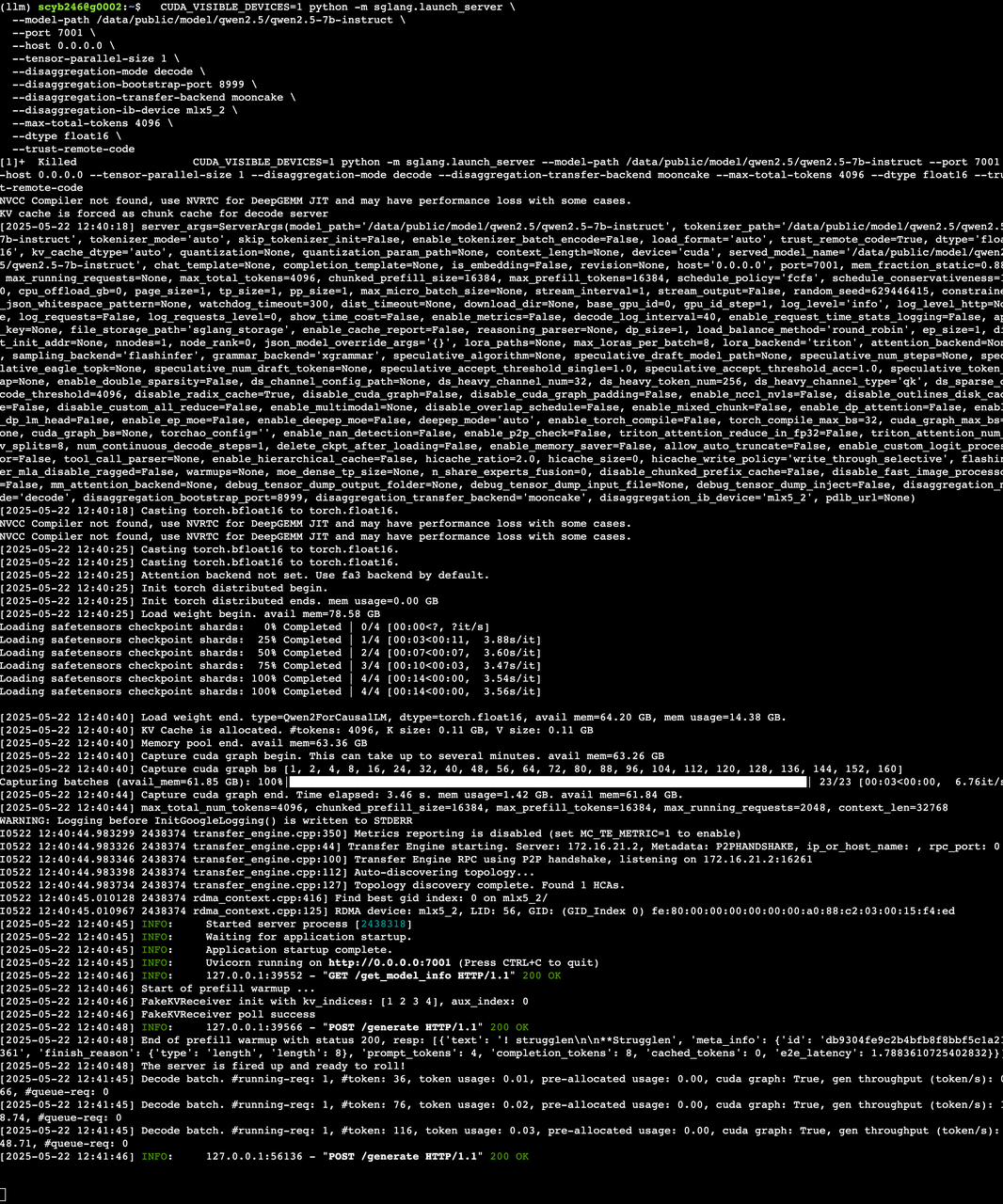
4.3 简易版路由 mini_lb
python -m sglang.srt.disaggregation.mini_lb \--prefill http://127.0.0.1:7000 \--prefill-bootstrap-ports 8998 \--decode http://127.0.0.1:7001 \--host 0.0.0.0 \--port 8000 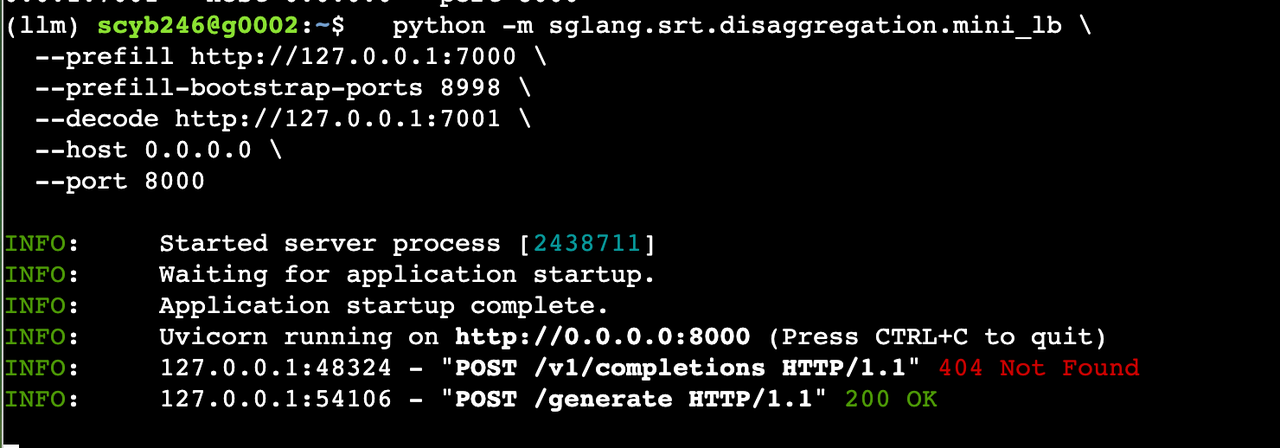
4.4 测试
curl -X POST http://localhost:8000/generate -H "Content-Type: application/json" -d '{"text": "请介绍一下你自己","max_new_tokens": 32,"temperature": 0.7}'
五、小结
kv 缓存概念理解起来就很痛苦。经过各种查资料问大模型才理解整个过程。相当不容易。现在的示例只是提供了 SGLang 的 Mooncake 框架的直传也属于 NCCL 的方式。还没有体现出分布式多级缓存。如果是生产环境则需要将并行策略和多级缓存融合后再实施。
相关文章:
SGlang 推理模型优化(PD架构分离)
一、技术背景 随着大型语言模型(LLM)广泛应用于搜索、内容生成、AI助手等领域,对模型推理服务的并发能力、响应延迟和资源利用效率提出了前所未有的高要求。与模型训练相比,推理是一个持续进行、资源消耗巨大的任务,尤…...

TuyaOpen横空出世!涂鸦智能如何用开源框架重构AIoT开发范式?
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引子:AIoT开发的“不可能三角”被打破 当AI与物理世界深度融合的浪潮席卷全球,开发者们却始终面临一个“不可能三角”——开发…...
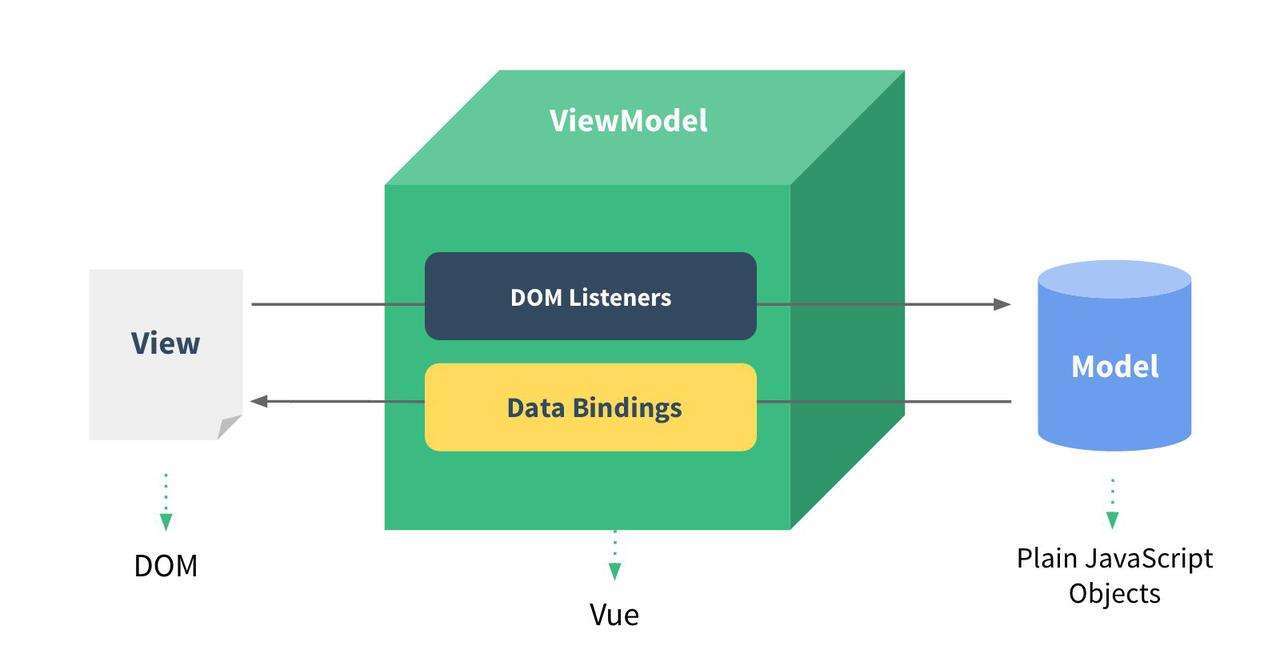
Vue语法【2】
1.插值表达式: 语法规则: {{Vue实例中data的变量名}}使用场景: 插值表达式一般使用在文本内容中,如果是元素的属性内容中则无法使用; 案例: <!DOCTYPE html> <html lang"en"> &l…...

2.2.1 05年T2
引言 本文将从一预习、二自习、三学习、四复习等四个阶段来分析2005年考研英语阅读第二篇文章。为了便于后续阅读,我将第四部分复习放在了首位。 四、复习 方法:错误思路分析总结考点文章梳理 4.1 错题分析 题目:26(细节题&…...
)
每日c/c++题 备战蓝桥杯(修理牛棚 Barn Repair)
修理牛棚 Barn Repair 题解 问题背景与挑战 在一个暴风雨交加的夜晚,Farmer John 的牛棚遭受了严重的破坏。屋顶被掀飞,大门也不翼而飞。幸运的是,许多牛正在度假,牛棚并未住满。然而,为了保护那些还在牛棚里的牛&am…...

6个月Python学习计划 Day 3
🎯 今日目标 掌握 while 和 for 循环的使用方式理解 range() 的工作机制实践:打印 1~100、累加、九九乘法表等常见程序逻辑 🧠 学习内容详解 while 循环 i 1 while i < 5:print(f"第 {i} 次循环")i 1📌 特点&…...

Linux虚拟文件系统(2)
2.3 目录项-dentry 目录项,即 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。和上一章中超级块和索引节点不同,目录项并不是实际存在于磁盘上的,…...
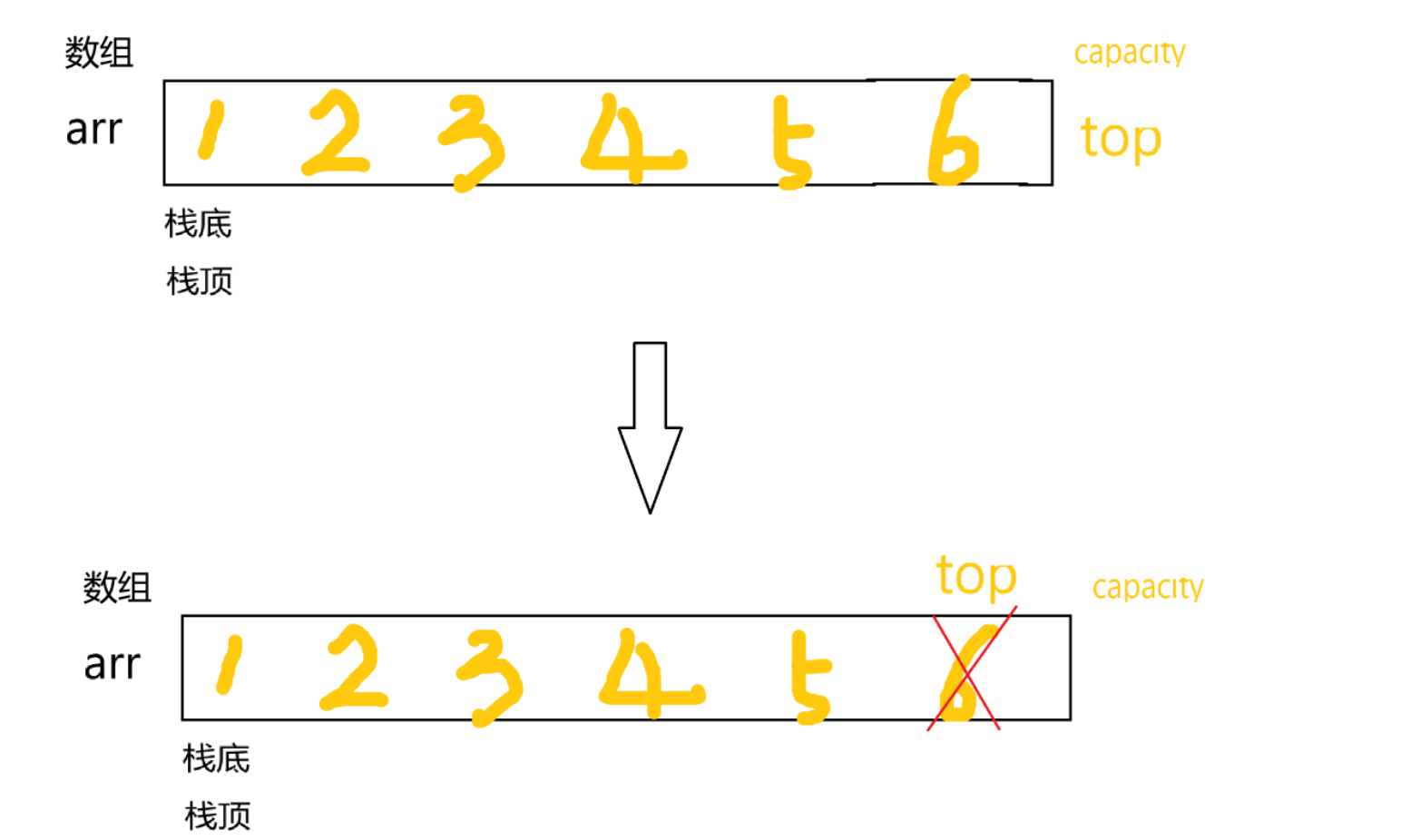
【数据结构】栈和队列(上)
目录 一、栈(先进后出、后进先出的线性表) 1、栈的概念及结构 2、栈的底层结构分析 二、代码实现 1、定义一个栈 2、栈的初始化 3、入栈 3、增容 4、出栈 5、取栈顶 6、销毁栈 一、栈(先进后出、后进先出的线性表) 1、…...

科技赋能·长效治理|无忧树建筑修缮渗漏水长效治理交流会圆满举行!
聚焦行业痛点,共话长效未来!5月16日,由无忧树主办的主题为“科技赋能长效治理”的建筑修缮渗漏水长效治理技术交流会在上海圆满举行。来自全国的建筑企业代表、专家学者、技术精英齐聚一堂,共探渗漏治理前沿技术,见证科…...
【闲聊篇】java好丰富!
1、在学习mybatis-plus的文档时,发现引入了solon依赖,才发现这是一个对标spring生态的框架,有意思! 还有若依框架,真的好丰富~~~~~~~ 2、今天面试官问我,他说很少遇到用redission做延迟队列的。后面我就反…...

STL中list的模拟
这里写目录标题 list 的节点 —— ListNodelist 的 “导览员” —— ListIteratorlist 的核心 —— list 类构造函数迭代器相关操作容量相关操作 结尾 在 C 的 STL(标准模板库)中,list 是一个十分重要的容器,它就像一个灵活的弹簧…...
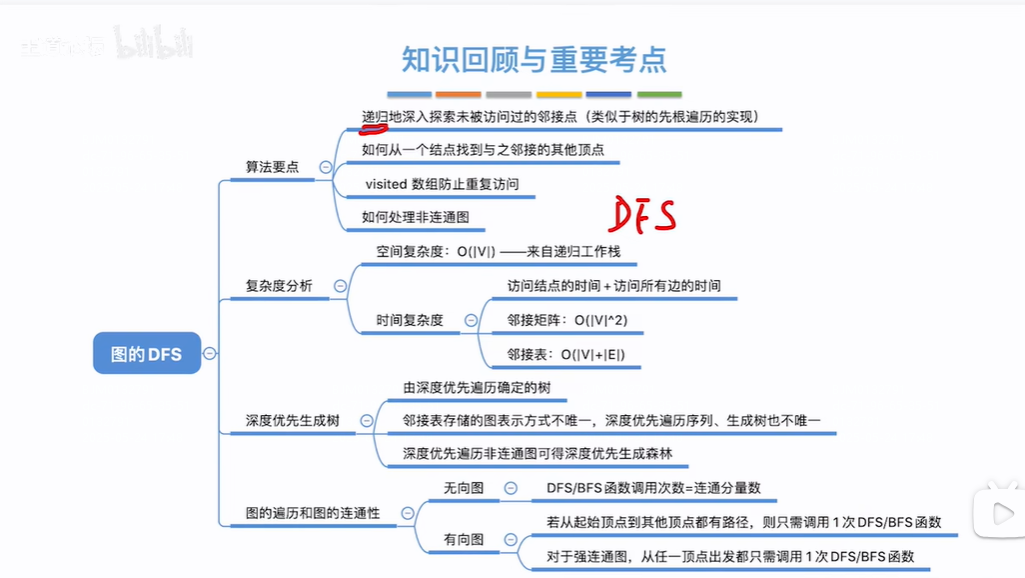
6.3.2图的深度优先遍历
知识总览: 树的先根遍历: 采用递归一直找某个节点的子树直到找不到从上往下找 访问根节点1,1的子树有2、3、4,访问2,2节点子树有5访问5,5没有子树,退回到2,2还有子树6访问6,6没有子树再退回到2,2的子树都被访问了再退…...
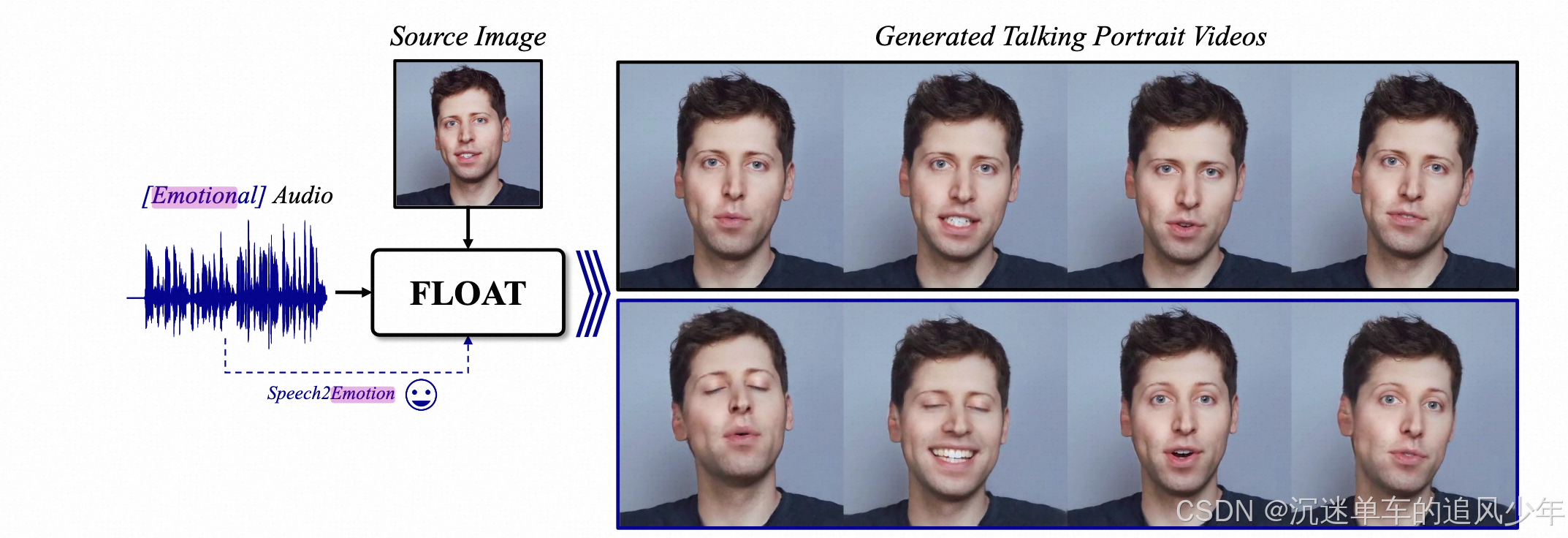
畅游Diffusion数字人(30):情绪化数字人视频生成
畅游Diffusion数字人(0):专栏文章导航 前言:仅从音频生成此类运动极具挑战性,因为它在音频和运动之间存在一对多的相关性。运动视频的情绪是多元化的选择,之前的工作很少考虑情绪化的数字人生成。今天解读一个最新的工作FLOAT,可以生成制定情绪化的数字人视频。 目录 贡献…...
UE5 Va Res发送请求、处理请求、json使用
文章目录 介绍发送一个Get请求发送Post请求设置请求头请求体带添json发送请求完整的发送蓝图 处理收到的数据常用的json处理节点 介绍 UE5 自带的Http插件,插件内自带json解析功能 发送一个Get请求 只能写在事件图表里 发送Post请求 只能写在事件图表里 设置…...
.openEndDrawer();不生效问题)
关于flutter中Scaffold.of(context).openEndDrawer();不生效问题
原因: 在 Flutter 中,Scaffold.of(context) 会沿着当前的 context 向上查找最近的 Scaffold。如果当前的 widget 树层级中没有合适的 Scaffold(比如按钮所在的 context 是在某个子 widget 中),就找不到它。 解决办法…...

【C++】深入理解C++中的函数与运算符重载
文章目录 前言一、什么是重载?1.1 函数重载1.1.1 函数重载的规则1.1.2 示例:函数重载 1.2 运算符重载1.2.1 运算符重载的规则1.2.2 示例:运算符重载 1.2.3 运算符重载的注意事项 二、重载的注意事项2.1 重载的二义性2.2 默认参数和重载2.3 运…...
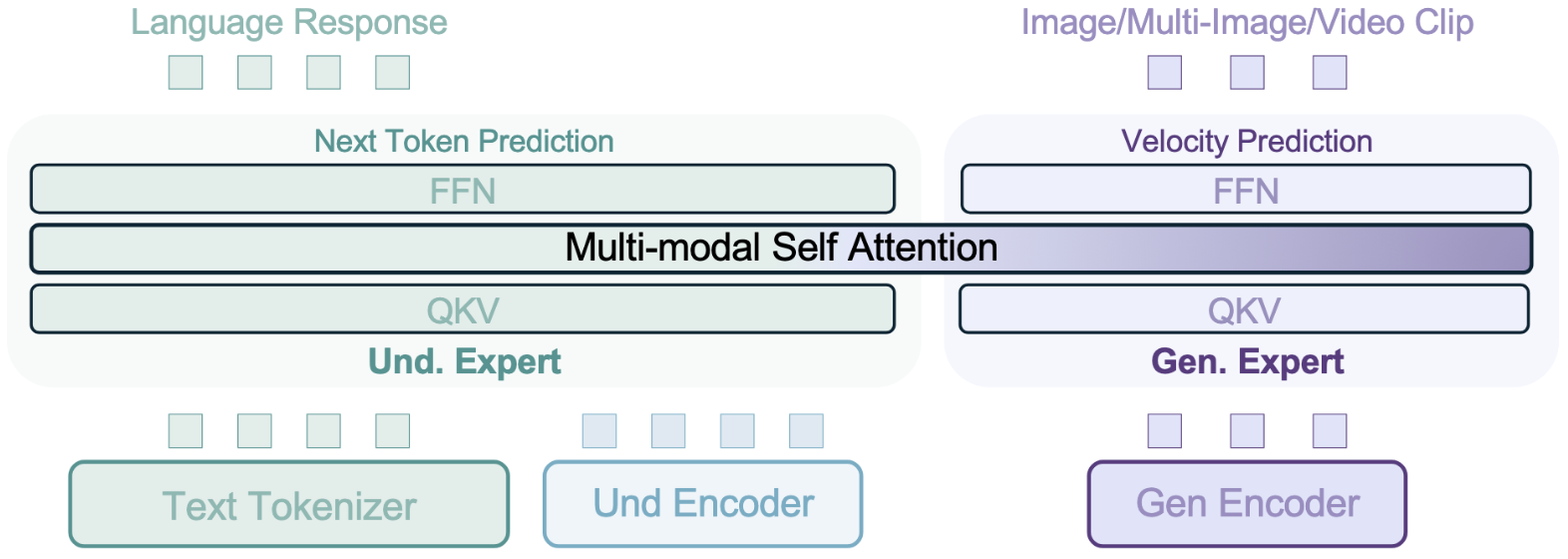
【读代码】BAGEL:统一多模态理解与生成的模型
一、项目概览 1.1 核心定位 BAGEL是字节跳动推出的开源多模态基础模型,具有70亿激活参数(140亿总参数)。该模型在统一架构下实现了三大核心能力: 多模态理解:在MME、MMBench等9大评测基准中超越Qwen2.5-VL等主流模型文本生成图像:生成质量媲美SD3等专业生成模型智能图像…...
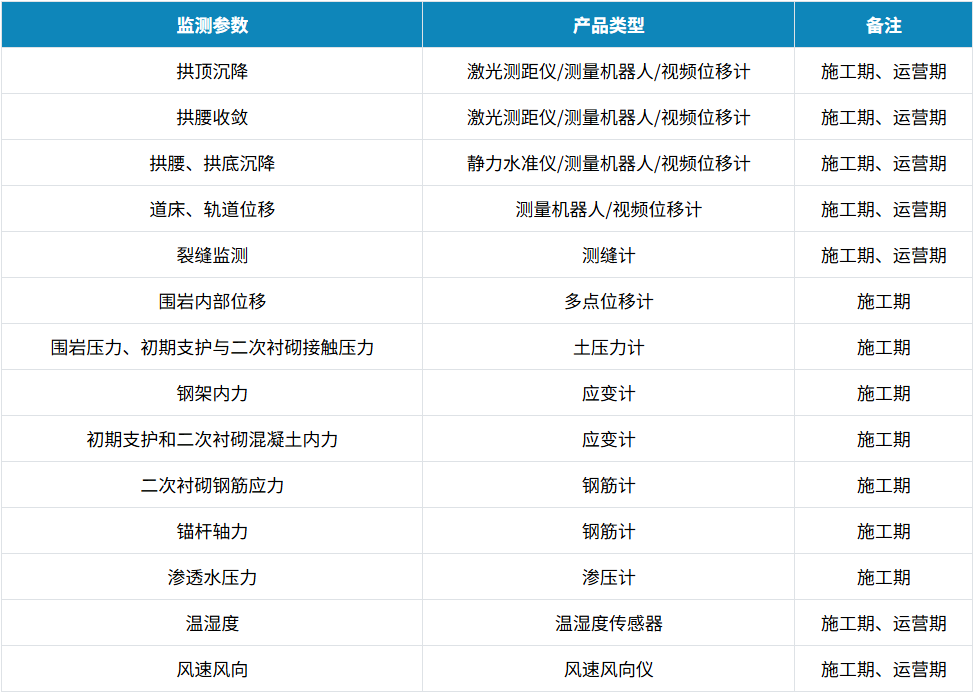
隧道自动化监测解决方案
行业现状 隧道作为一种重要的交通运输通道,不管是缓解交通压力,还是让路网结构更趋于完善,它都有着不可估量的作用。隧道在运营过程中,由于受到材料退化、地震、人为因素等影响会发生隧道主体结构的损坏和劣化。若不及时检修和维护…...

如何通过EventChannel实现Flutter与原生平台的双向通信?
在Flutter开发中,EventChannel是处理单向数据流的核心组件,尤其适用于原生平台(Android/iOS)主动向Flutter端推送实时数据的场景,例如传感器数据、后台任务通知等。虽然EventChannel本身以原生到Flutter的单向通信为主,但结合特定设计模式,仍可实现双向交互。本文将详细…...

游戏引擎学习第307天:排序组可视化
简短谈谈直播编程的一些好处。 上次结束后,很多人都指出代码中存在一个拼写错误,因此这次我们一开始就知道有一个 bug 等待修复,省去了调试寻找错误的时间。 今天的任务就是修复这个已知 bug,然后继续排查其他潜在的问题。如果短…...

java接口自动化初识
简介 了解什么是接口和为什么要做接口测试。并且知道接口自动化测试应该学习哪些技术以及接口自动化测试的落地过程。 一、什么是接口 在这里我举了一个比较生活化的例子,比如我们有一台笔记本,在笔记本的两端有很多插口。例如:USB插口。那…...

工作流引擎-01-Activiti 是领先的轻量级、以 Java 为中心的开源 BPMN 引擎,支持现实世界的流程自动化需求
前言 大家好,我是老马。 最近想设计一款审批系统,于是了解一下关于流程引擎的知识。 下面是一些的流程引擎相关资料。 工作流引擎系列 工作流引擎-00-流程引擎概览 工作流引擎-01-Activiti 是领先的轻量级、以 Java 为中心的开源 BPMN 引擎&#x…...

时序数据库IoTDB的分片与负载均衡策略深入解析
一、引言 随着数据库服务的业务负载增加,扩展服务资源成为必然需求。扩展方式主要分为纵向扩展和横向扩展。纵向扩展通过增加单台机器的能力(如内存、硬盘、处理器)来实现,但受限于单台机器的硬件能力。而横向扩展则通过增加更多…...
NVM安装使用及问题解决
目录 一、前言 二、NVM安装 三、配置下载源 四、nvm使用 五、安装nvm list available没有的版本 六、问题解决 一、前言 如果你开发 Node.js 项目,可能会遇到这些问题: ①新项目需要 Node.js 18,但老项目只能用 Node.js 14,…...

C++学习之STL学习:string类使用
在之前的学习中,我们初步了解到了STL的概念,接下来我们将深入学习STL中的string类的使用,后续还会结合他们的功能进行模拟实验 目录 为什么要学习string类? 标准库中的string类 string类(了解) auto和范围…...

基于 STC89C52 的养殖场智能温控系统设计与实现
摘要 本文提出一种基于 STC89C52 单片机的养殖场环境温度智能控制系统,通过集成高精度温度传感器、智能执行机构及人机交互模块,实现对养殖环境的实时监测与自动调控。系统具备温度阈值设定、超限报警及多模式控制功能,可有效提升养殖环境稳定性,降低能耗与人工成本。 一…...

redis哨兵服务
配置主机Host67为master服务器配置主机host68为 slave服务器配置主机host69运行哨兵服务测试配置 IP地址主机名192.168.10.167redis167192.168.10.168redis168192.168.10.169redis169 步骤一:配置主机Host67为master服务器 [rootredis169 ~]# vim /etc/redis.c…...

5月24日day35打卡
模型可视化与推理 知识点回顾: 三种不同的模型可视化方法:推荐torchinfo打印summary权重分布可视化进度条功能:手动和自动写法,让打印结果更加美观推理的写法:评估模式 作业:调整模型定义时的超参数&#x…...

嵌入式<style>设计模式
每天分享一个web前端开发技巧。 今天分享的主题是,如何提升前端代码的内聚性。我们在写<style></style>的时候,往往把大量无关联的样式写在同一个<style>下,而且离相关的html元素很远,这样导致每次想修改某个元…...

Kotlin 中该如何安全地处理可空类型?
在 Kotlin 中,可空类型(如 String?)是语言设计的核心特性之一,旨在从编译时避免 NullPointerException(NPE)。 1 核心处理方式 1.1 安全调用操作符(?.) 直接调用可空对象的方法…...