Python60日基础学习打卡D35
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每100个epoch的损失值和对应的epoch数
losses = []start_time = time.time() # 记录开始时间for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值if (epoch + 1) % 200 == 0:losses.append(loss.item()) # item()方法返回一个Python数值,loss是一个标量张量print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.plot(range(len(losses)), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()一、模型结构可视化
理解一个深度学习网络最重要的2点:
- 了解损失如何定义的,知道损失从何而来----把抽象的任务通过损失函数量化出来
- 了解参数总量,即知道每一层的设计才能退出---层设计决定参数总量
为了了解参数总量,我们需要知道层设计,以及每一层参数的数量。下面介绍1几个层可视化工具:
1.1 nn.model自带的方法(直接print)
# nn.Module 的内置功能,直接输出模型结构
print(model)# nn.Module 的内置功能,返回模型的可训练参数迭代器
for name, param in model.named_parameters():print(f"Parameter name: {name}, Shape: {param.shape}")# 提取权重数据
import numpy as np
weight_data = {}
for name, param in model.named_parameters():if 'weight' in name:weight_data[name] = param.detach().cpu().numpy()# 可视化权重分布
fig, axes = plt.subplots(1, len(weight_data), figsize=(15, 5))
fig.suptitle('Weight Distribution of Layers')for i, (name, weights) in enumerate(weight_data.items()):# 展平权重张量为一维数组weights_flat = weights.flatten()# 绘制直方图axes[i].hist(weights_flat, bins=50, alpha=0.7)axes[i].set_title(name)axes[i].set_xlabel('Weight Value')axes[i].set_ylabel('Frequency')axes[i].grid(True, linestyle='--', alpha=0.7)plt.tight_layout()
plt.subplots_adjust(top=0.85)
plt.show()# 计算并打印每层权重的统计信息
print("\n=== 权重统计信息 ===")
for name, weights in weight_data.items():mean = np.mean(weights)std = np.std(weights)min_val = np.min(weights)max_val = np.max(weights)print(f"{name}:")print(f" 均值: {mean:.6f}")print(f" 标准差: {std:.6f}")print(f" 最小值: {min_val:.6f}")print(f" 最大值: {max_val:.6f}")print("-" * 30)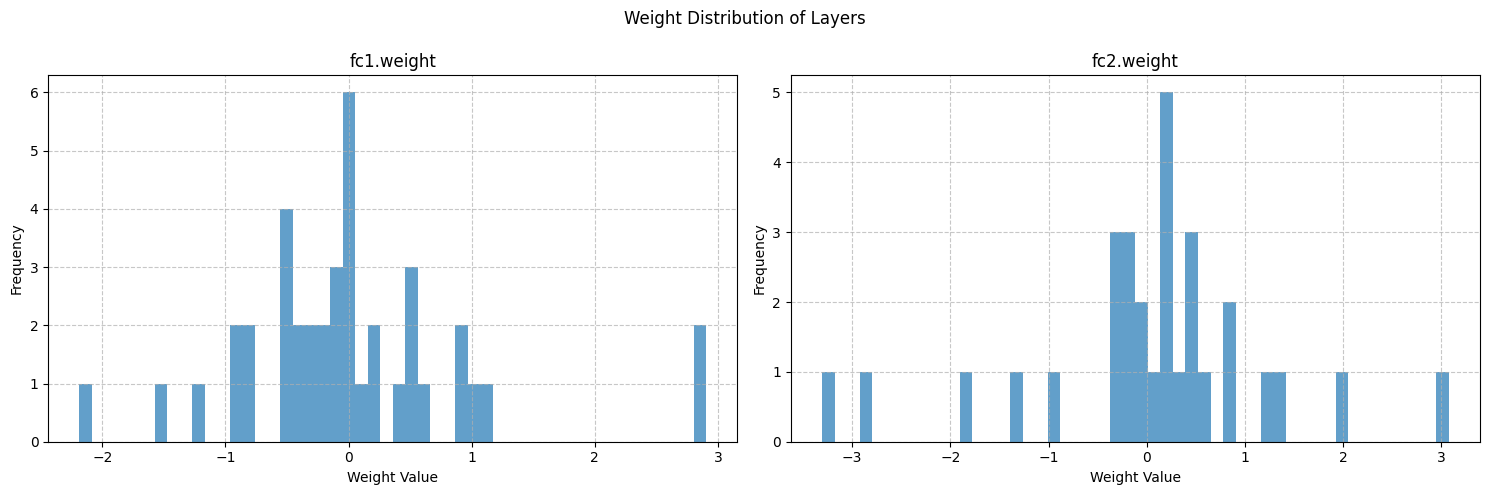
=== 权重统计信息 === fc1.weight:均值: 0.013520标准差: 0.935024最小值: -2.185144最大值: 2.903806 ------------------------------ fc2.weight:均值: 0.027174标准差: 1.232366最小值: -3.307564最大值: 3.074636 ------------------------------
对比 fc1.weight 和 fc2.weight 的统计信息 ,它们的均值、标准差、最值等存在的差异同样具有参考价值
权重统计信息可以为超参数调整提供参考。例如,如果发现权重标准差过大导致训练不稳定,可以尝试调整学习率,使权重更新更平稳;或者改变权重初始化方法,使初始权重分布更合理。如果最小值和最大值在训练后期仍波动较大,可能需要考虑调整正则化参数,防止过拟合或欠拟
1.2 torchsummary库的summary方法
# pip install torchsummary -i https://pypi.tuna.tsinghua.edu.cn/simplefrom torchsummary import summary
# 打印模型摘要,可以放置在模型定义后面
summary(model, input_size=(4,))----------------------------------------------------------------Layer (type) Output Shape Param # ================================================================Linear-1 [-1, 10] 50ReLU-2 [-1, 10] 0Linear-3 [-1, 3] 33 ================================================================ Total params: 83 Trainable params: 83 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.00 Params size (MB): 0.00 Estimated Total Size (MB): 0.00 ----------------------------------------------------------------
因为输入的神经网是自己设置的,所以不需要显示输入层的尺寸。 但是在使用该方法时,input_size=(4,) 参数是必需的,因为 PyTorch 需要知道输入数据的形状才能推断模型各层的输出形状和参数数量。
这是因为PyTorch 的模型在定义时是动态的,它不会预先知道输入数据的具体形状。nn.Linear(4, 10) 只定义了 “输入维度是 4,输出维度是 10”,但不知道输入的批量大小和其他维度,比如卷积层需要知道输入的通道数、高度、宽度等信息——并非所有输入数据都是结构化数据
因此,要生成模型摘要(如每层的输出形状、参数数量),必须提供一个示例输入形状input_size=(4,),让 PyTorch “运行” 一次模型,从而推断出各层的信息。
summary 函数的核心逻辑是:
- 创建一个与 input_size 形状匹配的虚拟输入张量(通常填充零)summary(model, input_size=input_size)
- 将虚拟输入传递给模型,执行一次前向传播(但不计算梯度)
- 记录每一层的输入和输出形状,以及参数数量
- 生成可读的摘要报告
不同场景下的 input_size 示例
| 模型类型 | 输入类型 | input_size 示例 | 实际输入形状(batch_size=32) |
|---|---|---|---|
| MLP(单样本) | 一维特征向量 | (4,) | (32, 4) |
| CNN(图像) | 三维图像(C,H,W) | (3, 224, 224) | (32, 3, 224, 224) |
| RNN(序列) | 二维序列(seq_len, feat) | (10, 5) | (32, 10, 5) |
其中最开始的参数的值是默认初始化的,初始化有很多方法,后面接触到复杂的模型再提
构建神经网络的时候
- 输入层不需要写:x多少个特征,输入层就有多少神经元
- 隐藏层需要写,从第一个隐藏层可以看出特征的个数
- 输出层的神经元和任务有关,比如分类任务,输出层有3个神经元,一个对应每个类别
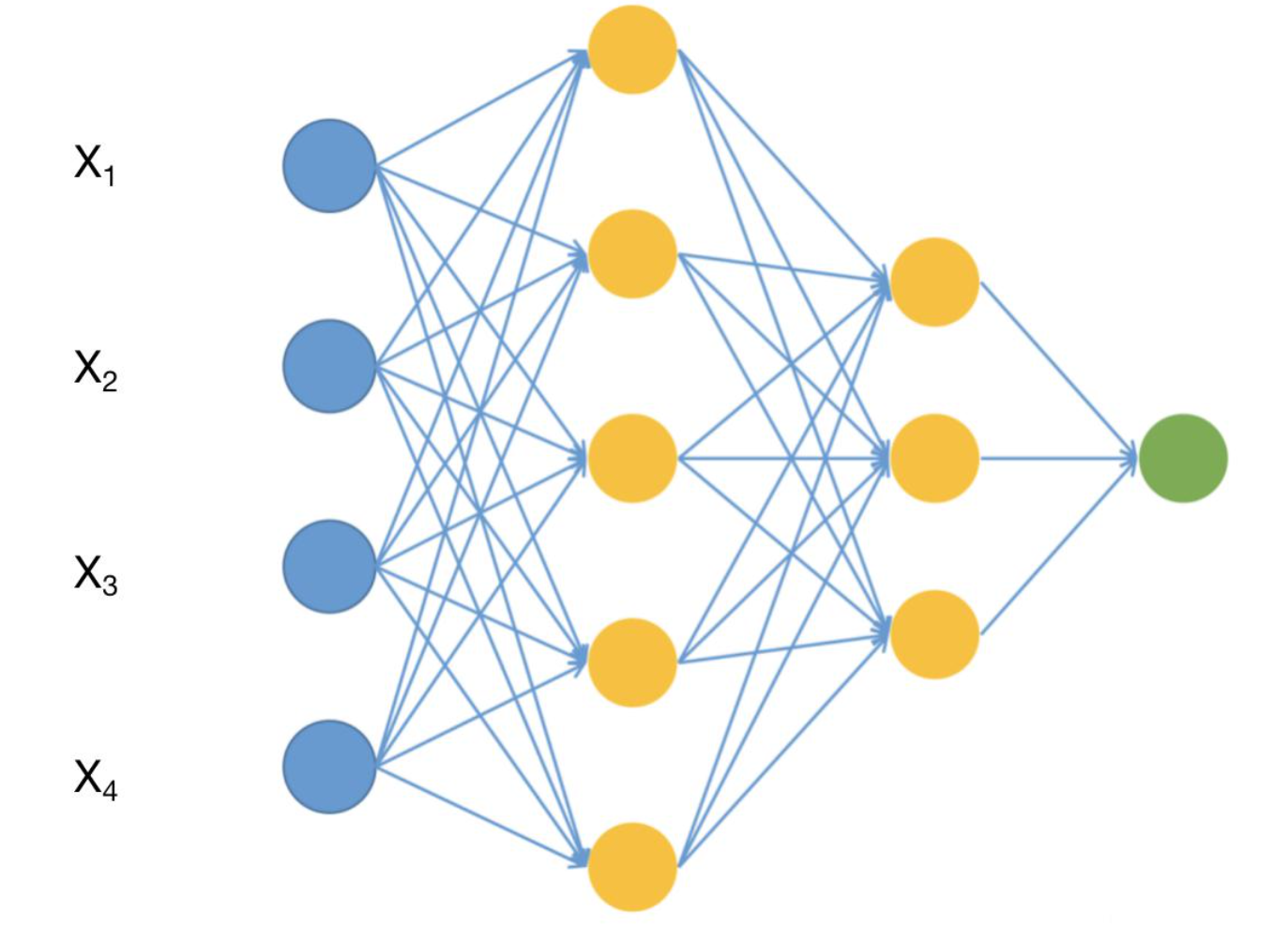
可学习参数计算
- Linear-1对应self.fc1 = nn.Linear(4, 10),表明前一层有4个神经元,这一层有10个神经元,每2个神经元之间靠着线相连,所有有4*10个权重参数+10个偏置参数=50个参数
- relu层不涉及可学习参数,可以把它和前一个线性层看成一层,图上也是这个含义
- Linear-3层对应代码 self.fc2 = nn.Linear(10,3),10*3个权重参数+3个偏置=33个参数
总参数83个,占用内存几乎为0
1.3 torchinfo库的summary方法
torchinfo 是提供比 torchsummary 更详细的模型摘要信息,包括每层的输入输出形状、参数数量、计算量等。
from torchinfo import summary
summary(model, input_size=(4, ))========================================================================================== Layer (type:depth-idx) Output Shape Param # ========================================================================================== MLP [3] -- ├─Linear: 1-1 [10] 50 ├─ReLU: 1-2 [10] -- ├─Linear: 1-3 [3] 33 ========================================================================================== Total params: 83 Trainable params: 83 Non-trainable params: 0 Total mult-adds (M): 0.00 ========================================================================================== Input size (MB): 0.00 Forward/backward pass size (MB): 0.00 Params size (MB): 0.00 Estimated Total Size (MB): 0.00 ==========================================================================================
torchinfo这个库常常和tensorboard一起使用,我们后面会介绍
二、 进度条功能
我们介绍下tqdm这个库,他非常适合用在循环中观察进度。尤其在深度学习这种训练是循环的场景中。他最核心的逻辑如下
-
创建一个进度条对象,并传入总迭代次数。一般用with语句创建对象,这样对象会在with语句结束后自动销毁,保证资源释放。with是常见的上下文管理器,这样的使用方式还有用with打开文件,结束后会自动关闭文件。
-
更新进度条,通过pbar.update(n)指定每次前进的步数n(适用于非固定步长的循环)。
2.1 手动更新
from tqdm import tqdm # 先导入tqdm库
import time # 用于模拟耗时操作# 创建一个总步数为10的进度条
with tqdm(total=10) as pbar: # pbar是进度条对象的变量名# pbar 是 progress bar(进度条)的缩写,约定俗成的命名习惯。for i in range(10): # 循环10次(对应进度条的10步)time.sleep(0.5) # 模拟每次循环耗时0.5秒pbar.update(1) # 每次循环后,进度条前进1步100%|██████████| 10/10 [00:05<00:00, 1.95it/s]
from tqdm import tqdm
import time# 创建进度条时添加描述(desc)和单位(unit)
with tqdm(total=5, desc="下载文件", unit="个") as pbar:# 进度条这个对象,可以设置描述和单位# desc是描述,在左侧显示# unit是单位,在进度条右侧显示for i in range(5):time.sleep(1)pbar.update(1) # 每次循环进度+1下载文件: 100%|██████████| 5/5 [00:05<00:00, 1.01s/个]
unit 参数的核心作用是明确进度条中每个进度单位的含义,使可视化信息更具可读性。在深度学习训练中,常用的单位包括:
- epoch:训练轮次(遍历整个数据集一次)。
- batch:批次(每次梯度更新处理的样本组)。
- sample:样本(单个数据点)
2.2 自动更新
from tqdm import tqdm
import time# 直接将range(3)传给tqdm,自动生成进度条
# 这个写法我觉得是有点神奇的,直接可以给这个对象内部传入一个可迭代对象,然后自动生成进度条
for i in tqdm(range(3), desc="处理任务", unit="epoch"):time.sleep(1)处理任务: 100%|██████████| 3/3 [00:03<00:00, 1.01s/epoch]
for i in tqdm(range(3), desc="处理任务", unit="个")这个写法则不需要在循环中调用update()方法,更加简洁
实际上这2种写法都随意选取,这里都介绍下
# 用tqdm的set_postfix方法在进度条右侧显示实时数据(如当前循环的数值、计算结果等):
from tqdm import tqdm
import timetotal = 0 # 初始化总和
with tqdm(total=10, desc="累加进度") as pbar:for i in range(1, 11):time.sleep(0.3)total += i # 累加1+2+3+...+10pbar.update(1) # 进度+1pbar.set_postfix({"当前总和": total}) # 显示实时总和累加进度: 100%|██████████| 10/10 [00:03<00:00, 3.22it/s, 当前总和=55]
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库用于进度条显示# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每100个epoch的损失值和对应的epoch数
losses = []
epochs = []start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:losses.append(loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Loss': f'{loss.item():.4f}'})# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# # 可视化损失曲线
# plt.figure(figsize=(10, 6))
# plt.plot(epochs, losses)
# plt.xlabel('Epoch')
# plt.ylabel('Loss')
# plt.title('Training Loss over Epochs')
# plt.grid(True)
# plt.show()
使用设备: cuda:0
训练进度: 100%|██████████| 20000/20000 [00:10<00:00, 1885.37epoch/s, Loss=0.0630] Training time: 10.61 seconds
三、 模型的推理
之前我们说完了训练模型,那么现在我们来测试模型。测试这个词在大模型领域叫做推理(inference),意味着把数据输入到训练好的模型的过程。

注意损失和优化器在训练阶段。
# 在测试集上评估模型,此时model内部已经是训练好的参数了
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度计算,可以提高模型推理速度outputs = model(X_test) # 对测试数据进行前向传播,获得预测结果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引# 这个函数返回2个值,分别是最大值和对应索引,参数1是在第1维度(行)上找最大值,_ 是Python的约定,表示忽略这个返回值,所以这个写法是找到每一行最大值的下标# 此时outputs是一个tensor,p每一行是一个样本,每一行有3个值,分别是属于3个类别的概率,取最大值的下标就是预测的类别# predicted == y_test判断预测值和真实值是否相等,返回一个tensor,1表示相等,0表示不等,然后求和,再除以y_test.size(0)得到准确率# 因为这个时候数据是tensor,所以需要用item()方法将tensor转化为Python的标量# 之所以不用sklearn的accuracy_score函数,是因为这个函数是在CPU上运行的,需要将数据转移到CPU上,这样会慢一些# size(0)获取第0维的长度,即样本数量correct = (predicted == y_test).sum().item() # 计算预测正确的样本数accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%')测试集准确率: 96.67%
模型的评估模式简单来说就是评估阶段会关闭一些训练相关的操作和策略 ,比如更新参数 正则化等操作,确保模型输出结果的稳定性和一致性。
可能有同学好奇,为什么评估模式不关闭梯度计算,推理不是不需要更新参数么?
主要还是因为在某些场景下,评估阶段可能需要计算梯度(虽然不更新参数)。例如计算梯度用于可视化(如 CAM 热力图,主要用于cnn相关)。所以为了避免这种需求不被满足,还是需要手动关闭梯度计算。
相关文章:
Python60日基础学习打卡D35
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time import matplotlib.pyplot as plt# 设置GPU设…...

Python经典算法实战
在编程的世界里,算法是解决问题的灵魂,而Python以其简洁优雅的语法成为实现算法的理想语言。无论你是初学者还是有一定经验的开发者,《Python经典算法实战》都能带你深入算法的殿堂,从理论到实践,一步步构建起扎实的编…...

spring+tomcat 用户每次发请求,tomcat 站在线程的角度是如何处理用户请求的,spinrg的bean 是共享的吗
对于 springtomcat 用户每次发请求,tomcat 站在线程的角度是如何处理的 比如 bio nio apr 等情况 tomcat 配置文件中 maxThreads 的数量是相对于谁来说的? 以及 spring Controller 中的全局变量:各种bean 对于线程来说是共享的吗? 一、Tomca…...
目标检测 RT-DETR(2023)详细解读
文章目录 主干网络:Encoder:不确定性最小Query选择Decoder网络: 将DETR扩展到实时场景,提高了模型的检测速度。网络架构分为三部分组成:主干网络、混合编码器、带有辅助预测头的变换器编码器。具体来说,先利…...

微信小程序 隐私协议弹窗授权
开发微信小程序的第一步往往是隐私协议授权,尤其是在涉及用户隐私数据时,必须确保用户明确知晓并同意相关隐私政策。我们才可以开发后续的小程序内容。友友们在按照文档开发时可能会遇到一些问题,我把所有的授权方法和可能遇到的问题都整理出…...

题目 3325: 蓝桥杯2025年第十六届省赛真题-2025 图形
题目 3325: 蓝桥杯2025年第十六届省赛真题-2025 图形 时间限制: 2s 内存限制: 192MB 提交: 494 解决: 206 题目描述 小蓝要画一个 2025 图形。图形的形状为一个 h w 的矩形,其中 h 表示图形的高,w 表示图形的宽。当 h 5,w 10 时,图形如下所…...
金众诚业财一体化解决方案如何提升项目盈利能力?
在工程项目管理领域,复杂的全生命周期管理、成本控制的精准性以及业务与财务的高效协同,是决定项目盈利能力的核心要素。随着数字化转型的深入,传统的项目管理方式已难以满足企业对效率、透明度和盈利能力的需求。基于金蝶云星空平台打造的金…...
)
bitbar环境搭建(ruby 2.4 + rails 5.0.2)
此博客为武汉大学WA学院网络安全课程,理论课大作业Web环境搭建。 博主搭了2天!!!血泪教训是还是不能太相信ppt上的教程。 一开始尝试了ppt上的教程,然后又转而寻找网络资源 cs155源代码和docker配置,做到…...

从零起步搭建基于华为云构建碳排放设备管理系统的产品设计
目录 🌿 华为云 IoT:轻松上手碳排放设备管理系统搭建 🌍 逐步搭建搭建规划 🚀 一、系统蓝图:5大核心模块,循序渐进 1️⃣ 设备管理与数据采集层 2️⃣ 数据传输与协议转换层 3️⃣ 数据处理与分析层…...
LabVIEW中EtherCAT从站拓扑离线创建及信息查询
该 VI 主要用于演示如何离线创建 EtherCAT 从站拓扑结构,并查询从站相关信息。EtherCAT(以太网控制自动化技术)是基于以太网的实时工业通信协议,凭借其高速、高效的特性在自动化领域广泛应用。与其他常见工业通讯协议相比…...

SpringBoot-11-基于注解和XML方式的SpringBoot应用场景对比
文章目录 1 基于注解的方式1.1 @Mapper1.2 @select1.3 @insert1.4 @update1.5 @delete2 基于XML的方式2.1 namespace2.2 resultMap2.3 select2.4 insert2.5 update2.6 delete3 service和controller3.1 service3.2 controller4 注解和xml的选择如果SQL简单且项目规模较小,推荐使…...
Flutter 3.32 新特性
2天前,Flutter发布了最新版本3.32,我们来一起看下29到32有哪些变化。 简介 欢迎来到Flutter 3.32!此版本包含了旨在加速开发和增强应用程序的功能。准备好在网络上进行热加载,令人惊叹的原生保真Cupertino,以及与Fir…...

前端面试热门知识点总结
URL从输入到页面展示的过程 版本1 1.用户在浏览器的地址栏输入访问的URL地址。浏览器会先根据这个URL查看浏览器缓存-系统缓存-路由器缓存,若缓存中有,直接跳到第6步操作,若没有,则按照下面的步骤进行操作。 2.浏览器根据输入的UR…...
windows和mac安装虚拟机-详细教程
简介 虚拟机:Virtual Machine,虚拟化技术的一种,通过软件模拟的、具有完整硬件功能的、运行在一个完全隔离的环境中的计算机。 在学习linux系统的时候,需要安装虚拟机,在虚拟机上来运行操作系统,因为我使…...

【Hive 开发进阶】窗口函数深度解析:OVER/NTILE/RANK 实战案例与行转列高级技巧
一、窗口函数 OVER 详解 窗口函数用于在分组内进行数据排名、聚合计算等操作,语法格式: 函数名() over([partition by 分组字段] [order by 排序字段] [window子句])案例:员工信息与部门平均工资 create table emp (id int,dept string,sa…...

在STM32上配置图像处理库
在STM32上配置并使用简单的图像滤波库(以实现均值滤波为例,不依赖复杂的大型图像处理库,方便理解和在资源有限的STM32上运行)为例,给出代码示例,使用STM32CubeIDE开发环境和HAL库,假设已经初始化好了相关GPIO和DMA(如果有图像数据传输需求),并且图像数据存储在一个二…...
【C++】vector容器实现
目录 一、vector的成员变量 二、vector手动实现 (1)构造 (2)析构 (3)尾插 (4)扩容 (5)[ ]运算符重载 5.1 迭代器的实现: (6&…...

RocketMQ 深度解析:消息中间件核心原理与实践指南
一、RocketMQ 概述 1.1 什么是 RocketMQ RocketMQ 是阿里巴巴开源的一款分布式消息中间件,后捐赠给 Apache 基金会成为顶级项目。它具有低延迟、高并发、高可用、高可靠等特点,广泛应用于订单交易、消息推送、流计算、IoT 等场景。 1.2 核心特性 高吞…...
使用Docker Compose部署Dify
目录 1. 克隆项目代码2. 准备配置文件3. 配置环境变量4. 启动服务5. 验证部署6. 访问服务注意事项 1. 克隆项目代码 首先,克隆Dify项目的1.4.0版本: git clone https://github.com/langgenius/dify.git --branch 1.4.02. 准备配置文件 进入docker目录…...

基于 Vue3 与 exceljs 实现自定义导出 Excel 模板
在开发中,我们需要常常为用户提供更多的数据录入方式,Excel 模板导出与导入是一个常见的功能点。本文将介绍如何使用 Vue3、exceljs 和 file-saver 实现一个自定义导出 Excel 模板,并在特定列添加下拉框选择的数据验证功能。 技术选型 excelj…...

杰发科技AC7840——CSE硬件加密模块使用(1)
1. 简介 2. 功能概述 3. 简单的代码分析 测试第二个代码例程 初始化随机数 这里的CSE_CMD_RND在FuncID中体现了 CSE_SECRET_KEY在17个用户KEY中体现 最后的读取RNG值,可以看出计算结果在PRAM中。 总的来看 和示例说明一样,CSE 初次使用,添加…...
前端地图数据格式标准及应用
前端地图数据格式标准及应用 坐标系EPSGgeojson标准格式基于OGC标准的地图服务shapefile文件3D模型数据常见地图框架 坐标系EPSG EPSG(European Petroleum Survey Group)是一个国际组织,负责维护和管理地理坐标系统和投影系统的标准化编码 E…...
threejs几何体BufferGeometry顶点
1. 几何体顶点位置数据和点模型 本章节主要目的是给大家讲解几何体geometry的顶点概念,相对偏底层一些,不过掌握以后,你更容易深入理解Threejs的几何体和模型对象。 缓冲类型几何体BufferGeometry threejs的长方体BoxGeometry、球体SphereGeometry等几…...
向量数据库选型实战指南:Milvus架构深度解析与技术对比
导读:随着大语言模型和AI应用的快速普及,传统数据库在处理高维向量数据时面临的性能瓶颈日益凸显。当文档经过嵌入模型处理生成768到1536维的向量后,传统B-Tree索引的检索效率会出现显著下降,而现代应用对毫秒级响应的严苛要求使得…...

java方法重写学习笔记
方法重写介绍 子类和父类有两个返回值,参数,名称都一样的方法, 子类的方法会覆盖父类的方法。 调用 public class Overide01 {public static void main(String[] args) {Dog dog new Dog();dog.cry();} }Animal类 public class Animal {…...
)
解决WPF短暂的白色闪烁(白色闪屏)
在 WPF 应用程序启动时出现 短暂的白色闪烁(白色闪屏),通常是由于以下原因导致的: 主要原因 WPF 默认窗口背景是白色,在加载 UI 之前会短暂显示白色背景。 解决方案 设置窗口背景为透明或黑色(推荐&…...
)
如何在Java中处理PDF文档(教程)
在开发文档管理系统、自动化工具或商业应用程序时,Java开发者常需处理PDF文档的编辑需求。无论是添加页面、调整内容尺寸、插入水印还是添加注释,选择一套可靠易用的Java PDF开发工具包至关重要。 JPedal(Java PDF开发工具包)的新…...

TensorBoard安装与基本操作指南(PyTorch)
文章目录 什么是TensorBoard?TensorBoardX与TensorBoard的依赖关系易混关系辨析Pytorch安装TensorBoard并验证1. TensorBoard安装和访问2. TensorBoard主要界面介绍实用技巧 什么是TensorBoard? TensorBoard是TensorFlow生态系统中的一款强大的可视化工…...

基于PyTorch的残差网络图像分类实现指南
以下是一份超过6000字的详细技术文档,介绍如何在Python环境下使用PyTorch框架实现ResNet进行图像分类任务,并部署在服务器环境运行。内容包含完整代码实现、原理分析和工程实践细节。 基于PyTorch的残差网络图像分类实现指南 目录 残差网络理论基础服务…...

2025/5/25 学习日记 linux进阶命令学习
tree:以树状结构显示目录下的文件和子目录,方便直观查看文件系统结构。 -d:仅显示目录,不显示文件。-L [层数]:限制显示的目录层级(如 -L 2 表示显示当前目录下 2 层子目录)。-h:以人类可读的格…...