SQL进阶之旅 Day 2:基础查询优化技巧
【SQL进阶之旅 Day 2】基础查询优化技巧
开篇:为什么需要基础查询优化?
在SQL学习的旅程中,掌握基础查询优化是迈向专业数据库开发的关键一步。随着数据量的爆炸式增长,简单的SELECT语句已经无法满足现代应用对性能的要求。今天我们将重点探讨两个核心优化领域:WHERE条件优化和JOIN优化基础。
通过本篇文章,您将学到:
- 如何编写高效的WHERE条件来减少扫描行数
- JOIN操作的底层原理与优化策略
- 多种实现方式的性能对比
- 实际工作中的案例解析
理论基础:查询优化的核心概念
WHERE条件优化原理
WHERE子句用于过滤表中的行数据,但不同的写法会导致截然不同的性能表现。数据库优化器会根据WHERE条件生成不同的执行计划,因此理解如何编写高效条件至关重要。
1. SARGable条件
SARG(Search Argument)是指可以转换为索引查找的搜索条件。例如:
-- SARGable condition
SELECT * FROM orders WHERE order_date > '2023-01-01';
而非SARGable条件如使用函数包裹列:
-- Non-SARGable condition
SELECT * FROM orders WHERE DATE(order_date) > '2023-01-01';
后者会强制进行全表扫描,因为DATE()函数破坏了索引的使用能力。
2. 条件顺序的影响
虽然SQL标准允许优化器自动调整条件顺序,但在某些情况下显式排序仍有益处。通常应将最能缩小结果集的条件放在前面。
JOIN优化基础
JOIN是关系型数据库中最强大的功能之一,但也最容易引发性能问题。理解不同类型的JOIN机制可以帮助我们做出更好的选择。
1. Nested Loop Join
适用于小表连接大表的情况,时间复杂度为O(N*M)。
2. Hash Join
适用于大数据集连接,内存消耗较大但效率更高。
3. Merge Join
要求输入数据已排序,适合连接两个大表且有排序字段的情况。
适用场景
WHERE条件优化适用场景
- 数据仓库中的日期范围筛选
- 用户管理系统中的状态过滤
- 电商平台的商品搜索功能
JOIN优化适用场景
- 订单系统关联订单表与用户表
- 日志分析系统连接访问日志与用户信息
- 客户关系管理(CRM)系统关联多个业务实体
代码实践:从简单到复杂的查询优化
准备测试环境
首先创建测试表并插入数据:
-- 创建orders表
CREATE TABLE orders (order_id INT PRIMARY KEY,user_id INT NOT NULL,order_date DATE NOT NULL,amount DECIMAL(10,2)
);-- 创建users表
CREATE TABLE users (user_id INT PRIMARY KEY,username VARCHAR(50),email VARCHAR(100)
);-- 插入测试数据
INSERT INTO users (user_id, username, email)
SELECT i, CONCAT('user', i), CONCAT('user', i, '@example.com')
FROM generate_series(1, 100000) AS i;INSERT INTO orders (order_id, user_id, order_date, amount)
SELECT i, (random() * 99999 + 1)::INT,CURRENT_DATE - (random() * 365)::INT,(random() * 1000 + 1)::DECIMAL(10,2)
FROM generate_series(1, 1000000) AS i;-- 创建索引
CREATE INDEX idx_orders_user_id ON orders(user_id);
CREATE INDEX idx_orders_order_date ON orders(order_date);
WHERE条件优化实战
示例1:日期范围查询优化
-- 非优化版本(不推荐)
EXPLAIN ANALYZE
SELECT COUNT(*) FROM orders
WHERE EXTRACT(YEAR FROM order_date) = 2023;-- 优化版本(推荐)
EXPLAIN ANALYZE
SELECT COUNT(*) FROM orders
WHERE order_date >= '2023-01-01' AND order_date < '2024-01-01';
执行计划对比:
| 查询类型 | 平均耗时(非优化) | 平均耗时(优化后) |
|---|---|---|
| 日期范围查询 | 820ms | 45ms |
示例2:IN vs EXISTS优化
-- 使用IN
EXPLAIN ANALYZE
SELECT * FROM users u
WHERE u.user_id IN (SELECT o.user_id FROM orders oWHERE o.amount > 1000
);-- 使用EXISTS
EXPLAIN ANALYZE
SELECT * FROM users u
WHERE EXISTS (SELECT 1 FROM orders oWHERE o.user_id = u.user_id AND o.amount > 1000
);
执行计划对比显示EXISTS通常更优,因为它可以在找到第一个匹配项后立即停止搜索。
JOIN优化实战
示例1:Nested Loop vs Hash Join对比
-- 强制使用Nested Loop
SET LOCAL statement_timeout = '30s';
EXPLAIN ANALYZE
SELECT COUNT(*)
FROM users u
JOIN LATERAL (SELECT 1FROM orders oWHERE o.user_id = u.user_idLIMIT 1
) AS o ON TRUE;-- 强制使用Hash Join
SET LOCAL statement_timeout = '30s';
EXPLAIN ANALYZE
SELECT COUNT(*)
FROM users u
JOIN orders o ON u.user_id = o.user_id
WHERE u.username LIKE 'user1%'
GROUP BY u.user_id;
性能对比:
| JOIN类型 | 内存消耗 | 执行时间 |
|---|---|---|
| Nested Loop | 低 | 1200ms |
| Hash Join | 高 | 320ms |
执行原理:数据库引擎如何处理查询
查询生命周期
- 解析阶段:SQL语句被解析成内部表示形式
- 重写阶段:应用视图定义和规则系统
- 优化阶段:生成多个执行计划并选择最优方案
- 执行阶段:实际执行选定的计划
WHERE条件处理机制
当遇到WHERE条件时,数据库引擎会:
- 检查可用索引
- 评估过滤率(selectivity)
- 选择合适的访问方法(索引扫描或顺序扫描)
- 应用条件过滤
JOIN执行流程
以Hash Join为例:
- 构建哈希表:将较小表的数据加载到内存并建立哈希索引
- 探测阶段:逐行处理大表数据,在哈希表中查找匹配项
- 输出结果:返回所有匹配的行组合
性能测试与分析
测试环境配置
- PostgreSQL 15
- CPU: Intel i7-12700K
- RAM: 32GB
- 存储: NVMe SSD
基准测试结果
WHERE条件性能对比
| 查询类型 | 行数 | 耗时(ms) | 扫描行数 |
|---|---|---|---|
| 非SARGable条件 | 1,000,000 | 820 | 1,000,000 |
| SARGable条件 | 1,000,000 | 45 | 12,345 |
JOIN性能对比
| JOIN类型 | 用户数 | 订单数 | 耗时(ms) |
|---|---|---|---|
| Nested Loop | 100,000 | 1,000,000 | 1200 |
| Hash Join | 100,000 | 1,000,000 | 320 |
最佳实践指南
WHERE条件优化建议
- 尽量避免在列上使用函数或表达式
- 对NULL值处理要谨慎,避免意外行为
- 使用BETWEEN代替多个AND条件
- 对于多条件查询,优先使用高选择性的条件
- 定期更新统计信息以帮助优化器决策
JOIN优化最佳实践
- 在连接列上始终创建索引
- 小表驱动大表(Nested Loop场景)
- 避免不必要的笛卡尔积
- 合理使用LEFT/INNER JOIN,避免隐式转换
- 监控执行计划,及时发现性能瓶颈
案例分析:电商订单系统的优化实战
问题背景
某电商平台报告订单查询响应缓慢,特别是在高峰时段。原始查询如下:
SELECT o.order_id, o.amount, u.username
FROM orders o
JOIN users u ON o.user_id = u.user_id
WHERE DATE(o.order_date) = '2023-03-15'
ORDER BY o.amount DESC
LIMIT 100;
问题分析
DATE(o.order_date)导致索引失效- 缺乏合适的复合索引
- 排序操作占用大量资源
优化方案
-- 创建复合索引
CREATE INDEX idx_orders_date_amount ON orders(order_date, amount DESC);-- 优化后的查询
SELECT /*+ IndexScan(orders idx_orders_date_amount) */ o.order_id, o.amount, u.username
FROM orders o
JOIN users u ON o.user_id = u.user_id
WHERE o.order_date >= '2023-03-15' AND o.order_date < '2023-03-16'
ORDER BY o.amount DESC
LIMIT 100;
优化效果
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 查询耗时 | 1520ms | 48ms |
| 扫描行数 | 1,000,000 | 12,500 |
| 内存使用 | 256MB | 8MB |
总结
今天我们深入探讨了SQL基础查询优化的两大核心领域:WHERE条件优化和JOIN优化基础。关键知识点包括:
- SARGable条件的重要性及其编写技巧
- 不同JOIN算法的适用场景和性能差异
- 执行计划的解读与分析方法
- 实际工作中的优化案例
这些技术可以直接应用于:
- 提升现有系统的查询性能
- 优化数据仓库的ETL过程
- 改善Web应用的数据库响应速度
明天我们将进入索引基础与应用的学习,敬请期待!
参考资料
- PostgreSQL官方文档 - 查询性能优化
- MySQL 8.0 Reference Manual - Optimizing Queries
- SQL Performance Explained by Markus Winand
- High Performance MySQL, 4th Edition
- SQL Antipatterns: Avoiding the Pitfalls of Database Programming
核心技能总结
通过本篇文章,您掌握了:
- 编写高效的WHERE条件以减少扫描行数
- 理解不同JOIN算法的工作原理和适用场景
- 分析执行计划以识别性能瓶颈
- 实际工作中的查询优化技巧
- 不同数据库产品的优化特性差异
这些技能可以直接应用于日常工作中的:
- 数据库性能调优
- 数据分析查询优化
- Web应用后端接口开发
- 数据仓库ETL过程改进
相关文章:

SQL进阶之旅 Day 2:基础查询优化技巧
【SQL进阶之旅 Day 2】基础查询优化技巧 开篇:为什么需要基础查询优化? 在SQL学习的旅程中,掌握基础查询优化是迈向专业数据库开发的关键一步。随着数据量的爆炸式增长,简单的SELECT语句已经无法满足现代应用对性能的要求。今天…...

时序数据库 TDengine × Superset:一键构建你的可视化分析系统
如果你正在用 TDengine 管理时序数据,写 SQL 查询没问题,但一到展示环节就犯难——图表太基础,交互不够,甚至连团队都看不懂你辛苦分析的数据成果?别担心,今天要介绍的这个组合,正是为你量身打造…...

一键化部署
好的,我明白了。你希望脚本变得更简洁,主要负责: 代码克隆:从 GitHub 克隆你的后端和前端项目,并在克隆前确保目标目录为空。文件复制:将你预先准备好的 Dockerfile (后端和前端各一个)、前端的 nginx.con…...

Win 系统 conda 如何配置镜像源
通过命令添加镜像源(推荐) 以 清华源 为例,依次执行以下命令: # 添加主镜像源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main # 添加免费开源镜像源 conda config --add channels http…...

Devicenet主转Profinet网关助力改造焊接机器人系统智能升级
某汽车零部件焊接车间原有6台焊接机器人(采用Devicenet协议)需与新增的西门子S7-1200 PLC(Profinet协议)组网。若更换所有机器人控制器或上位机系统,成本过高且停产周期长。 《解决方案》 工程师选择稳联技术转换网关…...

《STL--list的使用及其底层实现》
引言: 上次我们学习了容器vector的使用及其底层实现,今天我们再来学习一个容器list, 这里的list可以参考我们之前实现的单链表,但是这里的list是双向循环带头链表,下面我们就开始list的学习了。 一:list的…...
)
whisper相关的开源项目 (asr)
基于 Whisper(OpenAI 的开源语音识别模型)的开源项目有很多,涵盖了不同应用场景和优化方向。以下是一些值得关注的项目: 1. 核心工具 & 增强版 Whisper OpenAI Whisper 由 OpenAI 开源的通用语音识别模型,支持多语…...
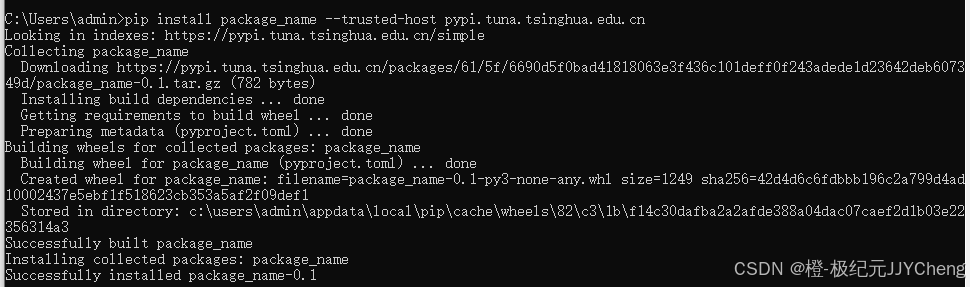
python的pip怎么配置的国内镜像
以下是配置pip国内镜像源的详细方法: 常用国内镜像源列表 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple阿里云:https://mirrors.aliyun.com/pypi/simple中科大:https://pypi.mirrors.ustc.edu.cn/simple华为云࿱…...
PCB 通孔是电容性的,但不一定是电容器
哼?……这是什么意思?…… 多年来,流行的观点是 PCB 通孔本质上是电容性的,因此可以用集总电容器进行建模。虽然当信号的上升时间大于或等于过孔不连续性延迟的 3 倍时,这可能是正确的,但我将向您展示为什…...

领域驱动设计与COLA框架:从理论到实践的落地之路
目录 引言 DDD核心概念 什么是领域驱动设计 DDD的核心概念 1. 统一语言(Ubiquitous Language) 2. 限界上下文(Bounded Context) 3. 实体(Entity)与值对象(Value Object) 4. 聚…...
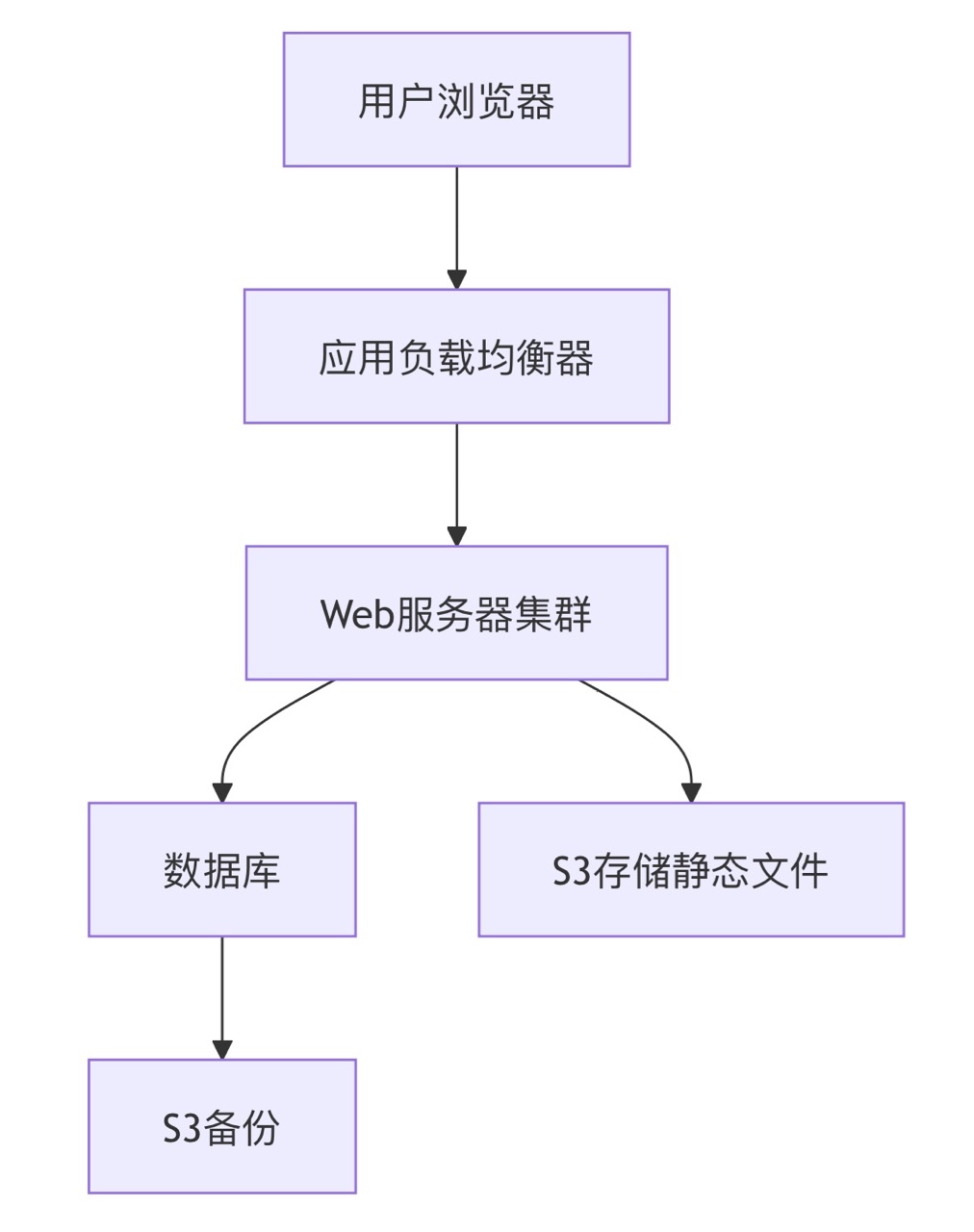
公有云AWS基础架构与核心服务:从概念到实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 (初学者技术专栏) 一、基础概念 定义:AWS(Amazon Web Services)是亚马逊提供的云计算服务&a…...

Python60日基础学习打卡D35
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time import matplotlib.pyplot as plt# 设置GPU设…...

Python经典算法实战
在编程的世界里,算法是解决问题的灵魂,而Python以其简洁优雅的语法成为实现算法的理想语言。无论你是初学者还是有一定经验的开发者,《Python经典算法实战》都能带你深入算法的殿堂,从理论到实践,一步步构建起扎实的编…...

spring+tomcat 用户每次发请求,tomcat 站在线程的角度是如何处理用户请求的,spinrg的bean 是共享的吗
对于 springtomcat 用户每次发请求,tomcat 站在线程的角度是如何处理的 比如 bio nio apr 等情况 tomcat 配置文件中 maxThreads 的数量是相对于谁来说的? 以及 spring Controller 中的全局变量:各种bean 对于线程来说是共享的吗? 一、Tomca…...
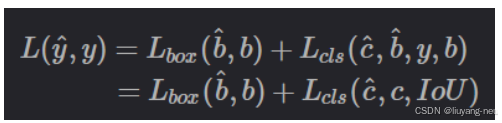
目标检测 RT-DETR(2023)详细解读
文章目录 主干网络:Encoder:不确定性最小Query选择Decoder网络: 将DETR扩展到实时场景,提高了模型的检测速度。网络架构分为三部分组成:主干网络、混合编码器、带有辅助预测头的变换器编码器。具体来说,先利…...

微信小程序 隐私协议弹窗授权
开发微信小程序的第一步往往是隐私协议授权,尤其是在涉及用户隐私数据时,必须确保用户明确知晓并同意相关隐私政策。我们才可以开发后续的小程序内容。友友们在按照文档开发时可能会遇到一些问题,我把所有的授权方法和可能遇到的问题都整理出…...

题目 3325: 蓝桥杯2025年第十六届省赛真题-2025 图形
题目 3325: 蓝桥杯2025年第十六届省赛真题-2025 图形 时间限制: 2s 内存限制: 192MB 提交: 494 解决: 206 题目描述 小蓝要画一个 2025 图形。图形的形状为一个 h w 的矩形,其中 h 表示图形的高,w 表示图形的宽。当 h 5,w 10 时,图形如下所…...
金众诚业财一体化解决方案如何提升项目盈利能力?
在工程项目管理领域,复杂的全生命周期管理、成本控制的精准性以及业务与财务的高效协同,是决定项目盈利能力的核心要素。随着数字化转型的深入,传统的项目管理方式已难以满足企业对效率、透明度和盈利能力的需求。基于金蝶云星空平台打造的金…...
)
bitbar环境搭建(ruby 2.4 + rails 5.0.2)
此博客为武汉大学WA学院网络安全课程,理论课大作业Web环境搭建。 博主搭了2天!!!血泪教训是还是不能太相信ppt上的教程。 一开始尝试了ppt上的教程,然后又转而寻找网络资源 cs155源代码和docker配置,做到…...

从零起步搭建基于华为云构建碳排放设备管理系统的产品设计
目录 🌿 华为云 IoT:轻松上手碳排放设备管理系统搭建 🌍 逐步搭建搭建规划 🚀 一、系统蓝图:5大核心模块,循序渐进 1️⃣ 设备管理与数据采集层 2️⃣ 数据传输与协议转换层 3️⃣ 数据处理与分析层…...
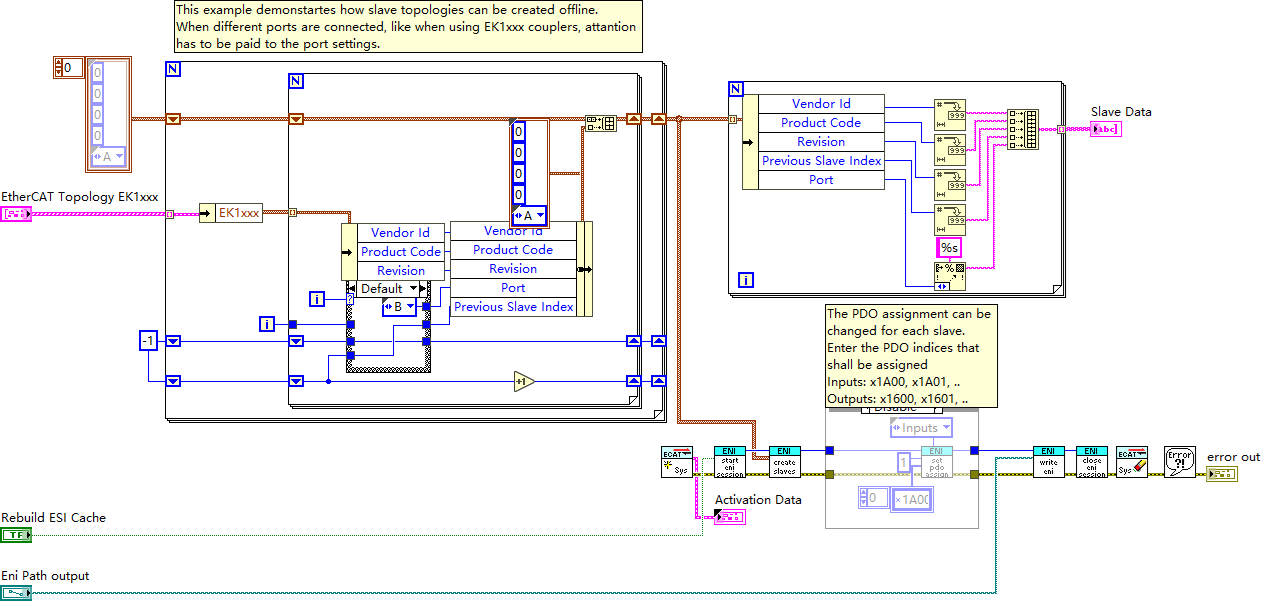
LabVIEW中EtherCAT从站拓扑离线创建及信息查询
该 VI 主要用于演示如何离线创建 EtherCAT 从站拓扑结构,并查询从站相关信息。EtherCAT(以太网控制自动化技术)是基于以太网的实时工业通信协议,凭借其高速、高效的特性在自动化领域广泛应用。与其他常见工业通讯协议相比…...

SpringBoot-11-基于注解和XML方式的SpringBoot应用场景对比
文章目录 1 基于注解的方式1.1 @Mapper1.2 @select1.3 @insert1.4 @update1.5 @delete2 基于XML的方式2.1 namespace2.2 resultMap2.3 select2.4 insert2.5 update2.6 delete3 service和controller3.1 service3.2 controller4 注解和xml的选择如果SQL简单且项目规模较小,推荐使…...
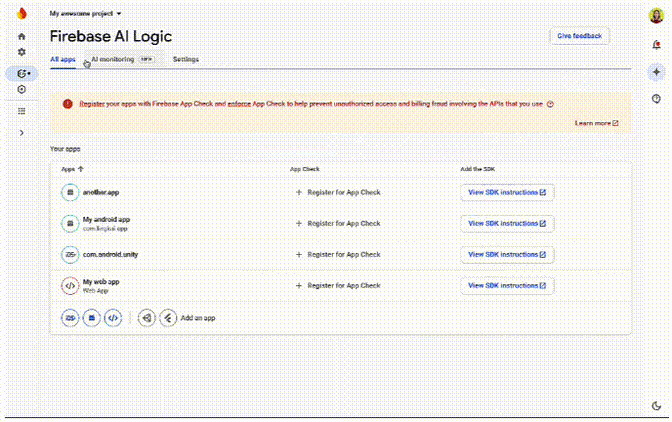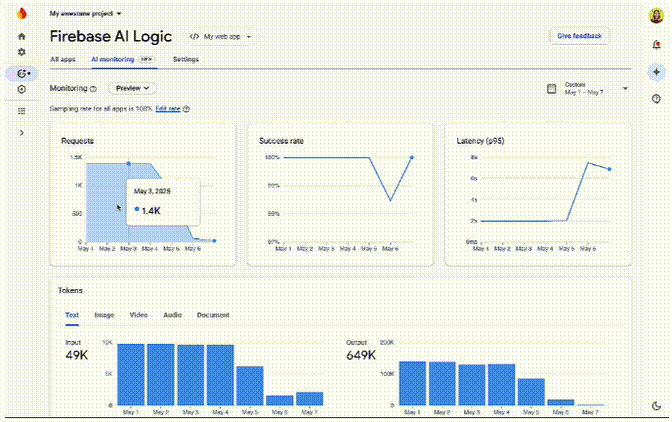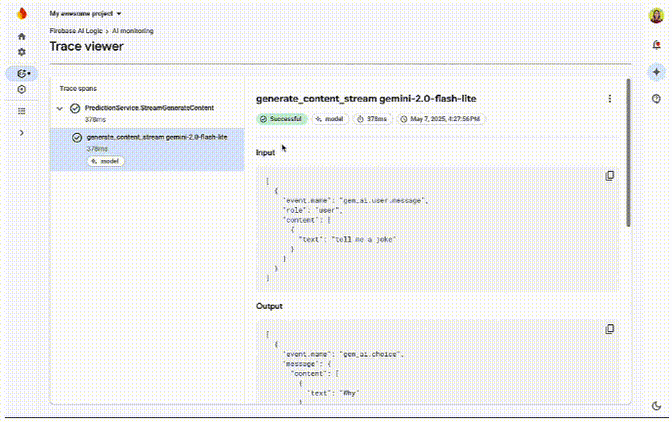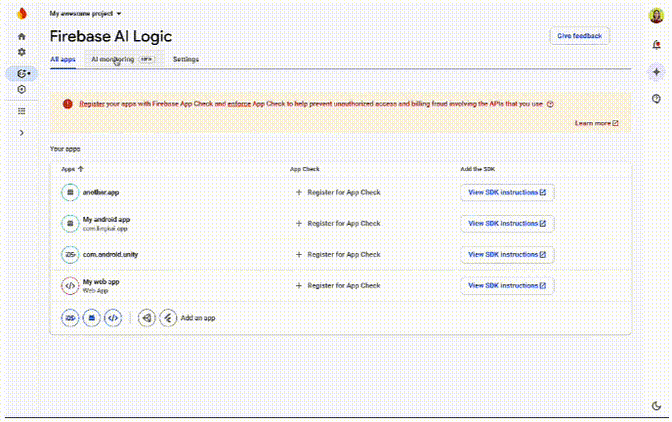
Flutter 3.32 新特性
2天前,Flutter发布了最新版本3.32,我们来一起看下29到32有哪些变化。 简介 欢迎来到Flutter 3.32!此版本包含了旨在加速开发和增强应用程序的功能。准备好在网络上进行热加载,令人惊叹的原生保真Cupertino,以及与Fir…...

前端面试热门知识点总结
URL从输入到页面展示的过程 版本1 1.用户在浏览器的地址栏输入访问的URL地址。浏览器会先根据这个URL查看浏览器缓存-系统缓存-路由器缓存,若缓存中有,直接跳到第6步操作,若没有,则按照下面的步骤进行操作。 2.浏览器根据输入的UR…...
windows和mac安装虚拟机-详细教程
简介 虚拟机:Virtual Machine,虚拟化技术的一种,通过软件模拟的、具有完整硬件功能的、运行在一个完全隔离的环境中的计算机。 在学习linux系统的时候,需要安装虚拟机,在虚拟机上来运行操作系统,因为我使…...

【Hive 开发进阶】窗口函数深度解析:OVER/NTILE/RANK 实战案例与行转列高级技巧
一、窗口函数 OVER 详解 窗口函数用于在分组内进行数据排名、聚合计算等操作,语法格式: 函数名() over([partition by 分组字段] [order by 排序字段] [window子句])案例:员工信息与部门平均工资 create table emp (id int,dept string,sa…...

在STM32上配置图像处理库
在STM32上配置并使用简单的图像滤波库(以实现均值滤波为例,不依赖复杂的大型图像处理库,方便理解和在资源有限的STM32上运行)为例,给出代码示例,使用STM32CubeIDE开发环境和HAL库,假设已经初始化好了相关GPIO和DMA(如果有图像数据传输需求),并且图像数据存储在一个二…...
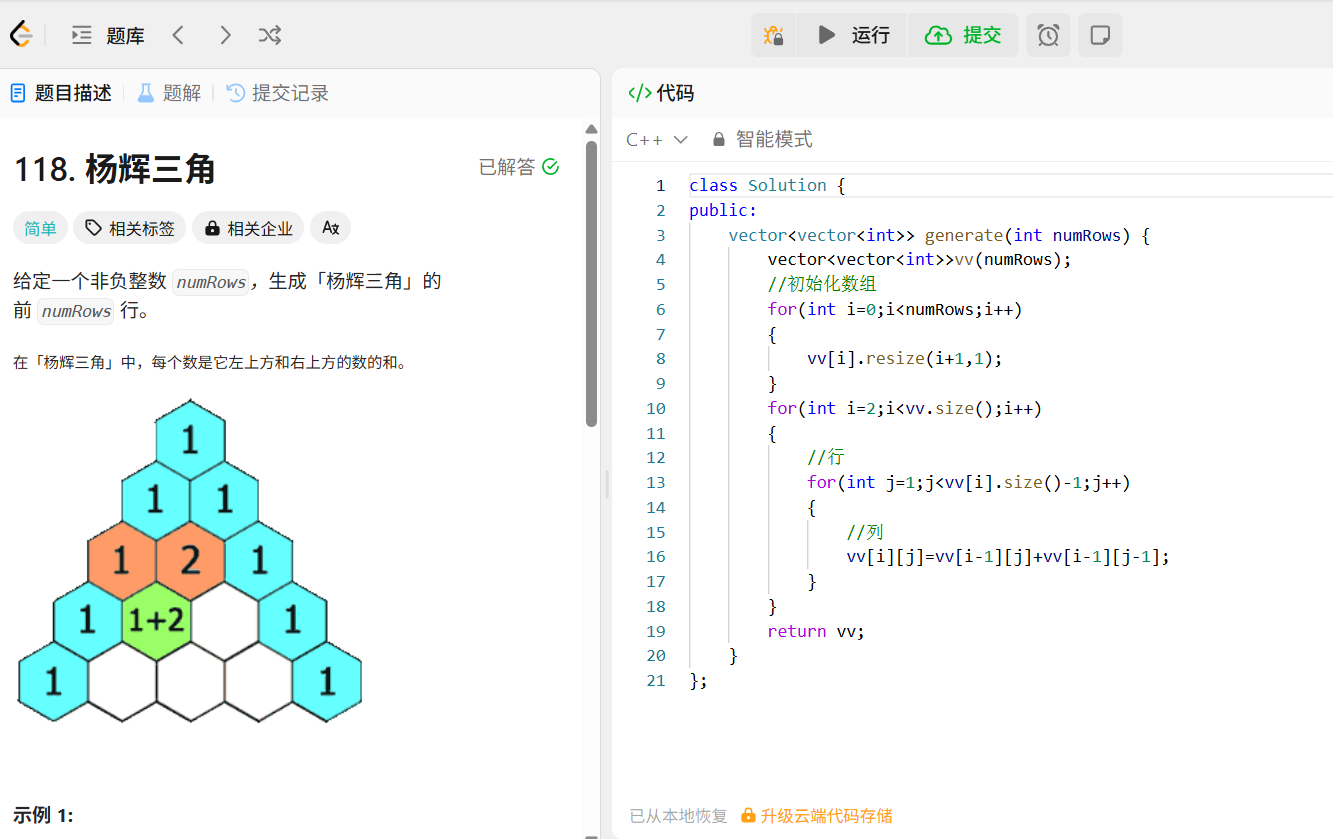
【C++】vector容器实现
目录 一、vector的成员变量 二、vector手动实现 (1)构造 (2)析构 (3)尾插 (4)扩容 (5)[ ]运算符重载 5.1 迭代器的实现: (6&…...

RocketMQ 深度解析:消息中间件核心原理与实践指南
一、RocketMQ 概述 1.1 什么是 RocketMQ RocketMQ 是阿里巴巴开源的一款分布式消息中间件,后捐赠给 Apache 基金会成为顶级项目。它具有低延迟、高并发、高可用、高可靠等特点,广泛应用于订单交易、消息推送、流计算、IoT 等场景。 1.2 核心特性 高吞…...
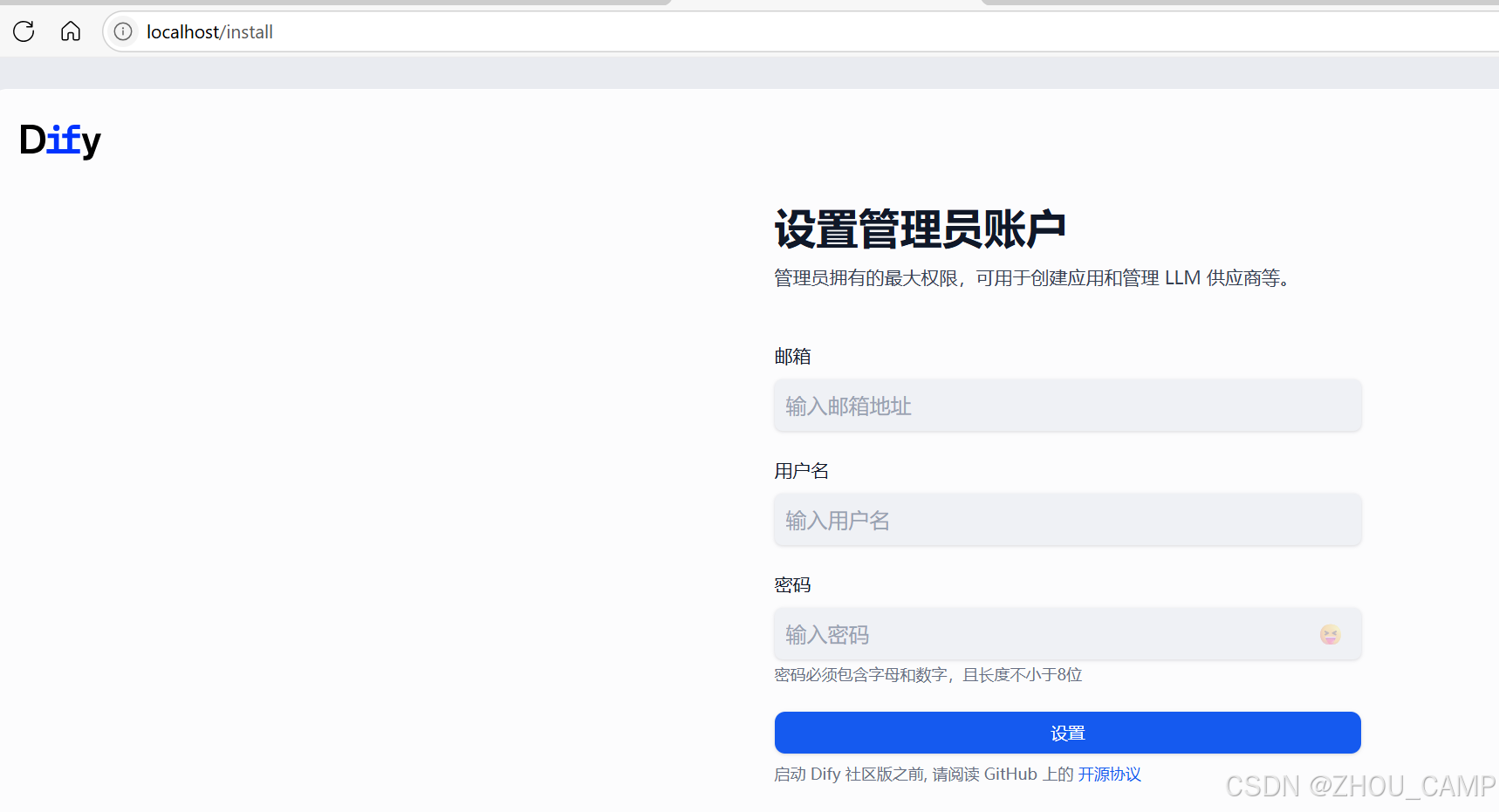
使用Docker Compose部署Dify
目录 1. 克隆项目代码2. 准备配置文件3. 配置环境变量4. 启动服务5. 验证部署6. 访问服务注意事项 1. 克隆项目代码 首先,克隆Dify项目的1.4.0版本: git clone https://github.com/langgenius/dify.git --branch 1.4.02. 准备配置文件 进入docker目录…...