我的第1个爬虫程序——豆瓣Top250爬虫的详细步骤指南
我的第1个爬虫程序——豆瓣Top250爬虫的详细步骤指南

一、创建隔离开发环境
1. 使用虚拟环境(推荐venv)
# 在项目目录打开终端执行
python -m venv douban_env # 创建虚拟环境
source douban_env/bin/activate # Linux/macOS激活
douban_env\Scripts\activate # Windows激活
2. 安装依赖库
pip install requests beautifulsoup4 lxml
3. 生成依赖清单
pip freeze > requirements.txt
二、项目架构设计
douban_top250/
├── config/ # 配置文件
│ └── settings.py
├── core/ # 核心逻辑
│ ├── spider.py
│ └── storage.py
├── utils/ # 工具函数
│ └── helper.py
├── output/ # 输出目录
├── main.py # 主入口
└── requirements.txt # 依赖清单
三、分步实现
步骤1:创建配置文件 config/settings.py
# 请求配置
HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36','Referer': 'https://movie.douban.com/'
}# 目标URL配置
BASE_URL = 'https://movie.douban.com/top250'# 存储配置
OUTPUT_DIR = './output'
CSV_HEADERS = ['标题', '评分', '年份', '国家', '类型', '链接']# 容错配置
SAFE_MODE = True # 遇到错误时跳过条目而不是终止
UNKNOWN_PLACEHOLDER = "未知" # 数据缺失时的占位符
步骤2:编写工具类 utils/helper.py
import random
import timedef random_delay(min=1, max=3):"""随机延迟防止被封"""time.sleep(random.uniform(min, max))def make_soup(html):"""创建BeautifulSoup对象"""from bs4 import BeautifulSoupreturn BeautifulSoup(html, 'lxml')
步骤3:核心爬虫逻辑 core/spider.py
import requests
from config import settings
from utils.helper import random_delay, make_soupclass DoubanSpider:def __init__(self):self.session = requests.Session()self.session.headers.update(settings.HEADERS)def fetch_page(self, url):"""获取页面内容"""try:random_delay()response = self.session.get(url)response.raise_for_status() # 自动处理HTTP错误return response.textexcept requests.RequestException as e:print(f"请求失败: {str(e)}")return Nonedef parse_page(self, html):"""改进后的解析方法"""soup = make_soup(html)movies = []for item in soup.find_all('div', class_='item'):try:# 标题与链接title = item.find('span', class_='title').text.strip()rating = item.find('span', class_='rating_num').text.strip()link = item.find('a')['href']# 详细信息解析(稳健版)info_div = item.find('div', class_='bd')info_text = info_div.p.get_text(" ", strip=True) # 用空格替代换行# 使用正则表达式提取年份/国家/类型import repattern = r'(\d{4})[^/]*(.*?)\s+/\s+(.*?)$'match = re.search(pattern, info_text)if match:year = match.group(1).strip()country = match.group(2).strip().replace('/', ' ') # 处理国家中的斜杠genre = match.group(3).strip()else:year = country = genre = "N/A" # 无法解析时填充默认值movies.append({'标题': title,'评分': rating,'年份': year,'国家': country,'类型': genre,'链接': link})except Exception as e:print(f"解析条目失败: {str(e)}")continue # 跳过当前条目return moviesdef get_all_pages(self):"""处理分页"""all_movies = []start = 0while True:url = f"{settings.BASE_URL}?start={start}"html = self.fetch_page(url)if not html:breakmovies = self.parse_page(html)if not movies:breakall_movies.extend(movies)start += 25# 检查是否还有下一页if start >= 250: # Top250最多250条breakreturn all_movies
步骤4:数据存储模块 core/storage.py
import csv
import json
import os
from config import settingsclass DataStorage:@staticmethoddef save_csv(data, filename='douban_top250.csv'):os.makedirs(settings.OUTPUT_DIR, exist_ok=True)path = os.path.join(settings.OUTPUT_DIR, filename)with open(path, 'w', newline='', encoding='utf-8') as f:writer = csv.DictWriter(f, fieldnames=settings.CSV_HEADERS)writer.writeheader()writer.writerows(data)print(f"数据已保存至 {path}")@staticmethoddef save_json(data, filename='douban_top250.json'):os.makedirs(settings.OUTPUT_DIR, exist_ok=True)path = os.path.join(settings.OUTPUT_DIR, filename)with open(path, 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=2)print(f"数据已保存至 {path}")
步骤5:主程序 main.py
from core.spider import DoubanSpider
from core.storage import DataStoragedef main():# 检查robots协议print("豆瓣 robots.txt 重要条款:")print("User-agent: *")print("Disallow: /search") # 实际需查看最新内容# 执行爬虫spider = DoubanSpider()movies_data = spider.get_all_pages()# 存储数据if movies_data:DataStorage.save_csv(movies_data)DataStorage.save_json(movies_data)else:print("未获取到有效数据")if __name__ == '__main__':main()
四、运行与验证
- 在激活的虚拟环境中执行:
python main.py
- 检查
output/目录生成的 CSV 和 JSON 文件

五、高级优化建议
- 异常处理增强:
# 在spider类中添加重试机制
def fetch_page(self, url, retries=3):for attempt in range(retries):try:# ...原有代码...except requests.RequestException as e:if attempt == retries - 1:raiseprint(f"重试中 ({attempt+1}/{retries})...")time.sleep(2 ** attempt) # 指数退避
- 请求头轮换:
# 在settings.py中添加多个User-Agent
USER_AGENTS = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36'
]# 在helper.py中添加选择函数
def get_random_user_agent():return random.choice(settings.USER_AGENTS)
- 代理设置(如果需要):
# 在spider初始化时添加
def __init__(self, proxy=None):if proxy:self.session.proxies = {'http': proxy, 'https': proxy}
六、法律合规检查
- 访问 https://www.douban.com/robots.txt 查看协议
- 重点条款:
User-agent: *
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /forum/search
Disallow: /game/search
- 合规措施:
- 限制请求频率(代码中已实现随机延迟)
- 不绕过反爬机制
- 仅用于学习用途
- 不存储敏感信息
通过这个结构化的项目实现,你可以:
- 保持代码的可维护性
- 方便后续扩展功能(如添加代理支持)
- 符合Python最佳实践
- 有效管理依赖项
下一步可以尝试:
- 添加日志记录模块
- 实现数据库存储(MySQL/MongoDB)
- 使用Scrapy框架重构项目
- 部署到服务器定时运行
相关文章:
我的第1个爬虫程序——豆瓣Top250爬虫的详细步骤指南
我的第1个爬虫程序——豆瓣Top250爬虫的详细步骤指南 一、创建隔离开发环境 1. 使用虚拟环境(推荐venv) # 在项目目录打开终端执行 python -m venv douban_env # 创建虚拟环境 source douban_env/bin/activate # Linux/macOS激活 douban_env\Scri…...

Selenium 测试框架 - C#
🚀Selenium C# 自动化测试实战:以百度搜索为例 本文将通过一个简单示例,手把手教你如何使用 Selenium + C# 实现百度搜索自动化测试。适合初学者快速上手,也适合作为企业 UI 自动化测试模板参考。 🧩 一、安装必要 NuGet 包 在 Visual Studio 的 NuGet 管理器中安装以下…...

JavaWeb:SpringBoot工作原理详解
一、SpringBoot优点 1.为所有Spring开发者更快的入门 2.开箱即用,提供各种默认配置来简化项目配置 3.内嵌式容器简化Web项目 4.没有冗余代码生成和XML配置的要求 二、SpringBoot 运行原理 2.1. pom.xml spring-boot-dependencies: 核心依赖在父工程中;…...

5.25本日总结
一、英语 复习list6list25 二、数学 写14讲课后题,学习15讲部分 三、408 完成计网5.3题目,学习计组第二章 四、总结 今日所学内容不难,但是英语最近的进度缓慢,单词记忆情况不好,阅读也很久没有再写,…...

OpenGL Chan视频学习-6 How Shaders Work in OpenGL
bilibili视频链接: 【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973 一、知识点整理 1.1 着色器 1.1.1 阐述 实际上是代码。需要告诉GPU发送数据要干啥,也是着色器的本质。…...
dify_plugin数据库中的表总结
本文使用dify-plugin-daemon v0.1.0版本,主要对dify_plugin数据库中的数据表进行了总结。 一.agent_strategy_installations 源码位置:dify-plugin-daemon\internal\types\models\agent.go type AgentStrategyInstallation struct {ModelTenantID …...

【数据仓库面试题合集④】SQL 性能调优:面试高频场景 + 调优策略解析
随着业务数据规模的持续增长,SQL 查询的执行效率直接影响到数据平台的稳定性与数据产出效率。因此,在数据仓库类岗位的面试中,SQL 性能调优常被作为重点考察内容。 本篇将围绕常见 SQL 调优问题,结合实际经验,整理出高频面试题与答题参考,助你在面试中游刃有余。 🎯 高…...
HarmonyOS学习——UIAbility组件(上)
UIAbility组件概述 应用程序有几种界面交互形式 UIAbility:应用程序的入口 概述 UIAbility组件是一种包含UI的应用组件,主要用于和用户交互。 UIAbility的设计理念: 原生支持应用组件级的跨端迁移和多端协同。 支持多设备和多窗口形态。…...

【Linux】磁盘空间不足
错误提示: no space left on device 经典版(block占用) 模拟 dd if/dev/zero of/var/log/nginx.log bs1M count2000排查 #1. df -h 查看哪里空间不足,哪个分区#2. du -sh详细查看目录所占空间 du -sh /* 排查占用空间大的目录 du -sh /var/* du…...

持续更新 ,GPT-4o 风格提示词案例大全!附使用方式
本文汇集了各类4o风格提示词的精选案例,从基础指令到复杂任务,从创意写作到专业领域,为您提供全方位的参考和灵感。我们将持续更新这份案例集,确保您始终能够获取最新、最有效的提示词技巧。 让我们一起探索如何通过精心设计的提…...

线性代数之张量计算,支撑AI算法的数学原理
目录 一、张量计算的数学本质 1、线性代数:张量的几何与代数性质 2、微积分:梯度与自动微分 3、优化理论:张量分解与正则化 4、张量计算的核心操作 二、张量计算在AI算法中的作用 1、数据表示与处理 2、神经网络的参数表示 3、梯度计算与优化 三、张量计算在AI中的…...
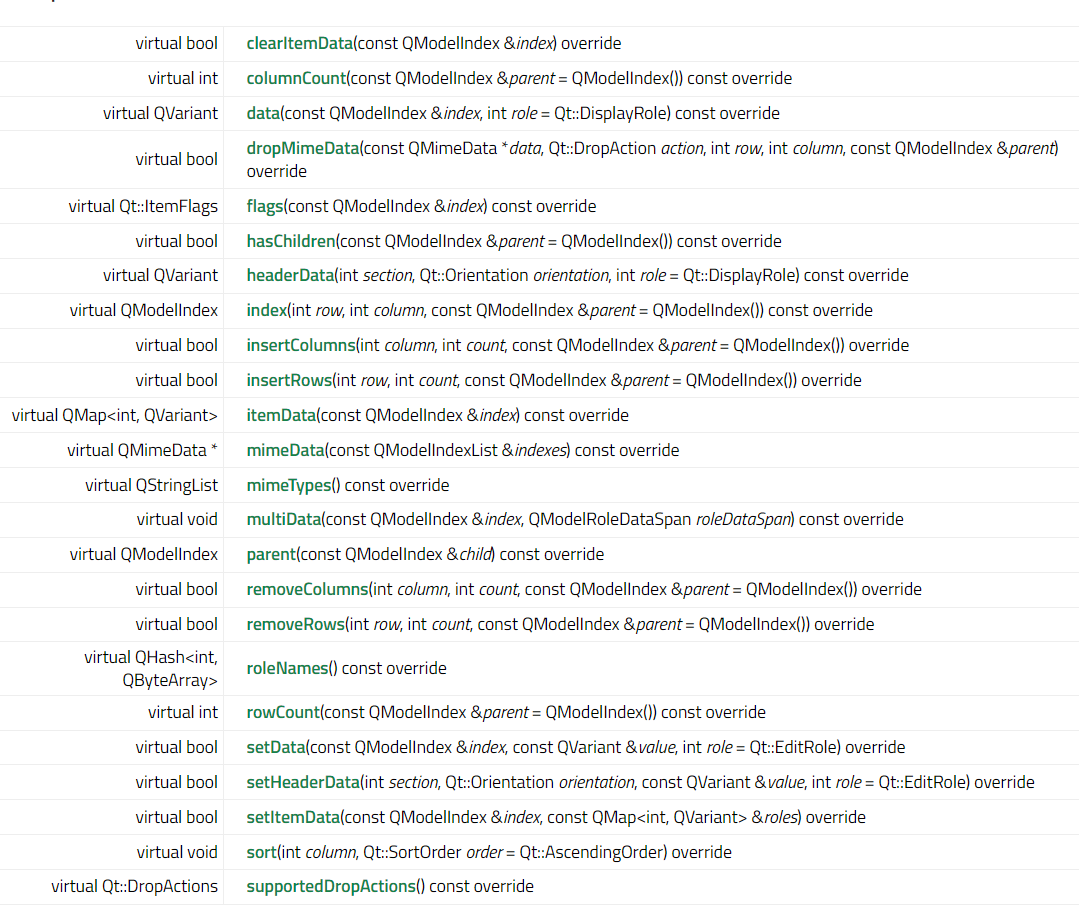
QStandardItemModel的函数和信号介绍
前言 Qt版本:6.8.0 QStandardItem函数介绍 函数 部分函数有不同的重载来适应不同的模型,例如appendrow 构造函数与析构函数 1. QStandardItemModel(QObject *parent nullptr) 说明:创建一个空的模型(0行0列)。参数: parent&…...
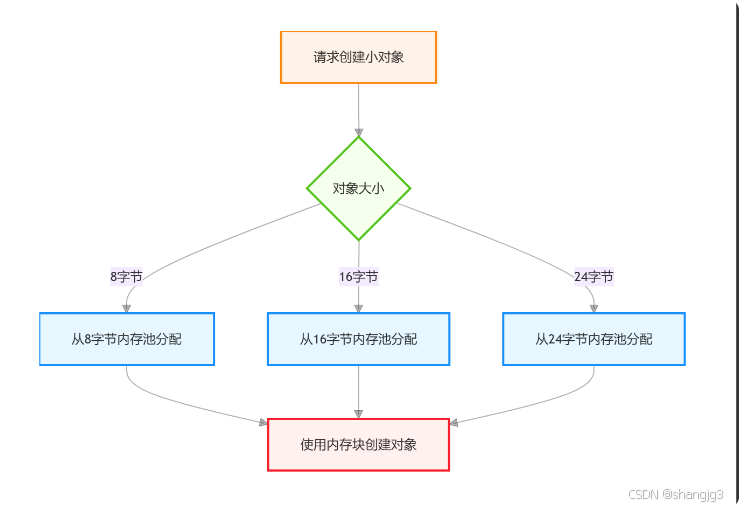
Python 内存管理机制详解:从分配到回收的全流程剖析
在 Python 编程中,开发者无需像 C/C 那样手动分配和释放内存,但这并不意味着内存管理与我们无关。了解 Python 内存管理机制,能帮助我们编写出更高效、稳定的代码。接下来,我们将深入剖析 Python 内存管理的各个环节,并…...
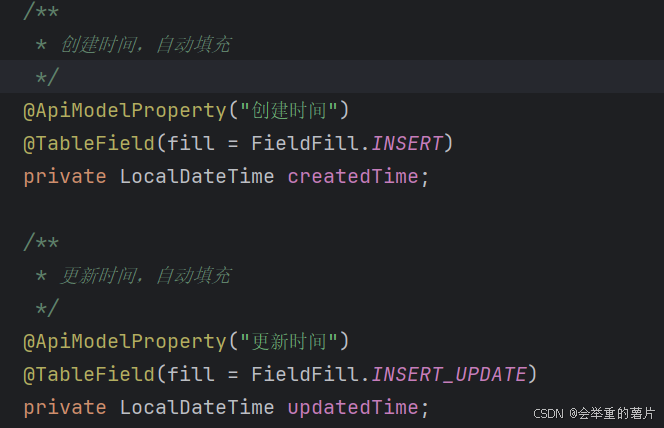
【报错】Error attempting to get column ‘created_time‘ from result set.解决方法
postman报错以下内容 {"code": "500","msg": "查询失败:Error attempting to get column created_time from result set. Cause: java.sql.SQLFeatureNotSupportedException\n; null; nested exception is java.sql.SQLFeatur…...

Redis 3.0~8.0特性与数据结构全面解析
目录 引言 第一部分:Redis版本演进与核心特性 Redis 3.0(2015年):分布式架构的里程碑 Redis 4.0(2017年):模块化与性能优化 Redis 5.0(2018年):流数据结构…...
Google 推出 Flow —— AI 电影制作新平台
这周, Google I/O 2025 大会上发布了一些重磅 AI 公告。 他们推出了全新的图像模型 Imagen 4,还发布了升级版视频生成器 Veo 3、升级版 Gemini Pro 模型,以及一系列其他令人印象深刻的更新。 但将所有这些生成式媒体工具整合在一起的,是他们称为 Flow 的平台。 什么是 F…...
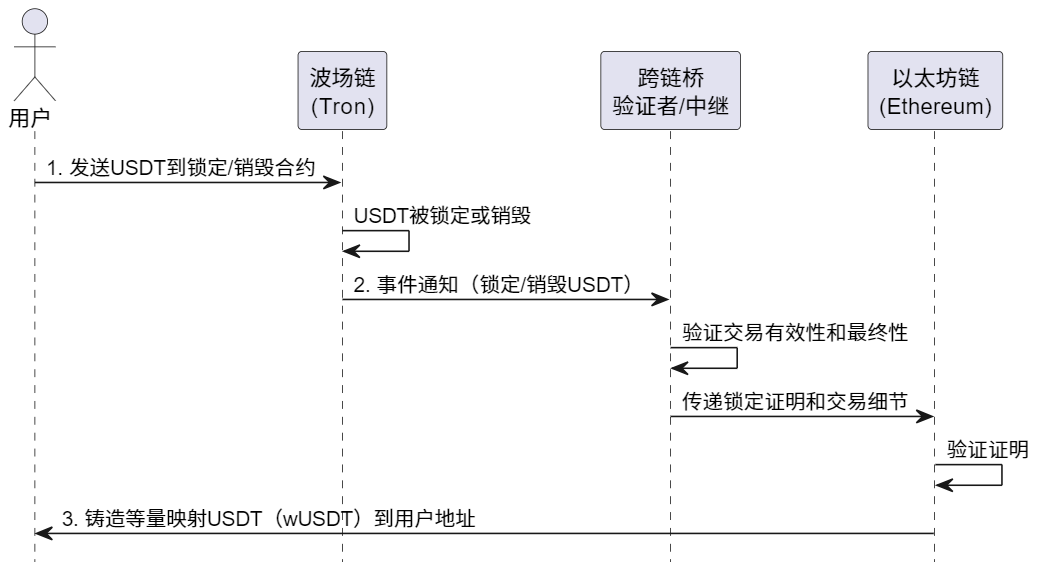
跨链风云:打破区块链孤岛,实现价值自由流转
嘿,各位技术爱好者们!今天我们来聊一个区块链领域非常火热且至关重要的话题——跨链技术。你可能听说过,比如想把在波场(Tron)链上的USDT转移到以太坊(Ethereum)网络上,这个过程就涉…...

鸿蒙开发:了解$$运算符
前言 本文基于Api13 有这样一个需求,一个Text组件,一个TextInput组件,要求Text组件同步展示TextInput组件里的内容,也就是TextInput组件输入什么内容,就要在Text组件里展示什么内容,这个需求如何实现呢&…...
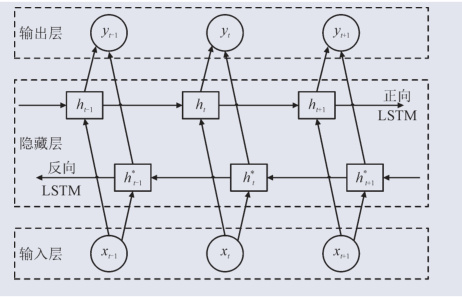
基于CEEMDAN-Transformer-BiLSTM的多特征风速气候预测的完整实现方案及PyTorch源码解析
基于CEEMDAN-Transformer-BiLSTM的多特征风速气候预测的完整实现方案及PyTorch源码解析 一、模型架构设计 1.1 整体框架 该模型采用三级架构设计(图1): CEEMDAN分解层:对非平稳风速序列进行自适应分解多模态特征融合模块&#…...

特征预处理
作为机器学习初学者,理解特征预处理就像学做菜前必须学会的"洗菜、切配、腌制"——它直接决定了最终模型的口感(性能)。我会用最生活化的比喻代码示例带你轻松掌握这个必备技能。 一、为什么要特征预处理? 原始数据的问…...

第七课 医学影像学临床研究数据管理与统计分析思路
引言 医学影像学作为现代医学的重要组成部分,在疾病诊断、治疗监测和预后评估中发挥着关键作用。随着影像技术的快速发展和临床研究需求的不断增长,如何有效管理和分析医学影像学研究数据已成为临床研究成功的关键因素。本文将系统介绍医学影像学临床研究中的数据管理流程、…...

基于TypeScript的全栈待办事项应用Demo
Demo地址:git clone https://gitcode.com/rmbnetlife/todo-app.git Todo List 应用 这是一个基于TypeScript的全栈待办事项应用,前端使用React,后端使用Node.js和Express。 项目概述 这个Todo List应用允许用户: 查看所有待办…...

obsidian 中的查找和替换插件,支持正则
最近用着 obsidian 时,发现想要在当前文档中 查找和替换 内容时,没有自动查找和替换的功能,去插件市场查找也没有发现好用的插件,那就自己写一个吧。 全程用的 AI 来写的,当然,我对 JS/CSS/TypeScript 等没…...

国际荐酒师(香港)协会亮相新西兰葡萄酒巡展深度参与赵凤仪大师班
国际荐酒师(香港)协会率团亮相2025新西兰葡萄酒巡展 深度参与赵凤仪MW“百年百碧祺”大师班 广州/上海/青岛,2025年5月12-16日——国际荐酒师(香港)协会(IRWA)近日率专业代表团出席“纯净独特&…...
【深度学习】2. 从梯度推导到优化策略:反向传播与 SGD, Mini SGD
反向传播算法详解 1. 前向传播与输出层误差定义 假设我们考虑一个典型的前馈神经网络,其最后一层为 softmax 分类器,损失函数为交叉熵。 前向传播过程 对于某一隐藏层神经元 j j j: 输入: x i x_i xi 权重: w j…...
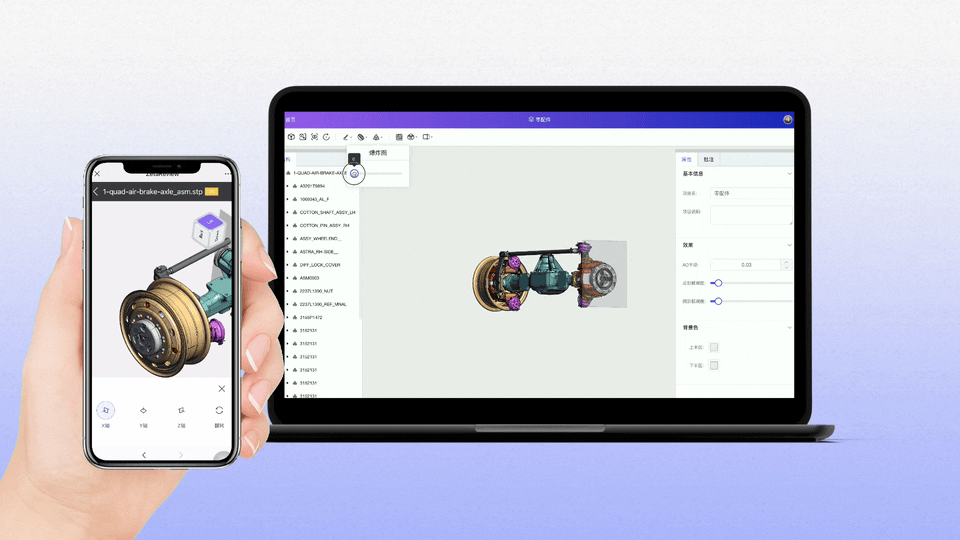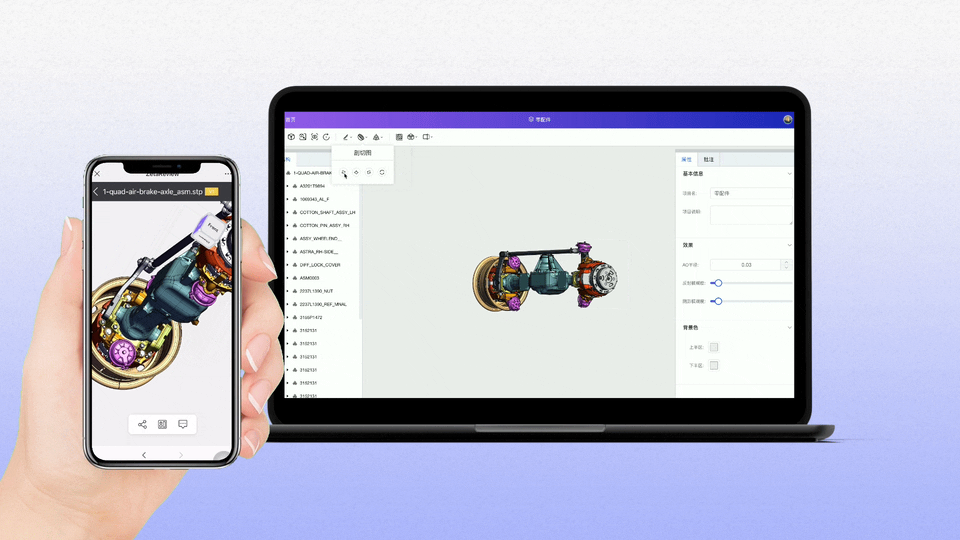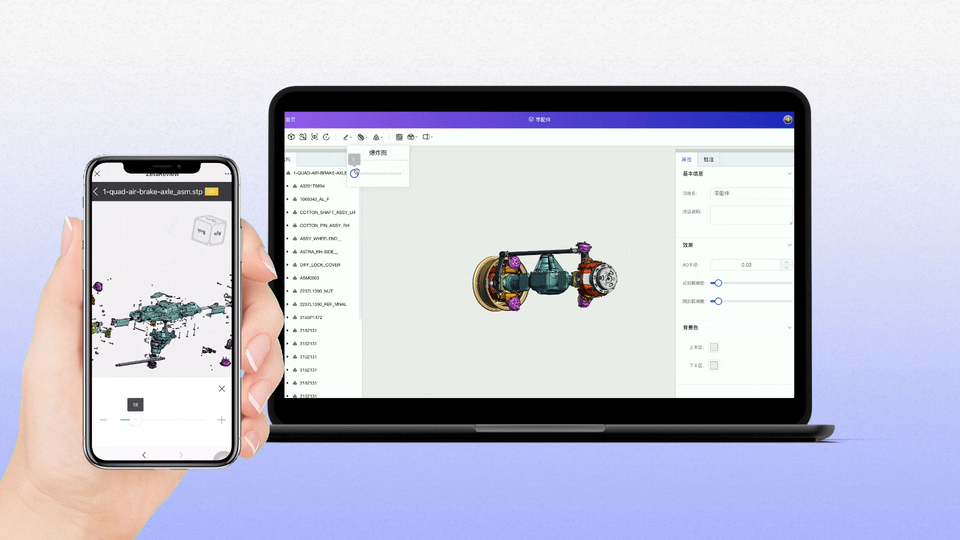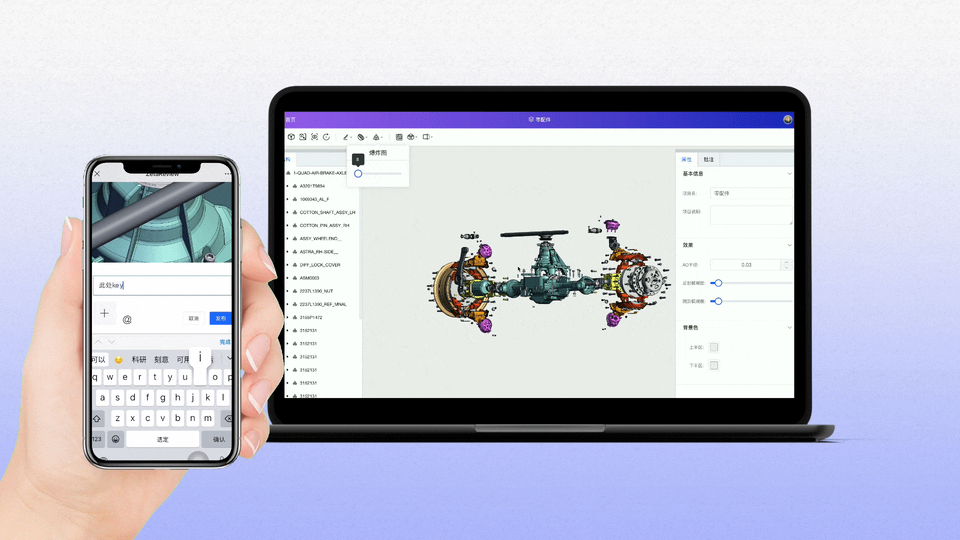
工业软件国产化:构建自主创新生态,赋能制造强国建设
随着全球产业环境的变化和技术的发展,建立自主可控的工业体系成为我国工业转型升级、走新型工业化道路、推动国家制造业竞争水平提升的重要抓手。 市场倒逼与政策护航,国产化进程双轮驱动 据中商产业研究院预测,2025年中国工业软件市场规模…...

UART、RS232、RS485基础知识
一、UART串口通信介绍 UART是一种采用异步串行、全双工通信方式的通用异步收发传输器功能。 硬件电路: •简单双向串口通信有两根通信线(发送端TX和接收端RX) •TX与RX要交叉连接 •当只需单向的数据传输时,可以只接一根通信线…...
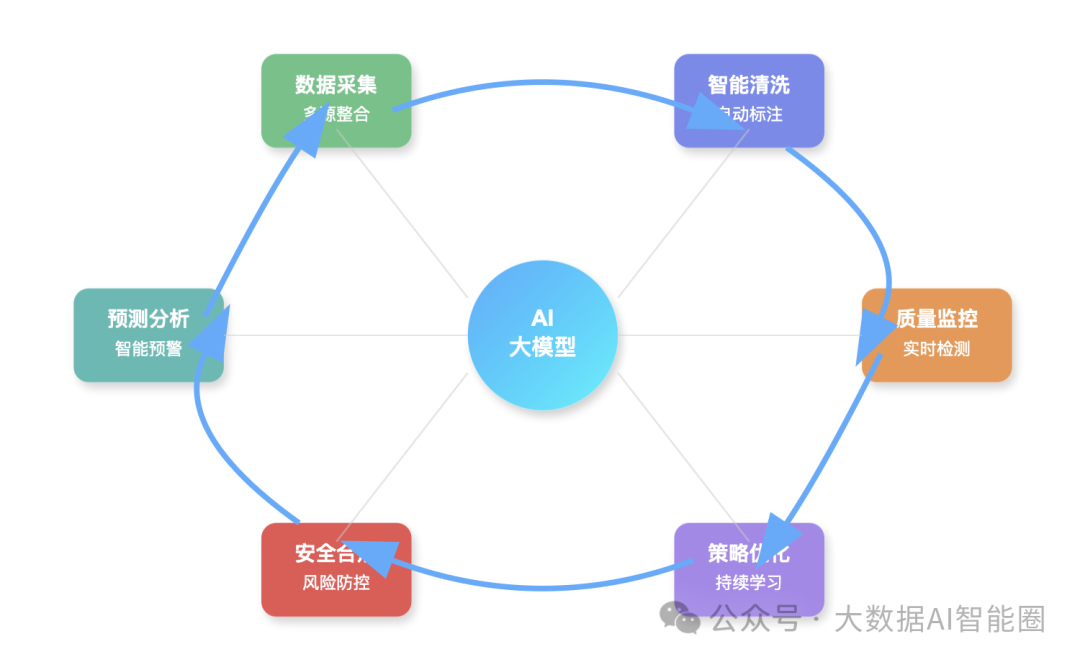
AI重塑数据治理的底层逻辑
AI重塑数据治理的底层逻辑 人治模式:一个必然失败的商业逻辑智治模式:重新定义数据治理的商业模式结语 上个月,一位老友约我喝茶。他是某知名互联网公司的数据总监,聊天时满脸愁容。 “润总,我们公司数据治理团队有50多…...

基于 AI 实现阿里云的智能财务管家
新钛云服已累计为您分享844篇技术干货 为了解决传统账单处理中人工查询效率低下、响应速度慢及易出错等问题,同时顺应AI技术发展趋势,提升服务智能化水平。随着业务规模扩大和账单数据复杂度增加,人工处理已难以满足高效管理需求。我们想到通…...

【成品论文】2025年电工杯数学建模竞赛B题50页保奖成品论文+matlab/python代码+数据集等(后续会更新)
文末获取资料 多约束条件下城市垃圾分类运输调度问题 摘要 随着城市化进程加快,城市生活垃圾产量持续增长,垃圾分类运输已成为城市环境治理的关键环节。本文针对城市垃圾分类运输中的路径优化与调度问题,综合考虑不同垃圾类型、车辆载重约束…...