Python打卡训练营学习记录Day36
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。
- 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。
-
import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组操作。 import matplotlib.pyplot as plt #用于绘制各种类型的图表 import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。 import warnings warnings.filterwarnings("ignore")import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time from tqdm import tqdm # 导入tqdm库用于进度条显示# 设置中文字体(解决中文显示问题) plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体 plt.rcParams['axes.unicode_minus'] = False # 正常显示负号 data = pd.read_csv('data.csv') #读取数据# 设置GPU设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(f"使用设备: {device}")# 先筛选字符串变量 discrete_features = data.select_dtypes(include=['object']).columns.tolist() # Home Ownership 标签编码 home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4 } data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码 years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11 } data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码,记得需要将bool类型转换为数值 data = pd.get_dummies(data, columns=['Purpose']) data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比 list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名 for i in data.columns:if i not in data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名 for i in list_final:data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名# Term 0 - 1 映射 term_mapping = {'Short Term': 0,'Long Term': 1 } data['Term'] = data['Term'].map(term_mapping) data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列 continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表# 连续特征用中位数补全 for feature in continuous_features: mode_value = data[feature].mode()[0] #获取该列的众数。data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多 # 所以这里我们还是只划分一次数据集 from sklearn.model_selection import train_test_split X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除 y = data['Credit Default'] # 标签 # 按照8:2划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集 # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据 scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) X_train = torch.FloatTensor(X_train).to(device) y_train = torch.LongTensor(y_train.values).to(device) X_test = torch.FloatTensor(X_test).to(device) y_test = torch.LongTensor(y_test.values).to(device) batch_size = 64 train_dataset = torch.utils.data.TensorDataset(X_train, y_train) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)input_size=X_train.shape[1] class MLP(nn.Module):def __init__(self, input_size): # 添加input_size参数super(MLP, self).__init__()self.fc1 = nn.Linear(input_size, 64) # 输入维度为实际特征数self.relu = nn.ReLU()self.dropout = nn.Dropout(0.2) # 新增dropout层防止过拟合self.fc2 = nn.Linear(64, 2) # 输出改为2个神经元(二分类问题)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.dropout(out)out = self.fc2(out)return out# 实例化模型 model = MLP(input_size=X_train.shape[1]).to(device) # 分类问题使用交叉熵损失函数 criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001) # 改为Adam优化器 criterion = nn.CrossEntropyLoss()num_epochs = 20000 best_loss = float('inf') patience = 5 min_delta = 0.001 counter = 0 # 添加记录列表 loss_history = [] epoch_list = []start_time = time.time() with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:for epoch in range(num_epochs):model.train()epoch_loss = 0.0# 训练步骤for inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()epoch_loss += loss.item() * inputs.size(0)# 计算平均epoch损失avg_loss = epoch_loss / len(train_loader.dataset)loss_history.append(avg_loss) epoch_list.append(epoch+1) # 更新进度条pbar.set_postfix({'Train Loss': f'{avg_loss:.4f}'})pbar.update(1)# 早停逻辑(基于训练损失)if avg_loss < best_loss - min_delta:best_loss = avg_losscounter = 0best_weights = model.state_dict().copy() # 保存最佳权重else:counter += 1if counter >= patience:print(f"\n早停触发!第 {epoch+1} 个epoch后停止")break# 加载最佳模型权重 model.load_state_dict(best_weights)time_all = time.time() - start_time print(f'训练时间: {time_all:.2f}秒')# 可视化损失曲线 plt.figure(figsize=(10, 6)) plt.plot(epoch_list, loss_history) plt.xlabel('Epoch') plt.ylabel('Loss') plt.title('Training Loss over Epochs') plt.grid(True) plt.show()# 评估模型 model.eval() # 设置模型为评估模式 with torch.no_grad(): # torch.no_grad()的作用是禁用梯度计算,可以提高模型推理速度outputs = model(X_test) # 对测试数据进行前向传播,获得预测结果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引correct = (predicted == y_test).sum().item() # 计算预测正确的样本数accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%')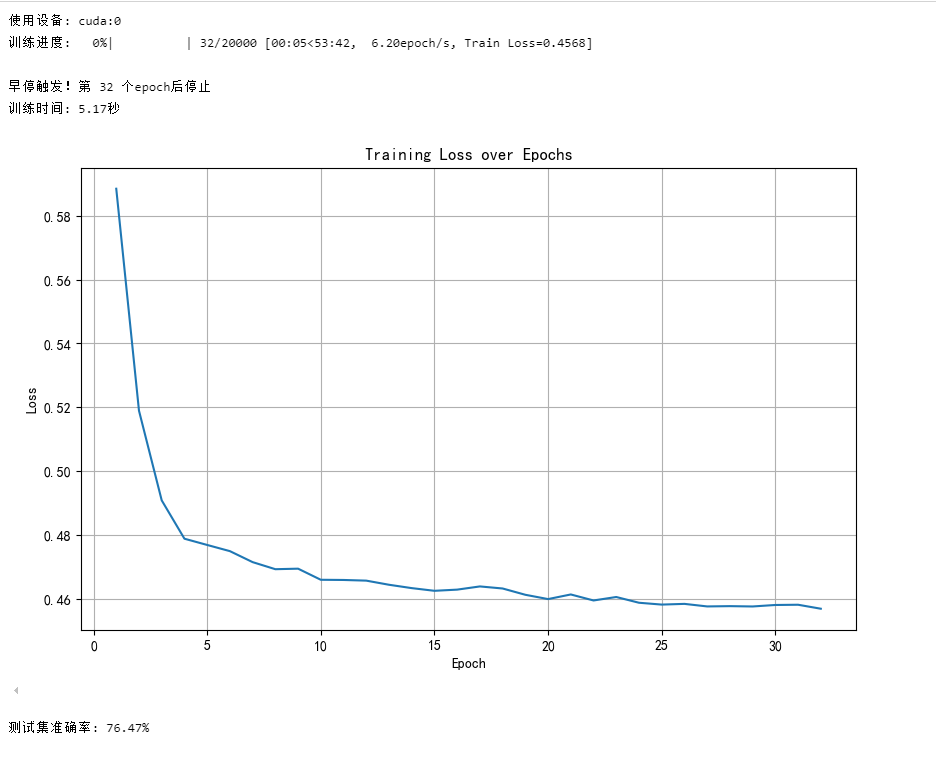
@浙大疏锦行
相关文章:
Python打卡训练营学习记录Day36
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。 import pandas as pd #用于数据处理和分析,可处理表格数…...

### Mac电脑推送文件至Gitee仓库步骤详解
**核心流程及命令说明:** #### 1. **配置全局Git用户信息** bash git config --global user.name "shenguanling" git config --global user.email "3259125968qq.com" - **作用**:设置提交代码时的作者信息࿰…...

官方SDK停更后的选择:开源维护的Bugly Unity SDK
腾讯Bugly,为移动开发者提供专业的异常上报和运营统计,帮助开发者快速发现并解决异常,同时掌握产品运营动态,及时跟进用户反馈。 但是,免费版的Unity SDK已经很久不更新了,会有一些问题和特性缺失ÿ…...

什么是智能体agent?
文章目录 什么是智能体agent?最基本的核心思想我们是如何走到今天以及为什么是现在如何从思维上剖析“一个智能体系统”痛苦的教训结论 什么是智能体agent? 原文链接:https://windsurf.com/blog/what-is-an-agent 本文探讨了AI智能体的核心概…...

【多线程】Java 实现方式及其优缺点
以下是 Java 多线程实现方式及其优缺点的详细说明: 一、Java 多线程核心实现方式 1. 继承 Thread 类 public class MyThread extends Thread {Overridepublic void run() {System.out.println("Thread running: " Thread.currentThread().getName());}…...
Obsidian 数据可视化深度实践:用 DataviewJS 与 Charts 插件构建智能日报系统
Obsidian 数据可视化深度实践:用 DataviewJS 与 Charts 插件构建智能日报系统 一、核心架构解析 本系统基于 Obsidian 的 DataviewJS 和 Charts 插件,实现日报数据的自动采集、可视化分析及智能回溯功能(系统架构原理见)。其技术…...

Three.js 海量模型加载性能优化指南
一、性能瓶颈分析 1.1 常见性能杀手 问题类型典型表现影响范围Draw Call 爆炸每帧渲染调用超过1000次GPU 渲染性能内存占用过高浏览器进程内存突破1GB加载速度/崩溃风险模型文件过大单个GLB文件超过50MB网络传输时间几何数据冗余重复模型独立加载CPU/GPU资源浪费 1.2 性能监…...

6.4.3_有向无环图描述表达式
有向无环图: 有向图中不存在环即为有向无环图DAG图,即如下V0->V4->v3->V0或者V4->V1->v4就存在环不是有向无环图,即在一个路径中一个顶点不能出现2次? DAG描述表达式: 算术表达式用树来表示࿰…...

力扣第157场双周赛
1. 最大质数子字符串之和 给定一个字符串 s,找出可以由其 子字符串 组成的 3个最大的不同质数 的和。 返回这些质数的 总和 ,如果少于 3 个不同的质数,则返回 所有 不同质数的和。 质数是大于 1 且只有两个因数的自然数:1和它本身…...

青少年编程与数学 02-019 Rust 编程基础 19课题、项目发布
青少年编程与数学 02-019 Rust 编程基础 19课题、项目发布 一、准备工作1. 创建和配置项目2. 编写代码和测试3. 文档注释 二、构建发布版本1. 构建优化后的可执行文件2. 静态链接(可选) 三、发布到 crates.io1. Crates.io核心功能使用方法特点最新动态 2…...
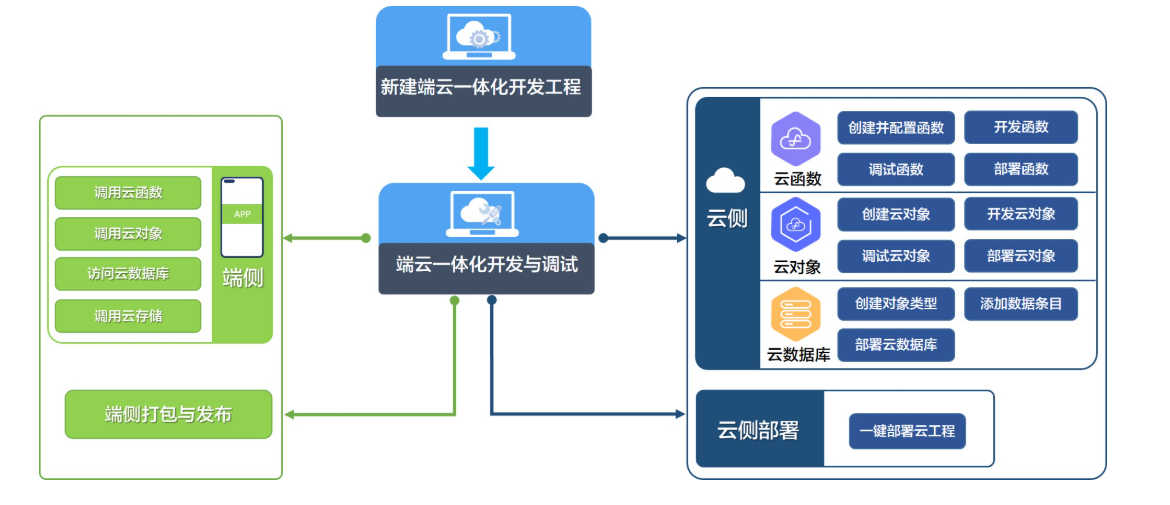
【HarmonyOS Next之旅】DevEco Studio使用指南(二十五) -> 端云一体化开发 -> 业务介绍(二)
目录 1 -> 工作原理 2 -> 约束与限制 2.1 -> 支持的设备 2.2 -> 支持的国家/地区 2.3 -> 支持的签名方式 3 -> 总结 3.1 -> 关键功能与工具 3.2 -> 开发流程 3.3 -> 典型场景与优化 3.4 -> 常见问题与解决 3.5 -> 总结 1 -> 工…...

LLaMA-Factory 微调模型与训练数据量对应关系
在使用LLaMA-Factory的LoRA技术微调1.5B和7B模型时,数据量需求主要取决于任务类型、数据质量以及模型规模。以下是基于现有研究和实践的具体分析: 一、数据量需求的核心影响因素 模型规模与数据量的关系 通常情况下,模型参数越多(…...

数据库与Redis数据一致性解决方案
在写数据时保证 Redis 和数据库数据一致,可采用以下方案,需根据业务场景权衡选择: 1. 先更新数据库,再更新 Redis 步骤: 写入 / 更新数据库数据。删除或更新 Redis 缓存。适用场景:读多写少,对缓存一致性要求不高(短暂不一致可接受)。风险:若第二步失败,导致缓存与…...

Spring Boot AI 之 Chat Client API 使用大全
ChatClient提供了一套流畅的API用于与AI模型交互,同时支持同步和流式两种编程模型。 流畅API包含构建Prompt组成元素的方法,这些Prompt将作为输入传递给AI模型。从API角度来看,Prompt由一系列消息组成,其中包含指导AI模型输出和行为的指令文本。 AI模型主要处理两类消息: …...
分身空间:手机分身多开工具,轻松实现多账号登录
分身空间是一款功能强大的手机分身多开工具APP,专为需要同时登录多个账号的用户设计。它支持多开各种游戏和软件,让用户可以轻松实现多账号同时在线,提升使用效率和体验。无论是社交软件、游戏还是办公应用,分身空间都能帮助你轻松…...

音视频之视频压缩及数字视频基础概念
系列文章: 1、音视频之视频压缩技术及数字视频综述 一、视频压缩编码技术综述: 1、信息化与视频通信: 什么是信息: 众所周知,人类社会的三大支柱是物质、能量和信息。具体而言,农业现代化的支柱是物质&…...

Ubuntu 24.04部署安装Honeyd蜜罐
🌴 前言 最近有个大作业,里面要求我们部署Hoenyd蜜罐,在网上搜了一通,发现相关的教程竟然少的可怜,即使有比较详细的教程,也是好几年前的了,跟着做一遍报一堆错,无奈之下࿰…...

C++复习核心精华
一、内存管理与智能指针 内存管理是C区别于其他高级语言的关键特性,掌握好它就掌握了C的灵魂。 1. 原始指针与内存泄漏 先来看看传统C的内存管理方式: void oldWay() {int* p new int(42); // 分配内存// 如果这里发生异常或提前return,…...

Android中获取控件尺寸进阶方案
在Android开发中,很多场景都需要获取控件(View)的宽高信息,比如动态布局调整、动画效果实现等。然而,直接在Activity的onCreate()中调用控件的getWidth()或getHeight()`方法,得到结果却是0,因为控件还没完成布局测量。 本文总结了几种获取控件大小的实用方法,并对各方…...

云原生安全之PaaS:从基础到实践的技术指南
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 云原生安全之PaaS:从基础到实践的技术指南 一、基础概念 PaaS(Platform as a Service)平台 PaaS是一种云计算服务模型…...
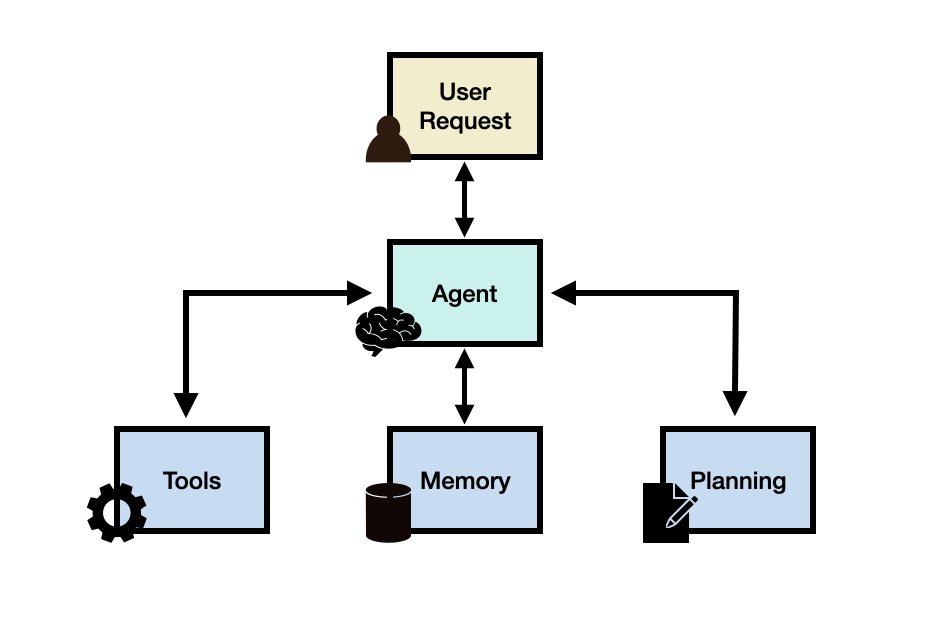
MCP技术体系介绍
MCP,全称时Model Context Protocol,模型上下文协议,由Claude母公司Anthropic于2014年11月正式提出。 MCP的核心作用是统一了Agent开发过程中大模型调用外部工具的技术实现流程,从而大幅提高Agent的开发效率。在MCP诞生之前,不同外部工具各有不同的调用方法。 要连接这些…...

《深入探秘:从底层搭建Python微服务之FastAPI与Docker部署》
FastAPI作为一款现代、快速的Web框架,在Python微服务开发领域独树一帜。它基于Python 3.6的类型提示功能,融合了Starlette和Pydantic的优势,具备诸多令人瞩目的特性。 FastAPI的性能表现十分卓越,可与Go和Node.js相媲美。这得益于…...

深入解析Spring Boot与JUnit 5集成测试的最佳实践
深入解析Spring Boot与JUnit 5集成测试的最佳实践 引言 在现代软件开发中,单元测试和集成测试是确保代码质量的重要手段。Spring Boot作为当前最流行的Java Web框架之一,提供了丰富的测试支持。而JUnit 5作为最新的JUnit版本,引入了许多新特…...

我的第1个爬虫程序——豆瓣Top250爬虫的详细步骤指南
我的第1个爬虫程序——豆瓣Top250爬虫的详细步骤指南 一、创建隔离开发环境 1. 使用虚拟环境(推荐venv) # 在项目目录打开终端执行 python -m venv douban_env # 创建虚拟环境 source douban_env/bin/activate # Linux/macOS激活 douban_env\Scri…...

Selenium 测试框架 - C#
🚀Selenium C# 自动化测试实战:以百度搜索为例 本文将通过一个简单示例,手把手教你如何使用 Selenium + C# 实现百度搜索自动化测试。适合初学者快速上手,也适合作为企业 UI 自动化测试模板参考。 🧩 一、安装必要 NuGet 包 在 Visual Studio 的 NuGet 管理器中安装以下…...

JavaWeb:SpringBoot工作原理详解
一、SpringBoot优点 1.为所有Spring开发者更快的入门 2.开箱即用,提供各种默认配置来简化项目配置 3.内嵌式容器简化Web项目 4.没有冗余代码生成和XML配置的要求 二、SpringBoot 运行原理 2.1. pom.xml spring-boot-dependencies: 核心依赖在父工程中;…...

5.25本日总结
一、英语 复习list6list25 二、数学 写14讲课后题,学习15讲部分 三、408 完成计网5.3题目,学习计组第二章 四、总结 今日所学内容不难,但是英语最近的进度缓慢,单词记忆情况不好,阅读也很久没有再写,…...

OpenGL Chan视频学习-6 How Shaders Work in OpenGL
bilibili视频链接: 【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973 一、知识点整理 1.1 着色器 1.1.1 阐述 实际上是代码。需要告诉GPU发送数据要干啥,也是着色器的本质。…...
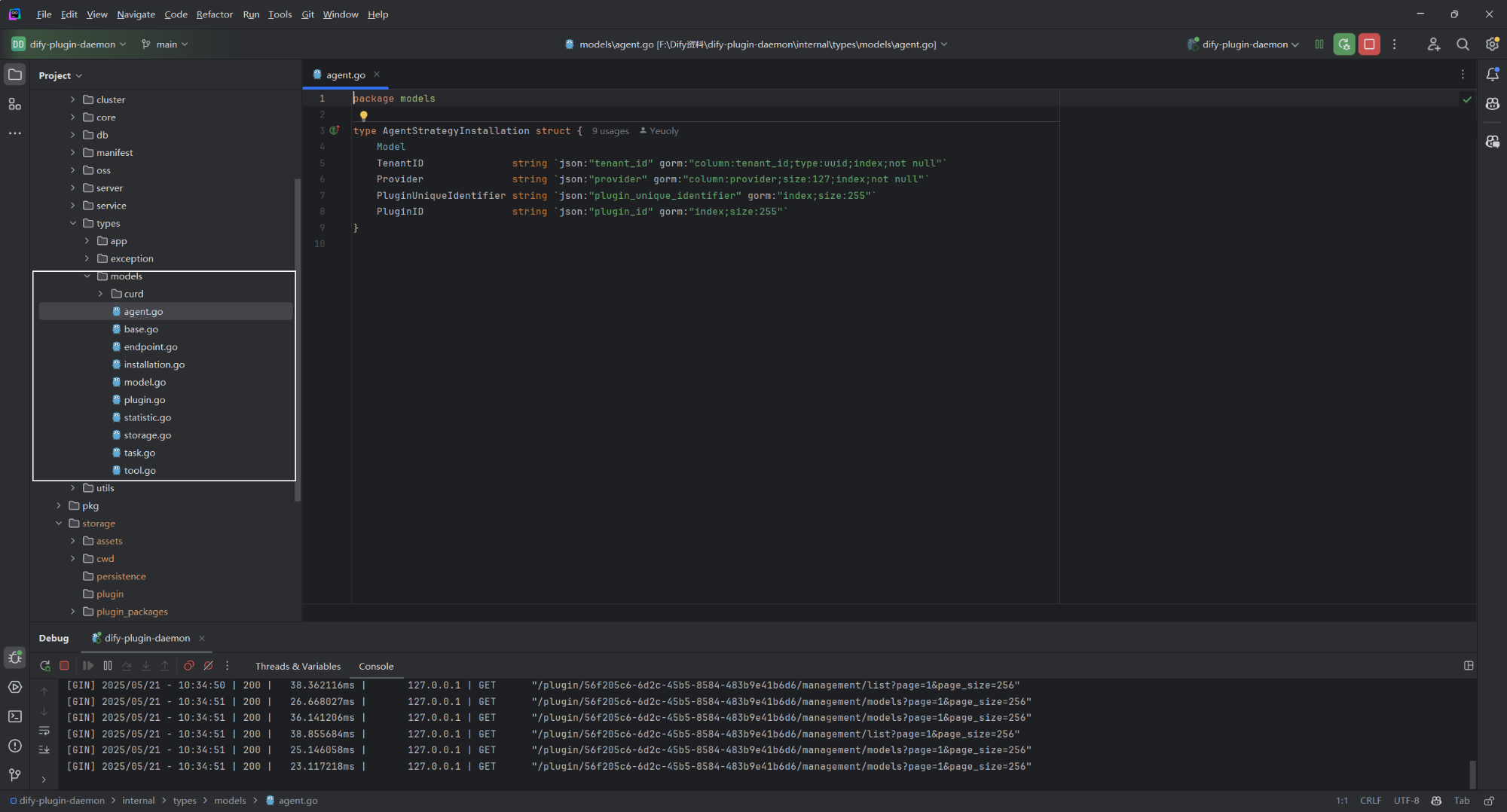
dify_plugin数据库中的表总结
本文使用dify-plugin-daemon v0.1.0版本,主要对dify_plugin数据库中的数据表进行了总结。 一.agent_strategy_installations 源码位置:dify-plugin-daemon\internal\types\models\agent.go type AgentStrategyInstallation struct {ModelTenantID …...

【数据仓库面试题合集④】SQL 性能调优:面试高频场景 + 调优策略解析
随着业务数据规模的持续增长,SQL 查询的执行效率直接影响到数据平台的稳定性与数据产出效率。因此,在数据仓库类岗位的面试中,SQL 性能调优常被作为重点考察内容。 本篇将围绕常见 SQL 调优问题,结合实际经验,整理出高频面试题与答题参考,助你在面试中游刃有余。 🎯 高…...