PyTorch Image Models (timm) 技术指南
timm
- PyTorch Image Models (timm) 技术指南
- 功能概述
- 一、引言
- 二、timm 库概述
- 三、安装 timm 库
- 四、模型加载与推理示例
- 4.1 通用推理流程
- 4.2 具体模型示例
- 4.2.1 ResNeXt50-32x4d
- 4.2.2 EfficientNet-V2 Small 模型
- 4.2.3 DeiT-3 large 模型
- 4.2.4 RepViT-M2 模型
- 4.2.5 ResNet-RS-101
- 4.2.6 Vision Transformer (ViT)
- 4.2.7 Swin Transformer
- 4.2.8 Swin Transformer V2
- 4.2.9 Swin Transformer V2 Cr
- 4.2.10 Levit
- 4.3 加载自定义模型
- 4.4 提取模型的中间特征
- 4.5 冻结模型的部分层
- 4.6 创建模型时指定输入图像尺寸
- 4.7 数据预处理阶段调整图像尺寸
- 4.8 调整输出分类个数
- 4.9 综合示例
- 更多模型说明
- 五、timm 库近期更新
- 5.1 2025 年 2 月 21 日更新
- 5.2 其他更新
- 六、分布式训练支持
- 七、学习率调度器
- 7.1 余弦退火调度器(CosineLRScheduler)
- 7.2 多步学习率调度器(MultiStepLRScheduler)
- 八、总结
- 九、参考资料
PyTorch Image Models (timm) 技术指南
timm(PyTorch Image Models)是一个广泛使用的 PyTorch 库,它集合了大量的图像模型、层、实用工具、优化器、调度器、数据加载器/增强器以及参考训练/验证脚本。以下是对 timm 库的详细介绍,包括功能、模型案例、加载与使用示例以及相关教程的信息。
功能概述
- 丰富的图像模型:包含众多预训练的图像分类、目标检测、语义分割等模型,如 ResNet、EfficientNet、ViT 等。
- 实用工具:提供了一系列用于模型训练、验证和推理的实用工具,如优化器、调度器、数据加载器和增强器等。
- 模型构建与管理:支持轻松构建和管理不同类型的模型,包括模型的初始化、权重加载和保存等。
- 分布式训练:支持分布式训练,方便在多个 GPU 或节点上进行高效训练。
一、引言
在深度学习领域,图像分类、目标检测等任务常常需要使用预训练的图像模型。PyTorch Image Models (timm) 是一个功能强大的库,它提供了大量预训练的图像模型,涵盖了各种架构,方便开发者快速搭建和训练自己的模型。本文将详细介绍 timm 库的使用,包括模型加载、推理以及近期更新的模型和功能。
二、timm 库概述
timm 是一个基于 PyTorch 的图像模型库,它收集了众多先进的图像模型,如 ResNet、ViT、Swin Transformer 等,并提供了预训练的权重。通过 timm,开发者可以轻松地加载这些模型,进行图像分类、特征提取等任务。
三、安装 timm 库
在使用 timm 之前,需要先安装该库。可以使用以下命令进行安装:
pip install timm
四、模型加载与推理示例
4.1 通用推理流程
以下是一个通用的使用 timm 加载模型并进行推理的示例代码:
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练模型
model = timm.create_model('model_name', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"Predicted class index: {predicted_idx.item()}")
在上述代码中,'model_name' 需要替换为具体的模型名称,'path_to_your_image.jpg' 需要替换为实际的图像文件路径。
4.2 具体模型示例
4.2.1 ResNeXt50-32x4d
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 ResNeXt50-32x4d 模型
model = timm.create_model('resnext50_32x4d', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"ResNeXt50-32x4d Predicted class index: {predicted_idx.item()}")
4.2.2 EfficientNet-V2 Small 模型
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 EfficientNet-V2 Small 模型
model = timm.create_model('efficientnetv2_s', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"EfficientNet-V2 Small Predicted class index: {predicted_idx.item()}")
4.2.3 DeiT-3 large 模型
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 DeiT-3 large 模型
model = timm.create_model('deit3_large_patch16_384', pretrained=True)
model.eval()# 定义图像预处理转换,注意输入尺寸为 384x384
transform = transforms.Compose([transforms.Resize(384),transforms.CenterCrop(384),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"DeiT-3 large Predicted class index: {predicted_idx.item()}")
4.2.4 RepViT-M2 模型
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 RepViT-M2 模型
model = timm.create_model('repvit_m2', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"RepViT-M2 Predicted class index: {predicted_idx.item()}")
4.2.5 ResNet-RS-101
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 ResNet-RS-101 模型
model = timm.create_model('resnetrs101', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"ResNet-RS-101 Predicted class index: {predicted_idx.item()}")
4.2.6 Vision Transformer (ViT)
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 ViT-Base/32 模型
model = timm.create_model('vit_base_patch32_224', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"ViT-Base/32 Predicted class index: {predicted_idx.item()}")
4.2.7 Swin Transformer
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 Swin Transformer 模型
model = timm.create_model('swin_base_patch4_window7_224', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"Swin Transformer Predicted class index: {predicted_idx.item()}")
4.2.8 Swin Transformer V2
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 Swin Transformer V2 模型
model = timm.create_model('swinv2_base_window12_192_22k', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"Swin Transformer V2 Predicted class index: {predicted_idx.item()}")
4.2.9 Swin Transformer V2 Cr
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 Swin Transformer V2 Cr 模型
model = timm.create_model('swinv2_cr_base_224', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"Swin Transformer V2 Cr Predicted class index: {predicted_idx.item()}")
4.2.10 Levit
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 Levit 模型
model = timm.create_model('levit_256', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"Levit Predicted class index: {predicted_idx.item()}")
4.3 加载自定义模型
如果你需要加载自定义的模型,可以使用 timm.create_model 函数,并指定模型的名称和相关参数:
import timm# 创建自定义的 EfficientNet 模型
model = timm.create_model('efficientnet_b0', pretrained=False, num_classes=10)
print(model)
4.4 提取模型的中间特征
import torch
import timm# 加载预训练的模型
model = timm.create_model('resnet18', pretrained=True, features_only=True)# 生成随机输入
x = torch.randn(1, 3, 224, 224)# 提取中间特征
features = model(x)
for i, feat in enumerate(features):print(f"Feature {i} shape: {feat.shape}")
4.5 冻结模型的部分层
import torch
import timm
from timm.utils.model import freeze# 加载预训练的模型
model = timm.create_model('resnet18', pretrained=True)# 冻结模型的前几层
submodules = [n for n, _ in model.named_children()]
freeze(model, submodules[:submodules.index('layer2') + 1])# 检查冻结情况
print(model.layer2[0].conv1.weight.requires_grad) # 输出: False
print(model.layer3[0].conv1.weight.requires_grad) # 输出: True
在使用 timm 库加载预训练模型后,我们经常需要根据具体的任务需求调整模型的参数,例如输入图像尺寸、输出分类个数等。下面将结合提供的代码片段详细介绍如何进行这些参数的调整。
4.6 创建模型时指定输入图像尺寸
部分模型在创建时可以通过 img_size 参数指定输入图像的尺寸。以下是一个使用 SwinTransformer 模型的示例:
import timm
import torch# 加载预训练的 SwinTransformer 模型,并指定输入图像尺寸为 384x384
model = timm.create_model('swin_base_patch4_window7_224', pretrained=True, img_size=(384, 384))
model.eval()# 随机生成一个符合指定尺寸的输入张量进行测试
input_tensor = torch.randn(1, 3, 384, 384)
with torch.no_grad():output = model(input_tensor)
print("Output shape:", output.shape)
在上述代码中,我们通过 img_size=(384, 384) 指定了输入图像的尺寸为 384x384。
4.7 数据预处理阶段调整图像尺寸
除了在创建模型时指定输入图像尺寸,还需要在数据预处理阶段将输入图像调整为指定的尺寸。可以使用 torchvision.transforms 来实现这一点,示例如下:
from torchvision import transforms
from PIL import Image# 定义图像预处理转换,将图像调整为 384x384
transform = transforms.Compose([transforms.Resize((384, 384)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)
print("Output shape:", output.shape)
在这个示例中,我们使用 transforms.Resize((384, 384)) 将输入图像调整为 384x384 的尺寸。
4.8 调整输出分类个数
输出分类个数的调整通常在创建模型时通过 num_classes 参数来实现。以下是一个使用 MetaFormer 模型的示例:
import timm# 加载预训练的 MetaFormer 模型,并指定输出分类个数为 10
model = timm.create_model('metaformer', pretrained=True, num_classes=10)
model.eval()# 随机生成一个输入张量进行测试
input_tensor = torch.randn(1, 3, 224, 224)
with torch.no_grad():output = model(input_tensor)
print("Output shape:", output.shape)
在上述代码中,我们通过 num_classes=10 指定了模型的输出分类个数为 10。
4.9 综合示例
下面是一个综合示例,展示了如何同时调整输入图像尺寸和输出分类个数:
import timm
import torch
from torchvision import transforms
from PIL import Image# 加载预训练的 SwinTransformer 模型,调整输入图像尺寸为 384x384,输出分类个数为 10
model = timm.create_model('swin_base_patch4_window7_224', pretrained=True, img_size=(384, 384), num_classes=10)
model.eval()# 定义图像预处理转换,将图像调整为 384x384
transform = transforms.Compose([transforms.Resize((384, 384)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)
print("Output shape:", output.shape)
在这个综合示例中,我们同时调整了输入图像尺寸和输出分类个数,并进行了图像预处理和推理操作。
通过以上方法,我们可以根据具体的任务需求灵活调整预训练模型的输入图像尺寸和输出分类个数。
更多模型说明
除了上述示例中的模型,timm 库还包含了许多其他的模型,如 Aggregating Nested Transformers、BEiT、Big Transfer ResNetV2 (BiT) 等。你可以在 timm 的官方文档 https://huggingface.co/docs/timm 中找到完整的模型列表。
要使用其他模型,只需将 timm.create_model 函数中的模型名称替换为你想要使用的模型名称即可。例如,要使用 BEiT 模型,可以使用以下代码:
import torch
import timm
from PIL import Image
from torchvision import transforms# 加载预训练的 BEiT 模型
model = timm.create_model('beit_base_patch16_224', pretrained=True)
model.eval()# 定义图像预处理转换
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open('path_to_your_image.jpg')
image = transform(image).unsqueeze(0)# 进行推理
with torch.no_grad():output = model(image)# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(f"BEiT Predicted class index: {predicted_idx.item()}")
五、timm 库近期更新
5.1 2025 年 2 月 21 日更新
- 新增 SigLIP 2 ViT 图像编码器:可从 https://huggingface.co/collections/timm/siglip-2-67b8e72ba08b09dd97aecaf9 获取。
- 新增 ‘SO150M2’ ViT 权重:使用 SBB 配方训练,在 ImageNet 上取得了很好的效果。例如,
vit_so150m2_patch16_reg1_gap_448.sbb_e200_in12k_ft_in1k的 top-1 准确率达到 88.1%。 - 更新 InternViT - 300M ‘2.5’ 权重。
- 发布 1.0.15 版本。
5.2 其他更新
在 2025 年 1 月至 2024 年 10 月期间,timm 库还进行了许多其他更新,包括添加新的优化器(如 Kron Optimizer、MARS 优化器等)、支持新的模型(如 convnext_nano、AIM - v2 编码器等)、修复一些 bug 以及改进代码结构等。
六、分布式训练支持
timm 库还提供了分布式训练的支持,相关代码在 timm/utils/distributed.py 中。以下是一些关键函数的介绍:
reduce_tensor:用于在分布式环境中对张量进行规约操作。distribute_bn:确保每个节点具有相同的运行时 BN 统计信息。init_distributed_device:初始化分布式训练设备。
以下是一个简单的分布式训练初始化示例:
import torch
from timm.utils.distributed import init_distributed_deviceargs = type('', (), {})() # 创建一个空的参数对象
device = init_distributed_device(args)
print(f"Device: {device}, World size: {args.world_size}, Rank: {args.rank}")
七、学习率调度器
timm 库提供了多种学习率调度器,可在 timm/scheduler 目录下找到相关代码。以下是一些常见的调度器及其使用示例:
7.1 余弦退火调度器(CosineLRScheduler)
import torch
import timm
from timm.scheduler.scheduler_factory import create_scheduler# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 定义调度器参数
scheduler_args = type('', (), {'sched': 'cosine','epochs': 100,'decay_epochs': 30,'warmup_epochs': 5
})()# 创建调度器
scheduler, num_epochs = create_scheduler(scheduler_args, optimizer)# 训练循环
for epoch in range(num_epochs):# 训练代码...scheduler.step(epoch)
7.2 多步学习率调度器(MultiStepLRScheduler)
import torch
import timm
from timm.scheduler.scheduler_factory import create_scheduler# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 定义调度器参数
scheduler_args = type('', (), {'sched': 'multistep','epochs': 100,'decay_milestones': [30, 60],'decay_rate': 0.1,'warmup_epochs': 5
})()# 创建调度器
scheduler, num_epochs = create_scheduler(scheduler_args, optimizer)# 训练循环
for epoch in range(num_epochs):# 训练代码...scheduler.step(epoch)
八、总结
PyTorch Image Models (timm) 是一个非常实用的图像模型库,它提供了丰富的预训练模型和便捷的使用接口,同时支持分布式训练和多种学习率调度器。通过本文的介绍,你可以快速上手 timm 库,进行图像分类等任务的开发。希望本文对你有所帮助,祝你在深度学习领域取得更好的成果!
九、参考资料
timm官方文档:https://huggingface.co/docs/timmtimm代码库:https://github.com/rwightman/pytorch-image-models
相关文章:
 技术指南)
PyTorch Image Models (timm) 技术指南
timm PyTorch Image Models (timm) 技术指南功能概述 一、引言二、timm 库概述三、安装 timm 库四、模型加载与推理示例4.1 通用推理流程4.2 具体模型示例4.2.1 ResNeXt50-32x4d4.2.2 EfficientNet-V2 Small 模型4.2.3 DeiT-3 large 模型4.2.4 RepViT-M2 模型4.2.5 ResNet-RS-1…...

基于Scikit-learn与Flask的医疗AI糖尿病预测系统开发实战
引言 在精准医疗时代,人工智能技术正在重塑临床决策流程。本文将深入解析如何基于MIMIC-III医疗大数据集,使用Python生态构建符合医疗AI开发规范的糖尿病预测系统。项目涵盖从数据治理到模型部署的全流程,最终交付符合DICOM标准的临床决策支…...

掌握聚合函数:COUNT,MAX,MIN,SUM,AVG,GROUP BY和HAVING子句的用法,Where和HAVING的区别
对于Java后端开发来说,必须要掌握常用的聚合函数:COUNT,MAX,MIN,SUM,AVG,掌握GROUP BY和HAVING子句的用法,掌握Where和HAVING的区别: ✅ 一、常用聚合函数(聚…...

【Node.js】高级主题
个人主页:Guiat 归属专栏:node.js 文章目录 1. Node.js 高级主题概览1.1 高级主题架构图 2. 事件循环与异步编程深度解析2.1 事件循环机制详解事件循环阶段详解 2.2 异步编程模式演进高级异步模式实现 3. 内存管理与性能优化3.1 V8 内存管理机制内存监控…...
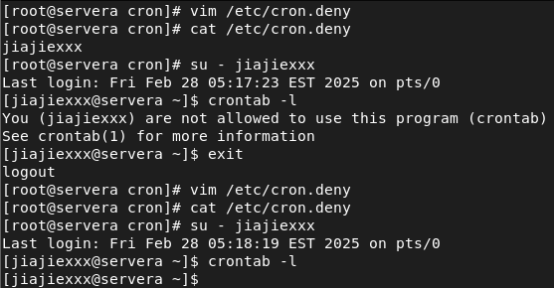
【Linux】定时任务 Crontab 与时间同步服务器
目录 一、用户定时任务的创建与使用 1.1 用户定时任务的使用技巧 1.2 管理员对用户定时任务的管理 1.3 用户黑白名单的管理 一、用户定时任务的创建与使用 1.1 用户定时任务的使用技巧 第一步:查看服务基本信息 systemctl status crond.service //查看周期性…...

【TCP/IP协议族详解】
目录 第1层 链路/网络接口层—帧(Frame) 1. 链路层功能 2. 常见协议 2.1. ARP(地址解析协议) 3. 常见设备 第2层 网络层—数据包(Packet) 1. 网络层功能 2. 常见协议 2.1. ICMP(互联网…...
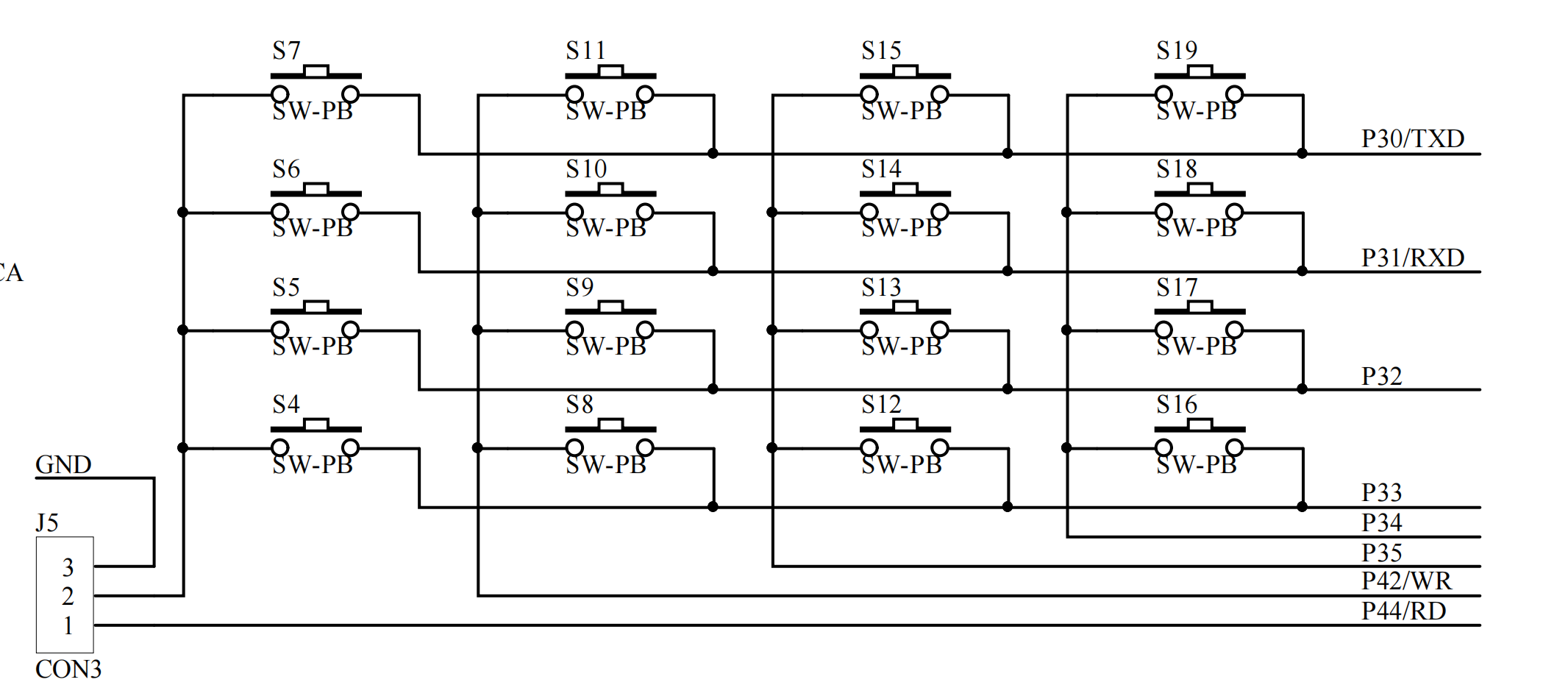
蓝桥杯电子赛_零基础利用按键实现不同数字的显现
目录 一、前提 二、代码配置 bsp_key.c文件 main.c文件 main.c文件的详细讲解 功能实现 注意事项 一、前提 按键这一板块主要是以记忆为主,我直接给大家讲解代码去实现我要配置的功能。本次我要做的项目是板子上的按键有S4~S19,我希望任意一个按键…...
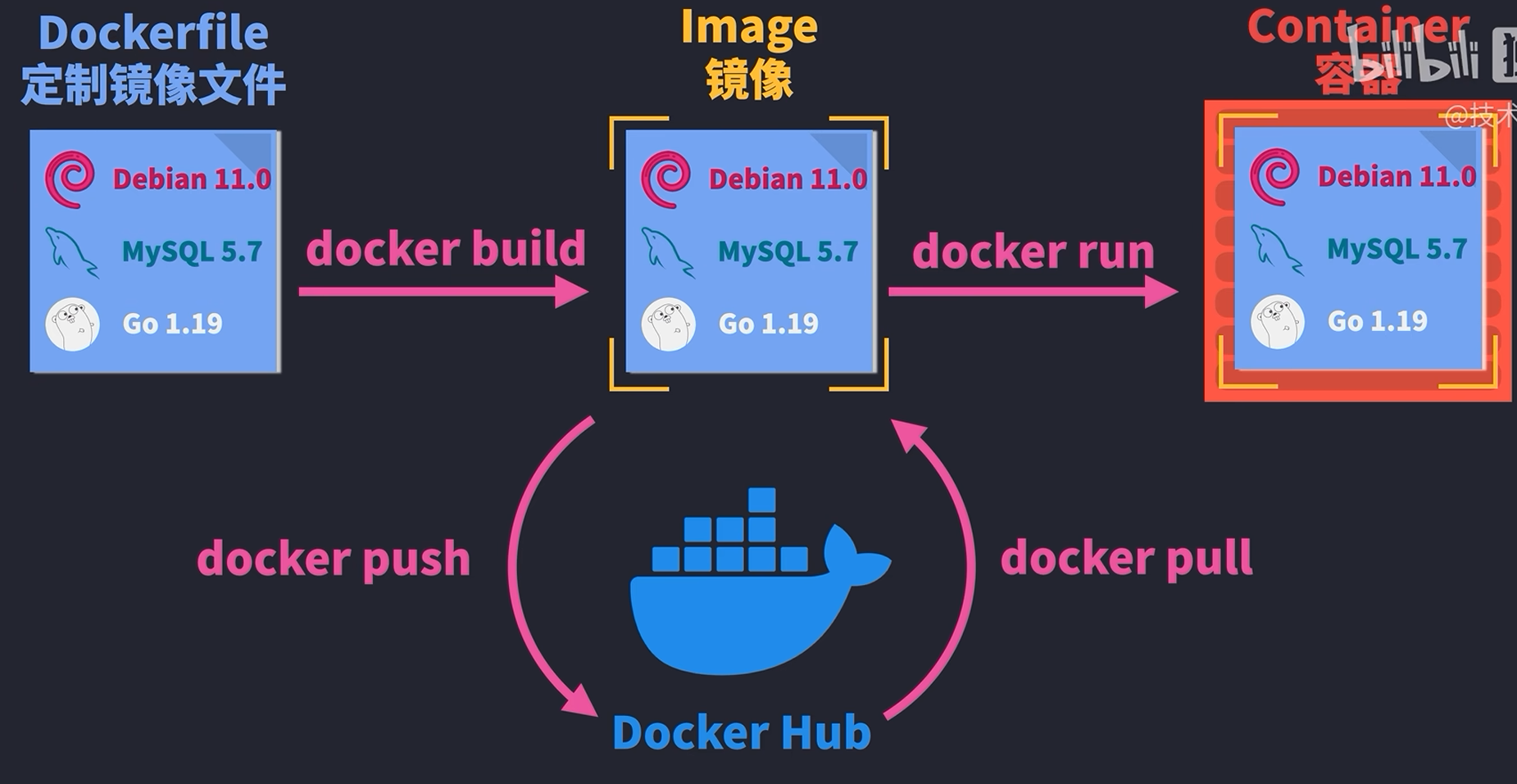
Docker架构详解
一,Docker的四大要素:Dockerfile、镜像(image)、容器(container)、仓库(repository) 1.dockerfile:在dockerfile文件中写构建docker的命令,通过dockerbuild构建image 2.镜像:就是一个只读的模板,镜像可以用来创建docker容器&…...
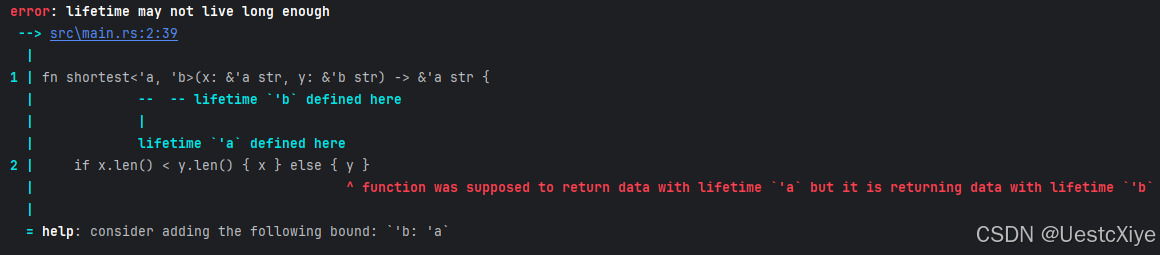
Rust 学习笔记:关于生命周期的练习题
Rust 学习笔记:关于生命周期的练习题 Rust 学习笔记:关于生命周期的练习题生命周期旨在防止哪种编程错误?以下代码能否通过编译?若能,输出是?如果一个引用的生命周期是 static,这意味着什么&…...
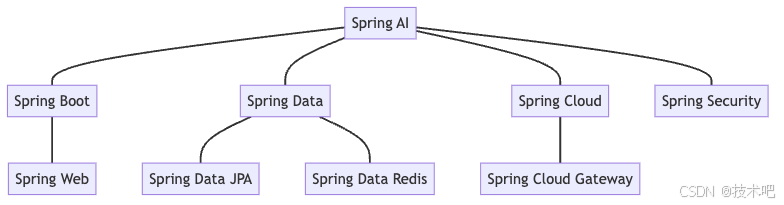
Spring AI 模块架构与功能解析
Spring AI 是 Spring 生态系统中的一个新兴模块,专注于简化人工智能和机器学习技术在 Spring 应用程序中的集成。本文将详细介绍 Spring AI 的核心组件、功能模块及其之间的关系,帮助具有技术基础的读者快速了解和应用 Spring AI。 Spring AI 的核心概念…...

单元测试学习笔记
单元测试是软件测试的基础层级,主要针对代码的最小可测试单元进行验证。单元测试可以帮助快速定位问题边界,提升代码可维护性,支持安全的重构操作。 测试对象: 独立函数/方法纯工具类(如数据处理函数)UI组…...

多模态大语言模型arxiv论文略读(九十)
Hybrid RAG-empowered Multi-modal LLM for Secure Data Management in Internet of Medical Things: A Diffusion-based Contract Approach ➡️ 论文标题:Hybrid RAG-empowered Multi-modal LLM for Secure Data Management in Internet of Medical Things: A Di…...
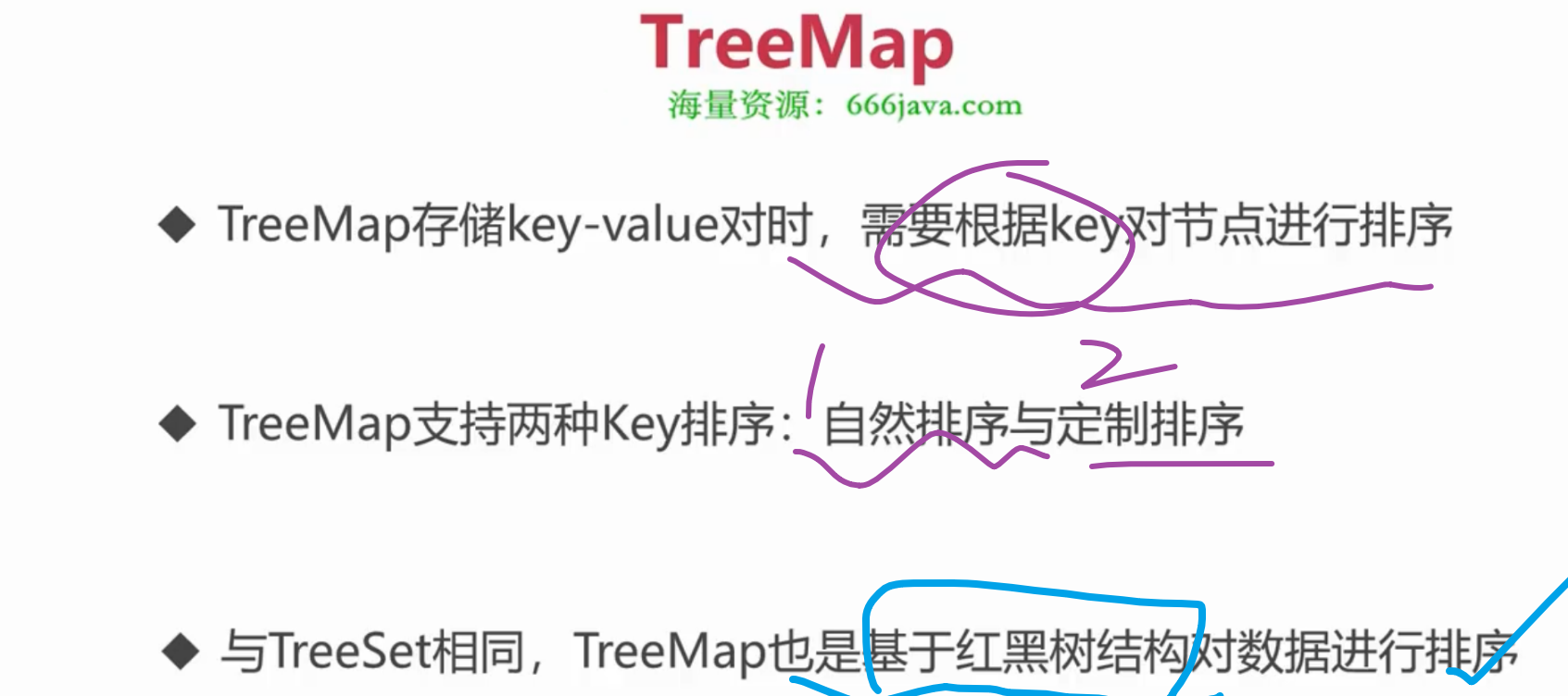
(1-6-1)Java 集合
目录 0.知识概述: 1.集合 1.1 集合继承关系类图 1.2 集合遍历的三种方式 1.3 集合排序 1.3.1 Collections实现 1.3.2 自定义排序类 2 List 集合概述 2.1 ArrayList (1)特点 (2)常用方法 2.2 LinkedList 3…...

spring5-配外部文件-spEL-工厂bean-FactoryBean-注解配bean
spring配外部文件 我们先在Spring里配置一个数据源 1.导c3p0包,这里我们先学一下hibernate持久化框架,以后用mybites. <dependency><groupId>org.hibernate</groupId><artifactId>hibernate-core</artifactId><version>5.2.…...

[安全清单] Linux 服务器安全基线:一份可以照着做的加固 Checklist
更多服务器知识,尽在hostol.com 嘿,各位服务器的“守护者”们!当你拿到一台崭新的Linux服务器,或者接手一台正在运行的服务器时,脑子里是不是会闪过一丝丝关于安全的担忧?“我的服务器安全吗?”…...

企业级单元测试流程
企业级的单元测试流程不仅是简单编写测试用例,而是一整套系统化、自动化、可维护、可度量的工程实践,贯穿从代码编写到上线部署的全生命周期。下面是一个尽可能完善的 企业级单元测试流程设计方案,适用于 Java 生态(JUnit Mockit…...

安卓开发用到的设计模式(2)结构型模式
安卓开发用到的设计模式(2)结构型模式 文章目录 安卓开发用到的设计模式(2)结构型模式1. 适配器模式(Adapter Pattern)2. 装饰器模式(Decorator Pattern)3. 代理模式(Pro…...
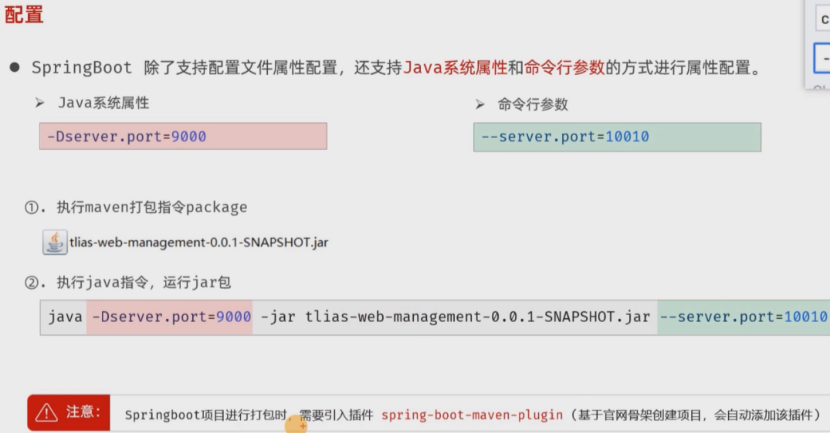
JavaWeb:SpringBoot配置优先级详解
3种配置 打包插件 命令行 优先级 SpringBoot的配置优先级决定了不同配置源之间的覆盖关系,遵循高优先级配置覆盖低优先级的原则。以下是详细的优先级排序及配置方法说明: 一、配置优先级从高到低排序 1.命令行参数 优先级最高,通过keyvalu…...
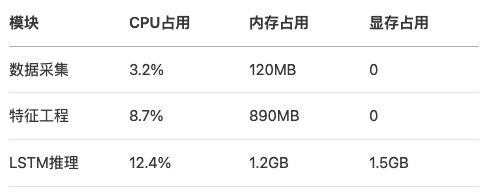
故障率预测:基于LSTM的GPU集群硬件健康监测系统(附Prometheus监控模板)
一、GPU集群健康监测的挑战与价值 在大规模深度学习训练场景下,GPU集群的硬件故障率显著高于传统计算设备。根据2023年MLCommons统计,配备8卡A100的服务器平均故障间隔时间(MTBF)仅为1426小时,其中显存故障占比达38%&…...
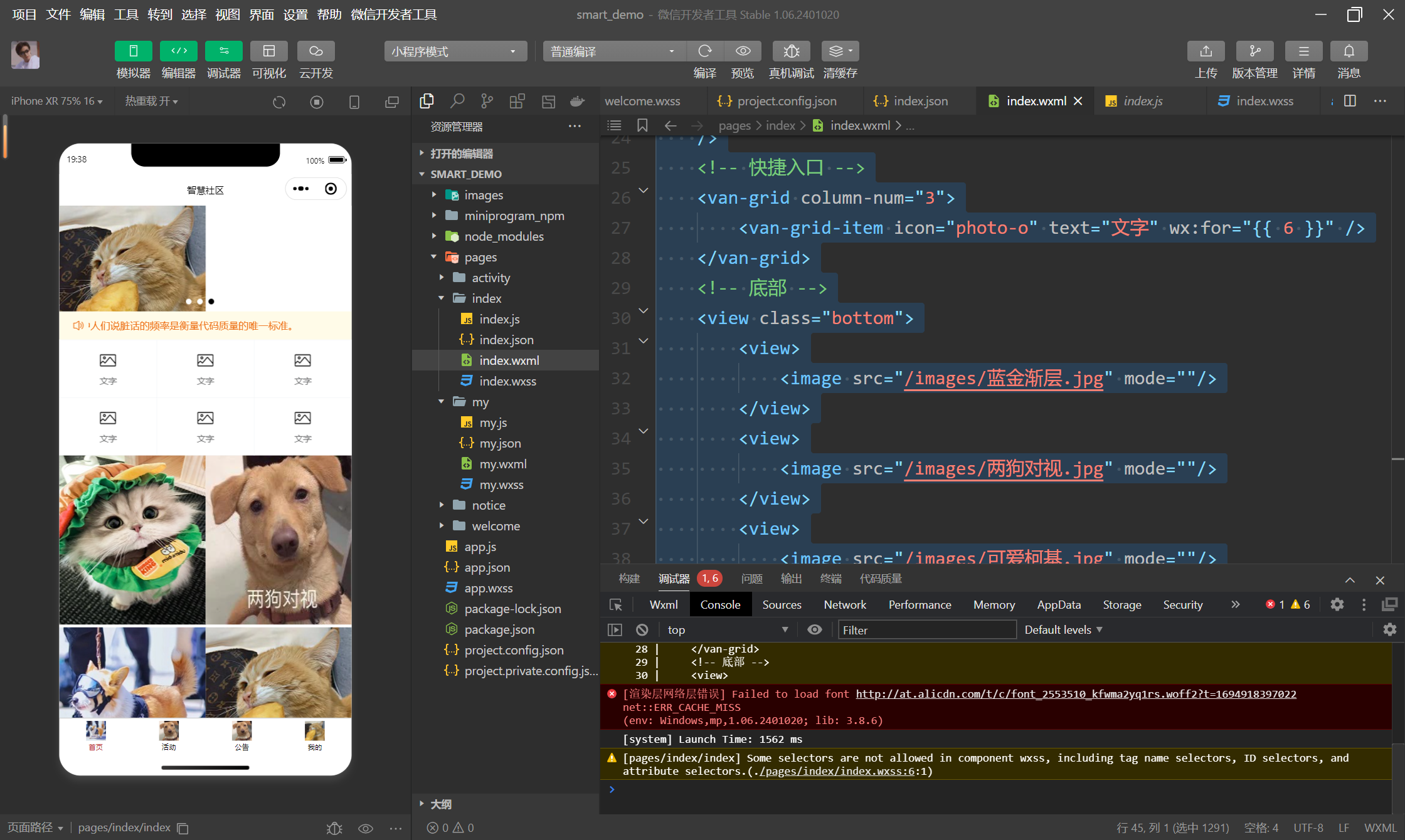
【b站计算机拓荒者】【2025】微信小程序开发教程 - chapter3 项目实践 -1 项目功能描述
1 项目功能描述 # 智慧社区-小程序-1 欢迎页-加载后端:动态变化-2 首页-轮播图:动态-公共栏:动态-信息采集,社区活动,人脸检测,语音识别,心率检测,积分商城-3 信息采集页面-采集人数…...

FFmpeg 安装包全攻略:gpl、lgpl、shared、master 区别详解
这些 FFmpeg 安装包有很多版本和变种,主要区别在于以下几个方面: ✅ 一、从名称中看出的关键参数: 1. 版本号 master:开发版,最新功能,但可能不稳定。n6.1 / n7.1:正式版本,更稳定…...

AI浪潮下,媒体内容运营的五重变奏
算法驱动的个性化推荐 在信息爆炸的时代,用户面临着海量的内容选择,如何让用户快速找到感兴趣的人工智能内容,成为媒体运营的关键。算法驱动的个性化推荐模式应运而生,它通过分析用户的行为数据,如浏览历史、点赞、评论、搜索关键词等,构建用户兴趣画像 ,再依据画像为用…...
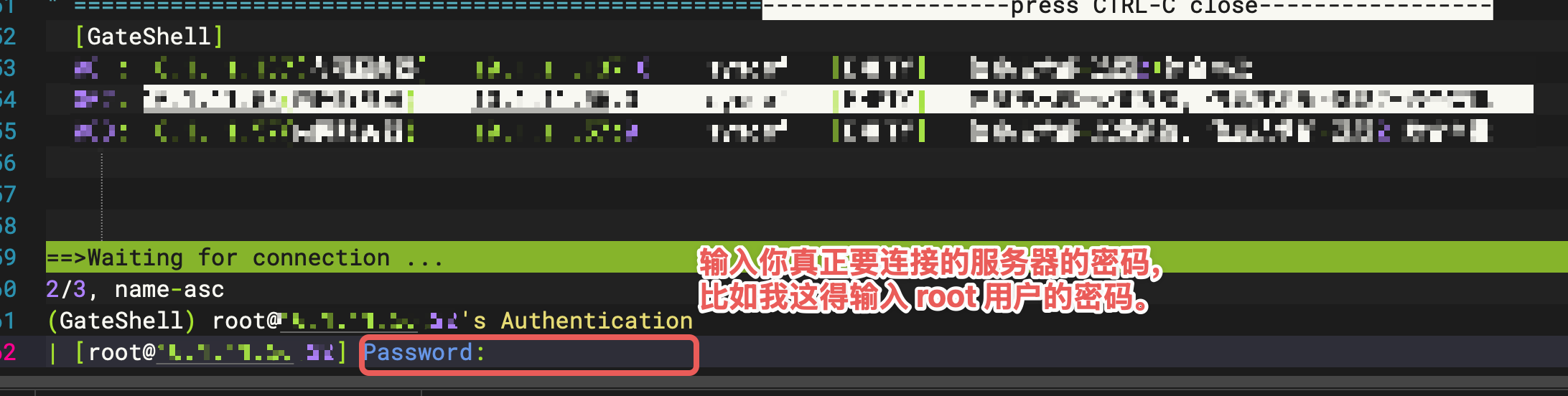
WindTerm 以 SSH 协议的方式通过安恒明御堡垒机间接访问服务器
1. 配置堡垒机秘钥 创建公私钥ssh-keygen -t rsa -b 4096执行完该命令后按照提示一路回车就能够创建出公私钥注意:在创建过程中会让你指定秘钥的存储位置以及对应的密码,最好自行指定一下 id_rsa 是私钥id_rsa.pub 是公钥 在堡垒机中指定创建好的私钥 …...

通过现代数学语言重构《道德经》核心概念体系,形成一个兼具形式化与启发性的理论框架
以下是对《道德经》的数学转述尝试,通过现代数学语言重构其核心概念,形成一个兼具形式化与启发性的理论框架: 0. 基础公理体系 定义: 《道德经》是一个动态宇宙模型 U(D,V,Φ),其中: D 为“道”的无限维…...
邂逅Node.js
首先先要来学习一下nodejs的基础(和后端开发有联系的) 再然后的学习路线是学习npm,yarn,cnpm,npx,pnpm等包管理工具 然后进行模块化的使用,再去学习webpack和git(版本控制工具&…...
学习路线)
计算机视觉(图像算法工程师)学习路线
计算机视觉学习路线 Python基础 常量与变量 列表、元组、字典、集合 运算符 循环 条件控制语句 函数 面向对象与类 包与模块Numpy Pandas Matplotlib numpy机器学习 回归问题 线性回归 Lasso回归 Ridge回归 多项式回归 决策树回归 AdaBoost GBDT 随机森林回归 分类问题 逻辑…...

GITLIbCICD流水线搭建
1,搭建gitLIb服务器,创建gitlibRunner 并且注册, 2. 写dockerfile 包块java程序运行的环境,jdk,参数等 , 2.1ai生成版本, # 基础镜像(JDK 17)FROM eclipse-temurin:1…...

详细介绍Qwen3技术报告中提到的模型架构技术
详细介绍Qwen3技术报告中提到的一些主流模型架构技术,并为核心流程配上相关的LaTeX公式。 这些技术都是当前大型语言模型(LLM)领域为了提升模型性能、训练效率、推理速度或稳定性而采用的关键组件。 1. Grouped Query Attention (GQA) - 分组…...

【慧游鲁博】【8】前后端用户信息管理:用户基本信息在小程序端的持久化与随时获取
文章目录 本次更新整体流程概述1. 用户登录流程前端登录处理 (login.vue)后端登录处理 (AuthServiceImpl.java) 2. 用户信息存储机制前端状态管理 (member.js) 3. 后续请求的身份验证登录拦截器 (LoginInterceptor.java)前端请求携带token 4. 获取用户信息获取用户信息接口 (Us…...

上位机知识篇---keil IDE操作
文章目录 前言文件操作按键新建打开保存保存所有编辑操作按键撤销恢复复制粘贴剪切全选查找书签操作按键添加书签跳转到上一个书签跳转到下一个书签清空所有书签编译操作按键编译当前文件构建目标文件重新构建调试操作按键进入调试模式复位全速运行停止运行单步调试逐行调试跳出…...