详细介绍Qwen3技术报告中提到的模型架构技术
详细介绍Qwen3技术报告中提到的一些主流模型架构技术,并为核心流程配上相关的LaTeX公式。
这些技术都是当前大型语言模型(LLM)领域为了提升模型性能、训练效率、推理速度或稳定性而采用的关键组件。
1. Grouped Query Attention (GQA) - 分组查询注意力 🎯
- 目的:GQA 旨在在保持多头注意力(Multi-Head Attention, MHA)大部分优势的同时,显著降低推理时的显存占用和计算开销,从而加快推理速度。它介于标准的多头注意力和多查询注意力(Multi-Query Attention, MQA,所有查询头共享同一份键和值)之间。
- 工作原理:
- 在标准的多头注意力中,每个“查询头”(Query Head)都有自己独立的“键头”(Key Head)和“值头”(Value Head)。
- 在GQA中,查询头被分成 N _ g N\_g N_g 组,组内的 N _ q / N _ g N\_q/N\_g N_q/N_g 个查询头共享同一份键头和值头。而不同组之间的键头和值头仍然是独立的。
- 其中 N _ q N\_q N_q 是总查询头数。如果分组数 N _ g = N _ q N\_g = N\_q N_g=N_q,则GQA等同于MHA;如果 N _ g = 1 N\_g = 1 N_g=1,则GQA退化为MQA。
多头注意力 (Multi-Head Attention - MHA)
分组查询注意力 (Grouped-Query Attention - GQA)
多查询注意力 (Multi-Query Attention - MQA)
- 优势:
- 减少K/V缓存:在自回归生成(解码)过程中,需要缓存之前所有token的键(K)和值(V)状态。GQA通过减少K/V头的数量,显著降低了这部分缓存的大小,从而降低了显存占用,尤其在处理长序列时效果明显。
- 提高推理效率:更少的K/V头意味着更少的计算量,尤其是在K/V投影和注意力得分计算的某些环节。
- 性能保持:相比于MQA可能带来的较大性能损失,GQA通过分组共享的方式,能在很大程度上保留MHA的建模能力和性能,是一种较好的折中方案。
- Qwen3中的应用:Qwen3的稠密模型中明确提到了使用GQA。例如,Qwen3-0.6B有16个查询头,KV头数为8 ,这意味着可能分成了8组,每2个查询头共享一组KV。对于更大的模型如Qwen3-32B,有64个查询头,KV头数为8 ,则每8个查询头共享一组KV。MoE模型也采用了GQA,例如Qwen3-235B-A22B有64个查询头,KV头数为4,意味着每16个查询头共享一组KV。
2. SwiGLU - Sigmoid-Weighted Linear Unit (门控线性单元激活函数) активировать
- 目的:SwiGLU 是一种改进的激活函数,旨在通过引入门控机制来提升神经网络(尤其是Transformer模型中前馈网络FFN部分)的性能和表达能力 。
- 工作原理:
- 传统的Transformer FFN层通常包含两个线性变换和一个ReLU(或GeLU)激活函数。
- GLU(Gated Linear Unit)是一类激活函数,它将输入通过两个线性变换,然后将其中一个变换的结果通过Sigmoid函数(作为门控),再与另一个线性变换的结果进行逐元素相乘。
- SwiGLU 是GLU的一个变体。在Transformer的FFN中,给定输入 x ∈ m a t h b b R d x \in \\mathbb{R}^d x∈mathbbRd,它通常通过三个权重矩阵 W , V ∈ R d × d _ m W, V \in \mathbb{R}^{d \times d\_m} W,V∈Rd×d_m 和 W _ 2 ∈ R d _ m × d W\_2 \in \mathbb{R}^{d\_m \times d} W_2∈Rd_m×d (其中 d _ m d\_m d_m 是中间隐藏层维度)进行计算。Qwen3报告中引用的Dauphin et al. (2017) 的工作,以及后续如PaLM、LLaMA等模型采用的形式,通常是:
SwiGLU ( x , W , V ) = Swish β ( x W ) ⊙ ( x V ) \text{SwiGLU}(x, W, V) = \text{Swish}_{\beta}(xW) \odot (xV) SwiGLU(x,W,V)=Swishβ(xW)⊙(xV)
其中 ⊙ \odot ⊙ 表示逐元素乘积, Swish _ β ( y ) = y ⋅ σ ( β y ) \text{Swish}\_{\beta}(y) = y \cdot \sigma(\beta y) Swish_β(y)=y⋅σ(βy) 是Swish激活函数, σ \sigma σ 是Sigmoid函数 σ ( z ) = ( 1 + e − z ) − 1 \sigma(z) = (1 + e^{-z})^{-1} σ(z)=(1+e−z)−1, β \beta β 通常设为1。
然后,这个结果会再通过一个线性层 W _ 2 W\_2 W_2:
FFN SwiGLU ( x ) = ( Swish β ( x W ) ⊙ ( x V ) ) W 2 \text{FFN}_{\text{SwiGLU}}(x) = (\text{Swish}_{\beta}(xW) \odot (xV)) W_2 FFNSwiGLU(x)=(Swishβ(xW)⊙(xV))W2
Mermaid 代码 (SwiGLU FFN层流程示意图):
- 优势:
- 更强的表达能力:门控机制允许网络根据输入动态地调整激活的强度,从而捕获更复杂的模式。
- 更好的性能:在许多LLM的实验中,使用SwiGLU(或其他GLU变体)替换传统的ReLU或GeLU,能在保持参数量大致相当(通过调整隐藏层大小)的情况下,带来模型性能的提升。
- Qwen3中的应用:Qwen3的稠密模型和MoE模型均明确采用了SwiGLU作为激活函数。
3. Rotary Positional Embeddings (RoPE) - 旋转位置嵌入 🔄
- 目的:RoPE 是一种用于在Transformer模型中注入相对位置信息的方法,它旨在克服传统绝对位置编码在处理长序列和泛化性方面的一些局限 。
- 工作原理:
- RoPE的核心思想是将位置信息编码到查询(Q)和键(K)向量中,通过对Q和K向量应用一个与它们在序列中的绝对位置 m m m 相关的旋转矩阵 R _ m R\_m R_m。
- 具体来说,对于一个 d d d 维的Q或K向量 x = [ x _ 0 , x _ 1 , … , x _ d − 1 ] T x = [x\_0, x\_1, \dots, x\_{d-1}]^T x=[x_0,x_1,…,x_d−1]T,可以将其视为 d / 2 d/2 d/2 个二维向量的拼接 x _ j = [ x _ 2 j , x _ 2 j + 1 ] T x\_j = [x\_{2j}, x\_{2j+1}]^T x_j=[x_2j,x_2j+1]T。RoPE对每个这样的二维子向量应用一个旋转操作 :
R m x j = ( cos ( m θ j ) − sin ( m θ j ) sin ( m θ j ) cos ( m θ j ) ) ( x 2 j x 2 j + 1 ) R_m x_j = \begin{pmatrix} \cos(m\theta_j) & -\sin(m\theta_j) \\ \sin(m\theta_j) & \cos(m\theta_j) \end{pmatrix} \begin{pmatrix} x_{2j} \\ x_{2j+1} \end{pmatrix} Rmxj=(cos(mθj)sin(mθj)−sin(mθj)cos(mθj))(x2jx2j+1)
其中 m m m 是token的绝对位置, t h e t a _ j = 10000 − 2 j / d \\theta\_j = 10000^{-2j/d} theta_j=10000−2j/d 是一组预定义的、与维度相关的非负频率。 - 经过RoPE编码后的查询向量 q _ m q\_m q_m 和键向量 k _ n k\_n k_n(它们原始未编码前分别为 q q q 和 k k k),它们的内积满足:
⟨ R m q , R n k ⟩ = ℜ ( ∑ j = 0 d / 2 − 1 ( q 2 j + i q 2 j + 1 ) ( k 2 j − i k 2 j + 1 ) e i ( m − n ) θ j ) \langle R_m q, R_n k \rangle = \Re(\sum_{j=0}^{d/2-1} (q_{2j} + iq_{2j+1})(k_{2j} - ik_{2j+1}) e^{i(m-n)\theta_j}) ⟨Rmq,Rnk⟩=ℜ(j=0∑d/2−1(q2j+iq2j+1)(k2j−ik2j+1)ei(m−n)θj)
这个内积仅取决于它们的相对位置 ( m − n ) (m-n) (m−n) 和它们原始的内容。
Mermaid 代码 (RoPE 位置编码示意图):
- 优势:
- 编码相对位置:注意力得分自然地依赖于相对距离,这更符合许多序列任务的本质。
- 良好的外推性:由于其周期性和相对编码的特性,RoPE在处理比训练时更长的序列时,表现出比某些绝对位置编码更好的泛化能力(尽管也有限度,需要配合YARN等技术进一步扩展)。
- 实现简单:它直接作用于Q和K向量,不需要额外的位置编码层或参数。
- Qwen3中的应用:Qwen3的稠密模型和MoE模型均使用了RoPE 。报告还提到,在预训练的第三阶段(长上下文阶段),遵循Qwen2.5的做法,使用ABF技术将RoPE的基础频率从10,000增加到1,000,000 ,并引入YARN 和双块注意力(DCA) 以在推理时实现序列长度容量的四倍增加 。
4. RMSNorm (Root Mean Square Layer Normalization) - 均方根层归一化 ⚖️
- 目的:RMSNorm 是对传统层归一化(Layer Normalization, LN)的一种简化,旨在减少计算量,提高效率,同时保持与LN相当或稍优的性能。
- 工作原理:
- 传统的LN首先计算输入 x ∈ R d x \in \mathbb{R}^d x∈Rd 的均值 μ = 1 d ∑ x _ i \mu = \frac{1}{d}\sum x\_i μ=d1∑x_i 和方差 σ 2 = 1 d ∑ ( x _ i − μ ) 2 \sigma^2 = \frac{1}{d}\sum (x\_i - \mu)^2 σ2=d1∑(x_i−μ)2,然后归一化 x ^ _ i = x _ i − μ σ 2 + ϵ \hat{x}\_i = \frac{x\_i - \mu}{\sqrt{\sigma^2 + \epsilon}} x^_i=σ2+ϵx_i−μ,最后进行仿射变换 y _ i = γ x ^ _ i + β y\_i = \gamma \hat{x}\_i + \beta y_i=γx^_i+β。
- RMSNorm移除了均值的计算和减去均值的操作,它只对输入进行重新缩放,缩放因子是输入的均方根(Root Mean Square)。其公式为:
RMS ( x ) = 1 d ∑ i = 1 d x i 2 \text{RMS}(x) = \sqrt{\frac{1}{d}\sum_{i=1}^d x_i^2} RMS(x)=d1i=1∑dxi2 output i = x i RMS ( x ) + ϵ ⋅ γ i \text{output}_i = \frac{x_i}{\text{RMS}(x) + \epsilon} \cdot \gamma_i outputi=RMS(x)+ϵxi⋅γi
其中 ϵ \epsilon ϵ 是一个很小的常数以防止除零。它通常不使用偏移因子 b e t a \\beta beta(或者说 β \beta β 固定为0)。
Mermaid 代码 (LayerNorm 与 RMSNorm 对比示意图):
- 优势:
- 计算效率更高:由于不需要计算均值,RMSNorm比LN的计算量更少,尤其是在GPU上可以更快。
- 性能相当或略好:在许多Transformer的实验中,RMSNorm被证明能够达到与LN相当甚至有时略好的性能,同时具有更好的效率。
- Qwen3中的应用:Qwen3的稠密模型和MoE模型均采用了RMSNorm,并且是预归一化(Pre-Normalization)的形式。预归一化是指在进入Transformer的子层(如自注意力层或FFN层)之前进行归一化,这通常有助于稳定训练。
5. QK-Norm (Query-Key Normalization) 🛡️
- 目的:为了进一步稳定大型Transformer模型的训练过程,特别是在注意力机制内部。不稳定的注意力得分可能导致梯度爆炸或消失。
- 工作原理:
- QK-Norm通常是指在计算注意力得分之前,对查询(Q)和/或键(K)向量进行某种形式的归一化。
- 报告中提到引入QK-Norm是为了确保Qwen3的稳定训练,并引用了Dehghani et al. (2023) 的工作 “Scaling vision transformers to 22 billion parameters” 。在该论文中,他们对Q和K分别应用了L2归一化,然后再计算点积 。
Q norm = Q ∥ Q ∥ 2 Q_{\text{norm}} = \frac{Q}{\|Q\|_2} Qnorm=∥Q∥2Q K norm = K ∥ K ∥ 2 K_{\text{norm}} = \frac{K}{\|K\|_2} Knorm=∥K∥2K AttentionScore ( Q , K ) = Q norm K norm T d k \text{AttentionScore}(Q, K) = \frac{Q_{\text{norm}} K_{\text{norm}}^T}{\sqrt{d_k}} AttentionScore(Q,K)=dkQnormKnormT
其中 d _ k d\_k d_k 是键向量的维度。
Mermaid 代码 (QK-Norm 在注意力计算中的应用示意图):
- 优势:
- 稳定训练:通过限制Q和K向量的范数,可以防止注意力得分过大或过小,从而使得训练过程更加稳定,尤其是在使用较低精度(如bfloat16)进行训练时。
- 可能改善性能:在一些情况下,这种归一化也有助于模型学习。
- Qwen3中的应用:Qwen3明确指出在注意力机制中引入了QK-Norm以确保稳定训练 。
6. 移除 QKV-bias (Query-Key-Value bias) ✂️
- 背景:在Transformer的早期版本或某些实现中,用于生成Q、K、V向量的线性投影层(即 Q = X W _ Q , K = X W _ K , V = X W _ V Q=XW\_Q, K=XW\_K, V=XW\_V Q=XW_Q,K=XW_K,V=XW_V)可能会包含偏置项(bias terms),例如 Q = X W _ Q + b _ Q Q=XW\_Q + b\_Q Q=XW_Q+b_Q。
- 目的:移除这些偏置项 b _ Q , b _ K , b _ V b\_Q, b\_K, b\_V b_Q,b_K,b_V。
- 原因/优势:
- 简化模型/减少参数:虽然减少的参数量不多,但符合模型设计趋向简洁的趋势。
- 可能提升稳定性或性能:在一些现代Transformer架构的实践中发现,移除这些偏置项并不会损害性能,有时甚至可能因为减少了模型的自由度或改变了优化的动态而略微有益于训练的稳定性或最终性能。层归一化(如RMSNorm)的存在可能使得这些偏置项变得不那么必要。
- 与归一化层的关系:当使用如LayerNorm或RMSNorm这类对整个激活向量进行操作的归一化层时,线性变换中的偏置项的效果可能会被归一化过程部分抵消或变得冗余。
- Qwen3中的应用:Qwen3明确提到了移除了在Qwen2中使用的QKV-bias 。这表明团队在Qwen3的设计中,基于实验或业界趋势,认为移除这些偏置项对于模型的性能和稳定性是中性或有利的。
综上所述,Qwen3采用的这些架构技术都是为了在模型的表达能力、训练稳定性、推理效率和整体性能之间取得更好的平衡,这些是当前大模型研发中非常关键的考量因素。
相关文章:

详细介绍Qwen3技术报告中提到的模型架构技术
详细介绍Qwen3技术报告中提到的一些主流模型架构技术,并为核心流程配上相关的LaTeX公式。 这些技术都是当前大型语言模型(LLM)领域为了提升模型性能、训练效率、推理速度或稳定性而采用的关键组件。 1. Grouped Query Attention (GQA) - 分组…...

【慧游鲁博】【8】前后端用户信息管理:用户基本信息在小程序端的持久化与随时获取
文章目录 本次更新整体流程概述1. 用户登录流程前端登录处理 (login.vue)后端登录处理 (AuthServiceImpl.java) 2. 用户信息存储机制前端状态管理 (member.js) 3. 后续请求的身份验证登录拦截器 (LoginInterceptor.java)前端请求携带token 4. 获取用户信息获取用户信息接口 (Us…...

上位机知识篇---keil IDE操作
文章目录 前言文件操作按键新建打开保存保存所有编辑操作按键撤销恢复复制粘贴剪切全选查找书签操作按键添加书签跳转到上一个书签跳转到下一个书签清空所有书签编译操作按键编译当前文件构建目标文件重新构建调试操作按键进入调试模式复位全速运行停止运行单步调试逐行调试跳出…...

Odoo: Owl Hooks 深度解析技术指南
你好!作为一名 Odoo 开发者,深入理解其前端框架 Owl.js,尤其是 Hooks,是提升开发效率和代码质量的关键。这份指南将带你从基础概念到高级应用,全面掌握 Odoo 18 中 Owl Hooks 的所有知识点。 1. Hooks 核心概念介绍 什…...
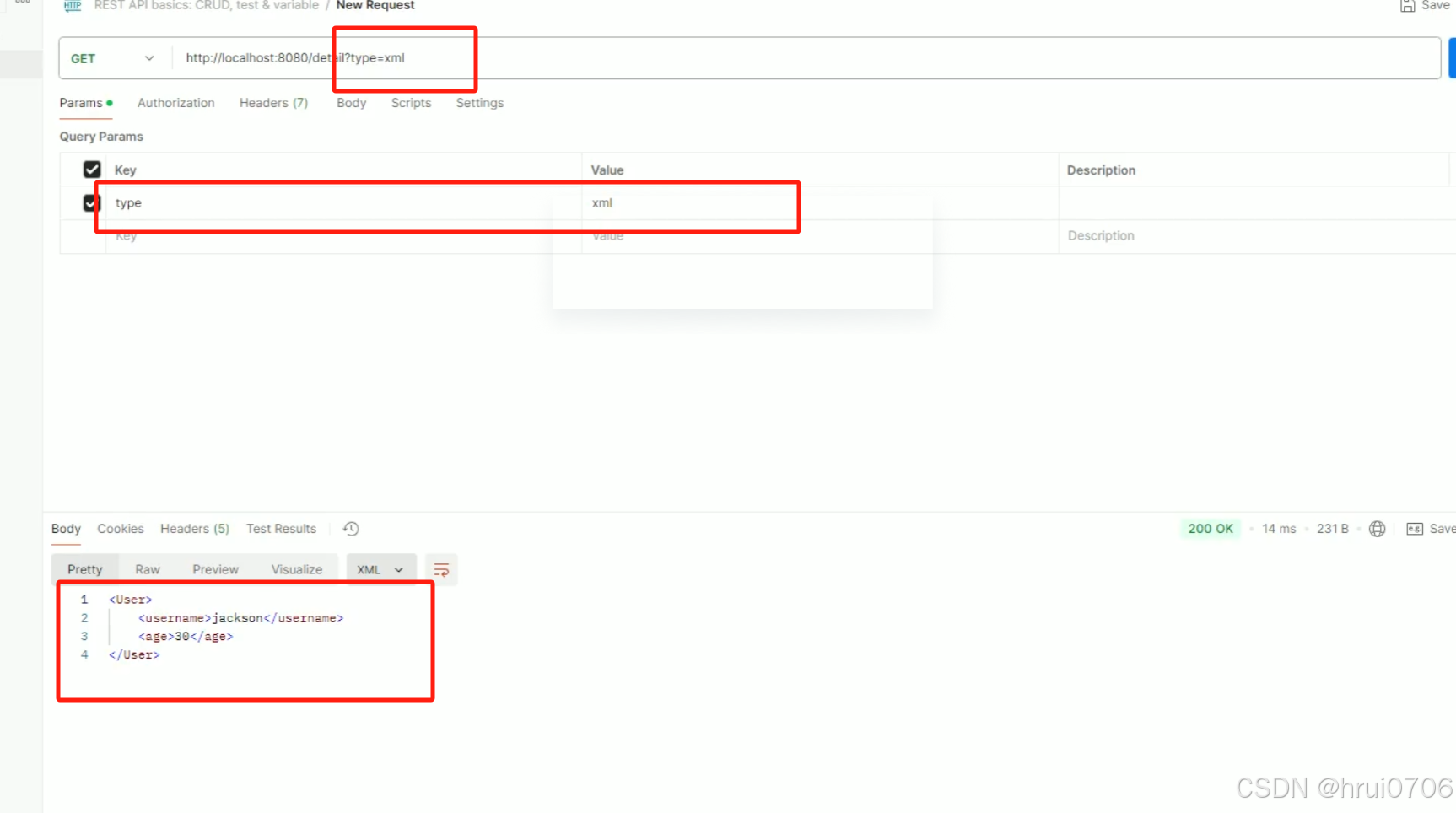
SpringBoot返回xml
默认情况下引入web依赖后自带了JackJson 返回JSON数据 你也可以引入fastJSON 那么方便使用可以用JSON.xxx 如果希望Boot默认返回xml数据 <dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml<…...
【案例篇】 实现简单SSM工程-后端
简介 本篇文章将带你从0到1的实现一个SSM项目,通过此案例可以让你在项目中对SpringBoot的使用有一个更加详细的认识,希望这个简单的案例能够帮到你。文章内容若存在错误或需改进的地方,欢迎大家指正!若对操作有任何疑问欢迎留言&a…...
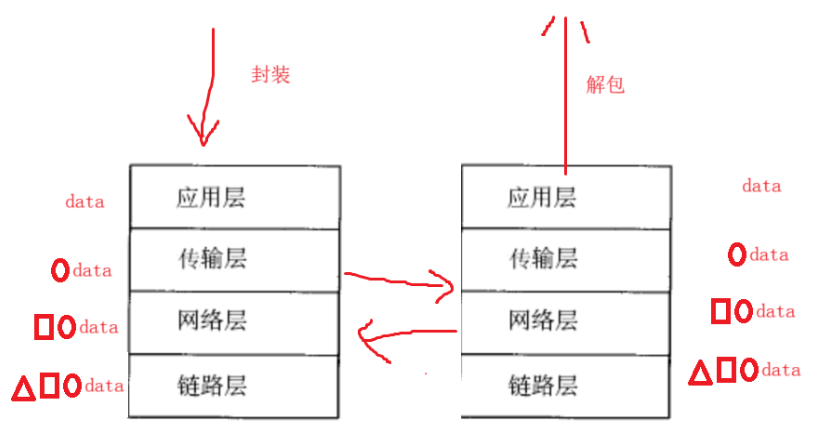
零基础学习计算机网络编程----网络基本知识
目录 1. 计算机网络发展 1.1 网络发展 1.2 媒介 2 认识协议 2.1 为什么要有协议 2.2 协议的本质 3 网络协议的初识 3.1 什么是协议分层 3.2 为什么会有 4. OSI七层模型 4.1 定义 5. TCP/IP五层(或四层)模型 5.1 有什么 6. 网络传输基本流程 6.1 网络传输流程图…...
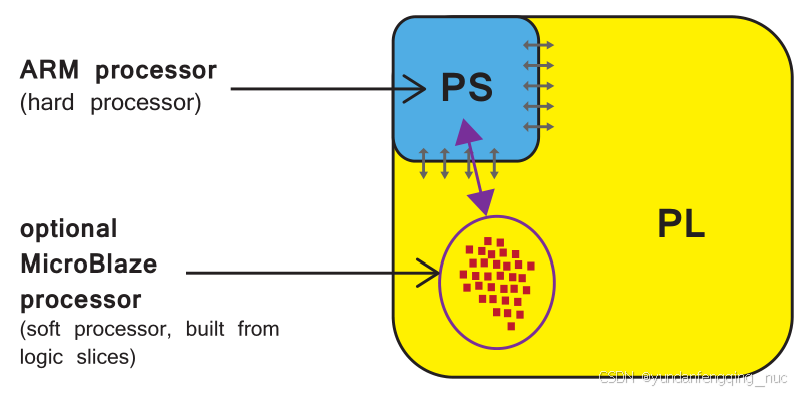
Zynq和Microblaze的区别和优势
Zynq芯片包含了一颗双核ARM Cortex-A9处理器,这是一颗“硬”处理器---它是芯片上专用 而且优化过的硅片原件。 MicroBlaze为“软”处理器,它是由可编程逻辑部分的单元组合而成的, 也就是说,一个 软处理器的实现和部署在FPGA的逻…...
FastAPI 支持文件下载
FastAPI 支持文件下载 FastAPI 支持文件上传 Python 获取文件类型 mimetype 文章目录 1. 服务端处理1.1. 下载小文件1.2. 下载大文件(yield 支持预览的)1.3. 下载大文件(bytes)1.4. 提供静态文件服务 2. 客户端处理2.1. 普通下载2…...
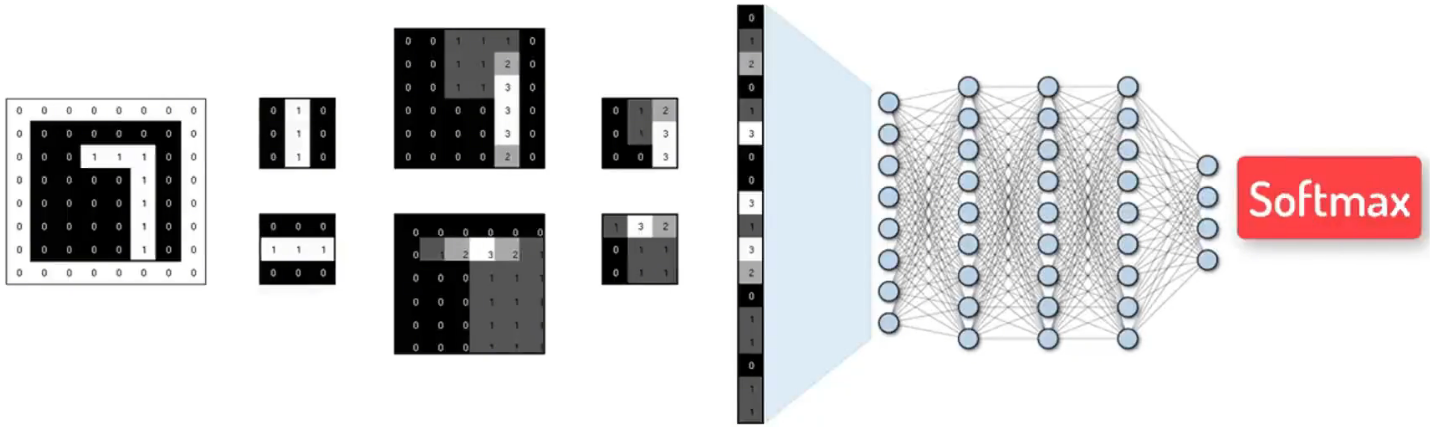
CNN卷积神经网络到底卷了啥?
参考视频:卷积神经网络(CNN)到底卷了啥?8分钟带你快速了解! 我们知道: 图片是由像素点构成,即最终的成像效果是由背后像素的颜色数值所决定 在Excel中:有这样一个由数值0和1组成的66…...

vue中v-clock指令
基础 v-cloak 是 Vue 中的一个非常实用的指令,用于防止在 Vue 实例尚未挂载完成前,用户看到模板中的插值语法(如 {{ message }})一闪而过。 ✅ 场景举例 你在页面还没加载完前,可能会看到这样一瞬间的内容ÿ…...
MIT 6.S081 2020Lab5 lazy page allocation 个人全流程
文章目录 零、写在前面一、Eliminate allocation from sbrk()1.1 说明1.2 实现 二、Lazy allocation2.1 说明2.2 实现 三、Lazytests and Usertests3.1 说明3.2 实现3.2.1 lazytests3.2.2 usertests 零、写在前面 可以阅读下4.6页面错误异常 像应用程序申请内存,内…...

C++初阶-list的使用2
目录 1.std::list::splice的使用 2.std::list::remove和std::list::remove_if的使用 2.1remove_if函数的简单介绍 基本用法 函数原型 使用函数对象作为谓词 使用普通函数作为谓词 注意事项 复杂对象示例 2.2remove与remove_if的简单使用 3.std::list::unique的使用 …...

PHP序列化数据格式详解
PHP序列化数据格式详解 概述 PHP序列化是将PHP变量(包括对象)转换为可存储或传输的字符串表示形式的过程。了解这些序列化格式对于数据处理、调试和安全性分析非常重要。本文将详细介绍PHP中各种数据类型的序列化表示方式。 基本数据类型序列化格式 …...

如何优化 MySQL 存储过程的性能?
文章目录 1. 优化 SQL 语句避免全表扫描减少子查询,改用 JOIN避免 SELECT 2. 合理使用索引3. 优化存储过程结构减少循环和临时变量避免重复计算 4. 使用临时表和缓存5. 优化事务处理6. 分析和监控性能7. 优化数据库配置8. 避免用户自定义函数(UDF&#…...

深度学习:损失函数与激活函数全解析
目录 深度学习中常见的损失函数和激活函数详解引言一、损失函数详解1.1 损失函数的作用与分类1.2 回归任务损失函数1.2.1 均方误差(MSE)1.2.2 平均绝对误差(MAE) 1.3 分类任务损失函数1.3.1 交叉熵损失(Cross-Entropy&…...

【大前端】Node Js下载文件
NodeJs 获取远程文件有很多方式,常见的方式有以下两种: - fetch(原生) - axios(插件) 通过 Fetch 下载文件,代码如下: import fs from node:fsfunction main(){fetch(http://xxx.x…...

自训练NL-SQL模型
使用T5小模型在笔记本上训练 nature language to SQL/自然语言 转SQL 实测通过。 本文介绍了如何在笔记本上使用T5小模型训练自然语言转SQL的任务。主要内容包括:1) 创建Python 3.9环境并安装必要的依赖包;2) 通过Hugging Face镜像下载wikisql数据集和T5-small模型;3) 实现…...
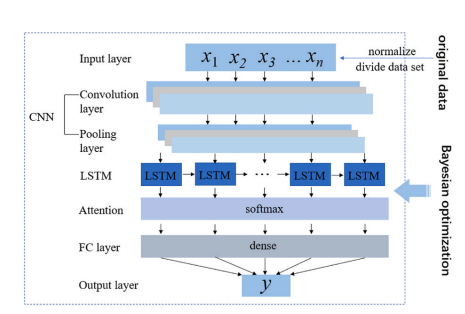
创新点!贝叶斯优化、CNN与LSTM结合,实现更准预测、更快效率、更高性能!
能源与环境领域的时空数据预测面临特征解析与参数调优双重挑战。CNN-LSTM成为突破口:CNN提取空间特征,LSTM捕捉时序依赖,实现时空数据的深度建模。但混合模型超参数(如卷积核数、LSTM层数)调优复杂,传统方法…...

【Flutter】创建BMI计算器应用并添加依赖和打包
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍创建BMI计算器应用并添加依赖和打包。 学其所用,用其所学。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...

【Linux 学习计划】-- 倒计时、进度条小程序
目录 \r 、\n、fflush 倒计时 进度条 进度条进阶版 结语 \r 、\n、fflush 首先我们先来认识这三个东西,这将会是我们接下来两个小程序的重点之一 首先是我们的老演员\n,也就是回车加换行 这里面其实包含了两个操作,一个叫做回车&…...
微服务的应用案例
从“菜市场”到“智慧超市”:一场微服务的变革之旅 曾经,我们的系统像一个熙熙攘攘的传统菜市场。所有功能模块(摊贩)都挤在一个巨大的单体应用中。用户请求(买菜的顾客)一多,整个市场就拥堵不堪…...

后端开发概念
1. 后端开发概念解析 1.1. 什么是服务器,后端服务 1.1.1. 服务器 服务器是一种提供服务的计算机系统,它可以接收、处理和响应来自其他计算机系统(客户端)的请求。服务器主要用于存储、处理和传输数据,以便客户端可以…...

2025网络安全趋势报告 内容摘要
2025 年网络安全在技术、法规、行业等多个维度呈现新趋势。技术上,人工智能、隐私保护技术、区块链、量子安全技术等取得进展;法规方面,数据安全法规进一步细化;行业应用中,物联网、工业控制系统安全升级,供…...
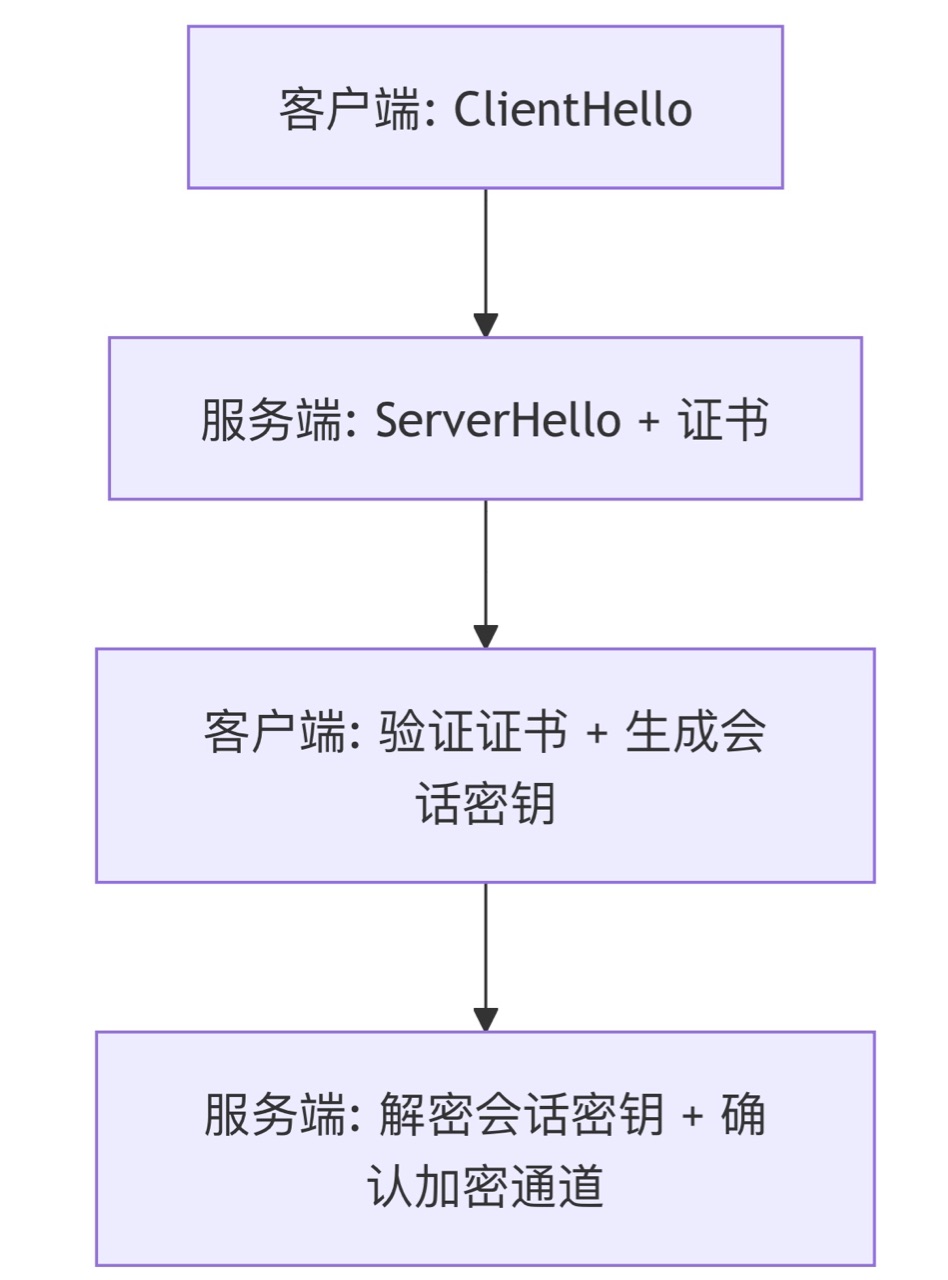
云原生安全基石:深度解析HTTPS协议(从原理到实战)
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念:HTTPS是什么? HTTPS(HyperText Transfer Protocol Secure)是HTTP协议的安全版本,…...

Autodl训练Faster-RCNN网络--自己的数据集(一)
参考文章: Autodl服务器中Faster-rcnn(jwyang)复现(一)_autodl faster rcnn-CSDN博客 Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)_faster rcnn autodl-CSDN博客 食用指南:先跟着参考文章一进行操作,遇到问题再来看我这里有没有解…...
python打卡day36
复习日 仔细回顾一下神经网络到目前的内容,没跟上进度的补一下进度 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。探索性作业(随意完成):尝试进入nn.M…...

8.Java 8 日期时间处理:从 Date 的崩溃到 LocalDate 的优雅自救
一、被 Date 逼疯的程序员:那些年踩过的坑 还记得刚学 Java 时被Date支配的恐惧吗? 想获取 "2023 年 10 月 1 日"?new Date(2023, 9, 1)—— 等等,为什么月份是 9?哦对,Java 的月份从 0 开…...
实现路径损耗预测)
基于Python的全卷积网络(FCN)实现路径损耗预测
以下是一份详细的基于Python的全卷积网络(FCN)实现路径损耗预测的技术文档。本方案包含理论基础、数据生成、模型构建、训练优化及可视化分析,代码实现约6000字。 基于全卷积网络的无线信道路径损耗预测系统 目录 问题背景与需求分析系统架构设计合成数据生成方法全卷积网络…...

【ubuntu】安装NVIDIA Container Toolkit
目录 安装NVIDIA Container Toolkit 安装依赖 添加密钥和仓库 配置中国科技大学(USTC) 镜像 APT 源 更新 APT 包列表 安装 NVIDIA Container Toolkit 验证安装 重启docker 起容器示例命令 【问题】如何在docker中正确使用GPU? 安装…...