FastAPI 支持文件下载
FastAPI 支持文件下载
FastAPI 支持文件上传
Python 获取文件类型 mimetype
文章目录
- 1. 服务端处理
- 1.1. 下载小文件
- 1.2. 下载大文件(yield 支持预览的)
- 1.3. 下载大文件(bytes)
- 1.4. 提供静态文件服务
- 2. 客户端处理
- 2.1. 普通下载
- 2.2. 分块下载
- 2.3. 显示进度条下载
- 2.4. 带有断点续传的下载
- 2.5. 带有超时和重试的下载
- 2.6. 完整的下载器实现
- 3. 异常处理
- 3.1. 中文文件名错误
- 3.2. 使用 mimetypes.guess_type
- 3.3. 使用 VUE Blob 下载乱码问题
参考:
https://blog.csdn.net/weixin_42502089/article/details/147689236
https://www.cnblogs.com/bitterteaer/p/17581746.html
修改下载缓冲区大小
https://ask.csdn.net/questions/8328950
对于文件下载,FastAPI 提供了 FileResponse 和 StreamingResponse 两种方式。 FileResponse 适合小文件,而 StreamingResponse 适合大文件,因为它可以分块返回文件内容。
1. 服务端处理
1.1. 下载小文件
使用 FileResponse 可以直接下载文件,而无需在内存中加载整个文件。
"""
fastapi + request 上传和下载功能
"""
from fastapi import FastAPI, UploadFile
from fastapi.responses import FileResponse
import uvicornapp = FastAPI()# filename 下载时设置的文件名
@app.get("/download/small/{filename}")
async def download_small_file(filename: str):print(filename)file_path = "./测试任务.pdf"return FileResponse(file_path, filename=filename, media_type="application/octet-stream")if __name__ == '__main__':uvicorn.run(app, port=8000)
保证当前目录下有名为“测试任务.pdf”的文件。
然后使用浏览器下载:
http://127.0.0.1:8000/download/small/ceshi.pdf

1.2. 下载大文件(yield 支持预览的)
使用 StreamingResponse 可以分块下载文件,这样不会占用太多服务器资源,特别适用于大文件的下载。
from fastapi.responses import StreamingResponse
from fastapi import HTTPException
@app.get("/download/big/{filename}")
async def download_big_file(filename: str):def iter_file(path: str):with open(file=path, mode="rb") as tfile:yield tfile.read()# while chunk := tfile.read(1024*1024): # 1MB 缓冲区# yield chunkfile_path = "./测试任务.pdf"if not os.path.exists(file_path):raise HTTPException(status_code=404, detail="File not found")# # 支持浏览器预览# return StreamingResponse(content=iter_file(path=file_path), status_code = 200,)# 直接下载return StreamingResponse(iter_file(path=file_path), media_type="application/octet-stream", headers={"Content-Disposition": f"attachment; filename={filename}"})
然后使用浏览器下载:
http://127.0.0.1:8000/download/big/ceshi_big.pdf
1.3. 下载大文件(bytes)
import io
@app.get("/download/bytes/{filename}")
async def download_bytes_file(filename: str):def read_bytes(path: str):content = "Error"with open(file=path, mode="rb") as tfile:content = tfile.read()# # 失败,需要转成bytes输出# return contentreturn io.BytesIO(content)file_path = "./测试任务.pdf"if not os.path.exists(file_path):raise HTTPException(status_code=404, detail="File not found")# 解决中文名错误from urllib.parse import quote# return StreamingResponse(content=read_bytes(path=file_path), media_type="application/octet-stream", # headers={"Content-Disposition": "attachment; filename={}".format(quote(filename))})return StreamingResponse(content=read_bytes(path=file_path), media_type="application/octet-stream", headers={"Content-Disposition": "attachment; filename={}".format(quote(filename))})
1.4. 提供静态文件服务
FastAPI 允许开发者使用 StaticFiles 来提供静态文件服务。这类似于传统 Web 服务器处理文件的方式。
from fastapi.staticfiles import StaticFiles# app.mount("/static", StaticFiles(directory="static", html=True), name="free")
app.mount("/static", StaticFiles(directory="fonts", html=True), name="free")
尚未测试通过。
2. 客户端处理
参考(还有进度条, 带有断点续传的下载, 带有超时和重试的下载):
https://blog.csdn.net/u013762572/article/details/145158401
批量上传下载
https://blog.csdn.net/weixin_43413871/article/details/137027968
2.1. 普通下载
import requests
import os"""方式1,将整个文件下载在保存到本地"""
def download_file_bytes(file_name):# 以下三个地址均可以url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"# response = requests.get(url, params={"filename": "1.txt"})response = requests.get(url)# print(response.text)with open(file_name, 'wb') as file:# file.write(response.text)file.write(response.content)if __name__ == '__main__':download_file_bytes("本地测试下载文件bytes.pdf")
2.2. 分块下载
import requests
import os"""方式2,通过流的方式一次写入8192字节"""
def download_file_big(file_name):# 以下三个地址均可以url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"# url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"# url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"# response = requests.get(url, params={"filename": "./测试任务.pdf"}, stream=True)response = requests.get(url, stream=True)with open(file_name, 'wb') as file:for chunk in response.iter_content(chunk_size=8192):file.write(chunk)if __name__ == '__main__':download_file_big("本地测试下载文件big.pdf")
2.3. 显示进度条下载
import requests
import os
from tqdm import tqdmdef download_file_tqdm(file_name):# 以下三个地址均可以# url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"# url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"response = requests.get(url, stream=True)if response.status_code == 200:file_size = int(response.headers.get('content-length', 0))# 显示进度条progress = tqdm(response.iter_content(chunk_size=8192), total=file_size,unit='B', unit_scale=True)with open(file_name, 'wb') as f:for data in progress:f.write(data)return Truereturn Falseif __name__ == '__main__':download_file_tqdm("本地测试下载文件tqdm.pdf")
运行结果:
> python.exe .\fast_client.py
1.92kB [00:00, 14.0kB/s]
2.4. 带有断点续传的下载
# 带有断点续传的下载
def resume_download(file_name):# 以下三个地址均可以# url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"# url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"# 获取已下载文件大小initial_pos = os.path.getsize(file_name) if os.path.exists(file_name) else 0# 设置 Headerheaders = {'Range': f'bytes={initial_pos}-'}response = requests.get(url, stream=True, headers=headers)# 追加模式打开文件mode = 'ab' if initial_pos > 0 else 'wb'with open(file_name, mode) as f:for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)
尚未测试
2.5. 带有超时和重试的下载
# 带有超时和重试的下载
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
import time
def download_with_retry(file_name, max_retries=3, timeout=30):# 以下三个地址均可以# url = "http://127.0.0.1:8000/download/small/ceshi_samll.pdf"# url = "http://127.0.0.1:8000/download/big/ceshi_big.pdf"url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"session = requests.Session()# 设置重试策略retries = Retry(total=max_retries,backoff_factor=1,status_forcelist=[500, 502, 503, 504])session.mount('http://', HTTPAdapter(max_retries=retries))session.mount('https://', HTTPAdapter(max_retries=retries))try:response = session.get(url, stream=True, timeout=timeout)with open(file_name, 'wb') as f:for chunk in response.iter_content(chunk_size=8192):if chunk:f.write(chunk)return Trueexcept Exception as e:print(f"Download failed: {str(e)}")return False尚未测试
2.6. 完整的下载器实现
import requests
from tqdm import tqdm
import os
from pathlib import Path
import hashlibclass FileDownloader:def __init__(self, chunk_size=8192):self.chunk_size = chunk_sizeself.session = requests.Session()def get_file_size(self, url):response = self.session.head(url)return int(response.headers.get('content-length', 0))def get_file_hash(self, file_path):sha256_hash = hashlib.sha256()with open(file_path, "rb") as f:for byte_block in iter(lambda: f.read(4096), b""):sha256_hash.update(byte_block)return sha256_hash.hexdigest()def download(self, url, save_path, verify_hash=None):save_path = Path(save_path)# 创建目录save_path.parent.mkdir(parents=True, exist_ok=True)# 获取文件大小file_size = self.get_file_size(url)# 设置进度条progress = tqdm(total=file_size,unit='B',unit_scale=True,desc=save_path.name)try:response = self.session.get(url, stream=True)with save_path.open('wb') as f:for chunk in response.iter_content(chunk_size=self.chunk_size):if chunk:f.write(chunk)progress.update(len(chunk))progress.close()# 验证文件完整性if verify_hash:downloaded_hash = self.get_file_hash(save_path)if downloaded_hash != verify_hash:raise ValueError("File hash verification failed")return Trueexcept Exception as e:progress.close()print(f"Download failed: {str(e)}")if save_path.exists():save_path.unlink()return Falsedef download_multiple(self, url_list, save_dir):results = []for url in url_list:filename = url.split('/')[-1]save_path = Path(save_dir) / filenamesuccess = self.download(url, save_path)results.append({'url': url,'success': success,'save_path': str(save_path)})return results# 使用示例
downloader = FileDownloader()# 单文件下载
url = "http://127.0.0.1:8000/download/bytes/ceshi_bytes.pdf"
downloader.download(url, save_path="downloads/file.pdf")# # 多文件下载
# urls = [
# "https://example.com/file1.pdf",
# "https://example.com/file2.pdf"
# ]
# results = downloader.download_multiple(urls, "downloads")
运行结果:
> python.exe .\fast_client_plus.py
file.pdf: 9.18MB [00:00, 60.2MB/s]
3. 异常处理
3.1. 中文文件名错误
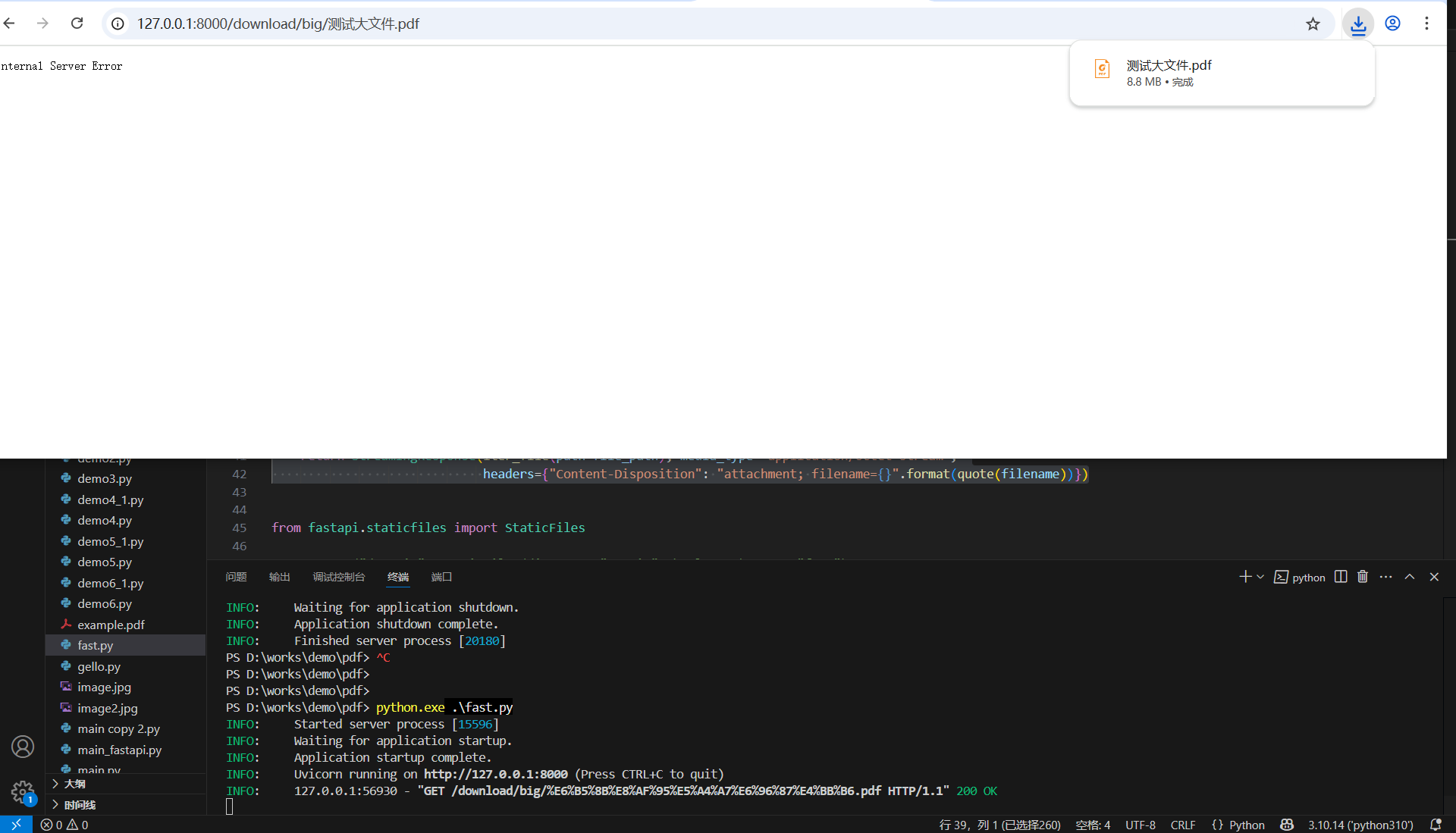
下载文件时,当传递文件名为中文时,报错。
# 解决中文名错误from urllib.parse import quotereturn StreamingResponse(iter_file(path=file_path), media_type="application/octet-stream", headers={"Content-Disposition": "attachment; filename={}".format(quote(filename))})
3.2. 使用 mimetypes.guess_type
mimetypes.guess_type 是 Python 标准库 mimetypes 中的一个函数,用于根据文件名或 URL 猜测文件的 MIME 类型。该函数的基本用法如下:
import mimetypes
# 参数
# url:可以是文件名或 URL 的字符串。
# strict:一个布尔值,默认为True,表示仅使用 IANA 注册的官方 MIME 类型。如果设置为 False,则还包括一些常用的非标准 MIM E类型。
# 返回值
# 函数返回一个元组 (type, encoding):
# type:文件的 MIME 类型,如果无法猜测则返回 None。
# encoding:文件的编码格式,如果无法确定则返回 None。
mimetypes.guess_type(url, strict=True)
服务端修改 media_type
from urllib.parse import quotefrom mimetypes import guess_type# 返回一个元组 ('application/pdf', None)content_type = guess_type(file_path)[0]return StreamingResponse(content=read_bytes(path=file_path), media_type=content_type, headers={"Content-Disposition": "attachment; filename={}".format(quote(filename))})
客户端返回:
{'date': 'Fri, 23 May 2025 01:04:55 GMT', 'server': 'uvicorn', 'content-disposition': 'attachment; filename=ceshi_bytes.pdf', 'content-type': 'application/pdf', 'Transfer-Encoding': 'chunked'}
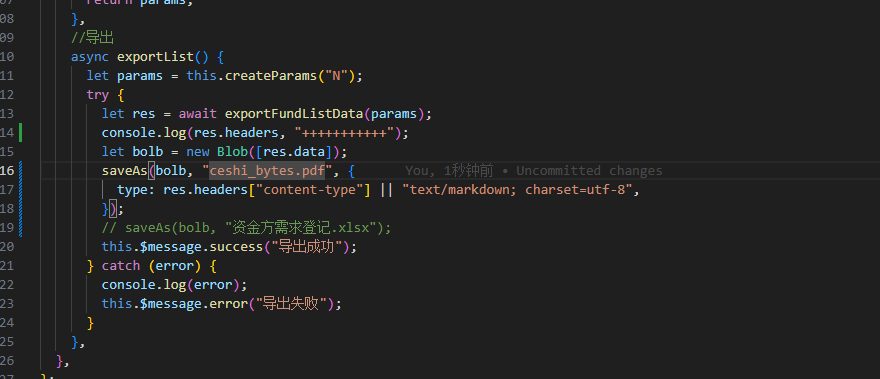
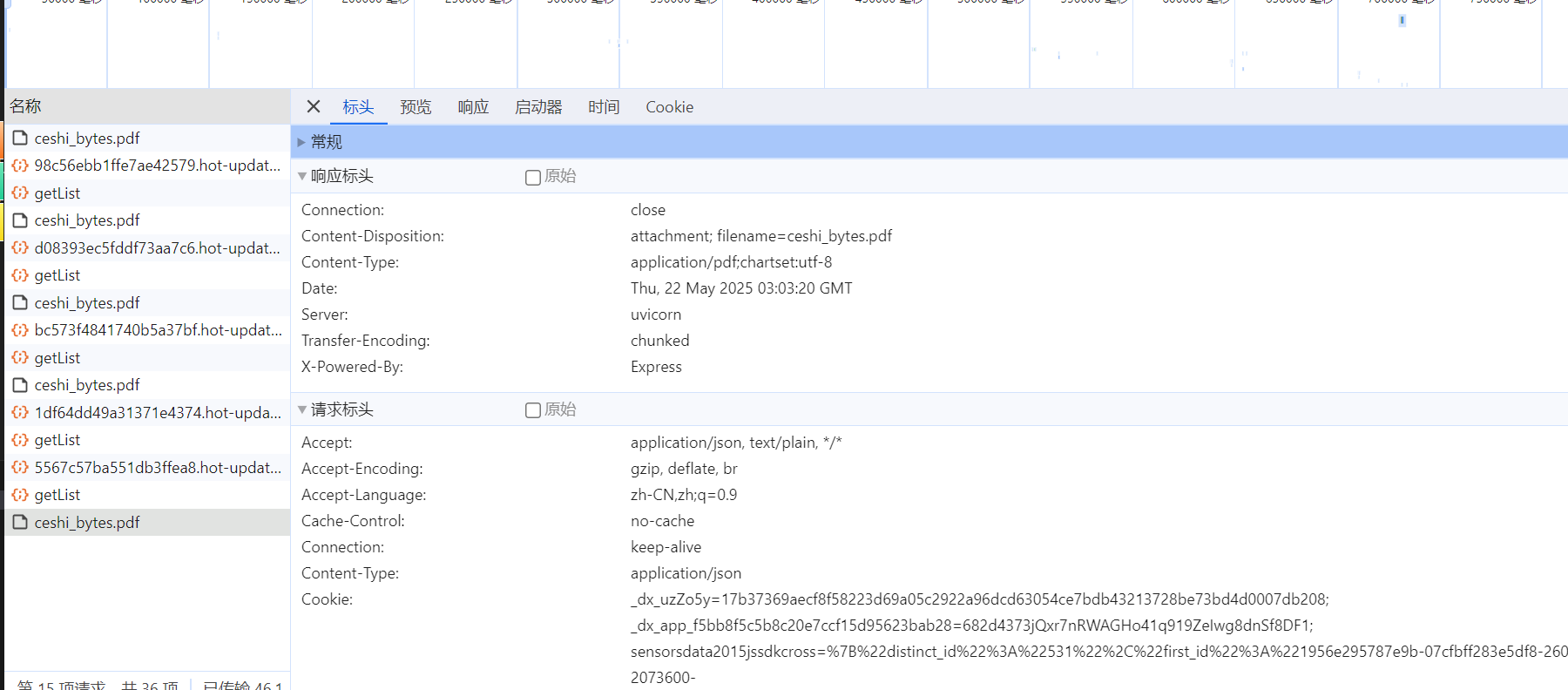
3.3. 使用 VUE Blob 下载乱码问题
前端大佬说:
content-type 应该是 application/pdf
response-type 应该是 blob
相关文章:
FastAPI 支持文件下载
FastAPI 支持文件下载 FastAPI 支持文件上传 Python 获取文件类型 mimetype 文章目录 1. 服务端处理1.1. 下载小文件1.2. 下载大文件(yield 支持预览的)1.3. 下载大文件(bytes)1.4. 提供静态文件服务 2. 客户端处理2.1. 普通下载2…...
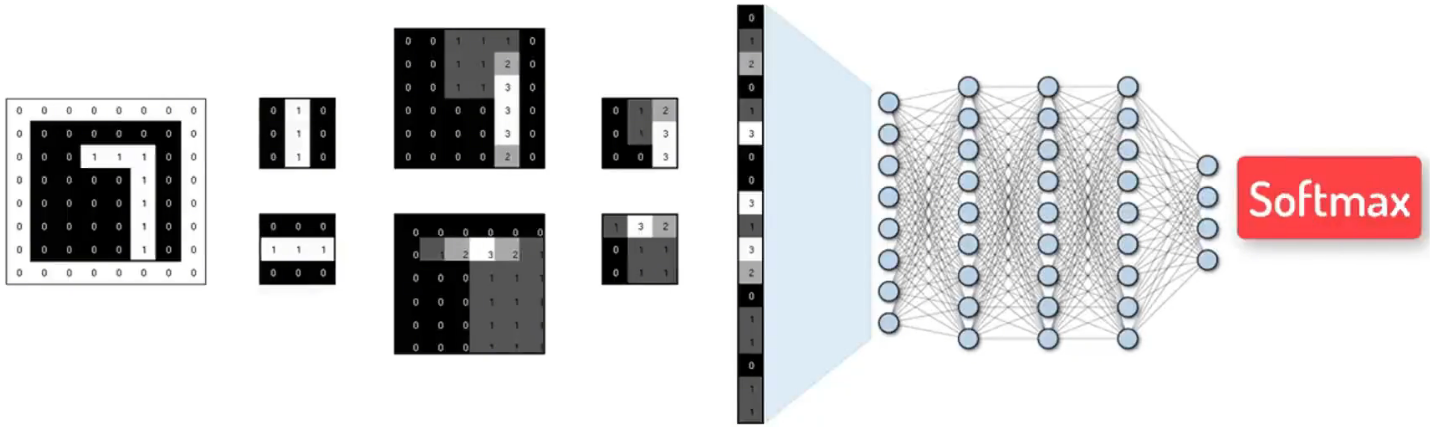
CNN卷积神经网络到底卷了啥?
参考视频:卷积神经网络(CNN)到底卷了啥?8分钟带你快速了解! 我们知道: 图片是由像素点构成,即最终的成像效果是由背后像素的颜色数值所决定 在Excel中:有这样一个由数值0和1组成的66…...

vue中v-clock指令
基础 v-cloak 是 Vue 中的一个非常实用的指令,用于防止在 Vue 实例尚未挂载完成前,用户看到模板中的插值语法(如 {{ message }})一闪而过。 ✅ 场景举例 你在页面还没加载完前,可能会看到这样一瞬间的内容ÿ…...
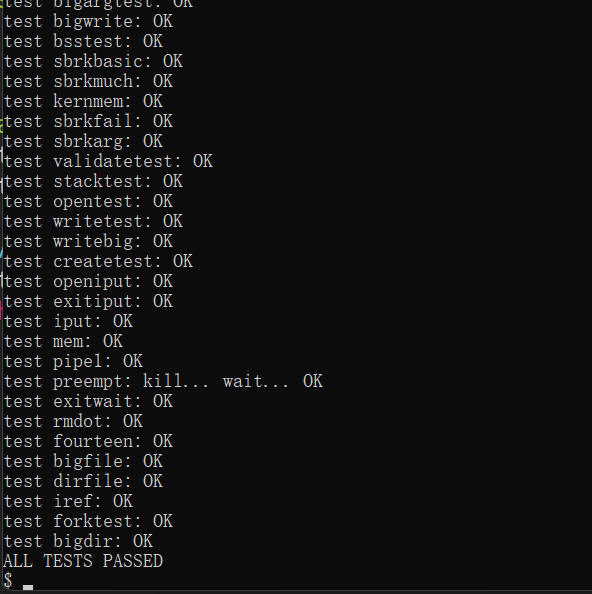
MIT 6.S081 2020Lab5 lazy page allocation 个人全流程
文章目录 零、写在前面一、Eliminate allocation from sbrk()1.1 说明1.2 实现 二、Lazy allocation2.1 说明2.2 实现 三、Lazytests and Usertests3.1 说明3.2 实现3.2.1 lazytests3.2.2 usertests 零、写在前面 可以阅读下4.6页面错误异常 像应用程序申请内存,内…...

C++初阶-list的使用2
目录 1.std::list::splice的使用 2.std::list::remove和std::list::remove_if的使用 2.1remove_if函数的简单介绍 基本用法 函数原型 使用函数对象作为谓词 使用普通函数作为谓词 注意事项 复杂对象示例 2.2remove与remove_if的简单使用 3.std::list::unique的使用 …...

PHP序列化数据格式详解
PHP序列化数据格式详解 概述 PHP序列化是将PHP变量(包括对象)转换为可存储或传输的字符串表示形式的过程。了解这些序列化格式对于数据处理、调试和安全性分析非常重要。本文将详细介绍PHP中各种数据类型的序列化表示方式。 基本数据类型序列化格式 …...

如何优化 MySQL 存储过程的性能?
文章目录 1. 优化 SQL 语句避免全表扫描减少子查询,改用 JOIN避免 SELECT 2. 合理使用索引3. 优化存储过程结构减少循环和临时变量避免重复计算 4. 使用临时表和缓存5. 优化事务处理6. 分析和监控性能7. 优化数据库配置8. 避免用户自定义函数(UDF&#…...

深度学习:损失函数与激活函数全解析
目录 深度学习中常见的损失函数和激活函数详解引言一、损失函数详解1.1 损失函数的作用与分类1.2 回归任务损失函数1.2.1 均方误差(MSE)1.2.2 平均绝对误差(MAE) 1.3 分类任务损失函数1.3.1 交叉熵损失(Cross-Entropy&…...

【大前端】Node Js下载文件
NodeJs 获取远程文件有很多方式,常见的方式有以下两种: - fetch(原生) - axios(插件) 通过 Fetch 下载文件,代码如下: import fs from node:fsfunction main(){fetch(http://xxx.x…...

自训练NL-SQL模型
使用T5小模型在笔记本上训练 nature language to SQL/自然语言 转SQL 实测通过。 本文介绍了如何在笔记本上使用T5小模型训练自然语言转SQL的任务。主要内容包括:1) 创建Python 3.9环境并安装必要的依赖包;2) 通过Hugging Face镜像下载wikisql数据集和T5-small模型;3) 实现…...
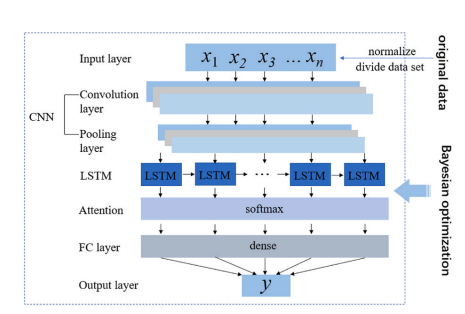
创新点!贝叶斯优化、CNN与LSTM结合,实现更准预测、更快效率、更高性能!
能源与环境领域的时空数据预测面临特征解析与参数调优双重挑战。CNN-LSTM成为突破口:CNN提取空间特征,LSTM捕捉时序依赖,实现时空数据的深度建模。但混合模型超参数(如卷积核数、LSTM层数)调优复杂,传统方法…...

【Flutter】创建BMI计算器应用并添加依赖和打包
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍创建BMI计算器应用并添加依赖和打包。 学其所用,用其所学。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...

【Linux 学习计划】-- 倒计时、进度条小程序
目录 \r 、\n、fflush 倒计时 进度条 进度条进阶版 结语 \r 、\n、fflush 首先我们先来认识这三个东西,这将会是我们接下来两个小程序的重点之一 首先是我们的老演员\n,也就是回车加换行 这里面其实包含了两个操作,一个叫做回车&…...
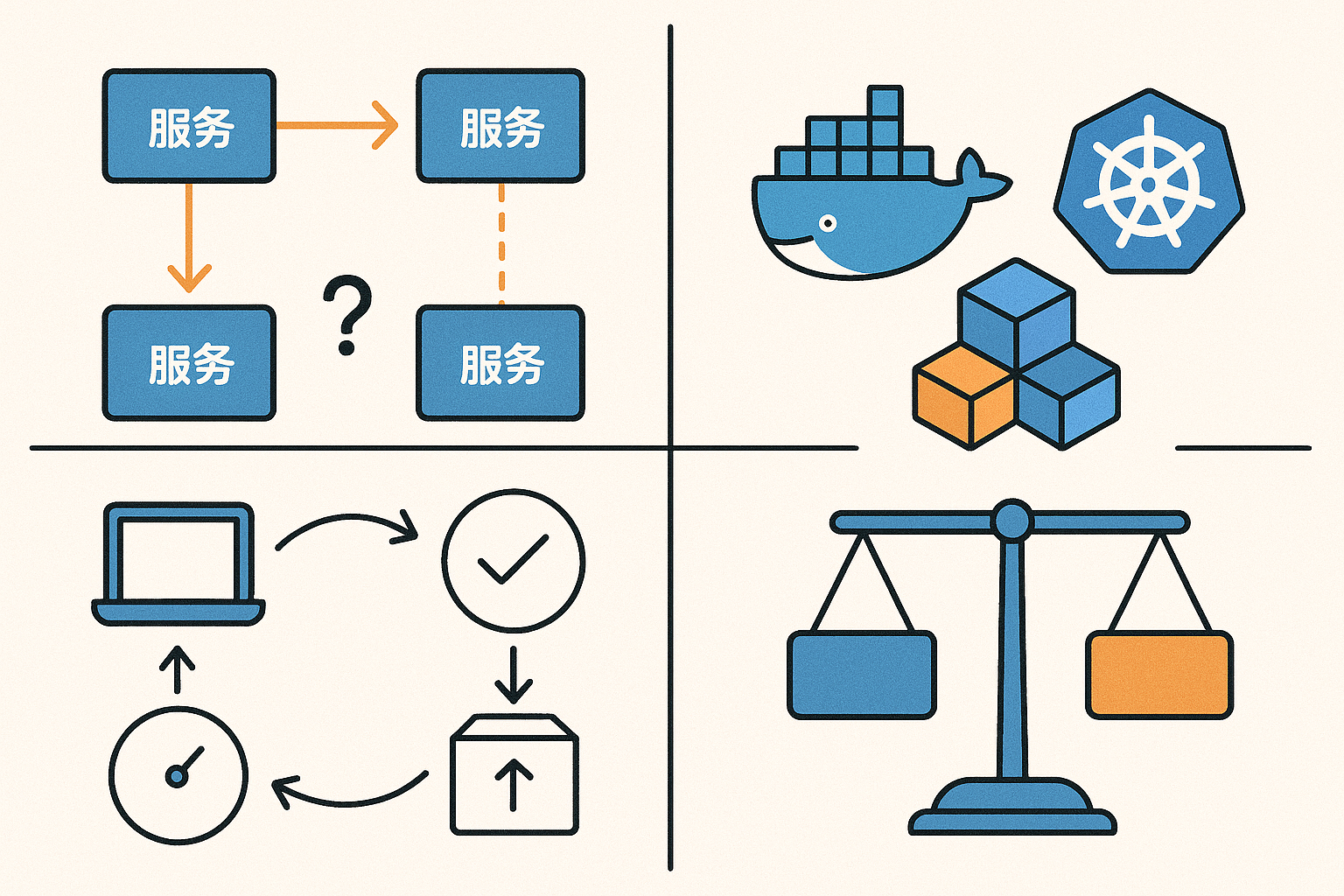
微服务的应用案例
从“菜市场”到“智慧超市”:一场微服务的变革之旅 曾经,我们的系统像一个熙熙攘攘的传统菜市场。所有功能模块(摊贩)都挤在一个巨大的单体应用中。用户请求(买菜的顾客)一多,整个市场就拥堵不堪…...

后端开发概念
1. 后端开发概念解析 1.1. 什么是服务器,后端服务 1.1.1. 服务器 服务器是一种提供服务的计算机系统,它可以接收、处理和响应来自其他计算机系统(客户端)的请求。服务器主要用于存储、处理和传输数据,以便客户端可以…...

2025网络安全趋势报告 内容摘要
2025 年网络安全在技术、法规、行业等多个维度呈现新趋势。技术上,人工智能、隐私保护技术、区块链、量子安全技术等取得进展;法规方面,数据安全法规进一步细化;行业应用中,物联网、工业控制系统安全升级,供…...
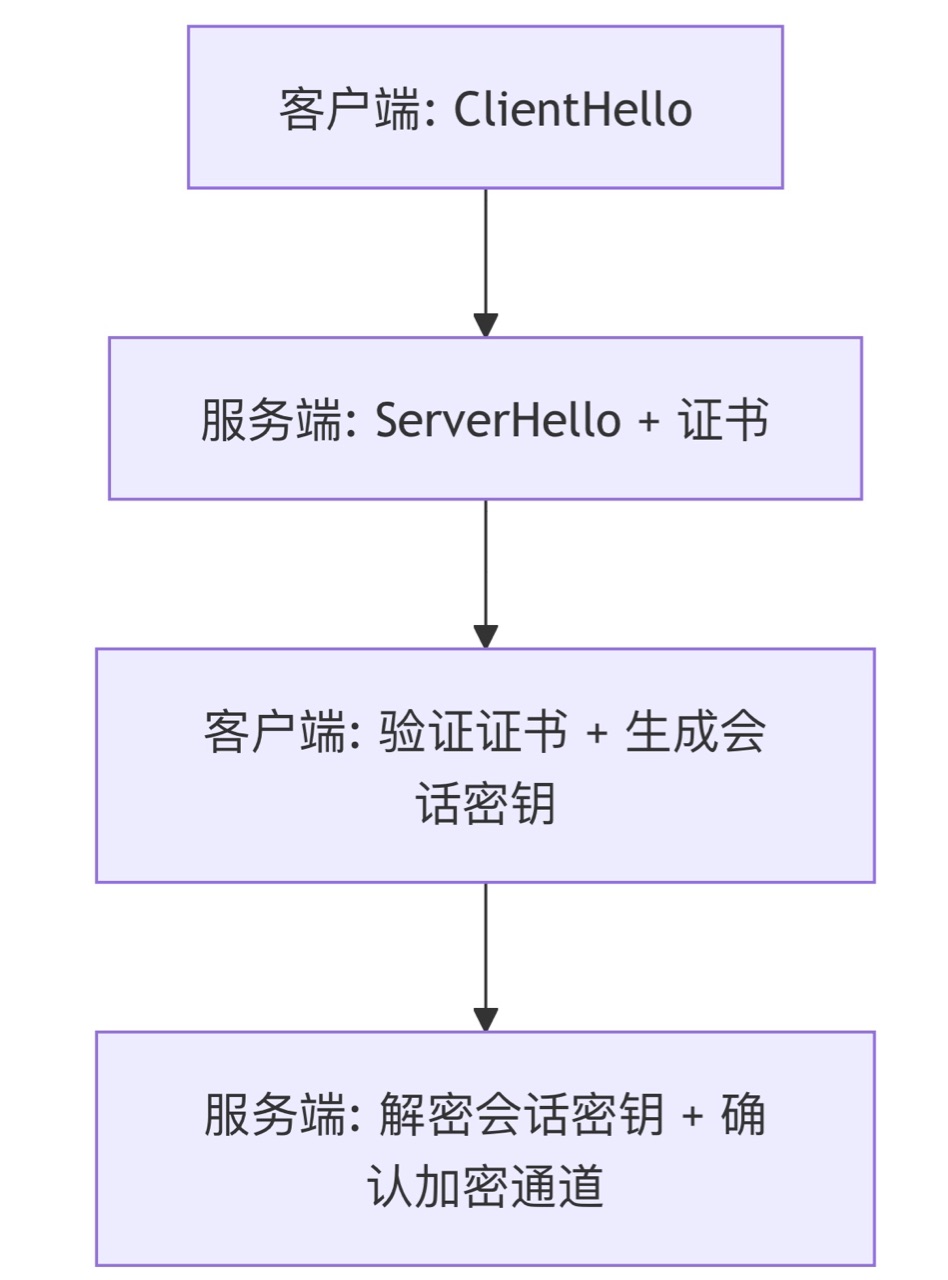
云原生安全基石:深度解析HTTPS协议(从原理到实战)
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念:HTTPS是什么? HTTPS(HyperText Transfer Protocol Secure)是HTTP协议的安全版本,…...

Autodl训练Faster-RCNN网络--自己的数据集(一)
参考文章: Autodl服务器中Faster-rcnn(jwyang)复现(一)_autodl faster rcnn-CSDN博客 Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)_faster rcnn autodl-CSDN博客 食用指南:先跟着参考文章一进行操作,遇到问题再来看我这里有没有解…...
python打卡day36
复习日 仔细回顾一下神经网络到目前的内容,没跟上进度的补一下进度 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。探索性作业(随意完成):尝试进入nn.M…...

8.Java 8 日期时间处理:从 Date 的崩溃到 LocalDate 的优雅自救
一、被 Date 逼疯的程序员:那些年踩过的坑 还记得刚学 Java 时被Date支配的恐惧吗? 想获取 "2023 年 10 月 1 日"?new Date(2023, 9, 1)—— 等等,为什么月份是 9?哦对,Java 的月份从 0 开…...
实现路径损耗预测)
基于Python的全卷积网络(FCN)实现路径损耗预测
以下是一份详细的基于Python的全卷积网络(FCN)实现路径损耗预测的技术文档。本方案包含理论基础、数据生成、模型构建、训练优化及可视化分析,代码实现约6000字。 基于全卷积网络的无线信道路径损耗预测系统 目录 问题背景与需求分析系统架构设计合成数据生成方法全卷积网络…...

【ubuntu】安装NVIDIA Container Toolkit
目录 安装NVIDIA Container Toolkit 安装依赖 添加密钥和仓库 配置中国科技大学(USTC) 镜像 APT 源 更新 APT 包列表 安装 NVIDIA Container Toolkit 验证安装 重启docker 起容器示例命令 【问题】如何在docker中正确使用GPU? 安装…...
Paimon和Hive相集成
Flink版本1.17 Hive版本3.1.3 1、Paimon集成Hive 将paimon-hive-connector.jar复制到auxlib中,下载链接Index of /groups/snapshots/org/apache/https://repository.apache.org/snapshots/org/apache/paimon/ 通过flink进入查看paimon /opt/softwares/flink-1.…...
:从愿景到落地的精益开发路径——Rally的全流程管理实践)
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践 在创业的黏性阶段,如何将抽象的愿景转化为可落地的产品功能?如何在快速迭代中保持战略聚焦?今天,我们通过Rally软…...
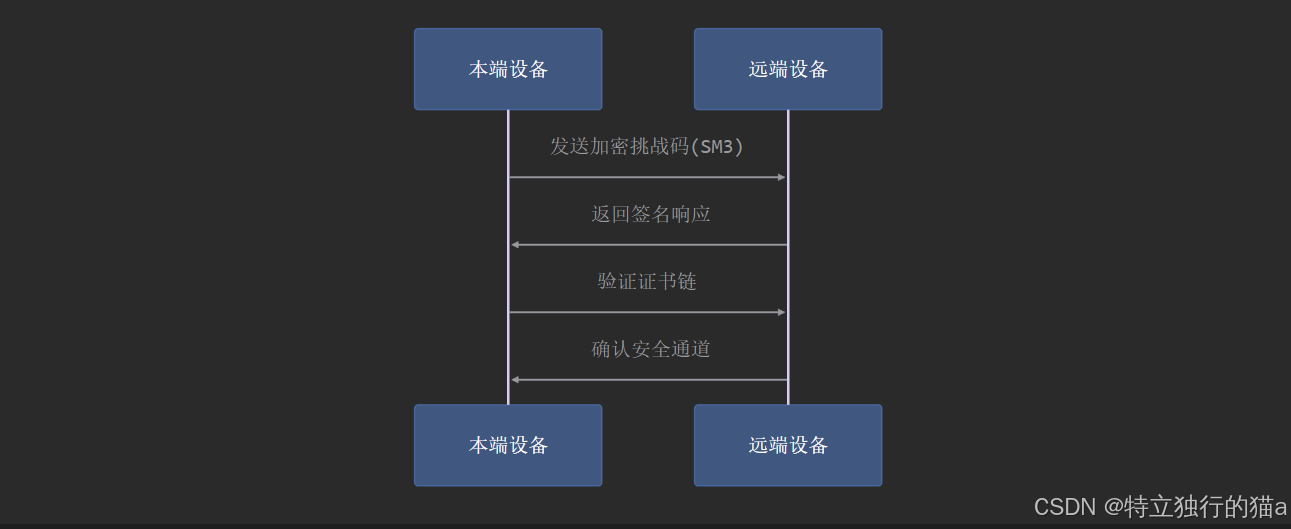
HarmonyOS 鸿蒙应用开发进阶:深入理解鸿蒙跨设备互通机制
鸿蒙跨设备互通(HarmonyOS Cross-Device Collaboration)是鸿蒙系统分布式能力的重要体现,通过创新的分布式软总线技术,实现了设备间的高效互联与能力共享。本文将系统性地解析鸿蒙跨设备互通的技术架构、实现原理及开发实践。 跨设…...

Vue.js教学第十五章:深入解析Webpack与Vue项目实战
Webpack 与 Vue 项目详解 在现代前端开发中,Webpack 作为最流行的模块打包工具之一,对于 Vue 项目的构建和优化起着至关重要的作用。本文将深入剖析 Webpack 的基本概念、在 Vue 项目中的应用场景,并详细讲解常用的 Webpack loaders 和 plugins 的配置与作用,同时通过实例…...

深入浅出 Python Testcontainers:用容器优雅地编写集成测试
在现代软件开发中,自动化测试已成为敏捷开发与持续集成中的关键环节。单元测试可以快速验证函数或类的行为是否符合预期,而集成测试则确保多个模块协同工作时依然正确。问题是:如何让集成测试可靠、可重复且易于维护? 这时&#…...
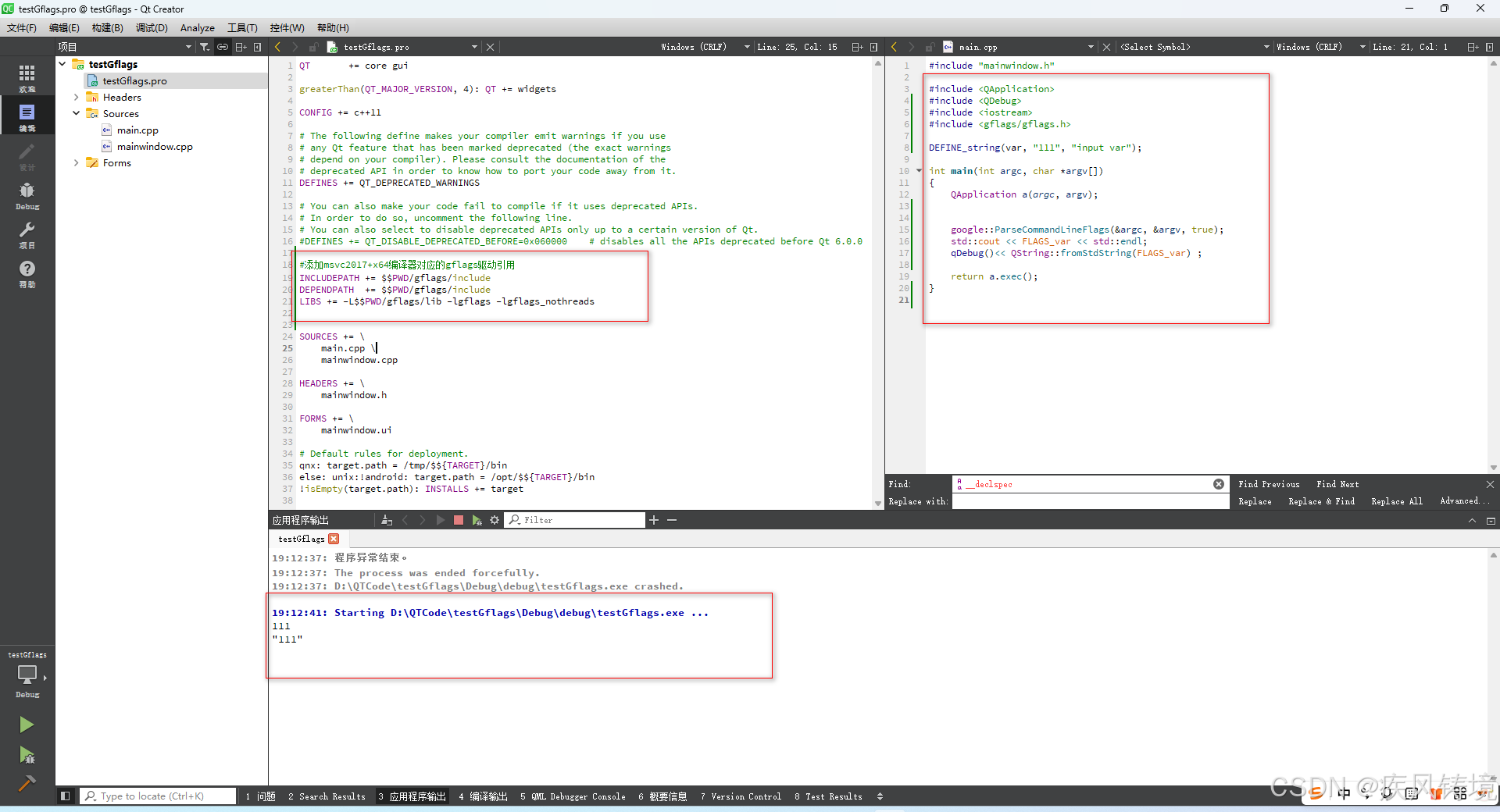
Cmake编译gflags过程记录和在QT中测试
由于在QT中使用PaddleOCR2.8存在这样那样的问题,查找貌似是gflags相关问题导致的,因此从头开始按相关参考文章编译一遍gflags源码,测试结果表明Qt5.14.2中使用MSVC2017X64编译器运行的QTgflags项目是正常。 详细编译步骤如下: 1、…...
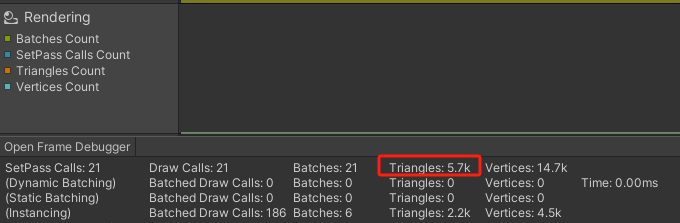
项目中Warmup耗时高该如何操作处理
1)项目中Warmup耗时高该如何操作处理 2)如何在卸载资源后Untracked和Other的内存都回收 3)总Triangles的值是否包含了通过GPU Instancing画的三角形 4)有没有用Lua来修复虚幻引擎中对C代码进行插桩Hook的方案 这是第432篇UWA技术知…...
制作一款打飞机游戏53:子弹样式
现在,我们有一个小程序可以发射子弹,但这些子弹并不完美,我们稍后会修复它们。 子弹模式与目标 在开始之前,我想修正一下,因为我观察到在其他射击游戏中有一个我想复制的简单行为。我们有静态射击、瞄准射击和快速射击…...