深度学习:损失函数与激活函数全解析
目录
- 深度学习中常见的损失函数和激活函数详解
- 引言
- 一、损失函数详解
- 1.1 损失函数的作用与分类
- 1.2 回归任务损失函数
- 1.2.1 均方误差(MSE)
- 1.2.2 平均绝对误差(MAE)
- 1.3 分类任务损失函数
- 1.3.1 交叉熵损失(Cross-Entropy)
- 1.3.2 合页损失(Hinge Loss)
- 1.4 损失函数对比实验
- 二、激活函数详解
- 2.1 激活函数的作用与特性
- 2.2 常见激活函数分析
- 2.2.1 Sigmoid函数
- 2.2.2 Tanh函数
- 2.2.3 ReLU函数
- 2.2.4 LeakyReLU函数
- 2.3 激活函数对比实验
- 三、损失函数与激活函数的组合策略
- 3.1 常见组合方式
- 3.2 组合实验分析
- 四、高级主题与最新进展
- 4.1 自定义损失函数实现
- 4.2 激活函数的最新发展
- 4.2.1 Swish函数
- 4.2.2 GELU函数
- 五、完整代码实现
- 六、总结与最佳实践
- 6.1 损失函数选择指南
- 6.2 激活函数选择指南
- 6.3 组合策略建议
深度学习中常见的损失函数和激活函数详解
引言
在深度学习中,损失函数和激活函数是模型训练过程中两个最核心的组件。损失函数衡量模型预测与真实值之间的差异,为优化算法提供方向;而激活函数为神经网络引入非线性能力,使网络能够学习复杂模式。本文将全面解析深度学习中常见的损失函数和激活函数,包括数学原理、特性分析、适用场景以及Python实现,并通过实验对比不同组合的效果。
一、损失函数详解
1.1 损失函数的作用与分类
损失函数(Loss Function)是用于衡量模型预测输出与真实值之间差异的函数,其数学表示为:
L ( θ ) = 1 N ∑ i = 1 N ℓ ( y i , f ( x i ; θ ) ) \mathcal{L}(\theta) = \frac{1}{N}\sum_{i=1}^N \ell(y_i, f(x_i; \theta)) L(θ)=N1i=1∑Nℓ(yi,f(xi;θ))
根据任务类型,损失函数主要分为三类:
1.2 回归任务损失函数
1.2.1 均方误差(MSE)
数学表达式:
MSE = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{N}\sum_{i=1}^N (y_i - \hat{y}_i)^2 MSE=N1i=1∑N(yi−y^i)2
特性分析:
- 对异常值敏感
- 可导且处处平滑
- 输出值域:[0, +∞)
Python实现:
def mean_squared_error(y_true, y_pred):"""计算均方误差(MSE)参数:y_true: 真实值数组,形状(n_samples,)y_pred: 预测值数组,形状(n_samples,)返回:mse值"""return np.mean(np.square(y_true - y_pred))
1.2.2 平均绝对误差(MAE)
数学表达式:
MAE = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{N}\sum_{i=1}^N |y_i - \hat{y}_i| MAE=N1i=1∑N∣yi−y^i∣
特性分析:
- 对异常值鲁棒
- 在0点不可导
- 输出值域:[0, +∞)
Python实现:
def mean_absolute_error(y_true, y_pred):"""计算平均绝对误差(MAE)参数:y_true: 真实值数组,形状(n_samples,)y_pred: 预测值数组,形状(n_samples,)返回:mae值"""return np.mean(np.abs(y_true - y_pred))
1.3 分类任务损失函数
1.3.1 交叉熵损失(Cross-Entropy)
二分类表达式:
L = − 1 N ∑ i = 1 N [ y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ] \mathcal{L} = -\frac{1}{N}\sum_{i=1}^N [y_i \log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)] L=−N1i=1∑N[yilog(y^i)+(1−yi)log(1−y^i)]
多分类表达式:
L = − 1 N ∑ i = 1 N ∑ c = 1 C y i , c log ( y ^ i , c ) \mathcal{L} = -\frac{1}{N}\sum_{i=1}^N \sum_{c=1}^C y_{i,c} \log(\hat{y}_{i,c}) L=−N1i=1∑Nc=1∑Cyi,clog(y^i,c)
Python实现:
def cross_entropy_loss(y_true, y_pred, epsilon=1e-12):"""计算交叉熵损失参数:y_true: 真实标签,形状(n_samples, n_classes)或(n_samples,)y_pred: 预测概率,形状(n_samples, n_classes)epsilon: 小常数防止log(0)返回:交叉熵损失值"""# 确保预测值在(0,1)区间y_pred = np.clip(y_pred, epsilon, 1. - epsilon)# 如果是二分类且y_true为一维if len(y_true.shape) == 1 or y_true.shape[1] == 1:loss = -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))else: # 多分类loss = -np.mean(np.sum(y_true * np.log(y_pred), axis=1))return loss
1.3.2 合页损失(Hinge Loss)
数学表达式:
L = 1 N ∑ i = 1 N max ( 0 , 1 − y i ⋅ y ^ i ) \mathcal{L} = \frac{1}{N}\sum_{i=1}^N \max(0, 1 - y_i \cdot \hat{y}_i) L=N1i=1∑Nmax(0,1−yi⋅y^i)
Python实现:
def hinge_loss(y_true, y_pred):"""计算合页损失(Hinge Loss)参数:y_true: 真实标签(±1),形状(n_samples,)y_pred: 预测值,形状(n_samples,)返回:hinge loss值"""return np.mean(np.maximum(0, 1 - y_true * y_pred))
1.4 损失函数对比实验
import matplotlib.pyplot as plt# 生成模拟数据
y_true = np.linspace(-3, 3, 100)
y_pred = np.zeros_like(y_true)# 计算不同损失
mse = [mean_squared_error(np.array([t]), np.array([p])) for t, p in zip(y_true, y_pred)]
mae = [mean_absolute_error(np.array([t]), np.array([p])) for t, p in zip(y_true, y_pred)]
hinge = [hinge_loss(np.array([1]), np.array([t])) for t in y_true] # 假设真实标签为1# 绘制曲线
plt.figure(figsize=(10, 6))
plt.plot(y_true, mse, label='MSE')
plt.plot(y_true, mae, label='MAE')
plt.plot(y_true, hinge, label='Hinge (y_true=1)')
plt.xlabel('Prediction - True Value')
plt.ylabel('Loss')
plt.title('Comparison of Loss Functions')
plt.legend()
plt.grid(True)
plt.show()
二、激活函数详解
2.1 激活函数的作用与特性
激活函数的主要作用:
- 引入非线性变换
- 决定神经元是否被激活
- 影响梯度传播过程
理想激活函数应具备的特性:
- 非线性
- 可微性(至少几乎处处可微)
- 单调性
- 输出范围适当
2.2 常见激活函数分析
2.2.1 Sigmoid函数
数学表达式:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
特性分析:
- 输出范围:(0,1)
- 容易导致梯度消失
- 输出不以0为中心
Python实现:
def sigmoid(x):"""Sigmoid激活函数参数:x: 输入数组返回:sigmoid激活后的输出"""return 1 / (1 + np.exp(-x))def sigmoid_derivative(x):"""Sigmoid函数的导数"""s = sigmoid(x)return s * (1 - s)
2.2.2 Tanh函数
数学表达式:
tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
特性分析:
- 输出范围:(-1,1)
- 以0为中心
- 比sigmoid梯度更强
Python实现:
def tanh(x):"""Tanh激活函数"""return np.tanh(x)def tanh_derivative(x):"""Tanh函数的导数"""return 1 - np.tanh(x)**2
2.2.3 ReLU函数
数学表达式:
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
特性分析:
- 计算简单
- 缓解梯度消失
- 存在"死亡ReLU"问题
Python实现:
def relu(x):"""ReLU激活函数"""return np.maximum(0, x)def relu_derivative(x):"""ReLU函数的导数"""return (x > 0).astype(float)
2.2.4 LeakyReLU函数
数学表达式:
LeakyReLU ( x ) = { x if x > 0 α x otherwise \text{LeakyReLU}(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha x & \text{otherwise} \end{cases} LeakyReLU(x)={xαxif x>0otherwise
Python实现:
def leaky_relu(x, alpha=0.01):"""LeakyReLU激活函数参数:x: 输入数组alpha: 负半轴的斜率"""return np.where(x > 0, x, alpha * x)def leaky_relu_derivative(x, alpha=0.01):"""LeakyReLU函数的导数"""dx = np.ones_like(x)dx[x < 0] = alphareturn dx
2.3 激活函数对比实验
# 生成输入数据
x = np.linspace(-5, 5, 100)# 计算各激活函数输出
y_sigmoid = sigmoid(x)
y_tanh = tanh(x)
y_relu = relu(x)
y_leaky = leaky_relu(x)# 绘制曲线
plt.figure(figsize=(12, 6))
plt.plot(x, y_sigmoid, label='Sigmoid')
plt.plot(x, y_tanh, label='Tanh')
plt.plot(x, y_relu, label='ReLU')
plt.plot(x, y_leaky, label='LeakyReLU (α=0.01)')
plt.xlabel('Input')
plt.ylabel('Output')
plt.title('Comparison of Activation Functions')
plt.legend()
plt.grid(True)
plt.show()
三、损失函数与激活函数的组合策略
3.1 常见组合方式
| 任务类型 | 推荐损失函数 | 推荐激活函数 | 说明 |
|---|---|---|---|
| 二分类 | 二元交叉熵 | Sigmoid | 输出层使用Sigmoid |
| 多分类 | 分类交叉熵 | Softmax | 输出层使用Softmax |
| 回归 | MSE/MAE | 无/线性 | 输出层通常不使用激活 |
| 多标签分类 | 二元交叉熵 | Sigmoid | 每个输出节点独立 |
3.2 组合实验分析
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd# 创建分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 测试不同组合
combinations = [{'loss': 'binary_crossentropy', 'output_activation': 'sigmoid'},{'loss': 'hinge', 'output_activation': 'tanh'},{'loss': 'mse', 'output_activation': 'sigmoid'}
]results = []for combo in combinations:model = Sequential([Dense(64, activation='relu', input_shape=(20,)),Dense(32, activation='relu'),Dense(1, activation=combo['output_activation'])])model.compile(optimizer='adam',loss=combo['loss'],metrics=['accuracy'])history = model.fit(X_train, y_train,epochs=50,batch_size=32,validation_split=0.2,verbose=0)test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)results.append({'Loss Function': combo['loss'],'Activation': combo['output_activation'],'Test Accuracy': test_acc,'Test Loss': test_loss})# 显示结果
df_results = pd.DataFrame(results)
print(df_results[['Loss Function', 'Activation', 'Test Accuracy', 'Test Loss']])
四、高级主题与最新进展
4.1 自定义损失函数实现
import tensorflow as tfdef focal_loss(y_true, y_pred, alpha=0.25, gamma=2.0):"""Focal Loss实现参数:y_true: 真实标签y_pred: 预测概率alpha: 类别平衡参数gamma: 难易样本调节参数返回:focal loss值"""# 防止数值溢出y_pred = tf.clip_by_value(y_pred, 1e-7, 1 - 1e-7)# 计算交叉熵部分cross_entropy = -y_true * tf.math.log(y_pred)# 计算focal weightfocal_weight = alpha * tf.pow(1 - y_pred, gamma)# 计算focal lossloss = focal_weight * cross_entropy# 按样本求和return tf.reduce_sum(loss, axis=-1)# 在Keras模型中使用
model.compile(optimizer='adam',loss=focal_loss,metrics=['accuracy'])
4.2 激活函数的最新发展
4.2.1 Swish函数
数学表达式:
Swish ( x ) = x ⋅ σ ( β x ) \text{Swish}(x) = x \cdot \sigma(\beta x) Swish(x)=x⋅σ(βx)
Python实现:
def swish(x, beta=1.0):"""Swish激活函数参数:x: 输入beta: 可学习参数"""return x * sigmoid(beta * x)def swish_derivative(x, beta=1.0):"""Swish函数的导数"""sig = sigmoid(beta * x)return sig + beta * x * sig * (1 - sig)
4.2.2 GELU函数
数学表达式:
GELU ( x ) = x Φ ( x ) \text{GELU}(x) = x \Phi(x) GELU(x)=xΦ(x)
其中 Φ ( x ) \Phi(x) Φ(x)是标准正态分布的累积分布函数
Python实现:
def gelu(x):"""GELU激活函数"""return 0.5 * x * (1 + tf.math.erf(x / tf.sqrt(2.0)))
五、完整代码实现
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.layers import Layerclass ActivationFunctions:"""常见激活函数实现集合"""@staticmethoddef sigmoid(x):return 1 / (1 + np.exp(-x))@staticmethoddef tanh(x):return np.tanh(x)@staticmethoddef relu(x):return np.maximum(0, x)@staticmethoddef leaky_relu(x, alpha=0.01):return np.where(x > 0, x, alpha * x)@staticmethoddef swish(x, beta=1.0):return x * ActivationFunctions.sigmoid(beta * x)@staticmethoddef plot_activations(x_range=(-5, 5), n_points=100):"""绘制各激活函数曲线"""x = np.linspace(x_range[0], x_range[1], n_points)plt.figure(figsize=(12, 6))plt.plot(x, ActivationFunctions.sigmoid(x), label='Sigmoid')plt.plot(x, ActivationFunctions.tanh(x), label='Tanh')plt.plot(x, ActivationFunctions.relu(x), label='ReLU')plt.plot(x, ActivationFunctions.leaky_relu(x), label='LeakyReLU (α=0.01)')plt.plot(x, ActivationFunctions.swish(x), label='Swish (β=1.0)')plt.title('Activation Functions Comparison')plt.xlabel('Input')plt.ylabel('Output')plt.legend()plt.grid(True)plt.show()class CustomLossFunctions:"""自定义损失函数集合"""@staticmethoddef focal_loss(y_true, y_pred, alpha=0.25, gamma=2.0):"""Focal Loss实现"""y_pred = tf.clip_by_value(y_pred, 1e-7, 1 - 1e-7)cross_entropy = -y_true * tf.math.log(y_pred)focal_weight = alpha * tf.pow(1 - y_pred, gamma)return tf.reduce_sum(focal_weight * cross_entropy, axis=-1)@staticmethoddef contrastive_loss(y_true, y_pred, margin=1.0):"""对比损失实现"""square_pred = tf.square(y_pred)margin_square = tf.square(tf.maximum(margin - y_pred, 0))return tf.reduce_mean(y_true * square_pred + (1 - y_true) * margin_square)@staticmethoddef plot_losses(y_true=1, pred_range=(-1, 2), n_points=100):"""绘制不同损失函数曲线"""pred = np.linspace(pred_range[0], pred_range[1], n_points)# 计算各损失mse = (pred - y_true)**2mae = np.abs(pred - y_true)hinge = np.maximum(0, 1 - y_true * pred)plt.figure(figsize=(10, 6))plt.plot(pred, mse, label='MSE')plt.plot(pred, mae, label='MAE')plt.plot(pred, hinge, label='Hinge (y_true=1)')plt.title('Loss Functions Comparison (y_true=1)')plt.xlabel('Prediction')plt.ylabel('Loss')plt.legend()plt.grid(True)plt.show()class Swish(Layer):"""可学习的Swish激活层"""def __init__(self, trainable_beta=True, **kwargs):super(Swish, self).__init__(**kwargs)self.trainable_beta = trainable_betaif self.trainable_beta:self.beta = self.add_weight(name='beta',shape=(1,),initializer='ones',trainable=True)else:self.beta = 1.0def call(self, inputs):if self.trainable_beta:return inputs * tf.sigmoid(self.beta * inputs)else:return inputs * tf.sigmoid(inputs)def get_config(self):config = super(Swish, self).get_config()config.update({'trainable_beta': self.trainable_beta})return config# 使用示例
if __name__ == "__main__":# 绘制激活函数ActivationFunctions.plot_activations()# 绘制损失函数CustomLossFunctions.plot_losses()# 构建包含Swish的模型model = tf.keras.Sequential([tf.keras.layers.Dense(64, input_shape=(20,)),Swish(trainable_beta=True),tf.keras.layers.Dense(1, activation='sigmoid')])model.compile(optimizer='adam',loss=CustomLossFunctions.focal_loss,metrics=['accuracy'])print("Model with Swish activation and Focal Loss compiled successfully.")
六、总结与最佳实践
6.1 损失函数选择指南
-
分类任务:
- 二分类:二元交叉熵 + Sigmoid
- 多分类:分类交叉熵 + Softmax
- 类别不平衡:Focal Loss
-
回归任务:
- 一般情况:MSE
- 存在异常值:MAE或Huber Loss
-
特殊任务:
- 度量学习:对比损失
- 生成对抗网络:Wasserstein Loss
6.2 激活函数选择指南
-
隐藏层:
- 首选:ReLU及其变种(LeakyReLU, PReLU)
- 深层网络:Swish或GELU
- 需要负值输出:Tanh
-
输出层:
- 二分类:Sigmoid
- 多分类:Softmax
- 回归:线性(无激活)
6.3 组合策略建议
通过本文的系统分析,读者应该能够根据具体任务选择合适的损失函数和激活函数组合,并理解其背后的数学原理和实现细节。在实际应用中,建议通过实验验证不同组合在特定数据集上的表现,以获得最佳性能。
相关文章:

深度学习:损失函数与激活函数全解析
目录 深度学习中常见的损失函数和激活函数详解引言一、损失函数详解1.1 损失函数的作用与分类1.2 回归任务损失函数1.2.1 均方误差(MSE)1.2.2 平均绝对误差(MAE) 1.3 分类任务损失函数1.3.1 交叉熵损失(Cross-Entropy&…...

【大前端】Node Js下载文件
NodeJs 获取远程文件有很多方式,常见的方式有以下两种: - fetch(原生) - axios(插件) 通过 Fetch 下载文件,代码如下: import fs from node:fsfunction main(){fetch(http://xxx.x…...

自训练NL-SQL模型
使用T5小模型在笔记本上训练 nature language to SQL/自然语言 转SQL 实测通过。 本文介绍了如何在笔记本上使用T5小模型训练自然语言转SQL的任务。主要内容包括:1) 创建Python 3.9环境并安装必要的依赖包;2) 通过Hugging Face镜像下载wikisql数据集和T5-small模型;3) 实现…...
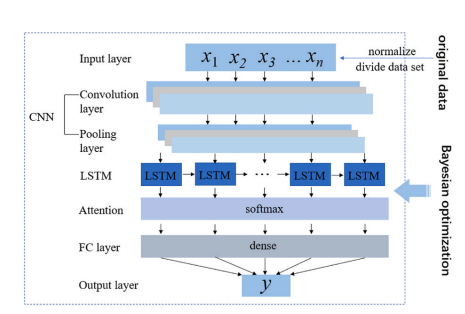
创新点!贝叶斯优化、CNN与LSTM结合,实现更准预测、更快效率、更高性能!
能源与环境领域的时空数据预测面临特征解析与参数调优双重挑战。CNN-LSTM成为突破口:CNN提取空间特征,LSTM捕捉时序依赖,实现时空数据的深度建模。但混合模型超参数(如卷积核数、LSTM层数)调优复杂,传统方法…...

【Flutter】创建BMI计算器应用并添加依赖和打包
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍创建BMI计算器应用并添加依赖和打包。 学其所用,用其所学。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...

【Linux 学习计划】-- 倒计时、进度条小程序
目录 \r 、\n、fflush 倒计时 进度条 进度条进阶版 结语 \r 、\n、fflush 首先我们先来认识这三个东西,这将会是我们接下来两个小程序的重点之一 首先是我们的老演员\n,也就是回车加换行 这里面其实包含了两个操作,一个叫做回车&…...
微服务的应用案例
从“菜市场”到“智慧超市”:一场微服务的变革之旅 曾经,我们的系统像一个熙熙攘攘的传统菜市场。所有功能模块(摊贩)都挤在一个巨大的单体应用中。用户请求(买菜的顾客)一多,整个市场就拥堵不堪…...

后端开发概念
1. 后端开发概念解析 1.1. 什么是服务器,后端服务 1.1.1. 服务器 服务器是一种提供服务的计算机系统,它可以接收、处理和响应来自其他计算机系统(客户端)的请求。服务器主要用于存储、处理和传输数据,以便客户端可以…...

2025网络安全趋势报告 内容摘要
2025 年网络安全在技术、法规、行业等多个维度呈现新趋势。技术上,人工智能、隐私保护技术、区块链、量子安全技术等取得进展;法规方面,数据安全法规进一步细化;行业应用中,物联网、工业控制系统安全升级,供…...
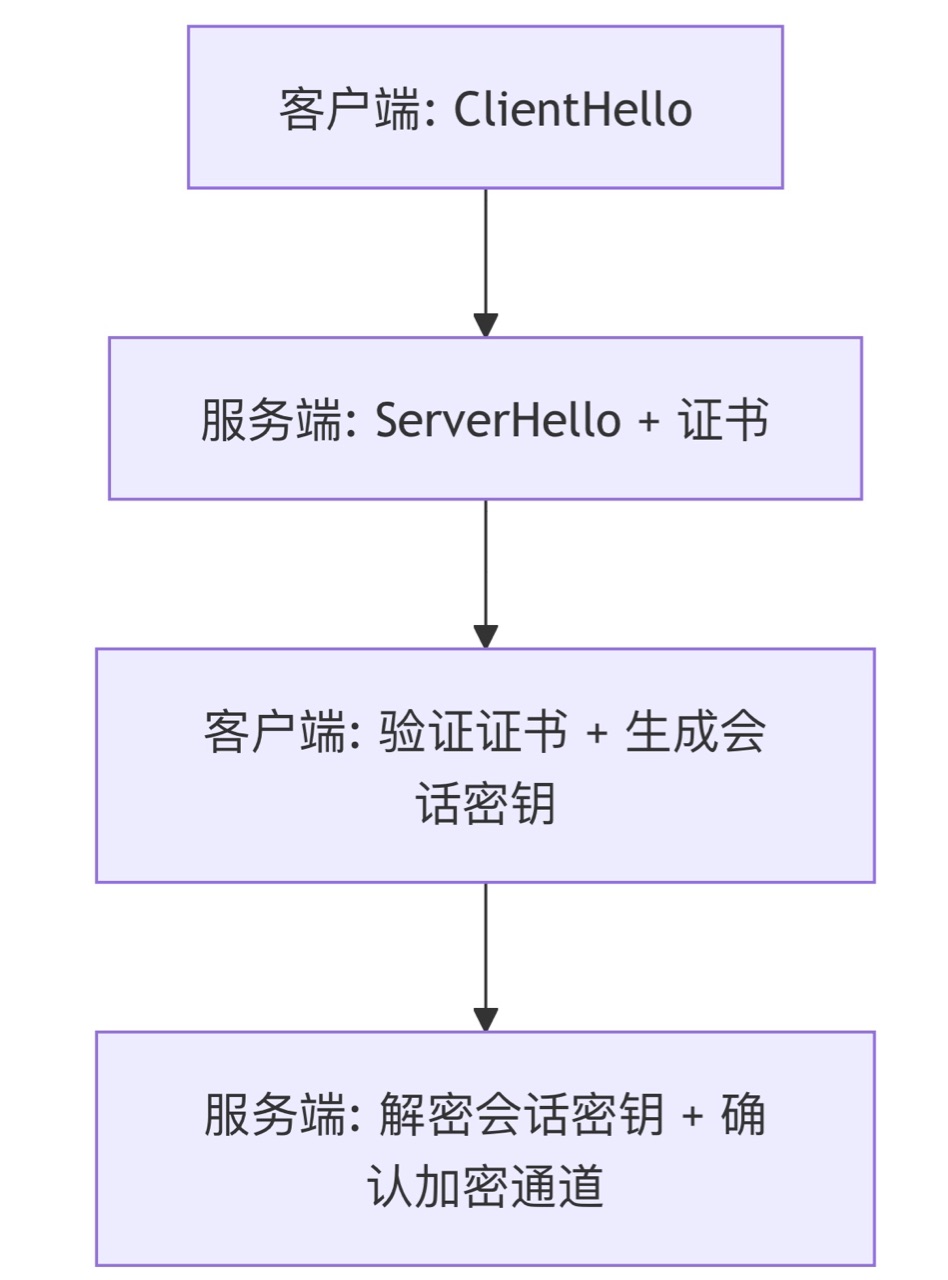
云原生安全基石:深度解析HTTPS协议(从原理到实战)
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念:HTTPS是什么? HTTPS(HyperText Transfer Protocol Secure)是HTTP协议的安全版本,…...

Autodl训练Faster-RCNN网络--自己的数据集(一)
参考文章: Autodl服务器中Faster-rcnn(jwyang)复现(一)_autodl faster rcnn-CSDN博客 Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)_faster rcnn autodl-CSDN博客 食用指南:先跟着参考文章一进行操作,遇到问题再来看我这里有没有解…...
python打卡day36
复习日 仔细回顾一下神经网络到目前的内容,没跟上进度的补一下进度 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。探索性作业(随意完成):尝试进入nn.M…...

8.Java 8 日期时间处理:从 Date 的崩溃到 LocalDate 的优雅自救
一、被 Date 逼疯的程序员:那些年踩过的坑 还记得刚学 Java 时被Date支配的恐惧吗? 想获取 "2023 年 10 月 1 日"?new Date(2023, 9, 1)—— 等等,为什么月份是 9?哦对,Java 的月份从 0 开…...
实现路径损耗预测)
基于Python的全卷积网络(FCN)实现路径损耗预测
以下是一份详细的基于Python的全卷积网络(FCN)实现路径损耗预测的技术文档。本方案包含理论基础、数据生成、模型构建、训练优化及可视化分析,代码实现约6000字。 基于全卷积网络的无线信道路径损耗预测系统 目录 问题背景与需求分析系统架构设计合成数据生成方法全卷积网络…...

【ubuntu】安装NVIDIA Container Toolkit
目录 安装NVIDIA Container Toolkit 安装依赖 添加密钥和仓库 配置中国科技大学(USTC) 镜像 APT 源 更新 APT 包列表 安装 NVIDIA Container Toolkit 验证安装 重启docker 起容器示例命令 【问题】如何在docker中正确使用GPU? 安装…...
Paimon和Hive相集成
Flink版本1.17 Hive版本3.1.3 1、Paimon集成Hive 将paimon-hive-connector.jar复制到auxlib中,下载链接Index of /groups/snapshots/org/apache/https://repository.apache.org/snapshots/org/apache/paimon/ 通过flink进入查看paimon /opt/softwares/flink-1.…...
:从愿景到落地的精益开发路径——Rally的全流程管理实践)
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践 在创业的黏性阶段,如何将抽象的愿景转化为可落地的产品功能?如何在快速迭代中保持战略聚焦?今天,我们通过Rally软…...
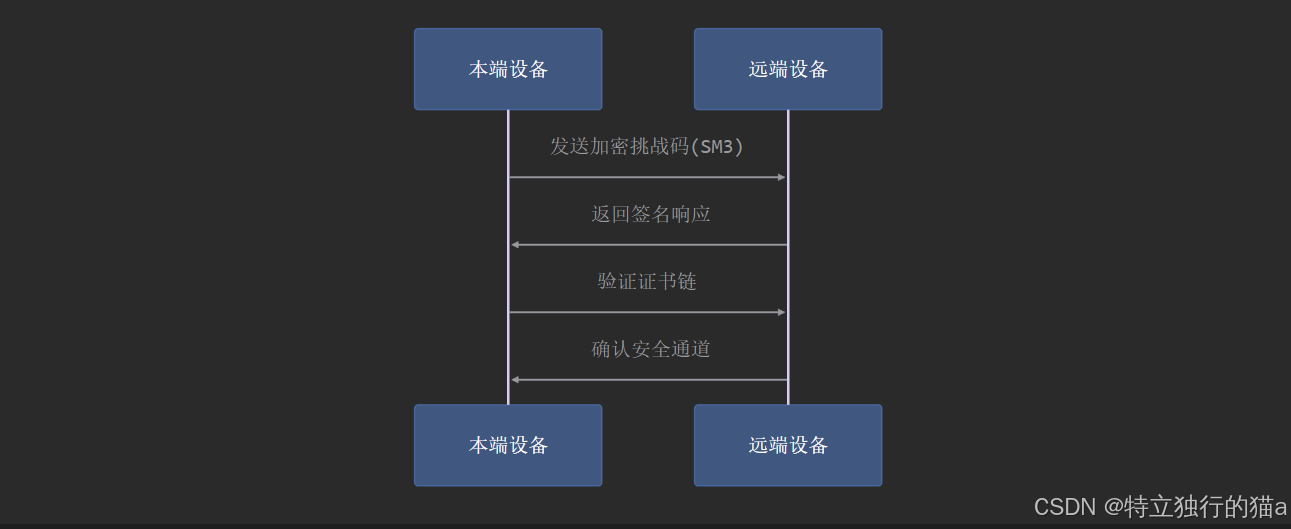
HarmonyOS 鸿蒙应用开发进阶:深入理解鸿蒙跨设备互通机制
鸿蒙跨设备互通(HarmonyOS Cross-Device Collaboration)是鸿蒙系统分布式能力的重要体现,通过创新的分布式软总线技术,实现了设备间的高效互联与能力共享。本文将系统性地解析鸿蒙跨设备互通的技术架构、实现原理及开发实践。 跨设…...

Vue.js教学第十五章:深入解析Webpack与Vue项目实战
Webpack 与 Vue 项目详解 在现代前端开发中,Webpack 作为最流行的模块打包工具之一,对于 Vue 项目的构建和优化起着至关重要的作用。本文将深入剖析 Webpack 的基本概念、在 Vue 项目中的应用场景,并详细讲解常用的 Webpack loaders 和 plugins 的配置与作用,同时通过实例…...

深入浅出 Python Testcontainers:用容器优雅地编写集成测试
在现代软件开发中,自动化测试已成为敏捷开发与持续集成中的关键环节。单元测试可以快速验证函数或类的行为是否符合预期,而集成测试则确保多个模块协同工作时依然正确。问题是:如何让集成测试可靠、可重复且易于维护? 这时&#…...
Cmake编译gflags过程记录和在QT中测试
由于在QT中使用PaddleOCR2.8存在这样那样的问题,查找貌似是gflags相关问题导致的,因此从头开始按相关参考文章编译一遍gflags源码,测试结果表明Qt5.14.2中使用MSVC2017X64编译器运行的QTgflags项目是正常。 详细编译步骤如下: 1、…...
项目中Warmup耗时高该如何操作处理
1)项目中Warmup耗时高该如何操作处理 2)如何在卸载资源后Untracked和Other的内存都回收 3)总Triangles的值是否包含了通过GPU Instancing画的三角形 4)有没有用Lua来修复虚幻引擎中对C代码进行插桩Hook的方案 这是第432篇UWA技术知…...
制作一款打飞机游戏53:子弹样式
现在,我们有一个小程序可以发射子弹,但这些子弹并不完美,我们稍后会修复它们。 子弹模式与目标 在开始之前,我想修正一下,因为我观察到在其他射击游戏中有一个我想复制的简单行为。我们有静态射击、瞄准射击和快速射击…...

Windows磁盘无法格式化及磁盘管理
简述:D盘使用了虚拟分区,结果导致无法格式化。 一、无法格式化磁盘 因为以前划分C盘的时候,空间划小了,所以在下载一些程序的依赖包之后爆红。当我想要把D盘的空间分给C盘时,发现D盘无法格式化。在网上没有找到合适的…...
详解与实现)
每日算法 -【Swift 算法】Z 字形变换(Zigzag Conversion)详解与实现
Swift | Z 字形变换(Zigzag Conversion)详解与实现 🧩 题目描述 给定一个字符串 s 和一个行数 numRows,请按照从上往下、再从下往上的“Z”字形排列这个字符串,并按行输出最终结果。例如: 输入ÿ…...

Docker运维-5.3 配置私有仓库(Harbor)
1. harbor的介绍 Harbor(港湾),是一个用于存储和分发 Docker 镜像的企业级 Registry 服务器。以前的镜像私有仓库采用官方的 Docker Registry,不便于管理镜像。 Harbor 是由 VMWare 在 Docker Registry 的基础之上进行了二次封装,加进去了很…...
day 36
利用前面所学知识,对之前的信贷项目,利用神经网络训练 # 先运行之前预处理好的代码 import pandas as pd import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组…...
mybatis-plus使用记录
MyBatis-Plus 学习笔记 一、 快速入门 MyBatis-Plus (MP) 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 1. 引入 Maven 依赖 要使用 MyBatis-Plus,首先需要在项目的 pom.xml 文件中引入相…...
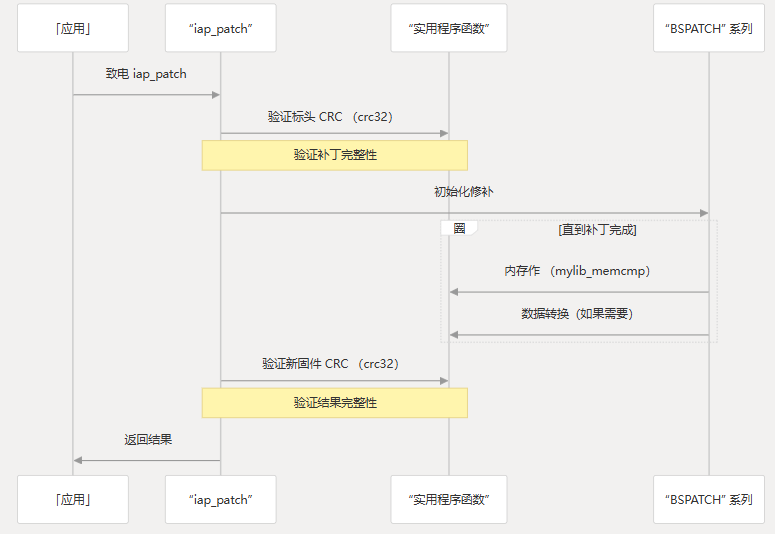
Mcu_Bsdiff_Upgrade
系统架构 概述 MCU BSDiff 升级系统通过使用二进制差分技术,提供了一种在资源受限的微控制器上进行高效固件更新的机制。系统不传输和存储完整的固件映像,而是只处理固件版本之间的差异,从而显著缩小更新包并降低带宽要求。 该架构遵循一个…...
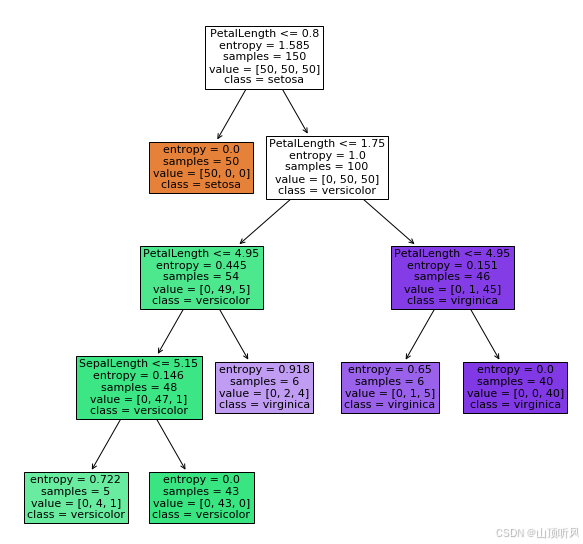
有监督学习——决策树
任务 1、基于iris_data.csv数据,建立决策树模型,评估模型表现; 2、可视化决策树结构; 3、修改min_samples_leaf参数,对比模型结果 代码工具:jupyter notebook 参考资料 20.23 决策树(1)_哔哩哔哩_bil…...