day 36
利用前面所学知识,对之前的信贷项目,利用神经网络训练
# 先运行之前预处理好的代码
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('data.csv') #读取数据# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表# 连续特征用中位数补全
for feature in continuous_features: mode_value = data[feature].mode()[0] #获取该列的众数。data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集# 打印下尺寸
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)将数据转换成合适类型
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train.values).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test.values).to(device)模型训练
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(31, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 2) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每100个epoch的损失值和对应的epoch数
losses = []start_time = time.time() # 记录开始时间for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值if (epoch + 1) % 200 == 0:losses.append(loss.item()) # item()方法返回一个Python数值,loss是一个标量张量print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.plot(range(len(losses)), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()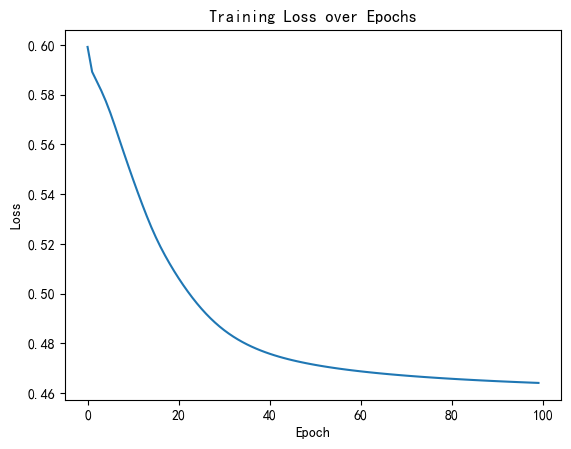
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度计算,可以提高模型推理速度outputs = model(X_test) # 对测试数据进行前向传播,获得预测结果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引correct = (predicted == y_test).sum().item() # 计算预测正确的样本数accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%')测试集准确率: 77.07%
@浙大疏锦行
相关文章:
day 36
利用前面所学知识,对之前的信贷项目,利用神经网络训练 # 先运行之前预处理好的代码 import pandas as pd import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组…...
mybatis-plus使用记录
MyBatis-Plus 学习笔记 一、 快速入门 MyBatis-Plus (MP) 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 1. 引入 Maven 依赖 要使用 MyBatis-Plus,首先需要在项目的 pom.xml 文件中引入相…...
Mcu_Bsdiff_Upgrade
系统架构 概述 MCU BSDiff 升级系统通过使用二进制差分技术,提供了一种在资源受限的微控制器上进行高效固件更新的机制。系统不传输和存储完整的固件映像,而是只处理固件版本之间的差异,从而显著缩小更新包并降低带宽要求。 该架构遵循一个…...
有监督学习——决策树
任务 1、基于iris_data.csv数据,建立决策树模型,评估模型表现; 2、可视化决策树结构; 3、修改min_samples_leaf参数,对比模型结果 代码工具:jupyter notebook 参考资料 20.23 决策树(1)_哔哩哔哩_bil…...

华为OD机试真题——启动多任务排序(2025B卷:200分)Java/python/JavaScript/C/C++/GO最佳实现
2025 B卷 200分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...

AWS云与第三方通信最佳实践:安全、高效的数据交互方案
引言 在当今的云计算时代,企业经常需要在AWS云环境中存储和处理数据,同时还需要与第三方应用或服务进行数据交互。如何安全、高效地实现这种通信是许多企业面临的挑战。本文将详细探讨几种AWS云与第三方通信的方案,并分析它们的优缺点,帮助您为自己的业务场景选择最佳解决…...

Ubuntu Server 24 设置 WiFi 网络的方案
一、配置流程 1. 确认无线网卡信息 首先需明确无线网卡接口名称及当前连接状态: ip link show # 查看网络接口(寻找状态为 "UP" 的无线接口,如 wlan0、wlx* 或 wlp1s0) iwconfig # 确认无线网…...

【redis】redis和hiredis的基本使用
总结: 介绍了一下redis和hiredis的安装步骤,用一个简单的demo演示了使用redis的基本过程。 启动redis步骤 1、下载redis:https://github.com/redis/redis 2、编译命令:make 3、编译产物:libredis.a(静…...

大模型时代,Python 近红外光谱与 Transformer 模型:学习的必要性探究
在当下大语言模型盛行的时代,各类新技术如潮水般不断涌现,让人应接不暇。身处这样的浪潮之中,不少人心中都会泛起疑问:Python 近红外光谱和 Transformer 模型还有学习的必要性吗?今天,就让我们深入探讨一番…...

产品经理常用术语大全
作为一名产品经理,不仅需要具备跨领域的知识和技能,还需要熟练掌握一系列专业术语,以便更有效地沟通、规划和执行产品开发过程中的各项任务。以下是一篇详细介绍产品经理日常工作中常见术语的文章,旨在帮助新手快速入门࿰…...
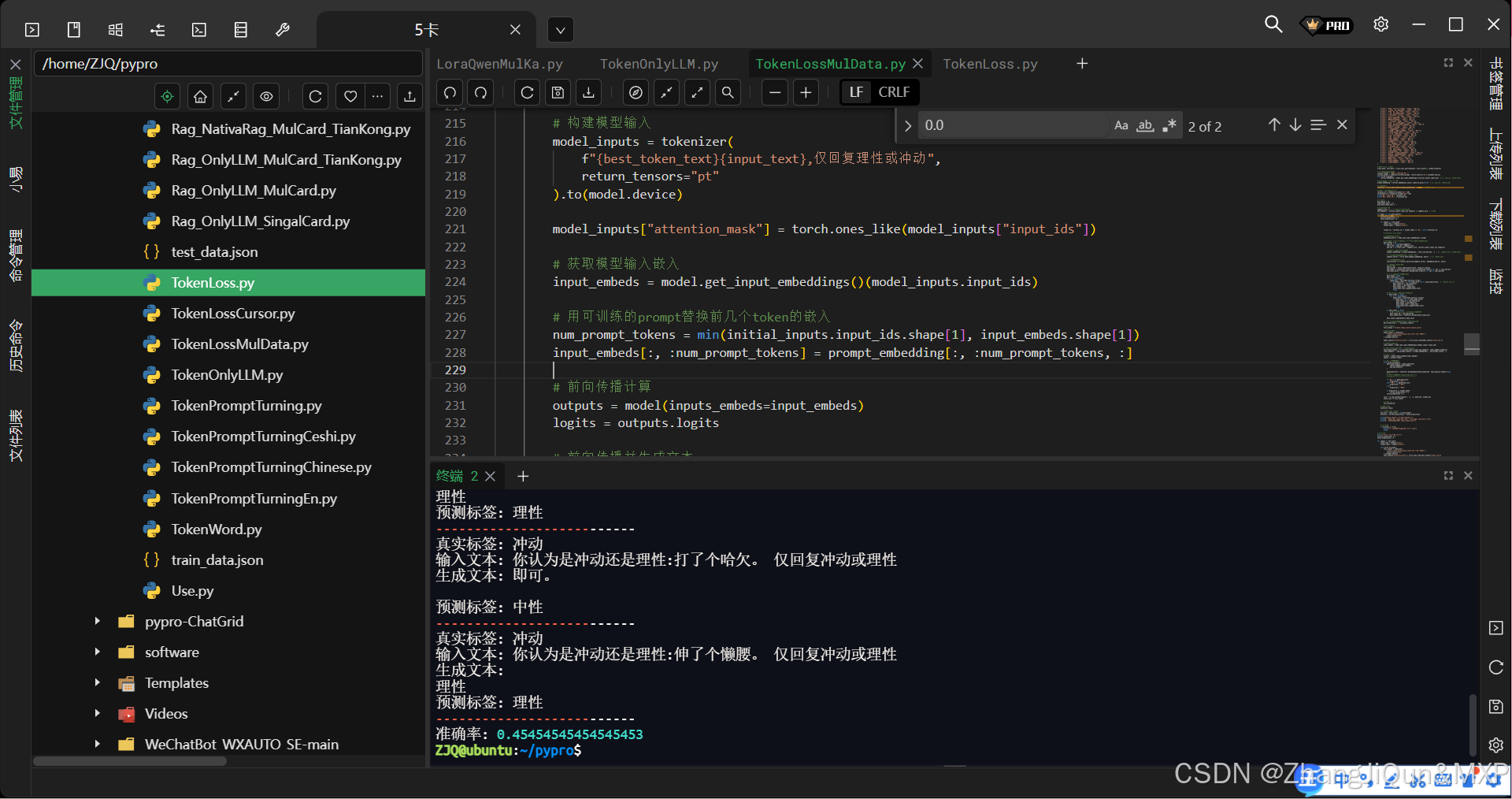
梯度优化提示词:精准引导AI分类
基于梯度优化的提示词工程方法,通过迭代调整提示词的嵌入向量,使其能够更有效地引导模型做出正确分类。 数据形式 训练数据 train_data 是一个列表,每个元素是一个字典,包含两个键: text: 需要分类的文本描述label: 对应的标签(“冲动"或"理性”)示例数据: …...
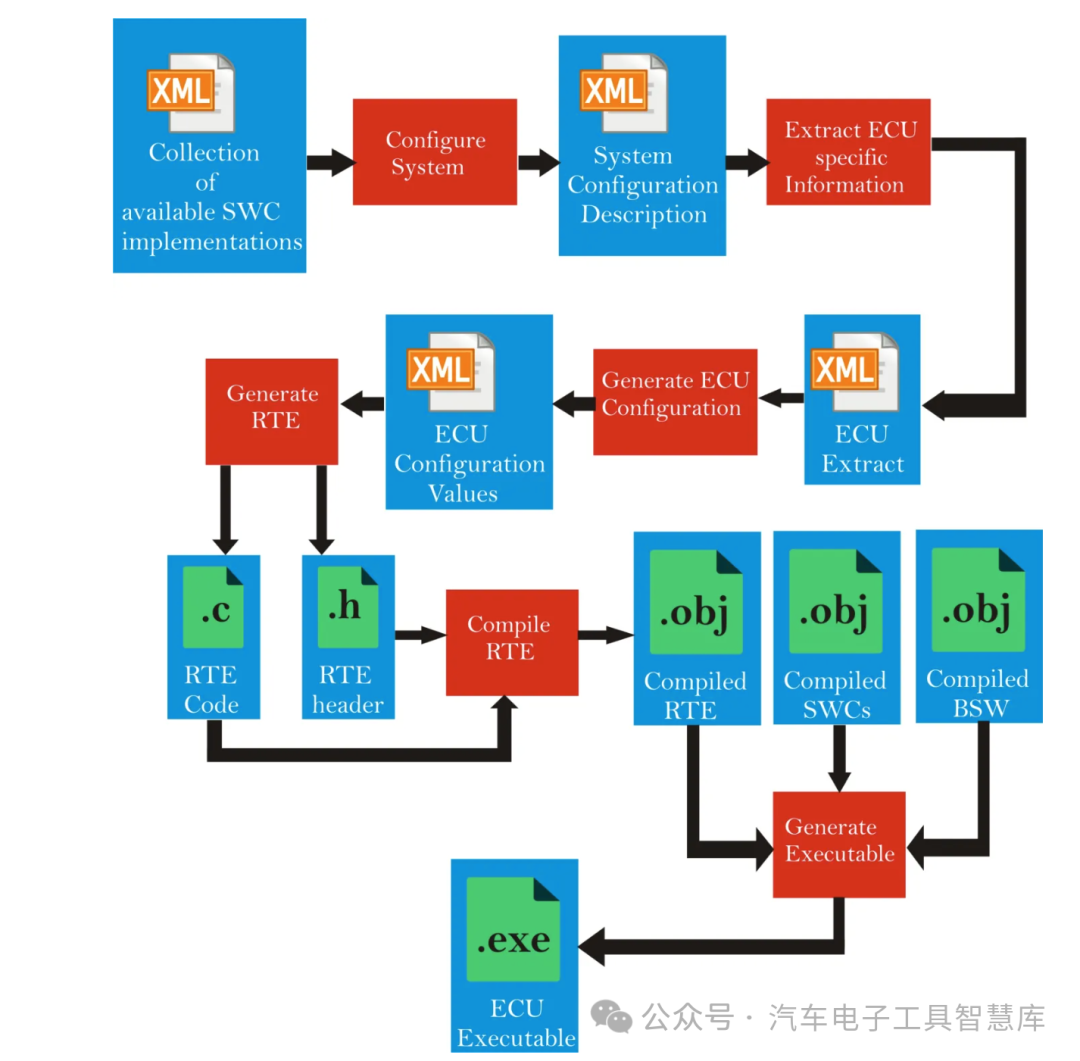
AUTOSAR 运行时环境 (RTE)
目录 往期推荐 什么是运行时环境? AUTOSAR 中的运行时环境 (RTE) RTE 的应用 RTE 的生成 关于RTE API的一些信息 RTE生成后文件之间的关系 往期推荐 2025汽车行业新宠:欧企都在用的工具软件ETAS工具链自动化实战指南<一>ET…...

Bolt.new:重塑 Web 开发格局的 AI 利器
根据 Menlo Ventures 2024 年的调查,在主流 AI 应用场景中,AI 编程工具的采用率以 51% 位居榜首,代码生成成为最易落地且受欢迎的场景。科技巨头谷歌 CEO Sundar Pichai 在 2024 年 10 月财报会议上透露,公司超四分之一的新代码由…...

RK3588 RKNN ResNet50推理测试
RK3588 RKNN ResNet50推理测试 一、背景二、性能数据三、操作步骤3.1 安装依赖3.2 安装rknn-toolkit,更新librknnrt.so3.3 下载推理图片3.4 生成`onnx`模型转换脚本3.5 生成rknn模型3.6 运行rknn模型一、背景 在嵌入式设备上进行AI推理时,我们面临着算力有限、功耗敏感等挑战…...
SQLMesh 宏操作符详解:提升 SQL 查询的灵活性与效率
SQLMesh 提供了一系列强大的宏操作符(如 WITH、JOIN、WHERE 等),用于动态构建 SQL 查询。这些操作符不仅简化了复杂查询的编写,还提高了代码的可读性和可维护性。本文将深入探讨这些操作符的使用场景、语法及实际案例,…...

leetcode513.找树左下角的值:递归深度优先搜索中的最左节点追踪之道
一、题目本质与核心诉求解析 在二叉树算法问题中,"找树左下角的值"是一个典型的结合深度与位置判断的问题。题目要求我们找到二叉树中最深层最左边的节点值,这里的"左下角"有两个关键限定: 深度优先:必须是…...
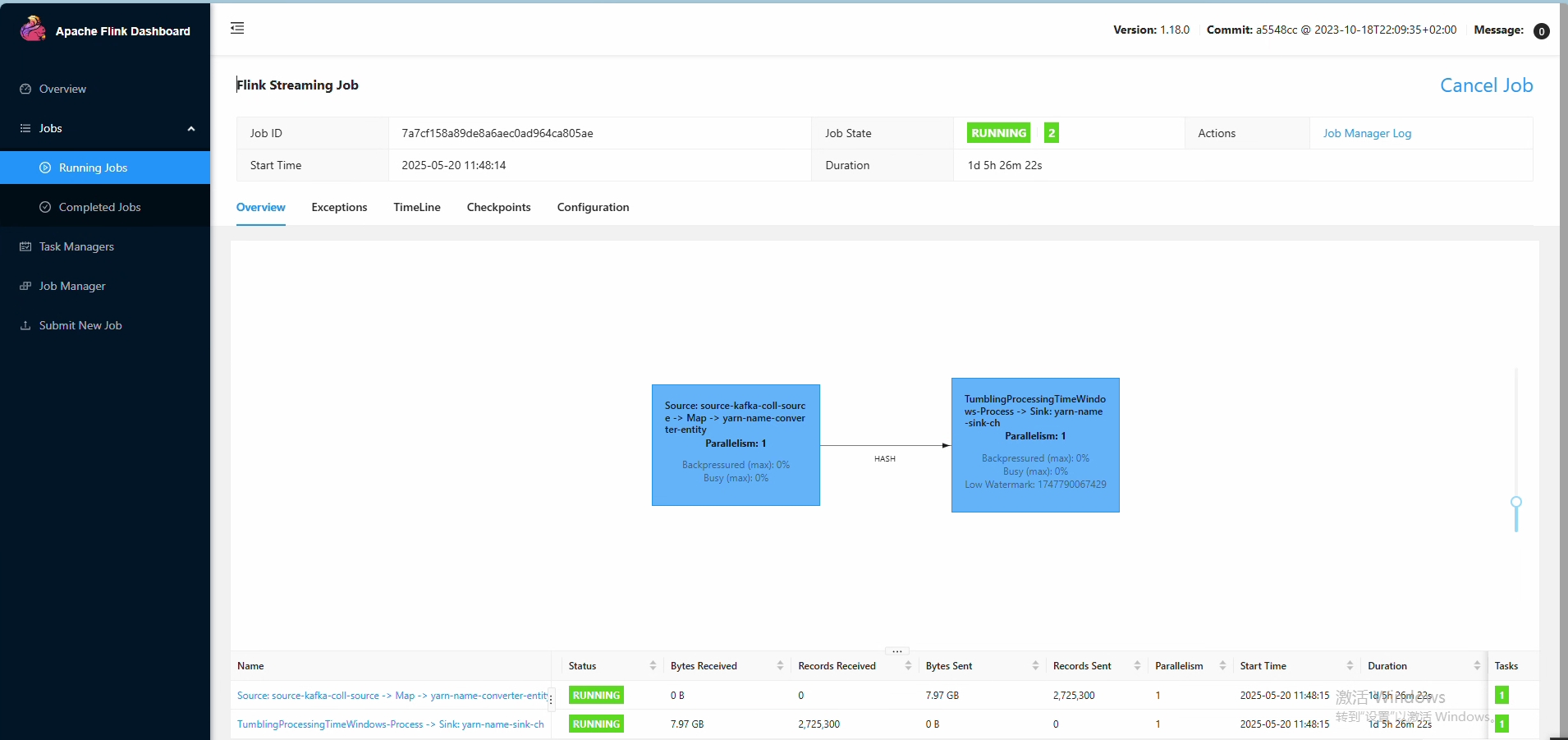
基于Flink的数据中台管理平台
基于Flink做的数据中台工程项目。数据从source到clickhouse全流程的验证。集成元数据管、数据资产、数据发现功能,自主管理元数据变更,集成元数据版本管理。 同时,对整个大数据集群使用到的组件或者是工具进行管理。比如nacos、kafka、zookee…...

AI-Ready TapData:如何基于 MCP 协构建企业级 AI 实时数据中枢?(含教程)
随着企业对私有大模型、行业大模型的探索逐渐深入,“AI应用是否真正落地”,越来越取决于企业是否拥有结构化、实时、可交互的高质量数据。而现实是,大多数企业的核心业务数据依旧被困在多个异构系统、孤岛数据库和 ETL 流程之中,导…...

Spring Boot 登录实现:JWT 与 Session 全面对比与实战讲解
Spring Boot 登录实现:JWT 与 Session 全面对比与实战讲解 2025.5.21-23:11今天在学习黑马点评时突然发现用的是与苍穹外卖jwt不一样的登录方式-Session,于是就想记录一下这两种方式有什么不同 在实际开发中,登录认证是后端最基础也是最重要…...

【HTML-5】HTML 实体:完整指南与最佳实践
1. 什么是 HTML 实体? HTML 实体是一种在 HTML 文档中表示特殊字符的方法,这些字符如果直接使用可能会与 HTML 标记混淆,或者无法通过键盘直接输入。实体由 & 符号开始,以 ; 分号结束。 <p>这是一个小于符号的实体&am…...
SpringBoot 项目实现操作日志的记录(使用 AOP 注解模式)
本文是博主在做关于如何记录用户操作日志时做的记录,常见的项目中难免存在一些需要记录重要日志的部分,例如权限和角色设定,重要数据的操作等部分。 博主使用 Spring 中的 AOP 功能,结合注解的方式,对用户操作过的一些…...
AI|Java开发 IntelliJ IDEA中接入本地部署的deepseek方法
目录 连接本地部署的deepseek: IntelliJ IDEA中使用deepseek等AI: 用法一:让AI写代码 用法二:选中这段代码,右键,可以让其解释这段代码的含义。这时显示的解释是英文的。 连接本地部署的deepseek&#…...

【疑难杂症】Vue前端下载文件无法打开 已解决
由于刚学了VUE不久,不清楚底层逻辑。我遇到从后台下载文件无法打开的问题。 测试下来是,请求时未设置 responseType: blob。 axios 默认的 responseType 是 json ,会尝试将响应体解析为JSON。但文件下载场景需要后端返回二进制流࿰…...
【1——Android端添加隐私协议(unity)1/3】
前言:这篇仅对于unity 发布Android端上架国内应用商店添加隐私协议,隐私协议是很重要的东西,没有这个东西,是不上了应用商店的。 对于仅仅添加隐私协议,我知道有三种方式,第一种和第二种基本一样 1.直接在unity里面新…...

Linux之概述和安装vm虚拟机
文章目录 操作系统概述硬件和软件操作系统常见操作系统 初识LinuxLinux的诞生Linux内核Linux发行版 虚拟机介绍虚拟机 VMware WorkStation安装虚拟化软件VMware WorkStation 安装查看VM网络连接设置VM存储位置 在VMware上安装Linux(发行版CentOS7)安装包获取CentOS7 安装 Mac系…...

深入理解 Linux 的 set、env 和 printenv 命令
在 Linux 和类 Unix 系统中,环境变量是配置和管理 Shell 及进程行为的核心机制。set、env 和 printenv 是与环境变量交互的三个重要命令,每个命令都有其独特的功能和用途。本文将详细探讨这三个命令的区别,帮助大家更好地理解和使用这些命令。…...
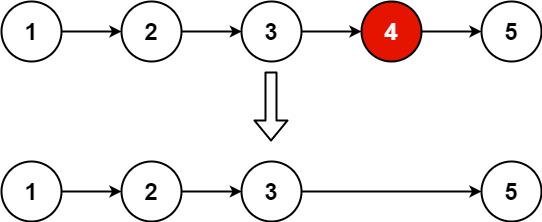
LeetCode热题100--19.删除链表的倒数第N个结点--中等
1. 题目 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 示例 2: 输入:head [1], n 1 输出:[] 示例…...

开发AR导航助手:ARKit+Unity+Mapbox全流程实战教程
引言 在增强现实技术飞速发展的今天,AR导航应用正逐步改变人们的出行方式。本文将手把手教你使用UnityARKitMapbox开发跨平台AR导航助手,实现从虚拟路径叠加到空间感知的完整技术闭环。通过本教程,你将掌握: AR空间映射与场景理…...
git学习与使用(远程仓库、分支、工作流)
文章目录 前言简介git的工作流程git的安装配置git环境:git config --globalgit的基本使用新建目录初始化仓库(repository)添加到暂存区新增/修改/删除 文件状态会改变 提交到仓库查看提交(commit)的历史记录git其他命令…...

嵌入式预处理链接脚本lds和map文件
在嵌入式开发中,.lds.S 文件是一个 预处理后的链接脚本(Linker Script),它结合了 C 预处理器(Preprocessor) 的功能和链接脚本的语法。它的核心作用仍然是 定义内存布局和链接规则,但通过预处理…...