C++初阶-list的使用2
目录
1.std::list::splice的使用
2.std::list::remove和std::list::remove_if的使用
2.1remove_if函数的简单介绍
基本用法
函数原型
使用函数对象作为谓词
使用普通函数作为谓词
注意事项
复杂对象示例
2.2remove与remove_if的简单使用
3.std::list::unique的使用
3.1std::list::unique的第二个函数的简单介绍
基本语法
基本示例
使用函数对象作为谓词
处理自定义类型
注意事项
3.2std::list::unique函数的使用
4.std::list::merge的使用
5.std::list::sort函数以及std::swap(list)的使用
6.C++迭代器(非常重要)
1. 输入迭代器 (input_iterator_tag)
2. 输出迭代器 (output_iterator_tag)
3. 前向迭代器 (forward_iterator_tag)
4. 双向迭代器 (bidirectional_iterator_tag)
5. 随机访问迭代器 (random_access_iterator_tag)
6.每个容器所对应的迭代器以及注意事项
1. 序列容器 (Sequence Containers)
std::array
std::vector
std::deque (双端队列)
std::list (双向链表)
std::forward_list (单向链表)
2. 关联容器 (Associative Containers)
std::set/std::multiset
std::map/std::multimap
3. 无序关联容器 (Unordered Associative Containers)
std::unordered_set/std::unordered_multiset
std::unordered_map/std::unordered_multimap
4. 容器适配器 (Container Adaptors)
std::stack 和 std::queue
特殊迭代器
std::string
std::string_view
迭代器类别对算法的影响
7.简单解释
7.总结

1.std::list::splice的使用
该函数是list新增的一个函数,所以需要进行额外的讲解:

splice这个函数翻译过来是:拼接、粘接的意思,也就是说可以在该list对象的position位置粘接一部分东西,但是它必须是另外一个list对象的一部分或者全部,这里是它的每个函数的用法简介:

所以说这个函数的功能还是比较多的,但是这个位置position我们需要注意:这个position我们不能直接和vector和string那样写的,所以我们如果拼接数据不是在头部或者尾部的情况下我们不能用l1.begin()+n的方式,因为这种方式是没定义的。我们可以用之前我们学过的insert的那种方式,这里讲解一下如何使用:
第一个函数的使用:
//splice函数的使用
int main()
{list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });list<int> l2({ 6,3,1,8,0 });cout << "l1粘接之前:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2粘接之前:";for (const auto& e : l2){cout << e << " ";}cout << endl;//(1)//不能这样写//l2.splice(l1.begin() + 1, l1);//会在迭代器的分类里面讲到//list是双向迭代器,只支持++、--//只有随机迭代器支持+、-操作//我们之前学过的那些string和vector都是随机迭代器,可以使用//要这样写auto i1 = std::next(l1.begin(), 1);l1.splice(i1, l2);cout << "l1第一次粘接之后:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2第一次粘接之后:";for (const auto& e : l2){cout << e << " ";}cout << endl;return 0;
}那么最终运行结果为:
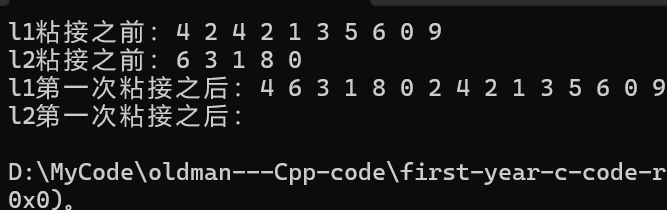
但是如果我们想要插入尾结点那么就不能l1.end()了,因为
l1.end() 是指向 尾后位置(one-past-the-last element) 的迭代器,它并不指向任何实际元素。根据C++标准:
-
splice函数(第三个重载函数)的第三个参数(要剪切的元素位置)必须指向一个有效的元素 -
end()迭代器不指向任何实际元素,因此不能用于剪切操作
所以我们如果想插入尾结点不能直接l1.end(),而应该插入它前一个结点才是正确的,比如以splice第三个重载的使用为例。以下是splice第二个函数的使用:
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//splice函数的使用2
int main()
{list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });list<int> l2({ 6,3,1,8,0 });cout << "l1粘接之前:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2粘接之前:";for (const auto& e : l2){cout << e << " ";}cout << endl;//(2)//或者auto i2 = l2.begin();//l2的第四个位置粘接std::advance(i2, 3);//错误//l2.splice(i2, l1, l1.end());//正确l2.splice(i2, l1, std::prev(l1.end()));cout << "l1第二次粘接之后:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2第二次粘接之后:";for (const auto& e : l2){cout << e << " ";}cout << endl;return 0;
}那么最终运行结果为:
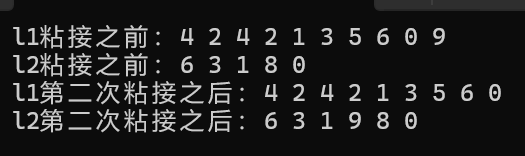
第三个函数的用法如下:
//splice函数的使用3
int main()
{list<int> l1({ 4,2,4,2,1,3,5,6,0,9 });list<int> l2({ 6,3,1,8,0 });cout << "l1粘接之前:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2粘接之前:";for (const auto& e : l2){cout << e << " ";}cout << endl;//(3)//也可以auto i3 = l2.begin();//在l2的第四个位置开始粘接std::advance(i3, 3);l2.splice(i3, l1, l1.begin(), l1.end());cout << "l1第三次粘接之后:";for (const auto& e : l1){cout << e << " ";}cout << endl;cout << "l2第三次粘接之后:";for (const auto& e : l2){cout << e << " ";}cout << endl;return 0;
}那么最终运行结果如下:
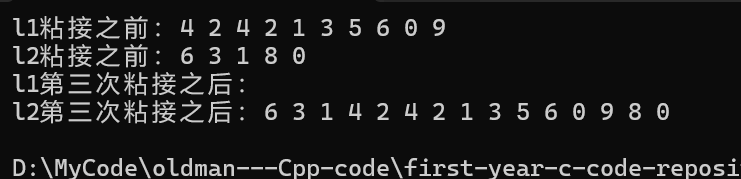
为什么这次没报错,因为:
-
splice的范围版本接受的是 [first, last) 半开区间 -
标准明确规定
last可以是end()迭代器 -
这表示"从 first 开始到容器末尾的所有元素"
而且基本上迭代器的last指针通常是不插入这个位置的数据的(可能没有数据)。
可以看到:splice函数看似简单,但是我们需要注意的地方还是比较多的,我们还是要注意它的用法,否则很容易报错,而且我们在写i1、i2的时候我们要注意如果i1指向l1的结点,那么就是l1.splice(i1,……),不然可能会报错(自己粘接自己),如果是粘接一段迭代器区间,那么可以自己粘接自己!
2.std::list::remove和std::list::remove_if的使用

这个函数也是在list容器中新增的一个函数,所以需要额外介绍一下它用法,我们来看一下它的用法:

也就是说它可以删除值为val的所有结点,在该函数的介绍中也能了解它的很多东西,所以这里就不做解释了。

这个函数我们又有些看不懂了,如果按照正常思维,我们也应该是满足值为val且满足pred的条件就可以了,为什么这个是函数模板?我们来看一下它的介绍:

这个函数我们还是没看懂它如何用的,那我们还是问一下deepseek吧!(以下是deepseek的生成结果,如果不想看的话可以跳到2.2)
2.1remove_if函数的简单介绍
std::list::remove_if 是 C++ STL 中 list 容器的一个成员函数,用于根据特定条件移除列表中的元素。
基本用法
#include <list>
#include <iostream>int main() {std::list<int> numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};// 移除所有偶数numbers.remove_if([](int n) { return n % 2 == 0; });// 输出结果: 1 3 5 7 9for (int n : numbers) {std::cout << n << " ";}return 0;
}函数原型
template <class Predicate>
void remove_if(Predicate pred);-
red: 一元谓词(接受一个元素作为参数并返回 bool 的函数或函数对象) -
返回类型: void(直接修改原列表)
使用函数对象作为谓词
struct IsGreaterThan {int value;IsGreaterThan(int v) : value(v) {}bool operator()(int n) const { return n > value; }
};int main() {std::list<int> numbers = {5, 12, 3, 8, 15, 7};// 移除所有大于10的元素numbers.remove_if(IsGreaterThan(10));// 输出结果: 5 3 8 7for (int n : numbers) {std::cout << n << " ";}return 0;
}使用普通函数作为谓词
bool isNegative(int n) {return n < 0;
}int main() {std::list<int> numbers = {-2, -1, 0, 1, 2, -3};// 移除所有负数numbers.remove_if(isNegative);// 输出结果: 0 1 2for (int n : numbers) {std::cout << n << " ";}return 0;
}注意事项
-
remove_if会遍历整个列表,时间复杂度为 O(n) -
被移除的元素会被销毁,内存被释放
-
与
std::remove_if算法不同,list 的成员函数remove_if会真正删除元素,而不只是移动元素 -
在遍历过程中修改列表是安全的,因为这是 list 的特性
复杂对象示例
#include <list>
#include <string>struct Person {std::string name;int age;
};int main() {std::list<Person> people = {{"Alice", 25},{"Bob", 17},{"Charlie", 30},{"David", 16}};// 移除所有未成年人(年龄<18)people.remove_if([](const Person& p) { return p.age < 18; });// 剩下的都是成年人for (const auto& p : people) {std::cout << p.name << " (" << p.age << ")\n";}return 0;
}std::list::remove_if 是一个高效的方式来根据条件删除 list 中的元素,特别适合与 lambda 表达式结合使用。
2.2remove与remove_if的简单使用
在刚刚的remove_if的众多用法中我们只要掌握最基本的用法即可,建议还是传递一个返回值为bool的进去。简单来说就是remove_if能删除链表中若把链表所存储的值代入结果为true的值,所以remove_if函数在之后的用法还是比较多的,至于那个基本用法中的[]……我们暂时用这种方式即可,它是Lambda表达式,这个感兴趣的可以去搜索资料。
那么我在这里演示一下两个函数的用法,两个函数都是删除链表中的一些元素:
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//remove和remove_if的使用
bool isou(int a)
{return a % 2 == 0;
}
int main()
{//removelist<int> l1({ 4,2,4,6,76,3,2,1,9,0,3,5 });cout << "remove之前:";for (const auto& e : l1){cout << e << " ";}cout << endl;l1.remove(3);cout << "remove之后:";for (const auto& e : l1){cout << e << " ";}cout << endl;//remove_iflist<int> l2({ 2,4,6,3,1,7,9,0,8,5,7 });cout << "remove_if之前:";for (const auto& e : l2){cout << e << " ";}cout << endl;l2.remove_if(isou);cout << "remove_if之后:";for (const auto& e : l2){cout << e << " ";}cout << endl;return 0;
}那么最终运行结果为:
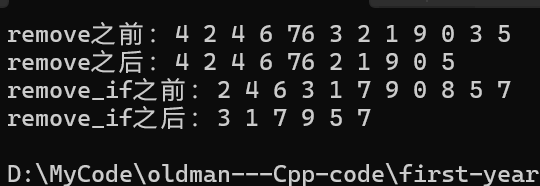
3.std::list::unique的使用

unique也是在string和vector之后新增的一个函数,我们可以通过它函数名的意思知道这个函数大概是什么意思,这个函数名字的中文的意思是单独的,那么来看一下它的介绍吧:

也就是说它可以删除连续的重复的元素,然后使每个结点与它的前后结点(除只有一个结点外)所存的值都不相同,这个函数也经常结合sort函数即排序后使用,所以这是第一个函数的用法;第二个函数和remove_if差不多,但是也有些不同,以下是deepseek的搜索结果:
3.1std::list::unique的第二个函数的简单介绍
std::list::unique 的带谓词版本允许你自定义判断相邻元素是否"唯一"的标准,而不仅仅是简单的相等比较。
基本语法
template <class BinaryPredicate>
void unique(BinaryPredicate binary_pred);-
binary_pred:一个二元谓词(接受两个元素作为参数并返回 bool 的函数或函数对象) -
功能:移除所有满足
binary_pred的连续重复元素
基本示例
#include <list>
#include <iostream>int main() {std::list<int> numbers = {1, 2, 2, 3, 4, 4, 4, 5, 6, 6, 7};// 使用默认比较(operator==)numbers.unique();// 结果:1, 2, 3, 4, 5, 6, 7// 使用自定义谓词 - 当两数差的绝对值小于等于1时视为相同numbers = {1, 2, 4, 5, 7, 8, 10};numbers.unique([](int a, int b) { return std::abs(a - b) <= 1; });// 结果:1, 4, 7, 10return 0;
}使用函数对象作为谓词
struct AreConsecutive {bool operator()(int a, int b) const {return b == a + 1;}
};int main() {std::list<int> nums = {1, 2, 4, 5, 7, 8, 10};nums.unique(AreConsecutive());// 移除后一个元素是前一个元素+1的相邻元素// 结果:1, 4, 7, 10return 0;
}处理自定义类型
struct Person {std::string name;int age;bool operator==(const Person& other) const {return name == other.name && age == other.age;}
};int main() {std::list<Person> people = {{"Alice", 25},{"Alice", 25}, // 重复{"Bob", 30},{"Bob", 31}, // 不同{"Charlie", 40},{"Charlie", 40} // 重复};// 移除姓名和年龄完全相同的连续记录people.unique();// 剩余: Alice(25), Bob(30), Bob(31), Charlie(40)// 自定义谓词 - 只比较姓名people.unique([](const Person& a, const Person& b) {return a.name == b.name;});// 剩余: Alice(25), Bob(30), Charlie(40)return 0;
}注意事项
-
只移除连续重复项:
unique只检查相邻元素,不相邻的重复元素不会被移除std::list<int> nums = {1, 2, 1, 2, 1}; nums.unique(); // 不会有任何变化,因为没有连续重复 -
谓词要求:谓词应该是等价关系(自反、对称、传递的)
-
排序后再使用:如果需要移除所有重复项(不仅是连续的),应先排序
std::list<int> nums = {1, 2, 1, 2, 1}; nums.sort(); nums.unique(); // 结果: 1, 2 -
性能:时间复杂度为 O(n),因为 list 的迭代器是双向的
-
与
std::unique的区别:-
std::list::unique是成员函数,真正删除元素 -
std::unique是算法,只移动元素到容器末尾,不改变容器大小
-
这个带谓词的 unique 版本提供了极大的灵活性,让你可以定义什么样的元素应该被视为"重复"的。
3.2std::list::unique函数的使用
第二个重载的函数的参数与remove_if函数的不同就是:它所需要传的参数需要两个,因为这样才满足需要删除的条件是什么,才好进行删除。至于:

这个需要自己去搜索结果了,这里没办法细讲!
知道了这么多,我在这里演示一下两个函数的用法:
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//unique的使用
bool panduan(int a, int b)
{//判断绝对值是否小于2//小于2则认为相同return abs(a - b) < 2;
}
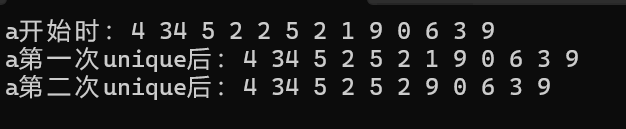
int main()
{list<int> a({ 4,34,5,2,2,5,2,1,9,0,6,3,9 });cout << "a开始时:";for (const auto& e : a){cout << e << " ";}cout << endl;a.unique();cout << "a第一次unique后:";for (const auto& e : a){cout << e << " ";}cout << endl;a.unique(panduan);cout << "a第二次unique后:";for (const auto& e : a){cout << e << " ";}cout << endl;return 0;
}那么运行结果为:
4.std::list::merge的使用

该函数还是list新增的一个函数,这里我们先看一下它的介绍:

这个函数用得很少,在这里就只演示用法即可(第一个是默认排成升序的,第二个是可以排成降序的):
#define _CRT_SECURE_NO_WARNINGS 1
#include<list>
#include<iostream>
using namespace std;
//merge的使用
int main()
{list<int> l1({ 3,4,52,5,1,9,90,8,7,3 });list<int> l2({ 4,2,4,6,2,1,8,0,2,6 });//先排序l1.sort();l2.sort();//(1)//再merge//merge后仍然是有序的l1.merge(l2);for (const auto& e : l1){cout << e << " ";}cout << endl;//(2)list<int> l3({ 5,6,3,2,4,9,20,97 });//排成降序不能这样写//l3.sort();//我们想要排成降序就这样写(了解基本用法,之后会讲)greater<int> gt;//sort函数等下讲l3.sort(gt);l1.sort(gt);//第二个参数还是要加上的!l1.merge(l3, gt);for (const auto& e : l1){cout << e << " ";}cout << endl;return 0;
}那么运行结果为:

5.std::list::sort函数以及std::swap(list)的使用

这个函数第一个是排成升序,第二个是排成降序,但是我们第二个函数的参数现阶段只要知道用这种方式即可:greater<int> gt;l1.sort(gt);但是记得gt的类型也要和l1一样。

这个函数也是专门针对list设计的swap函数,这个就是为了防止之后我们调用了算法库里面的函数,这个可以见我的string的模拟实现4的博客!
这个函数就不讲解它的用法了,我在这里只讲解为什么我们不用算法库里面的sort函数?
这个其实涉及到迭代器的继承关系,其中子类时特殊的父类,而在算法库的sort函数的参数是RandomAccessIterator,是最特殊的子类,只能传递随机迭代器。
6.C++迭代器(非常重要)
我在这里讲解的继承关系现在只是皮毛!!!因为这涉及到子父类的继承关系,这些将会在C++的继承博客中进行更详细讲解,这里我们只要在平常别乱用容器本身的迭代器与算法库里面的迭代器即可:
我们在C++官网中搜索:iterator,则会有:

这5个迭代器是以下迭代器:

我们是看不懂这个箭头的,也是很难理解的,我们只要知道这些分类即可。
所以以下是deepseek对它们比较简单的讲解:
这五个迭代器类别代表了C++中迭代器的不同能力和层级关系,它们构成了一种继承层次结构,从功能简单到功能强大依次是:
1. 输入迭代器 (input_iterator_tag)
-
能力:只读、单向
-
支持操作:
-
++(前缀和后缀) -
*(解引用,只能读取) -
==/!=比较
-
-
典型用途:从数据流中读取数据(如
istream_iterator) -
限制:只能单次遍历,不能回退
2. 输出迭代器 (output_iterator_tag)
-
能力:只写、单向
-
支持操作:
-
++(前缀和后缀) -
*(解引用,只能写入)
-
-
典型用途:向数据流写入数据(如
ostream_iterator) -
限制:不能读取,不能回退,通常只能单次遍历
3. 前向迭代器 (forward_iterator_tag)
-
能力:可读可写、单向
-
支持操作:
-
包含输入迭代器的所有功能
-
可以多次遍历同一序列
-
-
典型用途:单向链表(如
std::forward_list的迭代器) -
特点:比输入/输出迭代器更强,支持多遍遍历
4. 双向迭代器 (bidirectional_iterator_tag)
-
能力:可读可写、双向移动
-
支持操作:
-
包含前向迭代器的所有功能
-
--(前缀和后缀,可以回退)
-
-
典型用途:双向链表(如
std::list的迭代器) -
特点:可以向前和向后移动
5. 随机访问迭代器 (random_access_iterator_tag)
-
能力:可读可写、随机访问
-
支持操作:
-
包含双向迭代器的所有功能
-
+/-整数(跳跃式移动) -
[]下标访问 -
<,>,<=,>=比较
-
-
典型用途:数组/向量(如
std::vector、std::array的迭代器) -
特点:功能最强大的迭代器类型
6.每个容器所对应的迭代器以及注意事项
以下是deepseek的搜索结果:
面是C++标准库中主要容器及其对应的迭代器类别:
1. 序列容器 (Sequence Containers)
std::array
-
迭代器类别:随机访问迭代器 (
random_access_iterator_tag) -
说明:支持所有随机访问操作,包括
+、-、[]等
std::vector
-
迭代器类别:随机访问迭代器 (
random_access_iterator_tag) -
说明:与数组类似,支持高效随机访问
std::deque (双端队列)
-
迭代器类别:随机访问迭代器 (
random_access_iterator_tag) -
说明:虽然内部结构比vector复杂,但仍提供随机访问能力
std::list (双向链表)
-
迭代器类别:双向迭代器 (
bidirectional_iterator_tag) -
说明:
-
支持
++和--操作 -
不支持随机访问(不能使用
+、-或[])
-
std::forward_list (单向链表)
-
迭代器类别:前向迭代器 (
forward_iterator_tag) -
说明:
-
只支持
++操作 -
不支持
--操作
-
2. 关联容器 (Associative Containers)
std::set/std::multiset
-
迭代器类别:双向迭代器 (
bidirectional_iterator_tag) -
说明:
-
元素已排序
-
支持双向遍历
-
std::map/std::multimap
-
迭代器类别:双向迭代器 (
bidirectional_iterator_tag) -
说明:
-
键值对已按键排序
-
支持双向遍历
-
3. 无序关联容器 (Unordered Associative Containers)
std::unordered_set/std::unordered_multiset
-
迭代器类别:前向迭代器 (
forward_iterator_tag) -
说明:
-
元素无序存储
-
只支持单向遍历
-
std::unordered_map/std::unordered_multimap
-
迭代器类别:前向迭代器 (
forward_iterator_tag) -
说明:
-
键值对无序存储
-
只支持单向遍历
-
4. 容器适配器 (Container Adaptors)
std::stack 和 std::queue
-
迭代器类别:不提供迭代器
-
说明:这些适配器专门设计为限制访问模式,不支持迭代
特殊迭代器
std::string
-
迭代器类别:随机访问迭代器 (
random_access_iterator_tag) -
说明:行为与
std::vector<char>类似
std::string_view
-
迭代器类别:随机访问迭代器 (
random_access_iterator_tag) -
说明:提供对字符串的视图,支持随机访问
迭代器类别对算法的影响
不同算法对迭代器有不同要求:
-
需要随机访问迭代器的算法:
-
std::sort -
std::binary_search -
std::nth_element
-
-
需要双向迭代器的算法:
-
std::reverse -
std::unique(带谓词版本) -
std::list::sort(成员函数)
-
-
只需要前向迭代器的算法:
-
std::search -
std::adjacent_find
-
-
只需要输入迭代器的算法:
-
std::find -
std::count -
std::accumulate
-
7.简单解释
这个迭代器的分类对我们之后是用算法库里面的函数还是用容器的函数都有很多注意的地方,比如:我们不能用算法库的sort,因为list是双向迭代器即:bidirectional_iterator_tag。这个迭代器可以支持++、---的操作,但是不支持+、-的操作,因此若用算法库里面的可能会导致有些问题。如果我们想用循环++、--的方式来访问除begin、end位置外的数据也是可以的,我们如果不知道哪种方式遍历链表更好一些,可以见以下图:
如何选择:
| 场景 | 推荐方式 | 原因 |
|---|---|---|
顺序遍历(如 for 循环) | ++it | 最高效,直接移动一步。 |
| 跳转多个位置 | std::advance(it, n) | 需要修改原迭代器时使用(如 it 需要指向新位置)。 |
| 临时计算新位置 | std::next(it, n) | 不修改原迭代器,适用于范围操作(如 std::next(begin, 2))。 |
随机访问容器(如 vector) | it + n | std::vector 支持 O(1) 随机访问,直接 +n 比 advance 更高效。 |
总结:
| 方法 | 是否修改原迭代器 | 时间复杂度(list) | 适用场景 |
|---|---|---|---|
++it | ✅ 是 | O(1)(单步) | 顺序遍历 |
std::advance | ✅ 是 | O(n)(多步) | 需要修改迭代器位置时 |
std::next | ❌ 否 | O(n)(多步) | 临时计算新位置(更安全) |
功能对比:
| 方法 | 作用 | 是否修改原迭代器 | 适用场景 |
|---|---|---|---|
it++ / ++it | 移动迭代器到下一个位置(单步) | 是 | 简单遍历(如 for 循环) |
std::advance(it, n) | 移动迭代器 n 步(可正可负) | 是 | 需要移动多步时(如跳转访问) |
std::next(it, n) | 返回移动 n 步后的新迭代器,不修改原迭代器 | 否 | 临时计算新位置(如获取下一个元素) |
推荐实践:
-
默认用
++遍历(最高效)。 -
需要跳转时用
std::advance(修改迭代器)。 -
临时计算用
std::next(不修改原迭代器,更安全)。
对于如何理解父子类的继承行为,我们可以认为:子类是特殊的父类,父类有的特征子类都有,我们若把子类认为是正方形,父类是长方形,这个就很容易理解了。
所以在用每个算法库里面的函数的时候还是要注意它的迭代器的类别:
如果有迭代器类型的参数且类型是Input_Iterator那么我们就只可读,也就是说只能传递Input类别的迭代器;同理对于参数是Output_Iterator类别的,那么就只能传递Output类别的迭代器;如果是单向迭代器,那么就能传递Input_Iterator、Output_Iterator和单向迭代器;如果是双向迭代器,那么可以传递除随机迭代器外的所有迭代器;如果参数类型是随机迭代器,那么就可以传递任意类型的迭代器!
我按照常用的容器,给出大概分类:vector、string、deque是随机迭代器;list、map、set是双向迭代器、forward_list、unodered_map、unordered_set是单向迭代器。
最后记住:算法库里面的sort函数是不能用来进行list的排序的!所以我们要注意!
7.总结
list的重要函数的使用已经全部讲完了,那些比较运算符的重载、逆置函数、得到一个迭代器这些都不重要,就不讲解了,我们主要是要懂得每个函数所对应的用法,已经一些注意事项。这个我用deepseek的也是比较多,因为我自己学的不是很深入,如果照着笔记讲还不如不写博客,所以我觉得还是用deepseek更全面一些,也方便我之后复习用!
好了,C++list的使用就到这里了,下讲将讲解:list的底层。不过下讲内容可能需要下周去了,因为这周四天更新了这是第8篇了,身体有些吃不消了,已经赶得上我的笔记内容了。
喜欢的可以一键三连哦,下讲再见!

相关文章:
C++初阶-list的使用2
目录 1.std::list::splice的使用 2.std::list::remove和std::list::remove_if的使用 2.1remove_if函数的简单介绍 基本用法 函数原型 使用函数对象作为谓词 使用普通函数作为谓词 注意事项 复杂对象示例 2.2remove与remove_if的简单使用 3.std::list::unique的使用 …...

PHP序列化数据格式详解
PHP序列化数据格式详解 概述 PHP序列化是将PHP变量(包括对象)转换为可存储或传输的字符串表示形式的过程。了解这些序列化格式对于数据处理、调试和安全性分析非常重要。本文将详细介绍PHP中各种数据类型的序列化表示方式。 基本数据类型序列化格式 …...

如何优化 MySQL 存储过程的性能?
文章目录 1. 优化 SQL 语句避免全表扫描减少子查询,改用 JOIN避免 SELECT 2. 合理使用索引3. 优化存储过程结构减少循环和临时变量避免重复计算 4. 使用临时表和缓存5. 优化事务处理6. 分析和监控性能7. 优化数据库配置8. 避免用户自定义函数(UDF&#…...

深度学习:损失函数与激活函数全解析
目录 深度学习中常见的损失函数和激活函数详解引言一、损失函数详解1.1 损失函数的作用与分类1.2 回归任务损失函数1.2.1 均方误差(MSE)1.2.2 平均绝对误差(MAE) 1.3 分类任务损失函数1.3.1 交叉熵损失(Cross-Entropy&…...

【大前端】Node Js下载文件
NodeJs 获取远程文件有很多方式,常见的方式有以下两种: - fetch(原生) - axios(插件) 通过 Fetch 下载文件,代码如下: import fs from node:fsfunction main(){fetch(http://xxx.x…...

自训练NL-SQL模型
使用T5小模型在笔记本上训练 nature language to SQL/自然语言 转SQL 实测通过。 本文介绍了如何在笔记本上使用T5小模型训练自然语言转SQL的任务。主要内容包括:1) 创建Python 3.9环境并安装必要的依赖包;2) 通过Hugging Face镜像下载wikisql数据集和T5-small模型;3) 实现…...
创新点!贝叶斯优化、CNN与LSTM结合,实现更准预测、更快效率、更高性能!
能源与环境领域的时空数据预测面临特征解析与参数调优双重挑战。CNN-LSTM成为突破口:CNN提取空间特征,LSTM捕捉时序依赖,实现时空数据的深度建模。但混合模型超参数(如卷积核数、LSTM层数)调优复杂,传统方法…...

【Flutter】创建BMI计算器应用并添加依赖和打包
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍创建BMI计算器应用并添加依赖和打包。 学其所用,用其所学。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...

【Linux 学习计划】-- 倒计时、进度条小程序
目录 \r 、\n、fflush 倒计时 进度条 进度条进阶版 结语 \r 、\n、fflush 首先我们先来认识这三个东西,这将会是我们接下来两个小程序的重点之一 首先是我们的老演员\n,也就是回车加换行 这里面其实包含了两个操作,一个叫做回车&…...
微服务的应用案例
从“菜市场”到“智慧超市”:一场微服务的变革之旅 曾经,我们的系统像一个熙熙攘攘的传统菜市场。所有功能模块(摊贩)都挤在一个巨大的单体应用中。用户请求(买菜的顾客)一多,整个市场就拥堵不堪…...

后端开发概念
1. 后端开发概念解析 1.1. 什么是服务器,后端服务 1.1.1. 服务器 服务器是一种提供服务的计算机系统,它可以接收、处理和响应来自其他计算机系统(客户端)的请求。服务器主要用于存储、处理和传输数据,以便客户端可以…...

2025网络安全趋势报告 内容摘要
2025 年网络安全在技术、法规、行业等多个维度呈现新趋势。技术上,人工智能、隐私保护技术、区块链、量子安全技术等取得进展;法规方面,数据安全法规进一步细化;行业应用中,物联网、工业控制系统安全升级,供…...
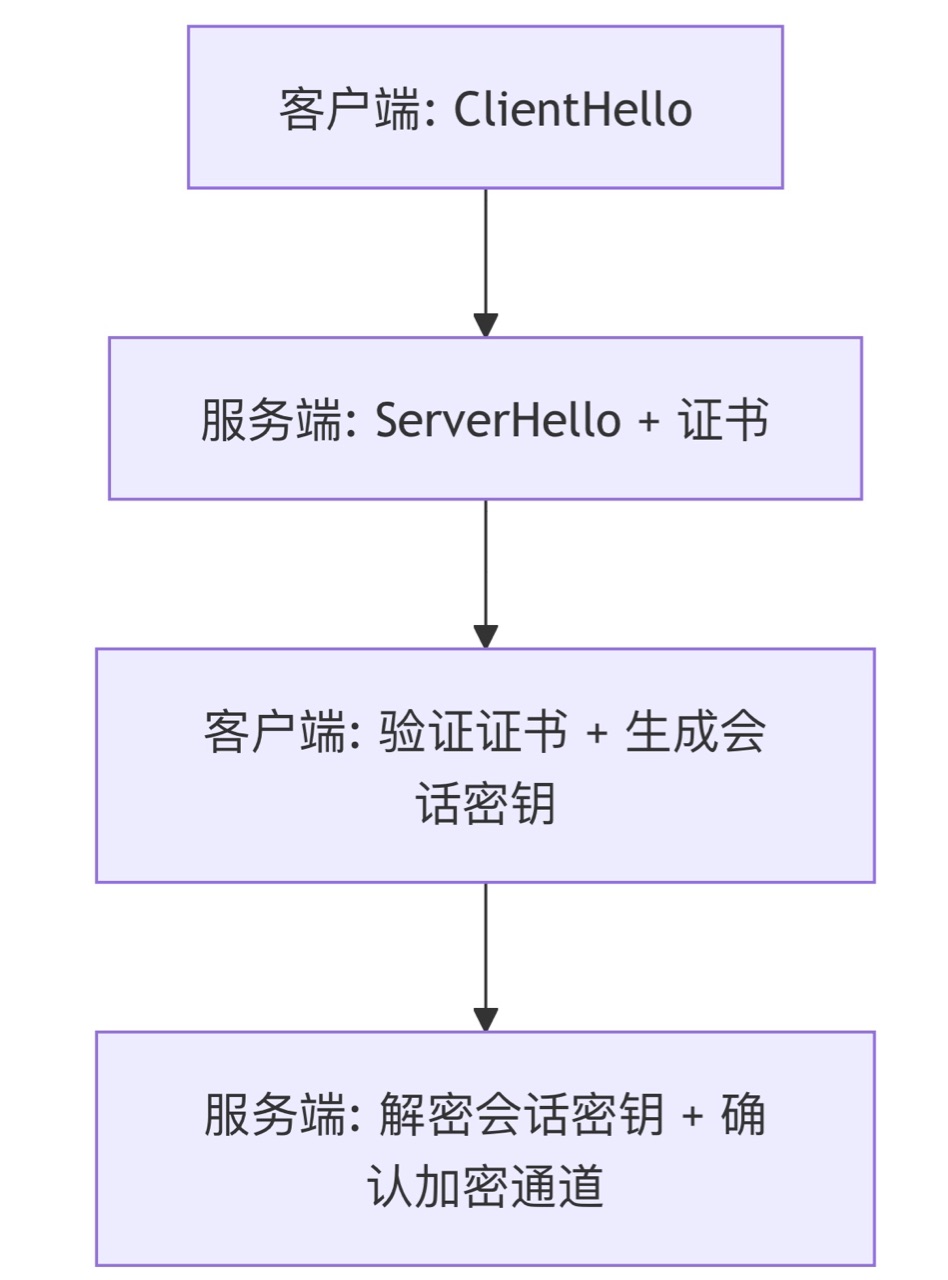
云原生安全基石:深度解析HTTPS协议(从原理到实战)
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念:HTTPS是什么? HTTPS(HyperText Transfer Protocol Secure)是HTTP协议的安全版本,…...

Autodl训练Faster-RCNN网络--自己的数据集(一)
参考文章: Autodl服务器中Faster-rcnn(jwyang)复现(一)_autodl faster rcnn-CSDN博客 Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)_faster rcnn autodl-CSDN博客 食用指南:先跟着参考文章一进行操作,遇到问题再来看我这里有没有解…...
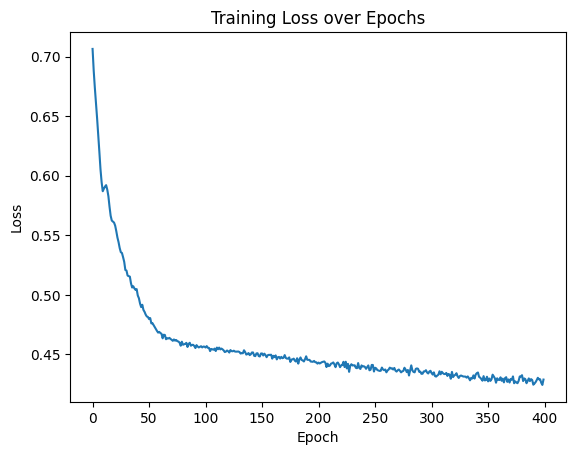
python打卡day36
复习日 仔细回顾一下神经网络到目前的内容,没跟上进度的补一下进度 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。探索性作业(随意完成):尝试进入nn.M…...

8.Java 8 日期时间处理:从 Date 的崩溃到 LocalDate 的优雅自救
一、被 Date 逼疯的程序员:那些年踩过的坑 还记得刚学 Java 时被Date支配的恐惧吗? 想获取 "2023 年 10 月 1 日"?new Date(2023, 9, 1)—— 等等,为什么月份是 9?哦对,Java 的月份从 0 开…...
实现路径损耗预测)
基于Python的全卷积网络(FCN)实现路径损耗预测
以下是一份详细的基于Python的全卷积网络(FCN)实现路径损耗预测的技术文档。本方案包含理论基础、数据生成、模型构建、训练优化及可视化分析,代码实现约6000字。 基于全卷积网络的无线信道路径损耗预测系统 目录 问题背景与需求分析系统架构设计合成数据生成方法全卷积网络…...

【ubuntu】安装NVIDIA Container Toolkit
目录 安装NVIDIA Container Toolkit 安装依赖 添加密钥和仓库 配置中国科技大学(USTC) 镜像 APT 源 更新 APT 包列表 安装 NVIDIA Container Toolkit 验证安装 重启docker 起容器示例命令 【问题】如何在docker中正确使用GPU? 安装…...
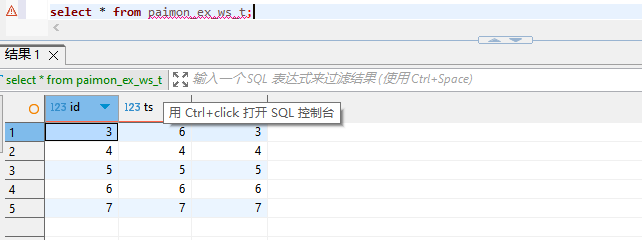
Paimon和Hive相集成
Flink版本1.17 Hive版本3.1.3 1、Paimon集成Hive 将paimon-hive-connector.jar复制到auxlib中,下载链接Index of /groups/snapshots/org/apache/https://repository.apache.org/snapshots/org/apache/paimon/ 通过flink进入查看paimon /opt/softwares/flink-1.…...
:从愿景到落地的精益开发路径——Rally的全流程管理实践)
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践 在创业的黏性阶段,如何将抽象的愿景转化为可落地的产品功能?如何在快速迭代中保持战略聚焦?今天,我们通过Rally软…...
HarmonyOS 鸿蒙应用开发进阶:深入理解鸿蒙跨设备互通机制
鸿蒙跨设备互通(HarmonyOS Cross-Device Collaboration)是鸿蒙系统分布式能力的重要体现,通过创新的分布式软总线技术,实现了设备间的高效互联与能力共享。本文将系统性地解析鸿蒙跨设备互通的技术架构、实现原理及开发实践。 跨设…...

Vue.js教学第十五章:深入解析Webpack与Vue项目实战
Webpack 与 Vue 项目详解 在现代前端开发中,Webpack 作为最流行的模块打包工具之一,对于 Vue 项目的构建和优化起着至关重要的作用。本文将深入剖析 Webpack 的基本概念、在 Vue 项目中的应用场景,并详细讲解常用的 Webpack loaders 和 plugins 的配置与作用,同时通过实例…...

深入浅出 Python Testcontainers:用容器优雅地编写集成测试
在现代软件开发中,自动化测试已成为敏捷开发与持续集成中的关键环节。单元测试可以快速验证函数或类的行为是否符合预期,而集成测试则确保多个模块协同工作时依然正确。问题是:如何让集成测试可靠、可重复且易于维护? 这时&#…...
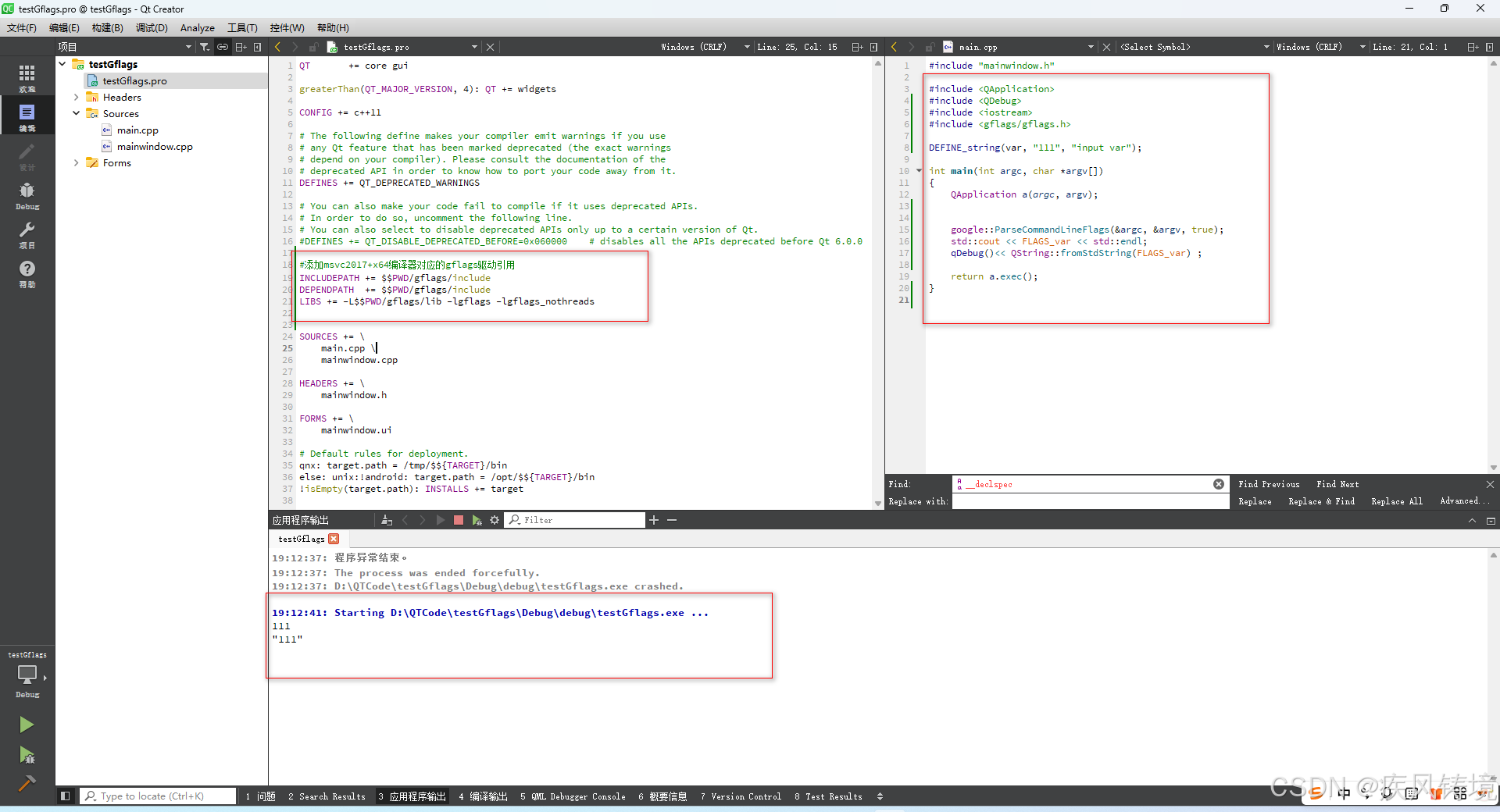
Cmake编译gflags过程记录和在QT中测试
由于在QT中使用PaddleOCR2.8存在这样那样的问题,查找貌似是gflags相关问题导致的,因此从头开始按相关参考文章编译一遍gflags源码,测试结果表明Qt5.14.2中使用MSVC2017X64编译器运行的QTgflags项目是正常。 详细编译步骤如下: 1、…...
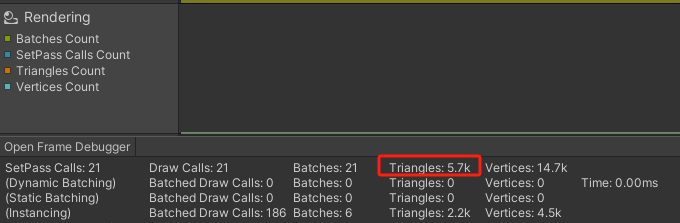
项目中Warmup耗时高该如何操作处理
1)项目中Warmup耗时高该如何操作处理 2)如何在卸载资源后Untracked和Other的内存都回收 3)总Triangles的值是否包含了通过GPU Instancing画的三角形 4)有没有用Lua来修复虚幻引擎中对C代码进行插桩Hook的方案 这是第432篇UWA技术知…...
制作一款打飞机游戏53:子弹样式
现在,我们有一个小程序可以发射子弹,但这些子弹并不完美,我们稍后会修复它们。 子弹模式与目标 在开始之前,我想修正一下,因为我观察到在其他射击游戏中有一个我想复制的简单行为。我们有静态射击、瞄准射击和快速射击…...

Windows磁盘无法格式化及磁盘管理
简述:D盘使用了虚拟分区,结果导致无法格式化。 一、无法格式化磁盘 因为以前划分C盘的时候,空间划小了,所以在下载一些程序的依赖包之后爆红。当我想要把D盘的空间分给C盘时,发现D盘无法格式化。在网上没有找到合适的…...
详解与实现)
每日算法 -【Swift 算法】Z 字形变换(Zigzag Conversion)详解与实现
Swift | Z 字形变换(Zigzag Conversion)详解与实现 🧩 题目描述 给定一个字符串 s 和一个行数 numRows,请按照从上往下、再从下往上的“Z”字形排列这个字符串,并按行输出最终结果。例如: 输入ÿ…...

Docker运维-5.3 配置私有仓库(Harbor)
1. harbor的介绍 Harbor(港湾),是一个用于存储和分发 Docker 镜像的企业级 Registry 服务器。以前的镜像私有仓库采用官方的 Docker Registry,不便于管理镜像。 Harbor 是由 VMWare 在 Docker Registry 的基础之上进行了二次封装,加进去了很…...
day 36
利用前面所学知识,对之前的信贷项目,利用神经网络训练 # 先运行之前预处理好的代码 import pandas as pd import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组…...