如何优化 MySQL 存储过程的性能?

文章目录
- 1. 优化 SQL 语句
- 避免全表扫描
- 减少子查询,改用 JOIN
- 避免 `SELECT `
- 2. 合理使用索引
- 3. 优化存储过程结构
- 减少循环和临时变量
- 避免重复计算
- 4. 使用临时表和缓存
- 5. 优化事务处理
- 6. 分析和监控性能
- 7. 优化数据库配置
- 8. 避免用户自定义函数(UDF)
- 9. 分批处理大数据量
- 性能优化示例
1. 优化 SQL 语句
存储过程的性能往往取决于其中 SQL 语句的效率。
避免全表扫描
确保 WHERE 子句中的条件字段有索引,避免全表扫描:
-- 未优化:可能触发全表扫描
SELECT * FROM orders WHERE order_date > '2023-01-01';-- 优化:为 order_date 添加索引
CREATE INDEX idx_order_date ON orders (order_date);
减少子查询,改用 JOIN
子查询效率较低,尽量用 JOIN 替代:
-- 未优化:子查询
SELECT * FROM employees
WHERE department_id IN (SELECT department_id FROM departments WHERE location = 'Beijing');-- 优化:JOIN
SELECT e.* FROM employees e
JOIN departments d ON e.department_id = d.department_id
WHERE d.location = 'Beijing';
避免 SELECT
只查询需要的字段,减少数据传输和内存开销:
-- 未优化
SELECT * FROM products;-- 优化
SELECT product_id, name, price FROM products;
2. 合理使用索引
- 为经常用于
WHERE、JOIN和ORDER BY的字段添加索引。 - 避免过度索引,索引会增加写操作的开销。
- 使用复合索引时,注意字段顺序(最左匹配原则)。
-- 为多条件查询创建复合索引
CREATE INDEX idx_customer_order ON orders (customer_id, order_date DESC);
3. 优化存储过程结构
减少循环和临时变量
循环(如 WHILE、FOR)在存储过程中效率较低,尽量用集合操作替代:
-- 未优化:循环逐条更新
WHILE condition DOUPDATE products SET stock = stock - 1 WHERE product_id = id;
END WHILE;-- 优化:批量更新
UPDATE products SET stock = stock - 1 WHERE product_id IN (1, 2, 3, ...);
避免重复计算
将重复使用的计算结果存储在临时变量中:
-- 未优化:重复计算
IF (SELECT COUNT(*) FROM orders WHERE customer_id = 100) > 10 THEN-- 再次查询相同条件SELECT SUM(amount) FROM orders WHERE customer_id = 100;
END IF;-- 优化:使用临时变量
DECLARE order_count INT;
SELECT COUNT(*) INTO order_count FROM orders WHERE customer_id = 100;IF order_count > 10 THENSELECT SUM(amount) FROM orders WHERE customer_id = 100;
END IF;
4. 使用临时表和缓存
对于复杂查询,使用临时表存储中间结果,避免重复计算:
DELIMITER $$CREATE PROCEDURE GetSalesReport()
BEGIN-- 创建临时表存储中间结果CREATE TEMPORARY TABLE temp_sales (product_id INT,total_sales DECIMAL(10,2));-- 插入中间结果INSERT INTO temp_salesSELECT product_id, SUM(amount) FROM orders GROUP BY product_id;-- 使用临时表进行最终查询SELECT p.name, t.total_sales FROM products pJOIN temp_sales t ON p.product_id = t.product_id;-- 删除临时表DROP TEMPORARY TABLE IF EXISTS temp_sales;
END$$DELIMITER ;
5. 优化事务处理
- 保持事务简短,减少锁持有时间。
- 避免在事务中进行耗时操作(如文件读写、网络请求)。
DELIMITER $$CREATE PROCEDURE TransferFunds(IN from_account INT, IN to_account INT, IN amount DECIMAL(10,2))
BEGINSTART TRANSACTION;-- 快速执行更新操作UPDATE accounts SET balance = balance - amount WHERE account_id = from_account;UPDATE accounts SET balance = balance + amount WHERE account_id = to_account;COMMIT;
END$$DELIMITER ;
6. 分析和监控性能
-
使用
EXPLAIN分析 SQL 语句的执行计划,检查是否使用了索引:EXPLAIN SELECT * FROM orders WHERE customer_id = 100; -
使用
SHOW PROFILE查看存储过程的详细执行时间:SET profiling = 1; CALL CalculateTotal(1001); SHOW PROFILES; SHOW PROFILE FOR QUERY 1; -- 查询 ID 可从 SHOW PROFILES 结果中获取
7. 优化数据库配置
根据服务器硬件调整 MySQL 配置参数,例如:
innodb_buffer_pool_size:增大缓冲池大小,减少磁盘 I/O。sort_buffer_size:调整排序缓冲区大小,优化排序操作。max_connections:根据并发需求调整最大连接数。
8. 避免用户自定义函数(UDF)
用户自定义函数(尤其是用 Python 或 C 编写的外部 UDF)会显著降低性能,尽量用内置函数替代。
9. 分批处理大数据量
对于大数据集操作,分批处理以减少内存占用:
DELIMITER $$CREATE PROCEDURE ProcessLargeData()
BEGINDECLARE offset INT DEFAULT 0;DECLARE batch_size INT DEFAULT 1000;DECLARE total_rows INT;-- 获取总记录数SELECT COUNT(*) INTO total_rows FROM large_table;WHILE offset < total_rows DO-- 分批处理UPDATE large_table SET status = 'processed' WHERE id BETWEEN offset AND offset + batch_size;SET offset = offset + batch_size;END WHILE;
END$$DELIMITER ;
性能优化示例
假设有一个存储过程查询订单总金额,但性能较差:
DELIMITER $$CREATE PROCEDURE GetOrderTotal(IN customerId INT)
BEGIN-- 未优化:全表扫描 + 子查询SELECT customer_id,(SELECT COUNT(*) FROM orders WHERE customer_id = c.customer_id) AS order_count,(SELECT SUM(amount) FROM orders WHERE customer_id = c.customer_id) AS total_amountFROM customers cWHERE c.customer_id = customerId;
END$$DELIMITER ;
优化后:
DELIMITER $$CREATE PROCEDURE GetOrderTotal(IN customerId INT)
BEGIN-- 优化:JOIN + 索引 + 聚合函数SELECT c.customer_id,COUNT(o.order_id) AS order_count,SUM(o.amount) AS total_amountFROM customers cLEFT JOIN orders o ON c.customer_id = o.customer_idWHERE c.customer_id = customerIdGROUP BY c.customer_id;
END$$DELIMITER ;
相关文章:
如何优化 MySQL 存储过程的性能?
文章目录 1. 优化 SQL 语句避免全表扫描减少子查询,改用 JOIN避免 SELECT 2. 合理使用索引3. 优化存储过程结构减少循环和临时变量避免重复计算 4. 使用临时表和缓存5. 优化事务处理6. 分析和监控性能7. 优化数据库配置8. 避免用户自定义函数(UDF&#…...

深度学习:损失函数与激活函数全解析
目录 深度学习中常见的损失函数和激活函数详解引言一、损失函数详解1.1 损失函数的作用与分类1.2 回归任务损失函数1.2.1 均方误差(MSE)1.2.2 平均绝对误差(MAE) 1.3 分类任务损失函数1.3.1 交叉熵损失(Cross-Entropy&…...

【大前端】Node Js下载文件
NodeJs 获取远程文件有很多方式,常见的方式有以下两种: - fetch(原生) - axios(插件) 通过 Fetch 下载文件,代码如下: import fs from node:fsfunction main(){fetch(http://xxx.x…...

自训练NL-SQL模型
使用T5小模型在笔记本上训练 nature language to SQL/自然语言 转SQL 实测通过。 本文介绍了如何在笔记本上使用T5小模型训练自然语言转SQL的任务。主要内容包括:1) 创建Python 3.9环境并安装必要的依赖包;2) 通过Hugging Face镜像下载wikisql数据集和T5-small模型;3) 实现…...
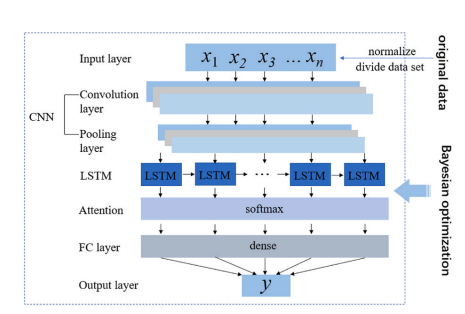
创新点!贝叶斯优化、CNN与LSTM结合,实现更准预测、更快效率、更高性能!
能源与环境领域的时空数据预测面临特征解析与参数调优双重挑战。CNN-LSTM成为突破口:CNN提取空间特征,LSTM捕捉时序依赖,实现时空数据的深度建模。但混合模型超参数(如卷积核数、LSTM层数)调优复杂,传统方法…...

【Flutter】创建BMI计算器应用并添加依赖和打包
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍创建BMI计算器应用并添加依赖和打包。 学其所用,用其所学。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,下…...

【Linux 学习计划】-- 倒计时、进度条小程序
目录 \r 、\n、fflush 倒计时 进度条 进度条进阶版 结语 \r 、\n、fflush 首先我们先来认识这三个东西,这将会是我们接下来两个小程序的重点之一 首先是我们的老演员\n,也就是回车加换行 这里面其实包含了两个操作,一个叫做回车&…...
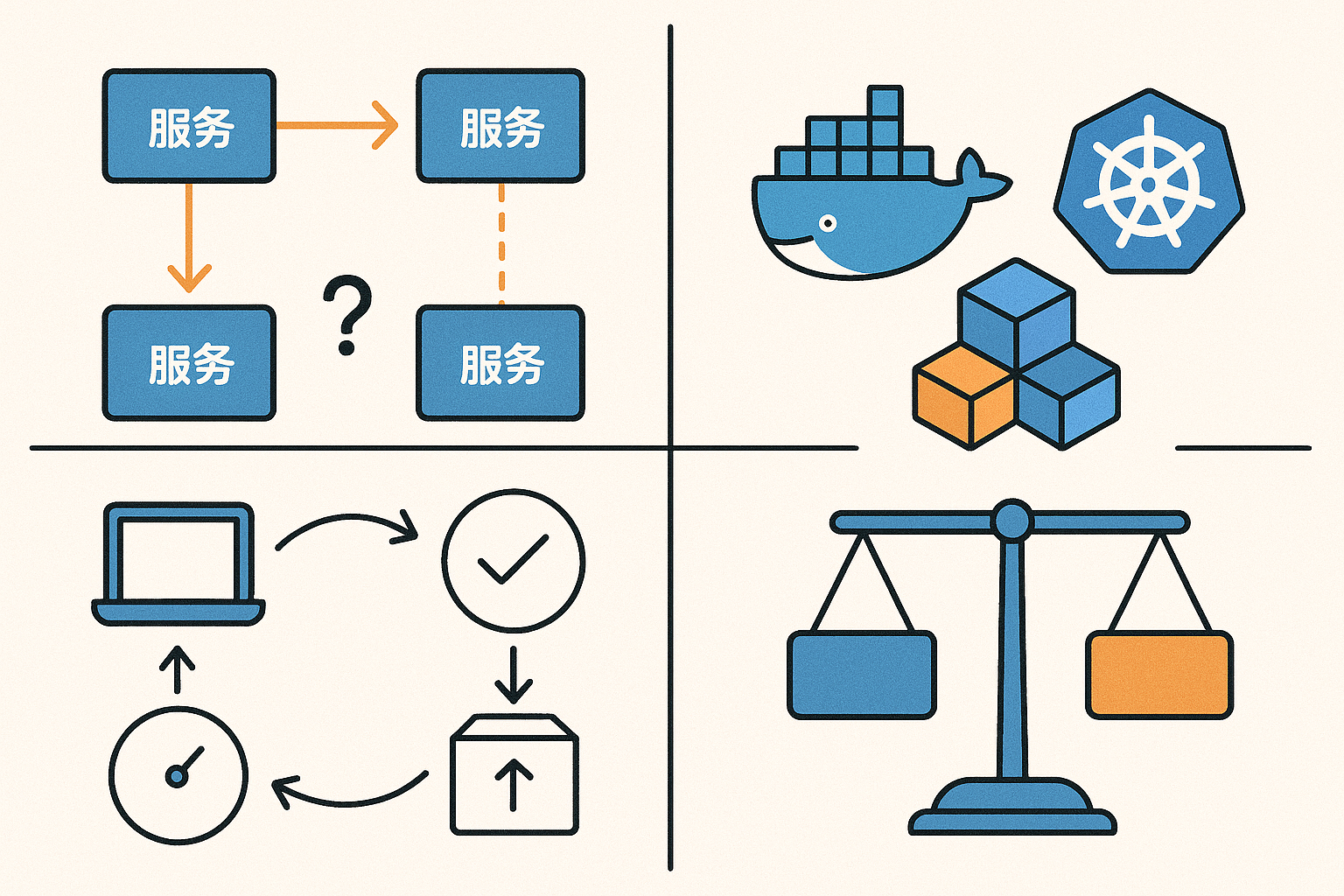
微服务的应用案例
从“菜市场”到“智慧超市”:一场微服务的变革之旅 曾经,我们的系统像一个熙熙攘攘的传统菜市场。所有功能模块(摊贩)都挤在一个巨大的单体应用中。用户请求(买菜的顾客)一多,整个市场就拥堵不堪…...

后端开发概念
1. 后端开发概念解析 1.1. 什么是服务器,后端服务 1.1.1. 服务器 服务器是一种提供服务的计算机系统,它可以接收、处理和响应来自其他计算机系统(客户端)的请求。服务器主要用于存储、处理和传输数据,以便客户端可以…...

2025网络安全趋势报告 内容摘要
2025 年网络安全在技术、法规、行业等多个维度呈现新趋势。技术上,人工智能、隐私保护技术、区块链、量子安全技术等取得进展;法规方面,数据安全法规进一步细化;行业应用中,物联网、工业控制系统安全升级,供…...
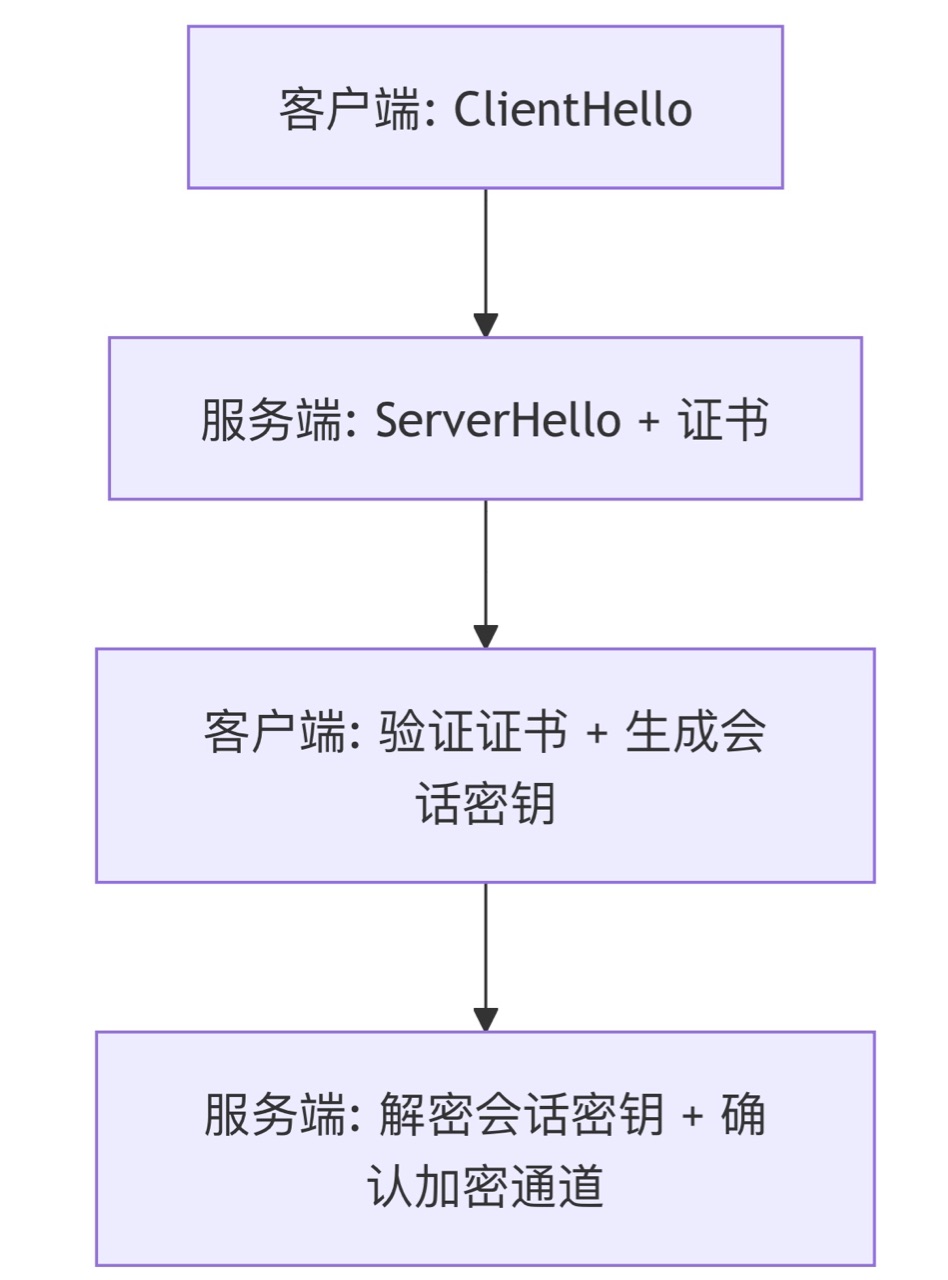
云原生安全基石:深度解析HTTPS协议(从原理到实战)
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念:HTTPS是什么? HTTPS(HyperText Transfer Protocol Secure)是HTTP协议的安全版本,…...

Autodl训练Faster-RCNN网络--自己的数据集(一)
参考文章: Autodl服务器中Faster-rcnn(jwyang)复现(一)_autodl faster rcnn-CSDN博客 Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)_faster rcnn autodl-CSDN博客 食用指南:先跟着参考文章一进行操作,遇到问题再来看我这里有没有解…...
python打卡day36
复习日 仔细回顾一下神经网络到目前的内容,没跟上进度的补一下进度 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。探索性作业(随意完成):尝试进入nn.M…...

8.Java 8 日期时间处理:从 Date 的崩溃到 LocalDate 的优雅自救
一、被 Date 逼疯的程序员:那些年踩过的坑 还记得刚学 Java 时被Date支配的恐惧吗? 想获取 "2023 年 10 月 1 日"?new Date(2023, 9, 1)—— 等等,为什么月份是 9?哦对,Java 的月份从 0 开…...
实现路径损耗预测)
基于Python的全卷积网络(FCN)实现路径损耗预测
以下是一份详细的基于Python的全卷积网络(FCN)实现路径损耗预测的技术文档。本方案包含理论基础、数据生成、模型构建、训练优化及可视化分析,代码实现约6000字。 基于全卷积网络的无线信道路径损耗预测系统 目录 问题背景与需求分析系统架构设计合成数据生成方法全卷积网络…...

【ubuntu】安装NVIDIA Container Toolkit
目录 安装NVIDIA Container Toolkit 安装依赖 添加密钥和仓库 配置中国科技大学(USTC) 镜像 APT 源 更新 APT 包列表 安装 NVIDIA Container Toolkit 验证安装 重启docker 起容器示例命令 【问题】如何在docker中正确使用GPU? 安装…...
Paimon和Hive相集成
Flink版本1.17 Hive版本3.1.3 1、Paimon集成Hive 将paimon-hive-connector.jar复制到auxlib中,下载链接Index of /groups/snapshots/org/apache/https://repository.apache.org/snapshots/org/apache/paimon/ 通过flink进入查看paimon /opt/softwares/flink-1.…...
:从愿景到落地的精益开发路径——Rally的全流程管理实践)
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践
精益数据分析(74/126):从愿景到落地的精益开发路径——Rally的全流程管理实践 在创业的黏性阶段,如何将抽象的愿景转化为可落地的产品功能?如何在快速迭代中保持战略聚焦?今天,我们通过Rally软…...
HarmonyOS 鸿蒙应用开发进阶:深入理解鸿蒙跨设备互通机制
鸿蒙跨设备互通(HarmonyOS Cross-Device Collaboration)是鸿蒙系统分布式能力的重要体现,通过创新的分布式软总线技术,实现了设备间的高效互联与能力共享。本文将系统性地解析鸿蒙跨设备互通的技术架构、实现原理及开发实践。 跨设…...

Vue.js教学第十五章:深入解析Webpack与Vue项目实战
Webpack 与 Vue 项目详解 在现代前端开发中,Webpack 作为最流行的模块打包工具之一,对于 Vue 项目的构建和优化起着至关重要的作用。本文将深入剖析 Webpack 的基本概念、在 Vue 项目中的应用场景,并详细讲解常用的 Webpack loaders 和 plugins 的配置与作用,同时通过实例…...

深入浅出 Python Testcontainers:用容器优雅地编写集成测试
在现代软件开发中,自动化测试已成为敏捷开发与持续集成中的关键环节。单元测试可以快速验证函数或类的行为是否符合预期,而集成测试则确保多个模块协同工作时依然正确。问题是:如何让集成测试可靠、可重复且易于维护? 这时&#…...
Cmake编译gflags过程记录和在QT中测试
由于在QT中使用PaddleOCR2.8存在这样那样的问题,查找貌似是gflags相关问题导致的,因此从头开始按相关参考文章编译一遍gflags源码,测试结果表明Qt5.14.2中使用MSVC2017X64编译器运行的QTgflags项目是正常。 详细编译步骤如下: 1、…...
项目中Warmup耗时高该如何操作处理
1)项目中Warmup耗时高该如何操作处理 2)如何在卸载资源后Untracked和Other的内存都回收 3)总Triangles的值是否包含了通过GPU Instancing画的三角形 4)有没有用Lua来修复虚幻引擎中对C代码进行插桩Hook的方案 这是第432篇UWA技术知…...
制作一款打飞机游戏53:子弹样式
现在,我们有一个小程序可以发射子弹,但这些子弹并不完美,我们稍后会修复它们。 子弹模式与目标 在开始之前,我想修正一下,因为我观察到在其他射击游戏中有一个我想复制的简单行为。我们有静态射击、瞄准射击和快速射击…...

Windows磁盘无法格式化及磁盘管理
简述:D盘使用了虚拟分区,结果导致无法格式化。 一、无法格式化磁盘 因为以前划分C盘的时候,空间划小了,所以在下载一些程序的依赖包之后爆红。当我想要把D盘的空间分给C盘时,发现D盘无法格式化。在网上没有找到合适的…...
详解与实现)
每日算法 -【Swift 算法】Z 字形变换(Zigzag Conversion)详解与实现
Swift | Z 字形变换(Zigzag Conversion)详解与实现 🧩 题目描述 给定一个字符串 s 和一个行数 numRows,请按照从上往下、再从下往上的“Z”字形排列这个字符串,并按行输出最终结果。例如: 输入ÿ…...

Docker运维-5.3 配置私有仓库(Harbor)
1. harbor的介绍 Harbor(港湾),是一个用于存储和分发 Docker 镜像的企业级 Registry 服务器。以前的镜像私有仓库采用官方的 Docker Registry,不便于管理镜像。 Harbor 是由 VMWare 在 Docker Registry 的基础之上进行了二次封装,加进去了很…...
day 36
利用前面所学知识,对之前的信贷项目,利用神经网络训练 # 先运行之前预处理好的代码 import pandas as pd import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组…...
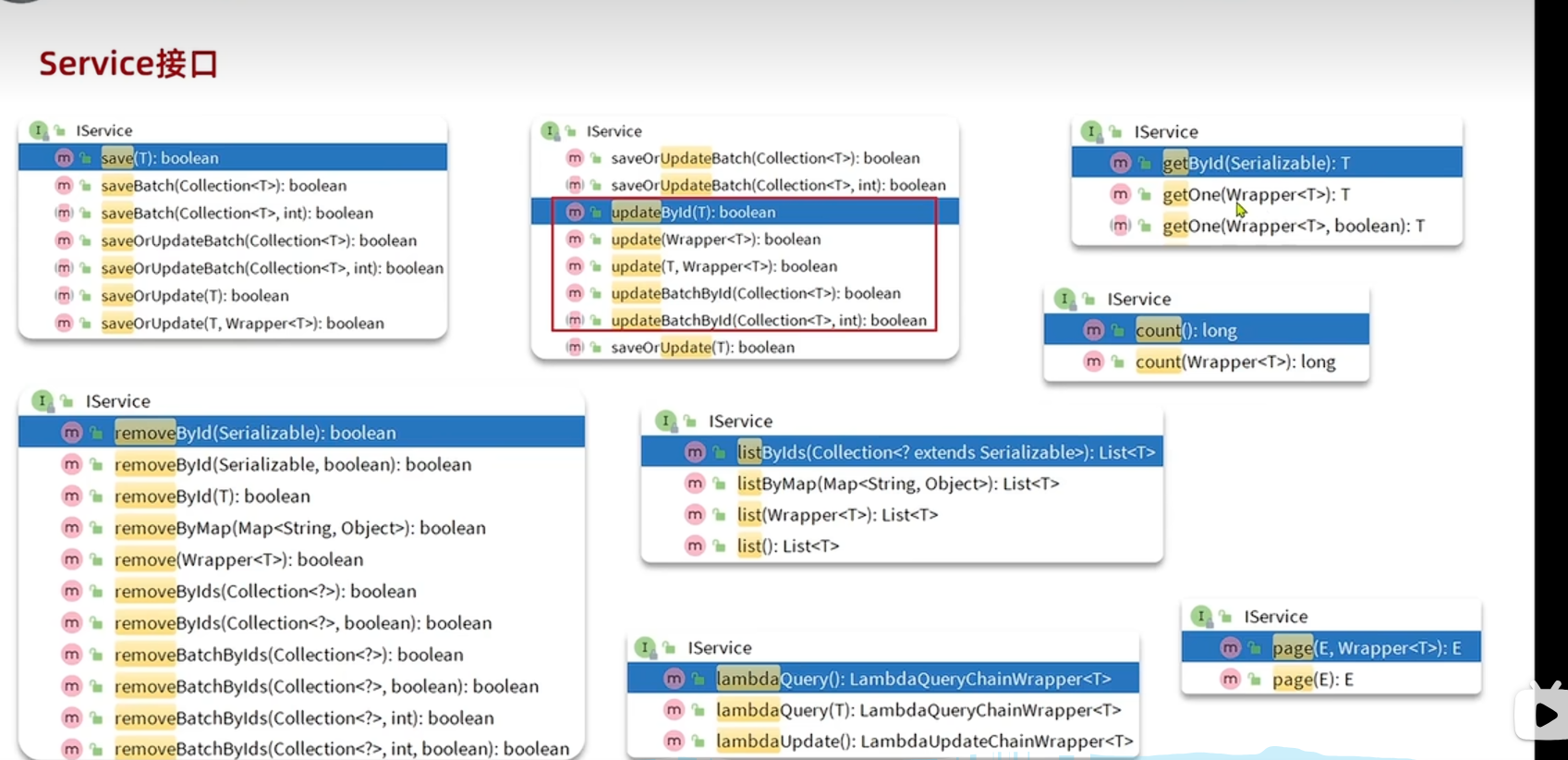
mybatis-plus使用记录
MyBatis-Plus 学习笔记 一、 快速入门 MyBatis-Plus (MP) 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 1. 引入 Maven 依赖 要使用 MyBatis-Plus,首先需要在项目的 pom.xml 文件中引入相…...
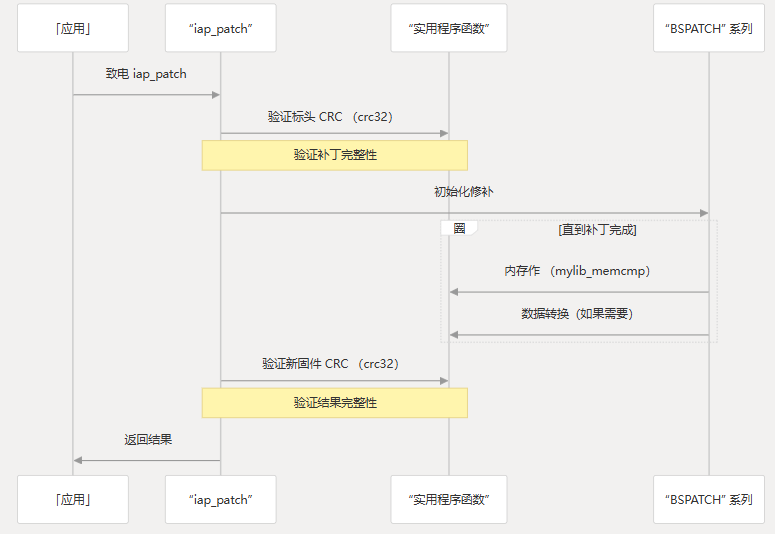
Mcu_Bsdiff_Upgrade
系统架构 概述 MCU BSDiff 升级系统通过使用二进制差分技术,提供了一种在资源受限的微控制器上进行高效固件更新的机制。系统不传输和存储完整的固件映像,而是只处理固件版本之间的差异,从而显著缩小更新包并降低带宽要求。 该架构遵循一个…...