《Drain日志解析算法》论文阅读笔记
这篇文档介绍了一种名为Drain的在线日志解析方法,它采用固定深度的解析树进行流式日志处理 [cite: 1, 6]。
摘要
日志记录了宝贵的系统运行时信息,广泛应用于Web服务管理中 [cite: 1]。典型的日志分析过程首先需要解析原始日志消息,因为它们通常是非结构化的 [cite: 2]。然后应用数据挖掘模型提取关键的系统行为信息 [cite: 3]。现有的大多数日志解析方法侧重于离线批量处理 [cite: 4]。然而,随着日志量的迅速增加,离线方法的模型训练变得非常耗时 [cite: 5]。为解决此问题,论文提出了一种名为Drain的在线日志解析方法,能够以流式和及时的方式解析日志 [cite: 6]。Drain使用固定深度的解析树,并编码了专门设计的解析规则以加速解析过程 [cite: 7]。Drain在五个真实世界日志数据集(包含超过1000万条原始日志消息)上进行了评估 [cite: 8]。实验结果显示,Drain在四个数据集上准确性最高,在其余一个数据集上准确性相当 [cite: 9]。此外,与最先进的在线解析器相比,Drain在运行时间上提升了51.85%~81.47% [cite: 10]。论文还通过一个异常检测任务的案例研究,验证了Drain在日志分析中的有效性 [cite: 11]。
I. 引言
云计算的普及使得面向服务的架构(SOA)成为主流 [cite: 13]。开发者越来越多地利用现有Web服务构建系统 [cite: 14]。尽管基于Web服务的系统开发便捷,但Web服务管理对服务提供商和用户都是一个重大挑战 [cite: 15]。服务提供商需要保证服务的无故障运行和SLA(服务等级协议)的达成 [cite: 16],而服务用户也需要有效管理所采用的服务 [cite: 17]。在此背景下,基于日志分析的服务管理技术得到了广泛研究 [cite: 18]。日志通常是记录服务运行时信息的唯一可用数据资源 [cite: 19]。日志消息是由开发者编写的日志记录语句(如printf(), logging.info())打印的一行文本 [cite: 20]。因此,应用数据挖掘模型从日志中获取系统行为洞察的日志分析技术被广泛用于服务管理 [cite: 21]。
日志分析面临的首要步骤是日志解析,即将非结构化的日志消息转换为结构化事件 [cite: 26]。一条非结构化日志消息通常包含时间戳、详细级别和原始消息内容等信息 [cite: 27]。例如:“081109 204655 556 INFO dfs.DataNode$PacketResponder: Received block blk_3587508140051953248 of size 67108864 from /10.251.42.84” [cite: 28]。
传统上,日志解析严重依赖手动设计和维护的正则表达式 [cite: 28]。但这种手动方法不适用于现代服务产生的日志,原因有三:
- 日志量迅速增加,使得手动方法不可行 [cite: 30]。例如,一个大规模服务系统每小时可产生50GB日志(1.2亿~2亿行) [cite: 31]。
- 系统通常由全球数百名开发者编写的组件构成,负责正则表达式的人可能不了解最初的日志记录目的,增加了手动管理的难度 [cite: 32, 33]。
- 现代系统中的日志记录语句更新频繁,需要定期检查所有日志记录语句以维护正确的正则表达式集,这既繁琐又容易出错 [cite: 34, 35]。
大多数现有日志解析器侧重于离线批量处理 [cite: 37]。一些方法基于源代码自动生成正则表达式,但这在源代码不可访问的情况下(如Web服务组件)并不可行 [cite: 38, 39]。数据驱动方法直接从原始日志消息中提取日志模板,但它们是离线的,受单机内存限制,并且与日志收集方式不符 [cite: 40, 41, 42]。典型的日志收集系统以流式方式将日志条目转发到中央服务器进行解析 [cite: 43]。离线解析器需要在收集一段时间的日志后才能进行训练 [cite: 44]。相比之下,在线日志解析器以流式方式解析日志,无需离线训练步骤 [cite: 45]。因此,当前系统迫切需要在线日志解析,但这方面的研究尚不充分,现有方法在准确性和效率上仍有不足 [cite: 46, 47]。
本文提出的Drain方法是一种在线日志解析方法,能够准确高效地以流式方式解析原始日志消息 [cite: 48]。Drain不依赖源代码或原始日志消息之外的任何信息 [cite: 49]。它能自动从原始日志消息中提取日志模板,并将其划分为不相交的日志组 [cite: 50]。Drain采用固定深度的解析树来指导日志组搜索过程,有效避免了构建过深和不平衡的树 [cite: 51]。解析树节点中紧凑地编码了专门设计的解析规则 [cite: 52]。
II. 日志解析概述
日志解析的目标是将原始日志消息转换为结构化的日志消息 [cite: 63]。原始日志消息包含时间戳和原始消息内容等非结构化数据 [cite: 63]。在解析过程中,解析器区分每个原始日志消息的常量部分和变量部分 [cite: 65]。常量部分是描述系统操作模板(即日志事件)的词元,例如 “Receiving block * src: * dest: *” [cite: 66]。变量部分是携带动态运行时系统信息的其余词元,如 “blk_3587” [cite: 67]。一个典型的结构化日志消息包含匹配的日志事件和感兴趣的字段(如HDFS块ID “blk_3587”) [cite: 68]。典型的日志解析器将日志解析视为一个聚类问题,它们将具有相同日志事件的原始日志消息聚类到一个日志组中 [cite: 69]。
III. 方法论
Drain是一种基于固定深度树的在线日志解析方法 [cite: 71]。
- 当新的原始日志消息到达时,Drain会首先根据领域知识使用简单的正则表达式对其进行预处理 [cite: 72]。
- 然后,Drain按照树的内部节点中编码的专门设计的规则搜索一个日志组(即树的叶节点) [cite: 73]。
- 如果找到合适的日志组,该日志消息将与该日志组中存储的日志事件进行匹配 [cite: 74]。
- 否则,将根据该日志消息创建一个新的日志组 [cite: 75]。
A. 整体树结构
为加速日志组搜索过程,Drain设计了一个固定深度的解析树 [cite: 81]。树的根节点在顶层;底层包含叶节点;树中的其他节点是内部节点 [cite: 82, 83]。根节点和内部节点编码了指导搜索过程的规则,不包含任何日志组 [cite: 84]。每个路径以一个叶节点结束,叶节点存储一个日志组列表 [cite: 84]。每个日志组有两部分:日志事件和日志ID [cite: 84]。日志事件是描述该组日志消息的最佳模板,由日志消息的常量部分组成 [cite: 85]。日志ID记录该组中日志消息的ID [cite: 85]。解析树的一个特殊设计是所有叶节点的深度相同,并由预定义参数depth固定 [cite: 85]。例如,图2中叶节点的深度固定为3 [cite: 85]。此参数限制了Drain在搜索过程中访问的节点数量,从而大大提高了效率 [cite: 85]。为避免树分支爆炸,还使用参数maxChild限制节点的子节点最大数量 [cite: 86]。
B. 步骤1:基于领域知识的预处理
Drain允许用户提供基于领域知识的简单正则表达式,用于表示常用变量(如IP地址、块ID) [cite: 91]。Drain会移除原始日志消息中与这些正则表达式匹配的词元 [cite: 92]。例如,图1中的块ID可以通过 “ b [ k _ [ 0 − 9 ] + b[k\_[0-9]+ b[k_[0−9]+” 移除 [cite: 93]。这些正则表达式通常非常简单,因为它们用于匹配词元而非整个日志消息,一个数据集通常只需要少量此类表达式 [cite: 93, 94]。
C. 步骤2:按日志消息长度搜索
Drain从解析树的根节点开始处理预处理后的日志消息 [cite: 97]。解析树的第1层节点代表其日志消息具有不同日志消息长度(词元数量)的日志组 [cite: 98, 99]。Drain根据预处理后日志消息的长度选择一个到第1层节点的路径 [cite: 100]。这是基于具有相同日志事件的日志消息可能具有相同长度的假设 [cite: 101]。
D. 步骤3:按前缀词元搜索
Drain从步骤2中搜索到的第1层节点遍历到叶节点 [cite: 102]。此步骤基于日志消息起始位置的词元更可能是常量的假设 [cite: 102]。Drain通过日志消息起始位置的词元选择下一个内部节点 [cite: 102]。此步骤中Drain遍历的内部节点数量为 ( d e p t h − 2 ) (depth-2) (depth−2) [cite: 103]。为避免分支爆炸(例如当日志消息以参数开头时),此步骤仅考虑不包含数字的词元 [cite: 108, 109]。如果词元包含数字,它将匹配一个特殊的内部节点"" [cite: 110, 111]。此外,maxChild参数限制了节点的子节点数,如果一个节点已有maxChild个子节点,任何不匹配的词元都将匹配其子节点中的特殊内部节点"" [cite: 112, 113]。
E. 步骤4:按词元相似度搜索
到达叶节点后,该叶节点包含一个日志组列表 [cite: 115]。这些日志组中的日志消息符合沿路径内部节点编码的规则 [cite: 116]。Drain计算日志消息与每个日志组的日志事件之间的相似度 s i m S e q simSeq simSeq [cite: 119]。
s i m S e q = ∑ i = 1 n e q u ( s e q 1 ( i ) , s e q 2 ( i ) ) n simSeq = \frac{\sum_{i=1}^{n}equ(seq_{1}(i),seq_{2}(i))}{n} simSeq=n∑i=1nequ(seq1(i),seq2(i)) [cite: 120]
其中, s e q 1 seq_1 seq1和 s e q 2 seq_2 seq2分别代表日志消息和日志事件; s e q ( i ) seq(i) seq(i)是序列的第i个词元;n是序列的日志消息长度 [cite: 121]。函数 e q u ( t 1 , t 2 ) equ(t_1, t_2) equ(t1,t2)在 t 1 = t 2 t_1=t_2 t1=t2时为1,否则为0 [cite: 122]。
找到具有最大 s i m S e q simSeq simSeq的日志组后,将其与预定义的相似度阈值 s t st st进行比较 [cite: 123]。如果 s i m S e q ≥ s t simSeq \ge st simSeq≥st,则返回该组作为最合适的日志组 [cite: 124]。否则,表示未找到合适的日志组 [cite: 125]。
F. 步骤5:更新解析树
如果步骤4返回了一个合适的日志组,Drain会将当前日志消息的ID添加到返回日志组的日志ID中 [cite: 126]。此外,返回日志组中的日志事件将被更新:扫描日志消息和日志事件中相同位置的词元,如果两个词元不同,则日志事件中该位置的词元将更新为通配符(即"") [cite: 127, 128, 129, 130]。
如果未找到合适的日志组,Drain会根据当前日志消息创建一个新的日志组,其中日志ID仅包含该日志消息的ID,日志事件即为该日志消息本身 [cite: 131]。然后,Drain将使用新的日志组更新解析树,沿路径添加缺失的内部节点和叶节点 [cite: 132, 133]。例如,如果新日志消息为 “Receive 120 bytes”,并且当前解析树中没有合适的路径,Drain会添加新的节点,如果 “120” 包含数字,则对应内部节点编码为 "" [cite: 134, 135]。
IV. 评估
A. 实验设置
- 日志数据集:评估使用了五个真实世界的数据集,包括BGL(蓝基因/L超级计算机)、HPC(高性能集群)、HDFS(Hadoop文件系统)、Zookeeper(分布式系统协调器)和Proxifier(代理客户端) [cite: 136, 149]。这些数据集涵盖了从超级计算机日志到分布式系统日志和单机软件日志的范围 [cite: 136]。HDFS数据集从Amazon EC2平台的203节点集群收集 [cite: 141]。
- 比较方法:Drain与四种现有的日志解析方法进行比较:两种离线解析器LKE [cite: 146] 和IPLOM [cite: 147],以及两种在线解析器SHISO [cite: 148] 和Spell [cite: 151]。
- 评估指标和实验设置:使用F-measure评估准确性,其定义为 A c c u r a c y = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l Accuracy = \frac{2 \times Precision \times Recall}{Precision + Recall} Accuracy=Precision+Recall2×Precision×Recall [cite: 153, 156]。其中, P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP, R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP [cite: 158]。TP(真阳性)决策是将具有相同日志事件的两条日志消息分配到同一日志组;FP(假阳性)决策是将具有不同日志事件的两条日志消息分配到同一日志组;FN(假阴性)决策是将具有相同日志事件的两条日志消息分配到不同日志组 [cite: 158, 159, 160]。实验在具有Intel Xeon E5-2670v2 CPU和128GB RAM的Linux服务器上运行 [cite: 163]。对于Drain的预处理,移除了明显的参数(如IP地址、核心ID等) [cite: 164]。Drain的参数设置(如
depth、st)如表II所示,maxChild经验性地设置为100 [cite: 165, 162]。
B. Drain的准确性
准确性衡量日志解析器将原始日志消息与正确日志事件匹配的程度 [cite: 169]。Drain在五个数据集中的四个上获得了最佳准确性,甚至优于离线方法 [cite: 175, 155]。在Proxifier数据集上,Drain的准确性(0.86)也具有可比性,仅次于Spell(0.87) [cite: 176, 155]。LKE由于其 O ( n 2 ) O(n^2) O(n2)的时间复杂度,在处理大数据集时表现不佳,因此在部分数据集上使用了2k条日志的样本进行评估 [cite: 173, 174]。Drain的整体最佳准确性归因于三个原因:1) 它结合了日志消息长度和前几个词元这些有效规则来构建固定深度树 [cite: 181];2) Drain仅使用不含数字的词元指导搜索过程,有效避免了过度分区 [cite: 182];3) 可调的树深度和相似度阈值 s t st st允许用户针对不同数据集进行细粒度调整 [cite: 183]。
C. Drain的效率
Drain在所有五个真实世界数据集上均需要最少的运行时间 [cite: 191, 157]。例如,Drain仅需2分钟即可解析400万条BGL日志消息,6分钟即可解析1000万条HDFS日志消息 [cite: 192]。与现有在线解析方法相比,Drain在运行时间上至少提升了51.85%,在HPC数据集上减少了81.47%的运行时间 [cite: 193, 194]。Drain的性能也优于现有的离线日志解析方法IPLOM [cite: 195]。作为一种在线方法,Drain不受单台计算机内存的限制,而这是大多数离线方法的瓶颈 [cite: 196, 197]。Drain的时间复杂度为 O ( ( d + c m ) n ) O((d+cm)n) O((d+cm)n),其中d是解析树的深度,c是叶节点中候选日志组的数量,m是日志消息长度,n是日志消息数量 [cite: 209]。由于d、m和c可以视为常数,因此Drain的时间复杂度为 O ( n ) O(n) O(n) [cite: 210, 211]。相比之下,SHISO和Spell的解析树深度可能在解析过程中增加,并且它们计算最长公共子序列的时间复杂度为 O ( m 1 m 2 ) O(m_1m_2) O(m1m2),而Drain使用的 s i m S e q simSeq simSeq计算复杂度为 O ( m 1 + m 2 ) O(m_1+m_2) O(m1+m2)(在Drain中 m 1 = m 2 m_1=m_2 m1=m2) [cite: 211, 212, 213, 214]。
D. Drain在真实世界异常检测任务中的有效性
为了评估Drain在后续日志挖掘任务中的有效性,论文在HDFS数据集上进行了一个异常检测案例研究 [cite: 218, 219]。HDFS数据集包含575,061个HDFS块的操作记录,共有29种日志事件类型,其中16,838个块被手动标记为异常 [cite: 220, 221]。原始论文使用主成分分析(PCA)来检测这些异常 [cite: 222]。异常检测流程包括日志解析和日志挖掘:首先将原始日志解析为结构化日志消息,然后生成事件计数矩阵,使用TF-IDF进行预处理,最后输入PCA模型进行异常判断 [cite: 223, 224, 227, 228, 229, 231]。
实验结果(表VI)表明,使用Drain进行解析时,异常检测性能接近最优 [cite: 243, 234]。Drain检测到10,720个真实异常,仅有278个错误警报 [cite: 244, 234]。尽管IPLOM表现出相同的检测性能,但它们的解析结果不同 [cite: 247, 234]。高解析准确率(如SHISO的0.93)并不总能保证在后续挖掘任务中的良好性能;使用SHISO会导致1,907个错误警报,远多于其他方法 [cite: 248, 249, 234]。在在线解析方法中,Drain不仅具有最高的解析准确性,而且在异常检测案例研究中也获得了近乎最佳的性能 [cite: 251]。
V. 相关工作
- 服务管理的日志分析:日志广泛用于服务管理任务,如业务模型挖掘、用户行为分析、异常检测、故障诊断和性能改进等 [cite: 252]。日志解析是实现自动化和有效日志分析的关键步骤 [cite: 252]。
- 日志解析:已有研究包括基于源代码的解析器(准确性高但源代码常不可得)和数据驱动方法(如LKE, IPLOM为离线方法;SHISO, Spell为在线方法) [cite: 254, 255, 256, 257, 258, 259]。Drain是一种在线解析器,在准确性和效率上均优于现有在线方法,甚至优于一些离线方法 [cite: 260, 261, 262]。
- Web服务系统的可靠性:许多研究致力于增强Web服务系统的可靠性,包括动态重配置、服务选择与推荐、基于客户端反馈的QoS监控等 [cite: 263, 264, 265, 266, 267]。Drain提出的在线日志解析器对日志分析技术至关重要,可以补充这些方法以增强Web服务系统的可靠性 [cite: 269]。
VI. 结论
日志解析对于基于日志分析的Web服务管理技术至关重要 [cite: 271]。本文提出的Drain是一种在线日志解析方法,它以流式方式解析原始日志消息 [cite: 272]。Drain采用固定深度的解析树来加速日志组搜索过程,并在其树节点中编码了专门设计的规则 [cite: 273]。在五个真实世界日志数据集上的实验表明,Drain在准确性和效率方面均显著优于现有的在线日志解析器 [cite: 274, 275]。Drain甚至取得了比受单机内存限制的顶尖离线日志解析器更好的性能 [cite: 276]。此外,一个真实世界异常检测任务的案例研究证明了Drain在日志分析任务中的有效性 [cite: 277]。
相关文章:

《Drain日志解析算法》论文阅读笔记
这篇文档介绍了一种名为Drain的在线日志解析方法,它采用固定深度的解析树进行流式日志处理 [cite: 1, 6]。 摘要 日志记录了宝贵的系统运行时信息,广泛应用于Web服务管理中 [cite: 1]。典型的日志分析过程首先需要解析原始日志消息,因为它们…...

MMAction2重要的几个配置参数
embed_dims(全称 embedding dimensions)是指每个 patch(块)或特征的通道数/维度,是 Transformer 或 Swin Transformer 等模型中最核心的特征表示维度。 embed_dims 必须能被 num_heads 整除 具体解释 在 Swin Transfo…...
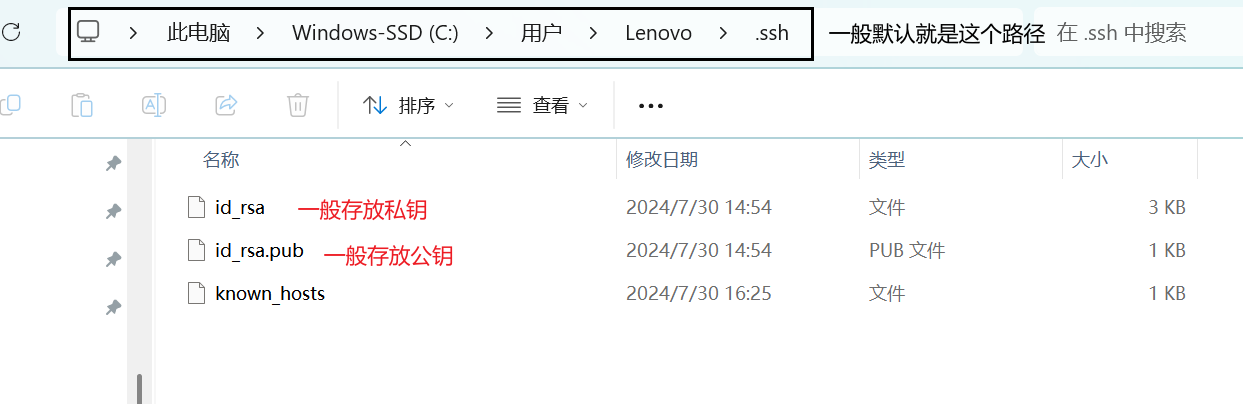
Windows系统如何查看ssh公钥
很多人只是一味的为拿到ssh公钥而努力,往往却会忽略了ssh公钥与私钥背后的作用。 咱们在这里会花两分钟。 一分钟速通概念,一分钟教会你如何获取。 一分钟速通概念: 如何生成: SHH 公钥 与 私钥 是基于非对称加密算法ÿ…...

UniApp+Vue3微信小程序二维码生成、转图片、截图保存整页
二维码生成工具使用uqrcode/js,版本4.0.7 官网地址:uQRCode 中文文档(不建议看可能会被误导) 本项目采用了npm引入方式,也可通过插件市场引入,使用上会略有不同 准备工作: 安装:pnpm…...

8.2 线性变换的矩阵
一、线性变换的矩阵 本节将对每个线性变换 T T T 都指定一个矩阵 A A A. 对于一般的列向量,输入 v \boldsymbol v v 在空间 V R n \pmb{\textrm V}\pmb{\textrm R}^n VRn 中,输出 T ( v ) T(\boldsymbol v) T(v) 在空间 W R m \textrm{\pmb W}\…...
【2025】嵌入式软考中级部分试题
大题: 大模型 神经网络 机器学习 深度学习的包含关系 不一定对 订阅-发布者模型 发布/订阅模式特点: ①解耦:发布者和订阅者之间没有直接联系,它们通过中间的消息代理(如消息队列或事件总线)进行通信。这种解耦使得系统更加灵活,可以独立地添加或移除发布者和订阅者…...
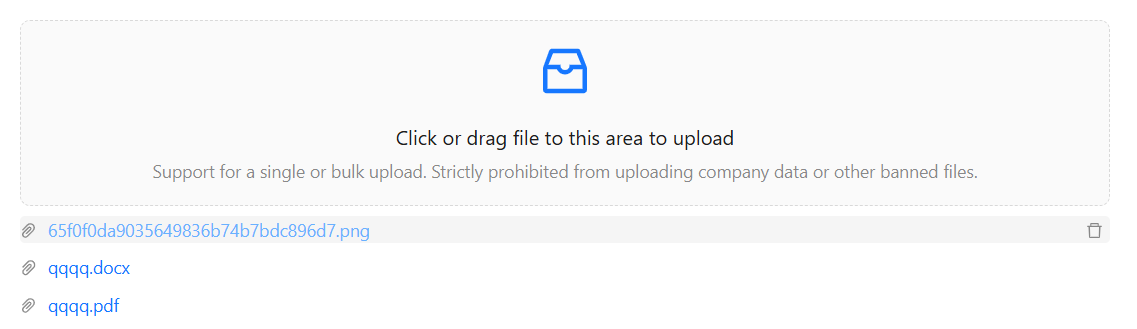
Antd中Upload组件封装及使用:
1.Upload上传组件功能: 文件校验 : 文件格式校验/文件大小校验/上传文件总个数校验 相关功能 : 拖拽功能/上传到远程(七牛)/文件删除及下载 2.组件效果展示: 3.疑难点及解决方案: Promise.all多文件并行上传到远程(七牛云): (1)在beforeUpload钩子函数中获取token (2)循环fi…...
Linux环境基础开发工具->vim
引入:vim是什么? vs叫作继承开发环境,我们可以在里面编辑代码,调式代码,运行代码....这种叫集成开发环境;而vim只用来编辑代码,也就是类似于在windows上打开一个记事本来写代码的操作 集成开发…...

跳板问题(贪心算法+细节思考)
首先直接看题: 这题直接贪心其实问题不大: 下面先展示我的一个错误代码: # include<iostream> # include<vector> # include<algorithm>using namespace std;int main() {int N,M;cin>>N>>M;vector<vecto…...
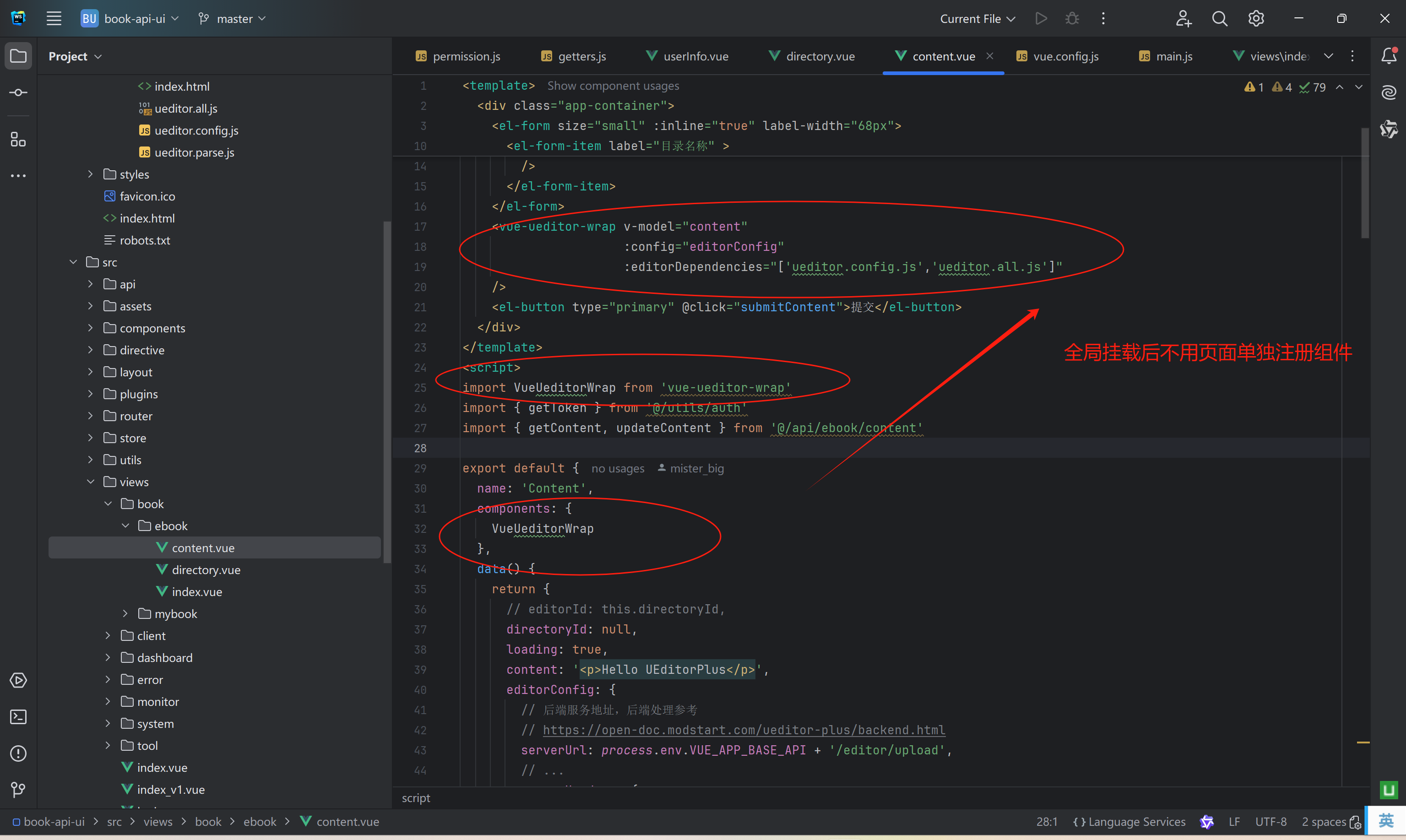
RuoYi前后端分离框架集成UEditorPlus富文本编辑器
一、背景 采用若依框架搭建了一个小型的电子书项目,项目前端、后端、移动端就一人,电子书的章节内容是以富文本内容进行呈现的,产品设计人员直接给了一个第三方收费的富文本编辑器截图放到开发文档中,提了一沓需求点,概况下来就是要做成下图中的样子。作为一个后端开发人…...
IPD流程落地:项目任务书Charter开发
目录 简介 第一个方面,回答的是Why的问题。 第二点,要回答做什么的问题,也就是产品定义What的问题。 第三点就是要回答执行策略与计划的问题,也就是How、When、Who的问题。 第四点是对上述这些分析的总结分析,要为…...
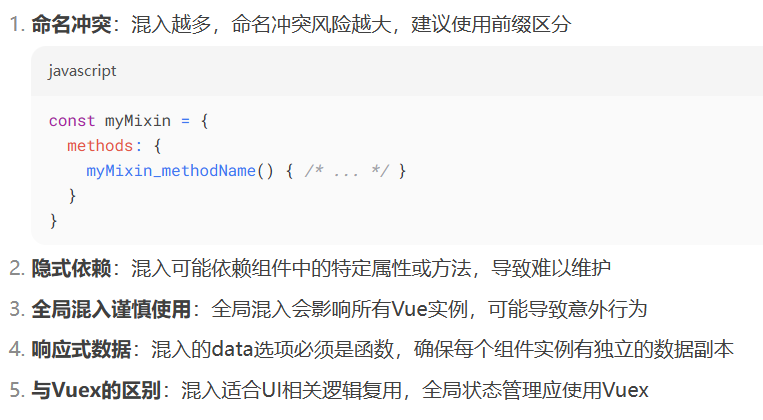
Vue 2 混入 (Mixins) 的详细使用指南
1.基本概念 混入 (Mixins) 是 Vue 2 中用于组件代码复用的重要特性,它允许你将可复用的功能分发到多个组件中。 混入是一种灵活的代码复用方式,可以包含任意组件选项(data、methods、生命周期钩子等)。当组件使用混入时ÿ…...

day020-sed和find
文章目录 1. sed1.1 查找、过滤文本1.1.1 根据行号取行1.1.2 根据行号取范围1.1.3 过滤出指定行1.1.4 过滤出指定范围内容 1.2 替换文件内容1.2.1 将文件中虚拟用户命令解释器替换成/bin/bash1.2.2 修改原文件并备份1.2.3 为每行开头加上# 1.3 反向引用(后向引用&am…...

OpenGL Chan视频学习-4 Vertex Buffers and Drawing a Triangle in OpenGL
一、视频链接 【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973 二、相关网站 docs.gl 三、代码整理 c #include <GL/glew.h> #include <GLFW/glfw3.h>#include<iostream>int…...
)
数据库事务的四大特性(ACID)
一、前言 在现代数据库系统中,事务(Transaction)是确保数据一致性和完整性的重要机制。事务的四大特性——原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)…...

网络安全全知识图谱:威胁、防护、管理与发展趋势详解
1 网络安全基础概念 1.1 什么是网络安全 网络安全是指通过技术、管理和法律等手段,保护计算机网络系统中的硬件、软件及其系统中的数据,不因偶然的或者恶意的原因而遭受到破坏、更改、泄露,确保系统连续可靠正常地运行,网络服务不…...
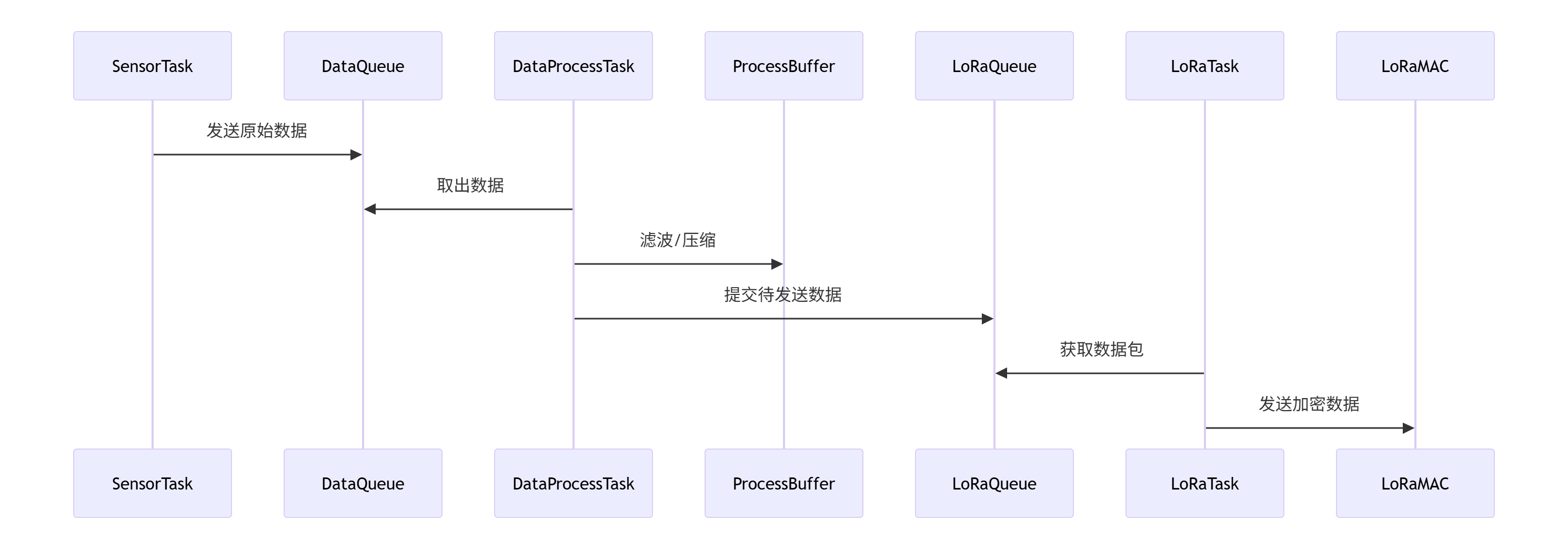
FreeRTOS 在物联网传感器节点的应用:低功耗实时数据采集与传输方案
FreeRTOS 在物联网传感器节点的应用:低功耗实时数据采集与传输方案 二、FreeRTOS 任务划分与优先级设计 任务名称优先级执行周期功能描述Sensor_Collect3100ms多传感器数据采集与预处理Data_Process2事件驱动数据滤波/压缩/异常检测LoRa_Transmit41s低功耗长距离数…...
)
解决 iTerm2 中 nvm 不生效的问题(Mac 环境)
解决 iTerm2 中 nvm 不生效的问题(Mac 环境) 标题 《为什么 iTerm2 无法使用 nvm?—— 解决 Mac 终端环境变量冲突指南》 问题描述 许多开发者在 Mac 上使用 nvm 管理 Node.js 版本时,发现: 原生终端:n…...

Linux环境下基于Docker安装 PostgreSQL数据库并配置 pgvector
文章目录 1 docker-compose 安装 PostgreSQL 容器内安装 pgvector1.1 基于 docker-compose 安装 PostgreSQL 数据库1.2 容器内配置 pgvector 2. docker-compose Dockerfile 形式直接配置PostgreSQL数据库及 pgvector参考资料 PostgreSQL是一种功能强大的开源关系数据库管理系…...
(9)-java+ selenium->元素定位之By name
1.简介 上一篇已经介绍了通过id来定位元素,继续介绍其他剩下的七种定位方法中的通过name来定位元素。本文来介绍Webdriver中元素定位方法之By name,顾名思义,就是我们想要定位的目标元素节点上,有一个name ="value"的属性,这样我们就可以通过name的value直接去…...

深浅拷贝?
一、定义: 浅拷贝:只复制对象的第一层属性,若第一层属性是引用类型(如对象、数组),则复制其内存地址,修改拷贝后的嵌套对象会影响原对象。 深拷贝:递归复制对象的所有层级…...

Beckhoff PLC 功能块 FB_CTRL_ACTUAL_VALUE_FILTER (模拟量滤波)
1. 功能块概览 名称:FB_CTRL_ACTUAL_VALUE_FILTER(实际值滤波控制功能块)。作用:对测量输入值进行合理性检查( plausibility check )和滤波处理,防止异常跳变(如传感器信号突变&…...

Mysql在SQL层面的优化
以下是MySQL在SQL层面的优化方法及详细案例,结合实际场景说明如何通过调整SQL语句提升性能: 1. 确保索引有效使用 案例:订单状态查询优化 问题SQL: SELECT * FROM orders WHERE status shipped AND create_time > 2023-01-…...

JVM规范之栈帧
JVM规范之栈帧 前言正文概述局部变量表操作数栈动态链接 总结参考链接 前言 上一篇文章了解了JVM规范中的运行时数据区: JVM规范之运行时数据区域 其中,栈是JVM线程私有的内存区,栈中存储的单位是帧(frames)ÿ…...
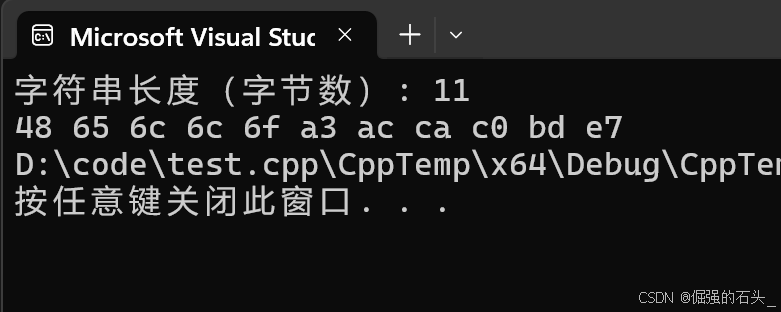
【C++指南】string(四):编码
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《C指南》 期待您的关注 引言 在 C 编程中,处理字符串是一项极为常见的任务。而理解字符串在底层是如何编码存储的&…...

深度学习之序列建模的核心技术:LSTM架构深度解析与优化策略
LSTM深度解析 一、引言 在深度学习领域,循环神经网络(RNN)在处理序列数据方面具有独特的优势,例如语音识别、自然语言处理等任务。然而,传统的 RNN 在处理长序列数据时面临着严重的梯度消失问题,这使得网…...

AI量化交易是什么?它是如何重塑金融世界的?
第一章:证券交易的进化之路 1.1 从喊价到代码:交易方式的革命性转变 在电子交易普及之前,证券交易依赖于交易所内的公开喊价系统。交易员通过手势、喊话甚至身体语言传递买卖信息,这种模式虽然直观,但效率低下且容易…...
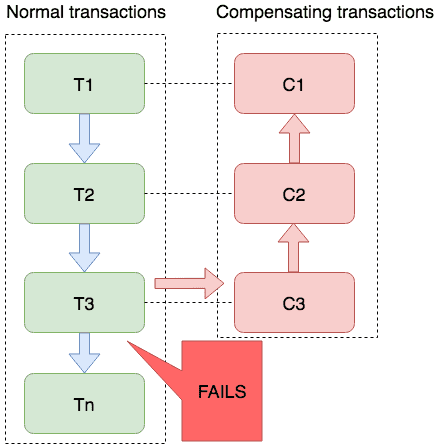
分布式事务处理方案
1. 使用Seata框架解决 1.1 XA 事务 1.1.1 XA整体流程 第一阶段 RM1开启XA事务-> 执行业务SQL -> 上报TC执行结果RM2开启XA事务-> 执行业务SQL -> 上报TC执行结果 第二阶段 TC根据 RM上报结果通知RM一起提交/回滚XA事务 1.1.2 XA特点 XA 模式必须要有数据库的支…...

CVE-2024-36467 Zabbix权限提升
漏洞描述 在Zabbix中,具有API访问权限的已认证用户(例如具有默认用户角色的用户)可以通过调用user.update API接口,将自己添加到任何用户组(如Zabbix管理员组)。然而,用户无法添加到已被禁用或…...
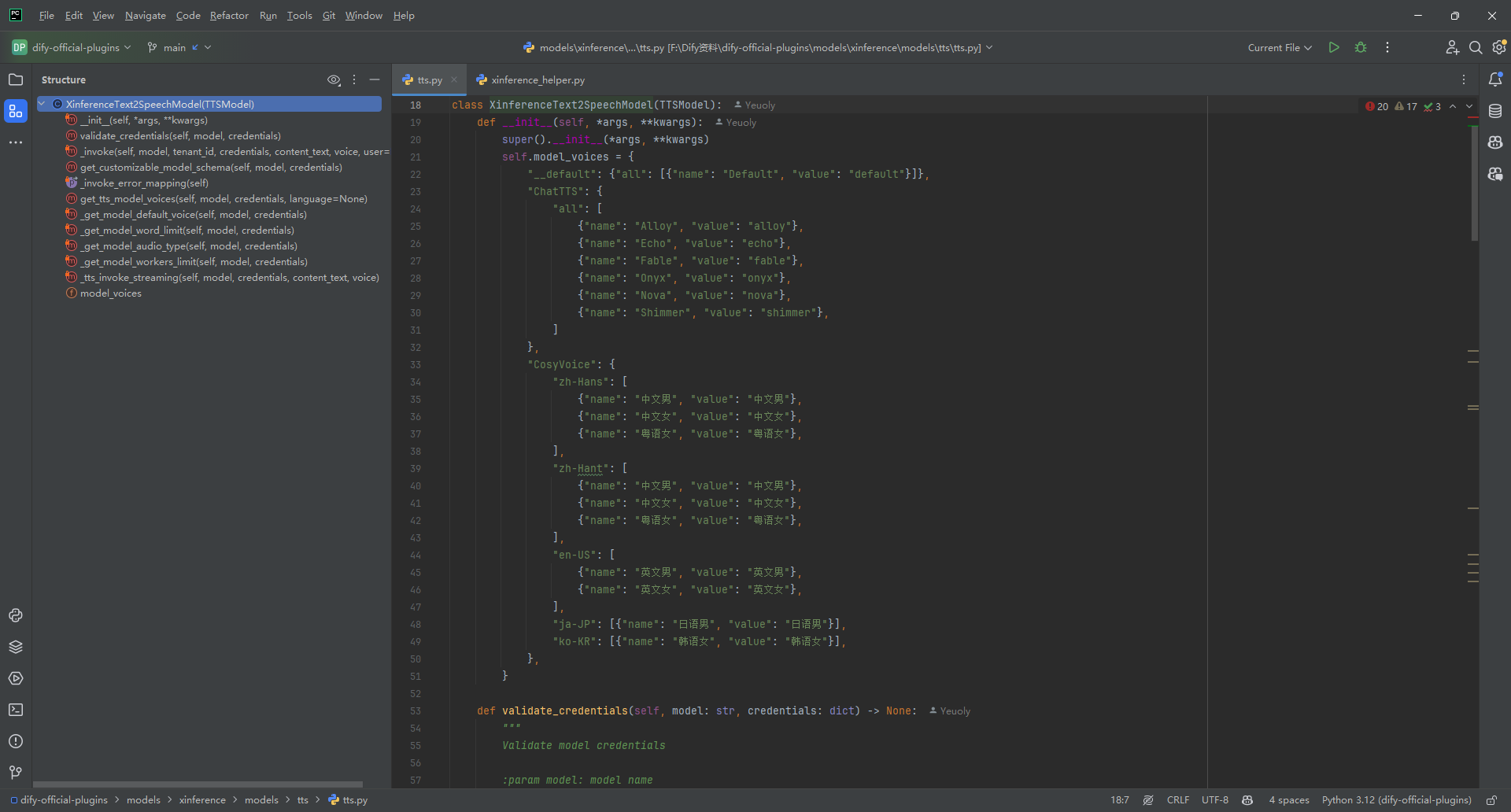
Dify中的自定义模型插件开发例子:以xinference为例
本文使用Dify v1.0.0-beta.1版本。模型插件结构基本是模型供应商(模型公司,比如siliconflow、xinference)- 模型分类(模型类型,比如llm、rerank、speech2text、text_embedding、tts)- 具体模型(…...