python打卡day37
知识点回顾:
- 过拟合的判断:测试集和训练集同步打印指标
- 模型的保存和加载
- 仅保存权重
- 保存权重和模型
- 保存全部信息checkpoint,还包含训练状态
- 早停策略
是否过拟合,可以通过同步打印训练集和测试集的loss曲线来判断(要点就是训练一定epoch后,就开始推理,然后接着训练)
正常训练(理想情况)
-
训练Loss和测试Loss 同步下降,最终趋于稳定
-
两条曲线的最终值接近,且测试Loss没有明显上升
过拟合
-
训练Loss 持续下降,但测试Loss 在某一阶段后开始上升
-
两条曲线之间的差距逐渐拉大(训练Loss远低于测试Loss)
欠拟合
-
训练Loss和测试Loss 均较高,且下降缓慢或停滞
-
两条曲线几乎重合,但Loss值远未达到预期
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库用于进度条显示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 4000 # 训练的轮数# 用于存储每20个epoch的损失值和对应的epoch数
train_losses = [] # 存储训练集损失
test_losses = [] # 新增:存储测试集损失
epochs = []start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 20 == 0:# 计算测试集损失,新增代码model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss') # 原始代码已有
plt.plot(epochs, test_losses, label='Test Loss') # 新增:测试集损失曲线
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend() # 新增:显示图例
plt.grid(True) # 添加网格线
plt.show()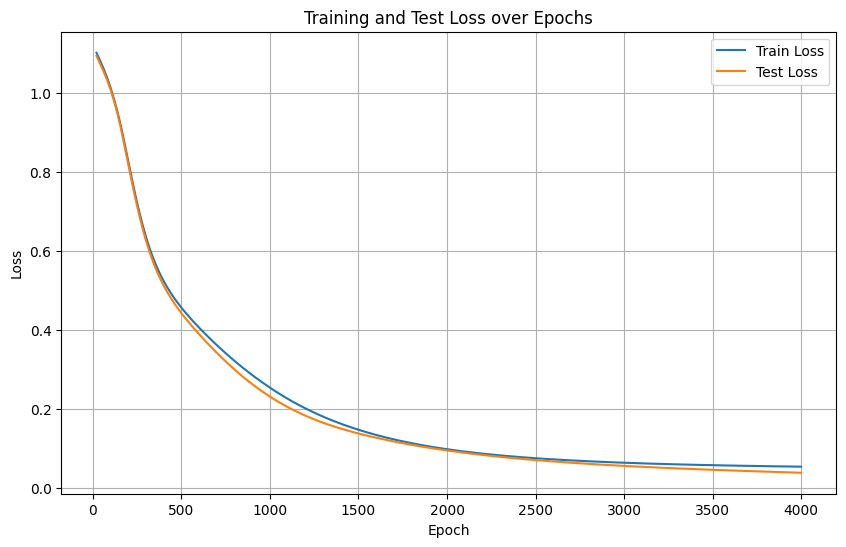
深度学习中模型的保存与加载主要涉及参数(权重)和整个模型结构的存储,同时需兼顾训练状态(如优化器参数、轮次等)以支持断点续训
1、仅保存模型参数(推荐)
- 原理:保存模型的权重参数,不保存模型结构代码。加载时需提前定义与训练时一致的模型类
- 优点:文件体积小(仅含参数),跨框架兼容性强(需自行定义模型结构)
# 保存模型参数
torch.save(model.state_dict(), "model_weights.pth") # 第一个参数是模型参数字典,第二个参数是保存名称及路径
# 加载参数(需先定义模型结构)
model = MLP() # 初始化与训练时相同的模型结构
model.load_state_dict(torch.load("model_weights.pth")) # torch.load()从文件中反序列化参数字典,load_state_dict()将参数字典加载到模型中
# model.eval() # 切换至推理模式(可选)2、保存模型+权重
- 原理:保存模型结构及参数
- 优点:加载时无需提前定义模型类
- 缺点:文件体积大,依赖训练时的代码环境(如自定义层可能报错)
# 保存整个模型
torch.save(model, "full_model.pth")# 加载模型(无需提前定义类,但需确保环境一致)
model = torch.load("full_model.pth")
# model.eval() # 切换至推理模式(可选)3、保存训练状态(断点续训)
- 原理:保存模型参数、优化器状态(学习率、动量)、训练轮次、损失值等完整训练状态,用于中断后继续训练
- 适用场景:长时间训练任务(如分布式训练、算力中断)
# 保存训练状态
checkpoint = {"model_state_dict": model.state_dict(),"optimizer_state_dict": optimizer.state_dict(),"epoch": epoch,"loss": best_loss,
}
torch.save(checkpoint, "checkpoint.pth")# 加载并续训
model = MLP()
optimizer = torch.optim.Adam(model.parameters())
checkpoint = torch.load("checkpoint.pth")model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
start_epoch = checkpoint["epoch"] + 1 # 从下一轮开始训练
best_loss = checkpoint["loss"]# 继续训练循环
for epoch in range(start_epoch, num_epochs):pass # 模型训练的代码块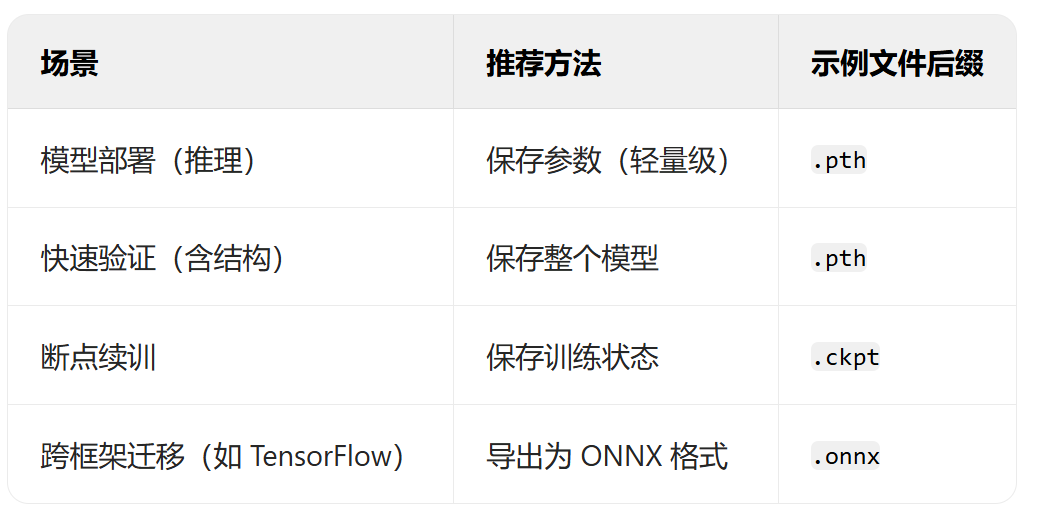
早停法
刚才也说了,过拟合是测试集的曲线会在某一时刻开始上升,那当曲线不再变好,此时提前终止训练,避免模型对训练集过度拟合,这就是早停法
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库用于进度条显示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 4000 # 训练的轮数# 用于存储每20个epoch的损失值和对应的epoch数
train_losses = [] # 存储训练集损失
test_losses = [] # 新增:存储测试集损失
epochs = []# ===== 新增早停相关参数 =====
best_test_loss = float('inf') # 记录最佳测试集损失
best_epoch = 0 # 记录最佳epoch
patience = 50 # 早停耐心值(连续多少轮测试集损失未改善时停止训练)
counter = 0 # 早停计数器
early_stopped = False # 是否早停标志
# ==========================start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 20 == 0:# 计算测试集损失,新增代码model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# ===== 新增早停逻辑 =====if test_loss.item() < best_test_loss: # 如果当前测试集损失小于最佳损失best_test_loss = test_loss.item() # 更新最佳损失best_epoch = epoch + 1 # 更新最佳epochcounter = 0 # 重置计数器# 保存最佳模型torch.save(model.state_dict(), 'best_model.pth')else:counter += 1if counter >= patience:print(f"早停触发!在第{epoch+1}轮,测试集损失已有{patience}轮未改善。")print(f"最佳测试集损失出现在第{best_epoch}轮,损失值为{best_test_loss:.4f}")early_stopped = Truebreak # 终止训练循环# ======================# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss') # 原始代码已有
plt.plot(epochs, test_losses, label='Test Loss') # 新增:测试集损失曲线
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend() # 新增:显示图例
plt.grid(True)
plt.show()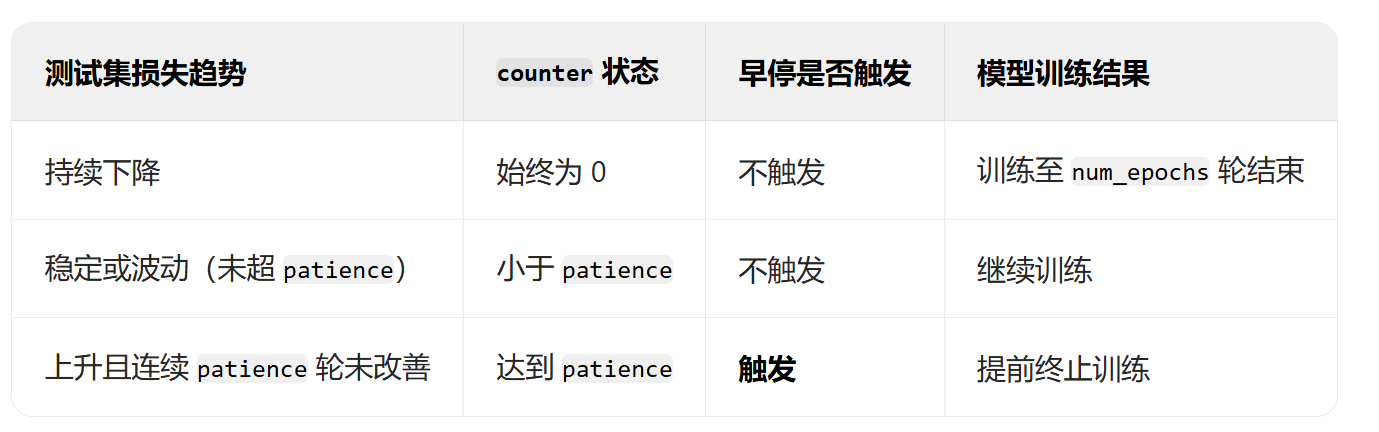
阈值patience的设置就很重要了。。。
相关文章:
python打卡day37
早停策略和模型权重保存 知识点回顾: 过拟合的判断:测试集和训练集同步打印指标模型的保存和加载 仅保存权重保存权重和模型保存全部信息checkpoint,还包含训练状态 早停策略 是否过拟合,可以通过同步打印训练集和测试集的loss曲线…...
)
Redis 5.0.10 集群部署实战(3 主 3 从,三台服务器)
本文详细介绍如何在三台服务器上部署 Redis 5.0.10 的集群(3 主 3 从),并为每个步骤、配置项和命令提供清晰的注释说明,确保生产环境部署稳定可靠。 1️⃣ 环境准备 目标架构:3 主 3 从,共 6 个节点,分布在 3 台服务器 服务器信息: 192.16.1.85 192.16.1.86 192.16.1.8…...

各个网络协议的依赖关系
网络协议的依赖关系 学习网络协议之间的依赖关系具有多方面重要作用,具体如下: 帮助理解网络工作原理 - 整体流程明晰:网络协议分层且相互依赖,如TCP/IP协议族,应用层协议依赖传输层的TCP或UDP协议来传输数据&#…...

OSC协议简介、工作原理、特点、数据的接收和发送
OSC协议简介 Open Sound Control(OSC) 是一种开放的、独立于传输的基于消息的协议,主要用于计算机、声音合成器和其他多媒体设备之间的通信。它提供了一种灵活且高效的方式来发送和接收参数化消息,特别适用于实时控制应用&#x…...

区块链可投会议CCF C--APSEC 2025 截止7.13 附录用率
Conference:32nd Asia-Pacific Software Engineering Conference (APSEC 2025) CCF level:CCF C Categories:软件工程/系统软件/程序设计语言 Year:2025 Conference time:December 2-5, 2025 in Macao SAR, China …...

【数字图像处理】_笔记
第一章 概述 1.1 什么是数字图像? 图像分为两大类:模拟图像与数字图像 模拟图像:通过某种物理(光、电)的强弱变化来记录图像上各个点的亮度信息 连续:从空间上和数值上是不间断的 举例&…...
从0开始学习R语言--Day10--时间序列分析数据
在数据分析中,我们经常会看到带有时间属性的数据,比如股价波动,各种商品销售数据,网站的网络用户活跃度等。一般来说,根据需求我们会分为两种,分析历史数据的特点和预测未来时间段的数据。 移动平均 移动平…...

基于开源链动2+1模式AI智能名片S2B2C商城小程序的产品驱动型增长策略研究
摘要:在数字化经济时代,产品驱动型增长(Product-Led Growth, PLG)已成为企业突破流量瓶颈、实现用户裂变的核心战略。本文以“开源链动21模式AI智能名片S2B2C商城小程序”(以下简称“链动AI-S2B2C系统”)为…...

每日算法 -【Swift 算法】反转整数的陷阱与解法:Swift 中的 32 位整数处理技巧
反转整数的陷阱与解法:Swift 中的 32 位整数处理技巧 在面试题和算法练习中,整数反转是一道非常经典的题目。乍一看很简单,但一旦加入“不能使用 64 位整数”和“不能溢出 32 位整数范围”这两个限制,问题就立刻变得有挑战性。本…...

使用 OpenCV 实现“随机镜面墙”——多镜片密铺的哈哈镜效果
1. 引言 “哈哈镜”是一种典型的图像变形效果,通过局部镜面反射产生扭曲的视觉趣味。在计算机视觉和图像处理领域,这类效果不仅有趣,还能用于艺术创作、交互装置、视觉特效等场景。 传统的“哈哈镜”往往是针对整张图像做某种镜像或扭曲变换…...
鸿蒙仓颉开发语言实战教程:页面跳转和传参
前两天分别实现了商城应用的首页和商品详情页面,今天要分享新的内容,就是这两个页面之间的相互跳转和传递参数。 首先我们需要两个页面。如果你的项目中还没有第二个页面,可以右键cangjie文件夹新建仓颉文件: 新建的文件里面没什…...

如何在Vue中实现延迟刷新列表:以Element UI的el-switch为例
如何在Vue中实现延迟刷新列表:以Element UI的el-switch为例 在开发过程中,我们经常需要根据用户操作或接口响应结果来更新页面数据。本文将以Element UI中的el-switch组件为例,介绍如何在状态切换后延迟1秒钟再调用刷新列表的方法࿰…...

最新Spring Security实战教程(十六)微服务间安全通信 - JWT令牌传递与校验机制
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...

MDM在智能健身设备管理中的技术应用分析
近年来,随着智能硬件的普及和健身行业的数字化转型,越来越多健身房引入了Android系统的智能健身设备,如智能动感单车、智能跑步机、体测仪等。这些设备通过内嵌的安卓终端,实现了健身内容播放、用户交互、远程课程等功能ÿ…...

OSPF ABR汇总路由
一、OSPF ABR汇总配置(手工汇总) 📌 场景示例 假设ABR连接区域0和区域1,区域1内存在多个子网(如10.1.0.0/24、10.1.1.0/24),需将其手动汇总为10.0.0.0/8并通告至区域0。 🔧 配置命…...
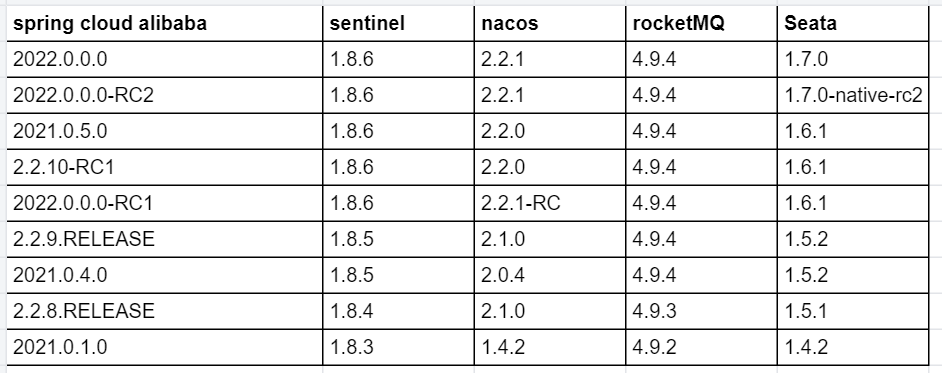
【五】Spring Cloud微服务开发:解决版本冲突全攻略
Spring Cloud微服务开发:解决版本冲突全攻略 目录 Spring Cloud微服务开发:解决版本冲突全攻略 概述 一、Spring Boot 二、Spring Cloud 三、Spring Cloud Alibaba 总结 概述 spring cloud微服务项目开发过程中经常遇到程序包版本冲突的问题&…...
Spring Boot微服务架构(二):开发调试常见中文问题
Spring Boot开发调试常见中文问题及解决方案 一、环境配置类问题 端口冲突 表现:启动时报错"Address already in use"解决:修改application.properties中的server.port或终止占用端口的进程 数据库连接失败 表现:启动时报错"…...
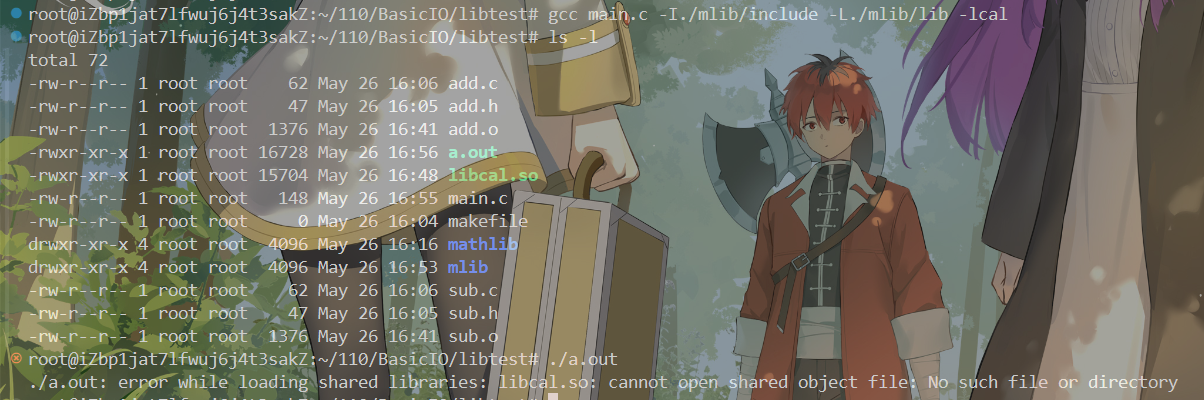
Linux基础IO----动态库与静态库
什么是库? 库是由一些.o文件打包在一起而形成的可执行程序的半成品。 如何理解这句话呢? 首先,一个程序在运行前需要进行预处理、编译、汇编、链接这几步。 预处理: 完成头文件展开、去注释、宏替换、条件编译等,最终…...
LeetCode百题刷004(哈希表优化两数和问题)
遇到的问题都有解决的方案,希望我的博客可以为你提供一些帮助 一、哈希策略优化两数和问题 题目地址:1. 两数之和 - 力扣(LeetCode)https://leetcode.cn/problems/two-sum/description/ 思路分析: 题目要求在一个整型…...
编码与new String()解码的字符集转换机制)
解析Java String.getBytes()编码与new String()解码的字符集转换机制
引言 在Java开发中,字符编码与解码是处理文本数据的基础操作,但稍有不慎就会导致乱码问题。理解字符串在内存中的存储方式以及如何正确使用编码转换方法,是保证跨平台、多语言兼容性的关键。本文将通过编码与解码的核心方法、常见问题场景及…...

从万有引力到深度学习,认识模型思维
从万有引力到深度学习,认识模型思维 引言 从牛顿发现万有引力定律到现代深度学习的崛起,“模型思维”始终是人类理解世界、解决问题的核心工具。它不仅是科学研究的基石,更是技术创新的底层逻辑。本文将从科学史、技术应用、认知效率等角度…...

2022 年 9 月青少年软编等考 C 语言八级真题解析
目录 T1. 道路思路分析T2. 控制公司思路分析T3. 发现它,抓住它思路分析T4. 青蛙的约会思路分析T1. 道路 题目链接:SOJ D1216 N N N 个以 1 ∼ N 1 \sim N 1∼N 标号的城市通过单向的道路相连,每条道路包含两个参数:道路的长度和需要为该路付的通行费(以金币的数目来表示…...
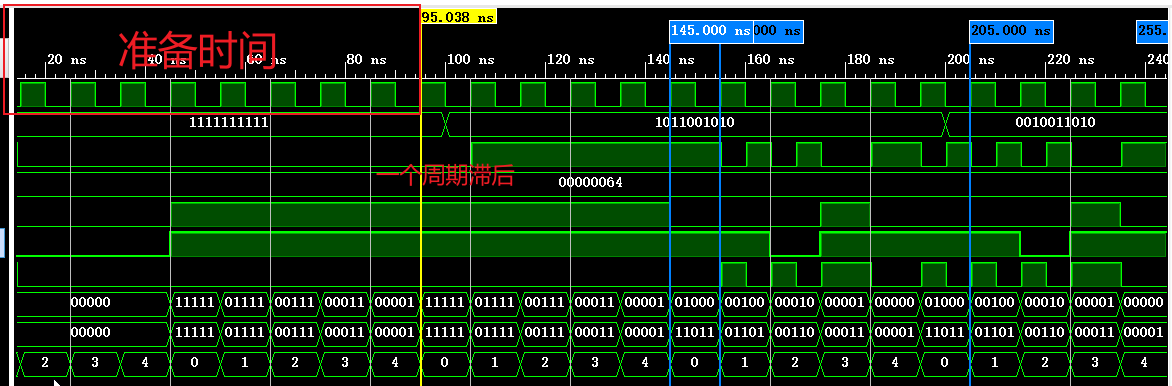
FPGA通信之VGA与HDMI
文章目录 VGA基本概念:水平扫描:垂直扫描: 时序如下:端口设计疑问为什么需要输出那么多端口不输出时钟怎么保证电子枪移动速度符合时序VGA转HDMI 仿真电路图代码总结:VGA看野火电子教程 HDMITMDS传输原理为什么使用TMD…...
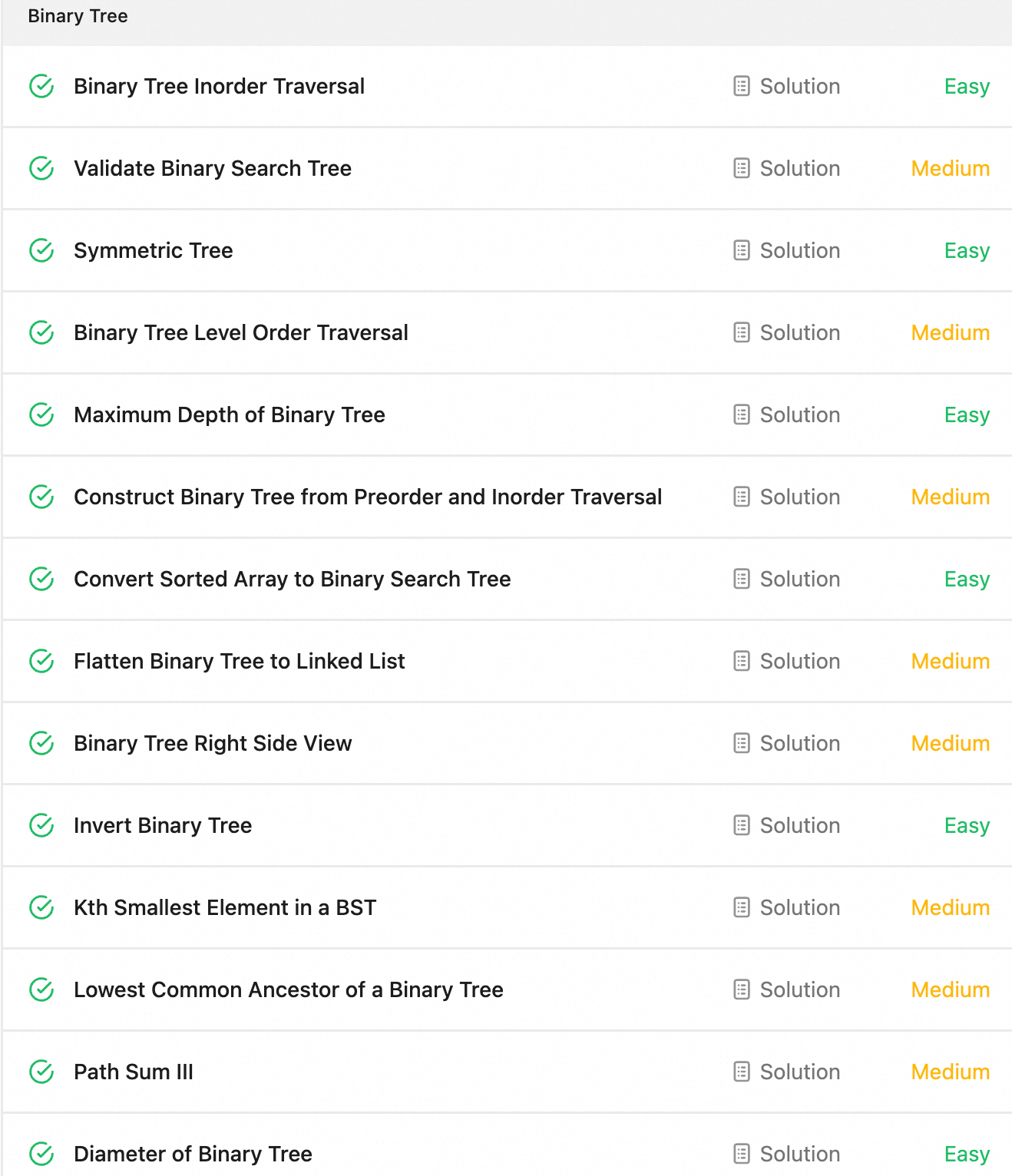
Leetcode百题斩-二叉树
二叉树作为经典面试系列,那么当然要来看看。总计14道题,包含大量的简单题,说明这确实是个比较基础的专题。快速过快速过。 先构造一个二叉树数据结构。 public class TreeNode {int val;TreeNode left;TreeNode right;TreeNode() {}TreeNode…...

修改 K8S Service 资源类型 NodePort 的端口范围
在 Kubernetes 中,Service 类型为 NodePort 时,默认分配的端口范围为 30000~32767。如果你希望使用自定义端口(如 8080、8888 等),就需要修改 kube-apiserver 的默认配置。 本文将详细介绍如何修改 Kubernetes 中 Nod…...

ACM Latex模板:合并添加作者和单位
目录: 1.ACM会议论文Latex模板,逐个添加作者和单位: 1)Latex: 2)效果: 2. ACM会议论文Latex模板,合并添加作者和单位: 1)Latex: 2&#x…...

爬虫IP代理技术深度解析:场景、选型与实战应用
目录 一、代理IP的核心技术架构 二、典型应用场景技术解析 场景1:电商价格监控系统 场景2:社交媒体舆情分析 场景3:金融数据采集 三、代理IP选型方法论 1. 性能评估矩阵 2. 成本优化模型 3. 风险管控体系 四、未来技术演进方向 五、…...
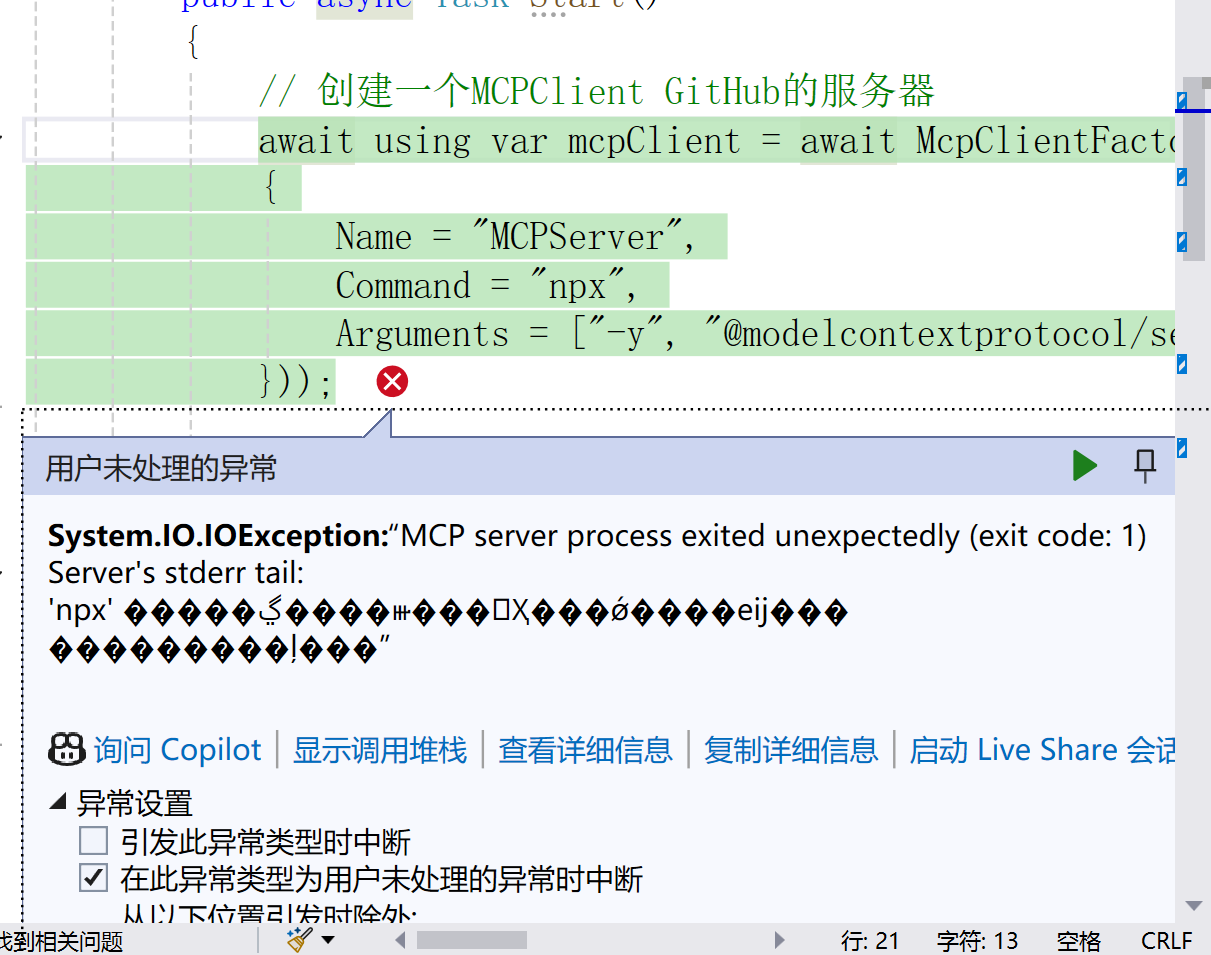
将MCP(ModelContextProtocol)与Semantic Kernel集成(调用github)
文章目录 将MCP(ModelContextProtocol)与Semantic Kernel集成(调用github)一、模型上下文协议(MCP)简介1.1 简介1.2 示例 二、集成步骤2.1 安装环境依赖2.2 构建语义内核(Kernel)2.3…...

游戏引擎学习第311天:支持手动排序
仓库: https://gitee.com/mrxiao_com/2d_game_7(已满) 新仓库: https://gitee.com/mrxiao_com/2d_game_8 回顾并为今天的内容定下基调 我们接下来要继续完成之前开始的工作,上周五开始的部分内容,虽然当时对最终效果还不太确定,但现在主要任…...
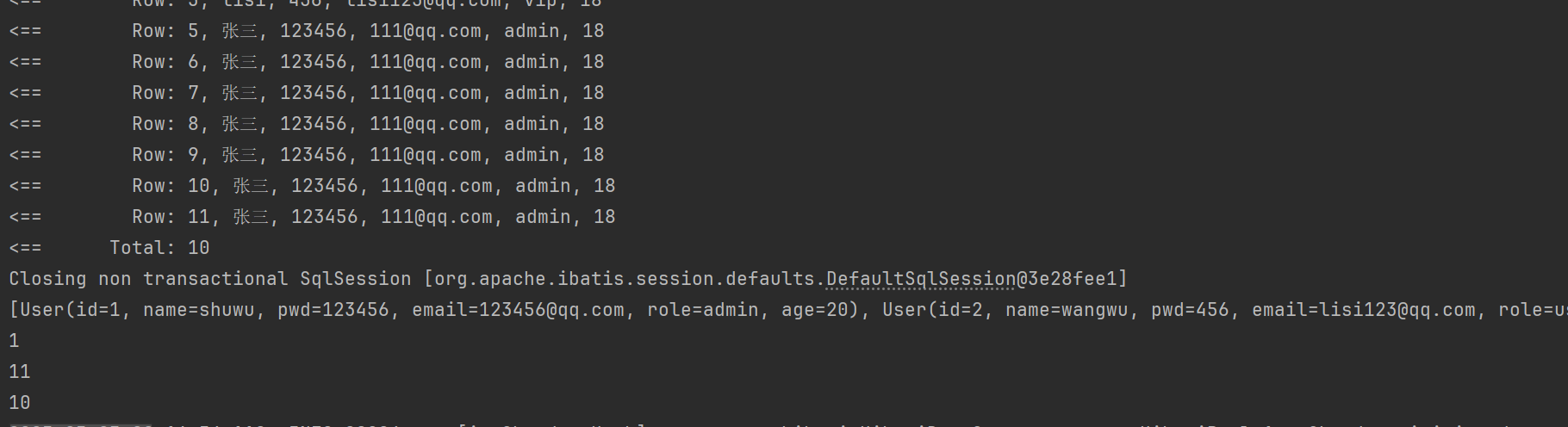
LambdaQueryWrapper、MybatisPlus提供的基本接口方法、增删改查常用的接口方法、自定义 SQL
DAY26.2 Java核心基础 MybatisPlus提供的基本接口方法 分页查询 导入依赖springboot整合Mybatis-plus <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.3</version&g…...