mongodb语法$vlookup性能分析
1 场景描述
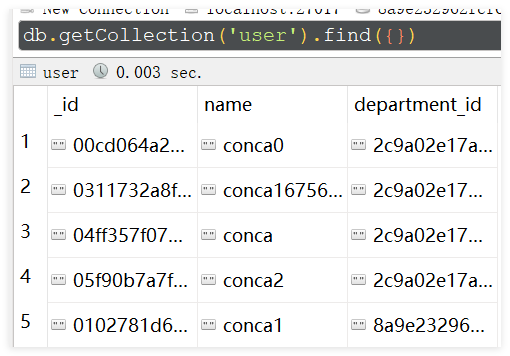
mongodb有两个表department和user表,
department表有_id,name,level,表有记录169w条
user表有_id,name,department_id,表有记录169w条,department_id没有创建索引,department_id是department的_id。
现在需要写个vlooup方法,查询level下面有多少用户。

2 user表$vlookup表department写法
db.user.aggregate([// 连接 department 表获取 level 信息{$lookup: {from: "department", // 关联的目标表localField: "department_id", // user 表的关联字段foreignField: "_id", // department 表的关联字段as: "dept" // 关联结果的别名}},// 展开 dept 数组(每个用户对应一个部门){$unwind: "$dept"},// 按层级分组并统计用户数量{$group: {_id: "$dept.level", // 按部门层级分组userCount: { $sum: 1 }, // 统计每个层级的用户数departmentNames: { $addToSet: "$dept.name" } // 收集部门名称}}
], { allowDiskUse: true });
3 department表$vlookup表user写法
db.department.aggregate([// 步骤1:关联 user 表(类似 VLOOKUP){$lookup: {from: "user", // 关联的集合名称(user 表)localField: "_id", // department 表的关联字段(_id)foreignField: "department_id", // user 表的关联字段(department_id)as: "users" // 将匹配的 user 文档存入 users 数组}},// 步骤2:计算每个 department 的用户数{$addFields: {user_count: { $size: "$users" } // 通过数组长度获取用户数}},// 步骤3:按 level 分组统计总用户数{$group: {_id: "$level", // 按 level 分组total_users: { $sum: "$user_count" } // 累加用户数}}
], { allowDiskUse: true });user表$vlookup表department写法 速度快于 department表$vlookup表user写法
为什么呢?
user表$vlookup表department写法:
先读取user表数据
读取user表字段department_id值
根据department_id值去user表_id关联查找,user表的_id有索引,所以速度快
4 将user表的数据分别切割成10w、50w、100w、150w
// 步骤 1:将符合条件的 50w 条数据写入新表
db.user.aggregate([{ $match: { /* 筛选条件,如:age > 30 */ } }, // 可选:添加筛选条件{ $limit: 1500000 }, // 限制迁移数量{ $out: "user150" } // 写入新表
], { allowDiskUse: true }); // 允许磁盘临时存储5 分别执行user表$vlookup表department写法sql,看看执行时间
user表10w 关联department表169w耗时10098ms
user表50w 关联department表169w耗时76067ms
user表100w 关联department表169w耗时174097ms
user表150w 关联department表169w耗时297307ms
假如读取一条user表耗时x,根据索引_id读取department耗时是y
100000x+100000y=10098
500000x+500000y=76067
1000000x+1000000y=174097
1500000x+1500000y=297307
处理1条数据大概需要0.1877ms
相关文章:
mongodb语法$vlookup性能分析
1 场景描述 mongodb有两个表department和user表, department表有_id,name,level,表有记录169w条 user表有_id,name,department_id,表有记录169w条,department_id没有创建索引,department_id是department的_id。 现…...

晶圆隐裂检测提高半导体行业效率
半导体行业是现代制造业的核心基石,被誉为“工业的粮食”,而晶圆是半导体制造的核心基板,其质量直接决定芯片的性能、良率和可靠性。晶圆隐裂检测是保障半导体良率和可靠性的关键环节。 晶圆检测 通过合理搭配工业相机与光学系统,…...

临床试验中的独立数据监查委员会
1. IDMC会议概况 1.1 核心职责 1.1.1 安全性监查 IDMC需评估不良事件(AE)和严重不良事件(SAE),确保受试者风险可控。这是其核心职责之一,通过严格的安全性监查,保障受试者的健康和安全,避免因试验带来的不可控风险。 1.1.2 有效性评估 在预先设定的期中分析中,IDMC要…...
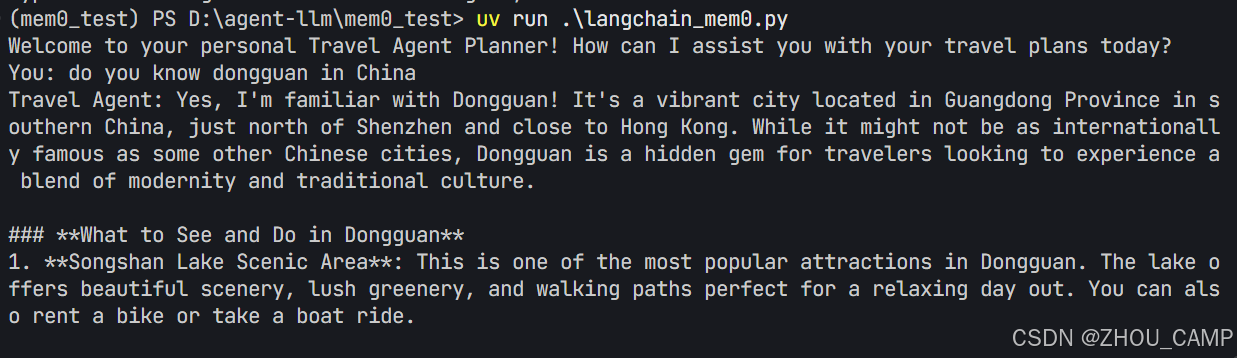
在 LangChain 中集成 Mem0 记忆系统教程
目录 简介环境准备基础配置核心组件说明1. 提示模板设计2. 上下文检索3. 响应生成4. 记忆存储 工作流程解析使用示例关键特性完整代码与效果 简介 Mem0 是一个强大的记忆系统,可以帮助 AI 应用存储和检索历史对话信息。本教程将介绍如何在 LangChain 应用中集成 Me…...

PTA练习题
文章目录 L1-101 别再来这么多猫娘了!(字符串查找-替换)L2-049 鱼与熊掌(set/暴力/vector)L2-050 懂蛇语(字符串匹配)L2-051 满树的遍历(前序)L2-001 紧急救援(最短路) L…...

华润电力招聘认知能力测评及性格测评真题题库考什么?
华润电力招聘测评包含逻辑推理、数字推理、语言理解三大类型的问卷。共计58题。测评限时60分钟。其中逻辑推理、数字推理、语言推理分别限时20分钟,如逾时未完成相关测试,测试将自动终止,请注意测评时间。为了确保测评的连贯性,建…...

Maven Profile在插件与依赖中的深度集成
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

手机平板等设备租赁行业MDM方案解析
目录 引言:MDM 在租赁行业的重要性日益凸显 用户场景:租赁公司面临的主要挑战 1. 设备丢失、逾期未还 2. 手动配置和恢复效率低 3. 非授权使用频繁 4. 时区设置混乱影响运维 5. 缺乏实时监管能力 EasyControl MDM:租赁设备的远程管控…...

【前端】使用HTTPS
在前端本地开发环境中使用 HTTPS 主要取决于你用的是哪个构建工具(如 Vite、Webpack、Vue CLI 等)。 目录 ViteWebpack本地生产环境 npx serve浏览器提示“不安全”解决方法上传github注意不要把key传上去 Vite npm install --save-dev types/node #安…...

Python应用“面向对象”小练习
大家好!面向对象编程是一种以 “对象” 为核心的编程思想。对象可以看作是具有特定属性和行为的实体。例如,一个学生可以是一个对象,他的属性包括姓名和年龄,行为可以是打招呼。 代码呈现: # 定义类和对象 class Student:def __init__(sel…...

如何调试CATIA CAA程序导致的CATIA异常崩溃问题
问题背景:我采用CATIA CAA编写了一个界面的小程序,功能运行成功,但是每次运行完,关闭CATIA的时候,都会弹出这个对话框,这个对话框的意思是CATIA运行崩溃,点击确定后,CATIA就会意外关…...
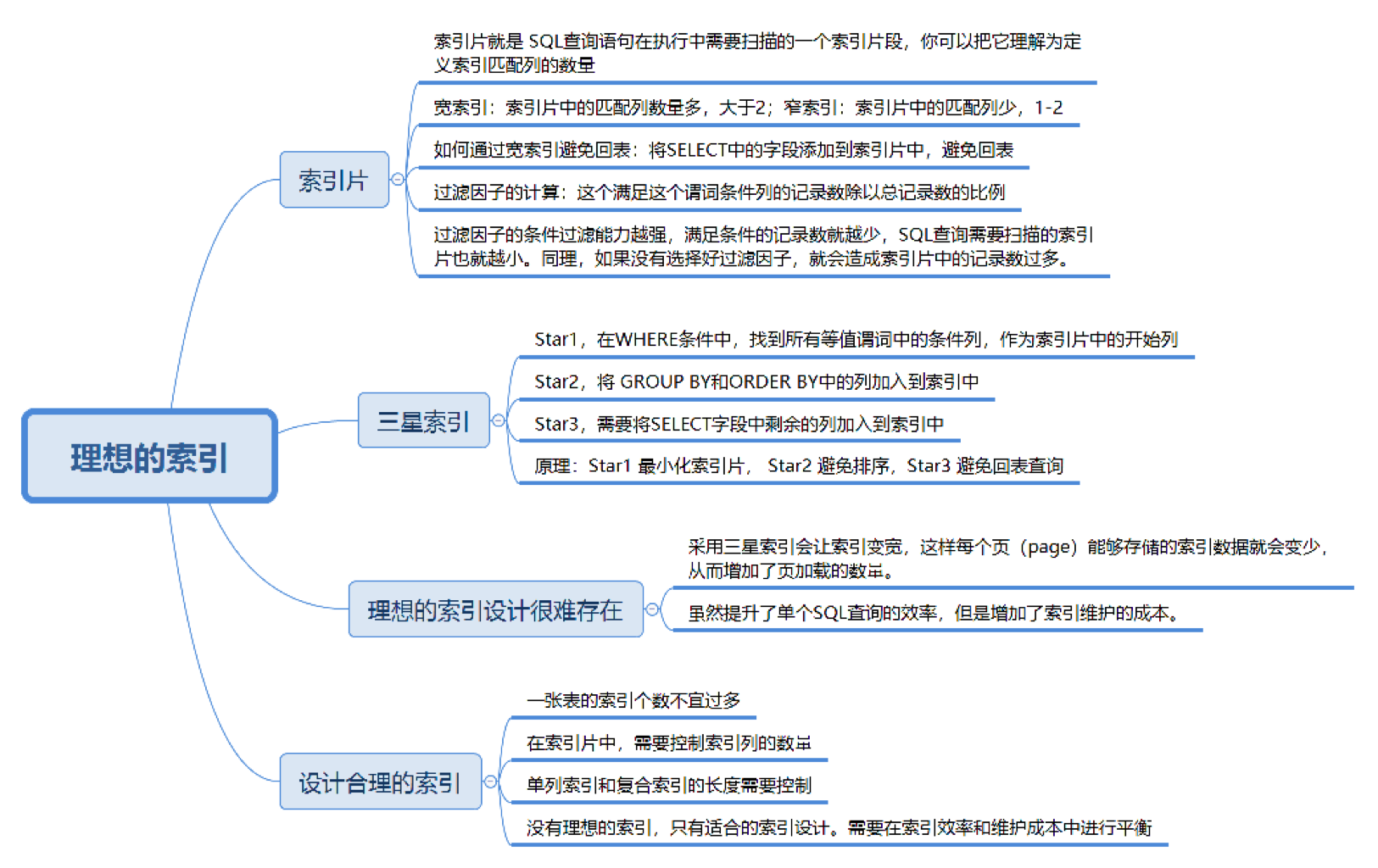
SQL查询效率以及索引设计
1. SQL 查询效率与数据库缓冲池机制 1.1. 数据库缓冲池(Buffer Pool) 磁盘 I/O 需要消耗的时间很多,而在内存中进行操作,效率则会高很多,为了能让数据表或者索引中的数据随时被我们所用,DBMS 会申请占用内…...
day37打卡
知识点回顾:浙大疏锦行 过拟合的判断:测试集和训练集同步打印指标模型的保存和加载 仅保存权重保存权重和模型保存全部信息checkpoint,还包含训练状态 早停策略 作业:对信贷数据集训练后保存权重,加载权重后继续训练50…...

分布式缓存:证明分布式系统的 CAP 理论
文章目录 Pre一、分布式系统背景与特点二、CAP 三要素详解三、CAP 定理的反证证明四、CP 架构与 AP 架构对比典型场景 五、CAP 理论在系统设计中的应用六、总结 Pre 分布式缓存:CAP 理论在实践中的误区与思考 分布式缓存:BASE理论实践指南 分布式 - 从…...

软件设计师“面向对象设计”真题考点分析——求三连
一、考点分值占比与趋势分析 综合知识历年考察统计 年份考题数分值占比考察重点2018334%继承类型、设计原则2019445.3%多态实现、类关系2020556.7%设计模式应用、接口隔离2021334%消息通信、封装特性2022668%开闭原则、组合模式2023556.7%模板方法、适配器模式2024445.3%单一…...

vue项目webpack、vite、rollup、parcel四种构建工具对比
以下是 Vue 项目中使用 Webpack 与其他主流构建工具(Vite、Rollup、Parcel)的对于项目的使用对比: 一、核心工具对比 特性WebpackViteRollupParcel构建原理Bundle-based(打包)ESM-based(原生模块)Bundle-based(专注库)Zero-config(自动分析)开发速度较慢(全量打包)…...
)
系统架构中的限流实践:构建多层防护体系(二)
系统架构中的限流实践:构建多层防护体系 一、接入层限流:流量拦截第一关二、应用层限流(服务内限流)Java生态方案对比三、分布式限流(跨服务限流)四、数据层限流(数据库/缓存限流)1. 数据库防护策略2. 缓存优化方案五、中间件层限流(消息队列/分布式服务)六、客户端限…...

Linux常见设备
linux上设备的分类? 设备分两种,字符设备和块设备。 块设备(Block Device):以固定大小数据块访问的设备(如磁盘、SSD),通常挂载后使用。 字符设备(Character Device)&…...
AI大模型学习二十八、ACE-Step:生成式AI音乐大模型简介与安装(一)
一、说明 先来一首创作的歌: 在大模型和生成式AI模型大规模发达的今天,利用大模型生成音乐也是其中一个重要的发展方向。今天我们就介绍一个这样的音乐生成模型ACE-Step,可基于关键字和歌词生成歌曲;基于歌曲生成伴奏等等功能。 …...
)
AI时代新词-AI芯片(AI - Specific Chip)
一、什么是AI芯片? AI芯片(AI - Specific Chip)是指专为人工智能(AI)计算任务设计的芯片。与传统的通用处理器(如CPU)相比,AI芯片针对深度学习、机器学习等AI应用进行了优化&#x…...

【多智能体系统开发框架AutoGen解析与实践】
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心架构图解核心作用讲解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现案例1:基础问答系统案例2:多专家协作 运行结果验证 三、性能对比测试方法论量化…...
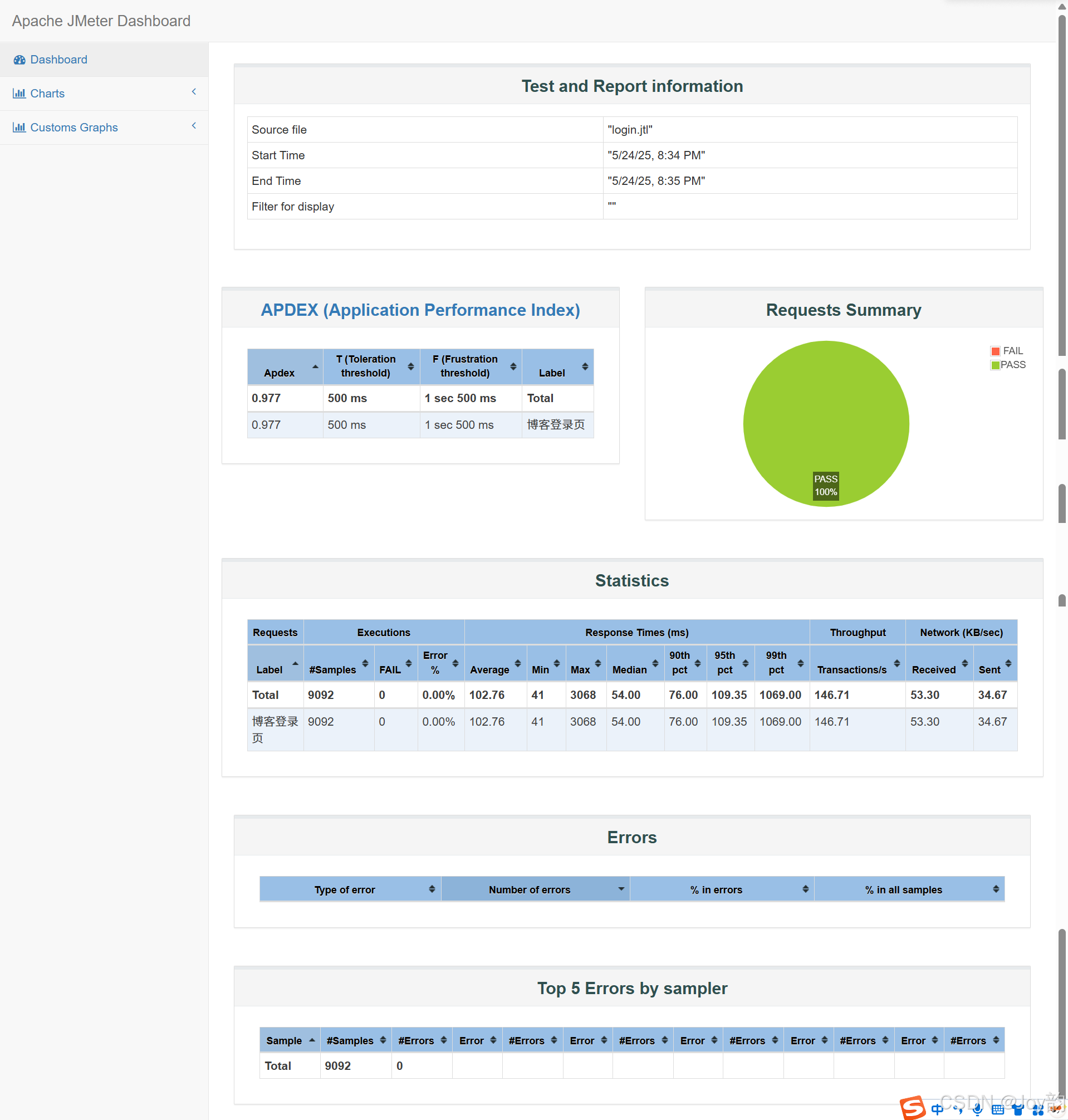
接口性能测试-工具JMeter的学习
接口登录链接http://111.230.19.204:8080/blog_login.html 一、JMeter基本使用流程 1、启动Jmeter 2、在“测试计划”下添加线程组 3、在“线程组”下添加“HTTP”取样器 4、填写“HTTP请求”的相关请求数据 5、在“线程组”下添加“查看结果树”监听器 6、点击“启动”按钮…...
python如何离线安装pandas,numpy
1.首先在有网的电脑上正常安装python(和离线环境一样的版本) 然后 pip install pandas (不嫌麻烦的话也可以自己手动去pandas PyPI 一个个下载) 安装好后导出相关包,使用如下指令 2.然后相关依赖包就…...
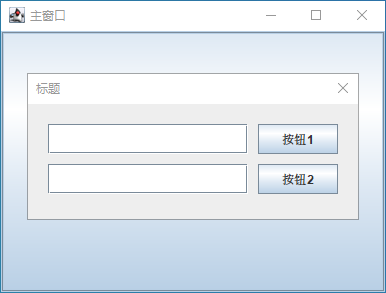
Java Swing 自定义JOptionPane
运行后的样式 import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener;public class demoB {public static void main(String[] args) {SwingUtilities.invokeLater(() -> {JFrame jf new JFrameDemo();jf.se…...

项目亮点 封装request请求模块
封装网络请求模块 统一管理和复用 在项目根目录的utils文件夹下 request模块更新 const http axios.create({baseURL: http://geek.itheima.net/v1_0,timeout: 5000 })定义根域名和超时时间 请求拦截器 请求发送之前拦截,做自定义的配置 // 添加请求拦截器 re…...

通过 Terraform 构建您的第一个 Azure Linux 虚拟机
欢迎来到 Azure Terraformer 第一期,我们将深入探讨如何在 Azure 上使用 Terraform 构建强大且可扩展的云解决方案。今天,我们将演示如何为 Azure Linux 虚拟机 (VM) 预配相关资源,例如资源组、公共 IP、网络接口和子网,以及如何从 Azure Key Vault 安全地获取 SSH 公钥。我…...

Linux连接服务器全攻略:从基础到进阶
在Linux系统下连接服务器是开发、运维人员的必备技能。无论是远程管理服务器、传输文件,还是进行开发调试,熟练掌握连接服务器的方法都能大幅提升工作效率。本文将从原理到实操,带你全面掌握Linux连接服务器的多种方式。 一、SSH协议基础 SSH…...

pg库分表操作步骤- PostgreSQL 分区表
原表结构 CREATE TABLE message (id VARCHAR(32) PRIMARY KEY,t_id VARCHAR(32),content TEXT,time TIMESTAMP,user_id VARCHAR(10),receive_user_id VARCHAR(10),type SMALLINT,send_flag SMALLINT,remark VARCHAR(50),receive_time TIMESTAMP );一、主表定义(父表…...

讯飞AI相关sdk集成springboot
星火认知大模型对话:(以spark 4.0 ultra 为例) demo上的功能比较简陋,网络上搜到的比较残缺,很多功能缺失,我这里自己收集资料和运用编程知识做了整理,得到了自己想要的一些功能,比…...
上安装`geckodriver`)
在麒麟系统(Kylin OS)上安装`geckodriver`
在麒麟系统(Kylin OS)上安装geckodriver并配置其通过--connect-existing和--marionette-port 2828参数连接到已存在的Firefox实例,可以按照以下步骤操作: 1. 安装Firefox浏览器 在麒麟系统中,可以通过以下命令安装Fi…...