day37打卡
知识点回顾:@浙大疏锦行
- 过拟合的判断:测试集和训练集同步打印指标
- 模型的保存和加载
- 仅保存权重
- 保存权重和模型
- 保存全部信息checkpoint,还包含训练状态
- 早停策略
作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮,并采取早停策略
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tqdm import tqdm
import matplotlib.pyplot as plt
import warnings
from sklearn.metrics import classification_reportwarnings.filterwarnings("ignore")# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 数据预处理
data = pd.read_csv(r'data.csv')
data = data.drop(['Id'], axis=1)# 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# 独热编码
data = pd.get_dummies(data, columns=['Purpose'])# Term列映射与重命名
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)# 列名验证
original_columns = data.columns.tolist()
data.rename(columns={'Term': 'Long Term'}, inplace=True)
new_columns = data.columns.tolist()if 'Long Term' not in new_columns:print(f"警告:列名重命名失败!原始列名: {original_columns}")if 'Term' in new_columns:print("使用原始列名'Term'继续处理...")else:raise KeyError("无法找到'Term'或'Long Term'列!")# 重新生成连续特征列表并验证
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist()
print(f"连续特征列表: {continuous_features}")# 缺失值处理
for feature in continuous_features:if feature not in data.columns:print(f"警告:列 '{feature}' 不存在,跳过该列!")continueif data[feature].isnull().sum() > 0:if data[feature].dtype in [np.float64, np.int64]:fill_value = data[feature].median()else:fill_value = data[feature].mode()[0]data[feature].fillna(fill_value, inplace=True)print(f"已填充 {feature} 列的 {data[feature].isnull().sum()} 个缺失值,填充值: {fill_value}")# 划分训练集和测试集
X = data.drop(['Credit Default'], axis=1)
y = data['Credit Default']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train.values).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test.values).to(device)# 定义MLP模型
class MLP(nn.Module):def __init__(self, input_size):super(MLP, self).__init__()self.fc1 = nn.Linear(input_size, 10)self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 2)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
input_size = X_train.shape[1]
model = MLP(input_size).to(device)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
def train_model(model, optimizer, num_epochs, save_path, is_continue=False):best_test_loss = float('inf')best_epoch = 0patience = 50counter = 0early_stopped = Falsetrain_losses = []test_losses = []epochs = []start_time = time.time()if is_continue:total_epochs = num_epochsprint(f"继续训练 {num_epochs} 轮")else:total_epochs = num_epochsprint(f"开始初始训练 {num_epochs} 轮")with tqdm(total=total_epochs, desc="训练进度", unit="epoch") as pbar:for epoch in range(total_epochs):# 前向传播model.train()outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 调试输出:打印当前损失值print(f"Epoch {epoch+1}, Train Loss: {loss.item():.4f}, Test Loss: {test_loss.item():.4f}")pbar.set_postfix({'Loss': f'{loss.item():.4f}'})# 早停逻辑if test_loss.item() < best_test_loss:best_test_loss = test_loss.item()best_epoch = epoch + 1counter = 0torch.save(model.state_dict(), save_path)else:counter += 1if counter >= patience:print(f"早停触发!在第{epoch+1}轮,测试集损失已有{patience}轮未改善。")print(f"最佳测试集损失出现在第{best_epoch}轮,损失值为{best_test_loss:.4f}")early_stopped = Truebreak# 更新进度条pbar.update(1)time_all = time.time() - start_timeprint(f'Training time: {time_all:.2f} seconds')# 调试输出:打印损失列表print(f"训练完成后,记录了 {len(epochs)} 个损失值")if epochs:print(f"Epochs范围: {min(epochs)} 到 {max(epochs)}")print(f"训练损失范围: {min(train_losses):.4f} 到 {max(train_losses):.4f}")print(f"测试损失范围: {min(test_losses):.4f} 到 {max(test_losses):.4f}")return model, best_test_loss, best_epoch, early_stopped, train_losses, test_losses, epochs# 第一阶段训练
initial_save_path = 'initial_model.pth'
model, best_test_loss, best_epoch, early_stopped, train_losses1, test_losses1, epochs1 = train_model(model, optimizer, num_epochs=20000, save_path=initial_save_path
)# 可视化第一阶段损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs1, train_losses1, label='初始训练 - 训练损失')
plt.plot(epochs1, test_losses1, label='初始训练 - 测试损失')# 设置坐标轴范围
if epochs1: # 确保有数据plt.xlim(min(epochs1), max(epochs1))all_losses = train_losses1 + test_losses1plt.ylim(min(all_losses) * 0.9, max(all_losses) * 1.1)plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('初始训练阶段的损失曲线')
plt.legend()
plt.grid(True)
plt.show()# 评估初始训练模型
model.eval()
with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'初始训练后的测试集准确率: {accuracy * 100:.2f}%')print(classification_report(y_test.cpu().numpy(), predicted.cpu().numpy(), target_names=['未违约', '违约']))# 第二阶段训练:加载权重并继续训练50轮
print("\n===== 开始第二阶段训练:加载权重并继续训练50轮 =====")# 重新实例化模型
continued_model = MLP(input_size).to(device)
continued_model.load_state_dict(torch.load(initial_save_path))# 定义新的优化器
continued_optimizer = optim.SGD(continued_model.parameters(), lr=0.001)# 继续训练50轮
continued_save_path = 'continued_model.pth'
continued_model, best_test_loss2, best_epoch2, early_stopped2, train_losses2, test_losses2, epochs2 = train_model(continued_model, continued_optimizer, num_epochs=50, save_path=continued_save_path, is_continue=True
)# 可视化第二阶段损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs2, train_losses2, label='继续训练 - 训练损失')
plt.plot(epochs2, test_losses2, label='继续训练 - 测试损失')# 设置坐标轴范围
if epochs2: # 确保有数据plt.xlim(min(epochs2), max(epochs2))all_losses2 = train_losses2 + test_losses2plt.ylim(min(all_losses2) * 0.9, max(all_losses2) * 1.1)# 添加调试输出
print(f"绘图数据 - Epochs: {epochs2}")
print(f"绘图数据 - 训练损失: {[round(loss, 4) for loss in train_losses2]}")
print(f"绘图数据 - 测试损失: {[round(loss, 4) for loss in test_losses2]}")plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('继续训练阶段的损失曲线')
plt.legend()
plt.grid(True)
plt.show()# 评估继续训练后的模型
continued_model.eval()
with torch.no_grad():outputs = continued_model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'继续训练后的测试集准确率: {accuracy * 100:.2f}%')print(classification_report(y_test.cpu().numpy(), predicted.cpu().numpy(), target_names=['未违约', '违约']))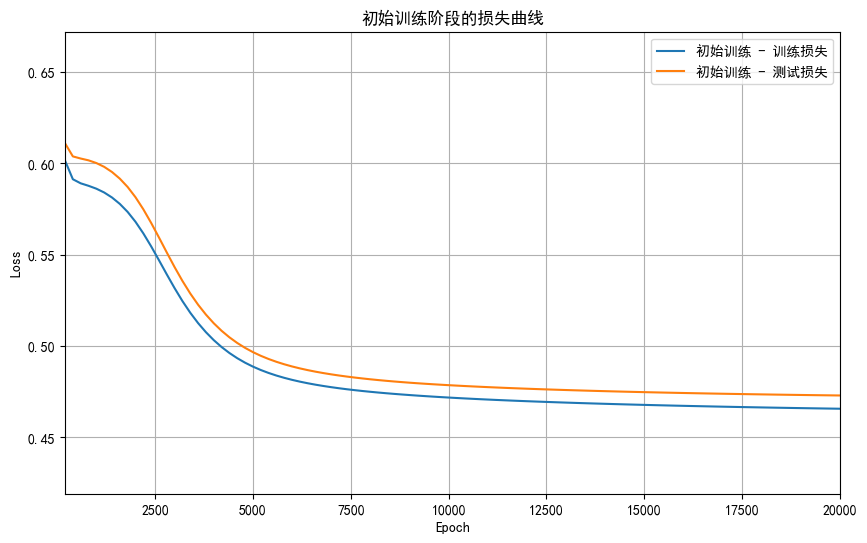
Training time: 0.19 seconds
训练完成后,记录了 0 个损失值
绘图数据 - Epochs: []
绘图数据 - 训练损失: []
绘图数据 - 测试损失: []
继续训练后的测试集准确率: 76.73%precision recall f1-score support未违约 0.75 0.99 0.86 1059违约 0.93 0.22 0.36 441accuracy 0.77 1500macro avg 0.84 0.61 0.61 1500
weighted avg 0.81 0.77 0.71 1500相关文章:
day37打卡
知识点回顾:浙大疏锦行 过拟合的判断:测试集和训练集同步打印指标模型的保存和加载 仅保存权重保存权重和模型保存全部信息checkpoint,还包含训练状态 早停策略 作业:对信贷数据集训练后保存权重,加载权重后继续训练50…...

分布式缓存:证明分布式系统的 CAP 理论
文章目录 Pre一、分布式系统背景与特点二、CAP 三要素详解三、CAP 定理的反证证明四、CP 架构与 AP 架构对比典型场景 五、CAP 理论在系统设计中的应用六、总结 Pre 分布式缓存:CAP 理论在实践中的误区与思考 分布式缓存:BASE理论实践指南 分布式 - 从…...

软件设计师“面向对象设计”真题考点分析——求三连
一、考点分值占比与趋势分析 综合知识历年考察统计 年份考题数分值占比考察重点2018334%继承类型、设计原则2019445.3%多态实现、类关系2020556.7%设计模式应用、接口隔离2021334%消息通信、封装特性2022668%开闭原则、组合模式2023556.7%模板方法、适配器模式2024445.3%单一…...

vue项目webpack、vite、rollup、parcel四种构建工具对比
以下是 Vue 项目中使用 Webpack 与其他主流构建工具(Vite、Rollup、Parcel)的对于项目的使用对比: 一、核心工具对比 特性WebpackViteRollupParcel构建原理Bundle-based(打包)ESM-based(原生模块)Bundle-based(专注库)Zero-config(自动分析)开发速度较慢(全量打包)…...
)
系统架构中的限流实践:构建多层防护体系(二)
系统架构中的限流实践:构建多层防护体系 一、接入层限流:流量拦截第一关二、应用层限流(服务内限流)Java生态方案对比三、分布式限流(跨服务限流)四、数据层限流(数据库/缓存限流)1. 数据库防护策略2. 缓存优化方案五、中间件层限流(消息队列/分布式服务)六、客户端限…...

Linux常见设备
linux上设备的分类? 设备分两种,字符设备和块设备。 块设备(Block Device):以固定大小数据块访问的设备(如磁盘、SSD),通常挂载后使用。 字符设备(Character Device)&…...
AI大模型学习二十八、ACE-Step:生成式AI音乐大模型简介与安装(一)
一、说明 先来一首创作的歌: 在大模型和生成式AI模型大规模发达的今天,利用大模型生成音乐也是其中一个重要的发展方向。今天我们就介绍一个这样的音乐生成模型ACE-Step,可基于关键字和歌词生成歌曲;基于歌曲生成伴奏等等功能。 …...
)
AI时代新词-AI芯片(AI - Specific Chip)
一、什么是AI芯片? AI芯片(AI - Specific Chip)是指专为人工智能(AI)计算任务设计的芯片。与传统的通用处理器(如CPU)相比,AI芯片针对深度学习、机器学习等AI应用进行了优化&#x…...

【多智能体系统开发框架AutoGen解析与实践】
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心架构图解核心作用讲解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现案例1:基础问答系统案例2:多专家协作 运行结果验证 三、性能对比测试方法论量化…...
接口性能测试-工具JMeter的学习
接口登录链接http://111.230.19.204:8080/blog_login.html 一、JMeter基本使用流程 1、启动Jmeter 2、在“测试计划”下添加线程组 3、在“线程组”下添加“HTTP”取样器 4、填写“HTTP请求”的相关请求数据 5、在“线程组”下添加“查看结果树”监听器 6、点击“启动”按钮…...
python如何离线安装pandas,numpy
1.首先在有网的电脑上正常安装python(和离线环境一样的版本) 然后 pip install pandas (不嫌麻烦的话也可以自己手动去pandas PyPI 一个个下载) 安装好后导出相关包,使用如下指令 2.然后相关依赖包就…...
Java Swing 自定义JOptionPane
运行后的样式 import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener;public class demoB {public static void main(String[] args) {SwingUtilities.invokeLater(() -> {JFrame jf new JFrameDemo();jf.se…...

项目亮点 封装request请求模块
封装网络请求模块 统一管理和复用 在项目根目录的utils文件夹下 request模块更新 const http axios.create({baseURL: http://geek.itheima.net/v1_0,timeout: 5000 })定义根域名和超时时间 请求拦截器 请求发送之前拦截,做自定义的配置 // 添加请求拦截器 re…...

通过 Terraform 构建您的第一个 Azure Linux 虚拟机
欢迎来到 Azure Terraformer 第一期,我们将深入探讨如何在 Azure 上使用 Terraform 构建强大且可扩展的云解决方案。今天,我们将演示如何为 Azure Linux 虚拟机 (VM) 预配相关资源,例如资源组、公共 IP、网络接口和子网,以及如何从 Azure Key Vault 安全地获取 SSH 公钥。我…...

Linux连接服务器全攻略:从基础到进阶
在Linux系统下连接服务器是开发、运维人员的必备技能。无论是远程管理服务器、传输文件,还是进行开发调试,熟练掌握连接服务器的方法都能大幅提升工作效率。本文将从原理到实操,带你全面掌握Linux连接服务器的多种方式。 一、SSH协议基础 SSH…...

pg库分表操作步骤- PostgreSQL 分区表
原表结构 CREATE TABLE message (id VARCHAR(32) PRIMARY KEY,t_id VARCHAR(32),content TEXT,time TIMESTAMP,user_id VARCHAR(10),receive_user_id VARCHAR(10),type SMALLINT,send_flag SMALLINT,remark VARCHAR(50),receive_time TIMESTAMP );一、主表定义(父表…...

讯飞AI相关sdk集成springboot
星火认知大模型对话:(以spark 4.0 ultra 为例) demo上的功能比较简陋,网络上搜到的比较残缺,很多功能缺失,我这里自己收集资料和运用编程知识做了整理,得到了自己想要的一些功能,比…...
上安装`geckodriver`)
在麒麟系统(Kylin OS)上安装`geckodriver`
在麒麟系统(Kylin OS)上安装geckodriver并配置其通过--connect-existing和--marionette-port 2828参数连接到已存在的Firefox实例,可以按照以下步骤操作: 1. 安装Firefox浏览器 在麒麟系统中,可以通过以下命令安装Fi…...
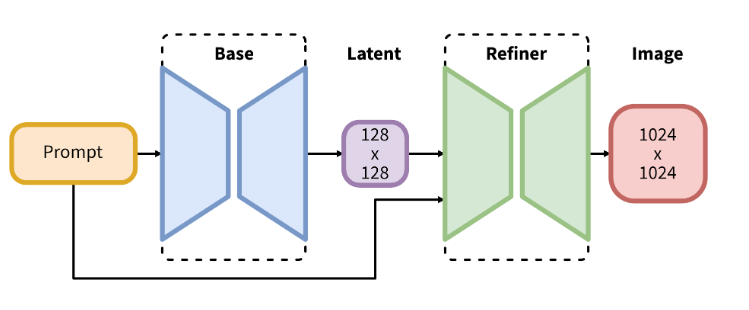
【图像大模型】Stable Diffusion XL:下一代文本到图像生成模型的技术突破与实践指南
Stable Diffusion XL:下一代文本到图像生成模型的技术突破与实践指南 一、架构设计与技术演进1.1 核心架构革新1.2 关键技术突破1.2.1 双文本编码器融合1.2.2 动态扩散调度 二、系统架构解析2.1 完整生成流程2.2 性能指标对比 三、实战部署指南3.1 环境配置3.2 基础…...

[闲谈]C语言的面向对象
C语言的面向对象 文章目录 C语言的面向对象一、面向对象编程的核心概念1. 封装2. 继承3. 多态 二、C语言实现封装的方法1. 定义结构体封装数据2. 实现成员方法3. 初始化对象4.应用场景5.注意事项 三、模拟继承的两种模式详解1. 组合模式(Composition Pattern&#x…...

C 语言指针之手写内存深度剖析与手写库函数:带你从0开始手撸库 附录1.5 万字实战笔记
一、指针入门:从野指针到空指针 1.1 野指针的第一次暴击:沃日 哪里来的Segmentation Fault ?????? 刚学指针时写过一段让我及其楠甭的代码,我x了xx的,最后才发现是为…...
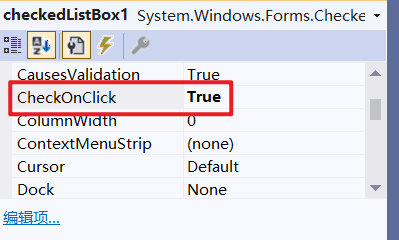
C#高级:Winform桌面开发中CheckedListBox的详解
一、基础设置 单击触发选择效果:需要选择下面这个为True 二、代码实现 1.设置数据源 /// <summary> /// 为CheckBoxList设置数据源 /// </summary> /// <param name"checkedListBox1"></param> /// <param name"data&…...

【Java学习笔记】final关键字
final 关键字 一、final 关键字介绍 1. final可以修饰类、属性、方法和局部变量 2. final 的使用场景 (1)类不能被继承时,可以使用final修饰 (2)类的某个属性不可以被更改,可以使用final修饰 ࿰…...
AI学习笔记二十八:使用ESP32 CAM和YOLOV5实现目标检测
若该文为原创文章,转载请注明原文出处。 最近在研究使用APP如何显示ESP32 CAM的摄像头数据,看到有人实现把ESP32 CAM的数据流上传,通过YOLOV5来检测,实现拉流推理,这里复现一下。 一、环境 arduino配置esp32-cam开发环…...
免费分享50本web全栈学习电子书
最近搞到一套非常不错的 Web 全栈电子书合集,整整 50 本,都是epub电子书格式,相当赞!作为一个被期末大作业和项目 ddl 追着跑的大学生,这套书真的救我狗命! 刚接触 Web 开发的时候,我天天对着空…...
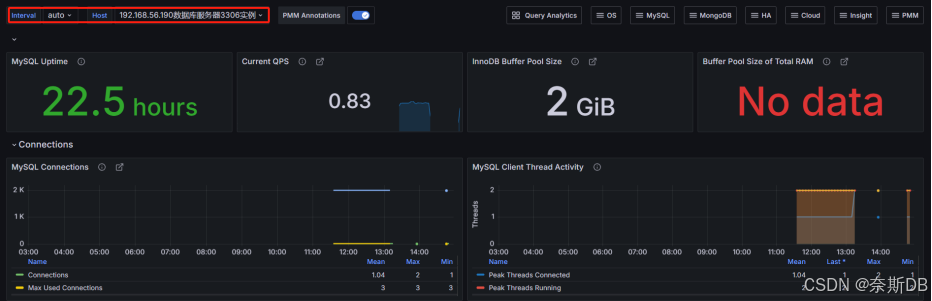
【prometheus+Grafana篇】基于Prometheus+Grafana实现MySQL数据库的监控与可视化
💫《博主主页》: 🔎 CSDN主页 🔎 IF Club社区主页 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了…...

全链路解析:影刀RPA+Coze API自动化工作流实战指南
在数字化转型加速的今天,如何通过RPA与API的深度融合实现业务自动化提效,已成为企业降本增效的核心命题。本文以「影刀RPA」与「Coze API」的深度协作为例,系统性拆解从授权配置、数据交互到批量执行的完整技术链路,助你快速掌握跨…...
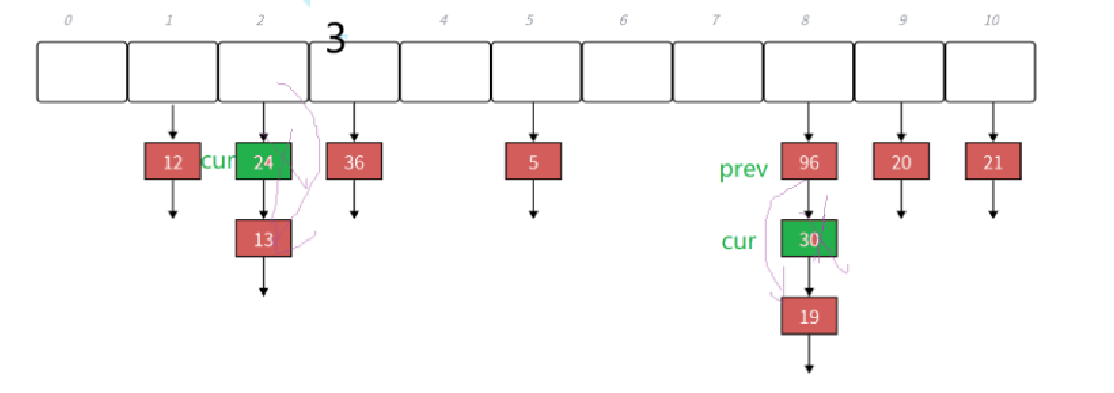
高阶数据结构——哈希表的实现
目录 1.概念引入 2.哈希的概念: 2.1 什么叫映射? 2.2 直接定址法 2.3 哈希冲突(哈希碰撞) 2.4 负载因子 2.5 哈希函数 2.5.1 除法散列法(除留余数法) 2.5.2 乘法散列法(了解)…...

window 显示驱动开发-报告渲染操作的可选支持
从 Windows 7 开始,显示微型端口驱动程序可以在 DXGK_PRESENTATIONCAPS 结构中设置其他成员,以指示驱动程序可以或不能支持的某些呈现操作。 从 Windows 7 开始,显示微型端口驱动程序可以通过 DXGK_PRESENTATIONCAPS 结构进一步声明其支持的…...

2025 年网络安全趋势报告
一、引言 自欧洲信息安全协会(Infosecurity Europe)首次举办活动的 30 年来,网络安全格局发生了翻天覆地的变化。如今,网络安全领导者必须应对众多威胁,维持法规合规性,并与董事会成员合作推进组织的网络安…...