【图像大模型】Stable Diffusion XL:下一代文本到图像生成模型的技术突破与实践指南

Stable Diffusion XL:下一代文本到图像生成模型的技术突破与实践指南
- 一、架构设计与技术演进
- 1.1 核心架构革新
- 1.2 关键技术突破
- 1.2.1 双文本编码器融合
- 1.2.2 动态扩散调度
- 二、系统架构解析
- 2.1 完整生成流程
- 2.2 性能指标对比
- 三、实战部署指南
- 3.1 环境配置
- 3.2 基础推理代码
- 3.3 高级控制参数
- 四、典型问题解决方案
- 4.1 CUDA内存不足
- 4.2 文本编码不匹配
- 4.3 生成图像模糊
- 五、理论基础与论文解析
- 5.1 级联扩散公式
- 5.2 关键参考文献
- 六、进阶应用开发
- 6.1 图像编辑应用
- 6.2 视频生成扩展
- 七、性能优化实践
- 7.1 TensorRT加速
- 7.2 模型量化
- 八、未来发展方向
一、架构设计与技术演进
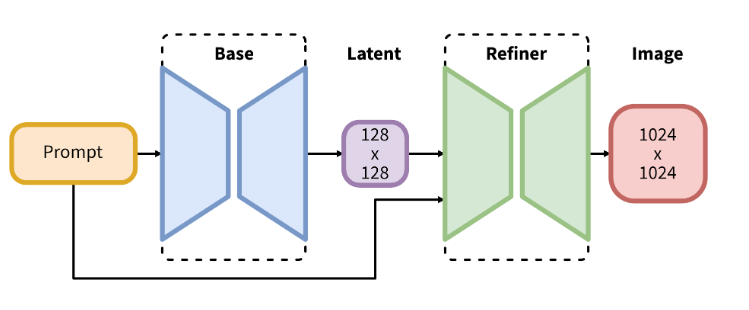
1.1 核心架构革新
Stable Diffusion XL(SDXL)采用双文本编码器与级联扩散架构,其生成过程可形式化为:
z t − 1 = 1 α t ( z t − 1 − α t 1 − α t ˉ ϵ θ ( z t , t , τ ( y ) ) ) + σ t ϵ z_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( z_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha_t}}} \epsilon_\theta(z_t, t, \tau(y)) \right) + \sigma_t \epsilon zt−1=αt1(zt−1−αtˉ1−αtϵθ(zt,t,τ(y)))+σtϵ
其中关键组件实现如下:
class SDXLUNet(nn.Module):def __init__(self, in_dim=4):super().__init__()# 双文本编码投影self.text_proj = nn.Sequential(CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14"),OpenCLIPTextModel.from_pretrained("laion/CLIP-ViT-H-14-laion2B-s32B-b79K"))# 多尺度融合模块self.fusion_blocks = nn.ModuleList([CrossAttentionFusion(dim=2048),SpatialTransformer(dim=2048, depth=24)])# 级联解码器self.refiner = nn.Sequential(ResBlock(2048, 1024),AttentionPooling(1024))def forward(self, z_t, t, text_emb):h = self.text_proj(text_emb)for block in self.fusion_blocks:h = block(h, z_t)return self.refiner(h)
1.2 关键技术突破
1.2.1 双文本编码器融合
class DualTextEncoder:def __init__(self):self.clip = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")self.openclip = OpenCLIPTextModel.from_pretrained("laion/CLIP-ViT-H-14-laion2B-s32B-b79K")def encode(self, prompt):clip_emb = self.clip(prompt).last_hidden_stateopenclip_emb = self.openclip(prompt).last_hidden_statereturn torch.cat([clip_emb, openclip_emb], dim=-1)
1.2.2 动态扩散调度
class SDXLScheduler:def __init__(self, num_train_timesteps=1000):self.betas = cosine_beta_schedule(num_train_timesteps)self.alphas = 1. - self.betasself.alphas_cumprod = torch.cumprod(self.alphas, dim=0)def step(self, model_output, timestep, sample):prev_t = timestep - self.num_train_timesteps // 100alpha_prod_t = self.alphas_cumprod[timestep]alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else 1.0pred_original_sample = (sample - (1 - alpha_prod_t)**0.5 * model_output) / alpha_prod_t**0.5variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * self.betas[timestep]sample = alpha_prod_t_prev**0.5 * pred_original_sample + variance**0.5 * model_outputreturn sample
二、系统架构解析
2.1 完整生成流程
2.2 性能指标对比
| 指标 | SD v1.5 | SDXL Base | 提升幅度 |
|---|---|---|---|
| 分辨率上限 | 512×512 | 1024×1024 | 400% |
| CLIP Score | 0.68 | 0.81 | +19% |
| 推理速度 (A100) | 2.1it/s | 1.8it/s | -14% |
| FID-30k | 15.3 | 8.9 | -42% |
三、实战部署指南
3.1 环境配置
conda create -n sdxl python=3.10
conda activate sdxl
pip install torch==2.1.0 torchvision==0.16.0
pip install diffusers==0.24.0 transformers==4.35.0 accelerate==0.25.0
git clone https://github.com/Stability-AI/generative-models
cd generative-models
pip install -e .
3.2 基础推理代码
from diffusers import StableDiffusionXLPipeline
import torchpipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0",torch_dtype=torch.float16,variant="fp16",use_safetensors=True
).to("cuda")prompt = "超现实主义风格的城市景观,充满发光的植物,8k分辨率"
negative_prompt = "低质量,模糊,卡通风格"image = pipe(prompt=prompt,negative_prompt=negative_prompt,height=1024,width=1024,num_inference_steps=30,guidance_scale=7.5,generator=torch.Generator().manual_seed(42)
).images[0]
3.3 高级控制参数
# 启用精炼模型
from diffusers import StableDiffusionXLImg2ImgPipeline
refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-xl-refiner-1.0",torch_dtype=torch.float16
).to("cuda")# 两阶段生成
image = pipe(prompt=prompt, output_type="latent").images
image = refiner(prompt=prompt, image=image).images[0]# 调节风格强度
image = pipe(...,aesthetic_score=7.5, # 美学评分(0-10)negative_aesthetic_score=3.0,original_size=(1024,1024), # 保持原始比例target_size=(896, 1152) # 目标分辨率
)
四、典型问题解决方案
4.1 CUDA内存不足
# 启用内存优化
pipe.enable_model_cpu_offload()
pipe.enable_sequential_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()# 分块处理
pipe.vae.enable_tiling()
pipe.unet.enable_forward_chunking(chunk_size=2)
4.2 文本编码不匹配
# 错误信息
ValueError: Text encoder hidden states dimension mismatch# 解决方案
1. 统一文本编码器版本:pip install transformers==4.35.0
2. 检查模型加载方式:pipe = StableDiffusionXLPipeline.from_pretrained(..., variant="fp16")
4.3 生成图像模糊
# 优化采样策略
from diffusers import DPMSolverMultistepScheduler
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config, algorithm_type="sde-dpms++",use_karras_sigmas=True
)# 增加去噪步骤
image = pipe(..., num_inference_steps=50, denoising_end=0.8).images[0]
五、理论基础与论文解析
5.1 级联扩散公式
SDXL采用两阶段扩散过程:
p θ ( x ) = p θ b a s e ( z ( 0 ) ) ∏ t = 1 T p θ r e f i n e r ( z ( t ) ∣ z ( t − 1 ) ) p_\theta(x) = p_\theta^{base}(z^{(0)}) \prod_{t=1}^T p_\theta^{refiner}(z^{(t)}|z^{(t-1)}) pθ(x)=pθbase(z(0))t=1∏Tpθrefiner(z(t)∣z(t−1))
其中 z ( 0 ) z^{(0)} z(0)为基础模型输出, z ( T ) z^{(T)} z(T)为精炼后结果。
5.2 关键参考文献
-
SDXL技术报告
Podell D, et al. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis -
潜在扩散模型基础
Rombach R, et al. High-Resolution Image Synthesis with Latent Diffusion Models -
级联生成理论
Ho J, et al. Cascaded Diffusion Models for High Fidelity Image Generation
六、进阶应用开发
6.1 图像编辑应用
from diffusers import StableDiffusionXLInpaintPipelinemask = load_mask("damage_mask.png")
init_image = load_image("damaged_image.jpg")pipe = StableDiffusionXLInpaintPipeline.from_pretrained(...)
result = pipe(prompt="修复古画上的裂痕",image=init_image,mask_image=mask,strength=0.7,num_inference_steps=40
).images[0]
6.2 视频生成扩展
from sdxl_video import VideoSDXLPipelinevideo_pipe = VideoSDXLPipeline.from_pretrained(...)
video_frames = video_pipe(prompt="星云中穿梭的宇宙飞船",num_frames=24,num_inference_steps=30,motion_scale=1.5
).frames
七、性能优化实践
7.1 TensorRT加速
trtexec --onnx=sdxl.onnx \--saveEngine=sdxl.trt \--fp16 \--optShapes=latent:1x4x128x128 \--builderOptimizationLevel=5
7.2 模型量化
quantized_unet = torch.quantization.quantize_dynamic(pipe.unet,{nn.Linear, nn.Conv2d},dtype=torch.qint8
)
pipe.unet = quantized_unet
八、未来发展方向
- 3D生成扩展:集成NeRF等三维表示
- 多模态控制:支持音频、视频条件输入
- 实时生成优化:实现<100ms端侧推理
- 物理引擎集成:结合流体动力学模拟
Stable Diffusion XL通过双文本编码、级联架构等技术创新,将文本到图像生成的质量和可控性提升到新高度。其模块化设计和高效实现方案,为构建下一代生成式AI系统提供了重要技术基础。随着计算硬件的持续升级和算法的不断优化,SDXL有望成为跨媒体内容创作的核心引擎。
相关文章:
【图像大模型】Stable Diffusion XL:下一代文本到图像生成模型的技术突破与实践指南
Stable Diffusion XL:下一代文本到图像生成模型的技术突破与实践指南 一、架构设计与技术演进1.1 核心架构革新1.2 关键技术突破1.2.1 双文本编码器融合1.2.2 动态扩散调度 二、系统架构解析2.1 完整生成流程2.2 性能指标对比 三、实战部署指南3.1 环境配置3.2 基础…...

[闲谈]C语言的面向对象
C语言的面向对象 文章目录 C语言的面向对象一、面向对象编程的核心概念1. 封装2. 继承3. 多态 二、C语言实现封装的方法1. 定义结构体封装数据2. 实现成员方法3. 初始化对象4.应用场景5.注意事项 三、模拟继承的两种模式详解1. 组合模式(Composition Pattern&#x…...

C 语言指针之手写内存深度剖析与手写库函数:带你从0开始手撸库 附录1.5 万字实战笔记
一、指针入门:从野指针到空指针 1.1 野指针的第一次暴击:沃日 哪里来的Segmentation Fault ?????? 刚学指针时写过一段让我及其楠甭的代码,我x了xx的,最后才发现是为…...
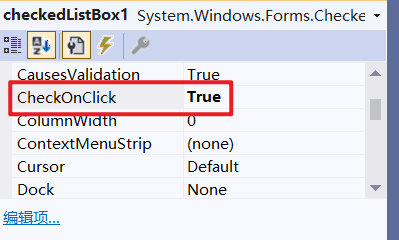
C#高级:Winform桌面开发中CheckedListBox的详解
一、基础设置 单击触发选择效果:需要选择下面这个为True 二、代码实现 1.设置数据源 /// <summary> /// 为CheckBoxList设置数据源 /// </summary> /// <param name"checkedListBox1"></param> /// <param name"data&…...

【Java学习笔记】final关键字
final 关键字 一、final 关键字介绍 1. final可以修饰类、属性、方法和局部变量 2. final 的使用场景 (1)类不能被继承时,可以使用final修饰 (2)类的某个属性不可以被更改,可以使用final修饰 ࿰…...
AI学习笔记二十八:使用ESP32 CAM和YOLOV5实现目标检测
若该文为原创文章,转载请注明原文出处。 最近在研究使用APP如何显示ESP32 CAM的摄像头数据,看到有人实现把ESP32 CAM的数据流上传,通过YOLOV5来检测,实现拉流推理,这里复现一下。 一、环境 arduino配置esp32-cam开发环…...
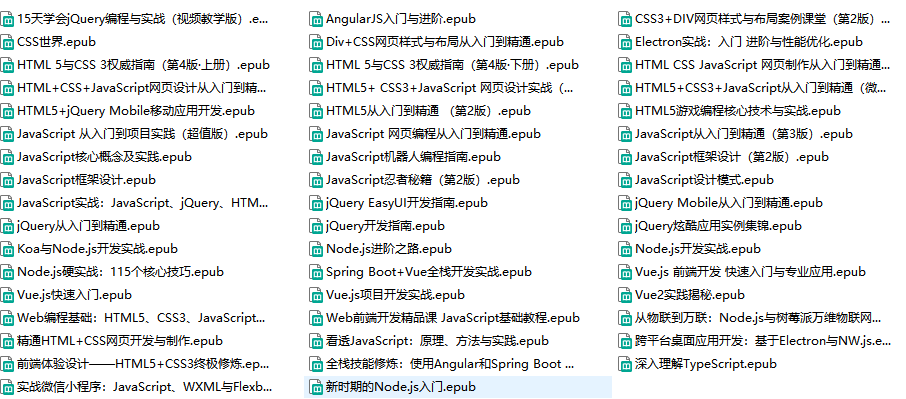
免费分享50本web全栈学习电子书
最近搞到一套非常不错的 Web 全栈电子书合集,整整 50 本,都是epub电子书格式,相当赞!作为一个被期末大作业和项目 ddl 追着跑的大学生,这套书真的救我狗命! 刚接触 Web 开发的时候,我天天对着空…...
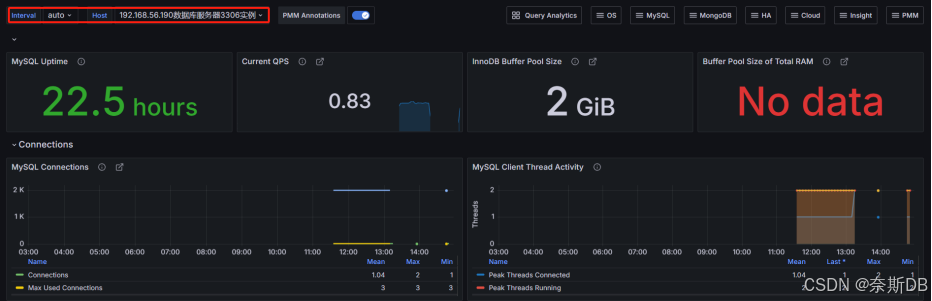
【prometheus+Grafana篇】基于Prometheus+Grafana实现MySQL数据库的监控与可视化
💫《博主主页》: 🔎 CSDN主页 🔎 IF Club社区主页 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了…...

全链路解析:影刀RPA+Coze API自动化工作流实战指南
在数字化转型加速的今天,如何通过RPA与API的深度融合实现业务自动化提效,已成为企业降本增效的核心命题。本文以「影刀RPA」与「Coze API」的深度协作为例,系统性拆解从授权配置、数据交互到批量执行的完整技术链路,助你快速掌握跨…...
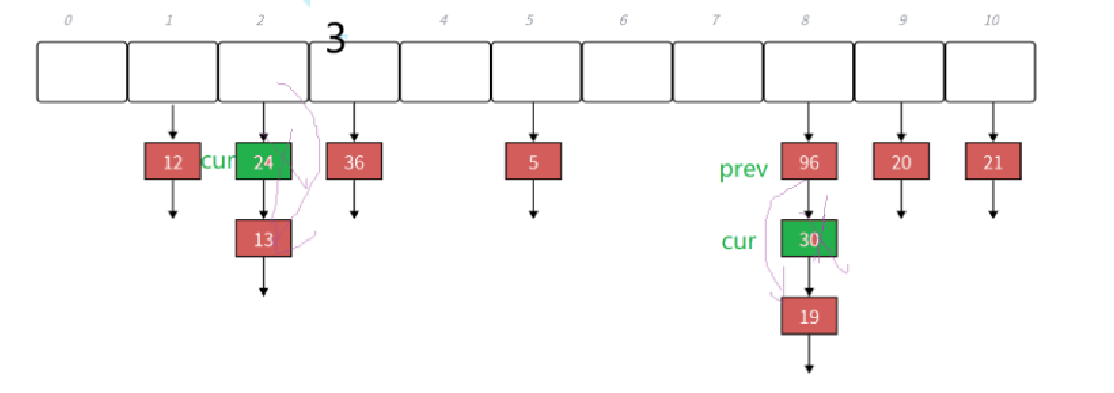
高阶数据结构——哈希表的实现
目录 1.概念引入 2.哈希的概念: 2.1 什么叫映射? 2.2 直接定址法 2.3 哈希冲突(哈希碰撞) 2.4 负载因子 2.5 哈希函数 2.5.1 除法散列法(除留余数法) 2.5.2 乘法散列法(了解)…...

window 显示驱动开发-报告渲染操作的可选支持
从 Windows 7 开始,显示微型端口驱动程序可以在 DXGK_PRESENTATIONCAPS 结构中设置其他成员,以指示驱动程序可以或不能支持的某些呈现操作。 从 Windows 7 开始,显示微型端口驱动程序可以通过 DXGK_PRESENTATIONCAPS 结构进一步声明其支持的…...

2025 年网络安全趋势报告
一、引言 自欧洲信息安全协会(Infosecurity Europe)首次举办活动的 30 年来,网络安全格局发生了翻天覆地的变化。如今,网络安全领导者必须应对众多威胁,维持法规合规性,并与董事会成员合作推进组织的网络安…...

uniapp 条件筛选
v3 版本 <template><view class"store flex "><view class"store_view"><view class"store_view_search flex jsb ac"><!-- <view class"store_view_search_select">全部</view> --><v…...
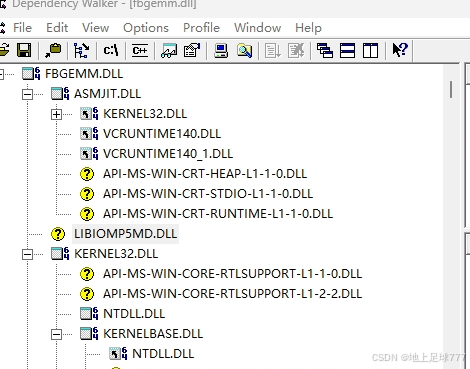
pytorch问题汇总
conda环境下 通过torch官网首页 pip安装 成功运行 后面通过conda安装了别的包 似乎因为什么版本问题 就不能用了 packages\torch_init_.py", line 245, in _load_dll_libraries raise err OSError: [WinError 127] 找不到指定的程序。 Error loading ackages\torch\lib\c…...

开发过的一个Coding项目
一、文档资料、人员培训: 1、文档资料管理:这个可以使用OnLineHelpDesk。 2、人员培训:可以参考Is an Online Medical Billing and Coding Program Right for You - MedicalBillingandCoding.org。 3、人员招聘、考核:可以在Onli…...
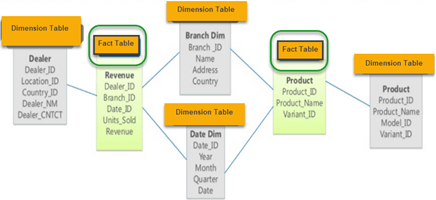
数据仓库维度建模详细过程
数据仓库的维度建模(Dimensional Modeling)是一种以业务用户理解为核心的设计方法,通过维度表和事实表组织数据,支持高效查询和分析。其核心目标是简化复杂业务逻辑,提升查询性能。以下是维度建模的详细过程࿱…...
python打卡day37
早停策略和模型权重保存 知识点回顾: 过拟合的判断:测试集和训练集同步打印指标模型的保存和加载 仅保存权重保存权重和模型保存全部信息checkpoint,还包含训练状态 早停策略 是否过拟合,可以通过同步打印训练集和测试集的loss曲线…...
)
Redis 5.0.10 集群部署实战(3 主 3 从,三台服务器)
本文详细介绍如何在三台服务器上部署 Redis 5.0.10 的集群(3 主 3 从),并为每个步骤、配置项和命令提供清晰的注释说明,确保生产环境部署稳定可靠。 1️⃣ 环境准备 目标架构:3 主 3 从,共 6 个节点,分布在 3 台服务器 服务器信息: 192.16.1.85 192.16.1.86 192.16.1.8…...

各个网络协议的依赖关系
网络协议的依赖关系 学习网络协议之间的依赖关系具有多方面重要作用,具体如下: 帮助理解网络工作原理 - 整体流程明晰:网络协议分层且相互依赖,如TCP/IP协议族,应用层协议依赖传输层的TCP或UDP协议来传输数据&#…...

OSC协议简介、工作原理、特点、数据的接收和发送
OSC协议简介 Open Sound Control(OSC) 是一种开放的、独立于传输的基于消息的协议,主要用于计算机、声音合成器和其他多媒体设备之间的通信。它提供了一种灵活且高效的方式来发送和接收参数化消息,特别适用于实时控制应用&#x…...

区块链可投会议CCF C--APSEC 2025 截止7.13 附录用率
Conference:32nd Asia-Pacific Software Engineering Conference (APSEC 2025) CCF level:CCF C Categories:软件工程/系统软件/程序设计语言 Year:2025 Conference time:December 2-5, 2025 in Macao SAR, China …...

【数字图像处理】_笔记
第一章 概述 1.1 什么是数字图像? 图像分为两大类:模拟图像与数字图像 模拟图像:通过某种物理(光、电)的强弱变化来记录图像上各个点的亮度信息 连续:从空间上和数值上是不间断的 举例&…...
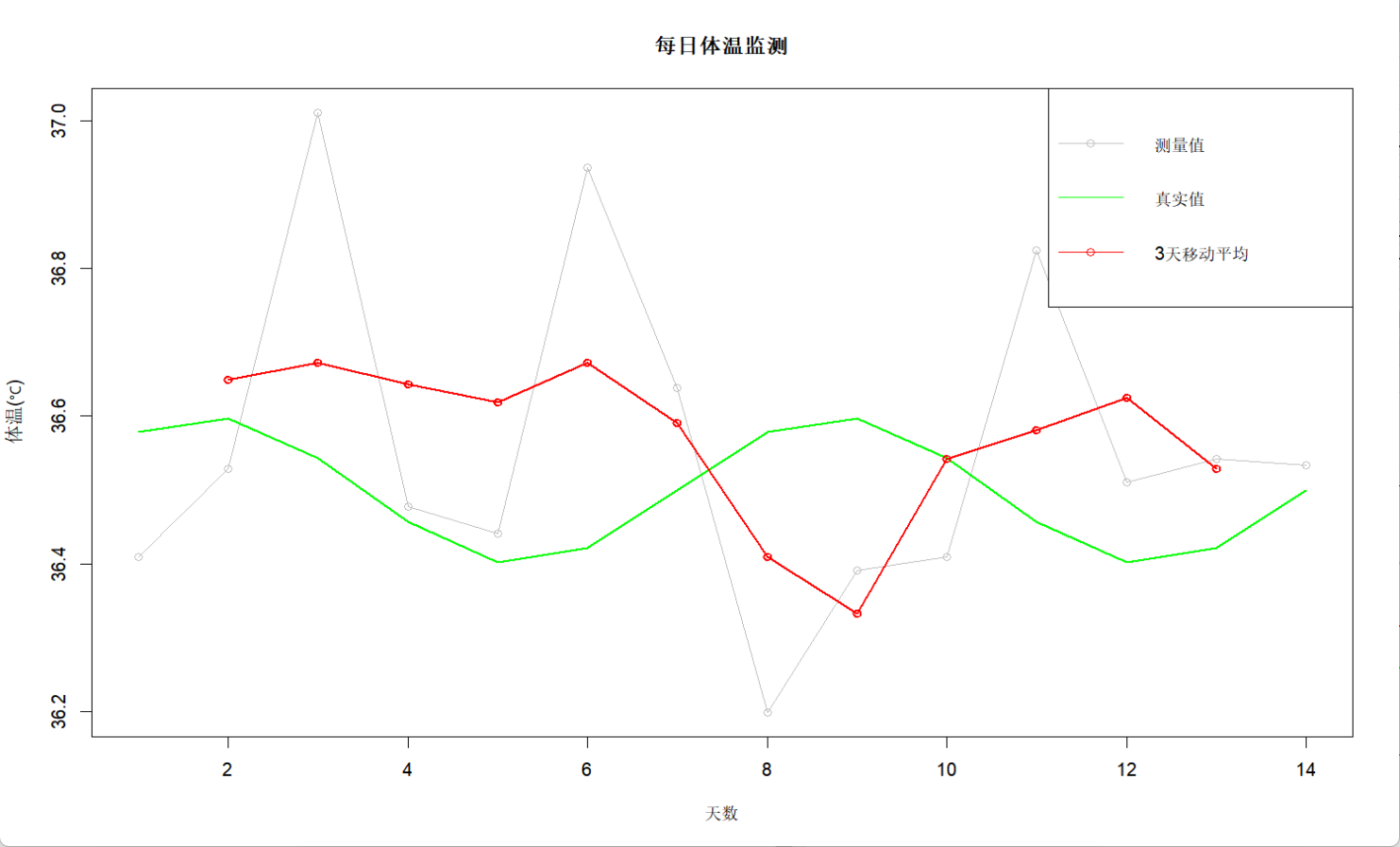
从0开始学习R语言--Day10--时间序列分析数据
在数据分析中,我们经常会看到带有时间属性的数据,比如股价波动,各种商品销售数据,网站的网络用户活跃度等。一般来说,根据需求我们会分为两种,分析历史数据的特点和预测未来时间段的数据。 移动平均 移动平…...

基于开源链动2+1模式AI智能名片S2B2C商城小程序的产品驱动型增长策略研究
摘要:在数字化经济时代,产品驱动型增长(Product-Led Growth, PLG)已成为企业突破流量瓶颈、实现用户裂变的核心战略。本文以“开源链动21模式AI智能名片S2B2C商城小程序”(以下简称“链动AI-S2B2C系统”)为…...

每日算法 -【Swift 算法】反转整数的陷阱与解法:Swift 中的 32 位整数处理技巧
反转整数的陷阱与解法:Swift 中的 32 位整数处理技巧 在面试题和算法练习中,整数反转是一道非常经典的题目。乍一看很简单,但一旦加入“不能使用 64 位整数”和“不能溢出 32 位整数范围”这两个限制,问题就立刻变得有挑战性。本…...

使用 OpenCV 实现“随机镜面墙”——多镜片密铺的哈哈镜效果
1. 引言 “哈哈镜”是一种典型的图像变形效果,通过局部镜面反射产生扭曲的视觉趣味。在计算机视觉和图像处理领域,这类效果不仅有趣,还能用于艺术创作、交互装置、视觉特效等场景。 传统的“哈哈镜”往往是针对整张图像做某种镜像或扭曲变换…...
鸿蒙仓颉开发语言实战教程:页面跳转和传参
前两天分别实现了商城应用的首页和商品详情页面,今天要分享新的内容,就是这两个页面之间的相互跳转和传递参数。 首先我们需要两个页面。如果你的项目中还没有第二个页面,可以右键cangjie文件夹新建仓颉文件: 新建的文件里面没什…...

如何在Vue中实现延迟刷新列表:以Element UI的el-switch为例
如何在Vue中实现延迟刷新列表:以Element UI的el-switch为例 在开发过程中,我们经常需要根据用户操作或接口响应结果来更新页面数据。本文将以Element UI中的el-switch组件为例,介绍如何在状态切换后延迟1秒钟再调用刷新列表的方法࿰…...

最新Spring Security实战教程(十六)微服务间安全通信 - JWT令牌传递与校验机制
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...

MDM在智能健身设备管理中的技术应用分析
近年来,随着智能硬件的普及和健身行业的数字化转型,越来越多健身房引入了Android系统的智能健身设备,如智能动感单车、智能跑步机、体测仪等。这些设备通过内嵌的安卓终端,实现了健身内容播放、用户交互、远程课程等功能ÿ…...