高阶数据结构——哈希表的实现
目录
1.概念引入
2.哈希的概念:
2.1 什么叫映射?
2.2 直接定址法
2.3 哈希冲突(哈希碰撞)
2.4 负载因子
2.5 哈希函数
2.5.1 除法散列法(除留余数法)
2.5.2 乘法散列法(了解)
2.5.3 全域散列法(了解)
2.5.4 处理哈希冲突
2.5.4.1 开放地址法:
2.5.4.1.1 线性探测
2.5.4.1.1.1 基本框架
2.5.4.1.1.2 插入+线性探测
2.5.4.1.1.3 查找+线性探测
2.5.4.1.1.4 删除+线性探测
2.5.4.1.1.5 总结:
2.5.4.1.1 二次探测
2.5.4.2 链地址法:
2.5.4.2.1 基本框架:
2.5.4.2.2 插入+扩容:
2.5.4.2.3 查找:
2.5.4.2.4 删除:
2.5.4.2.4 析构:
2.5.4.2.5 代码总结:
1.概念引入
咱们一开始看见哈希,之前从来没见过这个东西,是不是感到很厉害的样子?相信大家都去过超市吧,当你买了一个商品,你拿到柜台,人家一输入这个商品的名称,机器上面就会显示这个物品的价格,是不是查找很快速。这其实就是一种哈希表的实现。
2.哈希的概念:
哈希(hash)又称散列,是⼀种组织数据的方式。从译名来看,有散乱排列的意思。本质就是通过哈希 函数把关键字Key跟存储位置建立⼀个映射关系,查找时通过这个哈希函数计算出Key存储的位置,进 行快速查找。
2.1 什么叫映射?
咱们打个比方,比如你上高中的时候,你班里有个人叫做张三,但是他有个外号叫做“鸡哥”,那么鸡哥就是他,当别人喊鸡哥的时候,张三知道喊的就是他,而不是李四,这就是映射。即可以快速的找到那个人。
一般哈希的实现方法有很多种,下面咱们来讲一种关键字的范围比较集中的。
2.2 直接定址法
当关键字的范围比较集中时,直接定址法就是非常简单高效的方法,比如⼀组关键字都在[0,99]之间, 那么我们开⼀个100个数的数组,每个关键字的值直接就是存储位置的下标。再比如⼀组关键字值都在 [a,z]的小写字母,那么我们开⼀个26个数的数组,每个关键字acsii码-aascii码就是存储位置的下标。 也就是说直接定址法本质就是用关键字计算出一个绝对位置或者相对位置。
2.3 哈希冲突(哈希碰撞)
已知咱们使用的直接定址法是每个元素有每个元素的空,互相不占用彼此的空间。但是事实上真是如此嘛?并不是,理想状态上是哈希冲突为0,但也只是理想状态,咱们只有不断地减少哈希冲突,不可能消灭哈希冲突。那么哈希冲突(哈希碰撞)就是,我有两个不同的值,但是占用了同一个位置。那么此时就需要方法去解决这个哈希冲突。
当关键字的范围比较分散时,直接定址法就很浪费内存甚至内存不够用。
2.4 负载因子
再讲能够实现的方法之前,还得讲一个东西,那就是负载因子,这个是用来判断扩容的时机的。即负载因子到达一定得值就扩容。那么这个负载因子是如何计算的呢?假设哈希表中已经映射存储了N个值,哈希表的大小为M,那么 N 负载因子 =N/M ,负载因子有些地方 也翻译为载荷因子/装载因子等,他的英文为loadfactor。负载因子越大,哈希冲突的概率越高,空间 利用率越高;负载因子越小,哈希冲突的概率越低,空间利用率越低;(这个M是size(),不是capacity())
你想一想,这个负载因子可以想像为就是空间占有率(空间利用率),这个空间利用率高了,那么这个插入的元素就多了,那么相应的哈希冲突的概率是不是就提高了,因为没有剩余的空间了,所有的空间都有数据,你碰到一个跟你值相同的概率就会增大。
2.5 哈希函数
咱们之前说了,要设计一个方法去解决哈希冲突,那么设计的方法就是哈希函数。⼀个好的哈希函数应该让N个关键字被等概率的均匀的散列分布到哈希表的M个空间中,但是实际中却 很难做到,但是我们要尽量往这个方向去考量设计。
2.5.1 除法散列法(除留余数法)
1.除法散列法也叫做除留余数法,这个方法用来找到映射的位置。假设哈希表的大小为M,那么通过key除以M的余数作为 映射位置的下标,也就是哈希函数为:h(key)=key%M。
插话:咱们知道取模,只能取整数的模,如果key是整数还好,直接模就可以了,那如果说key不是整数呢?比如浮点数,字符串,结构体,那么该怎么办呢?咱们在这只讲字符串的处理方法,叫做BKDR 哈希算法:
由Brian Kernighan 和 Dennis Ritchie 提出
用于将字符串转换为哈希值。它的核心思想是通过一个质数种子(如31、131等)不断乘以当前哈希值并加上字符的ASCII码值,从而生成一个分布均匀的哈希值。
BKDR 算法的核心公式为:
hash=(hash×seed)+current_char
seed:预定义的质数(如 31、131、1313 等),作为乘法基数。
current\_char:字符串当前字符的 ASCII 值。
hash:初始值为 0,逐字符迭代计算最终哈希值。为什么要引入一个种子呢?
假如,有一个字符串是"abc",另外一个字符串是"bca",这俩字符串肯定是不一样的对吗,那么如果说咱们只加它们对应的ascii值的话,就会导致它们最后的哈希结果是一样的,但这不是咱们想要的结果,所以为了避免这种情况的出现,就引入了一个种子,每次加之后,都乘以这个种子,那么就可以避免这种情况的出现了。
计算过程示例(以
seed = 131,字符串"abc"为例):
初始值:
hash = 0处理字符
hash=0×131+97=97hash=0×131+97=97'a'(ASCII 97):处理字符
hash=97×131+98=12,785hash=97×131+98=12,785'b'(ASCII 98):处理字符
hash=12,785×131+99=1,675,854hash=12,785×131+99=1,675,854'c'(ASCII 99):最终哈希值为 1,675,854。
那么这个种子为什么一定要选择131呢?哈哈,这是两位大佬进行很多次试验后得出的,要是真想知道,可以去问两位大佬。
代码实现:
//对于可以直接转换为整形的,直接转换即可
template<class K>
struct HashFunc
{size_t operator()(const K& key) const{return (size_t)key;}
};// 对于string类型(不可以直接转换为整形的)需要进行特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key) const{size_t hash = 0;for (auto ch : key){hash += ch;hash *= 131;}return hash;}
};2.那么这个M的选择,也是有讲究的。要尽量避免M为某些值,如2的幂,10的幂等。如果是2^x ,那么key%2^x 本质相当于保留key的后X位(这个是保留的二进制的key的后x位),那么后x位相同的值,计算出的哈希值都是⼀样的,就冲突了。如: {63 , 31}看起来没有关联的值,如果M是16,也就是 2^4,那么计算出的哈希值都是15,因为63的二进制后8位是00111111,31的⼆进制后8位是00011111。(这里就只比较了二进制的后8位,但咱们知道二进制有32位,这里有个知识点,就是比较的位数越多,哈西冲突的概率就越小。所以这里只比较了8位,肯定不好)如果是 10^x(10进制) ,就更明显了,保留的都是 10进值的后x位,如:{112,12312},如果M是100,也就是10^2 ,那么计算出的哈希值都是12。(这里也不是比较的全部的位数)
3.当使用除法散列法时,建议M取不太接近2的整数次幂的⼀个质数(素数)。(这个其实不用太担心,因为咱们库里面会给的,就是素数集合,咱们只要用就可以了)。
2.5.2 乘法散列法(了解)
上面讲的是触发散列法,这个讲乘法散列法,下面还会讲一个全域散列法,但这俩只是了解,你真正的使用的时候,还是除法散列法使用的最多。可以理解为,除法散列法是讲一个大数字,化为需要的哈希值。而乘法散列法是将一个小数字,化为需要的哈希值。
1.乘法散列法对哈希表大小M没有要求,他的大思路第⼀步:用关键字K乘上常数A(0<A<1),并抽取出k*A的小数部分。第二步:后再用M乘以k*A的小数部分,再向下取整。
2.h(key) = floor(M ×((A ×key)%1.0)) ,其中floor表示对表达式进行下取整,A∈(0,1),这里 最重要的是A的值应该如何设定,Knuth认为 A =( − 5 1)/2 = 0.6180339887.... (黄金分割点]) 比较好。
3.乘法散列法对哈希表大小M是没有要求的,假设M为1024,key为1234,A=0.6180339887,A*key = 762.6539420558,取小数部分为0.6539420558, M×((A×key)%1.0)=0.6539420558*1024= 669.6366651392,那么h(1234)=669。
4.适用于常规数据场景,无需对抗攻击,且需快速哈希计算的场景(如内部数据结构)。
2.5.3 全域散列法(了解)
1.如果存在⼀个恶意的对手,他针对我们提供的散列函数,特意构造出⼀个发⽣严重冲突的数据集, 比如,让所有关键字全部落入同⼀个位置中。这种情况是可以存在的,只要散列函数是公开且确定的,就可以实现此攻击。解决方法自然是见招拆招,给散列函数增加随机性,攻击者就方法找出确定可以导致最坏情况的数据。这种方法叫做全域散列。
2. h ab (key) = ((a ×key +b)%P)%M ,P需要选⼀个足够大的质数,a可以随机选[1,P-1]之间的 h (8) = 任意整数,b可以随机选[0,P-1]之间的任意整数,这些函数构成了⼀个P*(P-1)组全域散列函数组。假设P=17,M=6,a=3,b=4,则 h 34 (8)= ((3 ×8+4)%17)%6 = 5 。
3.需要注意的是每次初始化哈希表时,随机选取全域散列函数组中的⼀个散列函数使用,后续增删查改都固定使用这个散列函数,否则每次哈希都是随机选⼀个散列函数,那么插入是⼀个散列函数,查找又是另⼀个散列函数,就会导致找不到插入的key了。
4.适用于安全敏感场景(如网络服务处理用户输入),防止恶意攻击导致哈希性能退化。
2.5.4 处理哈希冲突
咱们一般还是选择除法散列法来处理哈希冲突。当然哈希表无论选择什么哈希函数也避免不了 冲突,那么插⼊数据时,如何解决冲突呢?主要有两种两种方法,开放定址法和链地址法。
2.5.4.1 开放地址法:
在开放定址法中所有的元素都放到哈希表里,当⼀个关键字key用哈希函数计算出的位置冲突了,则按 照某种规则找到⼀个没有存储数据的位置进行存储,开放定址法中负载因子一定是小于的。这⾥的规 则有三种:线性探测、二次探测、双重探测。
2.5.4.1.1 线性探测
1.从发生冲突的位置开始,依次线性向后探测,直到寻找到下一个没有存储数据的位置为止,如果走 到哈希表尾,则回绕到哈希表头的位置。
2.h(key) = hash0 = key % M i = {1,2,3,...,M −1} , hash0位置冲突了,则线性探测公式为:hc(key,i) = hashi = (hash0+i) % M , i = {1,2,3,...,M −1},(就是从当前位置开始往后找,遇到表尾,直接%M,就可以回到表头了,所以%M的作用是为了回到表头。直到找到空位置去存放这个key)因为负载因子小于1,则最多探测M-1次,⼀定能找到⼀个存储key的位置。(由于负载因子是小于1的,所以整个空间总有空位置,所以总有位置给我存储key的值)。
3.下⾯演示{19,30,5,36,13,20,21,12}等这一组值映射到M=11的表中。

h(19) = 8 , h(30) = 8 , h(5) = 5 , h(36) = 3 , h(13) = 2 , h(20) = 9 , h(21) = 10 , h(12) = 1
 在看代码之前,我还是想说一下,就是对于开放地址法,咱们要创建一整个表,那么表中的元素,需要存储键值对,以及元素此时的状态(这里不光存储键值对,存储key也可以,只不过这里咱们用键值对来实现)。
在看代码之前,我还是想说一下,就是对于开放地址法,咱们要创建一整个表,那么表中的元素,需要存储键值对,以及元素此时的状态(这里不光存储键值对,存储key也可以,只不过这里咱们用键值对来实现)。
2.5.4.1.1.1 基本框架
//根据当前容量 n,返回一个预定义的素数表中大于等于 n 的最小素数,用于哈希表扩容。
inline unsigned long __stl_next_prime(unsigned long n)
{// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;// >=const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}
enum State
{EXIST,EMPTY,DELETE
};
//开放寻址法需要一个连续存储的数组,每个位置不仅要存储数据,
//还需要记录该位置的状态(是否被占用、已删除等),因此每个元素是HashData结构体,所以是vector<HashData<K, V>> _tables;
//直接存储键值对和状态
//那么既然每个元素是HashData结构体,那么自然_table[i],访问的是元素
//自然这个也是可以调用HashData这个结构体里的成员变量的
//例如_table[i]._kv,_table[i].__state
//那么由于_table是vector类型的,只不过_table中的元素是HashData结构体
//所以说_table是可以调用vector中的任意成员函数的。//每个元素的类型
template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY;
};//在C++中,模板类或函数可以指定默认模板参数。这意味着当用户不显式提供某个模板参数时,
//编译器会使用默认值。在这里,`class Hash = HashFunc<K>` 表示如果用户没有为第三个模板参数
// (即 `Hash`)提供具体类型,编译器将默认使用 `HashFunc<K > ` 作为该参数的类型
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
public:HashTable(size_t n = __stl_next_prime(0)):_tables(n), _n(0){}
private:vector<HashData<K, V>> _tables;size_t _n; // 实际存储的数据个数
};2.5.4.1.1.2 插入+线性探测
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))return false;//找不到才插入,找到了插入干啥// 扩容,负载因子==0.7就扩容if ((double)_n / (double)_tables.size() >= 0.7){HashTable<K, V, Hash> newht(__stl_next_prime(_tables.size() + 1));// 遍历旧表,将旧表的数据全部重新映射到新表for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._state == EXIST){newht.Insert(_tables[i]._kv);}}_tables.swap(newht._tables);}Hash hs;size_t hash0 = hs(kv.first) % _tables.size();size_t hashi = hash0;size_t i = 1;// 线性探测, (hash0+i) % Mwhile (_tables[hashi]._state == EXIST){hashi = hash0 + i;i++;hashi %= _tables.size();}//因为你是插入元素,所以说那个结构体里的成员变量都需要修改_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;
}大家看插入代码,逻辑其实很简单,主要就是求出哈希值,求出哈希值之后,就去找为空的位置进行插入。插入完了之后别忘了更新元素中的成员变量的状态。(这里的插入,是以hash0作为一开始的值,i是不断增加的,从而实现了不断向后寻找空状态的代码)并且更新实际存储的元素数量_n。
再看扩容代码,当负载因子为0.7的时候进行扩容,别忘了强转,因为两个整数相除得不到浮点数。之后创建一个哈希表,表中的元素位置的数量,看上面的素数表。注意,这里的表的类型是HashTable<K, V, Hash>,那是因为这里咱们只创建了一个表,但是等到了下面(待会讲的哈希桶),表的类型是vector<Node*>,里面的每个元素是 Node* 类型(指向哈希节点的指针)。之后判断原表中的元素存不存在,若存在,就使用递归插入到新表中(复用插入那部分的代码)。插入完了之后,别忘了交换两个表的指针。因为你定义的新表是临时变量(在函数中定义的),出了作用域就销毁了,而咱们不要旧表,要新表,所以将他俩交换一下(交换指针即可)。从而,旧表出了作用域就销毁了。非常nice。
这里还需要强调的一点是,代码中的Hash hs,其实是实例化了一个仿函数。目的就是将key转换为可以模的整形数。
2.5.4.1.1.3 查找+线性探测
//这个仅仅只是为了寻找元素,所以返回类型是HashData<K,V>(元素类型),而没有第三个模板参数
HashData<K, V>* Find(const K& key)
{Hash hs;size_t hash0 = hs(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST&& _tables[hashi]._kv.first == key){return &_tables[hashi];}// 线性探测,(hash0+i) % Mhashi = hash0 + i;i++;hashi %= _tables.size();}return nullptr;
}这里的查找你只能到元素状态不为空的地方去查找吧。并且你如果查找到了那个值,那个值的状态还得是存在(这个后面删除的部分会讲为什么),这样才可以返回这个元素的地址。否则就是往后线性探测,直到找到位置。如果最后还没有找到,那么就返回nullptr即可。
2.5.4.1.1.4 删除+线性探测
bool Erase(const K& key)
{HashData<K, V>* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}else{return false;}
}这个删除没什么好说的,只是用到了一个伪删除。将要被删除的元素的状态置为删除状态即可。那么这样的话,如果查找元素的时候,如果不加个元素的状态判断语句,很可能就将已经删除的元素也给查找上去,所以这就是为什么查找要加一个判断状态必须存在,接下来才是查找的元素与表中的元素相不相等。
2.5.4.1.1.5 总结:
完整代码:
//根据当前容量 n,返回一个预定义的素数表中大于等于 n 的最小素数,用于哈希表扩容。
inline unsigned long __stl_next_prime(unsigned long n)
{// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;// >=const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;
}//对于可以直接转换为整形的,直接转换即可
template<class K>
struct HashFunc
{size_t operator()(const K& key) const{return (size_t)key;}
};// 对于string类型(不可以直接转换为整形的)需要进行特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key) const{size_t hash = 0;for (auto ch : key){hash += ch;hash *= 131;}return hash;}
};namespace open_adrress
{enum State{EXIST,EMPTY,DELETE};//开放寻址法需要一个连续存储的数组,每个位置不仅要存储数据,//还需要记录该位置的状态(是否被占用、已删除等),因此每个元素是HashData结构体,所以是vector<HashData<K, V>> _tables;//直接存储键值对和状态//那么既然每个元素是HashData结构体,那么自然_table[i],访问的是元素//自然这个也是可以调用HashData这个结构体里的成员变量的//例如_table[i]._kv,_table[i].__state//那么由于_table是vector类型的,只不过_table中的元素是HashData结构体//所以说_table是可以调用vector中的任意成员函数的。//每个元素的类型template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};//在C++中,模板类或函数可以指定默认模板参数。这意味着当用户不显式提供某个模板参数时,//编译器会使用默认值。在这里,`class Hash = HashFunc<K>` 表示如果用户没有为第三个模板参数// (即 `Hash`)提供具体类型,编译器将默认使用 `HashFunc<K > ` 作为该参数的类型template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:HashTable(size_t n = __stl_next_prime(0)):_tables(n), _n(0){}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;//找不到才插入,找到了插入干啥// 扩容,负载因子==0.7就扩容if ((double)_n / (double)_tables.size() >= 0.7){HashTable<K, V, Hash> newht(__stl_next_prime(_tables.size() + 1));// 遍历旧表,将旧表的数据全部重新映射到新表for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._state == EXIST){newht.Insert(_tables[i]._kv);}}_tables.swap(newht._tables);}Hash hs;size_t hash0 = hs(kv.first) % _tables.size();size_t hashi = hash0;size_t i = 1;// 线性探测, (hash0+i) % Mwhile (_tables[hashi]._state == EXIST){hashi = hash0 + i;i++;hashi %= _tables.size();}//因为你是插入元素,所以说那个结构体里的成员变量都需要修改_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;}//这个仅仅只是为了寻找元素,所以返回类型是HashData<K,V>(元素类型),而没有第三个模板参数HashData<K, V>* Find(const K& key){Hash hs;size_t hash0 = hs(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST&& _tables[hashi]._kv.first == key){return &_tables[hashi];}// 线性探测,(hash0+i) % Mhashi = hash0 + i;i++;hashi %= _tables.size();}return nullptr;}bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}else{return false;}}private:vector<HashData<K, V>> _tables;size_t _n; // 实际存储的数据个数};线性探测的比较简单且容易实现,线性探测的问题假设,hash0位置连续冲突,hash0,hash1, hash2位置已经存储数据了,后续映射到hash0,hash1,hash2,hash3的值都会争夺hash3位 置,这种现象叫做群集/堆积。下面的二次探测可以⼀定程度改善这个问题。
2.5.4.1.1 二次探测
1.从发生冲突的位置开始,依次左右按二次方跳跃式探测,直到寻找到下⼀个没有存储数据的位置为 止,如果往右走到哈希表尾,则回绕到哈希表头的位置;如果往左走到哈希表头,则回绕到哈希表尾的位置;
2.h(key) = hash0 = key % M , hash0位置冲突了,则二次探测公式为: hc(key,i) = hashi = (hash0±i ) % M , i = {1,2,3,..., M/2}
3.⼆次探测当hashi = (hash0−i )%M时,当hashi<0时,需要hashi+=M.
4.下面演示{19,30,52,63,11,22}等这⼀组值映射到M=11的表中

h(19) = 8, h(30) = 8, h(52) = 8, h(63) = 8, h(11) = 0, h(22) = 0
 其实就是讲填的每个元素的间隔增大了,从而减少冲突,但是这个本质上解决不了问题,所以 引入了另外一种方法:
其实就是讲填的每个元素的间隔增大了,从而减少冲突,但是这个本质上解决不了问题,所以 引入了另外一种方法:
2.5.4.1.1 双重散列(了解)
1.第⼀个哈希函数计算出的值发生冲突,使用第⼆个哈希函数计算出⼀个跟key相关的偏移量值,不断往后探测,直到寻找到下一个没有存储数据的位置为止。
2. h 1 (key) = hash0 = key % M , hash0位置冲突了,则双重探测公式为: hc(key,i) = hashi = (hash0+ i∗h(key)) % M, i ={1,2,3,..., M}。
3.要求h2(key)<M且h2(key)和M互为质数,有两种简单的取值方法:1、当M为2整数幂时,
h2(key)从[0,M-1]任选一个奇数;2、当M为质数时,h2(key)=key%(M-1)+ 1。
4.保证h2(key)与M互质是因为根据固定的偏移量所寻址的所有位置将形成一个群,若最大公约数
p=gcd(M,hi(key))>1,那么所能寻址的位置的个数为M/P<M,使得对于一个关键字来
说无法充分利用整个散列表。举例来说,若初始探查位置为1,偏移量为3,整个散列表大小为12,那么所能寻址的位置为[1,4,7,10},寻址个数为12/gcd(12,3)=4。
5.下面演示{19,30,52,74},等这⼀组值映射到M=11的表中,设 h(key) = 2 key%10+1。

2.5.4.2 链地址法:
解决冲突的思路:
开放定址法中所有的元素都放到哈希表里,链地址法中所有的数据不再直接存储在哈希表中,哈希表 中存储⼀个指针,没有数据映射这个位置时,这个指针为空,有多个数据映射到这个位置时,我们把 这些冲突的数据链接成⼀个链表,挂在哈希表这个位置下面,链地址法也叫做拉链法或者哈希桶。
下面演示{19,30,5,36,13,20,21,12,24,96}等这⼀组值映射到M=11的表中。

h(19) = 8 , h(30) = 8 , h(5) = 5 , h(36) = 3 , h(13) = 2 , h(20) = 9 , h(21) = 10 , h(12) = 1,h(24) = 2,h(96) = 88
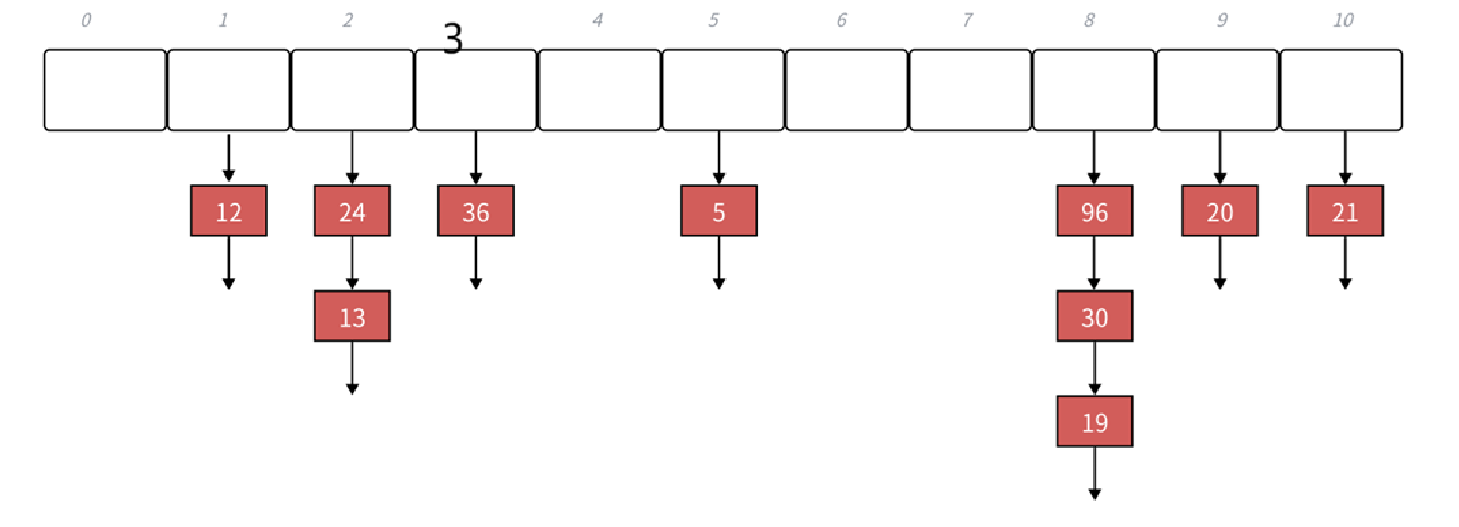 需要注意的是上面的0,1,2,3,4.........这些才是同,而桶下面挂的不是桶,而是链表,链表存储元素。
需要注意的是上面的0,1,2,3,4.........这些才是同,而桶下面挂的不是桶,而是链表,链表存储元素。
2.5.4.2.1 基本框架:
//而链地址法的每个桶是一个链表,因此_tables的每个元素是一个指向链表头节点的指针,所以是vector<Node*> _tables;
// 即vector里存的是每个元素,又因为每个元素是指针,所以存的是Node*
// 在下一个类中,进行了typedef HashNode<K, V> Node;
// 所以说,表中的每个元素也是可以使用HashNode的成员变量的。
//链表节点(Node)包含实际的键值对和指向下一个节点的指针。
template<class K, class V>
struct HashNode
{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V> Node;
public:HashTable(size_t n = __stl_next_prime(0)):_tables(n, nullptr)//创建一个大小为n的数组,每个桶初始化为空指针//这个是整个大的外壳是_table,是要初始化为n个元素,每个桶初始化为空指针//而上面写的HashNode的初始化是针对于每个元素的初始化,可以看成是外壳里面的小部分, _n(0){}
private:vector<Node*> _tables;//每个元素是一个链表的头指针,表示哈希桶中的一个桶size_t _n; // 实际存储有效数据个数
};这里的表中的元素需要存储的不同于开放地址法,这个表中元素需要存储的是键值对以及指向下一个元素的指针!
2.5.4.2.2 插入+扩容:
咱们先来看插入:
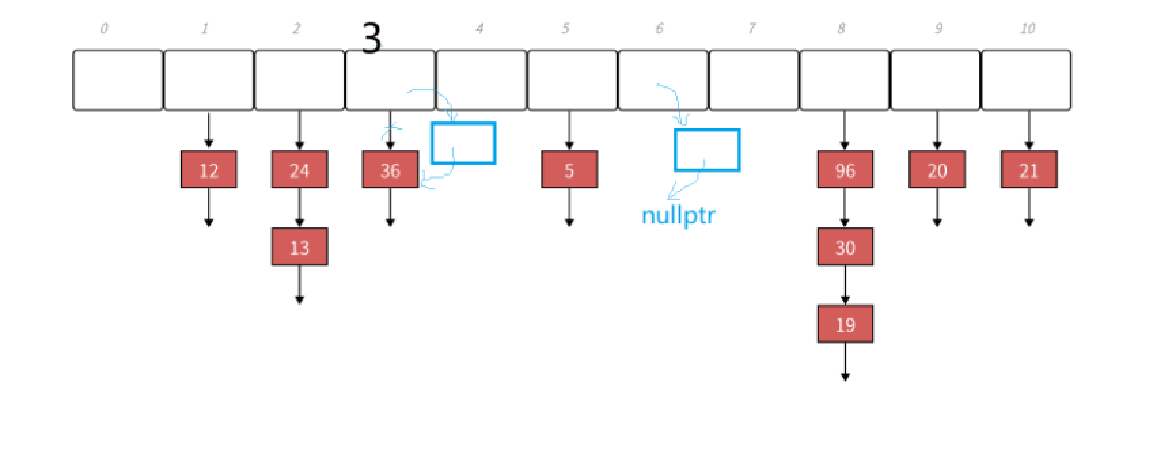
插入一般选择头插,而头插入的话,分为桶中有元素以及桶中没有元素。这两种方法都是同一种代码:
// 头插
Node* newnode = new Node(kv);
newnode->_next = _tables[hashi];// 将当前节点的 next 指向新表的当前桶头节点
_tables[hashi] = newnode;// 更新新表的当前桶头节点为当前节点
//这种插入方法既适用于桶中有节点的,也适用于桶中没有节点的,即当前节点是最新节点
//如果新表的桶 `hashi` 已经有节点A,那么插入节点B后,B的 `_next` 指向A,
// 新表的头节点变为B,形成 `B->A` 的结构。
++_n;那么扩容,有两种方法。
方法一:

HashTable<K, V> newht(__stl_next_prime(_tables.size() + 1));// 遍历旧表,将旧表的数据全部重新映射到新表
// 为每个节点创建新的`Node`对象(因为`newht.Insert`会创建新节点)。
for (size_t i = 0; i < _tables.size(); i++)
{Node* cur = _tables[i];while (cur){newht.Insert(cur->_kv);cur = cur->_next;}
}
_tables.swap(newht._tables);
/*特点递归插入:遍历旧表的每个节点,调用 newht.Insert 将数据插入新表。这会触发完整的插入逻辑(计算哈希、处理冲突)。内存开销:每个节点会重新创建新的 Node 对象,旧节点随后被释放(旧表析构时)。潜在问题:重复计算哈希:每次插入都要重新计算哈希值。内存分配频繁:为每个节点分配新内存,效率较低。*/这种写法得递归复用插入的那部分代码,并且还得重新创建节点,还得释放旧表中的节点,很浪费空间,效率还不高。
方法二:

// 扩容vector<Node*> newtables(__stl_next_prime(_tables.size() + 1), nullptr);//表示创建一个大小为 __stl_next_prime(_tables.size() + 1) 的数组,// 每个桶初始化为空指针。// 遍历旧表,将旧表的数据全部重新映射到新表//复用旧节点,仅调整指针,不创建新节点。for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// cur头插到新表size_t hashi = hs(cur->_kv.first) % newtables.size();cur->_next = newtables[hashi];// 将当前节点的 next 指向新表的当前桶头节点newtables[hashi] = cur;// 更新新表的当前桶头节点为当前节点cur = next;}_tables[i] = nullptr;//遍历旧表的每个桶后,将旧表的桶指针设为`nullptr`。//这是因为节点已经被转移到新表中,旧表不再拥有这些节点的所有权,// 避免重复释放或访问已转移的节点}_tables.swap(newtables);
}
/*特点节点复用:直接复用旧表的 Node 节点,仅调整指针指向,不创建新对象。高效内存管理:无需分配新内存,避免频繁的 new / delete 操作。哈希计算优化:每个节点只需计算一次哈希值(旧表节点直接插入新表对应桶)*/。
第二种方法就很好了,直接拿着节点过去,也不用担心创建,销毁节点的问题了。效率自然也是高了不少,那么还有一些其他的注意事项,我都写在了代码中,大家自行阅读。所以更推荐大家使用第二种扩容方式。
总代码:
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first))return false;Hash hs;// 负载因子到1扩容,if (_n == _tables.size()){//HashTable<K, V> newht(__stl_next_prime(_tables.size() + 1));遍历旧表,将旧表的数据全部重新映射到新表// 为每个节点创建新的`Node`对象(因为`newht.Insert`会创建新节点)。//for (size_t i = 0; i < _tables.size(); i++)//{// Node* cur = _tables[i];// while (cur)// {// newht.Insert(cur->_kv);// cur = cur->_next;// }//}//_tables.swap(newht._tables);/*特点递归插入:遍历旧表的每个节点,调用 newht.Insert 将数据插入新表。这会触发完整的插入逻辑(计算哈希、处理冲突)。内存开销:每个节点会重新创建新的 Node 对象,旧节点随后被释放(旧表析构时)。潜在问题:重复计算哈希:每次插入都要重新计算哈希值。内存分配频繁:为每个节点分配新内存,效率较低。*/// 扩容vector<Node*> newtables(__stl_next_prime(_tables.size() + 1), nullptr);//表示创建一个大小为 __stl_next_prime(_tables.size() + 1) 的数组,// 每个桶初始化为空指针。// 遍历旧表,将旧表的数据全部重新映射到新表//复用旧节点,仅调整指针,不创建新节点。for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// cur头插到新表size_t hashi = hs(cur->_kv.first) % newtables.size();cur->_next = newtables[hashi];// 将当前节点的 next 指向新表的当前桶头节点newtables[hashi] = cur;// 更新新表的当前桶头节点为当前节点cur = next;}_tables[i] = nullptr;//遍历旧表的每个桶后,将旧表的桶指针设为`nullptr`。//这是因为节点已经被转移到新表中,旧表不再拥有这些节点的所有权,// 避免重复释放或访问已转移的节点}_tables.swap(newtables);}/*特点节点复用:直接复用旧表的 Node 节点,仅调整指针指向,不创建新对象。高效内存管理:无需分配新内存,避免频繁的 new / delete 操作。哈希计算优化:每个节点只需计算一次哈希值(旧表节点直接插入新表对应桶)*/。//方法二直接复用旧节点,通过指针调整高效转移,避免了重复内存分配,//因此效率显著优于方法一。//方法一由于创建新节点和额外的插入操作,效率较低,尤其在数据量大时更为明显。//其实二者显著的差别就是,第一种是得创建新节点,因为它只传递了桶节点中的值//第二种是可以直接将那个桶节点直接搬运到新的哈希表中的,这个是不需要创建新节点的size_t hashi = hs(kv.first) % _tables.size();// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];// 将当前节点的 next 指向新表的当前桶头节点_tables[hashi] = newnode;// 更新新表的当前桶头节点为当前节点//这种插入方法既适用于桶中有节点的,也适用于桶中没有节点的,即当前节点是最新节点//如果新表的桶 `hashi` 已经有节点A,那么插入节点B后,B的 `_next` 指向A,// 新表的头节点变为B,形成 `B->A` 的结构。++_n;return true;
}2.5.4.2.3 查找:
Node* Find(const K& key)
{Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;
}查找没什么好说的,就是找到了就返回,没找到就继续寻找。
2.5.4.2.4 删除:
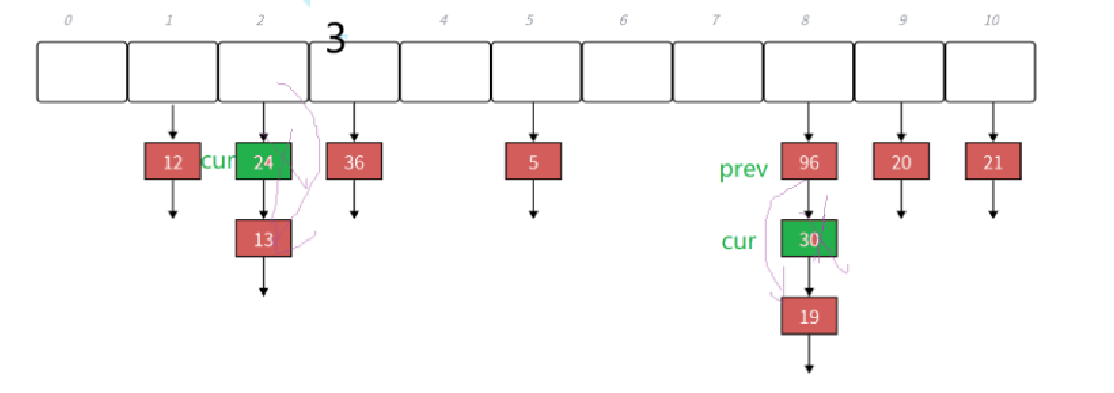
bool Erase(const K& key)
{Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}--_n;delete cur;return true;}prev = cur;cur = cur->_next;}return false;
}删除分为删除桶中的第一个元素以及删除中间的元素。中间的if(prev==nullptr),就是为了删除桶中的第一个元素而准备的。其实跟链表的删除差不了多少。
2.5.4.2.4 析构:
~HashTable()
{for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}
}析构函数的话,类似于链表的析构,遍历析构,最后别忘了将桶置为空。因为桶中的元素都没有了,那么这个桶就没有存在的必要了。
2.5.4.2.5 代码总结:
namespace hash_bucket
{//而链地址法的每个桶是一个链表,因此_tables的每个元素是一个指向链表头节点的指针,所以是vector<Node*> _tables;// 即vector里存的是每个元素,又因为每个元素是指针,所以存的是Node*// 在下一个类中,进行了typedef HashNode<K, V> Node;// 所以说,表中的每个元素也是可以使用HashNode的成员变量的。//链表节点(Node)包含实际的键值对和指向下一个节点的指针。template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:HashTable(size_t n = __stl_next_prime(0)):_tables(n, nullptr)//创建一个大小为n的数组,每个桶初始化为空指针//这个是整个大的外壳是_table,是要初始化为n个元素,每个桶初始化为空指针//而上面写的HashNode的初始化是针对于每个元素的初始化,可以看成是外壳里面的小部分, _n(0){}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;Hash hs;// 负载因子到1扩容,if (_n == _tables.size()){//HashTable<K, V> newht(__stl_next_prime(_tables.size() + 1));遍历旧表,将旧表的数据全部重新映射到新表// 为每个节点创建新的`Node`对象(因为`newht.Insert`会创建新节点)。//for (size_t i = 0; i < _tables.size(); i++)//{// Node* cur = _tables[i];// while (cur)// {// newht.Insert(cur->_kv);// cur = cur->_next;// }//}//_tables.swap(newht._tables);/*特点递归插入:遍历旧表的每个节点,调用 newht.Insert 将数据插入新表。这会触发完整的插入逻辑(计算哈希、处理冲突)。内存开销:每个节点会重新创建新的 Node 对象,旧节点随后被释放(旧表析构时)。潜在问题:重复计算哈希:每次插入都要重新计算哈希值。内存分配频繁:为每个节点分配新内存,效率较低。*/// 扩容vector<Node*> newtables(__stl_next_prime(_tables.size() + 1), nullptr);//表示创建一个大小为 __stl_next_prime(_tables.size() + 1) 的数组,// 每个桶初始化为空指针。// 遍历旧表,将旧表的数据全部重新映射到新表//复用旧节点,仅调整指针,不创建新节点。for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// cur头插到新表size_t hashi = hs(cur->_kv.first) % newtables.size();cur->_next = newtables[hashi];// 将当前节点的 next 指向新表的当前桶头节点newtables[hashi] = cur;// 更新新表的当前桶头节点为当前节点cur = next;}_tables[i] = nullptr;//遍历旧表的每个桶后,将旧表的桶指针设为`nullptr`。//这是因为节点已经被转移到新表中,旧表不再拥有这些节点的所有权,// 避免重复释放或访问已转移的节点}_tables.swap(newtables);}/*特点节点复用:直接复用旧表的 Node 节点,仅调整指针指向,不创建新对象。高效内存管理:无需分配新内存,避免频繁的 new / delete 操作。哈希计算优化:每个节点只需计算一次哈希值(旧表节点直接插入新表对应桶)*/。//方法二直接复用旧节点,通过指针调整高效转移,避免了重复内存分配,//因此效率显著优于方法一。//方法一由于创建新节点和额外的插入操作,效率较低,尤其在数据量大时更为明显。//其实二者显著的差别就是,第一种是得创建新节点,因为它只传递了桶节点中的值//第二种是可以直接将那个桶节点直接搬运到新的哈希表中的,这个是不需要创建新节点的size_t hashi = hs(kv.first) % _tables.size();// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];// 将当前节点的 next 指向新表的当前桶头节点_tables[hashi] = newnode;// 更新新表的当前桶头节点为当前节点//这种插入方法既适用于桶中有节点的,也适用于桶中没有节点的,即当前节点是最新节点//如果新表的桶 `hashi` 已经有节点A,那么插入节点B后,B的 `_next` 指向A,// 新表的头节点变为B,形成 `B->A` 的结构。++_n;return true;}Node* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;}bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}--_n;delete cur;return true;}prev = cur;cur = cur->_next;}return false;}private:vector<Node*> _tables;//每个元素是一个链表的头指针,表示哈希桶中的一个桶size_t _n; // 实际存储有效数据个数};OK,今天的文章到底结束。
...............
相关文章:
高阶数据结构——哈希表的实现
目录 1.概念引入 2.哈希的概念: 2.1 什么叫映射? 2.2 直接定址法 2.3 哈希冲突(哈希碰撞) 2.4 负载因子 2.5 哈希函数 2.5.1 除法散列法(除留余数法) 2.5.2 乘法散列法(了解)…...

window 显示驱动开发-报告渲染操作的可选支持
从 Windows 7 开始,显示微型端口驱动程序可以在 DXGK_PRESENTATIONCAPS 结构中设置其他成员,以指示驱动程序可以或不能支持的某些呈现操作。 从 Windows 7 开始,显示微型端口驱动程序可以通过 DXGK_PRESENTATIONCAPS 结构进一步声明其支持的…...

2025 年网络安全趋势报告
一、引言 自欧洲信息安全协会(Infosecurity Europe)首次举办活动的 30 年来,网络安全格局发生了翻天覆地的变化。如今,网络安全领导者必须应对众多威胁,维持法规合规性,并与董事会成员合作推进组织的网络安…...

uniapp 条件筛选
v3 版本 <template><view class"store flex "><view class"store_view"><view class"store_view_search flex jsb ac"><!-- <view class"store_view_search_select">全部</view> --><v…...
pytorch问题汇总
conda环境下 通过torch官网首页 pip安装 成功运行 后面通过conda安装了别的包 似乎因为什么版本问题 就不能用了 packages\torch_init_.py", line 245, in _load_dll_libraries raise err OSError: [WinError 127] 找不到指定的程序。 Error loading ackages\torch\lib\c…...

开发过的一个Coding项目
一、文档资料、人员培训: 1、文档资料管理:这个可以使用OnLineHelpDesk。 2、人员培训:可以参考Is an Online Medical Billing and Coding Program Right for You - MedicalBillingandCoding.org。 3、人员招聘、考核:可以在Onli…...
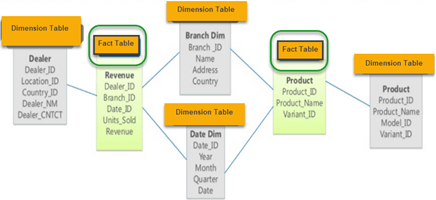
数据仓库维度建模详细过程
数据仓库的维度建模(Dimensional Modeling)是一种以业务用户理解为核心的设计方法,通过维度表和事实表组织数据,支持高效查询和分析。其核心目标是简化复杂业务逻辑,提升查询性能。以下是维度建模的详细过程࿱…...
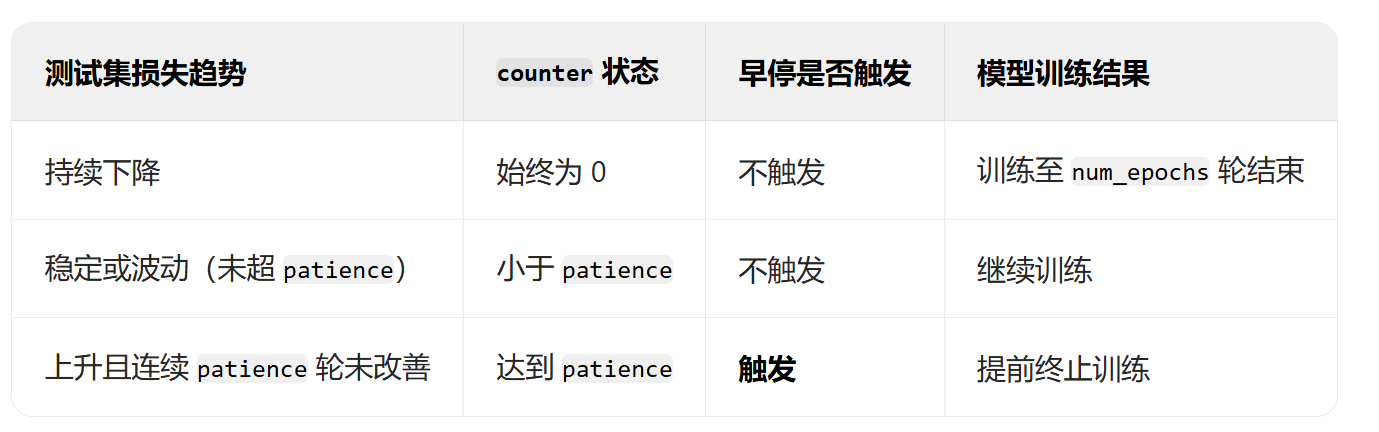
python打卡day37
早停策略和模型权重保存 知识点回顾: 过拟合的判断:测试集和训练集同步打印指标模型的保存和加载 仅保存权重保存权重和模型保存全部信息checkpoint,还包含训练状态 早停策略 是否过拟合,可以通过同步打印训练集和测试集的loss曲线…...
)
Redis 5.0.10 集群部署实战(3 主 3 从,三台服务器)
本文详细介绍如何在三台服务器上部署 Redis 5.0.10 的集群(3 主 3 从),并为每个步骤、配置项和命令提供清晰的注释说明,确保生产环境部署稳定可靠。 1️⃣ 环境准备 目标架构:3 主 3 从,共 6 个节点,分布在 3 台服务器 服务器信息: 192.16.1.85 192.16.1.86 192.16.1.8…...

各个网络协议的依赖关系
网络协议的依赖关系 学习网络协议之间的依赖关系具有多方面重要作用,具体如下: 帮助理解网络工作原理 - 整体流程明晰:网络协议分层且相互依赖,如TCP/IP协议族,应用层协议依赖传输层的TCP或UDP协议来传输数据&#…...

OSC协议简介、工作原理、特点、数据的接收和发送
OSC协议简介 Open Sound Control(OSC) 是一种开放的、独立于传输的基于消息的协议,主要用于计算机、声音合成器和其他多媒体设备之间的通信。它提供了一种灵活且高效的方式来发送和接收参数化消息,特别适用于实时控制应用&#x…...

区块链可投会议CCF C--APSEC 2025 截止7.13 附录用率
Conference:32nd Asia-Pacific Software Engineering Conference (APSEC 2025) CCF level:CCF C Categories:软件工程/系统软件/程序设计语言 Year:2025 Conference time:December 2-5, 2025 in Macao SAR, China …...

【数字图像处理】_笔记
第一章 概述 1.1 什么是数字图像? 图像分为两大类:模拟图像与数字图像 模拟图像:通过某种物理(光、电)的强弱变化来记录图像上各个点的亮度信息 连续:从空间上和数值上是不间断的 举例&…...
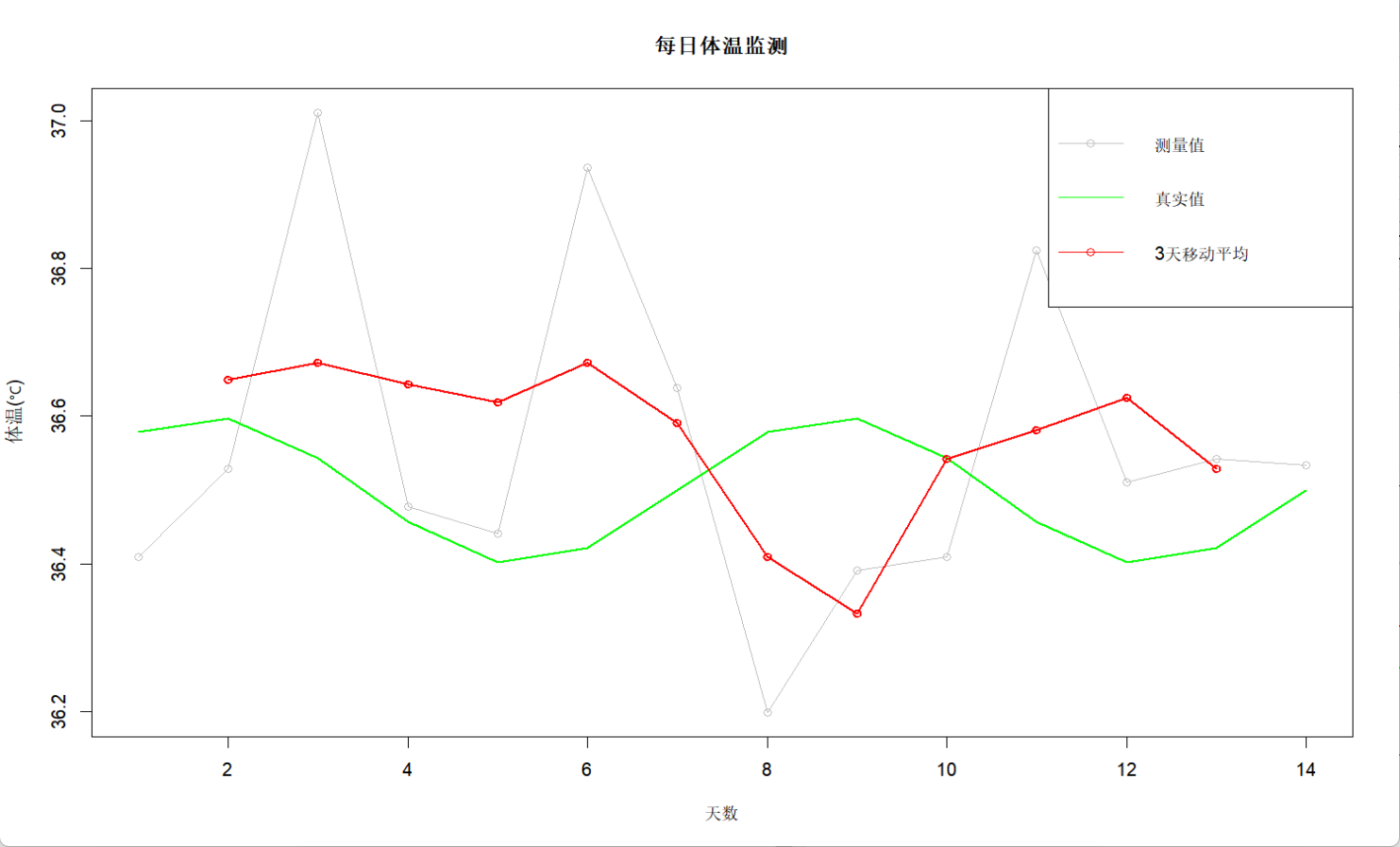
从0开始学习R语言--Day10--时间序列分析数据
在数据分析中,我们经常会看到带有时间属性的数据,比如股价波动,各种商品销售数据,网站的网络用户活跃度等。一般来说,根据需求我们会分为两种,分析历史数据的特点和预测未来时间段的数据。 移动平均 移动平…...

基于开源链动2+1模式AI智能名片S2B2C商城小程序的产品驱动型增长策略研究
摘要:在数字化经济时代,产品驱动型增长(Product-Led Growth, PLG)已成为企业突破流量瓶颈、实现用户裂变的核心战略。本文以“开源链动21模式AI智能名片S2B2C商城小程序”(以下简称“链动AI-S2B2C系统”)为…...

每日算法 -【Swift 算法】反转整数的陷阱与解法:Swift 中的 32 位整数处理技巧
反转整数的陷阱与解法:Swift 中的 32 位整数处理技巧 在面试题和算法练习中,整数反转是一道非常经典的题目。乍一看很简单,但一旦加入“不能使用 64 位整数”和“不能溢出 32 位整数范围”这两个限制,问题就立刻变得有挑战性。本…...

使用 OpenCV 实现“随机镜面墙”——多镜片密铺的哈哈镜效果
1. 引言 “哈哈镜”是一种典型的图像变形效果,通过局部镜面反射产生扭曲的视觉趣味。在计算机视觉和图像处理领域,这类效果不仅有趣,还能用于艺术创作、交互装置、视觉特效等场景。 传统的“哈哈镜”往往是针对整张图像做某种镜像或扭曲变换…...
鸿蒙仓颉开发语言实战教程:页面跳转和传参
前两天分别实现了商城应用的首页和商品详情页面,今天要分享新的内容,就是这两个页面之间的相互跳转和传递参数。 首先我们需要两个页面。如果你的项目中还没有第二个页面,可以右键cangjie文件夹新建仓颉文件: 新建的文件里面没什…...

如何在Vue中实现延迟刷新列表:以Element UI的el-switch为例
如何在Vue中实现延迟刷新列表:以Element UI的el-switch为例 在开发过程中,我们经常需要根据用户操作或接口响应结果来更新页面数据。本文将以Element UI中的el-switch组件为例,介绍如何在状态切换后延迟1秒钟再调用刷新列表的方法࿰…...

最新Spring Security实战教程(十六)微服务间安全通信 - JWT令牌传递与校验机制
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...

MDM在智能健身设备管理中的技术应用分析
近年来,随着智能硬件的普及和健身行业的数字化转型,越来越多健身房引入了Android系统的智能健身设备,如智能动感单车、智能跑步机、体测仪等。这些设备通过内嵌的安卓终端,实现了健身内容播放、用户交互、远程课程等功能ÿ…...

OSPF ABR汇总路由
一、OSPF ABR汇总配置(手工汇总) 📌 场景示例 假设ABR连接区域0和区域1,区域1内存在多个子网(如10.1.0.0/24、10.1.1.0/24),需将其手动汇总为10.0.0.0/8并通告至区域0。 🔧 配置命…...
【五】Spring Cloud微服务开发:解决版本冲突全攻略
Spring Cloud微服务开发:解决版本冲突全攻略 目录 Spring Cloud微服务开发:解决版本冲突全攻略 概述 一、Spring Boot 二、Spring Cloud 三、Spring Cloud Alibaba 总结 概述 spring cloud微服务项目开发过程中经常遇到程序包版本冲突的问题&…...
Spring Boot微服务架构(二):开发调试常见中文问题
Spring Boot开发调试常见中文问题及解决方案 一、环境配置类问题 端口冲突 表现:启动时报错"Address already in use"解决:修改application.properties中的server.port或终止占用端口的进程 数据库连接失败 表现:启动时报错"…...
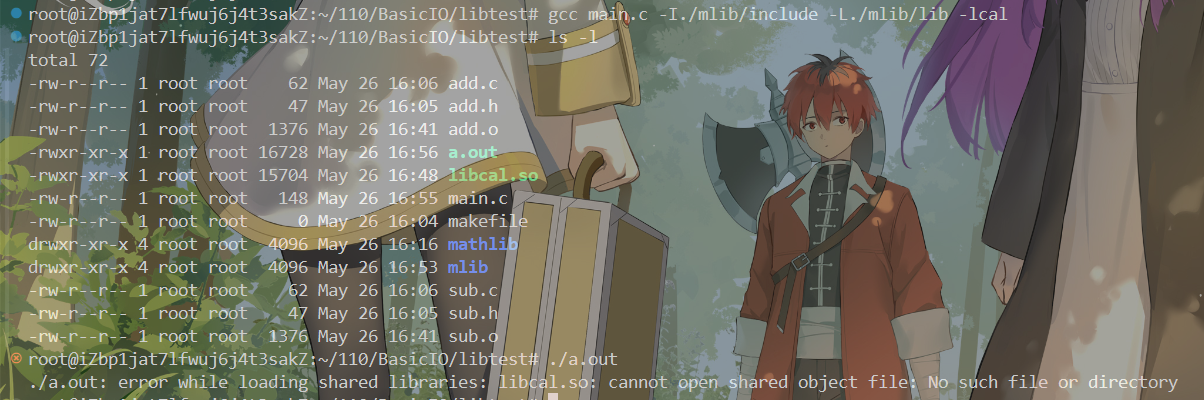
Linux基础IO----动态库与静态库
什么是库? 库是由一些.o文件打包在一起而形成的可执行程序的半成品。 如何理解这句话呢? 首先,一个程序在运行前需要进行预处理、编译、汇编、链接这几步。 预处理: 完成头文件展开、去注释、宏替换、条件编译等,最终…...
LeetCode百题刷004(哈希表优化两数和问题)
遇到的问题都有解决的方案,希望我的博客可以为你提供一些帮助 一、哈希策略优化两数和问题 题目地址:1. 两数之和 - 力扣(LeetCode)https://leetcode.cn/problems/two-sum/description/ 思路分析: 题目要求在一个整型…...
编码与new String()解码的字符集转换机制)
解析Java String.getBytes()编码与new String()解码的字符集转换机制
引言 在Java开发中,字符编码与解码是处理文本数据的基础操作,但稍有不慎就会导致乱码问题。理解字符串在内存中的存储方式以及如何正确使用编码转换方法,是保证跨平台、多语言兼容性的关键。本文将通过编码与解码的核心方法、常见问题场景及…...

从万有引力到深度学习,认识模型思维
从万有引力到深度学习,认识模型思维 引言 从牛顿发现万有引力定律到现代深度学习的崛起,“模型思维”始终是人类理解世界、解决问题的核心工具。它不仅是科学研究的基石,更是技术创新的底层逻辑。本文将从科学史、技术应用、认知效率等角度…...

2022 年 9 月青少年软编等考 C 语言八级真题解析
目录 T1. 道路思路分析T2. 控制公司思路分析T3. 发现它,抓住它思路分析T4. 青蛙的约会思路分析T1. 道路 题目链接:SOJ D1216 N N N 个以 1 ∼ N 1 \sim N 1∼N 标号的城市通过单向的道路相连,每条道路包含两个参数:道路的长度和需要为该路付的通行费(以金币的数目来表示…...
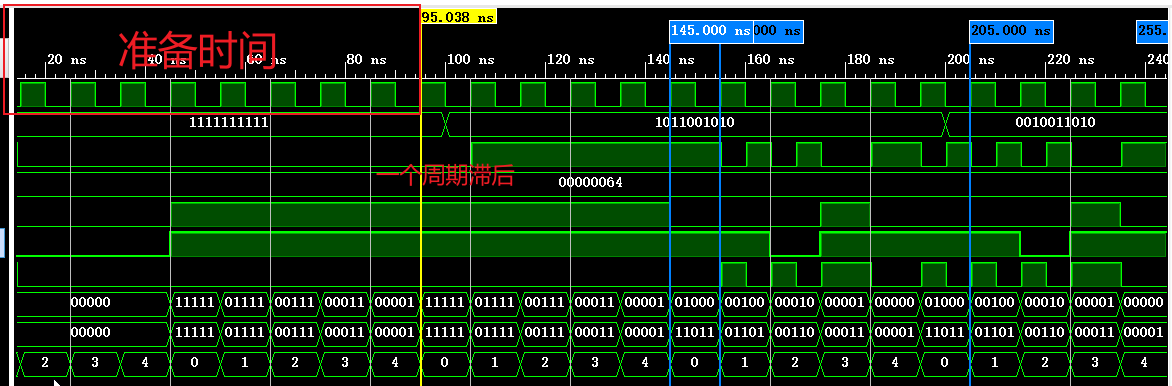
FPGA通信之VGA与HDMI
文章目录 VGA基本概念:水平扫描:垂直扫描: 时序如下:端口设计疑问为什么需要输出那么多端口不输出时钟怎么保证电子枪移动速度符合时序VGA转HDMI 仿真电路图代码总结:VGA看野火电子教程 HDMITMDS传输原理为什么使用TMD…...