51c自动驾驶~合集55
我自己的原文哦~ https://blog.51cto.com/whaosoft/13935858
#Challenger
端到端碰撞率暴增!清华&吉利,框架:低成本自动生成复杂对抗性驾驶场景~
自动驾驶系统在对抗性场景(Adversarial Scenarios)中的可靠性是安全落地的核心挑战。当前测试数据多依赖真实采集的常规场景,缺乏刻意构造的高风险驾驶场景。为此,清华大学联合吉利研究院提出全新框架Challenger,实现多视角、高保真对抗驾驶视频的自动化生成,在其生成的高挑战性数据集上验证显示,主流端到端模型碰撞率最高提升26.1倍!
❝
论文链接:
代码仓库(GitHub):Pixtella/Challenger:https://github.com/Pixtella/Challenger
项目主页:Challenger:https://pixtella.github.io/Challenger/
数据集(Hugging Face):Pixtella/Adv-nuSc · Datasets at Hugging Face:https://huggingface.co/datasets/Pixtella/Adv-nuSc
生成对抗性场景示例:
交替前进

左侧超车

正面会车、掉头、侧方超车

从左侧疾驰而过

拥堵场景变道

从左侧加塞

研究背景
在自动驾驶领域,评估系统的鲁棒性和安全性是至关重要的。然而,现有的大规模自动驾驶数据集,如nuScenes、OpenScene等,主要包含自然交通流,缺乏刻意设计的具有挑战性的交互场景。这些数据集难以系统地评估自动驾驶系统在罕见但高风险事件下的表现。为了解决这一问题,先前工作已提出多种对抗性场景生成方法,但这些方法大多基于抽象的轨迹或鸟瞰图(BEV)表示,无法提供逼真的传感器数据来真正测试端到端自动驾驶系统(end-to-end autonomous driving system)的极限。另有部分方法(如NeuroNCAP等)需要大量人力手动设计对抗性场景,或需要大量计算资源,难以实现复杂多样对抗性测试场景的批量生成。因此,如何自动、低开销地生成多样化、物理合理且逼真的对抗性驾驶视频,成为自动驾驶评估领域的一个重要空白。
研究团队提出的Challenger框架能够生成物理合理且逼真的对抗性驾驶视频。该框架通过结合基于扩散模型的轨迹生成器、物理感知规划模拟器和多视图神经渲染器,实现了基于真实驾驶场景自主生成对抗性驾驶场景。该项工作的核心贡献包括:
- 提出对抗性驾驶视频生成任务:为提升自动驾驶系统的安全性和可靠性评估效率,作者首次提出对抗性驾驶视频生成任务,并开发了统一框架Challenger。该框架通过多轮物理感知轨迹优化和渲染兼容的对抗性评分,实现了低成本的对抗性视频生成。
- 在nuScenes数据集上验证有效性:在nuScenes数据集上,Challenger成功生成了涵盖加塞、尾随、阻挡等多种对抗性驾驶行为的多样化且逼真的视频。这些视频覆盖了包括十字路口、环形交叉路口以及停车场等在内的多种动态交通场景。
- 显著降低先进自动驾驶模型性能并揭示可转移的失败模式:Challenger生成的视频使当前最先进的自动驾驶模型(如UniAD、VAD、SparseDrive和DiffusionDrive)的性能显著下降,并揭示了这些模型之间可转移的失败模式,为研究人员提供了深入了解模型脆弱性的机会。
方法

图1:Challenger系统框架图
Challenger 方法流程简述
Challenger 首先读取真实数据集(如 nuScenes)中交通参与者的 3D边界框(bounding boxes) 与 鸟瞰图地图(BEV Map) 来初始化驾驶场景。在此基础上,系统随机选取一辆背景车辆作为对抗智能体(adversarial agent),其余交通参与者保持不变。
随后,Challenger 会在一系列关键帧(keyframes)上对该对抗车辆的行为轨迹进行规划,并在关键帧之间连续执行这些轨迹。在每一个关键帧处,Challenger 会执行一个多轮轨迹优化(multi-round refinement)的过程,以高效搜索对抗性轨迹空间,具体步骤如下:
- 第一轮,从一个基于扩散模型的轨迹生成器(diffusion-based trajectory generator)中采样一批轨迹候选;
- 候选轨迹输入物理感知的规划模拟器(physics-aware planning simulator) ,利用LQR 控制器 与 车辆运动学模型模拟对抗车辆的行驶轨迹;
- 轨迹评分器对模拟轨迹进行评估,选出表现最优的一批轨迹;
- 这批轨迹被重复采样、加入扰动噪声、再通过扩散模型去噪重建,作为下一轮的输入;
- 以上步骤重复进行若干轮,以逐步收敛至最优对抗轨迹。
最终,挑选出最优轨迹作为当前关键帧的对抗计划,并将其作用到驾驶场景中。该过程将在所有关键帧上重复进行,生成完整的扰动行为序列。
在轨迹规划完成后,Challenger 利用一个多视角神经渲染器(multiview neural renderer),将这些对抗性场景转换为逼真的多摄像头视频输出,将用于后续评测端到端自动驾驶模型。
扩散轨迹生成器
Challenger首先训练一个无条件扩散模型(unconditional diffusion model),学习自然驾驶轨迹的分布 。每条轨迹表示为自车坐标系下的二维路径序列。训练数据来自 nuPlan 数据集,包含大量真实轨迹样本。
在生成过程中,模型从高斯噪声出发,通过逐步去噪,生成符合人类驾驶风格的轨迹。它还可用于轨迹微调,即对已有轨迹加噪后再去噪,从而实现多样化输出。
物理感知的规划模拟器
为了确保生成轨迹的物理可行性,Challenger引入了一个物理感知仿真器:
- 使用LQR 控制器生成车辆控制指令(转向与加速度)。
- 用自行车运动学模型(Kinematic Bicycle Model)模拟车辆运动。
该模块确保轨迹能被现实车辆动态执行,且适配当前背景车辆的物理特性(如轴距、轮距等)。
轨迹评分器
为了高效选择具有挑战性的轨迹,Challenger设计了一个复合评分函数,评价每条轨迹的可行性与对自车的挑战程度:
- 道路约束性:偏离可驾驶区域的轨迹将被惩罚;
- 碰撞率:导致对抗车辆与其他交通参与者碰撞的轨迹将被惩罚;
- 对抗性:与自车发生危险接近行为(但未发生碰撞)的轨迹将获得奖励。
该评分机制无需渲染图像即可快速评估轨迹,有利于高效搜索。
多轮轨迹优化
Challenger采用多轮迭代采样优化策略提升轨迹质量:
- 第0轮:从扩散模型采样一簇初始轨迹;
- 每轮:
- 用仿真器模拟轨迹;
- 使用轨迹评分器对轨迹打分;
- 重采样(Resample)得分高的轨迹;
- 加噪 + 扩散模型去噪,生成新的轨迹簇;
- 进入下一轮。
该过程逐步收敛到既物理可行又具对抗性的轨迹。

图2:多轮轨迹优化、轨迹评分器(Trajectory Scoring)的定性示意结果
多视角神经渲染器
最终,Challenger使用MagicDriveDiT作为神经渲染器,将生成的BEV轨迹与3D包围盒转化为六视角真实感视频。其具备:
- 高分辨率;
- 跨时域一致性;
- 能渲染复杂的城市场景与对抗行为。
此渲染器保证最终视频的视觉质量,适用于端到端自动驾驶模型的测试输入。
扩展至多对抗车辆

图3:Challenger生成包含多辆对抗车辆的程序框图
虽然当前版本的Challenger尚未引入对抗智能体之间的高层次交互关系,但其提供了一种结构清晰、可复用的扩展流程以支持包含多辆对抗车辆的场景生成。具体而言:
- 初始对抗生成:首先,使用 Challenger 生成一个包含单个对抗车辆的驾驶场景;
- 重新注入场景:在神经渲染之前,将该场景重新输入 Challenger,并选定另一个背景车辆作为新的对抗智能体;
- 重复迭代:重复上述过程,当前轮生成的对抗车辆会将先前的对抗车辆视为环境中的一部分,从而逐步引入多个对抗参与者;
- 最终渲染:在所有对抗智能体行为均规划完成后,统一执行多视角渲染,生成最终的视频输出。
实验
实验设置
数据集
本研究基于nuScenes数据集构建实验环境。nuScenes是一个大规模的多模态感知数据集,包含1000 个场景,每个场景时长为 20 秒,标注频率为2Hz,含有车辆、行人等物体的3D边界框(3D bounding boxes)标注,是当前端到端自动驾驶研究中的常用数据集。
具体地:
- 研究团队使用nuScenes验证集,共包含 150 个场景,6019 个样本,作为 Challenger 的实验基础;
- 为评估神经渲染器带来的视觉效果差异,作者将原始验证集用Challenger框架中的多视角神经渲染器重新渲染,称为 nuScenes-val-R;
- 另外,作者使用 Challenger 生成了新的对抗性数据集 Adv-nuSc,包含156 个场景,6115 个样本,该数据集包含带有挑战行为的背景车辆,用于测试自动驾驶系统的鲁棒性。

图4:来自三个数据集的示例数据
端到端自动驾驶模型
研究团队评估了四个当前主流的基于视觉的端到端自动驾驶模型,包括UniAD,VAD,SparseDrive,DiffusionDrive。
这些模型均基于多视角相机图像(multi-view camera images) 输入,预测未来3 秒内的自车轨迹(ego trajectory)。所有模型采用官方公开的预训练权重进行评估。
定量实验结果

表1:主流端到端自动驾驶模型在各数据集上的碰撞率
评估指标采用三秒碰撞率(collision rate),即预测轨迹在未来3 秒与任何其他物体发生碰撞的样本比例。
实验发现:
- 在nuScenes原始数据 和nuScenes-val-R上,各模型性能基本持平,碰撞率变化较小,说明虽然神经渲染带来了一定的分布漂移,但其影响非常有限。
- 在对抗性数据集 Adv-nuSc 上,所有模型的碰撞率显著上升,暴露出在面临挑战性行为时的脆弱性与泛化能力不足。
该实验结果清晰表明:Challenger 能够有效构造暴露自动驾驶系统失败模式的场景。
攻击可转移性实验
为进一步验证 Challenger 所生成的对抗场景是否对未知的自动驾驶系统 也能产生破坏效果,本节引入了攻击可迁移性(transferability)的评估实验。
实验设计:
- 引入替代模型(Surrogate Model):在Challenger系统中选定一个端到端自动驾驶模型作为替代模,随后生成一批对抗性场景并测试替代模型的表现
- 样本筛选:仅保留那些替代模型在至少一个样本中无法安全通行(发生碰撞)的场景;这一策略旨在聚焦更具挑战性的对抗场景,从而提升其对其他模型造成失败的可能性。
- 跨模型评估:对保留下来的场景,用其余三个模型分别评估;如果这些模型在至少一个样本中也发生碰撞,则说明该攻击对其具有迁移性。

图5:Challenger可以对端到端自动驾驶模型进行可转移的攻击
多组对比结果显示:大量对抗场景不仅能诱导替代模型失败,也会导致其它未见模型发生碰撞;攻击可在模型间迁移,在黑盒(black-box)条件下依然有效;这表明目前多种主流端到端自动驾驶系统可能存在共同脆弱性。
自动驾驶模型失败模式
研究团队通过对主流端到端自动驾驶模型在Adv-nuSc数据集上的部分失败样本的人工审查,识别出了两种典型的失效类型:
预测失败(Misforecasting):即使周围环境已明确展现潜在风险,自动驾驶系统未能正确预测其他交通参与者的行为轨迹,导致碰撞。这一问题主要归因于Challenger所生成的对抗性场景与原始训练数据之间存在协变量偏移(covariate shift)。
规划失败(Misplanning):指即便模型对周围环境的预测较为准确,但最终生成的驾驶决策存在严重风险,反映出规划模块对于复杂交互场景缺乏鲁棒性。


图6:部分对抗性场景下,端到端自动驾驶模型错误预测他车轨迹


图7:部分对抗性场景下,端到端自动驾驶模型无法作出安全的驾驶决策
结论
该项工作提出了一种名为Challenger的创新框架,它能够以低成本生成多样化、复杂且高度逼真的驾驶场景。该框架结合了基于扩散的轨迹生成器、具备物理意识的规划模拟器以及多视角神经渲染器,从而合成传感器级别的视频数据,以挑战当前最先进的端到端自动驾驶(E2E AD)系统。研究结果表明,Challenger生成的驾驶场景使得现有E2E AD模型的碰撞率激增,凸显了这些系统在应对对抗性交通交互时的脆弱性。此外,研究发现,这些对抗攻击通常可以在不同的模型架构之间迁移,这进一步揭示了当前端到端自动驾驶模型可能存在的共同漏洞。希望这项研究能为自动驾驶模型的鲁棒性和泛化能力提供更深入的洞察,以应对现实世界的复杂性。
#VLA模型最新综述
近80多个VLA 模型,涉及架构、训练,实时推理等
视觉 - 语言 - 动作(VLA)模型是人工智能领域的变革性进展,致力于将感知、自然语言理解和实体动作统一于一个计算框架。我们全面总结了 VLA 模型的最新进展,从五个主题展开呈现该领域全景。先奠定 VLA 系统概念基础,追溯其从跨模态学习架构到通用智能体(集成视觉 - 语言模型、动作规划器和分层控制器)的演变。研究采用严格文献综述框架,涵盖过去三年 80 多个 VLA 模型。关键进展领域包括架构创新、参数高效训练策略和实时推理加速。应用领域多样,如仿人机器人、自动驾驶汽车、医疗和工业机器人、精准农业、增强现实导航等。主要挑战涉及实时控制、多模态动作表示、系统可扩展性、对未知任务的泛化以及道德部署风险等。借鉴前沿研究成果,提出针对性解决方案,包括智能体人工智能适应、跨实体泛化和统一的神经符号规划。前瞻性讨论勾勒未来路线图,VLA 模型、视觉 - 语言模型和智能体人工智能将融合,为符合社会规范、自适应且通用的实体智能体提供动力。这项工作为推进智能、实用的机器人技术和通用人工智能奠定基础。
在视觉 - 语言 - 动作(VLA)模型出现前,机器人技术和人工智能进展在不同领域各自发展,包括能识别图像的视觉系统、理解生成文本的语言系统以及控制运动的动作系统。这些系统在各自领域表现尚可,但难以协同工作,也难以应对复杂环境和现实挑战。
如图 1 所示,传统基于卷积神经网络(CNNs)的计算机视觉模型专为狭窄任务设计,需大量标记数据和繁琐重训练,且缺乏语言理解和将视觉洞察转化为行动的能力。语言模型(如大语言模型 LLMs)革新了文本理解和生成,但局限于处理语言,无法感知物理世界。机器人领域基于动作的系统依赖手工策略或强化学习,能实现特定行为但难以泛化。
视觉 - 语言模型(VLMs)虽结合了视觉和语言实现多模态理解,但存在整合差距,难以生成或执行连贯动作。多数人工智能系统最多擅长两种模态,难以将视觉、语言、动作完全整合,导致机器人难以协调多种能力,呈现碎片化架构,泛化能力差且需大量工程工作,凸显了实体人工智能的瓶颈。
VLA 模型大约在 2021-2022 年被提出,谷歌 DeepMind 的 RT-2 率先引入变革性架构,统一感知、推理和控制。VLA 模型集成视觉输入、语言理解和运动控制能力,早期方法通过扩展视觉 - 语言模型包含动作标记来实现集成,提高了机器人的泛化、解释语言命令和多步推理能力。
VLA 模型是追求统一多模态智能的变革性步骤,利用整合多种信息的大规模数据集,使机器人能在复杂环境中推理和行动。从孤立系统到 VLA 范式的演进标志着向开发自适应和可泛化实体智能体的根本性转变。进行全面系统综述很有必要,这有助于阐明 VLA 模型的概念和架构原则,阐述技术发展轨迹,描绘应用,审视挑战,并向学界传达研究方向和实际考虑因素。
我们系统分析了 VLA 模型的基本原理、发展进展与技术挑战,旨在深化对 VLA 模型的理解,明确其局限并指明未来方向。我们先探讨关键概念,包括 VLA 模型的构成、发展历程、多模态集成机制,以及基于语言的标记化和编码策略,为理解其跨模态结构与功能奠定基础。接着,统一阐述近期进展与训练效率策略,涵盖架构创新、数据高效学习框架、参数高效建模技术和模型加速策略,这些成果助力 VLA 系统在不降低性能的同时,降低计算成本,推动其向实际应用拓展。随后,深入讨论 VLA 系统的局限性,如推理瓶颈、安全隐患、高计算需求、泛化能力有限和伦理问题等,并分析潜在解决方案。
视觉 - 语言 - 动作模型的概念
VLA 模型是新型智能系统,能在动态环境中联合处理视觉输入、解释自然语言并生成可执行动作。技术上,它结合视觉编码器(如 CNNs、ViTs)、语言模型(如 LLMs、transformers)和策略模块或规划器,采用多模态融合技术(如交叉注意力机制等),将感官观察与文本指令对齐。
与传统视觉运动流水线不同,VLA 模型支持语义基础,可进行情境感知推理、功能检测和时间规划。典型的 VLA 模型通过相机或传感器观察环境,解释语言目标(如 “捡起红色的苹果”)(图 5),输出高低级动作序列。近期进展通过整合模仿学习等模块提升样本效率和泛化能力。
我们探讨 VLA 模型从基础融合架构向可在实际场景(如机器人技术、导航、人机协作等)中部署的通用智能体的演变。VLA 模型作为多模态人工智能系统,统一视觉感知、语言理解和物理动作生成,使机器人或 AI 智能体通过端到端学习解释感官输入、理解情境并自主执行任务,弥合早期系统中视觉识别、语言理解和运动执行间的脱节,突破其能力限制。
演进与时间线
2022 - 2025 年,VLA 模型快速发展,经历三个阶段:
- 基础集成(2022 - 2023 年):早期 VLA 模型通过多模态融合架构实现基本视觉运动协调。如将 CLIP 嵌入与运动原语结合,展示 604 个任务的通用能力,通过规模化模仿学习在操作任务成功率达 97%,引入基于 transformer 的规划器实现时间推理。但这些基础工作缺乏组合推理能力,促使功能基础创新 。
- 专业化与实体推理(2024 年):第二代 VLA 模型纳入特定领域归纳偏差。借助检索增强训练提升少样本适应能力,通过 3D 场景图集成优化导航。引入可逆架构提高内存效率,用物理感知注意力解决部分可观测性问题。同时,以对象为中心的解耦改进组合理解,通过多模态传感器融合拓展应用到自动驾驶领域,这些进展需要新的基准测试方法。
- 泛化与安全关键部署(2025 年):当前系统注重鲁棒性和与人类对齐。集成形式验证用于风险感知决策,通过分层 VLA 模型展示全身控制能力。优化计算效率用于嵌入式部署,结合神经符号推理进行因果推断。新兴范式如的功能链和的仿真到现实转移学习解决跨实体挑战,通过自然语言基础连接 VLA 模型与人在回路接口。
图 6 展示 2022 - 2025 年 47 个 VLA 模型综合时间线。最早的 VLA 系统如 CLIPort等为操作和控制奠定基础,随后如 ACT等集成视觉思维链推理和功能基础,Diffusion Policy等引入随机建模和可扩展数据管道。2024 年 Deer - VLA等增加领域专业化和内存高效设计,Occllama等解决部分可观测性和用户交互问题,后续以机器人为重点的 VLA 模型不断创新。最近的模型强调泛化和部署,如 SafeVLA 等纳入验证、全身控制和内存系统,Gr00t N1 等实现仿真到现实转移和空间基础,展现 VLA 模型从模块化学习向通用、安全的实体智能发展的轨迹。
多模态集成:从孤立的流水线到统一的智能体
VLA 模型的核心进展在于多模态集成能力,能在统一架构中联合处理视觉、语言和动作。传统机器人系统将感知、自然语言理解和控制作为离散模块,通过手动接口或数据转换连接,缺乏适应性,难以泛化指令。
现代 VLA 模型利用大规模预训练编码器和基于 transformer 的架构,进行端到端模态融合,能在同一计算空间中处理视觉观察和语言指令,实现灵活推理。例如在 “捡起红色成熟苹果” 任务中,视觉编码器识别物体及其属性,语言模型编码指令,两者通过交叉注意力等机制融合,生成统一潜在空间指导动作策略。
CLIPort 率先展示多模态协同效应,用 CLIP 嵌入实现语义基础,无需显式语言解析确定视觉运动策略;VIMA 通过联合处理视觉和指令标记,实现跨空间推理少样本泛化。
近期发展进一步深化融合。VoxPoser 用体素级推理解决 3D 对象选择歧义,RT - 2 融合视觉 - 语言标记实现零样本泛化,Octo 引入内存增强 transformer 支持长时决策。此外,Occllama 处理遮挡对象引用,ShowUI 实现自然语言交互控制。这些能力源于 VLA 模型对跨模态语义、空间和时间对齐的深度捕捉,为现实应用挑战提供了解决方案。
标记化与表示:VLA 模型如何编码世界
VLA 模型的核心创新在于基于标记的表示框架,可对感知、语言和物理动作空间进行整体推理,受自回归生成模型启发,能统一各模态到共享嵌入空间,既理解 “做什么” 也知道 “怎么做”。
- 前缀标记:编码上下文和指令:是 VLA 模型的上下文关键。它将环境图像和自然语言指令编码为紧凑嵌入,为模型内部表示打基础。如 “将绿色积木堆放在红色托盘上” 任务中(如图 7 所示),图像经视觉编码器处理,指令由大语言模型嵌入,转换为前缀标记,实现跨模态基础,解析空间引用和对象语义。
- 状态标记:嵌入机器人的配置:VLA 模型需了解内部物理状态,由状态标记实现,其编码智能体配置实时信息,包括关节位置等。图 8 展示了在操作和导航场景中,状态标记对情境感知和安全很重要。如机械臂靠近易碎物体时,状态标记编码关节角度等信息,与前缀标记融合,让变换器推理物理约束,调整电机指令;移动机器人中,状态标记封装里程计等空间特征,与环境和指令上下文结合生成导航动作,为情境感知提供机制,生成反映机器人内外部信息的动作序列。
- 动作标记:自回归控制生成:VLA 标记管道最后一层是动作标记,由模型自回归生成,代表运动控制下一步,每个标记对应低级控制信号。推理时,模型依据前缀和状态标记解码动作标记,将 VLA 模型转变为语言驱动的策略生成器,支持与现实驱动系统无缝集成,可微调。如 RT-2 和 PaLM-E 等模型,在苹果采摘任务中(如图 9 所示),模型接收前缀标记和状态标记,逐步预测动作标记以执行抓取动作,让 transformer 能像生成句子一样生成物理动作。
学习范式:数据来源与训练策略
训练 VLA 模型需混合学习范式,结合网络语义知识与机器人数据集的任务相关信息,通过两个主要数据源实现:
- 大规模互联网衍生语料库:如图 10 所示,像 COCO、LAION400M 等图像 - 字幕对,HowTo100M、WebVid 等指令跟随数据集,VQA、GQA 等视觉问答语料库构成模型语义先验基础。预训练视觉和语言编码器,使用对比或掩码建模目标,对齐视觉和语言模态,赋予 VLA 模型对世界的基本 “理解”,助力组合泛化、对象基础和零样本迁移。
- 机器人轨迹数据集:仅靠语义理解不足以执行物理任务。从现实世界机器人或高保真模拟器收集的机器人轨迹数据集,如 RoboNet、BridgeData 和 RT-X 等,提供视频 - 动作对、关节轨迹和环境交互。采用监督学习、强化学习或模仿学习,训练自回归策略解码器预测动作标记。
此外,最近的工作采用多阶段或多任务训练策略,如先在视觉 - 语言数据集上预训练,再在机器人演示数据上微调;或使用课程学习,从简单任务到复杂任务;还利用领域适应弥合数据分布差距。联合微调使数据集对齐,模型学习从视觉和语言输入映射到动作序列,促进新场景泛化。谷歌 DeepMind 的 RT-2 将动作生成视为文本生成,在多模态数据和机器人演示上训练,能灵活解释新指令,实现零样本泛化,这在传统控制系统和早期多模态模型中难以实现。
自适应控制与实时执行
VLA 的优势在于具备执行自适应控制的能力,能够依据传感器实时反馈来动态调整行为。这在果园、家庭、医院等动态且非结构化环境中意义重大,因为在这些环境里,像风吹动苹果、光照变化、人员出现等意外情况会改变任务参数。在执行任务时,状态标记会根据传感器输入和关节反馈实时更新,模型也会相应修改计划动作。例如在苹果采摘场景中,若目标苹果位置变动或有其他苹果进入视野,模型能动态重新解读场景并调整抓取轨迹。这种能力模仿了人类的适应性,是 VLA 系统相较于基于流水线的机器人技术的核心优势。
视觉 - 语言 - 动作模型的进展
VLA 模型的诞生受基于 transformer 的大语言模型(LLMs)成功的启发,特别是 ChatGPT 展示的语义推理能力,推动研究人员将语言模型扩展至多模态领域,并为机器人集成感知和动作。
2023 年 GPT-4 引入多模态功能,可处理文本和图像,促使将物理动作纳入模型。同时,CLIP 和 Flamingo 等视觉 - 语言模型(VLM)通过对比学习实现零样本对象识别,利用大规模网络数据集对齐图像与文本描述,为 VLA 模型奠定基础。
大规模机器人数据集(如 RT-1 的 130,000 个演示)为联合训练视觉、语言和动作组件提供了关键动作基础数据,涵盖多种任务和环境,助力模型学习可泛化行为。
谷歌在 2023 年推出 RT-2,作为里程碑式的 VLA 模型,统一视觉、语言和动作标记,将机器人控制视为自回归序列预测任务,使用离散余弦变换(DCT)压缩和字节对编码(BPE)离散化动作,使新对象处理性能提高 63%。多模态融合技术(如交叉注意力 transformer)结合图像与语言嵌入,让机器人执行复杂命令。此外,加州大学伯克利分校的 Octo 模型(2023)引入开源方法,拥有 9300 万个参数和扩散解码器,在 800,000 个机器人演示数据上训练,拓展了研究领域。
VLA 模型的架构创新
2023 年到 2024 年,VLA 模型在架构和训练方法上取得重大进展:
- 架构进展:
- 双系统架构:以 NVIDIA 的 Groot N1(2025)为例,结合快速扩散策略(系统 1,10ms 延迟用于低级控制)和基于 LLM 的规划器(系统 2,用于高级任务分解),实现战略规划和实时执行的高效协调,增强动态环境适应性。斯坦福大学的 OpenVLA(2024)推出 70 亿参数的开源 VLA 模型,在大量现实世界机器人演示上训练,使用双视觉编码器和 Llama 2 语言模型,性能优于大型模型 RT-2-X(550 亿参数)。
- 早期融合模型:在输入阶段融合视觉和语言表示,如 EFVLA 模型保留 CLIP 的表示对齐,接受图像 - 文本对,编码并融合嵌入,确保语义一致性,减少过拟合,增强泛化能力,在组合操作任务上性能提升 20%,对未见目标描述成功率达 85%,同时保持计算效率。
- 自校正框架:自校正 VLA 模型可检测并从失败中恢复,如 SC-VLA(2024)引入混合执行循环,默认行为预测姿势或动作,检测到失败时调用次要过程,查询 LLM 诊断并生成校正策略,在闭环实验中降低任务失败率 35%,提高杂乱和对抗环境的恢复能力。
- 训练方法改进:利用网络规模的视觉 - 语言数据(如 LAION-5B)和机器人轨迹数据(如 RT-X)联合微调,使语义知识与物理约束一致。合成数据生成工具(如 UniSim)创建逼真场景解决数据稀缺问题。低秩适应(LoRA)适配器提高参数效率,减少 GPU 使用时间 70%。基于扩散的策略(如 Physical Intelligence 的 pi 0 模型(2024))提高动作多样性,但需大量计算资源。
- VLA 模型架构多样,可按端到端与模块化、分层与扁平策略、低级控制与高级规划等进行分类。端到端模型直接处理原始感官输入,组件重点模型解耦各模块。分层架构分离战略决策与反应控制,低级策略模型生成多样运动但计算成本高,高级规划器专注子目标生成并委托细粒度控制。
VLA 模型的训练与效率提升
VLA 模型在训练和优化技术上进步迅速,可协调多模态输入、降低计算需求并实现实时控制,主要进展如下:
- 数据高效学习:在大规模视觉 - 语言语料库(如 LAION-5B)和机器人轨迹集合(如 Open X-Embodiment)上联合微调,使语义理解与运动技能一致。OpenVLA(70 亿参数)成功率比 550 亿参数的 RT-2 变体高 16.5%,体现联合微调在少参数下的强泛化能力。通过 UniSim 合成数据生成逼真场景,增强罕见边缘情况的场景,使模型在杂乱环境中的鲁棒性提升超 20%。自监督预训练采用对比目标(如 CLIP),在动作微调前学习联合视觉 - 文本嵌入,减少对特定任务标签的依赖,Qwen2-VL 利用自监督对齐,使下游抓取和放置任务的收敛速度加快 12%。
- 参数高效适应:低秩适应(LoRA)在冻结的 transformer 层插入轻量级适配器矩阵,可减少高达 70% 的可训练权重且保持性能。Pi-0 Fast 变体在静态骨干网络上使用 1000 万个适配器参数,仅以可忽略的精度损失实现 200Hz 的连续控制。
- 推理加速:双系统框架(如 Groot N1)中,压缩动作令牌(FAST)和并行解码使策略步骤速度提高 2.5 倍,以适度牺牲轨迹平滑度为代价实现低于 5ms 的延迟。硬件感知优化,包括张量核心量化和流水线注意力内核,将运行时内存占用缩小到 8GB 以下,可在嵌入式 GPU 上实现实时推理。这些方法让 VLA 模型成为能在动态现实环境中处理语言条件、视觉引导任务的实用智能体。
VLA 模型的参数高效方法与加速技术
基于数据高效训练的进展,近期工作聚焦于减少 VLA 模型参数占用、提高推理速度,这对在资源受限的机器人平台部署意义重大,具体如下:
- 低秩适应(LoRA):LoRA 向冻结的 transformer 层注入小的可训练秩分解矩阵,OpenVLA 中,2000 万个参数的 LoRA 适配器微调 70 亿参数骨干网络耗时不到 24 小时,与完全反向传播相比,GPU 计算量减少 70%,且经 LoRA 适应的模型在处理新任务时能保持高级语言基础和视觉推理能力,使大型 VLA 模型可在无超级计算资源的实验室使用。
- 量化:将权重精度降至 8 位整数(INT8)可使模型大小减半、片上吞吐量翻倍。OpenVLA 实验显示,Jetson Orin 上 INT8 量化在取放基准测试中保持 97% 全精度任务成功率,细粒度灵巧操作任务精度仅降 5%,带有逐通道校准的训练后量化等方法可进一步减少高动态范围传感器输入的精度损失,使 50W 的边缘模块实现 30Hz 的连续控制循环。
- 模型剪枝:结构化剪枝删除冗余的注意力头或前馈子层。早期对 Diffusion Policy 的研究表明,对基于 ConvNet 的视觉编码器剪枝 20%,抓握稳定性性能下降可忽略。类似方案应用于基于 transformer 的 VLA 模型(如 RDT-1B),内存占用减少 25%,任务成功率下降不到 2%,为小于 4GB 的部署奠定基础。
- 压缩动作标记化(FAST):FAST 将连续动作输出转换为频域标记,Pi-0 Fast 变体将 1000ms 动作窗口标记化为 16 个离散标记,在 3 亿参数的扩散头中实现 15 倍推理加速,可在桌面 GPU 上实现 200Hz 的策略频率,以最小轨迹粒度换取大幅加速,适用于动态任务的高频控制。
- 并行解码和动作分块:自回归 VLA 模型传统解码方式存在顺序延迟,并行解码架构(如 Groot N1)同时解码空间 - 时间标记组,在 7 自由度机械臂上以 100Hz 频率运行时,端到端延迟降低 2.5 倍,位置误差增加不到 3mm。动作分块将多步例程抽象为单个标记,在长时任务中推理步骤最多减少 40%。
- 强化学习 - 监督混合训练:iRe-VLA 框架在模拟中交替进行强化学习和基于人类演示的监督微调,利用直接偏好优化塑造奖励模型,使用保守 Q 学习避免外推误差,与纯强化学习相比,样本复杂度降低 60%,并保持语义保真度,为动态避障等任务生成稳健策略。
- 硬件感知优化:编译器级的图重写和内核融合(如 NVIDIA TensorRTLLM)利用目标硬件特性加速 transformer 推理和扩散采样。OpenVLA-OFT 中,与标准 PyTorch 执行相比,这些优化使 RTX A2000 GPU 上推理延迟降低 30%,每次推理能耗降低 25%,使移动机器人和无人机在严格功率预算下实现实时 VLA 模型成为可能。
总之,参数高效适应和推理加速技术使 VLA 部署更普及。LoRA 和量化让小实验室能在消费级硬件上微调运行大型 VLA 模型。剪枝和 FAST 标记化压缩模型和动作表示。并行解码和动作分块克服自回归策略瓶颈。混合训练稳定复杂环境中的探索,硬件感知编译确保实时性能,这些进展使 VLA 模型在多种机器人中嵌入成为现实,缩小了研究原型与实际应用的差距。
VLA 模型的应用
VLA 模型将感知、自然语言理解和运动控制集成,在多领域展现变革力量:
- 仿人机器人:VLA 模型使仿人机器人能感知环境、理解指令并执行复杂任务。如图 12 所示 Helix 利用完全集成的 VLA 模型实现高频全身操作,其双系统设计可处理输入并输出动作向量,能泛化任务并适应环境变化。VLA 驱动的仿人机器人在家庭、医疗、零售、物流和制造业等场景有应用,如家庭中清洁、准备饭菜,医疗中传递手术器械,零售中协助客户,物流和制造业中执行重复性任务。TinyVLA 和 MoManipVLA 等系统可在嵌入式低功耗硬件上运行,减少计算成本,实现移动部署。
- 自动驾驶系统:VLA 模型为自动驾驶车辆提供集成架构,使其能处理多模态输入并输出控制信号。如 CoVLA 提供数据集,结合视觉基础、指令嵌入和轨迹预测,使车辆能理解环境和指令,做出安全决策;OpenDriveVLA 通过分层对齐多视图视觉标记和自然语言输入,实现先进的规划和问答性能;ORION 结合多种组件,实现视觉问答和轨迹规划。在无人机领域,VLA 模型增强了无人机的能力,可执行高级命令。VLA 模型使自动驾驶系统能理解复杂环境,做出安全决策,超越传统流水线。
- 工业机器人:传统工业机器人缺乏语义基础和适应性,VLA 模型通过联合嵌入多模态信息,提供易于人类解释和更具泛化性的框架。如 CogACT 引入基于扩散的动作变换器,实现对动作序列的稳健建模,在不同机器人实体间快速适应,在复杂任务中成功率比先前模型高 59% 以上,减少编程开销,促进人机协作,标志着向智能工厂的重要转变。
- 医疗保健和医疗机器人:传统医疗机器人自主性和响应能力有限,VLA 模型集成视觉感知、语言理解和运动控制,增强手术机器人能力,如在手术中识别目标、执行动作,减少人为错误;在患者辅助中感知患者行为、理解语音请求并提供帮助。RoboNurse-VLA 展示了在手术室的可行性,VLA 模型在可解释性和可审计性上有优势,可适应不同医疗场景,减少开发时间和成本,在医疗保健中发挥关键作用。
- 精准农业和自动化农业:传统农业自动化系统需手动重编程,VLA 模型集成多模态感知、语言理解和动作生成,能适应不同地理区域和季节。如在果园和农田中,处理视觉输入,解析自然语言命令,执行如水果采摘、灌溉等任务,减少作物损伤,优化采摘率,支持动态重新配置和终身学习,减少对劳动力依赖,提高产量,增强环境可持续性。
- 基于视觉 - 语言 - 动作模型的交互式 AR 导航:传统 GPS 系统依赖刚性地图和有限用户输入,VLA 模型处理视觉和语言信息,生成动态导航提示。集成视觉编码器、语言编码器和动作解码器,推理空间布局和语义意图,支持交互循环,可与物联网传感器和数字孪生集成,实现个性化导航,重新定义人类与物理空间的交互方式。
视觉 - 语言 - 动作模型的挑战与局限
VLA 模型从研究原型转化为现实世界系统面临多种挑战,具体如下:
- 实时推理约束:实时推理是 VLA 模型部署的重大限制,自回归解码策略限制推理速度,如机械臂操作时,OpenVLA 和 Pi-0 等模型在顺序标记生成上面临挑战。新兴的并行解码方法(如 NVIDIA 的 Groot N1)虽能加速推理,但会牺牲轨迹平滑度。硬件限制也加剧了实时推理约束,处理高维视觉嵌入对内存带宽要求高,量化技术虽能缓解内存约束,但在高精度任务中模型精度会下降。
- 多模态动作表示与安全保证:
- 多模态动作表示:当前 VLA 模型准确表示多模态动作存在困难,传统离散标记化方法缺乏精度,基于连续多层感知器(MLP)的方法有模式崩溃风险。新兴扩散策略(如 Pi-Zero 和 RDT-1B 等模型)虽能捕捉多样动作可能性,但计算开销约为传统基于 transformer 解码器的三倍,在实时部署中不切实际,且在复杂动态任务中存在困难。
- 开放世界中的安全保证:VLA 模型在现实场景中确保安全性面临挑战,许多实现依赖预定义的硬编码力和扭矩阈值,在意外条件下适应性有限。碰撞预测模型在杂乱动态空间中准确率约 82%,紧急停止机制存在 200 到 500 毫秒的延迟,在高速操作或关键干预中存在危险。
- 数据集偏差、基础与对未见任务的泛化:
- 数据集偏差:VLA 模型的训练数据集常存在偏差,如网络爬取的存储库中约 17% 的关联倾向于刻板解释,导致模型在不同环境中语义不一致或响应不适当,如 OpenVLA 等模型在新颖环境中会忽略约 23% 的对象引用。
- 对未见任务的泛化:现有 VLA 模型在未见任务上性能显著下降,如专门在家庭任务上训练的 VLA 在工业或农业环境中可能失败,主要原因是对狭窄训练分布的过拟合和对多样化任务表示的接触不足,在零样本或少样本学习场景中表现有限。
- 系统集成复杂性与计算需求:
- 系统集成复杂性:双系统架构中集成 VLA 模型面临时间不匹配和特征空间不匹配的挑战。系统 2(如使用大型语言模型进行任务规划)和系统 1(执行快速低级运动动作)的操作节奏差异导致同步困难,如 NVIDIA 的 Groot N1 模型存在运动不平稳的问题。高维视觉编码器和低维动作解码器之间的特征空间不匹配也会降低感知理解和可操作命令之间的一致性,如 OpenVLA 和 RoboMamba 在从模拟环境移植到物理硬件部署时性能下降。
- 计算需求:先进 VLA 模型参数众多,对计算资源要求高,如一些模型需超过 28GB 的 VRAM,超出大多数边缘处理器和 GPU 的能力,限制了其在专门高资源环境外的实际适用性。
- VLA 部署中的鲁棒性与伦理挑战:
- 环境鲁棒性:VLA 模型在动态变化环境中保持稳定和准确性能存在困难,如视觉模块在低对比度或阴影场景中精度降低约 20-30%,语言理解在声学嘈杂或模糊环境中受影响,机器人操作在杂乱环境中任务成功率受影响。
- 伦理考量:文中虽未详细阐述伦理考量部分,但可推测 VLA 模型在实际部署中需考虑伦理问题,如模型决策的公平性、对用户的影响等。
讨论
如图 17 所示,VLA 模型面临多方面挑战,包括实时推理、多模态融合、数据集偏差、系统集成、鲁棒性和伦理等问题,同时也有相应的潜在解决方案和未来发展方向:
- 挑战:
- 实时推理:自回归解码器顺序性和多模态输入高维度,在资源受限硬件上实现实时推理困难。
- 多模态动作与安全:将视觉、语言和动作融合到连贯策略中,遇到意外环境变化时存在安全漏洞。
- 数据集与泛化:数据集偏差和基础错误损害模型泛化能力,在分布外任务上易失败。
- 系统集成:集成感知、推理、控制等不同组件,架构复杂,优化和维护困难。
- 计算需求:大型 VLA 系统能源和计算需求高,阻碍在嵌入式或移动平台部署。
- 鲁棒性与伦理:对环境可变性鲁棒性不足,存在隐私和偏差等伦理问题,引发社会和监管关注。
- 潜在解决方案:
- 实时推理约束:开发协调延迟、吞吐量和任务特定精度的架构,集成硬件加速器,使用模型压缩技术、渐进式量化策略和自适应推理架构,采用高效标记化方案,可实现低延迟推理,适用于对延迟敏感的应用。
- 多模态动作表示与安全保证:构建端到端框架统一感知、推理和控制,采用混合策略架构表示多样动作轨迹,利用实时风险评估模块确保安全,结合强化学习算法和在线模型适应技术优化动作选择,嵌入形式验证层,可生成安全的 VLA 系统。
- 数据集偏差、基础与对未见任务的泛化:策划大规模无偏差多模态数据集,对视觉 - 语言骨干网络微调,采用元学习框架和持续学习算法,进行迁移学习和仿真到现实的微调,使 VLA 能对未见对象、场景和任务进行泛化。
- 系统集成复杂性与计算需求:采用模型模块化和硬件 - 软件协同设计,注入 LoRA 适配器进行特定任务微调,通过知识蒸馏得到紧凑模型,结合混合精度量化和定制硬件加速器,利用工具链优化端到端的 VLA 图,TinyVLA 等架构可实现实时推理,适用于资源受限环境。
- VLA 部署中的鲁棒性与伦理挑战:利用域随机化和合成增强管道增强模型对环境变化的适应能力,使用自适应重新校准模块减轻漂移和传感器退化;通过偏差审计、对抗性去偏等技术解决伦理问题,实现隐私保护推理,建立监管框架,平衡技术与社会价值。
- 未来路线图:
多模态基础模型:出现大规模多模态基础模型,编码动态和常识知识,为动作学习者提供统一表示基础。
智能体、自监督终身学习:VLA 与环境持续交互,生成探索目标,自我校正,像人类学徒一样自主扩展能力。
分层、神经符号规划:采用分层控制架构,基于语言的顶级规划器分解任务,中级模块转换为运动计划,低级控制器生成平滑轨迹,融合神经符号确保可解释性和灵活性。
通过世界模型进行实时适应:VLA 维持内部预测性世界模型,对比预测与传感器反馈,使用基于模型的校正动作,可在非结构化环境中实现鲁棒性。
跨实体和迁移学习:未来 VLA 能在不同形态机器人间无缝转移技能,结合元学习,新机器人用少量校准数据启动先前技能。
安全、伦理和以人类为中心的对齐:集成实时风险估计器评估潜在危害,融入监管约束和社会意识政策,确保机器人尊重人类偏好和法律规范。
如图 18 所示,基于 VLA 的机器人技术未来在于集成视觉 - 语言模型(VLMs)、VLA 架构和智能体 AI 系统。以仿人助手 “Eva” 为例,在感知层,其基础 VLM 将视觉场景分割并模拟动态行为,实现高级视觉理解。当收到 “清理咖啡渍并给植物浇水” 的命令时,VLA 模块被激活,将语言输入和感官反馈结合,高级规划器分解任务,中级策略模块转换为运动轨迹,低级扩散策略控制器生成平滑关节运动。同时,Eva 的智能体 AI 模块支持持续学习和适应,遇到挑战时启动自我改进循环。此外,通过接近传感器、实时监控等确保安全性和对齐性,夜间还会回顾性能日志优化子策略。VLM、VLA 和智能体的结合是迈向实体通用人工智能的重要一步,能让机器人如 Eva 般感知、规划、行动、适应并与人类安全共存,改变智能系统与现实世界的交互方式,使其更稳健、可解释且符合人类需求。
结论
我们系统评估了过去三年 VLA 模型的发展、方法和应用。分析从 VLA 基本概念出发,追溯其发展历程,强调多模态集成从松散耦合到基于 transformer 架构的转变。我们研究了标记化和表示技术,关注 VLA 对视觉和语言信息的编码。探讨学习范式,介绍从监督学习到多模态预训练的数据集和训练策略,以及现代 VLA 针对动态环境的优化和对延迟敏感任务的支持。我们对主要架构创新分类,调查超 50 个近期 VLA 模型,研究训练和效率策略,包括参数高效方法和加速技术。我们分析了 VLA 在仿人机器人、自动驾驶等六个领域的应用。讨论挑战和局限性,聚焦实时推理、多模态动作表示等五个核心领域,从文献中提出潜在解决方案,如模型压缩等。最后,讨论和未来路线图阐述 VLM、VLA 架构和智能体 AI 系统的融合引领机器人技术走向通用人工智能的方向。
参考
[1] Vision-Language-Action Models: Concepts, Progress, Applications and Challenges
#AgentThink
超越GPT-4o!清华:自动驾驶VLM思维链推理统一框架
视觉-语言模型(Vision-Language Models, VLMs)在自动驾驶领域展现出巨大潜力,但它们在幻觉问题、推理效率以及缺乏现实世界验证方面的挣扎阻碍了其在精确感知和稳健的逐步推理中的应用。为了解决这些问题,本文提出了 AgentThink,这是一个开创性的统一框架,首次将链式思维(Chain-of-Thought, CoT)推理与动态的代理风格工具调用结合应用于自动驾驶任务。AgentThink 的核心创新包括:(i) 结构化数据生成:通过构建一个自动驾驶工具库,自动构造结构化的、自验证的推理数据,明确地将工具使用整合进多样化的驾驶场景;(ii) 两阶段训练流水线:采用监督微调(Supervised Fine-Tuning, SFT)结合GRPO,使VLM具备自主调用工具的能力;以及 (iii) 代理风格的工具使用评估:引入了一种新的多工具评估协议,以严格评估模型的工具调用和利用能力。在 DriveLMM-o1 基准测试中进行的实验表明,AgentThink 显著提升了整体推理得分53.91%,并增强了答案准确性达33.54%,同时显著提高了推理质量和一致性。此外,跨多个基准测试的消融研究和鲁棒零样本/少样本泛化实验进一步证明了该框架的强大能力。这些发现突显了开发值得信赖和工具感知的自动驾驶模型的前景。
- 论文链接:https://arxiv.org/abs/2505.15298
关键词:视觉-语言模型(Vision-Language Models, VLMs)、链式思维(Chain-of-Thought, CoT)推理、工具调用、自动驾驶、强化学习(Reinforcement Learning, RL)

简介
近年来,基础模型的发展为自动驾驶开辟了新的机会,其中预训练的大语言模型(LLMs)和视觉-语言模型(VLMs)被越来越多地用于实现高层次的场景理解、常识推理和决策制定。这些模型旨在超越传统的感知流水线——后者依赖于手工设计的组件,如物体检测、运动预测和基于规则的规划——通过提供丰富的语义表示和更广泛的泛化能力,从而奠定在大规模网络知识基础上的理解。
许多近期的方法将自动驾驶任务重新定义为视觉问答(VQA)问题,并通过对基础 VLMs 进行监督微调(SFT),使用特定任务提示进行物体识别、风险预测或运动规划。然而,如图 2(a) 所示,这些模型通常将推理视为静态输入到输出的映射,忽略了现实世界决策中至关重要的不确定性、复杂性和可验证性。因此,它们往往表现出较差的泛化能力、产生幻觉输出以及有限的可解释性。
为了提高鲁棒性和透明度,最近的研究探索了将链式思维(CoT)推理引入 VLMs,如图 2(b) 所示。一些方法采用刚性的 CoT 模板 ,以牺牲灵活性为代价促进结构化的逻辑推理;而另一些则采用开放式的推理格式,但可能过度拟合标记模式,导致浅层或冗余的推理。此外,大多数现有方法仅依赖从人工标注轨迹中进行模仿学习,缺乏检测知识不确定性和调用工具进行中间验证的能力。

这些挑战引出了一个关键问题:VLM 如何真正作为决策代理运作——意识到自己的知识边界、擅长验证,并能够从工具引导的反馈中学习?灵感来自于经验丰富的驾驶员,当他们不确定时会查阅诸如后视镜或 GPS 等辅助工具来完善判断。同样,一个有能力的自主代理不仅需要显式推理,还必须认识到自身的局限性,并动态使用工具,例如物体检测器或运动预测器,来指导其推理和决策过程。
因此,我们提出了 AgentThink,这是一种统一的 VLM 框架,用于自动驾驶,它将推理建模为一种代理风格的过程——在这种过程中,模型学会利用工具生成增强型推理链,验证中间步骤,并优化结论。如图 2(c) 所示,与盲目地将输入映射到输出不同,AgentThink 在推理过程中动态决定何时以及如何使用工具,以支持或修改推理路径。为了实现这一行为,我们创建了一个数据-训练-评估流水线。首先,我们构建了一个结构化的增强型推理轨迹数据集。然后,我们引入了一个两阶段的训练流水线:(i) 使用 SFT 来启动推理能力,以及 (ii) GRPO ,这是一种基于强化学习(RL)的策略,通过结构化奖励来优化推理深度和工具使用行为。最后,我们提出了一种超越答案正确性的综合评估协议,以评估工具选择、整合质量和推理-工具对齐情况。

如图 1 所示,在先进的 DriveLMM-o1 基准测试中的实验表明,AgentThink 在答案准确性和推理得分方面都达到了新的最佳表现,超过了现有模型。我们的方法在培养动态、工具感知的推理方面的有效性进一步通过全面的消融研究和在多个基准测试中的强大泛化能力得到了证实。这些结果强烈表明,赋予视觉-语言代理学习到的、动态调用的工具使用能力对于创建更加稳健、可解释和通用的自动驾驶系统至关重要。
总的来说,我们的贡献如下:
- 提出了 AgentThink,这是第一个将动态代理风格的工具调用整合进自动驾驶任务的视觉-语言推理框架。
- 开发了一个可扩展的数据生成流水线,该流水线生成结构化、自验证的数据,结合了工具使用和推理链。
- 引入了一个两阶段的训练流水线,结合 SFT 和 GRPO,使模型能够学习何时以及如何调用工具以增强推理性能。
- 设计了新的评估指标,专门针对自动驾驶工具调用,捕捉工具选择、整合质量以及推理与工具的对齐情况。
相关工作回顾自动驾驶中的语言模型
近年来,语言建模的进步为自动驾驶开辟了新的机会,特别是在实现可解释的推理、常识理解与决策制定方面。早期的研究通过将驾驶任务(如场景描述 、决策制定和风险预测)重新定义为文本提示,集成了诸如 GPT 系列等大语言模型(LLMs),从而实现了零样本或少样本推理。尽管这些方法展示了 LLMs 的推理潜力,但它们通常缺乏逐步的可解释性,并且在分布外场景中的泛化能力较差。
最近的工作通过提示策略、基于记忆的上下文构建或视觉输入增强了 LLMs 的功能。例如,DriveVLM引入了一种链式思维(CoT)方法,包括场景描述、分析和分层规划模块;而 DriveLM则专注于图结构的视觉问答。EMMA展示了多模态模型如何直接将原始相机输入映射到驾驶输出,包括轨迹和感知对象。尽管取得了这些进展,以 LLM 为中心和基于 VLM 的方法往往仍将推理视为静态的输入-输出映射,缺乏检测不确定性、执行中间验证或结合物理约束的能力。幻觉、过度依赖刚性模板以及缺乏领域特定的奖励反馈等问题依然存在。为了解决这些问题,我们的工作引入了一种基于强化学习(RL)的工具增强型推理框架,使自动驾驶能够进行动态且可验证的决策制定。
自动驾驶中的视觉问答
针对自动驾驶的视觉问答(VQA)已成为评估感知、预测和规划能力的基准范式。BDD-X、DriveBench、DriveMLLM、Nuscenes-QA和 DriveLMM-o1等基准提供了涵盖城市和高速公路环境中复杂推理场景的结构化问答任务。对于 VQA 任务,近期的方法如 Reason2Drive、Alphadrive、OmniDrive和 DriveCoT引入了 CoT 推理以增强模型的可解释性。
然而,许多方法采用刚性的推理模板或仅依赖模仿学习,使其容易过拟合和产生幻觉。这些方法往往忽略了动态推理过程,并未能使用外部工具验证中间步骤。相比之下,我们的框架在推理过程中结合了结构化数据生成、步骤级奖励和工具验证。通过 GRPO 进行强化学习(RL),我们优化了模型的推理轨迹,使其与正确性、效率和实际应用性对齐,为自动驾驶中的 VQA 开辟了新的方向。
方法详解
数据生成流水线
尽管已有研究探索了 VLMs 中的推理能力,但幻觉问题仍然存在。我们认为,可靠的自动驾驶推理(类似于人类决策)不仅需要内部知识,还需要在必要时调用外部工具的能力。为此,我们提出了一种增强型数据生成流水线。与现有仅关注推理步骤和最终答案的数据集不同,我们的流水线将明确的工具使用整合进推理过程。

工具库
我们开发了一个专门的工具库,灵感来源于 Agent-Driver,包含五个驾驶核心模块的功能:视觉信息、检测、预测、占用和地图,以及单视角视觉工具(开放词汇检测、深度估计、裁剪、缩放)。此外,还包括基础的单视角视觉工具,如开放词汇目标检测器和深度估计器。这些工具共同使模型能够提取全面的环境信息,以支持多样的感知和预测任务。
提示设计
初始的工具整合推理步骤和答案由 GPT-4o 自动生成,依据一个提示模板(如图 3 所示),该模板旨在引导生成增强型推理链,而不是直接输出答案。
具体而言,对于预训练的 VLM 模型 πθ、输入图像 V 和任务指令 L,在时间 t 的推理步骤 Rt 通过以下方式生成:
其中,Rt 表示第 t 个推理步骤,[R1, ..., Rt−1] 表示轨迹中先前生成的步骤。完整的推理轨迹表示为 TR=(R1, ..., RM),M 是最大推理步骤数。
每个推理步骤 Rt 包含五个关键元素:
- 选择的工具 (Tooli)
- 生成的子问题 (Subi)
- 不确定性标志 (UFi)
- 猜测的答案 (Ai)
- **下一个动作选择 (ACi)**,例如继续推理或结束。
如果内部知识足以回答 Subi,则输出 Ai 并将 UFi 设为 False;否则,UFi 设为 True,Ai 留空。
此过程重复 N 次,为每对 QA 生成结构化的推理轨迹。
数据评估
一个独立的 LLM 对每条数据进行事实准确性和逻辑一致性审核,剔除步骤不匹配或结论无法支持的样本。最终得到一个高质量语料库,将明确的工具使用与连贯、可验证的推理结合起来。
两阶段训练流水线
构建结构化数据集后,我们设计了一个两阶段训练流水线,逐步提升模型的推理能力和工具使用熟练度。
基于SFT的推理Warm-up
在第一阶段,我们在增强型 CoT 数据集上执行监督微调(SFT),以提升模型生成推理链和适当调用工具的能力。每个训练样本表示为 τ=(V, L, TR, A),其中 V 是视觉输入,L 是语言指令,TR 是逐步推理过程,A 是最终答案。
训练目标是最大化生成 TR 和 A 的似然:
其中 D 是训练数据集,Rt 表示第 t 个推理步骤或答案 token。
基于 RLFT 的推理增强
为了进一步优化模型超越模仿学习的表现,我们采用强化学习微调(RLFT),使用 GRPO(Group Relative Policy Optimization),它能够在不依赖学习的价值函数的情况下有效利用结构化奖励。
GRPO 概述:
GRPO 通过计算组内每个样本的相对优势来避免使用价值函数。给定一个问题 q 和 G 个响应 {oi}iG=1,从旧策略 πθold 中采样,GRPO 目标函数为:
其中分组剪切损失定义为:
重要性权重 wi 和归一化优势 Ai 为:
其中 ri 表示分配给输出 oi 的奖励,β 和 ϵ 是可调超参数。
奖励设计:
为了引导模型朝向准确、可解释且具备工具意识的推理方向发展,我们设计了一个结构化奖励函数,包含三个主要部分:

这种结构化奖励设计比通用相似度指标更具针对性和可解释性,使 GRPO 能够同时优化推理过程的质量和模型在需要时调用工具的能力。
推理与评估
在推理过程中,如图 4 所示,VLM 会动态访问预定义工具库中的工具,收集信息以支持逐步推理。这种动态调用机制提高了准确性,并反映了增强型训练数据的结构。然而,现有的基准测试忽略了对工具使用的评估。
为此,我们引入了三项新指标(如下表所示),用于评估模型在推理过程中的工具使用能力。

通过这些指标,我们能够更全面地评估模型在工具使用方面的表现,确保其在复杂驾驶场景中具备稳健性和可解释性。
实验结果分析
在本节中,我们进行了广泛的实验以验证 AgentThink 的有效性。我们的实验设计旨在回答以下核心问题:
- Q1. 动态增强推理能否在最终答案准确性和推理一致性方面优于现有的 VLM 基线模型?
- Q2. 我们结构化的奖励设计(最终答案、逐步推理、工具使用)是否对推理行为有显著贡献?
- Q3. AgentThink 在零样本和单一样本设置下的未见数据上泛化能力如何?
评价指标
我们采用了 DriveLMM-o1 的评价指标,具体利用整体推理得分来衡量 VLM 的推理能力,并采用多项选择质量(MCQ)来评估最终答案的准确性。此外,我们引入了新的指标来评估工具使用能力,如表 2 所述。
模型与实现
我们使用 Qwen2.5-VL-7B 作为基础模型,并冻结视觉编码器。通过 LoRA 进行监督微调(SFT),然后进行 GRPO 微调。我们将训练批次大小设置为每个设备 1。所有实验均使用 16× NVIDIA A800 GPU 进行。在 GRPO 调整阶段,我们对每个问题执行 2 次 rollout。其他设置详见附录 B。
主要实验结果
与开源 VLM 的比较:表 3 展示了在 DriveLMM-o1 基准测试中的主要结果,将 AgentThink 与一系列强大的开源 VLM 模型进行比较,包括 DriveLMM-o1、InternVL2.5、LLaVA-CoT和Qwen2.5-VL变体。

我们的完整模型 AgentThink 在所有类别中都达到了最先进的性能。它远远超过了基线 Qwen2.5-VL-7B,将整体推理得分从 51.77 提高到 79.68(+51.9%),并将最终答案准确性从 37.81% 提高到 71.35%(+33.5%)。相比于已经集成了一些推理能力的最强先前系统 DriveLMM-o1,AgentThink 在推理方面进一步提高了 +5.9%,在最终答案准确性方面提高了 +9.0%——这表明学习到的工具使用优于静态 CoT 或基于模仿的方法。
性能分解:除了推理和准确性之外,AgentThink 在驾驶特定指标(风险评估、交通规则遵守和场景理解)以及感知相关类别(相关性和缺失细节检测)方面也始终优于其他方法。这些收益反映了其能够利用动态工具调用和反馈,使其推理更有效地基于视觉上下文。
关键见解:与传统的 CoT 或基于提示的方法不同,AgentThink 学习何时以及为何调用外部工具,从而实现更具适应性和上下文感知的推理。这导致更好的决策质量、更少的幻觉以及在安全关键驾驶场景中的更高可信度。我们在附录 D 中提供了案例分析。

工具使用分析
如上所述,我们分析了不同的训练策略如何影响推理过程中的工具使用行为。表 5 报告了这三个维度的结果:(1) 工具使用恰当性,(2) 工具链连贯性,和 (3) 感知引导的对齐性。
强制通过提示调用工具但不包含推理结构的 DirectTool 基线显示出中等的链连贯性,但较低的恰当性和对齐性——这表明强制工具使用往往缺乏目的性。添加 SFT 提高了恰当性和对齐性,但由于缺乏对工具质量的反馈,进一步提升受到限制。结合结构化奖励的 GRPO 导致了显著的改进,教会模型选择性地调用工具并将输出连贯整合。我们的完整模型结合了 SFT 和 GRPO 以及完整的奖励,在所有指标中表现最佳。这表明监督和奖励塑造对于学习有效的、上下文感知的工具使用都是必不可少的。我们还评估了训练数据规模的影响,详见附录 E。
消融研究

在表 4 中,我们对 AgentThink 的奖励设计和训练策略进行了全面的消融研究。使用 SFT 或 GRPO 单独应用最终答案或逐步推理奖励,相较于基线模型可以带来适度的提升,分别提高任务准确性和推理一致性。然而,单独应用时它们的效果有限。
我们发现,在强化调整之前,结合 SFT 的 GRPO(不使用工具使用奖励)可以提供更好的性能,这表明预热推理是至关重要的。我们的完整 AgentThink 模型结合了所有三种奖励成分,达到了最优结果。它极大地提升了推理质量和答案准确性,从而强调了使用工具并在视觉上下文中扎根推理的重要性。
泛化能力评估
我们在一个新的 DriveMLLM 基准测试中评估了 AgentThink 的泛化能力,在零样本和单一样本设置下与一系列强大的基线模型进行比较,包括突出的 VLM 和任务特定变体(详细信息见表 6)。评价指标详见附录 F。
AgentThink 在零样本(26.52)和单一样本(47.24)得分上达到了最先进的性能,超过了 GPT-4o 和 LLaVA-72B。虽然像 DirectTool 这样的基线方法通过硬编码工具提示在感知任务结果上表现出色(例如,RHD 89.2 vs. 86.1,BBox 精度 92.4% vs. 91.7%),但它们在上下文刚性和碎片化推理-感知对齐方面存在问题。我们的模型通过有效协调显式推理与基于感知上下文的学习、自适应工具使用展示了优越的平衡。这突出了其学习到的工具使用机制相对于静态提示或单纯模型规模的优势,以实现稳健的泛化。
定性而言,如图 5 所示,AgentThink 成功地处理了各种基准测试(BDD-X, Navsim, DriveBench, DriveMLLM )上的挑战性零样本角落情况。在这些情况下,基础 Qwen 模型通常无法收集足够的信息或在推理过程中产生幻觉,导致错误的输出。相比之下,AgentThink 能够熟练地调用工具获取关键决策信息,从而正确回答这些问题。这进一步突出了其动态、增强工具推理在陌生环境中的实用价值。
结论
我们提出了 AgentThink,这是第一个统一框架,紧密融合了 CoT 推理与代理风格的工具调用,用于自动驾驶。通过可扩展的增强工具数据集和两阶段 SFT 与 GRPO 流水线,AgentThink 将 DriveLMM-o1 的推理得分从 51.77 提高到 79.68,将答案准确性从 37.81% 提高到 71.35%,比最强的先前模型高出 +5.9% 和 +9.0%。
除了性能提升之外,AgentThink 还通过使每个推理步骤基于工具输出,展示了更强的可解释性。结果验证了将显式推理与学习到的工具使用相结合是迈向更安全、更稳健的语言模型驱动任务的有希望路径。我们相信,这一框架为构建可信赖的基于 VLM 的代理奠定了基础,使其能够推广到复杂、动态的真实世界驾驶环境中。
限制
- 数据规模:我们的增强工具语料库总共包含 18k 条标注实例,限制了对长尾或罕见驾驶事件的暴露。需要一个更大且更多样化的数据集,以便模型内化更广泛的真实世界场景。
- 模型大小:我们依赖于 qwen2.5-VL-7B;7B 参数的足迹在嵌入式汽车硬件上带来了不小的内存和延迟开销。未来的工作应调查更轻量级的骨干(例如,~3B),在减轻车载资源约束的同时保留推理能力。
- 缺乏时间上下文:讨论的模型处理单帧、多视角图像作为输入。然而,由于缺乏顺序信息,它可能会误解依赖时间线索的场景,例如变化的交通灯。为了解决这个问题,可以考虑引入视频标记或采用递归记忆。
- 缺失 3D 模态:缺乏 LiDAR 或点云数据剥夺了模型精确的空间几何信息,增加了距离相关推理的不确定性。融合额外的模态预计将增强鲁棒性。
#轻舟智航解码安全智驾的“顶配”逻辑
无论中配、高配,安全都是顶配
2025智驾元年,在“智驾平权”浪潮席卷汽车行业的当下,随着中高阶智能辅助驾驶的大规模普及,智驾安全快速成为行业关注的焦点。
“无论中配、高配,安全都是顶配”,这是轻舟智航以“安全智驾”为核心提出的产品准则。
无论中配、高配,安全都是顶配
安全不是配置选项,而是智能辅助驾驶的“基础操作系统”。智驾平权,安全更要平权。轻舟智航将“安全+”战略全面贯彻于从技术研发到产品设计,再到企业发展的各个环节中。我们倡导的“安全顶配”逻辑是:
- 在同等配置条件下,打造业内领先的安全水平,并持续探索安全能力极限,朝着该配置所能达到的安全天花板不断逼近。
- 在有限的资源下,始终将安全置于功能全面性之上,优先保证安全而非功能的全面性。我们并不追求哪哪都能开,但求能开的地方都好开——也就是在明确的功能场景下,真正做到让用户心里更踏实。这是轻舟智航从用户价值出发定义智能辅助驾驶的基准。
轻舟智航倡导的安全“顶配”逻辑并非否定技术迭代的价值——就像传统汽车安全领域,基础车型都需要配备安全带和ABS,而豪华车型可能增加主动悬架或更多气囊。智驾安全同样需要“基础安全阈值”与“性能增强配置”。
- 基础安全阈值是必须全系标配的安全保障,包括满足功能安全ISO 26262要求的系统架构、确保足够覆盖ODD的感知冗余(如视觉+毫米波雷达的异构融合),符合人类生理极限的接管缓冲时间。
- 性能增强配置是允许差异化的配置,包括激光雷达带来的极端场景识别能力,超大算力支持的紧急避障算法迭代。
所谓“安全顶配”,是指所有车型都必须达到经过独立验证的基础安全阈值标准,而非强行统一硬件配置。正如没有安全带的汽车不能上市销售,缺乏最低安全限度的智能辅助驾驶系统也不应推向市场。只有在守住这条底线的前提下,通过算力、传感器数量的差异化实现商业价值才有意义。
轻舟方案的安全性目标
轻舟智航的目标就是让不同层级的智能辅助驾驶系统都远超业内标准——通过技术创新和算法升维,让中阶智能辅助驾驶系统在标准场景下也能达到与高阶系统相当甚至更高的安全水平;而高阶智能辅助驾驶系统则凭借更丰富的传感器组合与预见性决策能力,在极端工况和长尾场景中实现安全性的再进化。
安全智驾三重本质属性
基于超60万台的NOA大规模量产交付实践经验,结合与车企合作以及对用户需求的深刻洞察,轻舟智航认为,真正的安全是系统在极端场景下的“处理能力”与“责任边界”的乘积,具备以下三个本质属性:
- 算法泛化性——构建完备的认知,穿透“黑天鹅”事件的迷雾
为了达到优秀的完全水平,预期功能安全设计很重要,完备的分析与测试验证必不可少。其中,构建“场景量子纠缠式”测试体系是关键,即任何新识别、新采集的corner case需要扩展衍生其他安全相关的海量场景,确保算法逐步具备第一性原理推理能力和更强的泛化能力,而不是仅能处理训练集内场景或仅仅依赖固定规则决策。
- 系统确定性:对抗物理世界的混沌法则
智驾系统安全的基础是需要考虑基本的功能安全设计,尽可能缩小不确定性,构建失效保护机制,让系统能够满足“双失效容错”,即任意两个关键组件失效仍可安全停车,并且让系统在ODD范围内能够全面实现功能、性能,满足产品力指标要求。比如在传感器失效或者其他系统异常状态下,仍能做到安全可控。换句话说,就是用确定性设计消除不确定性风险。如果对于一些可能导致危害的软硬件失效情况缺乏安全的监控和处理,那么这些不确定性的累积,在车辆长久的运行周期内,遇到特定的环境场景时,终将会带来不安全的后果。
- 交互可靠性——责任边界明确,人机共驾的“透明化”革命
明确人机协同的确定性边界,才能更好的辅助人类驾驶,这是辅助驾驶系统安全性保障中必不可少的一部分。
一方面,在智驾系统退出时,需要留给驾驶员足够的时间进行接管和操作,这样才能给用户带来稳稳的安全感,避免慌乱接管情况下不安全事件的发生。系统在退出时需要考虑人类平均应激反应时间,并且还要充分考虑人员判断、执行到位的时间,才能保障用户安全平稳的接管。
另一方面,系统行为若缺乏足够的可预测性,可能引发用户因过度紧张而提前误接管——例如在系统本可安全处理的场景下,驾驶员因对系统行为信心不足而强行干预,反而可能触发不必要的碰撞。
因此,智驾系统既需要通过合理的接管机制保障安全,更需通过稳定、透明的决策逻辑建立用户信任,从根源上减少非必要的人为干预,实现真正可靠的人机共驾。
三重防线构建普惠安全
- 算法进化:数据驱动的安全闭环
在算法模型研发过程中,融入安全理念的考量,用技术范式的先进性驱动算法的安全性,并基于数十万用户、数十亿的里程数据反馈,以及数千万公里主动安全测试数据的闭环,实现全系车型智驾系统的安全能力进化。
- 协同高效:安全设计不是“堆料”而是“精准协同”
轻舟智航最新方案采用“征程6”芯片加多传感器融合架构,得益于芯片架构的深度优化,让低配车型也能承载高阶算法,通过视觉感知、毫米波雷达或激光雷达的异构融合,最大限度保障极端环境下的可靠性。在功能安全设计上,寻找合理的安全策略去替代冗余设计,实现降本的同时保障安全。例如中阶方案不采用激光雷达,只采用视觉传感器,那么就要从整体安全设计上采取一定策略,缩短与高阶方案的安全差距,比如提高视觉算法的精度与指标,并在纯视觉方案下置信度无法达到一定水平时需要采用提醒的方式,提示驾驶员观察前方,规避安全事故。
- 用户体验:安全的人机共驾逻辑
基于人类的反应速度设计安全接管策略以及良好的人机交互界面,通过驾驶员监测和方向盘握力传感等信息,实现接管准备度量化评估和接管提示。
轻舟智航基于海量的用户使用数据反馈,针对可能存在的用户安全风险场景,与车企客户联合首创并落地了多种安全策略功能。这些策略功能,主要从两个层面着手设计:
1. 稳定透明的决策逻辑:让系统行为具有足够的可预测性,避免引发用户的过度紧张,做出误接管、误干预等行为而导致的不必要碰撞。
2. 渐进式的责任移交:为用户提供足够的接管时间,避免系统退出警示时间过短,导致用户慌乱接管发生不安全事件。
技术创新的本质不是为了炫技,而是要真正转化为用户价值。智能平权时代,秉承对生命的敬畏,安全平权才是最根本的追求。因此,轻舟智航选择了一条本质的道路:剥离中阶、高阶分级的外衣,实现了“跨层级安全平权”,让安全成为智能辅助驾驶的“通用语言”,真正实现“能开的地方都好开”的智驾普惠。无论中配、高配,安全都是顶配,既是轻舟智航坚持“以创新驱动安全,以安全定义智驾”的技术使命,也是真正推动智驾平权,为用户创造价值的责任。唯有将安全嵌入技术基因,才能真正赢得用户长期信任,智能驾驶产业才真正踏上“行稳致远”的可持续发展之路。
此外,我们必须明确,智驾技术的发展是渐进式的,当下的智能辅助驾驶系统并不是所有的运行场景都能灵活自如的安全应对。对于智能驾驶系统的安全应用,必须明确运行设计条件ODC的范围,做好ODC动态管理,明确系统能力边界,通过用户培训与手册更新,实时同步功能范围,避免“能力错觉”导致的安全隐患。
智驾安全没有满分答案,也不存在完美方案,但必不可少的是永不停歇的技术改进。安全不是一蹴而就的任务,它需要在大规模的量产实践中累积数据与经验,才能逐步接近完美。
#LightEMMA
Zero-Shot 的VLA不靠谱
这个也是在EMMA-OpenEMMA 的基础上的拓展工作,主要是因为当大部分公司没有waymo那样体量的资源时,还能不能探索出一种更轻量的方式呢?说白了就是不想SFT,直接CoT,以zero-shot看不能解决。
结论很简单:就是不能。
LightEMMA
paper:arxiv.org/pdf/2505.00284
code:github.com/michigan-traffic-lab/LightEMMA
Motivation:
本文就提出了一种方法,直接zero-shot,不进行SFT了, 拿大模型Cot来进行推理。因此本文重点是评估这些大模型,而不是优化这些Vla的性能。
这里在nuscenes上对12个开源大模型进行比较,分析其优劣
最近相关工作和开源数据集如下:
比如前面的EMMA,OpenEMMA就不再赘述。
DriveGPT4 是一种基于 LLaMA2 的 VLM,在 BDD-X 数据集上训练并使用 ChatGPT 数据进行微调,支持多帧视频理解、文本查询和车辆控制预测。
DOLPHINS 使用指令调优进行上下文学习、适应和错误恢复。
DriveMLM 通过整合驾驶规则、用户输入和传感器数据,将 VLM 纳入行为规划,并在 CARLA 的 Town05 中进行闭环评估
有几个开源数据集可用于训练和评估VLM相关的自动驾驶系统,特别是 Waymo Open Dataset 和 nuScenes 。nuScenes-QA 、nuPrompt 、LingoQA 和 Reason2Drive 等。
方法架构
对于每个推理周期,当前前视摄像头图像和历史车辆驾驶数据都会输入到 VLM 中( 缺少导航信息输入)。采用思维链 (CoT) 提示策略,其最后阶段明确输出一系列预测的控制动作。这些作经过数值积分以生成预测的waypoints。所有 VLM 都使用一致的prompts和统一评估,且没有任何针对特定模型的SFT.
VLM Selection
一共十二种型号的VLM,来看看谁的zero-shot能力好吧。分别是:
GPT4o、GPT-4.1 、Gemini-2.0-Flash、Gemini-2.5-Pro 、Claude-3.5-Sonnet、Claude-3.7-Sonnet 、DeepSeek-VL216B、DeepSeek-VL2-28B 、LLaMA-3.2-11B-VisionInstruct、LLaMA-3.2-90B-Vision-Instruct 、Qwen2.5VL-7B-Instruct 和 Qwen2.5-VL-72B-Instruct
这里分为商业模型和开源模型:
商业模型:这里是通过付费 API 调用的。无需管理本地硬件、软件更新和可扩展性这些模型由提供商直接处理,从而简化了部署。
开源模型:从 HuggingFace 下载它们,并使用 H100 GPU 在本地部署。大多数型号只需要一个 H100 GPU,但较大的型号可能需要更多;在表 I 中报告了所需的最小 GPU 数量。为了促进多 GPU 部署,我们利用 PyTorch 的自动设备映射(automatic device mapping)来实现高效的 GPU 利用率。
在 HuggingFace 中有个重要的关键字是 device_map,它可以简单控制模型层部署在哪些硬件上。
设置参数 device_map="auto",Accelerate会自动检测在哪个设备放置模型的哪层参数(自动根据你的硬件资源分配模型参数)。其规则如下:
1.首先充分利用GPU上的显存资源
2.如果GPU上资源不够了,那么就将权重存储到内存
3.如果内存还不够用了,将会使用内存映射的技术,将剩余的参数存储到硬盘上
图像输入形式
camera输入方法也各不相同,之前X-driver提过VQ-VAE会丢失信息,采用了ViT encoder
本文的话,不使用任何视觉编码器,如 CLIP ,也不应用任何预处理。
结果表明,VLM仍然可以有效地描述场景,并直接从原始视觉输入中准确识别物体,证明对图像输入形式变化仍然比较稳定。
实验表明合并额外的帧不会产生明显的性能提升,多帧输入会让模型倾向于在多个帧中冗余地提取相同的特征,而不是捕获有意义的时空动态。此外,添加更多帧会导致处理时间和计算成本大致呈线性增加,而不会带来明显的性能优势。
VideoBERT 和 VideoMAE 等模型通过专门的时间编码支持视频输入,而不是简单地将视频视为帧序列。此类模型本质上采用不同的架构,并且可能会捕获更丰富的时间信息。但是本文没有探索时序图像输入形式。
之前EMMA没有对输入图像帧数进行ablation,现在补上了,直观上说更合理的是输入历史交通参与者的轨迹,时序信息的注入还需要探索更合理的方式。
历史驾驶信息输入:
也采用OpenEMMA的速度曲率形式表示车辆动作,这是一种可解释的格式,其中速度捕捉纵向运动,曲率描述横向运动。因为 VLM 通常难以有效地推理涉及隐含物理约束的坐标。
VLM Promoting(CoT 构建):
属于是常规操作了,这里采用一种简单的 CoT 方法来指导 VLM 进行场景理解和动作生成,其中每个阶段的输出与附加提示一起集成到后续阶段中,分三步:
- 场景描述:VLM 接收图像作为输入,并提示解释整个场景,包括车道标记、交通信号灯、车辆、行人活动和其他相关对象。比如:“该图像显示了正在进行道路建设或维护工作的城市街景...一名警察站在马路中间指挥交通......可以看到几辆工程车辆,包括一辆停在道路左侧的黑色自卸卡车以及其他工作车辆......在警官在场和可能的车道限制下,通过该施工区的交通似乎受到控制。”
- 高级驾驶意图:生成的场景描述与ego车辆的历史驾驶动作相结合,允许 VLM 在当前场景上下文中解释过去的行为并预测下一个高级驾驶动作。比如“鉴于当前正在施工的场景和一名警察在路中间指挥交通,自主车辆应显着减速约 2-3m/为可能的停车做准备,在接下来的 3 秒内将速度降低到约 3-4m/s。车辆应继续沿车道行驶,同时在警官的指示下准备完全停止。”
- 低级驾驶指令:场景描述和生成的高级指令用于提示VLM以指定格式输出结构化的低级驾驶动作列表,是(速度,曲率),如 [(v1, c1), (v2, c2), (v3, c3), (v4, c4), (v5, c5), (v6, c6)],无需额外的文本或解释。 比如“[(6.0, -0.001), (5.0, -0.001), (4.0, 0.0), (3.5, 0.0), (3.0, 0.0), (3.0, 0.0)].”
除了EMMA做了思维链的ablation ,其他好像都默认这个是有用,没用进一步量化了。
实验:
从 150 个测试场景中提取的总共 3,908 帧的 nuScenes 预测任务的性能。评估集中在两个方面:
- 模型的计算效率
- planning轨迹预测的准确性
推理时间和成本对比(终于看到了有做时耗分析的了):
表 I 总结了推理时间,显示了每个图像帧的平均处理时间和推理成本。
Gemini-2.0-Flash 的推理速度最快,每帧仅 4.5 秒,而 LLaMA-3.2-90b 的推理速度最慢,为 40.8 秒。
Qwen-2.5-72B 和 Gemini-2.5-Pro 的性能也相对较慢,每帧都需要 30 秒以上。
其余型号通常每帧运行约 10 秒,基本版本通常比高级版本运行得更快。
即使是最快的型号 Gemini-2.0-Flash 的处理时间(4.5s)也明显慢于实时更新频率。
为了真正有效地进行实际部署,这些模型的运行速度需要快一到两个数量级。
此外,基于 API 的商业模型依赖于稳定的互联网连接,在车端上使用根本不现实。
使用每个模型提供的官方说明计算每帧的平均输入和输出令牌数。
如表 I 所示,输入token的数量明显高于输出token,通常约为 6000 个输入token,而输出token大约为 300 个。
这基本与预期一致,因为输入包括图像数据,而输出是纯文本的。
但是LLaMA 模型每帧仅报告大约 1000 个输入令牌。其实是官方的 LLaMA token计数方法不包括图像token,只对文本进行计数。
此外,Gemini-2.5-Pro 的token计数在输入和输出token计算中出错了。
单使用相同的token计数设置计算的 Gemini-2.0-Flash 产生了一致且合理的结果
商业的token形式可以不用考虑了,一次推理的代价太高了
模型输出错误问题:
在最终的模型输出阶段,观察到不同的响应格式错误。尽管提示限制VLM输出 [(v1, c1), (v2, c2), (v3, c3), (v4, c4), (v5, c5), (v6, c6)] 格式的输出,但没有额外的文本,但偶尔会遇到偏差,例如缺少括号或逗号、额外的解释或标点符号以及不正确的列表长度。但可在 GitHub 中找到例子。
这里说明如果不进行SFT,指令跟随能力还是挺差的,指令调优我认为是必须的
模型输出错误率及planning对比结果
这也是nuscens的开环评估,zero-shot基本上就是第一秒就偏半米,这里值得关注的是,参数量越高的模型,加了prompt,但是错误输出率更高了,比如qwen和gpt4.1
比较值得关注的就是,居然zero-shot没有打得过simple baseline.
simple baseline.是什么呢?:就是固定速度和曲率将三秒内保持不变。。。。 可以说模型不进行SFT根本不具备可用的能力。zero-shot在自动驾驶planning任务上不成立
定性case分析
总结一下:zero-shot的VLA不具备路口左右转的能力,红灯有的模型能刹车,但是不会减速,而是直接重刹,不具备时序平滑,有的模型直接闯红灯。
当灯变绿时,有的模型可以具备启动通过的能力,但有的模型仍然没有获得绿灯通行的关联能力。
总结:
zero-shot VLA这事就不可能行,结合海量的业务标注数据(动态感知、静态感知、Occ、ego pose)进行SFT,再利用Cot这事还靠谱一点。
#车载摄像头为什么能看见东西?
在如今智能驾驶席卷汽车行业的背景下,大家对“摄像头”这个词早已耳熟能详。很多宣传中甚至暗示,车载摄像头越多,车辆就越智能。事实上,不只是汽车,摄像头几乎已经渗透进我们生活的各个角落:手机、电脑、小区监控、智能门铃……如今要找一个没有摄像头的场景,反而变得越来越难。
然而,尽管我们对摄像头如此熟悉,但若问起它的工作原理,恐怕许多人仍会感到陌生。摄像头究竟是如何“看见”世界的?它输出的是什么信号?在这些数据送入AI模型之前,又经历了哪些处理?本文将带你一起拆解摄像头背后的工作机制,看看它是如何看见东西的。

图1:既熟悉又陌生的摄像头示意图
看得见摸得着的摄像头器件拆解
我们不妨从最直观、最“看得见摸得着”的地方开始看看车载摄像头都有哪些关键组成部分?
以下图中的ZF车载摄像头为例,其内部结构主要由光学组件和两块核心电路板(PCB)构成。前端是镜头和图像传感器,属于“光学传感本体”;后端则是负责信号处理的ISP模块。
其中,图像传感器的作用是将光信号转换为电信号,属于核心的感知部件。示例中采用的是安森美的CMOS传感器。
后端的信号处理器则承担着“看得清”的任务,对原始图像进行一系列处理和优化。例子中使用的是Mobileye芯片,它不仅具备图像信号处理功能,还集成了目标识别、追踪等功能算法。

图2:车载摄像头示意图
位于图像传感器之上的,是一套精密的光学结构,包括保护片、镜头以及镜头支架等,确保光线经过必要的聚焦和过滤,最终准确地落在图像传感器表面,为后续成像打下基础。

图3:镜头与图像传感器位置关系示意图
图像传感器怎么“看得见”
我们再来看看图像传感器的微观原理结构,这对于我们理解摄像头为什么能看到东西很重要。
如下图4左侧所示,图像传感器其实像棋盘一样,划分了许多纵横交错的感光单元。每一个微小的感光单元就是我们常说的“像素”。譬如长3264个小单元,高2448个小单元的图像传感器,就有大概800万个像素。我们常说的200万像素、1000万像素摄像头就是指的对应的最小感光单元的数量。当然,像素越多,图像的分辨率就越高。
如下图 4右侧所示,当光子透过镜头进入到传感器时,首先会经过两层滤光层,然后才会到达将光信号转换为电信号的半导体感应层。
为什么需要两层滤光呢?
因为光电传感本质上依靠的是半导体的光电效应,即“光生电”。但这个效应中电的强弱主要由光强决定,对光的波长(对应我们感知的颜色)并不敏感,所以第一层需要把红外线和紫外线等肉眼不感知的光去掉,留下我们感兴趣的光。
而在可见光中,我们知道可以通过红蓝绿等原色来合成各种不同颜色。但是一个像素内的感光元件只能感知一种光强,也就是只有一个通道,那怎么办呢?柯达公司的工程师Bryce Bayer ,也就是拜耳阵列的发明人,想到了一种解决方案(Bayer pattern)。他将田字形的4个像素划为一组,在感光原件之上分别部署1个蓝色,1个红色和2个绿色的滤光片,这样每个像素就能获取到单一原色的光强。基于这个规律的设计,后续在信号处理时就可以通过插值近似还原每个像素点上的三原色分布。那为什么4个格子里,绿色独占一半呢?因为人眼对绿色最为敏感,所以如此“偏心”。而这个花花绿绿的分布,有没有觉得眼熟?没错,就是“马赛克”。

图4:图像传感器工作原理示意图
在每个像素里的感光元件,则主要有两种类型:CCD和CMOS。这两者其实都用到MOS技术,CCD的核心元件是MOS电容,而CMOS的核心元件则是MOSFET放大器。二者的主要区别是CCD在每个像素内产生电荷,传递到边缘之后再统一做放大处理,而CMOS则是在每个像素内进行电流放大。
类比一下,CCD就像是每个员工把自己工作做好之后报告给组长,组长再整理成大报告给经理,这样当然内容精炼、格式一致,报告质量较高,但是沟通效率和生产成本就较高。而CMOS就像是每个员工做好工作之后,直接提炼内容汇报给老板,这样会加快读取速度,降低沟通成本,但难免因为员工素质的参差不齐,影响汇报质量。
CCD和CMOS的对比如下图所示,在车载摄像头和手机摄像头等对功耗、尺寸、成本都敏感的使用场景下,CMOS图像传感器成为了主流选择。

图5:CCD和CMOS差异比较
ISP(图像信号处理)的架构拆解
经过图像传感器的光电转换和数模转换,现在图像传感器已经能按像素输出图像的原始信号了,然后每秒传出若干帧图像,就能串成动画,形成视频了。但需知道,这些原始图像有很多“瑕疵”,与我们肉眼所见相距甚远,可以理解为“毛坯”图像。必须经过一系列流水线般的图像信号处理,才能看清图像。接下来,我们就来看看常见的ISP都经历了什么处理。
第 1 步:黑电平校正(Black Level Correction)
本质是传感器“调零”。即使在黑暗中拍照,图像传感器也会输出非零电压(黑电平)。这一步是把“黑设为黑”。就像拍一张漆黑的照片,但画面底色却发灰。我们要先把底色擦干净。
第 2 步:镜头阴影校正(Lens Shading Correction)
镜头中间亮、边缘暗(光学特性导致)。这一步用增益让画面更均匀。就像用手电筒照地面,中间亮四周暗。我们要“补光”四周让画面一致。
第 3 步:坏点修复(Bad Pixel Correction)
图像传感器上不排除有一些像素坏了:一直亮、一直黑或数值异常,需修补。就像修复照片上的“灰尘点”,用周围颜色“抹掉”。
第 4 步:去马赛克(Demosaicing)
上文提到例如Bayer Pattern 用RGGB的阵列滤光形成了颜色马赛克,每个像素只有一个通道的颜色,我们要插值补全另两个颜色。就像拼图只给了红色碎片,我们要推测并拼出完整的彩色图像。
第 5 步:白平衡(Auto White Balance)
不同光源下(如黄光、蓝光)相同物体的颜色会有偏差。白平衡会让白色看起来始终是白的。就像一张白纸,在灯泡光下发黄,在日光下发蓝。白平衡就是纠正这种“偏色”。
第 6 步:颜色校正矩阵(Color Correction Matrix)
图像传感器原始颜色和真实颜色有不一致。用矩阵映射修正颜色偏差。就像图像传感器拍出来的红色可能发紫。颜色校正矩阵能把它拉回真正的“正红色”。
第 7 步:局部色调映射(Local Tone Mapping)
增强画面局部对比度,让暗部/亮部细节更清晰,画面更立体。说白就是暗处拉亮,亮处压低,细节更丰富。
第 8 步:噪声去除(Noise Reduction)
图像尤其在夜间会有颗粒感,需要降低噪声同时保留细节。就像在沙沙作响的录音里降噪,但又不能让声音变得模糊。
第 9 步:高动态范围合成(High Dynamic Range Merge)
为了亮部不过曝,暗部有细节。可以用多张不同曝光的图像融合出更高的动态范围。近年也有从图像传感器端完成动态范围合成的技术。比如车从隧道冲出来:既要看到隧道内黑暗处,又要看到出口的强光。高动态范围合成就能帮我们两全其美。
第 10 步:伽马校正(Gamma Correction)
人眼对亮度不是线性感知的,伽马校正是为了让显示出来的图像更符合人眼视觉。这一步就是做非线性处理,让图片看起来更“自然”。
第 11 步:锐化(Sharpening)
增强边缘细节,提升图像清晰度,让车道线、交通标志更明显。就像模糊照片加描边处理,轮廓更清晰,适合感知模型用。
第 12 步:颜色空间转换(Color Space Conversion)
将 RGB 转换为 YUV 等编码格式,以供视频压缩、显示或感知算法使用。RGB 是“显示友好”,YUV 是“压缩友好”,比如视频编码就常用 YUV420 格式。
当然每个实际产品应用中ISP的步骤都有所不同,会基于传感器型号、目标应用(例如给车机大屏显示还是给AI模型处理等)作相应调整。这些步骤里面,对辅助驾驶尤为重要的主要是下面三个,我们通过效果图进一步感受:
(1)高动态范围合成+局部色调映射。因为隧道、高架逆光场景多,必须同时看到暗部行人、亮部车道。

图6:高动态范围和局部色调映射处理示意图(左:处理前;右:处理后)
(2)降噪 + 锐化。因为这对夜间图像清晰度至关重要,直接影响夜间车道线识别、物体检测的性能。

图7:降噪和锐化示意图(左:处理前;右:处理后)
(3)白平衡+颜色校正矩阵。因为现在辅助驾驶一般同时使用多路摄像头,这处理可以保证多摄像头标定的一致性,否则会影响立体匹配和感知模型训练。
图8:白平衡和颜色校正示意图(左:处理前;右:处理后)
前端模组和ISP之间的传输
前面我们探讨完图像传感器和ISP,明白了“看得见”和“看得清”两部分。那么问题来了,这两部分之间怎么连接?
最直接的方法就是用一根高速线把它们连接起来。最常用的传输方式就是MIPI CSI-2(Camera Serial Interface 2),这是一种高速串行接口,由MIPI联盟定义。对于智能摄像头系统,前端摄像头模组和ISP处理芯片都集成在一个系统控制器里的方案,这就可以了。
但随着辅助驾驶技术的发展,越来越多的方案采用了多个边缘摄像头模组布置在车身的不同位置,然后再把图像传感器的数据传输到例如后备箱下方的中央控制器再进行处理。这种情况下,前端传感器模组和后端ISP之间的传输距离会多达几米,直接使用MIPI CSI-2线缆传输会让信号衰减严重,无法可靠传输。为此,我们引入 SerDes(串行器/解串器) 进行如下处理:
(1)串行器(Serializer):把来自摄像头模组的MIPI并行或低速串行数据转换成高速串行信号(如 GMSL、FPD-Link)。
(2)高速传输:使用汽车专用长距离高速线缆(如同轴线或屏蔽双绞线)进行远距离传输。
(3)解串器(Deserializer):在ISP端(即域控内部)将高速串行信号还原为MIPI CSI-2格式,供ISP处理。
总的来说,就是如果摄像头离处理器很近(在同一个控制器里),直接用 MIPI;如果摄像头离处理器很远(不在一个控制器里),就需要串行解串技术来传输。
当下行业动态
随着汽车智能化程度不断提升,车载摄像头作为环境感知的核心传感器之一,其装机量与技术要求正同步提升。根据Strategy Analytics 等机构预测,2025年全球车载摄像头出货量将突破6亿颗,中国市场占比超40%,成为全球最大单一市场。
在L2++、DMS、APA 等多场景推动下,中国新车平均摄像头装机量正由6颗迈向10颗以上。摄像头不仅数量增加,类型也从单一的后视演进至全车多点部署,广泛覆盖感知、安全与交互等核心环节。过去行业核心技术长期由日、美企业主导,但近年来中国本土厂商在多个节点上实现快速突破,已经逐步建立起完整自主的供应链体系。
在光学镜头环节,舜宇光学处于全球领先地位,具备完整车规量产与系统能力。其他厂商如联合光电、福晶科技也在加快布局,推动国产渗透率提升。
CMOS图像传感器领域则由豪威科技领衔,其产品在前视、环视、DMS等场景已实现量产,市场占有率已经全球前三。格科微、思特威等新势力正布局中低端细分市场。
ISP芯片环节仍以地平线、黑芝麻、英伟达、高通、安霸等为主,国产尚处追赶阶段,但已经有许多产品上车量产落地。
对我们汽车从业者来说,这无疑是利好。同时我们也要抓住机遇,尤其是多接触理解上下游技术,通过“跨界”来提升自己的竞争力。例如做图像处理的,不仅要调得好,还可以“懂算法”,多学点前端AI处理、视觉增强算法,与感知工程师沟通时就更有话语权。做销售的,也可以从客户的技术痛点出发,讲场景、通技术,做一个方案型销售。中国车载摄像头产业正在经历从“量变”到“质变”的关键阶段。不管你是研发工程师、产品经理,还是关注辅助驾驶的从业者,都别错过这场国产崛起的黄金窗口。
#理想汽车又一感知负责人将离职。。。
垃圾车要黄了吗,?
理想汽车辅助驾驶“端到端”模型负责人将于近期离职。负责人的职级为21级,直接汇报给理想辅助驾驶研发副总裁郎咸朋。
该负责人于2023年加入理想,主要负责辅助驾驶系统的规划控制模型。此前曾在百度的自动驾驶部门任职。
其负责的技术模块,是理想汽车“端到端”辅助驾驶方案落地的关键。由于方案效果不错,理想将辅助驾驶团队调整为“端到端”模型、世界模型、量产研发三大部门时,他也正式成为“端到端”模型负责人,直接汇报给郎咸朋。
在理想2年时间,他从P9(对应理想新职级体系19级)升到了21级,这种升职速度在理想内部并不多见。
据知情人士透露,目前该负责人已经退出理想最新的辅助驾驶方案VLA项目组,数周没有参加业务例会。但离职后,夏的去向尚未明确。
有知情人士告诉36氪汽车:大佬的离开,或许与理想的辅助驾驶技术路线变更有关。
“他认为端到端路线还有可以优化的空间,但理想内部已经押注了VLA(Vision-Language-Action,视觉-语言-动作)模型路线。”有知情人士说道。VLA技术路线由自动驾驶技术研发负责人贾鹏主导,此前贾鹏还曾负责理想世界模型等技术预研。
理想认为,VLA能通过3D和2D视觉的组合,完整地看到物理世界,而不像VLM仅能解析2D图像。同时,VLA拥有完整的脑系统,具备语言、CoT(思维链)推理能力,既能看,也能理解并真正执行动作,符合人类的运作方式。
不过也有行业人士告诉36氪汽车,VLA路线还在早期,还没经过大量落地实践,正如李想自己所言,“我们其实走的是一个无人区。
#基于显式混合专家和面向交互优化的场景自适应运动规划
比亚迪最新
- 论文链接:https://arxiv.org/pdf/2505.12311
摘要
本文介绍了基于显式混合专家和面向交互优化的场景自适应运动规划。尽管经过十多年的发展,复杂城市环境中的自动驾驶轨迹规划仍然面临着重大挑战。这些挑战包括难以适应轨迹的多模态性质、单个专家在管理多样化场景方面具有局限性以及对环境交互的考虑不足。为了解决这些问题,本文引入了EMoE-Planner,它结合了三种创新的方法。首先,显式混合专家(EMoE)根据场景特定信息来动态地选择专家。其次,规划器利用场景特定的查询来提供多模态先验,使模型着重于相关的目标区域。最后,通过考虑自车和其他智能体之间的交互来增强预测模型和损失计算,从而显著提升规划性能。本文使用Nuplan数据集与最先进的方法进行比较实验。仿真结果表明,本文模型在几乎所有测试场景中均始终优于SOTA模型。
主要贡献
本文的贡献总结如下:
1)本文提出了一种显式混合专家(EMoE)架构,它采用共享的场景路由器进行显式的场景分类,并且根据分类结果来选择对应的专家。该方法简化了每个专家的责任和学习复杂度,从而降低了训练难度并且提高了模型性能;
2)本文提出了一种新的场景特定查询,它使模型能够着重于目标点所在的区域。该查询同时在决策层和模态层向模型提供先验信息,使模型仅需少量的查询即可实现更好的训练效率和性能;
3)本文引入了面向交互的损失,它在损失函数中显式地考虑了自车和周围智能体之间的交互。此外,对周围智能体轨迹的预测考虑了其与自车的交互,这不仅提高了预测准确性,还间接优化了场景编码。
论文图片和表格
总结
本文引入了EMOE-Planner,这是一种通过利用场景信息和交互动态来增强城市自动驾驶中轨迹规划的新框架。该框架采用通过多个场景锚点生成的场景特定查询,使得模型的注意力聚焦于相关区域。混合专家(MoE)与共享场景路由器的结合允许将场景类型与对应的专家进行精准匹配,提升了模型对不同场景的响应能力并且提高了专家选择的透明度。此外,将自车和其他智能体之间的交互加入损失函数可以显著提高轨迹评分。在若干个NuPlan数据集上的基准评估表明,EMOE-Planner在闭环评估中超过了最先进的(SOTA)模型,并且与使用后处理的SOTA方法的性能相当,它降低了对基于规则的后处理的依赖性。
#DriveGPT
当智驾遇见大模型:如何重新定义驾驶智能?
https://arxiv.org/abs/2412.14415
当自动驾驶遇见大模型:DriveGPT 如何重新定义驾驶智能?


基于Transformer的基础模型在跨机器学习领域的序列建模任务中已日益普及。这类模型在处理序列数据时极具效力,能够捕捉长距离依赖关系和时间关系。其成功案例已在自然语言处理、时间序列预测和语音识别等领域得到体现,而在这些领域中,序列模式均扮演着关键角色。Transformer模型的核心优势之一,在于其能够从包含数百万训练样本的大型数据集中学习,进而借助不断增大的模型规模(参数规模可达数十亿)来解决复杂任务。
然而,尽管模型和数据集规模的扩大已成为文本预测等序列建模任务近期取得进展的关键因素,但这些扩展趋势能否直接应用于行为建模(尤其是驾驶任务)尚不明确,这是由于驾驶任务面临若干独特挑战。首先,驾驶任务涉及更广泛的输入模态,包括智能体轨迹和地图信息,这与仅依赖文本输入的语言任务有所不同。其次,行为建模需要空间推理能力和对物理运动学的理解,而这些能力通常超出了语言模型的范畴。最后,大规模驾驶数据集的收集需要耗费大量精力和资源,其难度远高于文本数据的收集。因此,现有研究往往受到训练数据可用性或模型可扩展性的限制。
在该项工作中,作者针对自动驾驶行为建模领域的数据规模和模型参数扩展展开了全面研究,其目标是预测交通智能体的未来动作,从而为规划和运动预测等关键任务提供支持。具体而言,作者在超过1亿个高质量人类驾驶示例上训练了一个基于Transformer的自回归行为模型,该数据量约为现有开源数据集的50倍。同时,将模型参数规模扩展至10亿级,远超已发表的现有行为模型。
随着训练数据量和模型参数数量的增加,观察到定量指标和定性行为均有所改善。更为重要的是,在广泛且多样化的数据集上训练的大型模型能够更好地处理罕见或边缘场景,而这些场景往往是自动驾驶车辆面临的重大挑战。因此,通过数据和模型参数扩展行为模型,在提升自动驾驶系统的安全性和鲁棒性方面展现出巨大潜力。
本文的主要贡献如下:
- 提出DriveGPT,一种用于驾驶场景的大型自回归行为模型,实现了模型参数和真实世界训练数据样本的双重扩展。
- 针对自回归行为模型,从数据规模、模型参数和计算量角度确定了基于经验的驾驶扩展规律。研究验证了扩展训练数据和计算量的价值,并观察到随着训练数据的增加,模型可扩展性得到提升,这一结果与语言模型扩展领域的相关研究一致。
- 通过扩展实验对模型进行了定量和定性比较,以验证其在真实驾驶场景中的有效性。研究展示了该模型在挑战性条件下通过闭环驾驶实现的实际部署效果。
- 在Waymo Open Motion Dataset上验证了模型的泛化能力。DriveGPT在运动预测任务中超越了先前的最先进模型,并且通过大规模预训练实现了性能提升。
DriveGPT架构实现
作者采用标准的编码器-解码器架构作为行为模型,其结构如图2所示。鉴于Transformer模型在相关序列建模任务中的可扩展性,作者将其作为编码器和解码器的主干架构。

问题表述
作者将该问题建模为针对目标智能体未来位置的序列预测任务,预测范围可延伸至时间 horizon 。通过应用链式法则,在每个步骤中基于驾驶上下文信息 和智能体历史位置 进行条件预测:
上下文信息包含目标智能体历史状态、附近智能体历史状态 和地图状态。智能体历史信息则包括先前历史步骤中的位置,例如若要预测步骤 的智能体位置,则需利用 。
作者将“状态”定义为完整的运动学状态,包括位置、方向、速度和加速度(这些信息通常可从智能体历史观测中获取),并将“位置”定义为二维 坐标以简化输出空间。
场景编码器
编码器采用标准的Transformer编码器架构(Shi等人,2022),其作用是将所有输入模态融合为一组场景嵌入token。该编码器接收原始输入特征,包括目标智能体历史状态、附近智能体历史状态和地图状态(以向量集合形式呈现),并将所有输入归一化为以智能体为中心的视角。每个向量通过类似PointNet的编码器(Gao等人,2020)映射为token嵌入。在编码器末端,应用自注意力Transformer(Vaswani等人,2017)将所有输入上下文融合为一组编码器嵌入 ,其中 为向量数量, 为token维度,这些嵌入用于概括驾驶场景。
类LLM的轨迹解码器
受LLM领域研究(Radford等人,2019)的启发,作者借鉴Seff等人(2023)的方法,采用Transformer解码器架构预测未来每个步骤的智能体位置分布。
解码器首先通过线性层将所有步骤的智能体位置token化为维度为 的嵌入,随后进行LayerNorm层和ReLU层处理。在每个步骤 ,解码器接收截至 时刻的智能体嵌入,并将其与编码器嵌入 进行交叉注意力计算,以预测下一时刻 的智能体位置分布。
输出为一组以Verlet动作(Rhinehart等人,2018;Seff等人,2023)表示的离散动作 ,Verlet动作可视为位置的二阶导数。通过以下公式可将Verlet动作映射为位置:
其中 为预测的Verlet动作, 假定为恒定速度步长。这种表示方式有助于通过少量动作预测平滑的轨迹。
训练
在训练DriveGPT模型时,作者采用教师强制(teacher forcing)方法,将真实未来位置作为输入提供给轨迹解码器,从而实现对所有未来步骤的并行预测。
作者在动作空间上使用单一交叉熵分类损失,目标动作选取为与真实未来轨迹最接近的动作。
推理
在推理阶段,作者采用标准的LLM设置,通过循环执行以下过程自回归地生成时间 horizon 内的轨迹:预测下一时刻的动作分布、采样动作并将其添加回输入序列。
作者以批量方式采样多个轨迹以近似分布,随后使用K均值算法(Seff等人,2023)将轨迹数量子采样至所需模式数。
缩放实验——验证模型扩展能力
数据扩展

数据扩展结果总结如图3所示。最小的220万样本数据集模拟了Waymo开放运动数据集(WOMD)(Ettinger等人,2021)的规模(该开源数据集包含约4.4万个场景,每个场景有多个目标智能体)。作者从内部研究数据集中选取了几个子集,以研究不同数量级的数据集扩展效果。他们的实验使用了比WOMD多50倍的数据,开拓了设计空间的新领域。
结果表明,无论模型规模如何,当模型在更多独特数据样本上训练时,性能均有所提升。从图3的缩放定律推断,若要使最佳损失再降低10%,需要额外增加3.5亿个训练样本;若要实现20%的提升,则需要约14亿个更多样本。因此,数据仍然是进一步提升驾驶性能的瓶颈。
最后,缩放结果在不同模型规模下保持相对一致。这一一致性表明,数据扩展比较可以在参数超过1000万的中等规模模型上进行。
模型扩展
作者研究了三个数量级(150万至140亿参数)的模型规模,具体如表2所示。为简化操作,他们通过增加Transformer的隐藏维度来扩大模型规模。研究发现,修改其他参数(如注意力头数和每个头的隐藏维度)不会导致结果显著变化(见附录B)。
与其他缩放研究(Kaplan等人,2020;Hoffmann等人,2022)一致,训练更大的模型对学习率敏感。对于每个模型规模,作者在不同学习率下进行了多次实验,以选择性能最佳的学习率,结果总结于表2。

图4的结果表明,增加训练数据量可增强模型扩展的有效性。具体而言,当数据集规模达到2100万时,在较大的模型规模范围内,验证损失的变化几乎不可见。超过2100万样本后,随着模型增大,验证损失逐渐改善——在4200万数据集上训练时,参数增加至1200万可改善性能;在1.2亿数据集上训练时,参数增加至9400万仍有效,之后达到平台期并最终出现过拟合。这些发现进一步表明,数据是模型扩展的主要瓶颈,这与LLM缩放文献中的观察结果一致(Kaplan等人,2020)。

计算扩展
在图5中,作者考察了计算量(以浮点运算量FLOPs衡量)对训练损失的影响。他们发现了一个单调递减的“最小边界”,该边界显示了截至当前计算值所观察到的最低训练损失。随着计算量增加,训练损失通常会降低,最初下降速度较快,但在较高FLOPs值时逐渐放缓。这一趋势与LLM缩放文献(如Hoffmann等人,2022)中的观察结果一致,尽管本研究探索的FLOP范围是这些研究的子集。

接下来,作者探讨了在固定计算预算下,数据规模和模型参数的最优组合。鉴于在他们所探索的规模下训练模型需要巨大的计算成本,有效利用数据至关重要。在这项研究中,他们将计算预算固定在不同的FLOP组中。对于固定的计算预算,资源可以分配给模型参数或数据样本,保持两者的乘积不变。图6绘制了不同计算预算下的性能表现。趋势清楚地表明,更大的计算预算会带来更好的性能,同时最佳模型规模也相应增大(如灰色“最佳”线所示)。结果进一步揭示,数据是主要瓶颈,因为在三个最大的FLOP组中,最小的模型表现优于其他模型。

解码器架构消融研究
作者将两种不同模型架构(自回归解码器和一次性解码器)的规模扩展了两个数量级。对于一次性解码器,作者采用了Nayakanti等人(2023)的方法,使用Transformer解码器,该解码器接收一组学习到的查询,并将其与场景嵌入进行交叉注意力计算以生成轨迹样本。之所以称为“一次性”解码器,是因为它一次性生成完整的轨迹,而自回归解码器则采用类似LLM的方式逐步生成轨迹。
结果总结如图7所示,由于两种解码器架构的损失定义不同,作者使用6秒时的最小最终位移误差(minFDE)作为衡量模型性能的指标。尽管在小规模参数下性能较差,但自回归解码器表现出更好的可扩展性,在参数超过800万时优于一次性基线模型。虽然作者发现一次性解码器更难扩展,但他们证实,自回归解码器在预测准确性方面可扩展至1亿参数,并将一次性解码器的进一步可扩展性研究留待未来工作。

规划和预测实验内部评估:自动驾驶规划
针对规划任务,作者使用由数百万高质量人类驾驶演示组成的内部研究数据集对模型进行训练,并通过自回归方式预测下一动作来生成自动驾驶轨迹,具体流程如3.5节所述。
作者通过批量过采样轨迹并将其二次采样为6条轨迹来近似分布(如Seff等人,2023年的方法)。尽管自动驾驶系统最终需选择单一轨迹用于规划,但返回多个样本有助于更好地理解多模态行为,并与运动预测指标保持一致。
作者通过一组标准几何指标(包括最小平均位移误差(mADE)、最小最终位移误差(mFDE)和遗漏率(MR))以及基于语义的指标(包括偏离道路率(Offroad)和碰撞率(Collision)),在综合测试集上衡量规划性能。所有指标均经过归一化处理,以突出相对性能变化。
数据扩展结果
作者对比了在不同规模数据集上训练的2600万参数DriveGPT模型。其中,基线数据集(220万样本)的规模模拟了典型行为建模数据集(如WOMD)的大小。
结果如表3所示,研究发现随着训练数据样本量的增加,预测的自动驾驶轨迹质量显著提升,无论是驾驶中的关键语义指标(如偏离道路率和碰撞率)还是几何指标均有改善。

作者在图8中进一步展示了两个定性示例,以说明在更多数据上训练的价值。在示例中,红色轨迹代表在1.2亿样本上训练的DriveGPT模型输出,粉色轨迹为在220万样本上训练的同一模型输出。结果显示,当使用更多数据训练时,该方法能够生成符合地图规则且无碰撞的轨迹,成功处理涉及乱穿马路的行人和两辆双排停放车辆的复杂交互场景。

模型扩展结果
作者使用1.2亿内部研究数据集训练了四个模型,并选择800万参数模型作为基线(该基线代表了模型开始优于一次性解码器的合理规模,如第4.4节所示)。
结果如表4所示,随着模型参数规模增加至9400万,所有指标均有所改善;当参数达到1.63亿时,碰撞率指标进一步提升(定性示例见附录D.1)。尽管图4显示验证损失在参数超过9400万后收益递减,但驾驶指标随模型容量增加持续优化,突显了引入更多参数对提升驾驶性能的潜力。

作者在图9中展示了一个定性示例:在右转场景中,包含9400万参数的较大规模DriveGPT模型(红色轨迹)生成的轨迹样本更贴近道路边界,而800万参数的较小模型(粉色轨迹)则表现较差。

闭环驾驶
作者展示了DriveGPT作为实时运动规划器在闭环场景中的部署效果。模型从工业级感知系统获取输入特征(该系统输出智能体状态和地图信息),并使用在完整数据集上训练的800万参数DriveGPT模型进行车辆控制,在单个车载GPU上实现了低于50毫秒的延迟。
在图10中,作者呈现了一个密集城市交通中的挑战性场景:两辆双排停放车辆阻挡前方路径,同时有对向车辆驶来。DriveGPT生成了平滑且安全的轨迹,成功绕过障碍物后返回原车道。

外部评估:运动预测
为与已发表的研究结果直接对比,作者在WOMD运动预测任务上对DriveGPT进行了评估。此外,通过在内部研究数据集上预训练并在规模较小的WOMD数据集上微调,作者探索了模型规模扩展的优势。
开源编码器
在外部评估中,作者使用了开源MTR(Shi等人,2022年)编码器,该编码器与3.2节中描述的架构类似。这一调整旨在提高结果的可重复性,并利用MTR的WOMD开源数据加载代码。解码器则沿用3.3节中所述的自回归架构。
预训练设置
为兼容WOMD数据集,作者对DriveGPT进行了细微调整:首先修改地图数据以匹配WOMD的语义定义,其次调整智能体数据以包含与WOMD一致的运动学特征。
作者通过在内部研究数据集上训练一个epoch(如第4章所述)对DriveGPT进行预训练,随后加载预训练检查点,并采用与MTR代码库相同的训练设置在WOMD数据集上进行30个epoch的微调,使用加权衰减学习率调度器。
结果
作者通过一组标准WOMD指标(包括minADE、minFDE、遗漏率和软mAP)衡量模型性能,所有指标均在测试集上计算,并覆盖三个不同预测时间范围。
表5展示了两种模型变体的结果:直接在WOMD上训练的DriveGPT-WOMD,以及在1.2亿内部研究数据集上预训练后微调的DriveGPT-Finetune。基线模型为一组具有代表性的先进模型。

结果表明,DriveGPT在几何指标上优于现有非集成先进模型。与使用多达8个副本集成的Wayformer(Nayakanti等人,2023年)和MotionLM(Seff等人,2023年)相比,该模型在未使用任何集成技术的情况下,实现了最优的minADE和minFDE指标,遗漏率指标排名第二。
尽管作者优先关注强调轨迹样本召回率的几何指标(即不遗漏关键轨迹),但模型因概率估计欠佳导致软mAP分数较低。这是由于长序列动作概率的复合计算会累积噪声(如公式(1)所示),导致样本概率不准确,而软mAP依赖于预测样本的准确概率分配,因此随着预测时间范围延长,软mAP差距扩大。这揭示了自回归解码器在概率估计中的局限性(LLM文献中亦有类似结论,如Jiang等人,2021年;Geng等人,2024年)。未来研究可探索为每个样本添加独立概率预测头,以提升概率估计准确性和软mAP分数。
值得注意的是,尽管内部数据集与公共WOMD数据集在轨迹分布、特征噪声和语义定义上存在显著差异,预训练仍使性能提升了3%。
表6中特定智能体的结果显示,与使用相同编码器的MTR相比,DriveGPT在车辆、行人和骑行者等所有智能体类型的预测中均实现了性能提升,进一步验证了该方法的泛化能力。

定性比较
图11展示了两个定性对比示例:在复杂路口场景中,DriveGPT(右)生成的轨迹相比MTR(左)更准确且更多样化,蓝色为真实未来轨迹。

总结
6. 结论
作者介绍了DriveGPT,这是一种类似LLM的自回归行为模型,旨在深入探究模型参数和数据集规模对自动驾驶的影响。通过系统分析模型性能与数据集规模、模型容量的关系,作者揭示了数据和计算的类LLM扩展规律,以及模型规模增大后的收益递减现象。研究通过定量和定性分析,展示了规模扩展在真实驾驶场景规划中的优势。此外,在公开运动预测基准测试中,DriveGPT不仅超越了先进基线模型,还通过大规模预训练实现了性能提升。
作者指出,行为建模的扩展规律与自然语言处理中的发现具有一致性,即数据和模型规模的增加可显著提升序列决策任务的性能。通过120M样本的训练和140亿参数的模型,DriveGPT在复杂场景(如交通密集区域的变道、绕行障碍物)中展现了更强的鲁棒性,验证了自回归Transformer架构在驾驶任务中的可行性。
然而,研究也暴露了当前方法的局限性。例如,自回归模型在长序列预测中存在概率估计误差累积的问题,导致软mAP指标欠佳;此外,极端天气或罕见场景的覆盖仍需更多样化的数据支持。未来研究方向包括引入概率预测头以优化输出分布估计、探索更高效的模型压缩技术以适配车载计算资源,以及在更大规模数据集上验证扩展规律的极限。
总体而言,该研究为自动驾驶行为建模提供了新的技术路径,证明了“大数据+大模型”范式在提升驾驶安全性和泛化能力中的价值,同时为后续研究在数据采集、模型优化和实际部署方面提供了参考依据。
#CoMo
上海AI Lab提出:无需微调为机器人任务生成有效伪动作标签机器人学习的发展困境机器人学习领域长期受限于数据稀缺、多样性不足和高度异质性等问题。传统依赖小规模机器人操作数据的训练模式,难以支撑复杂任务的泛化能力,而互联网中存在的海量无动作视频数据(如人类操作演示、日常场景记录等),为突破这一困境提供了新方向。现有研究尝试从无动作视频中提取潜在动作模型,常用逆动力学编码器-前向动力学解码器架构结合向量量化变分自动编码器(VQ-VAE)生成伪动作标签,但这类方法采用离散潜在动作表示,不可避免地导致信息丢失,且存在训练不稳定、难以处理细粒度动态等问题。连续运动表示的必要性
现实世界的运动本质上是连续的,离散表示无法捕捉复杂动态(如精细操作轨迹、物理交互细节)。视觉生成和机器人学习领域的研究已表明,连续表示在性能上具有优势,但直接学习连续运动面临“模型崩溃”挑战——编码器易优先捕获未来帧视觉外观用于像素重建,而非提取底层运动动态,导致模型退化为帧预测器,无法为策略训练提供有效动作表征。
CoMo框架的创新设计
早期时间特征差异机制:抑制模型崩溃
受动作识别中时间差异网络的启发,CoMo在编码器输入前移除未来帧特征,改用当前帧与未来帧的特征差异(Dt)与当前帧特征(Ft)的组合表示。这一设计通过抑制静态外观信息、增强动态运动线索,显著提升了训练稳定性。具体而言:
- 特征处理流程:使用MAE预训练的ViT提取当前帧与未来帧的令牌级特征,计算时间特征差异后,仅将当前帧特征与差异特征输入Motion Q-former进行注意力交互,最终得到运动表示Zt。
- 关键作用:避免模型依赖视觉外观捷径,强制其聚焦于运动动态提取,从根本上缓解了连续运动学习中的模型崩溃问题。
信息瓶颈导向的维度约束:平衡信息与噪声
基于信息瓶颈原理,CoMo通过约束潜在运动嵌入维度,在保留动作相关信息与过滤无关噪声间取得平衡。实验表明,过高的维度会引入更多静态背景噪声,影响动作回归精度;过低则导致运动细节丢失。经优化,将维度固定为128时,模型既能捕获足够运动细节,又能最小化背景干扰,实现了信息效率的最优化。
双指标评估体系:LP-MSE与S-PCFC
为解决传统重建误差无法有效评估运动表示质量的问题,CoMo提出两个新指标:
- 动作预测线性探测均方误差(LP-MSE):通过训练线性MLP从运动嵌入预测真实机器人动作,MSE越低表明嵌入中动作相关信息越丰富。
- 过去-当前与未来-当前运动余弦相似度(S-PCFC):计算时间对称段运动嵌入的相似度,高值表明模型依赖静态上下文,低值则说明运动表示更关注动态方向,能有效衡量捷径学习程度。
联合策略学习与零样本泛化能力
连续伪动作生成与统一训练
CoMo可从无动作视频中提取连续伪动作标签,与机器人动作数据形成共享连续分布,支持统一策略的联合学习。这一机制避免了传统方法中复杂的多阶段预训练和微调流程,实现了跨数据源(如机器人操作视频、人类演示视频)的无缝整合。具体而言:
- 数据增强:无动作视频通过IDM提取潜在运动嵌入,转化为带“伪动作”的轨迹数据。
- 策略架构:开发基于扩散和自回归的统一策略模型,同时处理真实动作与伪动作,利用大规模无动作数据提升策略泛化性。
零样本跨域迁移能力
CoMo在互联网视频(涵盖野外、人类、机器人场景)上训练后,可直接为未见过的机器人任务生成有效伪动作标签,无需微调。这种零样本泛化能力源于其对运动动态的抽象表示,而非特定场景的视觉特征,使机器人能从互联网数据中迁移通用操作知识到新任务。
实验验证与关键发现
模拟实验:性能全面超越基线
- LIBERO基准测试:与离散潜在动作(VQ)、朴素连续变体(w/o VQ)、RGB差异等方法相比,CoMo在平均成功率上提升显著(如LIBERO任务平均成功率达80.8%,较Pre-VQ提升7.2%)。LP-MSE指标显示其动作相关信息提取能力更强(0.784 vs Pre-VQ的2.967),S-PCFC表明其有效抑制了静态噪声(0.901 vs w/o VQ的0.989)。
- CALVIN基准测试:在长视距语言指令任务中,CoMo使平均任务完成长度从2.306提升至2.848,验证了其在复杂序列动作中的有效性。
维度缩放实验:揭示信息瓶颈理论实践
实验发现,潜在运动嵌入维度与性能呈非单调关系:维度从32增至128时,成功率提升且S-PCFC降低(从0.730到0.940),但超过128后性能下降。这印证了信息瓶颈理论——过高维度会引入冗余外观信息,干扰动作预测,而128维实现了信息保留与噪声过滤的最佳平衡。
真实世界实验:跨实体操作验证
使用Franka机器人执行拾取、开抽屉、插入等任务时,CoMo结合人类演示视频与机器人数据训练的策略,成功率较离散基线提升显著(如拾取任务从60%提升至75%)。其学习的潜在运动表示对背景变化鲁棒,能跨实体(人类与机器人)构建统一动作空间,支持跨域技能迁移。
结论与未来方向
核心贡献总结
CoMo框架通过早期时间特征差异机制和信息瓶颈维度约束,实现了从无动作视频中高效学习连续潜在运动。LP-MSE与S-PCFC为运动表示提供了低成本、高可靠性的评估工具,指导方法优化。通过连续伪动作生成,实现了互联网视频与机器人数据的统一策略训练,显著提升了机器人在模拟和真实场景中的泛化能力。
局限性与未来工作
- 现存差距:潜在运动与真实机器人动作仍存在性能差距(如LIBERO中DP方法成功率89.2% vs CoMo的80.8%),需引入额外时间监督提升运动表征的时序敏感性。
- 指标优化:LP-MSE与S-PCFC仍可进一步完善,以更全面评估复杂动态场景下的运动表示质量。
- 场景扩展:探索CoMo在多机器人协作、非结构化环境等更复杂场景中的应用,提升通用机器人的环境适应性。
参考
[1] CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning
#学习推理加速半年之总结与迷思
又到了写年中总结的时候,沿着半年前一月底也就是农历新年前写的 整理一下最近学习进度 (大模型推理加速技术的学习路线是什么?)的思路,继续整理一下这半年的学习进度。本来是六月底要写完的,拖拖拉拉到现在也一直没写完。
其实也都是学习笔记,归纳整理,留给自己日后回顾而已。
回头来看,一月底的笔记早就已经把推理加速加速范围框好,然后深入了其中几个点,还相应的补充了很多基础知识,半年就已经过去了,时光如逝岁月如梭啊。随着学习的深入,其实也是颇为迷思的,也颇感无力。大概是因为,第一,需要学习的东西太多了,目前已经形成的单推理方面的包括 algo、infra 等等方面的知识体系已经足够庞大,补课就要花很多时间。第二,新的东西发展速度太快,每天都有新鲜的论文出现,23xx 开头的 arxiv 有时候读起来都有恍如隔世的感觉(老辈子的文章了?),新的实现新的产品层出不穷,卷死了卷死了。第三,每一个研究交叉点,当我们看到它的时候,它早已经被人占领了,呵呵呵,其实这是再正常不过的,research 嘛,就是不要不停的 re- search,但是这之中带来的无助也是再真实不过的体感。第四,接下来大模型的发展将何去何从,而推理基础结构方向上的工作将往何处去,一方面感性告诉我们这么大的应用需求这么多的技术点肯定有的搞,而另一方面理性又跳出来一声冷笑都做成这样了还有啥好做的,怎能不迷思?
不吐槽了,还是整理一下具体深入的三个技术点:
1)量化。量化这块写了整整一个《量化那些事》系列:量化那些事之 AdaRound/BRECQ/QDrop,刀刀宁:量化那些事之 OmniQuant/SpinQuant 等、刀刀宁:量化那些事之蒸馏 QAT、刀刀宁:量化那些事之 AdaRound/BRECQ/QDrop、刀刀宁:再磕:GPTQ、SparseGPT 与 Hessian 矩阵、刀刀宁:量化那些事之AWQ、刀刀宁:笔记:Llama.cpp 代码浅析(四):量化那些事、刀刀宁:量化那些事之FP8与LLM-FP4 等等。
这些文章都是在研究量化技术本身,在低位制下存储参数,如何通过巧妙的量化技巧、修正量化网格、调整量化后参数等等方法,使得量化误差最小,抑或是将激活值也量化到低位制等等。同时,量化是有一个非常有用的模型加速技术,相比稀疏化等方法,量化方法则非常有效。(稀疏化的笔记也是有几篇的:Sparsity Attention,DejaVu、LLM in Flash、PowerInfer,SparseGPT、Wanda)
在多篇笔记中,刀刀宁:量化那些事之 KVCache 的量化 是非常有别于其他笔记的,因为这篇笔记的方法则是将量化技术用于了当前问题比较突出的长文本条件下的 KVCache 优化方面,在新的场景下产生了新的问题,并且有新的数据特点,形成了各种新的方法。其实也是和下面服务系统相结合最紧密的一类问题。这其实不管是在研究工作还是在工业实践中,都是一种很有效的研究方法,就是将有用的工具在各种场景下进行适配和应用。另外相似的则是,刀刀宁:量化那些事之 Diffusion 量化 ,这是跑偏线路属于 CV 方面的技术,和 LLM 相关度不高不过可能未来会用在多模态大模型中。同时,在 刀刀宁:量化那些事之性能评价指标 我们还讨论了量化的评价方法。
总的来说,站在技术角度,量化方法本身和各类问题之间相对来说,耦合度不高,是个很趁手的工具。
2)服务系统。服务系统是整个推理系统中的基础设施,核心架构。主要形成的笔记有这么几篇:刀刀宁:聊聊大模型推理服务中的优化问题,刀刀宁:聊聊大模型推理服务之长上下文,刀刀宁:聊聊大模型推理中的分离式推理,刀刀宁:聊聊大模型推理中的 KVCache 压缩,刀刀宁:聊聊大模型推理内存管理之 CachedAttention / MLA。笔记总数上没有量化多,但是其中有几篇笔记都是万字以上,还是信息量很大的。
服务系统主要面临的问题有,在大模型自回归结构下,上下文长度不确定不能提前预判,且当下最长可以到几百万。简单说就是,发请求的 prompt 不确定长度,发给用户的返回结果页不确定长度,同时两者间还明显不存在特殊的关联关系。同时服务中的请求数量和来访分布都不确定,虽然这在传统的服务系统中也很常见,但是在不确定性的长上下文时候,显然已经产生了一个既能结合过往几十年传统分布并行处理机制,同时又需要让当下长上下文自回归服务满足基本的服务质量目标(SLO),的新问题。
这个新问题下,传统分布并行处理中常见的问题,诸如,延时、吞吐、容错、内存优化等等问题,都会在这个新场景下重新涌现出来,变成新的问题。同理,在大模型训练的场景中,也是如此的。并且回看历史,在 CV CNN 时代,模型训练已经经历过一轮将所有传统分布并行处理方法都借鉴一遍的过程了,只不过当时 CNN 的推理任务相对来讲没有不确定的上下文关系,则是一个比较容易优化的方向,没有像现如今大模型推理如此的紧迫。
对于服务系统,从工业界的角度出发,scale up 之后的大模型不仅仅是模型 weights 的 scale up,还有上下文的 scale up,然后就还有请求规模的 scale up,再就是服务节点的 scale up,才能最终满足服务目标。这时,一个良好的软硬件系统是需要投入极大的研发成本的,也就是我们常说的推理框架,而开源社区中,我们则需要关注各种好用的框架,因为一个合格的 system 论文,都还是需要一个较为完善的系统实现。好用的框架,则比如微软的 deepspeed、开源大神的 llama.cpp、配合 pagedAttention 的 vllm 等等,目前各家在竞争之中,远远没有到尘埃落地的阶段。
套用佳瑞的黑铁黄金白银时代,当前服务系统的研究则早已经趋近于进入平稳的、拼实力的白银时代了,工业界早已在一部分情况下满足了一部分需求了,而学术界大概率也是很难在大系统下卷的过工业界的,但是其实还是零散的留下了很多的小的研究点,值得学术界进行深入把玩、微调、打磨。关键问题是我们如何能够洞察到这些偏小的研究点,其实这对于我们这些肉眼凡胎来讲也是很难很难的,也只能先跟上别人的脚步,看看有没有机会了。比如,continuous batching 这个技术在几篇代表性的论文出来之后,就已经很实用了,如果想深入做的话要么就是在特殊的场景下要么就需要引入复杂的优化方法,但是带来的系统 overhead 也变得很复杂。再比如, 分离式推理 会利用到自回归大模型下 prefill / decode 两个 character 迥然相异的阶段进行,节点调度、内存调度,以及在调度过程中引入新的统一管理视角,也就已经非常实用了,引入一些新的细致的内存管理方法,或许是个不错的思路。
3)投机推理。投机推理其实本质上是服务系统中的一个技术点,可能和 continuous batching 和分离式推理地位相同,不同的是投机推理相对独立,也就是相对和其他部件解耦合。笔记目前有三篇:刀刀宁:聊聊大模型推理服务之投机推理,刀刀宁:投机推理番外一:特征层 speculative decoding,刀刀宁:投机推理番外二:优化树结构,其中第一篇写的时候没刹住车也是直接干到两万字以上了。
投机推理是个很有趣的技术,我认为其技术,明线上是因为大模型开销大用小模型多跑几次,暗线上其实是因为单个请求解码时面临的巨大的硬件访存墙问题,小模型多跑的几次本质上就是在组织一个更大的 batch size,在单请求过程中搭乘 weights 读取后免费计算的顺风车,提高硬件计算单元利用率。也就是说如果访存墙形成的计算空间可以容纳几十倍的 batch size ,那么投机推理的上限也应该是这样的加速比,而事实上当前最好的方法的加速比也就只有 5 倍以内,这是因为当下的投机方法必然因为小模型能力问题造成事实上的大量浪费。而这就是当前投机推理天然存在的问题,还需要更牛逼的范式来解决这个问题。
(所以 Batched speculative decoding 也是个能做的点,AWS 已经出了一篇 BASS 2404.15778 了,我还没来得及仔细看)
目前主要着力思考的就这三个大的方向,多了也弄不过来了。接下来的时间还是在这个整体框架内进行更加深入的思考和研究。然后就是一点碎碎念,关于为什么写这些笔记,其实写笔记是一个传统技艺了,只不过现在伴随着新领域的学习,笔记从自己私有的 OneNote 转移到了公开的知乎上,而已。要知道这么多论文,读完就忘本来也是传统技艺,必须要记下来再随时翻阅。而我现在更多还是监督自己能够静下心来把文章读扎实,在和阅读的小伙伴的交流过程中查漏补缺进一步完善自己的知识体系,很多时候论文作者直接到笔记下面来留言讨论也真的是学习到了很多。熟悉我的论文笔记的小伙伴都知道,我的论文笔记一般会同时对比几篇相似的问题进行阅读,也就是我常说的要进行对比学习才有较高的学习效率,一次有效的对比学习可以简单的总结当前这个方向点上的研究状态,同时还能对比几个方法之间的区别、优劣等等,形成体系和脉络,也方便和其他的技术点进行融合和贯通。
当然还有一部分不得不提的技术点,就是网络结构方面的基础知识,其实反倒比较集中,一是方面 Attention 结构的优化,主要就是一些稀疏化的结构或者结构性稀疏化的结构,将平方的时间空间复杂度降低到 Log 甚至是线性的方法,还有将复杂度降低到常数的;另一方面则是直接改变 transformer 结构,换成 mamba、rwkv、ttt 等等这类新结构等等。这些方法其实对前面几个技术点的影响都比较大,也都存在各种结合的可能。 目前来看,肯定还是 transformer 架构最实用,但是在算法和系统相结合的背景下,关注一下新结构或许会有惊喜。
#自动驾驶和xx智能最新VLA综述
康奈尔大学!
视觉 - 语言 - 动作(VLA)模型是人工智能领域的变革性进展,致力于将感知、自然语言理解和实体动作统一于一个计算框架。我们全面总结了 VLA 模型的最新进展,从五个主题展开呈现该领域全景。先奠定 VLA 系统概念基础,追溯其从跨模态学习架构到通用智能体(集成视觉 - 语言模型、动作规划器和分层控制器)的演变。研究采用严格文献综述框架,涵盖过去三年 80 多个 VLA 模型。关键进展领域包括架构创新、参数高效训练策略和实时推理加速。应用领域多样,如仿人机器人、自动驾驶汽车、医疗和工业机器人、精准农业、增强现实导航等。主要挑战涉及实时控制、多模态动作表示、系统可扩展性、对未知任务的泛化以及道德部署风险等。借鉴前沿研究成果,提出针对性解决方案,包括智能体人工智能适应、跨实体泛化和统一的神经符号规划。前瞻性讨论勾勒未来路线图,VLA 模型、视觉 - 语言模型和智能体人工智能将融合,为符合社会规范、自适应且通用的实体智能体提供动力。这项工作为推进智能、实用的机器人技术和通用人工智能奠定基础。
一些介绍
在视觉 - 语言 - 动作(VLA)模型出现前,机器人技术和人工智能进展在不同领域各自发展,包括能识别图像的视觉系统、理解生成文本的语言系统以及控制运动的动作系统。这些系统在各自领域表现尚可,但难以协同工作,也难以应对复杂环境和现实挑战。
如图 1 所示,传统基于卷积神经网络(CNNs)的计算机视觉模型专为狭窄任务设计,需大量标记数据和繁琐重训练,且缺乏语言理解和将视觉洞察转化为行动的能力。语言模型(如大语言模型 LLMs)革新了文本理解和生成,但局限于处理语言,无法感知物理世界。机器人领域基于动作的系统依赖手工策略或强化学习,能实现特定行为但难以泛化。
视觉 - 语言模型(VLMs)虽结合了视觉和语言实现多模态理解,但存在整合差距,难以生成或执行连贯动作。多数人工智能系统最多擅长两种模态,难以将视觉、语言、动作完全整合,导致机器人难以协调多种能力,呈现碎片化架构,泛化能力差且需大量工程工作,凸显了实体人工智能的瓶颈。
VLA 模型大约在 2021-2022 年被提出,谷歌 DeepMind 的 RT-2 率先引入变革性架构,统一感知、推理和控制。VLA 模型集成视觉输入、语言理解和运动控制能力,早期方法通过扩展视觉 - 语言模型包含动作标记来实现集成,提高了机器人的泛化、解释语言命令和多步推理能力。
VLA 模型是追求统一多模态智能的变革性步骤,利用整合多种信息的大规模数据集,使机器人能在复杂环境中推理和行动。从孤立系统到 VLA 范式的演进标志着向开发自适应和可泛化实体智能体的根本性转变。进行全面系统综述很有必要,这有助于阐明 VLA 模型的概念和架构原则,阐述技术发展轨迹,描绘应用,审视挑战,并向学界传达研究方向和实际考虑因素。
我们系统分析了 VLA 模型的基本原理、发展进展与技术挑战,旨在深化对 VLA 模型的理解,明确其局限并指明未来方向。我们先探讨关键概念,包括 VLA 模型的构成、发展历程、多模态集成机制,以及基于语言的标记化和编码策略,为理解其跨模态结构与功能奠定基础。接着,统一阐述近期进展与训练效率策略,涵盖架构创新、数据高效学习框架、参数高效建模技术和模型加速策略,这些成果助力 VLA 系统在不降低性能的同时,降低计算成本,推动其向实际应用拓展。随后,深入讨论 VLA 系统的局限性,如推理瓶颈、安全隐患、高计算需求、泛化能力有限和伦理问题等,并分析潜在解决方案。
视觉 - 语言 - 动作模型的概念
VLA 模型是新型智能系统,能在动态环境中联合处理视觉输入、解释自然语言并生成可执行动作。技术上,它结合视觉编码器(如 CNNs、ViTs)、语言模型(如 LLMs、transformers)和策略模块或规划器,采用多模态融合技术(如交叉注意力机制等),将感官观察与文本指令对齐。
与传统视觉运动流水线不同,VLA 模型支持语义基础,可进行情境感知推理、功能检测和时间规划。典型的 VLA 模型通过相机或传感器观察环境,解释语言目标(如 “捡起红色的苹果”)(图 5),输出高低级动作序列。近期进展通过整合模仿学习等模块提升样本效率和泛化能力。
我们探讨 VLA 模型从基础融合架构向可在实际场景(如机器人技术、导航、人机协作等)中部署的通用智能体的演变。VLA 模型作为多模态人工智能系统,统一视觉感知、语言理解和物理动作生成,使机器人或 AI 智能体通过端到端学习解释感官输入、理解情境并自主执行任务,弥合早期系统中视觉识别、语言理解和运动执行间的脱节,突破其能力限制。
演进与时间线
2022 - 2025 年,VLA 模型快速发展,经历三个阶段:
- 基础集成(2022 - 2023 年):早期 VLA 模型通过多模态融合架构实现基本视觉运动协调。如将 CLIP 嵌入与运动原语结合,展示 604 个任务的通用能力,通过规模化模仿学习在操作任务成功率达 97%,引入基于 transformer 的规划器实现时间推理。但这些基础工作缺乏组合推理能力,促使功能基础创新 。
- 专业化与实体推理(2024 年):第二代 VLA 模型纳入特定领域归纳偏差。借助检索增强训练提升少样本适应能力,通过 3D 场景图集成优化导航。引入可逆架构提高内存效率,用物理感知注意力解决部分可观测性问题。同时,以对象为中心的解耦改进组合理解,通过多模态传感器融合拓展应用到自动驾驶领域,这些进展需要新的基准测试方法。
- 泛化与安全关键部署(2025 年):当前系统注重鲁棒性和与人类对齐。集成形式验证用于风险感知决策,通过分层 VLA 模型展示全身控制能力。优化计算效率用于嵌入式部署,结合神经符号推理进行因果推断。新兴范式如的功能链和的仿真到现实转移学习解决跨实体挑战,通过自然语言基础连接 VLA 模型与人在回路接口。
图 6 展示 2022 - 2025 年 47 个 VLA 模型综合时间线。最早的 VLA 系统如 CLIPort等为操作和控制奠定基础,随后如 ACT等集成视觉思维链推理和功能基础,Diffusion Policy等引入随机建模和可扩展数据管道。2024 年 Deer - VLA等增加领域专业化和内存高效设计,Occllama等解决部分可观测性和用户交互问题,后续以机器人为重点的 VLA 模型不断创新。最近的模型强调泛化和部署,如 SafeVLA 等纳入验证、全身控制和内存系统,Gr00t N1 等实现仿真到现实转移和空间基础,展现 VLA 模型从模块化学习向通用、安全的实体智能发展的轨迹。
多模态集成:从孤立的流水线到统一的智能体
VLA 模型的核心进展在于多模态集成能力,能在统一架构中联合处理视觉、语言和动作。传统机器人系统将感知、自然语言理解和控制作为离散模块,通过手动接口或数据转换连接,缺乏适应性,难以泛化指令。
现代 VLA 模型利用大规模预训练编码器和基于 transformer 的架构,进行端到端模态融合,能在同一计算空间中处理视觉观察和语言指令,实现灵活推理。例如在 “捡起红色成熟苹果” 任务中,视觉编码器识别物体及其属性,语言模型编码指令,两者通过交叉注意力等机制融合,生成统一潜在空间指导动作策略。
CLIPort 率先展示多模态协同效应,用 CLIP 嵌入实现语义基础,无需显式语言解析确定视觉运动策略;VIMA 通过联合处理视觉和指令标记,实现跨空间推理少样本泛化。
近期发展进一步深化融合。VoxPoser 用体素级推理解决 3D 对象选择歧义,RT - 2 融合视觉 - 语言标记实现零样本泛化,Octo 引入内存增强 transformer 支持长时决策。此外,Occllama 处理遮挡对象引用,ShowUI 实现自然语言交互控制。这些能力源于 VLA 模型对跨模态语义、空间和时间对齐的深度捕捉,为现实应用挑战提供了解决方案。
标记化与表示:VLA 模型如何编码世界
VLA 模型的核心创新在于基于标记的表示框架,可对感知、语言和物理动作空间进行整体推理,受自回归生成模型启发,能统一各模态到共享嵌入空间,既理解 “做什么” 也知道 “怎么做”。
- 前缀标记:编码上下文和指令:是 VLA 模型的上下文关键。它将环境图像和自然语言指令编码为紧凑嵌入,为模型内部表示打基础。如 “将绿色积木堆放在红色托盘上” 任务中(如图 7 所示),图像经视觉编码器处理,指令由大语言模型嵌入,转换为前缀标记,实现跨模态基础,解析空间引用和对象语义。
- 状态标记:嵌入机器人的配置:VLA 模型需了解内部物理状态,由状态标记实现,其编码智能体配置实时信息,包括关节位置等。图 8 展示了在操作和导航场景中,状态标记对情境感知和安全很重要。如机械臂靠近易碎物体时,状态标记编码关节角度等信息,与前缀标记融合,让变换器推理物理约束,调整电机指令;移动机器人中,状态标记封装里程计等空间特征,与环境和指令上下文结合生成导航动作,为情境感知提供机制,生成反映机器人内外部信息的动作序列。
- 动作标记:自回归控制生成:VLA 标记管道最后一层是动作标记,由模型自回归生成,代表运动控制下一步,每个标记对应低级控制信号。推理时,模型依据前缀和状态标记解码动作标记,将 VLA 模型转变为语言驱动的策略生成器,支持与现实驱动系统无缝集成,可微调。如 RT-2 和 PaLM-E 等模型,在苹果采摘任务中(如图 9 所示),模型接收前缀标记和状态标记,逐步预测动作标记以执行抓取动作,让 transformer 能像生成句子一样生成物理动作。
学习范式:数据来源与训练策略
训练 VLA 模型需混合学习范式,结合网络语义知识与机器人数据集的任务相关信息,通过两个主要数据源实现:
- 大规模互联网衍生语料库:如图 10 所示,像 COCO、LAION400M 等图像 - 字幕对,HowTo100M、WebVid 等指令跟随数据集,VQA、GQA 等视觉问答语料库构成模型语义先验基础。预训练视觉和语言编码器,使用对比或掩码建模目标,对齐视觉和语言模态,赋予 VLA 模型对世界的基本 “理解”,助力组合泛化、对象基础和零样本迁移。
- 机器人轨迹数据集:仅靠语义理解不足以执行物理任务。从现实世界机器人或高保真模拟器收集的机器人轨迹数据集,如 RoboNet、BridgeData 和 RT-X 等,提供视频 - 动作对、关节轨迹和环境交互。采用监督学习、强化学习或模仿学习,训练自回归策略解码器预测动作标记。
此外,最近的工作采用多阶段或多任务训练策略,如先在视觉 - 语言数据集上预训练,再在机器人演示数据上微调;或使用课程学习,从简单任务到复杂任务;还利用领域适应弥合数据分布差距。联合微调使数据集对齐,模型学习从视觉和语言输入映射到动作序列,促进新场景泛化。谷歌 DeepMind 的 RT-2 将动作生成视为文本生成,在多模态数据和机器人演示上训练,能灵活解释新指令,实现零样本泛化,这在传统控制系统和早期多模态模型中难以实现。
自适应控制与实时执行
VLA 的优势在于具备执行自适应控制的能力,能够依据传感器实时反馈来动态调整行为。这在果园、家庭、医院等动态且非结构化环境中意义重大,因为在这些环境里,像风吹动苹果、光照变化、人员出现等意外情况会改变任务参数。在执行任务时,状态标记会根据传感器输入和关节反馈实时更新,模型也会相应修改计划动作。例如在苹果采摘场景中,若目标苹果位置变动或有其他苹果进入视野,模型能动态重新解读场景并调整抓取轨迹。这种能力模仿了人类的适应性,是 VLA 系统相较于基于流水线的机器人技术的核心优势。
视觉 - 语言 - 动作模型的进展
VLA 模型的诞生受基于 transformer 的大语言模型(LLMs)成功的启发,特别是 ChatGPT 展示的语义推理能力,推动研究人员将语言模型扩展至多模态领域,并为机器人集成感知和动作。
2023 年 GPT-4 引入多模态功能,可处理文本和图像,促使将物理动作纳入模型。同时,CLIP 和 Flamingo 等视觉 - 语言模型(VLM)通过对比学习实现零样本对象识别,利用大规模网络数据集对齐图像与文本描述,为 VLA 模型奠定基础。
大规模机器人数据集(如 RT-1 的 130,000 个演示)为联合训练视觉、语言和动作组件提供了关键动作基础数据,涵盖多种任务和环境,助力模型学习可泛化行为。
谷歌在 2023 年推出 RT-2,作为里程碑式的 VLA 模型,统一视觉、语言和动作标记,将机器人控制视为自回归序列预测任务,使用离散余弦变换(DCT)压缩和字节对编码(BPE)离散化动作,使新对象处理性能提高 63%。多模态融合技术(如交叉注意力 transformer)结合图像与语言嵌入,让机器人执行复杂命令。此外,加州大学伯克利分校的 Octo 模型(2023)引入开源方法,拥有 9300 万个参数和扩散解码器,在 800,000 个机器人演示数据上训练,拓展了研究领域。
VLA 模型的架构创新
2023 年到 2024 年,VLA 模型在架构和训练方法上取得重大进展:
- 架构进展:
- 双系统架构:以 NVIDIA 的 Groot N1(2025)为例,结合快速扩散策略(系统 1,10ms 延迟用于低级控制)和基于 LLM 的规划器(系统 2,用于高级任务分解),实现战略规划和实时执行的高效协调,增强动态环境适应性。斯坦福大学的 OpenVLA(2024)推出 70 亿参数的开源 VLA 模型,在大量现实世界机器人演示上训练,使用双视觉编码器和 Llama 2 语言模型,性能优于大型模型 RT-2-X(550 亿参数)。
- 早期融合模型:在输入阶段融合视觉和语言表示,如 EFVLA 模型保留 CLIP 的表示对齐,接受图像 - 文本对,编码并融合嵌入,确保语义一致性,减少过拟合,增强泛化能力,在组合操作任务上性能提升 20%,对未见目标描述成功率达 85%,同时保持计算效率。
- 自校正框架:自校正 VLA 模型可检测并从失败中恢复,如 SC-VLA(2024)引入混合执行循环,默认行为预测姿势或动作,检测到失败时调用次要过程,查询 LLM 诊断并生成校正策略,在闭环实验中降低任务失败率 35%,提高杂乱和对抗环境的恢复能力。
- 训练方法改进:利用网络规模的视觉 - 语言数据(如 LAION-5B)和机器人轨迹数据(如 RT-X)联合微调,使语义知识与物理约束一致。合成数据生成工具(如 UniSim)创建逼真场景解决数据稀缺问题。低秩适应(LoRA)适配器提高参数效率,减少 GPU 使用时间 70%。基于扩散的策略(如 Physical Intelligence 的 pi 0 模型(2024))提高动作多样性,但需大量计算资源。
- VLA 模型架构多样,可按端到端与模块化、分层与扁平策略、低级控制与高级规划等进行分类。端到端模型直接处理原始感官输入,组件重点模型解耦各模块。分层架构分离战略决策与反应控制,低级策略模型生成多样运动但计算成本高,高级规划器专注子目标生成并委托细粒度控制。
VLA 模型的训练与效率提升
VLA 模型在训练和优化技术上进步迅速,可协调多模态输入、降低计算需求并实现实时控制,主要进展如下:
- 数据高效学习:在大规模视觉 - 语言语料库(如 LAION-5B)和机器人轨迹集合(如 Open X-Embodiment)上联合微调,使语义理解与运动技能一致。OpenVLA(70 亿参数)成功率比 550 亿参数的 RT-2 变体高 16.5%,体现联合微调在少参数下的强泛化能力。通过 UniSim 合成数据生成逼真场景,增强罕见边缘情况的场景,使模型在杂乱环境中的鲁棒性提升超 20%。自监督预训练采用对比目标(如 CLIP),在动作微调前学习联合视觉 - 文本嵌入,减少对特定任务标签的依赖,Qwen2-VL 利用自监督对齐,使下游抓取和放置任务的收敛速度加快 12%。
- 参数高效适应:低秩适应(LoRA)在冻结的 transformer 层插入轻量级适配器矩阵,可减少高达 70% 的可训练权重且保持性能。Pi-0 Fast 变体在静态骨干网络上使用 1000 万个适配器参数,仅以可忽略的精度损失实现 200Hz 的连续控制。
- 推理加速:双系统框架(如 Groot N1)中,压缩动作令牌(FAST)和并行解码使策略步骤速度提高 2.5 倍,以适度牺牲轨迹平滑度为代价实现低于 5ms 的延迟。硬件感知优化,包括张量核心量化和流水线注意力内核,将运行时内存占用缩小到 8GB 以下,可在嵌入式 GPU 上实现实时推理。这些方法让 VLA 模型成为能在动态现实环境中处理语言条件、视觉引导任务的实用智能体。
VLA 模型的参数高效方法与加速技术
基于数据高效训练的进展,近期工作聚焦于减少 VLA 模型参数占用、提高推理速度,这对在资源受限的机器人平台部署意义重大,具体如下:
- 低秩适应(LoRA):LoRA 向冻结的 transformer 层注入小的可训练秩分解矩阵,OpenVLA 中,2000 万个参数的 LoRA 适配器微调 70 亿参数骨干网络耗时不到 24 小时,与完全反向传播相比,GPU 计算量减少 70%,且经 LoRA 适应的模型在处理新任务时能保持高级语言基础和视觉推理能力,使大型 VLA 模型可在无超级计算资源的实验室使用。
- 量化:将权重精度降至 8 位整数(INT8)可使模型大小减半、片上吞吐量翻倍。OpenVLA 实验显示,Jetson Orin 上 INT8 量化在取放基准测试中保持 97% 全精度任务成功率,细粒度灵巧操作任务精度仅降 5%,带有逐通道校准的训练后量化等方法可进一步减少高动态范围传感器输入的精度损失,使 50W 的边缘模块实现 30Hz 的连续控制循环。
- 模型剪枝:结构化剪枝删除冗余的注意力头或前馈子层。早期对 Diffusion Policy 的研究表明,对基于 ConvNet 的视觉编码器剪枝 20%,抓握稳定性性能下降可忽略。类似方案应用于基于 transformer 的 VLA 模型(如 RDT-1B),内存占用减少 25%,任务成功率下降不到 2%,为小于 4GB 的部署奠定基础。
- 压缩动作标记化(FAST):FAST 将连续动作输出转换为频域标记,Pi-0 Fast 变体将 1000ms 动作窗口标记化为 16 个离散标记,在 3 亿参数的扩散头中实现 15 倍推理加速,可在桌面 GPU 上实现 200Hz 的策略频率,以最小轨迹粒度换取大幅加速,适用于动态任务的高频控制。
- 并行解码和动作分块:自回归 VLA 模型传统解码方式存在顺序延迟,并行解码架构(如 Groot N1)同时解码空间 - 时间标记组,在 7 自由度机械臂上以 100Hz 频率运行时,端到端延迟降低 2.5 倍,位置误差增加不到 3mm。动作分块将多步例程抽象为单个标记,在长时任务中推理步骤最多减少 40%。
- 强化学习 - 监督混合训练:iRe-VLA 框架在模拟中交替进行强化学习和基于人类演示的监督微调,利用直接偏好优化塑造奖励模型,使用保守 Q 学习避免外推误差,与纯强化学习相比,样本复杂度降低 60%,并保持语义保真度,为动态避障等任务生成稳健策略。
- 硬件感知优化:编译器级的图重写和内核融合(如 NVIDIA TensorRTLLM)利用目标硬件特性加速 transformer 推理和扩散采样。OpenVLA-OFT 中,与标准 PyTorch 执行相比,这些优化使 RTX A2000 GPU 上推理延迟降低 30%,每次推理能耗降低 25%,使移动机器人和无人机在严格功率预算下实现实时 VLA 模型成为可能。
总之,参数高效适应和推理加速技术使 VLA 部署更普及。LoRA 和量化让小实验室能在消费级硬件上微调运行大型 VLA 模型。剪枝和 FAST 标记化压缩模型和动作表示。并行解码和动作分块克服自回归策略瓶颈。混合训练稳定复杂环境中的探索,硬件感知编译确保实时性能,这些进展使 VLA 模型在多种机器人中嵌入成为现实,缩小了研究原型与实际应用的差距。
VLA 模型的应用
VLA 模型将感知、自然语言理解和运动控制集成,在多领域展现变革力量:
- 仿人机器人:VLA 模型使仿人机器人能感知环境、理解指令并执行复杂任务。如图 12 所示 Helix 利用完全集成的 VLA 模型实现高频全身操作,其双系统设计可处理输入并输出动作向量,能泛化任务并适应环境变化。VLA 驱动的仿人机器人在家庭、医疗、零售、物流和制造业等场景有应用,如家庭中清洁、准备饭菜,医疗中传递手术器械,零售中协助客户,物流和制造业中执行重复性任务。TinyVLA 和 MoManipVLA 等系统可在嵌入式低功耗硬件上运行,减少计算成本,实现移动部署。
- 自动驾驶系统:VLA 模型为自动驾驶车辆提供集成架构,使其能处理多模态输入并输出控制信号。如 CoVLA 提供数据集,结合视觉基础、指令嵌入和轨迹预测,使车辆能理解环境和指令,做出安全决策;OpenDriveVLA 通过分层对齐多视图视觉标记和自然语言输入,实现先进的规划和问答性能;ORION 结合多种组件,实现视觉问答和轨迹规划。在无人机领域,VLA 模型增强了无人机的能力,可执行高级命令。VLA 模型使自动驾驶系统能理解复杂环境,做出安全决策,超越传统流水线。
- 工业机器人:传统工业机器人缺乏语义基础和适应性,VLA 模型通过联合嵌入多模态信息,提供易于人类解释和更具泛化性的框架。如 CogACT 引入基于扩散的动作变换器,实现对动作序列的稳健建模,在不同机器人实体间快速适应,在复杂任务中成功率比先前模型高 59% 以上,减少编程开销,促进人机协作,标志着向智能工厂的重要转变。
- 医疗保健和医疗机器人:传统医疗机器人自主性和响应能力有限,VLA 模型集成视觉感知、语言理解和运动控制,增强手术机器人能力,如在手术中识别目标、执行动作,减少人为错误;在患者辅助中感知患者行为、理解语音请求并提供帮助。RoboNurse-VLA 展示了在手术室的可行性,VLA 模型在可解释性和可审计性上有优势,可适应不同医疗场景,减少开发时间和成本,在医疗保健中发挥关键作用。
- 精准农业和自动化农业:传统农业自动化系统需手动重编程,VLA 模型集成多模态感知、语言理解和动作生成,能适应不同地理区域和季节。如在果园和农田中,处理视觉输入,解析自然语言命令,执行如水果采摘、灌溉等任务,减少作物损伤,优化采摘率,支持动态重新配置和终身学习,减少对劳动力依赖,提高产量,增强环境可持续性。
- 基于视觉 - 语言 - 动作模型的交互式 AR 导航:传统 GPS 系统依赖刚性地图和有限用户输入,VLA 模型处理视觉和语言信息,生成动态导航提示。集成视觉编码器、语言编码器和动作解码器,推理空间布局和语义意图,支持交互循环,可与物联网传感器和数字孪生集成,实现个性化导航,重新定义人类与物理空间的交互方式。
视觉 - 语言 - 动作模型的挑战与局限
VLA 模型从研究原型转化为现实世界系统面临多种挑战,具体如下:
- 实时推理约束:实时推理是 VLA 模型部署的重大限制,自回归解码策略限制推理速度,如机械臂操作时,OpenVLA 和 Pi-0 等模型在顺序标记生成上面临挑战。新兴的并行解码方法(如 NVIDIA 的 Groot N1)虽能加速推理,但会牺牲轨迹平滑度。硬件限制也加剧了实时推理约束,处理高维视觉嵌入对内存带宽要求高,量化技术虽能缓解内存约束,但在高精度任务中模型精度会下降。
- 多模态动作表示与安全保证:
- 多模态动作表示:当前 VLA 模型准确表示多模态动作存在困难,传统离散标记化方法缺乏精度,基于连续多层感知器(MLP)的方法有模式崩溃风险。新兴扩散策略(如 Pi-Zero 和 RDT-1B 等模型)虽能捕捉多样动作可能性,但计算开销约为传统基于 transformer 解码器的三倍,在实时部署中不切实际,且在复杂动态任务中存在困难。
- 开放世界中的安全保证:VLA 模型在现实场景中确保安全性面临挑战,许多实现依赖预定义的硬编码力和扭矩阈值,在意外条件下适应性有限。碰撞预测模型在杂乱动态空间中准确率约 82%,紧急停止机制存在 200 到 500 毫秒的延迟,在高速操作或关键干预中存在危险。
- 数据集偏差、基础与对未见任务的泛化:
- 数据集偏差:VLA 模型的训练数据集常存在偏差,如网络爬取的存储库中约 17% 的关联倾向于刻板解释,导致模型在不同环境中语义不一致或响应不适当,如 OpenVLA 等模型在新颖环境中会忽略约 23% 的对象引用。
- 对未见任务的泛化:现有 VLA 模型在未见任务上性能显著下降,如专门在家庭任务上训练的 VLA 在工业或农业环境中可能失败,主要原因是对狭窄训练分布的过拟合和对多样化任务表示的接触不足,在零样本或少样本学习场景中表现有限。
- 系统集成复杂性与计算需求:
- 系统集成复杂性:双系统架构中集成 VLA 模型面临时间不匹配和特征空间不匹配的挑战。系统 2(如使用大型语言模型进行任务规划)和系统 1(执行快速低级运动动作)的操作节奏差异导致同步困难,如 NVIDIA 的 Groot N1 模型存在运动不平稳的问题。高维视觉编码器和低维动作解码器之间的特征空间不匹配也会降低感知理解和可操作命令之间的一致性,如 OpenVLA 和 RoboMamba 在从模拟环境移植到物理硬件部署时性能下降。
- 计算需求:先进 VLA 模型参数众多,对计算资源要求高,如一些模型需超过 28GB 的 VRAM,超出大多数边缘处理器和 GPU 的能力,限制了其在专门高资源环境外的实际适用性。
- VLA 部署中的鲁棒性与伦理挑战:
- 环境鲁棒性:VLA 模型在动态变化环境中保持稳定和准确性能存在困难,如视觉模块在低对比度或阴影场景中精度降低约 20-30%,语言理解在声学嘈杂或模糊环境中受影响,机器人操作在杂乱环境中任务成功率受影响。
- 伦理考量:文中虽未详细阐述伦理考量部分,但可推测 VLA 模型在实际部署中需考虑伦理问题,如模型决策的公平性、对用户的影响等。
讨论
如图 17 所示,VLA 模型面临多方面挑战,包括实时推理、多模态融合、数据集偏差、系统集成、鲁棒性和伦理等问题,同时也有相应的潜在解决方案和未来发展方向:
- 挑战:
- 实时推理:自回归解码器顺序性和多模态输入高维度,在资源受限硬件上实现实时推理困难。
- 多模态动作与安全:将视觉、语言和动作融合到连贯策略中,遇到意外环境变化时存在安全漏洞。
- 数据集与泛化:数据集偏差和基础错误损害模型泛化能力,在分布外任务上易失败。
- 系统集成:集成感知、推理、控制等不同组件,架构复杂,优化和维护困难。
- 计算需求:大型 VLA 系统能源和计算需求高,阻碍在嵌入式或移动平台部署。
- 鲁棒性与伦理:对环境可变性鲁棒性不足,存在隐私和偏差等伦理问题,引发社会和监管关注。
- 潜在解决方案:
- 实时推理约束:开发协调延迟、吞吐量和任务特定精度的架构,集成硬件加速器,使用模型压缩技术、渐进式量化策略和自适应推理架构,采用高效标记化方案,可实现低延迟推理,适用于对延迟敏感的应用。
- 多模态动作表示与安全保证:构建端到端框架统一感知、推理和控制,采用混合策略架构表示多样动作轨迹,利用实时风险评估模块确保安全,结合强化学习算法和在线模型适应技术优化动作选择,嵌入形式验证层,可生成安全的 VLA 系统。
- 数据集偏差、基础与对未见任务的泛化:策划大规模无偏差多模态数据集,对视觉 - 语言骨干网络微调,采用元学习框架和持续学习算法,进行迁移学习和仿真到现实的微调,使 VLA 能对未见对象、场景和任务进行泛化。
- 系统集成复杂性与计算需求:采用模型模块化和硬件 - 软件协同设计,注入 LoRA 适配器进行特定任务微调,通过知识蒸馏得到紧凑模型,结合混合精度量化和定制硬件加速器,利用工具链优化端到端的 VLA 图,TinyVLA 等架构可实现实时推理,适用于资源受限环境。
- VLA 部署中的鲁棒性与伦理挑战:利用域随机化和合成增强管道增强模型对环境变化的适应能力,使用自适应重新校准模块减轻漂移和传感器退化;通过偏差审计、对抗性去偏等技术解决伦理问题,实现隐私保护推理,建立监管框架,平衡技术与社会价值。
- 未来路线图:
多模态基础模型:出现大规模多模态基础模型,编码动态和常识知识,为动作学习者提供统一表示基础。
智能体、自监督终身学习:VLA 与环境持续交互,生成探索目标,自我校正,像人类学徒一样自主扩展能力。
分层、神经符号规划:采用分层控制架构,基于语言的顶级规划器分解任务,中级模块转换为运动计划,低级控制器生成平滑轨迹,融合神经符号确保可解释性和灵活性。
通过世界模型进行实时适应:VLA 维持内部预测性世界模型,对比预测与传感器反馈,使用基于模型的校正动作,可在非结构化环境中实现鲁棒性。
跨实体和迁移学习:未来 VLA 能在不同形态机器人间无缝转移技能,结合元学习,新机器人用少量校准数据启动先前技能。
安全、伦理和以人类为中心的对齐:集成实时风险估计器评估潜在危害,融入监管约束和社会意识政策,确保机器人尊重人类偏好和法律规范。
如图 18 所示,基于 VLA 的机器人技术未来在于集成视觉 - 语言模型(VLMs)、VLA 架构和智能体 AI 系统。以仿人助手 “Eva” 为例,在感知层,其基础 VLM 将视觉场景分割并模拟动态行为,实现高级视觉理解。当收到 “清理咖啡渍并给植物浇水” 的命令时,VLA 模块被激活,将语言输入和感官反馈结合,高级规划器分解任务,中级策略模块转换为运动轨迹,低级扩散策略控制器生成平滑关节运动。同时,Eva 的智能体 AI 模块支持持续学习和适应,遇到挑战时启动自我改进循环。此外,通过接近传感器、实时监控等确保安全性和对齐性,夜间还会回顾性能日志优化子策略。VLM、VLA 和智能体的结合是迈向实体通用人工智能的重要一步,能让机器人如 Eva 般感知、规划、行动、适应并与人类安全共存,改变智能系统与现实世界的交互方式,使其更稳健、可解释且符合人类需求。
结论
我们系统评估了过去三年 VLA 模型的发展、方法和应用。分析从 VLA 基本概念出发,追溯其发展历程,强调多模态集成从松散耦合到基于 transformer 架构的转变。我们研究了标记化和表示技术,关注 VLA 对视觉和语言信息的编码。探讨学习范式,介绍从监督学习到多模态预训练的数据集和训练策略,以及现代 VLA 针对动态环境的优化和对延迟敏感任务的支持。我们对主要架构创新分类,调查超 50 个近期 VLA 模型,研究训练和效率策略,包括参数高效方法和加速技术。我们分析了 VLA 在仿人机器人、自动驾驶等六个领域的应用。讨论挑战和局限性,聚焦实时推理、多模态动作表示等五个核心领域,从文献中提出潜在解决方案,如模型压缩等。最后,讨论和未来路线图阐述 VLM、VLA 架构和智能体 AI 系统的融合引领机器人技术走向通用人工智能的方向。
参考
[1] Vision-Language-Action Models: Concepts, Progress, Applications and Challenges
#2025,那些已经离开蔚来的人
快离开这个恶心的地方吧
辞去蔚来高级产品经理的工作后,夏夏选择成为了一名陶艺师。她在景德镇一家陶艺工坊待了八个月,每天与泥土为伴,拉坯、修坯、上釉,过程单调却充满疗愈感。她曾花两周时间烧制一组青花茶具,仅因釉色中一抹偶然晕染的冰裂纹。
夏夏觉得泥土是有生命的,相较于职场中需要时刻揣摩的“弦外之音”,她更享受与材料对话的纯粹。
在蔚来时,她负责智能座舱的交互设计,带领团队攻克过多个技术难关,年薪一度突破百万,在杭州全款购置了房产。然而,项目周期的无限压缩、跨部门协作的扯皮、以及“永远在线”的群提示音,让她逐渐失去了对工作的掌控感。前领导曾半开玩笑地提醒她:“职场是场马拉松,但蔚来人都在百米冲刺。”
离职后,这位领导在深夜发来消息:“你离开后,团队又走了三个人,我们是不是都太累了?”
1. “这个行业太快了,快到让人失去方向”
疾病让前蔚来员工小陈重新审视职业选择。2023年,他被诊断出焦虑症,医生建议他减少高强度工作。作为蔚来自动驾驶部门的算法工程师,他曾是团队中最年轻的骨干,但连续三年“996”后,他发现自己的代码开始频繁出错。
更让他心寒的是,当项目因外部政策变动搁浅时,公司选择裁撤整个团队,而非调整方向。小陈的妻子在另一家新能源车企工作,两人决定一起转型。他放弃了价值百万的期权,转行成为了一名新能源汽车自媒体人。
2021年校招进入蔚来的CC,曾是用户运营部门的明星员工。她至今记得蔚来中心里那杯永远免费的特饮,以及用户社群中热烈的互动。但当她开始筹备婚礼时,现实给了她沉重一击:部门要求全员“随叫随到”,即使周末也要处理用户投诉;更让她难以接受的是,一位休完产假的同事被调岗至边缘部门,理由是“家庭负担重,无法适应高强度工作”。CC开始思考:如果未来要平衡家庭与事业,自己是否还能留在这里?
35岁的林工则是被裁员的。他所在的某研发团队在2024年遭遇技术路线调整,整个部门被优化。作为老员工,他拿到了N+1的补偿,但看着入职不到一年的新人拿着更高的薪资,他感到一种荒诞的公平。
2. “停下来,才能听见内心的声音”
夏夏的陶艺之路始于一次云南旅行。在丽江,她偶遇一位陶艺家,对方告诉她:“泥土不会骗人,你付出多少,它就回报多少。”这句话击中了她
2024年春天,她辞去工作,带着积蓄来到景德镇。工坊的师傅是个沉默寡言的手艺人,第一天就让她从揉泥开始学起。“手要稳,心要静”,师傅的教导让她想起在蔚来时,团队为了一个交互细节争论到凌晨三点的场景。现在,她可以花一整天时间调整一个茶壶的把手弧度,直到它完全贴合手掌。
在景德镇的第八个月,夏夏的作品被选入当地陶艺展。她的作品《呼吸》是一组不规则的陶碗,表面布满细小的气孔,象征职场中那些被压抑的“呼吸”。展览开幕当天,她收到了前同事的微信:“看了你的作品,突然觉得我们好像一直在追赶一个不存在的终点。”
3. “让我离开,给我自由”
离开蔚来后,小陈和丈夫在杭州郊外租了一处农舍,改造成民宿。他们保留了老房子的木梁结构,用回收的车上旧物拼接做隔断,取名“慢泊”。小陈在社交媒体上分享改造过程,意外吸引了一批粉丝。有蔚来车主专程来住,只为听她聊聊“逃离大厂”的故事。民宿的收入虽不稳定,但足够覆盖生活开销。小陈说:“以前觉得成功是年薪百万,现在觉得是能随时停下来看一朵花开。”
CC和丈夫在成都开了一家咖啡馆,主打“车友社交空间”。他们将蔚来式的用户运营经验移植到咖啡馆:会员积分系统、主题沙龙、甚至复刻了NIO House的布局。开业三个月,咖啡馆成了当地新能源车友的聚集地。CC发现,自己依然在从事“连接人”的工作,但这次,她不再需要盯着KPI。
林工则选择了更艰难的道路——创业。他和几位前同事成立了一家储能技术公司,专攻家庭储能解决方案。他们将蔚来的电池技术经验转化为民用产品,初期融资困难时,甚至抵押了房产。“在蔚来时,我们总说‘用户企业’,现在我想真正做一家‘用户需要的企业’。”
4. “你可以飞得更远”
2025年初,夏夏在景德镇举办了首次个展。展品中有一件名为《重负》的作品:一个破碎的陶瓷汽车模型,裂缝中生长出青苔。她在展览前言中写道:“我们曾以为人生是赛道,后来发现它是一片原野。”
小陈的民宿成了“职场逃离者”的秘密基地。她发现,很多客人都是背着电脑来的,白天处理工作,晚上在院子里看星星。“他们需要的不是逃离,而是一个可以喘息的角落。”
CC的公司刚获得一笔天使投资,但他的头发已经白了一半。他常对团队说:“在蔚来,我们改变的是出行方式;在这里,我们想改变的是人们对工作的定义。”
2025年的春天,夏夏收到一封邮件。一位蔚来前同事写道:“看到你做的茶具,我突然明白,人生不是单选题。我也在准备离职了,想去做海洋保护志愿者。”
那些离开蔚来的人,或许并未真正离开。
他们只是卸下了在蔚来的特定角色,那角色曾如精致却稍显束缚的华服,承载着责任与期望,却也在一定程度上遮蔽了内心真实的渴望。如今,他们轻轻脱下这层外衣,像挣脱樊笼的飞鸟,在广阔天地间肆意翱翔;似冲破茧房的蝶,于斑斓世界里翩翩起舞。
他们只是换了一种方式,继续与这个世界对话。
祝看到这些文字的你我他:现在安好/未来更好。
#ReinboT
端到端VLA新范式!利用强化学习增强机器人视觉语言操作
视觉-语言-动作 (VLA) 模型通过模仿学习在通用机器人决策任务中展现出巨大潜力。然而,训练数据质量参差不齐往往会限制这些模型的性能。另一方面,离线强化学习 (RL) 擅长从混合质量数据中学习稳健的策略模型。我们提出Reinforced robot GPT (ReinboT),这是一种新颖的端到端 VLA 模型,它融合了 RL 最大化累积奖励的原理。ReinboT 通过预测能够捕捉操作任务细微差别的密集回报,从而更深入地理解数据质量分布。密集回报预测能力使机器人能够生成更稳健的决策行为,以最大化未来收益为目标。大量实验表明,ReinboT 在 CALVIN 混合质量数据集上达到了最佳性能,并在真实世界任务中展现出卓越的小样本学习和分布外泛化能力。
背景介绍
近年来,针对机器人通用xx智能的视觉-语言-动作 (VLA) 模型的研究蓬勃发展。VLA 模型通常基于模仿学习范式,其中预先训练好的视觉-语言模型在下游机器人数据上进行后训练。虽然通过大量的机器人训练数据,VLA 模型的语义泛化能力有所提升,但其在下游任务的操控精度方面仍然存在关键差距。
限制 VLA 模型性能的一个重要原因是训练数据源的质量通常参差不齐,即使它们来自成功的演示。尽管最近的模仿学习方法可以有效地复制演示的分布,但它们难以区分数据质量参差不齐和充分利用混合质量数据。另一方面,离线RL算法旨在利用先前收集的数据,而无需在线收集数据。尽管最初有人尝试将 VLA 与 RL 相结合,但对于视觉语言操作任务中广泛适用的密集奖励的设计,以及将 RL 中的收益最大化概念融入 VLA 模型仍未得到充分探索。
为此,我们提出了ReinboT,这是一种新颖的端到端 VLA 模型,用于实现 RL 的密集回报最大化概念。具体而言,高效且自动地将长视域操作任务轨迹分解为仅包含单个子目标的多个轨迹段,并设计了一种能够捕捉操作任务特征的密集奖励。事实上,复杂的机器人操作任务需要考虑许多因素,例如跟踪目标、降低能耗以及保持灵活稳定的行为。因此,所提出的奖励密集化方法的设计原理正是基于这些考虑,并且该方法仍然广泛应用于各种操作任务。
在 ReinboT 算法设计方面,我们认为强化学习算法中价值函数的准确估计一直是一个棘手的问题,尤其是在 Transformer 架构中。因此,我们利用累积奖励(即 ReturnToGo)作为一种新的模态数据,基于构建的密集奖励来表征数据质量特征。受之前研究的启发,我们对语言命令、图像状态(和本体感觉)、动作和 ReturnToGo 的联合分布建模最大回报序列。这是一个监督范式,它整合了强化学习的目标,即在给定当前条件下预测分布中的最大回报,从而考虑最大化动作的可能性。具体来说,我们利用预期回归使预测回报尽可能接近当前目标和状态下可以实现的最大回报。借助这种能力,ReinboT 可以在推理过程中预测最大回报,从而指导执行更优的行动。
总体而言,核心贡献包括:
- 提出了 ReinboT,这是一种新颖的端到端 VLA 模型,它集成了 RL 回报最大化原则,以增强机器人的操控能力。
- 引入了一种奖励密集化方法,使 ReinboT 能够细粒度地了解数据质量分布,从而实现更稳健的学习。
- 大量实验证明了 ReinboT 的卓越性能,在模拟和实际任务中均显著超越基线。
图 1. 提出的 ReinboT 模型。利用 CLIP对机器人语言指令进行编码,利用 ViT(以及感知器重采样器)对图像状态的原始像素空间进行压缩和编码,并利用 MLP 对机器人本体感觉进行编码。此外,基于 GPT 风格的 Transformer,引入三个预测 token 嵌入([RTG]、[ACTION] 和 [IMAGE]),分别用于预测 ReturnToGo、机器人动作和未来图像状态。ReturnToGo 解码器中的最后一层隐藏特征进一步用于预测机器人动作。ReturnToGo 中的密集奖励包含四个方面:子目标达成、任务进度、行为平滑性和任务完成度。
方法详解
旨在构建一个新颖的端到端 VLA 模型,将最大化密集奖励的原则融入机器人视觉运动控制中,如图 1 所示。首先,在设计密集奖励时考虑了四个主要因素(子目标达成、任务进度、行为平滑性和任务完成度),以捕捉机器人长视域操作任务的本质。然后我们详细阐述了如何构建一个新颖的端到端强化学习 VLA 模型和测试执行流程。最后讨论并分析了所提出的 ReinboT 如何有机地整合强化学习最大化奖励的原则。
奖励稠密化
对于长视域视觉语言操作任务,VLA 模型通常需要在遵循目标的同时,以最小的能量消耗保持鲁棒稳定的行为。因此,我们主要围绕这一原则设计一个广泛适用的密集奖励机制,以捕捉操作任务的本质。直观地,在机器人轨迹中,最小化状态距离的奖励是一种简单有效的方案,可以鼓励机器人直接移动到目标状态。然而,这种奖励仅限于任务仅包含一个目标的情况。对于需要操作具有多个子目标的长视域任务,这种奖励会引导机器人直接移动到最终目标状态,从而导致失败。
因此,首先将长视域操作任务划分为多个子目标序列,并为每个序列设计一个密集奖励。启发式过程会迭代每个演示轨迹中的状态,并确定该状态是否应被视为临界状态。判断基于两个主要约束:关节速度接近于零以及夹持器状态的变化。直观地讲,这发生在机器人达到预抓取姿势或过渡到新任务阶段时,或者在抓取或释放物体时。因此,将临界状态作为子目标是一个自然而合理的选择。
子目标达成:
图像状态和本体感觉都包含丰富的环境感知信息。因此,子目标实现奖励涵盖本体感受跟踪、像素强度、图像视觉质量和图像特征点。
任务进度:
考虑到分为几个子目标序列对整体轨迹的影响是不同的。后面的序列更接近最终的目标状态。子目标序列越接近最终目标状态,任务进展奖励越大。
行为平滑性:
为促进运动轨迹平滑自然,主要考虑抑制机械臂运动的关节速度和加速度以及动作的变化率,从而惩罚过于剧烈僵硬的轨迹运动。
任务完成度:
对于视觉语言操作任务,语言指令被视为与机器人行为相匹配的目标。相匹配则为1,否则为0.
基于这四个主要因素,我们可以构建能够捕捉长视域视觉语言操作任务本质的广义密集奖励函数为。通过利用设计的奖励信号,ReinboT 可以对训练数据的质量分布有更广泛和更深入的理解和识别,从而引导机器人执行更鲁棒和稳定的机器人决策动作。
端到端强化 VLA 模型
通过提出的密集奖励,我们可以获得用于长视界视觉语言操作任务的 ReturnToGo。我们进一步解释如何构建一种新颖的端到端强化 VLA 模型来实现 RL 最大化回报原则。提出的 ReinboT 模型利用 GPT 风格的 Transformer作为骨干网络,因为它可以灵活有效地使用不同类型的模态数据作为输入和输出。 CLIP用于编码语言指令,ViT(以及感知器重采样器)用于压缩和编码图像状态,MLP 用于编码本体感觉。我们引入动作和图像 token 嵌入([ACTION] 和 [IMAGE]),并分别通过动作解码器和图像解码器预测机器人动作和未来图像状态。最重要的是,我们将 ReturnToGo 视为一种新的数据模态,并学习 ReturnToGo 预测 token 嵌入 [RTG]:

通过 ReturnToGo 解码器预测给定语言指令、图像状态和本体感觉的最大回报。ReinboT 模型的损失函数包括 ReturnToGo 损失、手臂动作损失、夹持器动作损失 和未来图像损失:

ReinboT 中的模块化设计使得我们只需进行单次模型推理即可获得机器人动作,推理效率高于之前的模型。这种设计的更大好处是,在推理阶段,我们不需要像之前的模型那样手动设置 ReturnToGo 的初始值。这对于实际部署至关重要,因为它大大减轻了手动调整参数的繁琐,并且实际部署环境在很大程度上无法直接获得奖励。
仿真实验
设置。首先构建一个基于 CALVIN的混合质量数据集,其中包含长期操控任务,以检验所提出的 ReinboT 和基线算法的性能。该数据集包含少量 CALVIN ABC 中带有语言指令的数据(每个任务约 50 条轨迹)和大量不带语言指令的自主操作数据。除了 CALVIN 中人类远程操作在不带语言指令的情况下收集的原始数据(超过 20,000 条轨迹)之外,自主操作数据还包含经过训练的 VLA 行为策略 RoboFlamingo与环境 CALVIN D(超过 10,000 条轨迹)交互产生的故障数据。为了促进数据多样性,在交互过程中,RoboFlamingo 策略模型的动作被添加了不同程度的高斯噪声。我们研究在这些混合质量数据上进行训练,然后用语言指令对少量数据进行微调,最后在 CALVIN D 上测试泛化性能。表 1 显示了链中每个语言指令的成功率和完成任务的平均长度 (AL)。
泛化性能对比。
表1显示,模仿学习范式下的VLA模型仅对原始训练数据分布进行最大似然估计,难以捕捉并充分利用混合质量分布的特征,导致性能不理想。所提出的奖励能够更深入、更详细地表征数据质量分布,从而为 VLA 模型的训练带来更密集的监督信号。ReinboT 可以有效地运用强化学习的理念,利用密集回报最大化来增强长视域视觉语言操作任务。
密集奖励成分的消融。
表2所示,消融实验表明各奖励成分都能帮助模型深入识别数据质量的各个方面,对机器人的泛化性能有显著的影响。
超参数λ和m对性能的影响。我们进一步对ReinboT中引入的λ和m进行消融实验,并在CALVIN混合质量数据上进行训练,并在环境D上进行测试,以探究它们对模型性能的影响(图2)。超参数λ用于在模型对ReturnToGo的预测与其他模态之间进行权衡。预期回归参数m用于控制模型对不同预期水平的敏感度,从而调整模型对ReturnToGo分布的拟合特性。实验结果表明,当λ = 0.001且m = 0.9时,ReinboT的性能最佳。
预测的最大化强化学习回报的性质。
为了分析所提出的RinboGPT模型性能提升的根本原因,我们探索了预测的最大化强化学习回报的性质(图3)。结果表明,随着预期回归参数m的增加,ReturnToGo分布向更大的值偏移。因此,ReinboT能够有效地识别和区分训练数据的质量分布,并尽可能地预测在当前(及历史)状态下能够最大化回报的机器人动作。这意味着机器人在执行某个动作时,会考虑最大化未来一段时间的长期收益,而非仅仅考虑短期的当前(及历史)状态。这种能力可以有效提升ReinboT模型在长期操控任务中的泛化性能。
真实世界实验设置
我们对现实世界的任务进行了评估,以检验所提出的 ReinboT 是否能够在现实场景中执行有效的少样本学习和泛化。具体来说,我们考虑在机械臂 UR5 上拾取和放置杯子、碗和毛绒玩具等物体的任务。收集到的成功轨迹总数约为 530 条(数据分布如图 5 所示),模型首先在这些数据上进行训练。对于少样本学习评估,我们考虑三个物体抓取和放置任务(图 4(a-c))。每个任务仅包含 30 条成功轨迹,模型针对这三个任务进行了微调。对于 OOD 泛化评估,我们考虑包含未见指令、背景、干扰项和被操纵物体的场景(图 4(d-g))。
成功轨迹的ReturnToGo分布。
图 5 展示了现实中成功轨迹的 ReturnToGo 分布。结果表明,即使训练数据全部为成功轨迹,在我们提出的密集奖励指标下,其质量分布仍然不均匀。因此,有必要将 RL 的思想引入 VLA 模型,以深入识别数据分布并指导预测最大化数据质量的动作。
真实机器比较。
现实任务的定量性能比较如图 6 所示。实验结果表明,所提出的 ReinboT 在现实场景中具有出色的小样本学习和 OOD 泛化性能,并且显著优于基线方法。这得益于 ReinboT 能够有效地考虑最大化未来回报。RWR 的表现与 GR-1 相当。这可能是由于 RWR 对训练数据的过度拟合及其对数据重新加权的依赖,这在数据分布不均匀或数据量不足时可能导致优化问题。
结论
我们将 RL 中的最大化回报原则内化到 VLA 框架中,从而增强了机器人的长期操作能力。所提出的 ReinboT 可以预测描绘操作任务重要信息的最大密集回报,从而对数据质量有深入而详细的理解。这种能力使得机器人在采取决策行动时不仅能够考虑当前(和历史)状态,还能考虑未来的密集收益。与基线相比,ReinboT 在模拟和现实世界的视觉语言操作任务中都取得了优异的表现。我们的工作提高了机器人的视觉语言操作能力,有助于实现通用智能。一项有前途的工作是考虑模型和数据的扩展,以应对现实世界中丰富多样的机器人任务。
#ALN-P3
博世提出:自动驾驶中感知、预测和规划的统一语言对齐
- 论文链接:https://arxiv.org/pdf/2505.15158
摘要
本文介绍了ALN-P3:自动驾驶中感知、预测和规划的统一语言对齐。最新的进展探索了将大型语言模型(LLMs)集成到端到端自动驾驶系统中,以提高泛化性和可解释性。然而,大多数现有的方法受限于驾驶性能或者视觉语言推理能力,因此使其难以同时实现这两者。本文提出了ALN-P3,这是一种统一的共蒸馏框架,它引入了“快速”基于视觉的自动驾驶系统和“慢速”语言驱动的推理模块之间的跨模态对齐。ALN-P3结合了三种新的对齐机制:感知对齐(P1A)、预测对齐(P2A)和规划对齐(P3A),它们显式地将视觉tokens与相应的语言输出对齐。所有的对齐模块仅在训练过程中应用,在推理过程中不会产生额外的成本。在四个具有挑战性的基准(nuScenes、Nu-X、TOD3Cap和nuScenes QA)上进行的大量实验表明,ALN-P3显著提高了驾驶决策和语言推理能力,实现了最先进的结果。
主要贡献
本文的主要贡献总结如下:
1)本文提出了ALN-P3,这是一种新的共蒸馏框架,它引入了“慢速”和“快速”系统之间的对齐;
2)ALN-P3结合了三种对齐模块,即感知对齐(P1A)、预测对齐(P2A)和规划对齐(P3A),以显式地对齐每个核心驾驶任务的两个系统之间的视觉和语言表示;
3)ALN-P3是一种仅用于训练的方法,在推理过程中不会产生额外的计算成本,使其高效且适用于自动驾驶系统的实时部署;
4)在四个具有挑战性的基准上进行的大量实验表明,ALN-P3在规划和推理任务中始终优于现有的方法,从而验证了所提出的跨系统共蒸馏策略的有效性。
论文图片和表格
总结
本文引入了ALN-P3,这是一种实现自动驾驶系统中语言模型与感知-预测-规划(P3)栈之间全面对齐的统一框架。通过设计专门的对齐模块(即感知对齐(P1A)、预测对齐(P2A)和规划对齐(P3A)),ALN-P3弥补了空间推理和自然语言生成之间的差距。在规划、驾驶解释、3D密集描述和VQA任务中进行的大量实验表明,ALN-P3在驾驶安全性和多模态推理方面明显优于最先进的基线。
ALN-P3的一个关键优势在于,所有的对齐机制仅在训练过程中应用,而在推理过程中不会引入额外的延迟或者计算开销。这种设计确保了实时性能,同时提高了grounding和一致性。
#SOLVE
港中文MMLab :语言视觉与端到端网络在自动驾驶中的作用SOLVE
- 论文标题:SOLVE: Synergy of Language-Vision and End-to-End Networks for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.16805

核心创新点:
1. 基于SQ-Former的特征级协同架构
- 提出Sequential Q-Former(SQ-Former)视觉编码器,通过多任务感知查询对齐(scene-level静态信息→动态参与者→动态地图线索),实现视觉特征压缩与跨模态对齐。该架构通过collector queries与task-specific queries的串行交互,在3D位置嵌入(Pi)引导下提取场景级语义特征,显著减少传统方法中512个查询至384个查询的计算开销(对比OmniDrive),同时保持特征完整性。
2. 轨迹链式思维(Trajectory Chain-of-Thought, T-CoT)范式
针对VLM自回归生成轨迹的不确定性问题,设计两阶段轨迹优化机制:
- 轨迹选择 :通过聚类导航指令(直行/左转/右转)构建候选轨迹库(k-means聚类36条轨迹),结合MLP历史轨迹预测结果,利用top-k相似度匹配生成kl+1候选轨迹,并通过轨迹适配器(Trajectory Adapter)编码为统一token空间。
- 轨迹细化 :采用链式推理对参考轨迹(含航路点序列W={w1,...,wn})进行逐点优化,通过<point_token>注入文本提示模板,实现基于场景上下文的轨迹参数校正(速度/加速度约束)。
3. 时间解耦的协同预测策略(Temporal Decoupling Synergy)
- 提出异步轨迹初始化机制,通过内存缓冲区存储VLM生成的长期轨迹(超前于E2E模型预测时域),在E2E规划头中引入交叉注意力机制(多规划查询↔collector queries)进行轨迹初始化补偿。该策略在保持E2E实时性(<50ms延迟)的前提下,通过VLM先验知识提升E2E轨迹预测的L2误差降低1.0cm(对比基线方法)。
Human-like Semantic Navigation
- 论文标题:Human-like Semantic Navigation for Autonomous Driving using Knowledge Representation and Large Language Models
- 论文链接:https://arxiv.org/pdf/2505.16498

核心创新点:
1. 基于Answer Set Programming (ASP)的动态知识表示框架
- 提出将非单调逻辑推理(ASP)与自动驾驶导航结合,通过形式化规则编码交通法规及动态环境约束,突破传统依赖预定义地图的局限性。ASP的非单调特性支持实时环境信息更新(如突发改道、路标缺失),实现动态导航规划。
2. 大语言模型(LLM)驱动的自动化知识工程
- 首次验证LLM(如ChatGPT-4o、Grok-3)将自然语言导航指令(如“在第一个路口右转”)自动翻译为结构化ASP规则的可行性,解决传统人工构建逻辑规则的知识工程瓶颈。实验表明,LLM生成的DLV约束在80%以上测试案例中满足语法与语义正确性。
3. 双知识库协同推理架构
设计内在知识库 (Intrinsic KB)与外在知识库 (Extrinsic KB)双层结构:
- Intrinsic KB :手动编码通用交通规则(如环岛优先级、让行原则);
- Extrinsic KB :LLM动态生成任务特定约束(如“绕行施工区域”),融合实时感知数据(路口/环岛检测),实现语义级决策与低级控制解耦。
4. 可解释语义导航框架
- 通过ASP的声明式推理生成可追溯的决策路径(Answer Sets),替代端到端深度学习模型的“黑箱”决策。实验验证该框架在复杂场景(如未标注环岛)中生成符合人类驾驶逻辑的8种可行路径,显著提升动态环境下的导航鲁棒性。
5. 面向SAE L5的语义交互能力
- 支持自然语言指令与环境动态的双向适配,例如当路口变为环岛时,系统可动态调整语义解析(如将“右转”映射为环岛第三出口),突破传统基于坐标/拓扑地图的导航范式,向完全自动化(SAE Level 5)迈出关键一步。
Raw2Drive
- 论文标题:Raw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (in CARLA v2)
- 论文链接:https://arxiv.org/abs/2505.16394

核心创新点:
1. 双流模型基强化学习框架(Dual-stream MBRL)
- 提出首个基于原始传感器输入(Raw Sensor Input)的端到端自动驾驶模型基强化学习框架(Raw2Drive),突破了传统模仿学习(IL)与特权信息依赖的模型基方法(如Think2Drive)的限制。通过双流架构协同训练特权世界模型 (Privileged World Model,基于低维结构化数据)与原始传感器世界模型 (Raw Sensor World Model,基于高维多模态数据),解决了原始传感器数据噪声大、冗余高导致的建模难题。
2. 引导机制(Guidance Mechanism)设计
- Rollout Guidance :在序列生成(rollout)阶段,通过空间-时序对齐损失(Spatial-Temporal Alignment Loss)与抽象状态对齐损失(Abstract-State Alignment Loss),强制原始传感器世界模型与特权世界模型在确定性状态(Deterministic State)与随机状态(Stochastic State)上保持一致性,避免累积误差。
- Head Guidance :利用特权世界模型的奖励头(Reward Head)与连续标志头(Continue Flag Head)作为稳定监督信号,指导原始传感器策略的训练,规避原始传感器数据直接回归奖励函数的不稳定性。
3. 端到端性能突破与效率优化
- 在CARLA v2和Bench2Drive基准测试中,Raw2Drive成为首个基于原始传感器输入的RL端到端方法,显著超越现有IL方法(如UniAD、DriveTrans),在复杂交互场景(如泊车驶出、紧急制动)中展现更强鲁棒性。
- 训练效率提升:仅需64块H800 GPU天完成训练(复用Think2Drive预训练模型后可缩减至40 GPU天),远低于工业级IL方法的成本(如UniAD约30 GPU天但仅解决3-4个极端案例)。
4. 理论贡献
- 揭示了RL在自动驾驶中的潜力,通过世界模型对齐机制缓解了IL中的因果混淆(Causal Confusion)与分布偏移(Distribution Shift)问题,并验证了MBRL在高维原始传感器输入下的可行性,为行业提供了与现有感知-规划解耦范式正交的技术路径。
DriveMoE
- 论文标题:DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.16278
- 项目主页:https://thinklab-sjtu.github.io/DriveMoE/

核心创新点:
1. 场景专业化视觉MoE(Scene-Specialized Vision MoE)
- 动态多视角选择机制 :提出基于驾驶场景的视觉专家混合架构,通过可学习的视觉路由模块(Vision Router)动态筛选关键摄像头视图(如前视及上下文相关的侧/后视图),减少冗余视觉token处理,提升计算效率。
- 上下文感知的注意力策略 :模仿人类驾驶选择性关注机制,结合路线规划器提供的目标航点(goal waypoint)与前视图像嵌入(front-view embedding),生成相机视图的概率分布(Softmax输出),实现轻量级路由决策。
2. 技能专业化动作MoE(Skill-Specialized Action MoE)
- 行为驱动的流匹配规划架构 :在流匹配轨迹预测框架(flow-matching transformer)中引入动作MoE层,通过非共享专家模块(non-shared experts)分别优化特定驾驶技能(如换道、避障、紧急制动)。
- 稀疏激活与技能标签监督 :采用Top-K稀疏激活机制(如Top-1/Top-2专家),结合基于场景标注的技能标签(如Bench2Drive定义的5类技能),通过交叉熵损失(Action Router Loss)引导专家专业化分工,避免多任务平均效应。
3. 基于VLA的端到端框架扩展
- Drive-π0基础模型改进 :将源自xx智能领域的π0 Vision-Language-Action(VLA)模型扩展至自动驾驶领域,构建统一的视觉感知-语义理解-动作规划框架,支持连续动作分布建模。
- 双阶段训练策略 :第一阶段依赖专家标签监督路由模块训练;第二阶段过渡到完全自适应路由,增强模型对实际推理中路由误差的鲁棒性。
4. 状态迁移优化与评估验证
- 流匹配轨迹损失(Flow-Matching Loss, LFM) :联合优化动作MoE模块,确保轨迹预测精度。
- 负载均衡正则化(Load-Balancing Regularization) :防止专家模块利用率失衡,缓解“专家崩溃”(expert collapse)问题。
- Bench2Drive基准SOTA性能 :在闭环驾驶任务中,DriveMoE相较基线Drive-π0提升驾驶评分(DS)22.8%及成功率(SR)62.1%,验证了MoE架构在复杂场景(如激进转向、应急避障)中的鲁棒性。
Generative AI
- 论文标题:Generative AI for Autonomous Driving: A Review
- 论文链接:https://arxiv.org/abs/2505.15863

核心创新点:
1. 多模态感知与预测的统一建模
- 提出端到端多模态融合框架 (如MP3、ST-P3),整合LiDAR、摄像头、雷达等异构传感器数据,通过Transformer架构实现联合地图构建、目标检测与轨迹预测。
- 引入时空特征学习机制 (Spatio-Temporal Feature Learning),解决动态场景中多智能体交互的复杂性,提升预测一致性。
2. 生成式模型驱动的动态场景生成与规划
- 基于扩散模型(Diffusion Probabilistic Models )开发可控轨迹生成方法 (如MotionDiffuser、GenAD),支持多模态轨迹假设与不确定性量化(Aleatoric/Epi-stemic Uncertainty)。
- 提出语言驱动的场景生成范式 (Language-Driven Scenario Generation),通过大语言模型(LLM)实现语义级场景约束(如自然语言指令到交通规则映射)。
3. 混合式决策与规划框架
- 融合模型预测控制 (MPC)与生成式AI,构建物理感知的扩散规划模型 (Physics-Informed Diffusion Planning),结合控制屏障函数(CBF)与李雅普诺夫函数(Lyapunov Stability)保障安全性。
- 提出风险感知应急规划 (Risk-Aware Contingency Planning, RACP),集成多模态预测结果与博弈论优化,应对混合交通中的交互不确定性。
4. 高效实时生成技术
- 采用稀疏表示与低秩近似 (Sparse Scene Representation、Low-Rank Factorization),优化扩散模型计算效率(如SparseDrive、OccWorld),满足车载硬件实时性需求。
- 基于流匹配 (Conditional Flow Matching)实现百倍速预测加速(如FlowNav),平衡生成质量与推理速度。
5. 安全与可解释性增强
- 提出基于可达性分析的数据驱动安全过滤器 (Data-Driven Safety Filters),结合哈密尔顿-雅可比(Hamilton-Jacobi Reachability)理论,形式化验证生成轨迹的安全边界。
- 开发机械可解释性框架 (Mechanistic Interpretability),解析生成模型决策逻辑,支持故障归因与规则对齐。
6. 大规模仿真与基准测试
- 构建生成式闭环仿真平台 (如DriveArena、NAVSIM),支持长尾场景(Long-tail Scenarios)的自动化合成与验证,解决真实数据分布偏差问题。
- 提出多样性感知评估指标 (Diversity-Aware Metrics),量化生成场景的真实性与泛化能力。
#DriveMoE
性能暴涨60%!上交提出,基于MoE的端到端自动驾驶SOTA VLA模型~
端到端自动驾驶(E2E-AD)需要有效处理多视角的感官数据,并且能够稳健地应对各种复杂和多样化的驾驶场景,特别是罕见的操控动作。最近,Mixture-of-Experts(MoE)架构在大型语言模型(LLMs)中的成功表明,参数的专业化能够实现强大的可扩展性。在这项工作中,我们提出了DriveMoE,这是一种基于MoE的新型E2E-AD框架,具有场景专业化视觉MoE和技能专业化动作MoE。DriveMoE建立在我们的π0 Vision-Language-Action(VLA)基准之上(最初来自xx智能领域),称为Drive-π0。具体来说,我们在Drive-π0中添加了视觉MoE,通过训练一个路由选择器根据驾驶情境动态选择相关的视觉。这种设计模仿了人类驾驶的认知过程,在这一过程中,驾驶员会选择性关注关键的视觉线索,而不是详尽地处理所有视觉信息。此外,我们通过训练另一个路由选择器来激活针对不同驾驶行为的专业化专家模块,从而添加动作MoE。通过明确的行为专业化,DriveMoE能够在不遭受现有模型模式平均问题的情况下处理各种场景。在Bench2Drive闭环评估实验中,DriveMoE取得了最先进的(SOTA)性能,证明了在自动驾驶任务中结合视觉和动作MoE的有效性。我们将发布DriveMoE和Drive-π0的代码和模型。
- 论文链接:https://thinklab-sjtu.github.io/DriveMoE/
本文简介
现代自动驾驶在端到端范式下取得了显著进展,该范式直接将原始传感器输入映射为规划结果。这种范式带来了许多优势,如减少了工程复杂性、减轻了误差传播和全局目标优化。尽管在各种开环自驾车基准测试中取得了令人鼓舞的结果,现有的端到端模型在闭环设置中仍未取得令人满意的表现。在闭环设置中,训练好的驾驶模型可以很容易遇到分布外情况,因此需要更强的泛化能力和推理能力。

最近由于其强泛化性和跨域迁移能力,视觉语言模型(VLM)和视觉语言动作模型(VLA)受到了广泛关注。为了增强泛化性和上下文推理能力,最近的工作尝试将VLA引入自动驾驶领域。然而,现有的VLA方法仍然面临两个主要局限性。
首先,现有的VLA视觉处理器引入了信息冗余和显著的计算开销。如图1上部所示,有两种不同的多视角输入处理策略。第一种策略称为普通视觉处理器,它在每个时间步不加区分地处理所有可用的相机视图,导致了大量的计算负担和冗余的视觉表示,从而限制了效率和可扩展性。第二种策略称为基于查询的视觉处理器,它使用学习的查询(例如Q-former模块)来提取由语义上下文引导的一组紧凑的视觉token。然而,这些学习的查询通常会导致精确的几何和位置信息的丢失,并且需要大量的额外预训练工作。
其次,如图1下半部分所示,当前的VLA框架通常采用单一的统一策略网络设计,用于处理整个驾驶行为谱系。这种统一的方法倾向于使模型训练偏向更频繁出现的场景,从而不足以应对罕见但关键的驾驶操作,例如紧急制动或急转弯。这种缺乏明确的专业化的做法限制了它们在动态变化和高度依赖上下文的驾驶情境中的有效性。
解决这两个关键局限性需要架构上的创新,能够同时实现上下文感知的动态多视角选择和明确的细粒度技能专业化。与此同时,混合专家(MoE)架构通过将模型容量划分为多个专家模块,使得大型语言模型(LLMs)显著进步,在不增加计算需求的情况下扩展到更大的模型规模。尽管它们已被证明是成功的,但将MoE原则扩展到视觉和动作领域,特别是在自动驾驶领域,仍 largely 探索不足。目前的端到端驾驶模型继续主要依赖于统一的架构,而没有明确的动态专家选择或专业化的适应。这一差距促使探索利用基于MoE的专业化来改进自动驾驶中的视觉感知和决策组件。
为了解决这些挑战,我们提出了DriveMoE,这是一种基于我们提出的Drive-π0的新框架,是一个视觉语言动作(VLA)基础模型,从xx智能模型π0扩展而来。DriveMoE引入了Scene-Specialized Vision MoE和Skill-Specialized Action MoE,专门设计用于端到端的自动驾驶场景。DriveMoE动态选择上下文相关的相机视图,并激活针对特定技能的专家进行专业化规划。Vision MoE使用一个学习的路由器动态优先选择与当前驾驶情境一致的相机视图,并集成投影层,将这些选定的视图融合成一个连贯的视觉表示。这种方法模仿了人类注意力策略,仅允许高效处理关键的视觉输入。同时,Action MoE利用另一种路由机制在flow-matching规划架构内激活不同的专家,每个专家专注于处理特定的行为,如车道跟随、避障或激进操作。通过在感知和规划模块中引入基于上下文的动态专家选择,DriveMoE确保高效的资源利用和强大的专业化,显著改善了对罕见、复杂和长尾驾驶行为的处理。
本文的主要贡献如下:
- 扩展了最初为xx智能设计的VLA基础模型π0,进入自动驾驶领域,开发了Drive-π0作为视觉感知、上下文理解和动作规划的统一框架。
- 认识到xx智能与自动驾驶之间的差异,我们提出了DriveMoE,这是第一个将混合专家(MoE)整合到感知和决策中的框架,以解决多视角处理和多样化驾驶行为中的低效率问题。
- 设计了一个Scene-specialized Vision MoE用于动态相机视图选择,以及一个Skill-specialized Action MoE用于行为特定规划,解决了多视角冗余和技能专业化的挑战。
- 展示了DriveMoE在Bench2Drive闭环模拟基准测试中达到了最先进的(SOTA)性能,显著提高了对罕见驾驶行为的鲁棒性。
相关工作回顾
端到端自动驾驶中的VLM/VLA
大型语言模型(LLM)的发展显著加速了用于自动驾驶的视觉语言模型(VLM)的发展。这些模型凭借强大的泛化能力、开放集推理能力和可扩展性,已成为端到端驾驶任务的重要范式。著名例子包括DriveGPT-4、LMDrive和DriveLM[14],它们将感知和规划任务表述为离散标记的序列,从而提高了可解释性并促进了跨领域的知识迁移。然而,基于标记的建模本质上限制了表示连续控制命令和轨迹的能力,这对于需要精细控制的实际自动驾驶系统至关重要。为了解决这一局限性,xx智能社区提出了视觉语言动作(VLA)模型,该模型将动作表示为连续变量而非离散标记。通过序列预测和全局优化建模连续动作分布的方法如OpenVLA、Diffusion Policy和π0展示了强大的性能。尽管如此,这些方法通常依赖于特定任务的策略或指令条件模型,在复杂驾驶环境中遇到的行为长尾分布上难以泛化。
大语言模型中的混合专家(MoE)
稀疏混合专家(MoE)架构已成为扩展大型语言模型(LLM)的主流方法。通过用专家模块替换Transformer中的标准前馈层,像DeepSeekMoE和Mixtral-8x7B这样的模型在保持推理效率的同时,通过条件计算改进了任务专业化和表示能力。在机器人领域,MoE架构也被用来解决任务异质性和长尾数据分布的问题。例如MENTOR用MoE层替换MLP主干,以实现模块化专家之间的梯度路由,帮助缓解多任务学习中的梯度干扰。尽管在语言建模和机器人策略学习中取得了令人鼓舞的结果,但在端到端自动驾驶中使用MoE仍处于探索阶段。
算法详解

预备知识:Drive-π0 基线
我们首先建立一个强大的基线 Drive-π0,它基于最近提出的 π0 视觉语言动作(Vision-Language-Action, VLA)框架,并将其扩展到端到端自动驾驶领域。如图 2 所示,Drive-π0 的输入包括:
(i) 来自车载多视觉传感器的一系列环绕视图图像;
(ii) 一个固定的文本提示(例如,“请预测未来轨迹”);
(iii) 当前车辆状态(例如,速度、偏航率和过去轨迹)。
网络设计遵循 π0 框架,采用预训练的 Paligemma VLM作为主干,并使用基于流匹配的动作模块生成规划的未来轨迹。
动机:从 Drive-π0 到 DriveMoE
以 Drive-π0 为基线,我们识别出两个主要挑战:
(i) 采用视觉语言模型(VLM)处理时空环绕视图视频 token 对计算资源提出了重大挑战;
(ii) 即使有类似数据进行训练,罕见和困难场景下的驾驶性能仍然不足。这可能与不同行为之间的干扰效应有关,正如 π0 论文中提到的那样。
受 Mixture-of-Experts (MoE) 在 VLM 领域最新成功的启发,我们引入了 DriveMoE,它在 Drive-π0 的基础上添加了两个新的 MoE 模块,以解决上述挑战:
(i) 我们提出了一种 Scene-Specialized Vision MoE,根据当前驾驶情境动态选择最相关的视觉视图,从而有效减少冗余的视觉 token;
(ii) 我们在流匹配变压器中整合了一个 Skill-Specialized Action MoE,以生成更精确的未来轨迹分布,适用于不同的驾驶技能。
场景专业化视觉 MoE
典型的视觉语言动作模型(VLAs)通常一次只处理单个或少量图像,而自动驾驶必须处理多视角、多时间步的视觉输入。将所有视觉帧连接到一个 transformer 中会导致视觉 token 瓶颈——序列长度爆炸式增长,显著减慢训练和推理速度,并阻碍收敛。
现有的工作中采用了普通的视觉处理器直接处理所有视觉 token,而基于查询的压缩模块(例如 Q-Former)减少了 token 数量但牺牲了空间结构,通常将图像视为“补丁包”,没有精细的空间对应关系。
在这项工作中,我们寻求一种简单高效的方法,在不丢失对驾驶至关重要的丰富空间上下文的情况下减少 token 负载。受人类驾驶员自然优先考虑特定视觉信息的启发——基于驾驶情境——我们提出了一种 Scene-Specialized Vision Mixture-of-Experts (Vision MoE) 模块。
具体来说,如图 3 所示,我们的 Vision MoE 根据当前驾驶情况和路线规划器提供的未来目标点,动态选择最相关的视觉视图子集。与不切实际且昂贵的 token 级标注不同,视觉标注简单且成本低,允许有效集成人类先验知识。这种动态注意力策略显著减少了每个时间步处理的视觉 token 数量,极大提高了计算效率和决策准确性。

形式上,我们将时间 时视觉输入 的图像定义为 ,其中 表示可用的 个视觉视图。特别地,时间步 的前视图图像表示为 。我们引入了一个轻量级的视觉路由器模块 ,其输入为前视图嵌入 和未来目标点 ,并计算所有视觉视图上的概率分布 :
其中每个元素 表示时间步 时视觉视图 的选择概率。值得注意的是,路由发生在昂贵的主干计算之前,因此未被选中的视图可以完全跳过,以节省计算资源。因此,我们获得 VLM 的输入:
我们进一步将学习的位置嵌入(PE)唯一地分配给每个视觉视图,以保留不同视觉视图之间的空间和位置关系。视图选择的标签是通过手动设计的滤波器基于未来轨迹、边界框和地图注释的,详见附录 A。有了注释的二进制视觉视图选择标签 ,视觉路由器使用交叉熵损失进行训练:
该损失明确鼓励模型主动选择与决策相关的信息性视觉视图。 表示视觉路由器的损失权重。
技能专业化动作 MoE

人类驾驶员能够流畅地在不同的驾驶技能之间切换——例如在高速公路上平稳巡航、小心并入车流、迅速超车或紧急制动应对突发障碍。每种驾驶技能都关联着不同的行为模式和轨迹特征。尽管原始的 π0 流匹配解码器已经能够生成多样化的轨迹,但使用单一模型不可避免地会平均这些多样化的行为,导致模型无法准确生成罕见但安全关键的操作。
为了解决这些问题,受人类直觉的启发——即驾驶员会根据当前情境自然选择适当的驾驶技能,我们提出了一种基于原始流匹配轨迹变压器的 Skill-Specialized Action MoE 架构。核心思想是通过在解码器中用包含多个技能专用专家的 Mixture-of-Experts (MoE) 层替换每个密集前馈网络(FFN),来分解策略的行为表示。
形式上,考虑一个 Transformer 解码层 ,其输入隐藏状态 。我们在这一层中引入 个共享专家模型 和 个非共享专家模型 ,每个专家都是具有独立参数的 FFN。每个专家处理输入以产生输出 。同时,一个动作路由器 根据相同输入计算一组非共享路由 logit 。然后,我们通过 softmax 将这些 logit 转换为专家的概率分布:
更新后的特征结合各个专家的加权输出:
在实践中,我们使用稀疏激活机制仅选择排名最高的几个专家进行计算(仅激活 Top-1 或 Top-2 专家),从而减少计算量,防止专家之间的相互干扰,并增强专家技能的专业化程度。这种稀疏路由机制与我们在 Vision MoE 模块中使用的机制一致,确保每个专家清晰地专注于特定的行为模式。
为了明确引导模型朝着有意义的技能专业化方向发展——模仿结构化和直观的人类定义技能类别——我们利用驾驶技能标签 ,基于场景进行注释,并通过交叉熵损失训练技能路由器:
此外,我们使用流匹配轨迹损失 优化整个 Action MoE 模块,以确保准确的轨迹预测,并引入负载均衡正则化损失 以保持专家利用率的平衡,防止专家崩溃:
其中 表示流匹配策略的损失权重, 表示动作路由器的损失权重。我们在动作路由器中引入噪声,增加随机性并鼓励探索,有效缓解专家崩溃的风险。
两阶段训练:从教师强制到自适应训练
DriveMoE 加载了 Paligemma VLM 的预训练权重,并通过两阶段训练程序在自动驾驶场景中对其进行微调。第一阶段,视觉和动作 MoE 仅选择真实专家,同时联合训练路由器,这显著稳定了训练过程。
第二阶段,我们过渡到基于视觉和动作 MoE 路由器输出选择专家,不再依赖专家的真实标注。这增强了模型对潜在错误或路由器不准确性的鲁棒性,从而提高整体模型在现实推理条件下的泛化能力。
实验结果分析
数据集、基准与指标
我们使用 CARLA 模拟器(版本 0.9.15.1)进行闭环驾驶性能评估,并采用最新的公开闭环评估基准 Bench2Drive ,该基准包括 220 条短路线,每条路线包含一个具有挑战性的特殊情况,用于分析不同的驾驶能力。它提供了官方训练集,我们在其中使用基础集(1000 个片段,950 个训练,50 个测试/验证),以确保与其他所有基线的公平比较。
我们使用 Bench2Drive 的官方 220 条路线和官方指标进行评估。驾驶分数 (DS) 定义为路径完成率和违规分数的乘积,衡量任务完成情况和规则遵守情况。成功率 (SR) 衡量在规定时间内成功完成路线且不违反任何交通规则的百分比。效率量化车辆相对于周围交通的速度,鼓励在不过度激进的情况下取得进展。舒适性反映驾驶轨迹的平滑程度。同时,Bench2Drive 还评估了多个关键维度的驾驶能力,包括合并、超车、紧急制动、让行和交通标志等任务。
实现细节
视觉路由标注: 我们在 Bench2Drive数据集中引入了额外的视觉视图重要性标注。这种标注方法既经济又简单,但通过高效而有效地利用多视觉输入显著提升了模型性能。关于视觉标注规则的详细信息请参见附录 A。
动作路由标注: 我们保持技能定义与 Bench2Drive设置一致。共有五种驾驶技能:合并、超车、紧急制动、让行和交通标志。
Drive-π0: 我们使用连续两个前视图像作为输入,以有效估计周围交通代理的速度。此外,输入状态结合了当前和历史信息,包括位置、速度、加速度和航向角,使模型能够准确预测未来 10 个路径点。
DriveMoE: 我们使用连续两个前视图像加上一个由视觉路由器动态选择的视觉视图作为输入。连续前视图像主要用于捕捉时间变化以建模周围交通代理的速度,而动态视图则通过选择视觉路由器中的 Top-1 视图来增强空间感知。输入状态表示与 π0 框架保持一致,包括当前和历史的位置、速度、加速度和航向角信息。在动作模型中,我们采用 1 个共享专家和 6 个非共享专家。在训练和推理过程中,动作路由器选择的 Top-3 专家被用来生成最终的轨迹预测,包含 10 个未来路径点。我们采用两阶段后训练策略:
训练阶段 1: 我们训练模型 10 个 epoch。视觉语言模型 (VLM) 组件从 Paligemma-3b-pt-224 [43] 的预训练权重初始化。VLA 和 Action MoE 专家分别使用两个优化器进行优化,配置如下:学习率为 ,并启用 warmup 步骤。梯度裁剪应用于最大梯度范数为 1.0。使用梯度累积模拟批量大小为 1024。为了有效平衡不同损失组件,我们将视觉路由器损失权重 设为 0.05,动作路由器损失权重 设为 0.03,流匹配损失权重 设为 1。
训练阶段 2: 我们继续训练 5 个额外的 epoch,从第 1 阶段结束时的检查点初始化。在此阶段,输入的视觉视图和动作专家根据路由器的输出动态选择。我们将动作路由器损失权重 设为 0.025,强调轨迹学习。其他超参数与第 1 阶段保持一致。
PID 控制器: 所有方法使用相同的 PID 控制器进行公平比较。PID 控制器模块将当前车辆速度和模型预测的未来轨迹(包含 10 个路径点)作为输入,并输出油门、刹车和转向角命令。具体而言,对于转向控制,PID 增益为:, , ;对于速度控制,PID 增益为:, , 。期望车辆速度由预测轨迹的第 7 个路径点计算得出,而转向角由第 10 个路径点确定。此配置确保车辆控制稳定且响应迅速,符合模型的轨迹预测。
与SOTA对比

如表 2 所示,我们提出的方法在 Bench2Drive 闭环基准的驾驶分数和成功率方面达到了最先进的 (SOTA) 性能。具体来说,与基线 Drive-π0 相比,我们的方法将驾驶分数提高了 22.8%,将成功率提高了 62.1%。在开环指标上,我们的方法达到了最低的 L2 误差。我们观察到,基于扩散策略的轨迹预测相比传统方法显著降低了 L2 误差。然而,正如 AD-MLP、TransFuser++和 Bench2Drive 等先前研究所强调的那样,开环指标主要作为模型收敛的指示器,而闭环指标更能可靠地评估真实驾驶性能。此外,在多维能力评估中,如表 1 所示,我们的方法在五个关键能力和整体平均值上均达到最先进的结果。

消融实验
Drive-π0 与 DriveMoE 的对比: 我们进行了消融研究,以评估 DriveMoE 框架内 Vision MoE 和 Action MoE 组件的独立贡献。如表 3 所示,移除 Vision MoE 或 Action MoE 中的任何一个都会导致驾驶分数和成功率明显下降,表明每个组件对整体性能都有重要意义。与基线 Drive-π0 相比,我们的完整 DriveMoE 模型显著提升了驾驶性能,突出了两种 MoE 模块的互补有效性。

Vision MoE: 如表 5 所示,我们研究了摄像机视图选择和监督信号在 Vision MoE 模块中的贡献。基线(①,Drive-π0)使用两个连续的前视图像(Ifront t + Ifront t−1)主要用于估计周围代理的速度。添加第三个固定视图(如后视图(②)、前左视图(③)或前右视图(④))提供了额外的空间上下文,带来了适度的改进。通过引入无监督的动态选择视图(⑤),驾驶分数和成功率显著提高。最终,加入显式监督信号(⑥,DriveMoE)进一步增强了驾驶分数和成功率,证明了我们的 Vision MoE 模块在利用动态和受监督的多视角感知方面的有效性。

Action MoE: 我们研究了 Action MoE 中非共享专家数量的不同配置,如表 4 所示。具体而言,配置①对应于 Bench2Drive定义的原始五种技能,而②引入了一个额外的专家用于经典的 ParkingExits 场景,从而提高了性能。为了进一步分析专家专业化的效应,我们进行了额外实验:③增加了针对配置②中识别出的几个挑战性场景的专家,而④为 Bench2Drive 中的 44 个场景中的每一个分配了一个独特的专家。我们发现,过度增加专家数量(③,④)由于专家之间的负载不平衡,会对性能产生负面影响。因此,适当平衡专业化专家的数量对于最优驾驶性能至关重要。

这些结果显示了我们的路由器模块在实际应用中的高精度表现,进一步验证了 DriveMoE 在复杂驾驶环境下的鲁棒性和适应性。
结论
本文提出的 Drive-π0 改进了 DriveMoE,这是一种新颖的端到端自动驾驶框架,将混合专家(Mixture-of-Experts, MoE)架构整合进视觉和动作组件中。DriveMoE 通过场景专业化视觉 MoE 动态选择相关摄像头视图,有效解决了现有 VLA 模型中存在的问题,并通过技能专业化动作 MoE 激活针对特定驾驶行为的专业化专家模块,从而提升了模型性能。在 Bench2Drive 基准上的广泛评估表明,DriveMoE 在自动驾驶任务中取得了最先进的性能,显著提高了计算效率并增强了对罕见、安全关键驾驶场景的鲁棒性。将 MoE 引入端到端自动驾驶领域为未来的研究开辟了有希望的方向。我们将公开发布我们的代码和模型,以促进该领域的持续探索和进步。
#TransDiffuser
NAVSIM新SOTA!自动驾驶中基于解耦多模态表示的端到端轨迹生成~
- 论文链接:https://arxiv.org/pdf/2505.09315
摘要
本文介绍了自动驾驶中基于解耦多模态表示的端到端轨迹生成。近年来,扩散模型展示了其在从视觉生成到语言建模的不同领域的潜力。将其能力转移到现代自动驾驶系统也已成为一个有前景的方向。本文提出了TransDiffuser,这是一种基于编码器-解码器的端到端自动驾驶生成轨迹规划模型。其中,模型的输入为前视相机图像、激光雷达与当前车辆的运动信息,这些多模态信息作为去噪解码器的多模态条件输入。为了进一步缓解在生成候选轨迹时模式崩溃困境,本文在训练过程中引入了一种简单而有效的多模态表示去相关优化机制,提高模型对于多模态表示信息的进一步利用。
实验结果表明,TransDiffuser在NAVSIM数据集上实现了94.85的PDMS,并且不需要任何基于锚的先验轨迹。TransDiffuser和团队今年3月提出的TrajHF技术方案位于HuggingFace NAVSIM Leaderboard的前两名,进一步体现了理想汽车在自动驾驶技术上的实力。
主要贡献
本文的贡献总结如下:
1)本文提出了一种编码器-解码器生成轨迹模型TransDiffuser。它首先编码场景感知和自车的运动,然后利用编码信息作为去噪解码器的条件输入来解码多模态多样化的可行轨迹;
2)为了进一步提高生成轨迹的多样性,本文在训练过程中引入了一种计算高效的多模态表示去相关机制;
3)本文模型在NAVSIM基准上实现了最新的PDM得分94.85,而没有任何显式的引导,例如基于锚的轨迹或者预定义的词表。
相关工作
现有方法可以基本分为自回归(AR)、评分(Scoring)与扩散生成(Diffusion)三类。以UniAD、Transfuser为代表,传统基于自回归的模型往往只预测一条规划轨迹。以VADv2、英伟达Hydra-MDP系列为代表,基于Scoring的方案往往先采样或者选出多条候选轨迹,然后结合不同的指标或者策略,从中选出一条最优轨迹。以DiffusionDrive、GoalFlow为代表,基于扩散生成的方案,往往将环境信息与自车状态进行编码,利用基于扩散策略的生成式模型来生成多个模式的候选轨迹,最后选取其中最优的轨迹。
技术方案
冻结的Transfuser模块对当前自车的图像与激光雷达采集的点云进行特征融合与编码,同时对自车的运动信息通过简单的MLP架构进行编码。所编码的多模态信息会通过去噪解码器(Denoising Decoder)完成多模态特征进一步融合,解码最终轨迹。
对于解码器模块,Transfuser模块用于编码图像与激光雷达采集的点云信息,同时通过较为简单的MLP来编码自车的运动状态。在训练部分,使用去噪扩散概率模型作为优化框架,主要训练Denoising Decoder部分,通过特定方程实现状态的逐步去噪。需要注意的是,所提出的方案并不依赖轨迹词表或者锚点信息作为先验。
图1 | 所提出的TransDiffuser架构
相比于先前的工作,本项工作强调生成规划轨迹这一任务中潜在的模式坍塌(Mode collapse)挑战。这项挑战最初在DiffusionDrive这篇工作中被提出,具体是指生成式轨迹模型给出的多条候选轨迹的多样性受限,容易收敛到相似轨迹路线。
为了缓解这一问题,训练时通过约束多模态表示矩阵的相关矩阵的非对角相关系数趋近于零,降低不同模态维度间的冗余信息,从而拓展潜在表征空间的利用率。该机制在训练阶段作为附加优化目标,由权重因子平衡主要损失。具体而言,这里的多模态表示作为最终动作解码器的输入,通过提高此处的信息量,鼓励动作解码器生成更具多样性的轨迹,提高在连续动作空间中采样可行动作的效果。在图2的子图(d)中,团队对表示矩阵的奇异值谱进行可视化,可以看出优化后的多模态表示空间得到了进一步的利用。
图2 | 多模态表示去相关过程图示
实验结果
实验使用用于闭环评估的非反应式NAVSIM数据集,评价指标包含预测驾驶员模型分数(PDMS)。
表格2 | 通过闭环指标评估在Navtest上的性能
另外,团队参考DiffusionDrive这项工作提出的多样性指标(Diversity)进行评估,从实验结果也可以体现所提出的优化策略在提高生成多模式候选轨迹的多样性方面的有效性。
表格3 | 消融和灵敏度研究的实验结果
同时,可视化分析也表明了所提出的方案在尽可能保证安全性的同时,选取较为激进但可行的候选轨迹。
图3 | Transfuser和所提出框架的具有代表性示例的可视化结果
总结与未来工作
本项工作是团队3月的TrajHF模型的延伸工作,进一步体现了生成式端到端轨迹规划模型的性能上限。未来团队会继续聚焦于结合强化学习技术和“视觉-语言-行为”模型架构,以更好地与人类驾驶员指令或者风格对齐来生成多条规划轨迹。
相关文章:
51c自动驾驶~合集55
我自己的原文哦~ https://blog.51cto.com/whaosoft/13935858 #Challenger 端到端碰撞率暴增!清华&吉利,框架:低成本自动生成复杂对抗性驾驶场景~ 自动驾驶系统在对抗性场景(Adversarial Scenarios)中的可靠性是安全落…...

【前端基础】Promise 详解
文章目录 什么是 Promise?为什么要使用 Promise?创建 Promise消费 Promise (使用 Promise)1. .then(onFulfilled, onRejected)2. .catch(onRejected)3. .finally(onFinally) Promise 链 (Promise Chaining)Promise 的静态方法1. Promise.resolve(value)2…...
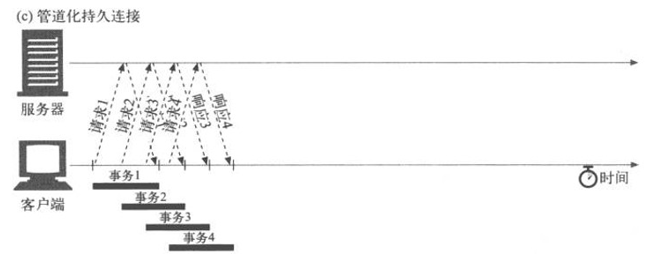
高性能管线式HTTP请求
高性能管线式HTTP请求:原理、实现与实践 目录 高性能管线式HTTP请求:原理、实现与实践 1. HTTP管线化的原理与优势 1.1 HTTP管线化的基本概念 关键特性: 1.2 管线化的优势 1.3 管线化的挑战 2. 高性能管线式HTTP请求的实现方案 2.1 技术选型与工具 2.2 Java实现:…...

c/c++的opencv膨胀
使用 OpenCV (C) 进行图像膨胀操作详解 图像膨胀 (Dilation) 是形态学图像处理中的另一种基本操作,与腐蚀操作相对应。它通常用于填充图像中的小孔洞、连接断开的物体部分、以及加粗二值图像中的物体。本文将详细介绍膨胀的原理,并演示如何使用 C 和 Op…...

react native搭建项目
React Native 项目搭建指南 React Native 是一个使用 JavaScript 和 React 构建跨平台移动应用的框架。以下是搭建 React Native 项目的详细步骤: 1. 环境准备 安装 Node.js 下载并安装 Node.js (推荐 LTS 版本) 安装 Java Development Kit (JDK) 对于 Androi…...
【CSS】九宫格布局
CSS Grid布局(推荐) 实现代码: <!doctype html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0"…...

Python用Transformer、Prophet、RNN、LSTM、SARIMAX时间序列预测分析用电量、销售、交通事故数据
原文链接: tecdat.cn/?p42219 在数据驱动决策的时代,时间序列预测作为揭示数据时序规律的核心技术,已成为各行业解决预测需求的关键工具。从能源消耗趋势分析到公共安全事件预测,不同领域的数据特征对预测模型的适应性提出了差异…...

java基础(面向对象进阶高级)泛型(API一)
认识泛型 泛型就等于一个标签(比如男厕所和女厕) 泛型类 只能加字符串: 把别人写好的东西,自己封装。 泛型接口 泛型方法、泛型通配符、上下限 怎么解决下面的问题? API object类 toString: equals: objects类 包装类 为什么上面的Integer爆红…...

学习心得(17--18)Flask表单
一. 认识表单:定义表单类 password2中末端的EqualTo(password)是将密码2与密码1进行验证,看是否相同 二.使用表单: 运行 如果遇到这个报错,就在该页面去添加 下面是举例: 这就是在前端的展示效…...

AI测试和敏捷测试有什么联系与区别?
AI测试与敏捷测试作为软件质量保障领域的两种重要方法,既有紧密联系也存在显著区别。以下是两者的联系与区别分析: 一、联系 共同目标:提升测试效率与质量 敏捷测试强调通过快速迭代、持续反馈和团队协作确保交付价值,而AI测试通…...

微信小程序进阶第2篇__事件类型_冒泡_非冒泡
在小程序中, 事件分为两种类型: 冒泡事件, 当一个组件上的事件被触发后,该事件会向父节点传递非冒泡事件, 当一个组件上的事件被触发后, 该事件不会向父节点传递。 一 冒泡事件 tap, touchst…...
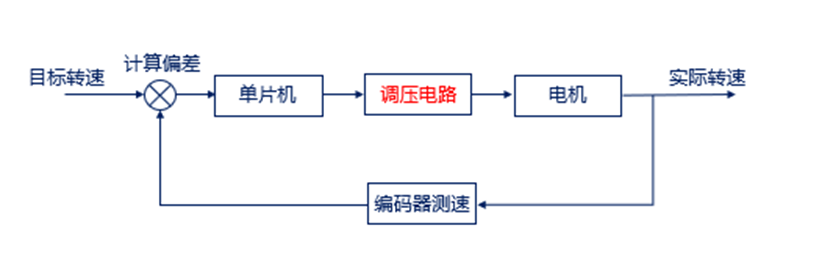
电机控制学习笔记
文章目录 前言一、电机二、编码器三、开环控制和闭环控制总结 前言 学习了解电机控制技术的一些原理和使用的方法。 一、电机 直流有刷电机 操作简单 使用H桥驱动直流有刷电机 直流有刷电机驱动板 电压检测 电流检测以及温度检测 直流无刷电机 使用方波或者正弦波进行换向…...

什么是前端工程化?它有什么意义
前端工程化是指通过工具、流程和规范,将前端开发从手工化、碎片化的模式转变为系统化、自动化和标准化的生产过程。其核心目标是 提升开发效率、保障代码质量、增强项目可维护性,并适应现代复杂 Web 应用的需求。 一、前端工程化的核心内容 1. 模块化开发 代码模块化:使用 …...
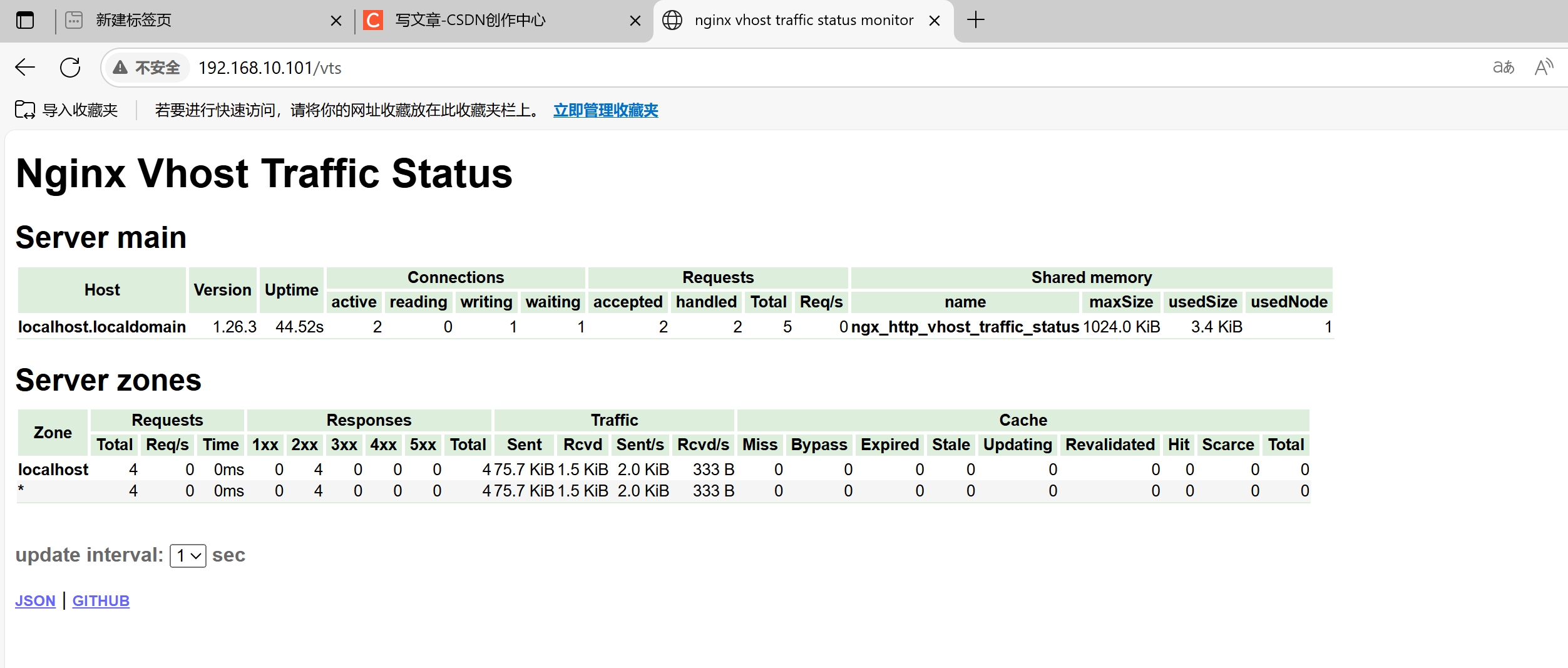
企业网站架构部署与优化-Nginx性能调优与深度监控
目录 #1.1Nginx性能调优 1.1.1更改进程数与连接数 1.1.2静态缓存功能设置 1.1.3设置连接超时 1.1.4日志切割 1.1.5配置网页压缩 #2.1nginx的深度监控 2.1.1GoAccess简介 2.1.2nginx vts简介 1.1Nginx性能调优 1.1.1更改进程数与连接数 (1)进程数 进程数…...

行列式的线性性质(仅限于单一行的加法拆分)
当然可以,以下是经过排版优化后的内容,保持了原始内容不变,仅调整了格式以提升可读性: 行列式的线性性质(加法拆分) 这个性质说的是:如果行列式的某一行(或某一列)的所有…...
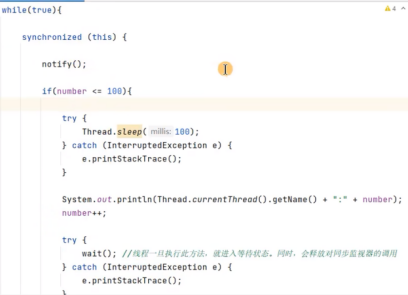
JAVA基础编程练习题--50道
一:循环结构 1.1 for循环 水鲜花数 (1)题目 (2)难点 如何获取三位数的个位数 如何计算一个数的立方 判断两数值是否相等 (3)代码 最大公约数 (1)题目 (2&…...

leetcode 93. Restore IP Addresses
题目描述 93. Restore IP Addresses 代码 回溯法 class Solution {vector<string> res; public:vector<string> restoreIpAddresses(string s) {string IP;int part 0;backtracking(s,0,IP,part);return res;}void backtracking(const string &s,int start…...

【东枫科技】基于Docker,Nodejs,GitSite构建一个KB站点
Docker 安装桌面版本,安装Node镜像 运行node镜像 需求 和外部的某个文件夹地址可以绑定端口可以绑定,方便server的访问 docker run -itd --name node-test -v C:/Users/fs/Documents/GitHub:/home/node -p 3000:3000 node进入终端 docker exec -it …...
pytest+allure+allure-pytest 报告输出遇到的问题汇总
文章目录 前言问题一:module allure has no attribute severity_level问题二:ERROR:file or directory not found: ‐vs问题三:生成的 html 报告是空的,明明有测试用例执行完成,但报告没有显示数据 前言 pytestallure…...
:Python常用内置模块及功能)
Python基础语法(十四):Python常用内置模块及功能
Python标准库提供了丰富的内置模块,无需额外安装即可使用。以下是按功能分类的常用内置模块及其核心功能: 一、文件与操作系统交互 1. os 模块 功能:操作系统接口常用方法:os.getcwd() # 获取当前工作目录 os.listdir() …...
【Opencv+Yolo】_Day1图像基本处理
目录 一、计算机中的视觉: 二、Opencv基本操作: 图片基础处理: 视频基本处理: 图像截取(截取,合并,只保留一个元素) 图像填充 数值计算 图像融合 阈值判断 图像平滑 图像腐…...

MySQL各种日志类型介绍
概述 MySQL 提供了多种日志类型,用于记录数据库的运行状态、操作历史和错误信息等,这些日志对于故障排查、性能优化、安全审计和数据恢复等具有重要作用。以下是 MySQL 中常见的日志类型及其详细介绍资料已经分类整理好:https://pan.quark.c…...

15.2【基础项目】使用 TypeScript 实现密码显示与隐藏功能
在现代 Web 应用中,允许用户切换密码的可见性不仅提升了用户体验,也让表单填写更便捷。使用 TypeScript 来实现这个功能,不仅具备强类型检查优势,还能提升代码的可维护性。 ✨ 我们要实现的功能 在这篇文章中,我们将…...

Django压缩包形式下载文件
通过web将minio上的文件以压缩包-文件夹-文件的形式下载到本地 import os from bx_mes import settings from io import BytesIO import zipfile from django.http import StreamingHttpResponse class FileRemote(GenericAPIView):def post(self,request):# 压缩包名folder_n…...

晚期NSCLC临床试验终点与分析策略
1. 案例背景 1.1 研究设计 1.1.1 适应症与分组 晚期非小细胞肺癌一线治疗,干预组为新型免疫检查点抑制剂联合化疗,对照组为化疗单药,随机双盲安慰剂对照III期试验。 1.1.2 目标框架 基于FDA或ICH指南,终点定义和分析策略影响试验科学性及监管审评。 2. 终点定义 2.1 主要…...
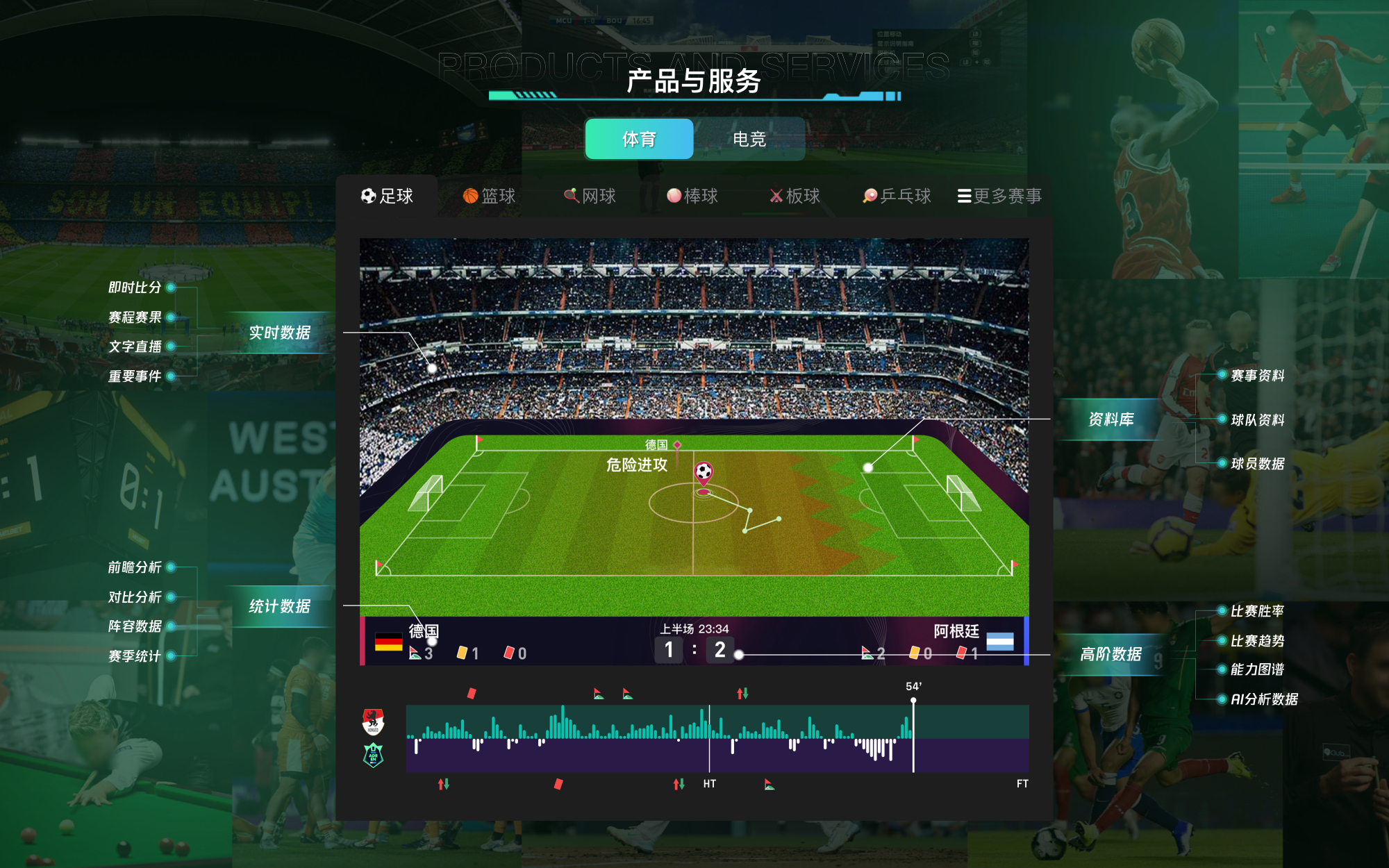
从比分滚动到数据革命:体育数据如何重构我们的观赛体验?
当凌晨三点的欧冠决赛与闹钟冲突时,当世界杯小组赛因时差难以全程跟进时,当代体育迷早已不再依赖电视直播 —— 打开手机里的比分网,实时跳动的体育大数据正构建着全新的观赛宇宙。这些曾经被视为 "辅助工具" 的平台,如…...

华为网路设备学习-23(路由器OSPF-LSA及特殊详解 二)
OSPF动态路由协议要求: 1.必须有一个骨干区域(Area 0)。有且仅有一个,而且连续不可分割。 2.所有非骨干区域(Area 1-n)必须和骨干区域(Area 0)直接相连,且所有区域之间…...
VPet虚拟桌宠,一款桌宠软件,支持各种互动投喂等. 开源免费并且支持创意工坊
📌 大家好,我是智界工具库,每天分享好用实用且智能的开源项目,以及在JAVA语言开发中遇到的问题,如果本篇文章对您有所帮助,请帮我点个小赞小收藏小关注吧,谢谢喲!😘 工具…...
新书速览|ASP.NET MVC高效构建Web应用
《ASP.NET MVC高效构建Web应用》 本书内容 《ASP.NET MVC高效构建Web应用》以目前流行的ASP.NET MVC 5、HTML和Razor为主线,全面系统地介绍ASP.NET MVC Web应用开发的方法,配套提供实例源码、PPT课件与作者一对一QQ答疑服务。 《ASP.NET MVC高效构建Web…...
MySQL 9.3 超详细下载安装教程(Windows版)附图文说明
MySQL 9.3 超详细下载安装教程(Windows版)附图文说明 💡 本文适用于Windows 10/11系统,包含完整的安装流程、环境配置和疑难解答。建议收藏备用! 一、下载MySQL 1. 访问官网 进入MySQL官方下载页面:http…...