WebSphere Application Server(WAS)8.5.5教程第十四讲:JPA
一、JPA
以下是对 JPA(Java Persistence API) 的深入详解,适用于具备一定 Java EE / Jakarta EE 背景的开发者,尤其是对数据持久化机制感兴趣的人员。
1、什么是 JPA?
Java Persistence API(JPA) 是 Java EE / Jakarta EE 标准中的一种 ORM(对象关系映射) 规范,它定义了一组用于管理 Java 对象与关系数据库之间映射关系的接口。
JPA 本身是一个规范,它不提供实现。常见的 JPA 实现包括:
-
Hibernate(最流行,也是 JPA 的参考实现)
-
EclipseLink(前身是 Oracle 的 TopLink)
-
OpenJPA(Apache 项目)
2、核心概念
1. 实体类(Entity)
-
使用
@Entity注解标识,是 JPA 管理的 POJO。 -
每个实体类对应数据库中的一张表。
@Entity
@Table(name = "users")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@Column(name = "username", nullable = false, unique = true)private String username;@Column(name = "email")private String email;// getters and setters
}
2. 主键(@Id, @GeneratedValue)
-
@Id:标注实体类的主键字段。 -
@GeneratedValue:指定主键的生成策略(如自增、序列等)。
主键生成策略包括:
-
AUTO: 自动选择策略(由 JPA 提供者决定) -
IDENTITY: 数据库自增 -
SEQUENCE: 使用数据库序列(Oracle、PostgreSQL等) -
TABLE: 使用表记录主键值(适用于无序列的数据库)
3. 实体管理器(EntityManager)
用于管理实体生命周期,包括:
-
新增(
persist()) -
查询(
find()、createQuery()) -
更新(
merge()) -
删除(
remove())
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();User user = new User();
user.setUsername("admin");
em.persist(user); // 新增em.getTransaction().commit();
em.close();
4. 查询语言(JPQL / Criteria API)
JPQL(Java Persistence Query Language)
类似 SQL,但面向的是实体类和属性,而不是表和字段。
List<User> users = em.createQuery("SELECT u FROM User u WHERE u.username = :name", User.class).setParameter("name", "admin").getResultList();
Criteria API
以面向对象的方式构造查询,适合动态条件构建。
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<User> query = cb.createQuery(User.class);
Root<User> root = query.from(User.class);
query.select(root).where(cb.equal(root.get("username"), "admin"));List<User> users = em.createQuery(query).getResultList();
5. 映射关系
一对一
@OneToOne
@JoinColumn(name = "profile_id")
private UserProfile profile;
一对多 / 多对一
@OneToMany(mappedBy = "user")
private List<Order> orders;@ManyToOne
@JoinColumn(name = "user_id")
private User user;
多对多
@ManyToMany
@JoinTable(name = "user_roles",joinColumns = @JoinColumn(name = "user_id"),inverseJoinColumns = @JoinColumn(name = "role_id"))
private List<Role> roles;
3、生命周期与状态转换
实体对象有以下几种状态:
| 状态 | 说明 |
|---|---|
| New | 新建对象,尚未与数据库绑定 |
| Managed | 与数据库中的一条记录关联 |
| Detached | 曾经被管理,现在被 EntityManager 分离 |
| Removed | 被标记为删除状态,事务提交后会被删除 |
4、事务管理(与 WAS 等容器的集成)
-
在 WAS 或 Spring 容器中,JPA 通常与事务管理器集成,配合
@Transactional注解使用。 -
在 Java EE 中,通过
@PersistenceContext注入EntityManager,自动绑定事务上下文。
@PersistenceContext
private EntityManager em;@Transactional
public void createUser(User user) {em.persist(user);
}
5、JPA 的优缺点
优点:
-
屏蔽数据库差异(可移植性高)
-
面向对象设计更自然,代码结构清晰
-
适合中大型应用的数据持久化层
缺点:
-
性能开销高于 JDBC(尤其在极限性能需求下)
-
学习曲线相对较高,特别是复杂关联映射和懒加载问题
-
与底层数据库调优结合不紧密
6、在企业级系统(如 BAW/WAS)中的应用场景
-
配合 EJB 或 Spring 服务层进行持久化操作
-
实现业务对象和数据库映射,提高业务逻辑的抽象度
-
利用 JPA 实现可扩展、维护性强的业务系统数据访问层
二、例子
下面是在 IBM BAW(Business Automation Workflow) 中使用 JPA(Java Persistence API)的实际应用,尤其是结合 Java 集成服务(Java Integration Service) 的使用场景,包括:
-
BAW 中使用 JPA 的典型场景
-
实践:创建基于 JPA 的 Java 集成服务
-
项目结构与配置详解
-
示例代码
-
事务管理与注意事项
1、BAW 中使用 JPA 的典型场景
在 IBM BAW 中,你可能会通过 Java 集成服务访问数据库以实现以下需求:
-
将流程变量保存为数据库记录(如表单数据、审批记录)
-
从数据库读取外部业务数据作为决策依据
-
持久化非流程类数据,如日志记录、审计信息、业务统计
如果你希望使用 ORM 的方式优雅地操作数据库,而不是 JDBC,那么就可以集成 JPA。
2、实践:使用 Java 集成服务调用 JPA
假设场景:
流程审批结束后,将审批结果(如 流程ID、审批人、审批意见、时间戳)持久化存储到业务数据库的 APPROVAL_LOG 表中。
3、工程结构与配置(外部项目)
你需要在 Process Designer 中的 Java 集成服务中引用一个外部构建的 JAR 包,该 JAR 是使用 Maven 或 Gradle 构建的 JPA 项目:
src/main/java
├── com.example.baw.jpa
│ ├── ApprovalLog.java # 实体类
│ ├── ApprovalLogService.java # 业务类
│ └── JpaUtil.java # 实用工具类(EntityManager 工厂)
resources
└── META-INF/persistence.xml # JPA 配置
4、关键代码说明
1. 实体类(ApprovalLog.java)
@Entity
@Table(name = "APPROVAL_LOG")
public class ApprovalLog {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String processId;private String approver;private String comment;@Temporal(TemporalType.TIMESTAMP)private Date timestamp;// getters & setters
}
2. persistence.xml(位于 META-INF)
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"version="2.1"><persistence-unit name="baw-approval-unit"><class>com.example.baw.jpa.ApprovalLog</class><properties><property name="javax.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/><property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/bawdb"/><property name="javax.persistence.jdbc.user" value="bawuser"/><property name="javax.persistence.jdbc.password" value="bawpass"/><property name="hibernate.dialect" value="org.hibernate.dialect.MySQL8Dialect"/><property name="hibernate.show_sql" value="true"/></properties></persistence-unit>
</persistence>
3. EntityManager 工具类(JpaUtil.java)
public class JpaUtil {private static final EntityManagerFactory emf =Persistence.createEntityManagerFactory("baw-approval-unit");public static EntityManager getEntityManager() {return emf.createEntityManager();}
}
4. 服务类(ApprovalLogService.java)
public class ApprovalLogService {public void saveApprovalLog(String processId, String approver, String comment) {EntityManager em = JpaUtil.getEntityManager();try {em.getTransaction().begin();ApprovalLog log = new ApprovalLog();log.setProcessId(processId);log.setApprover(approver);log.setComment(comment);log.setTimestamp(new Date());em.persist(log);em.getTransaction().commit();} catch (Exception e) {em.getTransaction().rollback();throw new RuntimeException("Failed to save approval log", e);} finally {em.close();}}
}
5、在 BAW 中集成使用
步骤:
-
使用 Maven 打包为 JAR:
mvn clean install -
将生成的
baw-jpa-approval.jar添加到 BAW 的 Process Designer 的 Java 集成服务 的类路径中 -
在 Java 集成服务中调用:
ApprovalLogService service = new ApprovalLogService();
service.saveApprovalLog(tw.local.processId,tw.local.currentUser,tw.local.approvalComment
);
将流程变量映射到调用参数,实现数据落库。
6、事务管理与注意事项
1. 事务必须在 Java 代码中开启/提交
因为 Java 集成服务并不自动管理事务,所以你必须显式调用 begin() 和 commit()。
2. 数据源配置
你可以通过以下两种方式指定数据源:
-
在
persistence.xml中配置 JDBC 连接信息(如上所示) -
使用 BAW / WAS 中配置的 JNDI 数据源(推荐生产使用)
<property name="javax.persistence.nonJtaDataSource" value="jdbc/YourDataSource"/>
并在 WAS 中配置该 JNDI 数据源。
7、小结
| 项目 | 说明 |
|---|---|
| 实体类定义 | @Entity 注解类映射数据库表 |
| JPA 配置位置 | META-INF/persistence.xml |
| 数据源推荐 | 使用 JNDI 引用 WAS 中配置的数据源 |
| 调用方式 | Java 集成服务中直接 new 调用 |
| 事务控制 | 代码中显式开启/提交事务 |
三、示例:部署到 BAW 的 Process Server
将使用 JPA 实现的持久化逻辑部署到 IBM BAW Process Server,一般通过打包为 JAR 并让 Java 集成服务 或 自定义服务调用。下面是一个完整部署过程的详细讲解:
1、目标
将一个使用 JPA 的 Java 模块(如 ApprovalLogService)部署到 BAW 流程服务中,并能在 Java 集成服务中调用。
2、部署结构总览
你需要准备以下几个部分:
-
JAR 包(含实体类、JPA 工具类、服务类)
-
数据源配置(WAS 控制台中配置 JNDI 数据源)
-
JPA 配置文件(
META-INF/persistence.xml) -
Java 集成服务(在 Process Designer 中编写,调用你的服务类)
-
流程变量映射与测试
3、步骤详解
1. 创建并打包 JAR 文件
推荐使用 Maven:
mvn clean package
确保 target/your-module.jar 中包含:
-
实体类(
@Entity) -
persistence.xml -
所有依赖类(如
ApprovalLogService.java、JpaUtil.java)
如果使用 Hibernate,请确认将其依赖(hibernate-core 等)也打包进来(可选用 shaded jar 或部署额外依赖)。
2. 上传 JAR 到 BAW 运行环境
你可以通过以下几种方式部署 JAR:
方法一:WAS 共享库方式(推荐)
-
打开 WebSphere Application Server 控制台
-
进入:环境 > 共享库
-
创建新的共享库,例如
baw-jpa-lib-
指定
Classpath为你的 JAR 包路径,例如:/opt/IBM/Jars/baw-jpa-approval.jar
-
-
进入
应用程序服务器 > server1 > Java 和进程管理 > 类装入器-
将刚创建的共享库添加为
共享库引用
-
-
编辑类装入器设置:
-
选择“类装入器”
-
类型建议选择:服务器级别(如已有项,点击进入即可)
-
-
找到“共享库引用(Shared Library References)”
-
点击“新建”,绑定你刚刚创建的
JPA-Library共享库 -
保存并同步配置
-
重启服务器(server1)
方法二:直接打包进 Process App(不推荐)
你也可以在 Process Designer 中通过 Manage Toolkit Dependencies → Add External JAR 来导入 JAR。
在流程设计中调用
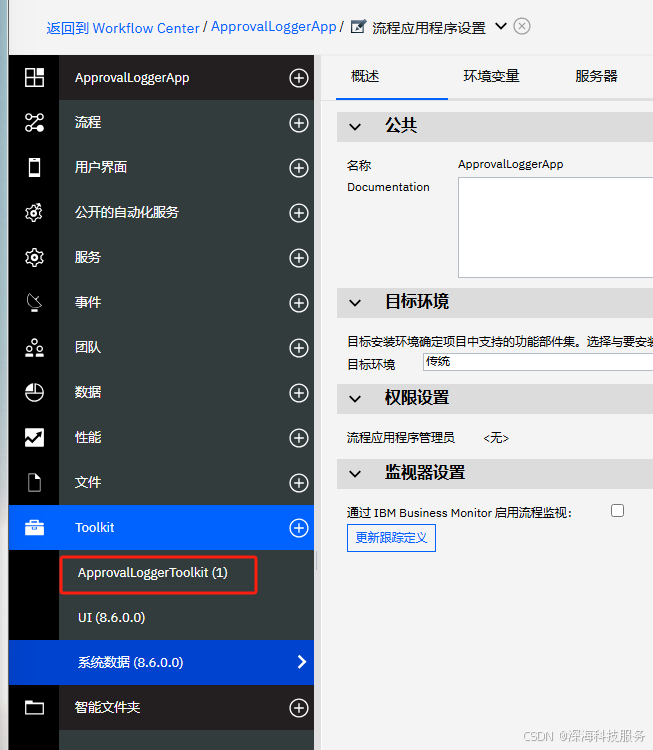
步骤一:创建一个新的 Toolkit(如果尚未创建)
-
打开 IBM Process Designer。
-
在“工具包”视图中点击“新建”按钮。
-
填写 Toolkit 名称,例如:
CustomJavaLibToolkit -
勾选你想支持的依赖类型(如集成服务、业务对象等),点击“完成”。
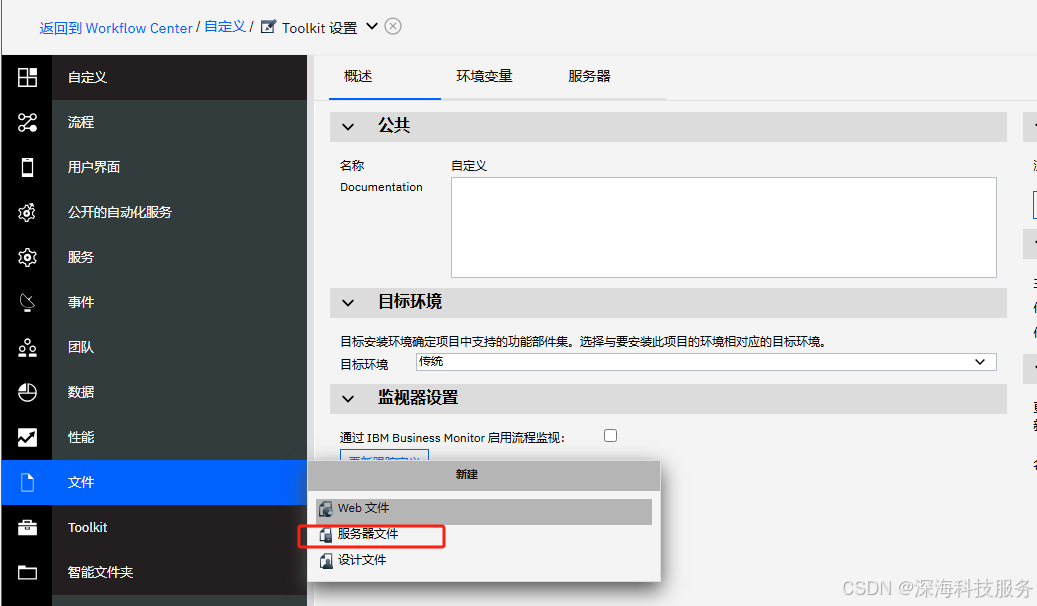
步骤二:导入 JAR 到服务器文件(Server File)
-
打开你刚创建的 Toolkit。
-
在左侧导航栏选择:
实现 (Implementation)>文件 (Files)。 -
点击“新建” > 选择“服务器文件 (Server File)”
-
上传你的 JAR 文件(例如
my-jpa-lib.jar) -
上传成功后,保存并发布(Snapshot)Toolkit。
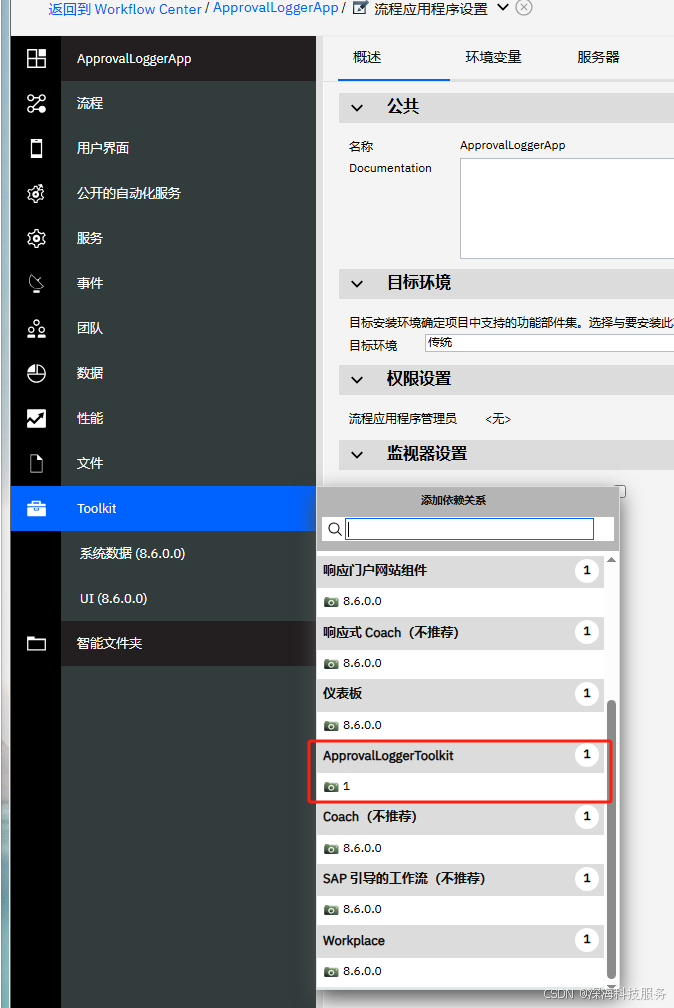
步骤三:在你的 Process App 中引用这个 Toolkit
-
打开目标流程应用(Process App)。
-
在“依赖项”中添加你刚刚创建的
CustomJavaLibToolkit。 -
保存并同步。
步骤四:在 Java 集成服务中调用 JAR 中的类
-
新建或打开一个 Java 集成服务。
-
在
Java 代码区域中,你就可以直接导入并使用 JAR 中的类了:
import com.example.util.MyHelper;MyHelper h = new MyHelper();
h.doSomething();
注意事项:
| 项目 | 说明 |
|---|---|
| 类可见性 | 上传的 JAR 会添加到 classpath,Java 服务中可直接调用 |
| 不能用于 BPD 脚本任务 | BPD 的脚本任务只能运行 JavaScript,无法引用 JAR |
| 避免类冲突 | 确保上传的 JAR 不与 BAW 内置库冲突(如 slf4j、commons) |
| JAR 尽量瘦身 | 保持 JAR 小巧、只放你自定义的逻辑类或 DAO 等 |
示例使用场景
比如你要在审批节点中记录一条操作日志到数据库:
ApprovalLogger logger = new ApprovalLogger();
logger.log("User123", "审批通过", "2025-05-18");
其中 ApprovalLogger 类已打包在你上传的 my-baw-utils.jar 中。
3. 配置 JNDI 数据源(推荐)
若你在 persistence.xml 中使用的是:
<property name="javax.persistence.nonJtaDataSource" value="jdbc/bawDS"/>
那你需要在 WAS 控制台中创建名为 jdbc/bawDS 的数据源:
-
资源 > JDBC > 数据源
-
点击新建,填写:
-
JNDI 名称:
jdbc/bawDS -
选择合适的 JDBC 提供程序(如 MySQL 或 Oracle)
-
配置数据库连接信息、驱动、测试连接
-
若使用硬编码的
jdbc:mysql://...方式,可在persistence.xml中直接提供连接参数,但 不推荐用于生产。
4. 使用 Java 集成服务调用
在 Process Designer 中:
-
创建 Java Integration Service
-
在 Java 代码中导入服务类并调用:
import com.example.baw.jpa.ApprovalLogService;ApprovalLogService service = new ApprovalLogService();
service.saveApprovalLog(tw.local.processId,tw.local.approver,tw.local.comment
);
Java 服务中访问的类必须能在类加载器中加载到 —— 所以共享库配置必须生效。
5. 流程变量映射与测试
确保在流程模型中设置了以下变量,并绑定到 Java 服务的输入:
| 变量名 | 类型 |
|---|---|
| processId | String |
| approver | String |
| comment | String |
通过 Web Process Designer 运行流程,流程结束后,在数据库中应能看到持久化的记录。
4、调试与问题排查
| 问题 | 原因 |
|---|---|
ClassNotFoundException | JAR 未添加到共享库或类加载器不正确 |
NoPersistenceUnitException | persistence.xml 配置路径或名称不正确 |
| 无法连接数据库 | 数据源 JNDI 错误或未启用 |
| Hibernate 抛出 dialect 不支持错误 | 缺少 Hibernate 配置或使用了错误版本 |
javax.persistence.TransactionRequiredException | 未正确开启事务 |
5、小结
| 项目 | 操作 |
|---|---|
| JAR 部署 | 使用 WAS 的共享库 |
| 数据库连接 | 使用 JNDI 数据源 jdbc/xxx |
| 流程中调用服务 | Java 集成服务调用你编写的 JPA 服务类 |
| 类加载 | 类必须加载到正确的类加载器 |
相关文章:
WebSphere Application Server(WAS)8.5.5教程第十四讲:JPA
一、JPA 以下是对 JPA(Java Persistence API) 的深入详解,适用于具备一定 Java EE / Jakarta EE 背景的开发者,尤其是对数据持久化机制感兴趣的人员。 1、什么是 JPA? Java Persistence API(JPA…...
Linux系统调用深度剖析
Linux系统调用深度剖析与实践案例 目录 Linux系统调用深度剖析与实践案例 一、Linux系统调用概述 二、进程管理相关系统调用 1. fork():进程克隆与多任务处理 2. exec系列:程序加载与替换 3. wait/waitpid:进程状态同步 三、文件操作相关系统调用 1. 文件描述符操作…...

动态规划-918.环形子数组的最大和-力扣(LeetCode)
一、题目解析 听着有点复杂,这里一图流。 将环形问题转化为线性问题。 二、算法原理 1.状态表示 2.状态转移方程 详细可以移步另一篇博客,53. 最大子数组和 - 力扣(LeetCode) 3.初始化 由于计算中需要用到f[i-1]和g[i-1]的值&…...
规范与要求)
Docker 镜像标签(Tag)规范与要求
Docker 镜像标签(Tag)规范与要求 背景 目前主流云厂商,如阿里云、百度云和腾讯云,均提供租户使用的镜像仓库服务。 各个厂商要求可能不太一样,比如华为:https://doc.hcs.huawei.com/zh-cn/usermanual/swr/swr_faq_0017.html 样…...

STM32:Modbus通信协议核心解析:关键通信技术
知识点1【 Modbus通信】 1、Modbus的概述 Modbus是OSI模型第七层的应用层报文传输协议 协议:说明有组包和解包的过程 2、通信机制 Modelbus是一个请求/应答协议 通信机制:主机轮询,从机应答的机制。每个从设备有唯一的地址,主…...
线程封装与互斥
目录 线程互斥 进程线程间的互斥相关背景概念 互斥量mutex 互斥量的接口 初始化互斥量有两种方法: 销毁互斥量 互斥量加锁和解锁 改进售票系统 互斥量实现原理探究 互斥量的封装 线程互斥 进程线程间的互斥相关背景概念 临界资源:多线程执行流共…...

鸿蒙OSUniApp 开发实时天气查询应用 —— 鸿蒙生态下的跨端实践#三方框架 #Uniapp
使用 UniApp 开发实时天气查询应用 —— 鸿蒙生态下的跨端实践 在移动互联网时代,天气应用几乎是每个人手机中的"标配"。无论是出行、旅游还是日常生活,实时获取天气信息都极为重要。本文将以"实时天气查询应用"为例,详…...

第十一天 5G切片技术在车联网中的应用
前言 在自动驾驶汽车每天产生4TB数据的时代,传统的移动网络已难以满足车联网的海量连接需求。中国移动2023年实测数据显示,某智能网联汽车示范区在传统5G网络下,紧急制动指令的传输延迟高达65ms,而5G网络切片技术将这个数值降低到…...
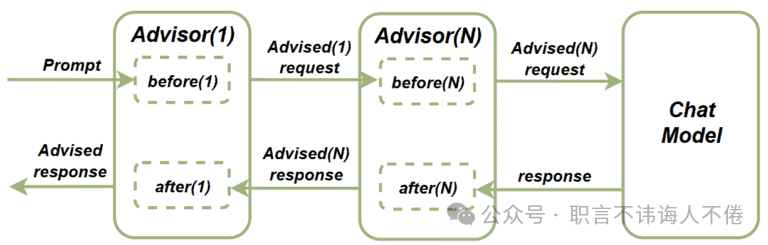
Spring AI 系列之一个很棒的 Spring AI 功能——Advisors
1. 概述 由AI驱动的应用程序已成为我们的现实。我们正在广泛地实现各种RAG应用程序、提示API,并利用大型语言模型(LLM)创建项目。借助 Spring AI,我们可以更快速地完成这些任务。 在本文中,我们将介绍一个非常有价值…...
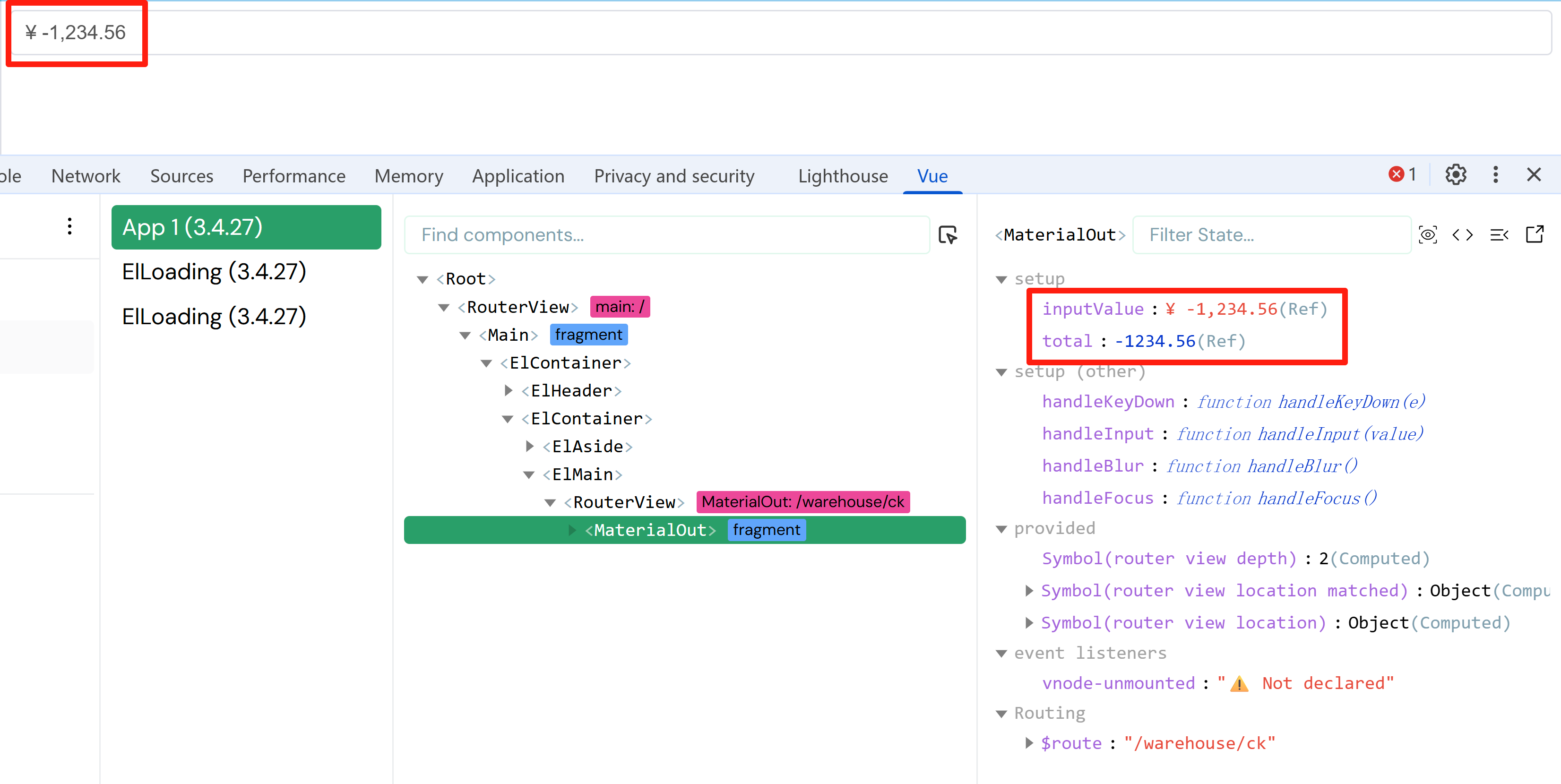
Vue3 + TypeScript + el-input 实现人民币金额的输入和显示
输入人民币金额的参数要求: 输入要求: 通过键盘,只允许输入负号、小数点、数字、退格键、删除键、方向左键、方向右键、Home键、End键、Tab键;负号只能在开头;只保留第一个小数点;替换全角输入的小数点&a…...
2.1 C++之条件语句
学习目标: 理解程序的分支逻辑(根据不同条件执行不同代码)。掌握 if-else 和 switch 语句的用法。能编写简单的条件判断程序(如成绩评级、游戏选项等)。 1 条件语句的基本概念 什么是条件语句? 程序在执…...

ZYNQ实战:可编程差分晶振Si570的配置与动态频率切换
为什么需要可编程差分晶振? 在现代FPGA和嵌入式系统中,高速串行通信(如GTP/GTX收发器)对参考时钟的精度和灵活性要求极高。例如,1G以太网需要125MHz时钟,SATA协议需120MHz,而DisplayPort则需135MHz。传统固定频率晶振无法满足多协议动态切换需求,而Si570凭借其10MHz~8…...

Linux `ls` 命令深度解析与高阶应用指南
Linux `ls` 命令深度解析与高阶应用指南 一、核心功能解析1. 基本作用2. 与类似命令对比二、选项系统详解1. 常用基础选项2. 进阶筛选选项三、高阶应用技巧1. 组合过滤查询2. 格式化输出控制3. 元数据深度分析四、企业级应用场景1. 存储空间监控2. 安全审计3. 自动化运维五、特…...
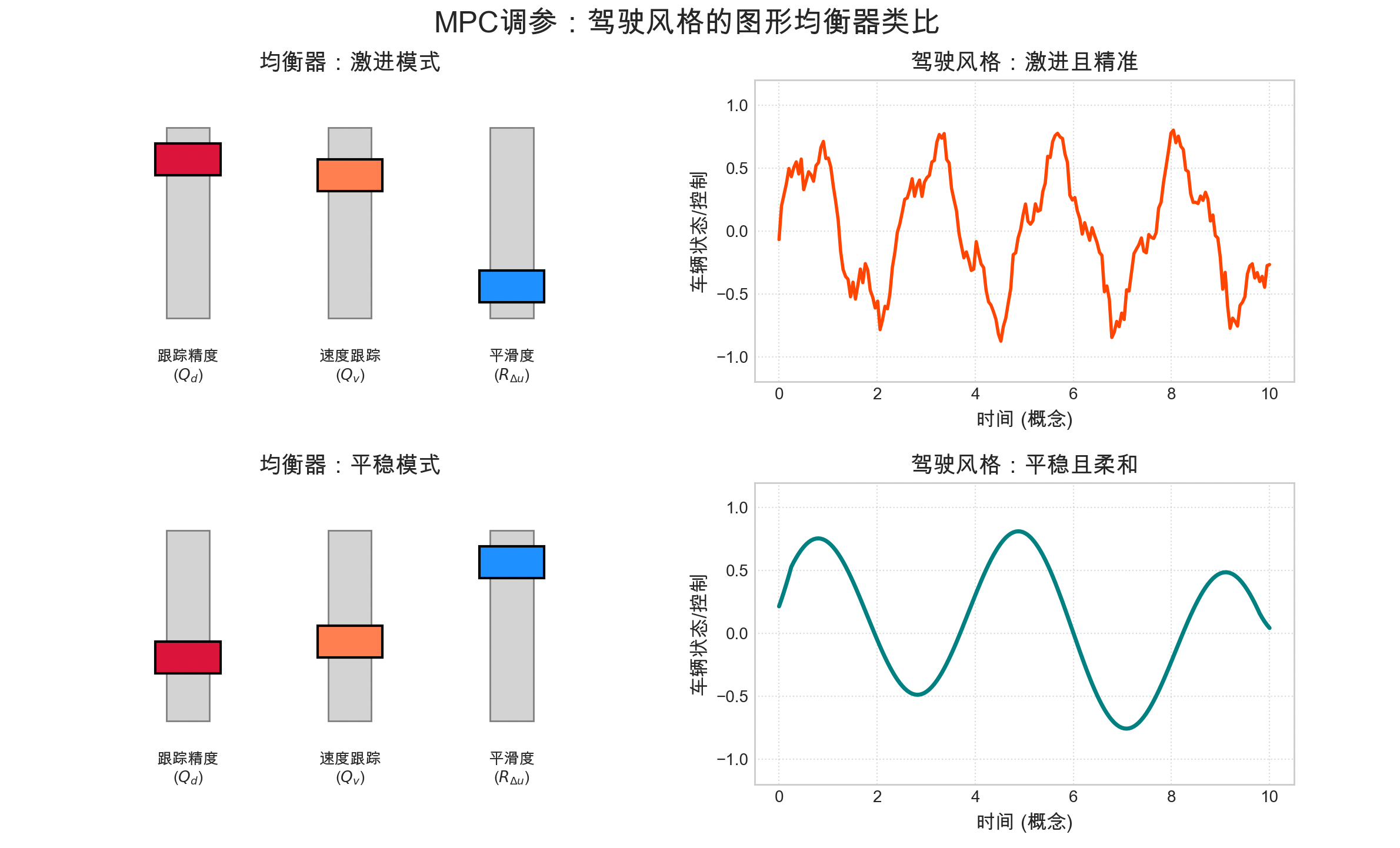
【MPC控制 - 从ACC到自动驾驶】5. 融会贯通:MPC在ACC中的优势总结与知识体系构建
【MPC控制 - 从ACC到自动驾驶】融会贯通:MPC在ACC中的优势总结与知识体系构建 在过去的四天里,我们一起经历了一段奇妙的旅程: Day 1: 我们认识了自适应巡航ACC这位“智能领航员”,并初见了模型预测控制MPC这位“深谋远虑的棋手…...

Day3 记忆内容:map set 高频操作
以下是 第三天 的详细学习内容,聚焦 map和set的高效应用,重点突破查找类题型和去重逻辑,助你提升代码效率! 📚 Day3 记忆内容:map & set 高频操作 1. map 核心操作(手写3遍) /…...

初等数论--Garner‘s 算法
0. 介绍 主要通过混合积的表示来逐步求得同余方程的解。 对于同余方程 { x ≡ v 0 ( m o d m 0 ) x ≡ v 1 ( m o d m 1 ) ⋯ x ≡ v k − 1 ( m o d m k − 1 ) \begin{equation*} \begin{cases} x \equiv v_0 \quad (\ \bmod \ m_0)\\ x \equiv v_1 \quad (\ \bmod \ m_1)…...

NV211NV212美光科技颗粒NV219NV220
NV211NV212美光科技颗粒NV219NV220 技术架构解析:从颗粒到存储系统 近期美光科技发布的NV211、NV212、NV219、NV220系列固态颗粒,凭借其技术突破引发行业关注。这些颗粒基于176层QLC堆叠工艺,单Die容量预计在2026年可达1Tb,相当…...

SQL解析工具JSQLParser
目录 一、引言二、JSQLParser常见类2.1 Class Diagram2.2 Statement2.3 Expression2.4 Select2.5 Update2.6 Delete2.7 Insert2.8 PlainSelect2.9 SetOperationList2.10 ParenthesedSelect2.11 FromItem2.12 Table2.13 ParenthesedFromItem2.14 SelectItem2.15 BinaryExpressio…...
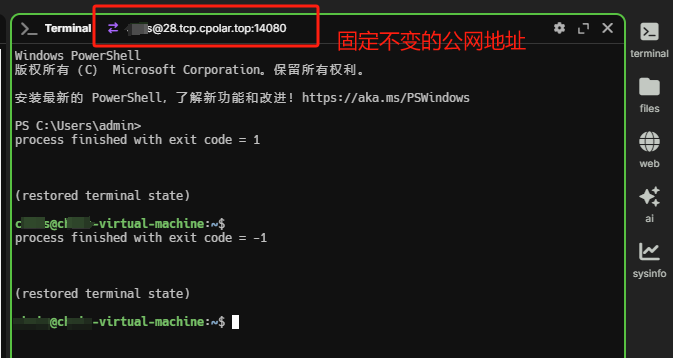
Wave Terminal + Cpolar:SSH远程访问的跨平台实战+内网穿透配置全解析
文章目录 前言1. Wave Terminal安装2. 简单使用演示3. 连接本地Linux服务器3.1 Ubuntu系统安装ssh服务3.2 远程ssh连接Ubuntu 4. 安装内网穿透工具4.1 创建公网地址4.2 使用公网地址远程ssh连接 5. 配置固定公网地址 前言 各位开发者朋友,今天为您介绍一款颠覆性操…...
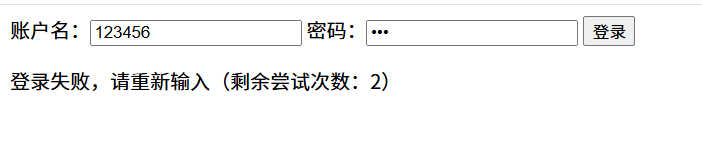
html使用JS实现账号密码登录的简单案例
目录 案例需求 思路 错误案例及问题 修改思路 案例提供 所需要的组件 <input>标签,<button>标签,<script>标签 详情使用参考:HTML 教程 | 菜鸟教程 案例需求 编写一个程序,最多允许用户尝试登录 3 次。…...
 函数和sort()函数的区别)
sorted() 函数和sort()函数的区别
在Python中,sorted() 函数和列表的 sort() 方法都用于排序,但它们之间有一些关键的区别: 返回值: sorted():返回一个新的列表,包含所有排序后的元素,原始列表不会被修改。sort():对列…...

Solr搜索:比传统数据库强在哪?
Solr 是一个基于 Apache Lucene 的开源搜索平台,广泛用于全文检索和数据分析。与传统的关系型数据库查询相比,Solr 在某些方面具有明显的优势,特别是在处理大规模文本数据和复杂的搜索需求时。以下是 Solr 相对于传统数据库查询的主要优势&am…...

【数据集】基于ubESTARFM法的100m 地温LST数据集(澳大利亚)
目录 数据概述一、输入数据与处理二、融合算法1. ESTARFM(Enhanced STARFM)2. ubESTARFM(Unbiased ESTARFM)代码实现数据下载参考根据论文《Generating daily 100 m resolution land surface temperature estimates continentally using an unbiased spatiotemporal fusion…...

51c自动驾驶~合集55
我自己的原文哦~ https://blog.51cto.com/whaosoft/13935858 #Challenger 端到端碰撞率暴增!清华&吉利,框架:低成本自动生成复杂对抗性驾驶场景~ 自动驾驶系统在对抗性场景(Adversarial Scenarios)中的可靠性是安全落…...

【前端基础】Promise 详解
文章目录 什么是 Promise?为什么要使用 Promise?创建 Promise消费 Promise (使用 Promise)1. .then(onFulfilled, onRejected)2. .catch(onRejected)3. .finally(onFinally) Promise 链 (Promise Chaining)Promise 的静态方法1. Promise.resolve(value)2…...
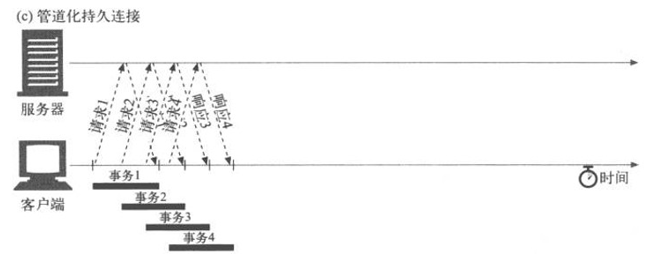
高性能管线式HTTP请求
高性能管线式HTTP请求:原理、实现与实践 目录 高性能管线式HTTP请求:原理、实现与实践 1. HTTP管线化的原理与优势 1.1 HTTP管线化的基本概念 关键特性: 1.2 管线化的优势 1.3 管线化的挑战 2. 高性能管线式HTTP请求的实现方案 2.1 技术选型与工具 2.2 Java实现:…...

c/c++的opencv膨胀
使用 OpenCV (C) 进行图像膨胀操作详解 图像膨胀 (Dilation) 是形态学图像处理中的另一种基本操作,与腐蚀操作相对应。它通常用于填充图像中的小孔洞、连接断开的物体部分、以及加粗二值图像中的物体。本文将详细介绍膨胀的原理,并演示如何使用 C 和 Op…...

react native搭建项目
React Native 项目搭建指南 React Native 是一个使用 JavaScript 和 React 构建跨平台移动应用的框架。以下是搭建 React Native 项目的详细步骤: 1. 环境准备 安装 Node.js 下载并安装 Node.js (推荐 LTS 版本) 安装 Java Development Kit (JDK) 对于 Androi…...
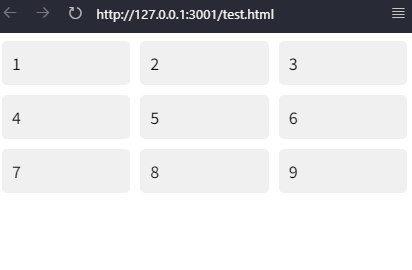
【CSS】九宫格布局
CSS Grid布局(推荐) 实现代码: <!doctype html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0"…...

Python用Transformer、Prophet、RNN、LSTM、SARIMAX时间序列预测分析用电量、销售、交通事故数据
原文链接: tecdat.cn/?p42219 在数据驱动决策的时代,时间序列预测作为揭示数据时序规律的核心技术,已成为各行业解决预测需求的关键工具。从能源消耗趋势分析到公共安全事件预测,不同领域的数据特征对预测模型的适应性提出了差异…...