论文阅读:Next-Generation Database Interfaces:A Survey of LLM-based Text-to-SQL
地址:Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL

摘要
由于用户问题理解、数据库模式解析和 SQL 生成的复杂性,从用户自然语言问题生成准确 SQL(Text-to-SQL)仍是一项长期挑战。传统的 Text-to-SQL 系统结合人工设计和深度神经网络已取得显著进展,随后预训练语言模型(PLM)在该任务上也实现了有前景的结果。然而,随着现代数据库和用户问题日益复杂,参数规模有限的 PLM 常生成错误 SQL,这需要更精细的定制化优化方法,从而限制了基于 PLM 系统的应用。最近,大型语言模型(LLM)随着模型规模的增加,在自然语言理解方面展现出显著能力,因此集成基于 LLM 的解决方案可为 Text-to-SQL 研究带来独特的机遇、改进和解决方案。本综述全面回顾了现有基于 LLM 的 Text-to-SQL 研究,具体包括:简要概述 Text-to-SQL 的技术挑战和演变过程;介绍用于评估 Text-to-SQL 系统的数据集和指标;系统分析基于 LLM 的 Text-to-SQL 的最新进展;最后总结该领域的剩余挑战,并提出对未来研究方向的展望。
概括
1. 研究背景与意义
- 核心任务:Text-to-SQL 旨在将自然语言问题转换为可执行的 SQL 查询,作为数据库的自然语言接口(NLIDB),帮助非技术用户便捷访问结构化数据,提升人机交互效率。
- LLM 的价值:LLM 通过强大的语义解析能力和知识储备,可缓解传统模型在复杂语义理解和跨领域泛化上的不足,同时结合数据库内容可减少 LLM 的 “幻觉” 问题。
2. 技术演进历程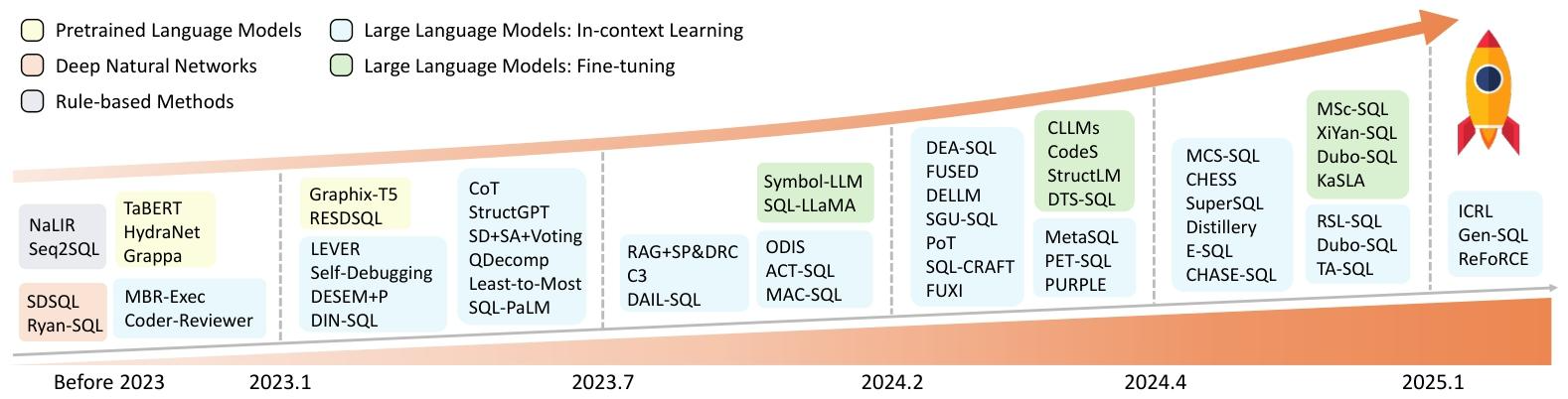
- 规则驱动阶段:早期依赖人工设计规则和模板,适用于简单场景,但难以处理复杂语义和模式变化。
- 深度学习阶段:基于序列到序列模型(如 LSTM、Transformer)和图神经网络(GNN),自动学习语义到 SQL 的映射,但存在语法错误和复杂操作生成困难。
- PLM 阶段:利用 BERT、RoBERTa 等预训练模型提升语义解析能力,引入模式感知编码优化数据库模式理解,但对复杂 SQL(如嵌套子查询)和跨领域泛化仍不足。
- LLM 阶段:通过上下文学习(ICL)和微调(FT)范式,结合思维链(CoT)、模式分解等技术,显著提升生成准确性,成为当前主流方向。
3. 关键挑战
- 语言复杂性与歧义性:自然语言的嵌套从句、指代消解等问题导致语义解析困难。
- 模式理解与表示:复杂数据库模式(多表关联、外键关系)的有效编码和匹配挑战。
- 复杂 SQL 操作生成:如窗口函数、外连接等低频操作的泛化能力不足。
- 跨领域泛化:不同领域的词汇、模式结构差异导致模型迁移能力弱。
- 计算效率与数据隐私:LLM 的高计算成本、长上下文处理限制,以及 API 调用中的数据泄露风险。
4. 未来研究方向
- 鲁棒性提升:针对真实场景中的噪声问题(如拼写错误、同义词),设计数据增强和抗干扰训练策略。
- 效率优化:通过模式过滤、模型压缩(如量化、剪枝)和本地部署,降低计算成本。
- 可解释性与隐私保护:结合注意力可视化、SHAP 值等技术提升模型透明度,探索联邦学习等隐私保护技术。
- 多模态与跨语言扩展:支持文本、图像等多模态输入,以及中文、越南语等跨语言场景。
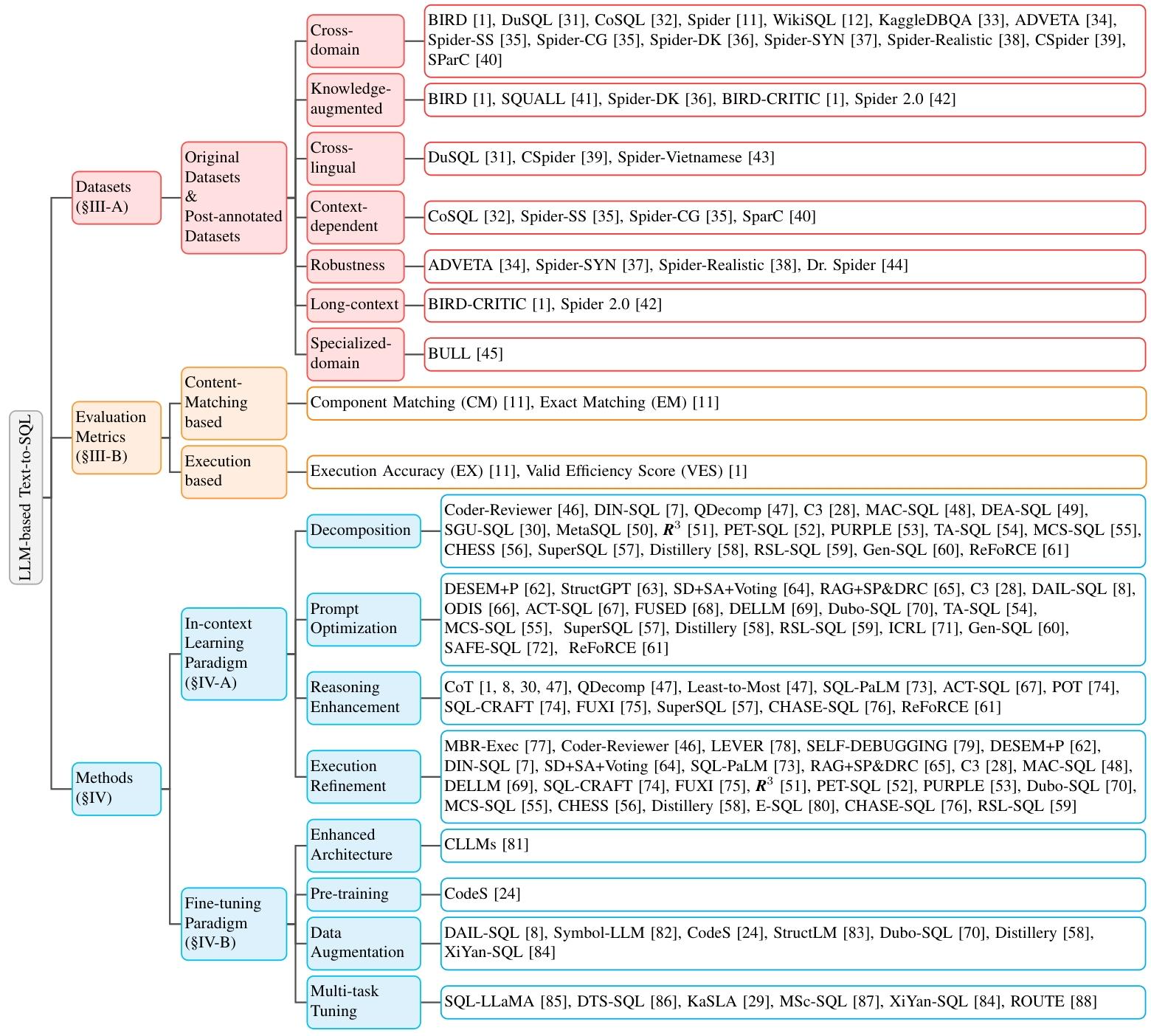
一、数据集
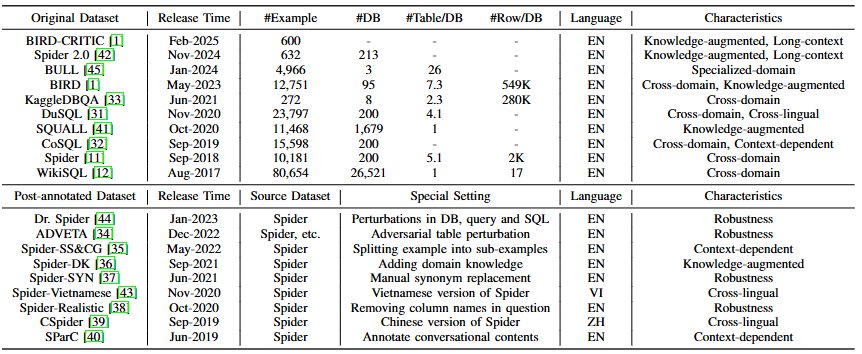
二、技术方法对比
1. 传统方法
| 方法 | 核心思想 | 优缺点 | 性能表现 | 评价指标 |
|---|---|---|---|---|
| 规则驱动 | 人工设计规则和模板,通过语法匹配生成 SQL。 | 优点:语法准确率高,适合简单场景。 缺点:泛化能力差,无法处理复杂语义和跨领域问题,维护成本高。 | 在简单数据集(如早期 WikiSQL)表现稳定,但在复杂场景(如 Spider)中准确率低于 50%。 | CM、EM |
| 深度学习 | 使用序列到序列模型(LSTM/Transformer)或图神经网络(GNN)自动学习语义到 SQL 的映射。 | 优点:减少人工规则依赖,支持复杂语义解析。 缺点:易生成语法错误(如缺少 JOIN 子句),对低频 SQL 操作(如窗口函数)泛化能力弱。 | 在 Spider 数据集上 EX 约 60%-70%,但对嵌套查询处理不佳。 | EX、CM |
| 预训练语言模型(PLM) | 基于 BERT、RoBERTa 等预训练模型,结合模式感知编码优化数据库模式理解。 | 优点:语义解析能力强于传统深度学习,支持跨领域迁移。 缺点:参数规模有限,复杂场景下易出错,需大量微调数据。 | 在 Spider 数据集上 EX 提升至 75%-85%,但对多表关联和领域知识依赖场景仍不足。 | EX、EM |
2. 基于 LLM 的方法
(1)上下文学习(ICL)范式
| 子方法 | 核心策略 | 优缺点 | 性能表现 | 评价指标 |
|---|---|---|---|---|
| 香草提示 | 零样本 / 少样本提示,直接拼接指令、问题和模式(如 SimpleDDL)。 | 优点:无需训练,快速部署。 缺点:零样本准确率低(如 ChatGPT 在 Spider 零样本 EX 约 50%),少样本依赖示例质量。 | 零样本 EX 约 40-60%,少样本(10-shot)EX 提升至 70-85%(如 GPT-4 在 BIRD 数据集)。 | EX、VES |
| 分解方法 | 将任务拆解为模式链接、SQL 生成、执行优化等阶段(如 DIN-SQL 的四阶段流水线)。 | 优点:降低复杂查询难度,提升逻辑连贯性。 缺点:多阶段流水线可能引入级联错误。 | 在 Spider 2.0 数据集上 EX 达 82%,优于单阶段模型。 | EX、CM |
| 提示优化 | 基于语义相似度 / 多样性选择少样本示例,过滤冗余模式(如 C3 的模式蒸馏)。 | 优点:减少输入冗余,提升示例相关性。 缺点:依赖高质量标注数据或外部检索工具。 | 在 ADVETA(对抗性数据集)上 EX 提升 15-20%,鲁棒性增强。 | EX、VES |
| 推理增强 | 通过思维链(CoT)或多路径推理引导 LLM 生成中间步骤(如 ACT-SQL 的自动 CoT 生成)。 | 优点:提升复杂查询的逻辑可解释性。 缺点:计算成本增加(如生成推理步骤耗时延长 2-3 倍)。 | 在 BIRD-CRITIC(长上下文数据集)上 EX 达 85%,优于无 CoT 基线。 | EX、EM |
| 执行优化 | 利用数据库执行结果反馈修正 SQL(如 Self-Debugging 的错误解释引导)。 | 优点:通过执行验证提升准确率。 缺点:依赖数据库实时访问,不适用于离线场景。 | 在 Spider-Realistic(缺失列名场景)上 EX 从 60% 提升至 80%。 | EX、VES |
分解方法、
提示优化、
推理增强、
执行优化
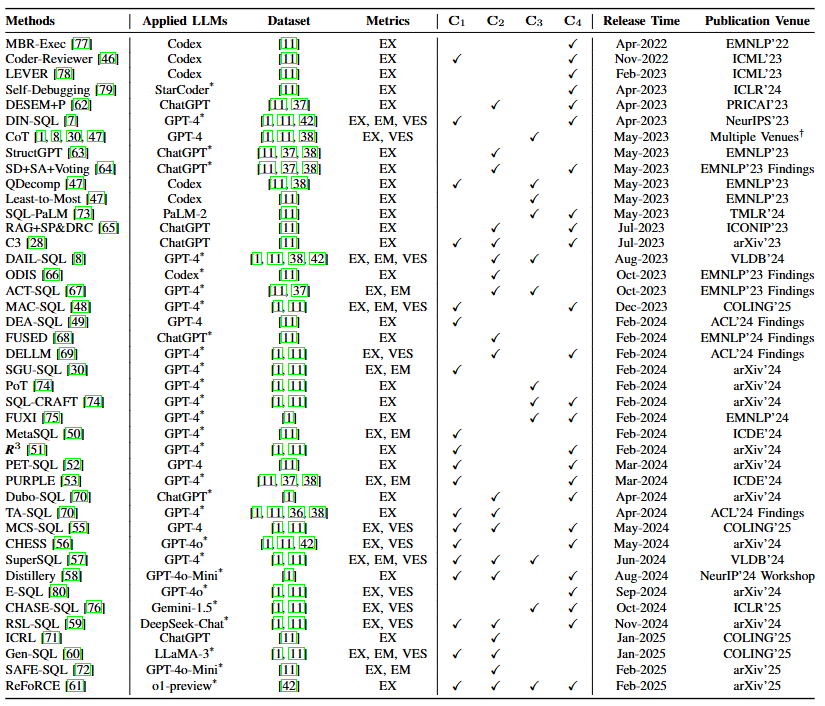
(2)微调(FT)范式
| 子方法 | 核心策略 | 优缺点 | 性能表现 | 评价指标 |
|---|---|---|---|---|
| 增强架构 | 设计专用解码模块加速 SQL 生成(如 CLLMs 的结构感知解码)。 | 优点:推理速度提升 30-50%,适合实时应用。 缺点:架构复杂度高,需定制开发。 | 在本地部署场景下延迟低于 100ms,EX 保持 80% 以上。 | EX、执行效率 |
| 预训练 | 在代码数据(如 StarCoder)上预训练,结合 SQL-specific 数据增强(如 CodeS 的三阶段预训练)。 | 优点:提升语法生成能力,减少 “幻觉”。 缺点:需大量计算资源(如训练成本是传统 PLM 的 5-10 倍)。 | 在 WikiSQL 数据集上 EX 达 90%,超越多数 ICL 方法。 | EX、EM |
| 数据增强 | 利用 ChatGPT 生成合成数据或骨架掩码增强多样性(如 SAFE-SQL 的自增强示例)。 | 优点:缓解数据稀缺问题,提升泛化能力。 缺点:合成数据可能引入偏差。 | 在低资源场景(如 1k 标注样本)下 EX 达 75%,优于基线。 | EX、数据效率 |
| 多任务调优 | 分阶段训练模式链接和 SQL 生成任务(如 DTS-SQL 的两阶段框架)。 | 优点:模块化训练提升跨领域能力。 缺点:训练流程复杂,需协调多任务平衡。 | 在跨领域数据集(如 CoSQL)上 EX 达 83%,优于单任务模型。 | EX、跨领域准确率 |
3. 传统方法 vs. LLM 方法
| 维度 | 传统方法 | LLM 方法 |
|---|---|---|
| 语义理解 | 依赖人工特征或浅层语义解析,歧义处理能力弱。 | 通过大规模预训练捕捉深层语义,CoT 等技术缓解歧义。 |
| 复杂操作支持 | 仅支持高频 SQL 语法,低频操作(如外连接)生成困难。 | 通过代码预训练和少样本示例,支持复杂操作(如窗口函数)。 |
| 跨领域泛化 | 需依赖领域特定微调,迁移成本高。 | ICL 范式通过少样本示例快速适应新领域(如 Spider-DK)。 |
| 计算成本 | 推理速度快,但训练需大量人工设计。 | ICL 依赖高成本 API 调用,FT 需大规模训练资源。 |
| 可解释性 | 规则或模型结构透明(如 GNN 的图节点注意力)。 | 黑箱模型,需依赖 SHAP/LIME 等后验解释工具。 |
三、评价指标总结
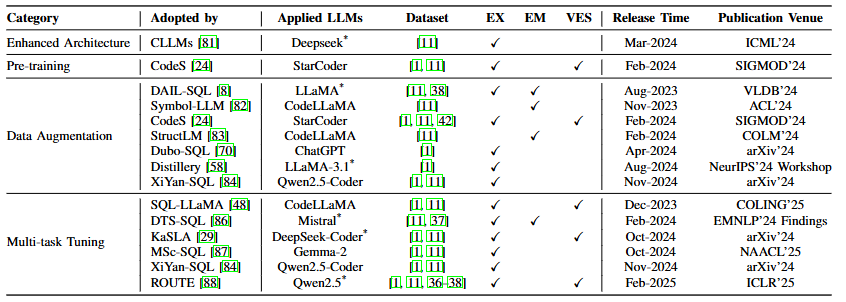
| 指标类型 | 指标名称 | 定义 | 适用场景 |
|---|---|---|---|
| 内容匹配 | 组件匹配(CM) | 计算 SELECT、WHERE 等 SQL 组件的 F1 分数,允许顺序无关匹配。 | 语法结构验证,不依赖数据库执行。 |
| 完全匹配(EM) | 预测 SQL 与真实 SQL 完全一致的比例。 | 严格语法正确性评估。 | |
| 执行结果 | 执行准确率(EX) | 执行预测 SQL 后,结果与真实结果一致的比例。 | 端到端功能验证,反映实际可用性。 |
| 有效效率分数(VES) | 结合执行结果正确性和效率(如执行时间)的综合指标,公式为 | 生产环境性能与准确性平衡评估。 |
四、性能对比与典型案例
| 方法 | 模型 | 数据集 | EX | EM | VES | 计算成本 |
|---|---|---|---|---|---|---|
| 规则驱动 | GRAPPA | Spider | 45% | 30% | - | 低(无训练成本) |
| 深度学习 | RyenSQL | Spider | 68% | 55% | - | 中(需 GPU 训练) |
| PLM | TaBERT | Spider | 78% | 65% | - | 中(预训练模型微调) |
| LLM-ICL | DIN-SQL (GPT-4) | BIRD | 89% | 82% | 0.85 | 高(API 调用成本) |
| LLM-FT | CodeS (StarCoder) | Spider 2.0 | 85% | 78% | 0.82 | 极高(三阶段预训练) |
五、未来趋势
- 混合架构:LLM + 传统符号系统(如规则引擎、知识库),平衡生成灵活性与逻辑严谨性(如 Tool-SQL 的检索器 + 检测器)。
- 自监督进化:利用无标注数据(如数据库日志)进行自训练,持续优化模型(如 Distillery 的失败案例迭代学习)。
- 边缘智能:针对本地化部署,开发轻量化模型(如量化 LLM)和增量更新策略(如在线学习适配新 Schema)。
相关文章:
论文阅读:Next-Generation Database Interfaces:A Survey of LLM-based Text-to-SQL
地址:Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL 摘要 由于用户问题理解、数据库模式解析和 SQL 生成的复杂性,从用户自然语言问题生成准确 SQL(Text-to-SQL)仍是一项长期挑战。传统的 Text-to-SQ…...
OS面试篇
用户态和内核态 用户态和内核态的区别? 内核态和用户态是操作系统中的两种运行模式。它们的主要区别在于权限和可执行的操作: 内核态(Kernel Mode):在内核态下,CPU可以执行所有的指令和访问所有的硬件资…...
FFMPEG-FLV-MUX编码
一、流程图 二、结构体 1 .AVOutputFormat 一、核心功能与作用 封装格式描述 AVOutputFormat保存了输出容器格式的元数据,包括: 短名称(name):如flv、mp4;易读名称(long_name)&…...

青少年编程与数学 02-020 C#程序设计基础 05课题、数据类型
青少年编程与数学 02-020 C#程序设计基础 05课题、数据类型 一、数据类型及其意义1. 数据类型的概念1.1 值类型(Value Types)1.2 引用类型(Reference Types) 2. 数据类型的重要性2.1 类型安全示例 2.2 内存管理示例 2.3 性能优化示…...
React vs Vue.js:选哪个框架更适合你的项目?
摘要 前端开发江湖里,React 和 Vue.js 堪称两大 “顶流” 框架,不少开发者在选择时都犯了难。用 React 吧,听说它性能超强,可学习曲线也陡峭;选 Vue.js,有人夸它上手快,但又担心功能不够强大。…...

Kafka|基础入门
文章目录 快速了解Kafka快速上手Kafka理解Kafka的集群Kafka集群的消息流转模型 快速了解Kafka 快速上手Kafka 启动zookeeper 启动kafka 创建topic - 启动发送者 - 启动消费者 Partition 0: [msg1] -> [msg2] -> [msg3] -> ...0 1 2Partition 1: [msg4…...
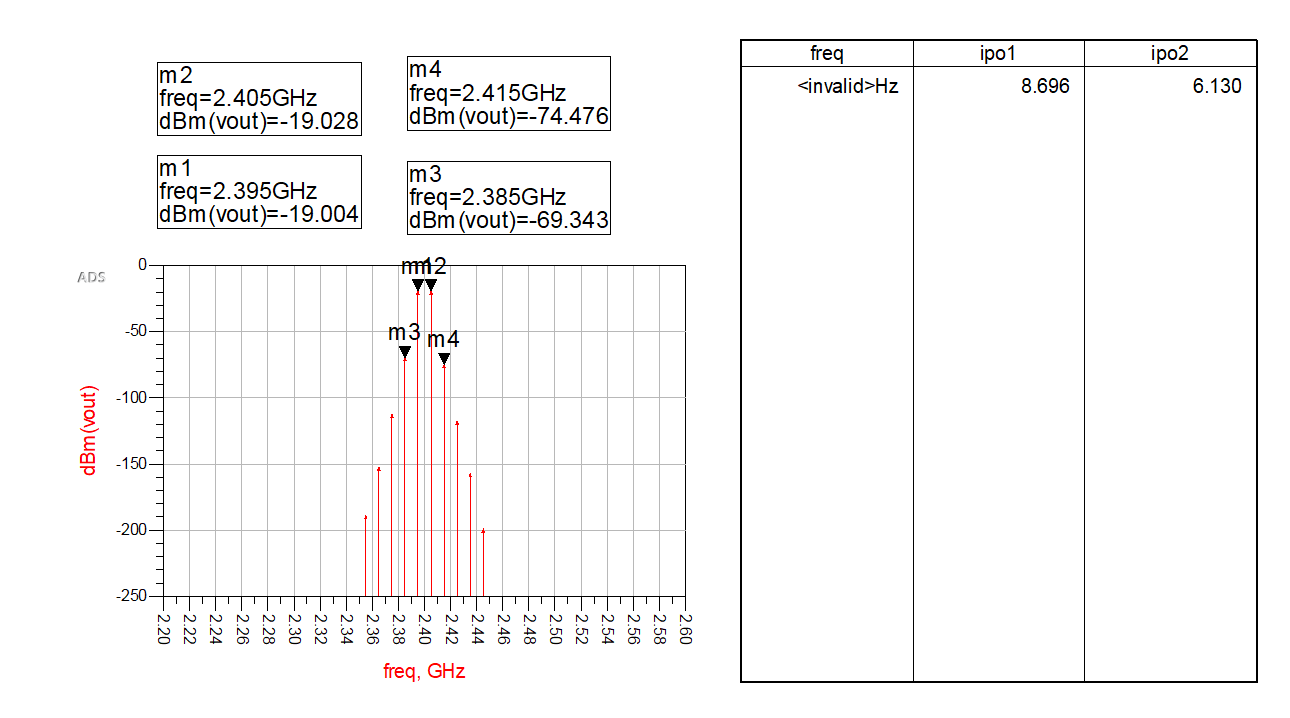
ADS学习笔记(五) 谐波平衡仿真
参考书籍:见资源绑定,书籍4.2 谐波平衡仿真 本文为对实验内容的补充 1. 三阶交调点坐标系图分析 我们来分析图1.5中“三阶交调点”坐标系图里的两条直线分别代表什么。 图中有两条向上倾斜的直线: 斜率较低的那条直线代表:基波输出功率 (Fundamental Out…...

MySQL存储引擎对比及选择指南
MySQL 存储引擎是数据库底层管理数据存储和操作的核心组件,不同存储引擎在事务支持、性能、锁机制、存储方式等方面存在显著差异。以下是常见存储引擎的对比及其适用场景: 1. InnoDB 事务支持:支持 ACID 事务(COMMIT/ROLLBACK&am…...

【IDEA问题】springboot本地启动应用报错:程序包不存在;找不到符号
问题: springboot本地启动应用报错: 程序包xxx不存在;找不到符号 解决方案: 1.确保用maven重新导入依赖 2.删除.idea文件夹 3.invalidate caches里,把能选择的都勾选上,然后清除缓存重启 4.再在上方工具栏…...
PETR- Position Embedding Transformation for Multi-View 3D Object Detection
旷视 ECCV 2022 纯视觉BEV方案transformer网络3D检测 paper:[2203.05625] PETR: Position Embedding Transformation for Multi-View 3D Object Detection code:GitHub - megvii-research/PETR: [ECCV2022] PETR: Position Embedding Transformation …...
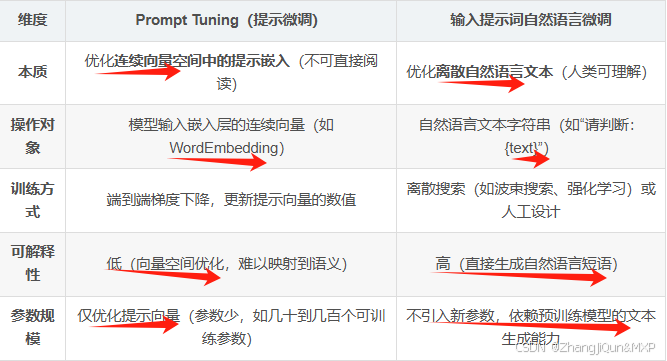
Prompt Tuning与自然语言微调对比解析
Prompt Tuning 与输入提示词自然语言微调的区别和联系 一、核心定义与区别 维度Prompt Tuning(提示微调)输入提示词自然语言微调本质优化连续向量空间中的提示嵌入(不可直接阅读)优化离散自然语言文本(人类可理解)操作对象模型输入嵌入层的连续向量(如WordEmbedding)自…...

二十七、面向对象底层逻辑-SpringMVC九大组件之HandlerAdapter接口设计
在 Spring MVC 框架中,HandlerAdapter 是一个看似低调却极为关键的组件。它的存在,不仅解决了不同类型处理器(Handler)的调用难题,更体现了框架设计中对解耦、扩展性和模块化的深刻思考。本文将从接口设计的角度&#…...
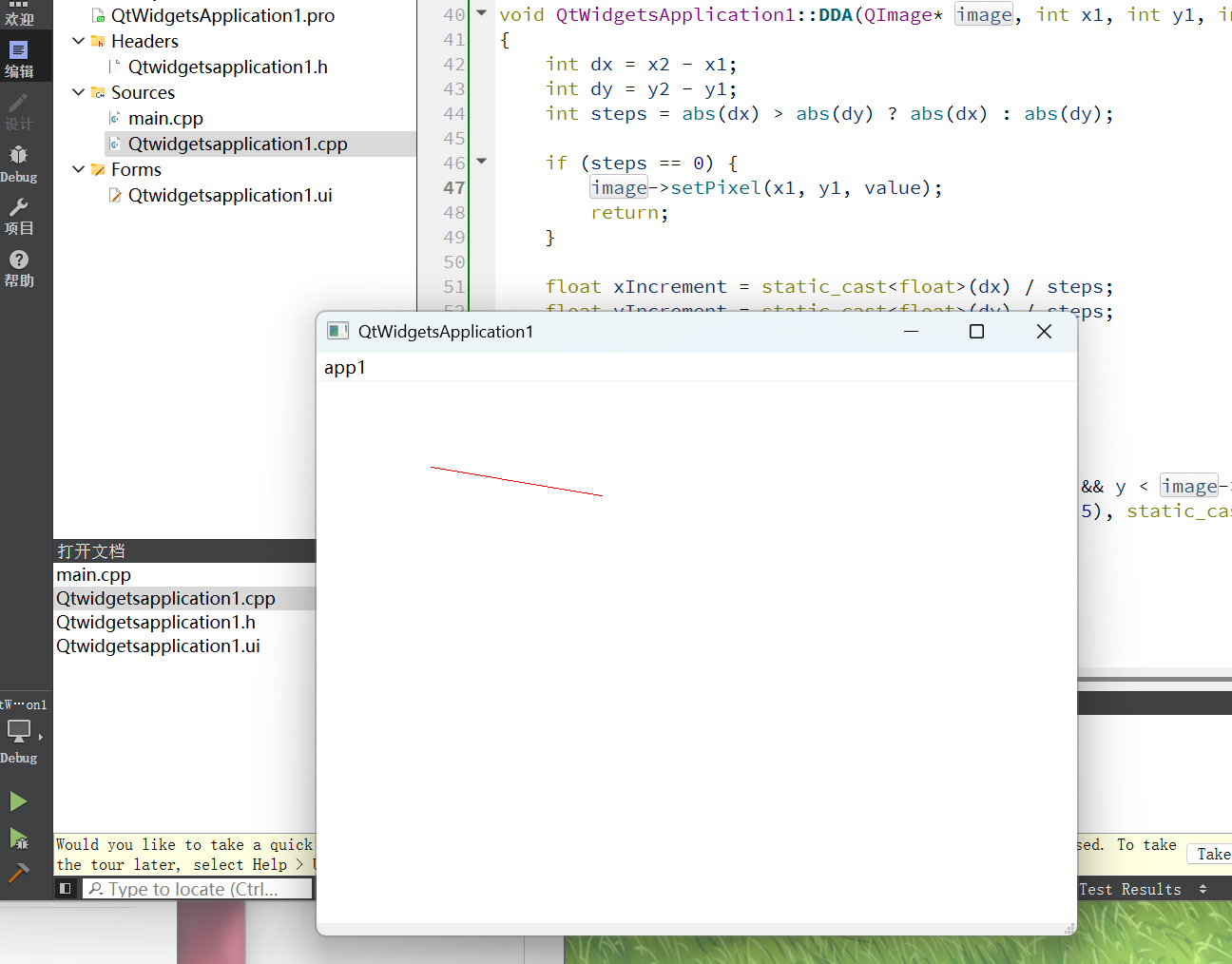
QT软件开发环境及简单图形的绘制-图形学(实验一)-[成信]
对于软件的安装这里就不多介绍了。 本文章主要是根据本校图形学的实验知道来做。 创建一个简单的计算机图形学程序 第一步:创建项目及配置 这里创建的项目名和类名尽量和我的一样,避免后面直接复制我的代码时会出现一些名字上面的错误。QtWidgetsAppl…...

项目部署一次记录
链路:(用户)客户端 → Nginx:192.168.138.100→ Tomcat (程序):192.168.138.101→ MySQL/Redis 打开数据库:systemctl start mysqld 重启网络: systemctl restart NetworkManager 关闭防火墙&am…...

单例模式,饿汉式,懒汉式,在java和spring中的体现
目录 饿汉式单例模式 懒汉式单例模式 Spring中的单例模式 关键差异对比 在Java和Spring中的应用场景 手写案例 单例模式是一种创建型设计模式,其核心在于确保一个类仅有一个实例,并提供一个全局访问点来获取该实例。下面将详细介绍饿汉式和懒汉式…...
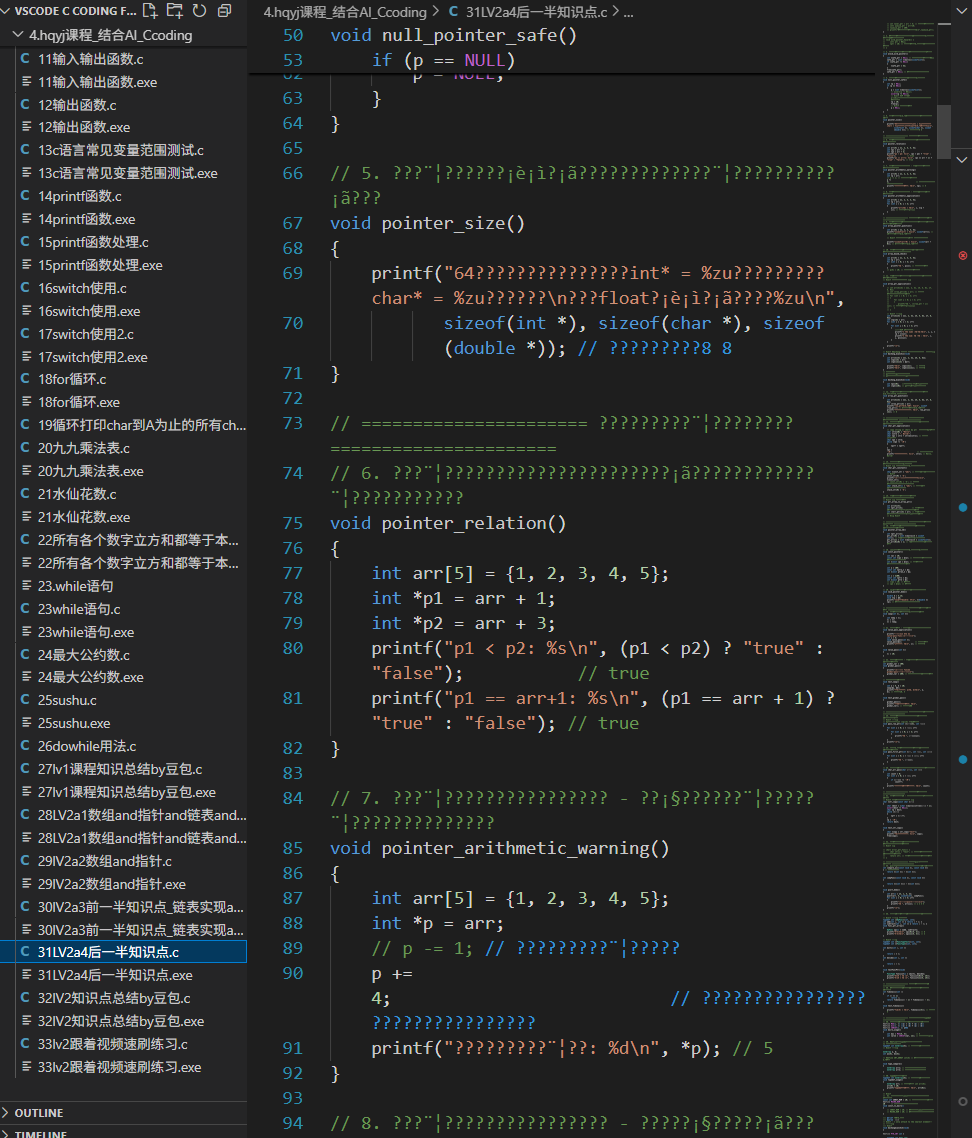
一文带你彻底理清C 语言核心知识 与 面试高频考点:从栈溢出到指针 全面解析 附带笔者手写2.4k行代码加注释
引言:C 语言的魅力与挑战 从操作系统内核到嵌入式系统,从高性能计算到网络编程,C 语言高效、灵活和贴近硬件的特性,始终占据着不可替代的地位。然而,C 语言的强大也伴随着较高的学习曲线,尤其是指针、内存管…...

【Redis】第1节|Redis服务搭建
一、Redis 基础概念 核心功能 内存数据库,支持持久化(RDB/AOF)、主从复制、哨兵高可用、集群分片。常用场景:缓存、分布式锁、消息队列、计数器、排行榜等。 安装环境 依赖 GCC 环境(C语言编译)࿰…...
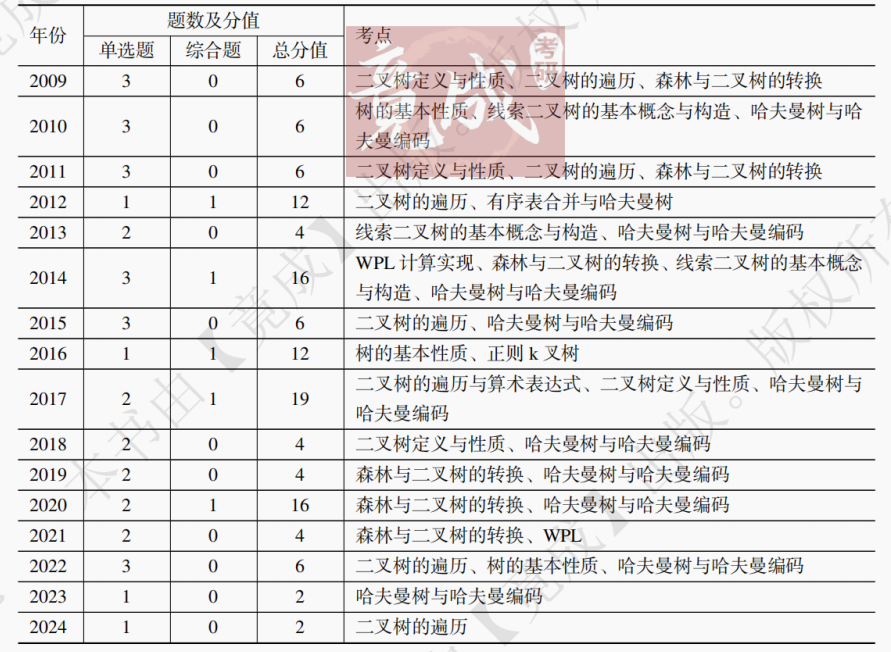
数据结构第5章 树与二叉树(竟成)
第 5 章 树与二叉树 【考纲内容】 1.树的基本概念 2.二叉树 (1)二叉树的定义及其主要特征 (2)二叉树的顺序存储结构和链式存储结构 (3)二叉树的遍历 (4)线索二叉树的基本概念和构造 …...
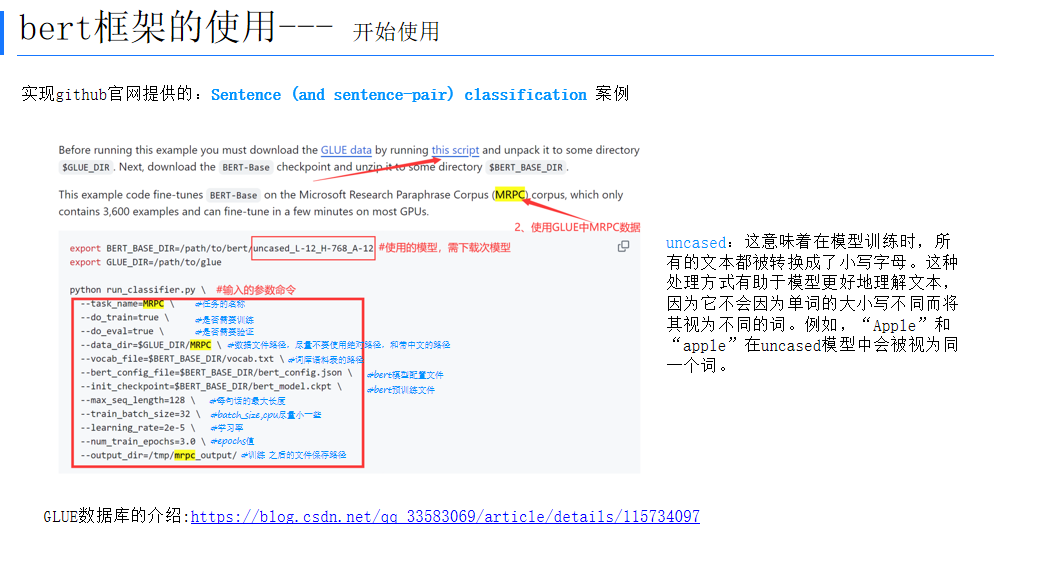
# 深入解析BERT自然语言处理框架:原理、结构与应用
深入解析BERT自然语言处理框架:原理、结构与应用 在自然语言处理(NLP)领域,BERT(Bidirectional Encoder Representations from Transformers)框架的出现无疑是一个重要的里程碑。它凭借其强大的语言表示能…...

ai学习--python部分-1.变量名及命名空间的存储
初学代码时总有一个问题困扰我:a 10 # a指向地址0x1234(存储10) 变量a的值10存储在0x1234,那么变量a需要存储吗?a又存储在什么地址呢 目录 1. 命名空间的本质 2. 命名空间的内存占用 3. …...

Cadence学习笔记之---PCB过孔替换、封装更新,DRC检查和状态查看
目录 01 | 引 言 02 | 环境描述 03 | 过孔替换 04 | 封装更新 05 | PCB状态查看 06 | DRC检查 07 | 总 结 01 | 引 言 终于终于来到了Cadence学习笔记的尾声! 在上一篇文章中,讲述了如何布线、如何铺铜,以及布线、铺铜过程中比较重要…...

Java基础 Day21
一、Stream 流 思想:流水线式思想 1、获取流对象(将数据放到流中) (1)集合获取 Stream 流对象 使用Collection接口的默认方法 default Stream<E> stream() 获取当前集合对象的 Stream 流(单列集…...
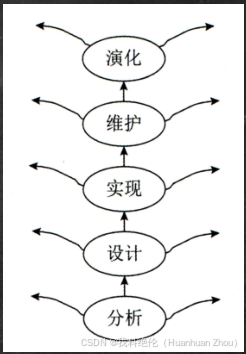
系统开发和运行知识
软件生存周期 软件生存周期包括可行性分析与项目开发计划、需求分析、概要设计、详细设计、编码和单元测试、综合测试及维护阶段。 1、可行性分析与项目开发计划 主要任务是确定软件的开发目标及可行性。该阶段应该给出问题定义、可行性分析和项目开发计划。 2、需求分析 需求…...
方式简析:`_name`、`_ip`、`_host`)
Elasticsearch 分片驱逐(Shard Exclusion)方式简析:`_name`、`_ip`、`_host`
在日常运维 Elasticsearch 集群过程中,常常需要将某个节点上的分片迁移出去,例如下线节点、腾出资源或进行维护操作。Elasticsearch 提供了简单直观的 shard exclusion 参数来实现这一目的,主要通过以下三个配置项: cluster.rout…...
【C++高级主题】异常处理(四):auto_ptr类
目录 一、auto_ptr 的诞生:为异常安全的内存分配而设计 1.1 传统内存管理的痛点 1.2 auto_ptr 的核心思想:RAII 与内存绑定 1.3 auto_ptr 的基本定义(简化版) 二、auto_ptr 的基本用法:将指针绑定到智能对象 2.1…...

STM32CubeMX配置使用通用定时器产生PWM
一、定时器PWM功能简介 定时器,顾名思义,就是定时的功能,定时器在单片机中算是除GPIO外最基本的外设。在ST中,定时器分为几种,基础定时器,通用定时器,高级定时器和低功耗定时器。其中定时器除了…...
WebSphere Application Server(WAS)8.5.5教程第十四讲:JPA
一、JPA 以下是对 JPA(Java Persistence API) 的深入详解,适用于具备一定 Java EE / Jakarta EE 背景的开发者,尤其是对数据持久化机制感兴趣的人员。 1、什么是 JPA? Java Persistence API(JPA…...
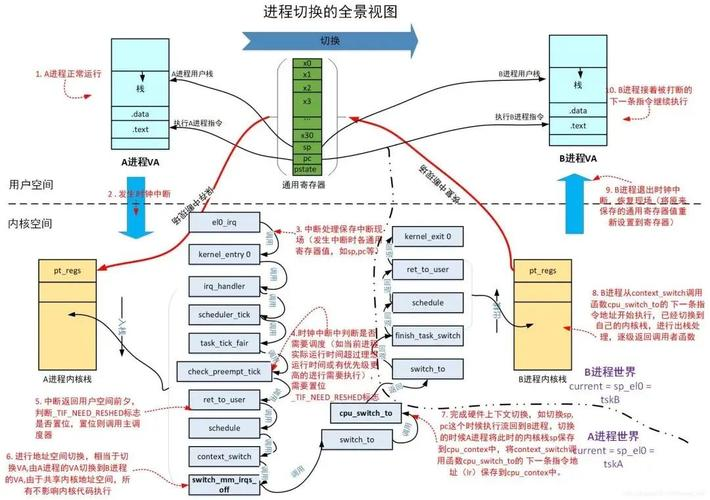
Linux系统调用深度剖析
Linux系统调用深度剖析与实践案例 目录 Linux系统调用深度剖析与实践案例 一、Linux系统调用概述 二、进程管理相关系统调用 1. fork():进程克隆与多任务处理 2. exec系列:程序加载与替换 3. wait/waitpid:进程状态同步 三、文件操作相关系统调用 1. 文件描述符操作…...

动态规划-918.环形子数组的最大和-力扣(LeetCode)
一、题目解析 听着有点复杂,这里一图流。 将环形问题转化为线性问题。 二、算法原理 1.状态表示 2.状态转移方程 详细可以移步另一篇博客,53. 最大子数组和 - 力扣(LeetCode) 3.初始化 由于计算中需要用到f[i-1]和g[i-1]的值&…...
规范与要求)
Docker 镜像标签(Tag)规范与要求
Docker 镜像标签(Tag)规范与要求 背景 目前主流云厂商,如阿里云、百度云和腾讯云,均提供租户使用的镜像仓库服务。 各个厂商要求可能不太一样,比如华为:https://doc.hcs.huawei.com/zh-cn/usermanual/swr/swr_faq_0017.html 样…...