LangChain03-图数据库与LangGraph
图数据库与LangGraph集成实践
1. 引言
在构建智能问答系统、推荐引擎或复杂决策流程时,传统的关系型数据库和向量数据库往往难以满足对实体关系建模和多跳推理的需求。图数据库(如 Neo4j、TigerGraph)通过节点-边-属性的结构化表示,能够高效存储和查询复杂的关系网络,而 LangGraph 作为 LangChain 的扩展框架,提供了基于有向无环图(DAG)的流程编排能力。
本文将深入解析 图数据库与 LangGraph 的集成实践,涵盖以下核心内容:
- 图数据库的核心原理与应用场景。
- LangGraph 的开发流程与图结构设计。
- GraphRAG(Graph Retrieval-Augmented Generation)技术的实现细节。
- 实战案例:医疗辅助诊断系统的构建与优化。
2. 图数据库核心原理与应用场景
2.1 图数据库的核心特性
图数据库以 图结构(Graph Structure) 为核心,通过 节点(Node) 和 边(Edge) 描述实体及其关系。相比关系型数据库,图数据库在以下场景中具有显著优势:
- 多跳查询:高效处理多层级关系(如“用户A的朋友的朋友”)。
- 动态关系建模:支持实时更新实体关系(如社交网络中的好友添加)。
- 语义关联增强:通过图遍历算法(如 BFS、DFS)挖掘隐含关系。
示例:Neo4j 的 Cypher 查询
// 查询用户 A 的朋友及其共同兴趣
MATCH (a:User {name: "Alice"}) -[:FRIEND]-> (f:User) -[:INTEREST]-> (i:Interest)
RETURN f.name, i.name
2.2 图数据库的典型应用场景
| 场景 | 技术优势 |
|---|---|
| 社交网络分析 | 快速查找好友链、社区发现 |
| 推荐系统 | 基于用户-商品关系的协同过滤 |
| 金融风控 | 检测欺诈团伙(如多跳关联分析) |
| 医疗辅助诊断 | 建立疾病-症状-药物的知识图谱,支持多跳推理 |
3. LangGraph 开发流程与图结构设计
3.1 LangGraph 的核心概念
LangGraph 是 LangChain 的扩展框架,通过 有向无环图(DAG) 协调多个 LLM 调用和工具执行。其核心组件包括:
- StateGraph:定义状态节点和边,控制流程逻辑。
- LLMGraphTransformer:将非结构化文本转化为图数据。
- GraphRAG:结合图搜索与向量搜索,实现上下文增强。
开发步骤(以 LangGraph 为例)
-
初始化图结构:
from langgraph.graph import StateGraph class AgentState(TypedDict): input: str # 用户输入 chat_history: list # 对话历史 agent_outcome: Union[AgentAction, AgentFinish, None] # 代理输出 builder = StateGraph(AgentState) -
添加节点与边:
def node_a(state: AgentState) -> AgentState: # 调用 LLM 生成意图识别结果 return updated_state def node_b(state: AgentState) -> AgentState: # 调用图数据库检索相关实体 return updated_state builder.add_node("intent_recognition", node_a) builder.add_node("knowledge_retrieval", node_b) builder.add_edge("intent_recognition", "knowledge_retrieval") -
编译与执行:
graph = builder.compile() result = graph.stream(input_data) -
可视化调试:
from IPython.display import display display(Mermaid(graph.get_graph().draw_mermaid()))
3.2 图结构设计原则
| 原则 | 说明 |
|---|---|
| 最小化冗余 | 避免重复存储相同关系(如用户-好友双向关系应合并为单条边)。 |
| 动态扩展性 | 设计可扩展的节点类型和关系(如支持新增“用户-产品”关系)。 |
| 索引优化 | 为高频查询路径创建索引(如为“疾病-症状”关系建立全文索引)。 |
4. GraphRAG 技术实现
4.1 GraphRAG 的核心流程
GraphRAG(Graph Retrieval-Augmented Generation)通过以下步骤增强 LLM 的上下文:
- 图搜索:从图数据库中检索相关实体和关系。
- 向量搜索:从向量数据库中检索相似语义的文档片段。
- 上下文融合:将图搜索结果与向量搜索结果合并,输入 LLM 生成答案。
代码示例:GraphRAG 的混合检索
from langchain_experimental import LLMGraphTransformer
from langchain.vectorstores import Qdrant
from langchain.embeddings import TongYiEmbeddings # 1. 图搜索(Neo4j)
query = "糖尿病的并发症有哪些?"
graph_results = neo4j_graph.query( "MATCH (d:Disease {name: '糖尿病'}) -[:LEADS_TO]-> (c:Complication) RETURN c.name"
) # 2. 向量搜索(Qdrant)
db = Qdrant.from_documents(docs, embeddings, url="http://localhost:6333")
vector_results = db.similarity_search(query, k=3) # 3. 上下文融合
context = f"Graph Results: {graph_results}\nVector Results: {vector_results}"
answer = llm.run(f"根据以下上下文回答:{context}\n问题:{query}")
4.2 图搜索与向量搜索的对比
| 特性 | 图搜索 | 向量搜索 |
|---|---|---|
| 数据模型 | 结构化(节点-边-属性) | 非结构化(向量表示) |
| 查询效率 | 多跳查询高效(O(1) 到 O(log N)) | 相似度计算高效(O(K)) |
| 语义理解 | 依赖人工定义的关系 | 自动学习语义(通过嵌入模型) |
| 适用场景 | 精确关系查询(如家族树) | 语义相似性检索(如文档摘要) |
5. 实战案例:医疗辅助诊断系统
5.1 系统需求分析
目标:构建一个基于图数据库的医疗辅助诊断系统,支持以下功能:
- 根据用户描述的症状,推荐可能的疾病。
- 提供疾病-并发症-治疗方案的关联信息。
- 支持多跳推理(如“糖尿病 → 视网膜病变 → 激光治疗”)。
挑战:
- 医疗知识更新频繁(需小时级同步)。
- 幻觉控制(避免推荐未经认证的治疗方案)。
5.2 图数据库设计
数据建模
-
实体类型:
Disease(疾病)Symptom(症状)Complication(并发症)Treatment(治疗方案)
-
关系类型:
HAS_SYMPTOM(疾病-症状)LEADS_TO(疾病-并发症)TREATS(治疗方案-疾病)
数据填充
使用 LLMGraphTransformer 将非结构化医学文献转化为图数据:
from langchain_experimental import LLMGraphTransformer transformer = LLMGraphTransformer(llm=ChatOpenAI())
graph_documents = transformer.convert_to_graph_documents(medical_texts)
neo4j_graph.add_graph_documents(graph_documents)
5.3 LangGraph 流程设计
节点设计
-
症状解析节点:
- 输入:用户描述的症状(如“头晕、恶心”)。
- 输出:映射到标准症状实体(如
Symptom: Dizziness)。
-
疾病推荐节点:
- 调用图数据库查询关联疾病(如
MATCH (s:Symptom)-[:HAS]->(d:Disease))。
- 调用图数据库查询关联疾病(如
-
治疗方案生成节点:
- 调用 LLM 生成个性化建议(如结合年龄、病史)。
代码示例
def symptom_parser(state: AgentState) -> AgentState: symptoms = extract_symptoms(state["input"]) # 提取症状关键词 standardized_symptoms = map_to_standard_symptoms(symptoms) # 映射到标准实体 return {**state, "symptoms": standardized_symptoms} builder.add_node("symptom_parser", symptom_parser)
5.4 性能优化
| 优化策略 | 实现方式 |
|---|---|
| 缓存高频查询结果 | 使用 Redis 缓存常见症状-疾病映射关系。 |
| 索引优化 | 为 Symptom.name 和 Disease.name 创建全文索引。 |
| 分布式图引擎 | 使用 TigerGraph 或 Neo4j Aura 实现水平扩展。 |
6. 未来展望
6.1 技术融合趋势
- 多模态图谱:整合医学影像、分子结构图等非文本数据。
- 联邦学习:跨机构的隐私保护型知识融合(如多家医院联合训练模型)。
- 认知推理引擎:结合符号推理(如 Prolog 规则)与神经推理的混合系统。
6.2 开发者实践建议
-
工具选型:
- 中小团队:Apache AGE + LangChain 开源版。
- 企业级:Neo4j Aura + LangChain 企业版(支持 RBAC 权限控制)。
-
评估体系:
- 使用 LangSmith 监控查询链路(追踪 Cypher 生成准确率、向量召回率等)。
7. 总结
图数据库与 LangGraph 的集成,为复杂关系建模和智能决策提供了全新的技术范式。通过 GraphRAG 技术,系统能够在保持语义关联性的同时,实现高效的多跳推理。在医疗、金融等垂直领域,这种融合架构已展现出超越传统方法的潜力,为行业智能化转型提供了坚实的技术基座。
参考资料:
- LangChain 官方文档
- Neo4j 与 LangChain 集成指南
- GraphRAG 在医疗领域的应用
版权声明:本文为 CSDN 博客原创内容,转载请注明出处。
相关文章:

LangChain03-图数据库与LangGraph
图数据库与LangGraph集成实践 1. 引言 在构建智能问答系统、推荐引擎或复杂决策流程时,传统的关系型数据库和向量数据库往往难以满足对实体关系建模和多跳推理的需求。图数据库(如 Neo4j、TigerGraph)通过节点-边-属性的结构化表示ÿ…...

rabbitmq单机多实例部署
RabbitMQ 单实例部署 单实例部署是指在一台服务器上运行一个 RabbitMQ 实例。这种部署方式适用于小型应用或开发环境,配置简单,资源占用较少。单实例部署的核心是安装 RabbitMQ 并启动服务,通常需要配置 Erlang 环境,因为 RabbitMQ 是基于 Erlang 编写的。单实例部署的优势…...
Linux10正式版发布,拥抱AI了!
📢📢📢📣📣📣 作者:IT邦德 中国DBA联盟(ACDU)成员,10余年DBA工作经验 Oracle、PostgreSQL ACE CSDN博客专家及B站知名UP主,全网粉丝10万 擅长主流Oracle、MySQL、PG、高斯…...

在离线 OpenEuler-22.03 服务器上升级 OpenSSH 的完整指南
当然可以!以下是一篇结构清晰、语言通俗易懂的技术博客草稿,供你参考和使用: 在离线 OpenEuler-22.03 服务器上升级 OpenSSH 的完整指南 背景介绍 最近在对一台内网的 OpenEuler-22.03 服务器进行安全扫描时,发现其 SSH 版本存在…...

全能邮箱全能邮箱:实现邮件管理的自动化!
全能邮箱全能邮箱:实现邮件管理的自动化! 全能邮箱全能邮箱的配置教程?如何注册烽火域名邮箱? 全能邮箱全能邮箱作为一种创新的邮件管理解决方案,正逐渐改变我们处理邮件的方式。蜂邮EDM将围绕全能邮箱全能邮箱&…...

[特殊字符] Linux 日志查看与分析常用命令全攻略
在日常运维与开发排查中,我们经常需要查看服务日志来定位问题。本文系统整理了几种常用的日志查看命令,包括 tail、cat、grep、split、sed 等,并结合实际应用场景,提供了完整的使用方式和示例。 📌 一、tail 命令 ——…...

mysql-tpcc-mysql压测工具使用
在Linux系统上安装和配置tpcc-mysql进行MySQL的TPC-C基准测试,通常涉及以下几个步骤。请注意,由于tpcc-mysql不是一个官方工具,它可能需要从第三方仓库获取,如Percona提供的版本。 前置条件 确保MySQL或MariaDB已安装࿱…...
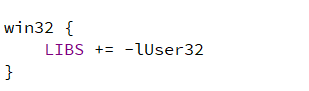
Qt找不到windows API报错:error: LNK2019: 无法解析的外部符号 __imp_OpenClipboard
笔者在开发中出现的bug完整报错如下: spcm_ostools_win.obj:-1: error: LNK2019: 无法解析的外部符号 __imp_OpenClipboard,函数 "void __cdecl spcmdrv::vCopyToClipboard(char const *,unsigned __int64)" (?vCopyToClipboardspcmdrvYAXPE…...

机试 | vector/array Minimum Glutton C++
题目地址 : C - Minimum Glutton #include<stdio.h> #include<iostream> #include<vector> #include<algorithm> using namespace std; int main() {//N:菜肴数,X:总甜度阈值,Y:总咸度阈值int…...

OpenCv高阶(十七)——dlib库安装、dlib人脸检测
文章目录 前言一、dlib库简介二、dlib库安装1、本地安装(离线)2、线上安装 三、dlib人脸检测原理1、HOG 特征提取2、 SVM 分类器训练3、 滑动窗口搜索4、非极大值抑制(NMS) 四、dlib人脸检测代码1、导入OpenCV计算机视觉库和dlib机…...

前端内容黑白处理、轮播图、奇妙的头像特效
1、内容黑白处理 (1)filter:滤镜 可以把包裹的区域中每一个像素点,经过固定的算法转换成另一种颜色来呈现 (2)grayscale:灰阶滤镜 取值范围:0~1取0:原图去1ÿ…...

蓝桥杯 10. 安全序列
当然可以,以下是整理后的 Markdown 格式题目描述: 题目描述 小蓝是工厂里的安全工程师,他负责安放工厂里的危险品。 工厂是一条直线,直线上有 n 个空位,小蓝需要将若干个油桶放置在这 n 个空位上。每 2 个油桶中间至…...
-java+ selenium->元素之By class name)
(10)-java+ selenium->元素之By class name
1.简介 继续介绍WebDriver关于元素定位大法,这篇介绍By ClassName。看到ID,NAME这些方法的讲解,应该知道,要做好Web自动化测试,最好是需要了解一些前端的基本知识。有了前端知识,做元素定位会很轻松,同样写网络爬虫也很有帮助 2.常用定位方法(8种) (1)id (2)nam…...
Git - .gitignore 文件
一、.gitignore 文件介绍 在使用 Git 进行版本控制时,.gitignore 文件是一个非常重要的配置文件,用于告诉 Git 哪些文件或目录不需要被追踪和提交到版本库中。合理使用 .gitignore 文件可以避免提交不必要的文件,如临时文件、编译生成的文件…...
混合编程注意事项与性能优化)
MPI与多线程(如OpenMP)混合编程注意事项与性能优化
文章目录 MPI与多线程(如OpenMP)混合编程注意事项与性能优化混合编程注意事项性能优化策略示例代码编译与运行性能调优建议 MPI与多线程(如OpenMP)混合编程注意事项与性能优化 混合编程注意事项 MPI初始化与线程支持级别: 需要在MPI_Init之前调用MPI_Init_thread指…...
——MAC)
计算机网络学习(八)——MAC
一、MAC 在计算机网络中,MAC(Media Access Control,媒体访问控制)地址是数据链路层的重要概念,它用于唯一标识网络中的设备,并且在局域网(如以太网)中发挥关键作用。 MAC 是硬件地址…...

英语六级-阅读篇
目录 2023年12月大学英语真题(二) 十五选十(Section A) 单词表 短语表 译文 Passage Two(Section C) 单词表 短语表 译文 简介:其实我总结这篇文章就是平时记忆该阅读文章单词中出现的…...

右键打开 pycharm 右键 pycharm
文件夹右键打开pycharm aaa.reg notepad 右下角把文件格式改为:ansi Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\Directory\Background\shell\PyCharm] "Open with PyCharm" "Icon""\"D:\\soft\\PyCharm 2024.1.4\\bi…...

机器人坐标系标定
机器人坐标系标定 机器人坐标系标定 1. 知识目标 理解机器人坐标系的定义掌握机器人坐标系的分类 2. 技能目标 能够正确标定机器人坐标系 3. 机器人坐标系的作用 代表不同的物体或边界示例: 相对于桌子、弓箭、坯料、其他机器或边界移动 用途: 使用…...

Flink流处理基础概论
文章目录 引言Flink基本概述传统数据架构的不足Dataflow中的几大基本概念Dataflow流式处理宏观流程数据并行和任务并行的区别Flink中几种数据传播策略Flink中事件的延迟和吞吐事件延迟事件的吞吐如何更好的理解事件的延迟和吞吐flink数据流的几种操作输入输出转换操作滚动聚合窗…...

【RabbitMQ】记录 InvalidDefinitionException: Java 8 date/time type
目录 1. 添加必要依赖 2. 配置全局序列化方案(推荐) 3. 配置RabbitMQ消息转换器 关键点说明 1. 添加必要依赖 首先确保项目中包含JSR-310支持模块: <dependency><groupId>com.fasterxml.jackson.datatype</groupId>&l…...
如何通过API接口实现自动化上货跨平台铺货?商品采集|商品上传实现详细步骤
一、引言:跨平台铺货的技术挑战与 API 价值 在电商多平台运营时代,商家需要将商品同步上架至淘宝、京东、拼多多、亚马逊、Shopee 等多个平台,传统手动铺货模式存在效率低下(单平台单商品上架需 30-60 分钟)、数据一致…...
《三维点如何映射到图像像素?——相机投影模型详解》
引言 以三维投影介绍大多比较分散,不少小伙伴再面对诸多的坐标系转换中容易弄混,特别是再写代码的时候可能搞错,所有这篇文章帮大家完整的梳理3D视觉中的投影变换的全流程,一文弄清楚这个过程,帮助大家搞清坐标系转换…...

Go 语言范围循环变量重用问题与 VSCode 调试解决方法
文章目录 问题描述问题原因1. Go 1.21 及更早版本的范围循环行为2. Go 1.22 的改进3. VSCode 调试中的问题4. 命令行 dlv debug 的正确输出 三种解决方法1. 启用 Go 模块2. 优化 VSCode 调试配置3. 修改代码以确保兼容性4. 清理缓存5. 验证环境 验证结果结论 在 Go 编程中&…...

青少年编程与数学 02-020 C#程序设计基础 04课题、常量和变量
青少年编程与数学 02-020 C#程序设计基础 04课题、常量和变量 一、主函数1. 主函数的基本格式2. 主函数的参数3. 主函数的返回值4. 主函数的作用5. 主函数的示例6. 主函数的注意事项 二、变量1. 变量的声明示例 2. 变量的初始化声明时初始化声明后赋值 3. 变量的类型3.1 值类型…...
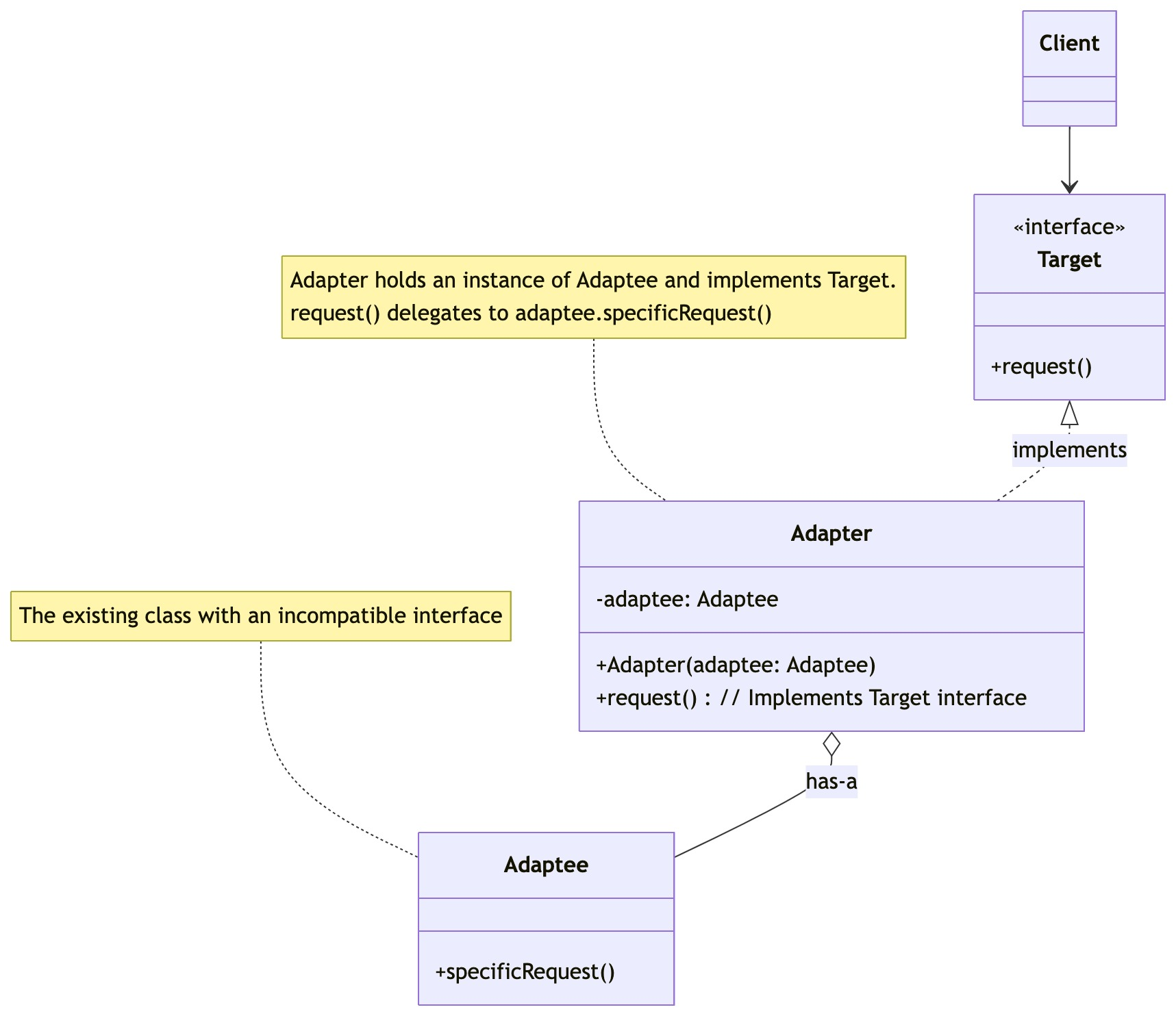
零基础设计模式——结构型模式 - 适配器模式
第三部分:结构型模式 - 适配器模式 (Adapter Pattern) 欢迎来到结构型模式的第一站!结构型模式关注的是如何将类或对象组合成更大的结构,同时保持结构的灵活性和效率。适配器模式是其中非常实用的一个,它能帮助我们解决接口不兼容…...

【QT】TXT文件的基础操作
目录 一、QT删除TXT文件内容 方法1:使用QFile打开文件并截断 方法2:使用QSaveFile(更安全的写入方式) 方法3:使用QTextStream 使用示例 注意事项 二、QT操作TXT文件:清空内容并写入新数据 完整实现代…...
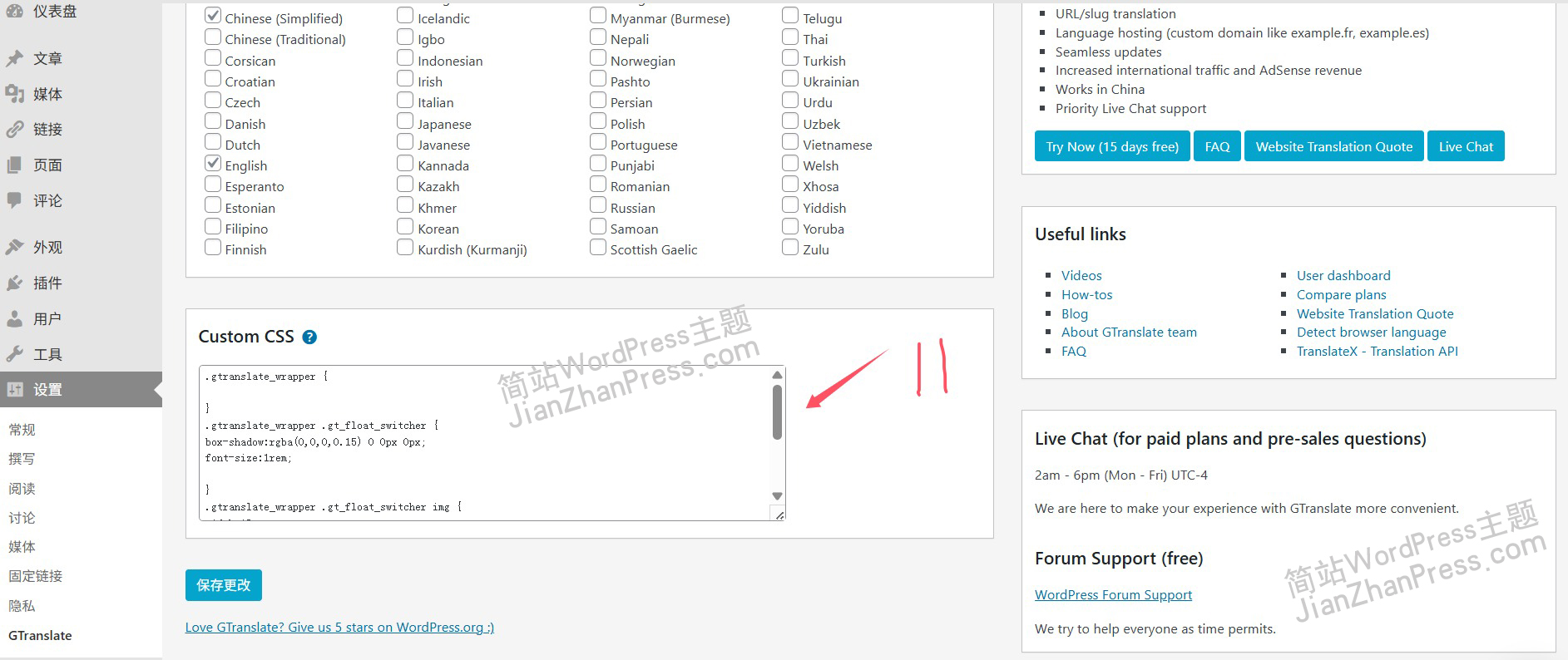
WordPress多语言插件安装与使用教程
WordPress多语言插件GTranslate的使用方法 在wordpress网站后台搜索多语言插件GTranslate并安装,安装完成、用户插件后开始设置,以下为设置方法: 1、先在后台左侧找到Gtranslate,进入到设置界面 2、选择要显示的形式,…...

互联网大厂Java求职面试:短视频平台大规模实时互动系统架构设计
互联网大厂Java求职面试:短视频平台大规模实时互动系统架构设计 面试背景介绍 技术总监(严肃脸): 欢迎来到我们今天的模拟面试,我是技术部的李总监,负责平台后端架构和高可用系统设计。今天我们将围绕一个…...

欣佰特科技|SenseGlove Nova2 力反馈数据手套:助力外科手术训练的精准触觉模拟
在医疗科技持续发展的背景下,虚拟现实(VR)技术正在改变外科手术培训的方式,而 SenseGlove Nova2 力反馈数据手套 在这一领域发挥着重要作用。 SenseGlove Nova2 力反馈数据手套 与 VirtualiSurg 手术模拟系统深度结合。其手部追踪…...