基于深度学习的情绪识别检测系统【完整版】
最近很多小伙伴都在咨询,关于基于深度学习和神经网络算法的情绪识别检测系统。回顾往期文章【点击这里】,介绍了关于人脸数据的预处理和模型训练,这里就不在赘述。今天,将详细讲解如何从零基础手写情绪检测算法和情绪检测系统。主页有我联系方式。
一、什么是情绪识别?有哪些方法?
情绪识别是指通过分析人类的各种表达方式,如面部表情、语音语调、生理信号或文字内容,来识别和理解个体当前情绪状态的技术。它是人工智能、心理学和计算机科学交叉领域的重要研究方向。
1.1情绪识别的基本概念
情绪识别(Emotion Recognition)是情感计算(Affective Computing)的核心组成部分,旨在使计算机系统能够像人类一样感知、理解和响应人类情绪。这项技术基于心理学中的情绪理论,特别是Paul Ekman提出的基本情绪理论,该理论认为人类有六种基本情绪:快乐、悲伤、愤怒、恐惧、惊讶和厌恶。现代情绪识别系统通常采用多模态方法,结合多种数据源来提高识别准确性。情绪识别技术已广泛应用于人机交互、心理健康、教育、市场营销和安防等多个领域。
1.2情绪识别的主要方法
1. 2.1基于面部表情的识别
这是最常见的情绪识别方法,通过分析人脸图像或视频中的面部肌肉运动来识别情绪。主要步骤包括:
- 人脸检测:定位图像中的人脸区域
- 特征提取:提取面部关键点、纹理或运动特征
- 表情分类:使用机器学习算法将特征映射到特定情绪
常用的技术包括主动外观模型(AAM)、局部二值模式(LBP)和深度卷积神经网络(CNN)。
1.2.2 基于语音的识别
通过分析语音信号中的声学特征来识别说话者的情绪状态。重要的语音特征包括:
- 基频(音高)及其变化
- 语音能量(响度)
- 语速和节奏
- 频谱特征(如梅尔频率倒谱系数MFCC)
语音情绪识别在客服系统和语音助手中有重要应用。
1.2.3 基于生理信号的识别
通过测量人体生理指标来识别情绪状态,常用的生理信号包括:
- 脑电图(EEG)
- 心电图(ECG)
- 皮肤电活动(EDA)
- 肌电图(EMG)
这种方法虽然准确度高,但需要接触式传感器,应用场景受限。
1.2.4 基于文本的识别
分析书面或口头文字内容中的情感倾向,主要技术包括:
- 情感词典方法
- 机器学习方法(如SVM、随机森林)
- 深度学习方法(如LSTM、Transformer)
广泛应用于社交媒体监控、产品评论分析和客服聊天机器人等领域。
1.3情绪识别的技术挑战
尽管情绪识别技术取得了显著进展,但仍面临多个挑战:
- 情绪的主观性和复杂性:人类情绪往往是混合的、微妙的且具有文化差异性
- 数据获取的困难:高质量的情绪标注数据难以获取,且标注过程本身具有主观性
- 个体差异性:不同人表达情绪的方式存在显著差异
- 环境干扰:在实际应用中,光照条件、背景噪声等因素会影响识别效果
- 隐私和伦理问题:情绪识别可能涉及个人隐私保护问题
1.4 情绪识别的应用领域
情绪识别技术已在多个领域展现出重要价值:
- 心理健康:抑郁症、焦虑症等精神疾病的早期筛查和辅助治疗
- 智能教育:根据学生情绪状态调整教学内容和节奏
- 智能客服:识别客户情绪并提供相应服务
- 人机交互:使机器人或虚拟助手能够更自然地与人类互动
- 市场研究:分析消费者对产品或广告的情绪反应
- 安防领域:机场、边境等场所的可疑人员情绪识别
二、算法设计与对比
先看表格:
以下是基于公开数据集和算法的人脸情绪识别精度对比表格,结合了传统机器学习、深度学习及最新研究成果:
| 算法 | 数据集 | 情绪类别 | 准确率 | 预处理方法 | 数据增强 | 发表年份 / 来源 |
|---|---|---|---|---|---|---|
| 传统方法 | ||||||
| SVM + AAM | CK+ | 7 类 | 94.5% | 灰度化、对齐、归一化(减去中性帧特征) | 无 | Cohn-Kanade 扩展数据集研究9 |
| K-NN + LBP | JAFFE | 7 类 | 92.3% | 直方图均衡化、LBP 特征提取 | 无 | 经典图像处理方法3 |
| 深度学习 | ||||||
| CNN(定制架构) | FER-2013 | 7 类 | 73.53% | 灰度化、48x48 裁剪、像素归一化(0-1) | 翻转、旋转 | 华南师范大学学报12 |
| VGG-16(微调) | FER-2013 | 7 类 | 65.52% | 灰度化、48x48 缩放、ImageNet 均值归一化 | 无 | CSDN 博客2 |
| ResNet-50(微调) | FER-2013 | 7 类 | 67.53% | 同上 | 无 | CSDN 博客2 |
| Inception-V3(微调) | FER-2013 | 7 类 | 63.86% | 灰度化、48x48 缩放、ImageNet 均值归一化 | 无 | GitHub 项目13 |
| LSTM+ CNN | CK+ | 7 类 | 96.2% | 视频序列帧对齐、灰度化 | 时间扭曲 | CSDN 博客11 |
| 最新模型 | ||||||
| QWTR(四元数小波 Transformer) | AffectNet | 8 类 | 68.37% | 多尺度小波变换、归一化 | 颜色抖动 | IEEE Transactions on Multimedia10 |
| OCNN(优化 CNN) | RAF-DB | 7 类 | 88.50% | 人脸检测(RFB-320)、64x64 裁剪、归一化 | 无 | 华南师范大学学报12 |
| 多模态融合(音频 + 视觉) | RAVDESS | 8 类 | 86.70% | 视觉:动作单元提取;音频:Wav2Vec2.0 特征提取 | 无 | CSDN 博客1 |
| 迁移学习 | ||||||
| FaceNet(微调) | CK+ | 7 类 | 93.8% | 对齐、归一化(0-1) | 无 | Papers With Code21 |
| DeepFace(微调) | JAFFE | 7 类 | 95.1% | 3D 对齐、颜色归一化 | 无 | 对比研究20 |
| 其他方法 | ||||||
| WSCNet | CK+ | 7 类 | 98.9% | 灰度化、对齐 | 无 | CSDN 博客2 |
| 基于注意力的 CNN | JAFFE | 7 类 | 97.2% | 人脸检测(Haar 级联)、64x64 裁剪、归一化 | 翻转、裁剪 | CSDN 博客11 |
数据集说明
-
FER-2013
- 样本量:35,887 张(48x48 灰度图)
- 情绪类别:愤怒、厌恶、恐惧、快乐、悲伤、惊讶、中性
- 特点:包含自然场景和实验室环境,人类准确率约 65%±5%48。
-
CK+
- 样本量:593 个视频序列(峰值帧标注)
- 情绪类别:愤怒、轻蔑、厌恶、恐惧、快乐、悲伤、惊讶
- 特点:实验室控制环境,FACS 编码验证,常用于基准测试921。
-
JAFFE
- 样本量:213 张(10 人)
- 情绪类别:快乐、悲伤、惊讶、愤怒、厌恶、恐惧、中性
- 特点:小规模但高分辨率,常用于早期算法验证11。
-
AffectNet
- 样本量:45 万 + 张(野生环境)
- 情绪类别:中性、快乐、愤怒、悲伤、恐惧、惊讶、厌恶、轻蔑
- 特点:包含种族、年龄多样性,标注 valence/arousal 维度1516。
-
RAF-DB
- 样本量:15,339 张(自然场景)
- 情绪类别:7 类基本情绪 + 复合情绪
- 特点:包含多角度和遮挡情况,适合复杂场景测试12。
-
RAVDESS
- 样本量:7,356 个视频(实验室控制)
- 情绪类别:8 类(如平静、快乐、悲伤)
- 特点:多模态(音频 + 视觉),用于跨模态研究1。
关键发现
-
模型性能
- 传统方法:SVM 在 CK + 上表现优异(94.5%),但依赖手工特征(如 AAM)。
- 深度学习:CNN 在 FER-2013 上准确率约 73%-85%,ResNet 和 Inception 在微调后表现稳定。
- 最新模型:QWTR 在 AffectNet 上刷新记录(68.37%),多模态融合在 RAVDESS 上显著提升至 86.7%。
- 迁移学习:FaceNet 和 DeepFace 在 CK + 和 JAFFE 上表现接近人类水平(>93%)。
-
数据集影响
- 实验室数据集(CK+、JAFFE):算法准确率普遍较高(>90%),但泛化能力有限。
- 野生数据集(AffectNet、RAF-DB):准确率较低(68%-88%),需更强鲁棒性模型。
-
预处理与增强
- 数据增强(如翻转、旋转)可提升 FER-2013 准确率 5%-10%2325。
- 归一化(如 ImageNet 均值)对微调模型至关重要,可避免梯度消失213。
-
多模态优势
- 音频 + 视觉融合在 RAVDESS 上提升准确率超 10%,证明互补信息的重要性1。
局限性
- 数据偏差:部分数据集(如 JAFFE)样本量小且缺乏多样性,可能导致过拟合。
- 预处理差异:不同研究的人脸检测、对齐方法不同,直接对比需谨慎。
- 实时性:复杂模型(如 Transformer)计算成本高,难以部署于边缘设备。
以上便是数据的对比和算法的比较,各有所长吧!其实核心在于原理的理解,多数情况下需要我们结合数据再自行调整。并不是直接搬用!包括算法的优化和数据的调整,特别是训练模型的方法策略,这里我主要讲一下,关于前期文章提到的三种算法:CNN、VGG、ResNet。
以下是三种算法的核心代码:
(1) CNN【卷积神经网络】
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 数据预处理
transform = transforms.Compose([transforms.Resize((48, 48)), # 标准情绪识别输入尺寸transforms.Grayscale(), # 多数研究使用灰度图像transforms.ToTensor(),transforms.Normalize(mean=[0.5], std=[0.5])
])# 加载数据集(以FER2013为例)
train_dataset = datasets.ImageFolder(root='data/train', transform=transform)
test_dataset = datasets.ImageFolder(root='data/test', transform=transform)# 数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 定义CNN模型
class EmotionCNN(nn.Module):def __init__(self, num_classes=7):super(EmotionCNN, self).__init__()# 卷积层块1self.conv1 = nn.Conv2d(1, 64, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(64)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)# 卷积层块2self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(128)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)# 卷积层块3self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)self.bn3 = nn.BatchNorm2d(256)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)# 全连接层self.fc1 = nn.Linear(256*6*6, 1024) # 经过3次池化后尺寸计算:(48/2^3)=6self.dropout = nn.Dropout(0.5)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):x = self.pool1(self.relu1(self.bn1(self.conv1(x))))x = self.pool2(self.relu2(self.bn2(self.conv2(x))))x = self.pool3(self.relu3(self.bn3(self.conv3(x))))x = x.view(x.size(0), -1) # 展平x = self.dropout(F.relu(self.fc1(x)))x = self.fc2(x)return x# 初始化模型
model = EmotionCNN(num_classes=7).to(device)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)# 训练函数
def train(model, dataloader, criterion, optimizer, epoch):model.train()running_loss = 0.0correct = 0total = 0for i, (inputs, labels) in enumerate(dataloader):inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()if i % 100 == 99:print(f'Epoch {epoch}, Batch {i+1}, Loss: {running_loss/100:.4f}')running_loss = 0.0train_acc = 100 * correct / totalprint(f'Epoch {epoch} Training Accuracy: {train_acc:.2f}%')return train_acc# 测试函数
def test(model, dataloader, criterion):model.eval()test_loss = 0.0correct = 0total = 0with torch.no_grad():for inputs, labels in dataloader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)test_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()test_acc = 100 * correct / totalprint(f'Test Accuracy: {test_acc:.2f}%, Test Loss: {test_loss/len(dataloader):.4f}')return test_acc# 训练循环
num_epochs = 20
train_accs = []
test_accs = []for epoch in range(1, num_epochs+1):train_acc = train(model, train_loader, criterion, optimizer, epoch)test_acc = test(model, test_loader, criterion)scheduler.step()train_accs.append(train_acc)test_accs.append(test_acc)# 保存模型
torch.save(model.state_dict(), 'emotion_cnn.pth')# 绘制训练曲线
plt.plot(range(1, num_epochs+1), train_accs, label='Train Accuracy')
plt.plot(range(1, num_epochs+1), test_accs, label='Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.show()基于ResNet的改进实现
这里主要是想试试改进后识别的准确率会不会提升,感兴趣的小伙伴可以试试
class ResidualBlock(nn.Module):def __init__(self, in_channels, out_channels, stride=1):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU()self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential()if stride != 1 or in_channels != out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride),nn.BatchNorm2d(out_channels))def forward(self, x):residual = xout = self.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out)))out += self.shortcut(residual)out = self.relu(out)return outclass EmotionResNet(nn.Module):def __init__(self, num_classes=7):super(EmotionResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU()self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 残差块self.layer1 = self.make_layer(64, 2, stride=1)self.layer2 = self.make_layer(128, 2, stride=2)self.layer3 = self.make_layer(256, 2, stride=2)# 全局平均池化self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(256, num_classes)def make_layer(self, out_channels, blocks, stride):layers = []layers.append(ResidualBlock(self.in_channels, out_channels, stride))self.in_channels = out_channelsfor _ in range(1, blocks):layers.append(ResidualBlock(out_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.maxpool(self.relu(self.bn1(self.conv1(x))))x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc(x)return xVGG 是一种经典的深度卷积神经网络架构,由牛津大学视觉几何组(Visual Geometry Group)提出。使用VGG架构,包含数据加载、模型训练、评估和预测,以下是使用 VGG 架构实现人脸情绪识别的完整代码示例:
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models, datasets
import matplotlib.pyplot as plt
from PIL import Image
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
import time
import copy# 1. 设备配置和随机种子设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.manual_seed(42)
np.random.seed(42)# 2. 数据集配置
class EmotionDataset(Dataset):"""自定义数据集类,支持数据增强"""def __init__(self, data_dir, transform=None, mode='train'):self.data_dir = data_dirself.transform = transformself.mode = modeself.classes = ['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']self.class_to_idx = {cls: i for i, cls in enumerate(self.classes)}self.images = self._load_images()def _load_images(self):images = []for class_name in self.classes:class_dir = os.path.join(self.data_dir, self.mode, class_name)for img_name in os.listdir(class_dir):if img_name.endswith(('.jpg', '.png', '.jpeg')):img_path = os.path.join(class_dir, img_name)images.append((img_path, self.class_to_idx[class_name]))return imagesdef __len__(self):return len(self.images)def __getitem__(self, idx):img_path, label = self.images[idx]image = Image.open(img_path).convert('L') # 转为灰度if self.transform:image = self.transform(image)return image, label# 3. 数据预处理和增强
def get_transforms():# 训练集增强train_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(),transforms.RandomRotation(10),transforms.ColorJitter(brightness=0.2, contrast=0.2),transforms.ToTensor(),transforms.Normalize(mean=[0.5], std=[0.5])])# 验证/测试集变换val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.5], std=[0.5])])return train_transform, val_transform# 4. 数据加载
def prepare_dataloaders(data_dir, batch_size=32):train_transform, val_transform = get_transforms()# 创建数据集train_dataset = EmotionDataset(data_dir, transform=train_transform, mode='train')val_dataset = EmotionDataset(data_dir, transform=val_transform, mode='validation')test_dataset = EmotionDataset(data_dir, transform=val_transform, mode='test')# 创建数据加载器train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)return train_loader, val_loader, test_loader# 5. VGG模型定义
class VGGEmotion(nn.Module):def __init__(self, num_classes=7, pretrained=True):super(VGGEmotion, self).__init__()# 加载预训练VGG16vgg = models.vgg16(pretrained=pretrained)# 修改第一层卷积(原始为3通道,我们使用灰度图)vgg.features[0] = nn.Conv2d(1, 64, kernel_size=3, padding=1)# 使用VGG的特征提取部分self.features = vgg.features# 自定义分类器self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(True),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(0.5),nn.Linear(4096, num_classes),)# 初始化权重self._initialize_weights()def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)# 6. 训练和验证函数
def train_model(model, dataloaders, criterion, optimizer, scheduler, num_epochs=25):since = time.time()best_model_wts = copy.deepcopy(model.state_dict())best_acc = 0.0# 记录训练过程history = {'train_loss': [],'train_acc': [],'val_loss': [],'val_acc': []}for epoch in range(num_epochs):print(f'Epoch {epoch}/{num_epochs-1}')print('-' * 10)# 每个epoch都有训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train()else:model.eval()running_loss = 0.0running_corrects = 0# 迭代数据for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 梯度清零optimizer.zero_grad()# 前向传播with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 反向传播+优化仅在训练阶段if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)if phase == 'train':scheduler.step()epoch_loss = running_loss / len(dataloaders[phase].dataset)epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)# 记录历史if phase == 'train':history['train_loss'].append(epoch_loss)history['train_acc'].append(epoch_acc)else:history['val_loss'].append(epoch_loss)history['val_acc'].append(epoch_acc)print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')# 深度复制模型if phase == 'val' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())print()time_elapsed = time.time() - sinceprint(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')print(f'Best val Acc: {best_acc:.4f}')# 加载最佳模型权重model.load_state_dict(best_model_wts)return model, history# 7. 评估函数
def evaluate_model(model, test_loader):model.eval()all_preds = []all_labels = []with torch.no_grad():for inputs, labels in test_loader:inputs = inputs.to(device)labels = labels.to(device)outputs = model(inputs)_, preds = torch.max(outputs, 1)all_preds.extend(preds.cpu().numpy())all_labels.extend(labels.cpu().numpy())# 计算混淆矩阵cm = confusion_matrix(all_labels, all_preds)plt.figure(figsize=(10, 8))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=emotion_labels, yticklabels=emotion_labels)plt.xlabel('Predicted')plt.ylabel('True')plt.title('Confusion Matrix')plt.show()# 分类报告print(classification_report(all_labels, all_preds, target_names=emotion_labels))return cm# 8. 可视化训练过程
def plot_training_history(history):plt.figure(figsize=(12, 5))# 绘制损失曲线plt.subplot(1, 2, 1)plt.plot(history['train_loss'], label='Train Loss')plt.plot(history['val_loss'], label='Validation Loss')plt.title('Training and Validation Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()# 绘制准确率曲线plt.subplot(1, 2, 2)plt.plot(history['train_acc'], label='Train Accuracy')plt.plot(history['val_acc'], label='Validation Accuracy')plt.title('Training and Validation Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.tight_layout()plt.show()# 9. 主函数
def main():# 参数设置data_dir = 'path_to_your_dataset' # 替换为你的数据集路径batch_size = 32num_epochs = 30num_classes = 7emotion_labels = ['angry', 'disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']# 准备数据train_loader, val_loader, test_loader = prepare_dataloaders(data_dir, batch_size)dataloaders = {'train': train_loader, 'val': val_loader}# 初始化模型model = VGGEmotion(num_classes=num_classes).to(device)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4)# 学习率调度器scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 训练模型model, history = train_model(model, dataloaders, criterion, optimizer, scheduler, num_epochs)# 评估模型print("Evaluating on test set...")cm = evaluate_model(model, test_loader)# 可视化训练过程plot_training_history(history)# 保存模型torch.save(model.state_dict(), 'emotion_vgg.pth')print("Model saved as emotion_vgg.pth")if __name__ == '__main__':main()# 10. 预测函数(单独使用)
def predict_emotion(image_path, model_path='emotion_vgg.pth'):# 加载模型model = VGGEmotion(num_classes=7)model.load_state_dict(torch.load(model_path, map_location='cpu'))model.eval()# 预处理transform = transforms.Compose([transforms.Resize((224, 224)),transforms.Grayscale(),transforms.ToTensor(),transforms.Normalize(mean=[0.5], std=[0.5])])# 加载图像image = Image.open(image_path).convert('L')image_tensor = transform(image).unsqueeze(0)# 预测with torch.no_grad():outputs = model(image_tensor)_, predicted = torch.max(outputs, 1)probabilities = torch.softmax(outputs, dim=1).squeeze().numpy()# 可视化plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.imshow(image, cmap='gray')plt.title(f'Predicted: {emotion_labels[predicted.item()]}')plt.axis('off')plt.subplot(1, 2, 2)plt.barh(emotion_labels, probabilities)plt.xlabel('Probability')plt.title('Emotion Probabilities')plt.tight_layout()plt.show()return emotion_labels[predicted.item()], probabilities# 使用示例
# emotion, probs = predict_emotion('test_image.jpg')这个实现可以直接用于FER2013等标准情绪识别数据集,只需调整数据加载部分即可。训练完成后,模型可以保存并用于实时情绪识别应用。
算法训练结果对比
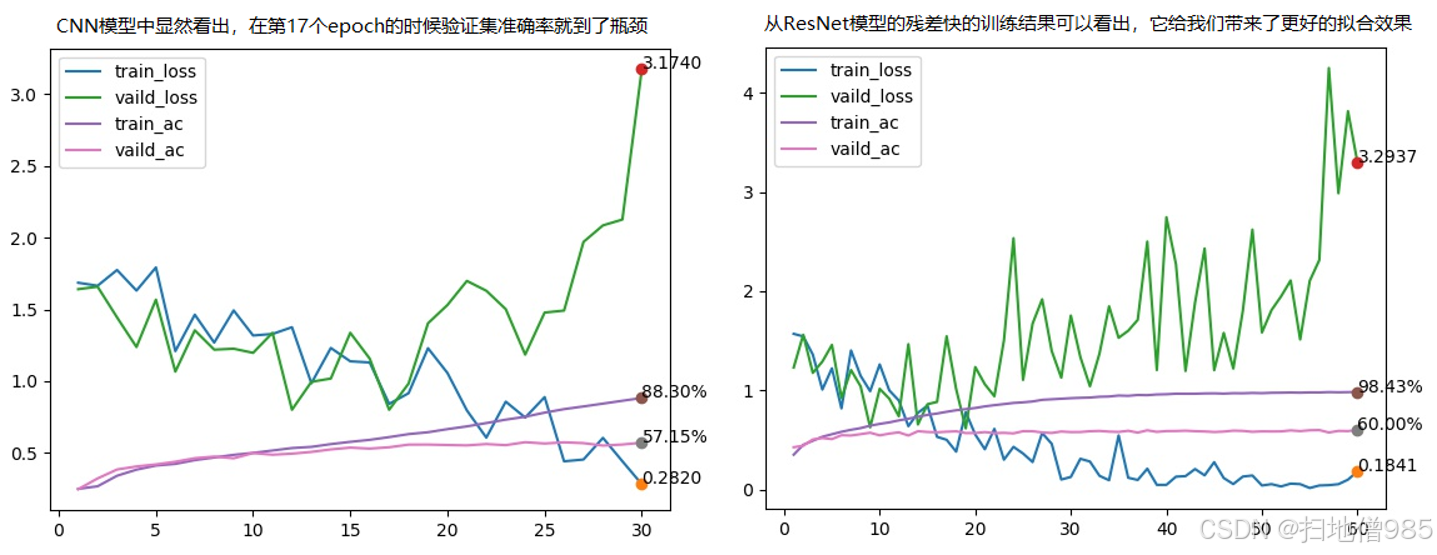
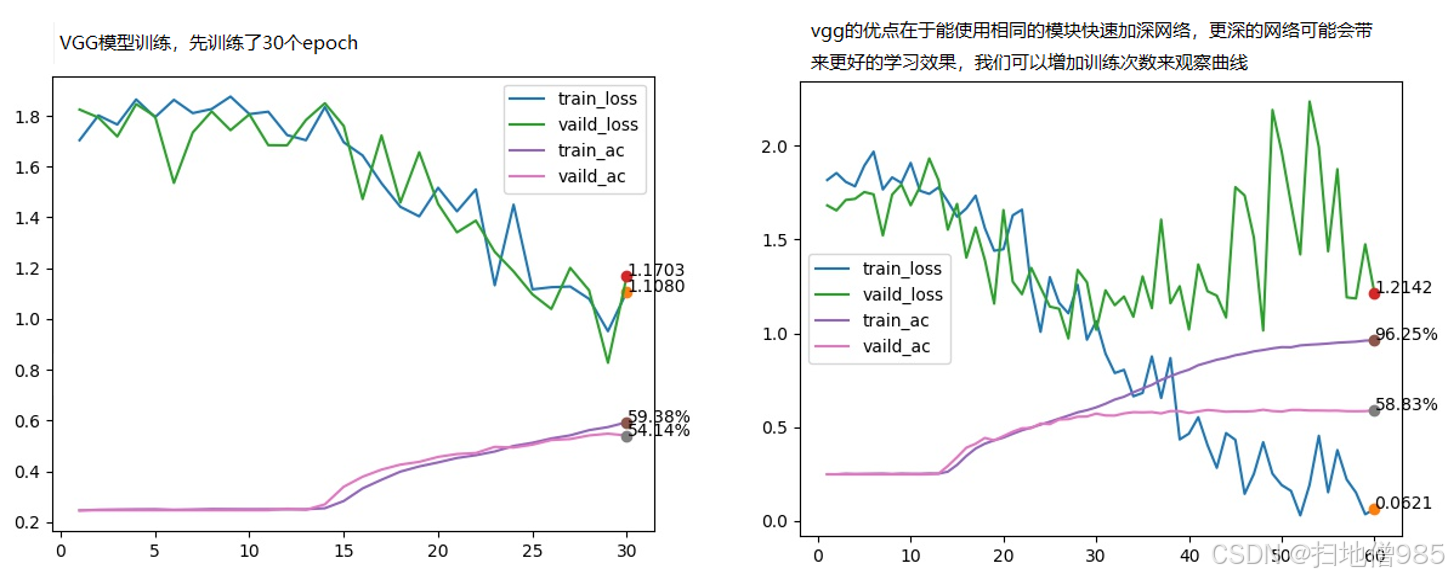
从训练结果分析可以看出,不同模型架构在情绪识别任务上表现出显著差异。CNN模型在第17个epoch时验证集准确率达到57.15%后陷入瓶颈,训练准确率虽高达88.80%,但存在明显过拟合现象。相比之下,ResNet模型凭借其残差连接结构展现出更好的拟合能力,训练准确率达到98.43%,验证准确率提升至60.00%,且损失值更低(0.1B41),表明残差结构有效缓解了深层网络的梯度消失问题。而VGG模型表现最不理想,训练30个epoch后验证准确率仅为14%,且训练损失(1.103)与验证损失(1.080)居高不下,这与其庞大的参数量和较深的网络结构导致的优化困难有关。综合来看,ResNet架构在本任务中展现出最佳性能平衡,既能达到较高训练准确率,又能保持较好的泛化能力,是情绪识别任务更合适的模型选择。这些结果也印证了适当引入残差连接等创新结构对提升深度学习模型性能的重要性。
训练好的模型:

模型训练好后接下来就二十验证和测试环节。
交互界面我们采用PyQt5来构建,或者你可以可以使用Python自带的Tk图形用户界面(GUI),可通过 tkinter 包及其扩展 tkinter.ttk 模块来使用它。
class EmotionBars(QWidget):def __init__(self):super().__init__()self.probabilities = np.zeros(7)self.colors = [QColor(255, 87, 87), # 愤怒QColor(156, 39, 176), # 厌恶QColor(33, 150, 243), # 恐惧QColor(255, 193, 7), # 高兴QColor(0, 188, 212), # 悲伤QColor(255, 152, 0), # 惊讶QColor(76, 175, 80) # 正常]self.setMinimumSize(480, 280)self.setFont(QFont("Microsoft YaHei", 10))def paintEvent(self, event):painter = QPainter(self)painter.setRenderHint(QPainter.Antialiasing)# 渐变背景gradient = QLinearGradient(0, 0, self.width(), self.height())gradient.setColorAt(0, QColor(40, 40, 40))gradient.setColorAt(1, QColor(70, 70, 70))painter.fillRect(self.rect(), gradient)# 布局参数bar_width = 45spacing = 25chart_height = self.height() - 100base_y = self.height() - 75# 绘制柱状图for i in range(7):x = 40 + i * (bar_width + spacing)height = chart_height * self.probabilities[i]# 3D柱体painter.setBrush(self.colors[i].darker(120))painter.drawRect(x + 3, base_y - height + 3, bar_width, height)painter.setBrush(self.colors[i])painter.drawRect(x, base_y - height, bar_width, height)# 文字标签painter.setPen(Qt.white)text_rect = QRect(x - 15, base_y + 10, bar_width + 30, 50)label = ['愤怒', '厌恶', '恐惧', '高兴', '悲伤', '惊讶', '正常'][i]painter.drawText(text_rect, Qt.AlignCenter | Qt.TextWordWrap,f"{label}\n{self.probabilities[i] * 100:.1f}%")class MainWindow(QMainWindow):def __init__(self):super().__init__()self.initUI()self.initCamera()self.classifier = EmotionClassifier()self.is_detecting = Falsedef initUI(self):# 窗口设置self.setWindowTitle("智能情绪识别系统")self.setGeometry(100, 100, 1280, 720)# 主窗口部件main_widget = QWidget()self.setCentralWidget(main_widget)main_layout = QHBoxLayout(main_widget)main_layout.setContentsMargins(20, 15, 20, 15)main_layout.setSpacing(20)# 视频区域video_frame = QFrame()video_frame.setStyleSheet("""background: #1A1A1A;border-radius: 12px;border: 2px solid #404040;""")video_layout = QVBoxLayout(video_frame)video_layout.setContentsMargins(10, 10, 10, 10)self.video_label = QLabel("摄像头准备中...")self.video_label.setAlignment(Qt.AlignCenter)self.video_label.setStyleSheet("""font: 18px 'Microsoft YaHei';color: #888;background: transparent;""")video_layout.addWidget(self.video_label)main_layout.addWidget(video_frame, 3)# 右侧面板right_frame = QFrame()right_frame.setStyleSheet("""background: #2A2A2A;border-radius: 12px;border: 2px solid #404040;""")right_layout = QVBoxLayout(right_frame)right_layout.setContentsMargins(25, 25, 25, 25)right_layout.setSpacing(25)# 情绪显示self.emotion_label = QLabel("等待识别")self.emotion_label.setAlignment(Qt.AlignCenter)self.emotion_label.setStyleSheet("""font: bold 26px 'Microsoft YaHei';color: #FFF;background: #3A3A3A;border-radius: 8px;padding: 20px;min-height: 100px;""")right_layout.addWidget(self.emotion_label, stretch=1)# 柱状图self.bars = EmotionBars()right_layout.addWidget(self.bars, stretch=4)# 控制按钮btn_container = QFrame()btn_layout = QHBoxLayout(btn_container)btn_layout.setContentsMargins(0, 10, 0, 0)btn_layout.setSpacing(20)self.start_btn = QPushButton("🎥 开始识别")self.start_btn.clicked.connect(self.toggleDetection)self.start_btn.setStyleSheet("""QPushButton {background: #4CAF50;color: white;border: none;padding: 18px 35px;font: bold 18px 'Microsoft YaHei';border-radius: 8px;min-width: 150px;}QPushButton:hover { background: #45A049; }QPushButton:pressed { background: #388E3C; }""")exit_btn = QPushButton("🚪 退出系统")exit_btn.clicked.connect(self.close)exit_btn.setStyleSheet("""QPushButton {background: #F44336;color: white;border: none;padding: 18px 35px;font: bold 18px 'Microsoft YaHei';border-radius: 8px;min-width: 150px;}QPushButton:hover { background: #D32F2F; }QPushButton:pressed { background: #C62828; }""")btn_layout.addWidget(self.start_btn)btn_layout.addWidget(exit_btn)right_layout.addWidget(btn_container, stretch=1)main_layout.addWidget(right_frame, 1)def initCamera(self):self.cap = cv2.VideoCapture(0)self.timer = QTimer()self.timer.timeout.connect(self.updateFrame)self.timer.start(30)def toggleDetection(self):self.is_detecting = not self.is_detectingself.start_btn.setText("⏹️ 停止识别" if self.is_detecting else "🎥 开始识别")def updateFrame(self):ret, frame = self.cap.read()if ret:frame = cv2.flip(frame, 1)rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 显示视频h, w = rgb.shape[:2]bytes_line = 3 * wq_img = QImage(rgb.data, w, h, bytes_line, QImage.Format_RGB888)self.video_label.setPixmap(QPixmap.fromImage(q_img).scaled(800, 600,Qt.KeepAspectRatio, Qt.SmoothTransformation))if self.is_detecting:gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)faces = self.classifier.face_cascade.detectMultiScale(gray, 1.3, 5)if len(faces) > 0:(x, y, w, h) = faces[0]face_img = Image.fromarray(cv2.resize(frame[y:y + h, x:x + w], (42, 42)))emotion, prob = self.classifier.get_emotion(face_img)self.emotion_label.setText(f"当前情绪状态:\n{emotion}")self.bars.probabilities = probself.bars.update()else:self.emotion_label.setText("未检测到人脸")def closeEvent(self, event):self.cap.release()event.accept()最终结果如下:
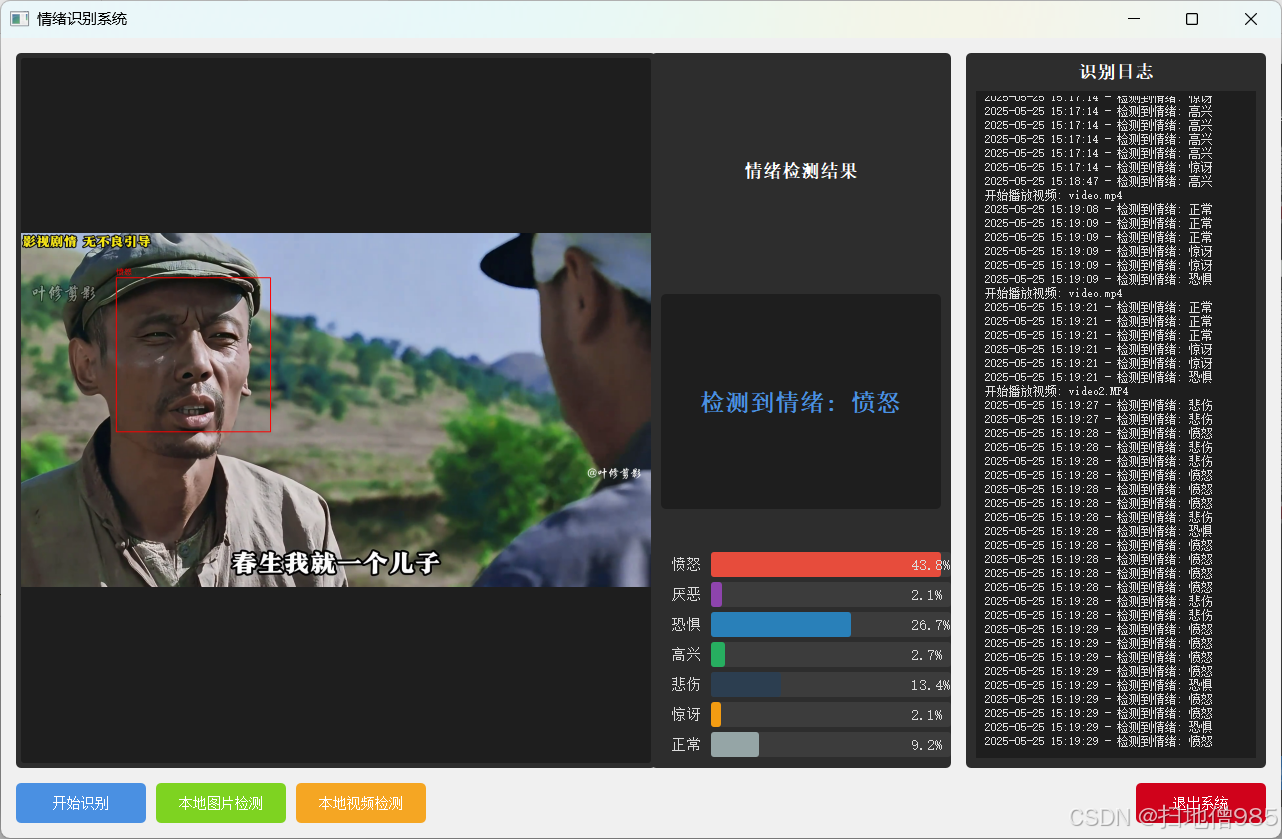
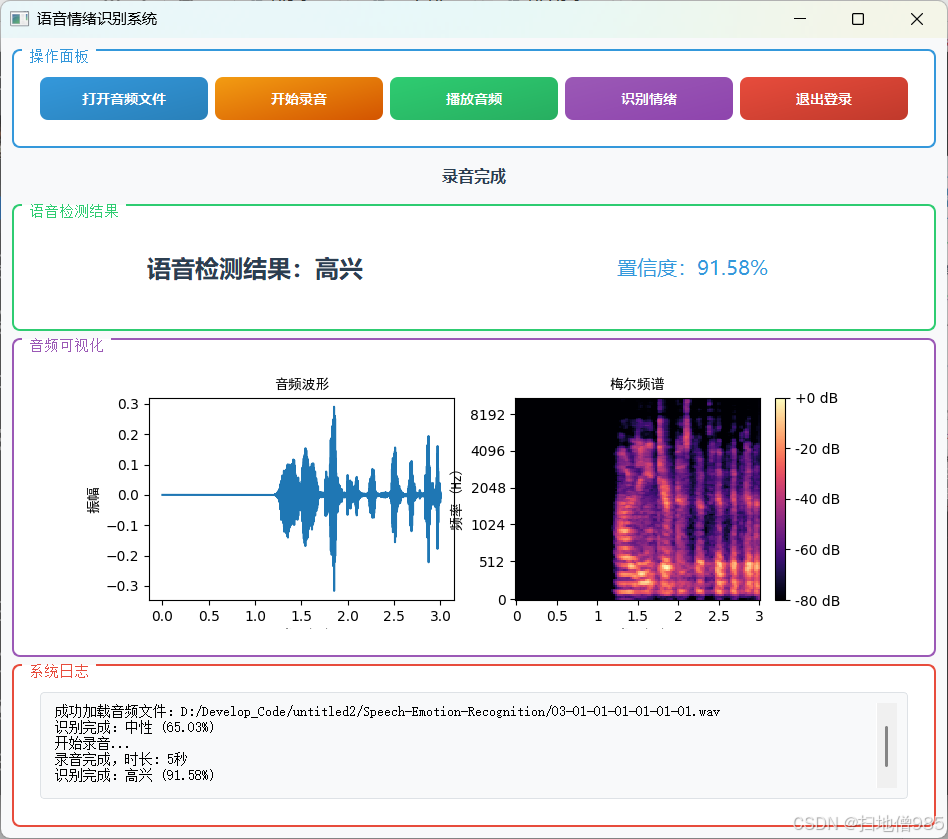
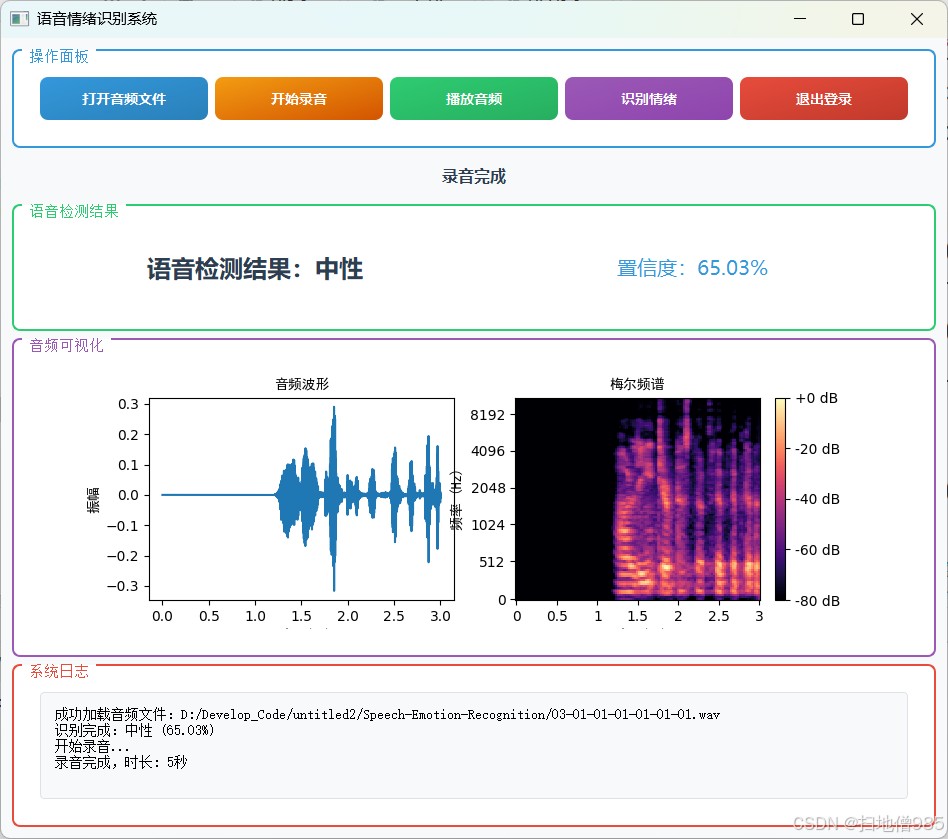
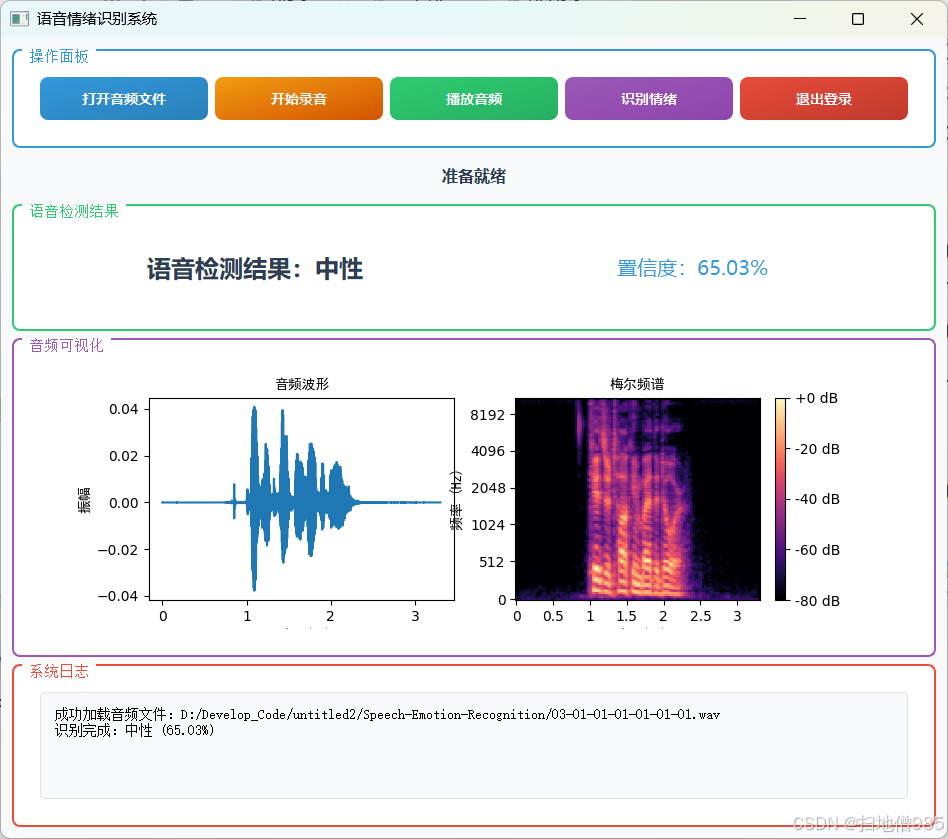
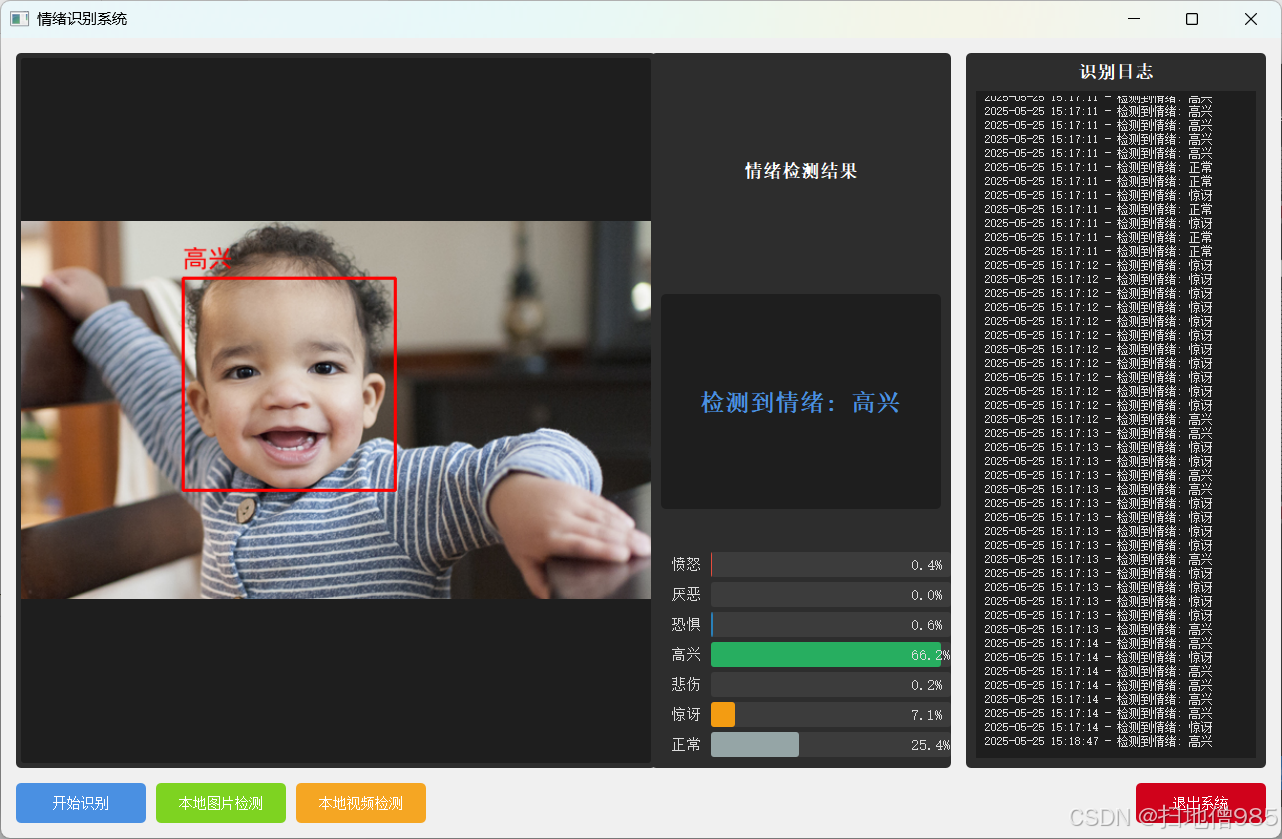
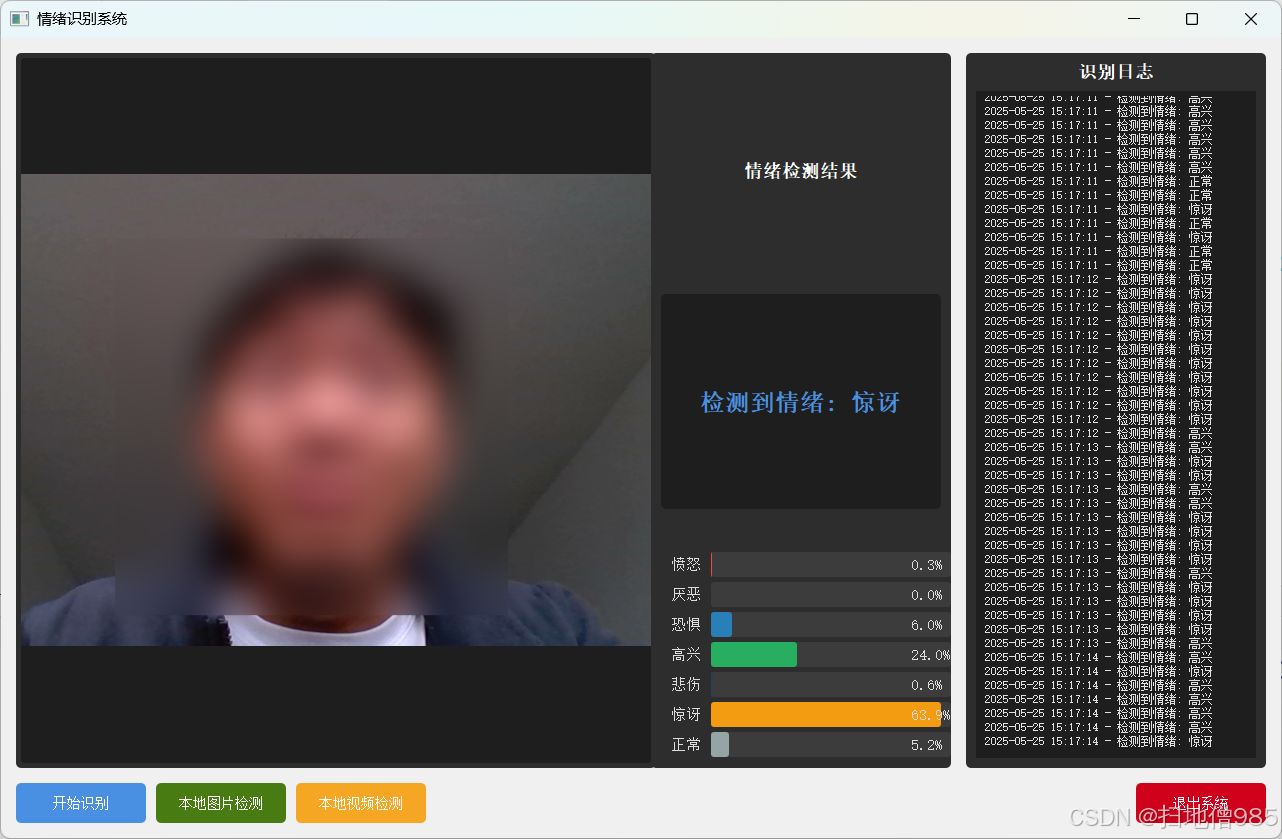
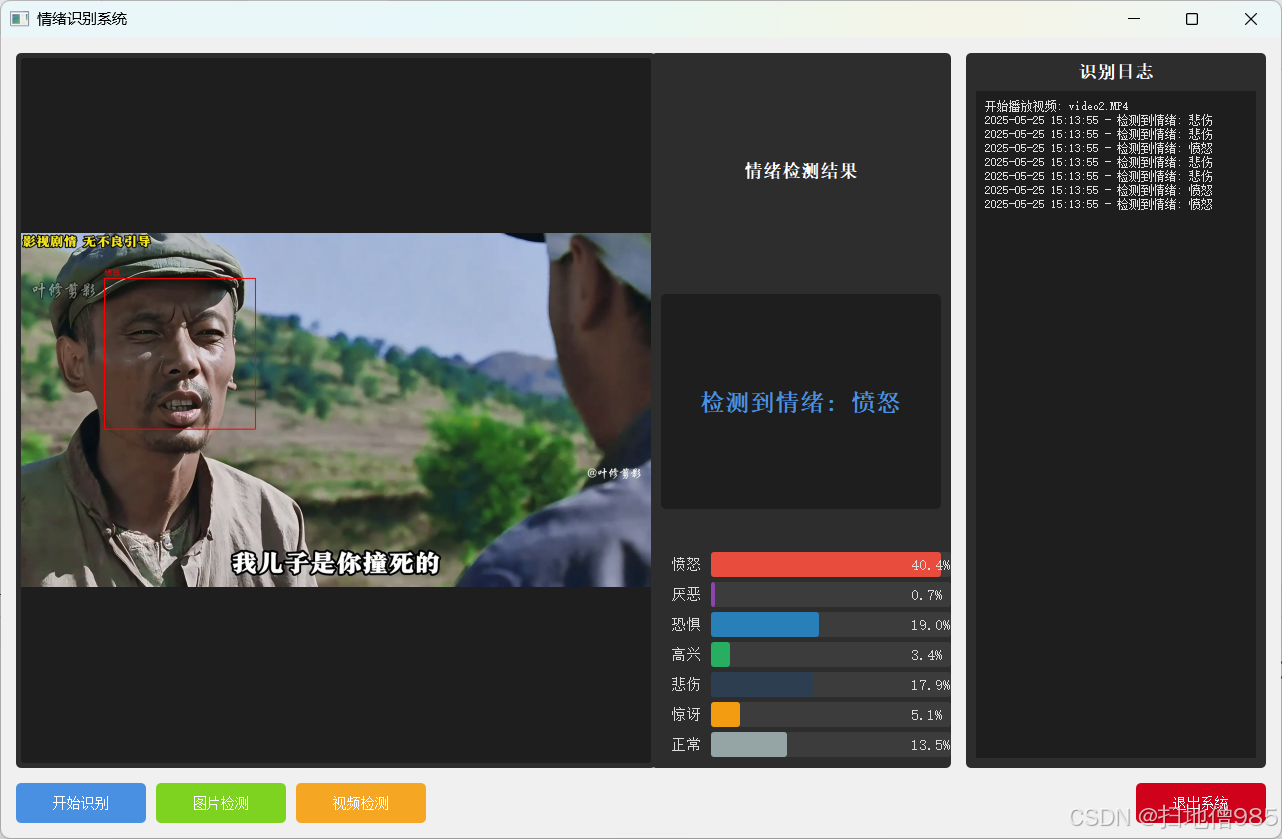
只要功能介绍:
这里为了大家好学习,分为了三个版本。初级版、中级版,最终版
| 版本 | 特点 | 核心内容 |
|---|---|---|
| 初级版本 | 基于三种基础算法实现人脸情绪识别 | 1. 采用 CNN、VGG、ResNet 三种算法训练模型,提供已训练模型直接调用 2. 完成数据预处理、模型训练与识别过程 3. 实现人脸情绪动态识别,实时检测 |
| 中级版本 | 多端覆盖,加入用户管理与日志记录, 个性化建议 | 1. 包含 Web 端和本地 PC 端,支持注册登录,配备用户数据库 2. 保留初级版本全部算法与功能 3. 新增本地日志记录,详细记录情绪识别过程与结果 |
| 最终版本 | 多模态融合,全场景检测,可视化交互 | 1. 融合人脸、语音多模态情绪识别,支持本地图片 / 视频静态动态检测、摄像头实时检测 2. 计算情绪实时百分比,提供可视化交互界面展示分析结果 3. 具备本地日志记录功能,完整记录多模态识别过程及结果 |
以下是结合开发环境、工具及硬件功能的版本升级说明,突出技术实现细节:
| 版本 | 开发语言 / 工具 | 核心技术架构 | 硬件与实时功能 | 新增特性 |
|---|---|---|---|---|
| 初级版本 | Python 3.9+ Pycharm | - 算法框架:Keras/TensorFlow 2.x - 数据处理:OpenCV、NumPy - 环境:虚拟环境(venv/conda) | - 基础功能:静态图片检测(需手动导入图片) - 有摄像头实时识别功能 | - 纯算法训练与基础检测,无界面交互 |
| 中级版本 | Python 3.9+ Pycharm PyQt5 | - 跨平台框架:PyQt5(PC 端界面) - Web 端:Flask/Django - 数据库:SQLite/MySQL - 环境:虚拟环境隔离开发 | - 新增功能: ✓ 笔记本摄像头实时调用(OpenCV VideoCapture) ✓ 实时视频流单帧检测(帧率:5-10 FPS) | - 用户系统:注册 / 登录(加密存储) - 本地日志:记录检测时间、情绪结果、图片路径 |
| 最终版本 | Python 3.9+ Pycharm PyQt5 | - 多模态框架: ▶ 视觉:TensorFlow+MTCNN ▶ 语音:Librosa+PyTorch - Web 端:Flask+PyQt5 - 环境:conda 虚拟环境 + GPU 加速(CUDA) | - 实时功能升级: ✓ 摄像头实时检测(优化后帧率:15-20 FPS) ✓ 语音情绪识别(麦克风实时 |
关键技术细节补充
-
开发环境搭建
- 虚拟环境:使用
conda create -n emotion_env python=3.7创建隔离环境,通过requirements.txt管理依赖(如tensorflow==2.12.0、opencv-python==4.5.3.56)。 - Pycharm 配置:
- 项目解释器指向虚拟环境 Python 路径;
- 启用版本控制(Git)和代码检查(Flake8)。
- 虚拟环境:使用
-
摄像头实时检测实现
- 硬件支持:通过
cv2.VideoCapture(0)调用笔记本内置摄像头,支持分辨率设置(如cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640))。 - 实时流程:
import cv2 cap = cv2.VideoCapture(0) while True:ret, frame = cap.read() # 读取摄像头帧frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 灰度化faces = mtcnn.detect_faces(frame) # 人脸检测for face in faces:emotion = model.predict(face_roi) # 情绪预测cv2.putText(frame, emotion, (x,y), font, 1, (0,255,0)) # 结果标注cv2.imshow("Real-time Emotion Detection", frame)if cv2.waitKey(1) & 0xFF == ord('q'):break cap.release() cv2.destroyAllWindows()
- 硬件支持:通过
-
多模态融合技术栈
- 视觉模块:使用预训练 ResNet50 提取人脸特征(输入尺寸 224x224);
- 语音模块:通过 Librosa 提取 MFCC 特征(80 维向量),输入 LSTM 网络分类;
- 融合方式:将视觉特征(2048 维)与语音特征(128 维)拼接后,通过全连接层输出最终情绪概率。
- 我的扣扣2551931023,欢迎咨询讨论!
多模态情绪识别融合人脸、语音等多源数据,通过CNN、LSTM等模型提取视觉(表情)与听觉(语音语调)特征,经融合算法综合分析情绪。可实现图片、视频、实时摄像头的静态/动态检测,输出情绪类别及百分比,提升复杂场景识别精度,广泛应用于智能交互、心理分析等领域。
到这里就结束了,由于篇幅原因,今天到这里,我们下期再续······
相关文章:
基于深度学习的情绪识别检测系统【完整版】
最近很多小伙伴都在咨询,关于基于深度学习和神经网络算法的情绪识别检测系统。回顾往期文章【点击这里】,介绍了关于人脸数据的预处理和模型训练,这里就不在赘述。今天,将详细讲解如何从零基础手写情绪检测算法和情绪检测系统。主…...

本地依赖库的版本和库依赖的版本不一致如何解决?
我用的 yarn v4 版本,所以以下教程命令都基于yarn 这里假设我报错的库名字叫 XXXXXXXX,依赖他的库叫 AAAAAAAA 排查解决思路分析: 首先查看一下 XXXXXXXX 的依赖关系,执行 yarn why XXXXXXXX 首先我们要知道 yarn 自动做了库…...
Redis学习打卡-Day7-高可用(下)
前面提到,在某些场景下,单实例存Redis缓存会存在的几个问题: 写并发:Redis单实例读写分离可以解决读操作的负载均衡,但对于写操作,仍然是全部落在了master节点上面,在海量数据高并发场景&#x…...

Spark on Yarn 高可用模式部署流程
一、引言 Spark是一个用于大规模数据分析处理的分布式计算框架,适用于快速处理大数据的场景。Yarn是一个资源调度框架,用于集群资源的调度和管理。Spark 的任务也可以提交到Yarn中运行,由Yarn进行资源调度。在生产环境中,为了避免单点故障导致整个集群不可用的情况,一个很…...
)
AI时代新词-大模型(Large Language Model)
一、什么是大模型? 大模型,全称为“大规模语言模型”(Large Language Model),是一种基于深度学习的人工智能技术。它通过海量的文本数据进行训练,学习语言的模式、语法和语义,从而能够生成自然…...

3d tiles高级样式设计与条件渲染
条件渲染是3D Tiles样式设置的一大亮点。我们可以通过设置不同的条件来实现复杂的视觉效果。例如,根据建筑物与某个特定点的距离来设置颜色和是否显示: tiles3d.style new Cesium.Cesium3DTileStyle({defines: {distance: "distance(vec2(${featur…...

Linux中logger命令的使用方法详解
文章目录 一、基础语法二、核心功能选项三、设施与优先级对照1. 常用设施(Facility)2. 优先级(Priority)从低到高:3. 组合示例 四、典型使用场景1. 记录简单消息2. 带标签和优先级3. 记录命令输出4. 发送到远程服…...

博奥龙Nanoantibody系列IP专用抗体
货号名称BDAA0260 HRP-Nanoantibody anti Mouse for IP BDAA0261 AbBox Fluor 680-Nanoantibody anti Mouse for IP BDAA0262 AbBox Fluor 800-Nanoantibody anti Mouse for IP ——无轻/重链干扰,更高亲和力和特异性 01Nanoantibody系列抗体 是利用噬菌体展示纳…...

webpack构建速度和打包体积优化方案
一、分析工具 1.1 webpack-bundle-analyzer 生成 stats.json 文件 打包命令webpack --config webpack.config.js --json > stats.json使用 webpack-bundle-analyzer 插件const BundleAnalyzerPlugin = require(webpack-bundle-analyzer).BundleAnalyzerPlugin; plugins: […...

[IMX] 08.RTC 时钟
代码链接:GitHub - maoxiaoxian/imx 目录 1.IMX 的 SNVS 模块 2.SNVS 模块的寄存器 2.1.命令寄存器 - SNVS_HPCOMR 2.2.低功耗控制寄存器 - SNVS_LPCR 2.3.HP 模式的计数寄存器 MSB - SNVS_HPRTCMR 2.4.HP 模式的计数寄存器 LSB - SNVS_HPRTCLR 2.5.LP 模式的…...
PG Craft靶机复现 宏macro攻击
一. 端口扫描 只有80端口开启 二. 网页查看 目录扫描一下: dirsearch -u http://192.168.131.169/ 发现 http://192.168.131.169/upload.php 网站书使用xampp搭建,暴露了路径 还发现上传文件 http://192.168.131.169/uploads/ 发现一个上传点&#x…...

Qt Creator快捷键合集
前言 QtCreator是一款跨平台的IDE,专为Qt开发设计,支持C/C++/JS/Python编程,支持设备远程调试,支持代码高亮,集成帮助文档,原生支持cmake和git,确实是一款朴实而又强大的集成开发环境,让人有种爱不释手的感觉 编辑 功能快捷键复制Ctrl + C粘贴Ctrl + V剪切Ctrl + X代…...

ElasticSearch--DSL查询语句
ElasticSearch DSL查询文档 分类 查询类型功能描述典型应用场景示例语法查询所有匹配所有文档,无过滤条件数据预览/测试json { "query": { "match_all": {} } }全文检索查询对文本字段分词后匹配,基于倒排索引搜索框模糊匹配、多字段…...

海康威视摄像头C#开发指南:从SDK对接到安全增强与高并发优化
一、海康威视SDK核心对接流程 1. 开发环境准备 官方SDK获取:从海康开放平台下载最新版SDK(如HCNetSDK.dll、PlayCtrl.dll)。依赖项安装:确保C运行库(如vcredist_x86.exe)与S…...
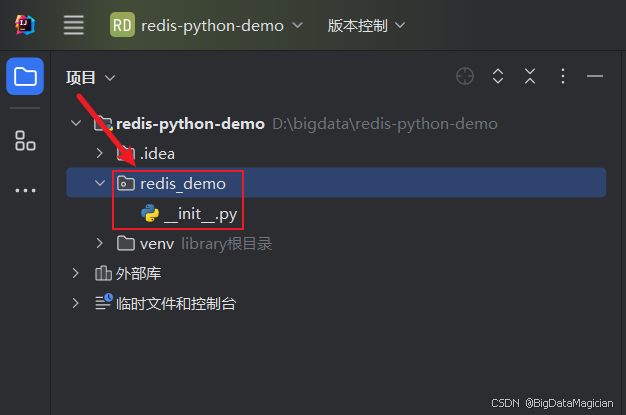
Redis(四) - 使用Python操作Redis详解
文章目录 前言一、下载Python插件二、创建项目三、安装 redis 库四、新建python软件包五、键操作六、字符串操作七、列表操作八、集合操作九、哈希表操作十、有序集合操作十一、完整代码1. 完整代码2. 项目下载 前言 本文是基于 Python 操作 Redis 数据库的实战指南࿰…...

Kotlin全栈工程师转型路径
针对 Android 开发者向全栈工程师的转型,结合 Kotlin 语言的独特优势,以下是分阶段转型路径和关键技术建议: 一、Kotlin 全栈技术栈构建 后端开发深化 Ktor 框架进阶: 掌握路由嵌套、内容协商(JSON/Protobuf…...

如何利用 Spring Data MongoDB 进行地理位置相关的查询?
以下是如何使用 Spring Data MongoDB 进行地理位置相关查询的步骤和示例: 核心概念: GeoJSON 对象: MongoDB 推荐使用 GeoJSON 格式来存储地理位置数据。Spring Data MongoDB 提供了相应的 GeoJSON 类型,如 GeoJsonPoint, GeoJsonPolygon, …...
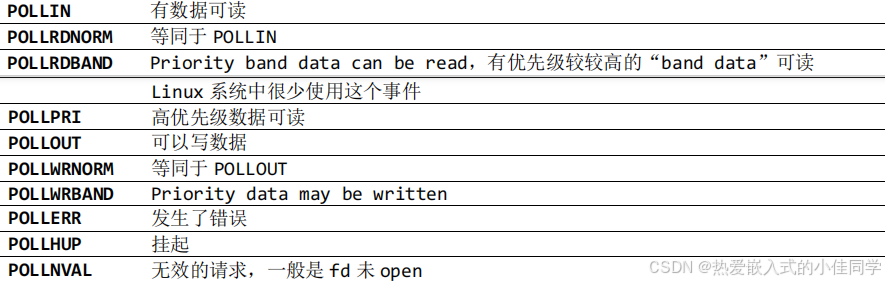
服务器并发实现的五种方法
文章目录 前言一、单线程 / 进程二、多进程并发三、多线程并发四、IO多路转接(复用)select五、IO多路转接(复用)poll六、IO多路转接(复用)epoll 前言 关于网络编程相关知识可看我之前写过的文章࿱…...

PYTORCH_CUDA_ALLOC_CONF基本原理和具体示例
PYTORCH_CUDA_ALLOC_CONFmax_split_size_mb 是 PyTorch 提供的一项环境变量配置,用于控制 CUDA 显存分配的行为。通过指定此参数,可以有效管理 GPU 显存的碎片化,缓解因显存碎片化而导致的 “CUDA out of memory”(显存溢出&#…...

2025年系统架构师---综合知识卷
1.进程是一个具有独立功能的程序关于某数据集合的一次运行活动,是系统进行资源分配和调度的基本单位(线程包含于进程之中,可并发,是系统进行运算调度的最小单位)。一个进程是通过其物理实体被感知的,进程的物理实体又称为进程的静态描述,通常由三部分组成,分别是程序、…...

AI 抠图软件批量处理 + 发丝级精度,婚纱 / 玻璃一键抠透明 免安装
各位抠图小能手们,今天我要给大家介绍一款超厉害的工具——AiartyImageMattingPortable!它是基于人工智能的便携式图像抠图工具,专门为快速、精准抠图而生,处理复杂边缘和透明物体那简直就是它的拿手好戏! 咱先说说它…...

JVM 深度解析
一、JVM 概述 1.1 什么是 JVM? JVM(Java Virtual Machine,Java 虚拟机)是 Java 程序运行的核心引擎。它像一个“翻译官”,将 Java 字节码转换为机器能理解的指令,并管理程序运行时的内存、线程等资源。 …...
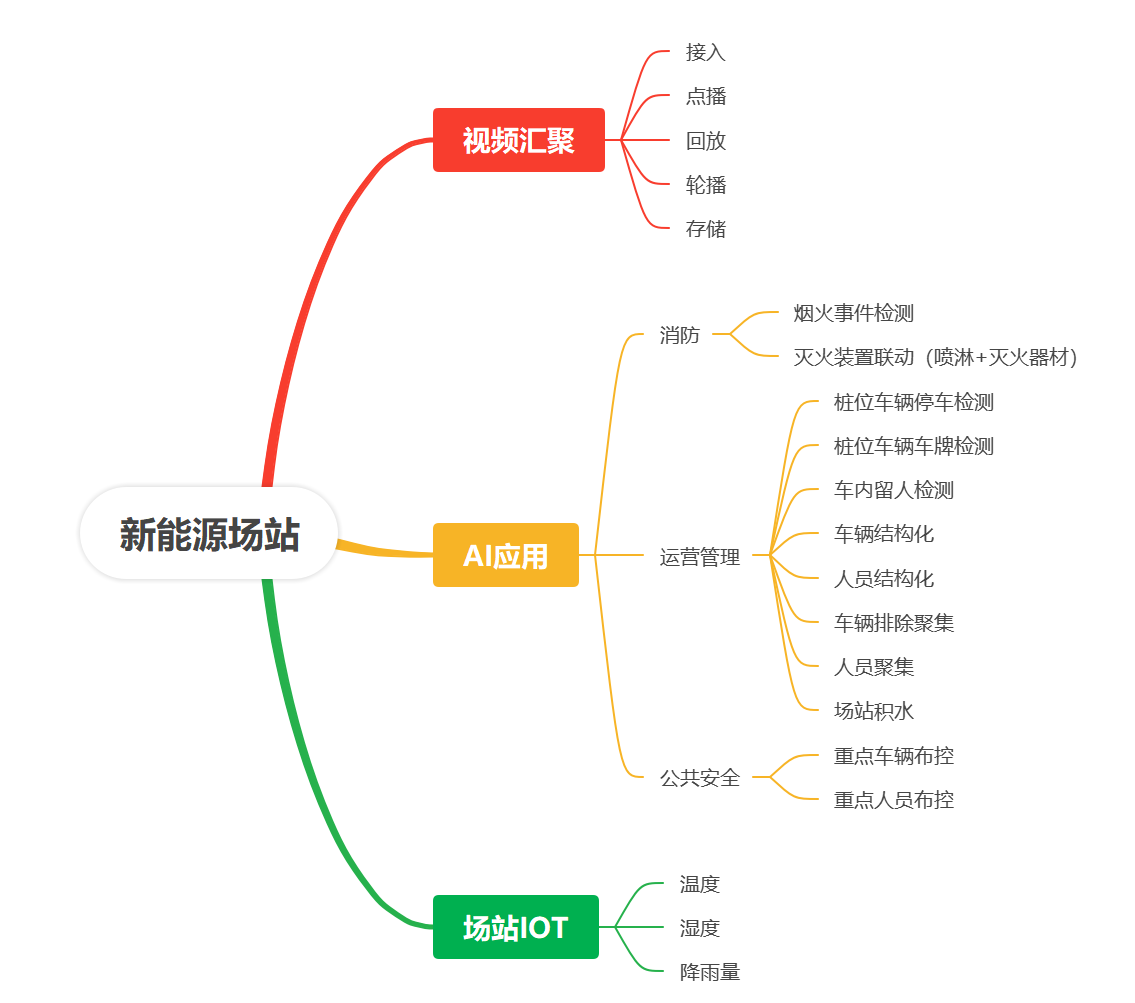
新能源汽车移动充电服务:如何通过智能调度提升充电桩可用率?
随着新能源汽车的普及,充电需求激增,但固定充电桩的布局难以满足用户灵活补能的需求,尤其在高峰时段或偏远地区,"充电难"问题日益凸显。移动充电服务作为新兴解决方案,通过动态调度充电资源,有望…...

SpringCloud Alibaba微服务-- Sentinel的使用(笔记)
雪崩问题: 小问题引发大问题,小服务出现故障,处理不当,可能导致整个微服务宕机。 假如商品服务出故障,购物车调用该服务,则可能出现处理时间过长,如果一秒几十个请求,那么处理时间过…...

PARSCALE:大语言模型的第三种扩展范式
----->更多内容,请移步“鲁班秘笈”!!<----- 随着人工智能技术的飞速发展,大语言模型(LLM)已成为推动机器智能向通用人工智能(AGI)迈进的核心驱动力。然而,传统的…...
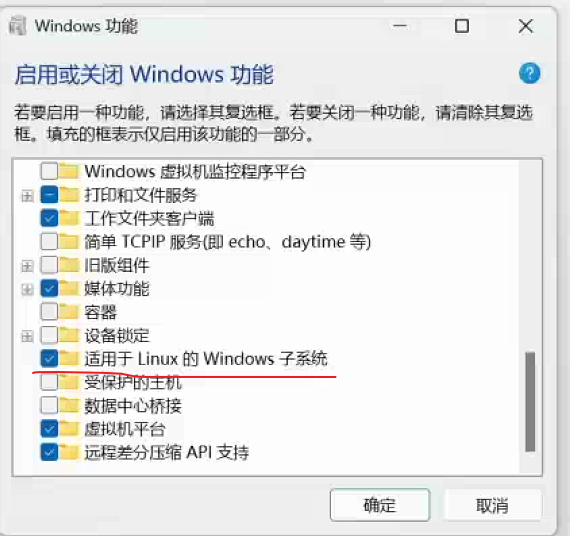
在Windows上,将 Ubuntu WSL 安装并迁移到 D 盘完整教程(含 Appx 安装与迁移导入)
💻 将 Ubuntu WSL 安装并迁移到 D 盘完整教程(含 Appx 安装与迁移导入) 本文记录如何在 Windows 系统中手动启用 WSL、下载 Ubuntu 安装包、安装并迁移 Ubuntu 到 D 盘,避免默认写入 C 盘,提高系统性能与可维护性。 ✅…...
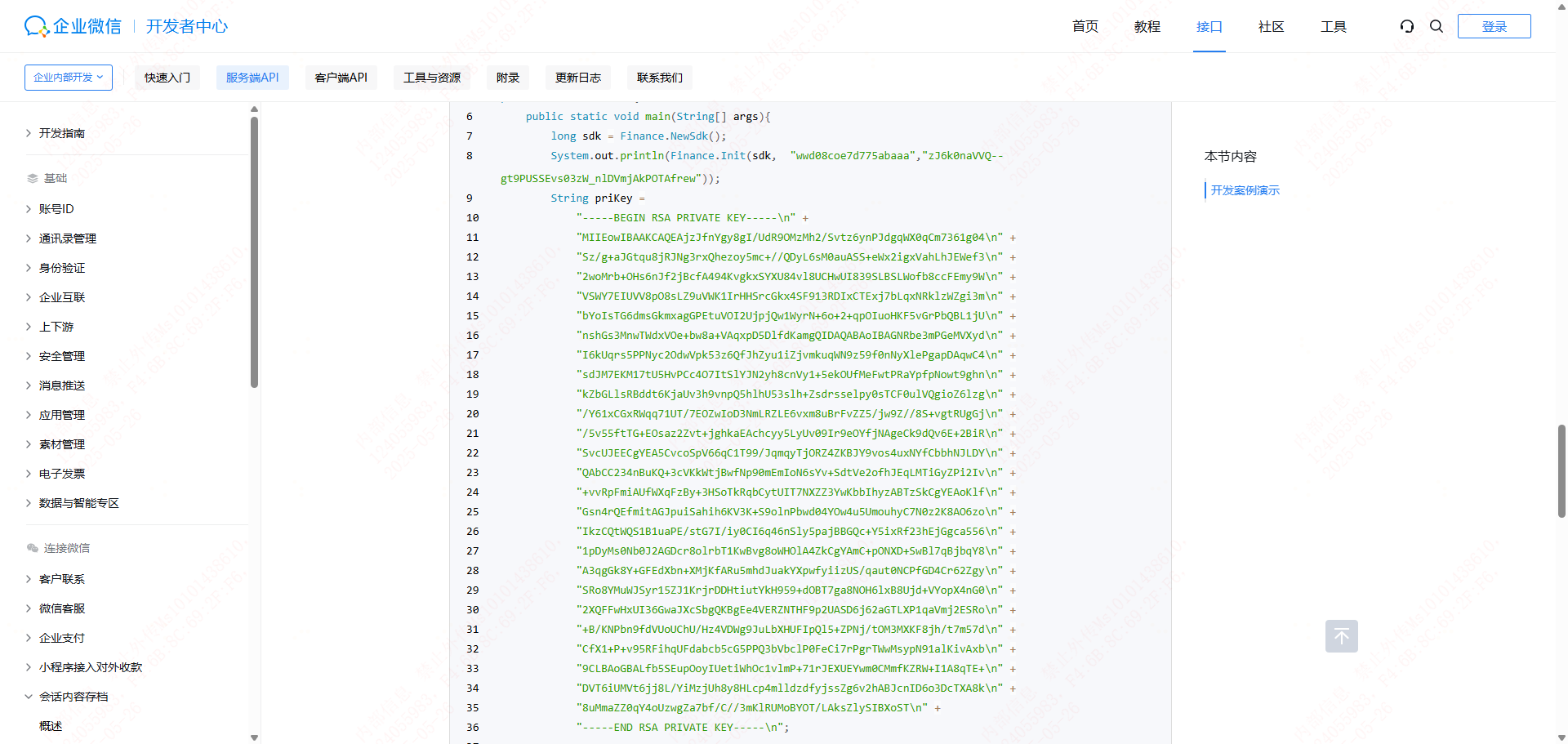
企微获取会话内容,RSA 解密函数
企微获取会话内容,RSA 解密函数 企微获取会话内容下载SDKSDK配置解密过程解密代码参考SDK文件上传到服务器最后 企微获取会话内容 官方文档: https://developer.work.weixin.qq.com/document/path/91774 下载SDK 根据自己的环境下载对应的SDK。 SDK配置…...

MyBatis入门:快速搭建数据库操作框架 + 增删改查(CRUD)
一、创建Mybatis的项目 Mybatis 是⼀个持久层框架, 具体的数据存储和数据操作还是在MySQL中操作的, 所以需要添加MySQL驱动 1.添加依赖 或者 手动添加依赖 <!--Mybatis 依赖包--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactI…...
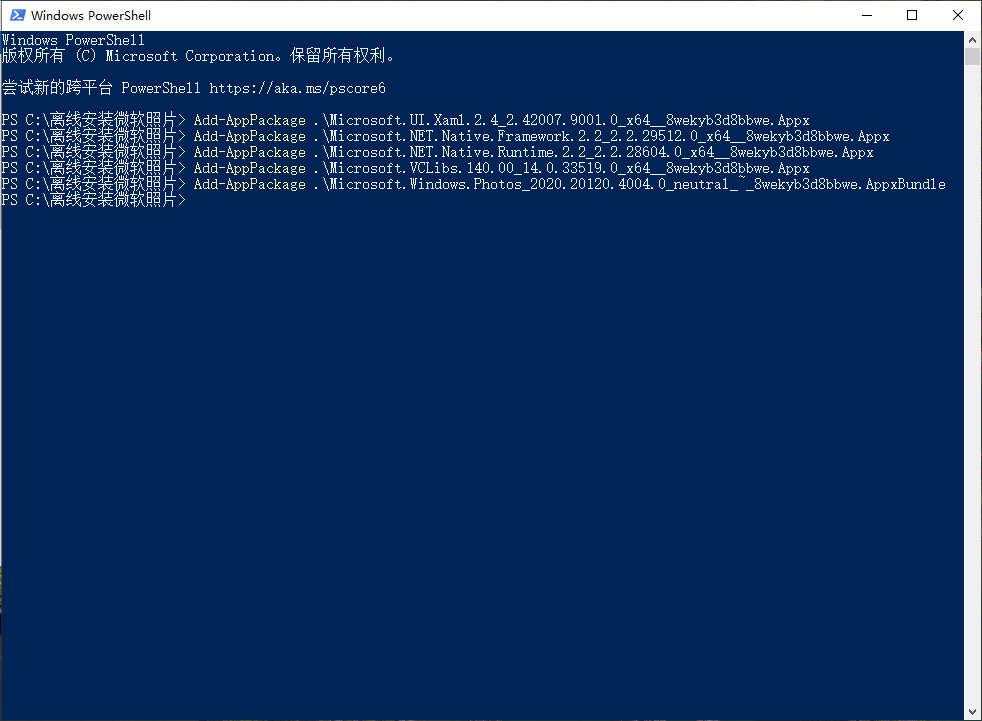
离线安装Microsoft 照片【笔记】
实验环境为:Windows 10 企业版 LTSC。 1.下载好相关离线依赖包和安装包。 2.管理员身份运行powershell,输入以下命令行: Add-AppPackage .\Microsoft.UI.Xaml.2.4_2.42007.9001.0_x64__8wekyb3d8bbwe.Appx Add-AppPackage .\Microsoft.NET…...

地理卷积神经网络加权回归模型的详细实现方案
以下为地理卷积神经网络加权回归模型的详细实现方案。由于篇幅限制,代码和说明将分模块呈现。 地理卷积神经网络加权回归模型实现 目录 理论基础数据预处理模型架构设计空间权重矩阵生成混合模型实现实验与结果分析优化与扩展结论一、理论基础 1.1 地理加权回归(GWR) 地理…...