PyTorch实现MLP信用评分模型全流程
知识点回顾:
- 过拟合的判断:测试集和训练集同步打印指标
- 模型的保存和加载
- 仅保存权重
- 保存权重和模型
- 保存全部信息checkpoint,还包含训练状态
- 早停策略
@浙大疏锦行
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
from tqdm import tqdm # 导入tqdm库用于进度条显示
import warnings
import time
warnings.filterwarnings("ignore") # 忽略所有警告信息
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")data = pd.read_csv('data.csv') #读取数据discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)# Years in current job 标签编码
years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名# Term 0 - 1 映射
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表# 连续特征用中位数补全
for feature in continuous_features: mode_value = data[feature].mode()[0] #获取该列的众数。data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 打印下尺寸
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放
# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train.values).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test.values).to(device)class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(31, 50) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(50, 30) # 隐藏层到输出层self.relu = nn.ReLU()self.fc3 = nn.Linear(30, 15) # 输出层self.relu = nn.ReLU()self.fc4 = nn.Linear(15, 2) # 输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)out = self.relu(out)out = self.fc3(out)out = self.relu(out)out = self.fc4(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
# optimizer = optim.SGD(model.parameters(), lr=0.01)# 使用自适应学习率的化器
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每200个epoch的损失值和对应的epoch数
train_losses = [] # 存储训练集损失
test_losses = [] # 新增:存储测试集损失
epochs = []start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:# 计算测试集损失,新增代码model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss') # 原始代码已有
plt.plot(epochs, test_losses, label='Test Loss') # 新增:测试集损失曲线
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend() # 新增:显示图例
plt.grid(True)
plt.show()# 在测试集上评估模型,此时model内部已经是训练好的参数了
# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度计算,可以提高模型推理速度outputs = model(X_test) # 对测试数据进行前向传播,获得预测结果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引correct = (predicted == y_test).sum().item() # 计算预测正确的样本数accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%')相关文章:

PyTorch实现MLP信用评分模型全流程
知识点回顾: 过拟合的判断:测试集和训练集同步打印指标模型的保存和加载 仅保存权重保存权重和模型保存全部信息checkpoint,还包含训练状态 早停策略 浙大疏锦行 import torch import torch.nn as nn import torch.optim as optim from skle…...

语音识别——文本转语音
python自带的pytts说话人的声音比较机械,edge-tts提供了更自然的语音合成效果,支持多种语音选择。 项目地址:GitHub - rany2/edge-tts: Use Microsoft Edges online text-to-speech service from Python WITHOUT needing Microsoft Edge or …...

跟着华为去变革 ——读《常变与长青》有感
《常变与长青》,是华为郭平总2024年上市的著作。走进这本书,我们能够清晰看到华为30多年的成长过程和伴随期间的变革历程:从一家设备代理商开始,起步蹒跚,砥砺前行,在闯过一个又一个磨难之后,成…...

图像分割技术的实现与比较分析
引言 图像分割是计算机视觉领域中的一项基础技术,其目标是将数字图像划分为多个图像子区域(像素的集合),以简化图像表示,便于后续分析和理解。在医学影像、遥感图像分析、自动驾驶、工业检测等众多领域,图…...

node.js配置变量
一、下载安装包 1、官网下载 大家可以在官网下载,适合自己电脑以及项目的需要的版本。 二、node.js安装 1、安装 双击下载的安装包文件,通常为 .exe 或 .msi 格式(Windows)或 .dmg 格式(Mac)。系统会…...
Ubuntu+Docker+内网穿透:保姆级教程实现安卓开发环境远程部署
文章目录 前言1. 虚拟化环境检查2. Android 模拟器部署3. Ubuntu安装Cpolar4. 配置公网地址5. 远程访问小结 6. 固定Cpolar公网地址7. 固定地址访问 前言 本文将详细介绍一种创新性的云开发架构:基于Ubuntu系统构建Android仿真容器环境,并集成安全隧道技…...

为什么需要清除浮动?清除浮动的方式有哪些?
导语: 在前端面试中,“清除浮动”几乎是每位面试官都会问到的基础题。虽然浮动已经不如 Flex 和 Grid 那么常用了,但它在许多老项目中仍然占有一席之地。理解浮动的机制、掌握清除浮动的方式,是面试中体现你前端基础扎实度的关键点。 一、面试主题概述 浮动(float)最初是…...

计算机网络学习20250526
SMTP——简单邮件传输协议 TCP 端口号:25 Alice给Bob发送邮件过程: Alice使用邮件代理程序写邮件给Bob用户代理把报文发给邮件服务器,放入报文队列中邮件服务器上SMTP客户端建立与Bob服务器上SMTP服务器的TCP连接经过初始的握手后ÿ…...
)
ArkUI:鸿蒙应用响应式与组件化开发指南(一)
文章目录 引言1.ArkUI核心能力概览1.1状态驱动视图1.2组件化:构建可复用UI 2.状态管理:从单一组件到全局共享2.1 状态装饰器2.2 状态传递模式对比 引言 鸿蒙生态正催生应用开发的新范式。作为面向全场景的分布式操作系统,鸿蒙的北向应用开发…...

YOLOv11改进 | Neck篇 | 双向特征金字塔网络BiFPN助力YOLOv11有效涨点
YOLOv11改进 | Neck篇 | 双向特征金字塔网络BiFPN助力YOLOv11有效涨点 引言 目标检测领域的最新进展表明,特征金字塔网络(FPN)的设计对模型性能具有决定性影响。本文详细介绍如何将**双向特征金字塔网络(BiFPN)**集成到YOLOv11的Neck部分,通过改进的多尺度特征融合机制…...

C/C++的OpenCV 进行轮廓提取
使用 C/C的OpenCV 进行轮廓提取 轮廓可以简单地描述为连接所有具有相同颜色或强度的连续点(沿着边界)的曲线。轮廓是形状分析以及对象检测和识别的有用工具。OpenCV 提供了非常方便的函数来查找和绘制轮廓。 本文将指导您完成使用 C 和 OpenCV 库从图像…...
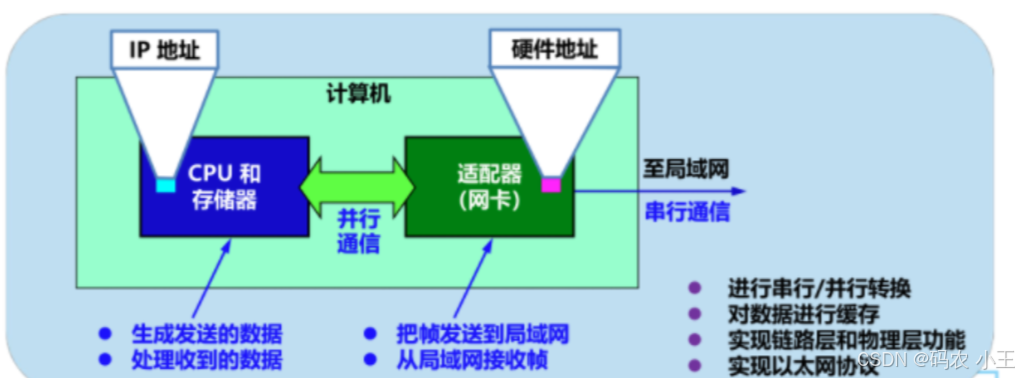
计算机网络总结(物理层,链路层)
目录 第一章 概述 1.基本概念 2.- C/S模式,B/S模式,P2P模式 3.- LAN,WAN,MAN,PAN的划分 4.电路交换与分组交换,数据报交换和虚电路交换 第二章 物理层 1.信号编码:不归零编码,曼切斯特编码 2.几种复用技术的特…...
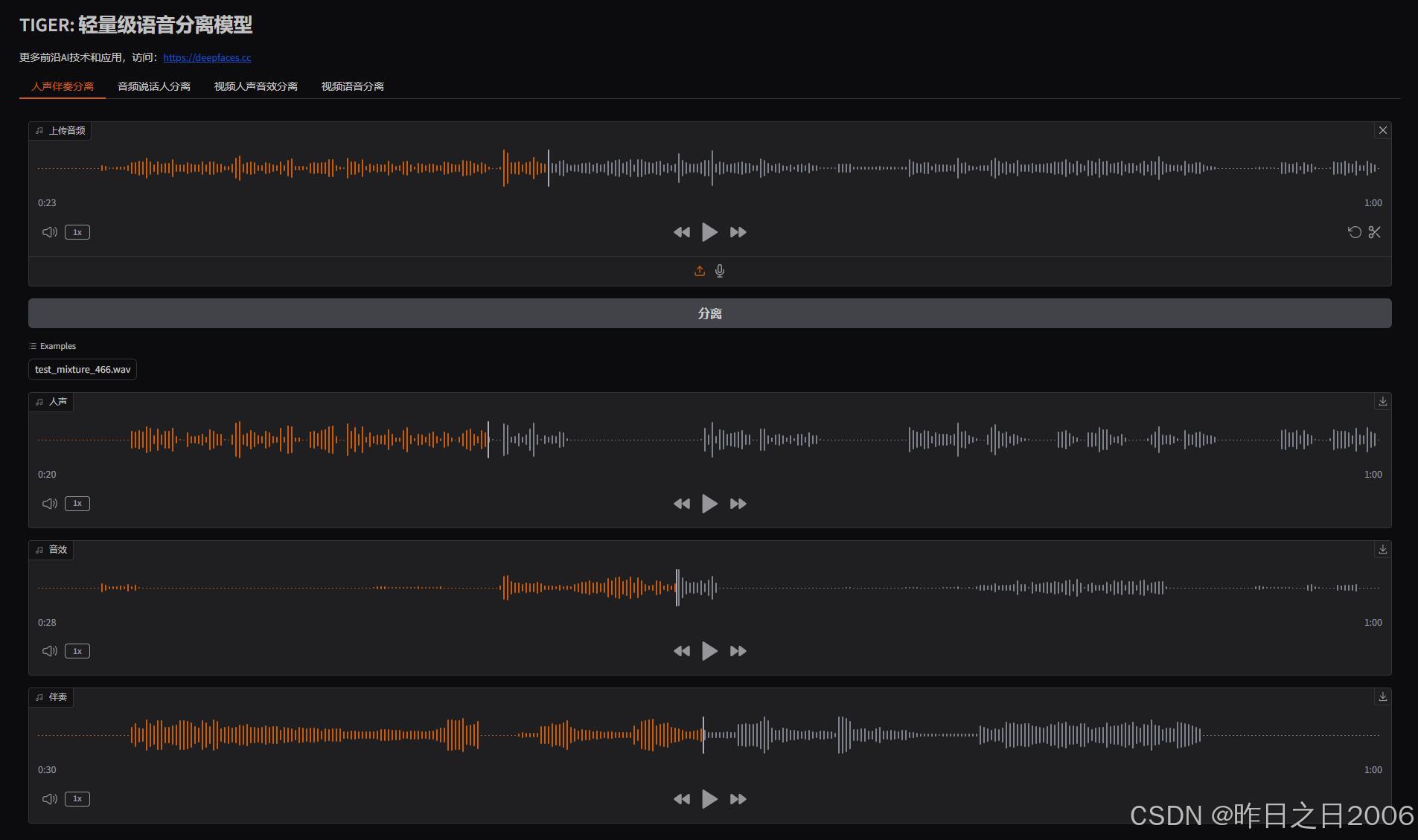
TIGER - 一个轻量高效的语音分离模型,支持人声伴奏分离、音频说话人分离等 支持50系显卡 本地一键整合包下载
TIGER 是一种轻量级语音分离模型,通过频段分割、多尺度及全频帧建模有效提取关键声学特征。该项目由来自清华大学主导研发,通过频率带分割、多尺度以及全频率帧建模的方式,有效地提取关键声学特征,从而实现高效的语音分离。 TIGER…...

yolov8,c++案例汇总
文章目录 引言多目标追踪案例人体姿态估计算法手势姿态估计算法目标分割算法 引言 以下案例,基于c,ncnn,yolov8既可以在windows10/11上部署, 也可以在安卓端部署, 也可以在嵌入式端部署, 服务器端可支持部署封装为DLL,支持c/c#/java端调用 多目标追踪案例 基于yolov8, ncnn,…...

无人机降落伞设计要点难点及原理!
一、设计要点 1. 伞体结构与折叠方式 伞体需采用轻量化且高强度的材料(如抗撕裂尼龙或芳纶纤维),并通过多重折叠设计(如三重折叠缝合)减少展开时的阻力,同时增强局部承力区域的强度。 伞衣的几何参数&am…...
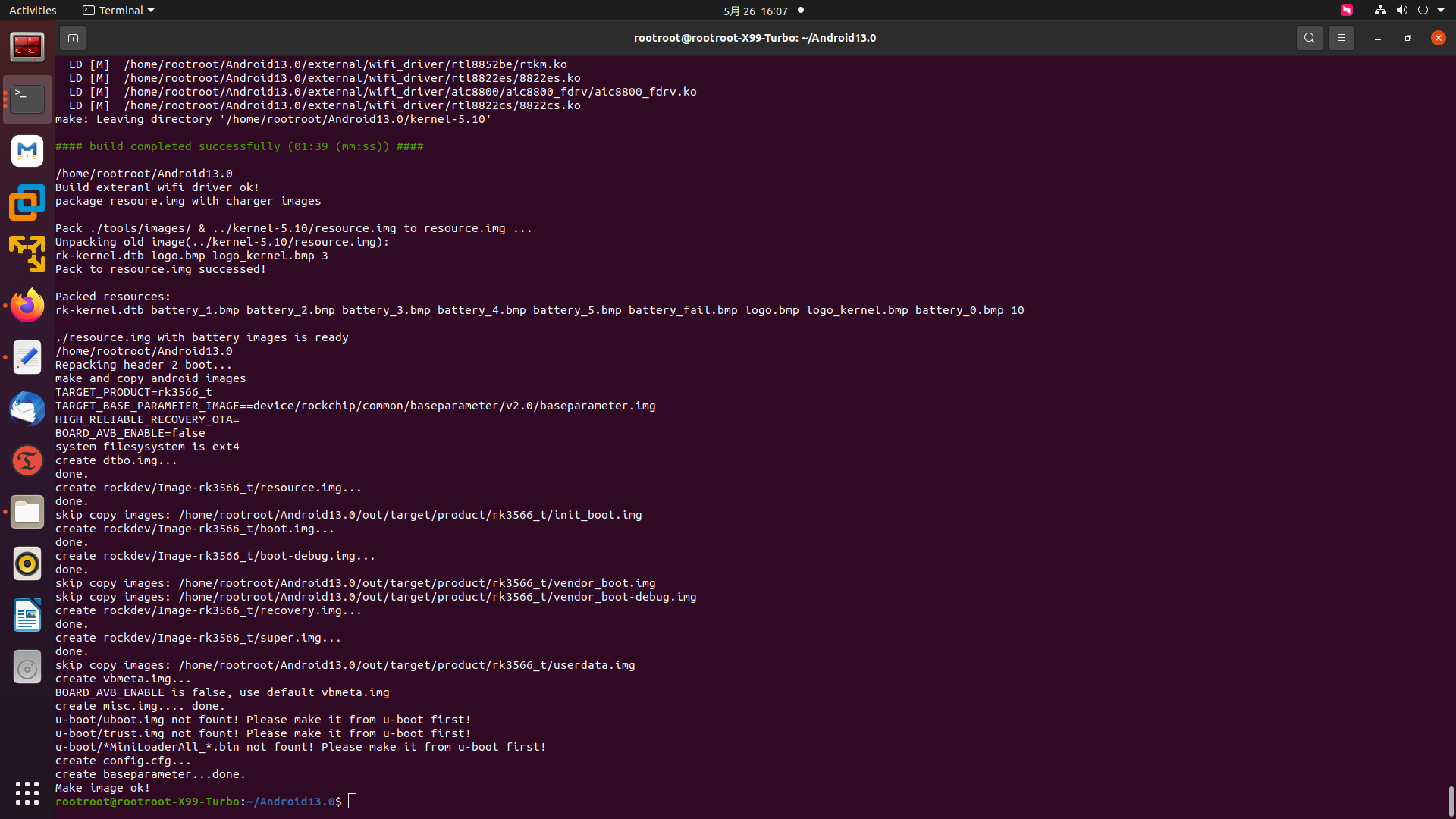
20250526给荣品PRO-RK3566的Android13单独编译boot.img
./build.sh init ./build.sh -K ./build.sh kernel 20250526给荣品PRO-RK3566的Android13单独编译boot.img 2025/5/26 15:25 缘起:需要给荣品PRO-RK3566的Android13单独编译内核,但是不想编译整个系统。于是: 如果特调试某些特别的改动/文件…...

vue3项目动态路由的相关配置踩坑记录
1.路由文件中引入store的报错解决 import { useUserStore } from /stores/user // 错误:此时 Pinia 未初始化const store useUserStore() // 报错 解决方案: import pinia,{ useUserStore } from /stores/user 或者在路由前置守卫中调用useUserSto…...

git子模块--命令--列表版
Git子模块指令查询手册 一、基本操作指令 添加子模块 git submodule add <仓库地址> [路径] 添加子模块并生成.gitmodules。 克隆含子模块项目 git clone --recursive <主仓库地址> 克隆主仓库及所有子模块。 初始化子模块 git submodule init 将.gitmodules…...
)
C++(4)
四、模板与容器 1. 模板 1.1 函数模板 #include <iostream> using namespace std;// 函数模板声明 template<typename T> // 也可使用 class T add(T a, T b) {return a b; }int main() {string a "hello";string b "world";cout <&…...
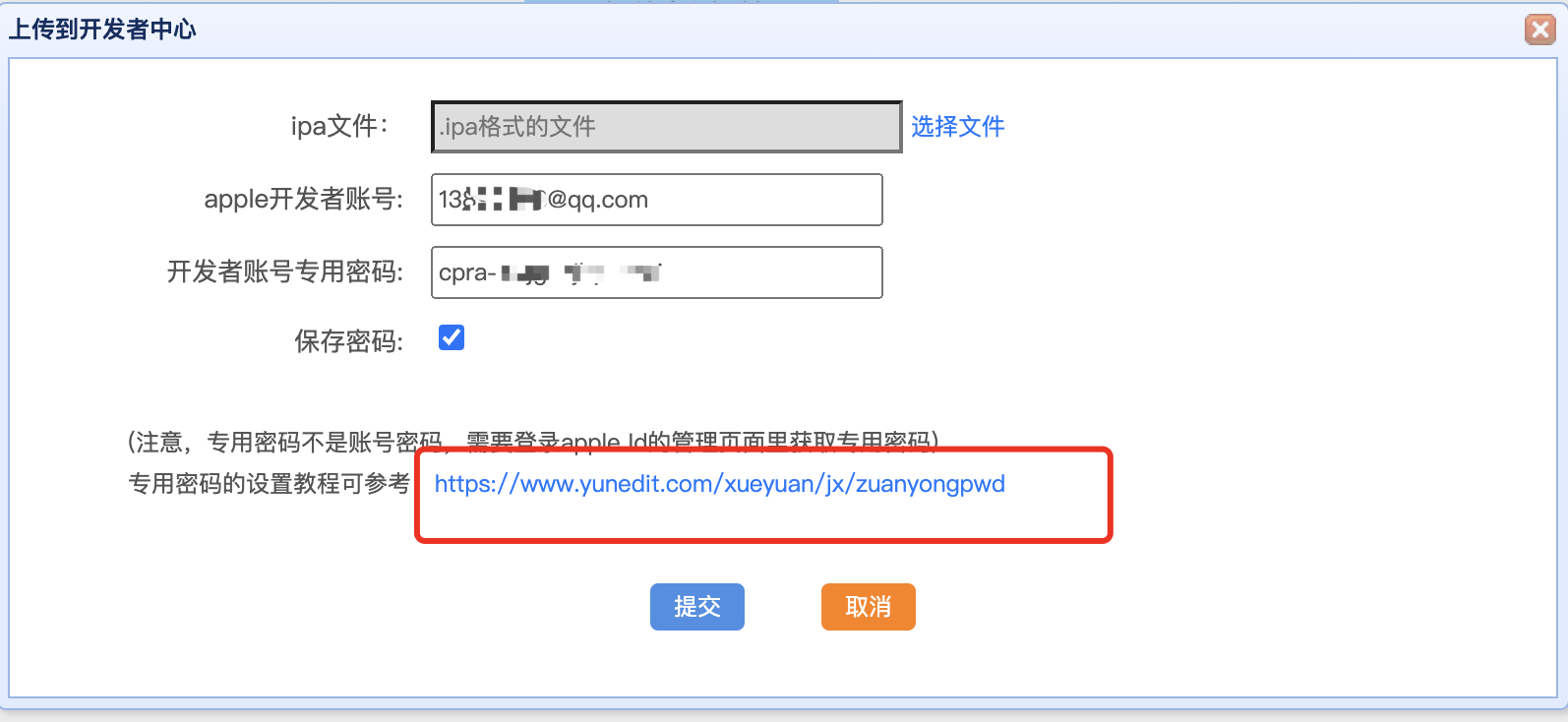
构建版本没mac上传APP方法
在苹果开发者的app store connect上架Ios应用的时候,发现需要使用xode等软件来上传iOS的APP。 但是不管是xcode也好,transporter也好,还是命令行工具也好,都必须安装在mac电脑才能使用,。 假如没有mac电脑࿰…...
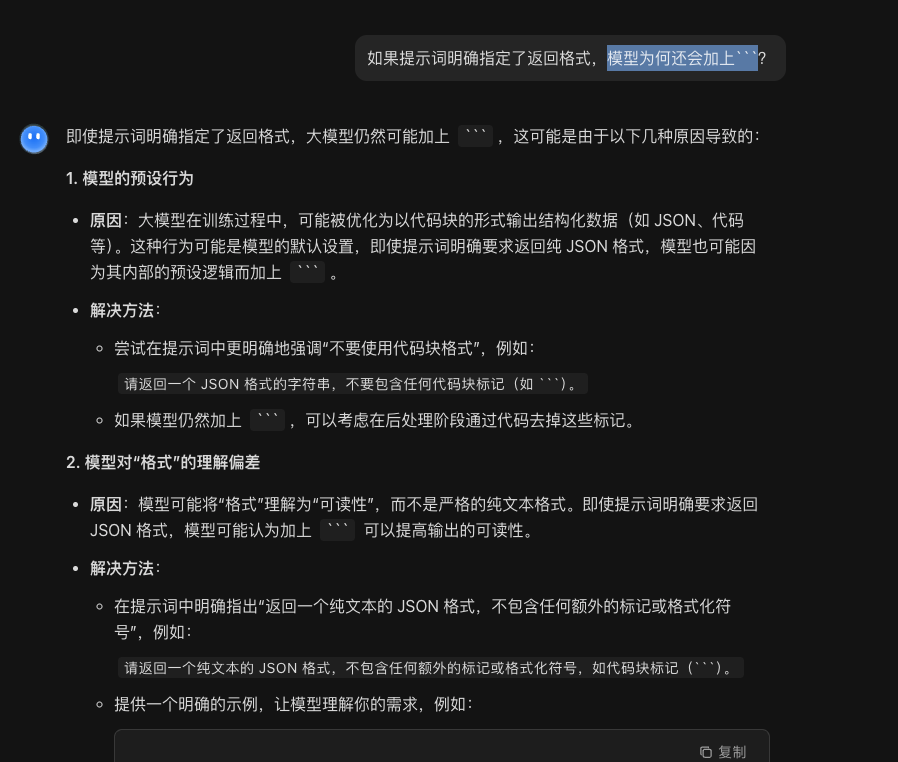
如何解决大模型返回的JSON数据前后加上```的情况
环境说明 springboot 应用使用dashscope-sdk-java对接阿里百练 deepseek v3模型 问题表现 已经指定了输出json格式,但指令不明确,输出JSON格式的写法如下 注:提示词一开始是能正常功能的,但过了几天就出现了异常,原…...

本地处理 + GPU 加速 模糊视频秒变 4K/8K 修复视频老旧素材
各位数码小达人们!你们知道吗,今天我要给大家介绍一款超厉害的工具——Video2X。它就像是一个神奇的魔法棒,能把低分辨率的视频、GIF和图像变成高清甚至4K的,而且画质细节一点都不会损失! 先来说说它的核心功能。第一…...

服务器异常数据问题解决 工具(tcpdump+wireshark+iptables)
问题: 某天一客户反馈,后台页面上显示的设备数据异常增长。现场实际只有2w台设备安装了助手(客户端),但是后台显示有16w的助手设备,并且还在持续且快速的增长。这些数据会被加载到缓存,时间久了,服务端程序…...

综合实现案例 LVS keepalived mysql 等
基于企业级高可用架构的 Linux 案例,整合 Nginx、HTTPS、LVS、Keepalived、MySQL 等服务,实现 Web 服务的负载均衡、高可用性及数据持久化。 案例场景:高可用 Web服务架构 目标 构建高可用 Web 集群,支持负载均衡和故障自动切换…...
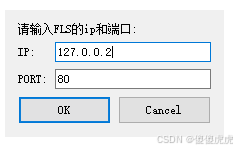
【QT】对话框dialog类封装
【QT】对话框dialog类封装 背景要点采用对输入框的信号监测实现端口和IP有效 实现 背景 在Qt 6.8.1 (MSVC 2022, x86_64)中进行编写,需要实现IP和端口号输入的弹窗,实现的方式有2种,其一,采用UI绘制,然后进行界面加载…...

2025/5/26 学习日记 基本/扩展正则表达式 linux三剑客之grep
在 Linux 系统中,正则表达式(Regular Expression可用于匹配、查找和替换符合特定模式的文本。根据语法和功能的不同,正则表达式可分为 基础正则表达式(BRE) 和 扩展正则表达式(ERE)。 基础正则…...

【后端高阶面经:消息队列篇】29、Kafka高性能探秘:零拷贝、顺序写与分区并发实战
一、 顺序写入:磁盘性能的极致挖掘 Kafka的高性能本质上源于对磁盘顺序访问的深度优化。 传统随机写入的磁盘操作需要磁头频繁寻道,机械硬盘的随机写性能通常仅为100IOPS左右,而Kafka通过追加日志(Append-Only Log)模式,将所有消息按顺序写入分区文件,使磁盘操作转化为…...

Spring Boot企业级开发五大核心功能与高级扩展实战
前言 在企业级应用开发中,Spring Boot已成为事实上的Java开发标准。本文将从企业实际需求出发,深入剖析Spring Boot五大必用核心功能,并扩展讲解三项高级开发技能,帮助开发者掌握构建健壮、高效、易维护的企业级应用的必备技术。…...

在SpringBoot项目中策略模式的使用
使用策略模式之前的代码 Overridepublic void updateExam(String id, ExamUpdateDTO examUpdateDTO) {logger.info("Service: 修改考试场次, ID: {}, 数据: {}", id, examUpdateDTO);Exam existingExam mongoDBUtils.findById(id, Exam.class);if (existingExam nu…...

在 Docker 中启动 Jupyter Notebook
文章目录 一、创建容器二、Conda安装三、安装 Jupyter四、启动 Jupyter五、注册内核来使用虚拟环境小结 一、创建容器 可以先查看宿主机8888端口是否被占用,无输出,表明端口未被任何进程占用,如果有LISTEN,可能在创建容器的时候需…...