orm详解--查询执行
深入解析 Django ORM 查询执行阶段 的核心机制,包括查询集的惰性特性、表达式树构建、SQL 编译过程及优化原理。以下是详细分析:
一、查询集(QuerySet)的惰性执行机制
1. 惰性特性的底层实现
- 核心类:
django.db.models.query.QuerySet - 关键属性:
query:存储查询逻辑的django.db.models.sql.Query对象_result_cache:结果缓存(初始为None,首次求值后填充)
- 惰性触发逻辑:
# 创建查询集(未执行 SQL) qs = Book.objects.filter(author="Doubao")# qs.query 对象此时包含: # { # 'model': Book, # 'where': [AND, =(author, "Doubao")], # 'limit': None, # 'offset': None, # 'order_by': [] # }
2. 链式操作原理
- 每次调用
filter()、exclude()、order_by()等方法时:- 创建新的
QuerySet对象 - 复制原
QuerySet的query对象 - 在新
query对象上添加操作
- 创建新的
- 示例代码:
qs1 = Book.objects.filter(author="Doubao") # QuerySet A qs2 = qs1.order_by("-price") # QuerySet B(复制 QuerySet A 的 query 并添加排序)# qs2.query 现在包含: # { # 'model': Book, # 'where': [AND, =(author, "Doubao")], # 'order_by': ["-price"] # }
二、查询表达式树(Query Expression Tree)
1. 核心组件
WhereNode类:表示 SQL 的WHERE子句- 操作类型:
AND、OR、NOT - 子节点:可以是其他
WhereNode或具体条件
- 操作类型:
Lookup类:表示具体的查询条件(如author="Doubao")- 包含:字段、操作符(如
exact、gt)、值
- 包含:字段、操作符(如
2. 复杂查询树构建示例
# Python 查询
books = Book.objects.filter(Q(author="Doubao") & Q(price__gt=50) | Q(published_date__year=2023)
)# 对应的表达式树结构(简化表示):
# WhereNode(connector=OR):
# ├─ WhereNode(connector=AND):
# │ ├─ Lookup(field=author, lookup=exact, value="Doubao")
# │ └─ Lookup(field=price, lookup=gt, value=50)
# └─ Lookup(field=published_date__year, lookup=exact, value=2023)
三、SQL 编译过程
1. 触发编译的操作
以下方法会触发 SQL 编译和执行:
- 迭代操作:
for book in queryset - 切片操作:
queryset[0:10](带步长的切片会强制求值) - 聚合方法:
count()、exists()、aggregate() - 获取单个对象:
first()、last()、get()
2. SQLCompiler 工作流程
- 核心类:
django.db.backends.*.compiler.SQLCompiler - 编译步骤:
- 生成 SELECT 列表:根据
values()或模型字段确定返回列 - 构建 FROM 子句:处理表名和别名
- 编译 WHERE 子句:将
WhereNode转换为 SQL 条件 - 处理 JOIN:根据关联关系生成 INNER JOIN/LEFT OUTER JOIN
- 添加 LIMIT/OFFSET:处理分页逻辑
- 生成 ORDER BY:根据
order_by()生成排序规则
- 生成 SELECT 列表:根据
3. 参数化查询实现
- 所有动态值通过占位符传递,防止 SQL 注入:
# Python 查询 Book.objects.filter(title__contains="Django")# 生成的 SQL(PostgreSQL 示例) SELECT "books"."id", "books"."title" FROM "books" WHERE "books"."title" LIKE %s;# 参数:['%Django%']
四、聚合查询的实现
1. annotate() 方法
- 实现原理:
- 在 SELECT 列表中添加聚合表达式
- 自动添加 GROUP BY 子句(如果需要)
- 示例:
# 查询每本书的评论数 books = Book.objects.annotate(review_count=Count("reviews"))# 生成的 SQL(简化) SELECT "books"."id", "books"."title", COUNT("reviews"."id") AS "review_count" FROM "books" LEFT OUTER JOIN "reviews" ON ("books"."id" = "reviews"."book_id") GROUP BY "books"."id";
2. F() 表达式与数据库计算
- 作用:直接在 SQL 中引用字段值,避免 Python 层面的数据传输
- 示例:
# 将所有书的价格提高 10% Book.objects.update(price=F("price") * 1.1)# 生成的 SQL UPDATE "books" SET "price" = "books"."price" * 1.1;
五、优化机制
1. 查询缓存
- 一级缓存:
QuerySet._result_cache- 首次求值后缓存结果
- 重复访问直接返回缓存
- 示例:
qs = Book.objects.all() list(qs) # 执行 SQL 并缓存结果 list(qs) # 直接从缓存获取,不执行 SQL
2. 延迟加载与预加载
- 延迟加载(Lazy Loading):
book = Book.objects.first() reviews = book.reviews.all() # 触发额外 SQL 查询 - 预加载(Eager Loading):
# 使用 prefetch_related() 减少查询次数 books = Book.objects.prefetch_related("reviews") for book in books:reviews = book.reviews.all() # 无需额外查询
六、源码分析示例
1. QuerySet.filter() 方法
# django/db/models/query.py
class QuerySet:def filter(self, *args, **kwargs):return self._filter_or_exclude(False, *args, **kwargs)def _filter_or_exclude(self, negate, *args, **kwargs):clone = self._chain() # 创建 QuerySet 副本clone.query.add_q(Q(*args, **kwargs)) # 添加查询条件到 query 对象if negate:clone.query.negate()return clone
2. SQLCompiler.as_sql() 方法
# django/db/backends/sqlite3/compiler.py
class SQLCompiler:def as_sql(self):# 生成 SELECT 列表select, select_params = self.get_select()# 生成 FROM 子句from_, from_params = self.get_from_clause()# 生成 WHERE 子句where, where_params = self.compile(self.query.where)# 生成 ORDER BY 子句order_by, order_params = self.get_order_by()# 组装完整 SQLsql = "SELECT %s FROM %s" % (select, from_)if where:sql += " WHERE %s" % whereif order_by:sql += " ORDER BY %s" % order_byreturn sql, select_params + from_params + where_params + order_params
七、常见性能陷阱与优化
1. N+1 查询问题
- 问题场景:
# 触发 1 次查询获取所有书 books = Book.objects.all()# 遍历每本书时触发 N 次查询获取作者 for book in books:print(book.author.name) # 每次循环触发一次 SQL - 优化方案:
# 使用 select_related() 减少查询次数到 1 次 books = Book.objects.select_related("author") for book in books:print(book.author.name) # 无需额外查询
2. 过度使用 values()
- 错误做法:
# 返回字典,失去模型方法 data = Book.objects.values("id", "title") - 优化方案:
# 使用 only() 仅加载需要的字段,保留模型实例 books = Book.objects.only("id", "title")
相关文章:

orm详解--查询执行
深入解析 Django ORM 查询执行阶段 的核心机制,包括查询集的惰性特性、表达式树构建、SQL 编译过程及优化原理。以下是详细分析: 一、查询集(QuerySet)的惰性执行机制 1. 惰性特性的底层实现 核心类:django.db.mode…...
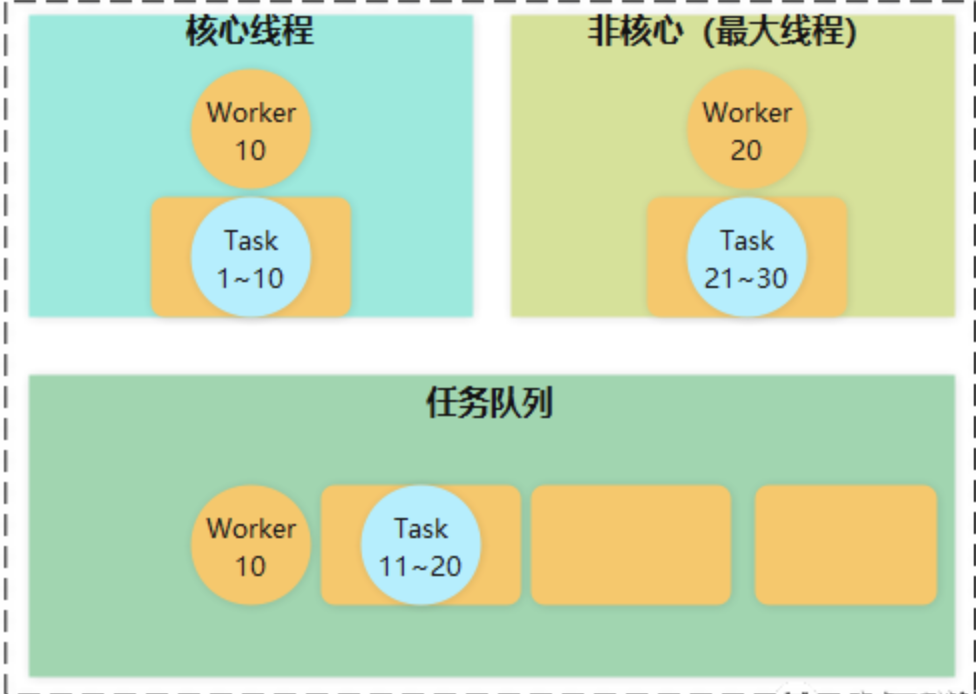
运行打印Hello World启动了多少线程?
序言 看网上说阿里二面问到了一个看似最简单且没有标准答案的一个问题,所有学习编程都是从打印hello World开始的,那运行打印启动了多少个线程? 启动了多少线程? 在运行一个简单的 “Hello World” 程序时,启动的线…...

C++项目中调用C#DLL的的方式
C项目中调用C#DLL的的方式 方法一:使用COM技术方法二:使用C/CLI方法三:使用P/Invoke(适用于C#导出非托管接口) 在C中调用C#编写的DLL,通常需要借助COM(Component Object Model&#…...

咳嗽止咳药笔记250526 , 磷酸苯丙哌林 , 喷托维林 , 右美沙芬
咳嗽止咳药笔记250526 止咳药的种类较多,根据作用机制可分为中枢性止咳药、外周性止咳药、祛痰药、抗组胺药及中成药等。以下是具体分类及效果分析: 一、中枢性止咳药 可待因 效果:直接抑制延髓咳嗽中枢,镇咳作用强且迅速&#x…...

vue pinia 独立维护,仓库统一导出
它允许您跨组件/页面共享状态 持久化 安装依赖pnpm i pinia-plugin-persistedstate 将插件添加到 pinia 实例上 pinia独立维护 统一导出 import { createPinia } from pinia import piniaPluginPersistedstate from pinia-plugin-persistedstateconst pinia creat…...

网络的协议和标准
网络的协议和标准 OSI参考模型 应用层 报文 网关 表示层 报文 会话层 报文 传输层 报文 网络层 数据包 路由器 数据链路层 帧 网桥交换机 物理层 位 中继器 集线器 TCP/IP协议簇 逻辑地址:每台设备都有一个ip地址 一个ip地址包包含网络号 子网络号 主机号可…...

十六进制字符转十进制算法
十六进制与十进制对照 十六进制十进制00112233445566778899A10B11C12D13E14F15 十六进制与十进制区别 十六进制是满16进1,十进制是满10进1,这里要注意下区别,16进制的字符里面为什么是0-9没有10,这里面进了一位,表示…...

跟Gemini学做PPT:汇报背景图寻找指南
PPT 汇报背景图寻找指南 既然前端功能已经完善,现在可以专注于汇报了。对于 PPT 背景图,你有几个选择: 1. 内置模板和主题: 优点: 最简单、快速,PowerPoint、Keynote、Google Slides 等演示软件都内置了…...
java交易所,多语言,外汇,黄金,区块链,dapp类型的,支持授权,划转,挖矿(源码下载)
目前这套主要是运营交易所类型的,授权的会贵点,编译后的是可以直接跑的,图片也修复了,后门也扫了 都是在跑的项目支持测,全开源 源码下载:https://download.csdn.net/download/m0_66047725/90887047 更多…...

(已开源-CVPR2024) RadarDistill---NuScenes数据集Radar检测第一名
本文介绍一篇Radar 3D目标检测模型:RadarDistill。雷达数据固有的噪声和稀疏性给3D目标检测带来了巨大挑战。在本文中,作者提出了一种新的知识蒸馏(KD)方法RadarDistill,它可以通过利用激光雷达数据来提高雷达数据的表征。RadarDistill利用三…...
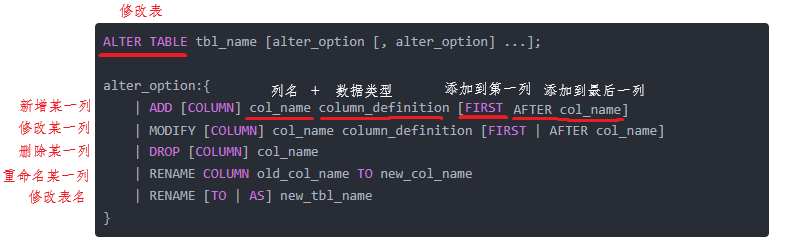
【MySQL】 数据库基础数据类型
一、数据库简介 1.什么是数据库 数据库(Database)是一种用于存储、管理和检索数据的系统化集合。它允许用户以结构化的方式存储大量数据,并通过高效的方式访问和操作这些数据。数据库通常由数据库管理系统(DBMS)管理&…...

中小企业AI算力如何选?【显卡租赁】VS【自建服务器】
对于中小企业而言和科研单位来讲,AI算力的选择需综合考虑成本、灵活性、数据安全和技术迭代风险等因素。以下是显卡租赁与自建服务器的对比分析,帮助中小企业做出最优决策: 1. 成本对比 自建服务器 高昂的前期投入:搭建一个中等规…...

OpenHarmony 4.1版本应用升级到5.0版本问题记录及解决方案
目录 1. ERROR: ArkTS:ERROR File: E:/Hap/applications_contacts-OpenHarmony-5.0.0-Release/entry/src/main/ets/Application/MyAbilityStage.ts:33:9 No overload matches this call. Overload 1 of 4, (slot: NotificationSlot): Promise, gave the following error. …...

std::initialzer_list 与花括号{}数据列表
author: hjjdebug date: 2025年 05月 22日 星期四 15:50:23 CST descrip: std::initialzer_list 与花括号{}数据列表 文章目录 1.{数值列表}是什么?1.1 数组初始化 时 , 称为数组初始化列表1.2. 当用于容器时, 称为容器初始化列表1.3. 对于结构体或类,{…...
)
萤石云实际视频实时接入(生产环境)
萤石云视频接入 本示例可用于实际接入萤石云开放平台视频,同时支持音频输入和输出。 实际优化内容 1.动态获取token 2.切换各公司和车间时,自动重新初始化播放器 let EZUIKit null; // 第三方库引用 let EZUIKitPlayers []; // 播放器实例数组 le…...

QT中常用的类
Qt 是一个功能强大的跨平台框架,提供了丰富的类库来开发 GUI 和应用程序。以下是 Qt 中常用的核心类,按模块分类整理: 1. GUI 和窗口管理 类名用途示例场景QWidget所有 GUI 控件的基类(按钮、窗口等&…...
:容器操作全栈技术指南 --- 从入门到生产级管控)
Docker系列(四):容器操作全栈技术指南 --- 从入门到生产级管控
引言 本指南以全链路视角拆解Docker技术栈,通过四大核心模块构建从入门到进阶的知识体系,助您系统性掌握容器化落地的关键能力。 容器生命周期管理(一)从创建、启停到资源清理,夯实容器操作的基础语法与核心场景&…...

poppler_path 是用于 Python 库如 pdf2image 进行 PDF 转换时
poppler_path 是用于 Python 库如 pdf2image 进行 PDF 转换时指定 Poppler 可执行文件路径的参数。为了让程序正常工作,需要先安装 Poppler,并配置环境变量或在代码中设置 poppler_path。 以下是 Poppler 的安装与环境变量配置方法,按操作系…...

鸿蒙OSUniApp 开发的多图浏览器组件#三方框架 #Uniapp
使用 UniApp 开发的多图浏览器组件 在移动应用开发中,图片浏览器是非常常见且实用的功能,尤其是在社交、资讯、电商等场景下,用户对多图浏览体验的要求越来越高。随着 HarmonyOS(鸿蒙)生态的不断壮大,开发…...

MongoDB 错误处理与调试完全指南:从入门到精通
在当今数据驱动的世界中,MongoDB 作为最流行的 NoSQL 数据库之一,因其灵活的数据模型和强大的扩展能力而广受开发者喜爱。然而,与任何复杂系统一样,在使用 MongoDB 过程中难免会遇到各种错误和性能问题。本文将全面介绍 MongoDB 的…...

React从基础入门到高级实战:React 核心技术 - 表单处理与验证深度指南
React 表单处理与验证深度指南 在现代 Web 应用中,表单是用户与应用交互的核心方式之一。无论是注册、登录、结账还是数据提交,表单都扮演着至关重要的角色。React 作为一款流行的前端框架,提供了多种处理表单的工具和方法,帮助开…...

【C++】stack,queue和priority_queue(优先级队列)
文章目录 前言一、栈(stack)和队列(queue)的相关接口1.栈的相关接口2.队列的相关接口 二、栈(stack)和队列(queue)的模拟实现1.stack的模拟实现2.queue的模拟实现 三、priority_queu…...
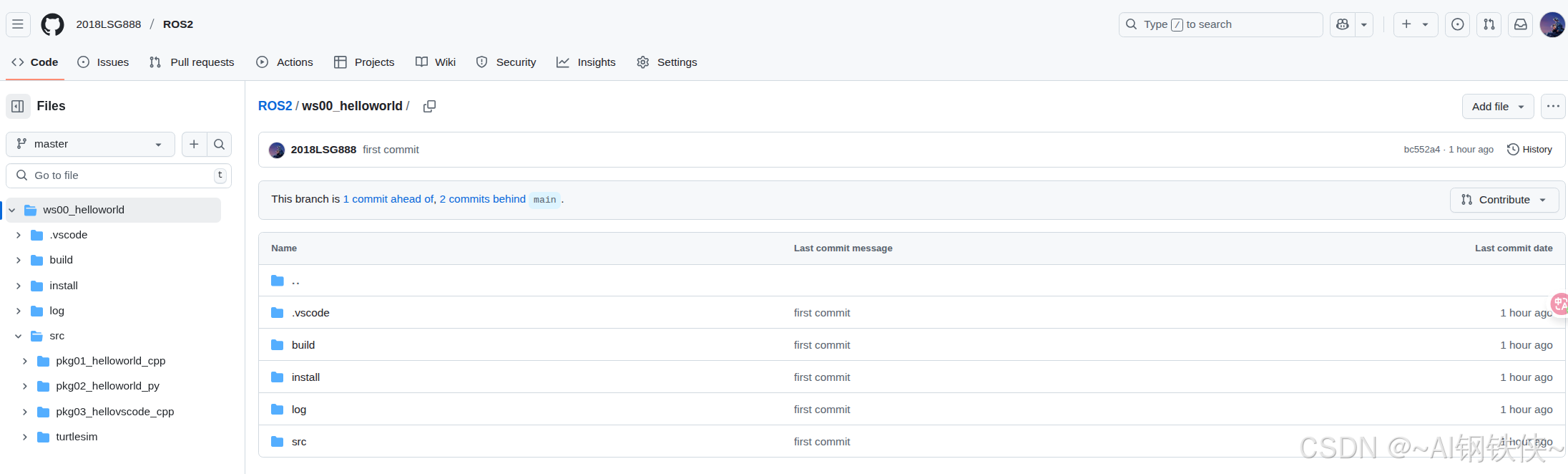
ubuntu中上传项目至GitHub仓库教程
一、到github官网注册用户 1.注册用户 地址:https://github.com/ 2.安装Git 打开终端,输入指令git,检查是否已安装Git 如果没有安装就输入指令 sudo apt-get install git 二、上传项目到github 1.创建项目仓库 进入github主页,点击号…...
)
[Java实战]Spring Boot整合达梦数据库连接池配置(三十四)
[Java实战]Spring Boot整合达梦数据库连接池配置(三十四) 一、HikariCP连接池配置(默认) 1. 基础配置(application.yml) spring:datasource:driver-class-name: dm.jdbc.driver.DmDriverurl: jdbc:dm://…...
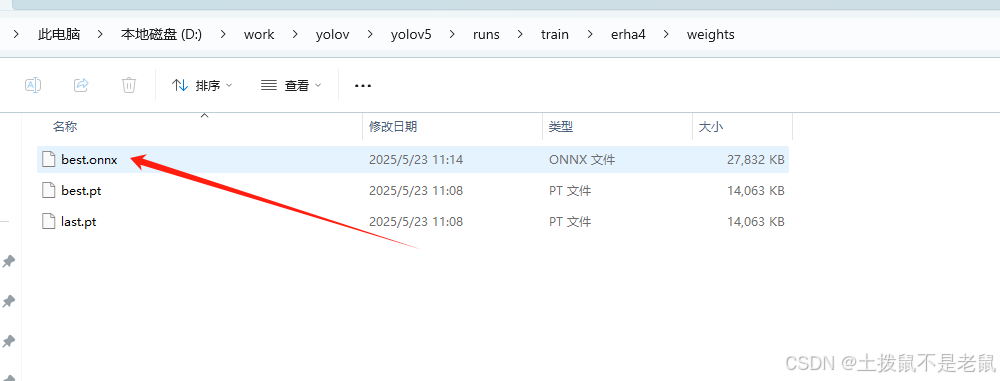
windows 下用yolov5 训练模型 给到opencv 使用
windows 使用yolov5训练模型,之后opencv加载模型进行推理。 一,搭建环境 安装 Anaconda 二,创建虚拟环境并安装yolov5 conda create -n yolov5 python3.9 -y conda activate yolov5 git clone https://github.com/ultralytics/yolov5 cd …...
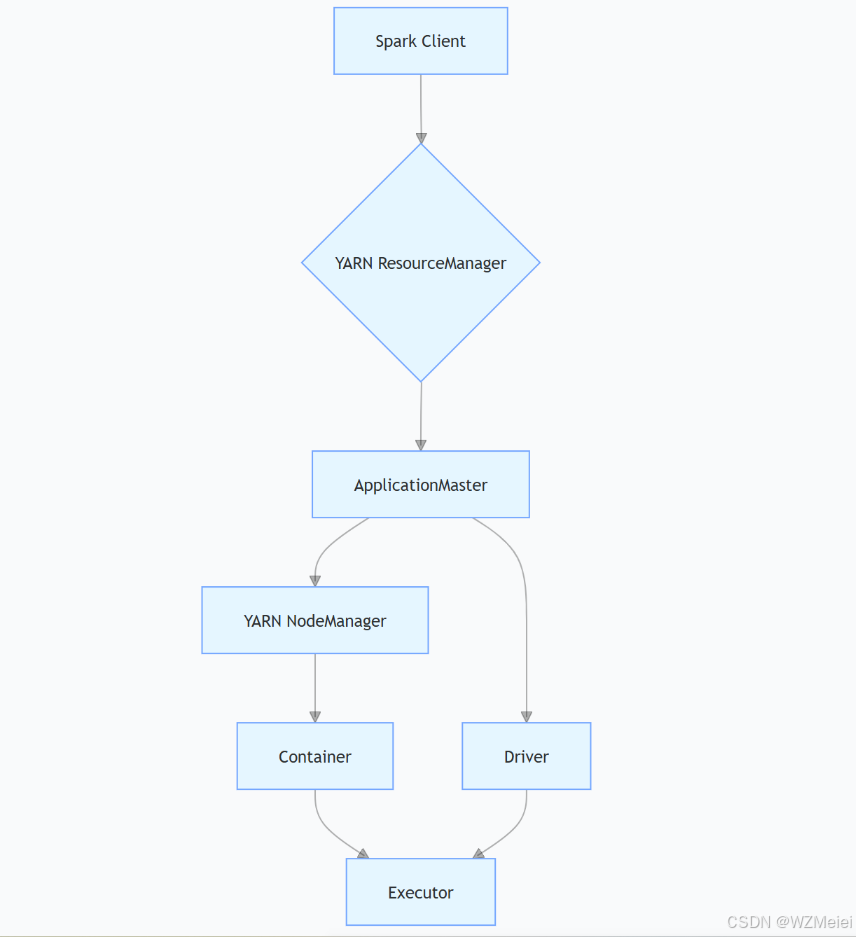
Spark集群架构解析:核心组件与Standalone、YARN模式深度对比(AM,Container,Driver,Executor)
一、核心组件定义与关系拆解 1. ApplicationMaster(AM) 定义:YARN 框架中的应用管理器,每个应用程序(如 Spark 作业)对应一个 AM。职责: 向 YARN 的 ResourceManager 申请资源(Con…...

Linux Kernel调试:强大的printk(二)
前言 如果你对printk的基本用法还不熟悉,请先阅读: Linux Kernel调试:强大的printk(一) 上一篇Linux Kernel调试:强大的printk(一)我们介绍了printk的基础知识和基本用法…...
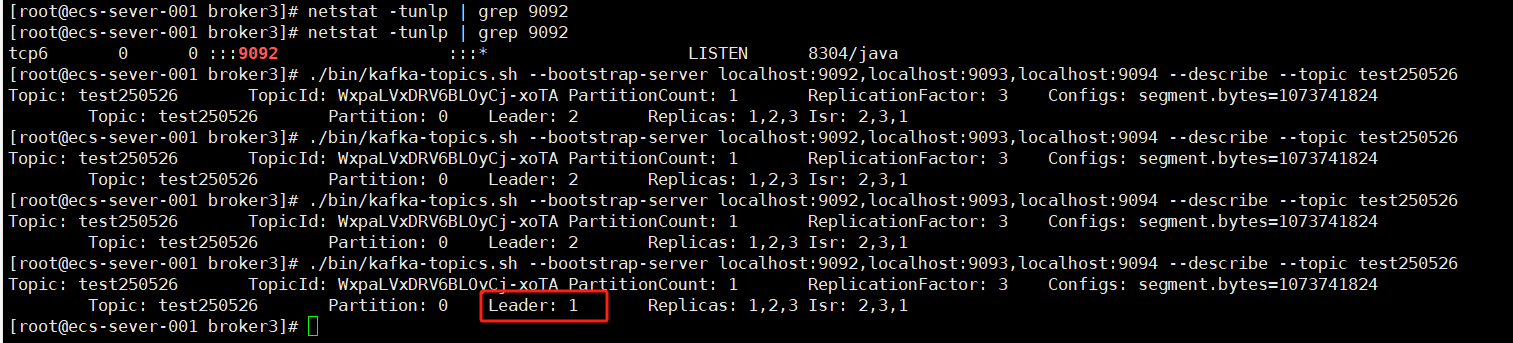
Kafka Kraft模式集群 + ssl
文章目录 启用集群资源规划准备证书创建相关文件夹配置文件启动各Kafka节点 故障转移测试spring boot集成 启用集群 配置集群时关键就是提前梳理好需要的网络资源,完成对应server.properties文件的配置。在执行前先把这些梳理好,可以方便后面的配置&…...

[crxjs]自己创建一个浏览器插件
参考官方 https://crxjs.dev/vite-plugin/getting-started/vue/create-project 按照流程操作会失败的原因 是因为跨域的问题, 在此处添加 server: {host: "localhost",port: 5173,cors: true,headers: {"Access-Control-Allow-Origin": "*",}…...
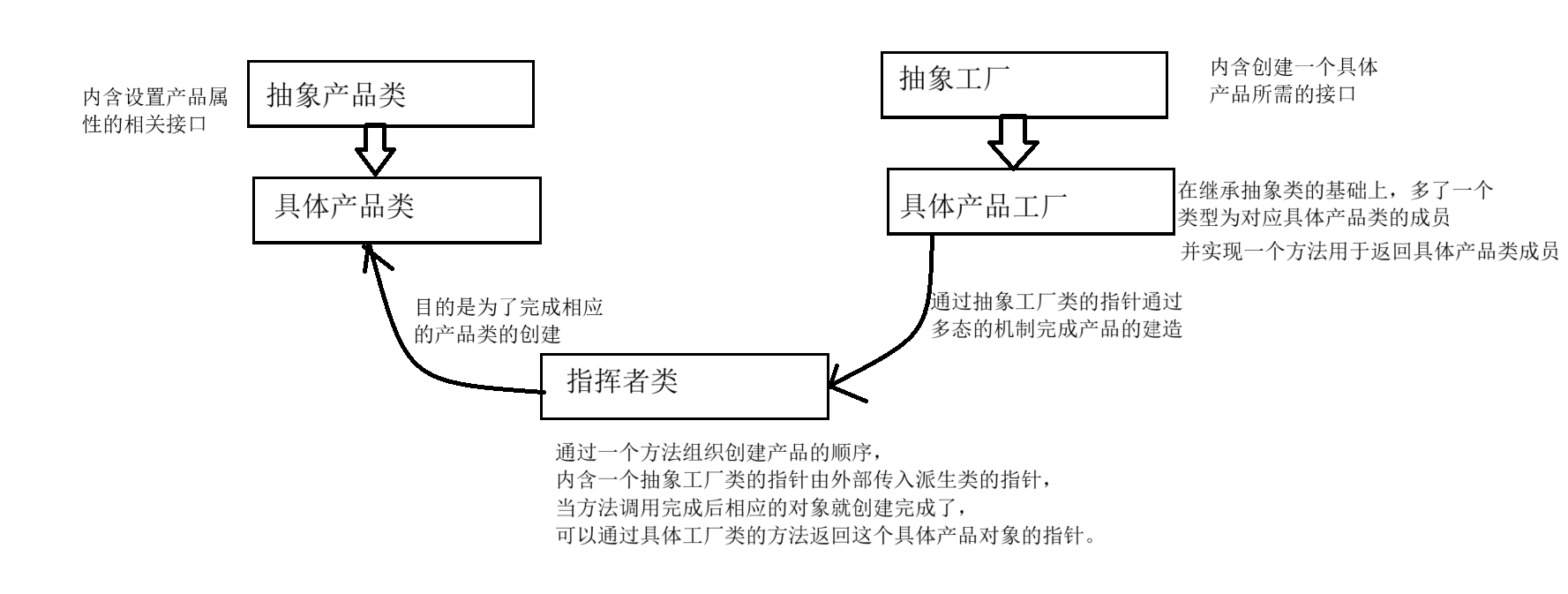
类的设计模式——单例、工厂以及建造者模式
1.单例模式 1.1 饿汉模式 单例模式:一个类只能创建一个对象,这个设计模式可以保证系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。 饿汉模式指在程序初始化时就创建一个唯一的实例对象。适用…...