小米玄戒O1架构深度解析(一):十核异构设计与缓存层次详解
前言
这两天,小米的全新SOC玄戒O1横空出世,引发了科技数码圈的一次小地震,那么小米的这颗所谓的自研SOC,内部究竟有着什么不为人知的秘密呢?我们一起一探究竟。
目录
- 前言
- 1 架构总览
- 1.1 基本构成
- 1.2 SLC缺席的原因探索
- 2. CPU设计
- 2.1 不同核心之间的差异
- 2.2 多核任务调度策略
- 2.2.1 多核任务调度核心逻辑
- 2.2.2 完全公平调度器
- 2.2.3 能效感知调度
- 2.3 超大核的分支预测方案
- 2.3.1 自适应混合预测算法
- 2.3.2 硬件结构深度优化
- 2.3.3 推测执行与恢复机制
- 2.3.4 AI驱动的动态学习
- 3. 后记
1 架构总览
1.1 基本构成
随着诸多科技博主对玄戒O1进行了 “开膛破肚”,这颗芯片的神秘面纱,也被一点点揭开(图片来自极客湾)。
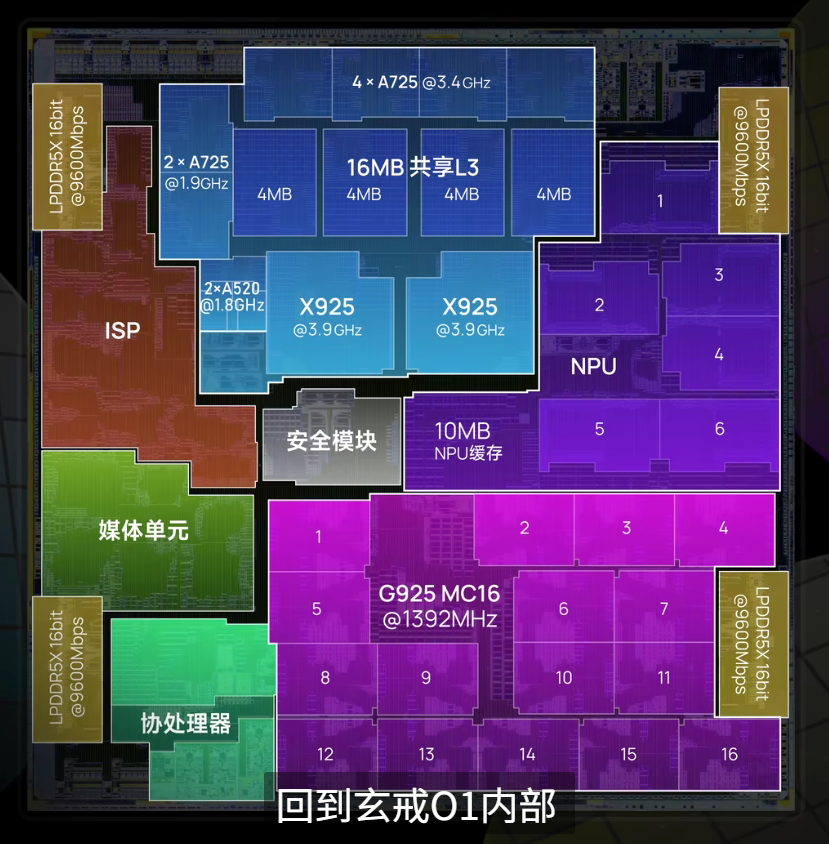
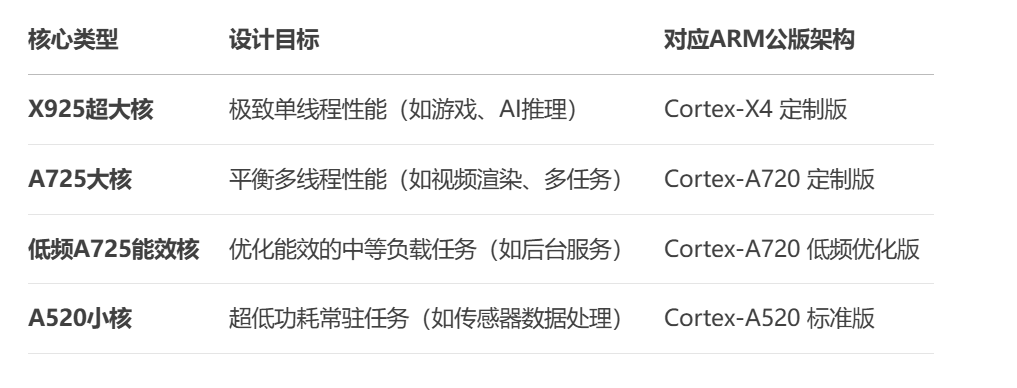
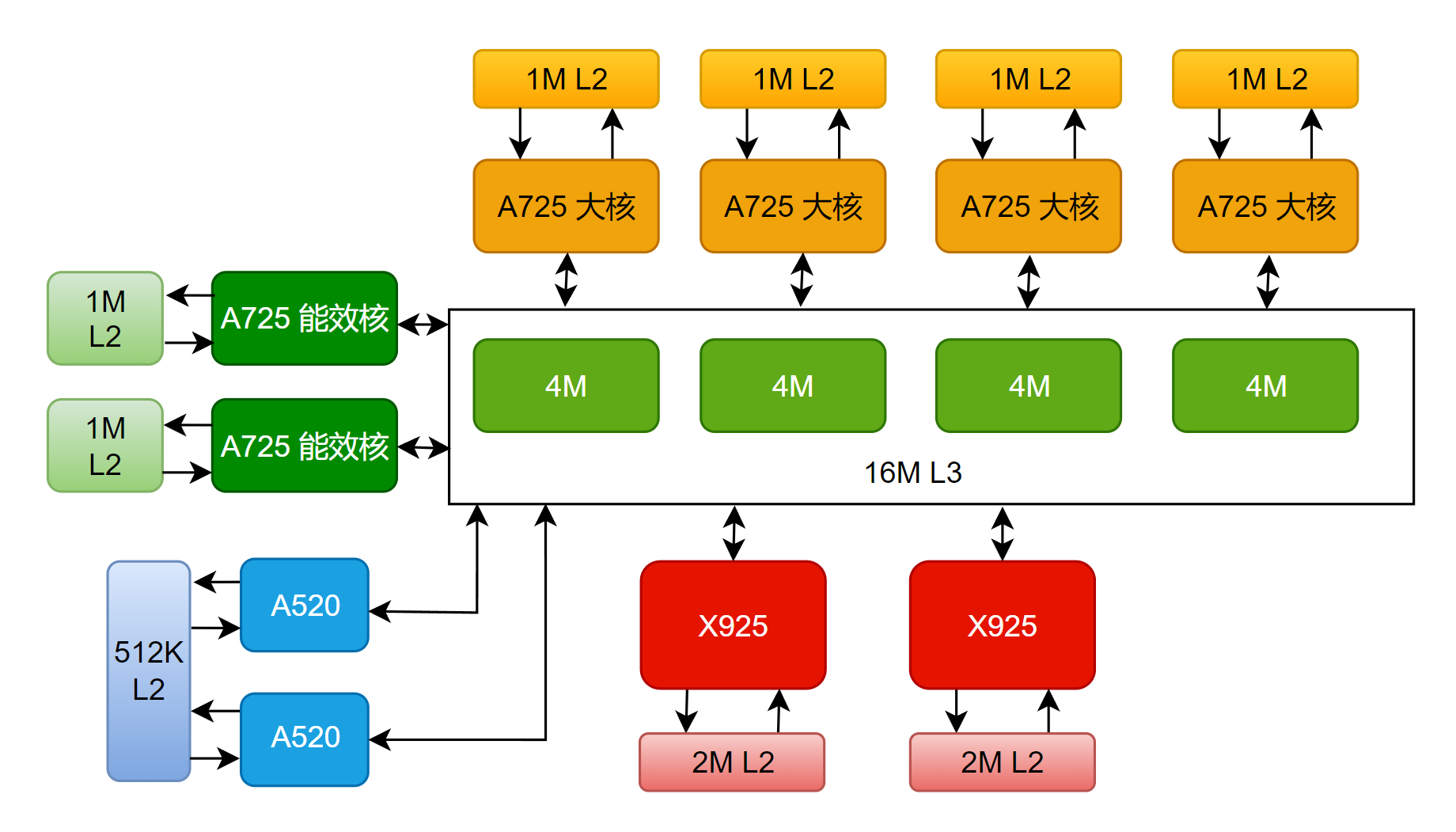
与宣传一致,玄戒O1采用了先进的台积电3nm N3E工艺,CPU方面采用了 “2+4+2+2” 十核四丛集架构(2颗X925超大核、4颗A725大核、2颗低频A725能效核、2颗A520超低功耗核)。各个核心的基本情况如下:
SOC内部没有分配SLC,而是直接采用了一个16M的L3缓存,外加各个核心专有的L2缓存(关于具体的缓存配置,会在第二章,也就是CPU部分详细展开)。
GPU配置方面也是相当豪华,搭载了16核ARM G925 GPU(也就是16个计算单元),每个CU包含128个FP32 ALU,总计 16 CU × 128 ALU = 2048个流处理器,按照惯例,还配有纹理单元和光栅化单元,此外共搭载4MB L2缓存。

我们来横向对比一下这款芯片与“友商”的产品
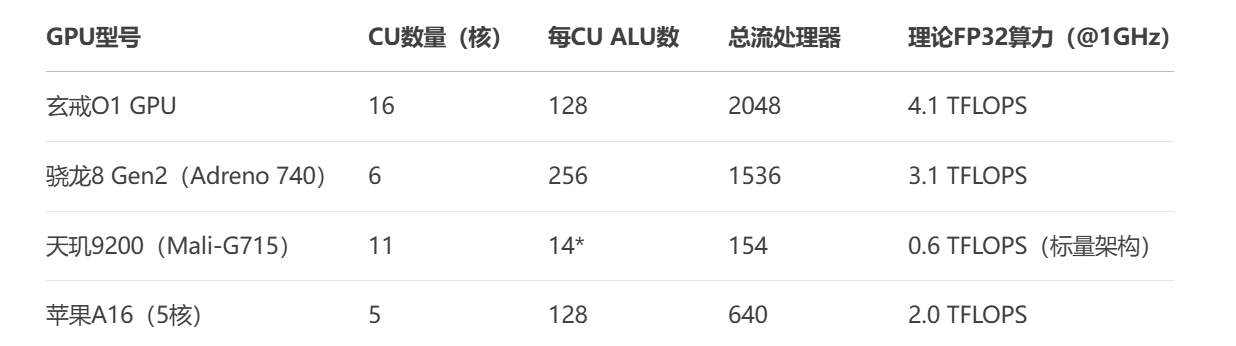
如此对比下来,理论上GPU的性能要比“友商”的产品强出不少。
那么,为什么小米选择了堆CU数量,而不是堆每CU的ALU数呢?分析下来有以下几点原因:
- 并行效率优化
任务划分更灵活:16个CU可独立处理不同渲染阶段(如几何、像素、计算),降低资源争抢。
适合移动端负载:手游多为多线程小任务(如粒子效果、后处理),而非单指令大规模计算。
- 功耗与面积平衡
面积成本:每增加1个CU需额外约1.2mm²(4nm工艺),16 CU总面积约19.2mm²。
功耗控制:多CU可动态关闭闲置单元(如关闭8个CU处理UI渲染),比高频少CU方案更省电。
- 驱动与生态适配
开发者友好:主流图形API(如Vulkan)更适应多CU的任务分发模式。
工具链成熟:高通Adreno架构的调试工具链可直接适配,减少开发成本。
玄戒O1的NPU(神经网络处理单元)是其自研芯片的核心模块之一,基于小米多年积累的 MACE(Mobile AI Compute Engine)框架演进而来。由6核心外加10MB缓存构成。作为首款完全自研的AI加速器,玄戒O1的NPU在架构设计、能效比和软硬协同上展现了独特创新。
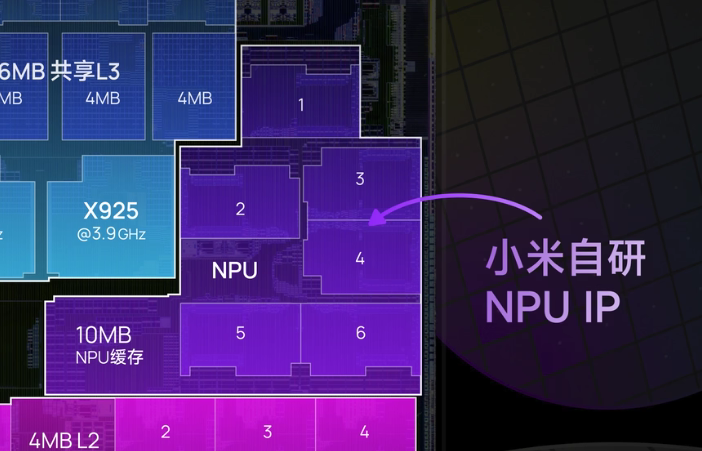
在软件生态上,同时兼容ONNX、TensorFlow Lite、PyTorch Mobile等神经网络架构,为软硬件协同开发提供了有利条件。
较之于所谓的CPU、GPU和NPU,一般的ISP并不会显得那么吸睛,玄戒O1的ISP(图像信号处理器)是其影像能力的核心引擎,通过自研架构和软硬协同优化,实现了从传感器原始数据到高质量成像的全流程突破。事实上,小米在很多年前,就已经在自研ISP了,最开始是在2017年,搭载在了小米5C上面。后又经几番迭代,日趋成熟。
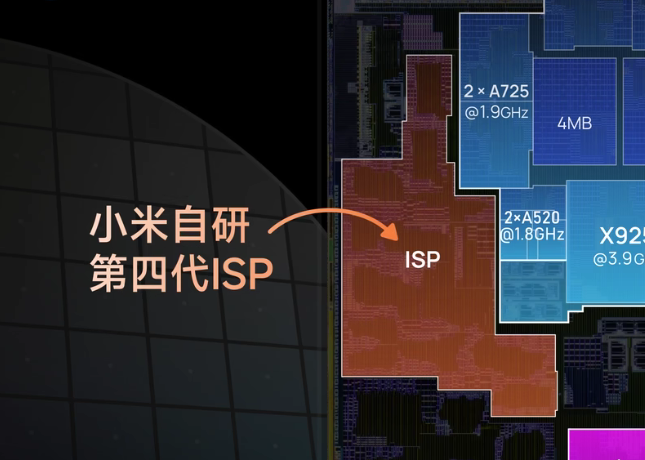
小米的ISP发展,大致可分为一下几个发展阶段:

那么,什么是3A加速呢?
3A分别指的是自动对焦(AF)、自动曝光(AE)、自动白平衡(AWB),它们是成像质量的核心控制参数。澎湃C1芯片的3A加速 指通过专用硬件电路(而非传统软件算法)实现这三大功能的超低延迟、高精度处理。
关于语义分割和多帧合成就更复杂了,有时间再说😊。
1.2 SLC缺席的原因探索
首先我们先捋清楚概念,什么是SLC缓存,与普通的缓存有什么不同?
SLC(系统级缓存): 一种共享缓存,通常被多个处理单元(如CPU、GPU、NPU)共同访问,用于减少对主存的依赖,降低延迟和功耗。例如,高通的骁龙芯片通常集成6-8MB的SLC,供所有核心共享。

独立缓存(单元级缓存):
每个处理单元(如CPU核心、GPU模块、NPU加速器)拥有自己的专用缓存(如L2/L3缓存),独立管理,不与其他单元共享数据。
那么,该如何理解极客湾所说的:“最终去掉SLC,增加各个单元各自的巨大缓存,应该是为了规避低功耗区间翻车的风险”?
所谓的低功耗时候的风险,指的是当芯片处于低功耗模式(如手机待机、轻度任务处理)时,若共享资源(如SLC)的设计无法高效协调多单元访问,可能导致两个问题:
性能波动:缓存争用导致响应延迟增加。
功耗反弹:频繁唤醒主存或维护缓存一致性,反而增加功耗。
也就是说,在轻度负载的应用场景,SLC还在工作,而如果将这部分直接“舍弃”,那么对于玄戒O1来说,可直接利用小核自带的缓存去应付,这样就节省了部分功耗。
2. CPU设计
玄戒O1的CPU核心并非均质化设计,而是按 性能/功耗比 严格分级:
X925超大核(3.9GHz):基于ARM Cortex-X4定制,专攻瞬时高负载(如游戏启动、AI推理);
A725大核(3.4GHz):处理中度多线程任务(如视频编码、多应用切换);
低频A725(1.89GHz):优化能效的轻量计算(如后台服务);
A520小核(1.8GHz):负责低功耗常驻任务(如传感器数据采集)。
这种设计源自 ARM的DynamIQ技术,允许不同架构核心共享L3缓存和内存控制器,但每个丛集可独立调节电压/频率(DVFS)。这样一来,对于降低整机功耗非常有利。
2.1 不同核心之间的差异
上面对大小核有了简单的介绍,接下来我们详细介绍一下这些核之间的差异。

可以看到,更大的核心,意味着拥有更深的流水线深度,以及更加丰富的分支预测预测单元和更多的ALU和重排序缓冲区(什么是流水线,以及什么是分支预测,可以参考我的这篇文章CPU流水线技术全面解读)。
简单来说:
- X925 通过更深的流水线和更大的ROB提升单线程性能,但功耗较高。
- A725 在性能与能效间平衡,适合多线程任务。
- A520 简化执行单元,减少面积和功耗,适合低负载场景。
关于缓存分配方面,为了方便数据的读写,当然是越大的核,配越大的缓存。超大核每个配置了2M的L2缓存,大核和能效核每个配置了1M的L2缓存,小核共用512k L2缓存,这些核共用16M L3缓存。
L1缓存一般集成在了各个核内部,从下面这张图可以看出来(图片来自ARM官网,相关技术手册)。

除此之外,不同的核,电源与工艺也不一样。

可见,超大核和大核由于功耗较高,可以根据任务的不同而选择睡眠或工作,而小核处于常开状态,从而在整体上控制可功耗,当然多核的调度策略远远没有这么简单,在下面章节中我们将重点讨论。
2.2 多核任务调度策略
2.2.1 多核任务调度核心逻辑
(1) 任务分类与优先级映射
- 实时性任务(如触控响应、音频处理)→ 由 X925超大核 处理,确保低延迟;
- 计算密集型任务(如游戏渲染、视频导出)→ 分配至 X925+A725大核,利用多线程并行;
- 能效敏感型任务(如后台同步、消息推送)→ 交由 A520小核,减少唤醒大核的功耗。
(2) 调度器算法(Linux CFS + 小米定制优化)
玄戒O1基于 Linux内核的完全公平调度器(CFS: completely Fair scheduler),但小米做了以下深度优化:
负载预测模型:通过历史使用数据(如APP启动模式)预判任务类型,提前分配核心;
能效感知调度(EAS):结合芯片的 能量模型(EM),计算每个任务在不同核心的 功耗/性能比,选择最优解;
线程迁移成本控制:避免频繁跨丛集迁移线程(如从X925切到A520),减少缓存失效带来的性能损失。
(3) 硬件级调度辅助(PMU与IPC监控)
性能监控单元(PMU):实时监测各核心的 IPC(每周期指令数)、缓存命中率,动态调整调度策略;
中断负载均衡:硬件中断(如网络数据包到达)会优先路由到空闲小核,避免打断大核的关键任务。
以上的内容,其他的都比较好理解,那么什么是完全公平调度器(CFS),什么又是能效感知调度(EAS)呢?
2.2.2 完全公平调度器
-
核心目标
公平性:确保所有任务按权重(优先级)公平分享CPU时间,避免饥饿。
低延迟:通过细粒度时间片分配(最小调度周期约1ms),快速响应交互任务。
普适性:适用于同构多核系统,不依赖特定硬件特性。 -
实现原理
虚拟运行时间(vruntime):
每个任务维护一个vruntime,表示其已消耗的“虚拟CPU时间”。CFS优先调度vruntime最小的任务,保证长期公平。
红黑树管理:
所有可运行任务按vruntime排序存入红黑树,调度器每次选择最左侧(最小vruntime)任务执行。
负载均衡:
定期检查各CPU负载,通过任务迁移平衡负载,但不感知能效差异。 -
局限性😟
异构核盲视:
将大核(高性能高功耗)与小核(低性能低功耗)视为等同,可能将轻量任务错误分配到大核,导致能效低下。
能耗不敏感:
调度决策仅基于CPU时间公平性,无法优化整体系统功耗。
鉴于以上的局限性,有了又来的能效感知调度策略。
2.2.3 能效感知调度
-
核心目标
能效优化:在满足性能需求的前提下,最小化系统功耗。
异构核适配:根据大核/小核的功耗特性,智能分配任务。
动态调节:结合CPU频率(DVFS)与任务需求,实现精细化控制。 -
实现原理
能量模型(Energy Model, EM):
预置每个CPU核心在不同频率下的功耗曲线(如X925@3.9GHz功耗4.2W,A520@1.8GHz功耗0.1W)。
能效成本函数:
计算任务在候选核心的 能效得分 = 性能需求 / 预期功耗,选择得分最高的目标核心。
与CFS的集成:
继承CFS的vruntime和红黑树机制,维持公平性基础。
负载均衡增强:在任务迁移时,优先考虑能效而非单纯负载均衡。 -
关键创新
CPU容量感知:
定义每个核心的“计算容量”(如X925容量=1024,A520=256),任务负载按容量归一化。
能效导向的唤醒决策:
唤醒空闲核心时,选择能效比最高的候选(而非默认的最小负载核心)。
2.3 超大核的分支预测方案
核心越大,流水线深度越深,则在预测失败后进行相关处理的成本越大。那设计一个优秀的分支预测算法就显得尤为重要。所以我们在此仅对该SOC超大核X925的分支预测原理进行分析(具体的分支预测方案这属于技术机密,我们不得而知,但是可以根据目前已知的一些分支预测方案做出合理推测)。
下图是一种常见的五级流水线内部结构图,作为参考:
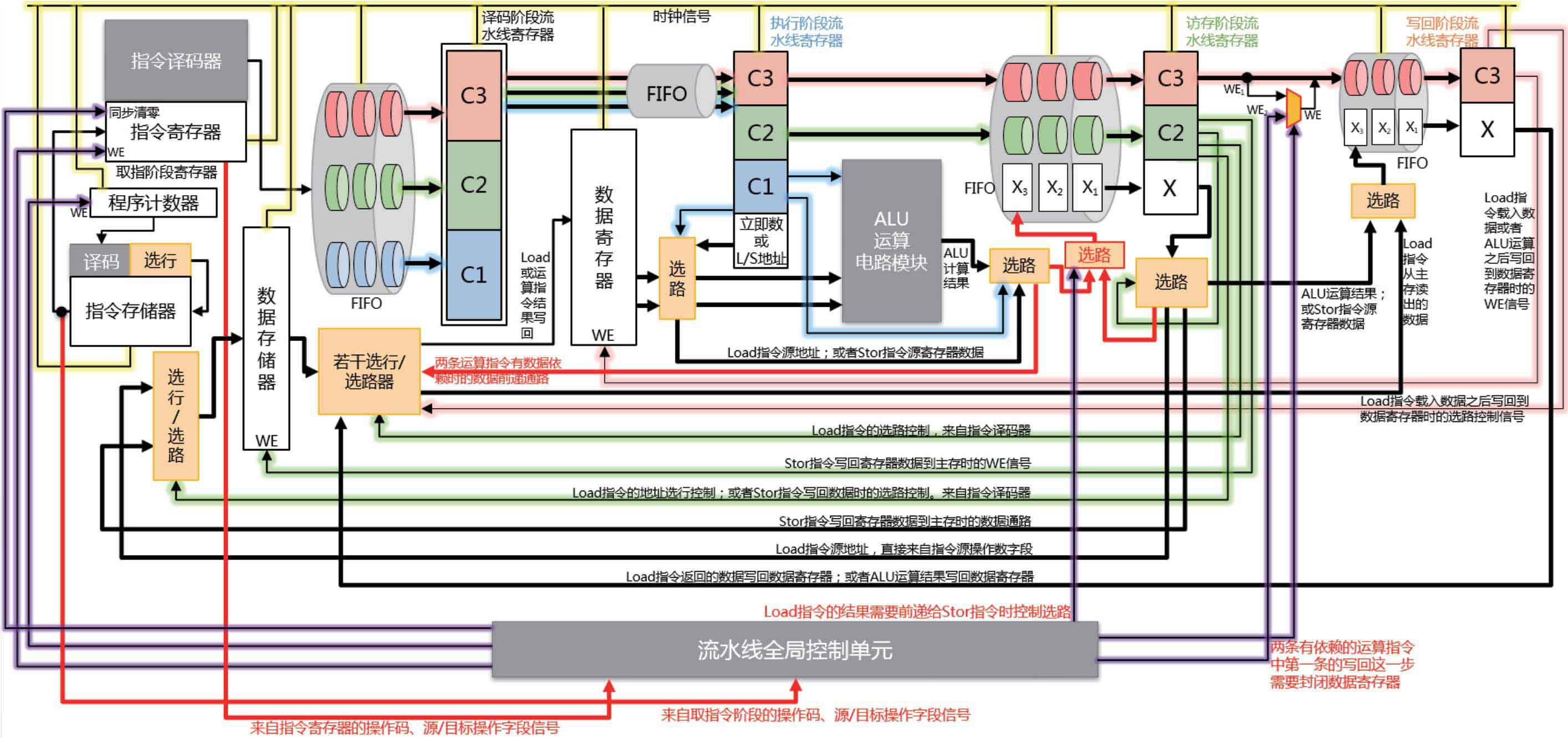
可能的分支预测解决方案有以下几个:
2.3.1 自适应混合预测算法
TAGE-SC-L 预测器:
采用多历史长度组合的预测机制,动态选择最佳历史深度(如4-bit至128-bit历史记录),通过几何级数分布的历史表覆盖不同分支模式(循环、条件跳转等)。
示例:对于频繁跳转的循环体(如for(i=0; i<N; i++)),短历史长度快速捕捉规律;对嵌套条件分支(如if(A && B || C)),长历史记录分析上下文依赖。
感知局部性增强:
引入分支地址哈希优化,减少BTB(Branch Target Buffer)冲突。例如,玄戒O1可能使用XOR折叠算法对分支指令地址进行哈希处理,分散到不同预测表项,降低别名(Aliasing)导致的误判。
2.3.2 硬件结构深度优化
分层式BTB设计:
L1 BTB:小容量、低延迟(1周期访问),缓存最近高频分支目标(如4K条目)。
L2 BTB:大容量、稍高延迟(3-4周期),存储低频但重要的分支(如16K条目),通过预取机制提前加载可能需要的条目。
使得CPU可以在较短时间内读取高频分支目标,提升整体处理效率。
分支目标预计算:
在指令解码阶段,对间接跳转(如switch-case、虚函数调用)的目标地址进行硬件加速计算,利用专用电路快速解析跳转表或寄存器值,减少目标查找延迟。
采用专用电路缩减跳转时间。
2.3.3 推测执行与恢复机制
误预测快速回滚:
采用Checkpoint寄存器堆,在分支预测时保存关键寄存器状态,误判时直接回滚至检查点,而非完全清空流水线,将恢复时间从20+周期缩短至5周期内。
动态推测深度调整:
根据工作负载特征(如高分支误判率时),自动限制推测执行的指令窗口大小(如从200条缩减至50条),避免因深度推测浪费能耗。
这也属于一种自我优化机制,去掉了部分高分支误判率的指令窗口,理论上就可以降低误判率。
2.3.4 AI驱动的动态学习
运行时行为建模:
集成轻量级神经网络协处理器,实时分析分支历史模式(如周期性、随机性),动态调整预测器权重。例如,检测到某分支近期误判率升高,自动切换至备选预测策略。
相当于一种自适应的分支预测,当然,这个神经网络不能设计得过于复杂,不然本身的功耗就不小,估计也就是哥多层感知机。

编译器反馈优化:
与定制化编译器(如玄铁LLVM)协作,通过__builtin_expect等指令标记高概率分支路径,辅助硬件预测器初始化历史状态。
3. 后记
总觉得还有很多东西可以写,比方说多核调度策略和分支预测很多细节没有写到。而且GPU, NPU和ISP部分没有单独作为一个章节进行展开。但我觉得可以将玄戒O1的分析做个系列文章。欢迎继续关注后续更新。
参考资料:
- 哔哩哔哩up主极客湾的视频小米自研玄戒O1芯片深度评测:直逼8 Elite!
- 《大话计算机》
- ARM官网数据手册
相关文章:
小米玄戒O1架构深度解析(一):十核异构设计与缓存层次详解
前言 这两天,小米的全新SOC玄戒O1横空出世,引发了科技数码圈的一次小地震,那么小米的这颗所谓的自研SOC,内部究竟有着什么不为人知的秘密呢?我们一起一探究竟。 目录 前言1 架构总览1.1 基本构成1.2 SLC缺席的原因探…...
)
Numba模块的用法(高性能计算)
文章目录 介绍核心装饰器与基础用法@jit(nopython=True):最常用的编译装饰器@njit的简写编译时指定类型签名并行加速(parallel=True)@cuda.jit: GPU 编程(CUDA)向量化函数(@vectorize)性能优化技巧调试与常见问题调试模式常见错误适用场景与局限性实例:加速蒙特卡洛模拟…...

Kafka自定义分区策略实战避坑指南
文章目录 概要代码示例小结 概要 kafka生产者发送消息默认根据总分区数和设置的key计算哈希取余数,key不变就默认存放在一个分区,没有key则随机数分区,明显默认的是最不好用的,那kafka也提供了一个轮询分区策略,我自己…...

PyTorch中cdist和sum函数使用示例详解
以下是PyTorch中cdist与sum函数的联合使用详解: 1. cdist函数解析 功能:计算两个张量间的成对距离矩阵 输入格式: X1:形状为(B, P, M)的张量X2:形状为(B, R, M)的张量p:距离类型(默认2表示欧式距离)输出:形状为(B, P, R)的距离矩阵,其中元素 d i j d_{ij} dij表示…...

[免费]微信小程序宠物医院管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序宠物医院管理系统(uni-appSpringBoot后端Vue管理端),分享下哈。 项目视频演示 【免费】微信小程序宠物医院管理系统(uni-appSpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibi…...

centos7.9使用docker-compose安装kafka
docker-compose配置文件 services:zookeeper:image: confluentinc/cp-zookeeper:7.0.1hostname: zookeepercontainer_name: zookeeperports:- "2181:2181"environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_TICK_TIME: 2000kafka:image: confluentinc/cp-kafka:7.0…...
ETL 工具与数据中台的关系与区别
ETL 工具和数据中台作为数据处理领域的关键概念,虽然存在一定的关联,但二者有着明显的区别。本文将深入剖析 ETL 工具与数据中台之不同。 一、ETL 工具概述 ETL 是数据仓库技术中的核心技术之一,其全称为 Extract(抽取ÿ…...
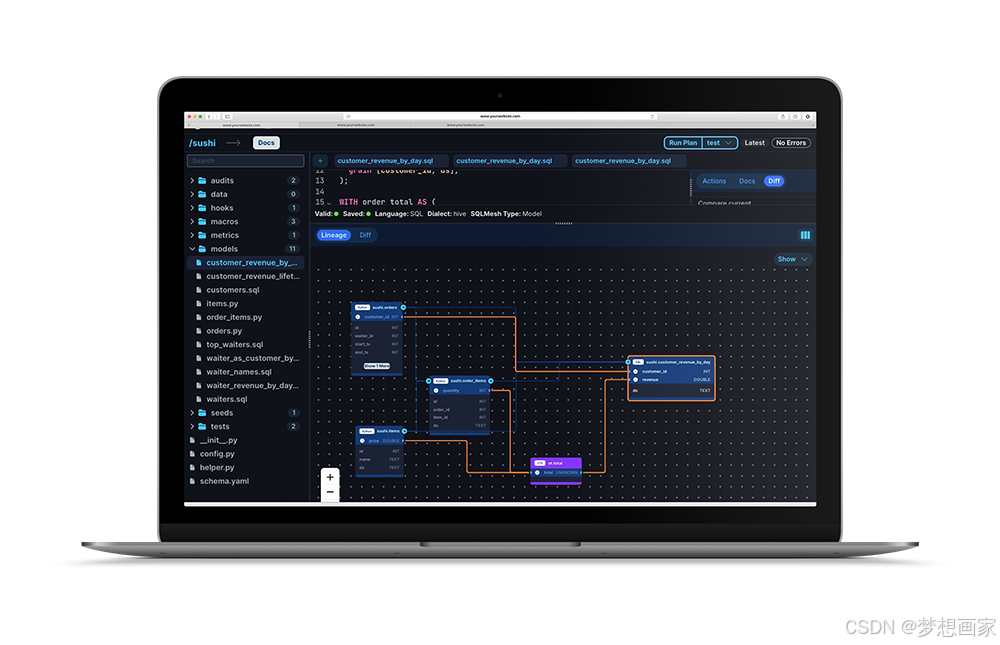
SQLMesh Typed Macros:让SQL宏更强大、更安全、更易维护
在SQL开发中,宏(Macros)是一种强大的工具,可以封装重复逻辑,提高代码复用性。然而,传统的SQL宏往往缺乏类型安全,容易导致运行时错误,且难以维护。SQLMesh 引入了 Typed Macros&…...
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法 flyfish 名字 Ulysses “Ulysses” 和 “奥德修斯(Odysseus)” 指的是同一人物,“Ulysses” 是 “Odysseus” 的拉丁化版本 《尤利西斯》(詹姆…...
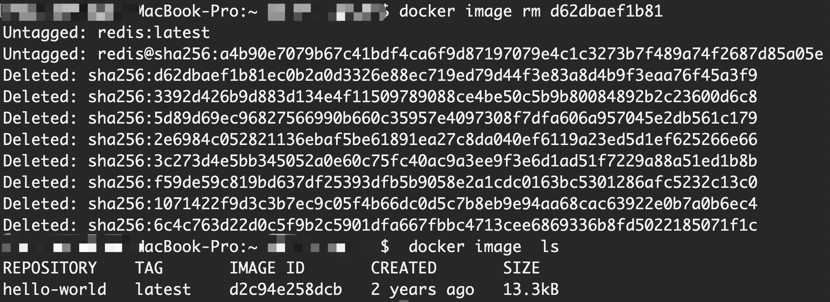
Docker 使用镜像[SpringBoot之Docker实战系列] - 第537篇
历史文章(文章累计530) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六》 《…...

解锁MCP:AI大模型的万能工具箱
摘要:MCP(Model Context Protocol,模型上下文协议)是由Anthropic开源发布的一项技术,旨在作为AI大模型与外部数据和工具之间沟通的“通用语言”。它通过标准化协议,让大模型能够自动调用外部工具完成任务&a…...
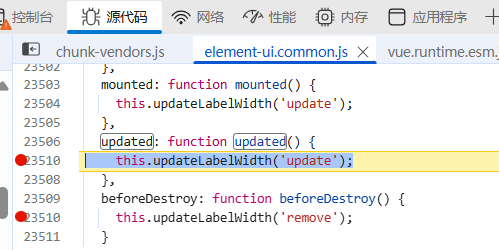
Error in beforeDestroy hook: “Error: [ElementForm]unpected width “
使用 element 的 form 时候报错: vue.runtime.esm.js:3065 Error: [ElementForm]unpected width at VueComponent.getLabelWidthIndex (element-ui.common.js:23268:1) at VueComponent.deregisterLabelWidth (element-ui.common.js:23281:1) at Vue…...

vscode包含工程文件路径
在 VSCode 中配置 includePath 以自动识别并包含上层目录及其所有子文件夹,需结合通配符和相对/绝对路径实现。以下是具体操作步骤及原理说明: 1. 使用通配符 ** 递归包含所有子目录 在 c_cpp_properties.json 的 includePath 中,${workspac…...
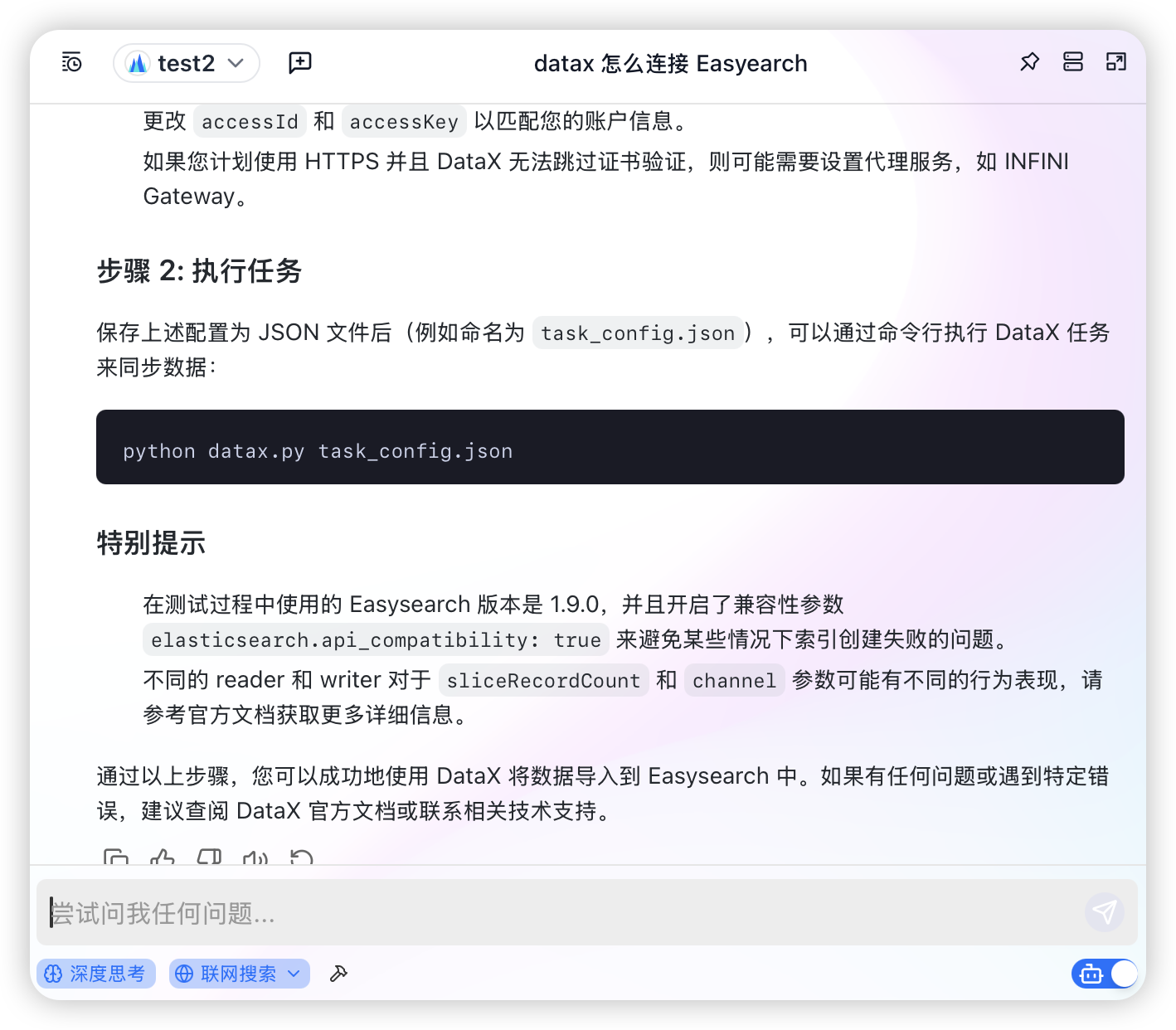
私有知识库 Coco AI 实战(七):摄入本地 PDF 文件
是否有些本地文件要检索?没问题。我们先对 PDF 类的文件进行处理,其他的文件往后稍。 Coco Server Token 创建一个 token 备用。 PDF_Reader 直接写个 python 程序解析 PDF 内容,上传到 Coco Server 就行了。还记得以前都是直接写入 Coco …...

GitLab 18.0 正式发布,15.0 将不再受技术支持,须升级【二】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

NtfsLookupAttributeByName函数分析之和Scb->AttributeName的关系
第一部分: VOID FindFirstIndexEntry ( IN PIRP_CONTEXT IrpContext, IN PSCB Scb, IN PVOID Value, IN OUT PINDEX_CONTEXT IndexContext ) { 。。。。。。 // // Lookup the attribute record from the Scb. // if (!NtfsLookupAt…...

STM32H7系列USART驱动区别解析 stm32h7xx_hal_usart.c与stm32h7xx_ll_usart.c的区别?
在STM32H7系列中,stm32h7xx_hal_usart.c和stm32h7xx_ll_usart.c是ST提供的两种不同层次的USART驱动程序,主要区别在于设计理念、抽象层次和使用场景: 1. HAL库(Hardware Abstraction Layer) 文件:stm32h7x…...

网络原理 | TCP与UDP协议的区别以及回显服务器的实现
目录 TCP与UDP协议的区别 基于 UDP 协议实现回显服务器 UDP Socket 编程常用 Api UDP 服务器 UDP 客户端 基于 TCP 协议实现回显服务器 TCP Socket 编程常用 Api TCP 服务器 TCP 客户端 TCP 服务端常见的 bug 客户端发送数据后,没有响应 服务器仅支持…...

IP动态伪装开关
IP动态伪装开关 在OpenWrt系统中,IP动态伪装(IP Masquerading)是一种网络地址转换(NAT)技术,用于在私有网络和公共网络之间转换IP地址。它通常用于允许多个设备共享单个公共IP地址访问互联网。以下是关于O…...
【Unity3D】将自动生成的脚本包含到C#工程文件中
我们知道,在用C#开发中,通过vs编辑器新建的脚本,会自动包含到vs工程中,而通过外部创建,比如复制别的工程或代码创建的C#脚本不会包含到vs工程。 在我们的日常开发中,通常会自动创建C#脚本,特别…...

解决leetcode第3509题.最大化交错和为K的子序列乘积
3509.最大化交错和为K的子序列乘积 难度:困难 问题描述: 给你一个整数数组nums和两个整数k与limit,你的任务是找到一个非空的子序列,满足以下条件: 它的交错和等于k。 在乘积不超过limit的前提下,最大…...
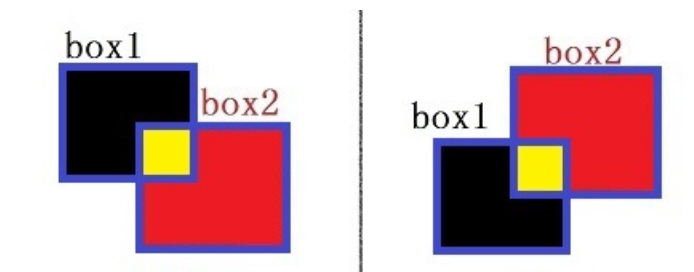
【Python 深度学习】1D~3D iou计算
一维iou 二维 import numpy as npdef iou_1d(set_a, set_b):# 获得集合A和B的边界 x1, x2 set_ay1, y2 set_b# 计算交集的上下界low max(x1,y1)high - min(x2, y2)# 计算交集if high - low < 0:inter 0else:inter high - low# 计算并集union (x2 -x1) (y2 - y1) - in…...
java23
1.美化界面 添加背景图片 所以我们添加背景图片要放在后面添加 添加图片边框 绝对路径: 相对(模块)路径: 第一个是绝对路径,第二个是相对路径,但是斜杠的方向不对 总结: 2.图片移动 先实现KeyListener接口…...

嵌入式工程师常用软件
1、 Git Git 是公司常用的版本管理工具,人人都要会。在线的 git 教程可以参考菜鸟教程: https://www.runoob.com/git/git-tutorial.html 电子书教程请在搜索栏搜索: git Git 教程很多,常用的命令如下,这些命令可…...
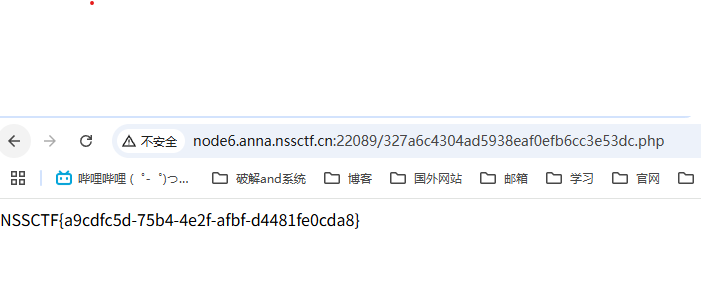
LitCTF2025 WEB
星愿信箱 使用的是python,那么大概率是ssti注入 测试{{5*5}} 发现需要包含文字,那么添加文字 可以看到被waf过滤了,直接抓包查看参数上fenjing 可以看到这里是json格式,其实fenjing也是支持json格式的 https://github.com/Marv…...

Redisson WatchDog会一直续期吗?
取决于加锁的方式。 Lock 方法有2种形式,如果指定了leaseTime (且不为-1), 不会启用watchDog机制. 如果没有指定leaseTime, 则会启动watchDog机制,且会一直续期,除非线程宕调或者续期失败。 p…...
Linux 下VS Code 的使用
这里以创建helloworld 为例。 Step 0:准备工作: Install Visual Studio Code. Install the C extension for VS Code. You can install the C/C extension by searching for c in the Extensions view (CtrlShiftX). Step 1: 创建工作目录 helloworld࿰…...

Android开发namespace奇葩bug
Android开发namespace奇葩bug namespace "com.yibanxxx.yiban"buildFeatures {buildConfig true}namespace 对应你的module的清单下的package...

watchEffect
在处理复杂异步逻辑时,Vue 3 的 watchEffect 相比传统的 watch 具有以下优势: 1. 自动追踪依赖 watchEffect 会自动收集其回调中使用的所有响应式依赖,无需手动指定监听源: import { ref, watchEffect } from vue;const count …...
Qt 布局管理器的层级关系
1、HomeWidget.h头文件: #ifndef HOMEWIDGET_H #define HOMEWIDGET_H#include <QWidget> #include <QPushButton> #include <QVBoxLayout> #include <QHBoxLayout>class HomeWidget : public QWidget {Q_OBJECTpublic:HomeWidget(QWidget …...