Day 37
继续之前的学习
过拟合的判断
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore") device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")iris = load_iris()
X = iris.data
y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return outmodel = MLP().to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01)num_epochs = 20000 # 用于存储每200个epoch的损失值和对应的epoch数
train_losses = []
test_losses = []
epochs = []start_time = time.time() with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:for epoch in range(num_epochs):outputs = model(X_train) train_loss = criterion(outputs, y_train)optimizer.zero_grad()train_loss.backward()optimizer.step()if (epoch + 1) % 200 == 0:model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})if (epoch + 1) % 1000 == 0:pbar.update(1000) if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) time_all = time.time() - start_time
print(f'Training time: {time_all:.2f} seconds')plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss')
plt.plot(epochs, test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend()
plt.grid(True)
plt.show()model.eval()
with torch.no_grad(): outputs = model(X_test) _, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和对应的索引correct = (predicted == y_test).sum().item() accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%') 模型的保存和加载
深度学习中模型的保存与加载主要涉及参数(权重)和整个模型结构的存储,同时需兼顾训练状态(如优化器参数、轮次等)以支持断点续训。
仅保存模型参数
-原理:保存模型的权重参数,不保存模型结构代码。加载时需提前定义与训练时一致的模型类。
-优点:文件体积小(仅含参数),跨框架兼容性强(需自行定义模型结构)
早停法(early stop)
我们梳理下过拟合的情况
正常情况:训练集和测试集损失同步下降,最终趋于稳定
过拟合:训练集损失持续下降,但测试集损失在某一时刻开始上升(或不再下降)
如果可以监控验证集的指标不再变好,此时提前终止训练,避免模型对训练集过度拟合。----监控的对象是验证集的指标。这种策略叫早停法。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 导入tqdm库用于进度条显示
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每200个epoch的损失值和对应的epoch数
train_losses = [] # 存储训练集损失
test_losses = [] # 存储测试集损失
epochs = []# ===== 新增早停相关参数 =====
best_test_loss = float('inf') # 记录最佳测试集损失
best_epoch = 0 # 记录最佳epoch
patience = 50 # 早停耐心值(连续多少轮测试集损失未改善时停止训练)
counter = 0 # 早停计数器
early_stopped = False # 是否早停标志
# ==========================start_time = time.time() # 记录开始时间# 创建tqdm进度条
with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:# 训练模型for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数train_loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()train_loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:# 计算测试集损失model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(train_loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 更新进度条的描述信息pbar.set_postfix({'Train Loss': f'{train_loss.item():.4f}', 'Test Loss': f'{test_loss.item():.4f}'})# ===== 新增早停逻辑 =====if test_loss.item() < best_test_loss: # 如果当前测试集损失小于最佳损失best_test_loss = test_loss.item() # 更新最佳损失best_epoch = epoch + 1 # 更新最佳epochcounter = 0 # 重置计数器# 保存最佳模型torch.save(model.state_dict(), 'best_model.pth')else:counter += 1if counter >= patience:print(f"早停触发!在第{epoch+1}轮,测试集损失已有{patience}轮未改善。")print(f"最佳测试集损失出现在第{best_epoch}轮,损失值为{best_test_loss:.4f}")early_stopped = Truebreak # 终止训练循环# ======================# 每1000个epoch更新一次进度条if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新进度条# 确保进度条达到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 计算剩余的进度并更新time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# ===== 新增:加载最佳模型用于最终评估 =====
if early_stopped:print(f"加载第{best_epoch}轮的最佳模型进行最终评估...")model.load_state_dict(torch.load('best_model.pth'))
# ================================# 可视化损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs, train_losses, label='Train Loss')
plt.plot(epochs, test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss over Epochs')
plt.legend()
plt.grid(True)
plt.show()# 在测试集上评估模型
model.eval()
with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'测试集准确率: {accuracy * 100:.2f}%') 相关文章:

Day 37
继续之前的学习 过拟合的判断 import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time import matpl…...
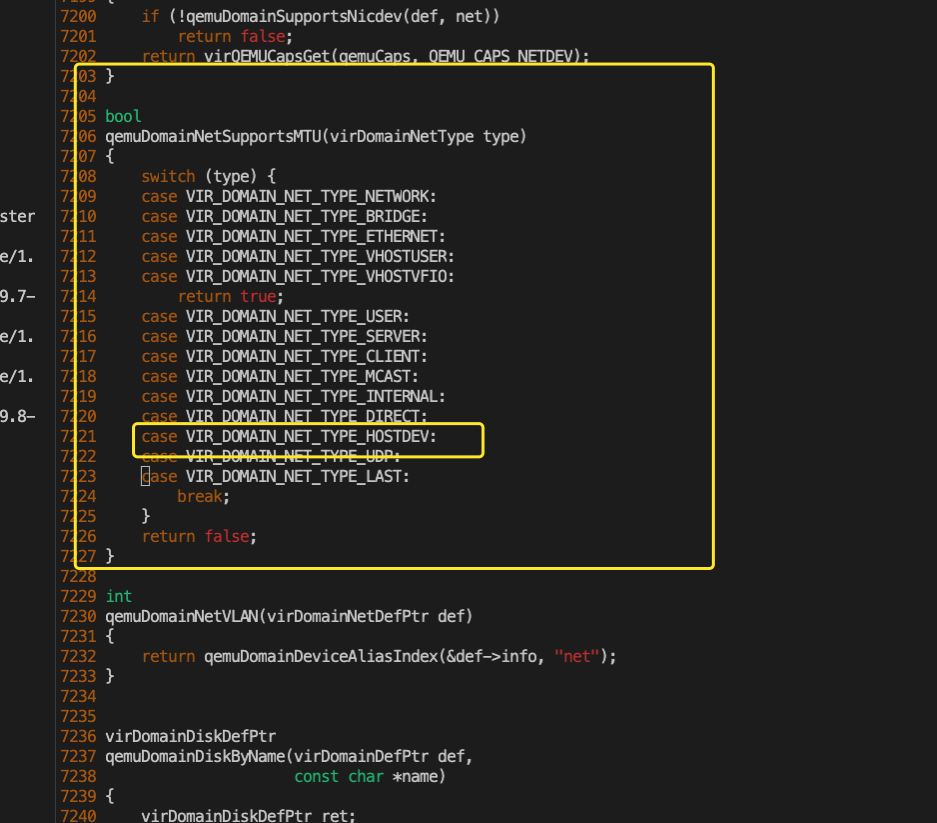
libvirt设置虚拟机mtu实现原理
背景 云计算场景下,可以动态调整虚拟机mtu,提高虚拟机网络性能。设置虚拟机(VM)virtio网卡的MTU(Maximum Transmission Unit)涉及 宿主机(Host)、QEMU/KVM、vhost-net后端 和 虚拟机内部的virtio驱动之间的协作。 原理分析 1.libvirt设置mtu分析 libv…...

AstroNex空间任务智能控制研究与训练数据集
数据集概述 AstroNex空间任务智能控制研究与训练数据集是朗迪锋科技基于Multiverse平台精心打造的首个全面覆盖航天器智能控制全周期的综合数据集产品。该数据集汇集了轨道动力学、姿态控制、机器视觉、环境感知等多维度数据,为航天器智能算法研发提供丰富的训练与…...

汽车副水箱液位传感器介绍
汽车副水箱液位传感器是现代车辆冷却系统中不可或缺的关键部件,其核心功能在于实时监测冷却液存量,确保发动机在最佳温度范围内稳定运行。随着汽车电子化程度不断提升,这一看似简单的传感器已发展成为集机械、电子、材料技术于一体的精密装置,其工作原理与技术演进值得深入…...

Docker+MobaXterm+x11实现容器UI界面转发本地
本文记录了搭建一个可直接ssh访问的container,并可通过x11转发界面的实现过程 0.1 实验环境 PC:windows 11 Server:Ubuntu 18.04 Docker image:Ubuntu 18.04 1. 获取Ubuntu 18.04的镜像 使用Dockerfile获取镜像,对…...

IEEE出版|2025年智能制造、机器人与自动化国际学术会议 (IMRA2025)
【重要信息】 会议官网:www.icimra.com 会议时间: 2025年11月14日-16日 会议地点: 中国湛江 截稿日期:2025年09月16日(一轮截稿) 接收或拒收通知:文章投递后5-7个工作日 会议提交检索:EI Compendex, Scopus IEEE出版|2025年…...
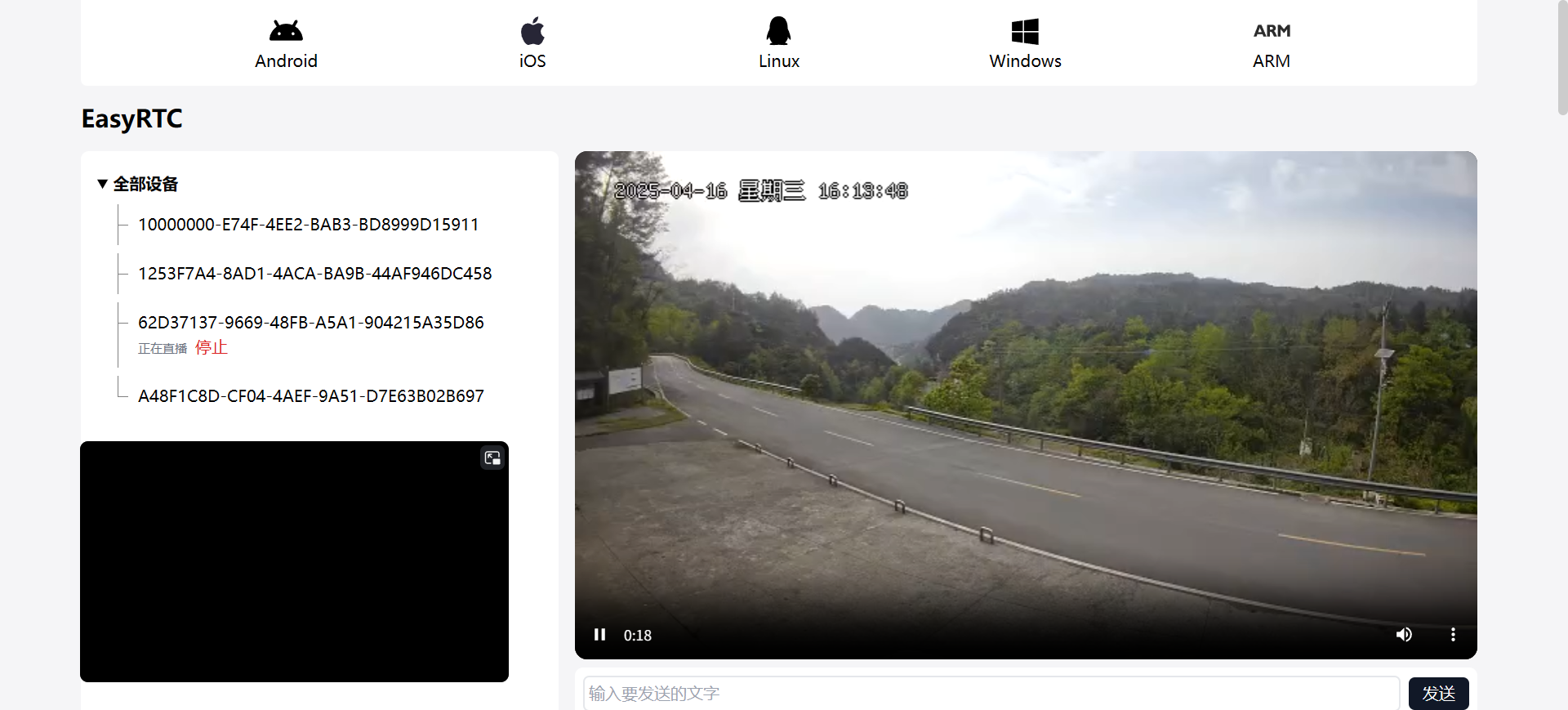
EasyRTC嵌入式SDK音视频实时通话助力WebRTC技术与智能硬件协同发展
一、概述 在万物互联的数字化浪潮下,智能硬件已广泛渗透生活与工业领域,实时音视频通信成为智能硬件实现高效交互的核心需求。WebRTC作为开源实时通信技术,为浏览器与移动应用提供免插件的音视频通信能力,而EasyRTC通过深度优化音…...
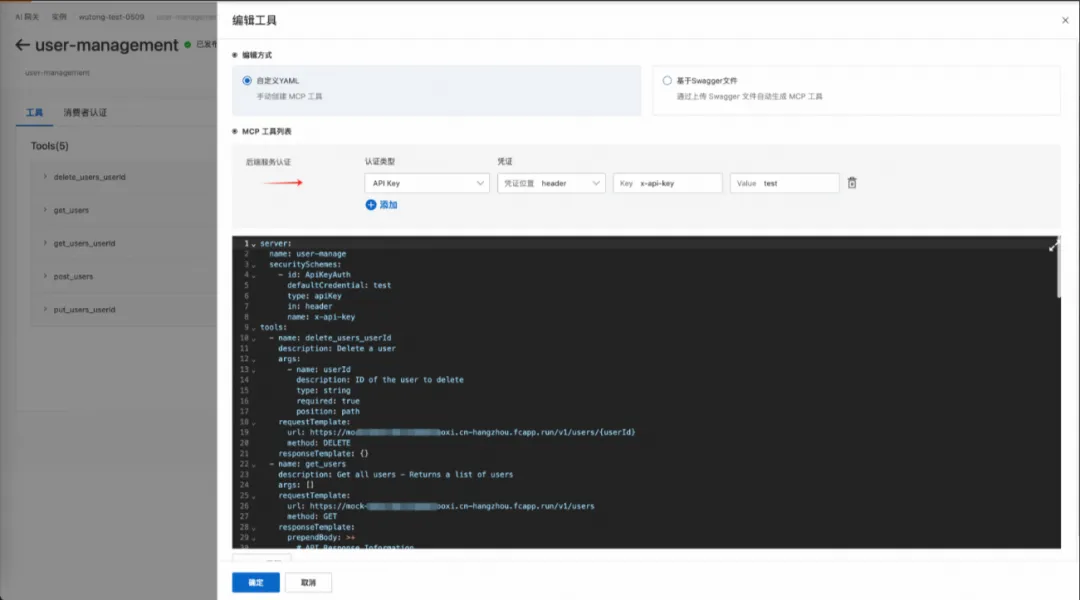
Higress MCP Server 安全再升级:API 认证为 AI 连接保驾护航
Higress MCP Server 安全再升级:API 认证为 AI 连接保驾护航 Higress 作为一款强大的 AI 原生 API 网关,致力于铺设 AI 与现实世界之间最短、最安全、最具成本效益的连接路径。其核心能力之一便是支持将现有的 OpenAPI 规范无缝转换为 MCP Server&#…...

多个vue2工程共享node_modules
手头有多个vue2项目,它们每个都需要一个node_modules,拷贝起来超级麻烦。于是想到能否共享一个node_modules呢?? 方法其实挺多,我选择了一个较简单的:符号连接法(win11平台) 创建方法很简单:比…...

蓝桥杯178 全球变暖
题目描述 你有一张某海域 NxN 像素的照片,"."表示海洋、"#"表示陆地,如下所示: ....... .##.... .##.... ....##. ..####. ...###. ....... 其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿。例如上…...

多模态理解大模型高性能优化丨前沿多模态模型开发与应用实战第七期
一、引言 在前序课程中,我们系统剖析了多模态理解大模型(Qwen2.5-VL、DeepSeek-VL2)的架构设计。鉴于此类模型训练需消耗千卡级算力与TB级数据,实际应用中绝大多数的用户场景均围绕推理部署展开,模型推理的效率影响着…...

mysql 合集
mysql 日志主要分为三个日志:redo log、binlog、undo log; redo log 主要是用来mysql 奔溃恢复 redo log 主要是有一个机制是 设置刷盘机制: 通过innodb_flush_log_at_trx_commit控制刷盘策略: 1:每次事务提交都刷盘(…...

Zustand V5教程:Vanilla Store 与 useStore 使用详解 + 实战 Demo
Zustand 是一个轻量、灵活的状态管理库。自从 Zustand v4 推出 Vanilla Store 后,我们可以更优雅地在组件外(如 API 拦截器、工具函数)访问状态,同时在组件内继续享受响应式的状态订阅。 本教程将通过一个“登录状态管理”示例&a…...
)
docker 搭建php 开发环境 添加扩展redis、swoole、xdebug(1)
docker-compose搭建lnmp 先决条件 首先需要安装docker 安装docker-compost 1、创建lnmp工作目录 #创建三个目录 mkdir lnmp && cd lnmp mkdir -p nginx/conf php mysql/data lnmp/www#编写nginx 配置文件 nginx/conf/default.conf vim nginx/conf/default.confserv…...

人脸识别技术合规备案最新政策详解
《人脸识别技术应用安全管理办法》将于2025年6月1日正式实施,该办法从技术应用、个人信息保护、技术替代、监管体系四方面构建了人脸识别技术的治理框架,旨在平衡技术发展与安全风险。 一、明确技术应用的边界 公共场所使用限制:仅在“维护公…...
高性能风控系统设计)
(16)高性能风控系统设计
文章目录 🚀 高性能风控系统设计:千万级QPS实时风控解决方案TL;DR🏗️ 系统整体架构💻 Java技术栈选型详解1️⃣ 接入层技术选型🔥 接入层代码示例 2️⃣ 规则引擎层技术选型🧠 规则引擎优化技巧 3️⃣ 数据…...
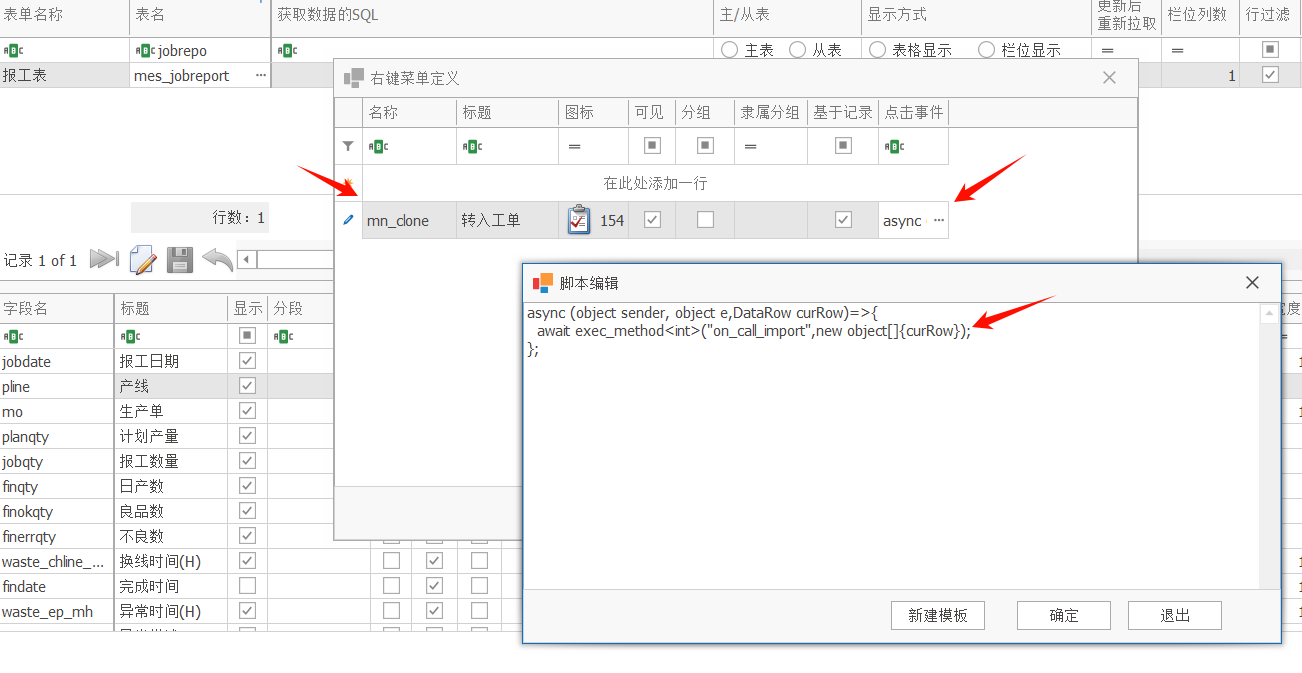
AStar低代码平台-脚本调用C#方法
修改报工表表单,右键定义弹出菜单,新增一个菜单项,并在点击事件脚本中编写调用脚本。 编译脚本,然后在模块代码里面定义这个方法: public async Task<int> on_call_import(DataRow curRow) {PrintDataRow(cur…...

企业级RAG技术实战指南:从理论到落地的全景解析
前言 在大模型技术日新月异的今天,检索增强生成(RAG)技术正成为企业突破AI应用瓶颈的关键利器。当传统AI系统还在处理结构化数据的泥潭中挣扎时,RAG技术已经打开了通向非结构化知识海洋的大门。这本《RAG技术实战指南》以独特的工…...
跳过输入)
getline()跳过输入
std::getline(cin, s) 第一个参数传递的是输入流:istream(输入流的基类), ifstream, istrstream 的引用; 第二个参数传递的是本地字符串引用,即从输入流读出来的东西要存放的位置。 会跳过getline()的输入 cin >> ch; getline(cin, s…...

【八股战神篇】RabbitMQ高频面试题
简述RabbitMQ五种模式 ? 延伸 请介绍一下RabbitMQ的特点 延伸 简述RabbitMQ的发布与订阅模式 延伸 RabbitMQ 如何保证消息不丢失? 延伸 RabbitMQ 如何保证消息有序? 延伸 专栏简介 八股战神篇专栏是基于各平台共上千篇面经…...
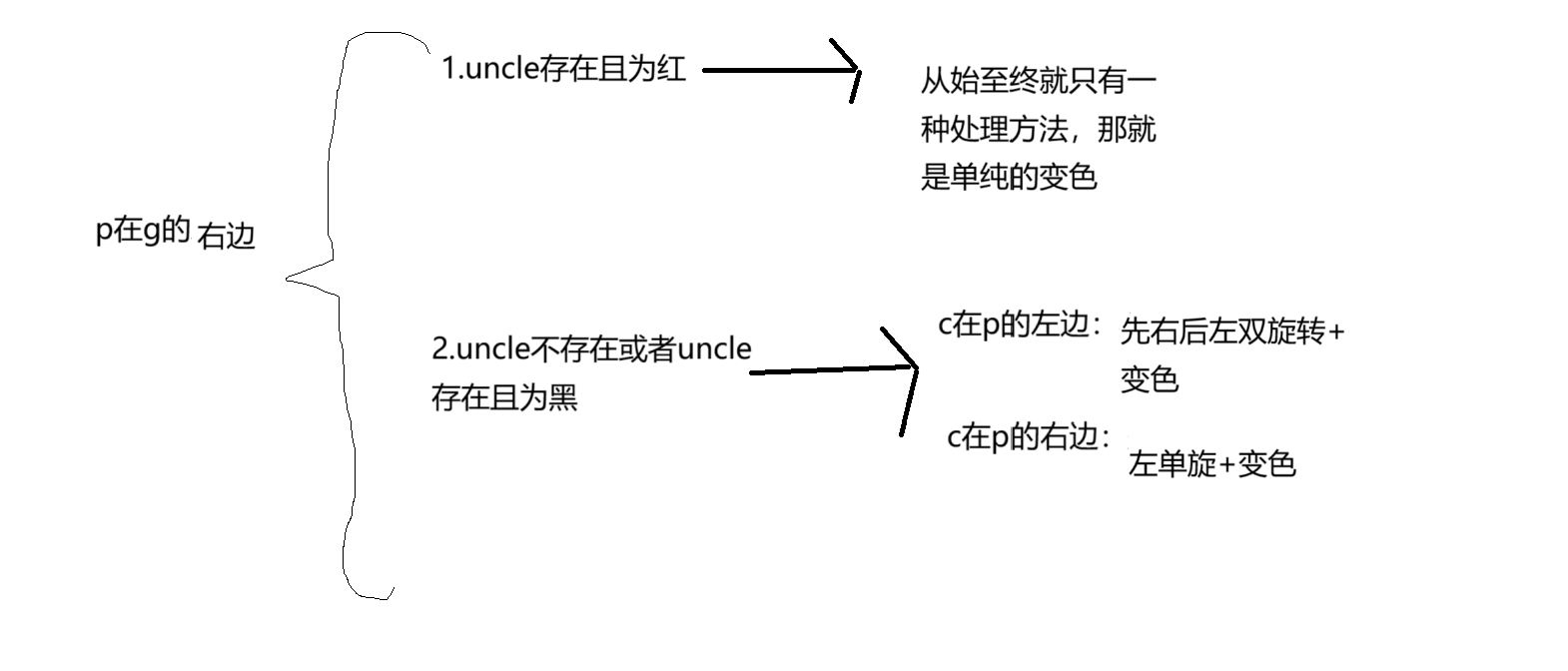
高阶数据结构——红黑树实现
目录 1.红黑树的概念 1.1 红黑树的规则: 1.2 红黑树的效率 2.红黑树的实现 2.1 红黑树的结构 2.2 红黑树的插入 2.2.1 不旋转只变色(无论c是p的左还是右,p是g的左还是右,都是一样的变色处理方式) 2.2.2 单旋变色…...

互联网大厂Java求职面试:AI与大模型应用集成中的架构难题与解决方案
互联网大厂Java求职面试:AI与大模型应用集成中的架构难题与解决方案 面试场景:AI与大模型应用集成的架构设计 面试官:技术总监 候选人:郑薪苦(搞笑但有技术潜力的程序员) 第一轮提问:系统架…...

安卓学习笔记-声明式UI
声明式UI Jetpack Compose 是 Google 推出的用于构建 Android UI 的现代化工具包。它采用 声明式编程模型(Declarative UI),用 Kotlin 编写,用于替代传统的 XML View 的方式。一句话概括:Jetpack Compose 用 Kotlin…...
AI天气预报进入“大模型时代“:如何用Transformer重构地球大气模拟?
引言:从数值预报到AI大模型的范式变革 传统的天气预报依赖于数值天气预报(NWP, Numerical Weather Prediction),通过求解大气动力学方程(如Navier-Stokes方程)进行物理模拟。然而,NWP计算成本极高,依赖超级计算机,且难以处理小尺度天气现象(如短时强降水)。 近年来…...
——2025-05-19)
本地项目如何设置https(2)——2025-05-19
在配置本地HTTPS时,安装mkcert工具本身是全局操作(安装在系统环境,与项目无关),但生成证书时需要进入项目目录操作。以下是具体说明: 安装 mkcert(全局操作) 安装位置:无…...
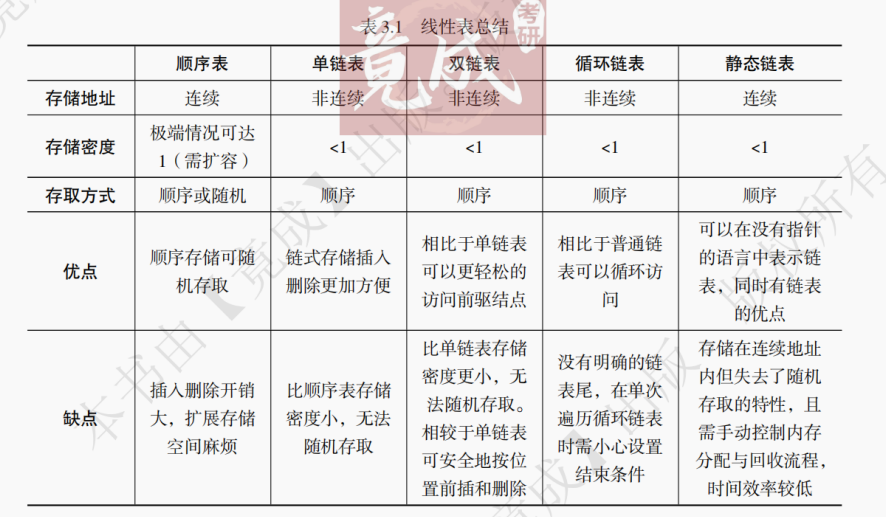
数据结构第3章 线性表 (竟成)
目录 第 3 章 线性表 3.1 线性表的基本概念 3.1.1 线性表的定义 3.1.2 线性表的基本操作 3.1.3 线性表的分类 3.1.4 习题精编 3.2 线性表的顺序存储 3.2.1 顺序表的定义 3.2.2 顺序表基本操作的实现 1.顺序表初始化 2.顺序表求表长 3.顺序表按位查找 4.顺序表按值查找 5.顺序表…...

JAVA面试复习知识点
面试中遇到的题目,记录复习(持续更新) Java基础 1.String的最大长度 https://www.cnblogs.com/wupeixuan/p/12187756.html 2.集合 Collection接口的实现: List接口:ArraryList、LinkedList、Vector Set接口:…...

项目中的流程管理之Power相关流程管理
一、低功耗设计架构规划(Power Plan) 低功耗设计的起点是架构级的电源策略规划,主要包括: 电源域划分 基于功能模块的活跃度划分多电压域(Multi-VDD),非关键模块采用低电压…...
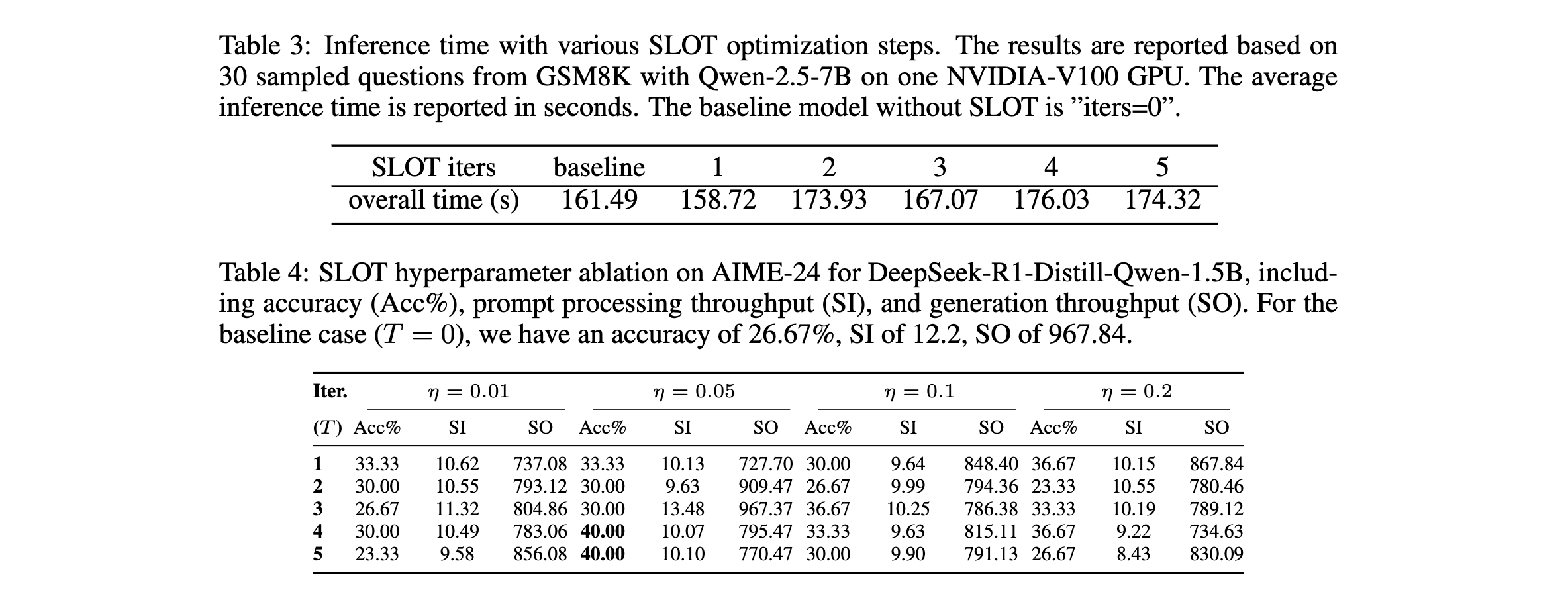
SLOT:测试时样本专属语言模型优化,让大模型推理更精准!
SLOT:测试时样本专属语言模型优化,让大模型推理更精准! 大语言模型(LLM)在复杂指令处理上常显不足,本文提出SLOT方法,通过轻量级测试时优化,让模型更贴合单个提示。实验显示&#x…...
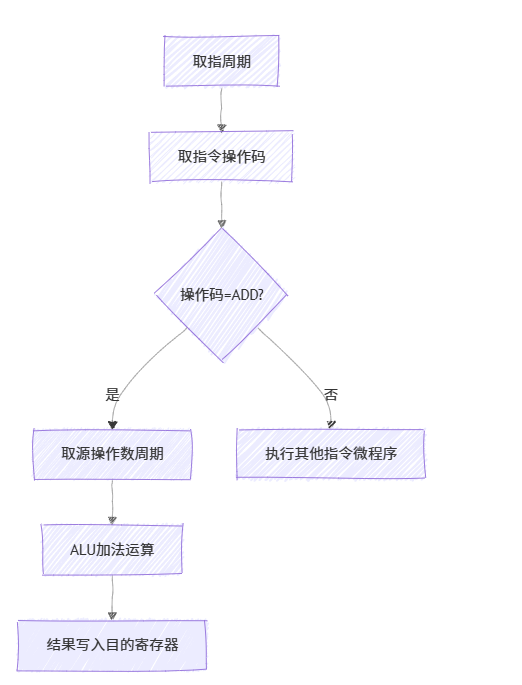
《计算机组成原理》第 10 章 - 控制单元的设计
目录 10.1 组合逻辑设计 10.1.1 组合逻辑控制单元框图 10.1.2 微操作的节拍安排 10.1.3 组合逻辑设计步骤 10.2 微程序设计 10.2.1 微程序设计思想的产生 10.2.2 微程序控制单元框图及工作原理 10.2.3 微指令的编码方式 1. 直接编码(水平型) 2.…...