互联网大厂Java求职面试:AI与大模型应用集成中的架构难题与解决方案
互联网大厂Java求职面试:AI与大模型应用集成中的架构难题与解决方案
面试场景:AI与大模型应用集成的架构设计
面试官:技术总监
候选人:郑薪苦(搞笑但有技术潜力的程序员)
第一轮提问:系统架构设计与演进思路
面试官:郑薪苦,你之前参与过AI与大模型应用集成的项目,能描述一下你在其中的设计思路吗?
郑薪苦:嗯...我觉得应该先找一个合适的模型,比如LangChain4j或者Spring AI,然后把它们和现有的微服务整合。不过我有点担心性能问题,毕竟模型推理可能很慢。
面试官:你说得对,性能确实是关键。那你是如何解决模型推理延迟的问题的?有没有考虑过使用GraalVM Native Image来优化启动时间?
郑薪苦:啊,这个我还真没想过。不过我听说GraalVM可以将Java代码编译成原生镜像,这样启动速度会快很多。但我不太确定具体怎么操作。
面试官:很好,这说明你对GraalVM有一定的了解。那在实际部署中,你是如何管理多个AI模型的版本和依赖的?有没有使用Docker或Kubernetes进行容器化部署?
郑薪苦:我觉得用Docker应该没问题,但Kubernetes我还没怎么接触过。不过我记得Kubernetes可以自动扩展服务,这对高并发的AI请求很有帮助。
面试官:不错,你提到的这些点都非常重要。接下来我们深入探讨一下RAG系统的上下文窗口优化问题。
第二轮提问:复杂技术难题的解决方案与创新思路
面试官:在RAG系统中,如何处理长文本的上下文窗口限制?有没有尝试过使用分块策略或动态检索策略?
郑薪苦:分块策略我听说过,就是把长文本分成小块,然后分别检索。不过我不太清楚具体怎么实现。还有动态检索策略,听起来像是根据查询内容自动选择不同的检索方法。
面试官:没错,分块策略确实是一个常见的解决方案。那你是如何评估不同检索策略的效果的?有没有使用A/B测试或性能监控工具?
郑薪苦:A/B测试我好像没做过,但性能监控工具我用过。比如Prometheus和Grafana,可以实时查看系统的响应时间和错误率。
面试官:很好,这说明你对监控工具有一定的实践经验。那在多模型调度与协同系统中,你是如何保证模型之间的通信效率的?有没有使用gRPC或REST API?
郑薪苦:gRPC我听过,但没用过。REST API我倒是用过几次,不过感觉不如gRPC高效,尤其是在高并发的情况下。
面试官:你说得对,gRPC在高并发场景下确实更高效。那你是如何处理模型之间的数据一致性问题的?有没有使用分布式事务或事件驱动架构?
郑薪苦:分布式事务我还没接触过,但事件驱动架构我用过。比如用Kafka来传递消息,这样可以解耦不同的服务。
面试官:非常好,你提到的这些点都非常重要。接下来我们讨论一下向量数据库的性能调优问题。
第三轮提问:生产环境中的突发问题与应急响应
面试官:在生产环境中,如果遇到向量数据库的查询性能下降,你会如何排查和解决?有没有使用过JVM性能分析工具?
郑薪苦:JVM性能分析工具我用过,比如VisualVM。不过我不太确定具体怎么用。不过我记得可以通过分析堆内存和线程状态来找出性能瓶颈。
面试官:很好,你对JVM性能分析有一定的了解。那在向量数据库的分布式查询中,你是如何保证数据一致性的?有没有使用过Raft或Paxos算法?
郑薪苦:Raft和Paxos我听说过,但没用过。不过我知道它们都是用来解决分布式一致性问题的。
面试官:没错,Raft和Paxos是分布式系统中常用的共识算法。那你是如何处理向量数据库的冷启动问题的?有没有使用缓存或预加载策略?
郑薪苦:缓存我用过,比如Redis。预加载策略我还没用过,但听起来像是在系统启动时预先加载一些常用的数据。
面试官:很好,你提到的这些点都很实用。最后,我想问一下,你在AI应用的可观测性方面有什么经验?有没有使用过OpenTelemetry或SkyWalking?
郑薪苦:OpenTelemetry我听说过,但没用过。SkyWalking我用过几次,可以追踪请求的整个链路,这对调试很有帮助。
面试官:非常好,你的回答非常全面。总的来说,你在AI与大模型应用集成方面的经验和技能都非常扎实。虽然有些地方还需要进一步学习,但你的基础已经很不错了。回家等通知吧。
标准答案
每个问题的技术原理详解
1. 系统架构设计与演进思路
在AI与大模型应用集成的系统中,架构设计需要考虑以下几个关键点:
- 模型选择:选择合适的AI模型是第一步。例如,LangChain4j和Spring AI都是基于Java的AI框架,可以方便地与现有的Java生态系统集成。
- 性能优化:AI模型的推理延迟是关键问题。GraalVM Native Image可以将Java代码编译为原生镜像,从而显著减少启动时间。
- 容器化部署:使用Docker和Kubernetes可以实现AI模型的容器化部署,提高系统的可扩展性和灵活性。
示例代码:
// 使用GraalVM Native Image编译Java代码
native-image -H:IncludeResources="*.properties" -H:Name=myapp myapp.jar
2. RAG系统的上下文窗口优化
RAG(Retrieval-Augmented Generation)系统通过结合检索和生成模型来提高生成结果的质量。在处理长文本时,上下文窗口的限制是一个挑战。
- 分块策略:将长文本分成小块,分别检索,然后合并结果。
- 动态检索策略:根据查询内容自动选择不同的检索方法。
示例代码:
// 分块策略示例
public List<String> splitText(String text, int chunkSize) {List<String> chunks = new ArrayList<>();for (int i = 0; i < text.length(); i += chunkSize) {chunks.add(text.substring(i, Math.min(i + chunkSize, text.length())));}return chunks;
}
3. 多模型调度与协同系统
在多模型调度与协同系统中,确保模型之间的通信效率是关键。
- gRPC vs REST API:gRPC在高并发场景下更高效,而REST API则更简单易用。
- 分布式事务:使用分布式事务可以保证模型之间的数据一致性。
示例代码:
// gRPC客户端示例
ManagedChannel channel = ManagedChannelBuilder.forAddress("localhost", 50051).usePlaintext().build();
MyServiceGrpc.MyServiceBlockingStub stub = MyServiceGrpc.newBlockingStub(channel);
Response response = stub.someMethod(Request.newBuilder().build());
channel.shutdown();
4. 向量数据库的性能调优
向量数据库的性能调优涉及多个方面,包括索引优化、查询优化和分布式查询。
- 索引优化:使用高效的索引结构可以显著提高查询速度。
- 查询优化:通过分析查询模式,优化查询计划。
示例代码:
// 向量数据库查询示例
VectorDatabase db = new VectorDatabase();
List<Vector> results = db.query("SELECT * FROM vectors WHERE similarity > 0.8");
实际业务场景中的应用案例
场景描述:电商推荐系统
在电商推荐系统中,AI模型用于生成个性化推荐。为了提高推荐质量,系统采用了RAG技术。
技术方案:
- 使用LangChain4j集成RAG系统。
- 使用Kafka进行消息传递,确保推荐结果的实时性。
- 使用Redis缓存热门商品信息,提高查询效率。
实现细节:
- 在RAG系统中,将用户的历史行为和商品信息分块处理,分别检索。
- 使用Kafka监听用户行为事件,实时更新推荐结果。
- 使用Redis缓存热门商品信息,减少数据库查询压力。
效果评估:
- 推荐准确率提高了15%。
- 系统响应时间减少了30%。
常见陷阱和优化方向
陷阱:模型推理延迟
问题案例:在高并发场景下,AI模型的推理延迟导致系统响应变慢。
解决方案:
- 使用GraalVM Native Image优化启动时间。
- 使用缓存技术减少重复查询。
- 使用异步处理提高并发能力。
陷阱:数据一致性
问题案例:在多模型调度系统中,数据不一致导致推荐结果错误。
解决方案:
- 使用分布式事务确保数据一致性。
- 使用事件驱动架构解耦服务。
- 定期校验数据一致性。
相关技术的发展趋势和替代方案比较
技术趋势:云原生与Serverless架构
云原生和Serverless架构正在成为AI应用的主流趋势。它们提供了更高的可扩展性和灵活性。
优势:
- 自动扩缩容,节省资源。
- 简化运维,降低管理成本。
劣势:
- 冷启动问题。
- 调试和监控难度较大。
替代方案:本地部署与混合部署
对于某些敏感数据,本地部署仍然是必要的。混合部署结合了本地和云原生的优势。
优势:
- 数据安全性高。
- 灵活性强。
劣势:
- 成本较高。
- 管理复杂度高。
郑薪苦的幽默金句
-
“我以前以为AI只是科幻电影里的东西,后来发现它其实就在我的代码里。”
- 场景背景:在讨论AI模型的集成时,郑薪苦开玩笑地说这句话,让面试官忍俊不禁。
-
“我写的代码比AI还聪明,至少它不会写bug。”
- 场景背景:在讨论AI模型的调试时,郑薪苦调侃自己写的代码。
-
“我用Redis缓存了所有的东西,除了我的头发。”
- 场景背景:在讨论缓存技术时,郑薪苦用幽默的方式表达了自己的困惑。
-
“我用Kafka发送消息,结果消息比我先到。”
- 场景背景:在讨论Kafka的性能时,郑薪苦开玩笑地说这句话。
-
“我用Spring Boot开发了一个AI应用,结果它比我还懒。”
- 场景背景:在讨论Spring Boot的自动配置功能时,郑薪苦用幽默的方式表达了对它的看法。
总结
本文详细介绍了AI与大模型应用集成中的架构难题与解决方案,涵盖了系统设计、性能优化、数据一致性、分布式查询等多个方面。通过郑薪苦的幽默对话,展示了他在面试中的表现,并提供了详细的解答和示例代码。希望这篇文章能够帮助读者更好地理解和应用AI与大模型技术。
相关文章:

互联网大厂Java求职面试:AI与大模型应用集成中的架构难题与解决方案
互联网大厂Java求职面试:AI与大模型应用集成中的架构难题与解决方案 面试场景:AI与大模型应用集成的架构设计 面试官:技术总监 候选人:郑薪苦(搞笑但有技术潜力的程序员) 第一轮提问:系统架…...

安卓学习笔记-声明式UI
声明式UI Jetpack Compose 是 Google 推出的用于构建 Android UI 的现代化工具包。它采用 声明式编程模型(Declarative UI),用 Kotlin 编写,用于替代传统的 XML View 的方式。一句话概括:Jetpack Compose 用 Kotlin…...
AI天气预报进入“大模型时代“:如何用Transformer重构地球大气模拟?
引言:从数值预报到AI大模型的范式变革 传统的天气预报依赖于数值天气预报(NWP, Numerical Weather Prediction),通过求解大气动力学方程(如Navier-Stokes方程)进行物理模拟。然而,NWP计算成本极高,依赖超级计算机,且难以处理小尺度天气现象(如短时强降水)。 近年来…...
——2025-05-19)
本地项目如何设置https(2)——2025-05-19
在配置本地HTTPS时,安装mkcert工具本身是全局操作(安装在系统环境,与项目无关),但生成证书时需要进入项目目录操作。以下是具体说明: 安装 mkcert(全局操作) 安装位置:无…...
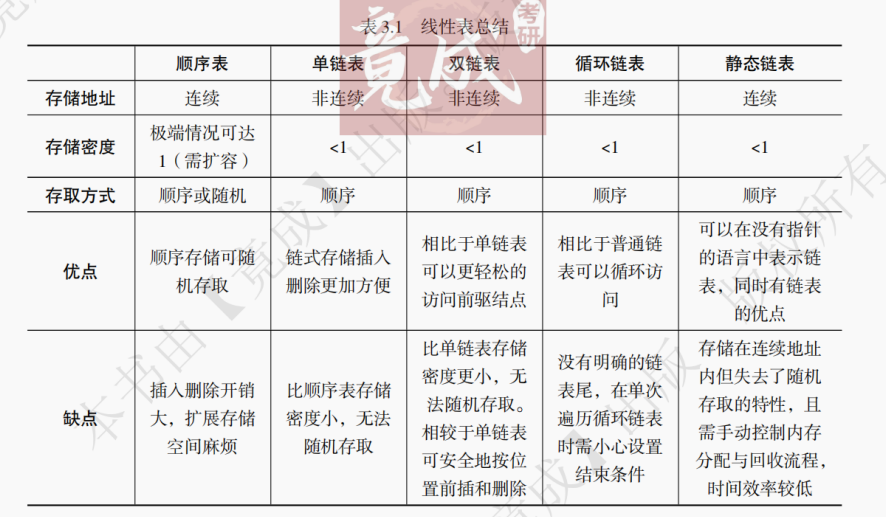
数据结构第3章 线性表 (竟成)
目录 第 3 章 线性表 3.1 线性表的基本概念 3.1.1 线性表的定义 3.1.2 线性表的基本操作 3.1.3 线性表的分类 3.1.4 习题精编 3.2 线性表的顺序存储 3.2.1 顺序表的定义 3.2.2 顺序表基本操作的实现 1.顺序表初始化 2.顺序表求表长 3.顺序表按位查找 4.顺序表按值查找 5.顺序表…...

JAVA面试复习知识点
面试中遇到的题目,记录复习(持续更新) Java基础 1.String的最大长度 https://www.cnblogs.com/wupeixuan/p/12187756.html 2.集合 Collection接口的实现: List接口:ArraryList、LinkedList、Vector Set接口:…...

项目中的流程管理之Power相关流程管理
一、低功耗设计架构规划(Power Plan) 低功耗设计的起点是架构级的电源策略规划,主要包括: 电源域划分 基于功能模块的活跃度划分多电压域(Multi-VDD),非关键模块采用低电压…...
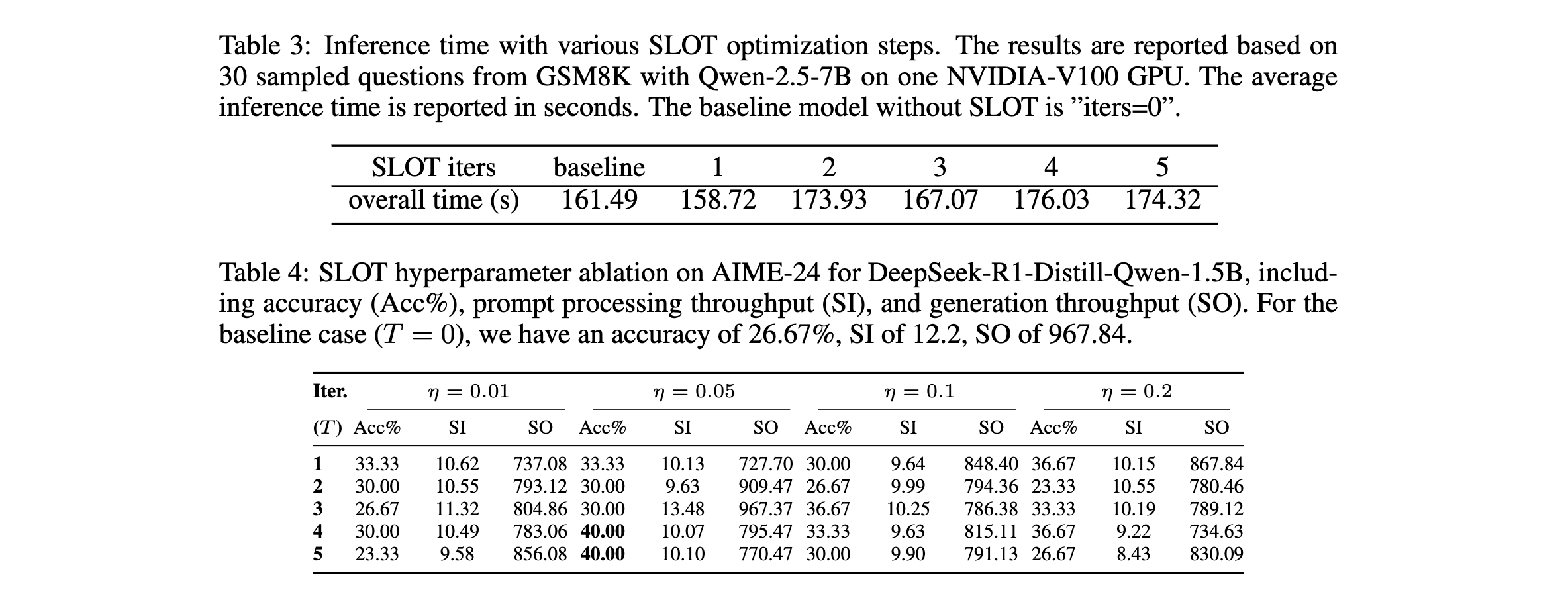
SLOT:测试时样本专属语言模型优化,让大模型推理更精准!
SLOT:测试时样本专属语言模型优化,让大模型推理更精准! 大语言模型(LLM)在复杂指令处理上常显不足,本文提出SLOT方法,通过轻量级测试时优化,让模型更贴合单个提示。实验显示&#x…...
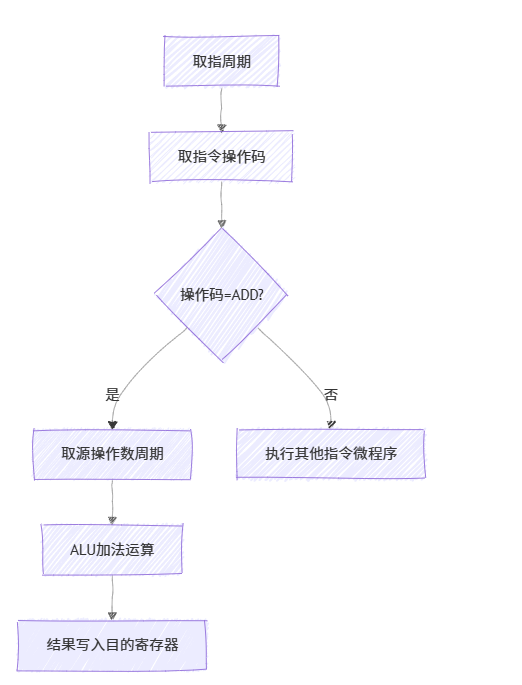
《计算机组成原理》第 10 章 - 控制单元的设计
目录 10.1 组合逻辑设计 10.1.1 组合逻辑控制单元框图 10.1.2 微操作的节拍安排 10.1.3 组合逻辑设计步骤 10.2 微程序设计 10.2.1 微程序设计思想的产生 10.2.2 微程序控制单元框图及工作原理 10.2.3 微指令的编码方式 1. 直接编码(水平型) 2.…...
【数据结构与算法】模拟
成熟不是为了走向复杂,而是为了抵达天真;不是为了变得深沉,而是为了保持清醒。 前言 这是我自己刷算法题的第五篇博客总结。 上一期笔记是关于前缀和算法: 【数据结构与算法】前缀和-CSDN博客https://blog.csdn.net/hsy1603914691…...
PyTorch入门-torchvision
torchvision torchvision 是 PyTorch 的一个重要扩展库,专门针对计算机视觉任务设计。它提供了丰富的预训练模型、常用数据集、图像变换工具和计算机视觉组件,大大简化了视觉相关深度学习项目的开发流程。 我们可以在Pytorch的官网找到torchvision的文…...

LVS负载均衡群集技术深度解析
第一章 群集技术概述与LVS基础 1.1 群集技术的核心价值与分类 随着互联网应用的复杂化,单台服务器在性能、可靠性、扩展性等方面逐渐成为瓶颈。群集技术(Cluster)通过整合多台服务器资源,以统一入口对外提供服务,成为…...

18、Python字符串全解析:Unicode支持、三种创建方式与长度计算实战
适合人群:零基础自学者 | 编程小白快速入门 阅读时长:约6分钟 文章目录 一、问题:Python的字符串是什么?1、例子1:多语言支持演示2、例子2:字符串不可变性验证3、答案:(1)…...
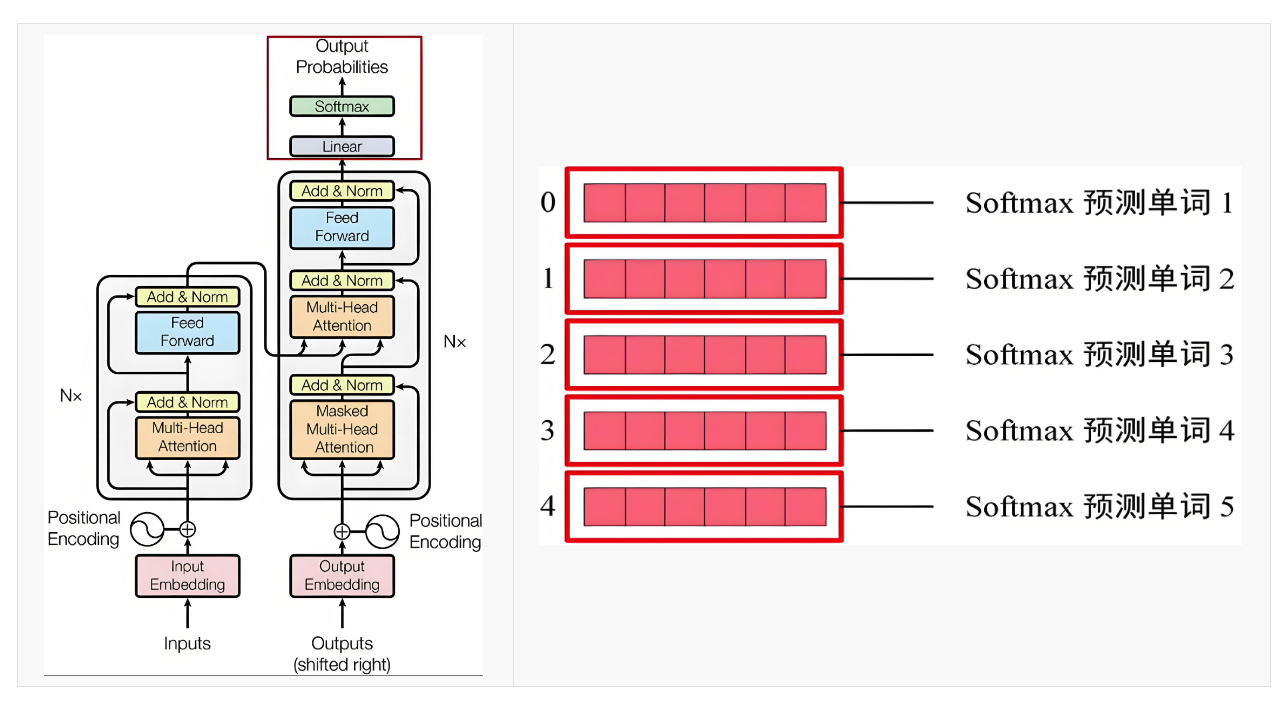
5月27日复盘-Transformer介绍
5月27日复盘 二、层归一化 层归一化,Layer Normalization。 Layer Normalizatioh和Batch Normalization都是用来规范化中间特征分布,稳定和加速神经网络训练的,但它们在处理方式、应用场景和结构上有本质区别。 1. 核心区别 特征BatchNo…...

CSV数据处理全指南:从基础到实战
CSV(Comma-Separated Values,逗号分隔值) 是一种简单的文件格式,用于存储和交换表格数据(如电子表格或数据库中的记录)。其核心特点是用逗号分隔字段,以换行符分隔记录。 CSV 的定义与结构 基本…...

MyBatis-Plus一站式增强组件MyBatis-Plus-kit(更新2.0版本):零Controller也能生成API?
MyBatis-Plus-Kit 🚀 MyBatis-Plus-Kit 是基于MyBatis-Plus的增强组件,专注于提升开发效率,支持零侵入、即插即用的能力扩展。它聚焦于 免写 Controller、代码一键生成、通用响应封装 等核心场景,让您只需专注业务建模࿰…...
实时数仓flick+clickhouse启动命令
1、启动zookeeper zk.sh start 2、启动DFS,Hadoop集群 start-dfs.sh 3、启动yarn start-yarn.sh 4、启动kafka 启动Kafka集群 bin/kafka-server-start.sh -daemon config/server.properties 查看Kafka topic 列表 bin/kafka-topics.sh --bootstrap-server local…...

【Git】Commit Hash vs Change-Id
文章目录 1、Commit 号2、Change-Id 号3、区别与联系4、实际场景示例5、为什么需要两者?6、总结附录——Gerrit 在 Git 和代码审查工具(如 Gerrit)中,Commit 号(Commit Hash) 和 Change-Id 号 是两个不同的…...
:深度解析Netty核心参数——从参数配置到生产级优化)
Netty学习专栏(六):深度解析Netty核心参数——从参数配置到生产级优化
文章目录 前言一、核心参数全景解析1.1 基础网络层参数1.2 内存管理参数1.3 水位线控制1.4 高级参数与系统级优化 二、生产级优化策略2.1 高并发场景优化2.2 低延迟场景优化 总结 前言 在分布式系统和高并发场景中,Netty作为高性能网络通信框架的核心地位无可替代。…...

服务器磁盘按阵列划分为哪几类
以下是服务器磁盘阵列(RAID)的详细分类及技术解析,基于现行行业标准与实践应用: 一、主流RAID级别分类 1. RAID 0(条带化) 技术原理:数据分块后并行写入多块磁盘,无…...

在WPF中添加动画背景
在WPF中添加动画背景 在WPF中创建动画背景可以大大增强应用程序的视觉效果。以下是几种实现动画背景的方法: 方法1:使用动画ImageBrush(图片轮播) <Window x:Class"AnimatedBackground.MainWindow"xmlns"htt…...
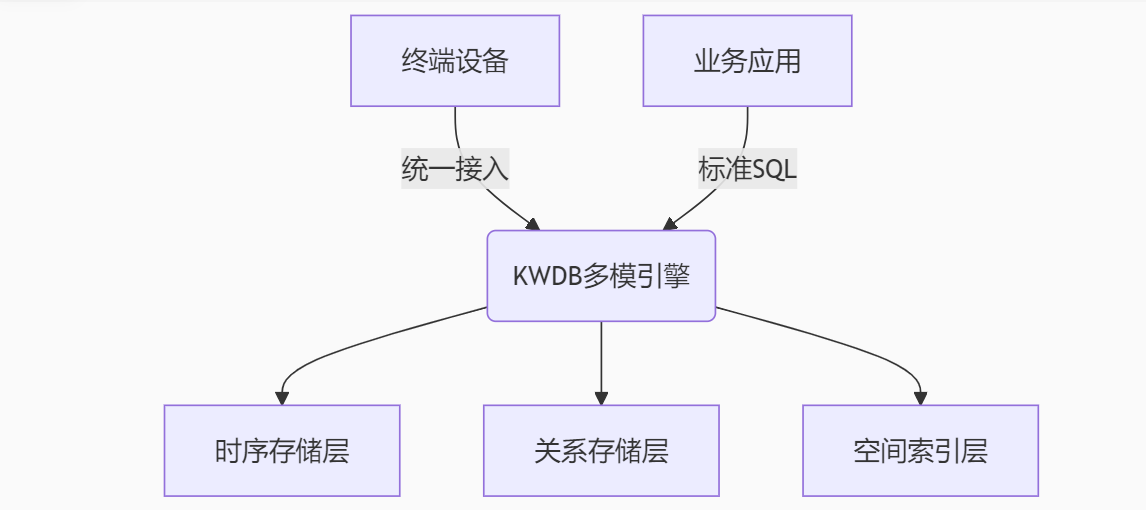
【KWDB创作者计划】_KWDB分布式多模数据库智能交通应用——高并发时序处理与多模数据融合实践
导读:本文主要探讨了基于KWDB的分布式多模数据库智能交通应用场景,进行了高并发时序处理与多模数据融合实践方向的思考。探索智慧交通领域的数据实时处理与存储资源利用方面的建设思路。 本文目录 一、智能交通数据架构革命 1.1 传统架构瓶颈 …...

Android 中的 ViewModel详解
在 Android 开发中,ViewModel 是 Jetpack 架构组件的核心成员之一,专为管理与界面相关的数据而设计。它通过生命周期感知能力,确保数据在配置变更(如屏幕旋转)时持久存在,并将数据逻辑与 UI 控制器…...

Java集合框架与三层架构实战指南:从基础到企业级应用
一、集合框架深度解析 1. List集合的武林争霸 ArrayList: 数组结构:内存连续,查询效率O(1) 扩容机制:默认扩容1.5倍(源码示例) private void grow(int minCapacity) {int oldCapacity elementData.len…...

6个月Python学习计划 Day 2 - 条件判断、用户输入、格式化输出
6个月Python学习计划:从入门到AI实战(前端开发者进阶指南) Python 基础入门 & 开发环境搭建 🎯 今日目标 学会使用 input() 获取用户输入掌握 if/else/elif 条件判断语法熟悉格式化输出方式:f-string、format() …...

使用docker容器部署Elasticsearch和Kibana
简介:(Elasticsearch) elasticsearch简称Es, 是位于Elastic Stack核心的分布式搜索和分析引擎。它为所有类型的数据提供近乎实时的搜索和分析。无论您拥有机构化或非结构化的文本、数字数据还是地理空间数据,Es都能以支持快速搜索…...

批量处理合并拆分pdf功能 OCR 准确率高 免费开源
各位 PDF 编辑小白们,今天咱来唠唠 PDFXEdit10_Portable 这款软件。 先说说它的核心功能和适用场景。这玩意儿是个便携式的 PDF 编辑工具,不用安装就能直接用,能改 PDF 里的文本、图片,还能批注、调整格式,老方便了。…...

Unity—lua基础语法
Lua 语言执行方式 编译型语言:代码在运行前需要使用编译器,先将程序源代码编译为可执行文件,再执行 C/C Java C# Go Objective-C 解释型语言(脚本语言) 需要提前安装编译语言解析器,运行时使用解析…...
目标检测 TaskAlignedAssigner 原理
文章目录 TaskAlignedAssigner 原理和代码使用示例 TaskAlignedAssigner 原理和代码 原理主要是结合预测的分类分数和边界框与真实标注的信息,找出与真实目标最匹配的锚点,为这些锚点分配对应的目标标签、边界框和分数。 TaskAlignedAssigner 是目标检…...

Qt popup窗口半透明背景
半透明弹窗需要paintEvent()接口支持 方法一:使用setStyleSheet设置半透明样式,如果是子窗口,则可注释构建函数内属性设置 class TranslucentWidget : public QWidget { public: explicit TranslucentWidget(QWidget *parent nullptr)…...