机器学习笔记【Week1】
一、机器学习简介(Introduction)
什么是机器学习?
定义(Tom Mitchell):
“A computer program is said to learn from experience E with respect to some task T and performance measure P, if its performance on T, as measured by P, improves with experience E.”
| 要素 | 示例 |
|---|---|
| Task T | 识别垃圾邮件、识别人脸、预测房价等 |
| Experience E | 历史邮件数据、历史房价数据 |
| Performance P | 分类准确率、均方误差(MSE)等 |
与传统编程的区别:
| 编程方式 | 输入 | 模型 | 输出 |
|---|---|---|---|
| 传统编程 | 规则 + 数据 | 人工设计的程序 | 得出结果 |
| 机器学习 | 数据 + 结果 | 算法训练生成的模型 | 模型进行预测 |
二、机器学习的分类
1. 监督学习(Supervised Learning)
- 有输入
x和已知输出y - 目标:学习函数
f(x) ≈ y
任务类型:
- 回归:输出是连续值(如房价)
- 分类:输出是离散类别(如垃圾邮件)
2. 非监督学习(Unsupervised Learning)
- 只有输入
x,没有输出标签y - 目标:发现数据内部结构,如聚类或降维
三、线性回归模型(Linear Regression)
什么是线性回归?
线性回归(Linear Regression)是一种回归算法,用于预测一个连续数值型输出(例如房价、工资等),假设输入变量 x x x 与输出 y y y 存在线性关系。
问题定义
根据输入变量
x预测连续输出y,例如房价预测。
假设函数(Hypothesis)
单变量线性回归的假设函数如下:
h θ ( x ) = θ 0 + θ 1 x h_\theta(x) = \theta_0 + \theta_1 x hθ(x)=θ0+θ1x
其中:
- x x x:输入特征(如房屋面积)
- y y y:真实标签(如房价)
- h θ ( x ) h_\theta(x) hθ(x):模型预测值
- θ 0 \theta_0 θ0:偏置项(intercept)
- θ 1 \theta_1 θ1:权重系数(slope)
在 Python 中表示为:
def hypothesis(theta, x):return theta[0] + theta[1] * x
四、代价函数(Cost Function)
为什么要最小化代价函数(Cost Function)?
预测值和真实值会存在误差,我们需要一个方式来衡量“预测得好不好”。
衡量预测值与实际值偏差的函数:
J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2 J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
m m m 是样本数量
该函数是一个关于 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1 的凸函数(抛物面)
Python 实现:
import numpy as npdef compute_cost(X, y, theta):m = len(y)predictions = X @ thetaerrors = predictions - yreturn (1 / (2 * m)) * np.dot(errors.T, errors)
五、梯度下降算法(Gradient Descent)
为什么使用梯度下降法(Gradient Descent)?
代价函数 J ( θ ) J(\theta) J(θ) 是一个关于参数 θ \theta θ 的二次函数图像(碗状),我们要找到那个最低点(最优参数):
梯度下降的思想:
- 随便选一组参数初始值(如 θ 0 = 0 \theta_0=0 θ0=0, θ 1 = 0 \theta_1=0 θ1=0)
- 计算当前点的“斜率方向”(导数)
- 朝着函数下降最快的方向(梯度的反方向)更新参数
- 重复多次,直到收敛到最低点(代价函数几乎不变)
梯度下降是如何收敛的?
- 如果学习率 α \alpha α 太大,可能“跨过了山谷”,导致震荡甚至发散;
- 如果太小,虽然能收敛,但需要非常多次迭代;
- 所以在实践中,一般尝试多个 α \alpha α,并可绘制 J ( θ ) J(\theta) J(θ) 的值随时间变化的曲线来观察收敛速度。
为什么加入 θ 0 \theta_0 θ0(bias)项?
假设没有偏置项 θ 0 \theta_0 θ0,那么模型强制通过原点。显然这不是普适的情况。
例如:
- 面积为 0 平方米的房子,不一定价格是 0 万元。
- 所以我们需要一个“可以整体平移”的能力,这就是偏置项的作用。
目标:最小化代价函数,找到最优参数 θ \theta θ
梯度更新公式:
θ j : = θ j − α ⋅ ∂ ∂ θ j J ( θ ) \theta_j := \theta_j - \alpha \cdot \frac{\partial}{\partial \theta_j} J(\theta) θj:=θj−α⋅∂θj∂J(θ)
- α \alpha α:学习率,表示每一步更新的速度
- 太小 → 收敛慢;太大 → 发散
导数告诉我们:该参数朝哪个方向走会让代价函数变小
在单变量线性回归中:
θ 0 : = θ 0 − α ⋅ 1 m ∑ ( h θ ( x ( i ) ) − y ( i ) ) \theta_0 := \theta_0 - \alpha \cdot \frac{1}{m} \sum (h_\theta(x^{(i)}) - y^{(i)}) θ0:=θ0−α⋅m1∑(hθ(x(i))−y(i))
θ 1 : = θ 1 − α ⋅ 1 m ∑ ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x ( i ) \theta_1 := \theta_1 - \alpha \cdot \frac{1}{m} \sum (h_\theta(x^{(i)}) - y^{(i)}) \cdot x^{(i)} θ1:=θ1−α⋅m1∑(hθ(x(i))−y(i))⋅x(i)
Python 实现:
def gradient_descent(X, y, theta, alpha, iterations):m = len(y)cost_history = []for i in range(iterations):predictions = X @ thetaerrors = predictions - ygradients = (1 / m) * (X.T @ errors)theta -= alpha * gradientscost_history.append(compute_cost(X, y, theta))return theta, cost_history
示例:房价预测(数据 + 可视化 + 训练)
示例数据:
| 面积 x(平方米) | 价格 y(万元) |
|---|---|
| 50 | 15 |
| 70 | 20 |
| 100 | 30 |
Python 全流程实现:
import numpy as np
import matplotlib.pyplot as plt# Step 1: 数据定义
X_raw = np.array([50, 70, 100])
y = np.array([15, 20, 30])
m = len(y)# Step 2: 加上 x0 = 1(常数项)
X = np.c_[np.ones(m), X_raw] # shape = (m, 2)
y = y.reshape(m, 1)
theta = np.zeros((2, 1))# Step 3: 设置学习率和迭代次数
alpha = 0.0001
iterations = 1000# Step 4: 梯度下降训练
theta, cost_history = gradient_descent(X, y, theta, alpha, iterations)# Step 5: 输出结果
print("Learned theta:", theta.ravel())
print("Final cost:", compute_cost(X, y, theta))# Step 6: 可视化拟合
plt.scatter(X_raw, y, color='red', label='Training data')
plt.plot(X_raw, X @ theta, label='Linear regression')
plt.xlabel("Area (sqm)")
plt.ylabel("Price (10k)")
plt.legend()
plt.grid(True)
plt.title("Linear Regression Fit")
plt.show()# Step 7: 可视化代价函数下降过程
plt.plot(range(iterations), cost_history)
plt.xlabel("Iterations")
plt.ylabel("Cost J(θ)")
plt.title("Gradient Descent Cost Convergence")
plt.grid(True)
plt.show()
六、线性代数基础复习(为后续多变量线性回归做准备)
| 概念 | 描述 |
|---|---|
| 向量 | 一维数组,如 x = [ x 1 , x 2 , . . . , x n ] T x = [x₁, x₂, ..., xₙ]^T x=[x1,x2,...,xn]T |
| 矩阵 | 二维数组,如 X = [ x ( 1 ) ; x ( 2 ) ; . . . ] X = [x^{(1)}; x^{(2)}; ...] X=[x(1);x(2);...] |
| 转置 | 行列互换:X.T |
| 矩阵乘法 | A @ B 表示矩阵点乘,要求形状兼容(如 A 是 m × n,B 必须是 n × 1) |
相关文章:

机器学习笔记【Week1】
一、机器学习简介(Introduction) 什么是机器学习? 定义(Tom Mitchell): “A computer program is said to learn from experience E with respect to some task T and performance measure P, if its per…...
什么是3D全景视角?3D全景有什么魅力?
什么是3D全景视角?3D全景视角的全面解析。 3D全景视角,又称为3D全景技术或3D实景技术,是新兴的富媒体技术,基于静态图像和虚拟现实(VR)技术,通过全方位、无死角地捕捉和展示环境,为…...

【Mini-F5265-OB开发板试用测评】按键控制测试
本文介绍了如何使用按键控制 MCU 引脚的输出电平。 原理 由原理图可知 板载用户按键 K1 和 K2 分别与主控的 PB0 和 PB1 相连。 代码 #define _MAIN_C_#include "platform.h" #include "gpio_key_input.h" #include "main.h"int main(void) …...

Debian重装系统后
安装配置java环境 手动安装 下载openJDK:openJDK 设置替代项 sudo update-alternatives --install /usr/bin/java java /opt/jdk-21.0.2/bin/java 1 sudo update-alternatives --install /usr/bin/javac javac /opt/jdk-21.0.2/bin/javac 1 sudo update-alternat…...

每日Prompt:古花卷
提示词 主体对象 一本展开的古画卷 古画卷内呈现的内容 一片微型春秋鲁国,有古代马车,孔子乘坐周游列国,颜回、子路、子贡、曾参紧随其后 古画卷的外观状态 表面已经开裂和风化,呈现出年代感和历史感 与文字描述的首句一致&…...
)
[学习]C语言指针函数与函数指针详解(代码示例)
C语言指针函数与函数指针详解 文章目录 C语言指针函数与函数指针详解一、引言二、指针函数(函数返回指针)定义与语法典型应用场景注意事项 三、函数指针(指向函数的指针)定义与声明初始化与调用赋值方式调用语法 高级应用回调函数…...

夏季用电高峰如何防患于未“燃”?电力测温技术守护城市生命线
随着夏季来临用电负荷激增,电力系统面临严峻的高温考验,电力测温技术的重要性愈发凸显,电力安全是城市生命线工程的核心环节,电力测温已从"可选功能"升级为"必要的基础安全设施"。通过实时感知、智能分析和快…...
)
浙大版《Python 程序设计》题目集6-3,6-4,6-5,6-6列表或元组的数字元素求和及其变式(递归解法)
目录 6-3 输入格式: 输出格式: 输入样例: 输出样例: 6-4 输入格式: 输出格式: 输入样例: 输出样例: 6-5 输入格式: 输出格式: 输入样例: 输出样例: 6-6 输入格式: 输出格式: 输入样例: 输出样例: 6-3 第6章-3 列表或元组的数字元素求和 分数 20 全屏浏览 切换布局 作者 陈春晖 …...

Leetcode 3563. Lexicographically Smallest String After Adjacent Removals
Leetcode 3563. Lexicographically Smallest String After Adjacent Removals 1. 解题思路2. 代码实现 题目链接:3563. Lexicographically Smallest String After Adjacent Removals 1. 解题思路 这次的最后一题同样没有自力搞定,简直了…… 这道题还…...
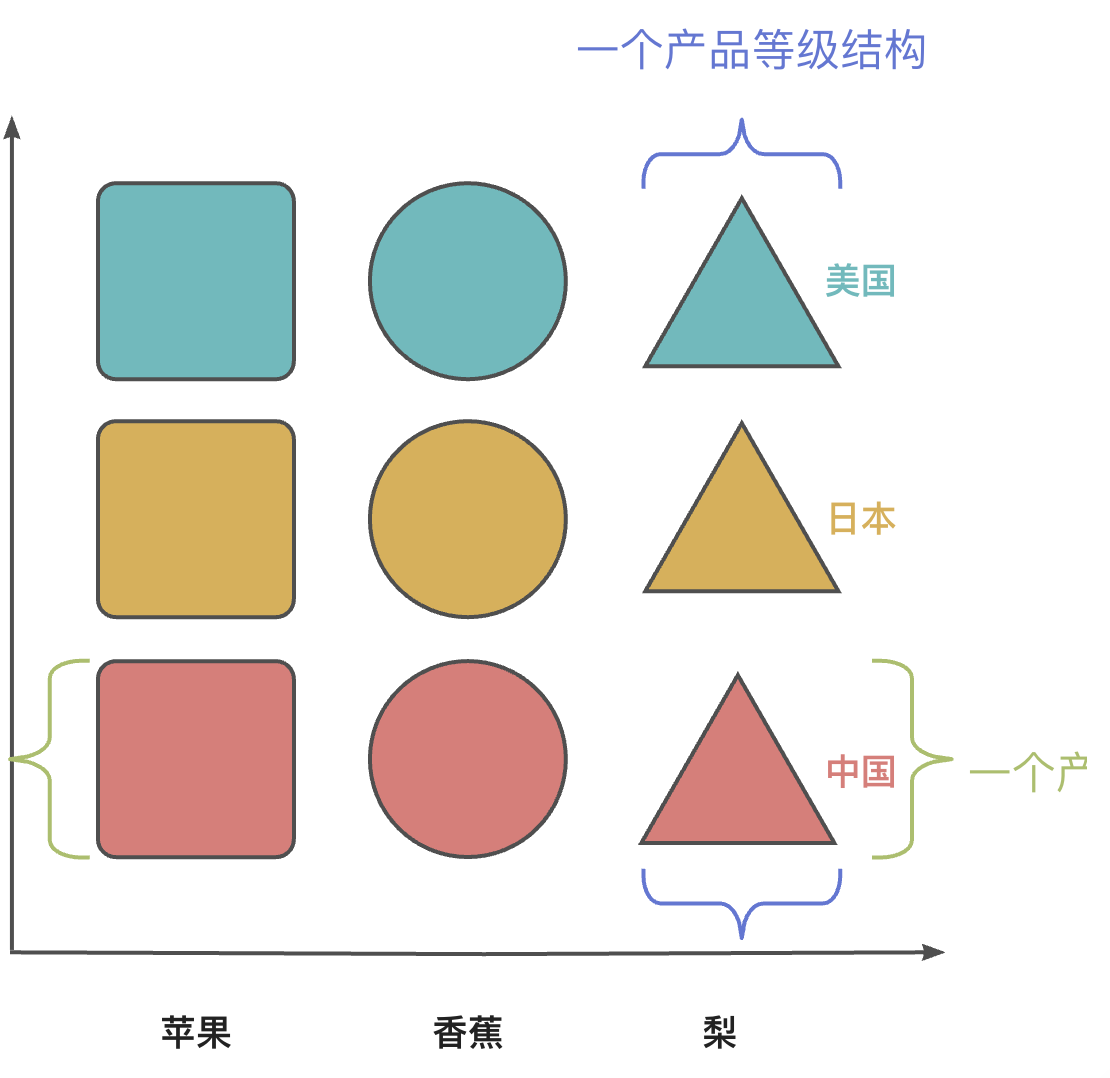
【创造型模式】抽象工厂方法模式
文章目录 抽象工厂方法模式产品族与产品等级结构抽象工厂方法模式的角色和职责抽象工厂方法模式的实现抽象工厂方法模式的优缺点适用场景 抽象工厂方法模式 工厂方法模式引入了“工厂等级结构”,解决了简单工厂方法过分依赖单一工厂的问题。但是工厂方法模式存在的一…...

一台手机怎样实现多IP上网?方法有多种
在数字时代,多IP上网已成为许多手机用户的刚需。本文将详细介绍如何通过不同技术手段实现手机多IP上网,帮助读者根据实际需求选择适合的解决方案。 一、为什么一台手机要实现多IP上网 手机实现多IP上网的典型场景包括: ①防止同一IP操作多个…...
)
【FFmpeg+SDL】播放音频时,声音正常但是有杂音问题(已解决)
下面这个函数是SDL音频的回调函数(修改后的) void fill_audio(void *udata,Uint8 *stream,int len) {static int cc 0;cc;qDebug()<<QString::fromLocal8Bit("想要填充:%1字节").arg(len)<<cc;AudioOutput* is static_cast<AudioOutput*>(udat…...

Linux 527 重定向 2>1 rsync定时同步(未完)
rsync定时同步 配环境 关闭防火墙、selinux systemctl stop firewalld systemctl disable firewalld setenforce0 vim /etc/SELINUX/config SELINUXdisable515 设置主机名 systemctl set-hostname code systemctl set-hostname backup 配静态ip rsync 需要稳定的路由表和端…...

3DVR拍摄指南:从理论到实践
3DVR拍摄指南:从理论到实践 3D虚拟现实(Virtual Reality,简称VR)作为近年来迅速崛起的高新技术,通过电脑模拟产生一个三维空间的虚拟世界,为使用者提供视觉、听觉乃至触觉的全方位感官模拟,使用户仿佛身临…...

OSI模型中的网络协议
一、电子邮件协议:从SMTP到MIME的扩展 电子邮件系统的核心协议包括SMTP(Simple Mail Transfer Protocol)、POP3(Post Office Protocol)和IMAP(Internet Message Access Protocol),但…...

【C/C++】线程局部存储:原理与应用详解
文章目录 1 基础概念1.1 定义1.2 初始化规则1.3 全局TLS vs 局部静态TLS 2 内存布局2.1 实现机制2.2 典型内存结构2.3 性能特点 3 使用场景/用途3.1 场景3.2 用途 4 注意事项5 对比其他技术6 示例代码7 建议7.1 调试7.2 优化 8 学习资料9 总结 在 C 多线程编程中,线…...

分块查找详解
1、原理 分块查找(Block Search)是一种结合顺序查找与索引查找的算法,适用于数据分块存储且块内无序但块间有序的场景。它通过“分块-建立索引-逐层定位”提高查找效率。 分块查找的核心思想 数据分块 将数据集划分为若干块(子…...

leetcode hot100刷题日记——21.不同路径
和20题一样的思路link 题解: class Solution { public:int dfs(int i,int j,vector<vector<int>>&memo){//超过了边界,return 0if(i<0||j<0){return 0;}//从(0,0)到(0,0…...

Elasticsearch 如何实现跨数据中心的数据同步?
实战场景: 双数据中心容灾,要求RPO<5分钟,RTO<30分钟 RPO(Recovery Point Objective): RPO指的是灾难发生后,系统能够恢复到的数据更新点的时间。简单来说,它衡量的是数据…...

C语言学习笔记三 --- V
文章目录 程序入门设计 --- C 语言第二周 核心语法📝2.1 C 语言笔记 | 注释的使用(让代码会“说话”)💡 **注释的作用**🔍 **注释的两种写法**⚠️ **注释的注意事项**🔧 **注释的实用场景**📌 **本节总结**:📝 2.2 C 语言笔记 | 关键字(保留字)深度解析💡 …...
通过JS模板引擎实现动态模块组件(Vite+JS+Handlebars)
1. 引言 在上一篇文章《实现一个前端动态模块组件(Vite原生JS)》中,笔者通过原生的JavaScript实现了一个动态的模块组件。但是这个实现并不完善,最大的问题就是功能逻辑并没有完全分开。比如模块的HTML: <div class"category-secti…...

梯度消失和梯度爆炸的原因及解决办法
梯度消失和梯度爆炸的原因是什么 问题分析 梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)本质上都是在深层神经网络中反向传播过程中,梯度在多层传播时逐渐缩小或放大的问题,导致模型难以…...
=1,则 a^φ(n)≡1(mod n)。)
欧拉定理:若 gcd(a,n)=1,则 a^φ(n)≡1(mod n)。
【欧拉定理简介】 欧拉定理:若 gcd(a,n)1,则 a^φ(n)≡1(mod n)。 (1)例如,a3,n10,gcd(3,10)1,φ(10)4,则 a^φ(n)3^481,81 mod 101,欧拉定理成立…...
fvm install 下载超时 过慢 fvm常用命令、flutter常用命令
Git 配置问题 确保 Git 使用的是 HTTPS,而不是 SSH。如果你有 .gitconfig,确保没有配置奇怪的代理: git config --global --get http.proxy git config --global --get https.proxy如果有代理设置且不需要,取消代理:…...

Python正则表达式:30秒精通文本处理
一、概述 1. 含义 正则表达式是一种记录文本规则的代码工具,用于描述字符串的结构和模式。它广泛应用于字符串的匹配、查找、替换、提取等操作。 2. 特点 语法复杂:符号多、规则灵活,可读性较差。功能强大:可以精确控制字符串…...

Introduction to SQL
目录 SQL特点 编辑 Select-From-Where Statements Meaning of Single-Relation Query Operational Semantics * In SELECT clauses Complex Conditions in WHERE Clause PATTERNS NULL Values Three-Valued Logic Multirelation Queries Aggregations NULL’s Ig…...

计算机视觉---YOLOv3
YOLOv3讲解 一、YOLOv3 核心架构与创新 YOLOv3(2018年发布)在YOLOv2基础上进行了全面升级,通过多尺度预测、更强大的骨干网络和优化的分类损失函数,显著提升了检测精度,尤其是小目标检测能力,同时保持了实…...

#RabbitMQ# 消息队列进阶
目录 消息可靠性 一 生产者的可靠性 1 生产者的重连 2 生产者的确认 (1 Confirm* (2 Return 二 MQ的可靠性 1 数据持久化 2 Lazy Queue* 三 消费者的可靠性 1 消费者确认机制 2 消费失败处理 3 业务幂等性 四 延迟消息 消息可靠性 在消息队列中,可靠性…...

React从基础入门到高级实战:React 核心技术 - React Router:路由管理
React Router:路由管理 在现代 Web 应用开发中,路由管理 是构建多页面或单页应用(SPA)的核心技术之一。React Router 是 React 生态中最受欢迎的路由管理库,它为开发者提供了强大的工具来实现页面导航、动态路由和权限…...
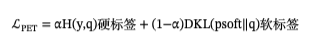
【深度学习】损失“三位一体”——从 Fisher 的最大似然到 Shannon 的交叉熵再到 KL 散度,并走进 PET·P-Tuning微调·知识蒸馏的实战
一页速览: 1912 Fisher 用最大似然把「让数据出现概率最高」变成参数学习; 1948 Shannon 把交叉熵解释成「最短平均编码长度」; 1951 Kullback-Leibler 用相对熵量化「多余信息」。 三条历史线落到今天深度学习同一个损失——交叉熵。 也…...