【深度学习】损失“三位一体”——从 Fisher 的最大似然到 Shannon 的交叉熵再到 KL 散度,并走进 PET·P-Tuning微调·知识蒸馏的实战
一页速览:
1912 Fisher 用最大似然把「让数据出现概率最高」变成参数学习;
1948 Shannon 把交叉熵解释成「最短平均编码长度」;
1951 Kullback-Leibler 用相对熵量化「多余信息」。
三条历史线落到今天深度学习同一个损失——交叉熵。
也就是我们常用的:CrossEntropyLoss 函数
下面按 时间 → 问题 → 数学 → 代码 的顺序拆解,并演示它们在二/多分类、大模型知识蒸馏(含温度 T)和 PET 软模板大模型微调里的角色。
1 三个名字、三个年代、一个目标
| 年代 | 人物 | 术语 | 初衷 | 关键论文 |
|---|---|---|---|---|
| 1912→1922 | R. A. Fisher | 最大似然 (MLE) | 用参数让训练数据出现的联合概率最大 | “On the mathematical foundations…” 1922 |
| 1948 | C. E. Shannon | 交叉熵 H(p,q) | 用 预测分布 q 压缩 真实分布 p 的平均比特数 | 《A Mathematical Theory of Communication》 |
| 1951 | S. Kullback & R. Leibler | KL 散度 DKL | 衡量 p→q 需要的额外信息量 | 《On Information and Sufficiency》 |
表示交叉熵, MLE 表示最大似然,
表示KL散度
一句话概览
最大似然(MLE)、交叉熵 H(p,q) 与 KL 散度 其实是同一指标在三位不同学者手中的“别名”。
1912-1922 Fisher 用它做参数估计;
1948 Shannon 用它算最短平均比特;
1951 Kullback-Leibler 把它写成“额外信息”。
由于 而熵 H(p) 只跟数据真分布有关、与模型参数毫无关系,最小 KL ⇔ 最小交叉熵 ⇔ 最大似然。


2 二/多分类:把公式算一遍
| 场景 | 激活 | 损失公式 | PyTorch |
|---|---|---|---|
| 二分类 | Sigmoid | -[y log ŷ+(1-y) log(1-ŷ)] | BCEWithLogitsLoss |
| 多分类 C≥2 | Softmax | -log qk | CrossEntropyLoss |
2.1 二分类示例
logits = torch.tensor([1.386, -0.847, 0.405]) # ≈[0.8,0.3,0.6]
labels = torch.tensor([1., 0., 1.])
loss = torch.nn.BCEWithLogitsLoss()(logits, labels) # ≈1.062.2 多分类示例:三分类为例子
logits = torch.tensor([[ 2.3, 0.1,-1.2],[ 0.2, 1.4, 0.0],[-0.5, 0.3, 2.1]])
labels = torch.tensor([0,1,2])
loss = torch.nn.CrossEntropyLoss()(logits, labels)C=2 时 Softmax+CCE 可化简为 Sigmoid+BCE,数学上等价 。
3 知识蒸馏:KL / 交叉熵 + 温度 T
核心损失
温度 T>1 让 logits 变平滑,更易传递「软知识」 。
为什么要温度? 把 logits / T (T>1) 能“压平”概率,使学生更容易学习细粒度信息

T, alpha = 4.0, 0.7
for x,y in loader:with torch.no_grad():p_soft = torch.softmax(teacher(x)/T, -1)q_logits = student(x)/Tq_log = torch.log_softmax(q_logits, -1)loss_kd = (p_soft*(p_soft.log()-q_log)).sum(1).mean()*T*T # KL 项loss_ce = torch.nn.CrossEntropyLoss()(q_logits*T, y) # 硬标签loss = alpha*loss_ce + (1-alpha)*loss_kdloss.backward(); opt.step()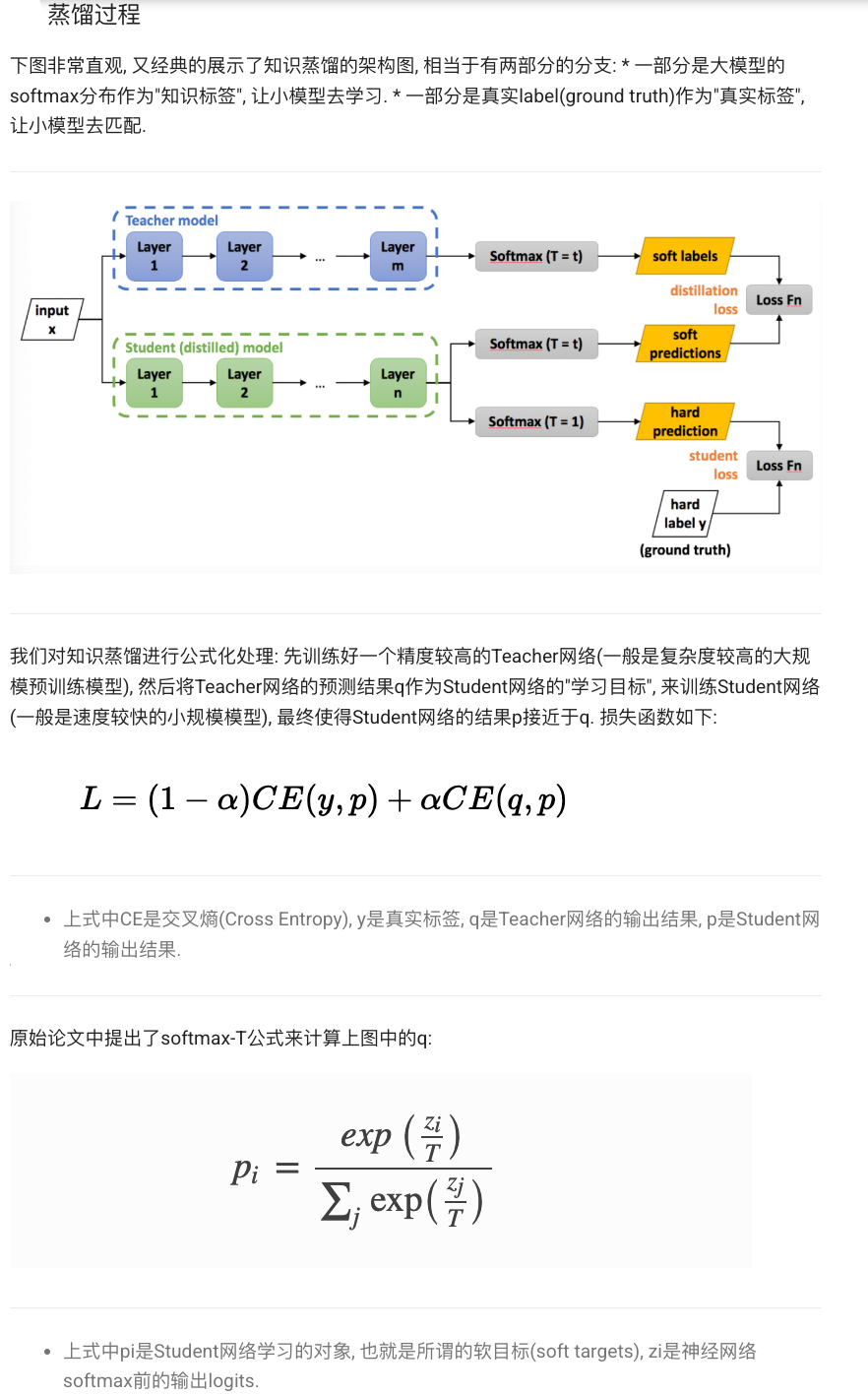
4 PET微调:把分类任务改成「完形填空」
说人话,就是自己弄一个[mask] ----》 映射表,这样以bert 为案例的预测出来的 【mask】通过映射表,就是我们的真实分类了,所以我们在微调的时候,把数据弄成原始句子 ➕ 【mask】模式,真实分类给进去,然后微调bert 模型,训练好的这个就是我们的老师,这个老师,去给其他样本进行打软标签, 也就是提供软标签这个,用于指导我们的另一个模型去拟合或者接近老师的答案。
(PET 产生的原因就是,因为我们的bert 在预训练的时候,就是MLM任务,我们直接把任务改成这种,就不用拟合或者说训练太久,即可达到好的效果。)
-
Stage-A:5-10 条标注 + Pattern T + Verbalizer V → 微调 K 个 BERT-MLM(填 [MASK],损失=交叉熵)。
-
Stage-B:老师集成给未标注文本打软标签
。
-
Stage-C:把
PVP 组件:Pattern T + Verbalizer V
例:"Review: <x>. Sentiment: [MASK]." ,terrible↔0,great↔1
Step-A 少量标注 → 微调 K 个教师 MLM
-
损失:CrossEntropyLoss 填 [MASK](即交叉熵)
Step-B 教师集成 → 大量未标注文本生成软标签 psoft
Step-C 学生分类器
# --- Stage-A: 训练 K 个教师 MLM ---
for T in patterns:teacher = BertForMaskedLM.from_pretrained('bert-base')finetune_mlm(teacher, few_shot_data, T, verbalizer) # 交叉熵填空teachers.append(teacher)# --- Stage-B: 生成软标签 ---
soft = []
for x in unlabeled:logits = [mask_logits(m,x,T,V) for m,T in zip(teachers,patterns)]soft.append(torch.mean(torch.stack(logits),0).softmax(-1)) # p_soft# --- Stage-C: 学生分类器 ---
student = BertForSequenceClassification.from_pretrained('bert-base')
for x, p_soft in zip(unlabeled, soft):q = student(x).log_softmax(-1)kl = (p_soft * (p_soft.log() - q)).sum()loss = kl # α=0,可选加硬标签交叉熵loss.backward(); opt.step()用 KL/交叉熵把学生分布 qθ 贴到教师软标签 psoft 上 。
5 2025 Prompt-Tuning ,lora 家族选型
| 方法 | 额外参数 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|---|
| Prompt-Tuning | 0 | 零成本 PoC | 方差大,需≥100B 模型 | 原型验证 |
| PET | 全量+集成 | 1-10 样本即可 | 两阶段工程复杂 | 极少标签 |
| P-Tuning v2 | 0.1-3 % | 稳定通用 | 需提示编码器 | NLU few-shot |
| PPT | 同上 + 预训 | 最优精度 | 预训练成本高 | 少样本高精度 |
| LoRA / QLoRA | 0.05-1 % | 工业主流 | 需改 Linear | 任务量产 |
一般都是用 P-Tuning v2 和 LoRA 这几个
参考文献
-
Fisher R. A., Maximum Likelihood (1922)
-
Shannon C. E., A Mathematical Theory of Communication (1948)
-
Kullback S., Leibler R., On Information and Sufficiency (1951)
-
PyTorch Docs — BCEWithLogitsLoss
-
PyTorch Docs — CrossEntropyLoss
-
Schick T., Schütze H., Pattern-Exploiting Training (EACL 2021)
-
Hinton G. et al., Distilling the Knowledge… (2015)
-
Liu X. et al., GPT Understands, Too — P-Tuning v2 (2021)
-
Gu P. et al., PPT: Pre-trained Prompt Tuning (ACL 2022)
-
Stats.SE 讨论 BCE vs CCE
-
KD 温度研究综述
一句话总结
Fisher 说:让样本出现概率最大;Shannon 说:把平均比特压到最小;Kullback-Leibler 说:去掉无用信息。
三句话 = 一个训练目标:把交叉熵降到最低。 无论你在训练模型,还是蒸馏学生,还是用一个小小 Prompt 让大模型「开窍」,它始终是深度学习的黄金公式。
相关文章:
【深度学习】损失“三位一体”——从 Fisher 的最大似然到 Shannon 的交叉熵再到 KL 散度,并走进 PET·P-Tuning微调·知识蒸馏的实战
一页速览: 1912 Fisher 用最大似然把「让数据出现概率最高」变成参数学习; 1948 Shannon 把交叉熵解释成「最短平均编码长度」; 1951 Kullback-Leibler 用相对熵量化「多余信息」。 三条历史线落到今天深度学习同一个损失——交叉熵。 也…...
5 分钟速通密码学!
让我们开始第一部分:密码学基础 (Cryptography Basics)。 第一部分:密码学基础 (Cryptography Basics) 1. 什么是密码学? 想象一下,在古代战争中,将军需要向远方的部队传递作战指令。如果直接派人送信,信…...

Linux——IP协议
1. 现实意义 • IP协议:提供一种能力,把数据报从主机A跨网络送到主机B • TCP/IP协议:核心功能,把数据100%可靠的从主机A跨网络送到主机B 注:TCP协议负责百分百可靠,通过三次握手、滑动窗口、拥塞控制、延…...
)
Lua 脚本在 Redis 中的运用-24 (使用 Lua 脚本实现原子计数器)
实践练习:使用 Lua 脚本实现原子计数器 实现原子计数器是许多应用程序中的常见需求,例如跟踪网站访问量、限制 API 请求或管理库存。虽然 Redis 提供了 INCR 命令用于递增整数,但在复杂场景或与其他操作结合时直接使用它可能并不足够。本课程探讨了如何在 Redis 中利用 Lua…...
Linux信号量(32)
文章目录 前言一、POSIX 信号量信号量的基础知识信号量的基本操作 二、基于环形队列实现生产者消费者模型环形队列单生产单消费模型多生产多消费模型 总结 前言 加油,加油!!! 一、POSIX 信号量 信号量的基础知识 互斥、同步 不只…...

技术视界 | 打造“有脑有身”的机器人:ABC大脑架构深度解析(上)
ABC大脑架构:连接大模型与物理世界的具身智能新范式 在具身智能和类人机器人技术快速发展的背景下,如何高效整合“大模型的认知理解能力”与“对真实物理世界的精准控制”,成为当前智能体系统设计中最具挑战性也是最关键的问题之一。尽管大语…...
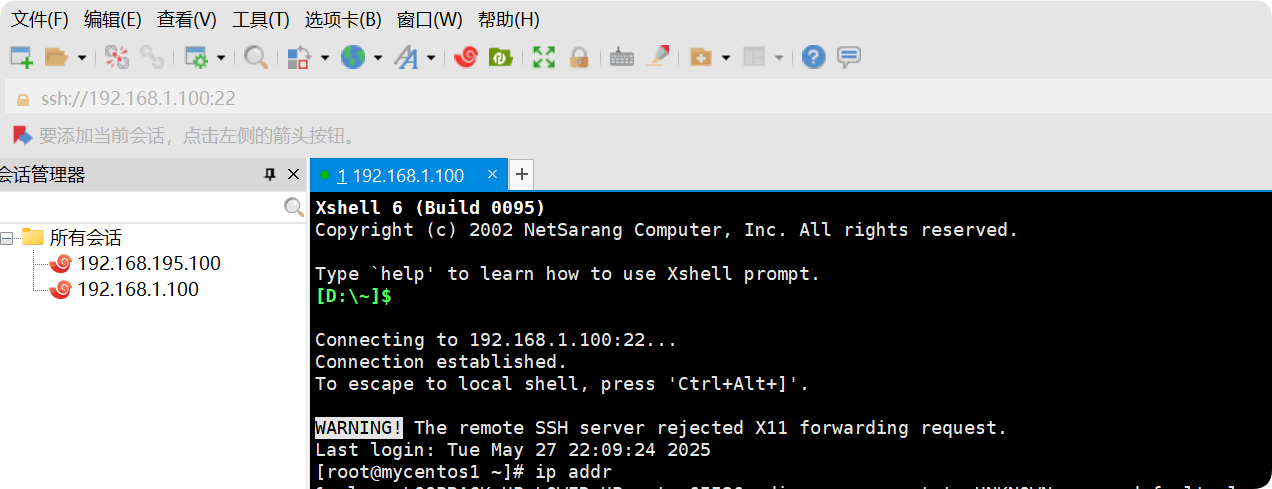
使用堡塔和XShell
使用堡塔和XShell 一、SSH协议介绍 SSH为SecureShell的缩写,由IETF的网络小组(NetworkWorkingGroup)所制定;SSH为建立在应用层基础上的安全协议。SSH是较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用SSH协议可以有效防止远程管理过程中…...
软件项目交付阶段,验收报告记录了什么?有哪些标准要求?
软件项目交付阶段,验收报告扮演着至关重要的角色,它相当于一份详尽的“成绩单”,具体记录了项目完成的具体情况以及是否达到了既定的标准。 项目基本信息 该环节将展示软件项目的核心信息,包括项目名称、开发团队构成、项目实施…...
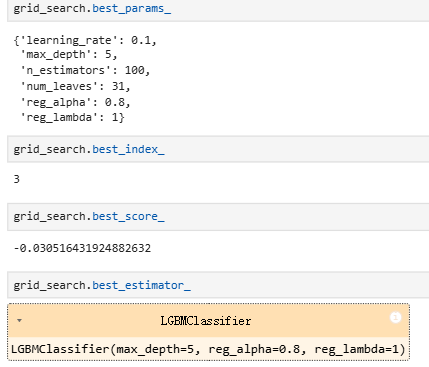
LightGBM的python实现及参数优化
文章目录 1. LightGBM模型参数介绍2. 核心优势3. python实现LightGBM3.1 基础实现3.1.1 Scikit-learn接口示例3.1.2 Python API示例 3.2 模型调优3.2.1 GridSearchCV简介3.2.2 LightGBM超参调优3.2.3 GridSearchCV寻优结果解读 在之前的文章 Boosting算法【AdaBoost、GBDT 、X…...

封装渐变堆叠柱状图组件附完整代码
组件功能 这是一个渐变堆叠柱状图组件,主要功能包括: 在一根柱子上同时显示高、中、低三种危险级别数据使用渐变色区分不同危险级别(高危红色、中危橙色、低危蓝色)悬停显示详细数据信息(包括总量和各级别数据&#…...

分布式项目保证消息幂等性的常见策略
Hello,大家好,我是灰小猿! 在分布式系统中,由于各个服务之间独立部署,各个服务之间依靠远程调用完成通信,再加上面对用户重复点击时的重复请求等情况,所以如何保证消息消费的幂等性是在分布式或…...

山东大学软件学院创新项目实训开发日志——第十三周
目录 1.开展prompt工程,创建个性化AI助理,能够基于身份实现不同角度和语言风格的回答。 2.对输出进行格式化,生成特定格式的会议计划文档。 3.学习到的新知识 本阶段我所做的工作 1.开展prompt工程,创建个性化AI助理ÿ…...

如何在sublime text中批量为每一行开头或者结尾添加删除指定内容
打开你的文件:首先,在 Sublime Text 中打开你想要编辑的文件,然后全选 行首插入: 选择所有行的开头: 使用快捷键 Ctrl Shift L(Windows/Linux)或 Cmd Shift L(Mac)&…...
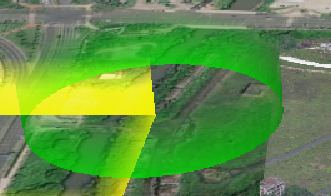
Cesium 透明渐变墙 解决方案
闭合路径修复 通过增加额外点确保路径首尾相接 透明渐变效果 使用RGBA颜色模式实现从完全不透明到完全透明的平滑渐变 参数可调性 提供多个可调参数,轻松自定义颜色、高度和圆环尺寸 完整代码实现 <!DOCTYPE html> <html> <head><meta …...

网络原理与 TCP/IP 协议详解
一、网络通信的本质与基础概念 1.1 什么是网络通信? 网络通信的本质是跨设备的数据交换,其核心目标是让不同物理位置的设备能够共享信息。这种交换需要解决三个核心问题: 如何定位设备? → IP地址如何找到具体服务?…...

day022-定时任务-故障案例与发送邮件
文章目录 1. cron定时任务无法识别命令1.1 故障原因1.2 解决方法1.2.1 对命令使用绝对路径1.2.2 在脚本开头定义PATH 2. 发送邮件2.1 安装软件2.2 配置邮件信息2.3 巡检脚本与邮件发送2.3.1 巡检脚本内容2.3.2 制作时任务发送邮件 3. 调取API发送邮件3.1 编写文案脚本3.2 制作定…...

新增 git submodule 子模块
文章目录 1、基本语法2、添加子模块后的操作3、拉取带有submodule的仓库 git submodule add 是 Git 中用于将另一个 Git 仓库作为子模块添加到当前项目中的命令。 子模块允许你将一个 Git 仓库作为另一个 Git 仓库的子目录,同时保持它们各自的提交历史独立。 1、基…...
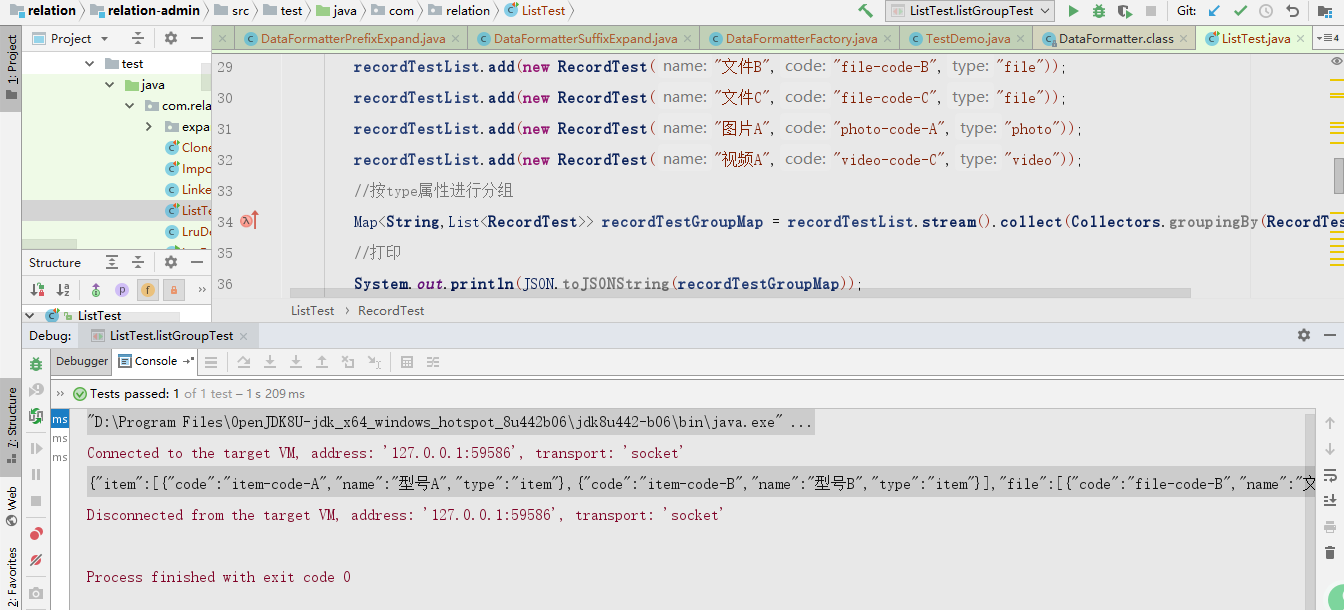
List优雅分组
一、前言 最近小永哥发现,在开发过程中,经常会遇到需要对list进行分组,就是假如有一个RecordTest对象集合,RecordTest对象都有一个type的属性,需要将这个集合按type属性进行分组,转换为一个以type为key&…...
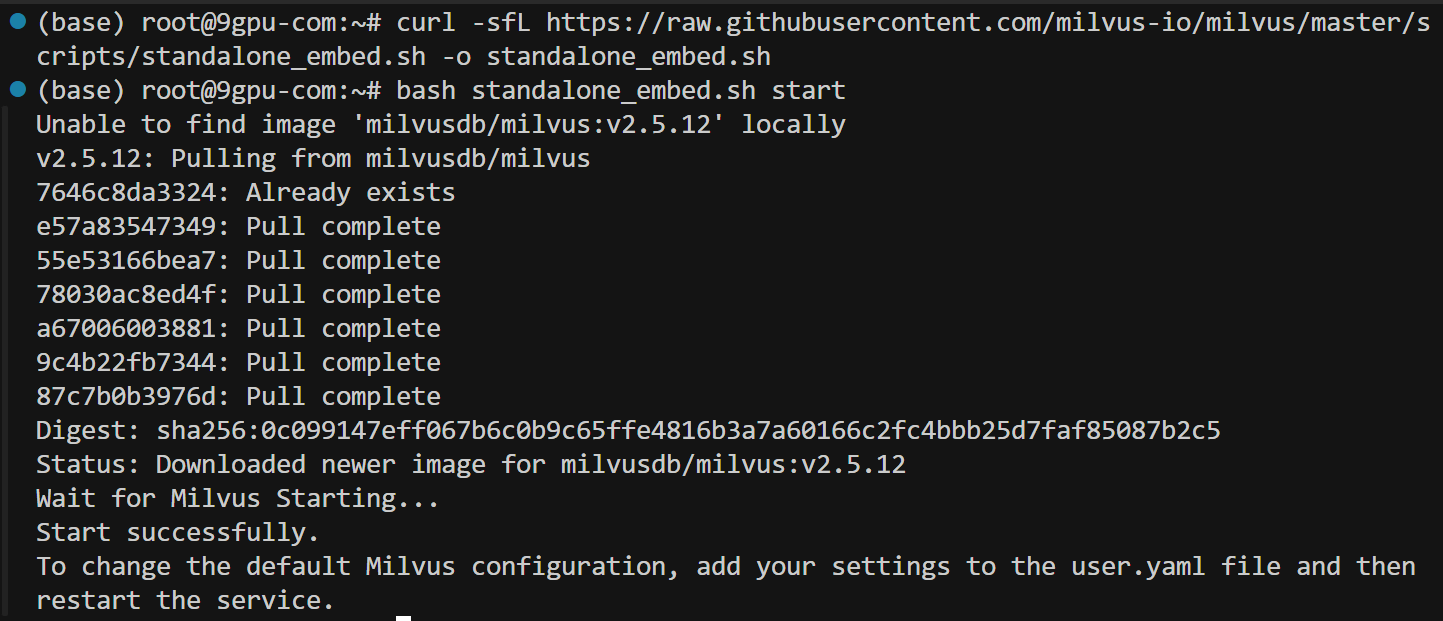
Linux 使用 Docker 安装 Milvus的两种方式
一、使用 Docker Compose 运行 Milvus (Linux) 安装并启动 Milvus Milvus 在 Milvus 资源库中提供了 Docker Compose 配置文件。要使用 Docker Compose 安装 Milvus,只需运行 wget https://github.com/milvus-io/milvus/releases/download/v2.5.10/milvus-standa…...

AR眼镜+AI视频盒子+视频监控联网平台:消防救援的智能革命
在火灾现场,每一秒都关乎生死。传统消防救援方式面临信息滞后、指挥盲区、环境复杂等挑战。今天,一套融合AR智能眼镜AI视频分析盒子智能监控管理平台的"三位一体"解决方案,正在彻底改变消防救援的作业模式,为消防员装上…...
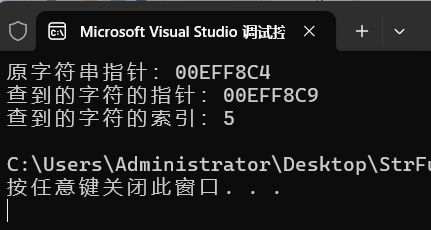
编程技能:字符串函数10,strchr
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:字符串函数09,strncmp 回到目录…...

使用tunasync部署企业内部开源软件镜像站-Centos Stream 9
使用tunasync部署企业内部开源软件镜像站 tunasync 是清华大学 TUNA 镜像源目前使用的镜像方案,本文将介绍如何使用 tunasync 部署企业内部开源软件镜像站。 基于tunasync mirror-web nginx进行镜像站点搭建。 1. tunasync设计 tunasync架构如下: …...

c/c++的opencv像素级操作二值化
图像级操作:使用 C/C 进行二值化 在数字图像处理中,图像级操作 (Image-Level Operations) 是指直接在图像的像素级别上进行处理,以改变图像的视觉特性或提取有用信息。这些操作通常不依赖于图像的全局结构,而是关注每个像素及其邻…...
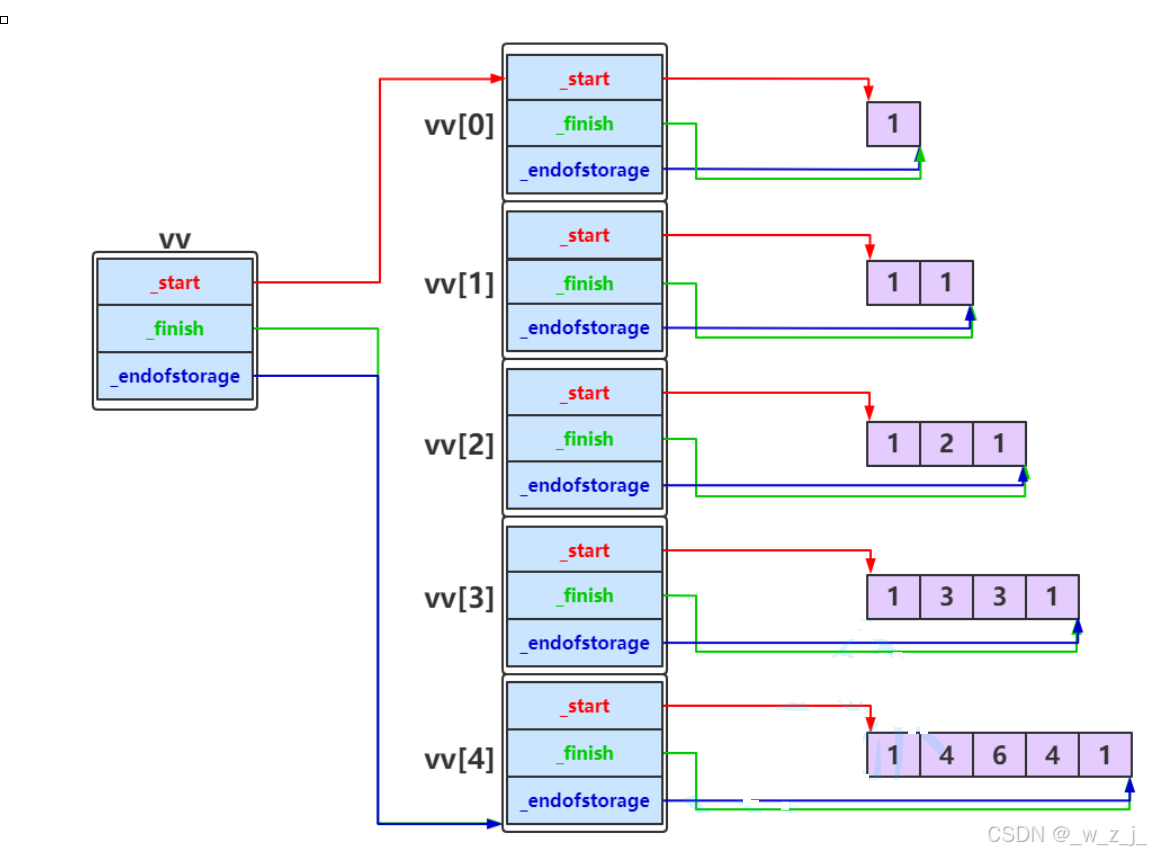
C++----Vector的模拟实现
上一节讲了string的模拟实现,string的出现时间比vector靠前,所以一些函数给的也比较冗余,而后来的vector、list等在此基础上做了优化。这节讲一讲vector的模拟实现,vector与模板具有联系,而string的底层就是vector的一…...

Mac redis下载和安装
目录 1、官网:https://redis.io/ 2、滑到最底下 3、下载资源 4、安装: 5、输入 sudo make test 进行编译测试 会提示 编辑 6、sudo make install 继续 7、输入 src/redis-server 启动服务器 8、输入 src/redis-cli 启动测试端 1、官网ÿ…...
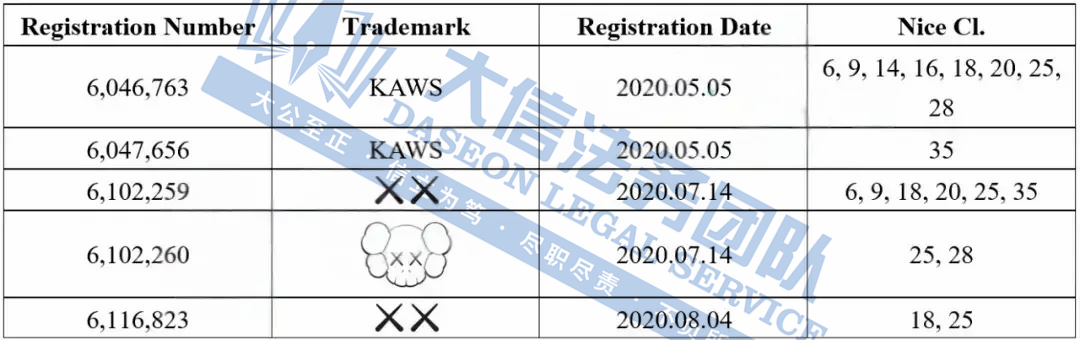
[25-cv-05718]BSF律所代理潮流品牌KAWS公仔(商标+版权)
潮流品牌KAWS公仔 案件号:25-cv-05718 立案时间:2025年5月21日 原告:KAWS, INC. 代理律所:Boies Schiller Flexner LLP 原告介绍 原告是一家由美国街头艺术家Brian Donnelly创立的公司,成立于2002年2月25日&…...
)
【PhysUnits】9 取负重载(negation.rs)
一、源码 这段代码是类型级二进制数(包括正数和负数)的取反和取负操作。它使用了类型系统来表示二进制数,并通过特质(trait)和泛型来实现递归操作。 use super::basic::{B0, B1, Z0, N1}; use core::ops::Neg;// 反…...
深度思考、弹性实施,业务流程自动化的实践指南
随着市场环境愈发复杂化,各类型企业的业务步伐为了跟得上市场节奏也逐步变得紧张,似乎只有保持极强的竞争力、削减成本、提升抗压能力才能在市场洪流中博得一席之位。此刻企业需要制定更明智的解决方案,以更快、更准确地优化决策流程。与简单…...

UWB:litepoint获取txquality里面的NRMSE
在使用litepoint测试UWB,获取txquality里面的NRMSE时,网页端可以正常获取NRMSE。但是通过SCPI 命令来获取NRMSE一直出错。 NRMSE数据类型和pyvisa问题: 参考了user guide,发现NRMSE的数值是ARBITRARY_BLOCK FLOAT,非string。 pyvisa无法解析会返回错误。 查询了各种办法…...
VUE npm ERR! code ERESOLVE, npm ERR! ERESOLVE could not resolve, 错误有效解决
VUE : npm ERR! code ERESOLVE npm ERR! ERESOLVE could not resolve 错误有效解决 npm install 安装组件的时候出现以上问题,npm版本问题报错解决方法:用上述方法安装完成之后又出现其他的问题 npm install 安装组件的时候出现以上问题&…...