C++----Vector的模拟实现
上一节讲了string的模拟实现,string的出现时间比vector靠前,所以一些函数给的也比较冗余,而后来的vector、list等在此基础上做了优化。这节讲一讲vector的模拟实现,vector与模板具有联系,而string的底层就是vector的一个特例,元素是char。
1.基本函数和成员变量
vector的成员变量有_start、_finish、_endofstorage。用来表示元素起始、终止、容量终止的三个位置。类模板的用途就类似于函数,给定参数,在类的定义中使用这个参数。和string一样先给出基本函数和成员变量,直接给出迭代器的定义,以及无参的默认构造函数。并得到size和capacity的值:
template<class T>class vector{public:typedef T* iterator;typedef const T* const_iterator;vector():_start(0),_finish(0),_endofstorage(0){}iterator begin(){return _start;}iterator end(){return _finish;}size_t size() const{return _finish - _start;}const_iterator begin()const {return _start;}const_iterator end()const {return _finish;}size_t capacity() const{return _endofstorage - _start;}private:iterator _start;iterator _finish;iterator _endofstorage;};2.增删查改
reserve、resize

void reserve(int n){if (n > capacity()){int sz = size();int cp = capacity();T* tmp = new T[n];if (_start)//防止拷贝空指针{memcpy(tmp, _start, sizeof(T) * size());delete[] _start;}_start = tmp;_finish = tmp + sz;_endofstorage = tmp +n;}}
//切记,size()和capacity()要在资源释放之前保留下来,否则释放_start的空间后
//会导致原来的地址失效,而size和capacity的定义要用到之前的_start资源,就会
//导致使用野指针访问已经失效的位置。如果是一开始的时候,_start赋初值为0,这时不用
//再删除资源,直接赋值给start就行void resize(size_t n, T value = T()){if (n > capacity()){reserve(n);}if (n > size()){while (_finish < _start + n){*_finish = value;_finish++;}}else{_finish = _start + n;}}
//当多于capacity时,开辟空间;多于size时,将多余的部分都换成value,否则将finish向前移动
//这个就是,只管标识,而不释放资源。查
T& operator[](size_t pos){if (pos < size()){return _start[pos];}}const T& operator[](size_t pos) const {if (pos < size()){return _start[pos];}}
//当调用的是const对象,那么我们肯定也不希望它返回的值被修改,所以也应该是constinsert、push_back
push_back是insert的特例,写出来insert就可以。vector的参数为迭代器和插入值,插入值是引用,这也是为了防止调用拷贝构造造成浪费,因为T有可能是自定义的类型。
insert的画图示意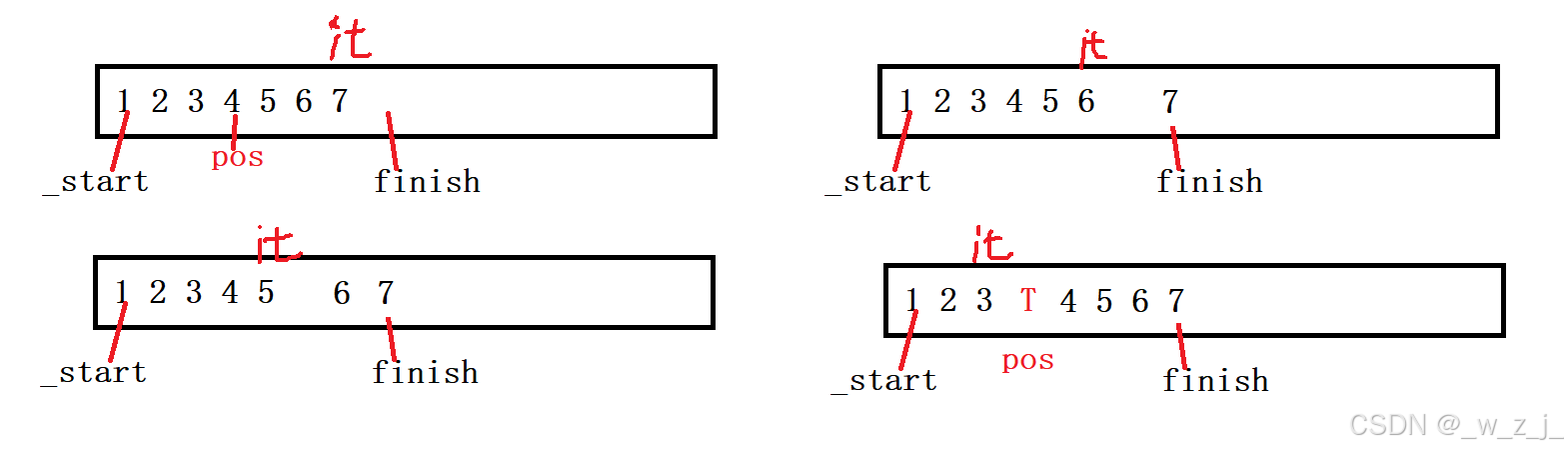
要注意容量是否足够,不足够记得开辟新空间。
void insert(iterator pos, const T& val){if (pos >= _start and pos <= _finish)//位置{if (_finish == _endofstorage)//容量{size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);}iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}*pos = val;_finish++;}}迭代器失效
野指针
void test4(){vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.insert(v1.end(), 5);for (auto e : v1){std::cout << e << " ";}}
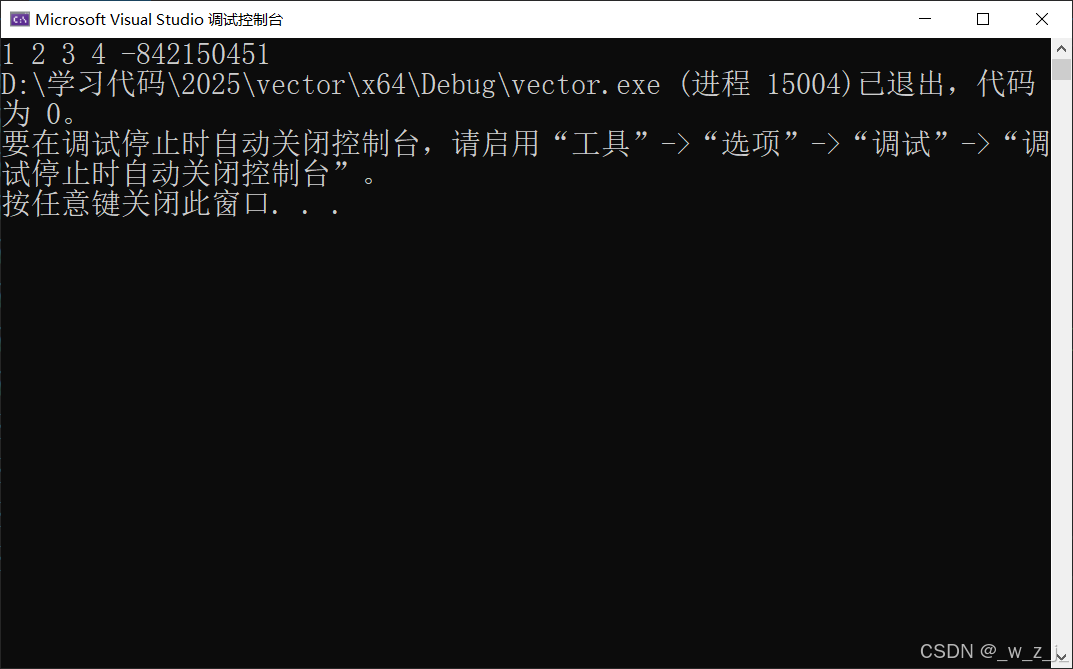
并没有出现5,这是怎么回事? 因为,要发生扩容,一开始给了4个位置空间,insert5时!发生了扩容,而pos还指向原来的位置,要在insert的扩容后面,更新一下pos:
void insert(iterator pos, const T& val){if (pos >= _start and pos <= _finish)//位置{if (_finish == _endofstorage)//容量{size_t n = pos - _start;size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);pos = _start + n;//扩容后更新pos}iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}*pos = val;_finish++;}接下来再看一种情况,在偶数位置插入10。
void test1(){vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);vector<int>::iterator it = v1.begin();while (it != v1.end()){if (*it % 2 == 0)//偶数前面插入10{v1.insert(it, 10);}it++;}for (auto e : v1){std::cout << e << " ";}}程序允许会出现异常,访问冲突。结合前面的例子,想一想为什么会出现访问错误问题?对了!这里的it,也就是上面的pos没有改变!那我们可不可以将insert中的pos改为引用呢?这样pos在insert函数改变了,it不也改变了?不可以!因为会出现比如insert(v.begin(),1)的调用情况,这时调用begin函数,得到返回值迭代器,由于返回的是值,不是引用,所以具有常性,const,而我们又要修改迭代器,这不是冲突了吗?而且在标准库中也没有使用引用,不符合使用规则。那么如何修改呢?给一个返回值就好。 每次在外面接收一下就ok了。
iterator insert(iterator pos, const T& val){if (pos >= _start and pos <= _finish)//位置{if (_finish == _endofstorage)//容量{size_t n = pos - _start;size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);pos = _start + n;//扩容后更新pos}iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}*pos = val;_finish++;}return pos;//使用标准库的实现方式,即不使用引用,而是直接返回一个新的迭代器。
//这样可以明确地告知调用者,原来的迭代器可能已经失效,应该使用返回的新迭代器。}void test1(){vector<int> v1;//v1.reserve(10);//虽然容量够,不用扩容, 但是it指向的位置变了,导致重复插入10v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);vector<int>::iterator it = v1.begin();while (it != v1.end()){if (*it % 2 == 0)//偶数前面插入10{it=v1.insert(it, 10);//pos虽然改变了,但是是传值引用,不改变it,扩容后it还是原来的位置}it++;}for (auto e : v1){std::cout << e << " ";}}指向位置意义改变
但是,运行上面的程序,仍然有问题。陷入了死循环,经过调试发现了问题,pos每次返回的都是插入后的位置,这就导致了1 10 2 3 4,每次it++后到2,又对2进行检查,又插入10......循环往复,所以不会停止,这就是令一种迭代器失效的情况--迭代器指向位置意义改变了。所以我们应该在插入后就++一次。
void test1(){vector<int> v1;//v1.reserve(10);//虽然容量够,不用扩容, 但是it指向的位置变了,导致重复插入10v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);vector<int>::iterator it = v1.begin();while (it != v1.end()){if (*it % 2 == 0)//偶数前面插入10{it=v1.insert(it, 10);//pos虽然改变了,但是是传值引用,不改变it,扩容后it还是原来的位置it++;}it++;}for (auto e : v1){std::cout << e << " ";}}这时insert大功告成,而push_back调用一下也行,自己写一下也行:
void push_back(const T& ch){if (_finish==_endofstorage){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);}*_finish = ch;_finish++;}void push_back(const T& ch){insert(end(),ch);}erase、pop_back
注意erase返回删除位置元素的迭代器就好,虽然看起来没什么大用,但是如果使用者想写一个缩容方案的erase就有用了!不过一般不考虑缩容,现在的硬件内存都比较便宜了,一般不太会拿时间换空间了。
void pop_back(){if (_start < _finish){--_finish;}}iterator erase(iterator pos)//返回原位置 {assert(pos >= _start and pos < _finish);iterator it = pos + 1;while (it != _finish){*(it - 1) = *it;it++;}_finish--;return pos;}在vs2019下,对迭代器失效检查的比较严格,而在linux下检查的比较宽松。但是使用时,一定要注意迭代器失效问题。
3.构造函数、析构函数、拷贝构造函数
析构函数
~vector(){if (_start){delete[]_start;}_start = _finish = _endofstorage = nullptr;}拷贝构造函数和构造函数
拷贝构造函数有经典版的:这里使用memcpy复制内容,逐字节复制
vector(const vector<T>& v){_start = new T[v.capacity()];_finish = _start + v.size();_endofstorage = _start + v.capacity();memcpy(_start, v._start, size()*sizeof(T));}也可以使用现代版的(string有提到,让别人去构造,窃取劳动果实),但是构造函数就要再重载几个,不能用无参的默认构造函数为现代版的拷贝构造使用。
有作为范围使用的,有给个数填充的:给范围使用的,告诉我们,在类模板中,照样可以嵌套函数模板使用!只要给的参数正确合理即可
vector(size_t n, const T& val = T()){reserve(n);for (int i = 0; i < n; i++){push_back(val);}}template <class InputIterator>vector(InputIterator first, InputIterator last ):_start(0),_finish(0),_endofstorage(0){while (first != last){push_back(*(first++));}}使用举例:
void test5(){vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.insert(v1.end(), 5);v1.insert(v1.end(), 6);vector<int> v2(v1.begin(), v1.end());for (auto e : v2){std::cout << e << " ";}string s1("123456789");vector<char> v3(s1.begin(), s1.end());for (auto e : v3){std::cout << e << " ";}}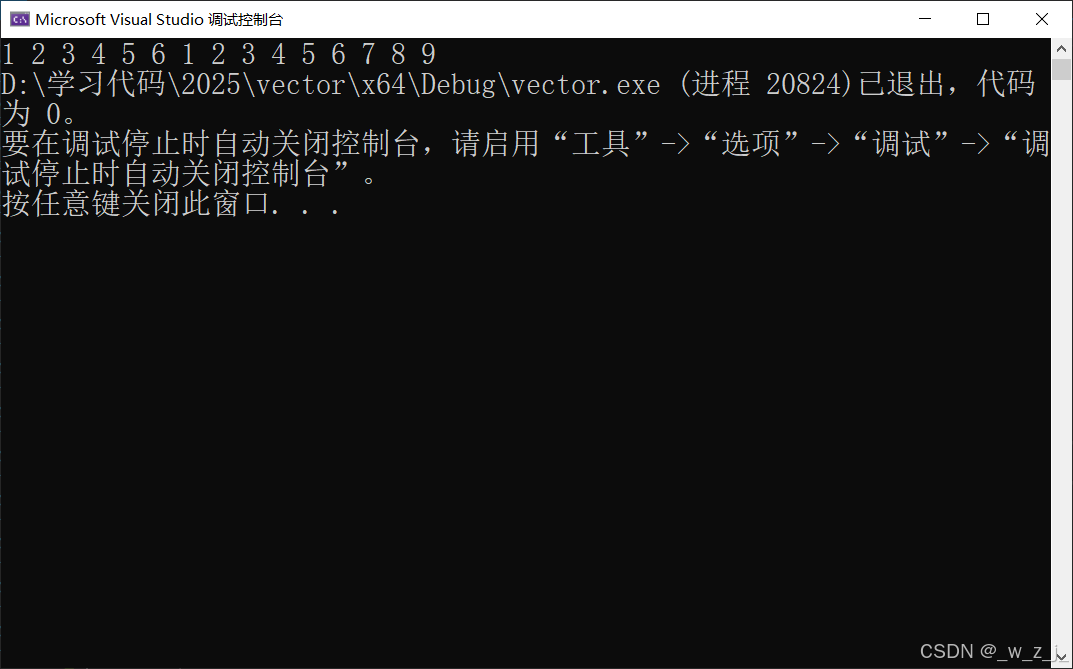
参数最优匹配问题:当我们想调用填充构造函数时,会发现报编译错误
void test6(){vector<int> v(5, 1);for (auto e : v){std::cout << e << " ";}}
我们发现它调用了范围构造函数!这是不对的,或者用排除法(出现错误的代码段分成几段,注释,编译,看看哪一部分编译不通过)找到错误!为什么呢?你看我们的参数是两个int,非常整齐,而 vector(size_t n, const T& val = T());前一个是size_t,与int不匹配需要转换才行,所以选择了参数更为整齐的vector(InputIterator first, InputIterator last )函数。有什么解决方法吗?源码中给出了又一个函数重载vector(int n, const T& val = T()),这样就不会报错了。
构造函数的弄好了,接下来搞一下拷贝构造的现代版本:
void swap(vector<T>& v){std::swap(this->_start,v._start);std::swap(this->_finish, v._finish);std::swap(this->_endofstorage, v._endofstorage);}
//首先要写一个swap函数用来交换vector内部资源vector(const vector<T>& v){vector<T> tmp(v.begin(), v.end());swap(tmp);}
//tmp用构造函数干的活得到的资源,被this窃取了!vector<T>& operator=(vector<T> v){swap(v);return *this;}
//而重载等于号就更简单了,由于不用使用引用传值
//连奴隶都不用重新找了,直接对传过来的奴隶窃取果实即可4.vector深浅拷贝问题
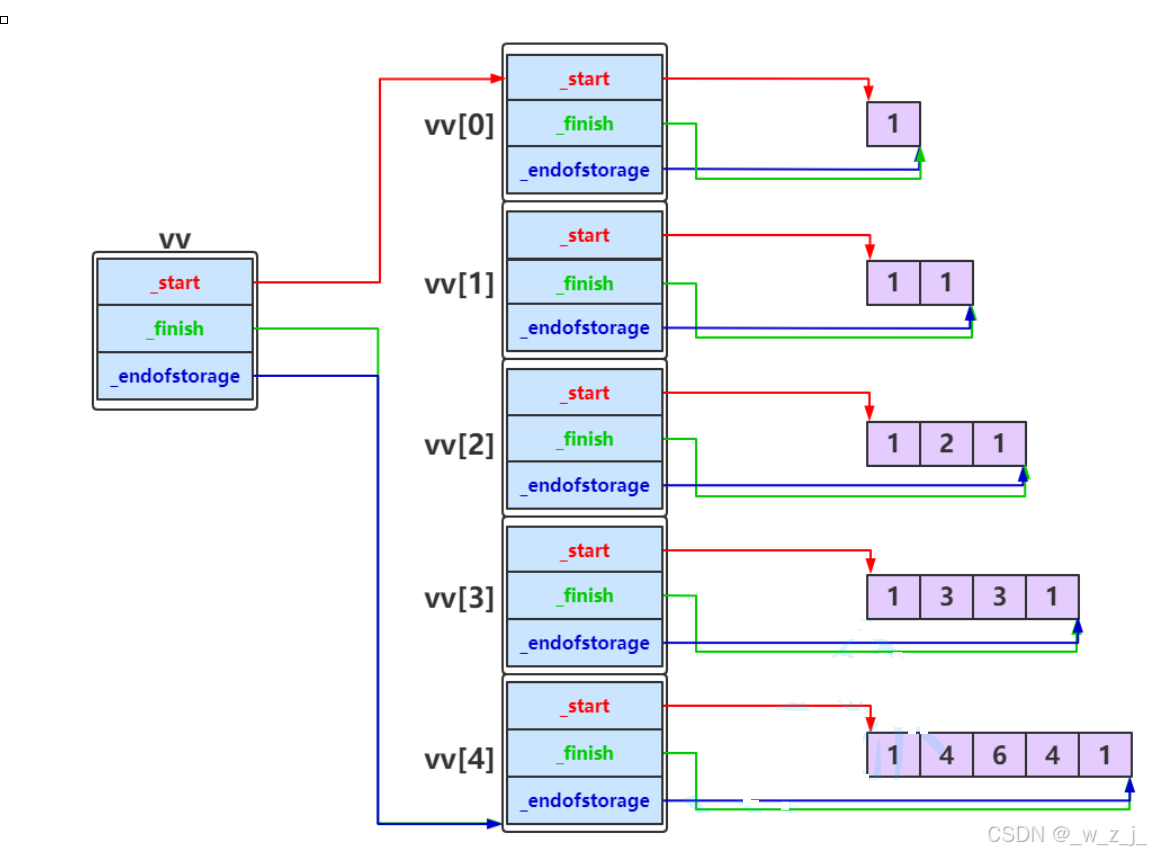
讲一个有意思的事情,我在用自己实现的vector写一个杨辉三角时,出现了问题。以下是杨辉三角的解决代码。在解决时,我发现执行到push_back时,自己实现的版本会出bug,而复用insert的就不会。经过调试发现vv.push_back(v);时,运行到*_finish = ch;时首先调用了拷贝构造函数,并没有先调用赋值函数,应该是在vs2019下先拷贝一个临时对象,然后再把临时对象赋值给finish,目的是为了防止赋值时出错从而使ch发生改动。接着有意思的地方就出现了,正常来说这个临时对象的未初始化资源(对象是vector<int>)应该是nullptr(有坑),但是在用自己写的push_back时调用拷贝构造时出现了下图的情况,该临时对象的_start不为nullptr,所以在拷贝构造结束后,tmp被交换得到了临时对象的资源,而其_start又不为空,所以在调用析构函数时出现了访问未分配资源的问题!后来才知道其实应该给拷贝构造函数赋初值操作。但是当时我复用insert时就不会出现这种情况,如图。应该是函数栈帧的构建导致编译器对内存的分配恰好使得分配的内存_start为nullptr。但是就是因为这两个一个可以用一个不可以用困扰了我好久。最后才发现给资源赋为空就行!我一开始还纳闷临时对象的初始资源是谁给的呢?调用拷贝构造之前调用构造??哈哈,后来上网查询才知道要自己赋初值。
class Solution {public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可*** @param num int整型* @return int整型vector<vector<>>*/vector<vector<int> > generate(int num) {vector<vector<int>> vv;for (int i = 0; i < num; i++){vector<int> v;for (int j = 0; j < i + 1; j++){if (j == 0 || j == i)v.push_back(1);elsev.push_back(vv[i - 1][j - 1] + vv[i - 1][j]);}vv.push_back(v);}return vv;}};void test7(){Solution s;vector<vector<int>> vv = s.generate(5);for (int i = 0; i < vv.size(); i++){vector<int> v = vv[i];for (int j = 0; j < v.size(); j++){cout << v[j];}printf("\n");}}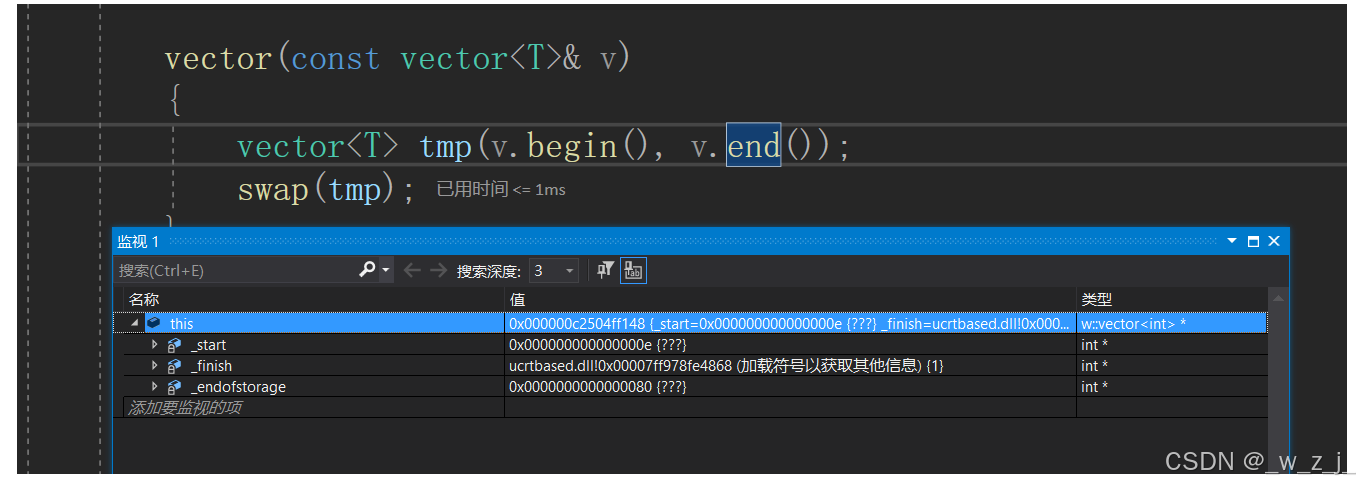
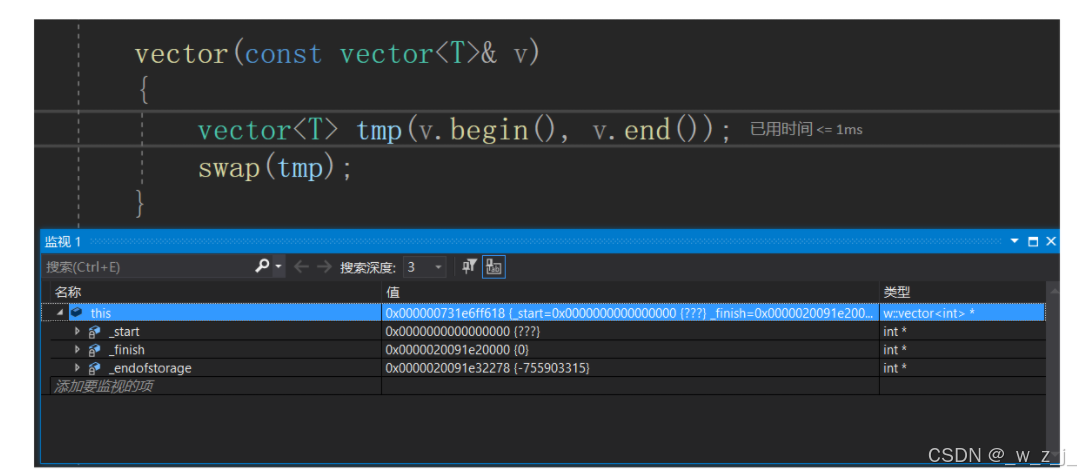
vector(const vector<T>& v): _start(nullptr), _finish(nullptr), _endofstorage(nullptr){vector<T> tmp(v.begin(), v.end());swap(tmp);}解决了这个问题后,其实仍然有问题没有解决。执行程序会出现问题,具体体现在扩容之后。
vector<vector<int> > generate(int num) {vector<vector<int>> vv;for (int i = 0; i < num; i++){vector<int> v;for (int j = 0; j < i + 1; j++){if (j == 0 || j == i)v.push_back(1);elsev.push_back(vv[i - 1][j - 1] + vv[i - 1][j]);}vv.push_back(v);}for (int i = 0; i < vv.size(); i++){vector<int> v = vv[i];for (int j = 0; j < v.size(); j++){cout << v[j]<<endl;}printf("\n");}return vv;}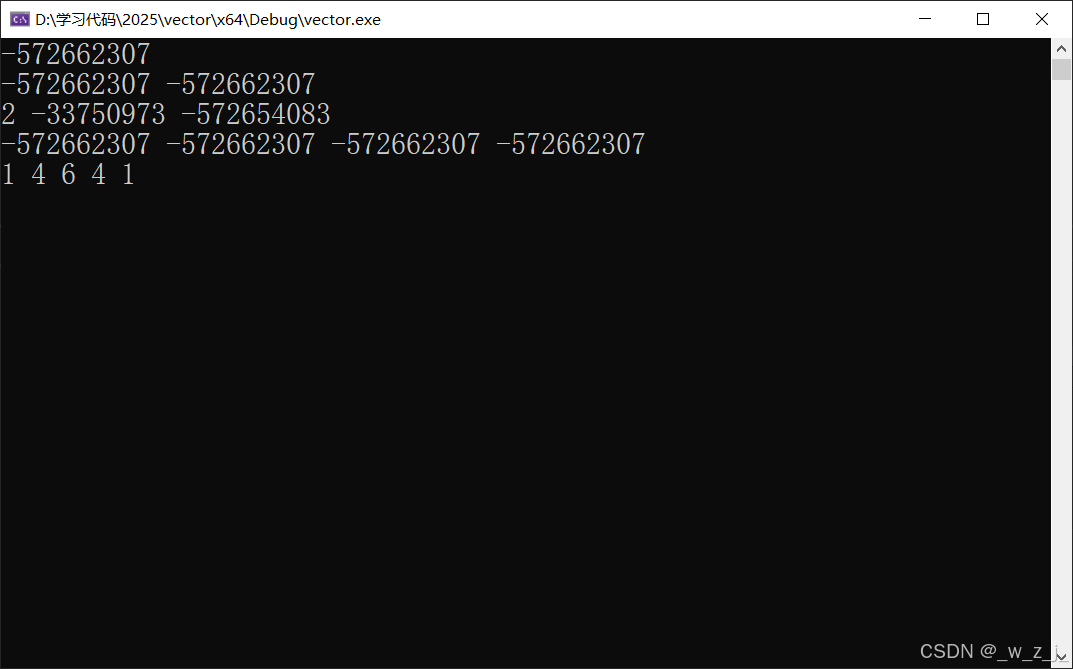 因为在reserve时,对原有的资源进行memcpy,而vv是一个vector<int>数组,它里面存放的是vector对象:所以会导致浅拷贝问题,就是我们已经把原来的释放了,但是新开辟的指针仍然指向被释放的空间就会出现bug,比如二次释放、访问野指针问题。
因为在reserve时,对原有的资源进行memcpy,而vv是一个vector<int>数组,它里面存放的是vector对象:所以会导致浅拷贝问题,就是我们已经把原来的释放了,但是新开辟的指针仍然指向被释放的空间就会出现bug,比如二次释放、访问野指针问题。
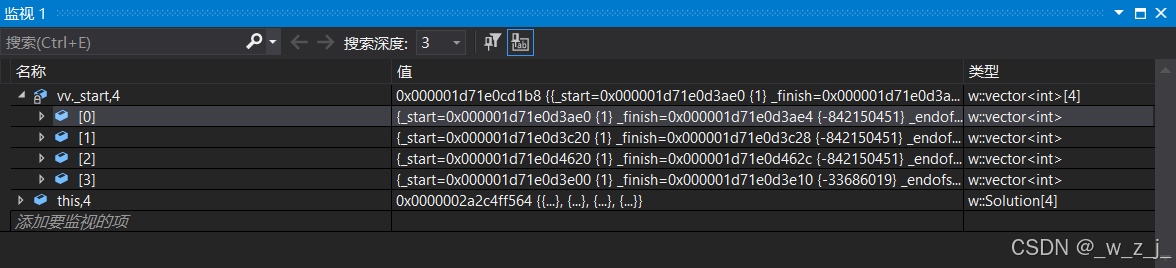
未reserve前的四个vector
reserve后的四个vector的资源被释放了!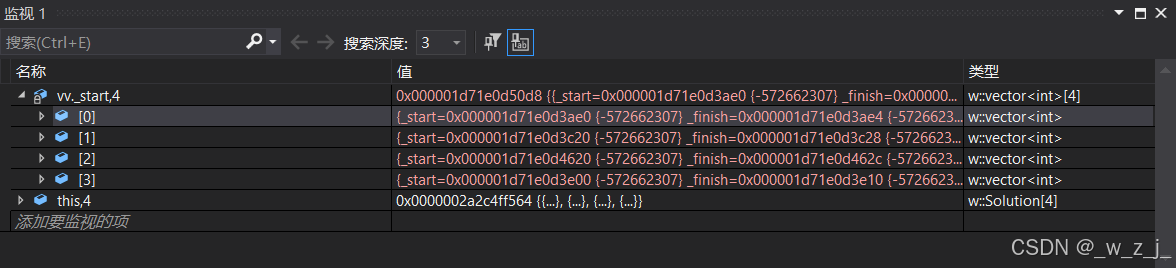
图中的红框中前四个vector的内容已经被释放了!由于前面的被释放了,他们又指向同一位置
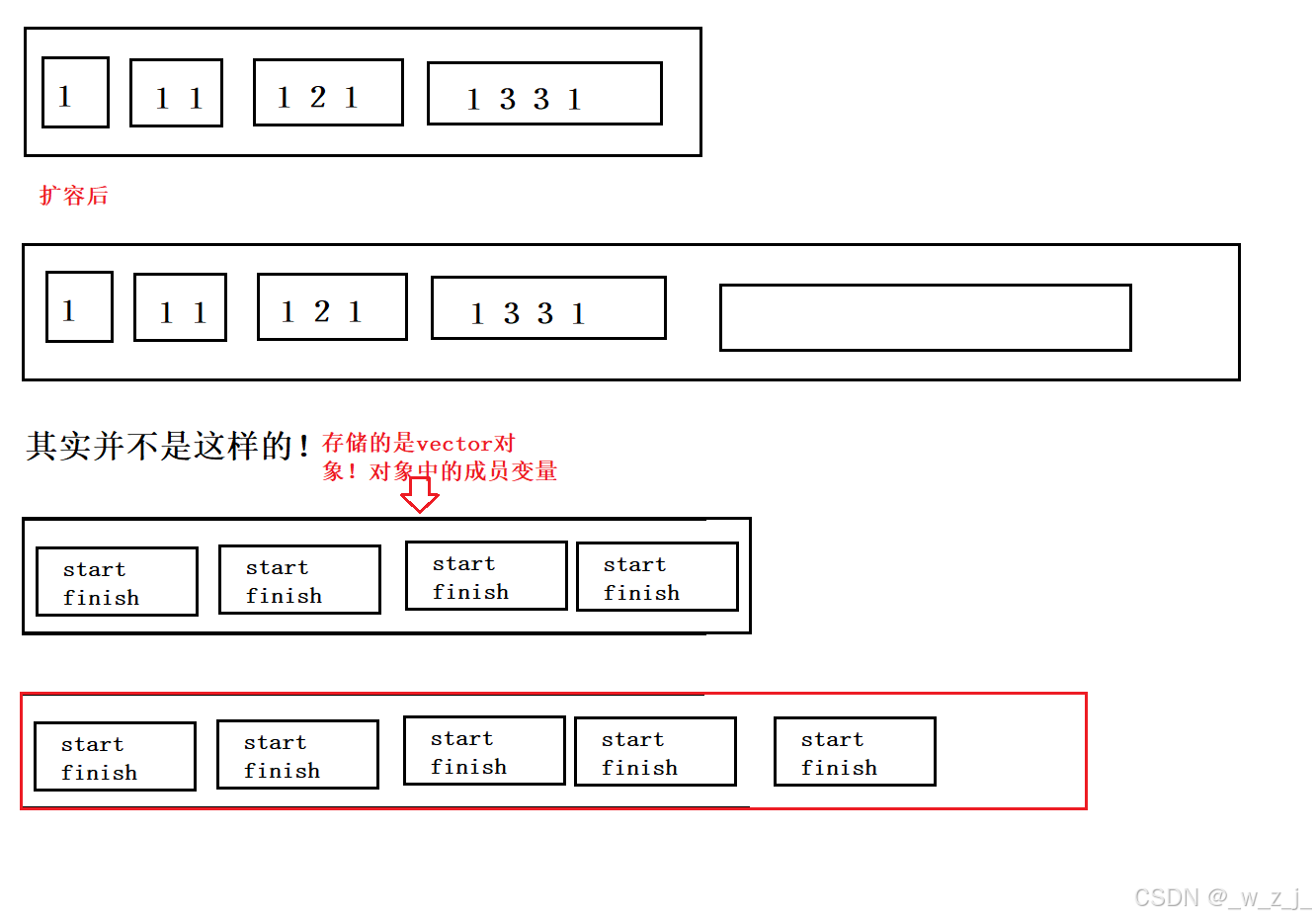
所以在reserve时,应该修改成
void reserve(int n){int sz = size();if (n > capacity()){T* tmp = new T[n];if (_start)//防止拷贝空指针{memcpy(tmp, _start, sizeof(T) * size());for (int i = 0; i < size(); i++){tmp[i] = _start[i];}delete[] _start;}_start = tmp;}_finish = _start + sz;_endofstorage = _start + n;}所以以后在书写自定义类型的拷贝时,一定要注意不要使用memcpy。
完整代码
namespace w
{template<class T>class vector{public:typedef T* iterator;typedef const T* const_iterator;vector():_start(0),_finish(0),_endofstorage(0){}vector(int n, const T& val = T()){reserve(n);for (int i = 0; i < n; i++){push_back(val);}}vector(size_t n, const T& val = T()){reserve(n);for (int i = 0; i < n; i++){push_back(val);}}template <class InputIterator>vector(InputIterator first, InputIterator last ):_start(0),_finish(0),_endofstorage(0){while (first != last){push_back(*(first++));}}~vector(){if (_start){delete[]_start; }_start = _finish = _endofstorage = nullptr;}void swap(vector<T>& v){std::swap(this->_start,v._start);std::swap(this->_finish, v._finish);std::swap(this->_endofstorage, v._endofstorage);}//vector(const vector<T>& v)//{// _start = new T[v.capacity()];// _finish = _start + v.size();// _endofstorage = _start + v.capacity();// memcpy(_start, v._start, size()*sizeof(T));//}vector(const vector<T>& v): _start(nullptr), _finish(nullptr), _endofstorage(nullptr){vector<T> tmp(v.begin(), v.end());swap(tmp);}vector<T>& operator=(vector<T> v){swap(v);return *this;}iterator begin(){return _start;}iterator end(){return _finish;}size_t size() const{return _finish - _start;}const_iterator begin()const {return _start;}const_iterator end()const {return _finish;}size_t capacity() const{return _endofstorage - _start;}void reserve(int n){int sz = size();if (n > capacity()){T* tmp = new T[n];if (_start)//防止拷贝空指针{//memcpy(tmp, _start, sizeof(T) * size());for (int i = 0; i < size(); i++){tmp[i] = _start[i];}delete[] _start;}_start = tmp;}_finish = _start + sz;_endofstorage = _start + n;}void push_back(const T& ch){//insert(end(), ch);if (_finish==_endofstorage){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);}*_finish = ch;_finish++;}void pop_back(){if (_start < _finish){--_finish;}}//void insert(iterator& pos, const T& val) 为什么一般不使用引用:// // 1.迭代器失效的定义:在C++标准中,迭代器失效是指迭代器的值变得无效,// 而不是指迭代器变量本身被销毁。即使你更新了it,在reserve操作之后,//原来的迭代器值已经失效,你只是通过重新计算给了它一个新的值。这可能会导致调用者对迭代器失效的误解。// 2.调用者的期望:调用者可能期望insert方法不会修改传入的迭代器it,// 而是返回一个新的迭代器。如果insert方法修改了it,这可能会违反调用者的期望,// 导致潜在的错误。//如果是v.insert(v.begin(),t);那么调用begin,返回参数,具有常性,无法调用insert//迭代器失效:1.野指针,重新扩容后pos指针没变;2.没有扩容,但是指向意义发生变化//返回值为插入位置的指针,就是为了防止迭代器失效,指向没有意义的地方,pos不可以用引用,因为你不知道传的是不是常量iterator insert(iterator pos, const T& val){if (pos >= _start and pos <= _finish)//位置{if (_finish == _endofstorage)//容量{size_t n = pos - _start;size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;reserve(newcapacity);pos = _start + n;//扩容后更新pos}iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}*pos = val;_finish++;}return pos;//使用标准库的实现方式,即不使用引用,而是直接返回一个新的迭代器。
//这样可以明确地告知调用者,原来的迭代器可能已经失效,应该使用返回的新迭代器。}iterator erase(iterator pos)//返回原位置 {assert(pos >= _start and pos < _finish);iterator it = pos + 1;while (it != _finish){*(it - 1) = *it;it++;}_finish--;return pos;}void resize(size_t n, T value = T()){if (n > capacity()){reserve(n);}if (n > size()){while (_finish < _start + n){*_finish = value;_finish++;}}else{_finish = _start + n;}}T& operator[](size_t pos){if (pos < size()){return _start[pos];}}const T& operator[](size_t pos) const {if (pos < size()){return _start[pos];}}private:iterator _start;iterator _finish;iterator _endofstorage;};class Solution {public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可*** @param num int整型* @return int整型vector<vector<>>*/vector<vector<int> > generate(int num) {vector<vector<int>> vv;for (int i = 0; i < num; i++){vector<int> v;for (int j = 0; j < i + 1; j++){if (j == 0 || j == i)v.push_back(1);elsev.push_back(vv[i - 1][j - 1] + vv[i - 1][j]);}vv.push_back(v);}for (int i = 0; i < vv.size(); i++){vector<int> v = vv[i];for (int j = 0; j < v.size(); j++){cout << v[j]<<" ";}printf("\n");}return vv;}};void test7(){Solution s;vector<vector<int>> vv = s.generate(5);for (int i = 0; i < vv.size(); i++){vector<int> v = vv[i];for (int j = 0; j < v.size(); j++){cout << v[j];}printf("\n");}}相关文章:
C++----Vector的模拟实现
上一节讲了string的模拟实现,string的出现时间比vector靠前,所以一些函数给的也比较冗余,而后来的vector、list等在此基础上做了优化。这节讲一讲vector的模拟实现,vector与模板具有联系,而string的底层就是vector的一…...

Mac redis下载和安装
目录 1、官网:https://redis.io/ 2、滑到最底下 3、下载资源 4、安装: 5、输入 sudo make test 进行编译测试 会提示 编辑 6、sudo make install 继续 7、输入 src/redis-server 启动服务器 8、输入 src/redis-cli 启动测试端 1、官网ÿ…...
[25-cv-05718]BSF律所代理潮流品牌KAWS公仔(商标+版权)
潮流品牌KAWS公仔 案件号:25-cv-05718 立案时间:2025年5月21日 原告:KAWS, INC. 代理律所:Boies Schiller Flexner LLP 原告介绍 原告是一家由美国街头艺术家Brian Donnelly创立的公司,成立于2002年2月25日&…...
)
【PhysUnits】9 取负重载(negation.rs)
一、源码 这段代码是类型级二进制数(包括正数和负数)的取反和取负操作。它使用了类型系统来表示二进制数,并通过特质(trait)和泛型来实现递归操作。 use super::basic::{B0, B1, Z0, N1}; use core::ops::Neg;// 反…...
深度思考、弹性实施,业务流程自动化的实践指南
随着市场环境愈发复杂化,各类型企业的业务步伐为了跟得上市场节奏也逐步变得紧张,似乎只有保持极强的竞争力、削减成本、提升抗压能力才能在市场洪流中博得一席之位。此刻企业需要制定更明智的解决方案,以更快、更准确地优化决策流程。与简单…...

UWB:litepoint获取txquality里面的NRMSE
在使用litepoint测试UWB,获取txquality里面的NRMSE时,网页端可以正常获取NRMSE。但是通过SCPI 命令来获取NRMSE一直出错。 NRMSE数据类型和pyvisa问题: 参考了user guide,发现NRMSE的数值是ARBITRARY_BLOCK FLOAT,非string。 pyvisa无法解析会返回错误。 查询了各种办法…...
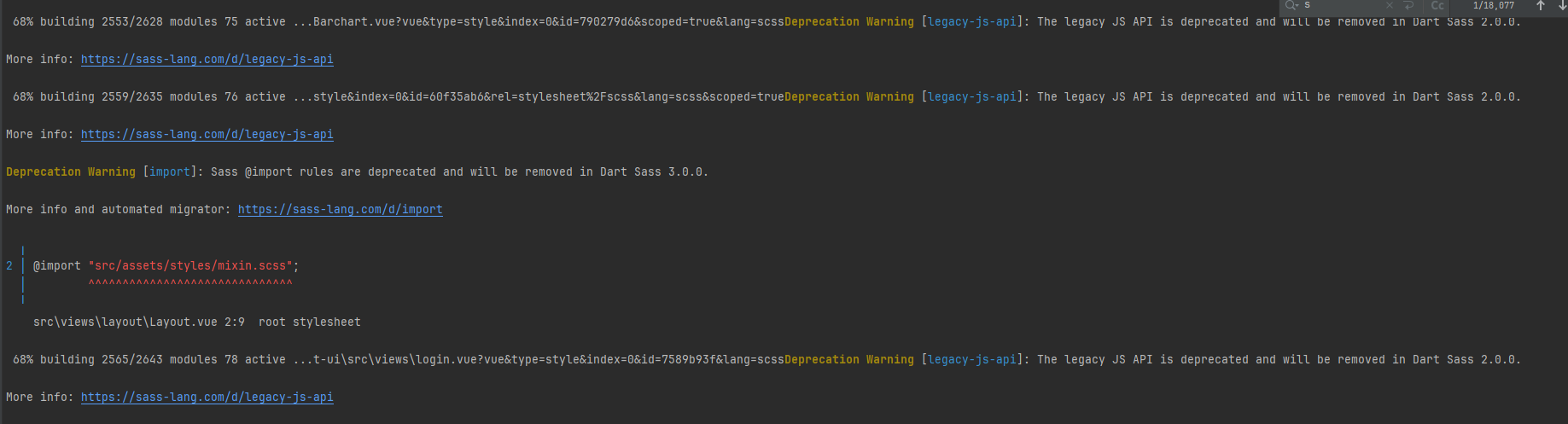
VUE npm ERR! code ERESOLVE, npm ERR! ERESOLVE could not resolve, 错误有效解决
VUE : npm ERR! code ERESOLVE npm ERR! ERESOLVE could not resolve 错误有效解决 npm install 安装组件的时候出现以上问题,npm版本问题报错解决方法:用上述方法安装完成之后又出现其他的问题 npm install 安装组件的时候出现以上问题&…...

IoT/HCIP实验-1/物联网开发平台实验Part1(快速入门,MQTT.fx对接IoTDA)
文章目录 实验介绍设备接入IoTDA进入IoTDA平台什么是IoTDA 开通服务创建产品和设备定义产品模型(Profile)设备注册简思(实例-产品-设备) 模拟.与平台通信虚拟设备/MQTT.fx应用 Web 控制台QA用户或密码错误QA证书导致的连接失败设备与平台连接成功 上报数…...
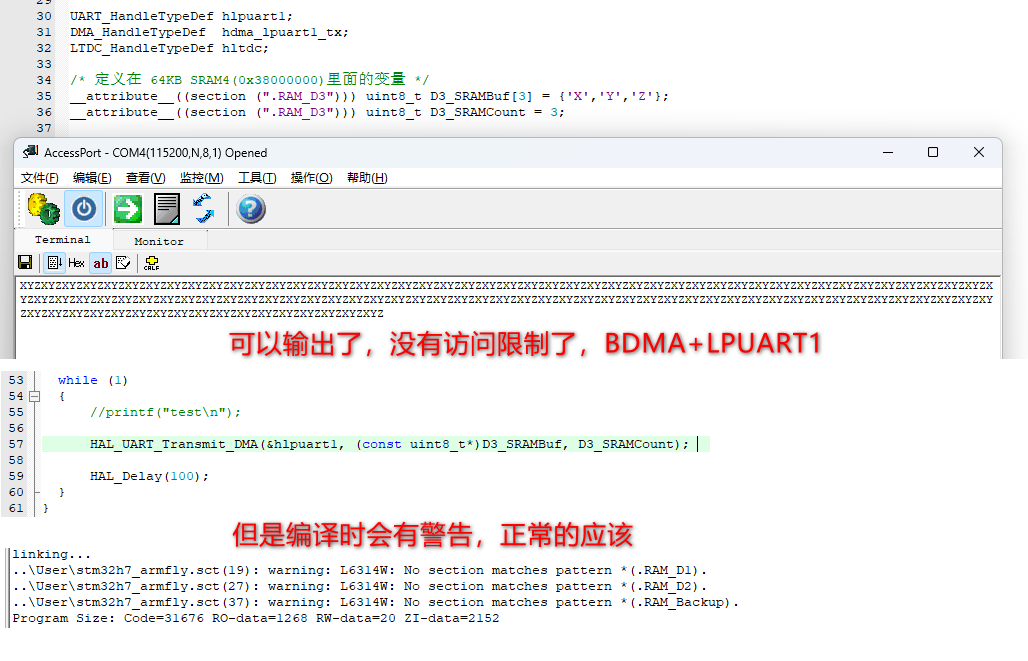
DMA STM32H7 Domains and space distrubution
DMA这个数据搬运工,对谁都好,任劳任怨,接受雇主设备的数据搬运业务。每天都忙碌着!哈哈哈。 1. DMA 不可能单独工作,必须接收其他雇主的业务,所以数据搬运业务的参与者是DMA本身和业务需求发起者。 2. 一…...
洪水危险性评价与风险防控全攻略:从HEC-RAS数值模拟到ArcGIS水文分析,一键式自动化工具实战,助力防洪减灾与应急管理
🔍 洪水淹没危险性是洪水损失评估、风险评估及洪水应急和管理规划等工作的重要基础。当前,我国正在开展的自然灾害风险普查工作,对洪水灾害给予了重点关注,提出了对洪水灾害危险性及风险评估的明确要求。洪水危险性及风险评估通常…...

Gemini Pro 2.5 输出
好的,我已经按照您的要求,将顶部横幅提示消息修改为右下角的 Toast 样式通知。 以下是涉及更改的文件及其内容: 1. my/src/html-ui.js 移除了旧的 #message-area div。在 <body> 底部添加了新的 #toast-container div 用于存放 Toas…...

SQL Server 和 MySQL 对比
下面是 SQL Server 和 MySQL 的详细对比,从功能、性能、成本、生态等多个维度展开,帮助你判断在什么情况下该选择哪一个。 ✅ 总览对比表 维度SQL ServerMySQL开发公司微软(Microsoft)Oracle(2008年起)是否…...
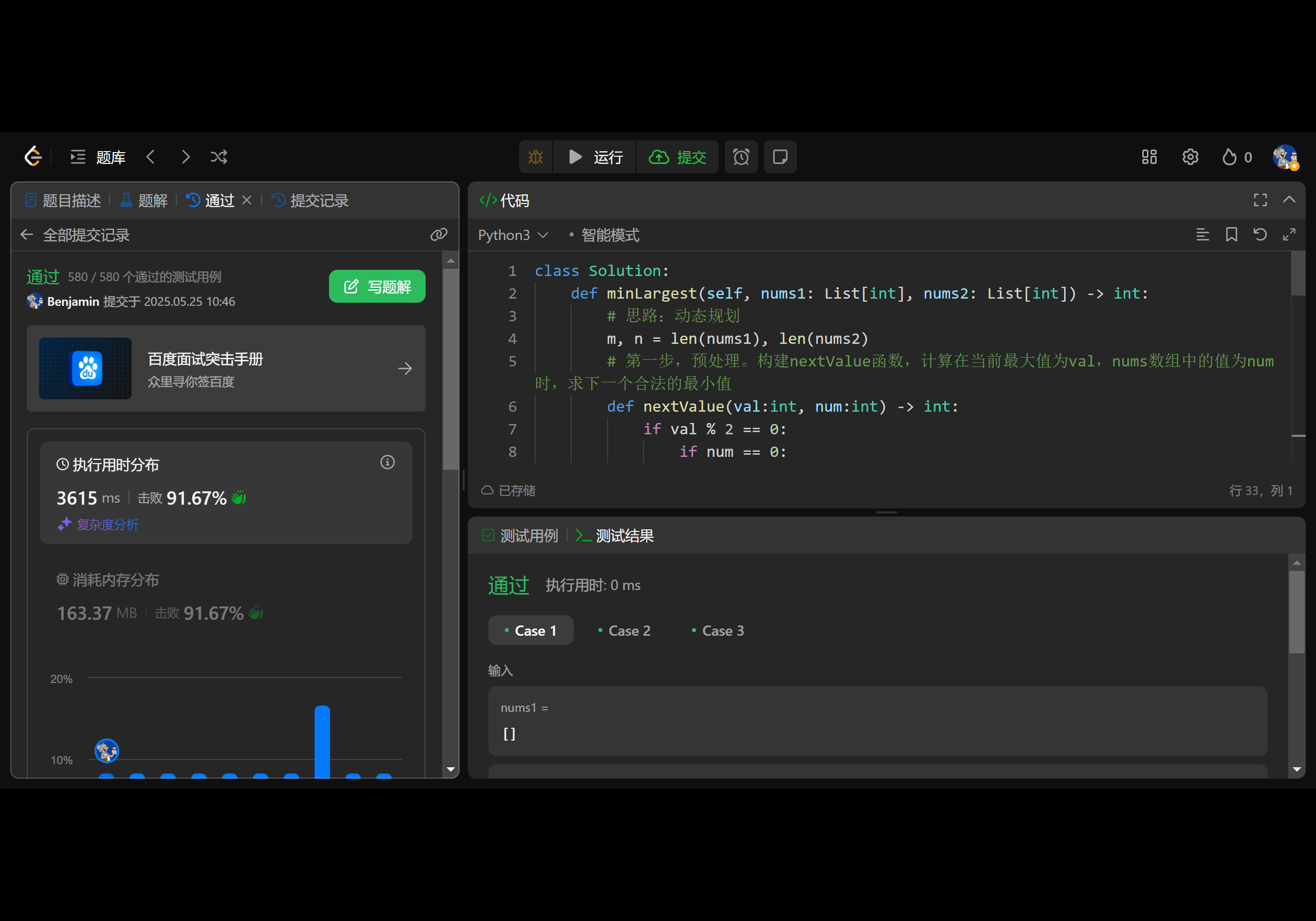
Leetcode 3269. 构建两个递增数组
1.题目基本信息 1.1.题目描述 给定两个只包含 0 和 1 的整数数组 nums1 和 nums2,你的任务是执行下面操作后使数组 nums1 和 nums2 中 最大 可达数字 尽可能小。 将每个 0 替换为正偶数,将每个 1 替换为正奇数。在替换后,两个数组都应该 递…...

三轴云台之积分分离PID控制算法篇
一、核心原理 积分分离PID控制的核心在于动态调整积分项的作用,以解决传统PID在三轴云台应用中的超调、振荡问题: 大误差阶段(如云台启动或快速调整时): 关闭积分项,仅使用比例(P)…...

【Elasticsearch】scripted_upsert
在 Elasticsearch 中,scripted_upsert 是一个用于更新操作的参数,它允许在文档不存在时通过脚本初始化文档内容,而不是直接使用 upsert 部分的内容。这种方式提供了更灵活的文档创建和更新逻辑。 scripted_upsert 的工作原理 当设置 scripte…...

uv - 一个现代化的项目+环境管理工具
参考: 【uv】Python迄今最好的项目管理环境管理工具(吧?)_哔哩哔哩_bilibili 项目需求 想象,每次创建一个项目的时候,我们需要去写 README. md, .git 仓库, .gitignore,你会感觉很头大 对于 …...

经典密码学和现代密码学的结构及其主要区别(2)维吉尼亚密码—附py代码
Vigenre cipher 维吉尼亚密码 维吉尼亚密码由布莱斯德维吉尼亚在 16 世纪发明,是凯撒密码的一个更复杂的扩展。它是一种多字母替换密码,使用一个关键字来确定明文中不同字母的多个移位值。 与凯撒密码不同,凯撒密码对所有字母都有固定的偏移…...

Elasticsearch 节点角色详解及协调节点请求策略
引言 Elasticsearch 集群中的节点可以承担多种角色,如主节点、数据节点、预处理节点和协调节点。合理配置和理解这些节点角色,对于保障集群的高可用性、性能优化以及请求调度至关重要。本文将深入解析各类节点的职责与配置方式,并介绍如何通…...

视频逐帧提取图片的工具
软件功能:可以将视频逐帧提取图片,可以设置每秒提取多少帧,选择提取图片质量测试环境:Windows 10软件设置:由于软件需要通过FFmpeg提取图片,运行软件前请先设置FFmpeg,具体步骤 1. 请将…...

数据结构第1章编程基础 (竟成)
第 1 章 编程基础 1.1 前言 因为数据结构的代码大多采用 C 语言进行描述。而且,408 考试每年都有一道分值为 13 - 15 的编程题,要求使用 C/C 语言编写代码。所以,本书专门用一章来介绍 408 考试所需的 C/C 基础知识。有基础的考生可以快速浏览…...

互联网大厂Java求职面试:AI大模型与云原生架构融合中的挑战
互联网大厂Java求职面试:AI大模型与云原生架构融合中的挑战 在互联网大厂的Java求职面试中,面试官往往以技术总监的身份,针对候选人对AI、大模型应用集成、云原生和低代码等新兴技术的理解与实践能力进行考察。以下是一个典型的面试场景&…...

msql的乐观锁和幂等性问题解决方案
目录 1、介绍 2、乐观锁 2.1、核心思想 2.2、实现方式 1. 使用 version 字段(推荐) 2. 使用 timestamp 字段 2.3、如何处理冲突 2.4、乐观锁局限性 3、幂等性 3.1、什么是幂等性 3.2、乐观锁与幂等性的关系 1. 乐观锁如何辅助幂等性…...

Python 实现桶排序详解
1. 核心原理 桶排序是一种非比较型排序算法,通过将数据分配到多个“桶”中,每个桶单独排序后再合并。其核心步骤包括: 分桶:根据元素的范围或分布,将数据分配到有限数量的桶中。桶内排序:对每个非空桶内的…...
——编码器(Encoder)、解码器(Decoder))
大模型(5)——编码器(Encoder)、解码器(Decoder)
文章目录 一、编码器(Encoder)1. 核心作用2. 典型结构(以Transformer为例)3. 应用场景 二、解码器(Decoder)1. 核心作用2. 典型结构(以Transformer为例)3. 应用场景 三、编码器与解码…...

Web3怎么本地测试连接以太坊?
ETHEREUM_RPC_URLhttps://sepolia.infura.io/v3/你的_INFURA_API_KEY 如果你没有 Infura Key,注册 Infura 或 Alchemy,拿一个免费测试网节点就行: Infura:https://infura.io Alchemy:Alchemy - the web3 developme…...
)
Vue-02 (使用不同的 Vue CLI 插件)
使用不同的 Vue CLI 插件 Vue CLI 插件扩展了 Vue 项目的功能,让你可以轻松集成 TypeScript、Vuex、路由等功能。它们可以自动进行配置和设置,从而节省您的时间和精力。了解如何使用这些插件对于高效的 Vue 开发至关重要。 了解 Vue CLI 插件 Vue CLI…...

理解vue-cli 中进行构建优化
在 Vue CLI 项目中进行构建优化,是前端性能提升的重要手段。它涉及到 Webpack 配置、代码分包、懒加载、依赖优化、图片压缩等多个方面。 🧱 基础构建优化 设置生产环境变量 NODE_ENVproduction Vue CLI 会自动在 npm run build 时开启以下优化&…...

理解计算机系统_线程(九):线程安全问题
前言 以<深入理解计算机系统>(以下称“本书”)内容为基础,对程序的整个过程进行梳理。本书内容对整个计算机系统做了系统性导引,每部分内容都是单独的一门课.学习深度根据自己需要来定 引入 接续理解计算机系统_线程(八):并行-CSDN博客,内容包括12.7…...
vue3基本类型和对象类型的响应式数据
vue3中基本类型和对象类型的响应式数据 OptionsAPI与CompstitionAPI的区别 OptionsAPI Options API • 特点:基于选项(options)来组织代码,将逻辑按照生命周期、数据、方法等分类。• 结构:代码按照 data 、 methods…...

3.8.4 利用RDD实现分组排行榜
本实战任务通过Spark RDD实现学生成绩的分组排行榜。首先,准备包含学生成绩的原始数据文件,并将其上传至HDFS。接着,利用Spark的交互式环境或通过创建Maven项目的方式,读取HDFS中的成绩文件生成RDD。通过map操作将数据映射为二元组…...