LightGBM的python实现及参数优化
文章目录
- 1. LightGBM模型参数介绍
- 2. 核心优势
- 3. python实现LightGBM
- 3.1 基础实现
- 3.1.1 Scikit-learn接口示例
- 3.1.2 Python API示例
- 3.2 模型调优
- 3.2.1 GridSearchCV简介
- 3.2.2 LightGBM超参调优
- 3.2.3 GridSearchCV寻优结果解读
在之前的文章 Boosting算法【AdaBoost、GBDT 、XGBoost 、LightGBM】理论介绍及python代码实现 中重点介绍了AdaBoost算法的理论及实现,今天对LightGBM 如何实现以及如何调参,着重分析一下。
LightGBM是基于决策树算法的分布式梯度提升框架,属于GBDT(Gradient Boosting Decision Tree)家族,与XGBoost、CatBoost并称为三大主流GBDT工具。
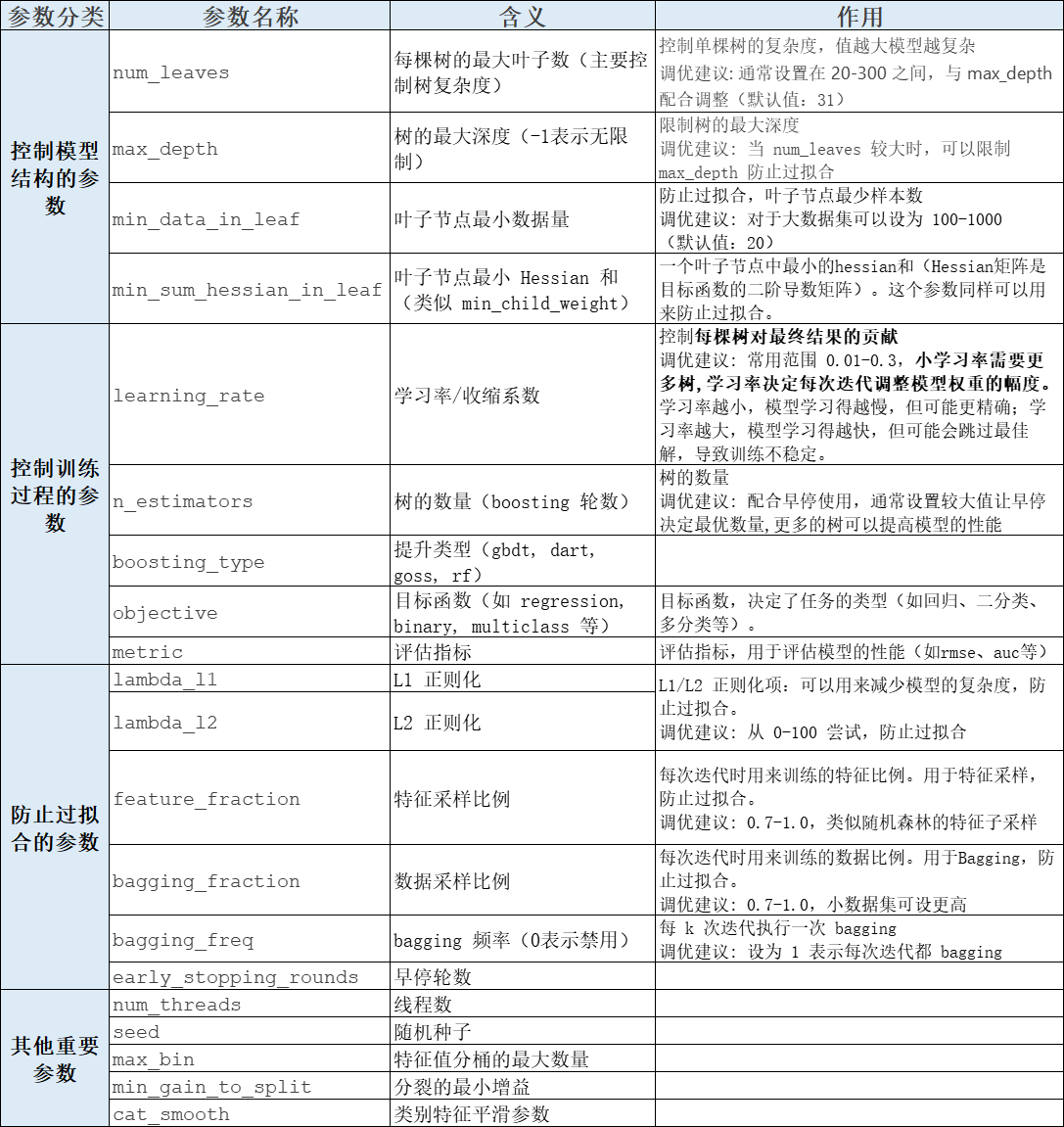
1. LightGBM模型参数介绍




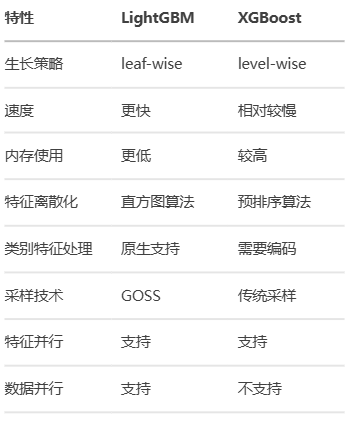
2. 核心优势

与XGBoost相比较
3. python实现LightGBM
3.1 基础实现
3.1.1 Scikit-learn接口示例
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import lightgbm as lgb
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix,mean_squared_error
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#导入数据
data = load_breast_cancer()
X = data.data
y = data.target# 分割数据集,80%作为训练集,20%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)# 创建Dataset
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)# 设置参数
params = {'objective': 'binary', #目标函数,决定了任务的类型(二分类 regression 回归)'metric': 'binary_logloss', #二分类对数损失(Binary Logarithmic Loss)'num_leaves': 31,'learning_rate': 0.05,'feature_fraction': 0.9
}# 训练模型
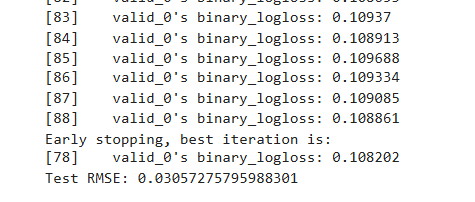
gbm = lgb.train(params,train_data,num_boost_round=100,valid_sets=[test_data],early_stopping_rounds=10)# 预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)# 评估
rmse = mean_squared_error(y_test, y_pred)
print(f'Test RMSE: {rmse}')
3.1.2 Python API示例
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import lightgbm as lgb
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix,mean_squared_error
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#导入数据
data = load_breast_cancer()
X = data.data
y = data.target# 分割数据集,80%作为训练集,20%作为测试集
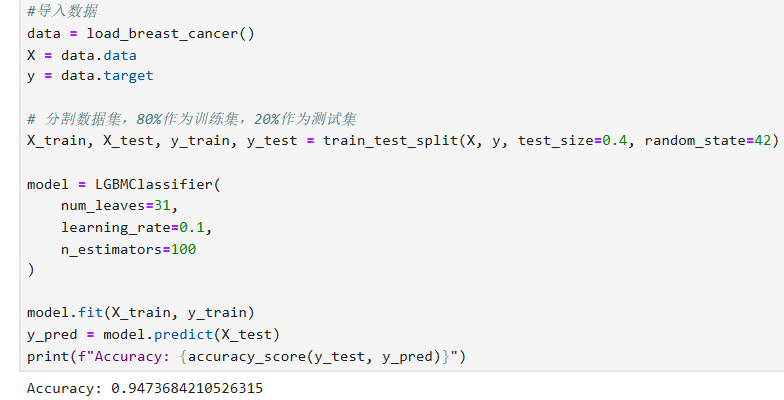
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)model = LGBMClassifier(num_leaves=31,learning_rate=0.1,n_estimators=100
)model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
3.2 模型调优
模型调优也参考之前自己写过的文档
Python模型优化超参寻优过程
GridSearchCV是scikit-learn库中用于超参数调优的重要工具,它通过网格搜索和交叉验证的方式寻找最优的模型参数组合,下面介绍使用GridSearchCV对LGBM参数调优。
3.2.1 GridSearchCV简介
关于GridSearchCV简单再介绍一下

机器学习-GridSearchCV scoring 参数设置!
3.2.2 LightGBM超参调优
(三)提升树模型:Lightgbm原理深入探究 这篇文章里的关于Lightgbm优化比较深入,感兴趣的可以仔细阅读。
本部分的实现即对LightGBM介绍的参数使用GridSearchCV进行调优,python代码见下
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.datasets import load_breast_cancer
import lightgbm as lgb
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix,mean_squared_error
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号#导入数据
breast_cancer = load_breast_cancer()
breast_cancer_df = pd.DataFrame(breast_cancer.data, columns=breast_cancer.feature_names)
breast_cancer_df['target'] = breast_cancer.targetdaoshu = 20
X = breast_cancer_df.iloc[:,:-1]
y = breast_cancer_df.iloc[:,-1]
XGB_X = X[:-daoshu]
XGB_y = y[:-daoshu]
# 分割数据集,80%作为训练集,20%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)lgb_class = lgb.LGBMClassifier()
# GridSearchCV 参数网格-----------------------------------------------------------
param_grid = {'max_depth': [5,7],'learning_rate': [0.1, 0.5],'n_estimators': [100, 500],'num_leaves':[31,51],'reg_alpha':[0.5,0.8,1],'reg_lambda':[0.5,1]
}grid_search = GridSearchCV(estimator=lgb_class, param_grid=param_grid, scoring='neg_mean_squared_error', cv=2, verbose=2)
grid_search.fit(X_train, y_train)
#网格查找每个参数时的-MSE
par =[]
par_mses = []
for i, par_mse in zip(grid_search.cv_results_['params'],grid_search.cv_results_['mean_test_score']):# print(i, par_mse)par.append(i)par_data = pd.DataFrame(par) par_mses.append(par_mse)par_rmsedata = pd.DataFrame(par_mses)
search_data = pd.concat([par_data,par_rmsedata],axis=1)
search_data = search_data.rename(columns={0:"neg_mean_squared_error"})
# 输出最优参数信息
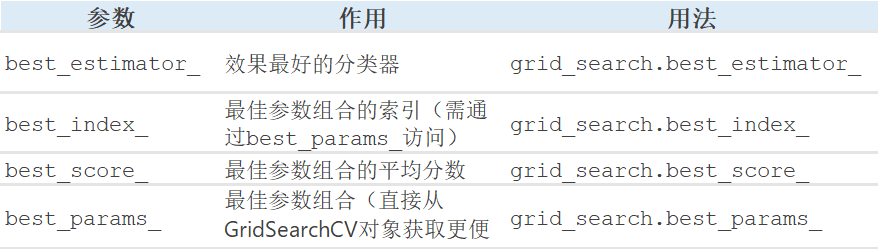
best_params = grid_search.best_params_
print('best_score:',grid_search.best_score_)
print(f"best_params: {best_params}")
print('best_index:',grid_search.best_index_)
print('best_estimator:',grid_search.best_estimator_)# 使用最优参数训练模型
lgb_class_optimized = lgb.LGBMClassifier(**best_params)
lgb_class_optimized.fit(XGB_X, XGB_y)
# 预测
y_pred_optimized = lgb_class_optimized.predict(X)
rmse_optimized = np.sqrt(mean_squared_error(y, y_pred_optimized))
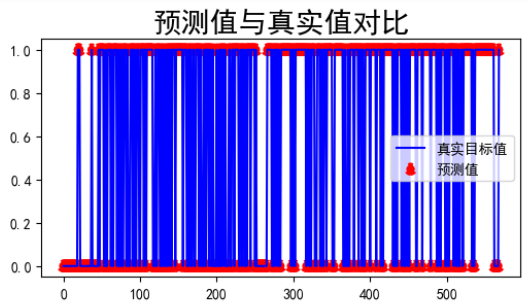
print(f"Optimized RMSE: {rmse_optimized:.4f}") #最终预测结果的 RMSE #可视化展示
pre_target = pd.DataFrame(y_pred_optimized)
predata= pd.concat([breast_cancer_df,pre_target],axis=1)
plt.figure(figsize=(6,3))
plt.plot(range(len(predata['target'])),predata['target'],c='blue')
plt.scatter(range(len(predata['target'])),predata.iloc[:,-1:],ls=':',c='red',lw=3)
plt.title('预测值与真实值对比', size= 20)
plt.legend(['真实目标值','预测值'])
plt.show()predata.tail()
部分结果展示

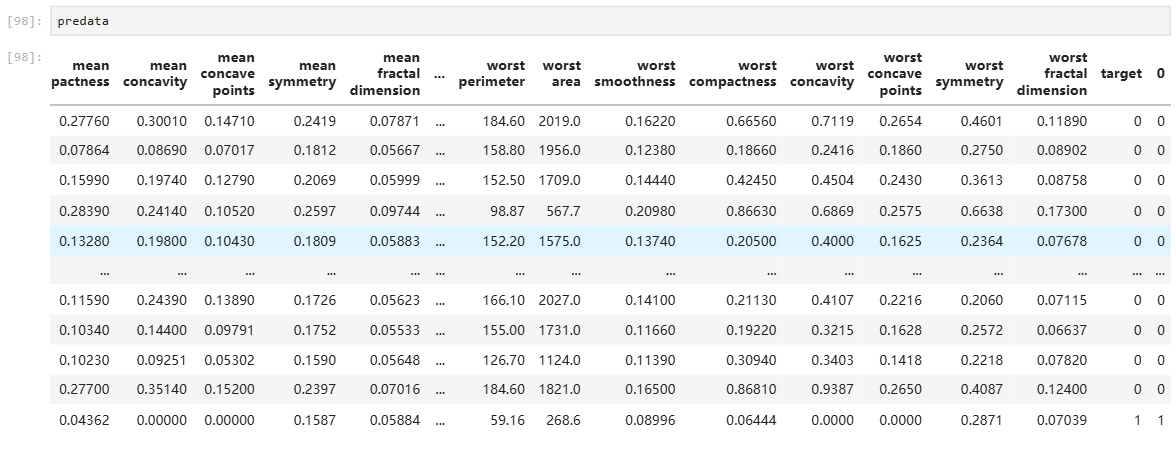
红色框为最优组合。
绘制 LightGBM 的树图并保存为 PDF 文件
# 方法一
try:tree_idx = lgb_class_optimized.best_iteration - 1 if lgb_class_optimized.best_iteration else lgb_class_optimized.num_trees() - 1ax = lgb.plot_tree(lgb_class_optimized, tree_index=tree_idx)
except AttributeError:ax = lgb.plot_tree(lgb_class_optimized, tree_index=-1) plt.gcf().set_size_inches(20,10)
plt.savefig('lgb_tree.pdf', format='pdf', dpi=600,bbox_inches='tight')
plt.show()
plt.close()
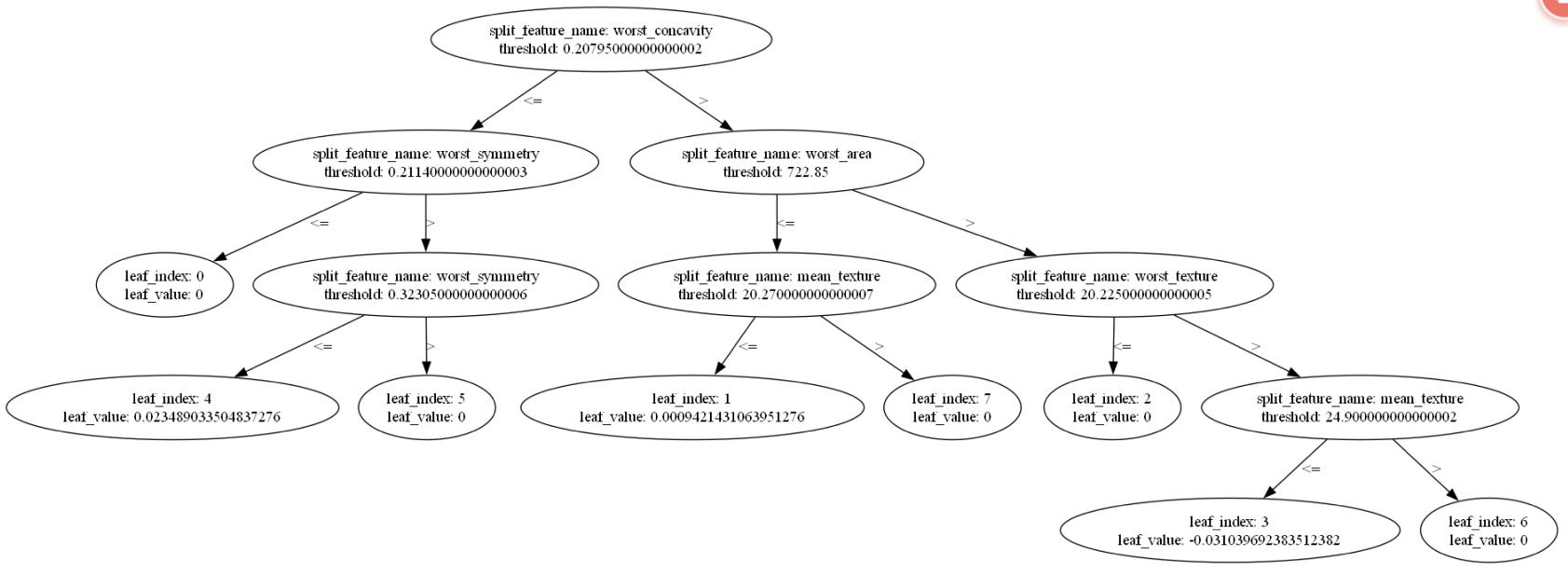
booster = lgb_class_optimized.booster_
lgb.plot_tree(booster, tree_index=booster.num_trees() - 1)
3.2.3 GridSearchCV寻优结果解读
# 最佳参数组合的详细信息
best_idx = grid_search.best_index_ # 即search_data表里的索引为 3
print(f"最佳参数组合: {grid_search.cv_results_['params'][best_idx]}")
print(f"平均验证分数: {grid_search.cv_results_['mean_test_score'][best_idx]:.4f}")
print(f"各折验证分数: {grid_search.cv_results_['split0_test_score'][best_idx]:.4f}, "f"{grid_search.cv_results_['split1_test_score'][best_idx]:.4f}, ...")

best_results = pd.DataFrame(grid_search.cv_results_).sort_values('rank_test_score')print("Top 5参数组合:")
print(best_results[['params', 'mean_test_score', 'std_test_score', 'rank_test_score']].head(5))print("\n训练时间分析:")
print(f"平均总训练时间: {best_results['mean_fit_time'].sum():.2f}秒")
print(f"最快组合训练时间: {best_results['mean_fit_time'].min():.2f}秒")
print(f"最慢组合训练时间: {best_results['mean_fit_time'].max():.2f}秒")
best_results.head(4)
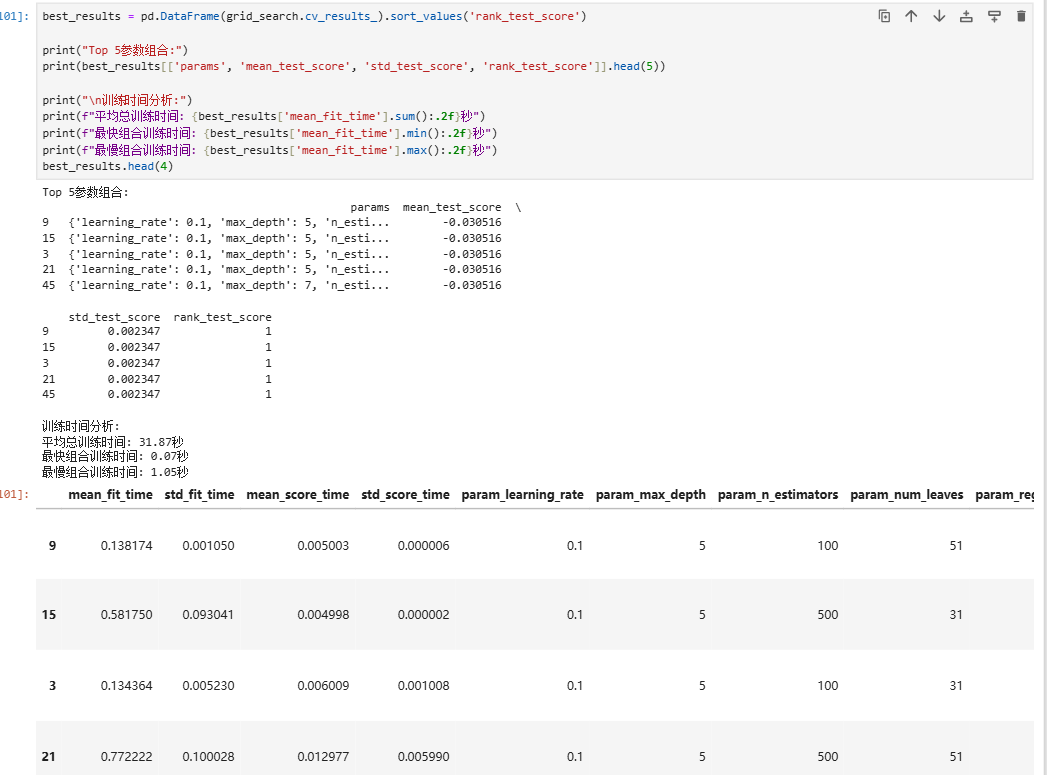
相关文章:
LightGBM的python实现及参数优化
文章目录 1. LightGBM模型参数介绍2. 核心优势3. python实现LightGBM3.1 基础实现3.1.1 Scikit-learn接口示例3.1.2 Python API示例 3.2 模型调优3.2.1 GridSearchCV简介3.2.2 LightGBM超参调优3.2.3 GridSearchCV寻优结果解读 在之前的文章 Boosting算法【AdaBoost、GBDT 、X…...

封装渐变堆叠柱状图组件附完整代码
组件功能 这是一个渐变堆叠柱状图组件,主要功能包括: 在一根柱子上同时显示高、中、低三种危险级别数据使用渐变色区分不同危险级别(高危红色、中危橙色、低危蓝色)悬停显示详细数据信息(包括总量和各级别数据&#…...

分布式项目保证消息幂等性的常见策略
Hello,大家好,我是灰小猿! 在分布式系统中,由于各个服务之间独立部署,各个服务之间依靠远程调用完成通信,再加上面对用户重复点击时的重复请求等情况,所以如何保证消息消费的幂等性是在分布式或…...

山东大学软件学院创新项目实训开发日志——第十三周
目录 1.开展prompt工程,创建个性化AI助理,能够基于身份实现不同角度和语言风格的回答。 2.对输出进行格式化,生成特定格式的会议计划文档。 3.学习到的新知识 本阶段我所做的工作 1.开展prompt工程,创建个性化AI助理ÿ…...

如何在sublime text中批量为每一行开头或者结尾添加删除指定内容
打开你的文件:首先,在 Sublime Text 中打开你想要编辑的文件,然后全选 行首插入: 选择所有行的开头: 使用快捷键 Ctrl Shift L(Windows/Linux)或 Cmd Shift L(Mac)&…...
Cesium 透明渐变墙 解决方案
闭合路径修复 通过增加额外点确保路径首尾相接 透明渐变效果 使用RGBA颜色模式实现从完全不透明到完全透明的平滑渐变 参数可调性 提供多个可调参数,轻松自定义颜色、高度和圆环尺寸 完整代码实现 <!DOCTYPE html> <html> <head><meta …...

网络原理与 TCP/IP 协议详解
一、网络通信的本质与基础概念 1.1 什么是网络通信? 网络通信的本质是跨设备的数据交换,其核心目标是让不同物理位置的设备能够共享信息。这种交换需要解决三个核心问题: 如何定位设备? → IP地址如何找到具体服务?…...

day022-定时任务-故障案例与发送邮件
文章目录 1. cron定时任务无法识别命令1.1 故障原因1.2 解决方法1.2.1 对命令使用绝对路径1.2.2 在脚本开头定义PATH 2. 发送邮件2.1 安装软件2.2 配置邮件信息2.3 巡检脚本与邮件发送2.3.1 巡检脚本内容2.3.2 制作时任务发送邮件 3. 调取API发送邮件3.1 编写文案脚本3.2 制作定…...

新增 git submodule 子模块
文章目录 1、基本语法2、添加子模块后的操作3、拉取带有submodule的仓库 git submodule add 是 Git 中用于将另一个 Git 仓库作为子模块添加到当前项目中的命令。 子模块允许你将一个 Git 仓库作为另一个 Git 仓库的子目录,同时保持它们各自的提交历史独立。 1、基…...
List优雅分组
一、前言 最近小永哥发现,在开发过程中,经常会遇到需要对list进行分组,就是假如有一个RecordTest对象集合,RecordTest对象都有一个type的属性,需要将这个集合按type属性进行分组,转换为一个以type为key&…...
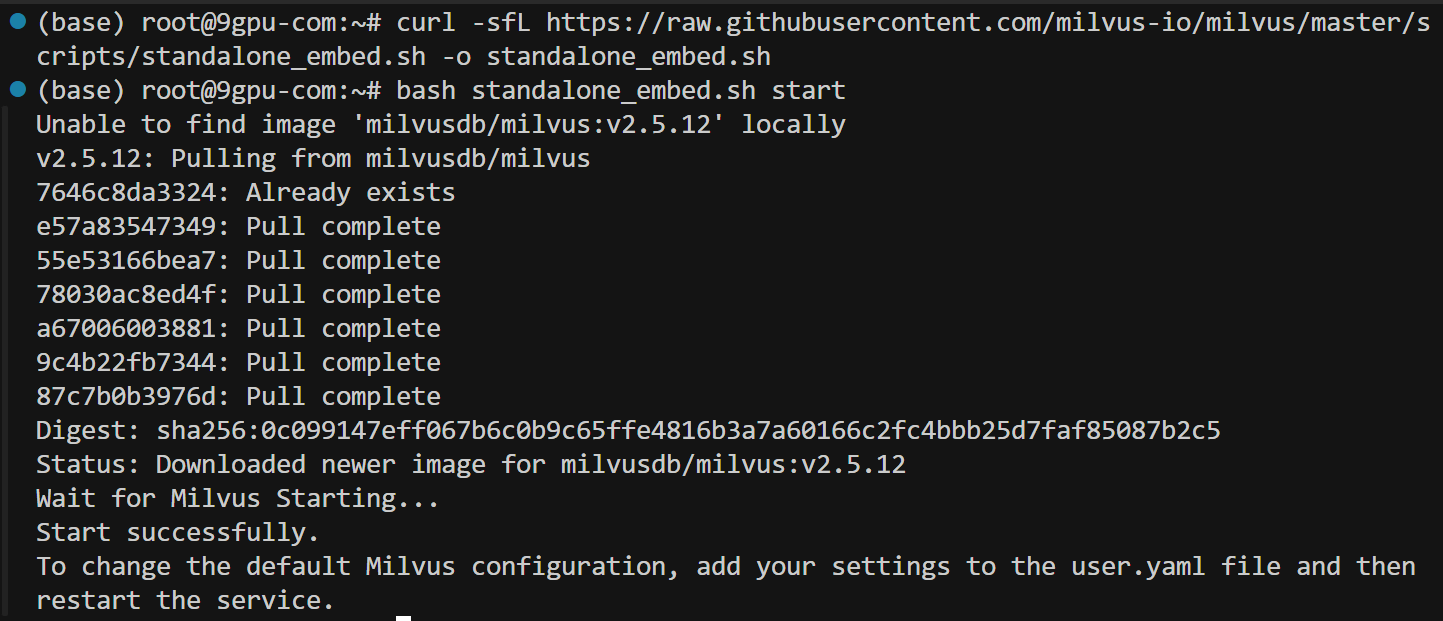
Linux 使用 Docker 安装 Milvus的两种方式
一、使用 Docker Compose 运行 Milvus (Linux) 安装并启动 Milvus Milvus 在 Milvus 资源库中提供了 Docker Compose 配置文件。要使用 Docker Compose 安装 Milvus,只需运行 wget https://github.com/milvus-io/milvus/releases/download/v2.5.10/milvus-standa…...

AR眼镜+AI视频盒子+视频监控联网平台:消防救援的智能革命
在火灾现场,每一秒都关乎生死。传统消防救援方式面临信息滞后、指挥盲区、环境复杂等挑战。今天,一套融合AR智能眼镜AI视频分析盒子智能监控管理平台的"三位一体"解决方案,正在彻底改变消防救援的作业模式,为消防员装上…...
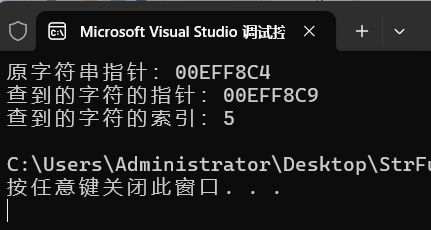
编程技能:字符串函数10,strchr
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:字符串函数09,strncmp 回到目录…...

使用tunasync部署企业内部开源软件镜像站-Centos Stream 9
使用tunasync部署企业内部开源软件镜像站 tunasync 是清华大学 TUNA 镜像源目前使用的镜像方案,本文将介绍如何使用 tunasync 部署企业内部开源软件镜像站。 基于tunasync mirror-web nginx进行镜像站点搭建。 1. tunasync设计 tunasync架构如下: …...

c/c++的opencv像素级操作二值化
图像级操作:使用 C/C 进行二值化 在数字图像处理中,图像级操作 (Image-Level Operations) 是指直接在图像的像素级别上进行处理,以改变图像的视觉特性或提取有用信息。这些操作通常不依赖于图像的全局结构,而是关注每个像素及其邻…...
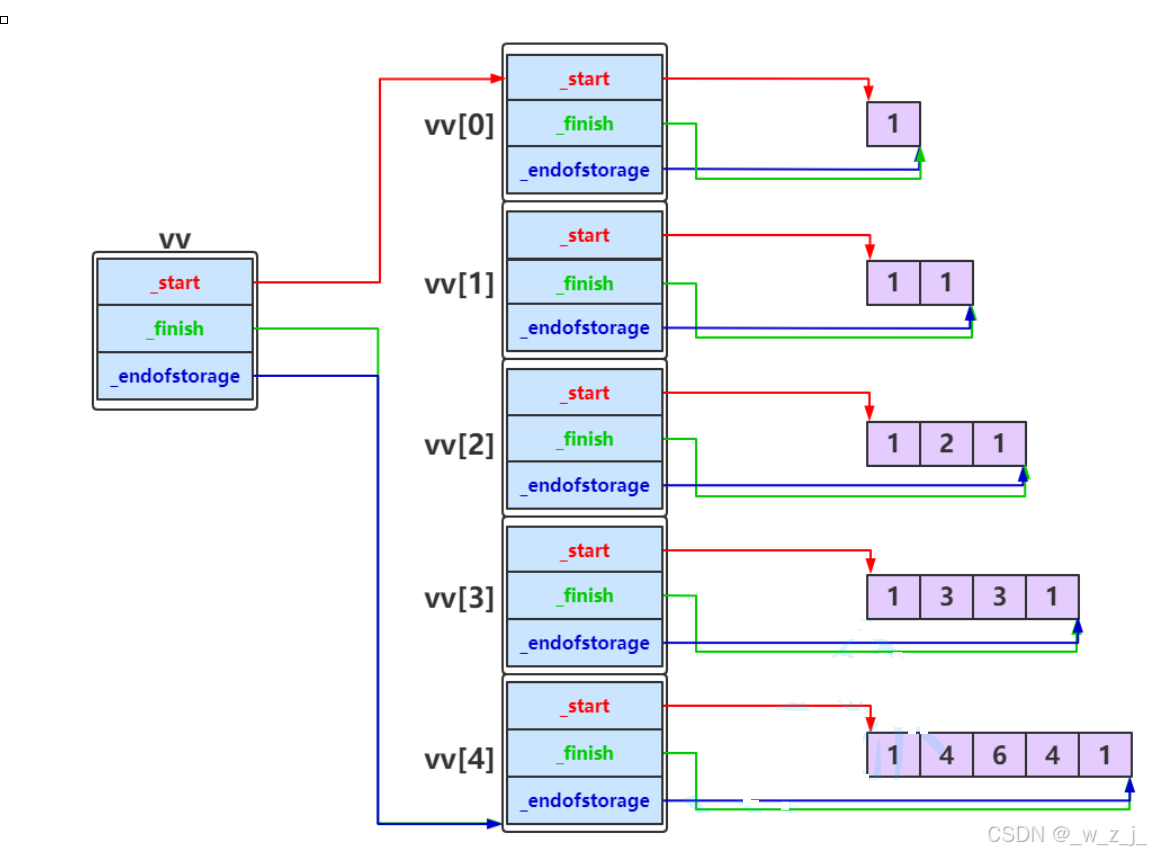
C++----Vector的模拟实现
上一节讲了string的模拟实现,string的出现时间比vector靠前,所以一些函数给的也比较冗余,而后来的vector、list等在此基础上做了优化。这节讲一讲vector的模拟实现,vector与模板具有联系,而string的底层就是vector的一…...

Mac redis下载和安装
目录 1、官网:https://redis.io/ 2、滑到最底下 3、下载资源 4、安装: 5、输入 sudo make test 进行编译测试 会提示 编辑 6、sudo make install 继续 7、输入 src/redis-server 启动服务器 8、输入 src/redis-cli 启动测试端 1、官网ÿ…...
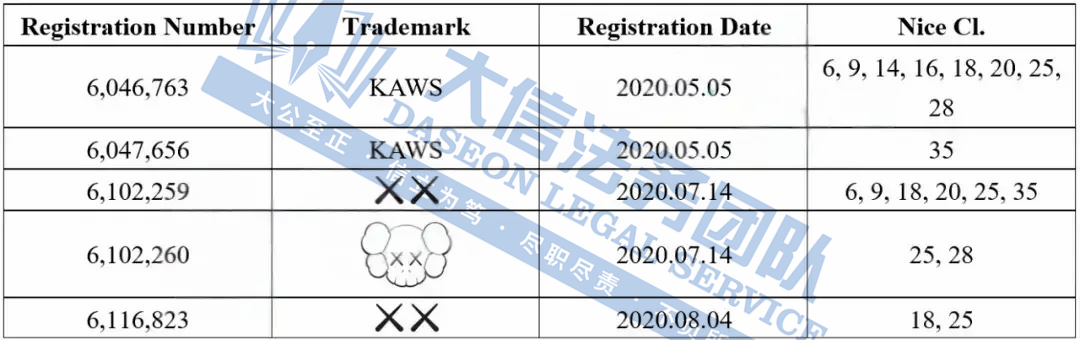
[25-cv-05718]BSF律所代理潮流品牌KAWS公仔(商标+版权)
潮流品牌KAWS公仔 案件号:25-cv-05718 立案时间:2025年5月21日 原告:KAWS, INC. 代理律所:Boies Schiller Flexner LLP 原告介绍 原告是一家由美国街头艺术家Brian Donnelly创立的公司,成立于2002年2月25日&…...
)
【PhysUnits】9 取负重载(negation.rs)
一、源码 这段代码是类型级二进制数(包括正数和负数)的取反和取负操作。它使用了类型系统来表示二进制数,并通过特质(trait)和泛型来实现递归操作。 use super::basic::{B0, B1, Z0, N1}; use core::ops::Neg;// 反…...
深度思考、弹性实施,业务流程自动化的实践指南
随着市场环境愈发复杂化,各类型企业的业务步伐为了跟得上市场节奏也逐步变得紧张,似乎只有保持极强的竞争力、削减成本、提升抗压能力才能在市场洪流中博得一席之位。此刻企业需要制定更明智的解决方案,以更快、更准确地优化决策流程。与简单…...

UWB:litepoint获取txquality里面的NRMSE
在使用litepoint测试UWB,获取txquality里面的NRMSE时,网页端可以正常获取NRMSE。但是通过SCPI 命令来获取NRMSE一直出错。 NRMSE数据类型和pyvisa问题: 参考了user guide,发现NRMSE的数值是ARBITRARY_BLOCK FLOAT,非string。 pyvisa无法解析会返回错误。 查询了各种办法…...
VUE npm ERR! code ERESOLVE, npm ERR! ERESOLVE could not resolve, 错误有效解决
VUE : npm ERR! code ERESOLVE npm ERR! ERESOLVE could not resolve 错误有效解决 npm install 安装组件的时候出现以上问题,npm版本问题报错解决方法:用上述方法安装完成之后又出现其他的问题 npm install 安装组件的时候出现以上问题&…...

IoT/HCIP实验-1/物联网开发平台实验Part1(快速入门,MQTT.fx对接IoTDA)
文章目录 实验介绍设备接入IoTDA进入IoTDA平台什么是IoTDA 开通服务创建产品和设备定义产品模型(Profile)设备注册简思(实例-产品-设备) 模拟.与平台通信虚拟设备/MQTT.fx应用 Web 控制台QA用户或密码错误QA证书导致的连接失败设备与平台连接成功 上报数…...
DMA STM32H7 Domains and space distrubution
DMA这个数据搬运工,对谁都好,任劳任怨,接受雇主设备的数据搬运业务。每天都忙碌着!哈哈哈。 1. DMA 不可能单独工作,必须接收其他雇主的业务,所以数据搬运业务的参与者是DMA本身和业务需求发起者。 2. 一…...
洪水危险性评价与风险防控全攻略:从HEC-RAS数值模拟到ArcGIS水文分析,一键式自动化工具实战,助力防洪减灾与应急管理
🔍 洪水淹没危险性是洪水损失评估、风险评估及洪水应急和管理规划等工作的重要基础。当前,我国正在开展的自然灾害风险普查工作,对洪水灾害给予了重点关注,提出了对洪水灾害危险性及风险评估的明确要求。洪水危险性及风险评估通常…...

Gemini Pro 2.5 输出
好的,我已经按照您的要求,将顶部横幅提示消息修改为右下角的 Toast 样式通知。 以下是涉及更改的文件及其内容: 1. my/src/html-ui.js 移除了旧的 #message-area div。在 <body> 底部添加了新的 #toast-container div 用于存放 Toas…...

SQL Server 和 MySQL 对比
下面是 SQL Server 和 MySQL 的详细对比,从功能、性能、成本、生态等多个维度展开,帮助你判断在什么情况下该选择哪一个。 ✅ 总览对比表 维度SQL ServerMySQL开发公司微软(Microsoft)Oracle(2008年起)是否…...
Leetcode 3269. 构建两个递增数组
1.题目基本信息 1.1.题目描述 给定两个只包含 0 和 1 的整数数组 nums1 和 nums2,你的任务是执行下面操作后使数组 nums1 和 nums2 中 最大 可达数字 尽可能小。 将每个 0 替换为正偶数,将每个 1 替换为正奇数。在替换后,两个数组都应该 递…...

三轴云台之积分分离PID控制算法篇
一、核心原理 积分分离PID控制的核心在于动态调整积分项的作用,以解决传统PID在三轴云台应用中的超调、振荡问题: 大误差阶段(如云台启动或快速调整时): 关闭积分项,仅使用比例(P)…...

【Elasticsearch】scripted_upsert
在 Elasticsearch 中,scripted_upsert 是一个用于更新操作的参数,它允许在文档不存在时通过脚本初始化文档内容,而不是直接使用 upsert 部分的内容。这种方式提供了更灵活的文档创建和更新逻辑。 scripted_upsert 的工作原理 当设置 scripte…...