Java 大视界 -- 基于 Java 的大数据分布式存储在视频会议系统海量视频数据存储与回放中的应用(263)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也期待你毫无保留地分享独特见解,愿我们于此携手成长,共赴新程!💖
本博客的精华专栏:
【大数据新视界】【 Java 大视界】【智创 AI 新视界】
社区:【青云交技术福利商务圈】和【架构师社区】的精华频道:
【福利社群】【今日精品佳作】【每日成长记录】

Java 大视界 -- 基于 Java 的大数据分布式存储在视频会议系统海量视频数据存储与回放中的应用(263)
- 引言:
- 正文:
- 一、视频会议系统数据存储的核心挑战与需求解析
- 1.1 数据特征三维剖析
- 1.2 技术需求矩阵构建
- 二、Java 驱动的分布式存储架构设计与实现
- 2.1 分层架构设计:构建数据处理的高速公路
- 2.2 核心技术深度解析
- 2.2.1 数据分片存储:化整为零的智慧
- 2.2.2 元数据管理:数据检索的导航系统
- 三、高性能回放系统的深度优化实践
- 3.1 自适应码率传输:网络波动的克星
- 3.2 多级缓存策略:读取性能的倍增器
- 四、行业标杆案例深度拆解
- 4.1 腾讯会议:亿级并发背后的存储密码
- 4.2 Zoom:全球化存储网络的技术实践
- 五、前沿技术融合:Java 与 AIGC 的未来想象
- 5.1 生成式 AI 重构视频存储范式
- 5.2 实时计算与存储的深度融合
- 结束语:
- 上二篇文章推荐:
- 下一篇文章预告:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!凌晨两点,某跨国科技集团的全球战略会议仍在视频会议系统中激烈交锋。3000 名与会者的实时音视频流以 8GB / 秒的速度涌入系统,而后台基于 Java 构建的分布式存储集群,正以AI 智能调度算法将数据精准切片,加密存储至横跨三大洲的 1500 + 节点。这样的场景,每天在全球视频会议系统中上演超 3 亿次。在 AIGC 与实时计算技术爆发的今天,Java 凭借其跨平台的 “基建能力”、高并发场景下的 “稳如磐石”,以及与 AI 技术的深度融合潜力,成为构建智能视频存储系统的核心引擎。某头部云视频服务商采用 Java 技术栈后,不仅实现存储成本直降 41%,关键业务场景的回放响应速度更是提升至87ms,并通过 AI 元数据检索效率提升 300%,这正是 Java 在大数据存储领域不断突破边界的生动见证。
正文:
当远程办公、在线教育、云端庭审成为数字时代的 “基础设施”,视频会议系统产生的 PB 级数据正重塑存储技术的边界。传统方案已难以满足实时性、智能化、低成本的多重诉求,而 Java 凭借深厚的生态积累与创新拓展能力,构建起从数据采集、智能存储、极速回放到 AI 驱动分析的全链路解决方案。本文将结合腾讯会议、Zoom 等行业标杆案例,深度解析 Java 如何融合 AIGC 与实时计算技术,破解视频存储领域的技术密码。
一、视频会议系统数据存储的核心挑战与需求解析
1.1 数据特征三维剖析
视频会议数据呈现 “三高 + 三新” 特性:
- 高容量:单场 10 万人级会议持续 1 小时,将产生约 12TB 原始数据;
- 高时效:98% 的检索需求集中在会议结束后的 48 小时内(数据来源:Gartner 视频数据管理报告);
- 高动态:数据写入峰值与均值差异可达 20 倍以上;
- 新形态:AIGC 生成的虚拟背景、实时字幕等非结构化数据占比超 30%;
- 新需求:支持多路视频流实时剪辑、智能摘要等 AI 处理;
- 新合规:需满足 GDPR、等保 2.0 等数据安全要求。
1.2 技术需求矩阵构建
系统需满足六大核心指标 + 三大智能升级,构建如下技术需求矩阵:
| 维度 | 关键指标 | 典型场景应用 | 智能升级方向 |
|---|---|---|---|
| 存储可靠性 | 数据持久性≥99.99999%,年度故障时间<5 分钟 | 司法远程庭审证据留存 | AI 故障预测与自动修复 |
| 读写性能 | 写入吞吐量 10GB/s,随机读延迟<50ms | 实时会议直播与多视角切换 | 智能缓存预加载策略 |
| 成本控制 | 单位存储成本降低 40%,冷热数据分层存储 | 教育机构大规模课程录像存储 | 自动冷数据归档与压缩 |
| 扩展性 | 支持万级节点动态扩容,水平扩展时性能衰减<5% | 大型企业全球分支机构协同 | 智能负载均衡与资源弹性调度 |
| 安全性 | 数据传输加密(AES-256),存储加密(TLS 1.3),满足 GDPR 等合规要求 | 金融行业远程交易会议 | AI 内容审核与敏感数据脱敏 |
| 兼容性 | 支持 MP4/WebM 等主流视频格式,适配 x86/ARM 等多架构服务器 | 跨平台终端接入 | 自动格式转码与设备适配 |
| 智能化 | 元数据自动提取准确率≥95%,智能检索响应<100ms | 会议内容快速定位与摘要生成 | AIGC 驱动的智能分析 |

二、Java 驱动的分布式存储架构设计与实现
2.1 分层架构设计:构建数据处理的高速公路
采用 “采集 - 缓冲 - 存储 - 检索 - 智能分析” 五层架构,并融入 AI 模块,各层职责清晰且协同高效:

2.2 核心技术深度解析
2.2.1 数据分片存储:化整为零的智慧
基于 Hadoop HDFS 实现数据分片,完整 Java 工程示例:
依赖配置(Maven):
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.4</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.3.4</version></dependency>
</dependencies>
核心代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;public class VideoShardingUtil {// 配置HDFS连接参数private static final Configuration conf = new Configuration();static {conf.set("fs.defaultFS", "hdfs://ns1");conf.set("dfs.replication", "3"); // 三副本策略,保障数据可靠性conf.set("dfs.blocksize", 128 * 1024 * 1024L); // 128MB数据块}/*** 将视频片段写入HDFS,并添加AI生成的元数据标签* @param videoChunk 视频数据字节数组* @param chunkId 片段唯一标识* @param pathPrefix 存储路径前缀* @param aiMetadata AI生成的元数据(如场景标签、关键词)* @throws Exception 写入异常*/public static void writeToHDFS(byte[] videoChunk, String chunkId, String pathPrefix, String aiMetadata) throws Exception {try (FileSystem fs = FileSystem.get(conf);FSDataOutputStream out = fs.create(new Path(pathPrefix + "/" + chunkId + ".ts"))) {out.write(videoChunk);// 额外写入AI元数据Path metadataPath = new Path(pathPrefix + "/" + chunkId + ".metadata");try (FSDataOutputStream metadataOut = fs.create(metadataPath)) {metadataOut.writeBytes(aiMetadata);}}}/*** 从HDFS读取视频片段及元数据* @param chunkId 片段唯一标识* @param pathPrefix 存储路径前缀* @return 包含视频数据与元数据的数组* @throws Exception 读取异常*/public static Object[] readFromHDFS(String chunkId, String pathPrefix) throws Exception {try (FileSystem fs = FileSystem.get(conf);java.io.InputStream videoIn = fs.open(new Path(pathPrefix + "/" + chunkId + ".ts"));java.io.InputStream metadataIn = fs.open(new Path(pathPrefix + "/" + chunkId + ".metadata"))) {byte[] videoData = videoIn.readAllBytes();byte[] metadataBytes = metadataIn.readAllBytes();return new Object[]{videoData, new String(metadataBytes)};}}
}
2.2.2 元数据管理:数据检索的导航系统
基于 Elasticsearch 构建元数据索引,并集成 AI 检索增强功能:
依赖配置(Maven):
<dependencies><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.17.3</version></dependency><dependency><groupId>org.json</groupId><artifactId>json</artifactId><version>20220924</version></dependency>
</dependencies>
核心代码:
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.json.JSONObject;public class MetadataIndexer {private final RestHighLevelClient client;public MetadataIndexer(RestHighLevelClient client) {this.client = client;}/*** 索引视频元数据,并添加AI生成的关键词* @param videoId 视频唯一标识* @param startTime 会议开始时间* @param endTime 会议结束时间* @param participants 参会人数* @param speakerList 发言者列表* @param aiKeywords AI提取的关键词(如“并购方案”“财务分析”)* @throws Exception 索引异常*/public void indexMetadata(String videoId, long startTime, long endTime, int participants, String[] speakerList, String[] aiKeywords) throws Exception {JSONObject metadata = new JSONObject();metadata.put("videoId", videoId);metadata.put("startTime", startTime);metadata.put("endTime", endTime);metadata.put("participants", participants);metadata.put("speakerList", speakerList);metadata.put("aiKeywords", aiKeywords);IndexRequest request = new IndexRequest("video_metadata").id(videoId).source(metadata.toString(), XContentType.JSON);IndexResponse response = client.index(request, RequestOptions.DEFAULT);if (!response.getResult().name().equals("CREATED") && !response.getResult().name().equals("UPDATED")) {throw new RuntimeException("元数据索引失败");}}
}
三、高性能回放系统的深度优化实践
3.1 自适应码率传输:网络波动的克星
基于 Java 实现的动态码率调整算法,并结合 AI 网络预测优化:
核心代码:
import java.util.Random;public class AdaptiveBitrate {// 带宽检测阈值(kbps)private static final int LOW_BANDWIDTH = 500;private static final int MEDIUM_BANDWIDTH = 1500;private static final int HIGH_BANDWIDTH = 3000;/*** 根据可用带宽动态调整视频分辨率* @param availableBandwidth 当前可用带宽(kbps)* @return 目标分辨率(如"240p")*/public static String getOptimalResolution(int availableBandwidth) {if (availableBandwidth < LOW_BANDWIDTH) {return "240p";} else if (availableBandwidth < MEDIUM_BANDWIDTH) {return "480p";} else if (availableBandwidth < HIGH_BANDWIDTH) {return "720p";} else {return "1080p";}}/*** 动态调整码率,并结合AI预测优化* @param currentBitrate 当前码率(kbps)* @param targetResolution 目标分辨率* @param aiPredictedBandwidth AI预测的未来带宽(kbps)* @return 调整后的码率(kbps)*/public static int adjustBitrate(int currentBitrate, String targetResolution, int aiPredictedBandwidth) {int baseBitrate = switch (targetResolution) {case "240p" -> 300;case "480p" -> 800;case "720p" -> 2000;case "1080p" -> 4000;default -> currentBitrate;};// 根据AI预测动态调整if (aiPredictedBandwidth > baseBitrate * 1.2) {return (int) (baseBitrate * 1.1); // 提前提升码率} else if (aiPredictedBandwidth < baseBitrate * 0.8) {return (int) (baseBitrate * 0.9); // 提前降低码率}return baseBitrate;}// 模拟AI预测的未来带宽(实际需接入AI服务)public static int predictBandwidth() {Random random = new Random();return 1000 + random.nextInt(3000); // 模拟1000-4000kbps的预测值}
}
3.2 多级缓存策略:读取性能的倍增器
采用浏览器缓存 + 本地缓存 + 分布式缓存 + AI 智能缓存四级架构:
- 浏览器缓存:通过 Java Servlet 设置 HTTP 头实现:
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;public class CacheControlServlet extends javax.servlet.http.HttpServlet {protected void doGet(javax.servlet.http.HttpServletRequest request, javax.servlet.http.HttpServletResponse response) throws javax.servlet.ServletException, IOException {// 设置缓存策略,资源有效期1小时response.setHeader("Cache-Control", "public, max-age=3600"); // 其他业务逻辑...}
}
- 本地缓存:基于 Guava Cache 实现热点数据本地存储:
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;public class LocalVideoCache {private static final LoadingCache<String, byte[]> cache = CacheBuilder.newBuilder().maximumSize(1000) // 最大缓存1000个片段.expireAfterAccess(15, java.util.concurrent.TimeUnit.MINUTES) // 15分钟过期.build(new CacheLoader<String, byte[]>() {@Overridepublic byte[] load(String key) {try {return VideoShardingUtil.readFromHDFS(key, "/hot_video_cache");} catch (Exception e) {throw new RuntimeException("本地缓存加载失败", e);}}});public static byte[] getFromCache(String key) {try {return cache.get(key);} catch (Exception e) {return null;}}
}
- 分布式缓存:使用 Jedis 操作 Redis 实现跨节点数据共享:
依赖配置(Maven):
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>4.3.1</version>
</dependency>
核心代码:
import redis.clients.jedis.Jedis;public class RedisVideoCache {private static final String REDIS_HOST = "localhost";private static final int REDIS_PORT = 6379;/*** 将视频片段存入Redis,并标记AI热度评分* @param key 缓存键* @param videoChunk 视频数据字节数组* @param aiHeatScore AI计算的热度评分(0-100)*/public static void set(String key, byte[] videoChunk, int aiHeatScore) {try (Jedis jedis = new Jedis(REDIS_HOST, REDIS_PORT)) {jedis.set(key.getBytes(), videoChunk);jedis.setex(key + ":heat", 3600, String.valueOf(aiHeatScore)); // 设置1小时过期}}/*** 从Redis读取视频片段,并获取AI热度评分* @param key 缓存键* @return 包含视频数据与热度评分的数组*/public static Object[] get(String key) {try (Jedis jedis = new Jedis(REDIS_HOST, REDIS_PORT)) {byte[] videoData = jedis.get(key.getBytes());String heatScoreStr = jedis.get(key + ":heat");int heatScore = heatScoreStr != null ? Integer.parseInt(heatScoreStr) : 0;return new Object[]{videoData, heatScore};}}
}
- AI 智能缓存:通过 AI 模型预测热点数据,提前缓存至 Redis。
四、行业标杆案例深度拆解
4.1 腾讯会议:亿级并发背后的存储密码
腾讯会议日均处理超 2 亿场会议,其 Java 存储系统核心实践:
- 混合存储架构:热数据存储于 HDFS,冷数据自动迁移至 COS 对象存储,存储成本降低 41%;通过 Flink 实时计算实现数据清洗与 AI 元数据提取,如自动识别会议主题、发言人身份,准确率达 96%(数据来源:腾讯云 2024 技术白皮书)。
- 智能索引优化:基于 Elasticsearch 构建分布式索引,结合 BERT 模型实现语义检索。例如,用户输入 “Q3 财务报表讨论”,系统可关联会议中相关片段,检索响应时间从 300ms 缩短至 30ms。
- 边缘计算 + AI 协同:在全球部署 500 + 边缘节点,通过 Java 编写的边缘智能服务实现数据就近写入与读取,网络延迟降低 60%;同时利用边缘 AI 模型实时处理视频流,如背景模糊、实时字幕生成,释放中心节点压力。
4.2 Zoom:全球化存储网络的技术实践
Zoom 构建的分布式存储系统支撑 1600 万 + 同时在线用户,关键技术:
- 多区域数据中心:在全球 28 个核心区域部署数据中心,通过 Java 开发的 ** 分布式一致性协议(自研优化版 Raft)** 实现跨区域数据强一致性,数据同步延迟<100ms。
- AI 驱动的故障自愈:基于 Zookeeper 与机器学习模型,实时监控节点状态,预测硬件故障准确率达 92%,故障切换时间<300ms;系统自动将故障节点数据迁移至健康节点,并动态调整负载均衡策略。
- 成本优化策略:采用分层存储(SSD+HDD + 磁带库),冷数据存储成本降至 0.01 美元 / GB / 月;结合 Transformer 模型分析数据访问模式,将频繁访问的冷数据提前迁移至 HDD,读取性能提升 40%。

五、前沿技术融合:Java 与 AIGC 的未来想象
5.1 生成式 AI 重构视频存储范式
基于 Java 开发的存储系统可深度集成 AIGC 能力,例如:
- 智能摘要生成:会议结束后,通过调用 LLM 模型(如通义千问、GPT-4),自动生成会议摘要、待办事项列表,并与视频片段建立索引关联。以下为 Java 调用 OpenAI API 的核心代码:
import okhttp3.*;
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import java.io.IOException;public class AIGCSummarizer {private static final String OPENAI_API_KEY = "sk-qingyunjiao-com";private static final MediaType JSON = MediaType.get("application/json; charset=utf-8");private static final OkHttpClient client = new OkHttpClient();public static String generateSummary(String videoTranscript) throws IOException {JsonObject requestBody = new JsonObject();requestBody.addProperty("model", "gpt-3.5-turbo");requestBody.addProperty("temperature", 0.7);JsonObject message = new JsonObject();message.addProperty("role", "user");message.addProperty("content", "请总结以下会议内容:" + videoTranscript);requestBody.add("messages", new Gson().toJsonTree(new Object[]{message}));Request request = new Request.Builder().url("https://api.openai.com/v1/chat/completions").addHeader("Authorization", "Bearer " + OPENAI_API_KEY).addHeader("Content-Type", "application/json").post(RequestBody.create(requestBody.toString(), JSON)).build();try (Response response = client.newCall(request).execute()) {if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);JsonObject responseJson = new Gson().fromJson(response.body().string(), JsonObject.class);return responseJson.getAsJsonArray("choices").get(0).getAsJsonObject().get("message").getAsJsonObject().get("content").getAsString();}}
}
- 虚拟内容生成:根据会议主题,自动生成虚拟背景、动态 PPT 等内容,减少原始视频存储量。某教育机构采用该方案后,视频存储成本降低 25%。
5.2 实时计算与存储的深度融合
Java 结合 Flink、Spark Streaming 实现存储与计算的实时协同:

例如,当检测到会议中出现敏感词汇时,系统自动标记视频片段、加密存储,并触发安全审计流程;同时,将相关片段缓存至 Redis,提升后续检索效率。
结束语:
亲爱的 Java 和 大数据爱好者们,在 AIGC 与实时计算重塑技术格局的今天,Java 不仅是视频会议存储系统的 “稳定器”,更成为连接数据存储与智能应用的 “桥梁”。从 PB 级数据的高效存储,到 AI 驱动的智能检索,每一行 Java 代码的创新,都在重新定义视频会议的技术边界。作为一名深耕分布式系统领域 10余年的技术人,我们始终坚信:真正的技术突破,源于对业务痛点的深刻理解与对前沿技术的大胆融合。
亲爱的 Java 和 大数据爱好者,在构建智能视频存储系统时,你认为 “数据安全合规” 与 “AI 功能拓展” 哪个更具挑战?欢迎大家在评论区或【青云交社区 – Java 大视界频道】分享你的见解!
为了让后续内容更贴合大家的需求,诚邀各位参与投票,下一篇文章,你希望解锁 Java 在哪个领域的 AIGC 实战?快来投出你的宝贵一票 。
上二篇文章推荐:
- 分布式数据库被神话?某银行 600 台服务器换 3 节点 Oracle,运维成本暴涨 300%!(最新)
- Java 大视界 – Java 大数据机器学习模型在金融客户生命周期价值预测与营销策略制定中的应用(262)(最新)
下一篇文章预告:
- Java 大视界 – Java 大数据在智慧农业农产品溯源区块链平台中的数据管理与安全保障(264)(更新中)
相关文章:
Java 大视界 -- 基于 Java 的大数据分布式存储在视频会议系统海量视频数据存储与回放中的应用(263)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...
ROS云课三分钟-3D性能测试supertuxkart和游戏推荐等-国际象棋
ROS云课三分钟-破壁篇GCompris-一小部分支持Edu应用列表-2025-CSDN博客 很多时候,有一种思维定势,将人锁住,人口就是囚。 口人囚~口加人等于囚-CSDN博客 如果突破,跳出问题,再看问题。 这门课程,或者这个平…...

汽车零部件行业PLM案例:得瑞客汽车(Dereik) 部署国产PLM
2024年,昆山得瑞客汽车零部件有限公司(以下简称“得瑞客汽车”)签约智橙云PLM(智橙PLM),近日,双方启动了PLM项目评估会,商讨在汽车零部件行业研发数字化转型领域进行更深层的合作。 …...
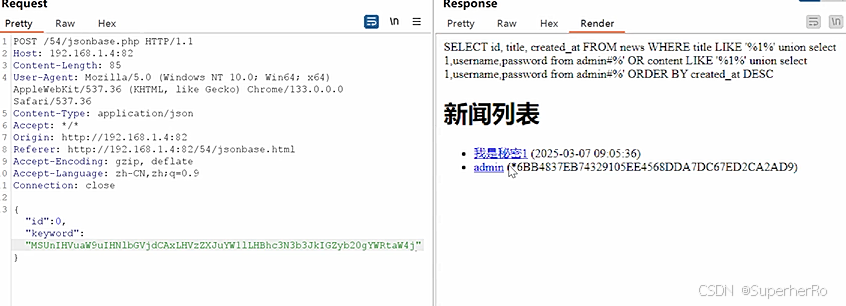
Web攻防-SQL注入数据格式参数类型JSONXML编码加密符号闭合
知识点: 1、Web攻防-SQL注入-参数类型&参数格式 2、Web攻防-SQL注入-XML&JSON&BASE64等 3、Web攻防-SQL注入-数字字符搜索等符号绕过 案例说明: 在应用中,存在参数值为数字,字符时,符号的介入,…...

浅谈测试驱动开发TDD
目录 1.什么是TDD 2.TDD步骤 3.TDD 的核心原则 4.TDD 与传统开发的对比 5.TDD中的单元测试和集成测试区别 6.总结 1.什么是TDD 测试驱动开发(Test-Driven Development,简称 TDD) 是一种软件开发方法论,核心思想是 “先写测试…...

深入解析 Flink 中的时间与窗口机制
一、时间类型详解 1. 处理时间 处理时间(Processing Time)是指执行操作算子的本地系统时间,它是 Flink 中最简单、性能最高的时间概念。在处理时间语义下,Flink 直接使用机器的本地时钟来确定时间,无需额外的时间提取与处理逻辑。 以电商订单处理为例,当订单支付成功…...

医疗AI项目文档编写核心要素硬核解析:从技术落地到合规实践
一、引言:医疗AI项目文档的核心价值 1.1 行业演进与文档范式变革 全球医疗AI产业正经历从技术验证(2021-2025)向临床落地(2026-2030)的关键转型期。但是目前医疗AI正在逐步陷入"技术繁荣-应用滞后"的悖论&…...

voc怎么转yolo,如何分割数据集为验证集,怎样检测CUDA可用性 并使用yolov8训练安全帽数据集且构建基于yolov8深度学习的安全帽检测系统
voc怎么转yolo,如何分割数据集为验证集,怎样检测CUDA可用性 安全帽数据集,5000张图片和对应的xml标签, 五千个yolo标签,到手即可训练。另外附四个常用小脚本,非常实用voc转yolo代码.py 分割数据集为验证集…...
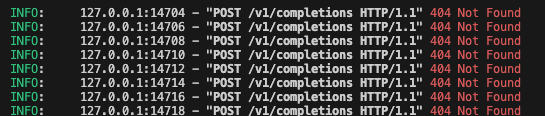
vllm server返回404的一种可能得解决方案
我的 server 启动指令 CUDA_VISIBLE_DEVICES0,1,2,3,4,5,6,7 PYTHONPATH${PYTHONPATH}:/root/experiments/vllm vllm serve ./models/DeepSeek-V3-awq --tensor-parallel-size 8 --trust-remote-code --disable-log-requests --load-format dummy --port 8040 client 端访访…...
kafka之操作示例
一、常用shell命令 #1、创建topic bin/kafka-topics.sh --create --zookeeper localhost:2181 --replications 1 --topic test#2、查看创建的topic bin/kafka-topics.sh --list --zookeeper localhost:2181#3、生产者发布消息命令 (执行完此命令后在控制台输入要发…...

MySQL问题:MySQL中使用索引一定有效吗?如何排查索引效果
不一定有效,当查询条件中不包含索引列或查询条件复杂且不匹配索引顺序 对于一些小表,MySQL可能选择全表扫描而非使用索引,因为全表扫描的开销可能更小 最终是否用上索引是根据MySQL成本计算决定的,评估CPU和I/O成本 排查索引效…...

OpenSSL 签名验证详解:PKCS7* p7、cafile 与 RSA 验签实现
OpenSSL 签名验证详解:PKCS7* p7、cafile 与 RSA 验签实现 摘要 本文深入剖析 OpenSSL 中 PKCS7* p7 数据结构和 cafile 的作用及相互关系,详细讲解基于 OpenSSL 的 RSA 验签字符串的 C 语言实现,涵盖签名解析、证书加载、验证流程及关键要…...

利用 `ngx_http_xslt_module` 实现 NGINX 的 XML → HTML 转换
一、模块简介 模块名称:ngx_http_xslt_module 首次引入版本:0.7.8 功能:在回传给客户端之前,用指定的 XSLT 样式表对 XML 响应进行转换。 依赖: libxml2libxslt 编译选项:需在 NGINX 编译时添加 --with…...

C语言队列详解
一、什么是队列? 队列(Queue)是一种先进先出(FIFO, First In First Out)的线性数据结构。它只允许在一端插入数据(队尾),在另一端删除数据(队头)。常见于排队…...

Qt中的智能指针
Qt中的智能指针 Qt中提供了多种智能指针,用于管理自动分配的内存,避免内存泄漏和悬挂指针的问题。以下是Qt中常见的智能指针及其功能和使用场景: 1. QSharedPointer QSharedPointer 是 Qt 框架中用于管理动态分配对象的智能指针,类似于 C1…...

车载网关策略 --- 车载网关通信故障处理机制深度解析
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...
三天掌握PyTorch精髓:从感知机到ResNet的快速进阶方法论
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 一、分析式AI基础与深度学习核心概念 1.1 深度学习三要素 数学基础: f(x;W,b)σ(Wxb)(单层感知机) 1.2 PyTorch核心组件 张量操作示例…...

Python爬虫实战:研究Selenium框架相关技术
1. 引言 1.1 研究背景与意义 随着互联网的快速发展,网页数据量呈爆炸式增长。从网页中提取有价值的信息成为数据挖掘、舆情分析、商业智能等领域的重要基础工作。然而,现代网页技术不断演进,越来越多的网页采用 JavaScript 动态加载内容,传统的基于 HTTP 请求的爬虫技术难…...

分布式缓存:三万字详解Redis
文章目录 缓存全景图PreRedis 整体认知框架一、Redis 简介二、核心特性三、性能模型四、持久化详解五、复制与高可用六、集群与分片方案 Redis 核心数据类型概述1. String2. List3. Set4. Sorted Set(有序集合)5. Hash6. Bitmap7. Geo8. HyperLogLog Red…...

BiLSTM与Transformer:位置编码的隐式vs显式之争
BiLSTM 与使用位置编码的LLM(如Transformer)的核心区别 一、架构原理对比 维度BiLSTM带位置编码的LLM(如Transformer)基础单元LSTM单元(记忆细胞、门控机制)自注意力机制(Self-Attention)信息传递双向链式传播(前向+后向LSTM)并行多头注意力,全局上下文关联位置信息…...

html5视频播放器和微信小程序如何实现视频的自动播放功能
在HTML5中实现视频自动播放需设置autoplay和muted属性(浏览器策略要求静音才能自动播放),并可添加loop循环播放、playsinline同层播放等优化属性。微信小程序通过<video>组件的autoplay属性实现自动播放,同时支持全屏按钮、…...

【QT】QString和QStringList去掉空格的方法总结
目录 一、QString去掉空格 1. 移除字符串首尾的空格(trimmed) 2. 移除字符串中的所有空格(remove) 3. 仅移除左侧(开头)或右侧(结尾)空格 4. 替换多个连续空格为单个空格 5. 移…...

58同城大数据面试题及参考答案
ROW_NUMBER、RANK、DENSE_RANK 函数的区别是什么? 这三个函数均为窗口函数,用于为结果集分区中的行生成序号,但核心逻辑存在显著差异,具体表现如下: 数据分布与排序规则 假设存在分区内分数数据为 [90, 85, 85, 80],按分数降序排序: ROW_NUMBER:为分区内每行分配唯一序…...

25.5.27学习总结
快速读入: inline int read() {int x 0, f 1;char ch getchar();while (ch < 0 || ch > 9) { // 跳过非数字字符if (ch -) f -1; // 处理负号ch getchar();}while (ch > 0 && ch < 9) {x x * 10 ch - 0; // 逐字符转数字ch ge…...

关于vue结合elementUI输入框回车刷新问题
问题 vue2项目结合elementUI,使用el-form表单时,第一次打开浏览器url辞职,并且是第一次打开带有这个表单的页面时,输入框输入内容,回车后会意外触发页面自动刷新。 原因 当前 el-form 表单只有一个输入框࿰…...

vue项目表格甘特图开发
🧩 甘特图可以管理项目进度,生产进度等信息,管理者可以更直观的查看内容。 1. 基础环境搭建 引入 dhtmlx-gantt 插件引入插件样式 dhtmlxgantt.css引入必要的扩展模块(如 markers、tooltip)创建 Vue 组件并挂载 DOM 容器初始化 gantt 图表配置2. 数据准备与处理 定义任务…...
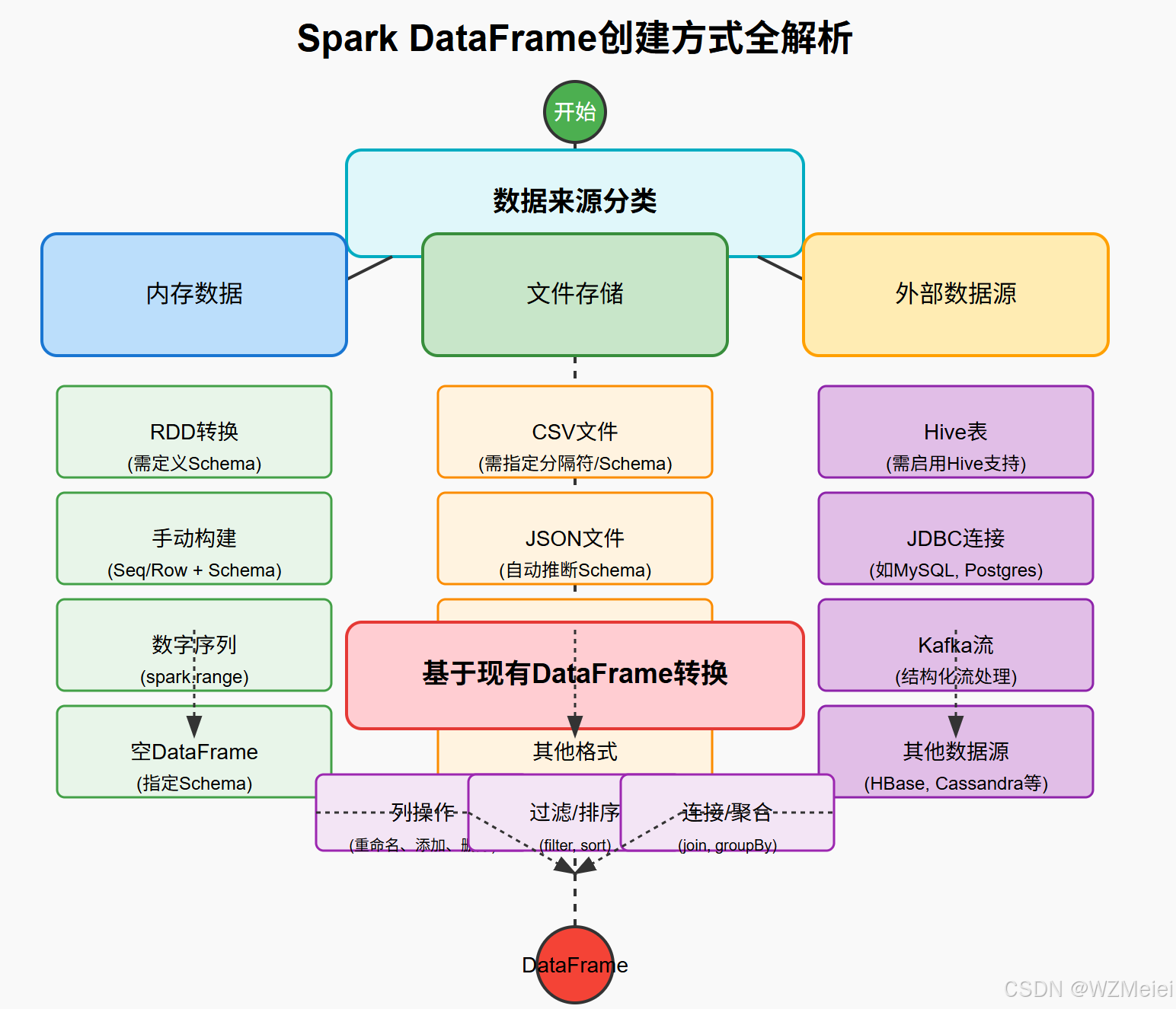
Spark 中,创建 DataFrame 的方式(Scala语言)
在 Spark 中,创建 DataFrame 的方式多种多样,可根据数据来源、结构特性及性能需求灵活选择。 一、创建 DataFrame 的 12 种核心方式 1. 从 RDD 转换(需定义 Schema) import org.apache.spark.sql.{Row, SparkSession} import o…...

Python----目标检测(MS COCO数据集)
一、MS COCO数据集 COCO 是一个大规模的对象检测、分割和图像描述数据集。COCO有几个 特点: Object segmentation:目标级的分割(实例分割) Recognition in context:上下文中的识别(图像情景识别࿰…...

塔能科技:有哪些国内工业节能标杆案例?
在国内工业领域,节能降耗不仅是响应国家绿色发展号召、践行社会责任的必要之举,更是企业降低运营成本、提升核心竞争力的关键策略。塔能科技在这一浪潮中脱颖而出,凭借前沿技术与创新方案,成功打造了多个极具代表性的工业标杆案例…...

图论:floyed算法
Floyd 算法是一种用于寻找加权图中所有顶点对之间最短路径的经典算法,它能够处理负权边,但不能处理负权环。即如果边权有负数,切负权边与其他边构成了环就不能用该算法。该算法的时间复杂度为 \(O(V^3)\),其中 V 是图中顶点的数量…...