深入解析 Flink 中的时间与窗口机制
一、时间类型详解
1. 处理时间
处理时间(Processing Time)是指执行操作算子的本地系统时间,它是 Flink 中最简单、性能最高的时间概念。在处理时间语义下,Flink 直接使用机器的本地时钟来确定时间,无需额外的时间提取与处理逻辑。
以电商订单处理为例,当订单支付成功后,系统需要实时统计每分钟的支付订单数量。若采用处理时间,Flink 会根据处理该订单数据的算子所在机器的本地时钟,将订单数据划分到对应的时间区间进行统计。这种方式处理速度快,无需与外部时间源同步,适用于对实时性要求极高,且对数据准确性要求相对较低的场景,如实时监控系统中快速展示数据趋势。但处理时间存在局限性,若数据在传输过程中有延迟,或者不同机器的时钟存在偏差,可能导致统计结果不准确。
在 Flink 代码中,使用处理时间非常简单,只需在执行环境中设置时间特征为处理时间即可:
| import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class ProcessingTimeExample { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); // 后续添加数据源、转换算子等操作 } } |
2. 摄入时间
摄入时间(Ingestion Time)指的是数据进入 Flink 的时间。在每个数据源节点,数据被接入 Flink 系统时,会被分配一个时间戳,这个时间戳就是摄入时间。与处理时间相比,摄入时间相对固定,因为它在数据进入 Flink 时就已确定,不会因后续算子处理延迟而改变。
例如,在日志收集系统中,日志数据从各个服务节点不断流入 Flink 集群。当这些日志数据到达 Flink 的 Kafka 数据源时,Flink 会为每条日志记录打上摄入时间戳。后续对日志数据进行分析,如统计每小时的日志产生量,使用摄入时间能更准确地反映数据实际进入系统的时间分布情况。不过,摄入时间的准确性依赖于数据源节点的时钟同步,如果数据源节点时钟不准确,也会影响数据时间的准确性。
在 Flink 中设置摄入时间的代码如下:
| import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.TimeCharacteristic; public class IngestionTimeExample { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime); // 后续添加数据源、转换算子等操作 } } |
3. 事件时间
事件时间(Event Time)是数据本身携带的时间,它反映了数据实际发生的时间。在许多场景下,数据的产生时间比其进入 Flink 系统的时间或处理时间更有意义。例如,在物联网设备监控中,传感器采集数据的时间才是真正反映设备状态变化的时间;在金融交易系统中,每笔交易发生的时间对于分析交易行为至关重要。
使用事件时间,Flink 需要从数据中提取时间戳字段,并指定时间戳分配器。同时,为了处理数据延迟到达的情况,Flink 引入了水位线(Watermark)机制。水位线用于衡量事件时间的进展,它表示在某个时间点,Flink 认为后续不会再出现早于该时间的事件数据。通过水位线,Flink 可以在一定程度上容忍数据延迟,确保窗口计算结果的准确性。
下面是一个使用事件时间和水位线的简单示例代码:
相关文章:

深入解析 Flink 中的时间与窗口机制
一、时间类型详解 1. 处理时间 处理时间(Processing Time)是指执行操作算子的本地系统时间,它是 Flink 中最简单、性能最高的时间概念。在处理时间语义下,Flink 直接使用机器的本地时钟来确定时间,无需额外的时间提取与处理逻辑。 以电商订单处理为例,当订单支付成功…...

医疗AI项目文档编写核心要素硬核解析:从技术落地到合规实践
一、引言:医疗AI项目文档的核心价值 1.1 行业演进与文档范式变革 全球医疗AI产业正经历从技术验证(2021-2025)向临床落地(2026-2030)的关键转型期。但是目前医疗AI正在逐步陷入"技术繁荣-应用滞后"的悖论&…...

voc怎么转yolo,如何分割数据集为验证集,怎样检测CUDA可用性 并使用yolov8训练安全帽数据集且构建基于yolov8深度学习的安全帽检测系统
voc怎么转yolo,如何分割数据集为验证集,怎样检测CUDA可用性 安全帽数据集,5000张图片和对应的xml标签, 五千个yolo标签,到手即可训练。另外附四个常用小脚本,非常实用voc转yolo代码.py 分割数据集为验证集…...
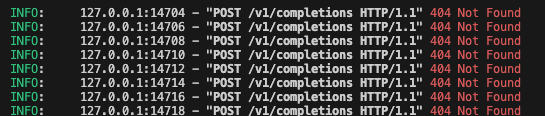
vllm server返回404的一种可能得解决方案
我的 server 启动指令 CUDA_VISIBLE_DEVICES0,1,2,3,4,5,6,7 PYTHONPATH${PYTHONPATH}:/root/experiments/vllm vllm serve ./models/DeepSeek-V3-awq --tensor-parallel-size 8 --trust-remote-code --disable-log-requests --load-format dummy --port 8040 client 端访访…...
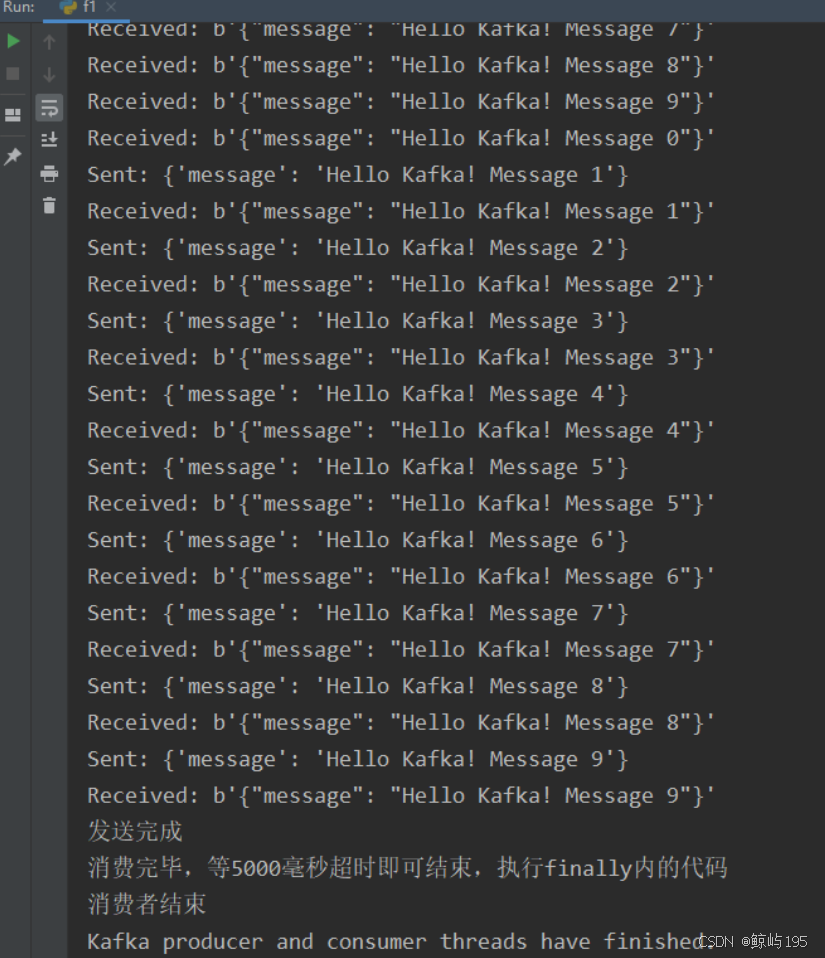
kafka之操作示例
一、常用shell命令 #1、创建topic bin/kafka-topics.sh --create --zookeeper localhost:2181 --replications 1 --topic test#2、查看创建的topic bin/kafka-topics.sh --list --zookeeper localhost:2181#3、生产者发布消息命令 (执行完此命令后在控制台输入要发…...

MySQL问题:MySQL中使用索引一定有效吗?如何排查索引效果
不一定有效,当查询条件中不包含索引列或查询条件复杂且不匹配索引顺序 对于一些小表,MySQL可能选择全表扫描而非使用索引,因为全表扫描的开销可能更小 最终是否用上索引是根据MySQL成本计算决定的,评估CPU和I/O成本 排查索引效…...

OpenSSL 签名验证详解:PKCS7* p7、cafile 与 RSA 验签实现
OpenSSL 签名验证详解:PKCS7* p7、cafile 与 RSA 验签实现 摘要 本文深入剖析 OpenSSL 中 PKCS7* p7 数据结构和 cafile 的作用及相互关系,详细讲解基于 OpenSSL 的 RSA 验签字符串的 C 语言实现,涵盖签名解析、证书加载、验证流程及关键要…...

利用 `ngx_http_xslt_module` 实现 NGINX 的 XML → HTML 转换
一、模块简介 模块名称:ngx_http_xslt_module 首次引入版本:0.7.8 功能:在回传给客户端之前,用指定的 XSLT 样式表对 XML 响应进行转换。 依赖: libxml2libxslt 编译选项:需在 NGINX 编译时添加 --with…...

C语言队列详解
一、什么是队列? 队列(Queue)是一种先进先出(FIFO, First In First Out)的线性数据结构。它只允许在一端插入数据(队尾),在另一端删除数据(队头)。常见于排队…...

Qt中的智能指针
Qt中的智能指针 Qt中提供了多种智能指针,用于管理自动分配的内存,避免内存泄漏和悬挂指针的问题。以下是Qt中常见的智能指针及其功能和使用场景: 1. QSharedPointer QSharedPointer 是 Qt 框架中用于管理动态分配对象的智能指针,类似于 C1…...

车载网关策略 --- 车载网关通信故障处理机制深度解析
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...
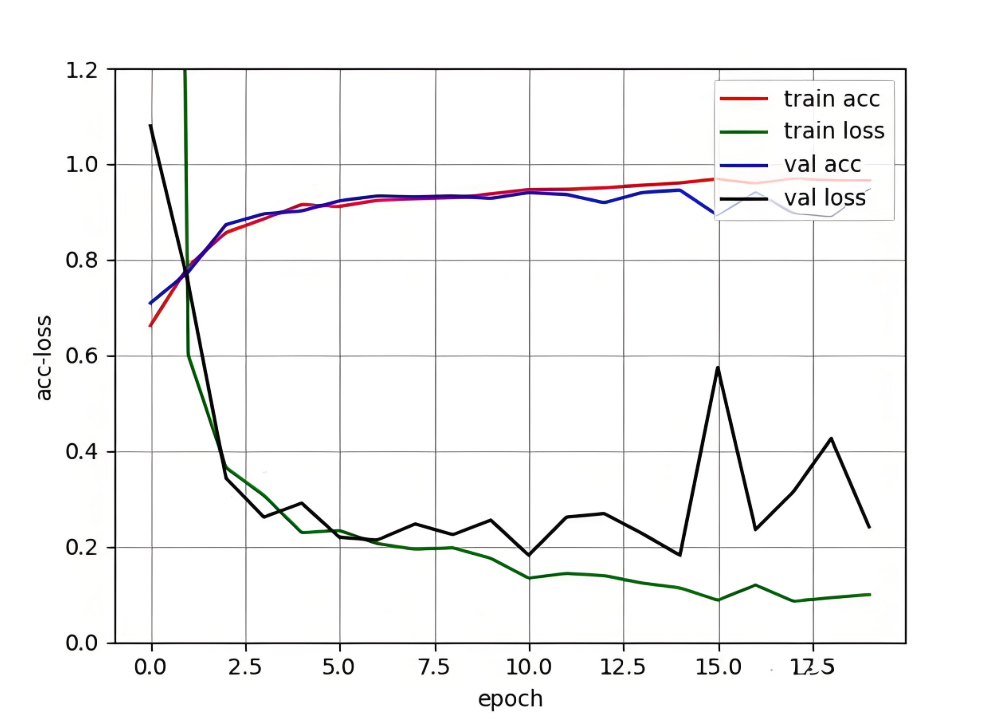
三天掌握PyTorch精髓:从感知机到ResNet的快速进阶方法论
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 一、分析式AI基础与深度学习核心概念 1.1 深度学习三要素 数学基础: f(x;W,b)σ(Wxb)(单层感知机) 1.2 PyTorch核心组件 张量操作示例…...

Python爬虫实战:研究Selenium框架相关技术
1. 引言 1.1 研究背景与意义 随着互联网的快速发展,网页数据量呈爆炸式增长。从网页中提取有价值的信息成为数据挖掘、舆情分析、商业智能等领域的重要基础工作。然而,现代网页技术不断演进,越来越多的网页采用 JavaScript 动态加载内容,传统的基于 HTTP 请求的爬虫技术难…...

分布式缓存:三万字详解Redis
文章目录 缓存全景图PreRedis 整体认知框架一、Redis 简介二、核心特性三、性能模型四、持久化详解五、复制与高可用六、集群与分片方案 Redis 核心数据类型概述1. String2. List3. Set4. Sorted Set(有序集合)5. Hash6. Bitmap7. Geo8. HyperLogLog Red…...

BiLSTM与Transformer:位置编码的隐式vs显式之争
BiLSTM 与使用位置编码的LLM(如Transformer)的核心区别 一、架构原理对比 维度BiLSTM带位置编码的LLM(如Transformer)基础单元LSTM单元(记忆细胞、门控机制)自注意力机制(Self-Attention)信息传递双向链式传播(前向+后向LSTM)并行多头注意力,全局上下文关联位置信息…...

html5视频播放器和微信小程序如何实现视频的自动播放功能
在HTML5中实现视频自动播放需设置autoplay和muted属性(浏览器策略要求静音才能自动播放),并可添加loop循环播放、playsinline同层播放等优化属性。微信小程序通过<video>组件的autoplay属性实现自动播放,同时支持全屏按钮、…...

【QT】QString和QStringList去掉空格的方法总结
目录 一、QString去掉空格 1. 移除字符串首尾的空格(trimmed) 2. 移除字符串中的所有空格(remove) 3. 仅移除左侧(开头)或右侧(结尾)空格 4. 替换多个连续空格为单个空格 5. 移…...

58同城大数据面试题及参考答案
ROW_NUMBER、RANK、DENSE_RANK 函数的区别是什么? 这三个函数均为窗口函数,用于为结果集分区中的行生成序号,但核心逻辑存在显著差异,具体表现如下: 数据分布与排序规则 假设存在分区内分数数据为 [90, 85, 85, 80],按分数降序排序: ROW_NUMBER:为分区内每行分配唯一序…...

25.5.27学习总结
快速读入: inline int read() {int x 0, f 1;char ch getchar();while (ch < 0 || ch > 9) { // 跳过非数字字符if (ch -) f -1; // 处理负号ch getchar();}while (ch > 0 && ch < 9) {x x * 10 ch - 0; // 逐字符转数字ch ge…...

关于vue结合elementUI输入框回车刷新问题
问题 vue2项目结合elementUI,使用el-form表单时,第一次打开浏览器url辞职,并且是第一次打开带有这个表单的页面时,输入框输入内容,回车后会意外触发页面自动刷新。 原因 当前 el-form 表单只有一个输入框࿰…...

vue项目表格甘特图开发
🧩 甘特图可以管理项目进度,生产进度等信息,管理者可以更直观的查看内容。 1. 基础环境搭建 引入 dhtmlx-gantt 插件引入插件样式 dhtmlxgantt.css引入必要的扩展模块(如 markers、tooltip)创建 Vue 组件并挂载 DOM 容器初始化 gantt 图表配置2. 数据准备与处理 定义任务…...
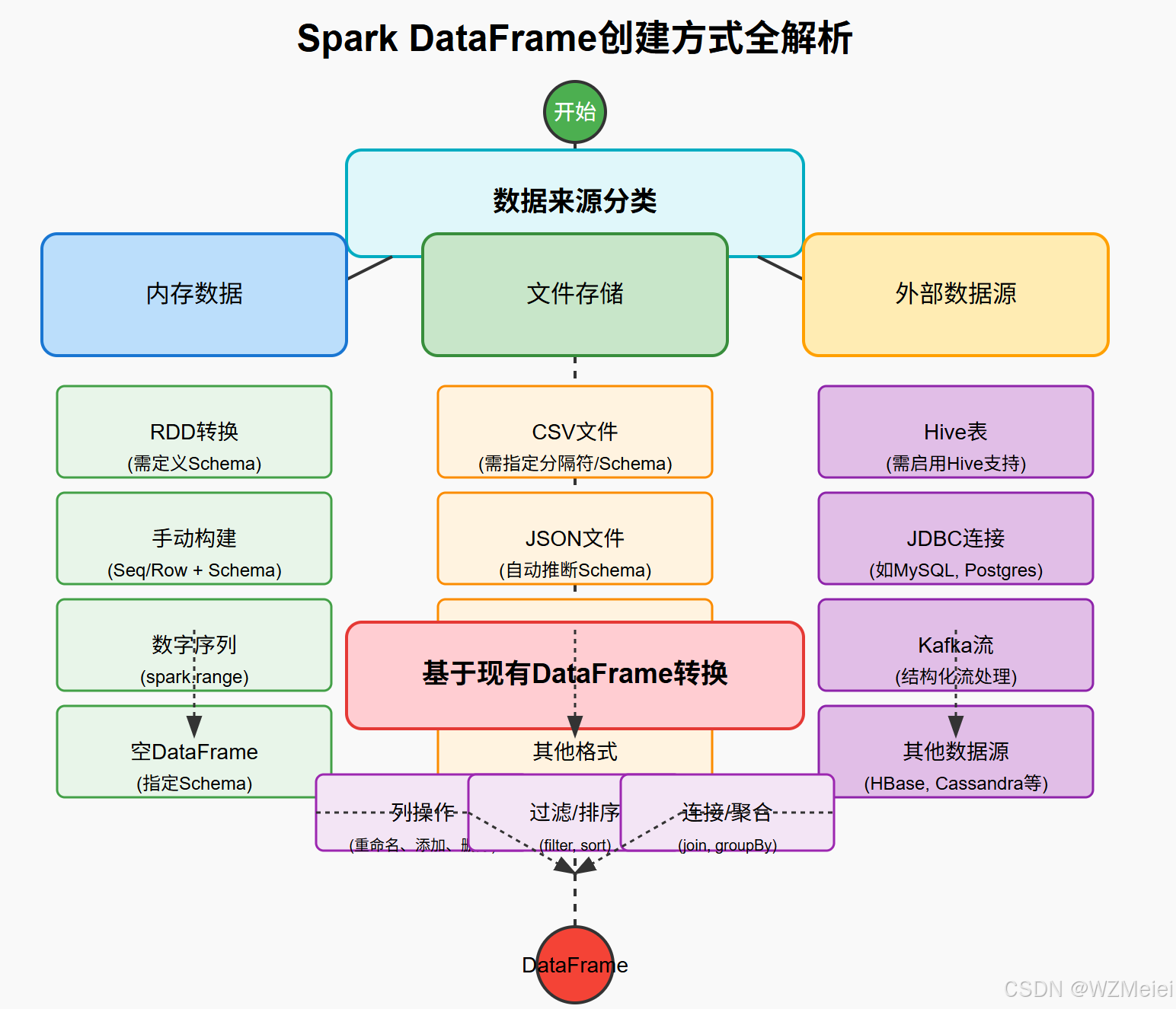
Spark 中,创建 DataFrame 的方式(Scala语言)
在 Spark 中,创建 DataFrame 的方式多种多样,可根据数据来源、结构特性及性能需求灵活选择。 一、创建 DataFrame 的 12 种核心方式 1. 从 RDD 转换(需定义 Schema) import org.apache.spark.sql.{Row, SparkSession} import o…...

Python----目标检测(MS COCO数据集)
一、MS COCO数据集 COCO 是一个大规模的对象检测、分割和图像描述数据集。COCO有几个 特点: Object segmentation:目标级的分割(实例分割) Recognition in context:上下文中的识别(图像情景识别࿰…...

塔能科技:有哪些国内工业节能标杆案例?
在国内工业领域,节能降耗不仅是响应国家绿色发展号召、践行社会责任的必要之举,更是企业降低运营成本、提升核心竞争力的关键策略。塔能科技在这一浪潮中脱颖而出,凭借前沿技术与创新方案,成功打造了多个极具代表性的工业标杆案例…...

图论:floyed算法
Floyd 算法是一种用于寻找加权图中所有顶点对之间最短路径的经典算法,它能够处理负权边,但不能处理负权环。即如果边权有负数,切负权边与其他边构成了环就不能用该算法。该算法的时间复杂度为 \(O(V^3)\),其中 V 是图中顶点的数量…...

嵌入式系统C语言编程常用设计模式---参数表驱动设计
参数表驱动设计是一种软件开发和系统设计中常用的方法,它通过参数表来控制程序的行为和流程,提高系统的灵活性、可维护性和可扩展性。它将系统的行为逻辑与具体参数分离,通过表格形式集中管理配置信息。这种模式在嵌入式系统、工业控制和自动…...
OpenCV CUDA模块图像过滤------创建一个行方向的一维积分(Sum)滤波器函数createRowSumFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::createRowSumFilter 是 OpenCV CUDA 模块中的一个函数,用于创建一个行方向的一维积分(Sum)滤波器。…...

Frequent values/gcd区间
Frequent values 思路: 这题它的数据是递增的,ST表,它的最多的个数只会在在两个区间本身就是最多的或中间地方产生,所以我用map数组储存每个值的左右临界点,在ST表时比较多一个比较中间值的个数就Ok了。 #define _…...
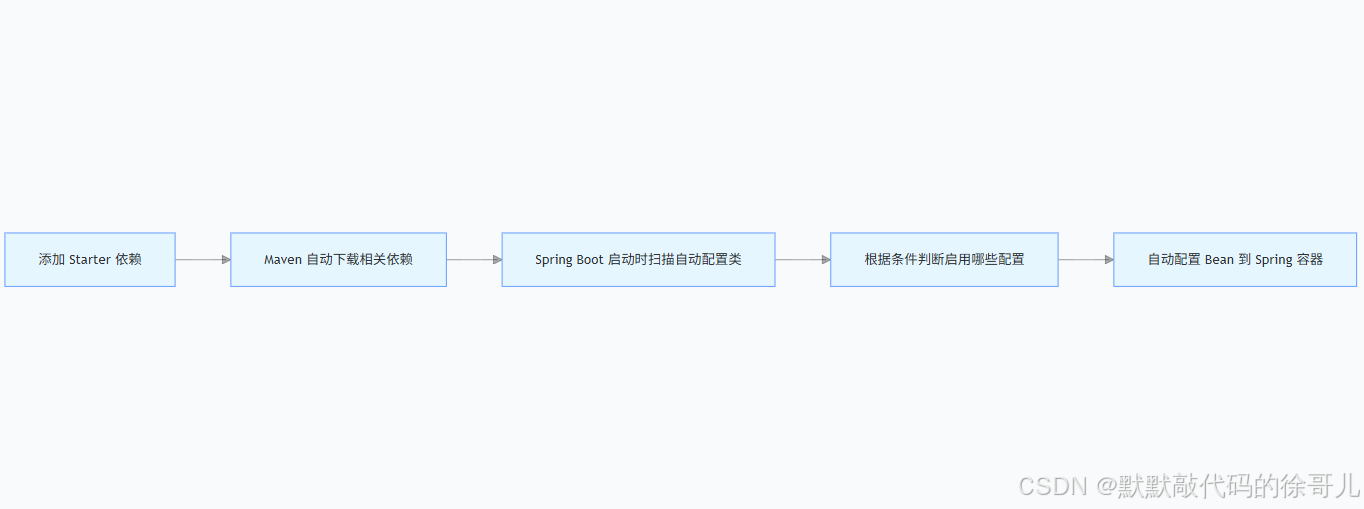
08SpringBoot高级--自动化配置
目录 Spring Boot Starter 依赖管理解释 一、核心概念 二、工作原理 依赖传递: 自动配置: 版本管理: 三、核心流程 四、常用 Starter 示例 五、自定义 Starter 步骤 创建配置类: 配置属性: 注册自动配置&a…...

Deep Evidential Regression
摘要 翻译: 确定性神经网络(NNs)正日益部署在安全关键领域,其中校准良好、鲁棒且高效的不确定性度量至关重要。本文提出一种新颖方法,用于训练非贝叶斯神经网络以同时估计连续目标值及其关联证据,从而学习…...