voc怎么转yolo,如何分割数据集为验证集,怎样检测CUDA可用性 并使用yolov8训练安全帽数据集且构建基于yolov8深度学习的安全帽检测系统
voc怎么转yolo,如何分割数据集为验证集,怎样检测CUDA可用性
安全帽数据集,5000张图片和对应的xml标签,
五千个yolo标签,到手即可训练。另外附四个常用小脚本,非常实用voc转yolo代码.py
分割数据集为验证集.py
检测cuda.py
批量重命名.py。继续

以下代码仅供参考!

5000张图片和对应的YOLO格式标签,并且还附带了一些实用的小脚本,我们可以直接进行模型训练、评估以及可视化。以下是详细的步骤:
当然可以。根据您的描述,您提到的四个实用小脚本分别是:
- VOC转YOLO代码
- 分割数据集为验证集
- 检测CUDA可用性
- 批量重命名
下面是每个脚本的详细实现。
1. VOC转YOLO代码
这个脚本用于将Pascal VOC格式的标注文件转换为YOLO格式。
[<title="Convert VOC Annotations to YOLO TXT Format">]
import os
import xml.etree.ElementTree as ET
from pathlib import Path# Define paths
base_path = Path('datasets/helmet')
annotations_dir = base_path / 'Annotations'
images_dir = base_path / 'JPEGImages'
output_labels_dir = base_path / 'labels'# Create output directory if it doesn't exist
os.makedirs(output_labels_dir, exist_ok=True)# Class names and their corresponding IDs
class_names = {'helmet': 0}def convert_annotation(xml_file):tree = ET.parse(xml_file)root = tree.getroot()image_width = int(root.find('size/width').text)image_height = int(root.find('size/height').text)label_lines = []for obj in root.findall('object'):class_name = obj.find('name').textbbox = obj.find('bndbox')xmin = float(bbox.find('xmin').text)ymin = float(bbox.find('ymin').text)xmax = float(bbox.find('xmax').text)ymax = float(bbox.find('ymax').text)# Convert bounding box to YOLO format (center_x, center_y, width, height)center_x = (xmin + xmax) / 2.0 / image_widthcenter_y = (ymin + ymax) / 2.0 / image_heightwidth = (xmax - xmin) / image_widthheight = (ymax - ymin) / image_heightclass_id = class_names[class_name]label_line = f"{class_id} {center_x} {center_y} {width} {height}\n"label_lines.append(label_line)return label_linesfor annotation_file in annotations_dir.glob('*.xml'):image_name = annotation_file.stem + '.jpg' # Assuming images are in JPEG formatlabel_file = output_labels_dir / (annotation_file.stem + '.txt')label_lines = convert_annotation(annotation_file)with open(label_file, 'w') as f:f.writelines(label_lines)print("Conversion completed.")
2. 分割数据集为验证集
这个脚本用于将数据集划分为训练集和验证集。
[<title="Split Dataset into Train and Validation Sets">]
import os
import random
from sklearn.model_selection import train_test_split
from pathlib import Path# Define paths
base_path = Path('datasets/helmet')
images_dir = base_path / 'JPEGImages'
annotations_dir = base_path / 'labels'
train_images_dir = base_path / 'images/train'
train_labels_dir = base_path / 'labels/train'
val_images_dir = base_path / 'images/val'
val_labels_dir = base_path / 'labels/val'# Create directories if they don't exist
os.makedirs(train_images_dir, exist_ok=True)
os.makedirs(train_labels_dir, exist_ok=True)
os.makedirs(val_images_dir, exist_ok=True)
os.makedirs(val_labels_dir, exist_ok=True)# List all image files
image_files = list(images_dir.glob('*.jpg')) # Adjust extension if necessary# Shuffle the image files
random.shuffle(image_files)# Split ratios
train_ratio = 0.8
val_ratio = 0.2# Calculate split indices
num_images = len(image_files)
train_split = int(num_images * train_ratio)# Split images and labels
train_images = image_files[:train_split]
val_images = image_files[train_split:]def copy_files(source_images, dest_images_dir, dest_labels_dir):for img_file in source_images:label_file = annotations_dir / (img_file.stem + '.txt')if label_file.exists():os.symlink(img_file, dest_images_dir / img_file.name)os.symlink(label_file, dest_labels_dir / label_file.name)copy_files(train_images, train_images_dir, train_labels_dir)
copy_files(val_images, val_images_dir, val_labels_dir)print("Dataset splitting completed.")
3. 检测CUDA可用性
这个脚本用于检测CUDA是否可用。
[<title="Check CUDA Availability">]
import torchdef check_cuda_availability():cuda_available = torch.cuda.is_available()if cuda_available:print(f"CUDA is available. Device count: {torch.cuda.device_count()}")print(f"Current device: {torch.cuda.current_device()}")print(f"Device name: {torch.cuda.get_device_name(torch.cuda.current_device())}")else:print("CUDA is not available.")if __name__ == "__main__":check_cuda_availability()
4. 批量重命名
这个脚本用于批量重命名文件夹中的所有图像文件。
[<title="Batch Rename Images">]
import os
from pathlib import Pathdef batch_rename_images(directory, prefix='image'):files = sorted(os.listdir(directory))for idx, filename in enumerate(files):if filename.endswith(('.png', '.jpg', '.jpeg')):new_filename = f"{prefix}{idx}.jpg"old_file = directory / filenamenew_file = directory / new_filenameos.rename(old_file, new_file)print(f'Renamed: {old_file} -> {new_file}')if __name__ == "__main__":directory = Path('datasets/helmet/JPEGImages') # Change this path to your images directorybatch_rename_images(directory)
使用说明
-
VOC转YOLO代码 (
convert_voc_to_yolo.py):- 确保
datasets/helmet/Annotations和datasets/helmet/JPEGImages目录存在,并且包含相应的XML标注文件和图像文件。 - 运行此脚本后,会在
datasets/helmet/labels目录下生成对应的TXT标签文件。
- 确保
-
分割数据集为验证集 (
split_dataset.py):- 确保
datasets/helmet/JPEGImages和datasets/helmet/labels目录存在,并且包含相应的图像文件和TXT标签文件。 - 运行此脚本后,会在
datasets/helmet/images/train,datasets/helmet/images/val,datasets/helmet/labels/train, 和datasets/helmet/labels/val目录下分别存储训练集和验证集的数据。
- 确保
-
检测CUDA可用性 (
check_cuda.py):- 运行此脚本以检查系统中CUDA是否可用以及相关信息。
-
批量重命名 (
batch_rename.py):- 修改
directory变量指向包含图像文件的目录。 - 运行此脚本后,目录中的所有图像文件将被重命名为
image0.jpg,image1.jpg, …。
- 修改
这些脚本应该能满足您处理安全帽数据集的需求。如果有任何问题或需要进一步的帮助,请告诉我!
-
环境准备:
- 安装必要的库。
-
数据集组织:
- 确认数据集的结构和路径。
-
模型定义与训练:
- 使用YOLOv8进行目标检测。
-
评估与可视化:
- 评估模型性能。
- 可视化结果。
环境准备
首先,我们需要安装必要的库。您可以使用以下命令来设置环境:
pip install ultralytics opencv-python-headless pandas scikit-learn
数据集组织
假设您的数据集已经按照YOLO格式组织好,并且包含以下文件夹结构:
datasets/helmet/
├── images/
│ ├── train/
│ │ ├── image0.jpg
│ │ ├── image1.jpg
│ │ └── ...
│ └── val/
│ ├── image0.jpg
│ ├── image1.jpg
│ └── ...
└── labels/├── train/│ ├── image0.txt│ ├── image1.txt│ └── ...└── val/├── image0.txt├── image1.txt└── ...
并且每个图像都有一个对应的TXT标签文件。
创建YAML配置文件
确保您有一个正确的YAML配置文件 helmet.yaml 来描述数据集。以下是示例配置文件:
[<title="YOLOv8 Configuration File for Helmet Detection">]
train: ../datasets/helmet/images/train
val: ../datasets/helmet/images/valnc: 1
names: ['helmet']
将上述内容保存为 datasets/helmet/helmet.yaml。
模型定义与训练
我们将使用YOLOv8进行目标检测。以下是训练脚本 train_detection.py:
[<title="Training Script for Helmet Detection using YOLOv8">]
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)# Train the model
results = model.train(data='../datasets/helmet/helmet.yaml',epochs=50,imgsz=640,batch=16,project='../runs/train',name='helmet_detection'
)# Evaluate the model
metrics = model.val()
results = model.export(format='onnx') # export the trained model to ONNX format
评估与可视化
使用YOLOv8自带的评估脚本来评估目标检测模型。
[<title="Evaluation Script for Helmet Detection using YOLOv8">]
from ultralytics import YOLO# Load the best model
best_model = YOLO('../runs/train/helmet_detection/weights/best.pt')# Evaluate the model on the validation dataset
metrics = best_model.val(data='../datasets/helmet/helmet.yaml', conf=0.5, iou=0.45)
print(metrics)
用户界面
我们将使用 PyQt5 创建一个简单的 GUI 来加载和运行模型进行实时预测。以下是用户界面脚本 ui.py:
[<title="PyQt5 Main Window for Helmet Detection">]
import sys
import cv2
import numpy as np
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget, QFileDialog
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import Qt, QTimer
from ultralytics import YOLO# Load model
detection_model = YOLO('../runs/train/helmet_detection/weights/best.pt')class MainWindow(QMainWindow):def __init__(self):super().__init__()self.setWindowTitle("安全帽检测系统")self.setGeometry(100, 100, 800, 600)self.initUI()def initUI(self):self.central_widget = QWidget()self.setCentralWidget(self.central_widget)self.layout = QVBoxLayout()self.image_label = QLabel(self)self.image_label.setAlignment(Qt.AlignCenter)self.layout.addWidget(self.image_label)self.load_image_button = QPushButton("加载图像", self)self.load_image_button.clicked.connect(self.load_image)self.layout.addWidget(self.load_image_button)self.start_prediction_button = QPushButton("开始预测", self)self.start_prediction_button.clicked.connect(self.start_prediction)self.layout.addWidget(self.start_prediction_button)self.stop_prediction_button = QPushButton("停止预测", self)self.stop_prediction_button.clicked.connect(self.stop_prediction)self.layout.addWidget(self.stop_prediction_button)self.central_widget.setLayout(self.layout)self.image_path = Noneself.timer = QTimer()self.timer.timeout.connect(self.update_frame)def load_image(self):options = QFileDialog.Options()file_name, _ = QFileDialog.getOpenFileName(self, "选择图像文件", "", "Images (*.png *.jpg *.jpeg);;All Files (*)", options=options)if file_name:self.image_path = file_nameself.display_image(file_name)def display_image(self, path):pixmap = QPixmap(path)scaled_pixmap = pixmap.scaled(self.image_label.width(), self.image_label.height(), Qt.KeepAspectRatio)self.image_label.setPixmap(scaled_pixmap)def start_prediction(self):if self.image_path is not None and not self.timer.isActive():self.timer.start(30) # Update frame every 30 msdef stop_prediction(self):if self.timer.isActive():self.timer.stop()self.image_label.clear()def update_frame(self):original_image = cv2.imread(self.image_path)image_rgb = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)# Detectionresults = detection_model.predict(image_rgb, size=640, conf=0.5, iou=0.45)[0]for box in results.boxes.cpu().numpy():r = box.xyxy[0].astype(int)cls = int(box.cls[0])conf = box.conf[0]# Map class ID to nameclass_names = ['安全帽']class_name = class_names[cls]# Draw bounding boxcv2.rectangle(image_rgb, (r[0], r[1]), (r[2], r[3]), (0, 255, 0), 2)# Put textfont = cv2.FONT_HERSHEY_SIMPLEXcv2.putText(image_rgb, f'{class_name} ({conf:.2f})', (r[0], r[1] - 10), font, 0.9, (0, 255, 0), 2)h, w, ch = image_rgb.shapebytes_per_line = ch * wqt_image = QImage(image_rgb.data, w, h, bytes_per_line, QImage.Format_RGB888)pixmap = QPixmap.fromImage(qt_image)scaled_pixmap = pixmap.scaled(self.image_label.width(), self.image_label.height(), Qt.KeepAspectRatio)self.image_label.setPixmap(scaled_pixmap)if __name__ == "__main__":app = QApplication(sys.argv)window = MainWindow()window.show()sys.exit(app.exec_())
请确保将路径替换为您实际的路径。
使用说明
-
配置路径:
- 确保
datasets/helmet目录结构正确,并且包含images和labels子目录。 - 确保
runs/train/helmet_detection/weights/best.pt是训练好的 YOLOv8 模型权重路径。
- 确保
-
运行脚本:
- 在终端中运行
train_detection.py脚本来训练目标检测模型。 - 在终端中运行
evaluate_detection.py来评估目标检测模型性能。 - 在终端中运行
ui.py来启动 GUI 应用程序。
- 在终端中运行
-
注意事项:
- 确保所有必要的工具箱已安装,特别是
ultralytics和PyQt5。 - 根据需要调整参数,如
epochs和batch_size。
- 确保所有必要的工具箱已安装,特别是
示例
假设您的数据文件夹结构如下:
datasets/
└── helmet/├── images/│ ├── train/│ │ ├── image0.jpg│ │ ├── image1.jpg│ │ └── ...│ └── val/│ ├── image0.jpg│ ├── image1.jpg│ └── ...└── labels/├── train/│ ├── image0.txt│ ├── image1.txt│ └── ...└── val/├── image0.txt├── image1.txt└── ...
并且每个图像都有一个对应的TXT标签文件。运行 ui.py 后,您可以点击按钮来加载图像并进行安全帽检测。
相关文章:
voc怎么转yolo,如何分割数据集为验证集,怎样检测CUDA可用性 并使用yolov8训练安全帽数据集且构建基于yolov8深度学习的安全帽检测系统
voc怎么转yolo,如何分割数据集为验证集,怎样检测CUDA可用性 安全帽数据集,5000张图片和对应的xml标签, 五千个yolo标签,到手即可训练。另外附四个常用小脚本,非常实用voc转yolo代码.py 分割数据集为验证集…...
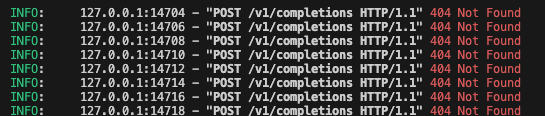
vllm server返回404的一种可能得解决方案
我的 server 启动指令 CUDA_VISIBLE_DEVICES0,1,2,3,4,5,6,7 PYTHONPATH${PYTHONPATH}:/root/experiments/vllm vllm serve ./models/DeepSeek-V3-awq --tensor-parallel-size 8 --trust-remote-code --disable-log-requests --load-format dummy --port 8040 client 端访访…...
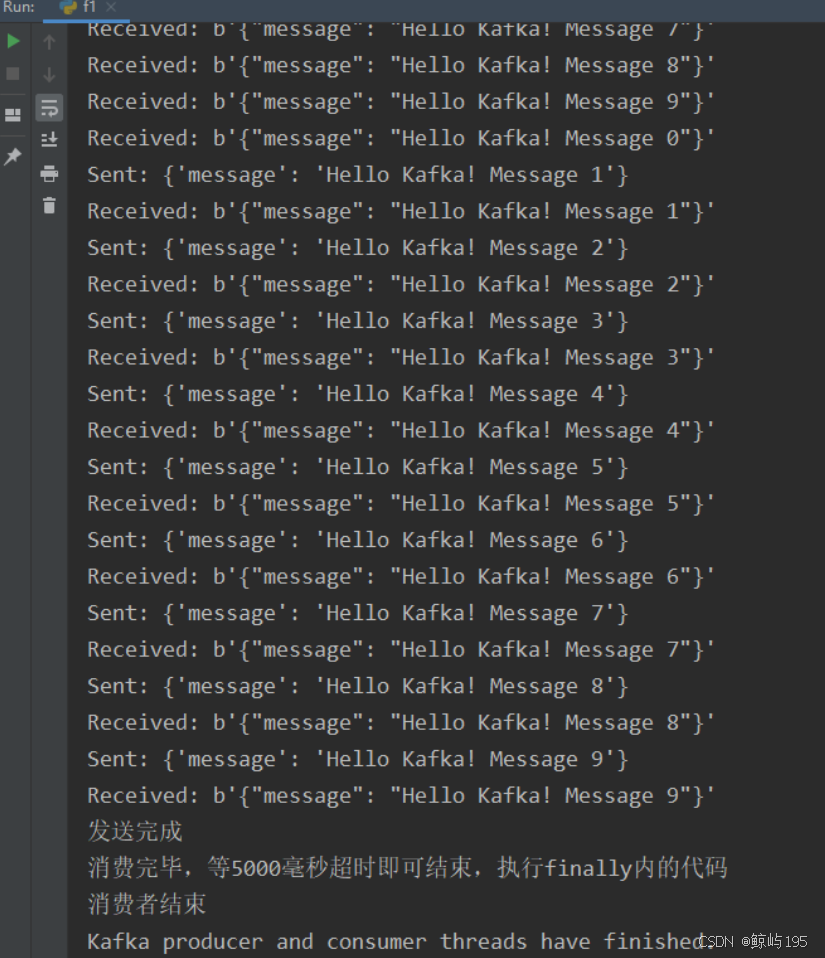
kafka之操作示例
一、常用shell命令 #1、创建topic bin/kafka-topics.sh --create --zookeeper localhost:2181 --replications 1 --topic test#2、查看创建的topic bin/kafka-topics.sh --list --zookeeper localhost:2181#3、生产者发布消息命令 (执行完此命令后在控制台输入要发…...

MySQL问题:MySQL中使用索引一定有效吗?如何排查索引效果
不一定有效,当查询条件中不包含索引列或查询条件复杂且不匹配索引顺序 对于一些小表,MySQL可能选择全表扫描而非使用索引,因为全表扫描的开销可能更小 最终是否用上索引是根据MySQL成本计算决定的,评估CPU和I/O成本 排查索引效…...

OpenSSL 签名验证详解:PKCS7* p7、cafile 与 RSA 验签实现
OpenSSL 签名验证详解:PKCS7* p7、cafile 与 RSA 验签实现 摘要 本文深入剖析 OpenSSL 中 PKCS7* p7 数据结构和 cafile 的作用及相互关系,详细讲解基于 OpenSSL 的 RSA 验签字符串的 C 语言实现,涵盖签名解析、证书加载、验证流程及关键要…...

利用 `ngx_http_xslt_module` 实现 NGINX 的 XML → HTML 转换
一、模块简介 模块名称:ngx_http_xslt_module 首次引入版本:0.7.8 功能:在回传给客户端之前,用指定的 XSLT 样式表对 XML 响应进行转换。 依赖: libxml2libxslt 编译选项:需在 NGINX 编译时添加 --with…...

C语言队列详解
一、什么是队列? 队列(Queue)是一种先进先出(FIFO, First In First Out)的线性数据结构。它只允许在一端插入数据(队尾),在另一端删除数据(队头)。常见于排队…...

Qt中的智能指针
Qt中的智能指针 Qt中提供了多种智能指针,用于管理自动分配的内存,避免内存泄漏和悬挂指针的问题。以下是Qt中常见的智能指针及其功能和使用场景: 1. QSharedPointer QSharedPointer 是 Qt 框架中用于管理动态分配对象的智能指针,类似于 C1…...

车载网关策略 --- 车载网关通信故障处理机制深度解析
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...
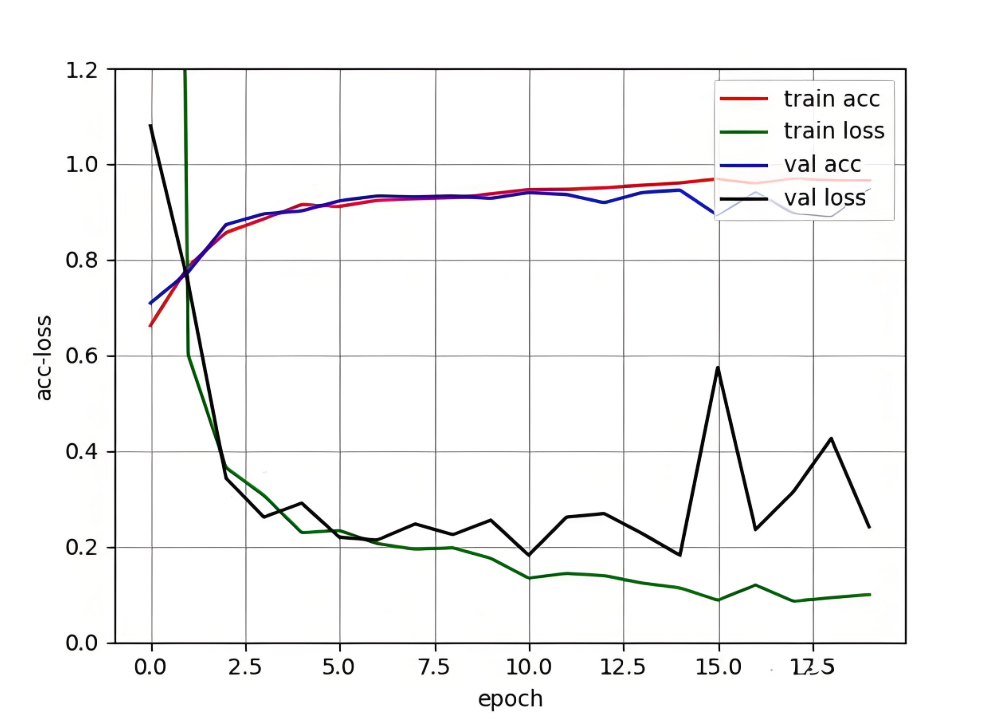
三天掌握PyTorch精髓:从感知机到ResNet的快速进阶方法论
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 一、分析式AI基础与深度学习核心概念 1.1 深度学习三要素 数学基础: f(x;W,b)σ(Wxb)(单层感知机) 1.2 PyTorch核心组件 张量操作示例…...

Python爬虫实战:研究Selenium框架相关技术
1. 引言 1.1 研究背景与意义 随着互联网的快速发展,网页数据量呈爆炸式增长。从网页中提取有价值的信息成为数据挖掘、舆情分析、商业智能等领域的重要基础工作。然而,现代网页技术不断演进,越来越多的网页采用 JavaScript 动态加载内容,传统的基于 HTTP 请求的爬虫技术难…...

分布式缓存:三万字详解Redis
文章目录 缓存全景图PreRedis 整体认知框架一、Redis 简介二、核心特性三、性能模型四、持久化详解五、复制与高可用六、集群与分片方案 Redis 核心数据类型概述1. String2. List3. Set4. Sorted Set(有序集合)5. Hash6. Bitmap7. Geo8. HyperLogLog Red…...

BiLSTM与Transformer:位置编码的隐式vs显式之争
BiLSTM 与使用位置编码的LLM(如Transformer)的核心区别 一、架构原理对比 维度BiLSTM带位置编码的LLM(如Transformer)基础单元LSTM单元(记忆细胞、门控机制)自注意力机制(Self-Attention)信息传递双向链式传播(前向+后向LSTM)并行多头注意力,全局上下文关联位置信息…...

html5视频播放器和微信小程序如何实现视频的自动播放功能
在HTML5中实现视频自动播放需设置autoplay和muted属性(浏览器策略要求静音才能自动播放),并可添加loop循环播放、playsinline同层播放等优化属性。微信小程序通过<video>组件的autoplay属性实现自动播放,同时支持全屏按钮、…...

【QT】QString和QStringList去掉空格的方法总结
目录 一、QString去掉空格 1. 移除字符串首尾的空格(trimmed) 2. 移除字符串中的所有空格(remove) 3. 仅移除左侧(开头)或右侧(结尾)空格 4. 替换多个连续空格为单个空格 5. 移…...

58同城大数据面试题及参考答案
ROW_NUMBER、RANK、DENSE_RANK 函数的区别是什么? 这三个函数均为窗口函数,用于为结果集分区中的行生成序号,但核心逻辑存在显著差异,具体表现如下: 数据分布与排序规则 假设存在分区内分数数据为 [90, 85, 85, 80],按分数降序排序: ROW_NUMBER:为分区内每行分配唯一序…...

25.5.27学习总结
快速读入: inline int read() {int x 0, f 1;char ch getchar();while (ch < 0 || ch > 9) { // 跳过非数字字符if (ch -) f -1; // 处理负号ch getchar();}while (ch > 0 && ch < 9) {x x * 10 ch - 0; // 逐字符转数字ch ge…...

关于vue结合elementUI输入框回车刷新问题
问题 vue2项目结合elementUI,使用el-form表单时,第一次打开浏览器url辞职,并且是第一次打开带有这个表单的页面时,输入框输入内容,回车后会意外触发页面自动刷新。 原因 当前 el-form 表单只有一个输入框࿰…...

vue项目表格甘特图开发
🧩 甘特图可以管理项目进度,生产进度等信息,管理者可以更直观的查看内容。 1. 基础环境搭建 引入 dhtmlx-gantt 插件引入插件样式 dhtmlxgantt.css引入必要的扩展模块(如 markers、tooltip)创建 Vue 组件并挂载 DOM 容器初始化 gantt 图表配置2. 数据准备与处理 定义任务…...
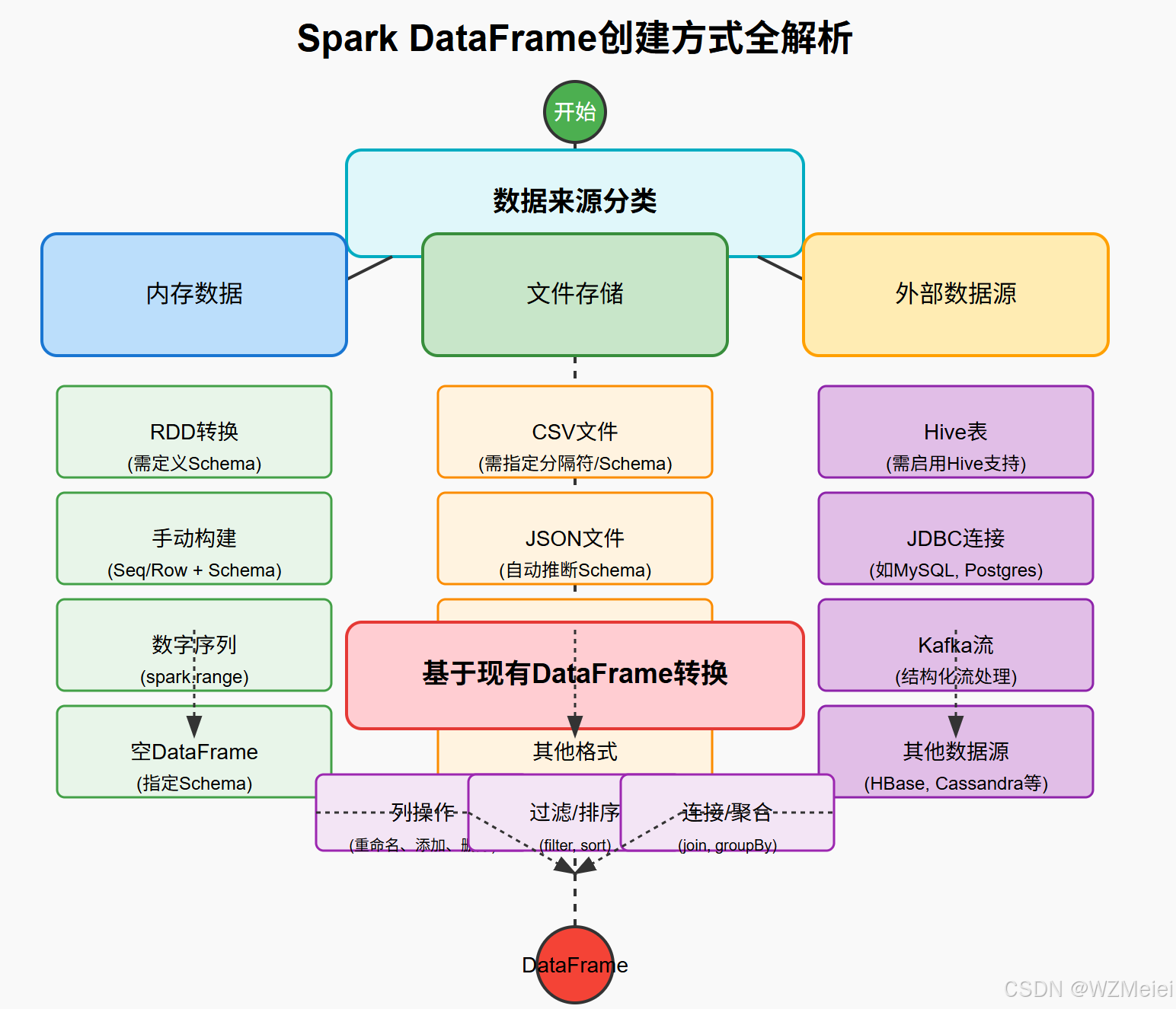
Spark 中,创建 DataFrame 的方式(Scala语言)
在 Spark 中,创建 DataFrame 的方式多种多样,可根据数据来源、结构特性及性能需求灵活选择。 一、创建 DataFrame 的 12 种核心方式 1. 从 RDD 转换(需定义 Schema) import org.apache.spark.sql.{Row, SparkSession} import o…...

Python----目标检测(MS COCO数据集)
一、MS COCO数据集 COCO 是一个大规模的对象检测、分割和图像描述数据集。COCO有几个 特点: Object segmentation:目标级的分割(实例分割) Recognition in context:上下文中的识别(图像情景识别࿰…...

塔能科技:有哪些国内工业节能标杆案例?
在国内工业领域,节能降耗不仅是响应国家绿色发展号召、践行社会责任的必要之举,更是企业降低运营成本、提升核心竞争力的关键策略。塔能科技在这一浪潮中脱颖而出,凭借前沿技术与创新方案,成功打造了多个极具代表性的工业标杆案例…...

图论:floyed算法
Floyd 算法是一种用于寻找加权图中所有顶点对之间最短路径的经典算法,它能够处理负权边,但不能处理负权环。即如果边权有负数,切负权边与其他边构成了环就不能用该算法。该算法的时间复杂度为 \(O(V^3)\),其中 V 是图中顶点的数量…...

嵌入式系统C语言编程常用设计模式---参数表驱动设计
参数表驱动设计是一种软件开发和系统设计中常用的方法,它通过参数表来控制程序的行为和流程,提高系统的灵活性、可维护性和可扩展性。它将系统的行为逻辑与具体参数分离,通过表格形式集中管理配置信息。这种模式在嵌入式系统、工业控制和自动…...
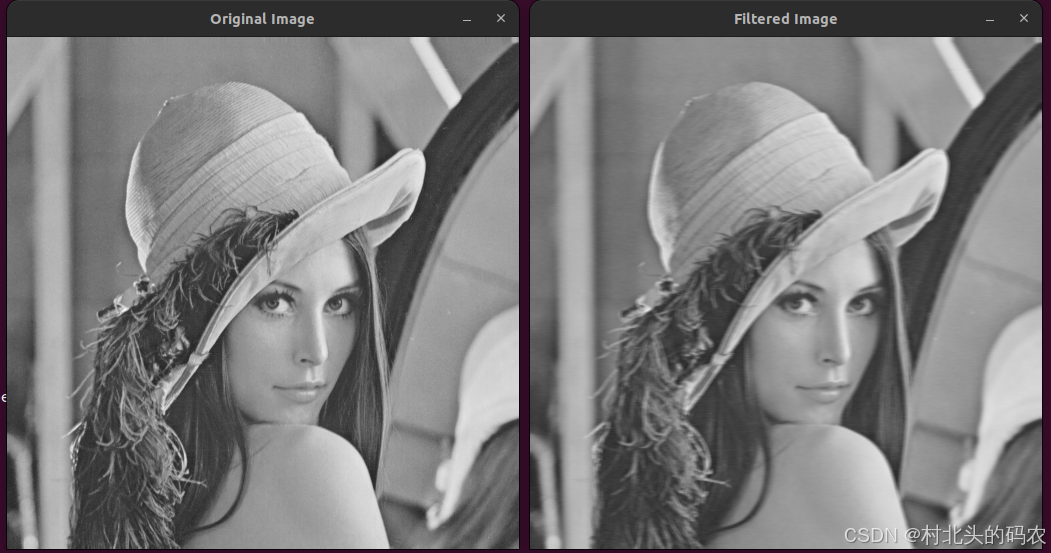
OpenCV CUDA模块图像过滤------创建一个行方向的一维积分(Sum)滤波器函数createRowSumFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::createRowSumFilter 是 OpenCV CUDA 模块中的一个函数,用于创建一个行方向的一维积分(Sum)滤波器。…...

Frequent values/gcd区间
Frequent values 思路: 这题它的数据是递增的,ST表,它的最多的个数只会在在两个区间本身就是最多的或中间地方产生,所以我用map数组储存每个值的左右临界点,在ST表时比较多一个比较中间值的个数就Ok了。 #define _…...
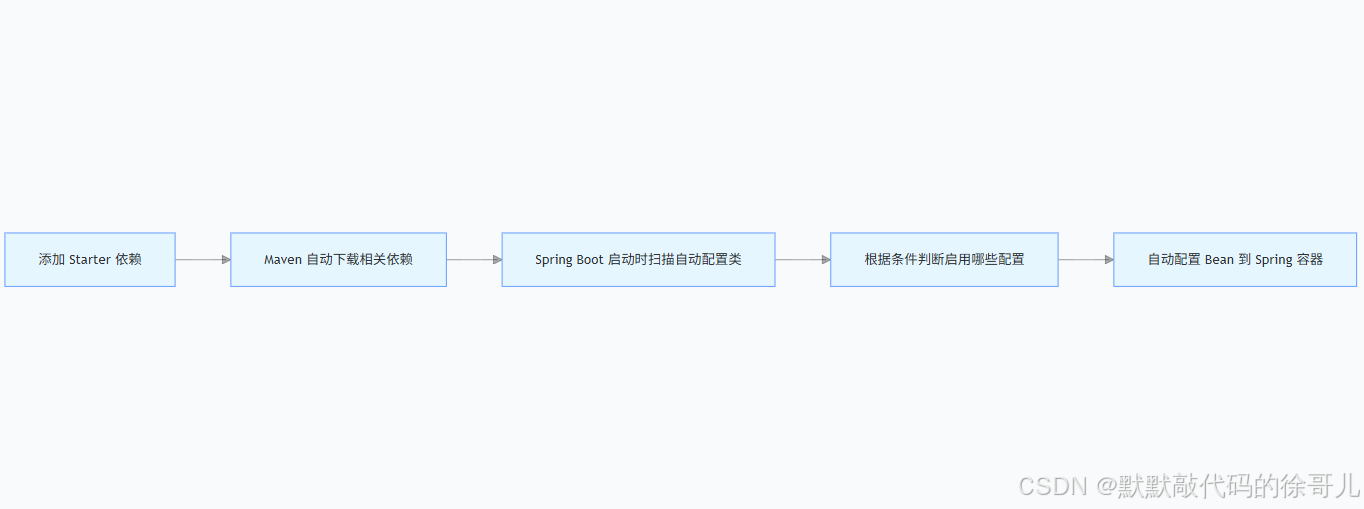
08SpringBoot高级--自动化配置
目录 Spring Boot Starter 依赖管理解释 一、核心概念 二、工作原理 依赖传递: 自动配置: 版本管理: 三、核心流程 四、常用 Starter 示例 五、自定义 Starter 步骤 创建配置类: 配置属性: 注册自动配置&a…...

Deep Evidential Regression
摘要 翻译: 确定性神经网络(NNs)正日益部署在安全关键领域,其中校准良好、鲁棒且高效的不确定性度量至关重要。本文提出一种新颖方法,用于训练非贝叶斯神经网络以同时估计连续目标值及其关联证据,从而学习…...
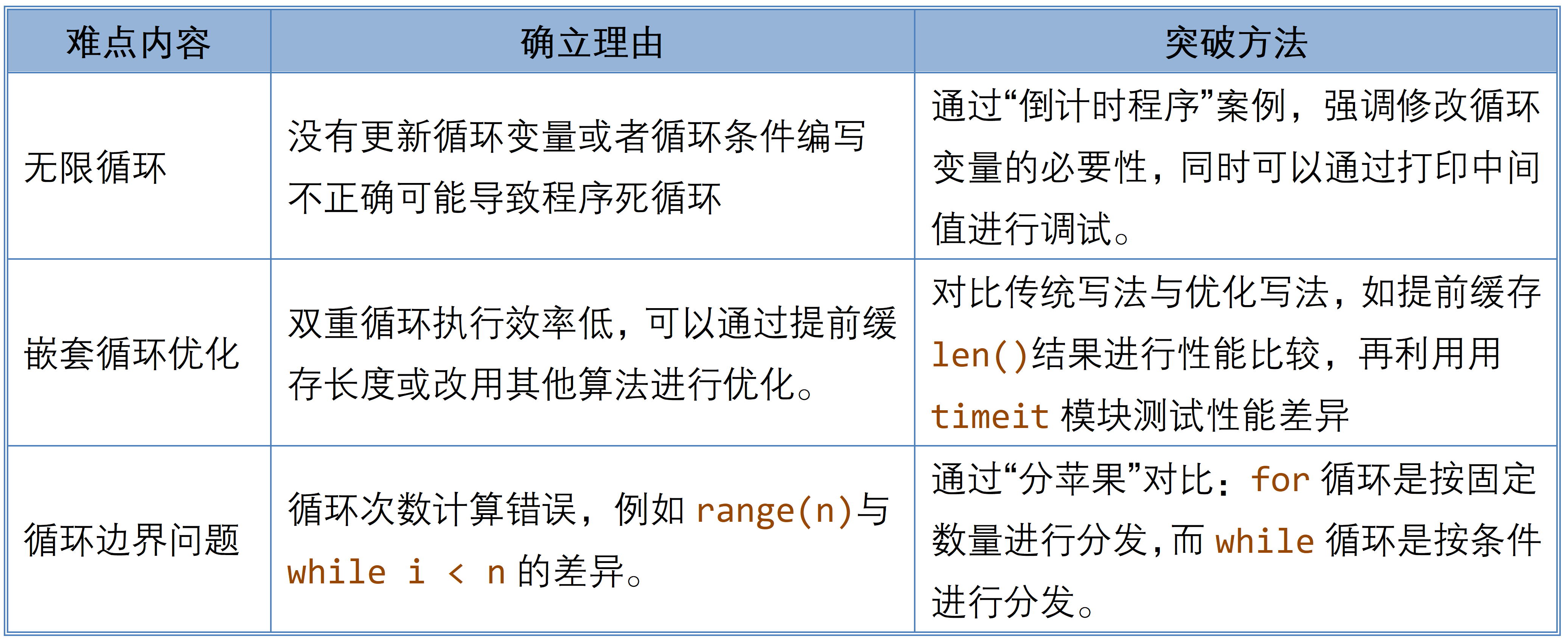
「Python教案」循环语句的使用
课程目标 1.知识目标 能使用for循环和while循环设计程序。能使用循环控制语句,break、continue、else设计程序。能使用循环实际问题。 2.能力目标 能根据需求合适的选择循环结构。能对嵌套循环代码进行调试和优化。能利用循环语句设计&am…...
linux快速入门-VMware安装linux,配置静态ip,使用服务器连接工具连接,快照和克隆以及修改相关配置信息
安装VMWare 省略,自己检索 安装操作系统-linux 注意:需要修改的我会给出标题,不要修改的直接点击下一步就可以 选择自定义配置 选择稍后安装操作系统 选择合适的内存 选择NAT模式 仅主机模式 虚拟机只能和主机通信,不能上网…...