好坏质检分类实战(异常数据检测、降维、KNN模型分类、混淆矩阵进行模型评估)
任务
好坏质检分类实战 task:
1、基于 data_class_raw.csv 数据,根据高斯分布概率密度函数,寻找异常点并剔除
2、基于 data_class_processed.csv 数据,进行 PCA 处理,确定重要数据维度及成分
3、完成数据分离,数据分离参数:random_state=4,test_size=0.4
4、建立 KNN 模型完成分类,n_neighbors 取 10,计算分类准确率,可视化分类边界
5、计算测试数据集对应的混淆矩阵,计算准确率、召回率、特异度、精确率、F1 分数
6、尝试不同的 n_neighbors(1-20),计算其在训练数据集、测试数据集上的准确率并作图。
参考资料
32.36 实战(二)_哔哩哔哩_bilibili
33.37 实战(三)_哔哩哔哩_bilibili
数据准备
数据集名称:data_class_raw.csv、data_class_processed.csv
点我转到百度网盘获取数据集 提取码: 8497
1、异常数据检测
加载数据
#load the data
import pandas as pd
import numpy as np
data = pd.read_csv('data_class_raw.csv')
data.head() 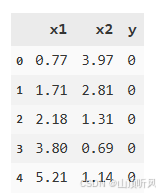
x1,x2 是芯片质量相关的两个维度,y 代表芯片质量是否合格。
#define X and y
X = data.drop(['y'], axis = 1)
y = data.loc[:,'y']原始数据可视化
#visualize the data
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize = (5,5))
bad = plt.scatter(X.loc[:,'x1'][y==0], X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1], X.loc[:,'x2'][y==1])
plt.legend((good,bad),('good','bad'))
plt.title('raw data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()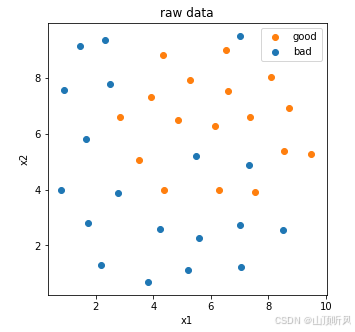
根据高斯分布概率密度函数,寻找异常点并剔除
#根据高斯分布概率密度函数,寻找异常点并剔除
#anomay detection
from sklearn.covariance import EllipticEnvelope
ad_model = EllipticEnvelope(contamination = 0.02)
ad_model.fit(X[y==0])
y_predict_bad = ad_model.predict(X[y==0])
print(y_predict_bad)[ 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 -1]找出异常点并画出异常点
#找出异常点并画出异常点
fig1 = plt.figure(figsize = (5,5))
bad = plt.scatter(X.loc[:,'x1'][y==0], X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1], X.loc[:,'x2'][y==1])
plt.scatter(X.loc[:,'x1'][y==0][y_predict_bad == -1], X.loc[:,'x2'][y==0][y_predict_bad == -1],marker = 'x', s=150)# 找出来的异常点
plt.legend((good,bad),('good','bad'))
plt.title('raw data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()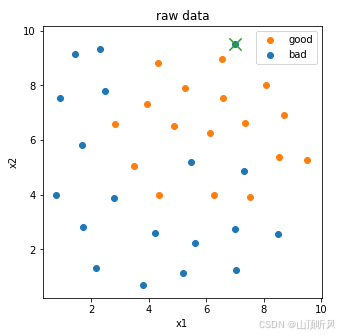
2、基于剔除了异常点的数据进行PCA处理
加载数据
#任务二:基于剔除了异常点的数据进行PCA处理
data = pd.read_csv('data_class_processed.csv')
data.head()
#define X and y
X = data.drop(['y'], axis = 1)
y = data.loc[:,'y']进行PCA的预处理
#接下来进行PCA的预处理
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
X_norm = StandardScaler().fit_transform(X) # 进行标准化处理
pca = PCA(n_components = 2) # 进行 2 维的PCA处理
X_reduced = pca.fit_transform(X_norm)#参数是标准化之后的数据
#下面计算各个维度上主成分标准差的比例是多少
var_ratio = pca.explained_variance_ratio_
print(var_ratio)#[0.5369408 0.4630592], 对应主成分的标准差的比例
fig4 = plt.figure(figsize = (5,5))
plt.bar([1,2], var_ratio)
plt.show()# 这两个主成分上的标准差都挺高的,也就意味着这两个维度的数据都需要进行保留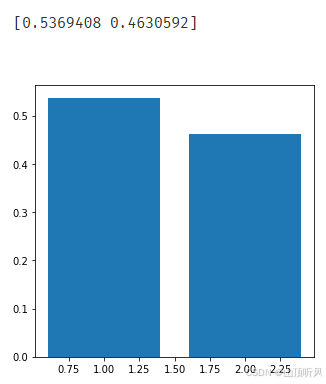
3、数据分离
# train and test split: random_state=4, test_size=0.4
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, random_state=4, test_size=0.4)
print(X_train.shape, X_test.shape, X.shape)![]()
4、KNN 模型进行分类
针对训练数据集建立KNN模型、进行训练和预测
#4、建立 KNN 模型完成分类,n_neighbors 取 10,计算分类准确率,可视化分类边界、
#针对训练数据集建立KNN模型
from sklearn.neighbors import KNeighborsClassifier
knn_10 = KNeighborsClassifier(n_neighbors = 10)
knn_10.fit(X_train, y_train)
y_train_predict = knn_10.predict(X_train)
y_test_predict = knn_10.predict(X_test)计算准确率
#4、建立 KNN 模型完成分类,n_neighbors 取 10,计算分类准确率,可视化分类边界、
#针对训练数据集建立KNN模型
from sklearn.neighbors import KNeighborsClassifier
knn_10 = KNeighborsClassifier(n_neighbors = 10)
knn_10.fit(X_train, y_train)
y_train_predict = knn_10.predict(X_train)
y_test_predict = knn_10.predict(X_test)![]()
可视化分类边界
流程:生成一些新的数据组,然后利用模型进行预测,最后画出模型的预测结果。
生成一些新的数据组
# 可视化分类边界(生成一些新的数据组,然后利用模型进行预测,最后画出模型的预测结果)
xx,yy = np.meshgrid(np.arange(0,10,0.05), np.arange(0,10,0.05))#观察到原来数据是0-10之间
print(xx)
print(yy.shape)# (200, 200), 200行, 200 列
x_range = np.c_[xx.ravel(),yy.ravel()]
#np.c_[xx.ravel(),yy.ravel()] 是 NumPy 中一种常用的数组拼接操作,
#通常与网格坐标生成(例如 np.meshgrid)结合使用,用于创建二维平面上所有可能的坐标点组合
print(x_range.shape) #(40000, 2) , 相当于200 行 200 列的组合进行预测
y_range_predict = knn_10.predict(x_range)画出分类边界
fig4 = plt.figure(figsize = (10,10))
knn_bad = plt.scatter(x_range[:,0][y_range_predict == 0], x_range[:,1][y_range_predict == 0])#所有行,第一列;所有行,第二列
knn_good = plt.scatter(x_range[:,0][y_range_predict == 1], x_range[:,1][y_range_predict == 1])#下面是原始数据
bad = plt.scatter(X.loc[:,'x1'][y==0], X.loc[:,'x2'][y==0])
good = plt.scatter(X.loc[:,'x1'][y==1], X.loc[:,'x2'][y==1])plt.legend((good,bad , knn_good, knn_bad),('good','bad','knn_good','knn_bad'))
plt.title('prediction result')
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()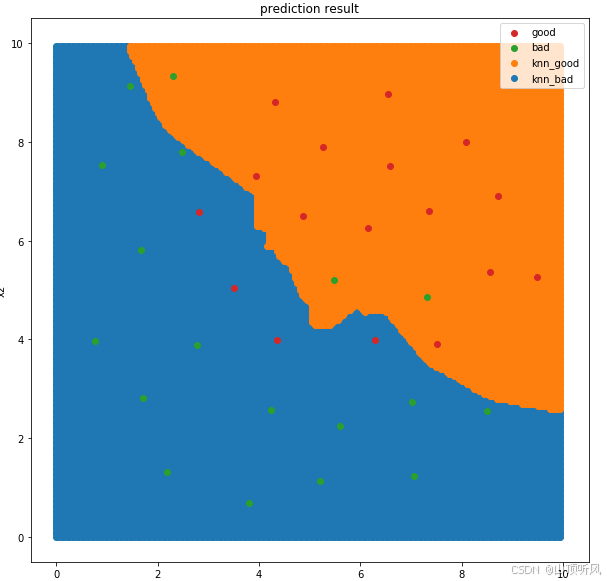
5、计算测试数据集对应的混淆矩阵
#5、计算测试数据集对应的混淆矩阵,计算准确率、召回率、特异度、精确率、F1 分数
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_test_predict) #计算测试数据的混淆矩阵
print(cm)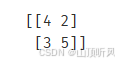
TP = cm[1,1]
TN = cm[0,0]
FP = cm[0,1]
FN = cm[1,0]
print(TP, TN, FP, FN)![]()
准确率:整体样本中,预测正确样本数的比例
・Accuracy = (TP + TN)/(TP + TN + FP + FN) 。
这里涉及机器学习等领域的评估指标概念 :
Accuracy(准确率):是一个衡量分类模型性能的指标 。
TP(True Positive,真正例 ):实际为正例且被模型正确预测为正例的样本数量。
TN(True Negative,真负例 ):实际为负例且被模型正确预测为负例的样本数量。
FP(False Positive,假正例 ):实际为负例但被模型错误预测为正例的样本数量。
FN(False Negative,假负例 ):实际为正例但被模型错误预测为负例的样本数量 。
accuracy = (TP + TN)/(TP + TN + FP + FN) #0.6428571428571429
print(accuracy#0.6428571428571429灵敏度(召回率):正样本中,预测正确的比例
・Sensitivity = Recall = TP/(TP + FN)
recall = TP/(TP+FN)
print(recall)#0.625特异度: 负样本中,预测正确的比例
Specificity = TN/(TN + FP)
specificity = TN/(TN + FP)
print(specificity)#0.6666666666666666精确率:预测结果为正的样本中,预测正确的比例
・Precision = TP/(TP + FP)
precision = TP/(TP + FP)
print(precision)#0.7142857142857143precision = TP/(TP + FP)
print(precision)#0.7142857142857143
f1 = 2*precision*recall/(precision + recall)
print(f1)#0.66666666666666666、KNN 尝试不同的 n_neighbors(1-20)
#尝试不同的 n_neighbors(1-20),计算其在训练数据集、测试数据集上的准确率并作图
# try different k and calculate the accuracy for each
n = [i for i in range(1,21)]
# print(n)#[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
accuracy_train = []
accuracy_test = []
for i in n:knn = KNeighborsClassifier(n_neighbors = i)knn.fit(X_train, y_train)y_train_predict = knn.predict(X_train) #进行训练数据的预测y_test_predict = knn.predict(X_test) #进行测试数据的预测accuracy_train_i = accuracy_score(y_train, y_train_predict)accuracy_test_i = accuracy_score(y_test, y_test_predict)accuracy_train.append(accuracy_train_i)accuracy_test.append(accuracy_test_i)
print(accuracy_train, accuracy_test)
fig5 = plt.figure(figsize=(12,5))
plt.subplot(121)
plt.plot(n, accuracy_train,marker = 'o') # 训练数据的准确率, n 是 n_neighbors 参数
plt.title('training accuracy vs n_neighbors')
plt.xlabel('n_neighbors')
plt.ylabel('accuracy')plt.subplot(122)
plt.plot(n, accuracy_test,marker = 'o') # 测试数据的准确率, n 是 n_neighbors 参数
plt.title('testing accuracy vs n_neighbors')
plt.xlabel('n_neighbors')
plt.ylabel('accuracy')plt.show()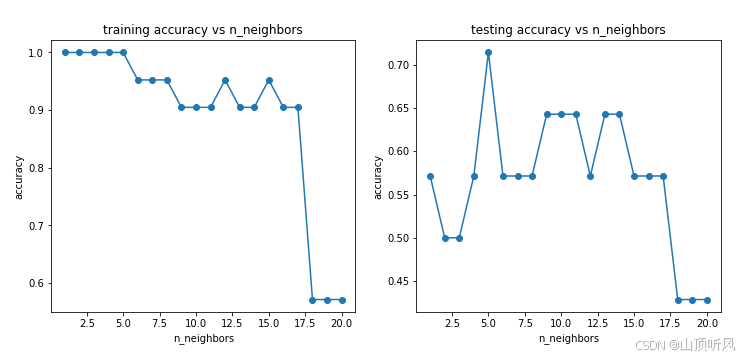
7、好坏质检分类实战 summary
1、通过进行异常检测,帮助找到了潜在的异常数据点;
2、通过 PCA 分析,发现需要保留 2 维数据集;
3、实现了训练数据与测试数据的分离,并计算模型对于测试数据的预测准确率
4、计算得到混淆矩阵,实现模型更全面的评估
5、通过新的方法,可视化分类的决策边界
6、通过调整核心参数 n_neighbors 值,在计算对应的准确率,可以帮助我们更好的确定使用哪个模型
7、核心算法参考链接:https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
相关文章:
好坏质检分类实战(异常数据检测、降维、KNN模型分类、混淆矩阵进行模型评估)
任务 好坏质检分类实战 task: 1、基于 data_class_raw.csv 数据,根据高斯分布概率密度函数,寻找异常点并剔除 2、基于 data_class_processed.csv 数据,进行 PCA 处理,确定重要数据维度及成分 3、完成数据分离,数据分离…...

链表:数据结构的灵动舞者
在数据结构的舞台之上,链表以它灵动的身姿演绎着数据的精彩故事。与顺序表的规整有序不同,链表展现出了别样的灵活性与独特魅力。今天,就让我们一同走进链表的世界,去领略它的定义、结构、操作,对比它与顺序表的优缺点…...
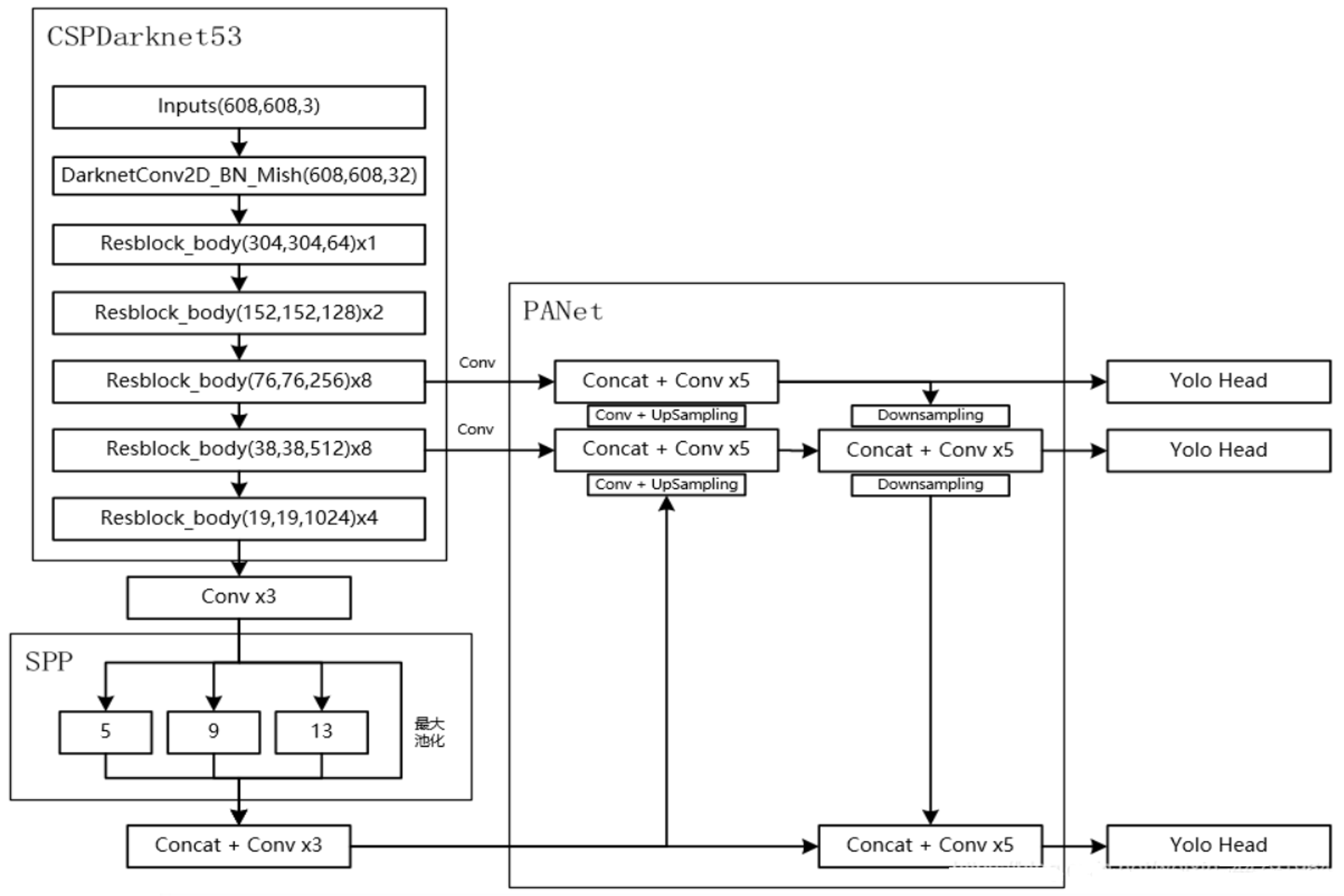
YOLOv4:目标检测的新标杆
引言 YOLO(You Only Look Once)系列作为目标检测领域的经典算法,以其高效的检测速度和良好的准确率闻名。2020年推出的YOLOv4在保持YOLO系列高速检测特点的同时,通过引入多项创新技术,将检测性能提升到了新高度。本文将详细介绍YOLOv4的核心…...
)
PyTorch 2.1新特性:TorchDynamo如何实现30%训练加速(原理+自定义编译器开发)
一、PyTorch 2.1动态编译架构演进 PyTorch 2.1的发布标志着深度学习框架进入动态编译新纪元。其核心创新点TorchDynamo通过字节码即时重写技术,将Python动态性与静态图优化完美结合。相较于传统JIT方案,TorchDynamo实现了零侵入式加速——开发者只需添加…...
LabVIEW通用测控平台设计
基于 LabVIEW 图形化编程环境,设计了一套适用于工业自动化、科研测试领域的通用测控平台。通过整合研华、NI等品牌硬件,实现多类型数据采集、实时控制及可视化管理。平台采用模块化架构,支持硬件灵活扩展,解决了传统测控系统开发周…...

【机器学习基础】机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN)
机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN) 一、算法逻辑1.1 基本概念1.2 关键要素距离度量K值选择 二、算法原理与数学推导2.1 分类任务2.2 回归任务2.3 时间复杂度分析 三、模型评估3.1 评估指标3.2 交叉验证调参 四、应用…...
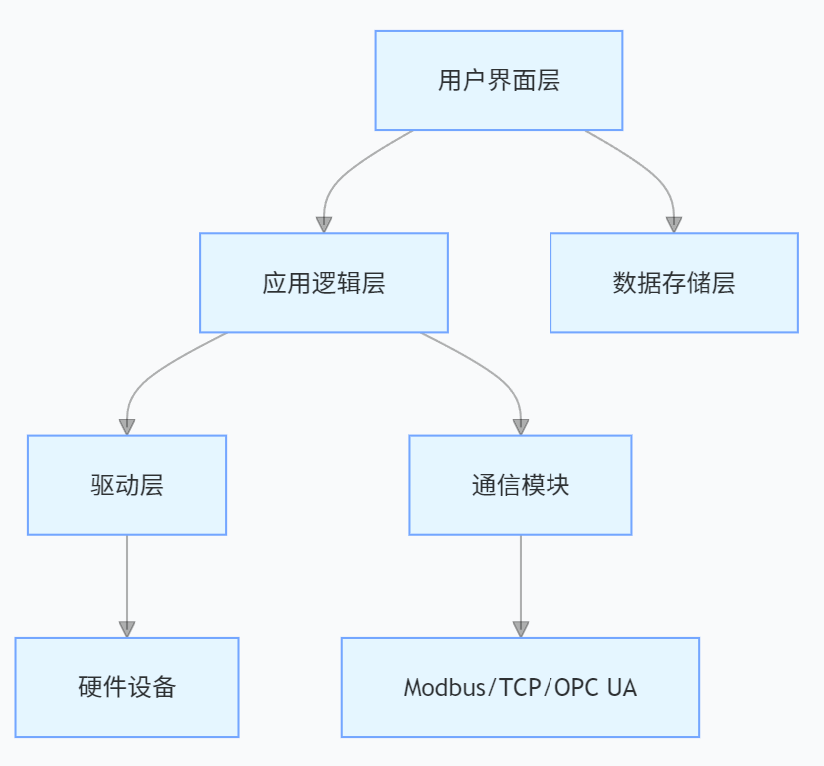
FastMoss 国际电商Tiktok数据分析 JS 逆向 | MD5加密
1.目标 目标网址:https://www.fastmoss.com/zh/e-commerce/saleslist 切换周榜出现目标请求 只有请求头fm-sign签名加密 2.逆向分析 直接搜fm-sign 可以看到 i["fm-sign"] A 进入encryptParams方法 里面有个S()方法加密,是MD5加密 3.代…...

Redis分布式缓存核心架构全解析:持久化、高可用与分片实战
一、持久化机制:数据安全双引擎 1.1 RDB与AOF的架构设计 Redis通过RDB(快照持久化)和AOF(日志持久化)两大机制实现数据持久化。 • RDB架构:采用COW(写时复制)技术,主进程…...
【Linux】基础开发工具(下)
文章目录 一、自动化构建工具1. 什么是 make 和 Makefile?2. 如何自动化构建可执行程序?3. Makefile 的核心思想4. 如何清理可执行文件?5. make 的工作原理5.1 make 的执行顺序5.2 为什么 make 要检查文件是否更新?5.2.1 避免重复…...

Python爬虫实战:研究Portia框架相关技术
1. 引言 1.1 研究背景与意义 在大数据时代,网络数据已成为企业决策、学术研究和社会分析的重要资源。据 Statista 统计,2025 年全球数据总量将达到 175ZB,其中 80% 以上来自非结构化网络内容。如何高效获取并结构化这些数据,成为数据科学领域的关键挑战。 传统爬虫开发需…...
chrome打不开axure设计的软件产品原型问题解决办法
1、打开原型文件夹,进入到其中的如下目录中:resources->chrome->axure-chrome-extension.crx,找到 Axure RP Extension for Chrome插件。 2、axure-chrome-extension.crx文件修改扩展名.rar,并解压到文件夹 axure-chrome-ex…...

达梦数据库-学习-23-获取执行计划的N种方法
目录 一、环境信息 二、说点什么 三、测试数据生成 四、测试语句 五、获取执行计划方法 1、EXPLAIN (1)样例 (2)优势 (3)劣势 2、ET (1)开启参数 (2ÿ…...

【数据结构】树形结构--二叉树
【数据结构】树形结构--二叉树 一.知识补充1.什么是树2.树的常见概念 二.二叉树(Binary Tree)1.二叉树的定义2.二叉树的分类3.二叉树的性质 三.二叉树的实现1.二叉树的存储2.二叉树的遍历①.先序遍历②.中序遍历③.后序遍历④.层序遍历 一.知识补充 1.什…...

Baklib构建企业CMS高效协作与安全管控体系
企业CMS高效协作体系构建 基于智能工作流引擎的设计逻辑,现代企业内容管理系统通过预设多节点审核路径与自动化任务分配机制,有效串联市场、技术、法务等跨部门协作链路。系统支持多人同时编辑与版本追溯功能,结合细粒度权限管控模块&#x…...
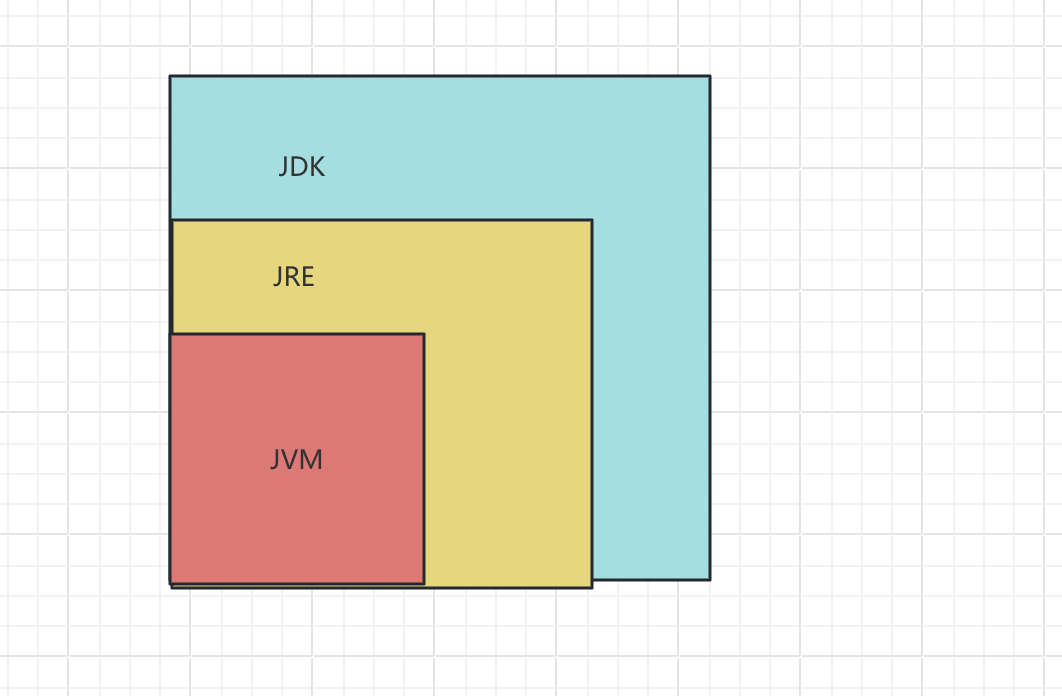
深入理解 JDK、JRE 和 JVM 的区别
在 Java 中,JDK、JRE 和 JVM 是非常重要的概念,它们各自扮演着不同的角色,却又紧密相连。今天,就让我们来详细探讨一下它们之间的区别。 一、JVM JVM 即 Java 虚拟机,它是整个 Java 技术体系的核心。JVM 提供了 Java…...

LSTM 与 TimesNet的时序分析对比解析
前言 Hi,我是GISerLiu🙂, 这篇文章是参加2025年5月Datawhale学习赛的打卡文章!💡 本文将深入探讨在自定义时序数据集上进行下游分类任务的两种主流分析方法。一种是传统的“先插补后分析”策略,另一种是采用先进的端到…...
图论学习笔记 4 - 仙人掌图
先扔张图: 为了提前了解我们采用的方法,请先阅读《图论学习笔记 3》。 仙人掌图的定义:一个连通图,且每条边只出现在至多一个环中。 这个图就是仙人掌图。 这个图也是仙人掌图。 而这个图就不是仙人掌图了。 很容易发现…...

语音识别算法的性能要求一般是多少
语音识别算法的性能要求因应用场景和实际需求而异,但以下几个核心指标是通用的参考标准。以下是具体说明: 1. 准确率(Accuracy) 语音识别的核心性能指标通常是词错误率(WER, Word Error Rate)和字符错误率…...

百度ocr的简单封装
百度ocr地址 以下代码为对百度ocr的简单封装,实际使用时推荐使用baidu-aip 百度通用ocr import base64 from enum import Enum, unique import requests import logging as logunique class OcrType(Enum):# 标准版STANDARD_BASIC "https://aip.baidubce.com/rest/2.0…...
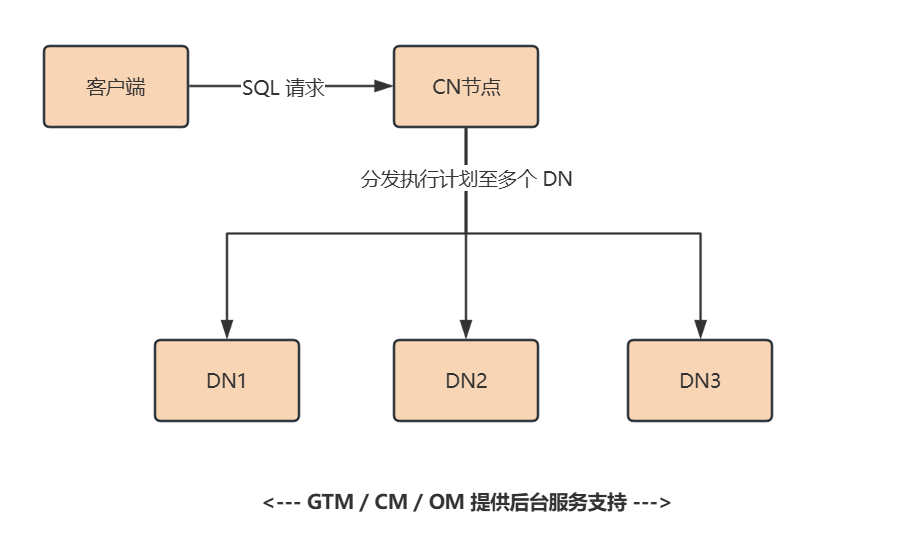
华为高斯数据库(GaussDB)深度解析:国产分布式数据库的旗舰之作
高斯数据库介绍 一、高斯数据库概述 GaussDB是华为自主研发的新一代分布式关系型数据库,专为企业核心系统设计。它支持HTAP(混合事务与分析处理),兼具强大的事务处理与数据分析能力,是国产数据库替代的重要选择。 产…...

LWIP 中,lwip_shutdown 和 lwip_close 区别
实际开发中,建议对 TCP 连接按以下顺序操作以确保可靠性: lwip_shutdown(newfd, SHUT_RDWR); // 关闭双向通信 lwip_close(newfd); // 释放资源...
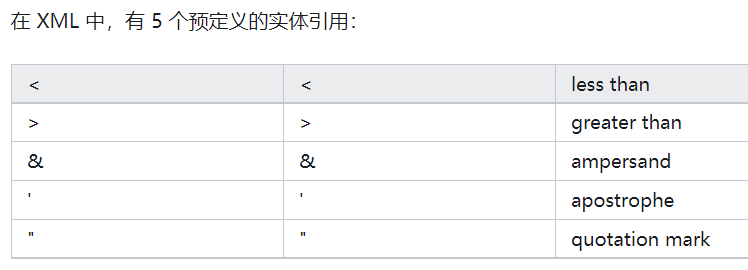
xml双引号可以不转义
最近在开发soap方面的协议,soap这玩意,就避免不了XML,这里我用到了pguixml库。 输入了这个XML后,发现<和>都被转义,但是""没有被转义,很是奇怪啊。毕竟去网上随便一搜转义字符,…...

互联网大厂Java面试:从Spring到微服务的挑战
文章简介 在这篇文章中,我们将模拟一场互联网大厂的Java面试,场景设置为企业协同与SaaS。面试官提出了一系列技术问题,涵盖了Java核心语言、Spring框架、微服务架构等技术点,并结合实际业务场景进行循序渐进的提问。最后…...

兰亭妙微 | 图标设计公司 | UI设计案例复盘
在「33」「312」新高考模式下,选科决策成为高中生和家长的「头等大事」。兰亭妙微公司受委托优化高考选科决策平台个人诊断报告界面,核心挑战是:如何将复杂的测评数据(如学习能力倾向、学科报考机会、职业兴趣等)转化为…...

OpenCV视觉图片调整:从基础到实战的技术指南
引言:数字图像处理的现代意义与OpenCV深度应用 在人工智能与计算机视觉蓬勃发展的今天,图像处理技术已成为多个高科技领域的核心支撑。根据市场研究机构Grand View Research的数据,全球计算机视觉市场规模预计将从2022年的125亿美元增长到2030年的253亿美元,年复合增长率达…...

C#日期和时间:DateTime转字符串全面指南
C#日期和时间:DateTime转字符串全面指南 在 C# 开发中,DateTime类型的时间格式化是高频操作场景。无论是日志记录、数据持久化,还是接口数据交互,合理的时间字符串格式都能显著提升系统的可读性和兼容性。本文将通过 20 实战示例…...
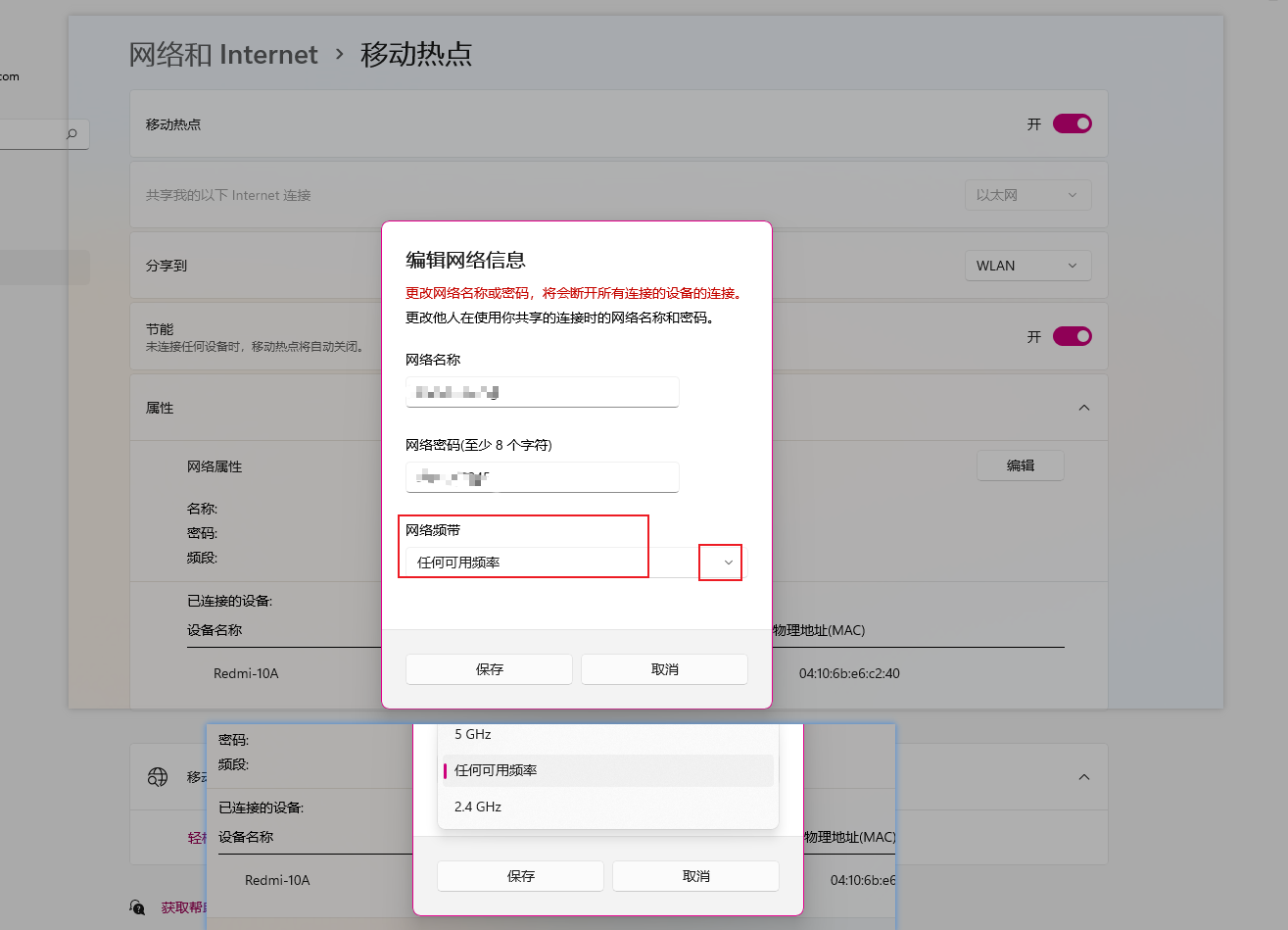
手机收不到WiFi,手动输入WiFi名称进行连接不不行,可能是WiFi频道设置不对
以下是电脑上分享WiFi后,部分手机可以看到并且能连接,部分手机不行,原因是:频道设置为5GHz,修改成,任何可用频率,则可...
批量文件重命名工具
分享一个自己使用 python 开发的小软件,批量文件重命名工具,主要功能有批量中文转拼音,简繁体转换,大小写转换,替换文件名,删除指定字符,批量添加编号,添加前缀/后缀。同时还有文件时…...

ATPrompt方法:属性嵌入的文本提示学习
ATPrompt方法:属性嵌入的文本提示学习 让视觉-语言模型更好地对齐图像和文本(包括未知类别)。 一、问题场景:传统方法的局限 假设你有一个模型,能识别图像中的物体并关联到文本标签(如“狗”“猫”)。 传统方法: 用“软提示”(可学习的文本标签)和“硬类别标记”…...

14.「实用」扣子(coze)教程 | Excel文档自动批量AI文档生成实战,中级开篇
随着AI编程工具及其能力的不断发展,编程将变得越来越简单。 在这个大趋势下,大师兄判断未来的编程将真正成为像office工具一样的办公必备技能。每个人通过 (专业知识/资源编程)将自己变成一个复合型的人才,大大提高生…...