【mysql】mysql的高级函数、高级用法
mysql是最常用的数据库之一,常见的函数用法大家应该都很熟悉,本文主要例举一些相对出现频率比较少的高级用法
(注:需注意mysql版本,大部分高级特性都是mysql8才有的)
多值索引与虚拟列
主要是解决字符串索引问题,光说概念会比较抽象 我们举两个例子来阐述
mysql文档地址:
https://dev.mysql.com/doc/refman/8.4/en/create-index.html#create-index-multi-valued:~:text=%E7%9A%84%E8%AF%A6%E7%BB%86%E4%BF%A1%E6%81%AF%E3%80%82-,%E5%A4%9A%E5%80%BC%E7%B4%A2%E5%BC%95,-InnoDB%E6%94%AF%E6%8C%81%E5%A4%9A
场景一: 我们日常开发中 经常会使用,分隔 (例如userIds), 但是随着数据量和需求的增加,会造成效率问题;终极解决方案是拆表 建立一个新的关系表,但如果涉及改动大,拆表是个大工程;有一个技巧就是将数据升级成json格式,为json字段建立索引;如果代码规范的话 我们只需要修改entity到DTO层的转换,外部都是调用DTO,改动量小很多;
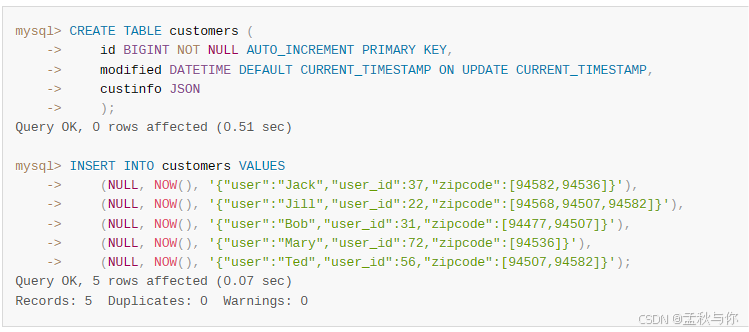
建立索引方式:
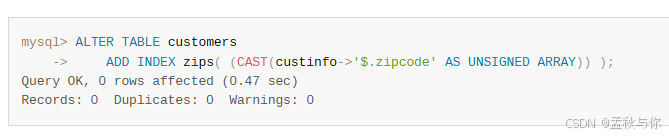
查询方式:
-- 索引方式 ref
SELECT * FROM customers WHERE 94507 MEMBER OF(custinfo->'$.zipcode');
-- 或 (索引方式range)
SELECT * FROM customersWHERE JSON_CONTAINS(custinfo->'$.zipcode', CAST('[94507,94582]' AS JSON));
json数据插入格式:
{"zipcode": [94536, 123]}
场景二: json字符串为普通的k-v 格式,但是我们需要通过对某个字段 例如姓名建立索引
可以建立虚拟列 对虚拟列建立索引
这样可以简化查询代码 (注意 如果是场景一 数组格式的数组要走索引 则不合适)
CREATE TABLE `file_test_phone` (`id` bigint NOT NULL,`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,`real_phone` json DEFAULT NULL,`phone` varchar(255) COLLATE utf8mb4_unicode_ci GENERATED ALWAYS AS (json_unquote(json_extract(`real_phone`,_utf8mb4'$.phone'))) VIRTUAL,PRIMARY KEY (`id`),UNIQUE KEY `uk_phone` (`phone`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
json字段插入数据格式:
{"phone": "123"}
将字符串拼接数据拆分
还是上面场景,如果不打算用这种方式,想要用传统的拆表来实现,拆表很容易,但是会涉及到历史数据迁移问题。
我们假设旧表 user表 有id 和 role_id字段,其中role_id是逗号分隔,

现在希望将role_id拆分出去
我们可以先将逗号拼接的字符串先转成数组字符串:
update user set role_id = concat ('[',role_id,']')

接着用以下语句数据迁移:
INSERT INTO user_role (id,user_id, role_id)
SELECT UUID_SHORT(),u.id AS user_id,CAST(JSON_UNQUOTE(js.value) AS UNSIGNED) AS role_id
FROM user u
JOIN JSON_TABLE(u.role_id,'$[*]' COLUMNS (value VARCHAR(255) PATH '$')) AS js
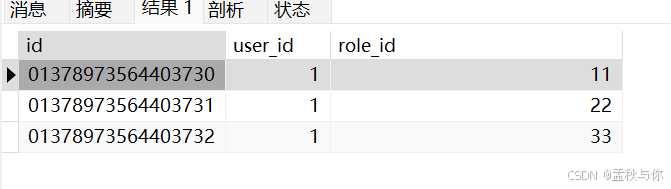
WHERE u.role_id IS NOT NULL AND JSON_VALID(u.role_id) AND JSON_LENGTH(u.role_id) > 0;JSON_TABLE 是作用于行数据的,所以我们看不到显式的join关联条件,执行后user_role数据示例:
分区
(仅讨论分区语法 博主个人感觉分区有点鸡肋 mysql的这个设计对数据来说或许合理 但对用户使用来说 并不友好;
当然这也是见仁见智 感兴趣可以自行造亿级以上数据测试 这是只是提供一种思路)
常用分区策略:
range分区: 比如按照年份分区
list分区:按照枚举值分区 比如根据省份
hash分区:按哈希值分区,适用于数据比较均匀的场景
key分区:类似HASH分区,但使用MySQL的内部哈希函数
mysql5.1之后就可以分区了 语法为
-- 移除分区
-- ALTER TABLE test_part REMOVE PARTITIONING;
-- 修改表分区 (如果是创建 则在建表语句后面跟上PARTITION )
ALTER TABLE test_part
PARTITION BY RANGE (code) (PARTITION p1 VALUES LESS THAN (100000000),PARTITION p2 VALUES LESS THAN (200000000),PARTITION p3 VALUES LESS THAN (300000000),PARTITION p4 VALUES LESS THAN MAXVALUE
);建表分区示例
-- 根据年份分区
CREATE TABLE orders (order_id INT NOT NULL,customer_id INT NOT NULL,order_date DATE NOT NULL,total DECIMAL(10, 2),PRIMARY KEY (order_id, order_date)
)
PARTITION BY RANGE (YEAR(order_date)) (PARTITION p2019 VALUES LESS THAN (2020),PARTITION p2020 VALUES LESS THAN (2021),PARTITION p2021 VALUES LESS THAN (2022),PARTITION pmax VALUES LESS THAN MAXVALUE
);分区可以避免跨表分页的问题,虽然数据物理隔离了 但是终归是在同一张表;但是必须注意的一点:分区字段必须是主键字段之一;
因为一旦有主键,它就成为表的核心约束,MySQL 必须保证 主键在全表范围内唯一,但如果主键不包含分区字段,那主键值一样的数据有可能落入不同分区这样就出现了主键冲突,MySQL 没法检测这个冲突 —— 所以为了防止这种“隐形冲突”,它强制要求主键必须包含分区字段,否则干脆不让你建表。
这个设计不得不吐槽了,例如oracle就可以做到分区后也全局检测,所以不用限制主键分区
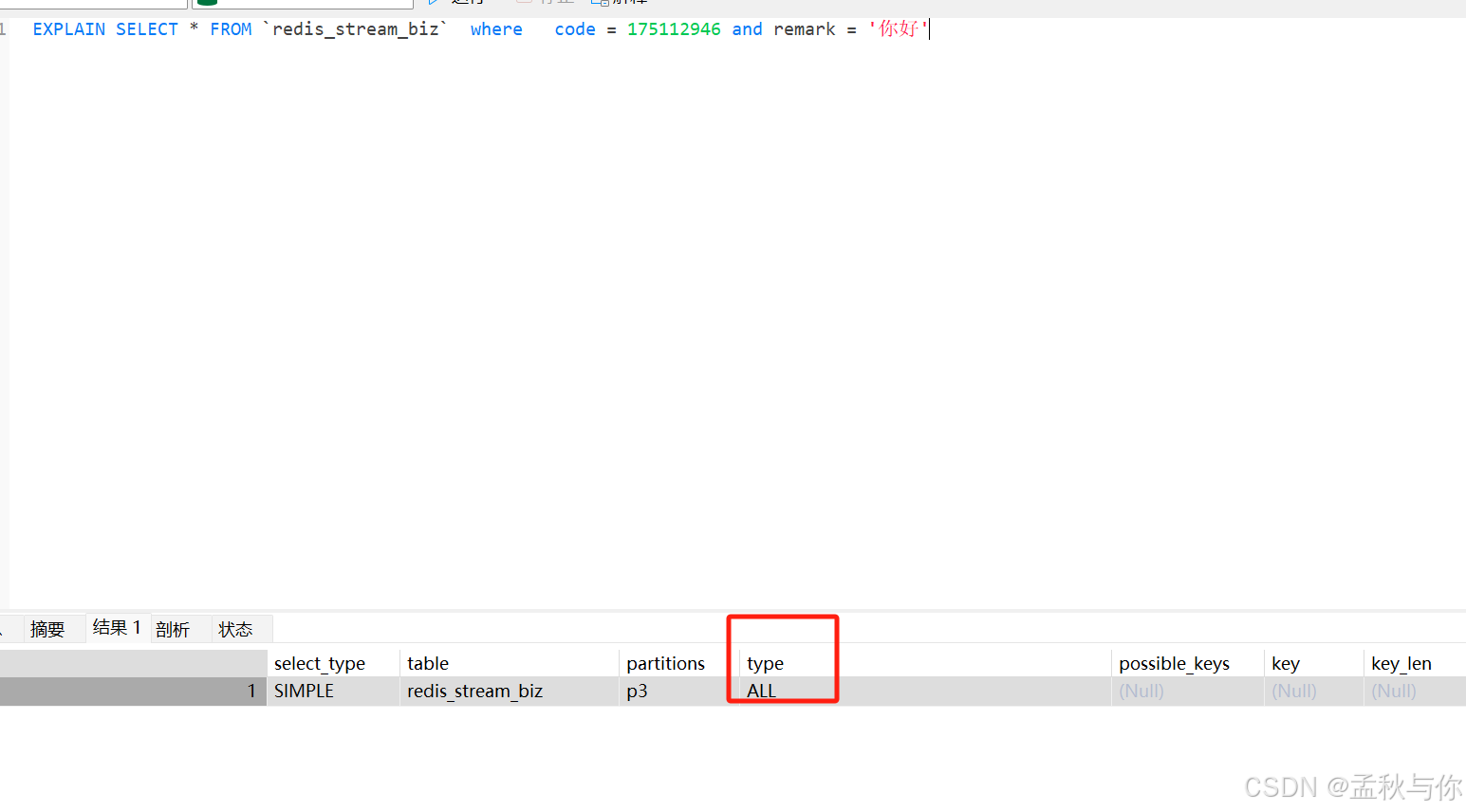
如下图 分区后反而降低了效率,主键本来就是聚促索引 弄成联合主键效率反而可能降低,在博主亲测的几千万级别数据 是完全没有必要分区(也没必要分表) , 不分区 建索引反而会快些
但是当表不存在主键的时候,最核心的性约束就不是主键了,而是唯一索引,这个时候 分区键是唯一索引字段就能分区成功了:
CREATE TABLE t1 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1, col2, col3)
)
PARTITION BY HASH(col3)
PARTITIONS 4;
-- 能执行成功
ALTER TABLE user_role_no_id PARTITION BY HASH(user_id) PARTITIONS 4;
那话又说回来,怎么会有大数据量的业务表不存在主键呢?
不存在主键的表(如配置表、字典表)又怎么会到分区的程度呢
这本身似乎是个悖论,所以我们平常见到的mysql分区应该也比较少;
[重申:本文仅介绍mysql有分区用法,实际使用可能需要斟酌再三]
相关文章:
【mysql】mysql的高级函数、高级用法
mysql是最常用的数据库之一,常见的函数用法大家应该都很熟悉,本文主要例举一些相对出现频率比较少的高级用法 (注:需注意mysql版本,大部分高级特性都是mysql8才有的) 多值索引与虚拟列 主要是解决字符串索引问题,光说…...

了解一下C#的SortedSet
基础概念 SortedSet 是 C# 中的一个集合类型,位于 System.Collections.Generic 命名空间下。它是一个自动排序的集合,用于存储不重复的元素,并且会根据元素的自然顺序(默认排序)或自定义比较器进行排序,内…...
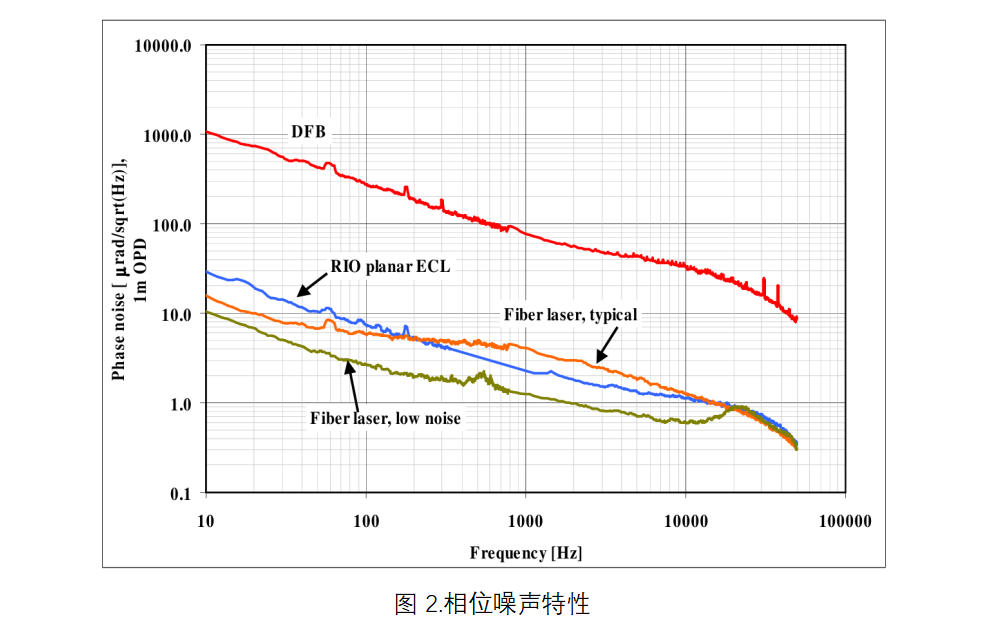
【平面波导外腔激光器专题系列】用于光纤传感的低噪声PLC外腔窄线宽激光器
----翻译自Mazin Alalusi等人的文章 摘要 高性价比的 1550 nm DWDM平面外腔 (PLANEX) 激光器是干涉测量、布里渊、LIDAR 和其他光传感应用的最佳选择。其线宽<3kHz、低相位/频率噪声和极低的RIN。 简介 高性能光纤分布式传感技术是在过去几年中开发…...
Pytorch里面多任务Loss是加起来还是分别backward? | Pytorch | 深度学习
当你在深度学习中进入“多任务学习(Multi-task Learning)”的领域,第一道关卡可能不是设计网络结构,也不是准备数据集,而是:多个Loss到底是加起来一起backward,还是分别backward? 这个问题看似简单,却涉及PyTorch计算图的构建逻辑、自动求导机制、内存管理、任务耦合…...

K8S Pod调度方法实例
以下是一篇面向企业用户、兼具通俗易懂和实战深度的 Kubernetes Pod 调度方法详解博文大纲与正文示例。全文采用“图文(代码块)并茂 问答穿插 类比”方式,模拟了真实终端操作及输出,便于读者快速上手。 一、引言 为什么要关注 P…...

【mindspore系列】- 算子源码分析
本文会介绍mindspore的算子源码结构、执行过程以及如何编写一个自定义的mindspore算子。 源码介绍 首先,我们先从https://gitee.com/mindspore/mindspore/ 官网中clone源代码下来。 clone好代码后,可以看到源码的文件夹结构如下(只列出比较重要的文件夹): docsmindspore…...

学习日记-day17-5.27
完成目标: 知识点: 1.日期相关类_Calendar日历类 常用方法:int get(int field) ->返回给定日历字段的值void set(int field, int value) :将给定的日历字段设置为指定的值void add(int field, int amount) :根据日历的规则,为给定的日历字段添加或…...
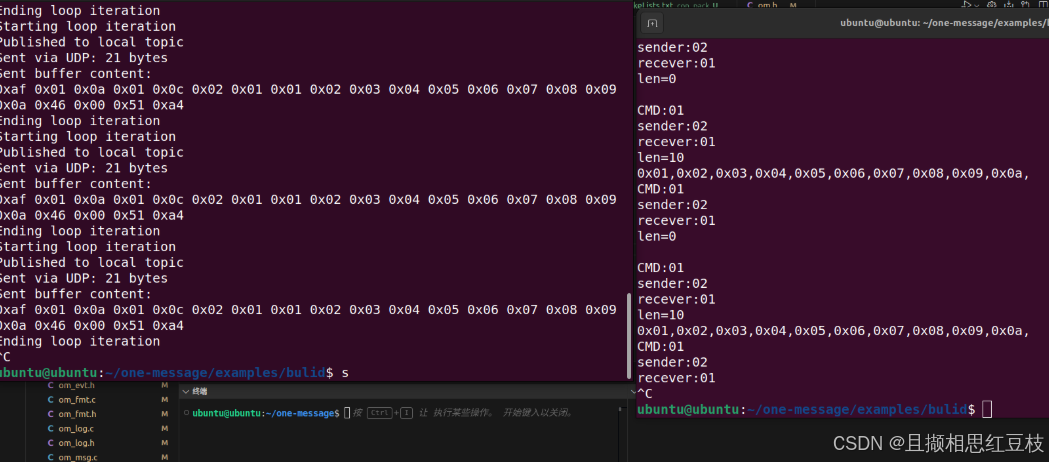
一种比较精简的协议
链接地址为:ctLink: 一个比较精简的支持C/C的嵌入式通信的中间协议。 本文采用的协议格式如下 *帧头 uint8_t 起始字节:0XAF\ *协议版本 uint8_t 使用的协议版本号:当前为0X01\ *负载长度 uint8_t 数据段内容长…...

网络常识:网线和光纤的区别
网络常识:网线和光纤的区别 一. 介绍二. 网线2.1 什么是网线?2.2 网线的主要类别2.3 网线的优势2.4 网线的劣势 三. 光纤3.1 什么是光纤?3.2 光纤的主要类别3.3 光纤的优势3.4 光纤的劣势 四. 网线 vs 光纤:谁更适合你?…...

OpenCV CUDA模块图像过滤------创建一个 Scharr 滤波器函数createScharrFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数用于创建一个 Scharr 滤波器(基于 CUDA 加速),用于图像的一阶导数计算。它常用于边缘检测任务中&#…...
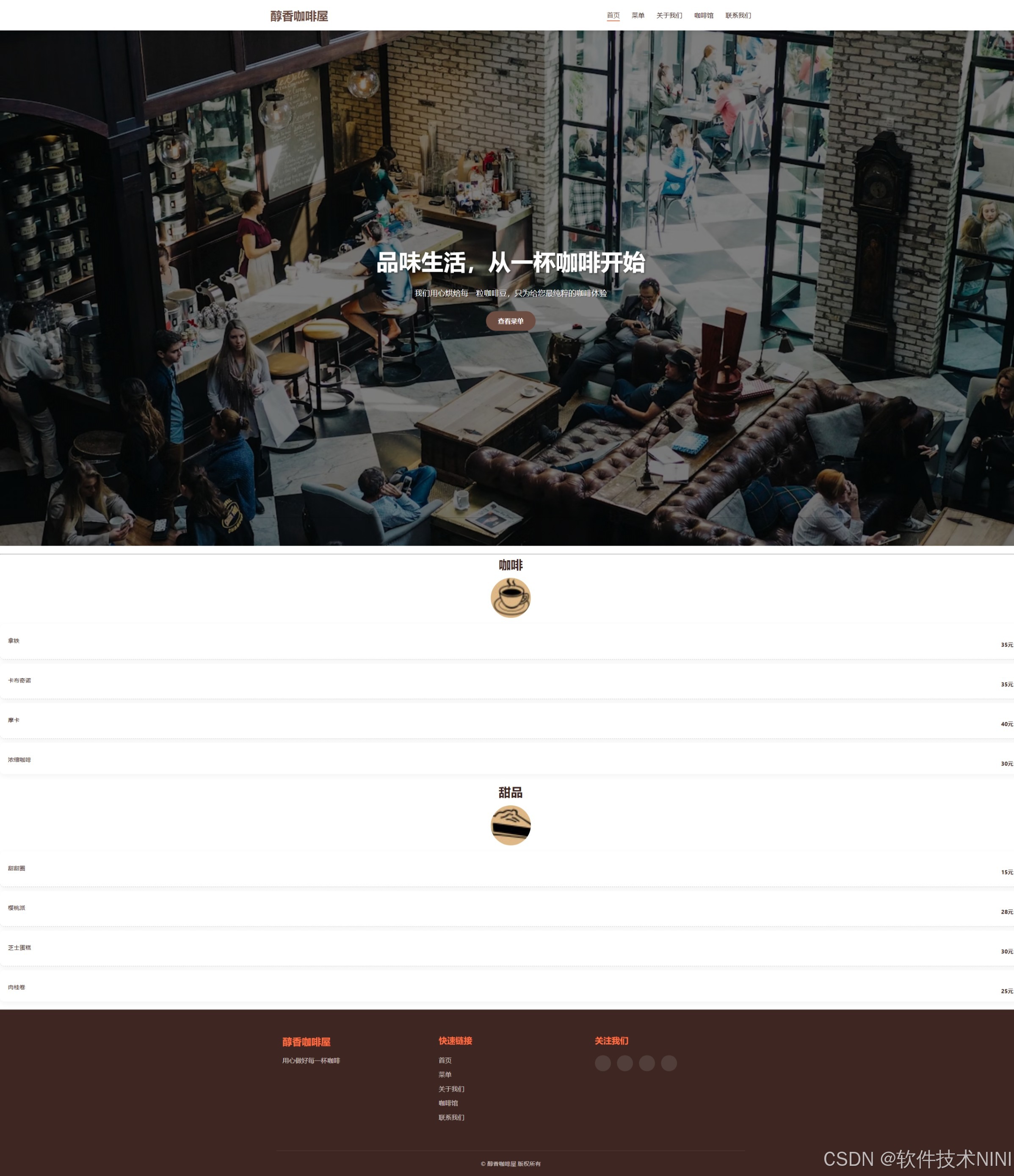
html css js网页制作成品——HTML+CSS+js醇香咖啡屋网页设计(5页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

[特殊字符] 构建高内聚低耦合的接口架构:从数据校验到后置通知的分层实践
在现代企业系统开发中,接口结构设计的质量直接影响系统的稳定性、扩展性与可维护性。随着业务复杂度上升,单一层次的接口实现往往难以应对功能膨胀、事务一致性、后置扩展等需求。因此,我们提出一种面向复杂业务场景的接口分层模型࿰…...

brep2seq 源码笔记2
数学公式是什么def forward(self, noise_1, noise_2, real_z_pNone): if(real_z_p): z_p_ self.downsample(real_z_p) input_2 z_p_ noise_2 z_f self.gen_z_f(input_2) output real_z_p z_f else: …...
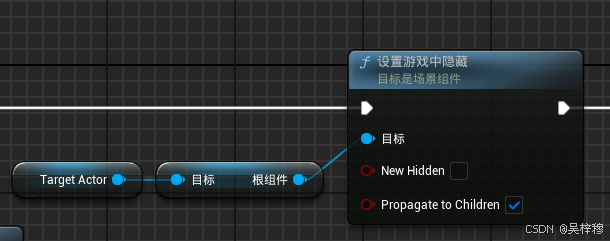
UE5 蓝图,隐藏一个Actor,同时隐藏它的所有子物体
直接用actor.sethideningame是不行的 要先找到根组件,这样就有覆盖子物体的选项了...

人工智能AI之机器学习基石系列 第 2 篇:数据为王——机器学习的燃料与预处理
专栏系列:《人工智能AI之机器学习基石》② 高质量的数据是驱动机器学习模型的强大燃料 🚀 引言:无米之炊与数据的重要性 在上一篇文章《什么是机器学习?——开启智能之门》中,我们一起揭开了机器学习的神秘面纱&…...
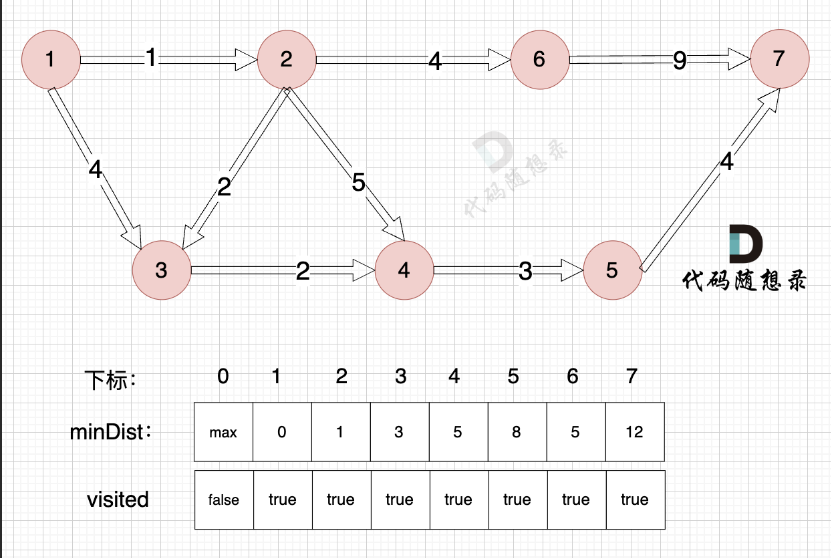
代码随想录算法训练营 Day58 图论Ⅷ 拓扑排序 Dijkstra
图论 题目 117. 软件构建 拓扑排序:给出一个有向图,把这个有向图转成线性的排序就叫拓扑排序。 当然拓扑排序也要检测这个有向图是否有环,即存在循环依赖的情况,因为这种情况是不能做线性排序的。所以拓扑排序也是图论中判断有向…...

实现单例模式的6种方法(Python)
目录 一. 基于模块的实现(简单,易用) 二. 重新创建时报错(不好用) 三. 只靠方法获取实例(不好用) 四. 类装饰器 五. 重写__new__方法 六. 元类 七. 总结 单例模式(Singleton Pattern)是一种设计模式,其核心目标是确保一个类…...

基于 STM32 的智慧农业温室控制系统设计与实现
摘要 本文提出一种基于 STM32 微控制器的智慧农业温室控制系统设计方案,通过集成多类型环境传感器、执行机构及无线通信模块,实现对温室内温湿度、光照、土壤湿度等参数的实时监测与自动调控。文中详细阐述硬件选型、电路连接及软件实现流程,并附关键代码示例,为智慧农业领…...

深度学习优化器相关问题
问题汇总 各类优化器SGDMomentumNesterovAdagardAdadeltaRMSpropAdam优化器 为什么Adam不一定最优而SGD最优的深度网络中loss除以10和学习率除以10等价吗L1,L2正则化是如何让模型变得稀疏的,正则化的原理L1不可导的时候该怎么办梯度消失和梯度爆炸什么原因ÿ…...

【免费】【无需登录/关注】度分秒转换在线工具
UVE Toolbox 功能概述 这是一个用于地理坐标转换的在线工具,支持两种转换模式: 十进制度 → 度分秒 度分秒 → 十进制度 使用方法 十进制度转度分秒 在"经度"输入框中输入十进制度格式的经度值(例如:121.46694&am…...
常见的垃圾回收算法原理及其模拟实现
1.标记 - 清除(Mark - Sweep)算法: 这是一种基础的垃圾回收算法。首先标记所有可达的对象,然后清除未被标记的对象。 缺点是会产生内存碎片。 原理: 如下图分配一段内存,假设已经存储上数据了 标记所有…...

fpga-编程线性序列机和状态机
一、线性序列机和有限状态机和(状态机-编程思想)的原理 序列机是什么:用计数器对时钟个数计数,根据相应时钟周期下的单个周期时间和计数个数可以确定某个时刻的时间,确定时间后再需要时间点转换电平! 采用…...
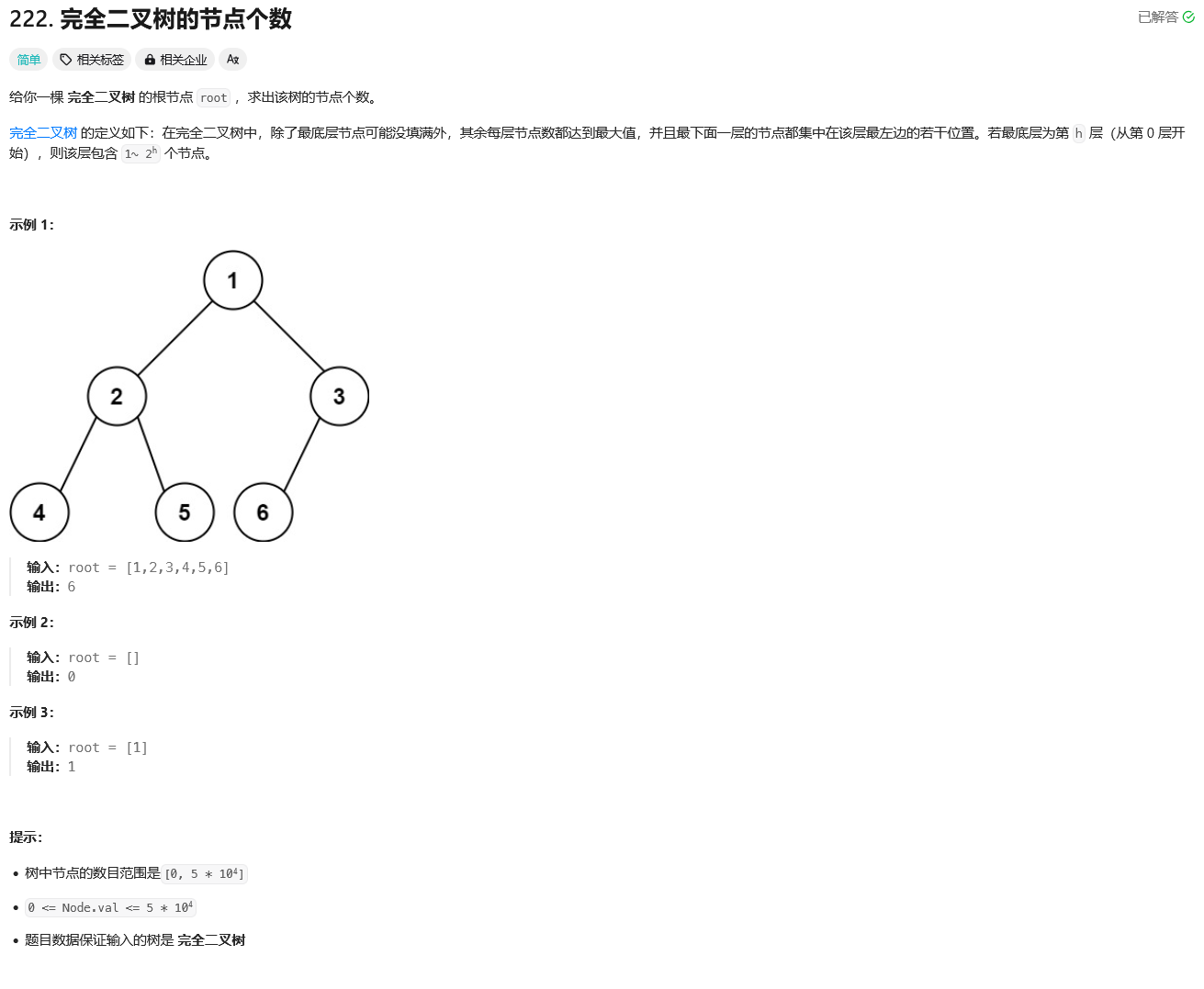
力扣面试150题--完全二叉树的节点个数
Day 51 题目描述 思路 根据完全二叉树的规律,完全二叉树的高度可以直接通过不断地访问左子树就可以获取,判断左右子树的高度: 1. 如果相等说明左子树是满二叉树, 然后进一步判断右子树的节点数(最后一层最后出现的节点必然在右子树中) 2. 如…...

Qt 多线程环境下的全局变量管理与密码安全
在现代软件开发中,全局变量的管理和敏感信息的保护是两个重要的课题。特别是在多线程环境中,不正确的全局变量使用可能导致数据竞争和不一致的问题,而密码等敏感信息的明文存储更是会带来严重的安全隐患。本文将介绍如何在 Qt 框架下实现一个…...

内网映射有什么作用,如何实现内网的网络地址映射到公网连接?
在网络环境中,内网映射是一项重要的技术,它允许用户通过外部网络访问位于内部网络中的设备或服务。如自己电脑上的程序提供他人使用,或在家远程管理公司办公OA等涉及不同网络间的通信和数据交互。nat123作为一款老牌的内网映射工具࿰…...
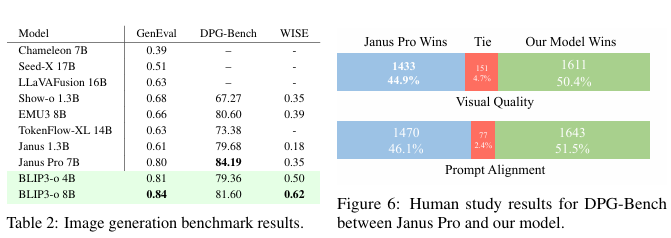
BLIP3-o:一系列完全开源的统一多模态模型——架构、训练与数据集
摘要 在近期关于多模态模型的研究中,将图像理解与生成统一起来受到了越来越多的关注。尽管图像理解的设计选择已经得到了广泛研究,但对于具有图像生成功能的统一框架而言,其最优模型架构和训练方案仍有待进一步探索。鉴于自回归和扩散模型在…...
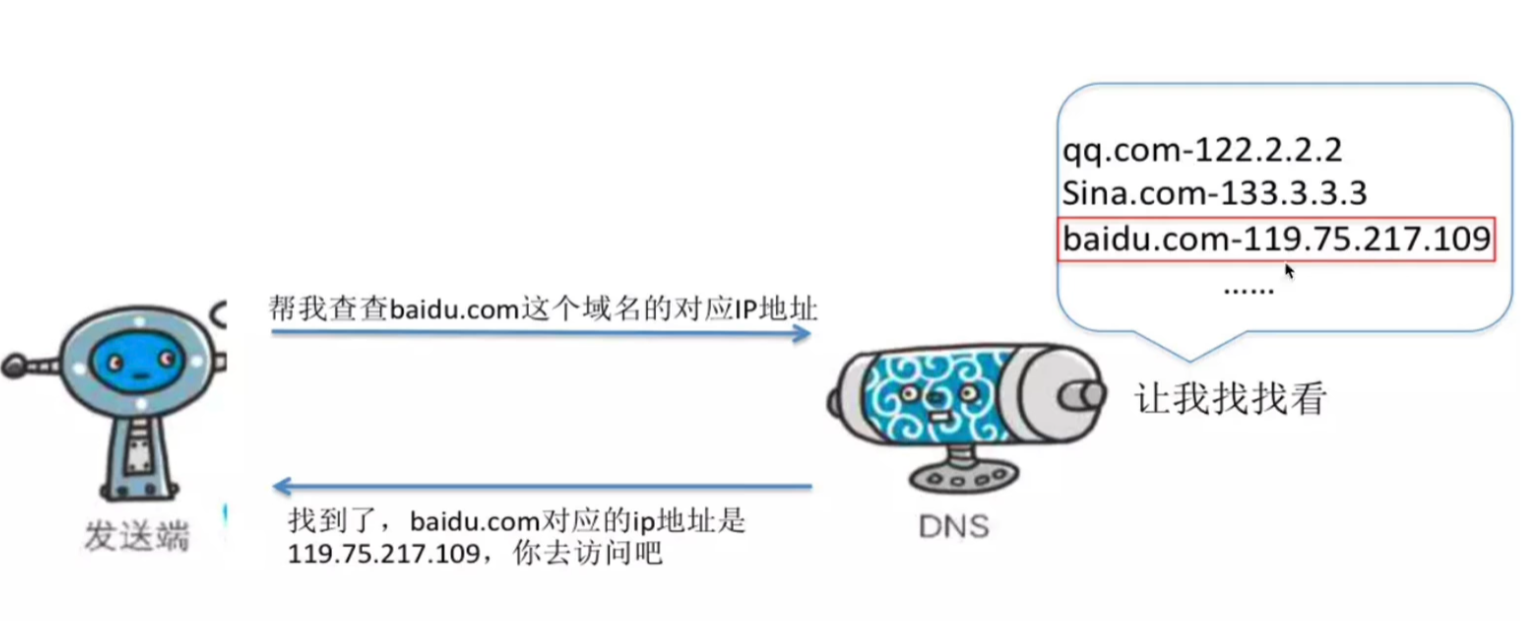
DNS解析流程入门篇
一、DNS 解析流程 1.1 浏览器输入域名 当在浏览器中输入 www.baidu.com 时,操作系统会按照以下步骤进行 DNS 解析: 检查本地 hosts 文件 :操作系统先检查本地的 /etc/hosts 文件,查看是否存在域名与 IP 地址的对应关系。如果找到…...

spring4第2课-ioc控制反转-依赖注入,是为了解决耦合问题
继续学习ioc控制反转, IOC(Inversion of Control)控制反转,也叫依赖注入, 目的是解决程序的耦合问题,轻量级spring的核心。 1.定义bean.xml <?xml version"1.0" encoding"UTF-8"…...
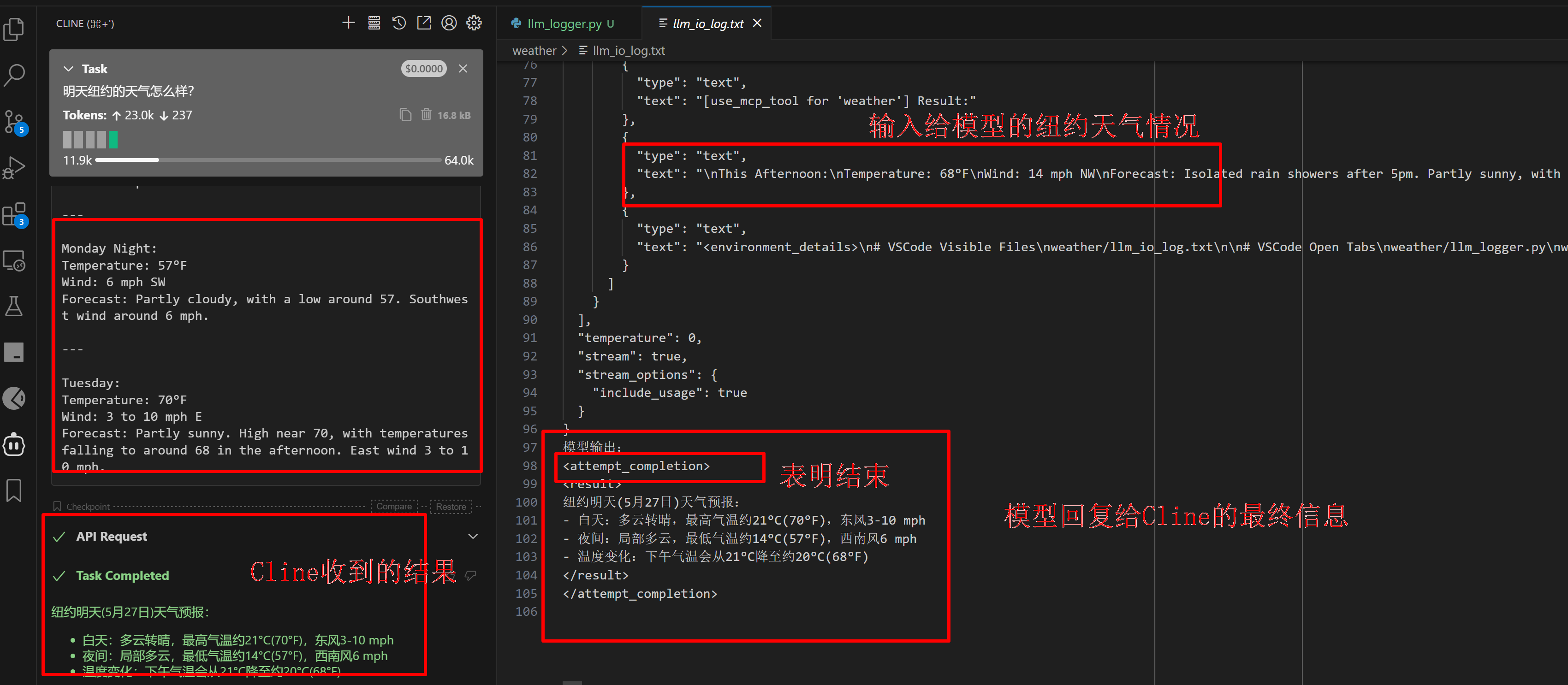
大模型系列22-MCP
大模型系列22-MCP 玩转 MCP 协议:用 Cline DeepSeek 接入天气服务什么是 MCP?环境准备:VScode Cline DeepSeek**配置 DeepSeek 模型:****配置 MCP 工具****uvx是什么?****安装 uv(会自动有 uvx 命令&…...
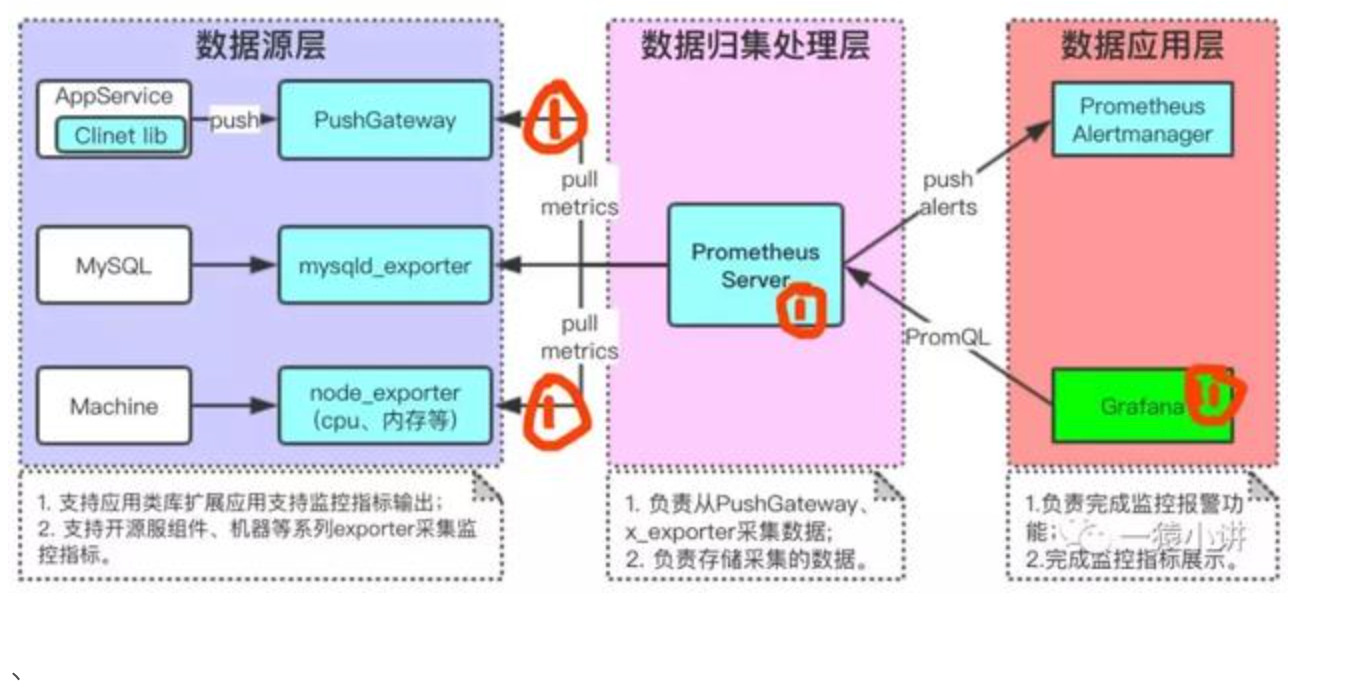
【监控】Prometheus+Grafana 构建可视化监控
在云原生和微服务架构盛行的今天,监控系统已成为保障业务稳定性的核心基础设施。作为监控领域的标杆工具,Prometheus和Grafana凭借其高效的数据采集、灵活的可视化能力,成为运维和开发团队的“标配”。 一、Prometheus Prometheus诞生于2012…...